Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
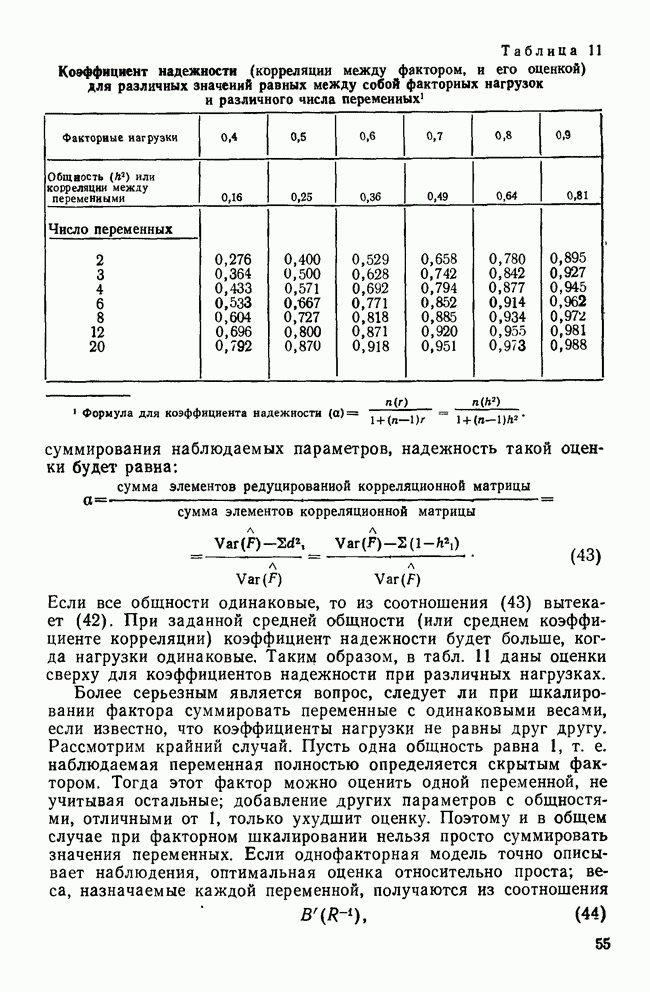
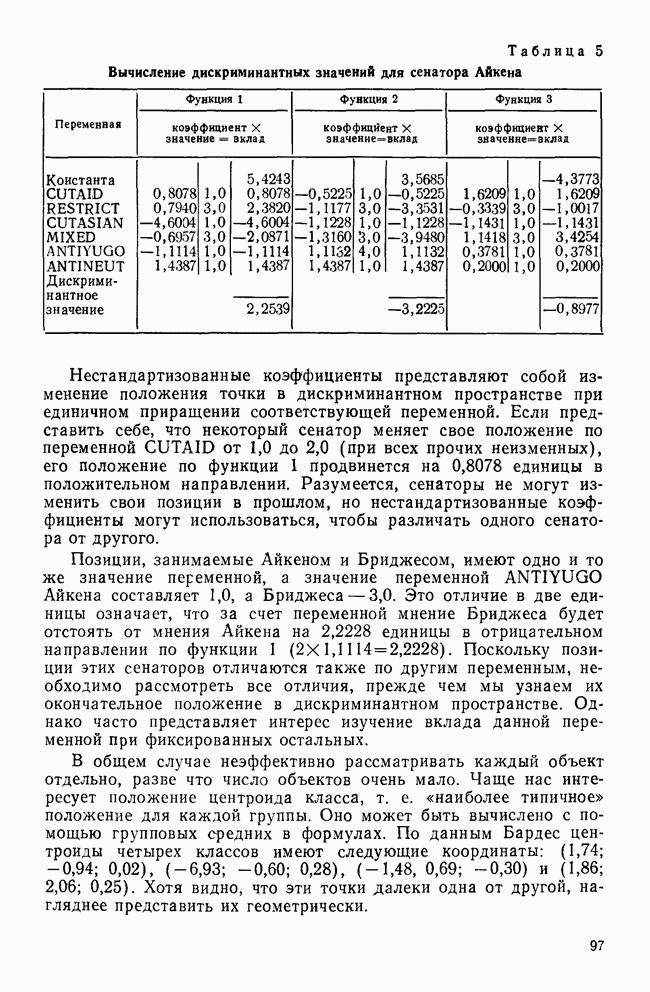
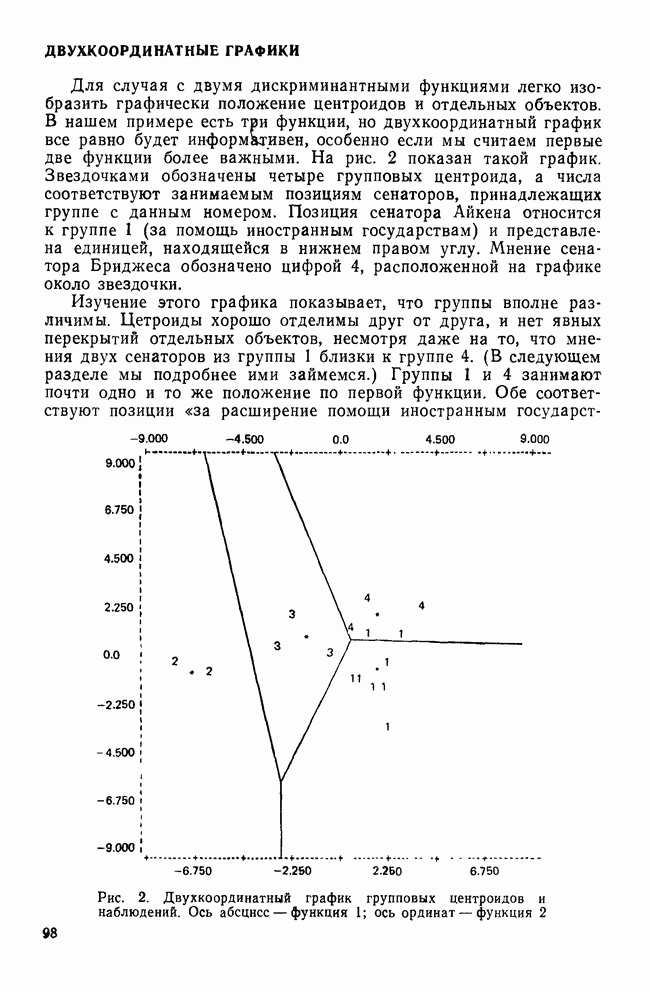
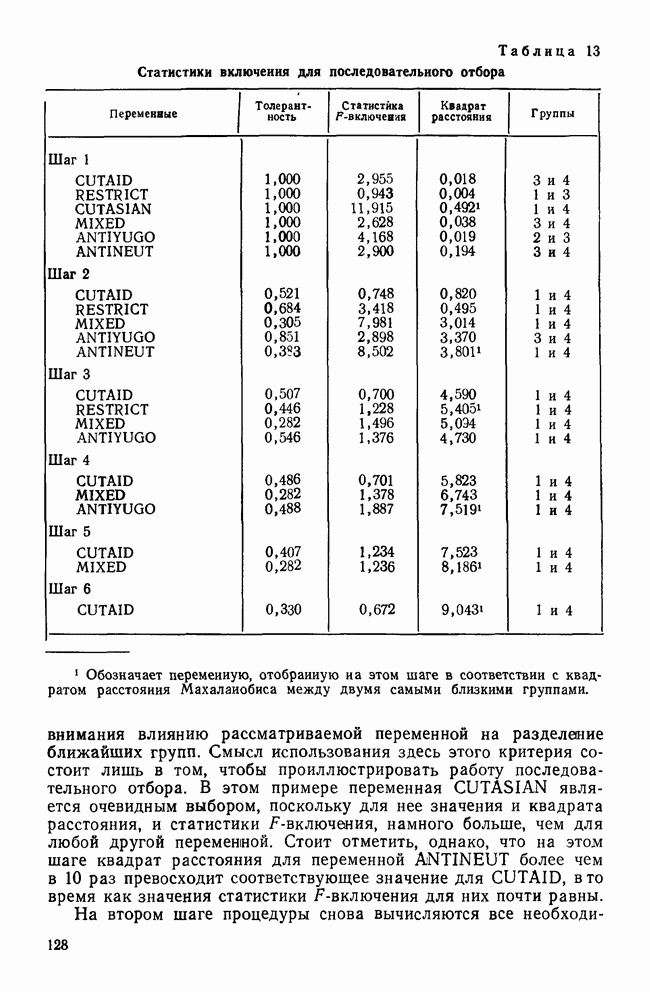
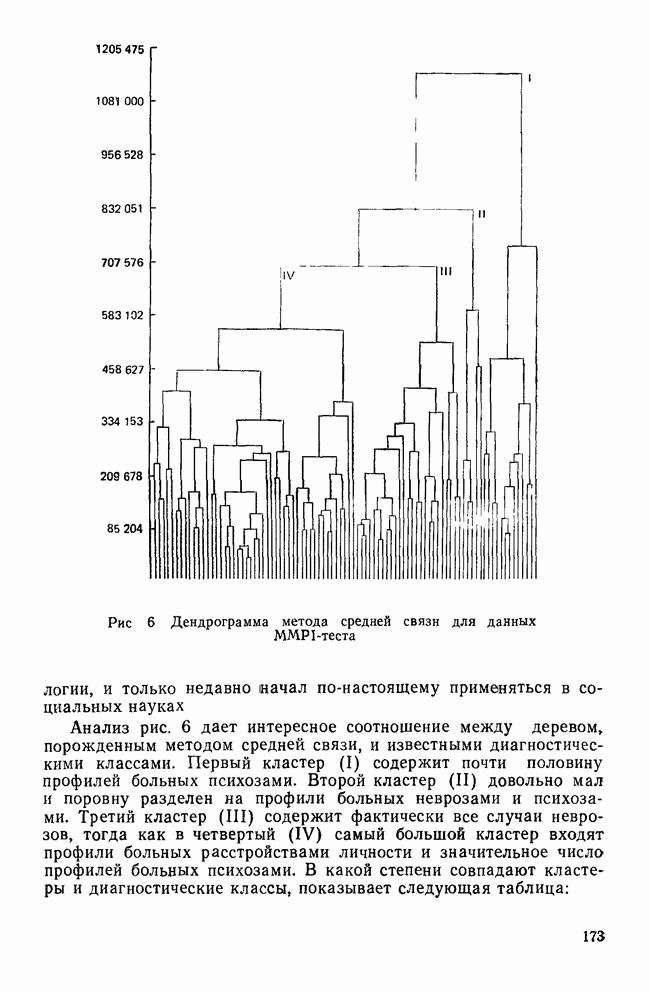
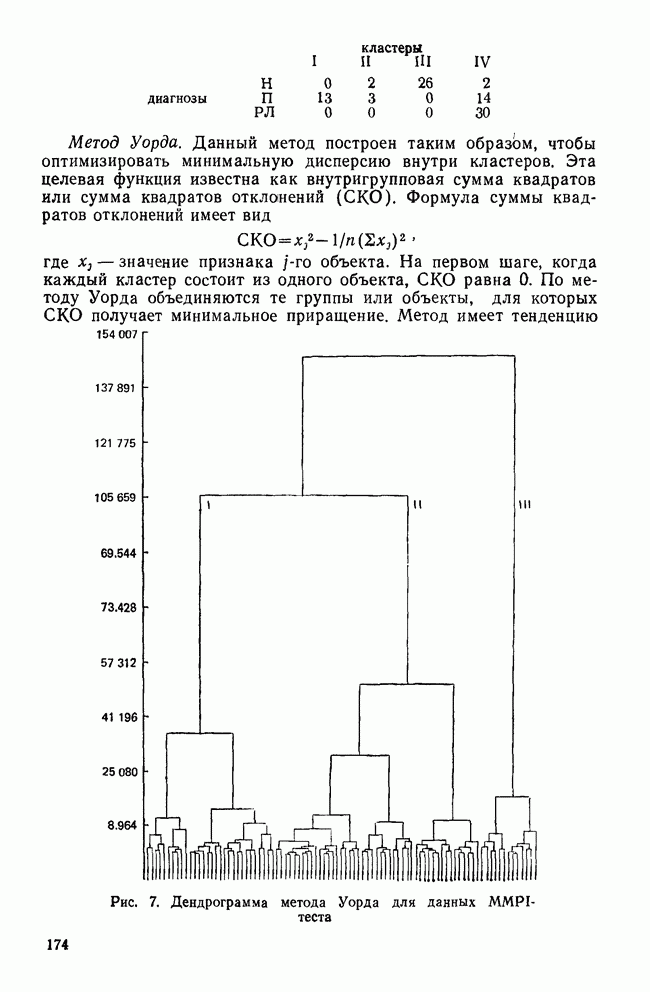
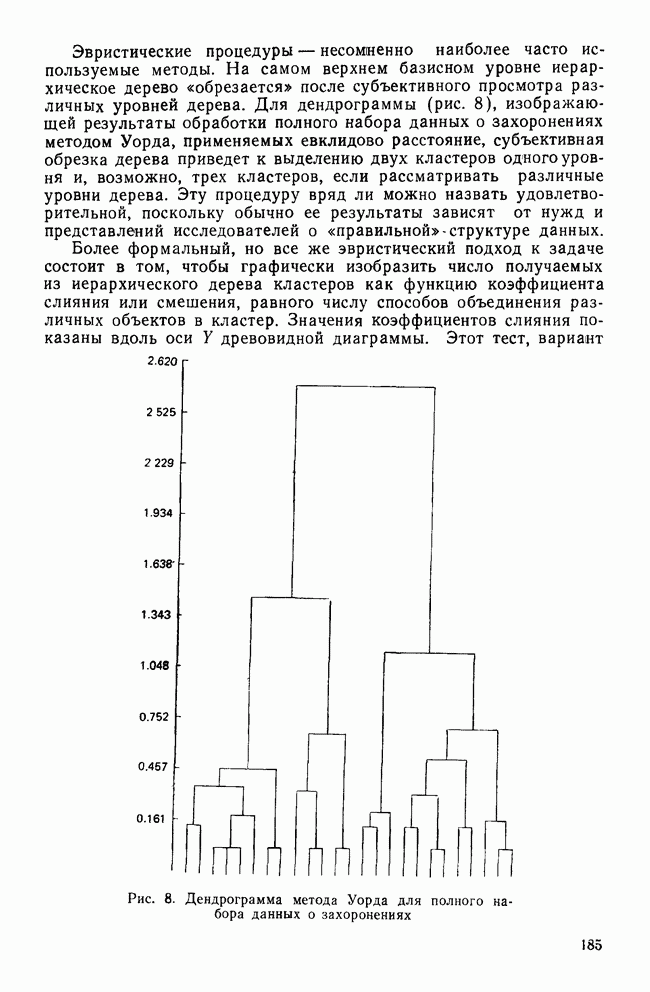
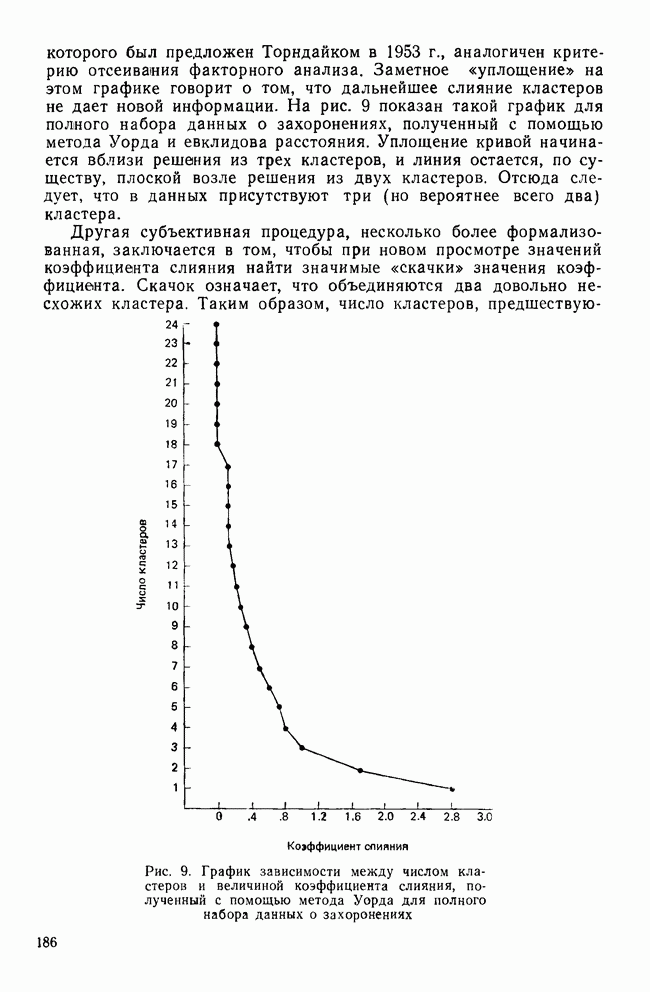
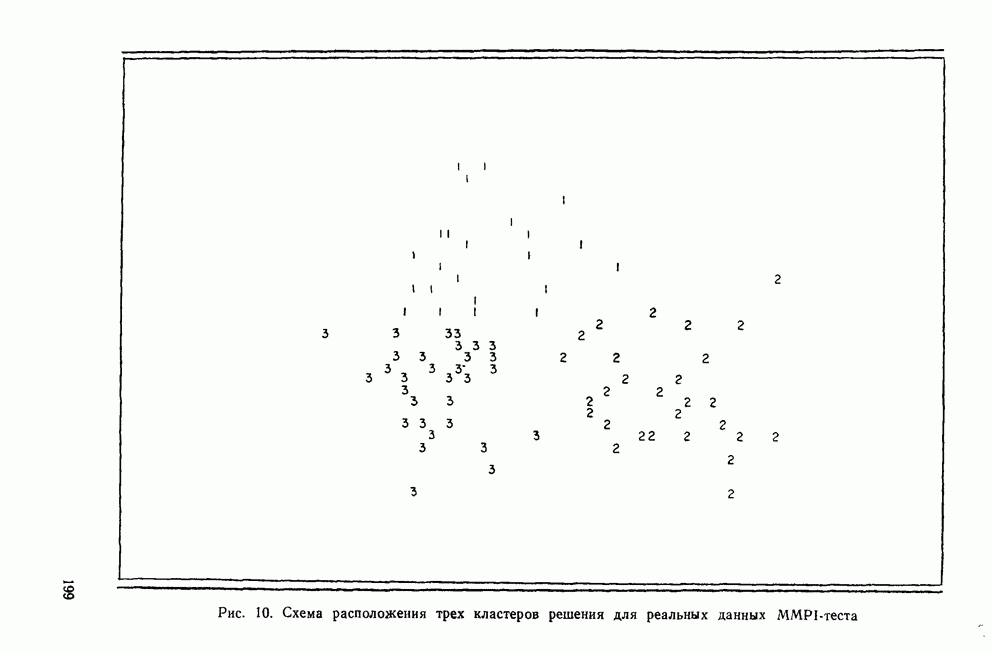
IV. МЕТОДЫ ПРОВЕРКИ ОБОСНОВАННОСТИ РЕШЕНИЙВ этом разделе обсуждаются пять методов проверки достоверности (обоснованности) решений кластерного анализа: 1) кофенетическая корреляция; 2) тесты значимости для признаков, используемых при создании кластеров; 3) повторная выборка; 4) тесты значимости для независимых признаков и 5) методы Монте-Карло. КОФЕНЕТИЧЕСКАЯ КОРРЕЛЯЦИЯКофенетическая корреляция была впервые предложена Сокэлом и Рольфом в 1962 г. Она является главной мерой обоснованности решения, предлагаемой специалистами по численной таксономии (Sneath and Sokal, 1973). Эта мера используется только вместе с иерархическим агломеративным методом. Кофенетическая корреляция необходима для определения, насколько хорошо характер отношений (сходство/несходство) между объектами представляется деревом или дендрограммой, полученными с помощью иерархического метода кластеризации. Решение для дашшх о шести захоронениях, полученное методом одиночной связи с использованием коэффициента Жаккарда, представлено в виде иерархического дерева (см. рис. 3). Просмотрев дерево, можно получить представление о сходствах для любой пары объектов. Например, объект ПЖЭ (подросток, женский пол, элитарный) и ВЖЭ (взрослый, женский пол, элитарный) довольно похожи, поскольку они объединяются относительно «высокой» ветвью дерева. С другой стороны, объекты РЖЭ и ПЖЭ мало похожи, так как они не объединяются в единый кластер до самого последнего шага (т. е. они объединяются лишь у основания дерева). С помощью дерева, приведенного на рис. 3, можно построить вторичную матрицу сходства между всеми парами объектов, соответствующую рассматриваемому иерархическому решению:
Каждый элемент матрицы представляет собой значение сходства для уровня, на котором определенная пара объектов была объединена в общий кластер. Важно отметить, что эта матрица сходства имеет не более Исходная матрица содержит до
Кофенетическая корреляция является корреляцией между значениями исходной матрицы сходства и вторичной матрицы сходства. Таким образом, кофенетическая корреляция для решения, полученного методом одиночной связи и показанного на рис. 3, равна Несмотря на довольно частое применение, кофенетическая корреляция имеет и явные недостатки. Во-первых, использование смешанного момента корреляции предполагает, что нормально распределенные значения в двух матрицах коррелированы. Это предположение обычно не выполняется для значений вторичной матрицы сходства, так как кластерные методы в значительной степени определяют распределение значений сходства в этой матрице. Таким образом, применение коэффициента корреляции для оценки степени сходства между значениями двух матриц не является оптимальным. Во-вторых, поскольку число различных значений во вторичной матрице сходства меньше, чем в исходной матрице, то и количество информации, содержащейся в каждой из двух матриц, весьма различно. Холгерссон (1978) провел исследование с помощью метода Монте-Карло для того, чтобы проанализировать характеристики кофенетической корреляции, и обнаружил, что она является плохим индикатором качества кластерного решения.
|
 |
Оглавление
|



































































































































































































 различных элементов, так как для иерархического агломеративного метода всегда требуется
различных элементов, так как для иерархического агломеративного метода всегда требуется  шагов объединения.
шагов объединения.
 различных элементов и имеет вид
различных элементов и имеет вид

