Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
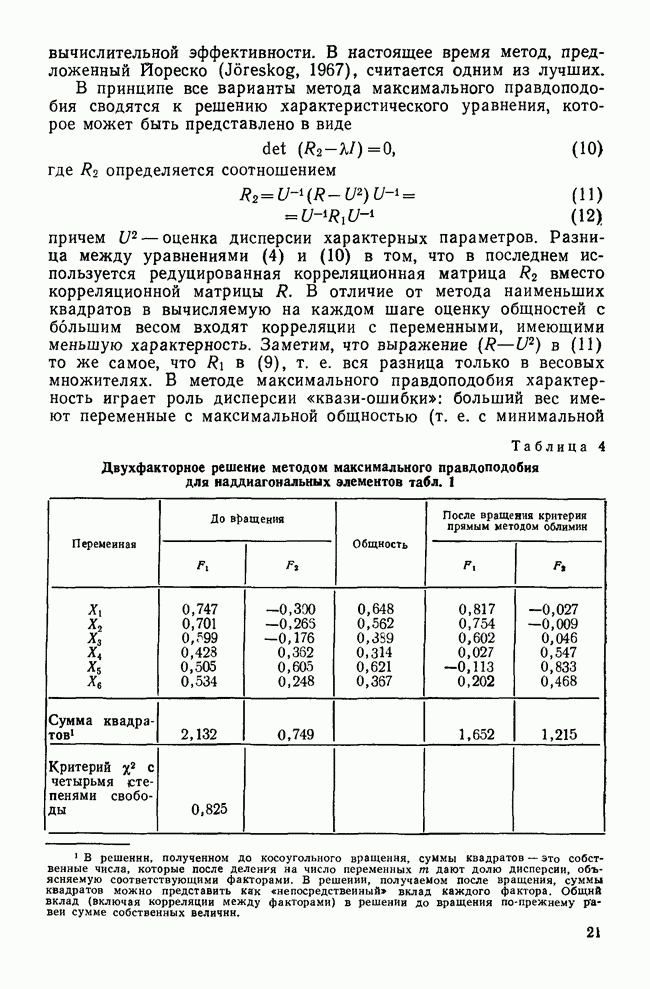
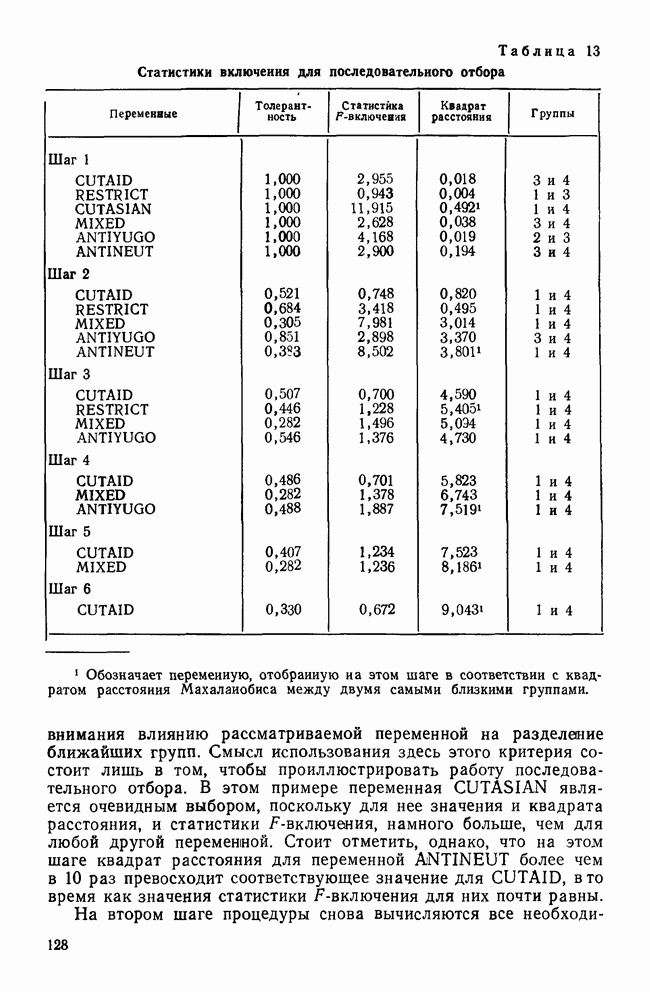
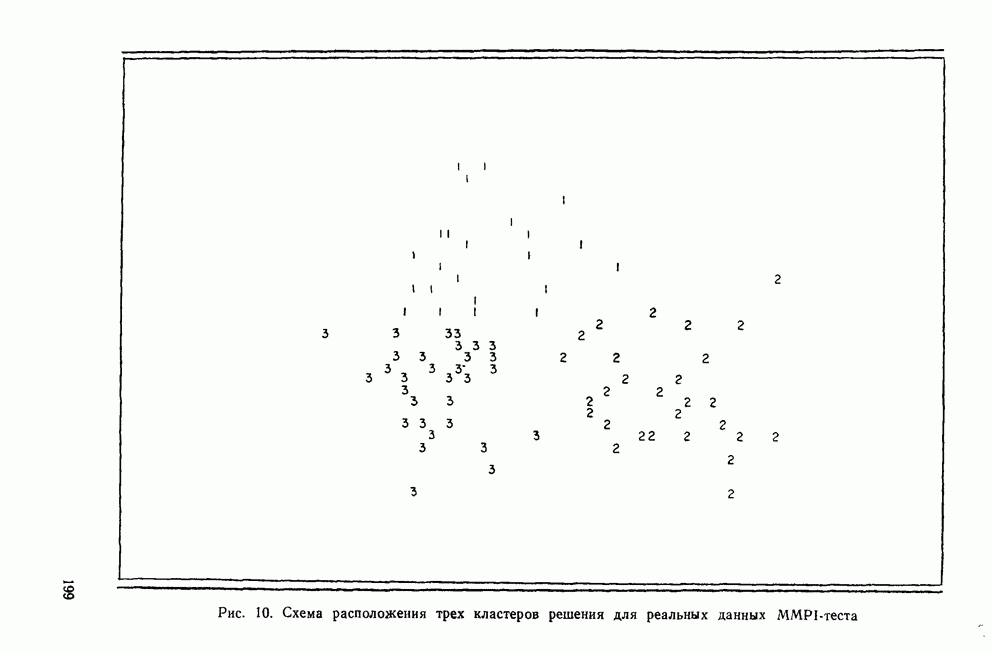
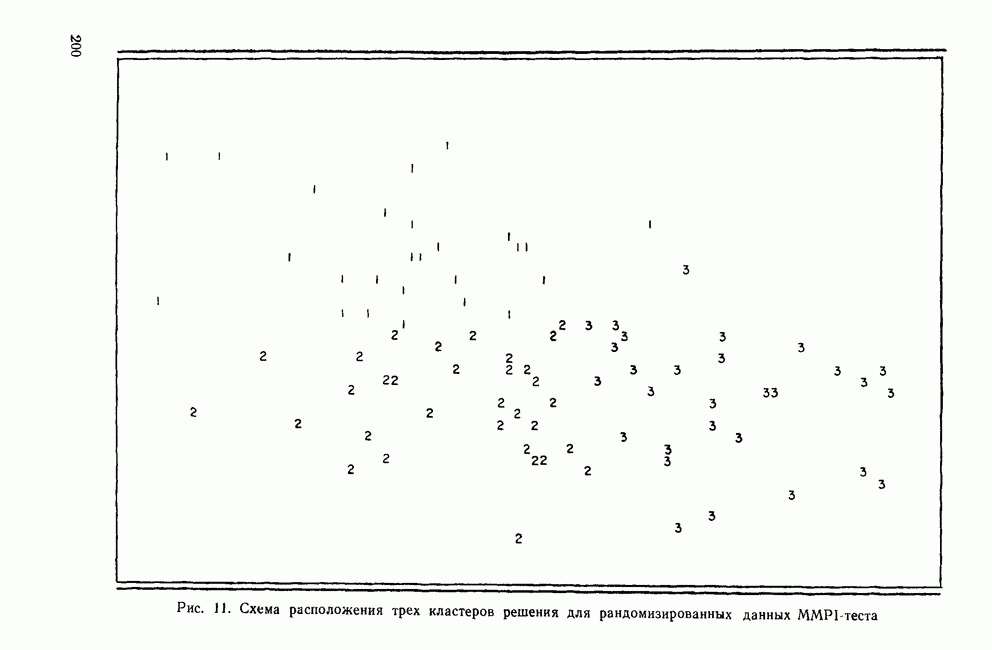
ПРИМЕР ИСПОЛЬЗОВАНИЯ ПРОЦЕДУРЫ ПОСЛЕДОВАТЕЛЬНОГО ОТБОРАДля того чтобы понять, как процедура последовательного отбора работает на практике, применим эту методику к данным Бардес о голосовании в сенате. Когда квадрат расстояния Махаланобиса используется в качестве критерия отбора, мы получаем результаты, приведенные в табл. 13. На первом шаге толерантность всегда равна 1,0, потому что переменные еще не были отобраны. По той же причине здесь статистика Таблица 13. Статистики включения для последовательного отбора
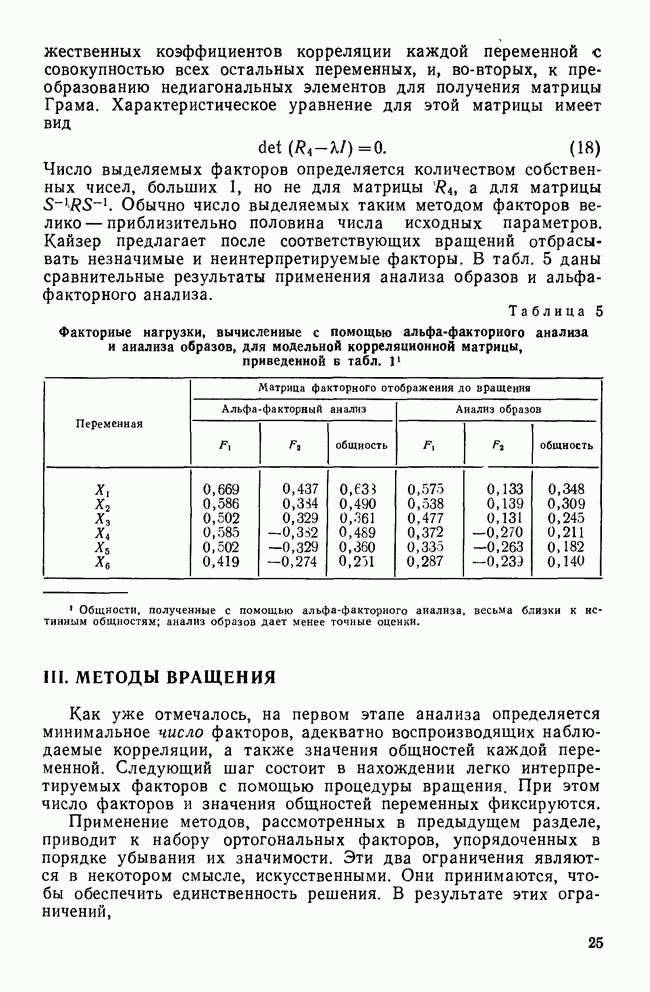
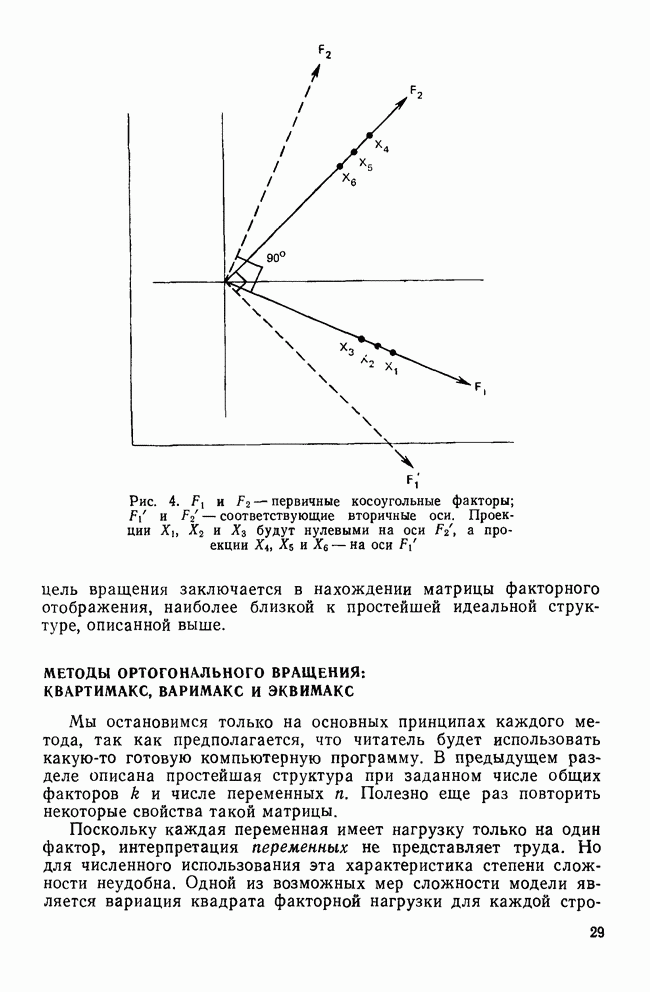
Смысл использования здесь этого критерия состоит лишь в том, чтобы проиллюстрировать работу последовательного отбора. В этом примере переменная CUTASIAN является очевидным выбором, поскольку для нее значения и квадрата расстояния, и статистики На втором шаге процедуры снова вычисляются все необходимые статистики с учетом отобранной переменной CUTASIAN. Теперь толерантность почти наверное станет меньше единицы, поскольку она равна единице минус квадрат корреляции между CUTASIAN и другой переменной. Статистика На шаге 3 процесс повторяется. Поскольку в качестве критерия выбора («включения») мы используем квадраты расстояний, следующей «включается» переменная RESTRICT. Однако если в качестве критерия отбора мы применяем Л-статистику Уилкса, косвенно измеряемую статистикой Остающиеся шаги проводятся таким же образом до тех пор, пока не будут включены все переменные. На шаге 6 CUTAID имеет настолько малое значение статистики К тому же на шаге 6 значение статистики Этот пример специально построен так, чтобы в конечном итоге были употреблены все переменные, поскольку реальное исследование Бардес также включало все шесть переменных. В действительности у нее были причины применять все переменные, поэтому она совсем не пользовалась процедурой последовательного отбора. Если кто-то собирается работать со всеми переменными, то вряд ли применение последовательного анализа принесет ему пользу. Разумно использовать эту методику для определения переменных, которые надо исключить из-за малого вклада в процесс различения. На основе данных табл. 13 можно даже утверждать, что отбор переменных должен быть оставлен на шаге 2, поскольку ни одно из значений Это дает нам право отбросить остальные четыре. В некоторых случаях использование большего числа переменных приводит к ухудшению классификации. Цель последовательного отбора — найти более экономичное подмножество, которое обладало бы такими же (если не лучшими) дискриминантными возможностями, что и полное множество. Кроме рассмотрения вопроса о возможности применения последовательного отбора, исследователь сталкивается с такими практическими проблемами, как влияние нарушений предположений, лежащих в основе дискриминантного анализа, и последствия пропуска данных. Заключительный раздел посвящен этим неприятным, но важным проблемам.
|
 |
Оглавление
|















































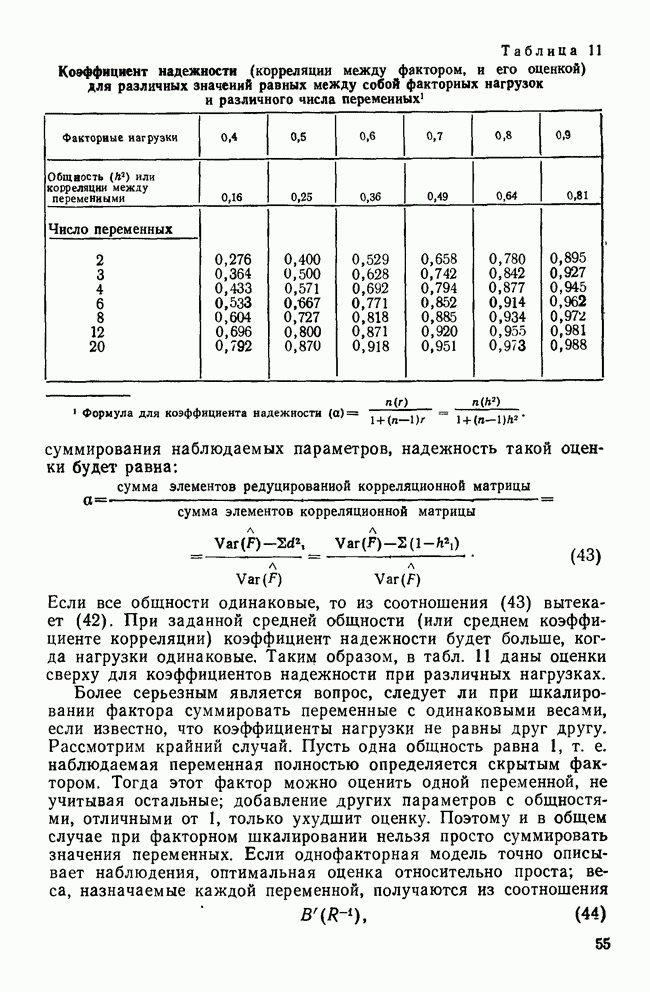









































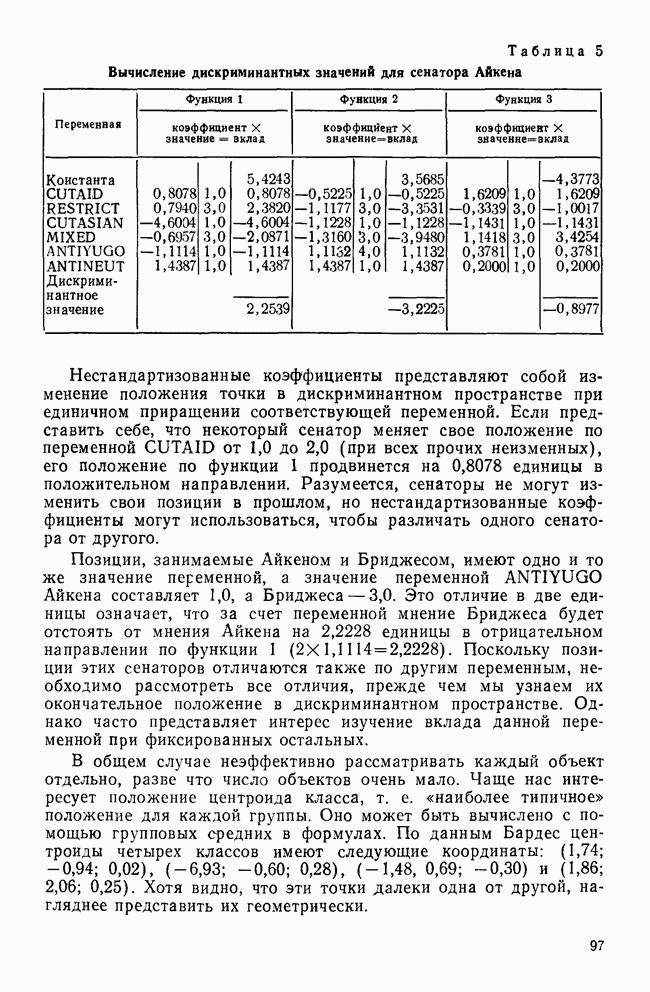
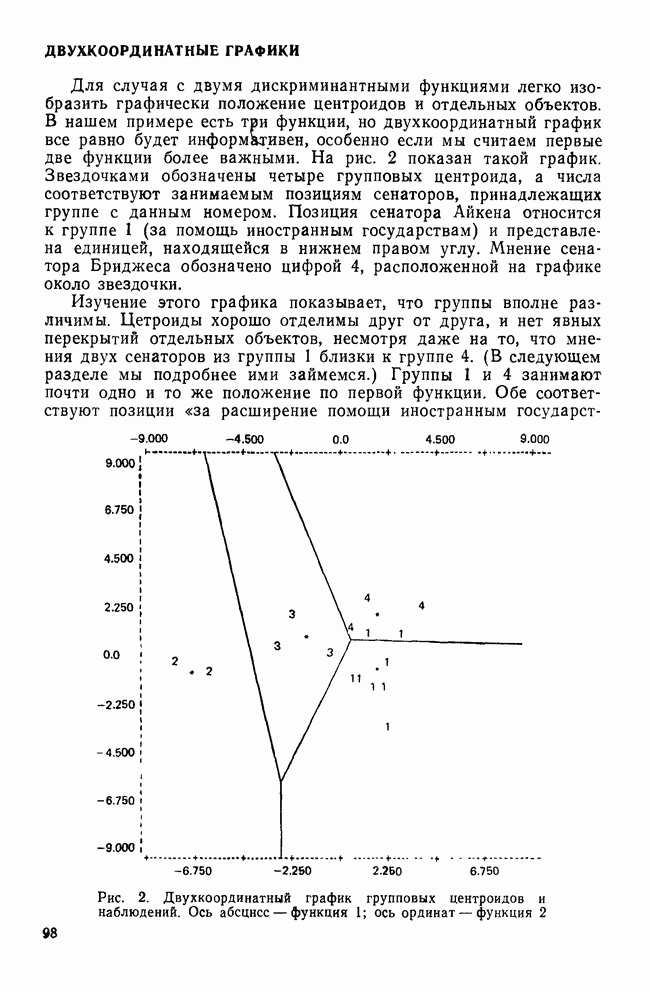















































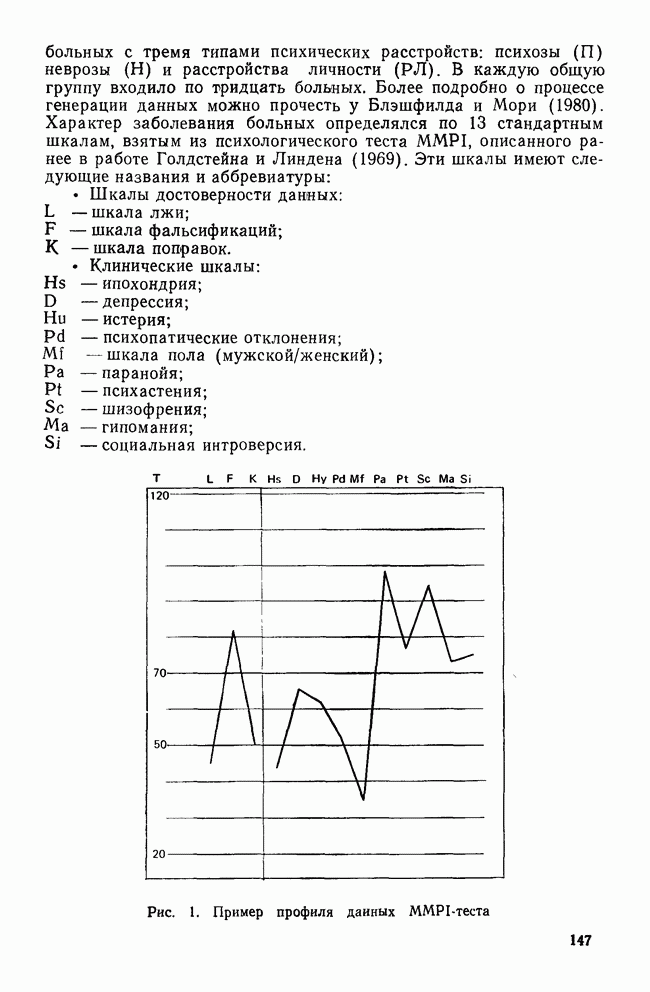








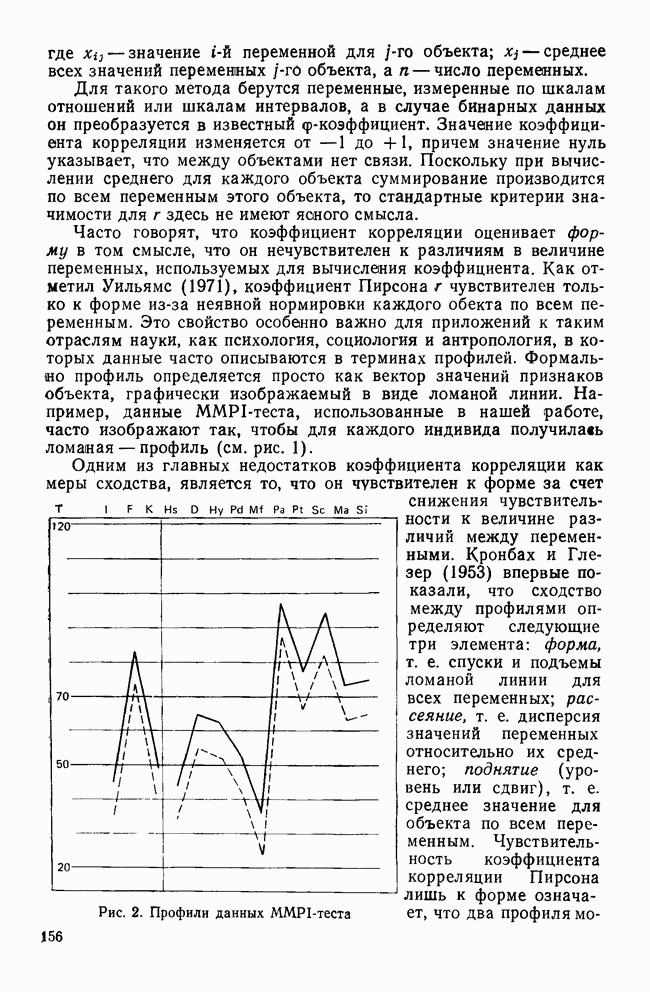













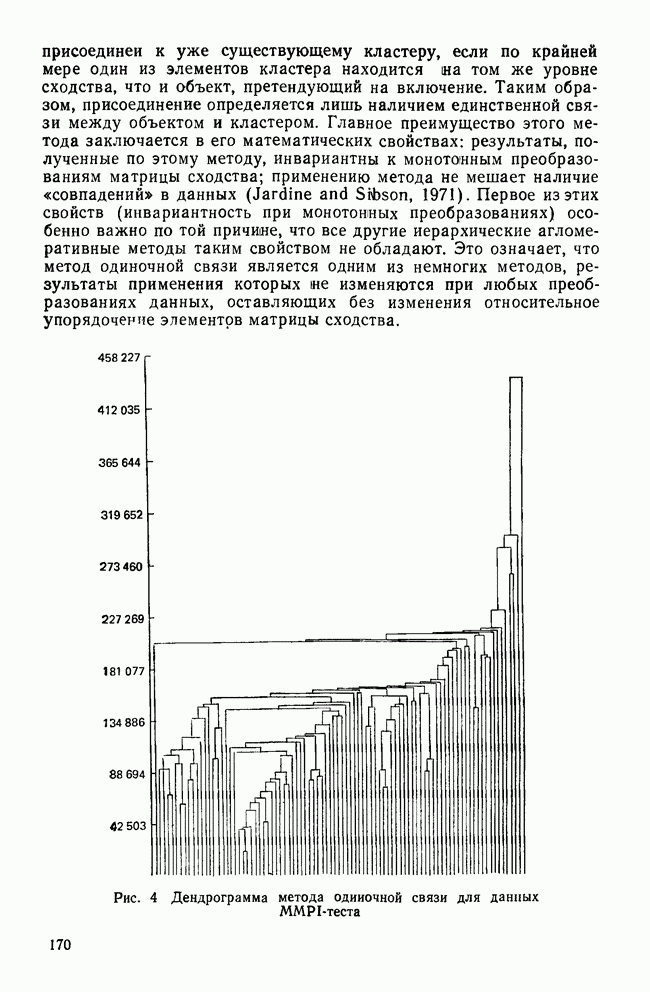
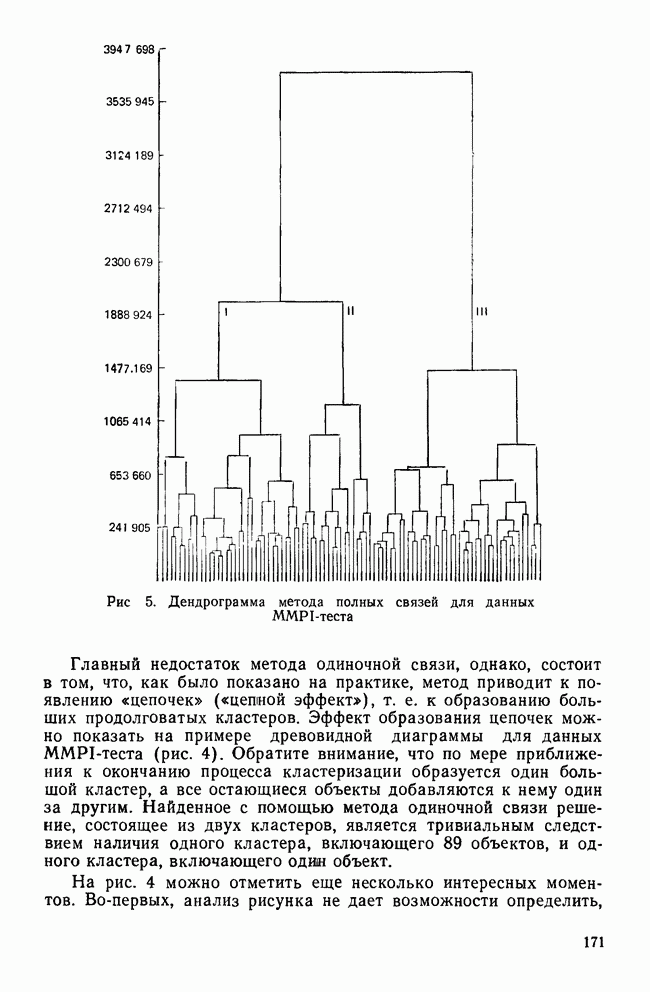






































 -включения соответствует одномерной
-включения соответствует одномерной  -статистике. В четвертом столбце даны значения
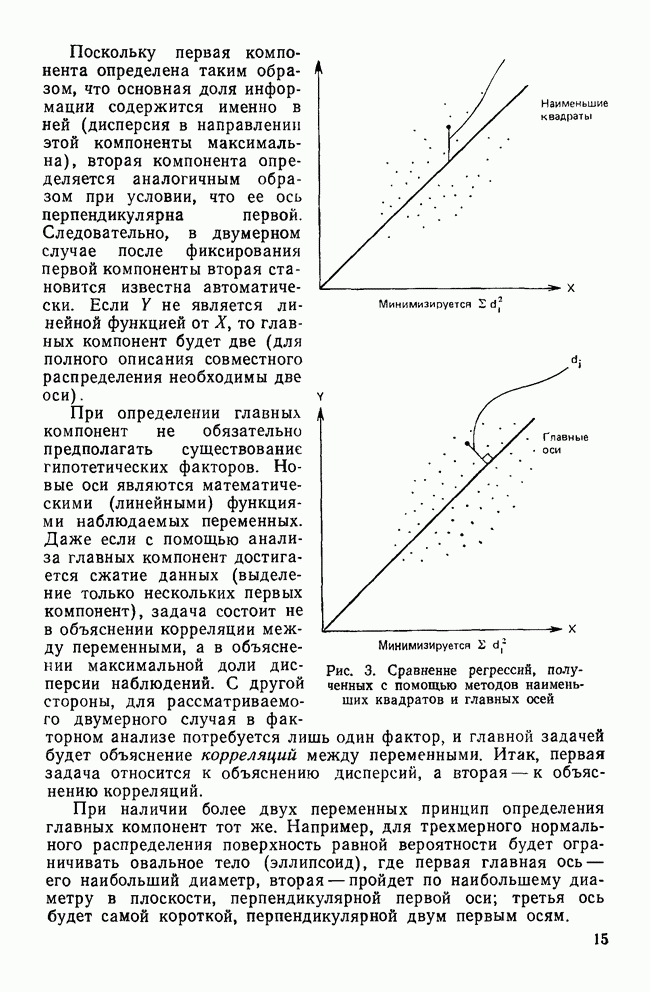
-статистике. В четвертом столбце даны значения  среди которых мы находим наибольшее. Это значение, равное 0,492, получено для переменной CUTASIAN при сравнении групп 1 и 4. Заметьте, что самая тесная пара (пара самых близких классов) для переменной CUTASIAN не является таковой ни для какой другой переменной (для четырех групп должны быть рассмотрены шесть пар). Наш выбор статистики квадрата расстояния в качестве критерия отбора основан на предположении, что мы хотим уделить больше внимания влиянию рассматриваемой переменной на разделение ближайших групп.
среди которых мы находим наибольшее. Это значение, равное 0,492, получено для переменной CUTASIAN при сравнении групп 1 и 4. Заметьте, что самая тесная пара (пара самых близких классов) для переменной CUTASIAN не является таковой ни для какой другой переменной (для четырех групп должны быть рассмотрены шесть пар). Наш выбор статистики квадрата расстояния в качестве критерия отбора основан на предположении, что мы хотим уделить больше внимания влиянию рассматриваемой переменной на разделение ближайших групп.

 -включения, намного больше, чем для любой другой переменной. Стоит отметить, однако, что на этом шаге квадрат расстояния для переменной ANTINEUT более чем в 10 раз превосходит соответствующее значение для CUTAID, в то время как значения статистики
-включения, намного больше, чем для любой другой переменной. Стоит отметить, однако, что на этом шаге квадрат расстояния для переменной ANTINEUT более чем в 10 раз превосходит соответствующее значение для CUTAID, в то время как значения статистики  -включения для них почти равны.
-включения для них почти равны.
 -включения равна частной
-включения равна частной  -статистике, отвечающей увеличению дискриминантных возможностей за счет использования соответствующей переменной после того, как переменная CUTASIAN реализовала все свои возможности. А квадрат расстояния равен наименьшей из величин, полученных для всех шести пар групп с помощью CUTASIAN и данной переменной. Здесь у ANTINEUT наибольшее из данных наименьших значений.
-статистике, отвечающей увеличению дискриминантных возможностей за счет использования соответствующей переменной после того, как переменная CUTASIAN реализовала все свои возможности. А квадрат расстояния равен наименьшей из величин, полученных для всех шести пар групп с помощью CUTASIAN и данной переменной. Здесь у ANTINEUT наибольшее из данных наименьших значений.
 -включения, то мы выбрали бы MIXED. Расхождение вызвано тем, что каждый критерий придает особое значение собственному аспекту процесса различения.
-включения, то мы выбрали бы MIXED. Расхождение вызвано тем, что каждый критерий придает особое значение собственному аспекту процесса различения.
 -включения, что порой лучше отказаться от ее анализа.
-включения, что порой лучше отказаться от ее анализа.
 -удаления для ANTINEUT, падает до величины 0,996. Некоторые исследователи могут прийти к заключению, что удаление ANTINEUT оправдано, так как это значение действительно слишком мало. Тогда переходим к шагу 7, на котором будет рассматриваться включение CUTAID и ANTINEUT. Как только обнаруживается, что ни одна из этих переменных не имеет достаточно высокого значения статистики
-удаления для ANTINEUT, падает до величины 0,996. Некоторые исследователи могут прийти к заключению, что удаление ANTINEUT оправдано, так как это значение действительно слишком мало. Тогда переходим к шагу 7, на котором будет рассматриваться включение CUTAID и ANTINEUT. Как только обнаруживается, что ни одна из этих переменных не имеет достаточно высокого значения статистики  -включения, процесс отбора будет остановлен и в дальнейшем дискриминантном анализе и классификации будут использоваться другие четыре переменные.
-включения, процесс отбора будет остановлен и в дальнейшем дискриминантном анализе и классификации будут использоваться другие четыре переменные.
 -статистики не является значимым на шаге 3. Поэтому после шага 2 можно перейти к классификации. Если классифицировать только по двум переменным (CUTASIAN и ANTINEUT), ошибок будет столько же или меньше, чем при классификации по всем шести переменным.
-статистики не является значимым на шаге 3. Поэтому после шага 2 можно перейти к классификации. Если классифицировать только по двум переменным (CUTASIAN и ANTINEUT), ошибок будет столько же или меньше, чем при классификации по всем шести переменным.