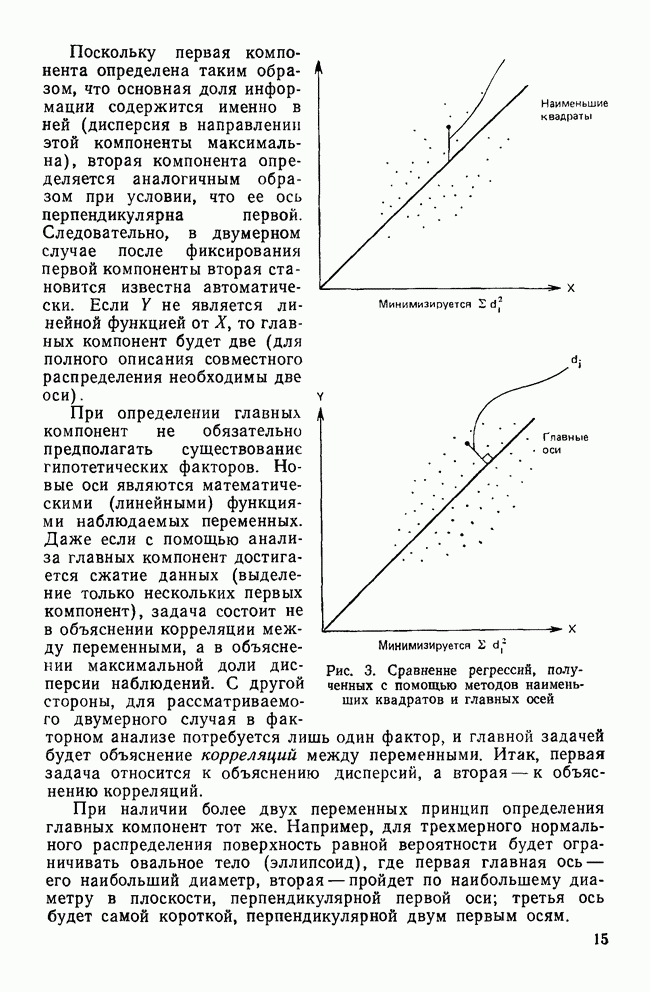
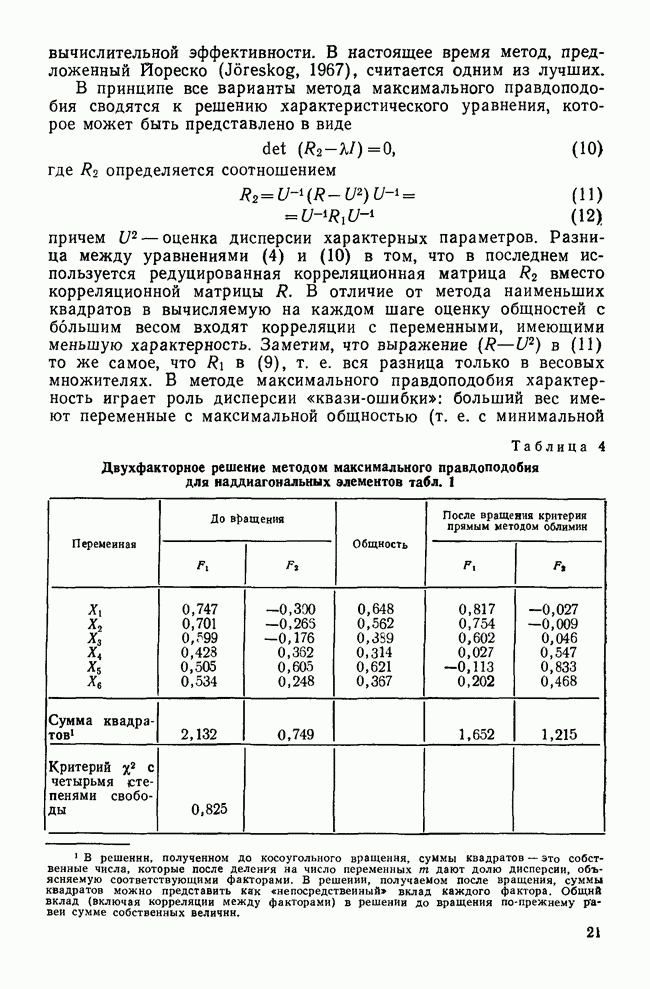
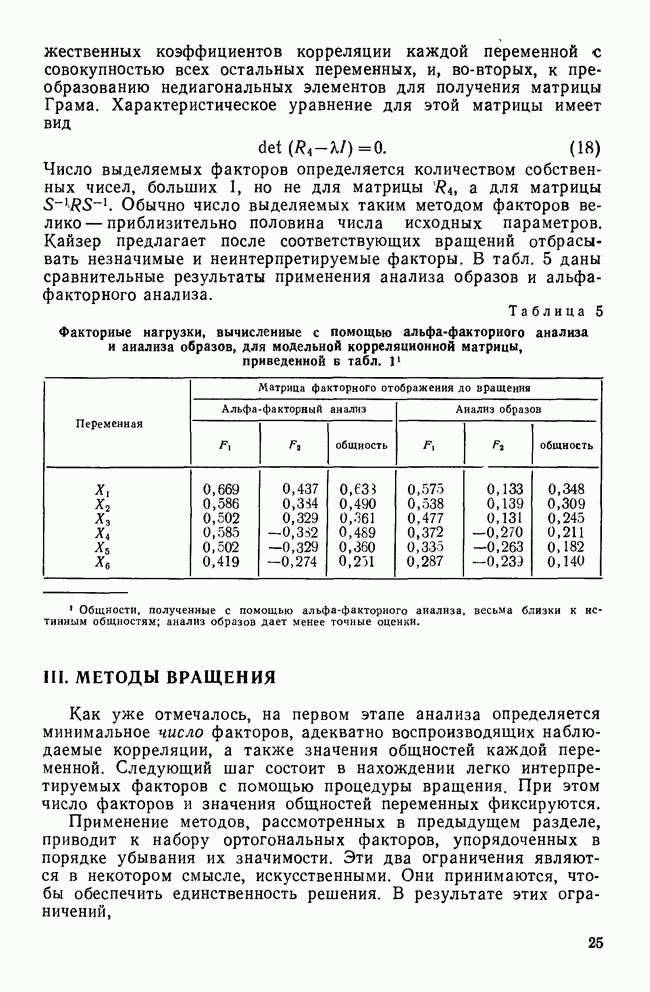
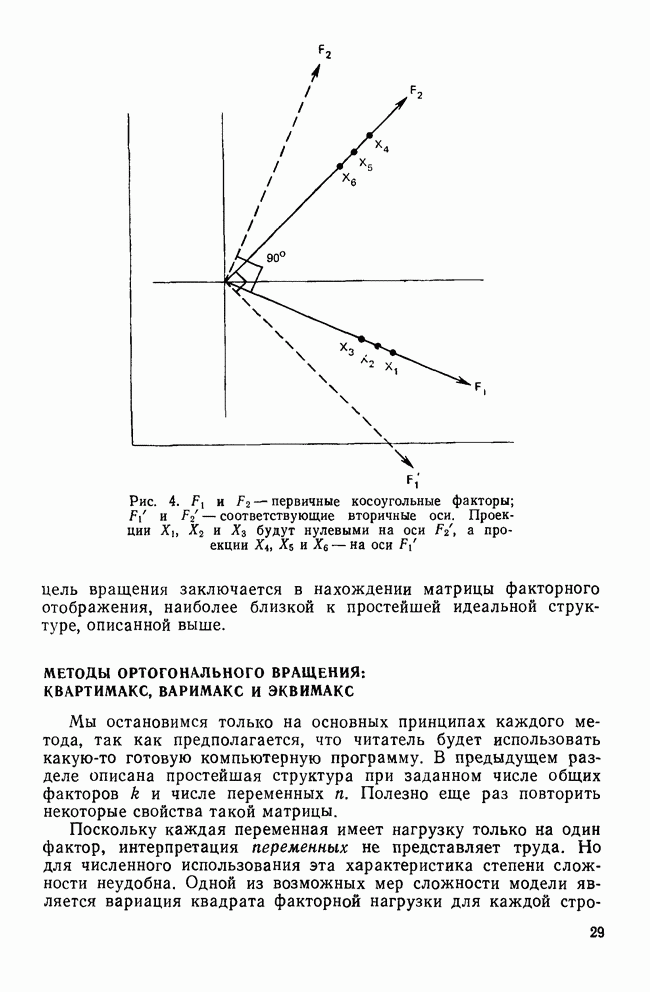
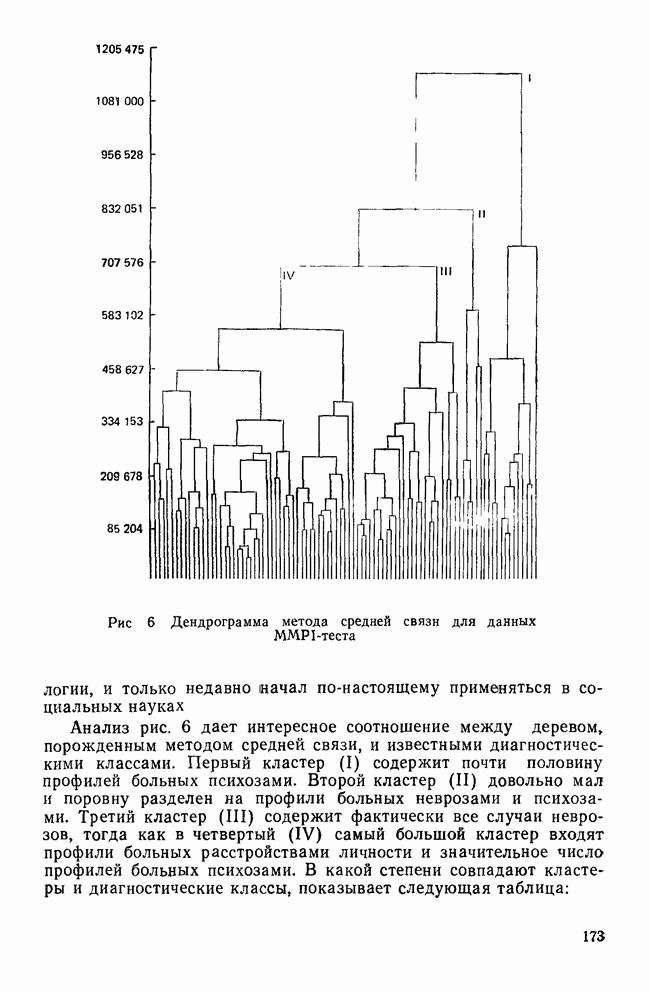
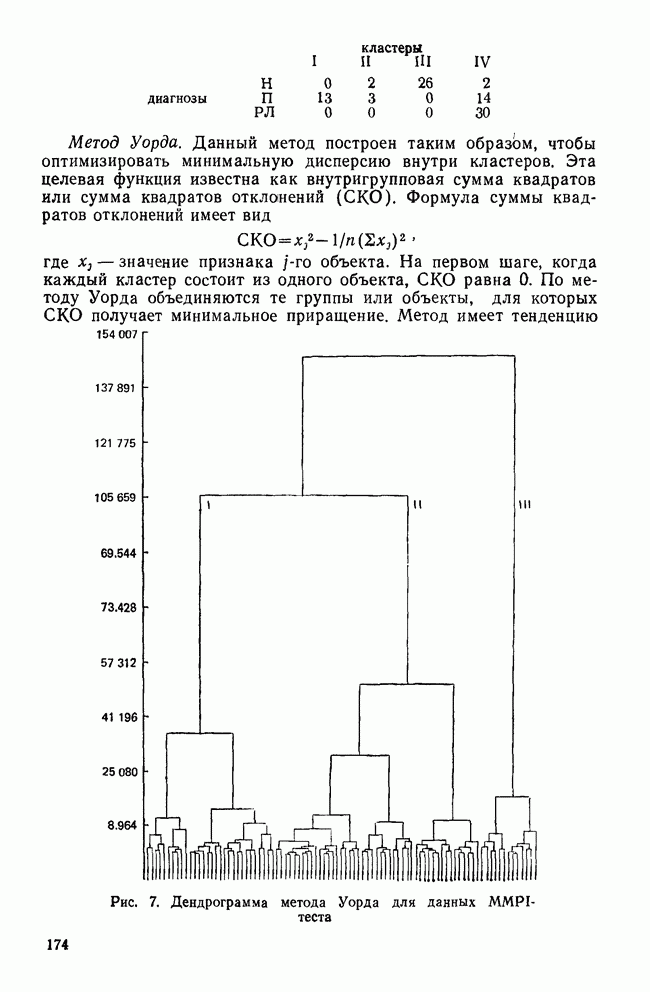
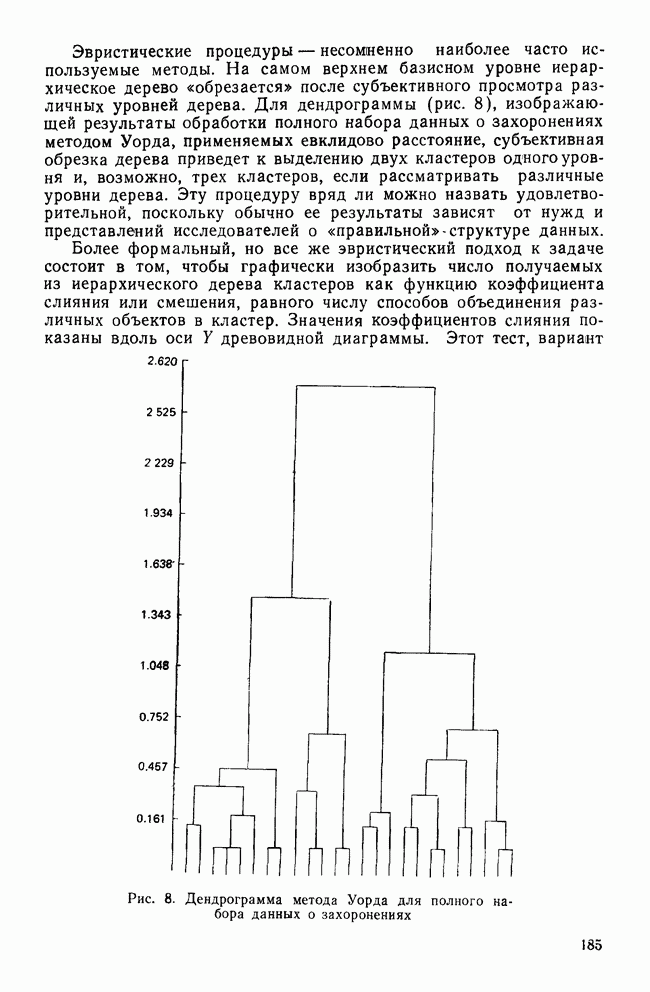
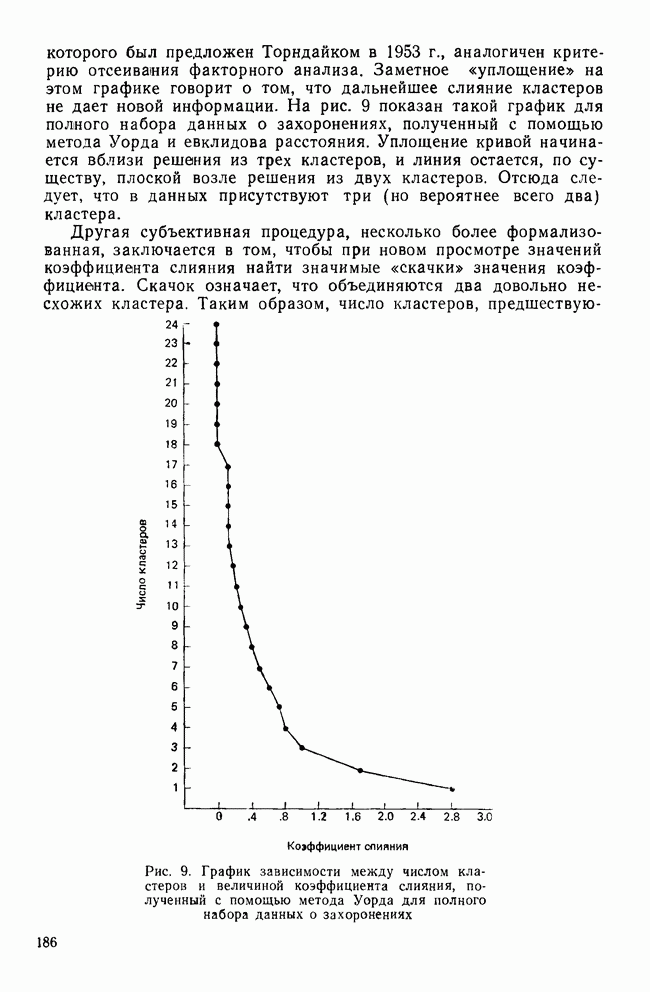
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
ПРОЦЕДУРЫ МОНТЕ-КАРЛОПоследний подход к обоснованию достоверности решений используется сравнительно мало и в некоторой степени труден для изложения. В сущности, этот подход заключается в применении процедур Монте-Карло, применяющих генераторы случайных чисел, для создания наборов данных с основными характеристиками, соответствующими характеристикам реальных данных, но не содержащих кластеров. Одни и те же методы кластеризации употребляются как к реальным данным, так и к искусственным, а полученные решения сравниваются с помощью подходящих методов. Пример такого процесса, использующий данные MMPI-теста, возможно лучший способ проиллюстрировать этот подход. Шаг 1. Создание рандомизированного набора данных. С помощью генератора случайных чисел создается множество искусственных данных, которое не имеет кластеров, но обладает теми же характеристиками, что и реальный набор данных. Чтобы сделать это, мы вычислили общие средние, стандартные отклонения и матрицу корреляций между признаками для исходного множества данных MMPI-теста о 90 больных. Далее для создания рандомизированного набора данных мы написали короткую программу на Фортране, которая использует генератор случайных чисел из пакета программ IMSL. Этот генератор порождает данные, являющиеся выборкой из генеральной совокупности с многомерным нормальным распределением с заданным вектором средних и заданной ковариационной матрицей. Первый шаг может показаться труднопреодолимым для пользователя, но в действительности такую программу довольно легко написать: требуется лишь 36 операторов Фортрана. В результате получаем рандомизированное множество данных о 90 гипотетических больных, которое не содержит кластеров. Шаг 2. Применение одного и того же метода кластерного анализа к обоим наборам данных. Для сравнения результатов кластерного анализа каждый из наборов данных подвергся обработке по итерационному методу Средние, найденные по рандомизированным данным, сильно отличаются от средних, найденных по реальным данным. Кроме того, отметим, что средние этих групп можно упорядочить по возрастанию. Другими словами, один кластер содержит сильно приподнятые профили, другой — умеренно приподнятые, а средние третьего кластера довольно малы. Наш опыт применения кластерного анализа к рандомизированным данным свидетельствует, что многие методы кластеризации формируют такие кластеры из случайных данных, которые можно упорядочить по возрастанию их средних. Шаг 3. Сравнение кластерных решений. Последний шаг заключается в сравнении выходных статистик кластерных решений, полученных по реальному и искусственному наборам данных. В этом случае мы воспользуемся мерой достоверности, основанной на
Обратите внимание, что большинство значений довольно велико. Действительно, за исключением значения признака Следующее множество значений представляет собой соответствующие F-отношения трехкластерного решения в случае рандомизированных данных. Поскольку в рандомизированных данных кластеров нет, то эти значения являются одноточечными оценками нулевых значений .Р-отношений. Вообще говоря, значения F-отношений трехкластерного решения не меньше значений
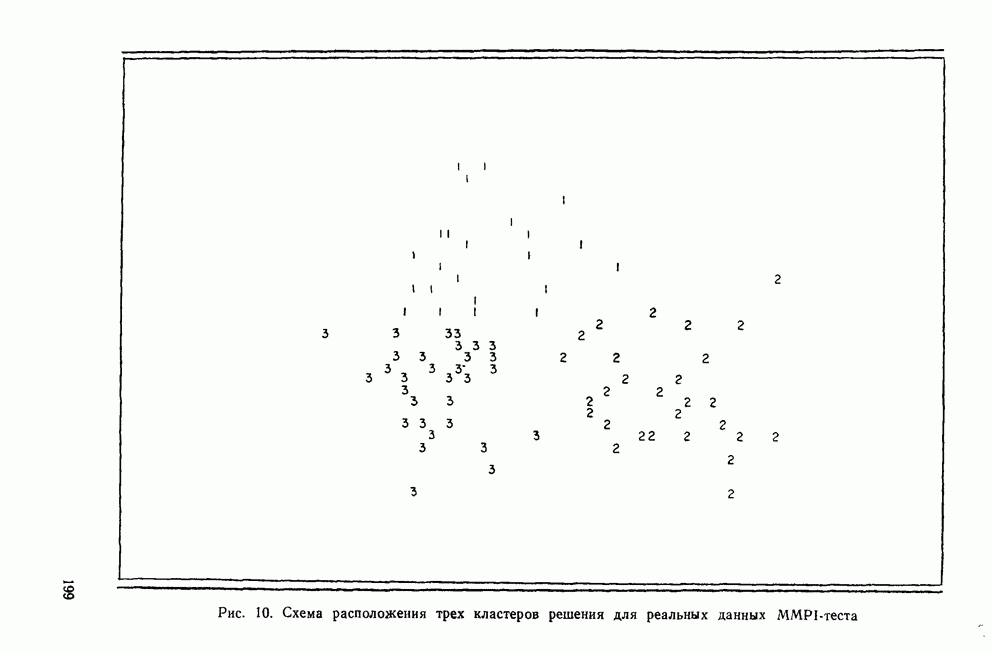
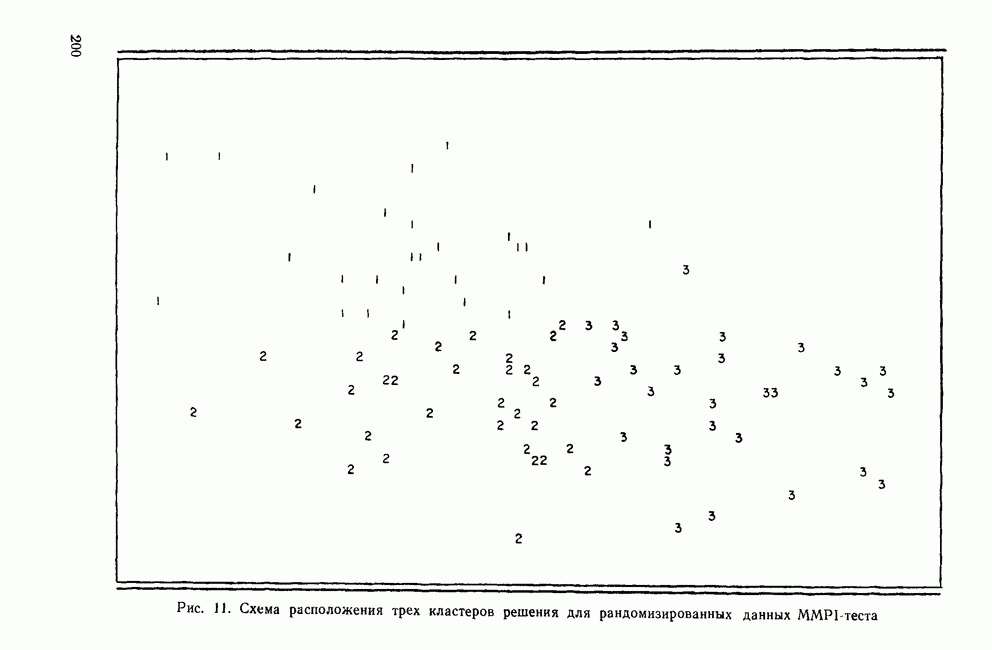
О чем же говорит результат сравнения? F-отношение, вычисленное с помощью программы BMDPKM, дает пользователю представление об однородности кластеров. Когда рассматриваются абсолютные значения первого множества F-отношений, они кажутся разумно большими и, по всей видимости, говорят о том, что кластеры в какой-то степени однородны. Однако F-отношения для данных, не имеющих кластеров, столь же велики. Это доказывает, что первое множество F-отношений недостаточно велико для того, чтобы пользователь мог отвергать нулевую гипотезу об отсутствии кластеров. Графический вывод программы BMDPKM можно использовать для наглядного представления структуры результатов. На рис. 10 показана схема расположения трех кластеров, представленных в двумерном пространстве основных компонент. На этой схеме очень хорошо видны три кластера. Однако если также изобразить кластеры рандомизированных данных (рис. 11), то три «кластера» кажутся непересекающимися, но не столь плотными, как реальные кластеры. Заметьте, что на схемах между кластерами нет очевидных границ. Вместо этого графическое отображение обоих решений показывает, что кластеры могут быть просто произвольным разбиением полного набора данных. Сравнивая графическое изображение реальных данных с изображением рандомизированных данных, видно, что пользователю будет трудно отбросить нулевую гипотезу об отсутствии кластеров. Следовательно, по результатам работы программы можно заключить, что решение из трех кластеров соответствует структуре реальных данных и что сформированные кластеры однородны и хорошо разделены. Использование метода Монте-Карло позволяет формализовать проведение сравнительного анализа результатов вычислительных программ кластеризации. Рассмотрим еще один набор данных MMPI-теста для 90 больных. Этот набор данных был выбран таким образом, чтобы имеющиеся в нем три группы больных (с психозами, неврозами и расстройствами личности) были очень плотными и хорошо выраженными. Вновь выполним три шага: 1) формирование рандомизированного множества данных; 2) проведение кластерного анализа реальных и рандомизированных данных; 3) сравнение результатов. Применялся тот же самый метод кластеризации BMDPKM. Результирующие выходные статистики F-отношения показаны ниже: (см. скан) Рис. 10. Схема расположения трех кластеров решения для реальных данных MMPI-теста (см. скан) Рис. 11. Схема расположения трех кластеров решения для рандомизированных данных ММРI-теста
Заметьте насколько больше
|
 |
Оглавление
|







































































































































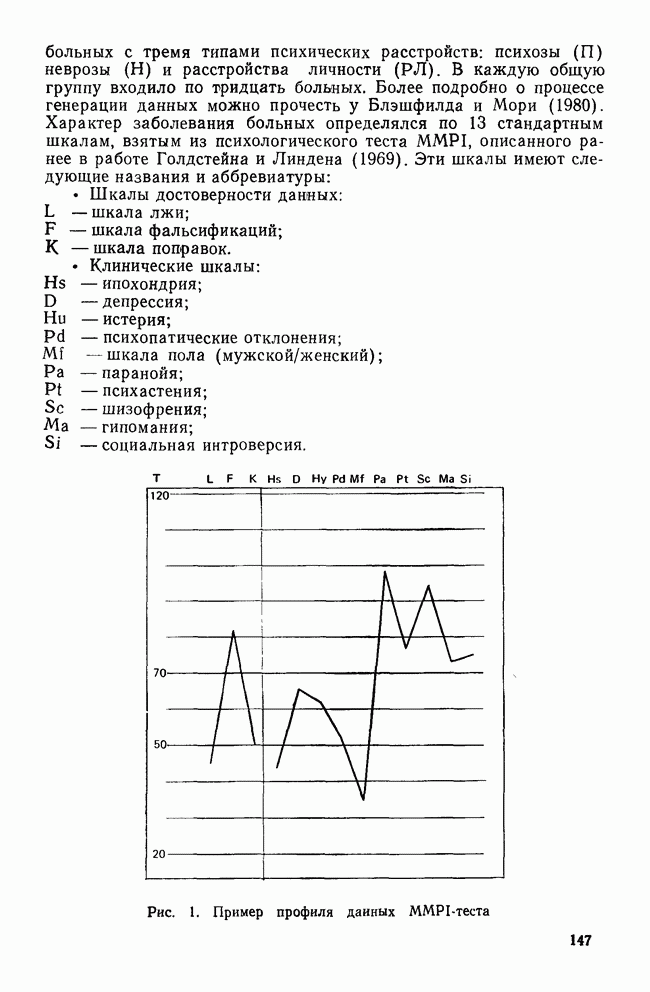








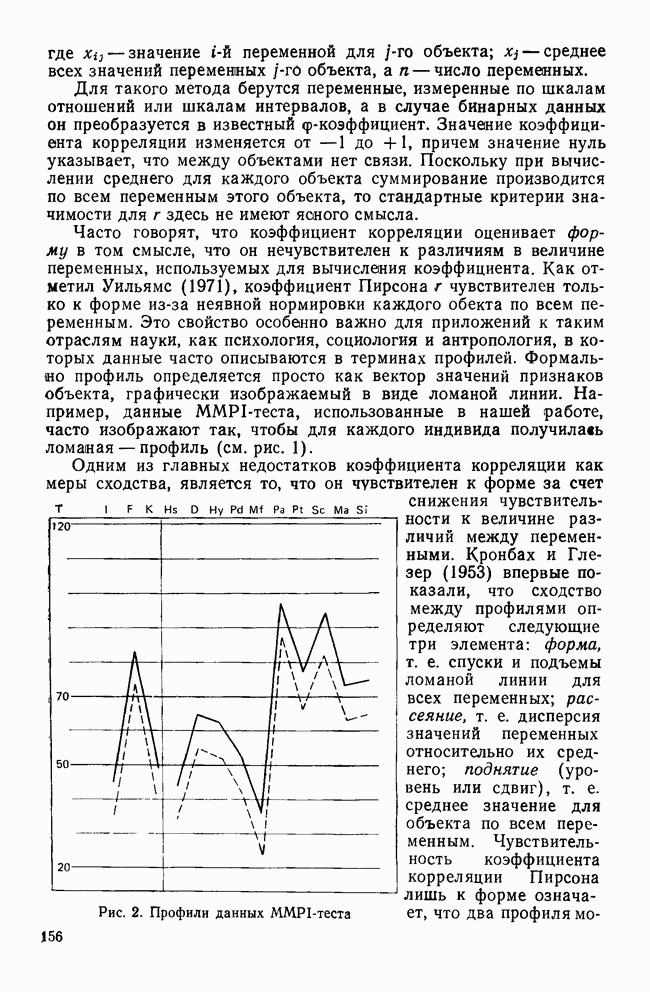













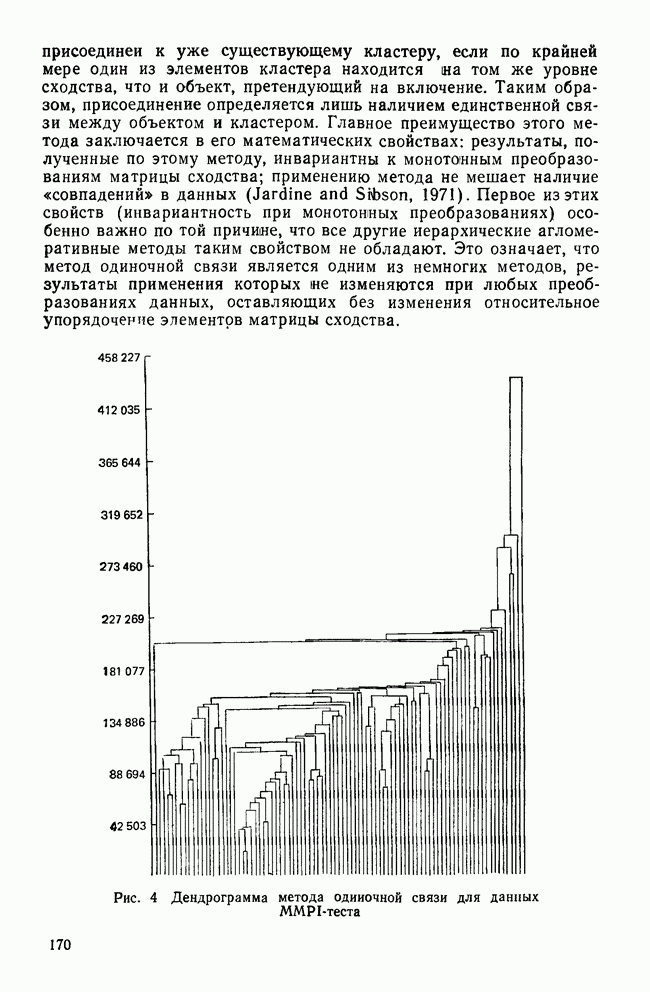
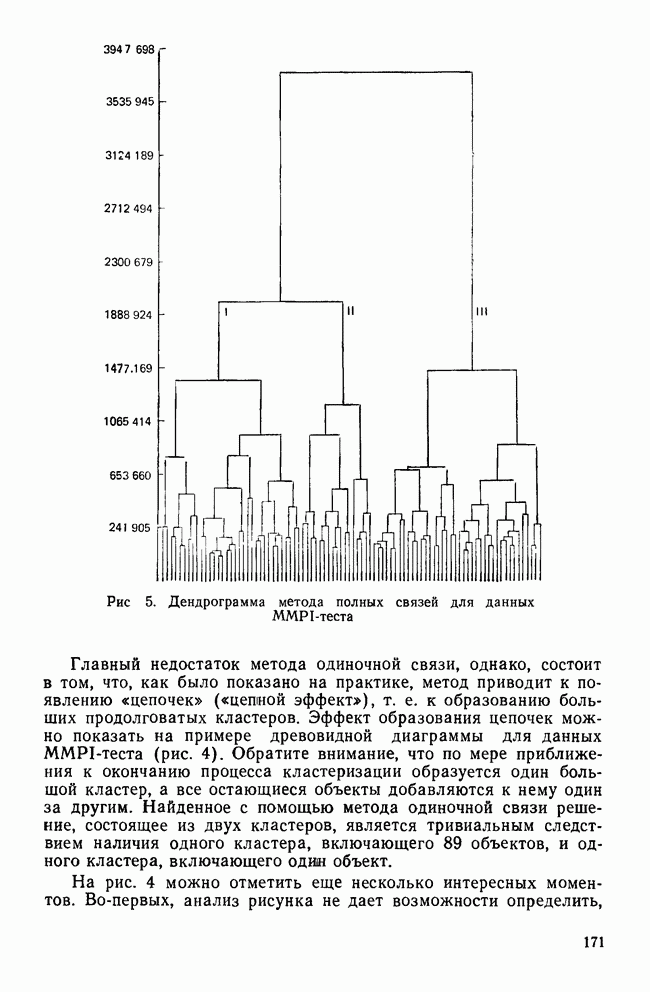






































 -средних (мы воспользовались процедурой BMDPKM). Программа начала свою работу с создания начального разбиения, а затем последовательно применяла метод
-средних (мы воспользовались процедурой BMDPKM). Программа начала свою работу с создания начального разбиения, а затем последовательно применяла метод  -средних, описанный в разд. III, для формирования заданного числа кластеров. Поскольку известно, что реальные данные состоят из трех групп, то мы решили рассмотреть только решение, в которое входят три кластера.
-средних, описанный в разд. III, для формирования заданного числа кластеров. Поскольку известно, что реальные данные состоят из трех групп, то мы решили рассмотреть только решение, в которое входят три кластера.
 -отношении, которая имеется в пакете программ BMDPKM. Значения F-отношения, вычисленные с помощью однофакторной ANOVA по кластерам для всех 13 признаков, приводятся ниже:
-отношении, которая имеется в пакете программ BMDPKM. Значения F-отношения, вычисленные с помощью однофакторной ANOVA по кластерам для всех 13 признаков, приводятся ниже:

 -отношение принимает значения от 9,4 до 69,7. Если применить тесты значимости к этим 13 признакам, то 12 из них окажутся значимыми. Однако, как было показано выше, такое использование тестов значимости неправомерно.
-отношение принимает значения от 9,4 до 69,7. Если применить тесты значимости к этим 13 признакам, то 12 из них окажутся значимыми. Однако, как было показано выше, такое использование тестов значимости неправомерно.
 -отношений реальных данных. Действительно, эти
-отношений реальных данных. Действительно, эти  -отношения имеют значения от 11,9 до 77,4 (опять, исключая признак
-отношения имеют значения от 11,9 до 77,4 (опять, исключая признак  ):
):


 -отношения для реальных данных, чем для рандомизированных. Почти все они являются трехзначными числами, и по любым стандартам они будут казаться очень большими величинами. На рис. 12 и 13 приведены схемы расположения кластеров для реальных и рандомизированных данных соответственно. Обратите внимание, что для реальных данных кластеры очень плотные и между ними существуют четкие границы. У рандомизированных данных такой структуры не отмечается. Хотя большинство процедур обоснования достоверности решений изучены плохо и требуют осторожного обращения, некоторые из них необходимо использовать во всех исследованиях, где применяется кластерный анализ. Читателю, желающему продолжить изучение затронутой здесь темы, предлагаем следующие работы: (Dubes and Jain, 1980; Rohlf, 1974; Skinner and Blashfield, 1982; Chambers and Kleiner, 1982).
-отношения для реальных данных, чем для рандомизированных. Почти все они являются трехзначными числами, и по любым стандартам они будут казаться очень большими величинами. На рис. 12 и 13 приведены схемы расположения кластеров для реальных и рандомизированных данных соответственно. Обратите внимание, что для реальных данных кластеры очень плотные и между ними существуют четкие границы. У рандомизированных данных такой структуры не отмечается. Хотя большинство процедур обоснования достоверности решений изучены плохо и требуют осторожного обращения, некоторые из них необходимо использовать во всех исследованиях, где применяется кластерный анализ. Читателю, желающему продолжить изучение затронутой здесь темы, предлагаем следующие работы: (Dubes and Jain, 1980; Rohlf, 1974; Skinner and Blashfield, 1982; Chambers and Kleiner, 1982).