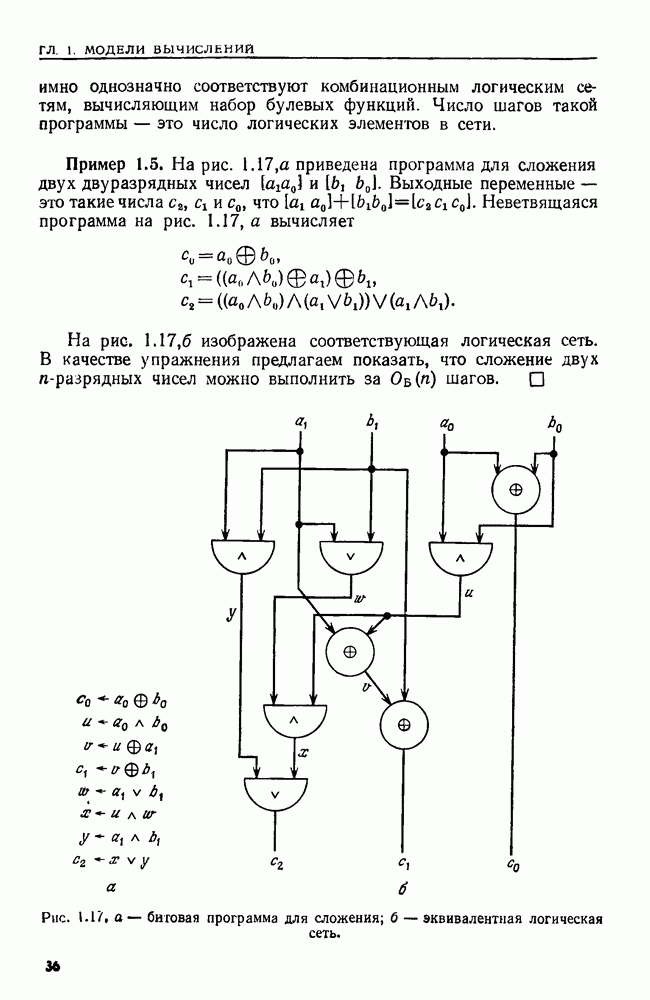
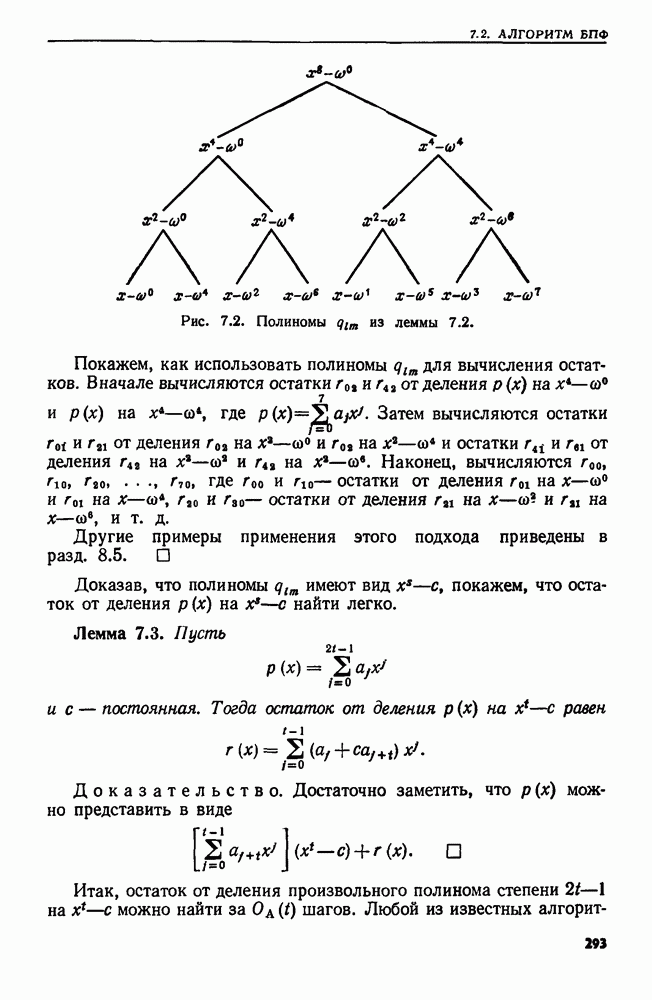
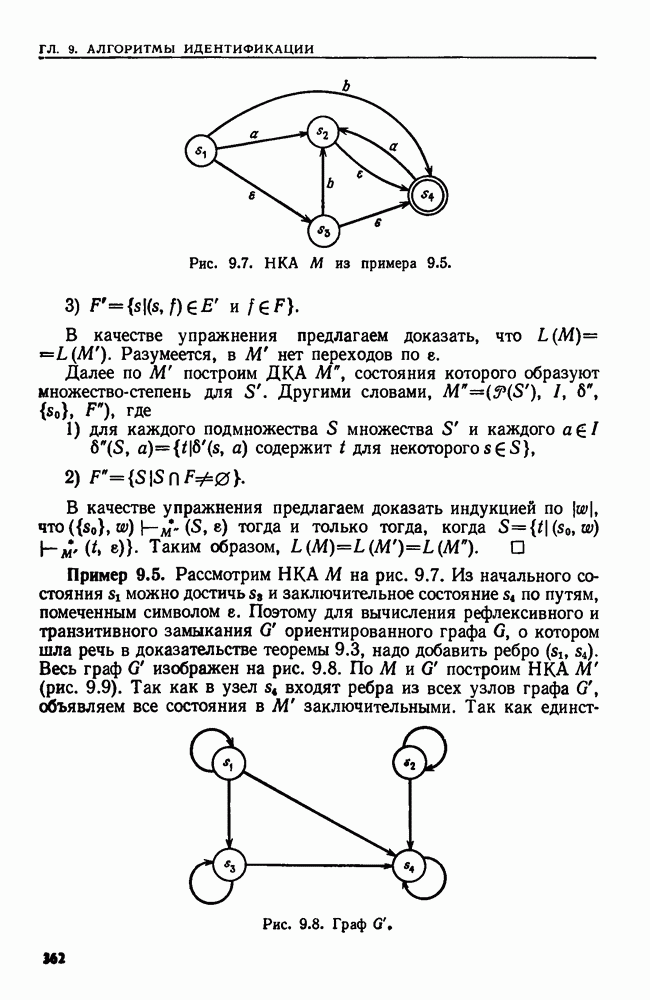
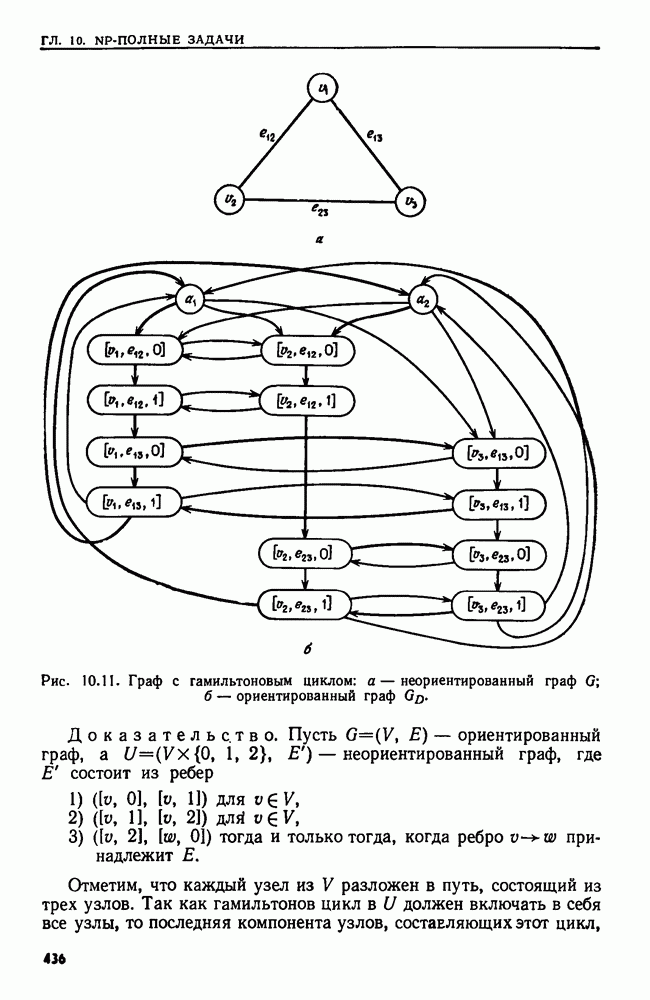
являются целые числа от  до
до  Сортировка осуществляется с помощью
Сортировка осуществляется с помощью  прохождений по данной последовательности, на каждом из которых применяется сортировка вычерпыванием. Во время первого прохождения кортежи упорядочиваются по их
прохождений по данной последовательности, на каждом из которых применяется сортировка вычерпыванием. Во время первого прохождения кортежи упорядочиваются по их  компонентам. Во время второго прохождения полученная последовательность упорядочивается по
компонентам. Во время второго прохождения полученная последовательность упорядочивается по  компонентам. При третьем последовательность, полученная после второго прохождения, упорядочивается по
компонентам. При третьем последовательность, полученная после второго прохождения, упорядочивается по  компонентам.и т. д. При
компонентам.и т. д. При  прохождении последовательность, полученная после
прохождении последовательность, полученная после  прохождения, упорядочивается по первым компонентам
прохождения, упорядочивается по первым компонентам 
Теперь элементы последовательности расположены в лексикографическом порядке.
Дадим точное описание этого алгоритма.
Алгоритм 3.1. Лексикографическая сортировка
Вход. Последовательность  где
где  есть
есть  -членный кортеж
-членный кортеж  в котором
в котором  целое число между
целое число между  (Удобной структурой данных для этой последовательности кортежей является массив размера
(Удобной структурой данных для этой последовательности кортежей является массив размера 
Выход. Последовательность  представляющая собой такую перестановку
представляющая собой такую перестановку  что
что  при
при 
Метод. Чтобы поместить  -членный кортеж
-членный кортеж  в некоторый черпак, в действительности надо сдвинуть лишь указатель на
в некоторый черпак, в действительности надо сдвинуть лишь указатель на  Поэтому кортеж
Поэтому кортеж  можно добавить в черпак за фиксированное время, а не только за время, ограниченное числом
можно добавить в черпак за фиксированное время, а не только за время, ограниченное числом  Для хранения "текущей" последовательности элементов применяется очередь, называемая ОЧЕРЕДЬ. Используется также массив
Для хранения "текущей" последовательности элементов применяется очередь, называемая ОЧЕРЕДЬ. Используется также массив  состоящий из
состоящий из  черпаков, в котором черпак
черпаков, в котором черпак  предназначен для хранения тех
предназначен для хранения тех  -членных кортежей, у которых число
-членных кортежей, у которых число  стоит в компоненте, рассматриваемой в данный момент. Алгоритм приведен на рис.
стоит в компоненте, рассматриваемой в данный момент. Алгоритм приведен на рис. 
Теорема 3.1. Алгоритм 3.1 лексикографически упорядочивает последовательность, состоящую из  -членных кортежей, калсдая компонента которых является целым числом меокду
-членных кортежей, калсдая компонента которых является целым числом меокду  и
и  за время
за время 
Доказательство. Доказательство корректности алгоритма 3.1 проводится индукцией по числу выполнений внешнего цикла. Предположение индукции таково: после  выполнений этого цикла кортежи в ОЧЕРЕДИ будут расположены в лексикографическом порядке по их
выполнений этого цикла кортежи в ОЧЕРЕДИ будут расположены в лексикографическом порядке по их  последним компонентам. Требуемый результат
последним компонентам. Требуемый результат

Рис. 3.1. Алгоритм лексикографической сортировки.
легко получить, если заметить, что  выполнение внешнего цикла упорядочивает множество кортежей по их
выполнение внешнего цикла упорядочивает множество кортежей по их  с конца компоненте, а в ситуации, когда два кортежа оказались в одном и том же черпаке, первый из них предшествует второму в лексикографическом порядке, определяемом
с конца компоненте, а в ситуации, когда два кортежа оказались в одном и том же черпаке, первый из них предшествует второму в лексикографическом порядке, определяемом  последними компонентами.
последними компонентами.
Одно выполнение внешнего цикла алгоритма 3.1 занимает время  Цикл повторяется
Цикл повторяется  раз, и это дает временную сложность
раз, и это дает временную сложность 
Алгоритм 3.1 находит разнообразные приложения. Долгое время он применялся в машинах, сортирующих перфокарты. С его помощью можно также упорядочить множество из  целых чисел, лежащих между
целых чисел, лежащих между  и
и  за время
за время  так как любое такое число можно считать
так как любое такое число можно считать  -членным кортежем цифр от
-членным кортежем цифр от  до
до  (т. е. представленным в системе счисления с основанием
(т. е. представленным в системе счисления с основанием 
Нашим последним обобщением сортировки вычерпыванием будет распространение ее на кортежи неодинаковой длины, которые мы будем называть цепочками. Если самая длинная цепочка имеет длину  то можно каждую цепочку дополнить специальным символом до длины
то можно каждую цепочку дополнить специальным символом до длины  и затем применить алгоритм 3.1. Однако, если длинных цепочек мало, такой подход по двум причинам приведет к неоправданной неэффективности. Во-первых, при каждом прохождении просматривается каждая цепочка; во-вторых, каждый черпак
и затем применить алгоритм 3.1. Однако, если длинных цепочек мало, такой подход по двум причинам приведет к неоправданной неэффективности. Во-первых, при каждом прохождении просматривается каждая цепочка; во-вторых, каждый черпак  анализируется даже в том случае, когда почти все черпаки
анализируется даже в том случае, когда почти все черпаки
пусты. Мы дадим алгоритм, сортирующий  -элементную последовательность цепочек различной длины, компонентами (т. е. буквами) которых служат числа между
-элементную последовательность цепочек различной длины, компонентами (т. е. буквами) которых служат числа между  и
и  время работы этого алгоритма на такой последовательности равно
время работы этого алгоритма на такой последовательности равно  где
где  длина 1-й цепочки, а
длина 1-й цепочки, а  Этот алгоритм полезен в ситуации, когда числа
Этот алгоритм полезен в ситуации, когда числа  имеют одинаковый порядок
имеют одинаковый порядок 
Суть этого алгоритма в том, что сначала он располагает цепочки в порядке убывания длин. Пусть  длина самой длинной цепочки. Тогда, как и в алгоритме 3.1, сортировка вычерпыванием применяется
длина самой длинной цепочки. Тогда, как и в алгоритме 3.1, сортировка вычерпыванием применяется  раз. Но первое такое применение (по самой правой компоненте) сортирует лишь цепочки длины
раз. Но первое такое применение (по самой правой компоненте) сортирует лишь цепочки длины  Второе применение сортирует (в соответствии с
Второе применение сортирует (в соответствии с  компонентой) те цепочки, длина которых не менее
компонентой) те цепочки, длина которых не менее 
Например, пусть нужно упорядочить последовательность из трех цепочек:  (Мы условились считать компонентами кортежей целые числа, но для удобства записи мы часто будем использовать буквы. Это не вызывает трудностей, потому что всегда, когда мы пожелаем, можно заменить
(Мы условились считать компонентами кортежей целые числа, но для удобства записи мы часто будем использовать буквы. Это не вызывает трудностей, потому что всегда, когда мы пожелаем, можно заменить  и с на 0, 1 и 2.) В этом примере
и с на 0, 1 и 2.) В этом примере  так что при первом прохождении последовательности сортируются только первые две цепочки по третьей компоненте. При этом
так что при первом прохождении последовательности сортируются только первые две цепочки по третьей компоненте. При этом  помещается в
помещается в  -черпак,
-черпак,  в с-черпак;
в с-черпак;  -чер-пак остается пустым. При втором прохождении эти же две цепочки сортируются по второй компоненте. Теперь
-чер-пак остается пустым. При втором прохождении эти же две цепочки сортируются по второй компоненте. Теперь  -черпак и
-черпак и  -черпак становятся занятыми, а с-черпак пустым. При третьем (последнем) прохождении сортируются все три цепочки по первой компоненте. На этот раз а- и
-черпак становятся занятыми, а с-черпак пустым. При третьем (последнем) прохождении сортируются все три цепочки по первой компоненте. На этот раз а- и  -черпаки оказываются занятыми, а с-черпак пустым.
-черпаки оказываются занятыми, а с-черпак пустым.
Заметим, что в общем случае при данном прохождении могут оказаться пустыми много черпаков. Поэтому полезен предварительный шаг, определяющий, какие черпаки будут при данном прохождении непустыми. Список непустых черпаков для каждого прохождения формируется в порядке возрастания номеров черпаков. Это позволяет сцепить непустые черпаки за время, пропорциональное их числу.
Алгоритм 3.2. Лексикографическая сортировка цепочек разной длины
Вход. Последовательность цепочек (кортежей)  компоненты которых представлены целыми числами от
компоненты которых представлены целыми числами от  до
до  Пусть
Пусть  длина цепочки
длина цепочки  наибольшее из чисел
наибольшее из чисел 
Выход. Перестановка  цепочек
цепочек  такая, что
такая, что
Метод.
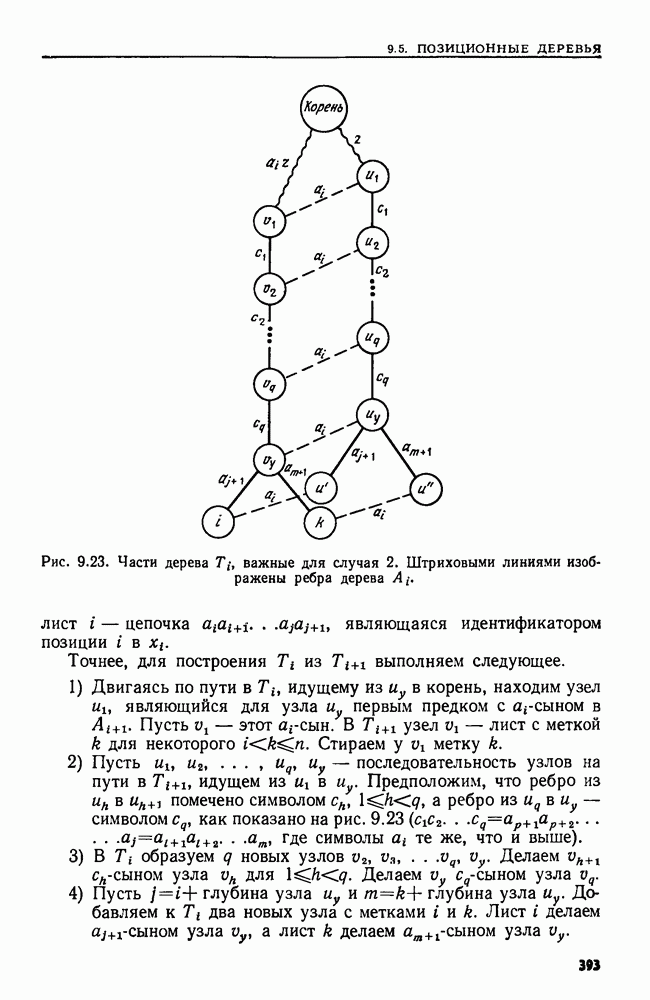
1. Начнем с формирования списков (по одному для каждого  тех символов, которые появляются в 1-й компоненте одной или более цепочек. Для этого сначала построим пары
тех символов, которые появляются в 1-й компоненте одной или более цепочек. Для этого сначала построим пары  для каждой компоненты
для каждой компоненты  каждой цепочки
каждой цепочки  Такая пара указывает, что в
Такая пара указывает, что в  компоненте некоторой цепочки стоит число
компоненте некоторой цепочки стоит число  Множество этих пар лексикографически упорядочивается с помощью очевидного обобщения алгоритма 3.1 Затем, просматривая упорядоченный так список слева направо, формируем упорядоченные списки
Множество этих пар лексикографически упорядочивается с помощью очевидного обобщения алгоритма 3.1 Затем, просматривая упорядоченный так список слева направо, формируем упорядоченные списки  для такие, что
для такие, что  содержит точно те символы, которые появляются в 1-й компоненте некоторой цепочки. Иными словами,
содержит точно те символы, которые появляются в 1-й компоненте некоторой цепочки. Иными словами,  содержит в упорядоченном виде все целые числа
содержит в упорядоченном виде все целые числа  для которых
для которых  при некотором
при некотором 
2. Определяем длину каждой цепочки. Затем формируем списки  для
для  такие, что
такие, что  содержит все цепочки длины
содержит все цепочки длины  (Хотя речь все время идет о перемещении цепочек, фактически мы передвигаем только указатели на них. Поэтому каждую цепочку можно добавить в список
(Хотя речь все время идет о перемещении цепочек, фактически мы передвигаем только указатели на них. Поэтому каждую цепочку можно добавить в список  за фиксированное число шагов.)
за фиксированное число шагов.)
3. Теперь сортируются цепочки по компонентам, как в алгоритме 3.1, начиная с компонент с номером  Однако после
Однако после  прохождения цепочек ОЧЕРЕДЬ содержит только те из них, длина которых не менее
прохождения цепочек ОЧЕРЕДЬ содержит только те из них, длина которых не менее  и они уже будут расположены в соответствии с компонентами, имеющими номера от
и они уже будут расположены в соответствии с компонентами, имеющими номера от  до
до  Списки типа
Списки типа  сформированные на шаге 1, помогают определить при каждом применении сортировки вычерпыванием занятые черпаки. Эта информация используется для того, чтобы ускорить сцепление черпаков. Соответствующая часть алгоритма на Упрощенном Алголе приведена на рис.
сформированные на шаге 1, помогают определить при каждом применении сортировки вычерпыванием занятые черпаки. Эта информация используется для того, чтобы ускорить сцепление черпаков. Соответствующая часть алгоритма на Упрощенном Алголе приведена на рис. 
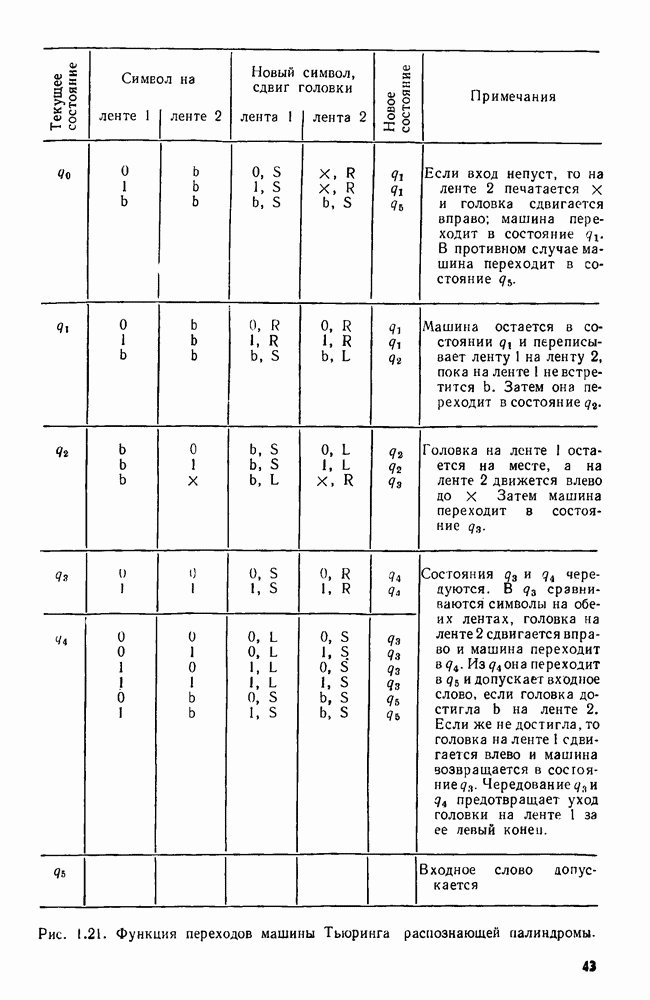
Пример 3.1. Упорядочим последовательность цепочек  с помощью алгоритма 3.2. Одно из возможных представлений этих цепочек — структура данных, изображенная на рис.
с помощью алгоритма 3.2. Одно из возможных представлений этих цепочек — структура данных, изображенная на рис.  это такой массив, что
это такой массив, что  указатель на представление
указатель на представление  цепочки, у которой длина и компоненты хранятся в массиве ДАННЫЕ. Клетка в массиве
цепочки, у которой длина и компоненты хранятся в массиве ДАННЫЕ. Клетка в массиве  куда указывает указатель из элемента
куда указывает указатель из элемента  дает число
дает число  символов в 1-й цепочке. Следующие
символов в 1-й цепочке. Следующие  клеток массива ДАННЫЕ содержат эти символы.
клеток массива ДАННЫЕ содержат эти символы.
Списки цепочек, используемые алгоритмом 3.2, в действительности являются списками указателей того же типа, что и в массиве ЦЕПОЧКА. В остальной части этого примера мы будем для
Рис. 3.2. (см. скан) Лексикографическая сортировка цепочек разной длины.
удобства писать в списках сами цепочки, а не указатели на них. Однако надо помнить, что в очередях хранятся эти указатели, а не сами цепочки.
В части 1 алгоритма 3.2 формируется пара  из первой цепочки, пары
из первой цепочки, пары  из второй и
из второй и  из третьей. Упорядоченный список этих пар выглядит так:
из третьей. Упорядоченный список этих пар выглядит так:

Просматривая его слева направо, заключаем, что


Рис. 3.3. Структура данных для цепочек.
В части 2 алгоритма 3.2 вычисляем  Следовательно,
Следовательно,  список
список  пуст и
пуст и  Поэтому часть 3 начинаем с того, что полагаем
Поэтому часть 3 начинаем с того, что полагаем  и затем располагаем эти цепочки по их третьей компоненте. Равенство
и затем располагаем эти цепочки по их третьей компоненте. Равенство  с гарантирует, что при построении упорядоченного списка в соответствии со строками 8—10 рис. 3.2 не обязательно присоединить
с гарантирует, что при построении упорядоченного списка в соответствии со строками 8—10 рис. 3.2 не обязательно присоединить  к концу списка ОЧЕРЕДЬ. Таким образом, после первого прохождения цикла в строках 3—10 рис. 3.2
к концу списка ОЧЕРЕДЬ. Таким образом, после первого прохождения цикла в строках 3—10 рис. 3.2  .
.
При втором прохождении ОЧЕРЕДЬ не меняется, так как список  пуст, а упорядочение по второй компоненте не изменяет порядок. При третьем прохождении мы, согласно строке 4, получаем
пуст, а упорядочение по второй компоненте не изменяет порядок. При третьем прохождении мы, согласно строке 4, получаем  Упорядочение по первой компоненте дает
Упорядочение по первой компоненте дает  получили правильный порядок. Заметим, что при третьем прохождении список
получили правильный порядок. Заметим, что при третьем прохождении список  становится пустым, а поскольку с не входит в список
становится пустым, а поскольку с не входит в список  не нужно присоединять
не нужно присоединять  к концу списка
к концу списка 
Теорема 3.2. Алгоритм 3.2 упорядочивает свой вход за время 
Доказательство. Простая индукция по числу прохождений внешнего цикла в программе на рис. 3.2 показывает, что после  прохождений список ОЧЕРЕДЬ содержит цепочки длины, не меньшей
прохождений список ОЧЕРЕДЬ содержит цепочки длины, не меньшей  и они расположены в соответствии с их компонентами с номерами от
и они расположены в соответствии с их компонентами с номерами от  Поэтому рассматриваемый алгоритм лексикографически упорядочивает свой вход.
Поэтому рассматриваемый алгоритм лексикографически упорядочивает свой вход.
Что касается затрачиваемого времени, то в части 1 расходуется время  на образование списка пар и
на образование списка пар и  на его упорядочение. Аналогично часть 2 занимает не более
на его упорядочение. Аналогично часть 2 занимает не более  времени.
времени.
Теперь исследуем часть 3 и программу на рис. 3.2. Пусть  число цепочек, имеющих
число цепочек, имеющих  компоненты. Пусть
компоненты. Пусть  число различных символов, появляющихся в
число различных символов, появляющихся в  компонентах цепочек (т. е.
компонентах цепочек (т. е.  длина списка
длина списка 
Рассмотрим фиксированное значение I в строке 3 рис. 3.2. Цикл в строках 5—7 занимает  времени, а в строках
времени, а в строках  времени. Шаг 4 выполняется за постоянное время, так что одно прохождение цикла в строках 3—10 занимает
времени. Шаг 4 выполняется за постоянное время, так что одно прохождение цикла в строках 3—10 занимает  времени. Таким образом, весь цикл занимает
времени. Таким образом, весь цикл занимает

времени. Так как

то строки 3—10 выполняются за время  Теперь, учитывая, что на строку 1 тратится постоянное время, а на строку 2 время
Теперь, учитывая, что на строку 1 тратится постоянное время, а на строку 2 время  получаем нужный результат.
получаем нужный результат.
Приведем пример, когда упорядочение возникает при разработке алгоритма.
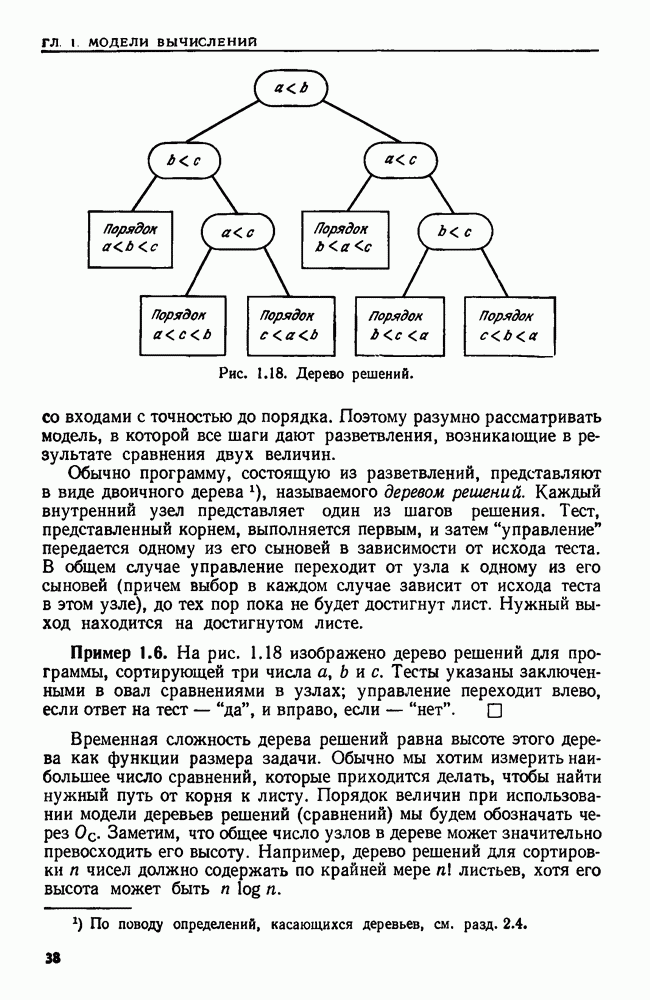
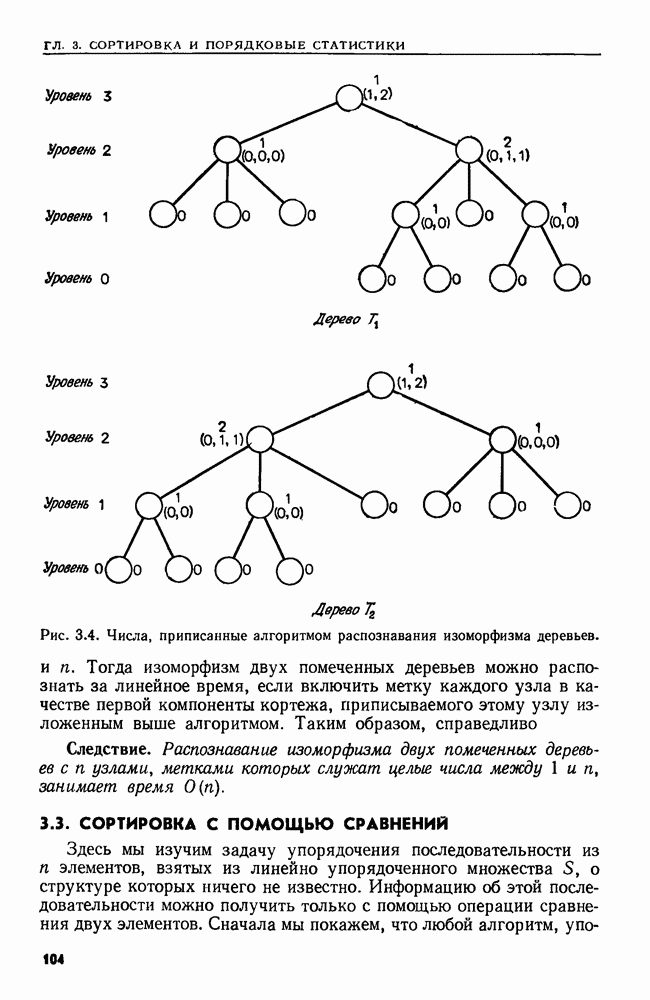
Пример 3.2. Два дерева называются изоморфными, если можно отобразить одно из них в другое, изменив порядок сыновей его узлов. Рассмотрим задачу распознавания изоморфизма двух данных деревьев  Следующий алгоритм делает это за время, пропорциональное числу узлов. Этот алгоритм приписывает целые числа узлам двух данных деревьев, начиная с узлов уровня
Следующий алгоритм делает это за время, пропорциональное числу узлов. Этот алгоритм приписывает целые числа узлам двух данных деревьев, начиная с узлов уровня  и двигаясь вверх до корней, так что деревья изоморфны тогда и только тогда, когда их корням приписано одно и то же число. Алгоритм работает так.
и двигаясь вверх до корней, так что деревья изоморфны тогда и только тогда, когда их корням приписано одно и то же число. Алгоритм работает так.
1. Приписать число  всем листьям деревьев
всем листьям деревьев 
2. (Индукция.) Предположим, что целые числа уже приписаны всем узлам, находящимся в деревьях  на уровне
на уровне  Пусть
Пусть  список узлов уровня
список узлов уровня  в дереве
в дереве  расположенных в порядке неубывания приписанных им чисел, а
расположенных в порядке неубывания приписанных им чисел, а  соответствующий список для
соответствующий список для 
3. Приписать нелистьям уровня  в дереве
в дереве  кортеж целых чисел следующим образом: просмотреть список
кортеж целых чисел следующим образом: просмотреть список  слева направо и для каждого узла
слева направо и для каждого узла  из
из  взять число, ему приписанное, в
взять число, ему приписанное, в
качестве очередной компоненты кортежа, который ставится в соответствии отцу узла  После выполнения этого шага каждому нелисту
После выполнения этого шага каждому нелисту  уровня
уровня  в дереве будет поставлен в соответствие кортеж
в дереве будет поставлен в соответствие кортеж  где
где  целые числа, приписанные сыновьям узла
целые числа, приписанные сыновьям узла  и расположенные в порядке неубывания. Обозначим через
и расположенные в порядке неубывания. Обозначим через  последовательность кортежей, построенных для узлов уровня
последовательность кортежей, построенных для узлов уровня  в дереве
в дереве 
4. Повторить шаг 3 для  пусть
пусть  последовательность кортежей, построенных для узлов уровня
последовательность кортежей, построенных для узлов уровня  в дереве
в дереве  .
.
5. Упорядочить  с помощью алгоритма 3.2. Пусть соответственно
с помощью алгоритма 3.2. Пусть соответственно  упорядоченные последовательности кортежей.
упорядоченные последовательности кортежей.
6. Если  не совпадают, то остановиться; в этом случае исходные деревья не изоморфны. В противном случае приписать число 1 тем узлам уровня
не совпадают, то остановиться; в этом случае исходные деревья не изоморфны. В противном случае приписать число 1 тем узлам уровня  в дереве
в дереве  которые представлены первым кортежем в
которые представлены первым кортежем в  число 2 — вторым отличающимся кортежем, и т. д. Так как эти целые числа приписаны узлам уровня
число 2 — вторым отличающимся кортежем, и т. д. Так как эти целые числа приписаны узлам уровня  в дереве
в дереве  построить список
построить список  из узлов, которым таким способом приписаны числа. Добавить к началу списка
из узлов, которым таким способом приписаны числа. Добавить к началу списка  все листья дерева
все листья дерева  расположенные на уровне
расположенные на уровне  Пусть
Пусть  соответствующий список узлов дерева
соответствующий список узлов дерева  Эти два списка теперь можно использовать для приписывания кортежей узлам уровня
Эти два списка теперь можно использовать для приписывания кортежей узлам уровня  с помощью процедуры на шаге 3.
с помощью процедуры на шаге 3.
7. Если корням деревьев  приписано одно и то же число, то
приписано одно и то же число, то  изоморфны.
изоморфны.
На рис. 3.4 иллюстрируется приписывание чисел и кортежей узлам двух изоморфных деревьев.
Теорема 3.3. Изоморфизм двух деревьев с  узлами можно распознать за время
узлами можно распознать за время 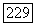
Доказательство. Теорема следует из формализации алгоритма, изложенного в примере 3.2. Доказательство корректности алгоритма мы опускаем. Время работы можно оценить, если заметить, что приписывание целых чисел узлам уровня 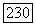 отличным от листьев, занимает время, пропорциональное числу узлов уровня
отличным от листьев, занимает время, пропорциональное числу узлов уровня 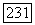 Суммирование по всем уровням дает время
Суммирование по всем уровням дает время 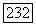 Работа по приписыванию чисел листьям также пропорциональна
Работа по приписыванию чисел листьям также пропорциональна  таким образом, весь алгоритм занимает время
таким образом, весь алгоритм занимает время 
Помеченным называется дерево, в котором узлам приписаны метки. Допустим, что метками узлов служат целые числа между 1
Рис. 3.4. (см. скан) Числа, приписанные алгоритмом распознавания изоморфизма деревьев.
 Тогда изоморфизм двух помеченных деревьев можно распознать за линейное время, если включить метку каждого узла в качестве первой компоненты кортежа, приписываемого этому узлу изложенным выше алгоритмом. Таким образом, справедливо
Тогда изоморфизм двух помеченных деревьев можно распознать за линейное время, если включить метку каждого узла в качестве первой компоненты кортежа, приписываемого этому узлу изложенным выше алгоритмом. Таким образом, справедливо
Следствие. Распознавание изоморфизма двух помеченных деревьев с  узлами, метками которых служат целые числа между
узлами, метками которых служат целые числа между 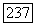 занимает время
занимает время 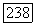































































































































































































































































































































































































































































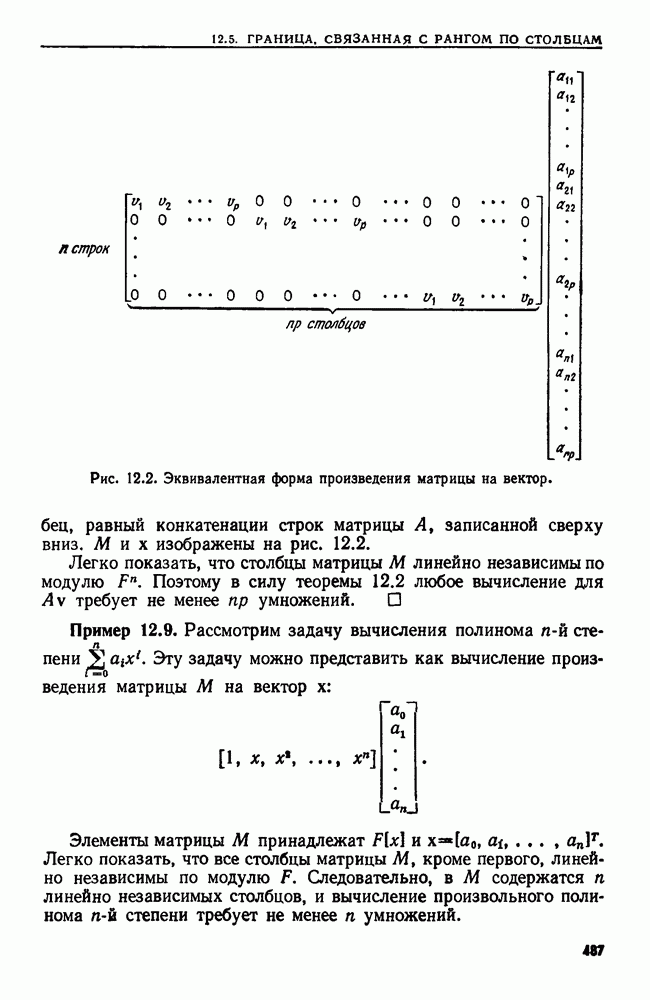


























 заключенных между
заключенных между  и
и  Если
Если  не слишком велико, ее можно упорядочить следующим образом.
не слишком велико, ее можно упорядочить следующим образом.
 пустых очередей по одной для каждого целого числа от
пустых очередей по одной для каждого целого числа от  до
до  Каждую такую очередь назовем черпаком.
Каждую такую очередь назовем черпаком.
 слева направо, помещая элемент
слева направо, помещая элемент  в очередь с номером
в очередь с номером 
 очереди приписывается к концу
очереди приписывается к концу  очереди) и получим в результате упорядоченную последовательность.
очереди) и получим в результате упорядоченную последовательность.
 очередь за постоянное время, то
очередь за постоянное время, то  элементов можно вставить в очереди за время
элементов можно вставить в очереди за время  Конкатенация (сцепление)
Конкатенация (сцепление)  очередей требует времени
очередей требует времени  Если
Если  есть
есть  то этот алгоритм сортирует
то этот алгоритм сортирует  целых чисел за время
целых чисел за время  Назовем его сортировкой вычерпыванием.
Назовем его сортировкой вычерпыванием.
 Лексикографическим порядком называется такое продолжение отношения на кортежи элементов из
Лексикографическим порядком называется такое продолжение отношения на кортежи элементов из  при котором
при котором  означает, что выполнено одно из условий:
означает, что выполнено одно из условий:
 что и для всех
что и для всех  справедливо
справедливо 

 -членных кортежей, компонентами которых
-членных кортежей, компонентами которых