Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
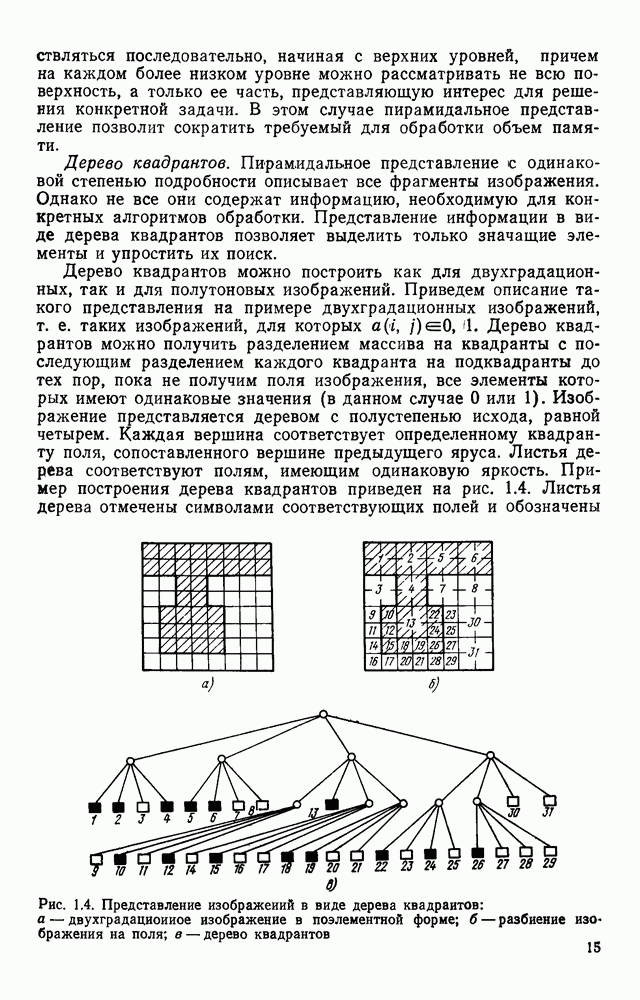
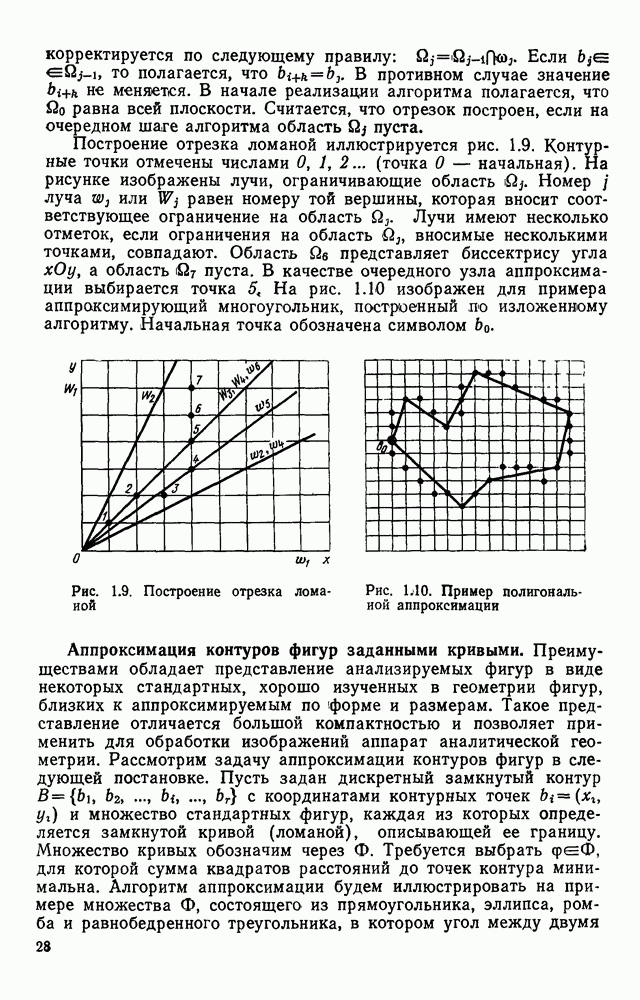
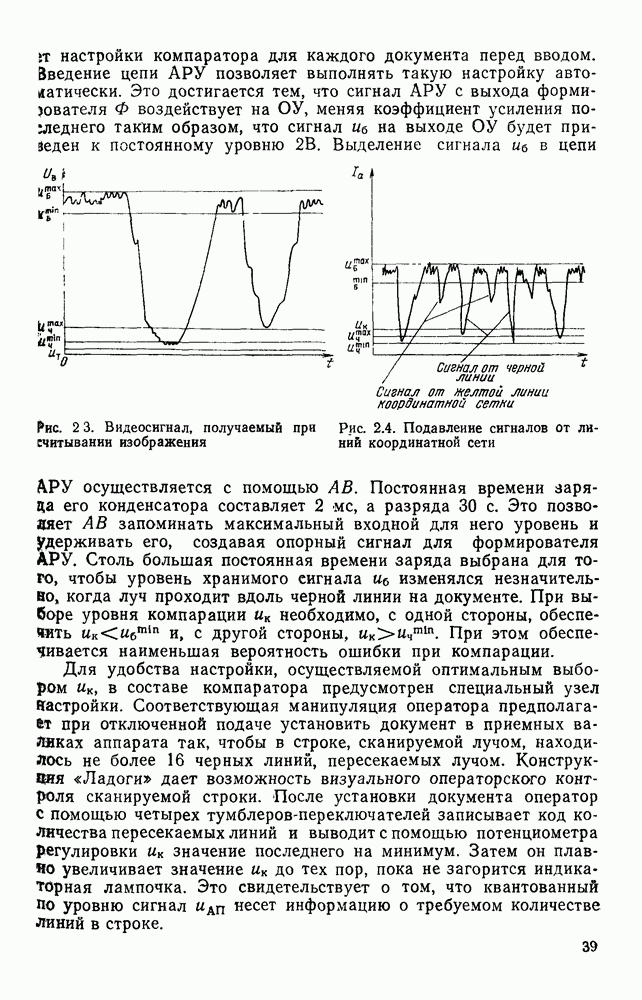
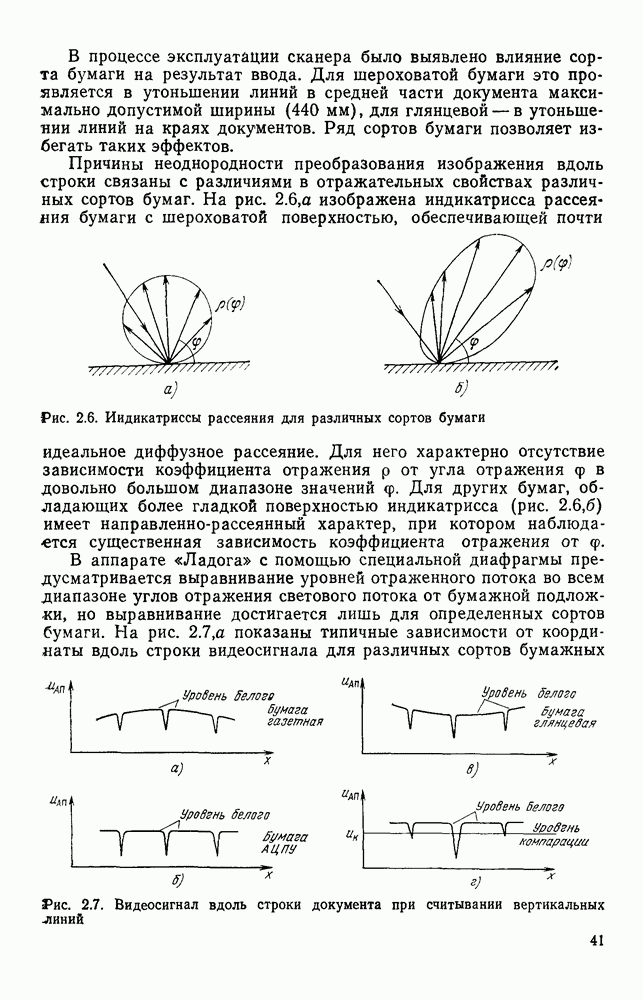
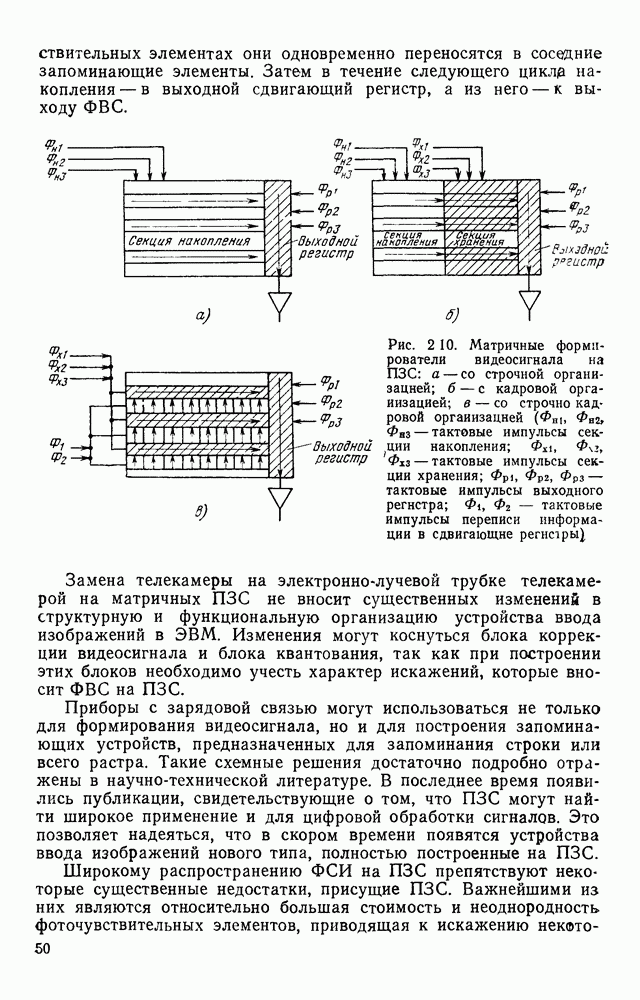
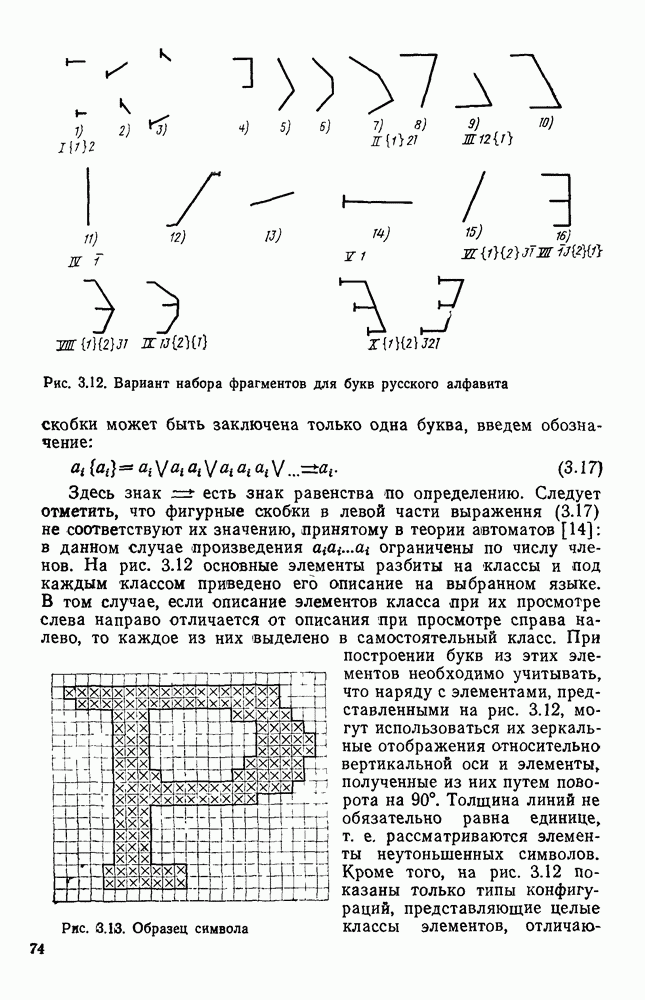
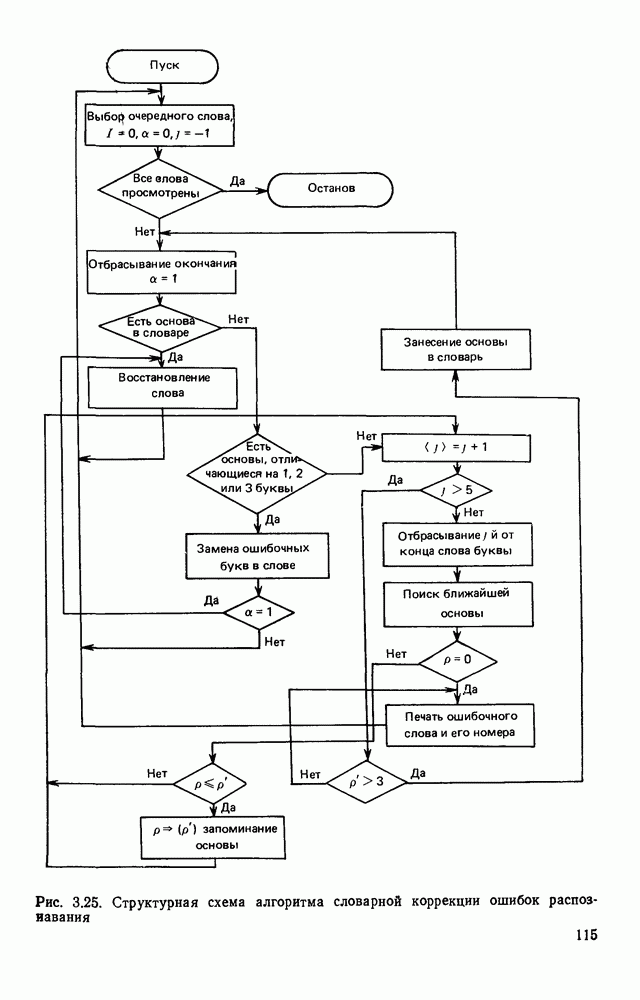
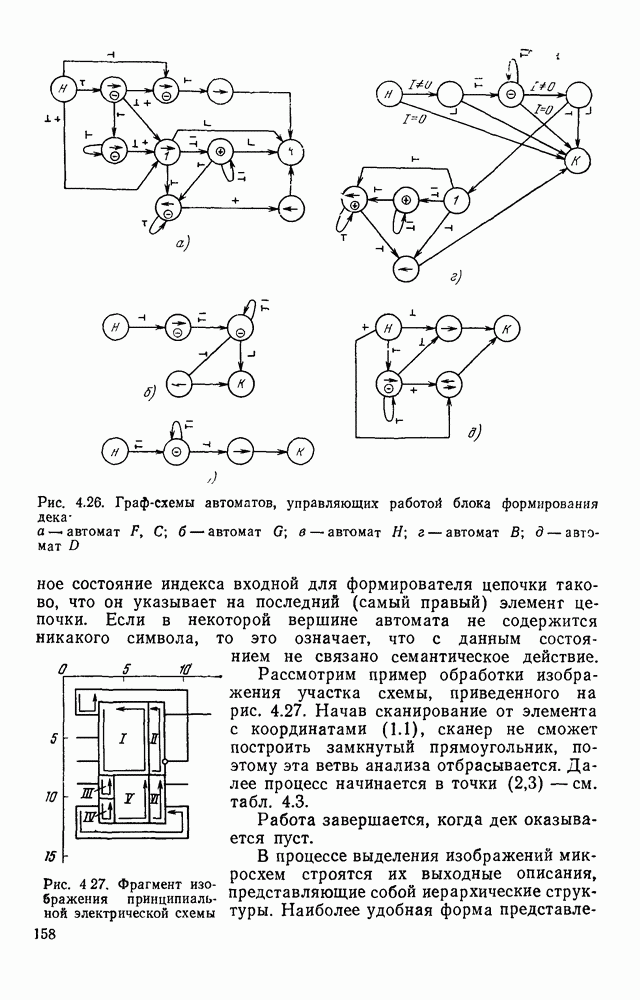
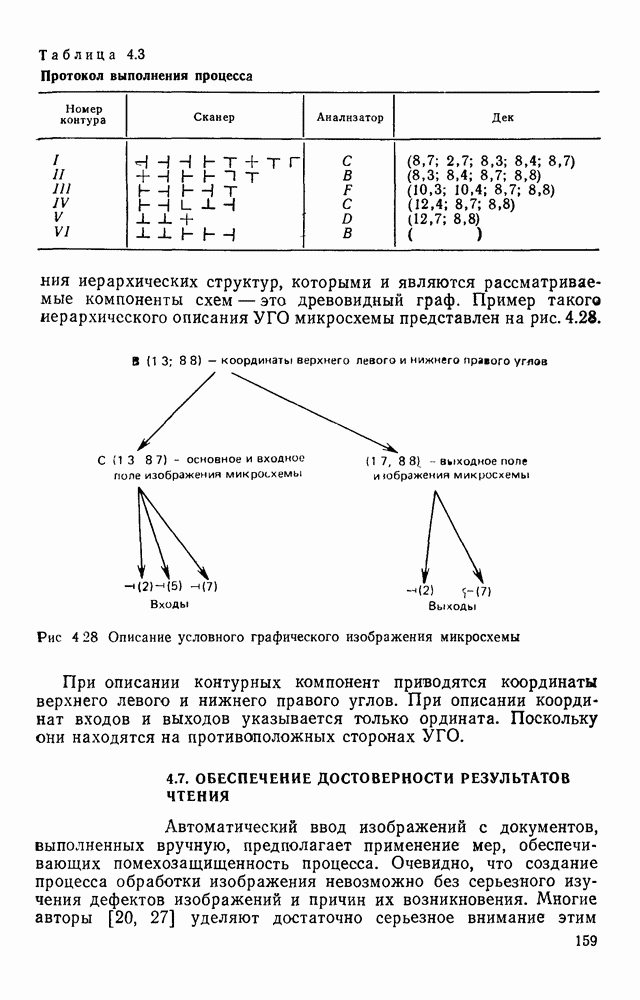
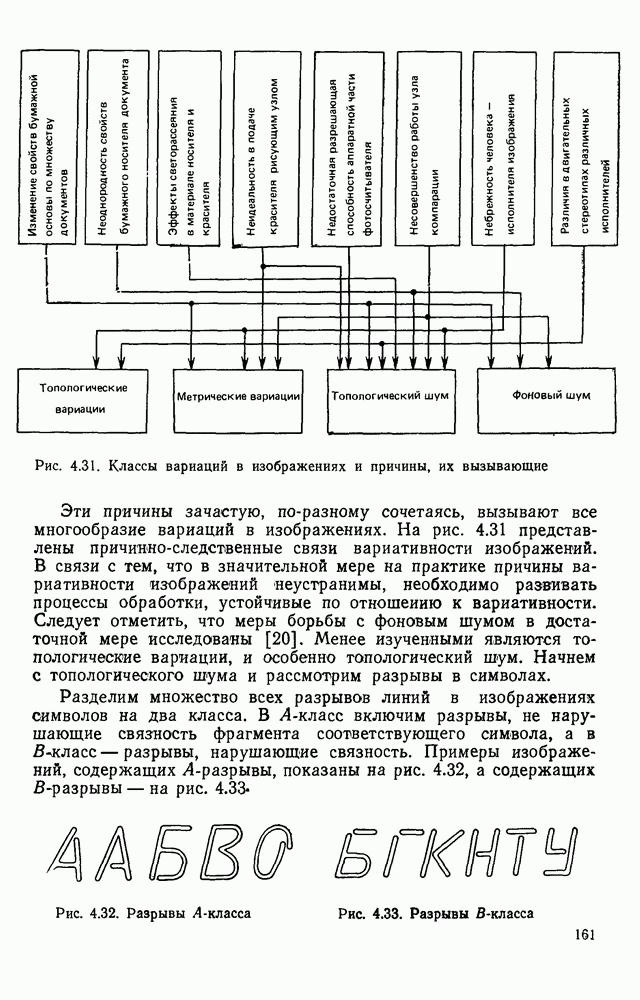
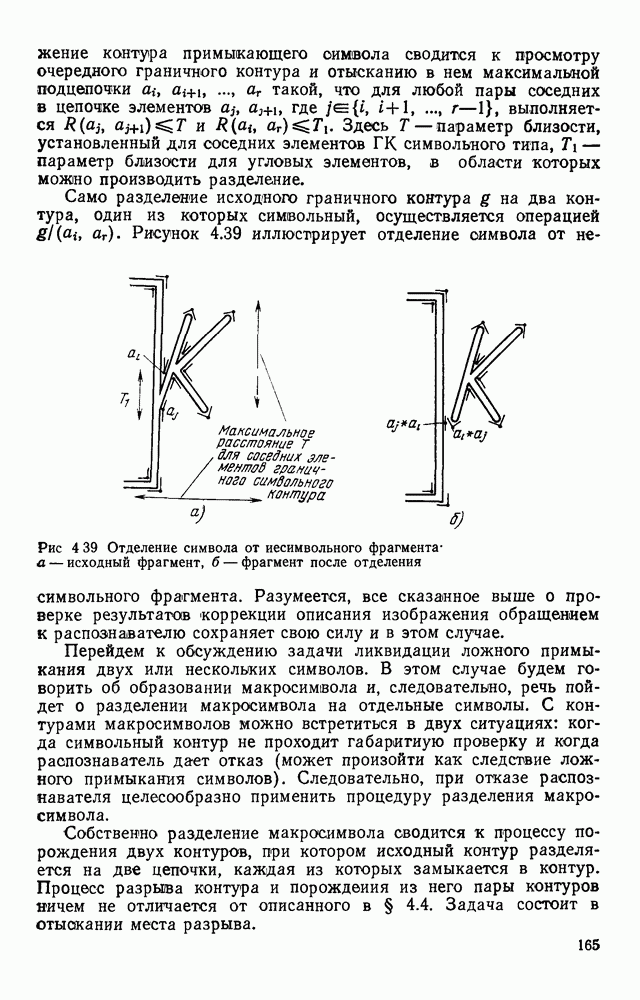
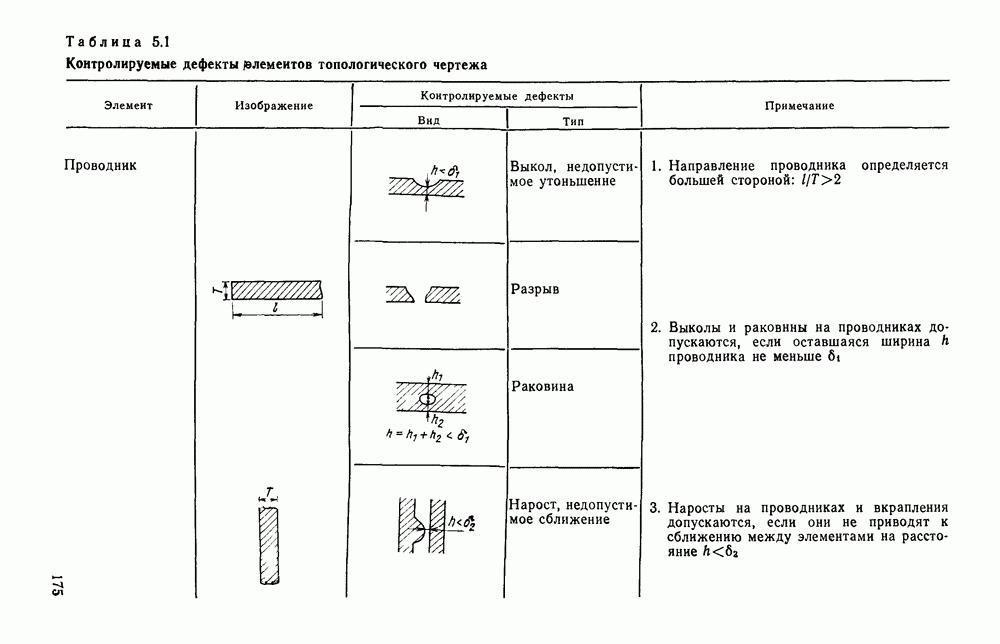
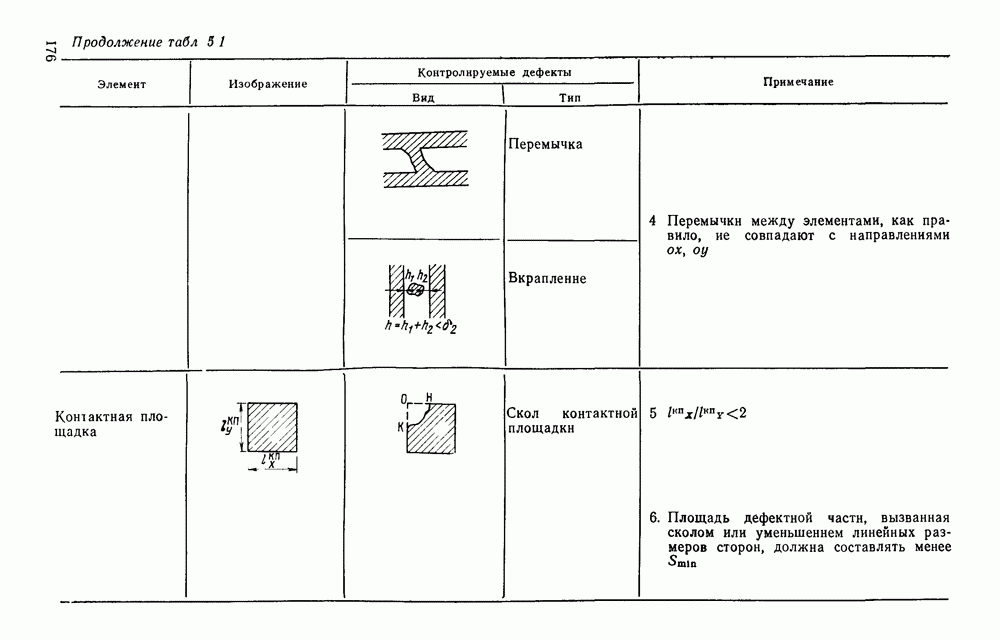
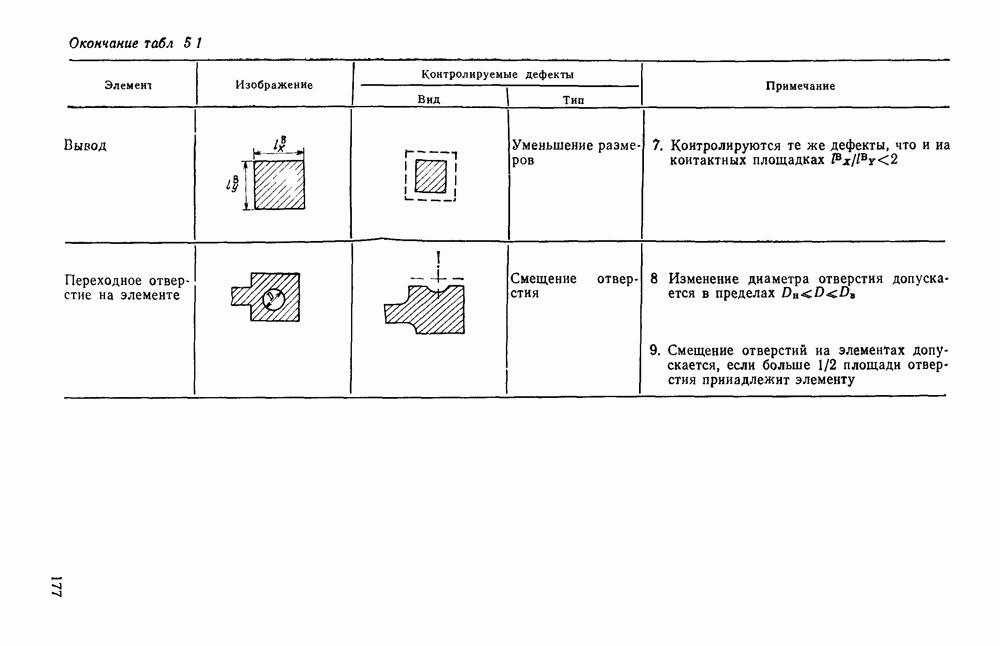
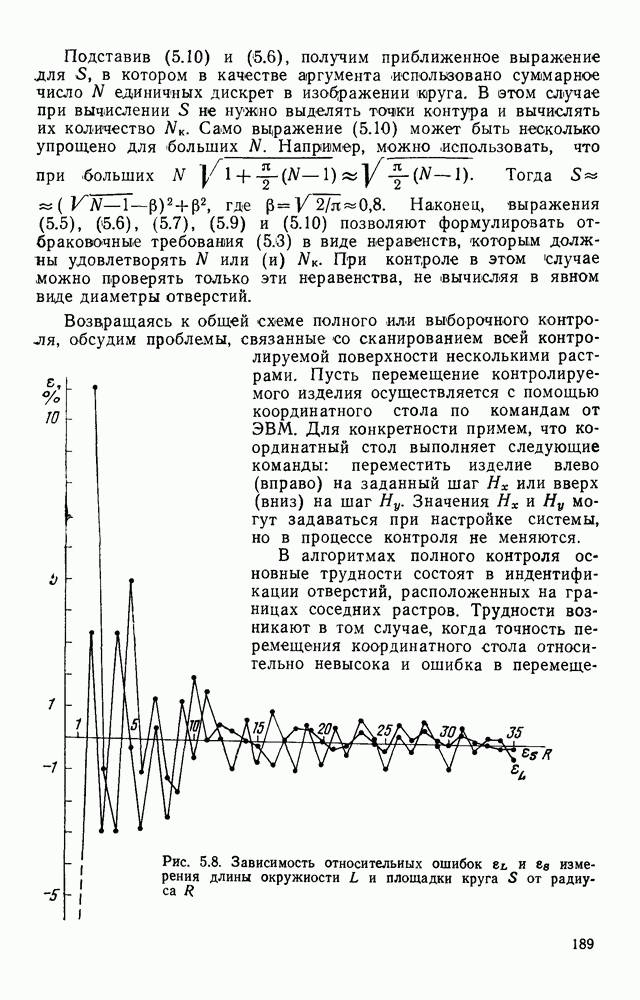
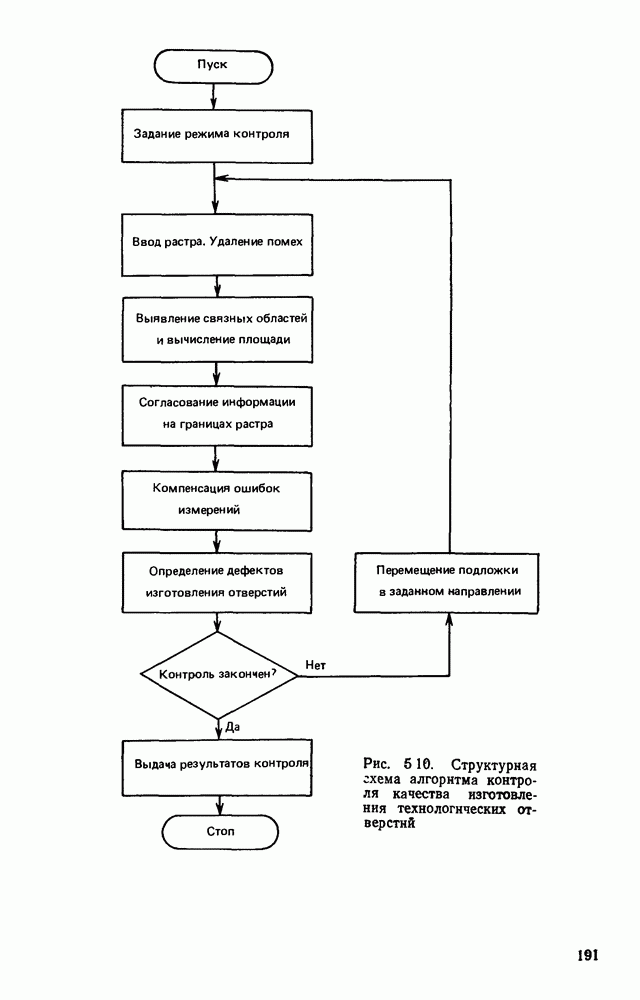
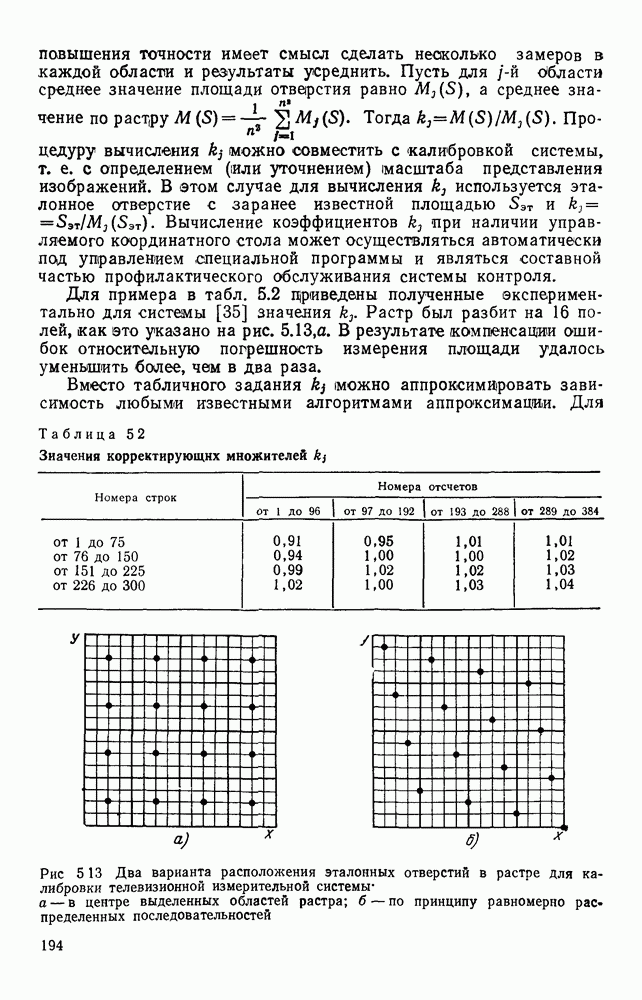
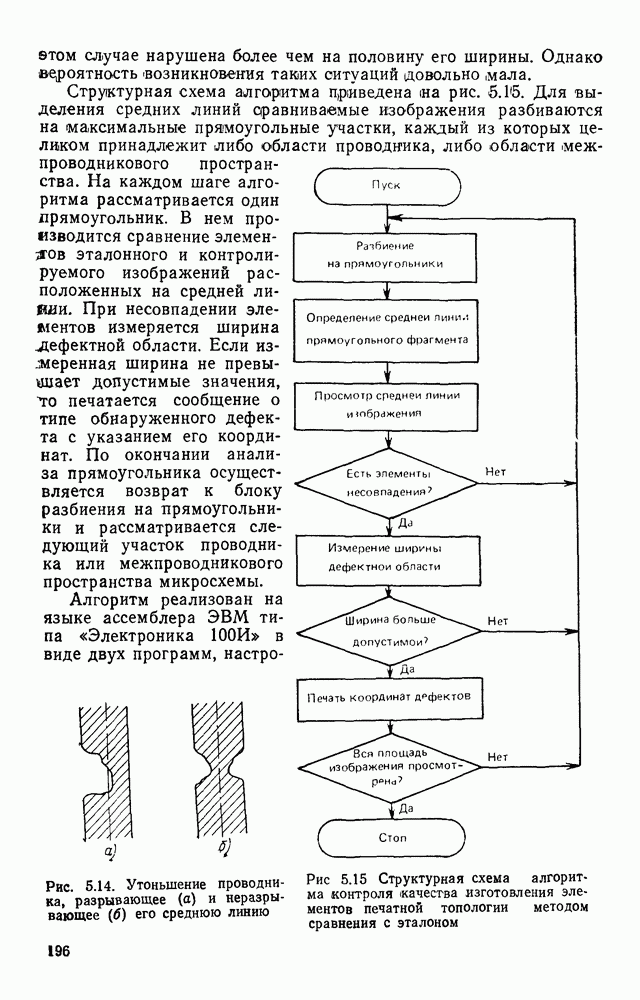
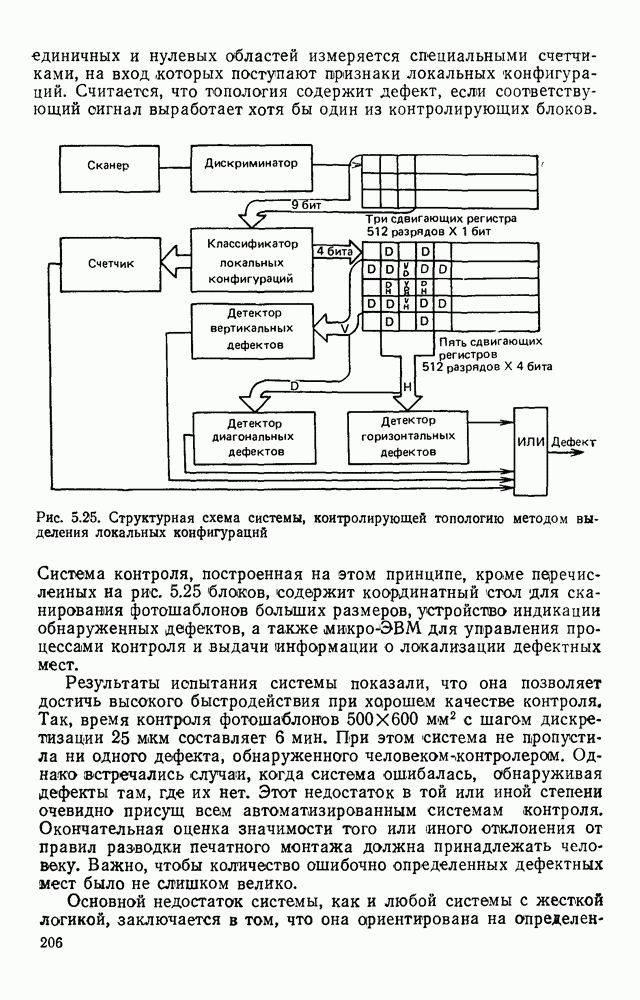
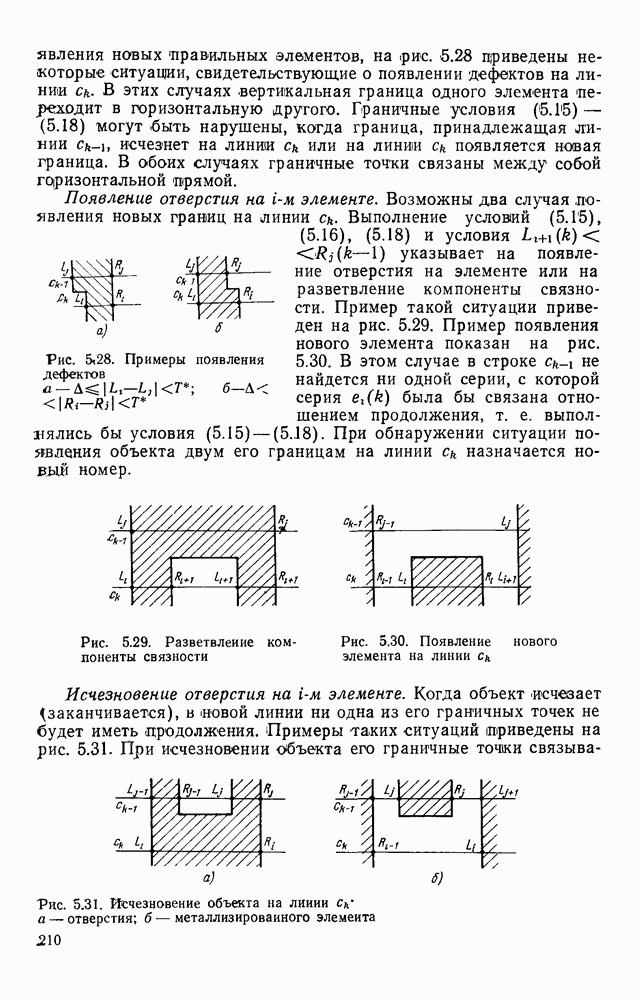
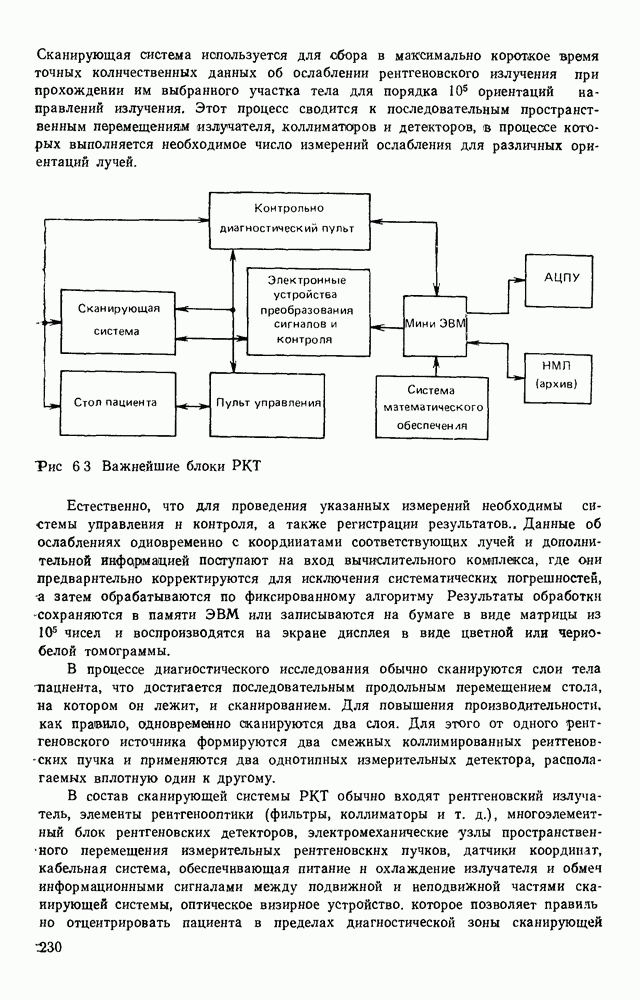
3.10. ОБНАРУЖЕНИЕ И ИСПРАВЛЕНИЕ ОШИБОК РАСПОЗНАВАНИЯПри любом способе распознавания, даже самом совершенном, возникают ошибки хотя бы потому, что распознающее устройство довольно сложная система, содержащая тысячи элементов, отказы компонентой или соединений в которой неизбежны. Однако при обработке осмысленного текста естественная избыточность языка позволяет нам беспрепятственно разбирать написанное непонятным почерком письмо или переданную с ошибками телеграмму. По имеющимся в настоящее время данным избыточности всех европейских языков примерно равны и составляют 70—80%. Это значит, что использование структурных свойств языка может доставить недостающую или потерянную за счет ошибок распознавания информацию. Наиболее простой способ использования закономерностей языка состоит в учете статистики отдельных букв, двубуквенных (диграмм) и многобуквенных сочетаний (р-грамм) в словах. Реализация этого способа в ЭВМ принципиальных трудностей не вызывает: если машина не может достоверно распознавать, какая из двух букв Использование ЭВМ для решения поставленной задачи открывает возможности для моделирования работы человека при чтении письма, написанного неразборчивым почерком. К сожалению, трудно точно указать, какие именно знания использует человек при корректировке текста, но важнейшими элементами этих знаний безусловно являются словарь языка, морфология, синтаксис, семантика Ясно, что если мы хотим создать программу для ЭВМ, моделирующую работу человека-корректора, то эти четыре элемента должны быть в ее основе. Построение такой программы — чрезвычайно сложное дело из-за сложности проблемы автоматизации синтаксического и семантического анализа. Более реальным является использование только словаря и морфологии языка. Будем считать, что при считывании и распознавании слово из «Л», то получится слово «ЛОРОГА», которого в словаре нет. На одну букву от «ЛОРОГА» отличаются, по крайней мере, два слова словаря «ДОРОГА» и «ПОРОГА». Правильный выбор может быть сделай в данном случае либо путем привлечения методов синтаксического анализа и семантики, лйбо из частотных соображений: буква «Д» примерно на 10% более вероятна в русском языке, чем буква «П» Однако, необходимо иметь в виду, что при считывании слова «ПОРОГА» также возможна замена буквы «П» на «Л», и в этом случае буквенный частотный критерий приведет к ошибке. Приведенный пример показывает, что использование только словаря не позволяет исправлять всех ошибок распознавания, однако, как будет показано ниже, значительная их часть может быть исправлена таким путем. В Пользу словарного метода коррекции, при его удачной реализации, говорит также тот факт, что он является первым необходимым этапом на пути создании более совершенных методов, использующих синтаксис и, возможно, семантику. Прежде чем перейти к детальному описанию словарного метода коррекции, рассмотрим способ наиболее экономного представлении словаря в памяти ЭВМ. С проблемой подобного рода лингвисты столкнулись при машинном переводе. В данном случае задача менее сложная, поскольку для словарной коррекции несущественно, какой частью речи является слово, в какой форме оно находится (род, число, лицо, падеж и т. д.), а кроме того, отсутствует необходимость поиска эквивалента слову одного языка в словаре другого. Проблема состоит в том, чтобы при минимальном объеме ЗУ представить в ЭВМ возможно большее число слов. Например, существительное и прилагательное в русском языке имеют два числа и шесть падежей, аналогичная картина наблюдается у глаголов, поэтому, если каждому слову читаемого текста непосредственно сопоставлять слово словаря, то объем словаря увеличивается в 5—7 раз по сравнению со словарем основных форм. В дальнейшем изложении нам потребуется ряд понятий, принятых в лингвистике. Словоформой называется отрезок текста между двумя соседними пробелами Морфемой называется часть словоформы. Все морфемы будем делить на основы и окончания, которые задаются своими списками. Списки (словарь) морфем определяются конструктором системы, и используемые нами окончания и основы далеко не всегда совпадают с их лингвистическими определениями. Процесс построения «словаря целесообразно организовать следующим образом: сначала задаться списком окончаний, а затем выделять основы. В табл. 3.7 приведен список используемых окончаний, все они разбиты на групшы. В группу включены окончания, совместимые с одной и той же основой. Например, в десятой группе находятся окончания, сочетающиеся с основами реч-, печ-, ноч-, и т. д. Процедура получения основ реализуется автоматически: в ЭВМ вводится список упорядоченных по числу букв окончаний и достаточно длинный текст, относящийся к выбранной отрасли знаний. В каждом слове текста отбрасывается окончание, причем поскольку окончания упорядочены так, что сначала идут более длинные из них, то возможность неполного отбрасывания окончания исключается Ясно, что термин «основа» к полученному остатку может применяться лишь условно, так как многие из остатков основами не являются. Например, в слове «дом» основа условно состоит из одной буквы «д», поскольку окончание — «ом» будет отброшено. Чтобы не искажать основы коротких слов, условимся в словах, состоящих из трех и Таблица 3.7. Группы окончаний (см. скан) Окончаний табл. 3.7 (см. скан) нее букв, окончания не отбрасывать. Это ограничение особенно важно для коррекции предлогов. Каждая основа снабжается меткой, указывающей группу окончаний, совместимую с этой основой. Необходимо подчеркнуть, что при ограниченном объеме ЗУ, которым располагают мини-ЭВМ, целесообразно строить специализированные словари, ориентирующиеся на коррекцию текстов определенного профиля, скажем газетный словарь, деловой, научно-технический и т. д. Однако, если ЭВМ сиайжена мощной дисковой памятью, то для нее можно создать и более универсальные словари. Будем различать два случая автоматической коррекции: коррекция ошибок распозиавания, коррекция отказов. При коррекции ошибок ничего не известно об их местонахождении, поэтому единственный путь обнаружения — сравнение каждого считанного слова со словами словаря. Если полученная после отбрасывания окончания основа не найдена в словаре, то возможны три варианта: в основе есть ошибки; из-за ошибки в слове неверно отброшено окончание, в результате чего получилась основа с другим числом букв; данной основы нет в словаре. С учетом этих ситуаций и построена граф-схема алгоритма (рис 3 25). Сначала ищем в словаре основу, отличающуюся от данной на одну, две или максимум три буквы, поскольку предполагается, что в основе не более трех ошибок. Еслн такай основа одна, то она берется за правильную основу, к ней присоединяется отброшенное окончание, и на этом процесс заканчивается. Если же основа не одна, то необходимо выбрать одну из них. Алгоритм выбора состоит в следующем. Учитывая метки групп окончаний, отбрасываем основы, не совместимые с данным окончанием. Выбор одной из оставшихся основ (если их не одна) осуществляется из статистических соображений. В процессе оценки надежности распознавания строится квадратная матрица (D), в которой каждому символу распознаваемого алфавита В ставятся в соответствие строка и столбец Элементу матрицы, стоящему на пересечении t-й строки в (см. скан) Рис. 3.25. Структурная схема алгоритма словарной коррекции ошибок распознавания матрицы определяют вероятности правильного распознавания символов алфавита. Пусть основа считанного слова Пусть слова Если словарь содержит все считываемые слова, то можно считать, что ошибочно считанное слово Пример. В процессе считывания слова получилось следующее сочетание букв: ХЛИГА. После отсечения окончания получаем основу ХЛИГ. В словаре основ длиной в четыре буквы этого слова нет. Ищем основу из четырех букв, отличающуюся на одну, две или три буквы. Основ, отличающихся на одну букву, также в словаре нет; на две буквы отличаются следующие основы: ХЛЕБ, ХЛОР, ХЛОП, СЛУГ, СЛОГ, СЛИВ, ВЛИВ, ПЛИТ, КНИГ, КЛИН, ДВИГ, ПЛУГ. Поскольку слово ХЛИГА имеет окончание -А, то основы ХЛОП, ВЛИВ, ДВИГ не совместимы с этим окончанием и должны быть отброшены. Выбор одной Если же в словаре основ не находится ни одной основы, отличающейся на букв, то либо из-за ошибки в окончании оно было отсечено неверно, либо слова нет в словаре. Поэтому последовательно буква за буквой отсекают последние буквы слова и для полученного остатка ищут подходящую основу в словаре основ. Если при отсечении последовательно от одной до пяти букв (наибольшая длина окончания в табл. 3.7 равна пяти) и соответствующем потоке отличающийся на минимальное число букв основы не найдется таковой при Рассмотрим случай отказа от распознавания. Большинство методов при отказе от распознавания обеспечивают (или могут обеспечить при соответствующей модификации) выдачу совокупности букв, выбор из которых распознающее устройство затрудняется сделать. Если эта совокупность букв, которую мы обозначим через Таблица 3.8 (см. скан) Таблица 3.9 (см. скан) место в слове и применяем алгоритм поиска ошибок. Ясно, что если совокупность Если в слове несколько отказов с совокупностями букв Пример. Рассмотрим две фразы, считанные устройством, средняя вероятность ошибки или сбоя которого составляет 0,1.
Ошибочные буквы подчеркнуты, места отказов обозначены скобками. Пусть
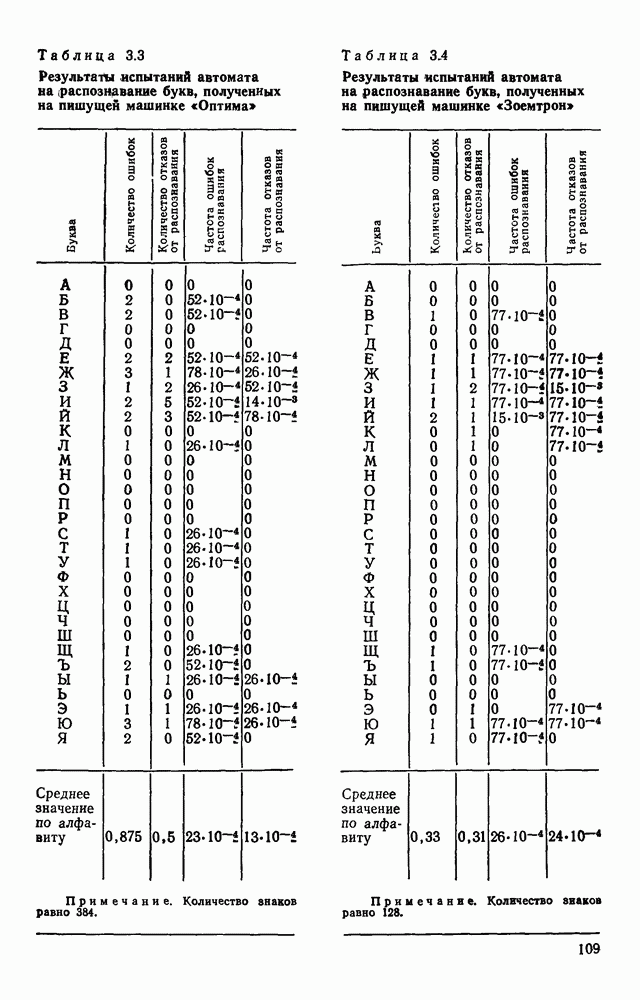
В данном примере из 16 допущенных ошибок были обнаружены две, не обнаружено три и скорректированы 11 ошибок и отказов. Эксперименты над теистами показали, что данный алгоритм позволяет обнаружить и исправить до 90% ошибок, из них примерно 80% автоматически исправляются, а остальные 10% лишь обнаруживаются. При этом слово с обнаруженной ошибкой выдается на печать со словами, стоящими слева и справа. Примеры работы алгоритма приведены в табл. 3 8, 3.9. Каждый текст приводится в трех редакциях первоначальный текст без искажений: тот же текст со случайным образом внесенными ошибками (ошибки составляют в среднем 10% букв); текст после автоматического обнаружения и исправления ошибок.
|
 |
Оглавление
|




































































































































































































 или
или  находится ниа растре в данный момент, то следует отдать предпочтение букве
находится ниа растре в данный момент, то следует отдать предпочтение букве  поскольку этот знак в русском языке встречается в среднем в 66 раз чаще, чем
поскольку этот знак в русском языке встречается в среднем в 66 раз чаще, чем  Аналогичным способом можно поступить, учитывая статистику двубуквенных и многобуквенных сочетаний. Однако этот способ имеет два основных недостатка: во-первых, вероятность ошибок остается довольно большой; во-вторых, с ростом числа букв в сочетании, т. е. при переходе к 3-, 4-граммам и выше, число
Аналогичным способом можно поступить, учитывая статистику двубуквенных и многобуквенных сочетаний. Однако этот способ имеет два основных недостатка: во-первых, вероятность ошибок остается довольно большой; во-вторых, с ростом числа букв в сочетании, т. е. при переходе к 3-, 4-граммам и выше, число  -грамм становитсн сравнимым с числом слов в словаре языка. В таких случаях более эффективной является словарная коррекция.
-грамм становитсн сравнимым с числом слов в словаре языка. В таких случаях более эффективной является словарная коррекция.
 букв воспринимается и записывается в память ЭВМ как слово такой же длины. Отклонения могут состоять лишь в заменах одних букв другими (ошибки) или отказах выбрать нужную букву из некоторой совокупности (отказы). Общая идея коррекции ошибок с помощью словаря выглядит довольно просто. Предположим, что в памяти машины хранятся все слова языка и что о месте ошибки в считанном слове нам ничего не известно. Тогда слово считается верно считанным, если оно совпадает с одним из слов словаря. Если же считанное слово не совпадает ни с одним из хранящихся в памяти машины, то оно считается неверио считанным и заменяется на слово словаря, отличающегося от него минимальным числом букв Если например, при чтении слова «ДОРОГА» произойдет ошибка в распознавании буквы
букв воспринимается и записывается в память ЭВМ как слово такой же длины. Отклонения могут состоять лишь в заменах одних букв другими (ошибки) или отказах выбрать нужную букву из некоторой совокупности (отказы). Общая идея коррекции ошибок с помощью словаря выглядит довольно просто. Предположим, что в памяти машины хранятся все слова языка и что о месте ошибки в считанном слове нам ничего не известно. Тогда слово считается верно считанным, если оно совпадает с одним из слов словаря. Если же считанное слово не совпадает ни с одним из хранящихся в памяти машины, то оно считается неверио считанным и заменяется на слово словаря, отличающегося от него минимальным числом букв Если например, при чтении слова «ДОРОГА» произойдет ошибка в распознавании буквы  так что она будет классифицирована как
так что она будет классифицирована как
 столбца, придадим значение вероятности того, что символ b, будет распознан как символ
столбца, придадим значение вероятности того, что символ b, будет распознан как символ  Ясно, что значения диагональных элементов
Ясно, что значения диагональных элементов
 имеет длину п. Допустим, что в словаре оказалось
имеет длину п. Допустим, что в словаре оказалось  слов длины
слов длины  , каждое из которых отличается от считанного слова Ф на
, каждое из которых отличается от считанного слова Ф на  буквы, и ни одного, отличающегося на меньшее число букв. Множество этих слов обозначим через 2. Каждое слово
буквы, и ни одного, отличающегося на меньшее число букв. Множество этих слов обозначим через 2. Каждое слово  можно считать полученным из считанного слова
можно считать полученным из считанного слова  путем сопоставления буквам слова
путем сопоставления буквам слова  букв слова
букв слова 
 имеют следующий вид:
имеют следующий вид: 
 получилось из истинного слова
получилось из истинного слова  за счет следующих подстановок
за счет следующих подстановок  Эти подстановки реализуются распознающим устройством, причем при отсутствии ошибки распознавания
Эти подстановки реализуются распознающим устройством, причем при отсутствии ошибки распознавания  а при ее наличии букве слова а, сопоставляется некоторая буква b алфавита В. Это сопоставление является случайным событием, и вероятность подстановки вместо буквы
а при ее наличии букве слова а, сопоставляется некоторая буква b алфавита В. Это сопоставление является случайным событием, и вероятность подстановки вместо буквы  буквы b определяется таблицей D. Поскольку все современные читающие устройства распознают каждую букву независимо от остальных, то вероятность
буквы b определяется таблицей D. Поскольку все современные читающие устройства распознают каждую букву независимо от остальных, то вероятность  замены слова
замены слова  словом
словом  равна произведению вероятностей подстановок
равна произведению вероятностей подстановок  которые определяются из матрицы (D) как ее элементы, стоящие на пересечении строки
которые определяются из матрицы (D) как ее элементы, стоящие на пересечении строки  и столбца
и столбца  В качестве истинного слова, сопоставляемого содержащему ошибки слову
В качестве истинного слова, сопоставляемого содержащему ошибки слову  , выбираем слова для которого вероятность
, выбираем слова для которого вероятность  максимальна,
максимальна,  , т. е. выбирается слово, оптимальное по критерию максимума правдоподобия.
, т. е. выбирается слово, оптимальное по критерию максимума правдоподобия.
 оставшихся основ определяется структурой матрицы
оставшихся основ определяется структурой матрицы 
 то считаем, что основы нет в словаре. В противном случае ошибка была в окончании, слово вместе с его порядковым номером в тексте выдается на печать
то считаем, что основы нет в словаре. В противном случае ошибка была в окончании, слово вместе с его порядковым номером в тексте выдается на печать
 нам известна, то процесс коррекции организуется довольно просто: последовательно подставляем каждую букву из
нам известна, то процесс коррекции организуется довольно просто: последовательно подставляем каждую букву из  на соответствующее
на соответствующее
 включает верную букву, то либо отказ будет ликвидирован с достоверностью, равной единице, либо слово будет заменено другим словом из словаря, отличающимся от нужного на одну букву.
включает верную букву, то либо отказ будет ликвидирован с достоверностью, равной единице, либо слово будет заменено другим словом из словаря, отличающимся от нужного на одну букву.
 , то необходимо перебрать все
, то необходимо перебрать все  вариантов (
вариантов ( -число элементов в
-число элементов в  ).
).

 . Применение описанного алгоритма дает следующий результат:
. Применение описанного алгоритма дает следующий результат:
