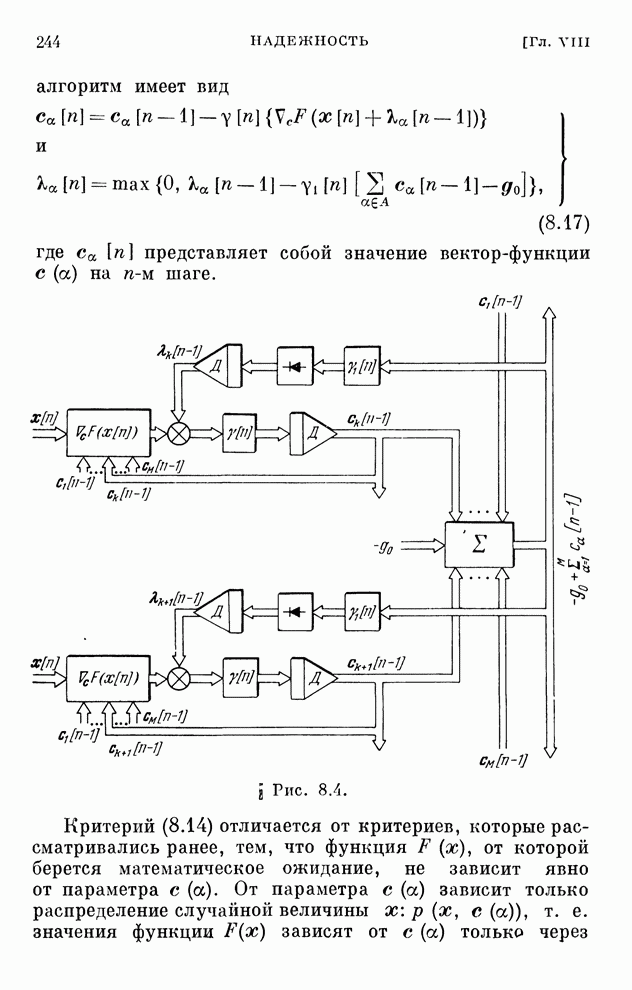
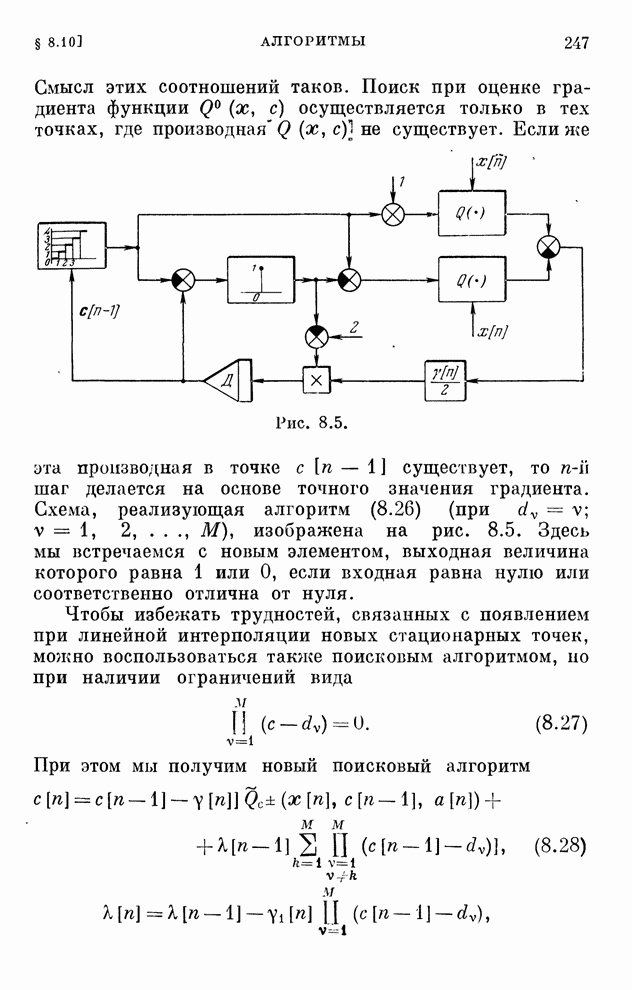
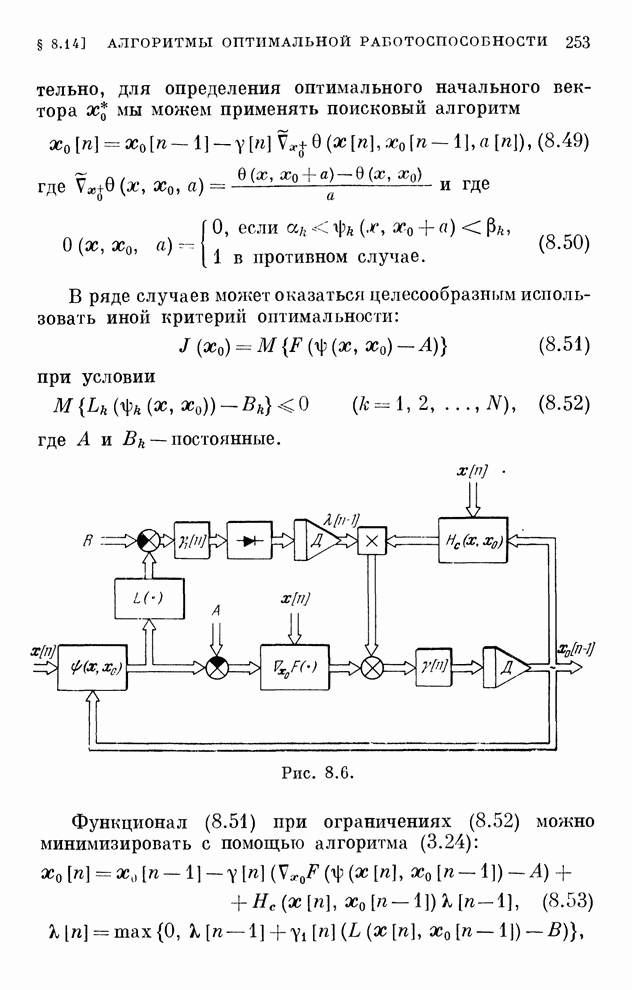
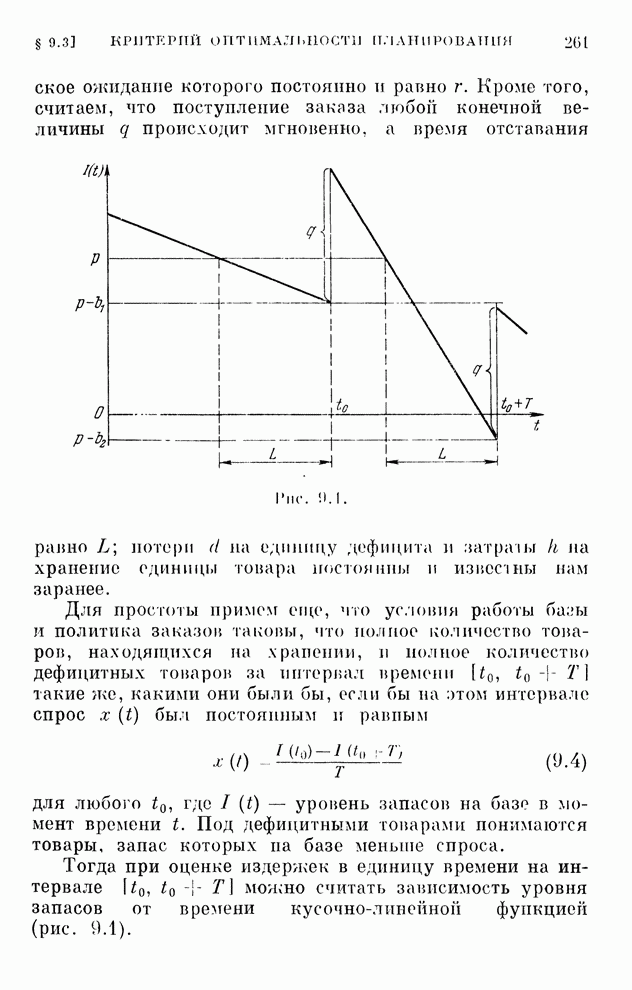
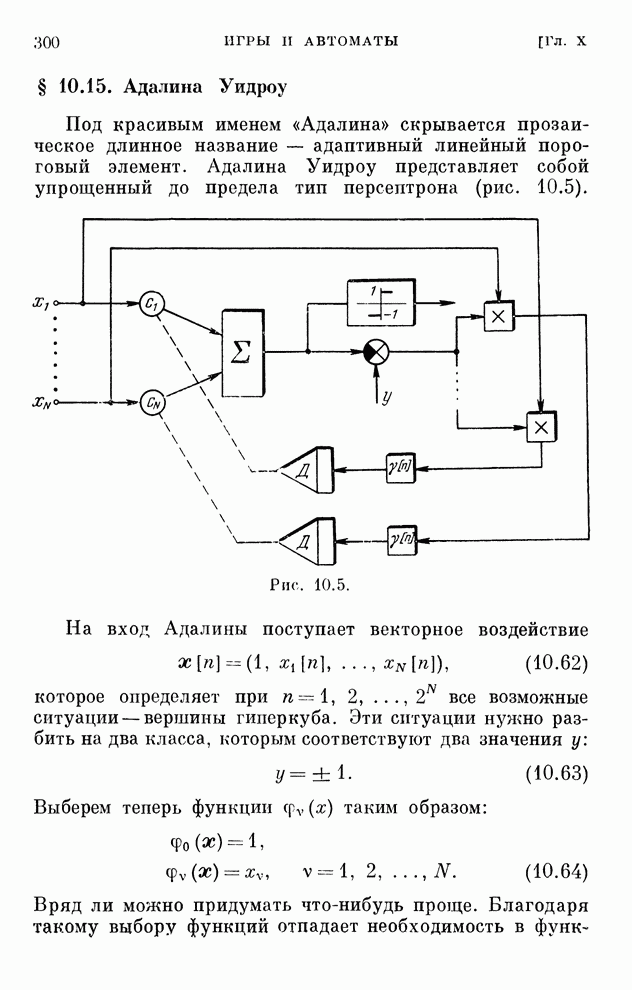
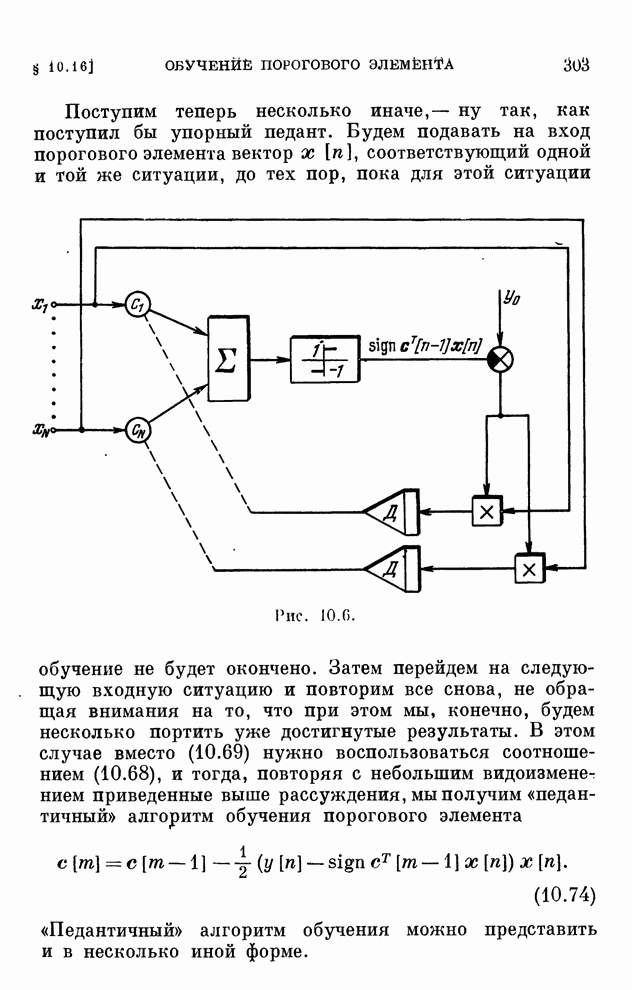
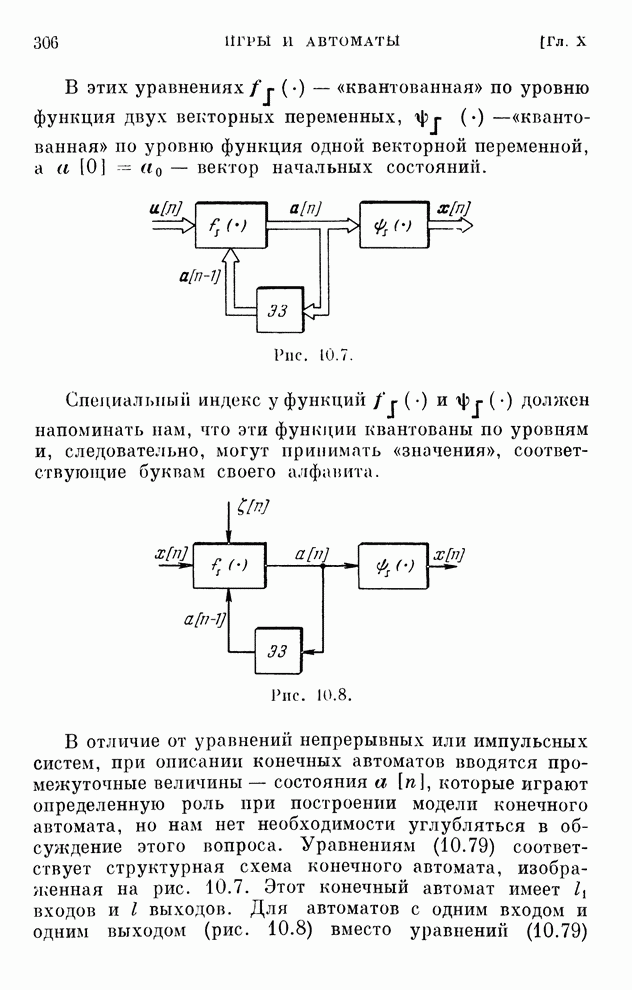
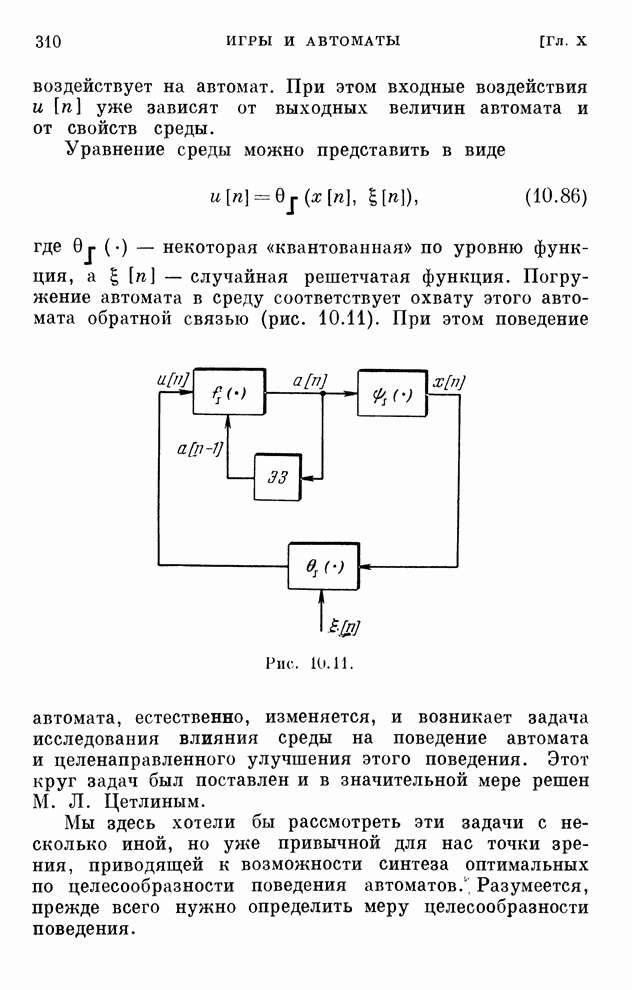
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
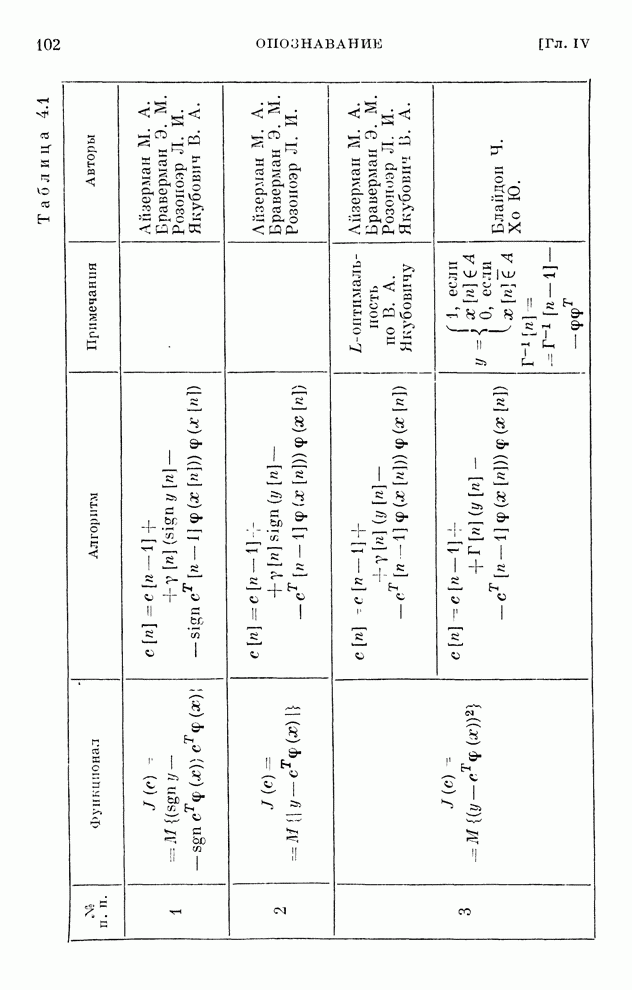
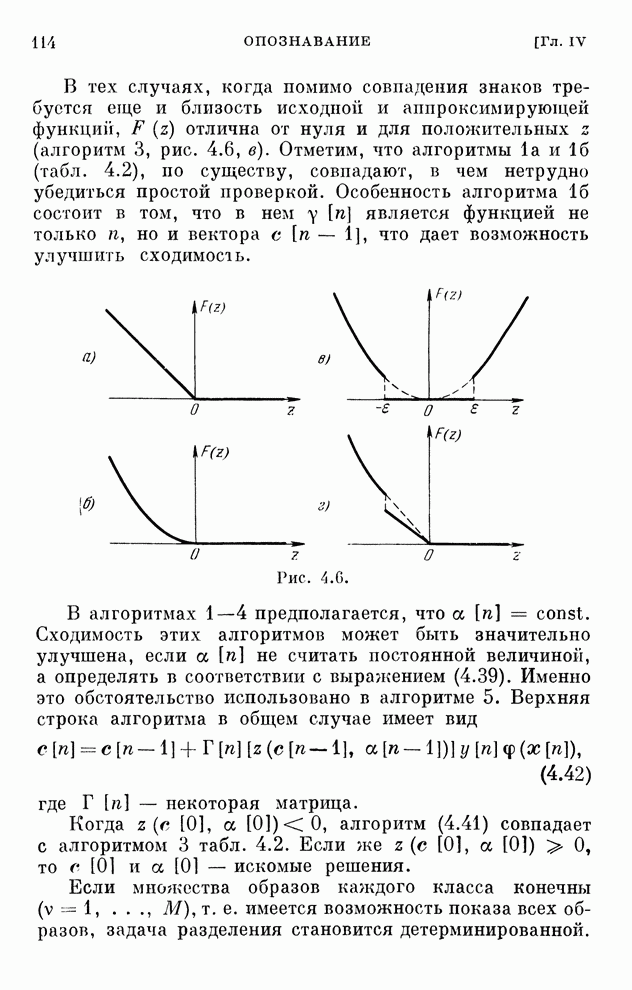
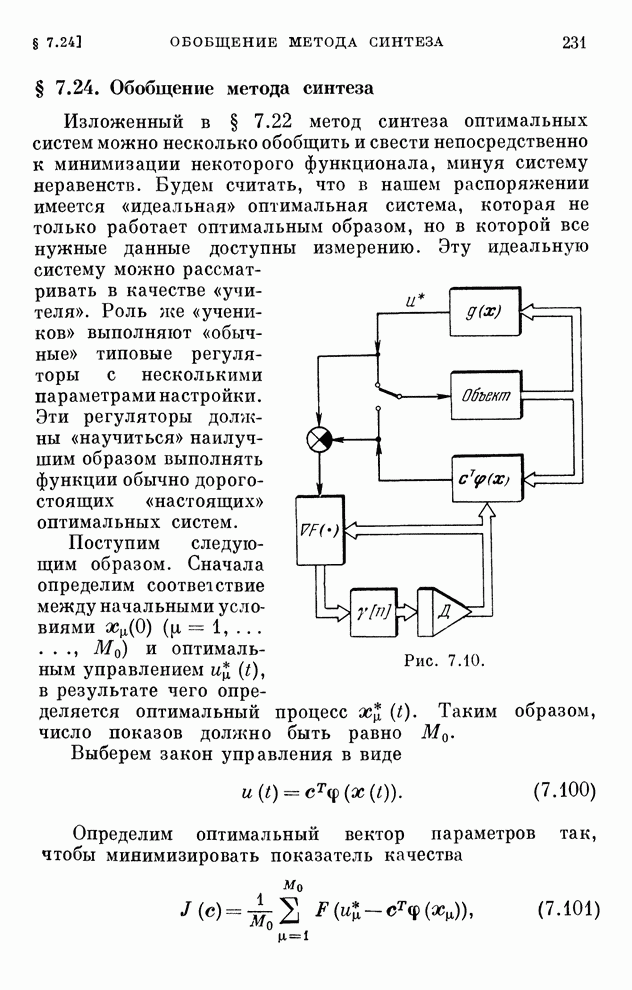
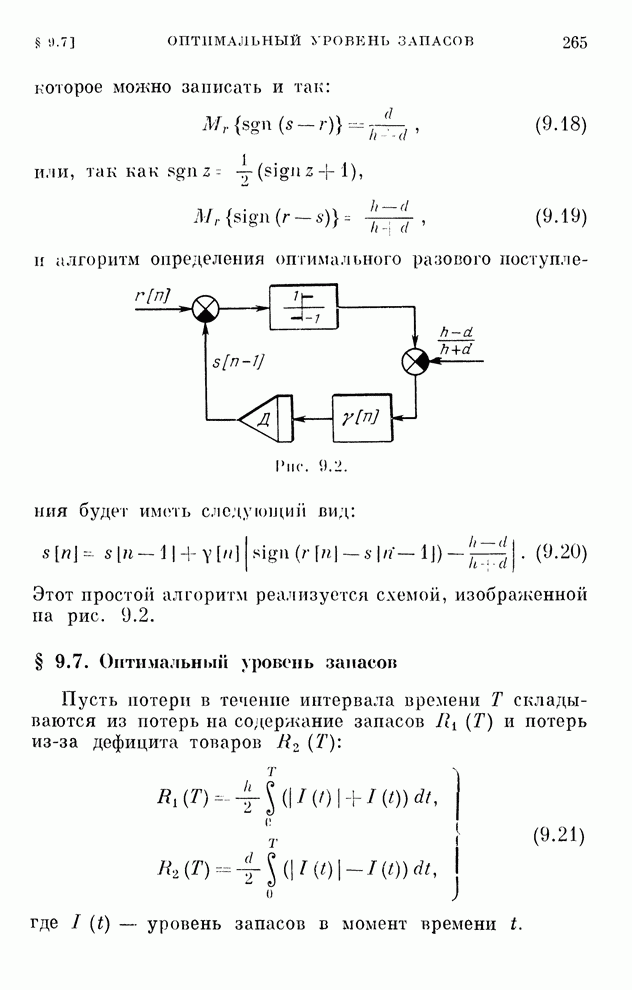
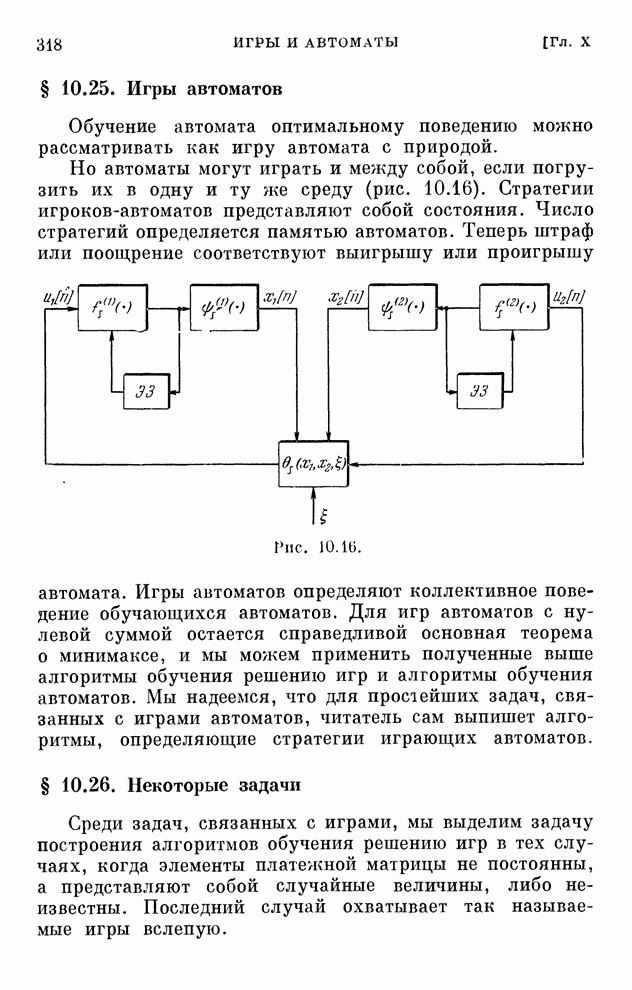
§ 10.5. Алгоритмы обучения решению игр
Представим
уравнения (10.15) в виде
 (10.19)
(10.19)
и
применим к ним вероятностные итеративные алгоритмы обычного типа. Тогда мы
получим алгоритмы обучения решению игр
 (10.20)
(10.20)
Здесь
 и
и  — оптимальные чистые
стратегии на шаге
— оптимальные чистые
стратегии на шаге  ;
определяется
номером максимальной компоненты вектора
;
определяется
номером максимальной компоненты вектора  , а определяется номером минимальной
компоненты вектора
, а определяется номером минимальной
компоненты вектора  .
Для сходимости алгоритмов обучения достаточно, чтобы коэффициенты
.
Для сходимости алгоритмов обучения достаточно, чтобы коэффициенты  и
и  удовлетворяли
обычным условиям (3.34, а). Алгоритмы (10.20) соответствуют процессу
последовательного совершенствования игроками стратегий, т. е. обучению игре
«опытным путем».
удовлетворяли
обычным условиям (3.34, а). Алгоритмы (10.20) соответствуют процессу
последовательного совершенствования игроками стратегий, т. е. обучению игре
«опытным путем».
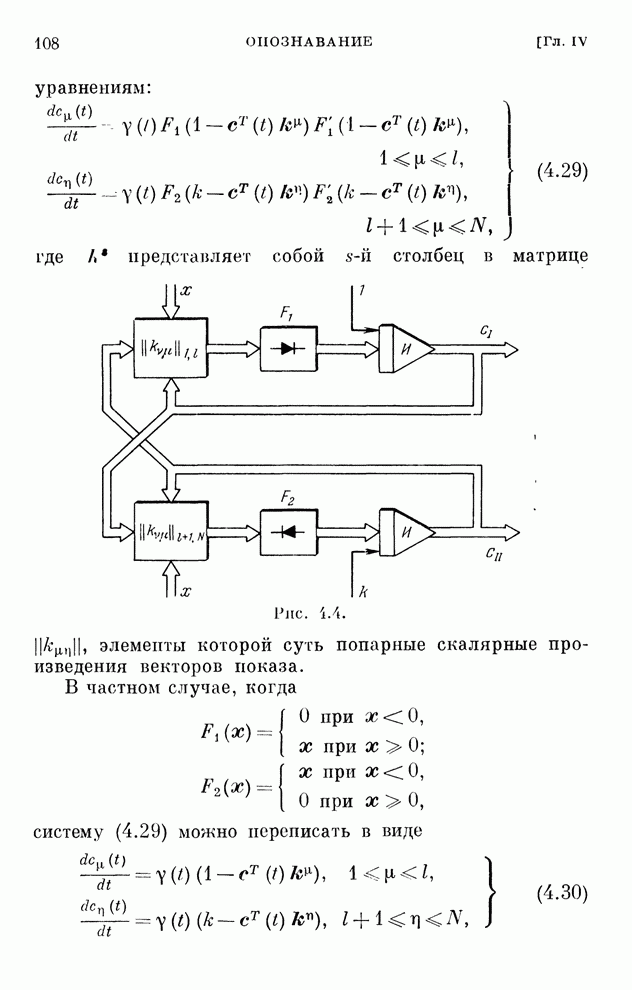
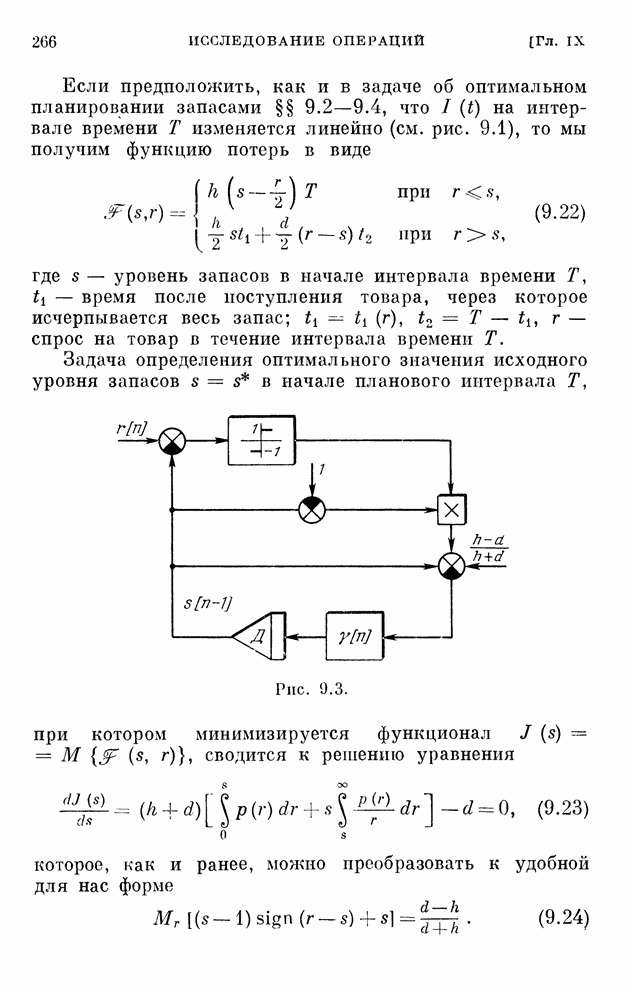
Подобным
же образом, представляя уравнения (10.18) в виде
 (10.21)
(10.21)
находим
алгоритмы обучения решению игр при наличии погрешностей:
 (10.22)
(10.22)
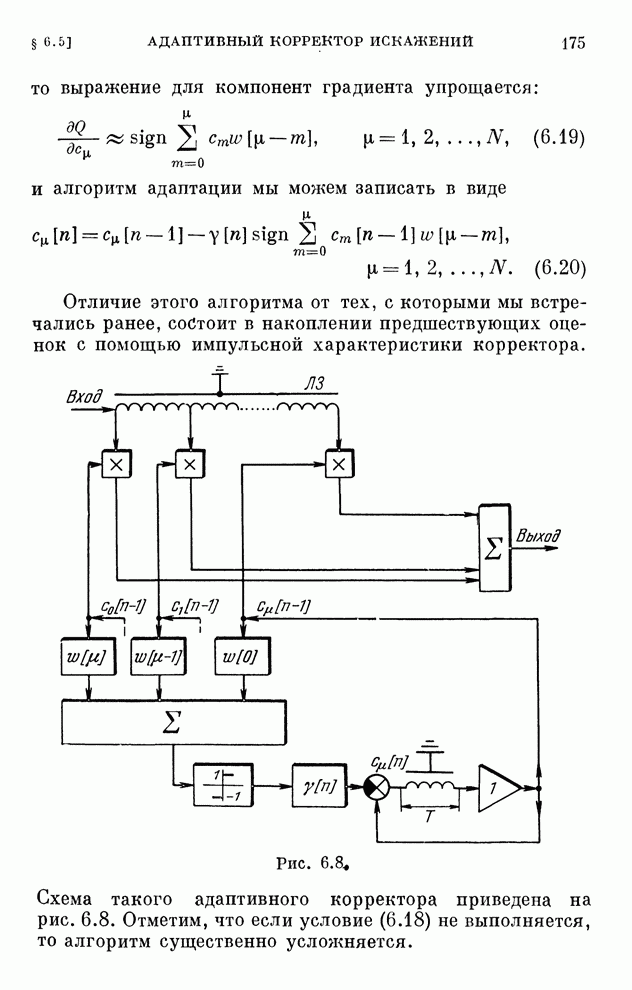
Алгоритмы
(10.22) соответствуют процессу последовательного совершенствования игроками
стратегий «опытным путем» при наличии мешающих факторов — погрешностей.
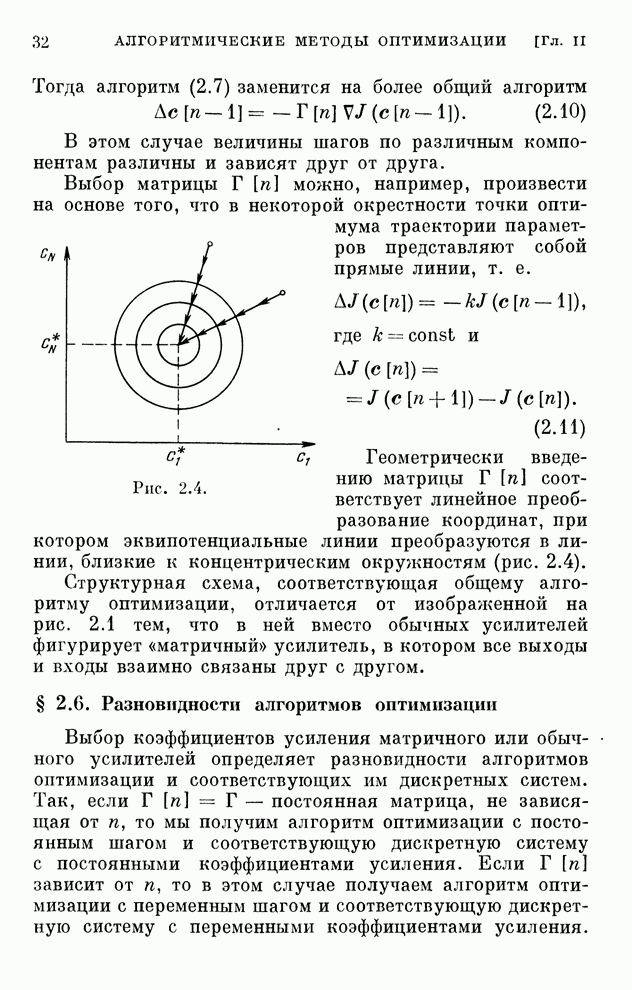
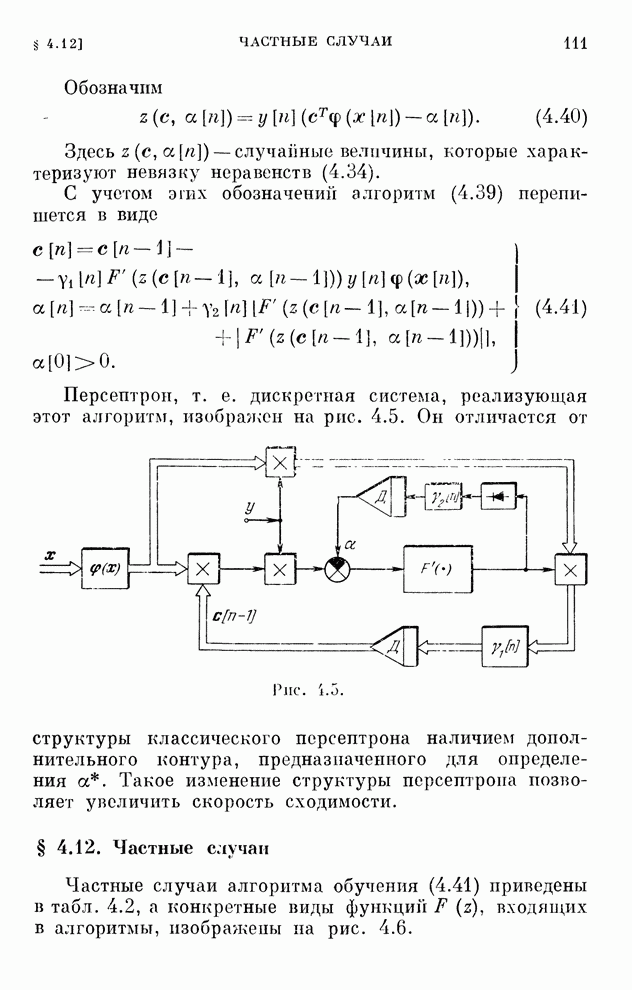
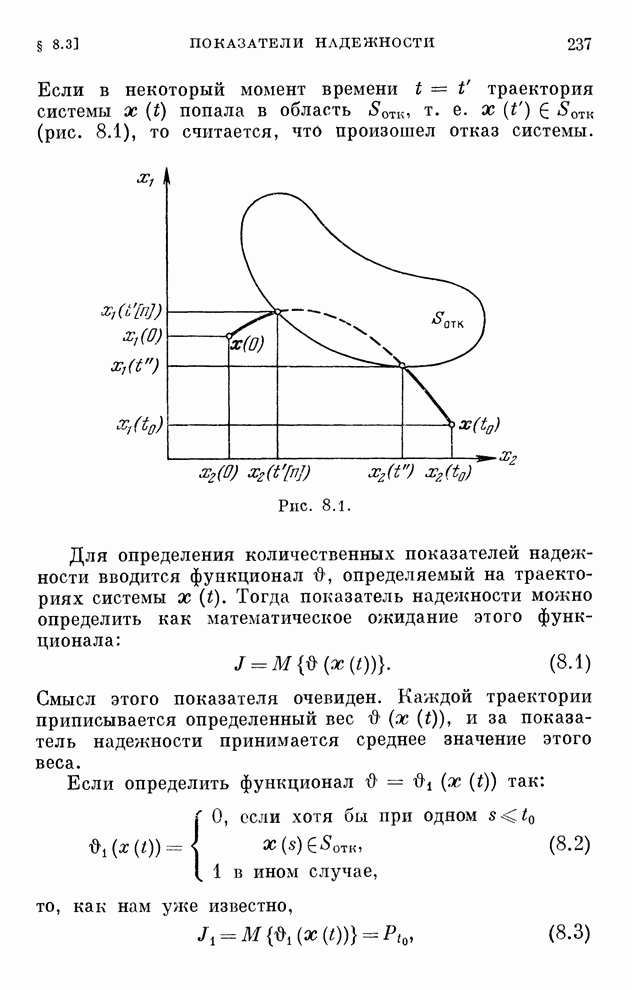
Любопытно
отметить, что наличие погрешностей с нулевым средним значением не является
препятствием к выработке оптимальных стратегий, лишь удлиняя время обучения.
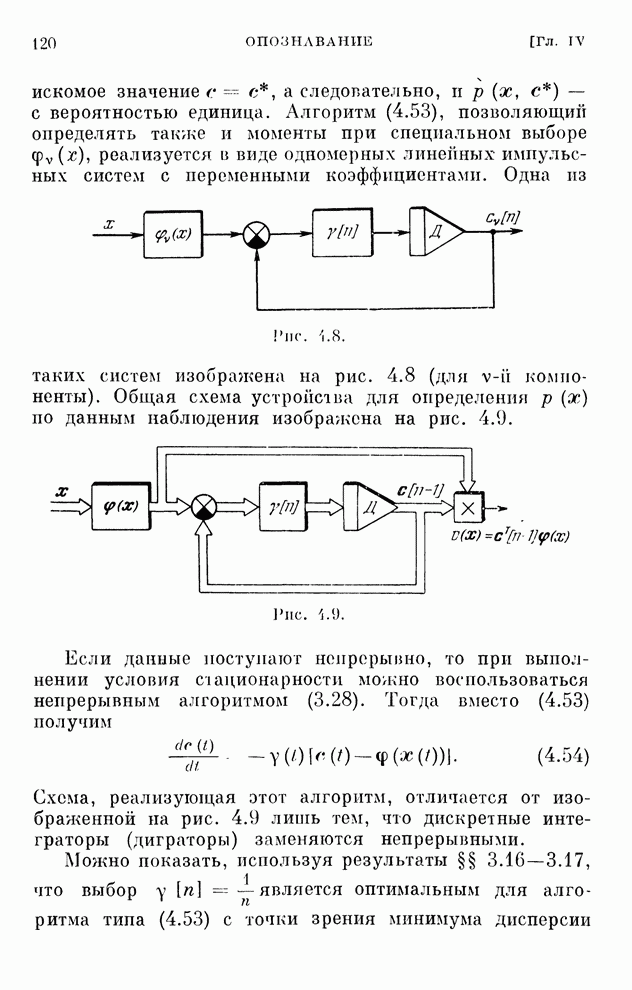
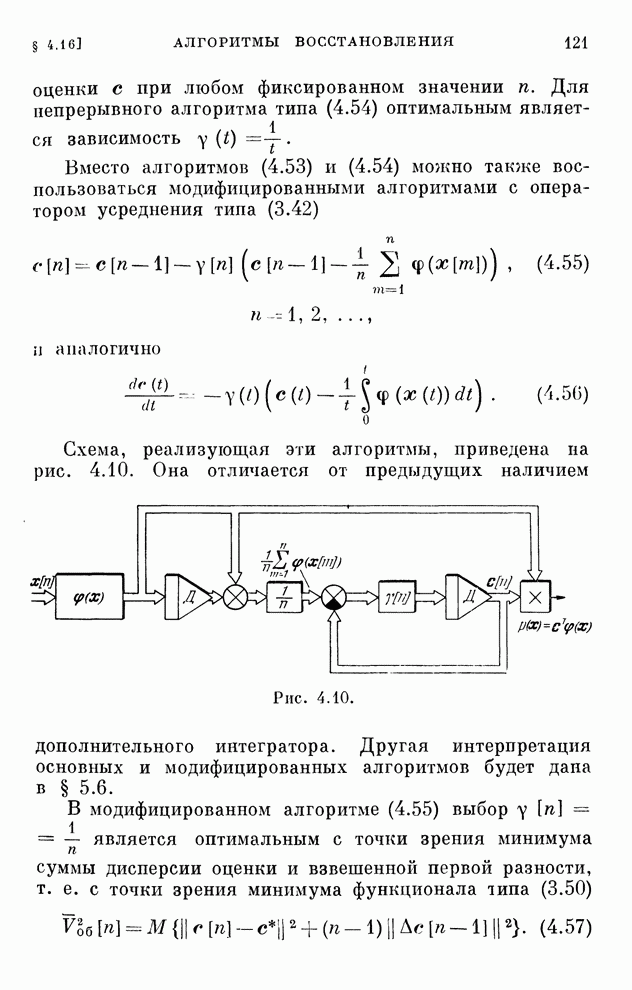
По  и
и  на каждом шагу
определяется функция
на каждом шагу
определяется функция
 (10.23)
(10.23)
которая
при  стремится
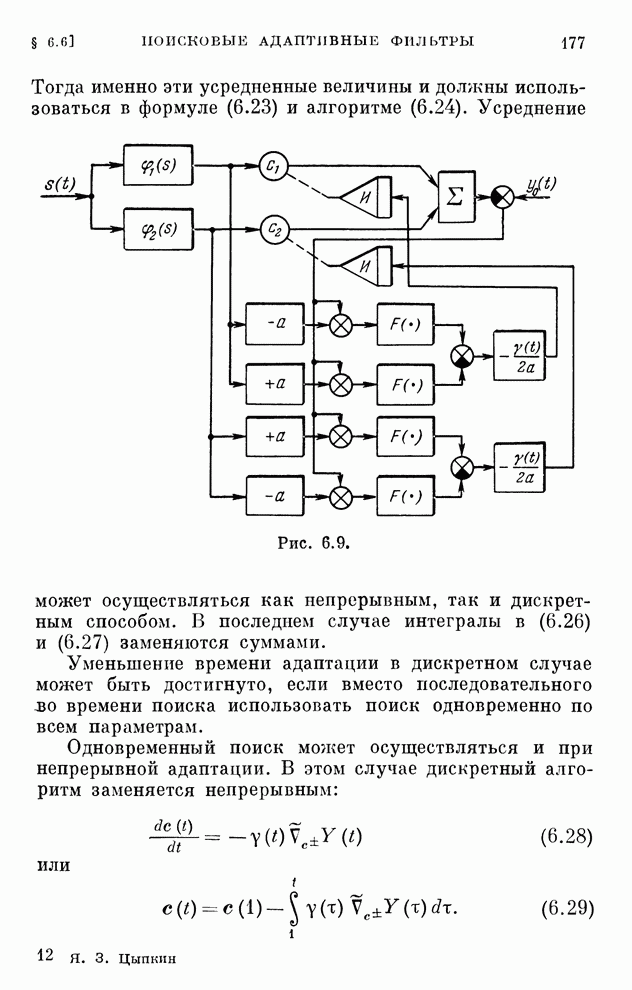
к величине, равной цене игры. Алгоритмы обучения решению игр (10.20), (10.22)
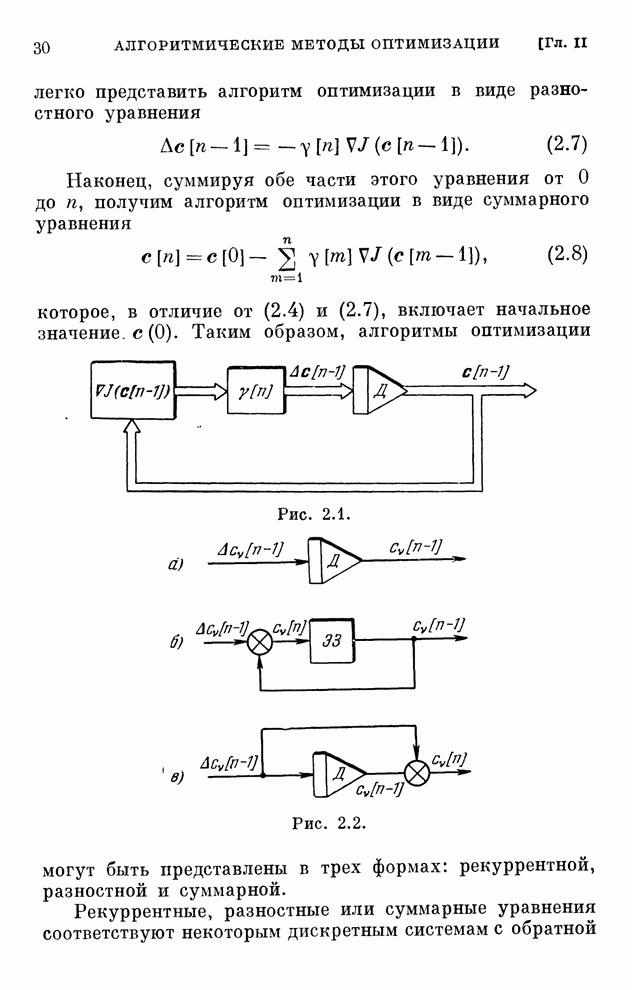
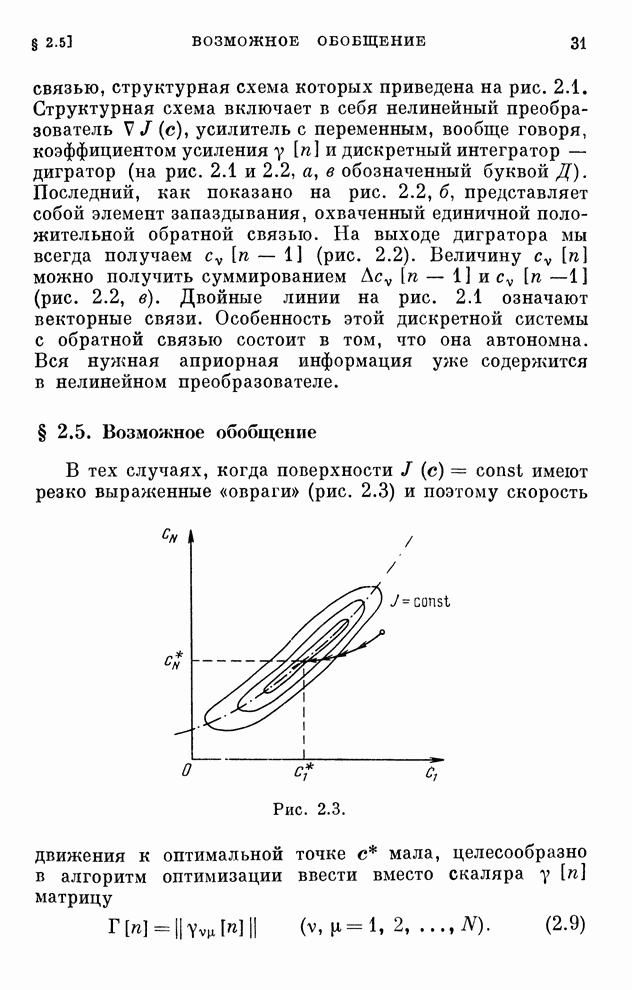
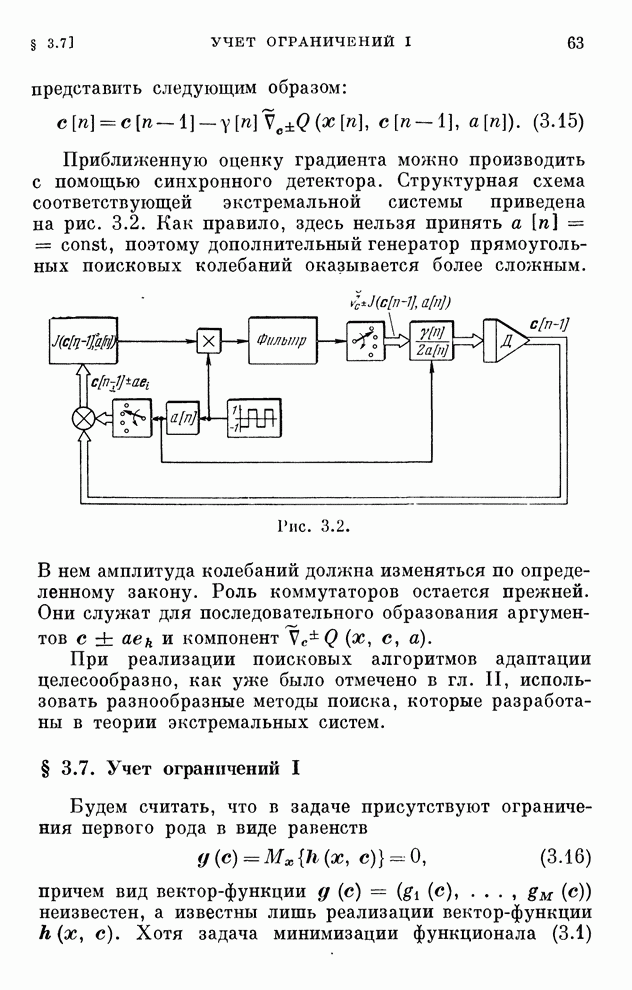
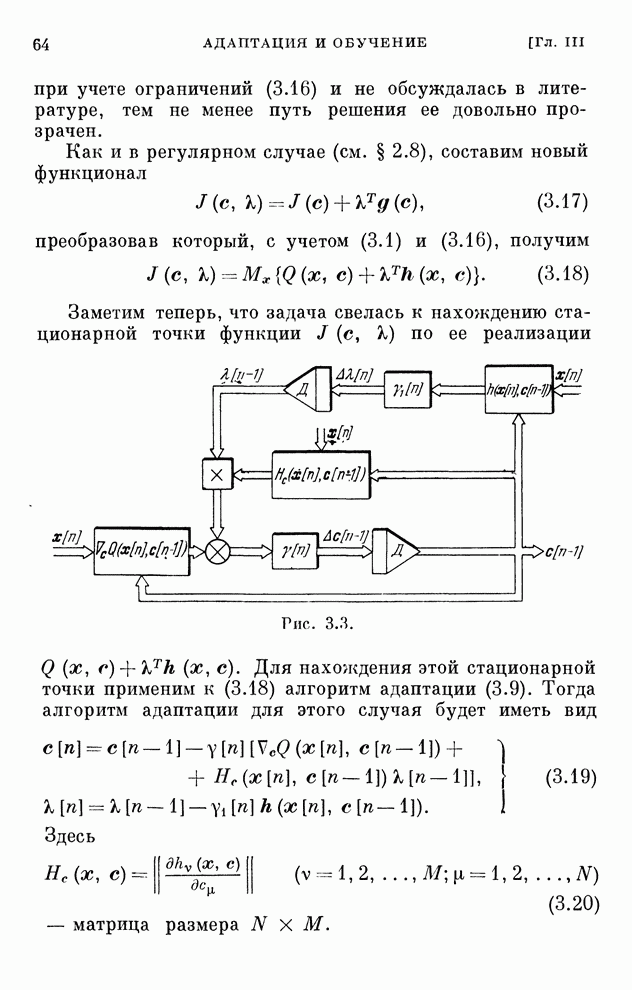
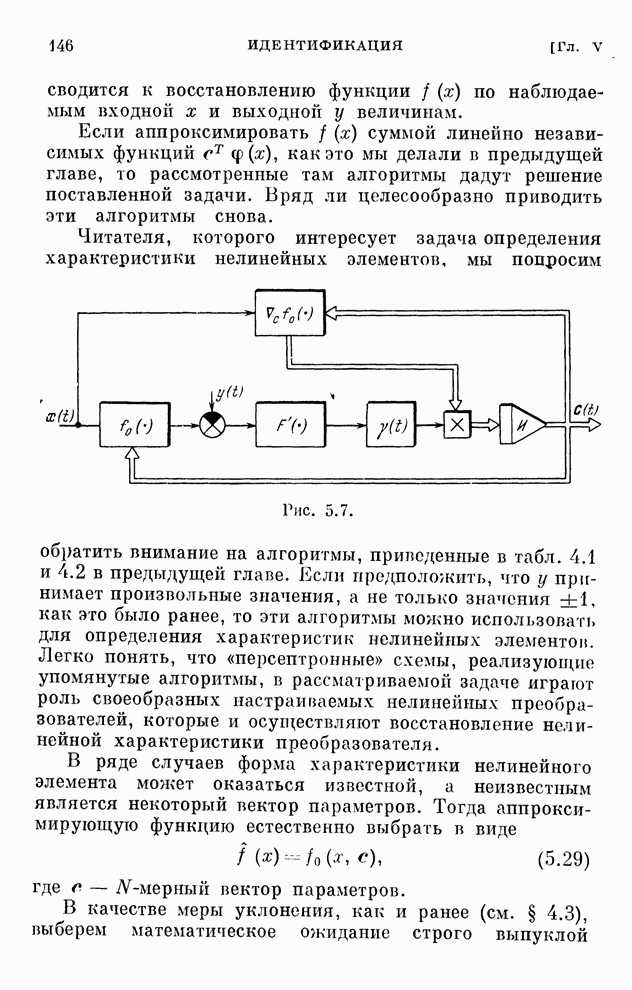
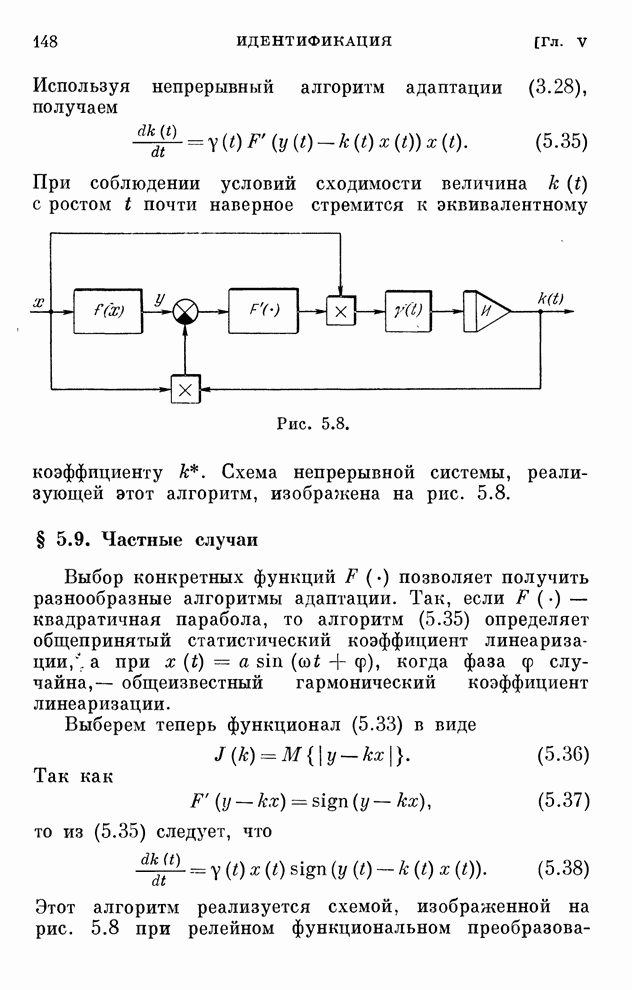
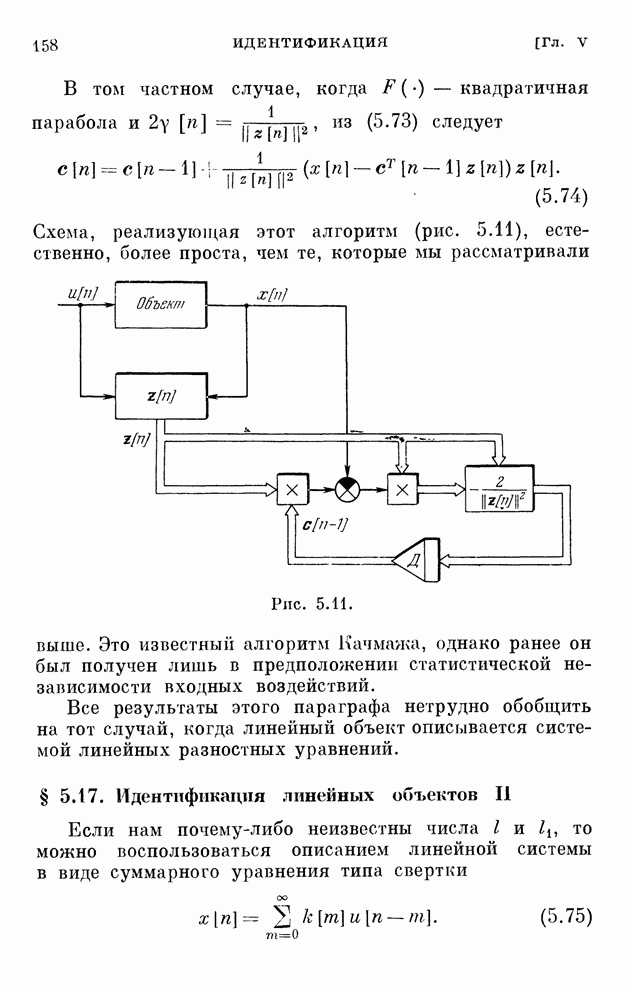
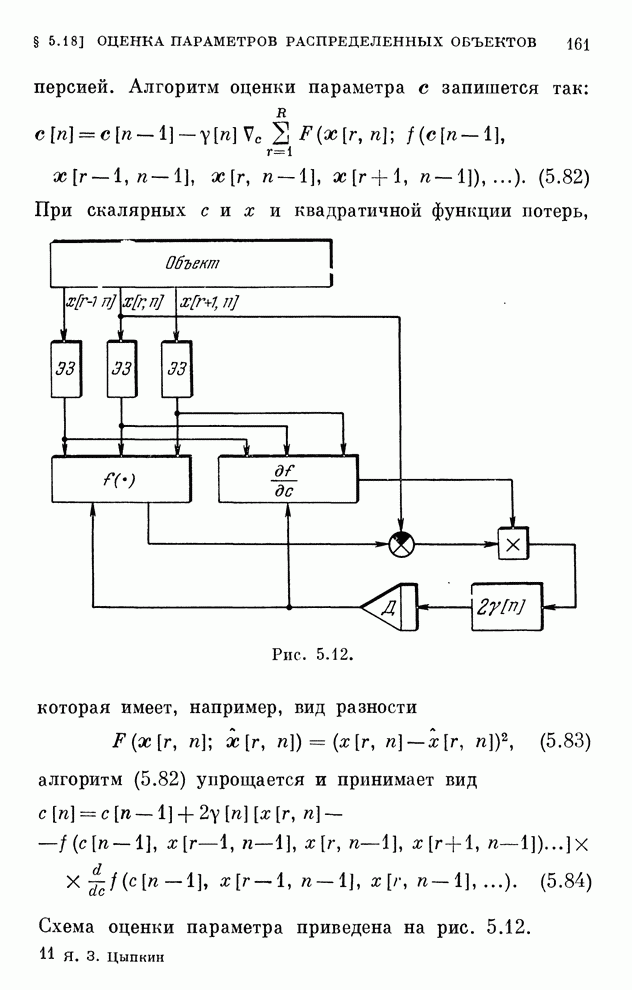
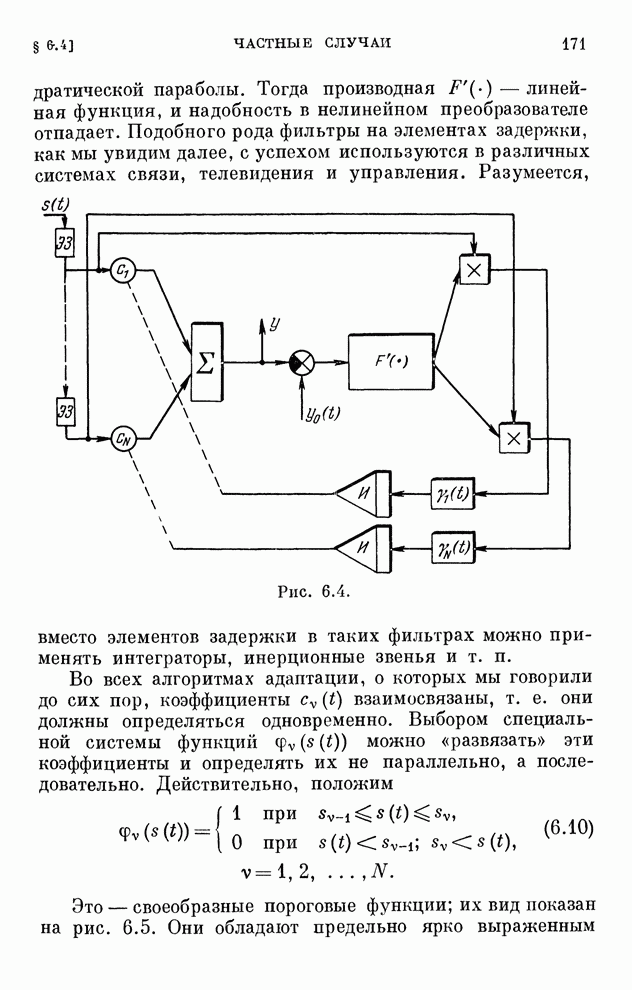
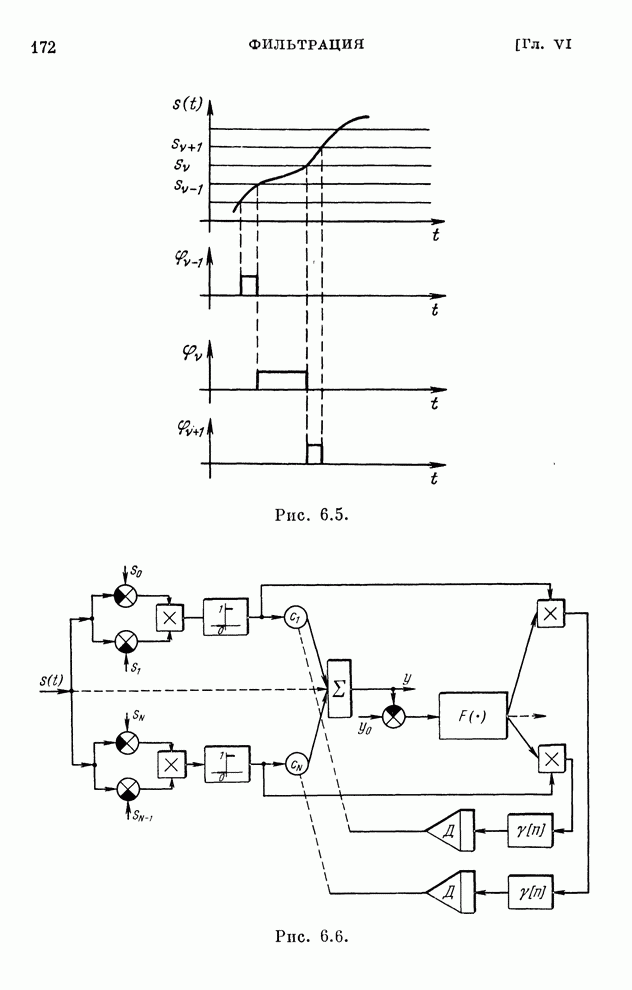
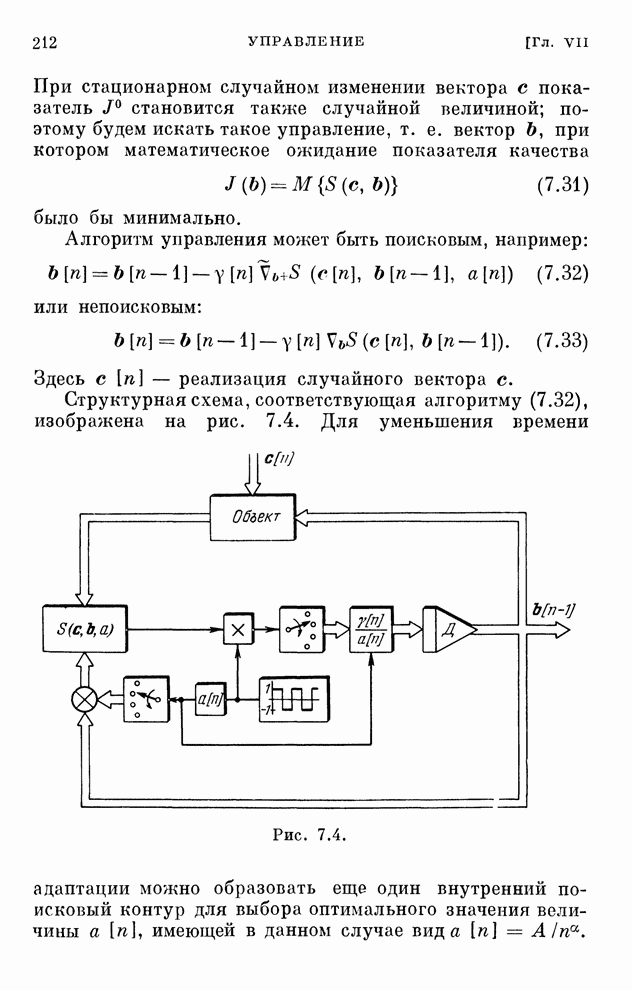
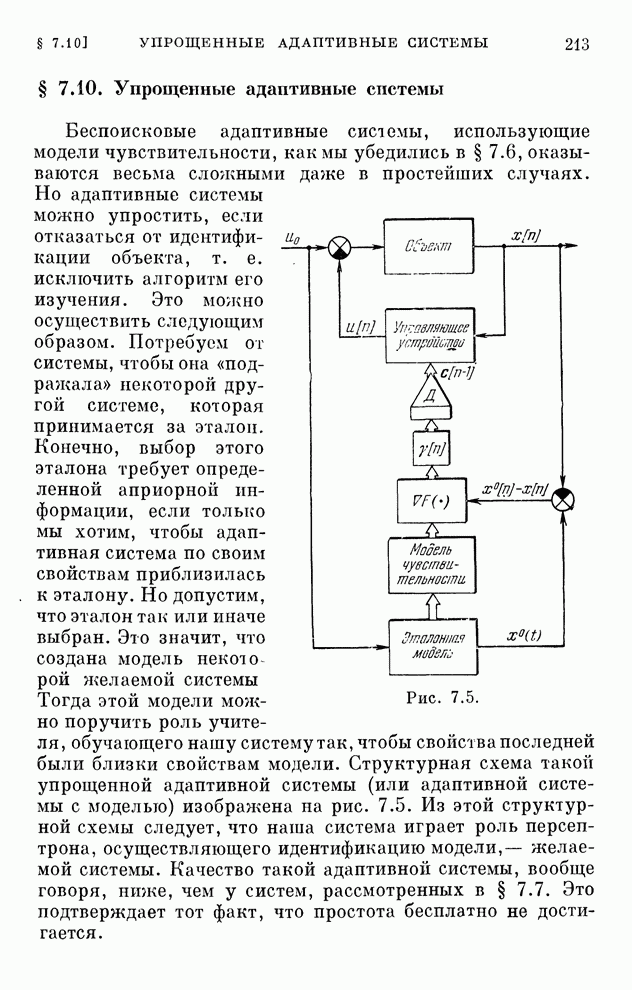
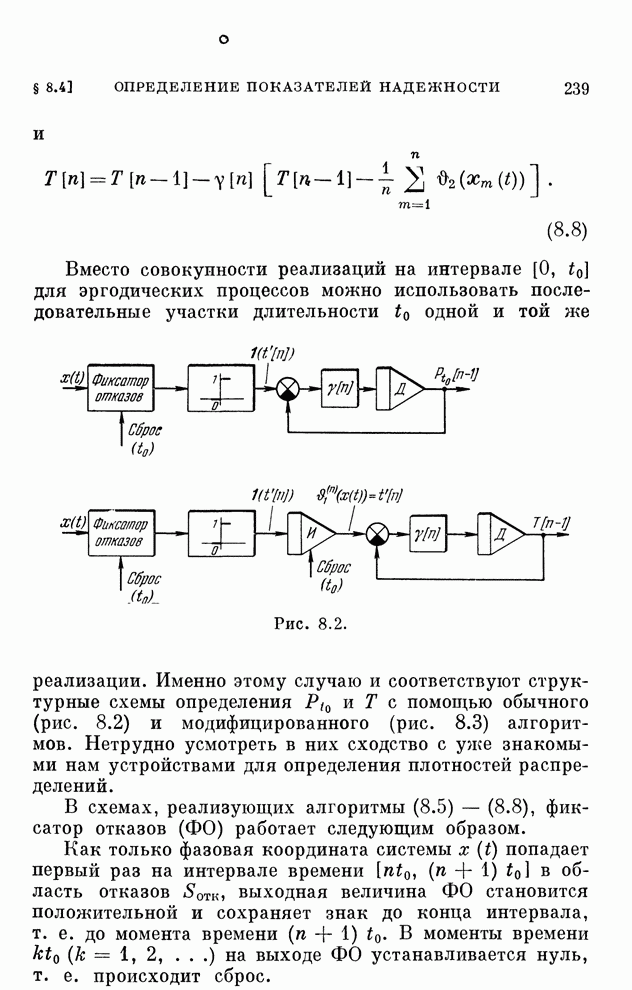
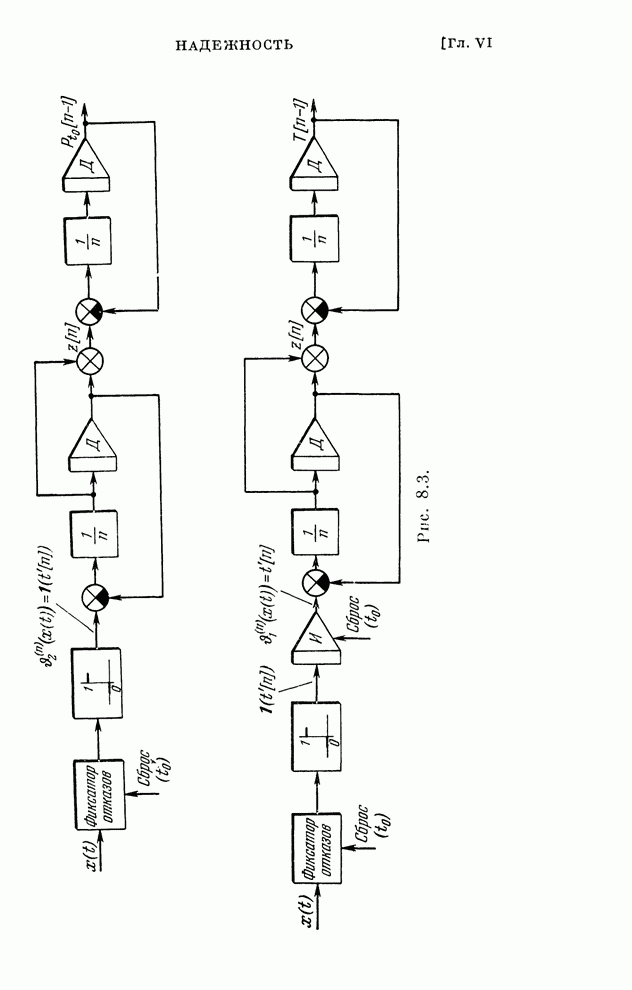
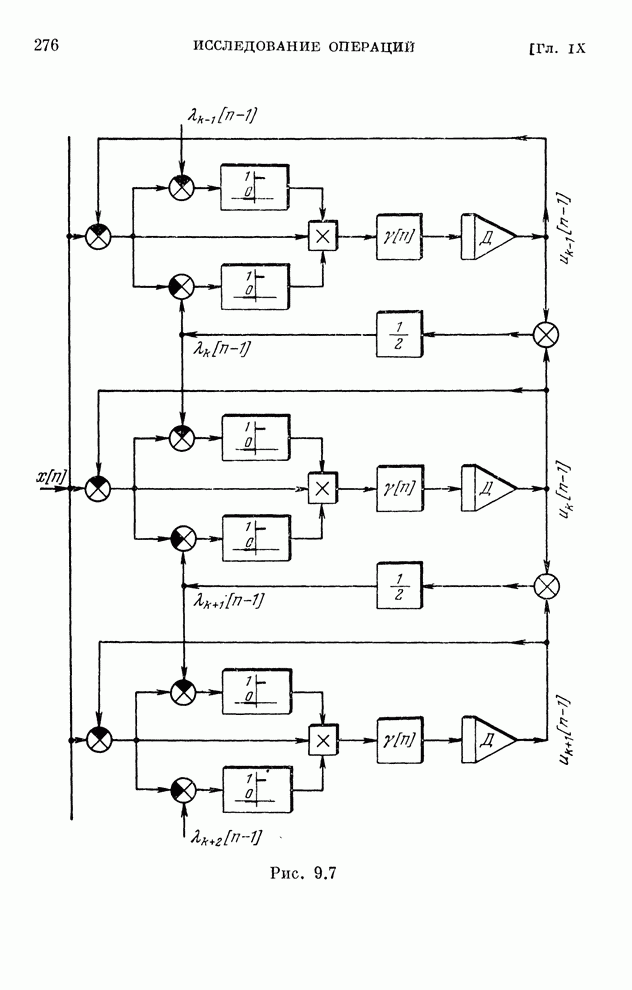
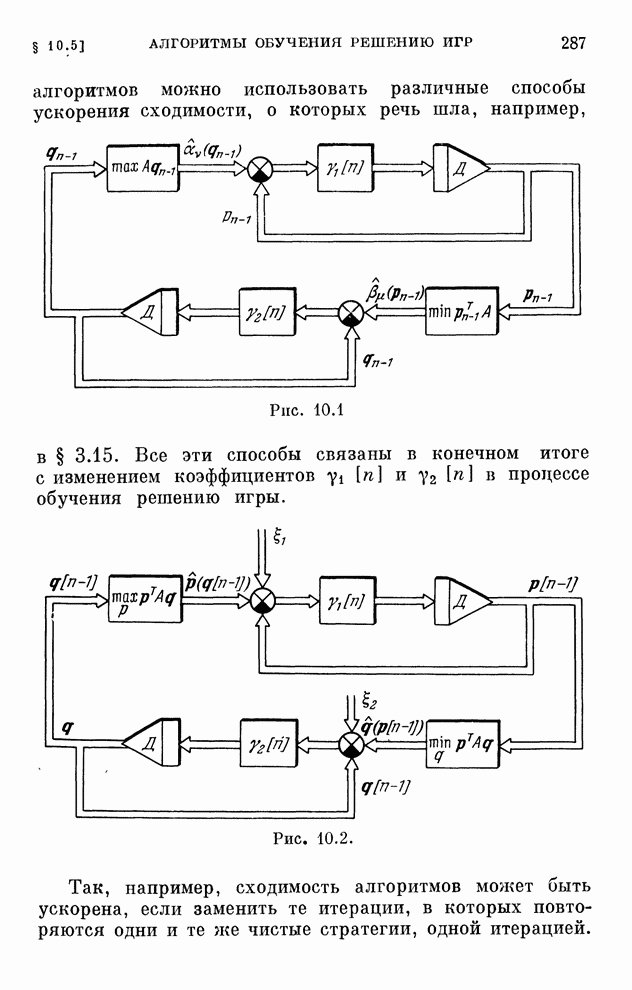
реализуются системами, схемы которых изображены на рис. 10.1 и 10.2.
стремится
к величине, равной цене игры. Алгоритмы обучения решению игр (10.20), (10.22)
реализуются системами, схемы которых изображены на рис. 10.1 и 10.2.
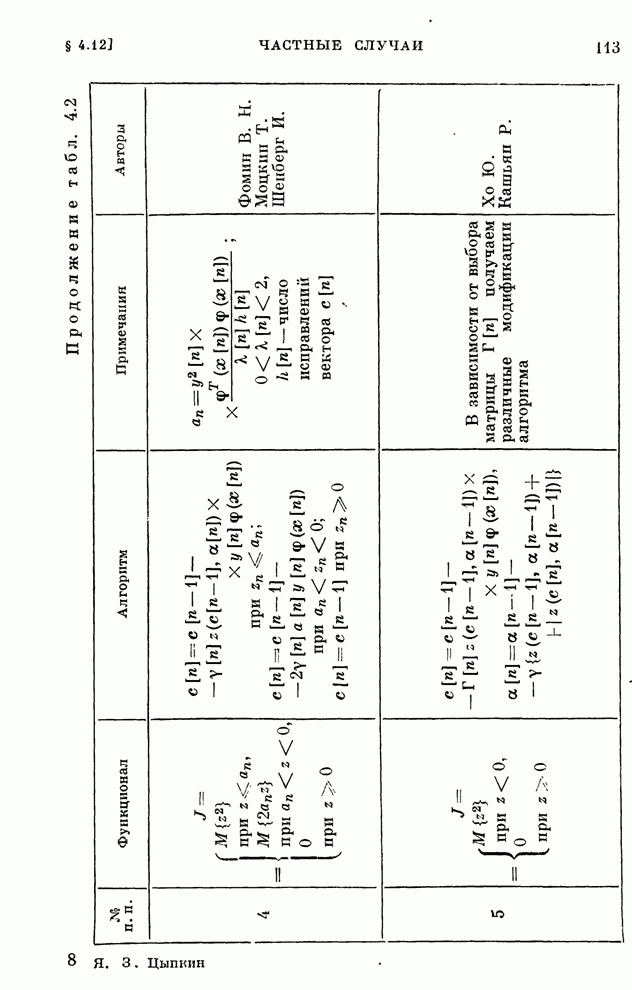
Полученные
общие алгоритмы обучения (10.20), (10.22) в частных случаях приводят и к
известным итерационным алгоритмам, приведенным в табл. 10.1.
Алгоритмы
обучения решению игр сходятся, вообще говоря, довольно медленно. Для ускорения
сходимости алгоритмов можно использовать различные способы ускорения
сходимости, о которых речь шла, например, в § 3.15. Все эти способы связаны в конечном
итоге с изменением коэффициентов и в процессе обучения решению игры.

Рис. 10.1

Рис. 10.2
Так,
например, сходимость алгоритмов может быть ускорена, если заменить те итерации,
в которых повторяются одни и те же чистые стратегии, одной итерацией. Это
соответствует такому выбору  :
:
 (10.24)
(10.24)
где
 — число итераций
на
— число итераций
на  -м шаге,
в которых повторились одни и те же чистые стратегии. Вооружившись алгоритмами
обучения решению игр, мы теперь можем заняться применением их к разнообразным
задачам.
-м шаге,
в которых повторились одни и те же чистые стратегии. Вооружившись алгоритмами
обучения решению игр, мы теперь можем заняться применением их к разнообразным
задачам.