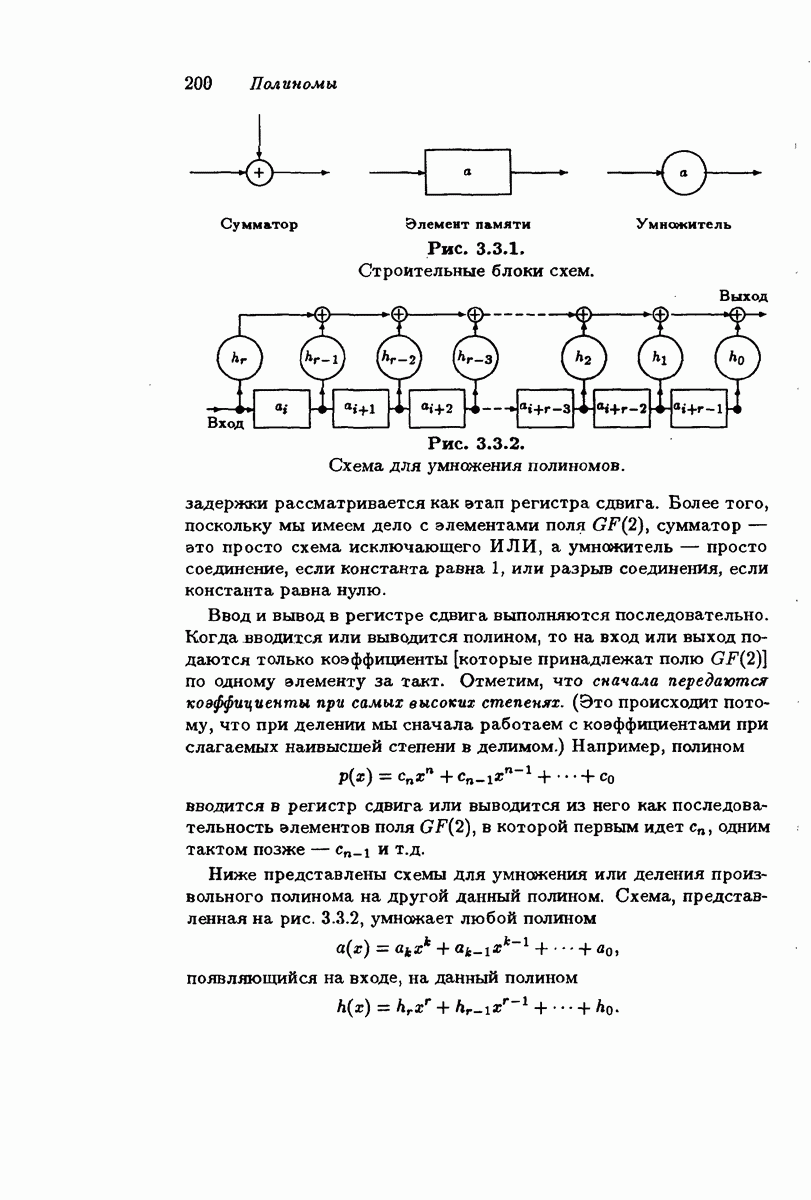
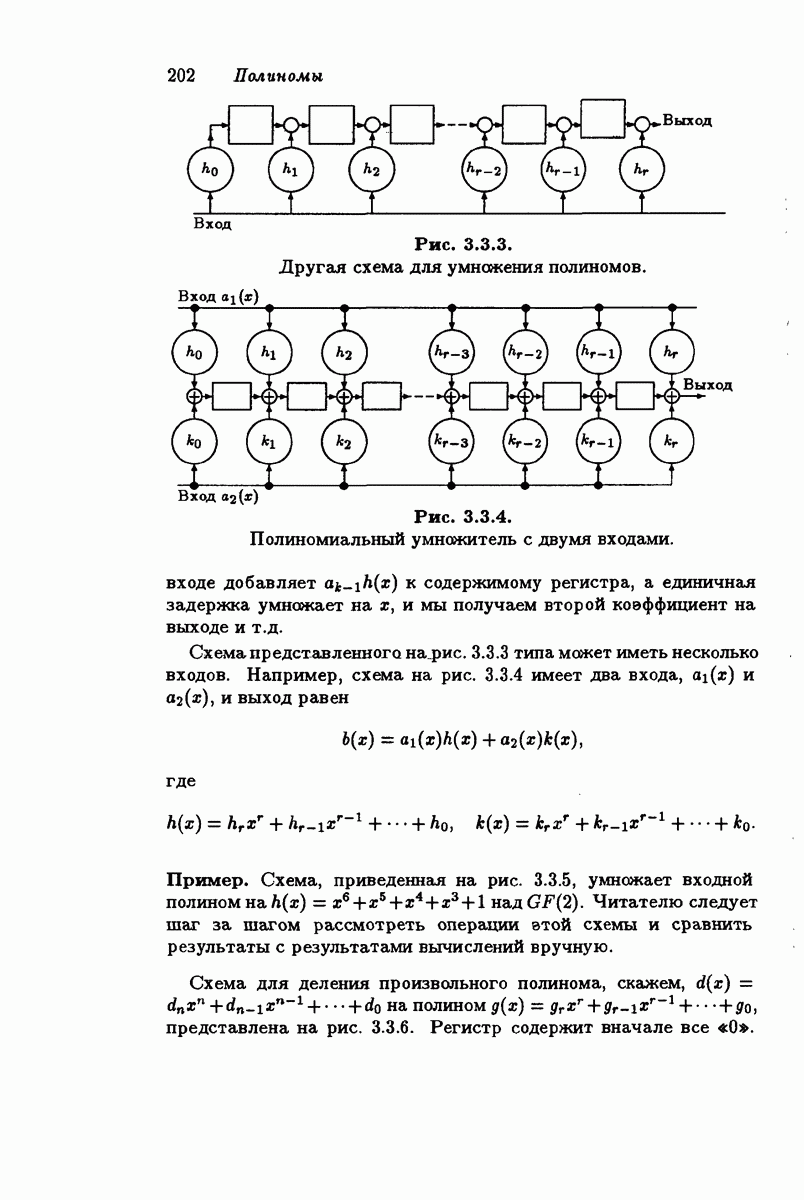
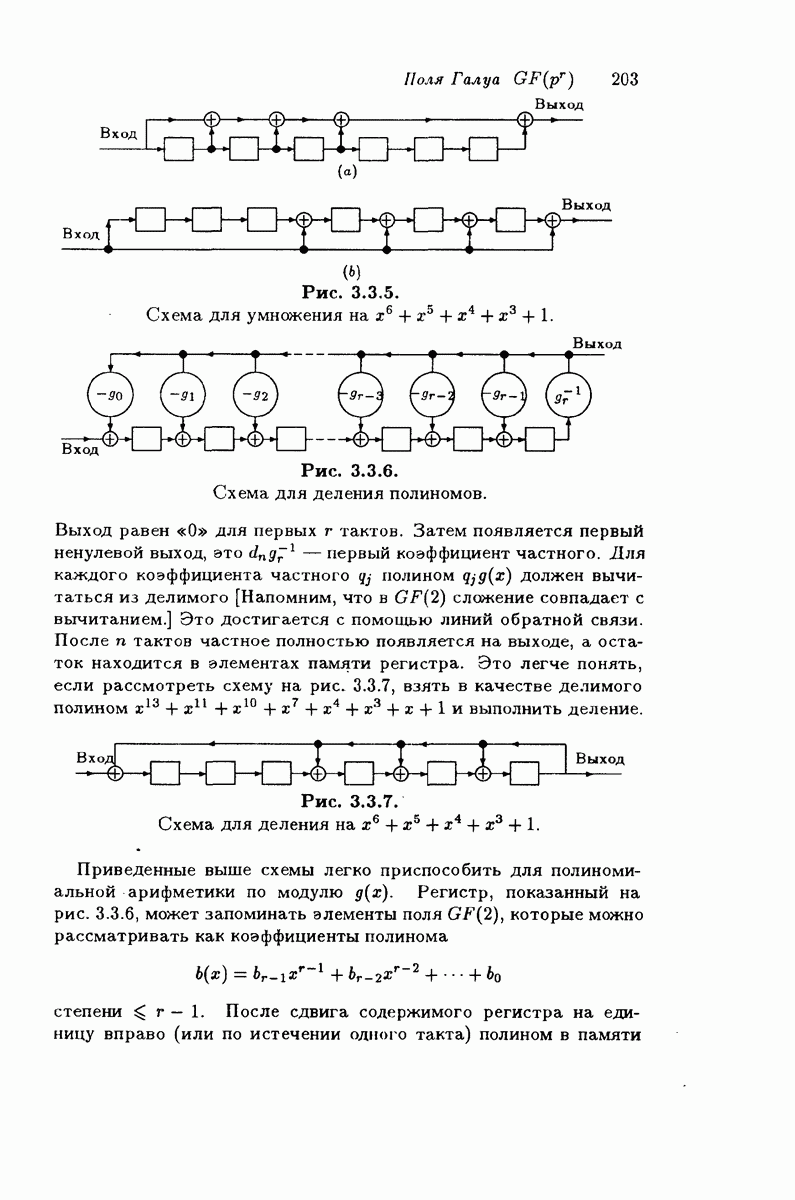
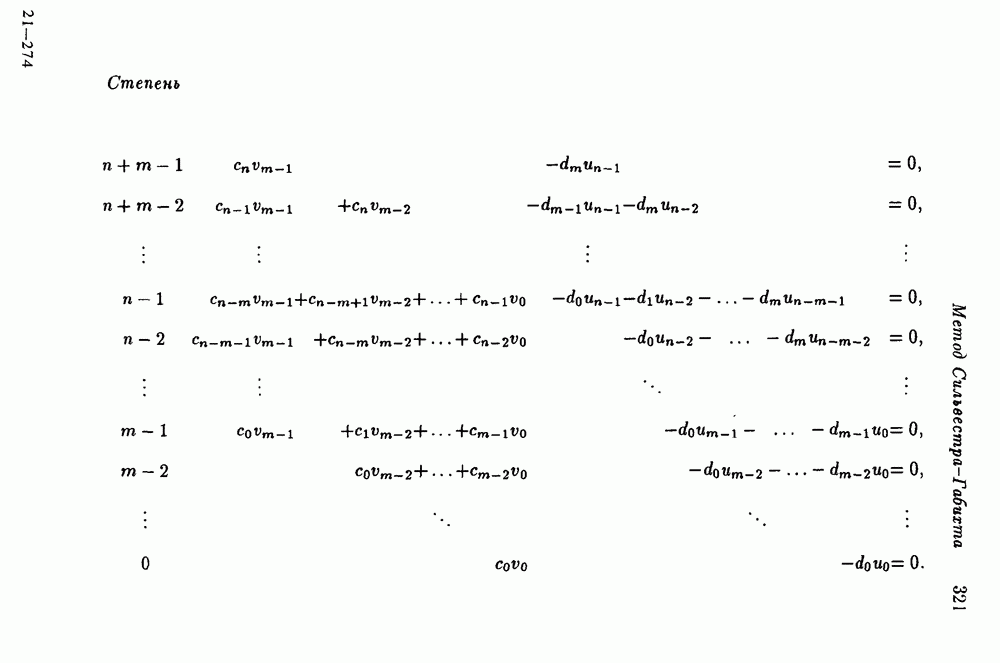
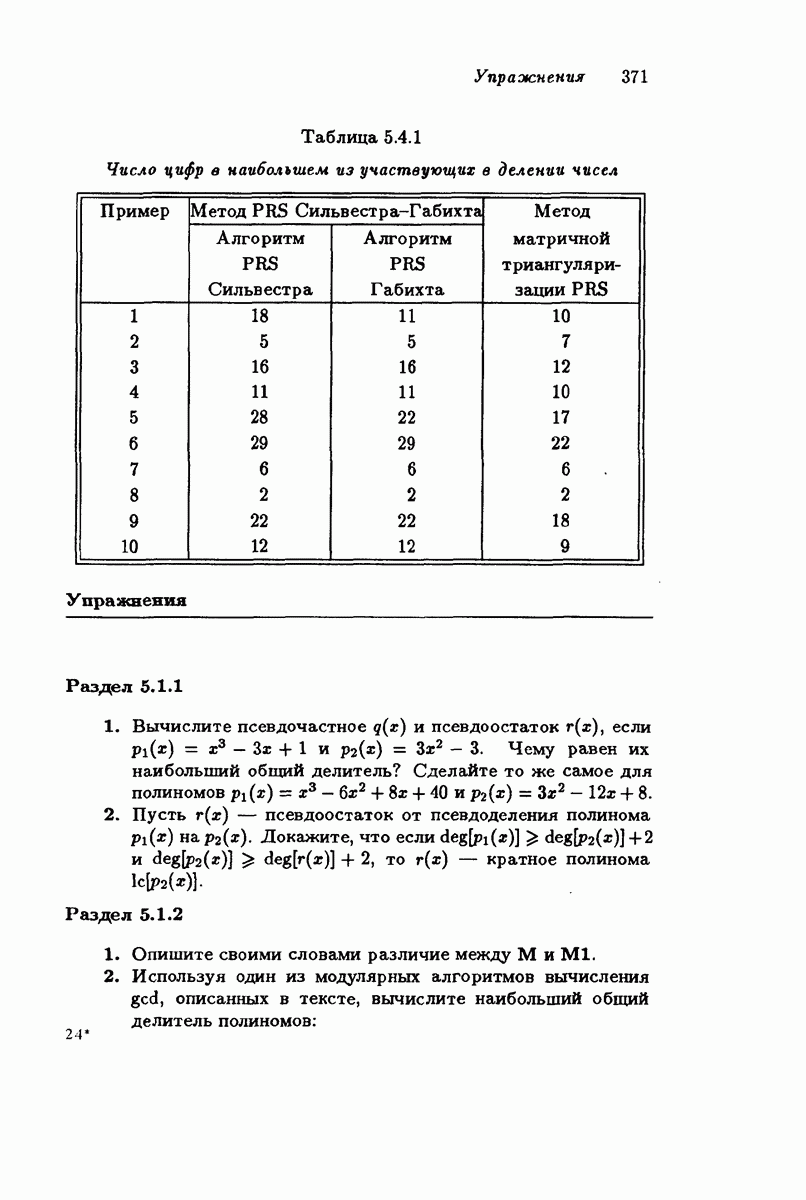
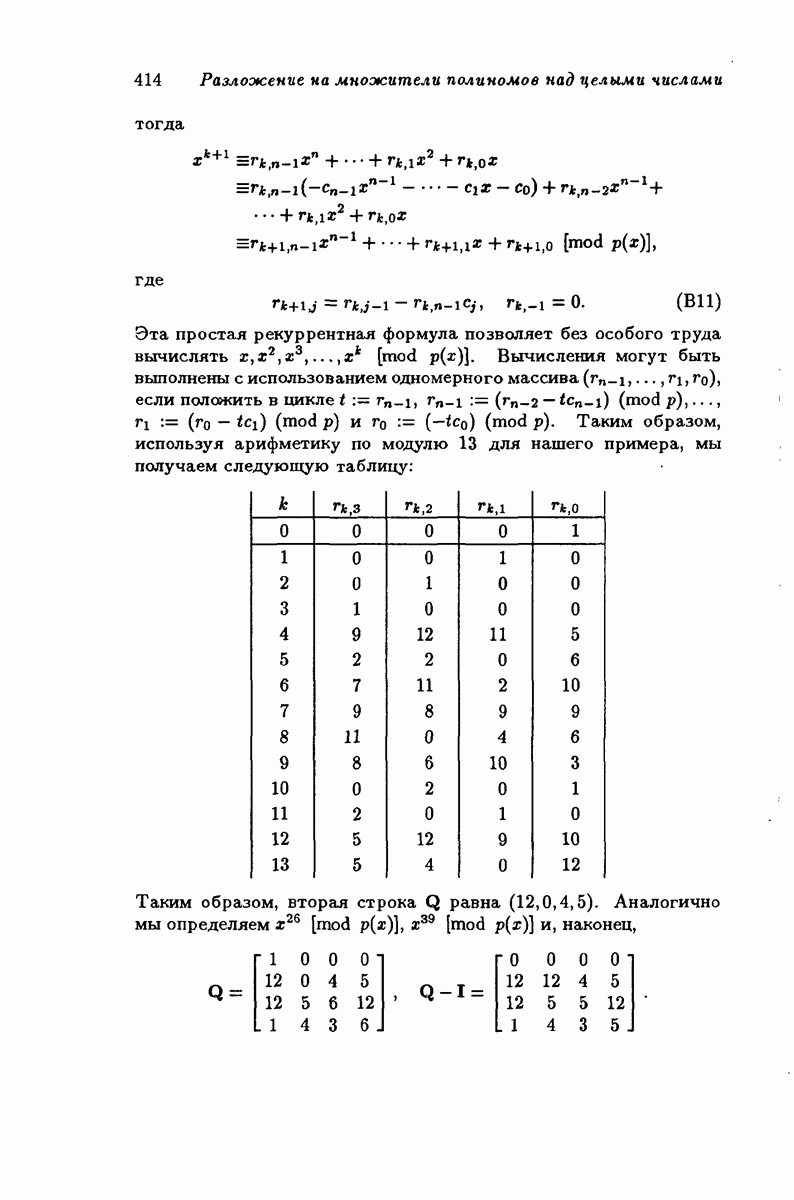
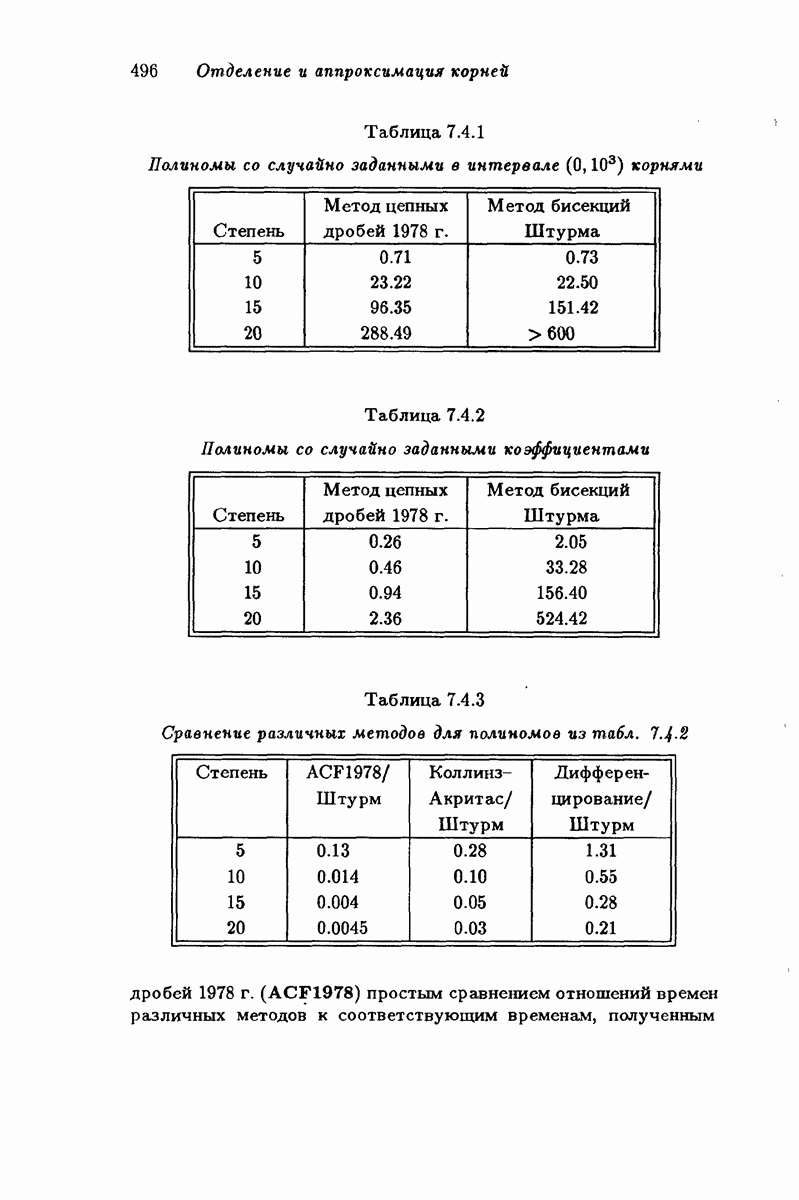
4.1.1. Коды Хэмминга
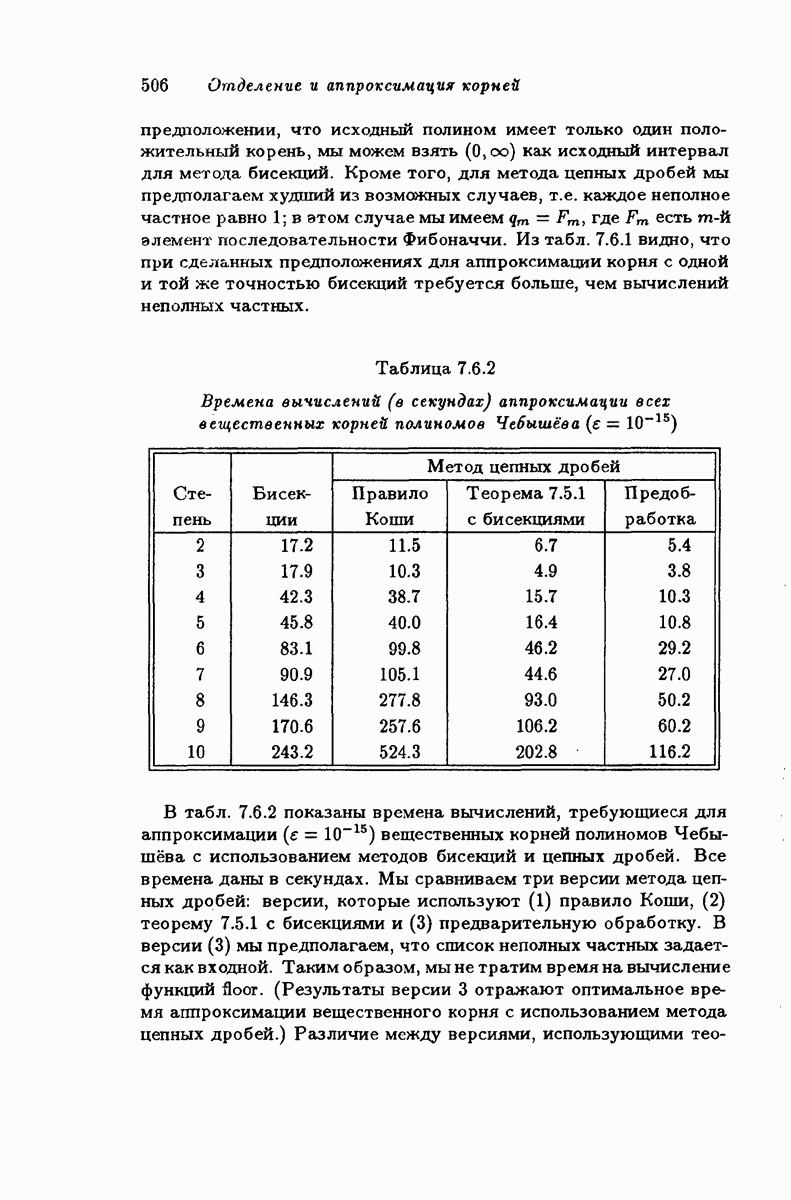
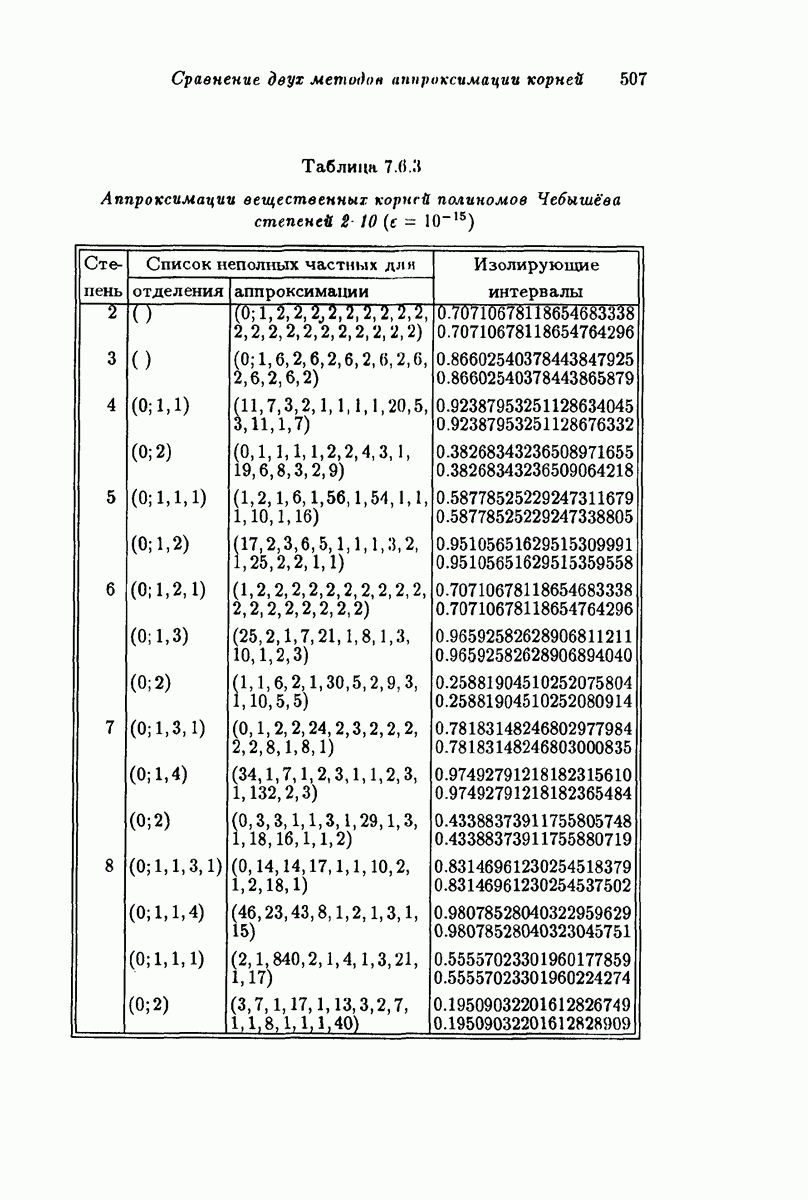
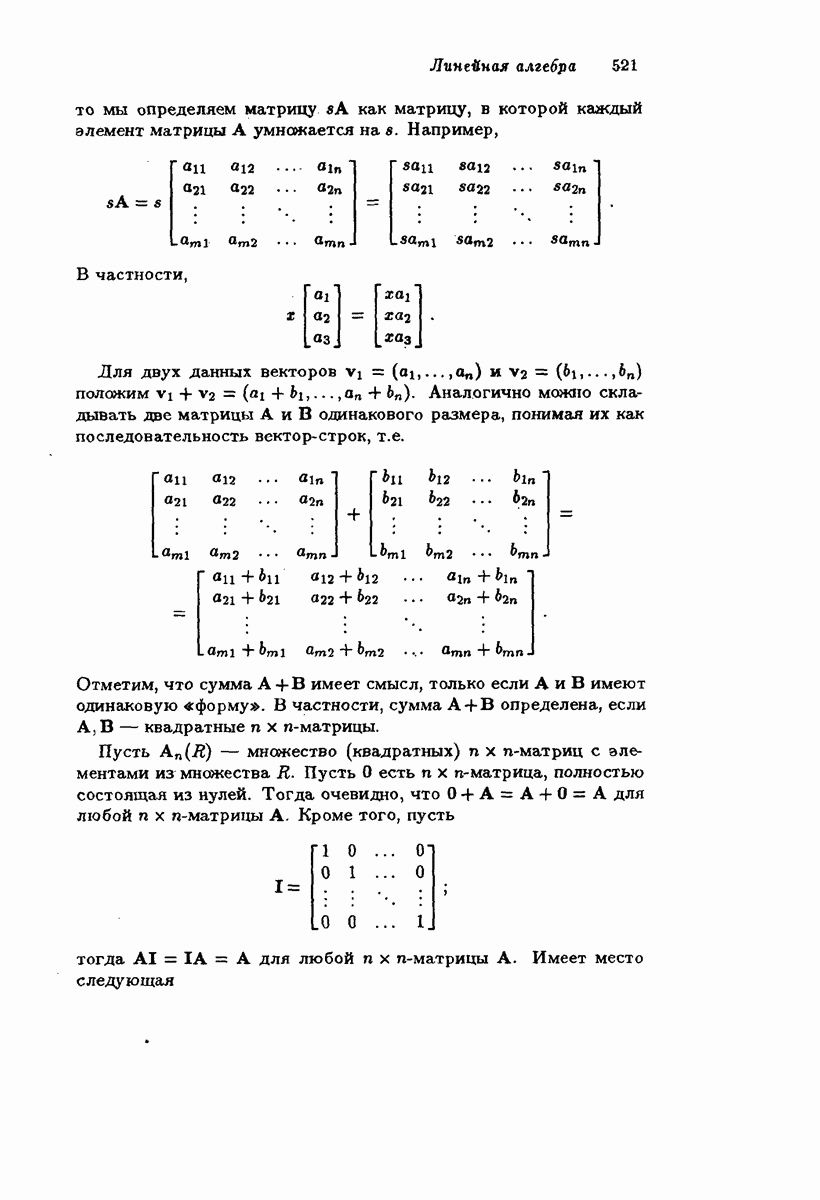
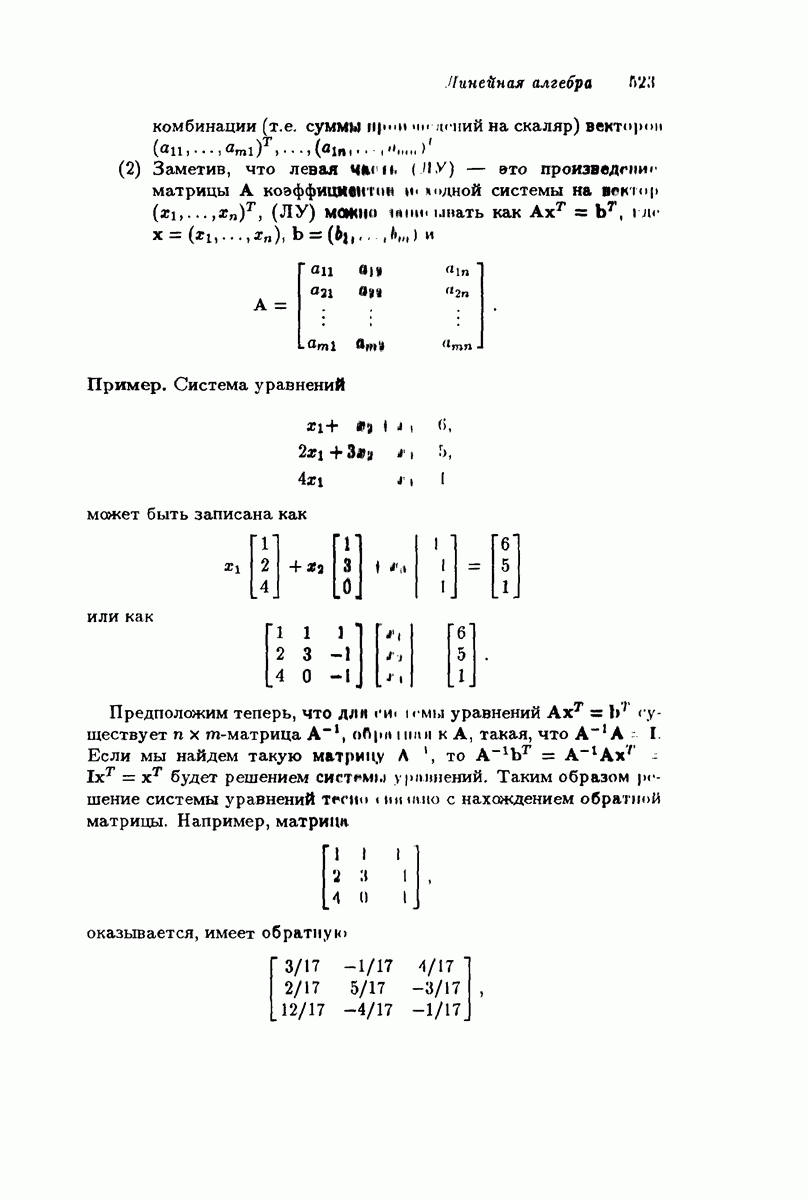
Подведем итог рассмотренному. Мы рассмотрели двоичный симметричный канал и код, состоящий из 2 кодовых слов длины  , скорость передачи информации которого равна
, скорость передачи информации которого равна  Чтобы получить высокую скорость передачи информации, нам хотелось бы иметь как можно больше кодовых слов. В то же время мы хотели бы исправлять как можно больше ошибок. Однако эти два желания противоречат друг другу, потому что чем больше у нас кодовых слов, тем ближе они будут друг к другу и, согласно лемме 4.1.5, тем меньше будет способность кода исправлять ошибки. Например, если
Чтобы получить высокую скорость передачи информации, нам хотелось бы иметь как можно больше кодовых слов. В то же время мы хотели бы исправлять как можно больше ошибок. Однако эти два желания противоречат друг другу, потому что чем больше у нас кодовых слов, тем ближе они будут друг к другу и, согласно лемме 4.1.5, тем меньше будет способность кода исправлять ошибки. Например, если  и мы хотим исправлять не более одной ошибки, то мы можем найти код с четырьмя кодовыми словами, а именно
и мы хотим исправлять не более одной ошибки, то мы можем найти код с четырьмя кодовыми словами, а именно  . Однако если
. Однако если  и мы хотим исправлять две ошибки, то мы не можем найти больше двух слов, (0,0,0,0,0), (1,1,1,1,1). Теорема 4.1.10 показывает, что требование увеличения способности исправлять ошибки для кода фиксированной длины
и мы хотим исправлять две ошибки, то мы не можем найти больше двух слов, (0,0,0,0,0), (1,1,1,1,1). Теорема 4.1.10 показывает, что требование увеличения способности исправлять ошибки для кода фиксированной длины  приводит к уменьшению максимального возможного числа кодовых слов.
приводит к уменьшению максимального возможного числа кодовых слов.
До сего времени мы полностью игнорировали одну проблему — насколько легко может быть осуществлено декодирование. Декодер в ближайшее кодовое слово, рассматриваемый нами ранее, декодирует полученный вектор v в кодовое слово и, расстояние  до которого минимально. Однако, чтобы сделать это, декодер должен содержать таблицу всех кодовых слов, и когда вектор v поступает на вход, он определяет, к какому кодовому слову и вектор v ближе всего. Однако такой декодер требует огромной памяти, и большое время декодирования сделает декодирование в реальном времени в большинстве случаев неприемлемым.
до которого минимально. Однако, чтобы сделать это, декодер должен содержать таблицу всех кодовых слов, и когда вектор v поступает на вход, он определяет, к какому кодовому слову и вектор v ближе всего. Однако такой декодер требует огромной памяти, и большое время декодирования сделает декодирование в реальном времени в большинстве случаев неприемлемым.
Далее мы развиваем теорию линейных (термин будет определен ниже) двоичных кодов, которые имеют много желательных характеристик в отношении сложности кодирования и декодирования.
Один из простейших примеров линейного двоичного кода  с повторением, т.е.
с повторением, т.е.  . Другими словами, этот код является
. Другими словами, этот код является  -мерным подпространством всех двоичных
-мерным подпространством всех двоичных  -кортежей, которое содержит два кодовых слова:
-кортежей, которое содержит два кодовых слова:  вектор из
вектор из  нулей, и
нулей, и  вектор из
вектор из  единиц. Получив вектор длины
единиц. Получив вектор длины  , пользователь может решить, какое кодовое слово было передано, использовав различные правила; например, если число полученных нулей/единиц больше, чем число полученных единиц/нулей, то пользователь может считать, что передавалось кодовое слово, состоящее из всех нулей/единиц. Эта схема обладает большой способностью обнаружения и исправления ошибок, но скорость передачи информации у нее очень низкая.
, пользователь может решить, какое кодовое слово было передано, использовав различные правила; например, если число полученных нулей/единиц больше, чем число полученных единиц/нулей, то пользователь может считать, что передавалось кодовое слово, состоящее из всех нулей/единиц. Эта схема обладает большой способностью обнаружения и исправления ошибок, но скорость передачи информации у нее очень низкая.
Другая крайность —  —
—  -коды с одной проверкой на четность, которые содержат только один контрольный бит,
-коды с одной проверкой на четность, которые содержат только один контрольный бит,  . То есть эти коды имеют очень высокую скорость передачи информации, но нулевую корректирующую способность; они могут только обнаруживать нечетное число ошибок. (Фактически любое нечетное число ошибок неотличимо от единичной ошибки.) Контрольный бит, который называется также битом четности, определяется как сумма
. То есть эти коды имеют очень высокую скорость передачи информации, но нулевую корректирующую способность; они могут только обнаруживать нечетное число ошибок. (Фактически любое нечетное число ошибок неотличимо от единичной ошибки.) Контрольный бит, который называется также битом четности, определяется как сумма  информационных цифр по модулю 2. В проверке на четность/нечетность последняя цифра выбирается так, чтобы общее число единиц было четно/нечетно. Например, в коде с проверкой на четность кодовое слово для 1101 равно 11011. Отметим, что любое четное число ошибок канала не может быть обнаружено. (Такие коды используются для хранения данных на магнитных лентах.)
информационных цифр по модулю 2. В проверке на четность/нечетность последняя цифра выбирается так, чтобы общее число единиц было четно/нечетно. Например, в коде с проверкой на четность кодовое слово для 1101 равно 11011. Отметим, что любое четное число ошибок канала не может быть обнаружено. (Такие коды используются для хранения данных на магнитных лентах.)
Нас интересуют коды со средней скоростью передачи информации и средними способностями исправления ошибок.
Рассмотрим описанный выше код с одной проверкой на четность. Заметим, что  информационных битов можно выбрать произвольно, в то время как
информационных битов можно выбрать произвольно, в то время как  бит, проверочный разряд, — это линейная комбинация первых
бит, проверочный разряд, — это линейная комбинация первых  битов и добавляется, чтобы помочь нам обнаруживать возможные ошибки передачи. Если обозначить информационные биты через
битов и добавляется, чтобы помочь нам обнаруживать возможные ошибки передачи. Если обозначить информационные биты через  , а проверочные — через
, а проверочные — через  то в коде с единственной проверкой на четность
то в коде с единственной проверкой на четность

Обобщим эту идею следующим образом. Пусть  суть к информационных битов, и предположим, что мы добавили
суть к информационных битов, и предположим, что мы добавили  проверочных битов, чтобы сформировать кодовое слово длины
проверочных битов, чтобы сформировать кодовое слово длины
 . (Это процедура кодирования.) В то время как каждый из к информационных битов формируется независимо от предыдущих,
. (Это процедура кодирования.) В то время как каждый из к информационных битов формируется независимо от предыдущих,  проверочных битов являются линейными комбинациями информационных, т.е.
проверочных битов являются линейными комбинациями информационных, т.е.

или, поскольку сложение в GF(2) совпадает с вычитанием,

Выписанная система уравнений может быть также записала в виде

или

где  — кодовое слово, определенное предыдущей системой уравнений,
— кодовое слово, определенное предыдущей системой уравнений,  — транспонированный вектор. Более точно, вектор v является кодовым словом кода, определенного матрицей Н, тогда и только тогда, когда v удовлетворяет системе
— транспонированный вектор. Более точно, вектор v является кодовым словом кода, определенного матрицей Н, тогда и только тогда, когда v удовлетворяет системе  Выписанные уравнения называются проверочными уравнениями,
Выписанные уравнения называются проверочными уравнениями,  -матрица Н называется проверочной матрицей.
-матрица Н называется проверочной матрицей.
Если  — два кодовых слова, то
— два кодовых слова, то

из чего мы делаем вывод, что  также кодовое слово. Поэтому кодовые слова образуют подпространство векторного пространства
также кодовое слово. Поэтому кодовые слова образуют подпространство векторного пространства  Мы говорим, что код линейный тогда и только тогда, когда кодовые слова образуют подпространство пространства
Мы говорим, что код линейный тогда и только тогда, когда кодовые слова образуют подпространство пространства 
Поскольку кодовые слова образуют подпространство, они могут быть выражены в виде линейных комбинаций к линейно независимых векторов, составляющих базис этого подпространства. Эти к линейно независимых векторов можно рассматривать как строки  матрицы G размера к
матрицы G размера к  , называемой порождающей матрицей рассматриваемого кода. Каждая строка
, называемой порождающей матрицей рассматриваемого кода. Каждая строка  - сама является кодовым словом, а значит,
- сама является кодовым словом, а значит,

откуда мы делаем вывод, что

Пример. Предположим, что для кода  мы имеем следующие проверочные уравнения:
мы имеем следующие проверочные уравнения:

Тогда проверочная матрица Н имеет вид

Порождающая матрица Н этого кода (см. теорему 4.1.11 ниже) — это

Кодовые слова — это  линейных комбинаций строк матрицы
линейных комбинаций строк матрицы 
Очевидно, что векторное пространство, получающееся из строк матрицы, не изменится, если мы выполним любую из следующих элементарных операций со строками:
1. Поменять любые две строки местами.
2. Умножить любую строку на ненулевой элемент.
3. Заменить строку ее суммой с любой другой строкой.
(В двоичном случае вторая операция бессмысленна, потому что единственный ненулевой элемент — это 1.)
Поскольку мы исследуем те свойства линейных кодов, которые связаны со способностью исправлять ошибки, заметим, что два кода, отличающиеся только порядком расположения цифр, имеют одну и ту же вероятность ошибки, и такие коды называются эквивалентными. Более точно, если V — векторное пространство строк матрицы G, то код V эквивалентен V тогда и только тогда, когда V — векторное пространство строк матрицы G, полученной переупорядочением столбцов матрицы G. Таким образом переупорядочение столбцов порождающей матрицы приводит к порождающей матрице эквивалентного кода. Более того, любая из перечисленных выше трех элементарных операций, выполненная над строками матрицы G, приводит к матрице G" с тем же самым векторным пространством, и поэтому G и G" — порождающие одного и того же кода. Объединяя эти два случая, видим, что если матрица G получена из матрицы G последовательностью элементарных операций над строками и переупорядочением столбцов, то  — порождающие матрицы эквивалентных кодов.
— порождающие матрицы эквивалентных кодов.
Обычно мы хотим, чтобы порождающая матрица была представлена в следующем виде:

т.е.  где I — единичная к
где I — единичная к  -матрица,
-матрица,  произвольная к
произвольная к  —
—  -матрица. Пользуясь элементарными операциями над строками, мы всегда можем привести порождающую матрицу к такому виду, и это лучше всего иллюстрируется приводимым ниже примером.
-матрица. Пользуясь элементарными операциями над строками, мы всегда можем привести порождающую матрицу к такому виду, и это лучше всего иллюстрируется приводимым ниже примером.
Пример. Предположим, что мы имеем порождающую матрицу

На каждом шаге мы выполняем операции, необходимые для того, чтобы привести один из столбцов к требуемому виду. Мы начинаем слева направо.
Для первого столбца мы прибавим первую строку ко второй и заменим вторую строку суммой:

Для второго столбца переставим вторую строку с третьей:

и заменим первую строку суммой первой и второй строк:

Для третьего столбца заменим первую и вторую строки их суммами с третьей строкой:

Таким образом мы убеждаемся, что последовательным применением элементарных операций мы всегда можем привести порождающую матрицу G к виду 
Пусть теперь  — вектор размерности
— вектор размерности  , и рассмотрим произведение а на порождающую матрицу
, и рассмотрим произведение а на порождающую матрицу 

где

Заметим, что если мы рассматриваем вектор а как вектор с информационными битами, то в кодовом слове b кода, полученного из G, первые к битов информационные, а остальные  — к компонент — линейные комбинации первых к. Таким образом кодирование чрезвычайно просто: достаточно умножить информационный вектор на порождающую матрицу. Упорядоченный код — это код, состоящий из кодовых слов, в каждом из которых первые к битов — информационные, а остальные — проверочные. Из сказанного выше следует, что любой линейный код эквивалентен упорядоченному. Мы говорим, что линейный код с кодовыми словами длины
— к компонент — линейные комбинации первых к. Таким образом кодирование чрезвычайно просто: достаточно умножить информационный вектор на порождающую матрицу. Упорядоченный код — это код, состоящий из кодовых слов, в каждом из которых первые к битов — информационные, а остальные — проверочные. Из сказанного выше следует, что любой линейный код эквивалентен упорядоченному. Мы говорим, что линейный код с кодовыми словами длины  имеет размерность к тогда и только тогда, когда он имеет к информационных битов, и, как мы уже видели, мы называем такие коды
имеет размерность к тогда и только тогда, когда он имеет к информационных битов, и, как мы уже видели, мы называем такие коды  -кодами.
-кодами.
Подводя итоги сказанному, мы видим, что двоичный линейный код длины  и размерности к — это
и размерности к — это  -мерное подпространство
-мерное подпространство  -мерного векторного пространства над
-мерного векторного пространства над  Таким образом, код полностью определяется порождающей матрицей G, строки которой суть базисные векторы этого подпространства. В качестве альтернативы, линейный код С может быть полностью определен проверочной матрицей Н, которая удовлетворяет уравнению
Таким образом, код полностью определяется порождающей матрицей G, строки которой суть базисные векторы этого подпространства. В качестве альтернативы, линейный код С может быть полностью определен проверочной матрицей Н, которая удовлетворяет уравнению  или
или  для любого кодового слова v. Мы говорим, что векторное пространство, определяющее код, ортогонально векторному пространству, определенному строками матрицы Н. Векторное пространство, определенное строками матрицы Н, можно также рассматривать как определяющее линейный код С: Н теперь — порождающая матрица,
для любого кодового слова v. Мы говорим, что векторное пространство, определяющее код, ортогонально векторному пространству, определенному строками матрицы Н. Векторное пространство, определенное строками матрицы Н, можно также рассматривать как определяющее линейный код С: Н теперь — порождающая матрица,  проверочная. Коды С и С называются дуальными кодами, и если С есть
проверочная. Коды С и С называются дуальными кодами, и если С есть  -код, то С является
-код, то С является 
 -кодом.
-кодом.
Теорема 4.1.11. Если V — код с порождающей матрицей  , где
, где  — единичная к
— единичная к  -матрица,
-матрица,  произвольная к
произвольная к 
 -матрица, то проверочная матрица этого кода равна
-матрица, то проверочная матрица этого кода равна 
Доказательство. Если  — кодовое слово, то
— кодовое слово, то

что в точности совпадает с  (Связь между G и Н станет понятней, если заметить, что в обоих случаях
(Связь между G и Н станет понятней, если заметить, что в обоих случаях  это коэффициент при
это коэффициент при  информационном бите в сумме, определяющей
информационном бите в сумме, определяющей  проверочный бит
проверочный бит 
Пример. Для порождающей матрицы

 находим проверочную матрицу
находим проверочную матрицу

Кодовые слова — это

Теорема 4.1.12. Код с проверочной матрицей Н имеет минимальный вес (а следовательно, кодовое расстояние) w тогда и только тогда, когда любое множество из  или меньшего числа столбцов матрицы Н линейно независимо.
или меньшего числа столбцов матрицы Н линейно независимо.
Локазательство. Мы докажем теорему в одном направлении, а остальную часть оставим читателю. Вектор  является кодовым словом тогда и только тогда, когда
является кодовым словом тогда и только тогда, когда  или, что эквивалентно, тогда и только тогда, когда
или, что эквивалентно, тогда и только тогда, когда

где  есть
есть  столбец матрицы Н. Таким образом, если w — минимальный вес кода, то не существует равной 0 линейной комбинации
столбец матрицы Н. Таким образом, если w — минимальный вес кода, то не существует равной 0 линейной комбинации  или меньшего числа столбцов матрицы Н.
или меньшего числа столбцов матрицы Н. 
Из теоремы 4.1.12 мы видим, что код может иметь кодовое расстояние 3 тогда и только тогда, когда любые  столбца проверочной матрицы Н линейно независимы. Однако два ненулевых вектора в
столбца проверочной матрицы Н линейно независимы. Однако два ненулевых вектора в  над GF(2) линейно независимы, если они просто различны. Поэтому мы можем построить код с кодовым расстоянием 3 (т.е. код может исправлять одну ошибку), если будем рассматривать в качестве проверочной матрицы Н матрицу, столбцы которой составляют все отличные от нуля элементы пространства
над GF(2) линейно независимы, если они просто различны. Поэтому мы можем построить код с кодовым расстоянием 3 (т.е. код может исправлять одну ошибку), если будем рассматривать в качестве проверочной матрицы Н матрицу, столбцы которой составляют все отличные от нуля элементы пространства  Значит, мы можем построить так называемые
Значит, мы можем построить так называемые  -коды Хэмминга, т.е.
-коды Хэмминга, т.е.  .
.
Определение 4.1.13. Пусть Н — проверочная матрица линейного  Если v — полученный вектор, то вектор
Если v — полученный вектор, то вектор  длины
длины  называется синдромом вектора
называется синдромом вектора 
Из этого определения видно, что вектор является кодовым словом тогда и только тогда, когда его синдром равен О. Если учитывать это, то процесс декодирования для кодов Хэмминга очень прост. Если v — полученный, а и — переданный вектор, где  мы действуем следующим образом: сначала вычисляем синдром вектора v, который равен
мы действуем следующим образом: сначала вычисляем синдром вектора v, который равен

Если произошла одна ошибка, то  — вектор с весом 1, т.е.
— вектор с весом 1, т.е.  компонент равны 0 и мы имеем «1» в
компонент равны 0 и мы имеем «1» в  позиции, где встретилась ошибка. Таким образом, произведение
позиции, где встретилась ошибка. Таким образом, произведение  будет
будет  столбцом матрицы Н, и мы получим переданный вектор, если прибавим к v вектор
столбцом матрицы Н, и мы получим переданный вектор, если прибавим к v вектор  , который состоит из нулей, за исключением
, который состоит из нулей, за исключением  позиции, которая равна 1.
позиции, которая равна 1.
Пример. Рассмотрим  -код Хэмминга с проверочной матрицей
-код Хэмминга с проверочной матрицей

и предположим, что получен вектор  что синдром вектора v равен
что синдром вектора v равен

что совпадает с четвертым столбцом матрицы Н; следовательно, вектор ошибок равен  и, добавляя его к v, мы получаем переданный вектор
и, добавляя его к v, мы получаем переданный вектор 
Рассмотрим теперь другую процедуру декодирования линейных кодов, т.е. мы получим другой взгляд на декодирование по максимуму правдоподобия, рассматривая смежные классы кода С в 
Пусть С — линейный ( -код над
-код над  ), где этот код рассматривается как подпространство пространства
), где этот код рассматривается как подпространство пространства  векторного пространства всех двоичных
векторного пространства всех двоичных  -кортежей. Факторпространство
-кортежей. Факторпространство  состоит из всех смежных классов
состоит из всех смежных классов 
для произвольного  , где каждый смежный класс содержит
, где каждый смежный класс содержит  векторов. Имеется разбиение множества
векторов. Имеется разбиение множества  вида
вида

Если получен вектор у, то у должен быть элементом одного из этих смежных классов, скажем  Если передано кодовое слово
Если передано кодовое слово  то вектор ошибок
то вектор ошибок  равене
равене  Следовательно, мы имеем следующее правило декодирования: если получен вектор у, то возможные векторы ошибки
Следовательно, мы имеем следующее правило декодирования: если получен вектор у, то возможные векторы ошибки  — это векторы из смежного класса, содержащего у. Наиболее вероятная ошибка — вектор
— это векторы из смежного класса, содержащего у. Наиболее вероятная ошибка — вектор  с минимальным весом в классе смежности вектора у. Поэтому у декодируется как
с минимальным весом в классе смежности вектора у. Поэтому у декодируется как  . (Вектор наименьшего веса в смежном классе называется лидером смежного класса. Если имеется несколько таких векторов, то произвольный из них выбирается в качестве лидера смежного класса.)
. (Вектор наименьшего веса в смежном классе называется лидером смежного класса. Если имеется несколько таких векторов, то произвольный из них выбирается в качестве лидера смежного класса.)
Чтобы использовать указанную схему декодирования, нам нужны таблицы смежных классов, и ниже мы покажем, как создавать таблицу декодирования Слепиана.
Пусть С — упомянутый выше  -линейиый код, и пусть
-линейиый код, и пусть  — кодовые слова, где
— кодовые слова, где  — нулевой вектор кода. Кодовые слова располагают в первой строке с нулевым вектором слева. Затем выбирают один из оставшихся векторов пространства
— нулевой вектор кода. Кодовые слова располагают в первой строке с нулевым вектором слева. Затем выбирают один из оставшихся векторов пространства  например
например  и помещают его под нулевым вектором. (Обычно
и помещают его под нулевым вектором. (Обычно  выбирается так, что он имеет наибольшую вероятность поступить на приемник, если передан нулевой вектор.) После этого заполняют вторую строку, помещая под каждым кодовым словом
выбирается так, что он имеет наибольшую вероятность поступить на приемник, если передан нулевой вектор.) После этого заполняют вторую строку, помещая под каждым кодовым словом  - вектор
- вектор  . Аналогично, второй вектор
. Аналогично, второй вектор  из
из  который еще не появился в таблице, помещают в первом столбце третьей строки, и строка заполняется тем же способом. Этот процесс продолжается до тех пор, пока все векторы из
который еще не появился в таблице, помещают в первом столбце третьей строки, и строка заполняется тем же способом. Этот процесс продолжается до тех пор, пока все векторы из  не появятся в таблице. Множество элементов строки образует смежный класс, и, если на каждом шаге вектор g выбирался как вектор наименьшего веса, не представленный в первых i столбцах, то элементы первого столбца гарантированно будут лидерами смежных классов (проверьте это на следующем ниже примере).
не появятся в таблице. Множество элементов строки образует смежный класс, и, если на каждом шаге вектор g выбирался как вектор наименьшего веса, не представленный в первых i столбцах, то элементы первого столбца гарантированно будут лидерами смежных классов (проверьте это на следующем ниже примере).
Два элемента  которые принадлежат одному и тому же смежному классу к, обладают следующим свойством:
которые принадлежат одному и тому же смежному классу к, обладают следующим свойством:  т.е. их сумма равна кодовому слову. Кроме того, каждый вектор из пространства
т.е. их сумма равна кодовому слову. Кроме того, каждый вектор из пространства  появляется в таблице ровно один раз. (В этом легко убедиться,
появляется в таблице ровно один раз. (В этом легко убедиться,
если предположить, что два вектора  совпадают, где
совпадают, где  смежных классов. Равенство
смежных классов. Равенство  имеет место тогда и только тогда, когда
имеет место тогда и только тогда, когда  где
где  кодовое слово; но тогда
кодовое слово; но тогда  принадлежит смежному классу, который имеет
принадлежит смежному классу, который имеет  в качестве лидера, а это противоречит методу построения таблицы, согласно которому первый элемент в каждой строке — это не появлявшийся ранее вектор.)
в качестве лидера, а это противоречит методу построения таблицы, согласно которому первый элемент в каждой строке — это не появлявшийся ранее вектор.)
Пример. Рассмотрим ( -линейный код, проверочные биты которого определяются уравнениями
-линейный код, проверочные биты которого определяются уравнениями

Тогда таблица Слепиана этого кода имеет вид

Отметим, что имеется  смежных класса, каждый из которых содержит
смежных класса, каждый из которых содержит  элементов. Следующие две теоремы показывают, как описанная выше таблица Слепиана мажет использоваться для декодирования линейных кодов.
элементов. Следующие две теоремы показывают, как описанная выше таблица Слепиана мажет использоваться для декодирования линейных кодов.
Теорема 4.1.14. Если мы пользуемся таблицей Слепиана для декодирования полученного вектора в кодовое слово, расположенное над ним, то полученный вектор v правильно декодируется в переданный вектор и тогда и только тогда, когда вектор ошибки  лидер смежного класса.
лидер смежного класса.
Доказательство. Если  лидер
лидер  смежного класса, то
смежного класса, то  - появляется в
- появляется в  смежном классе таблицы Слепиана под кодовым словом и и будет правильно декодирован. Однако если
смежном классе таблицы Слепиана под кодовым словом и и будет правильно декодирован. Однако если  не является лидером смежного класса, то полученный вектор v появится в некотором смежном классе, скажем
не является лидером смежного класса, то полученный вектор v появится в некотором смежном классе, скажем  с лидером
с лидером  Тогда v принадлежит
Тогда v принадлежит  строке таблицы, но не находится под и, потому что
строке таблицы, но не находится под и, потому что 
Теорема 4.1.15. Два вектора  принадлежат одному и тому же смежному классу тогда и только тогда, когда их синдромы равны.
принадлежат одному и тому же смежному классу тогда и только тогда, когда их синдромы равны.
Локазательство. Если и  принадлежат
принадлежат  смежному классу, то
смежному классу, то  . Значит,
. Значит,  откуда следует, что
откуда следует, что  .
.
Обратно, если  , то
, то  , откуда следует, что
, откуда следует, что  и если
и если  , то
, то  , откуда следует, что
, откуда следует, что  принадлежат одному и тому же смежному классу.
принадлежат одному и тому же смежному классу. 
Теперь мы в состоянии представить упрощенную процедуру декодирования, которая работает следующим образом. Сформируем таблицу декодирования, которая состоит из двух столбцов, первый составлен из  синдромов, а второй — из соответствующих лидеров смежных классов. Когда получен вектор v, то мы сначала вычисляем его синдром, а затем находим из таблицы соответствующий лидер смежного класса. Мы полагаем, что лидер смежного класса — это вектор ошибки, и, прибавляя его к вектору v, получаем переданный вектор и.
синдромов, а второй — из соответствующих лидеров смежных классов. Когда получен вектор v, то мы сначала вычисляем его синдром, а затем находим из таблицы соответствующий лидер смежного класса. Мы полагаем, что лидер смежного класса — это вектор ошибки, и, прибавляя его к вектору v, получаем переданный вектор и.
Пример. Для линейного  -кода, описанного в предыдущем примере, мы имеем следующую таблицу декодирования:
-кода, описанного в предыдущем примере, мы имеем следующую таблицу декодирования:

Мы видим, что декодирующей таблице для 
 -кода требуется список синдромов и лидеров смежных классов, соответствующих
-кода требуется список синдромов и лидеров смежных классов, соответствующих  смежным классам. Это может оказаться как дороже, так и дешевле, чем сравнивать полученный вектор со всеми возможными
смежным классам. Это может оказаться как дороже, так и дешевле, чем сравнивать полученный вектор со всеми возможными  кодовыми словами и выбирать ближайший. В
кодовыми словами и выбирать ближайший. В  -коде, например, имеется только
-коде, например, имеется только  смежных классов в противовес 280 кодовым словам, хотя
смежных классов в противовес 280 кодовым словам, хотя  — очень большое число.
— очень большое число.
Теорема 4.1.16. Пусть С есть  -линейный код, кодовые слова которого имеют одинаковую вероятность передачи. Тогда использование построенной выше таблицы Слепиана (т.е. лидеров смежных классов, имеющих наименьший вес в смежном классе) максимизирует вероятность правильного декодирования.
-линейный код, кодовые слова которого имеют одинаковую вероятность передачи. Тогда использование построенной выше таблицы Слепиана (т.е. лидеров смежных классов, имеющих наименьший вес в смежном классе) максимизирует вероятность правильного декодирования.
Доказательство Пусть  вектор в
вектор в  строке и
строке и  столбца таблицы Слепиана. Кодовые слова
столбца таблицы Слепиана. Кодовые слова  находятся в 0-й строк и наверху каждого столбца. Пусть
находятся в 0-й строк и наверху каждого столбца. Пусть  расстояние Хэмминга между полученным вектором
расстояние Хэмминга между полученным вектором  и кодовым словом
и кодовым словом  в которое декодируется
в которое декодируется  Мы уже видели, что вероятность правильного декодирования максимизируется, когда полученный вектор декодируется в ближайшее кодовое слово.
Мы уже видели, что вероятность правильного декодирования максимизируется, когда полученный вектор декодируется в ближайшее кодовое слово.
Предположим теперь, что вектор v появляется в таблице Слепиана под кодовым словом и, где  и пусть g — лидер смежного класса, содержащего v; более того, предположим, что
и пусть g — лидер смежного класса, содержащего v; более того, предположим, что  — ближайшее к v кодовое слово, причем
— ближайшее к v кодовое слово, причем  Тогда вес вектора
Тогда вес вектора  — и равен
— и равен  в то время как элемент
в то время как элемент  имеет вес
имеет вес  и находятся в том же самом смежном классе. Поскольку по определению g имеет наименьший вес в смежном классе,
и находятся в том же самом смежном классе. Поскольку по определению g имеет наименьший вес в смежном классе,  и, таким образом, v по крайней мере так же близок к и, как И к
и, таким образом, v по крайней мере так же близок к и, как И к