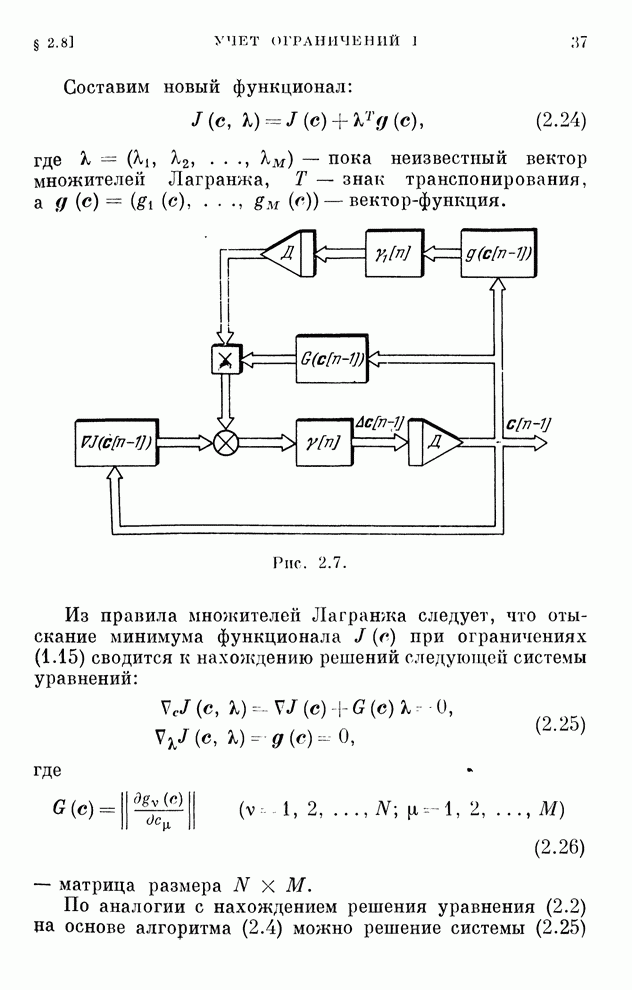
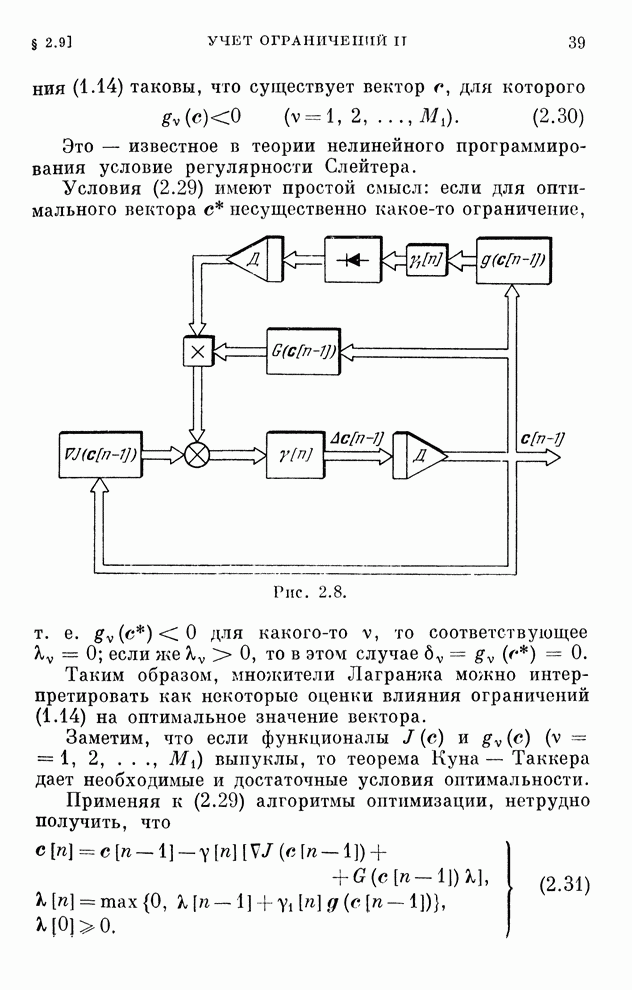
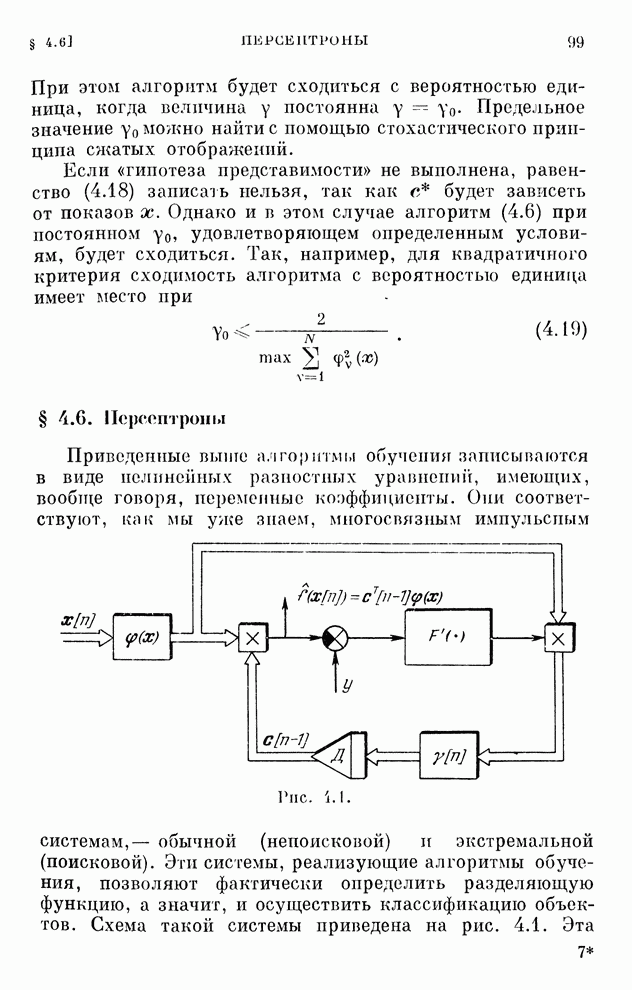
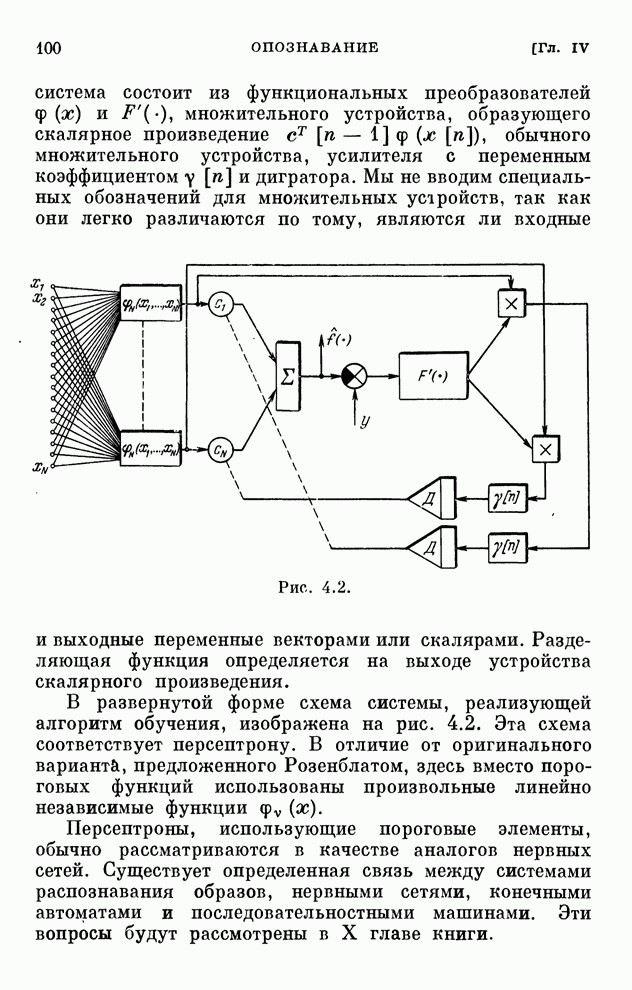
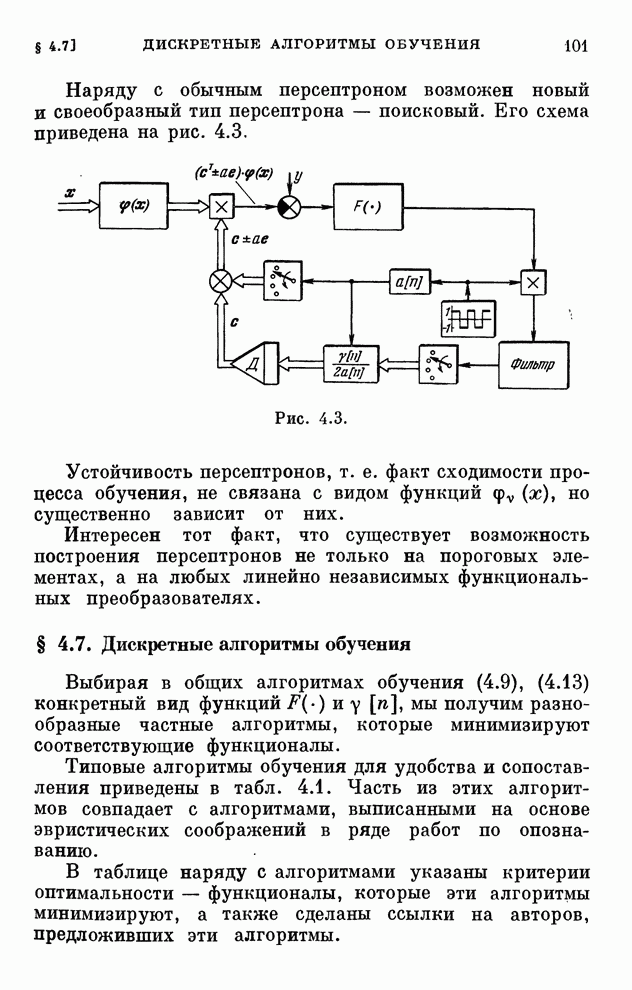
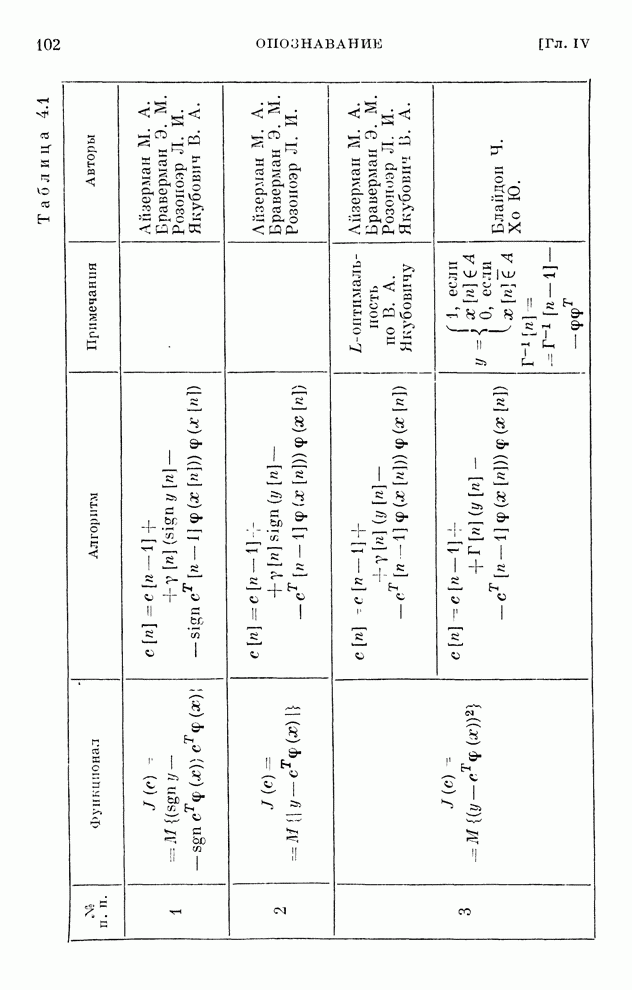
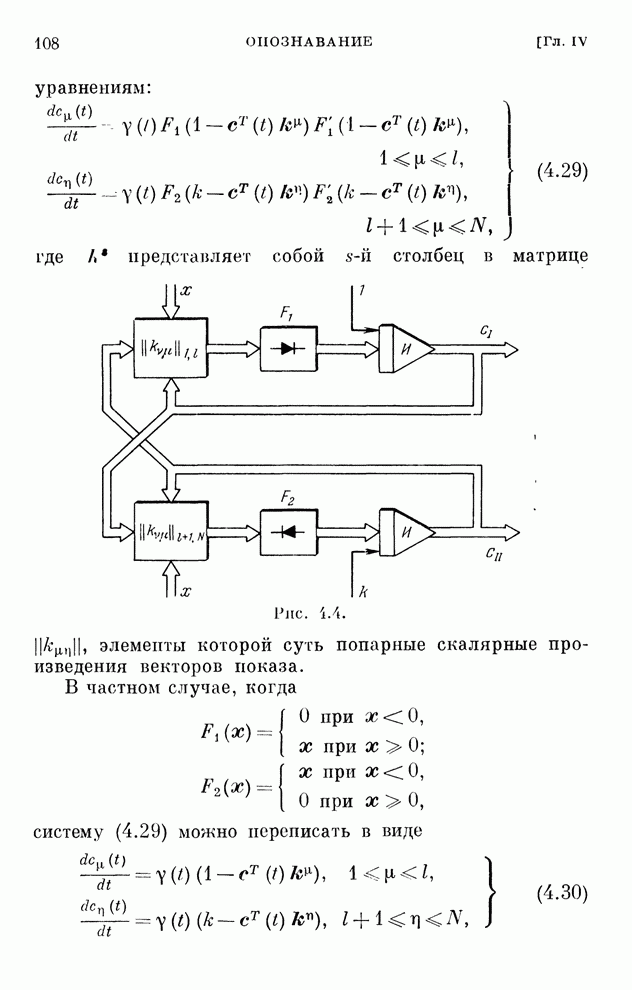
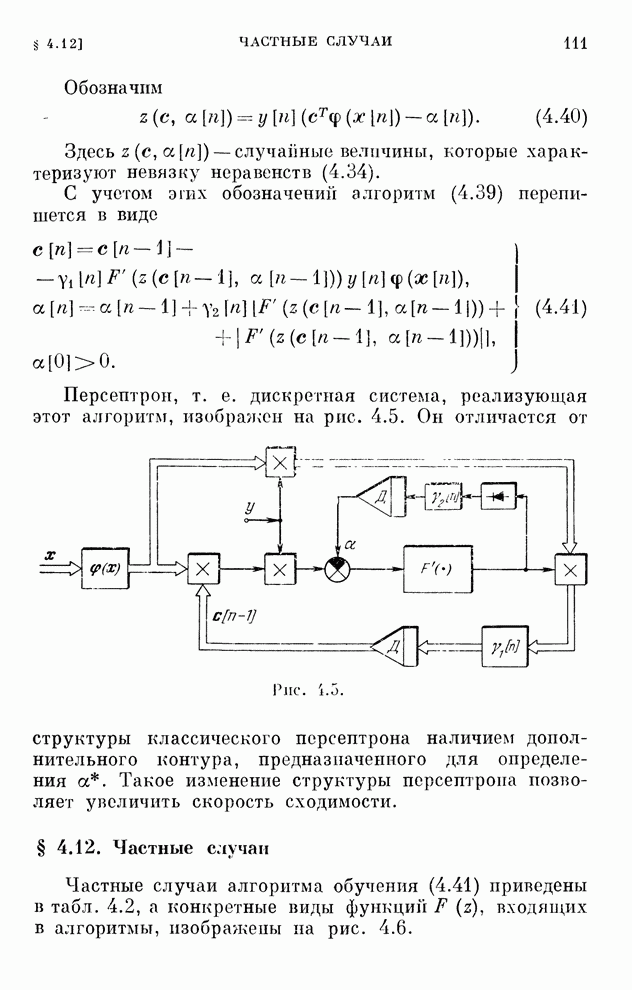
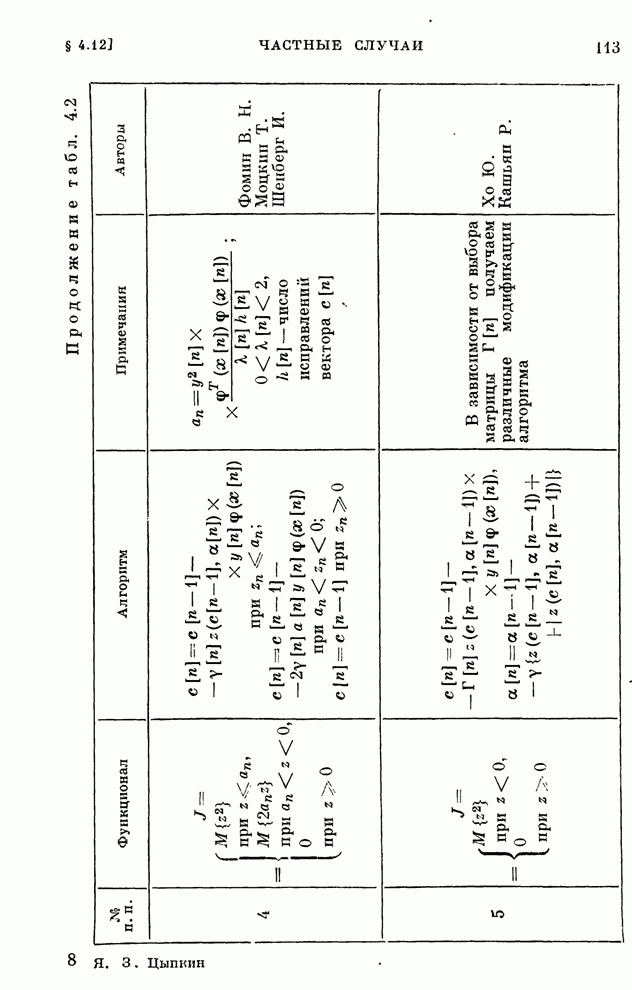
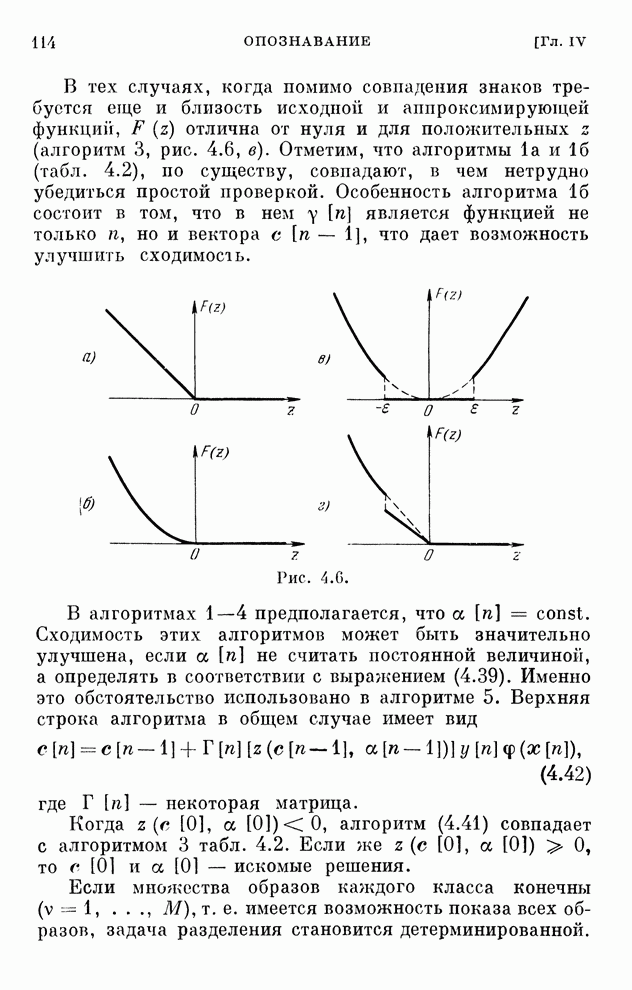
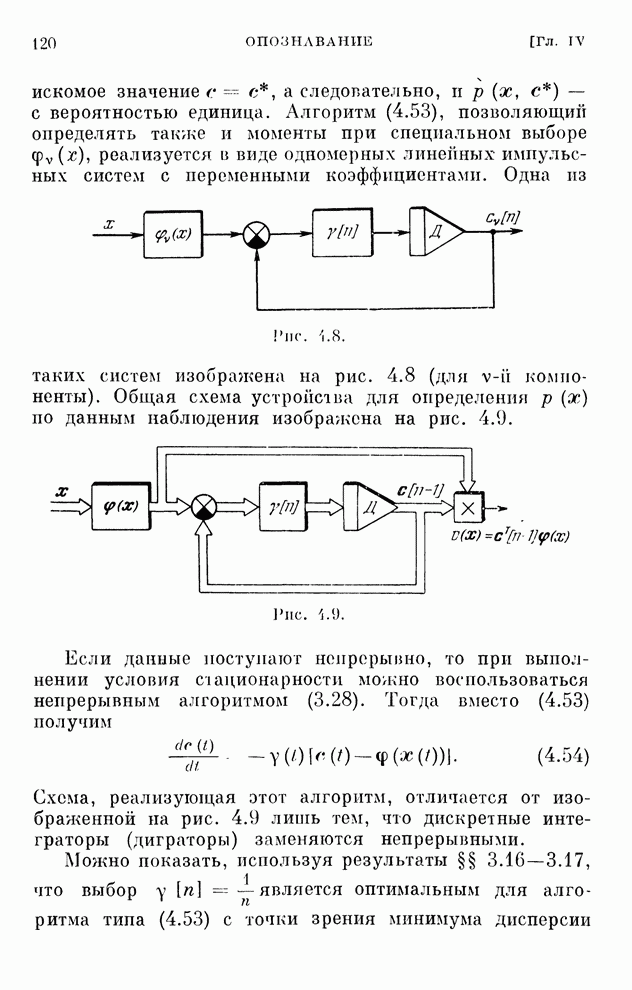
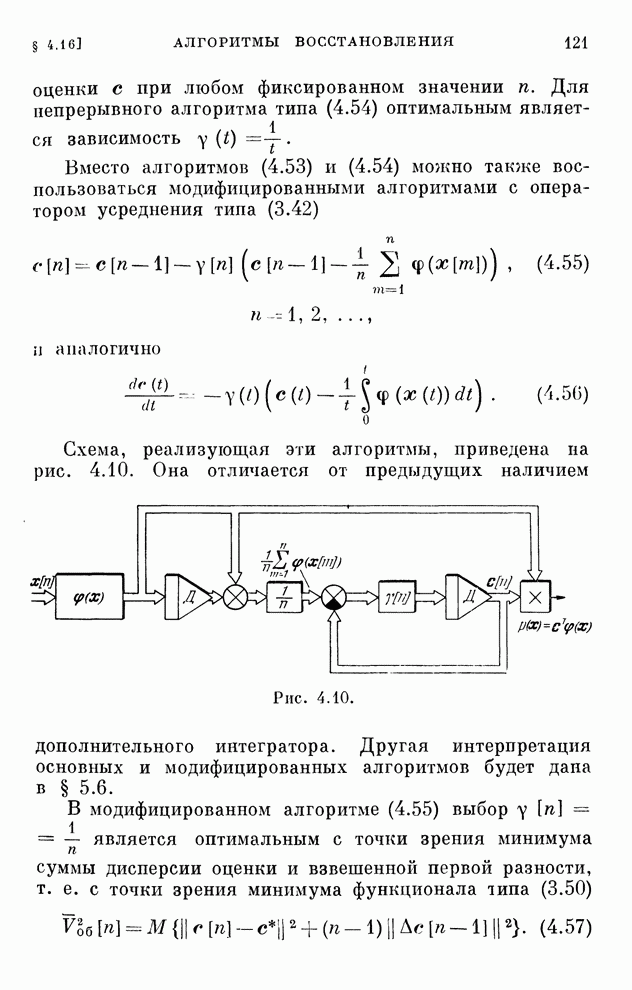
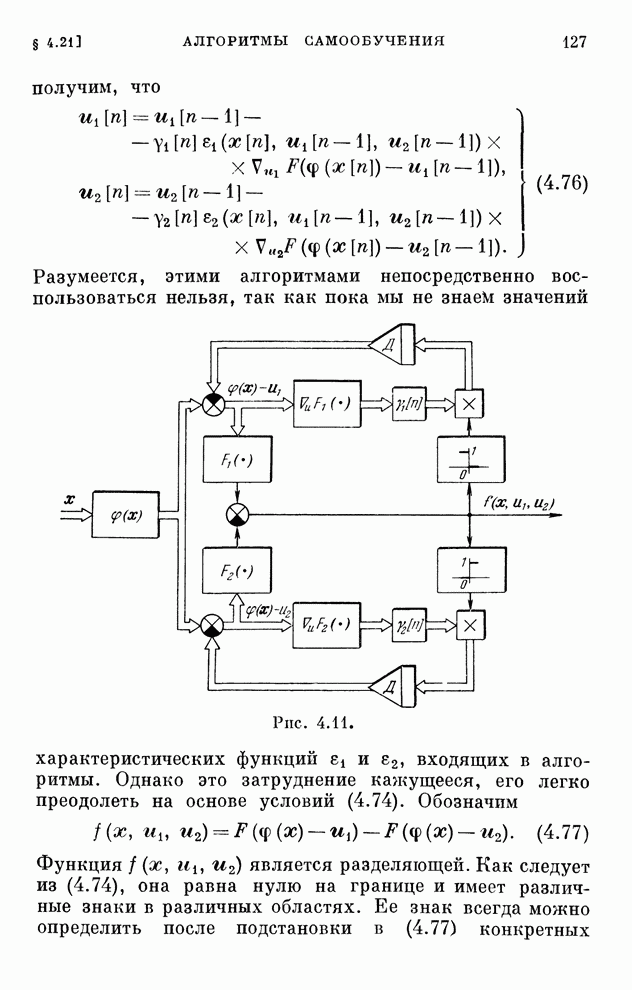
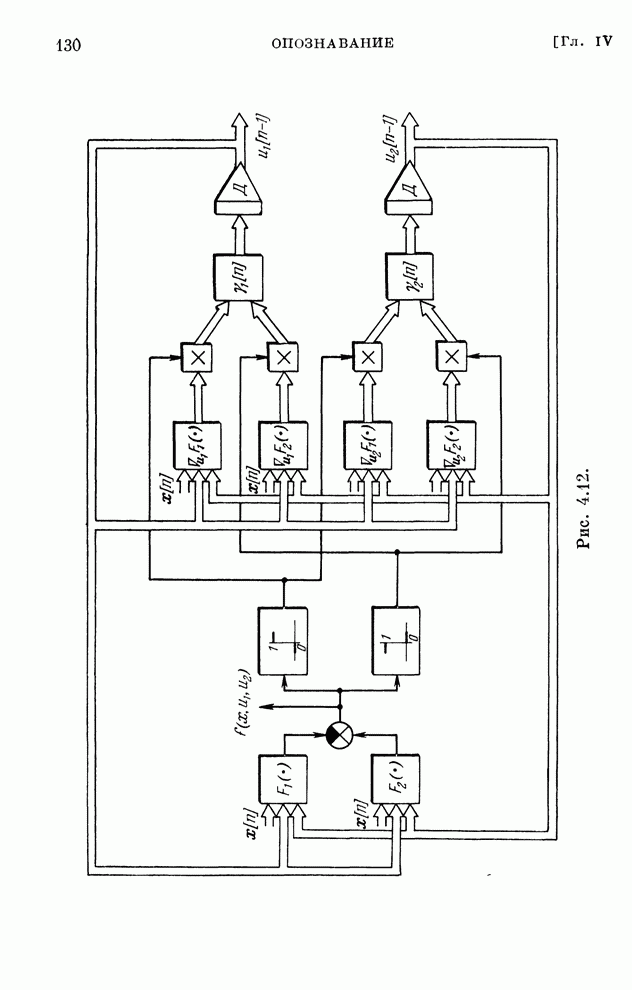
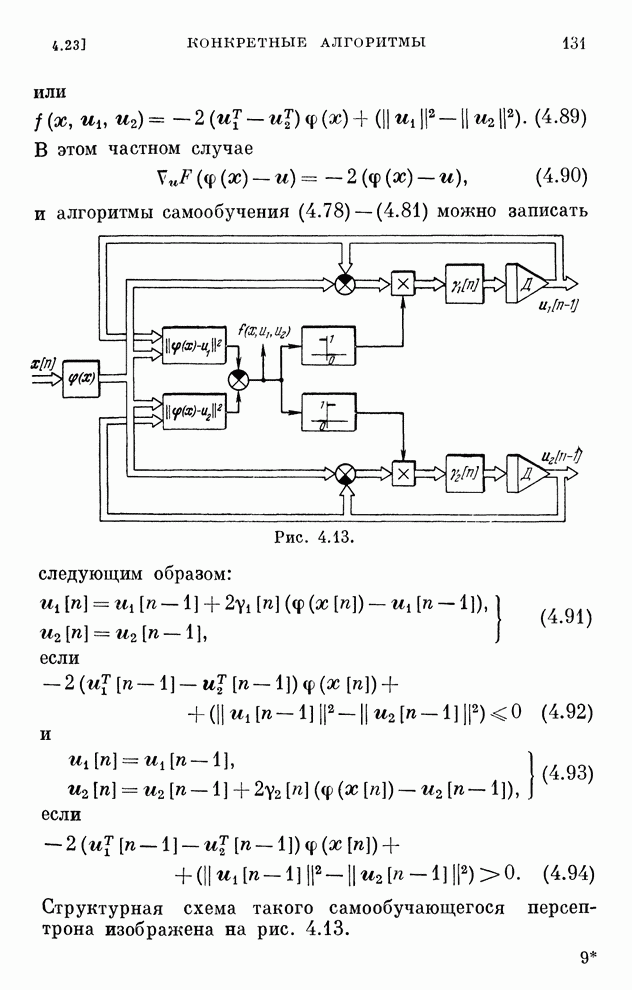
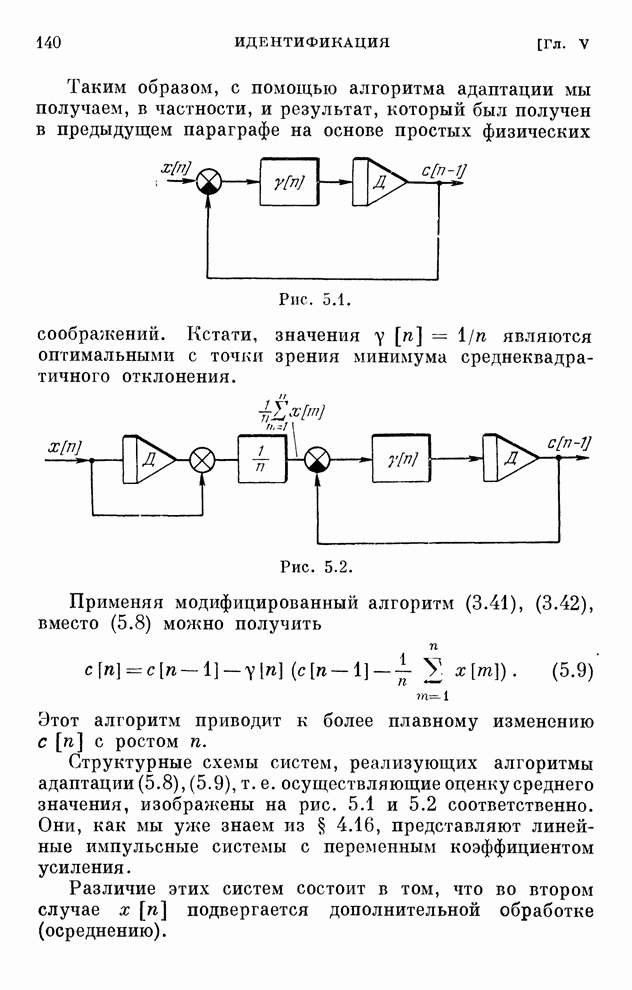
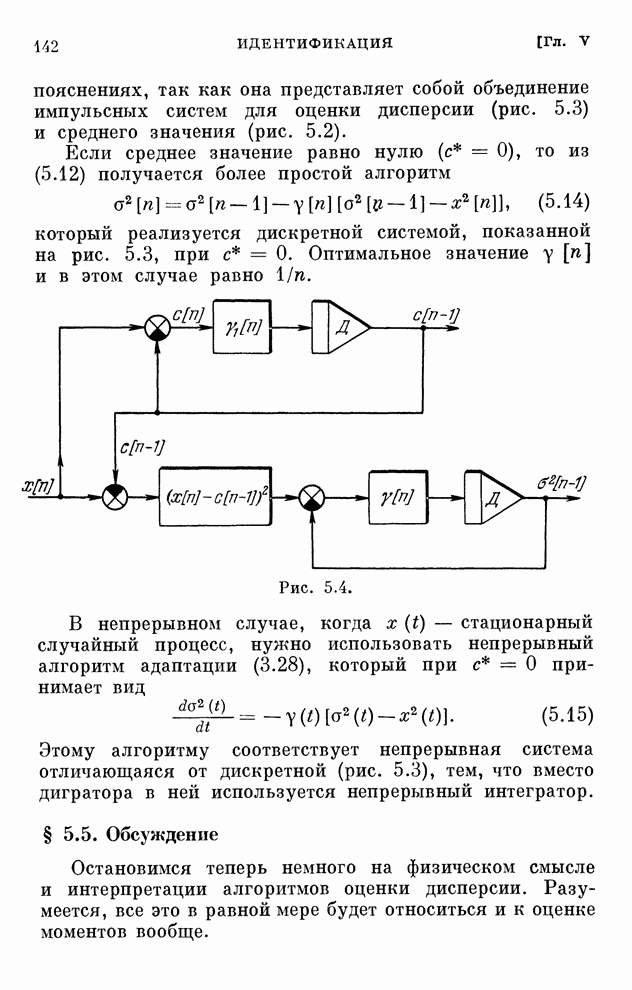
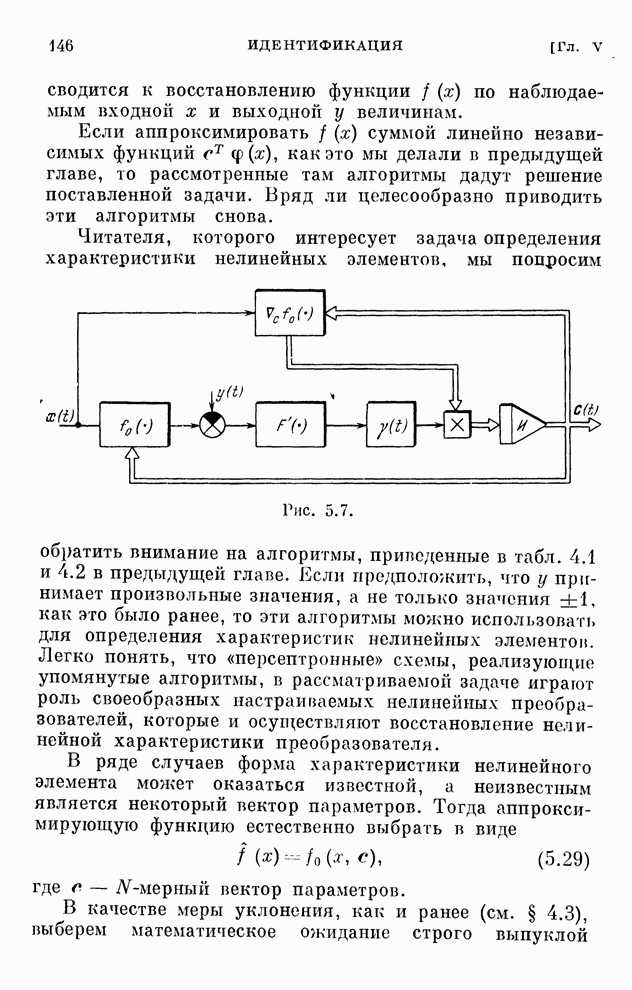
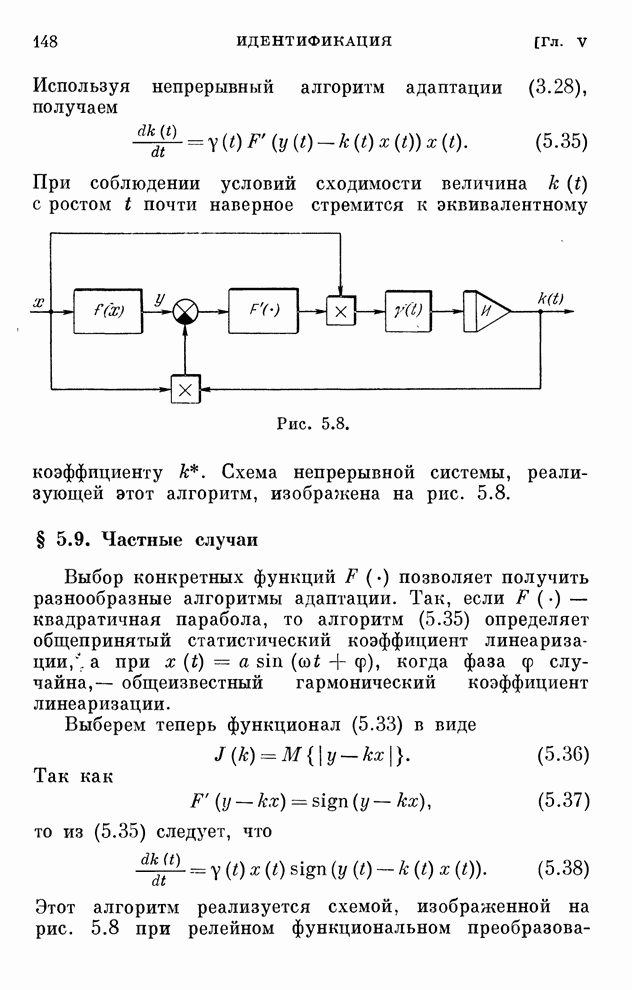
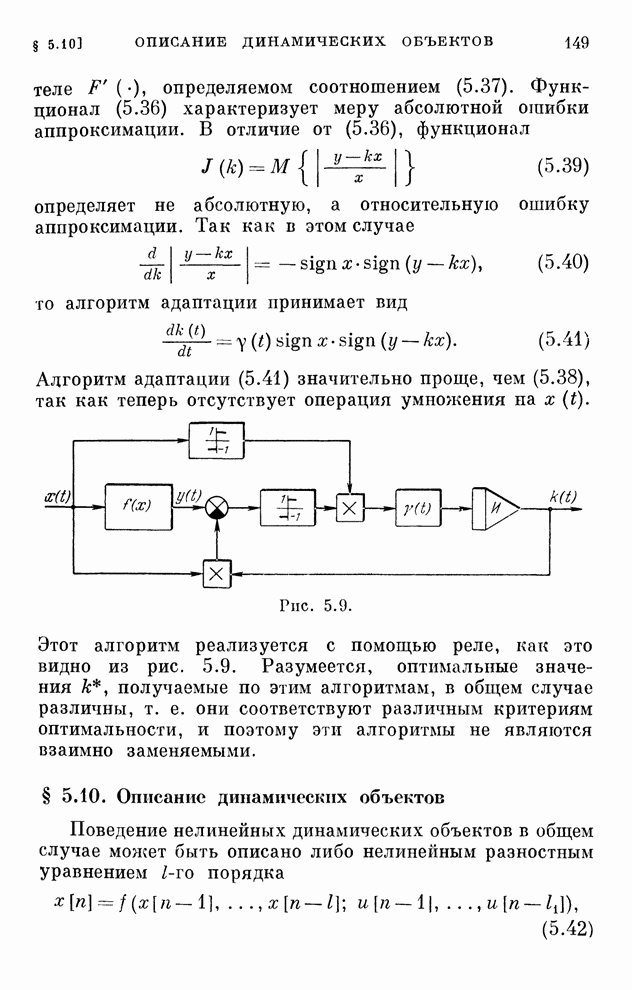
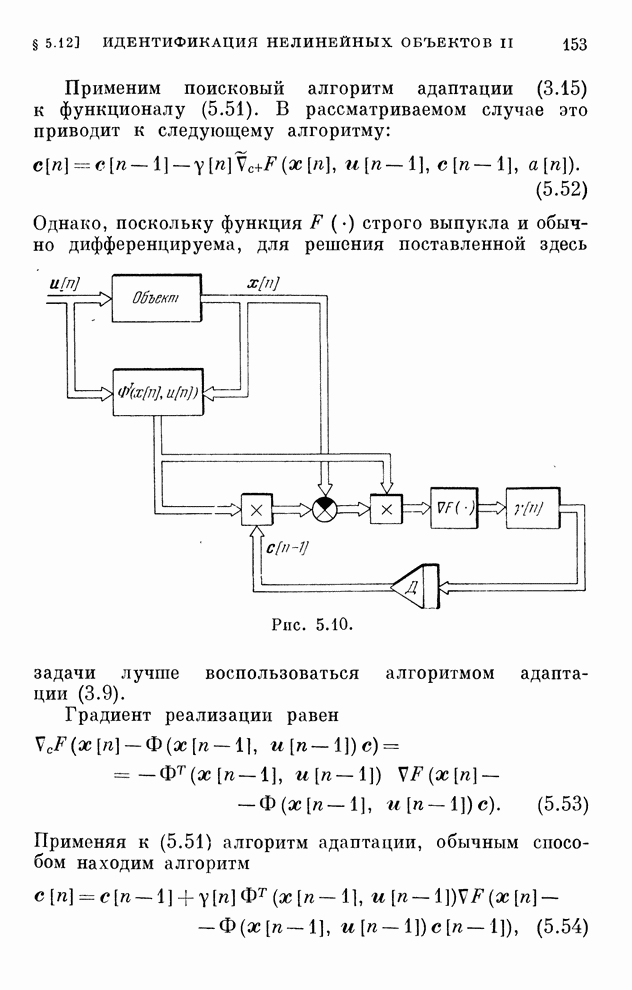
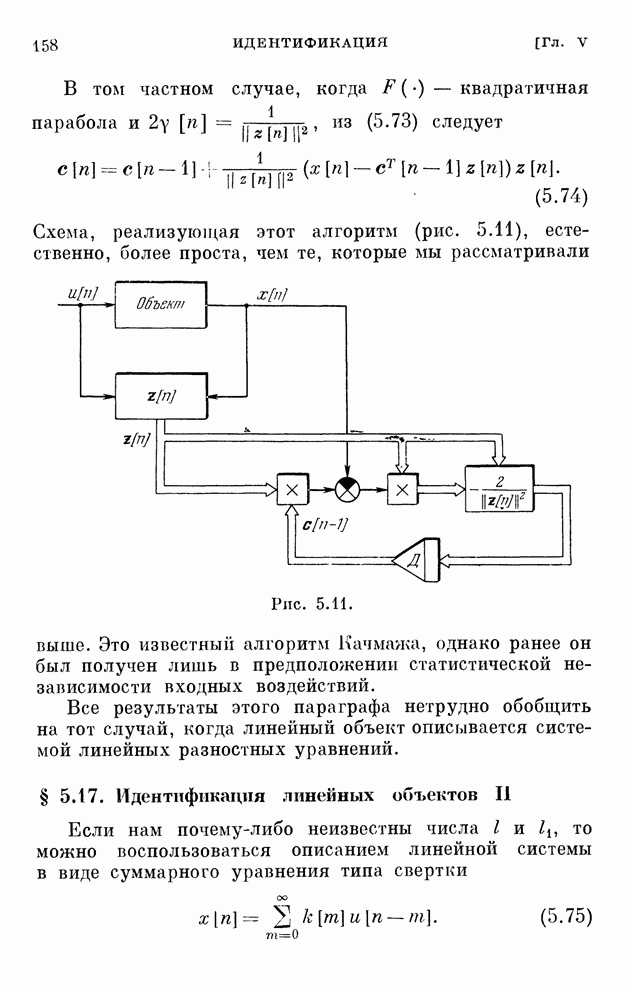
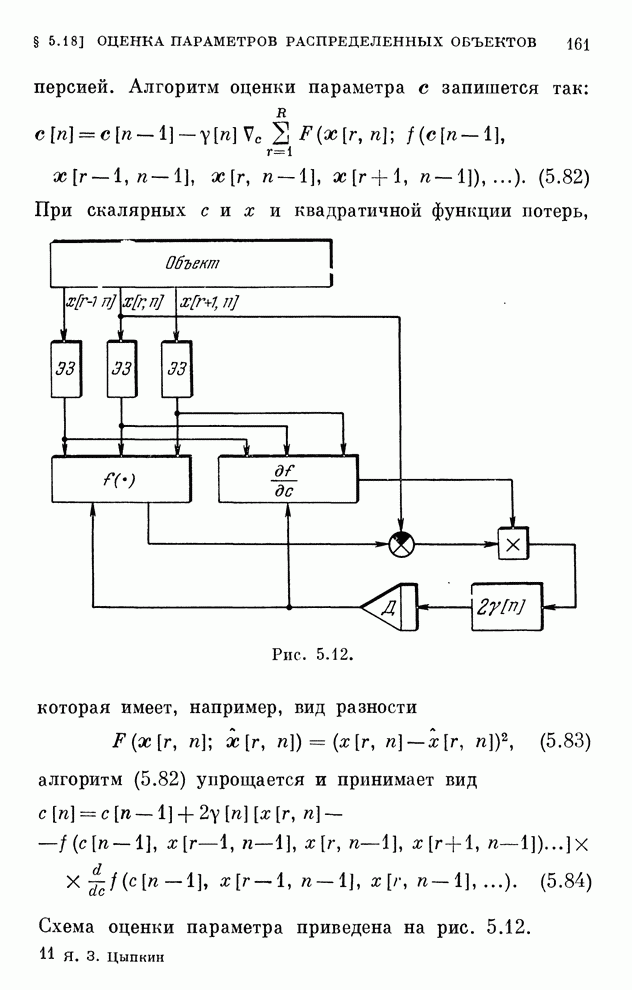
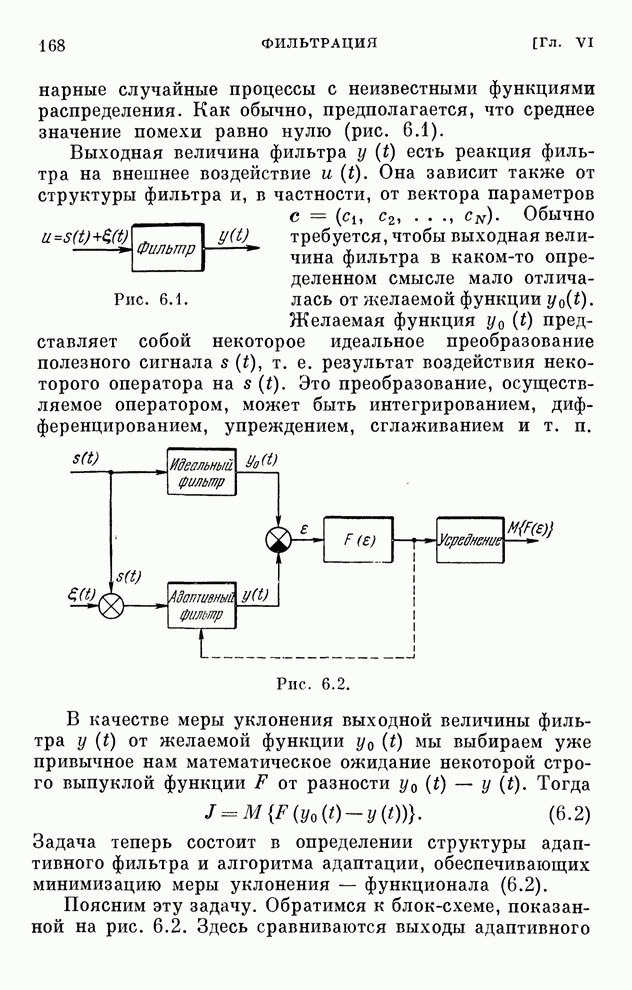
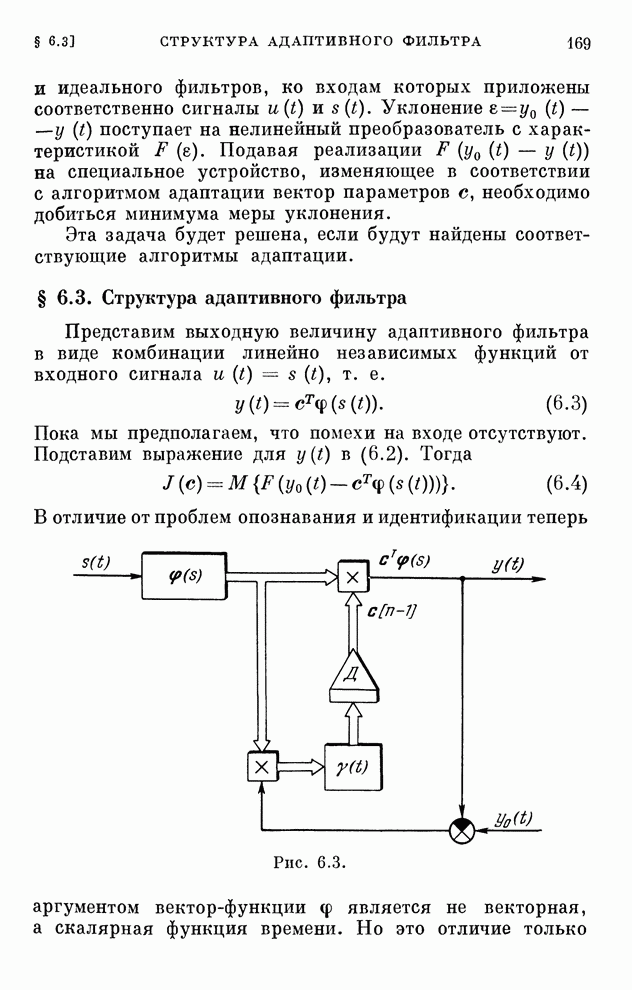
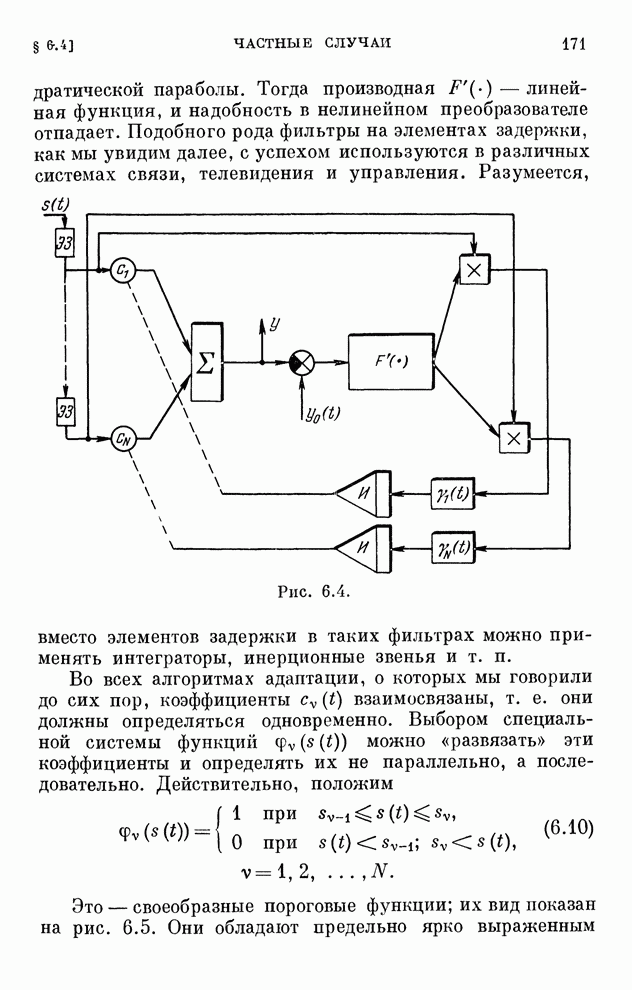
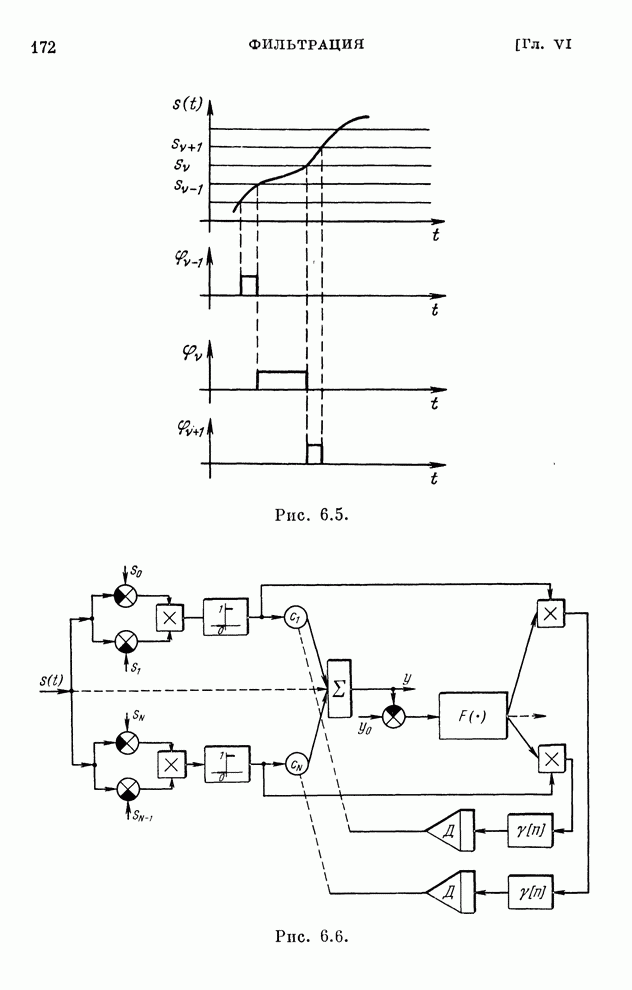
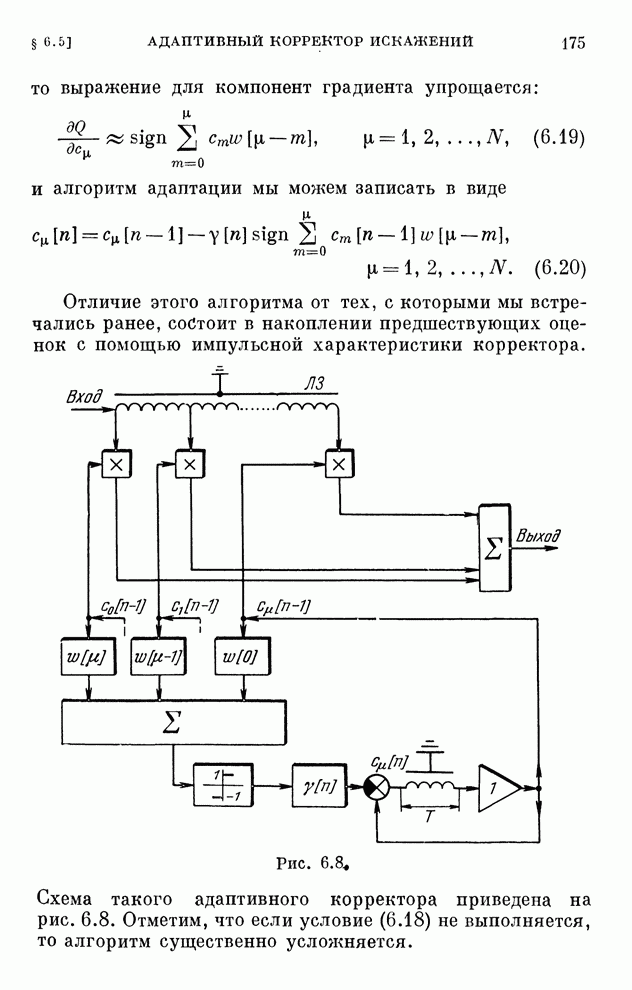
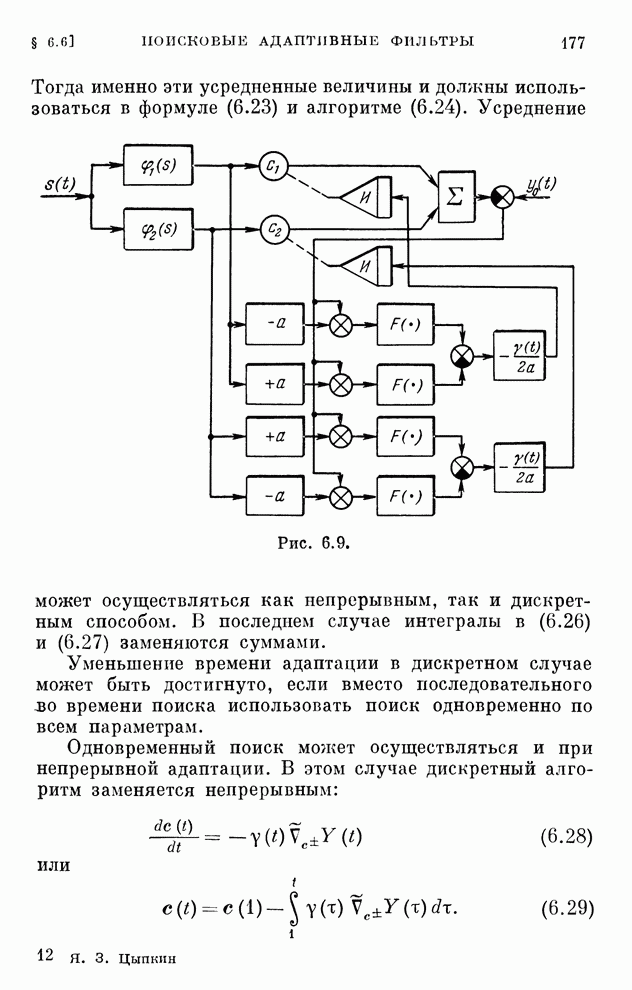
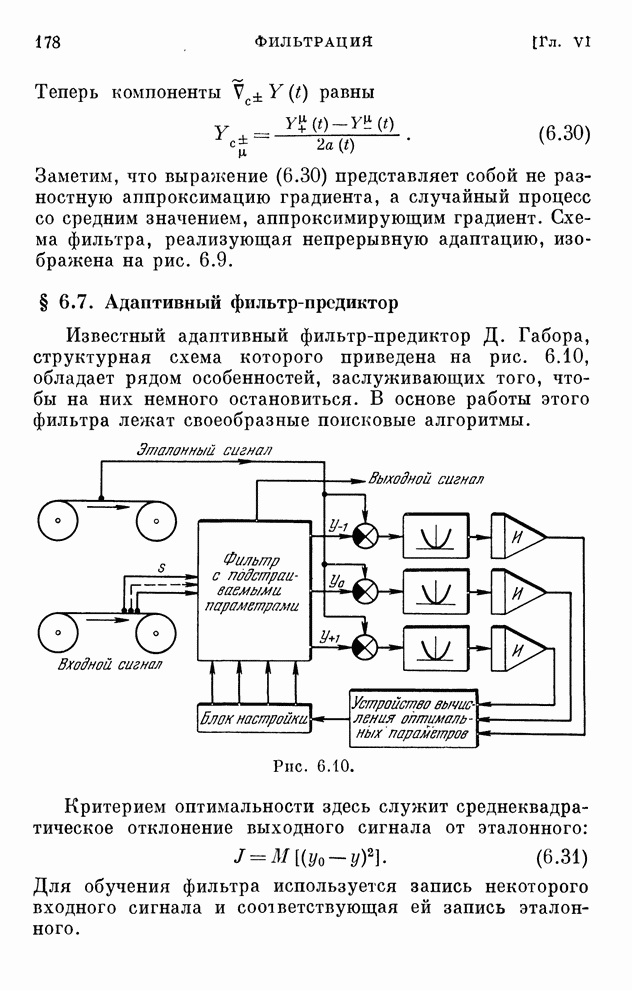
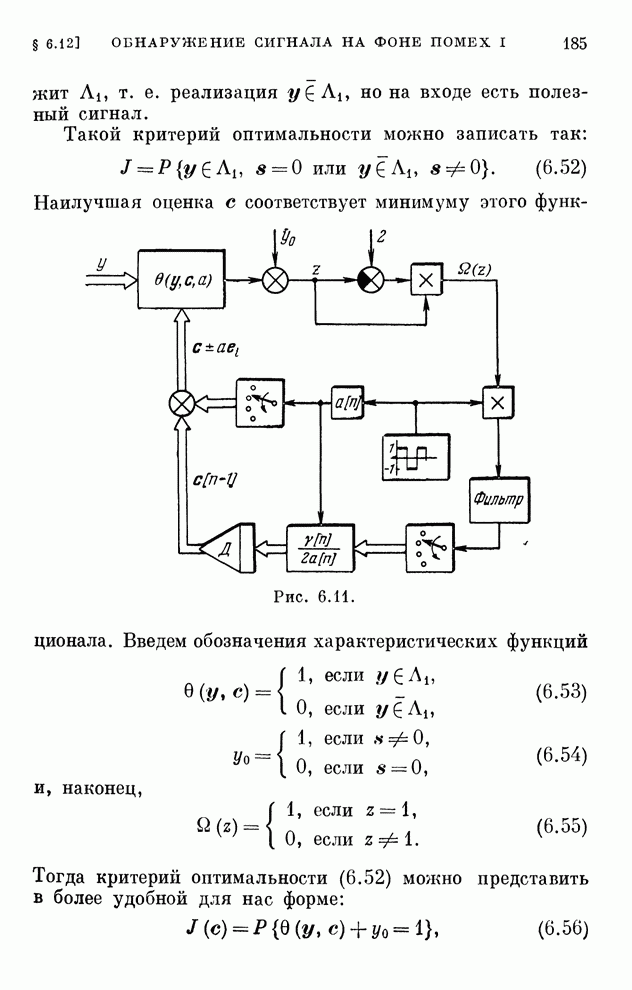
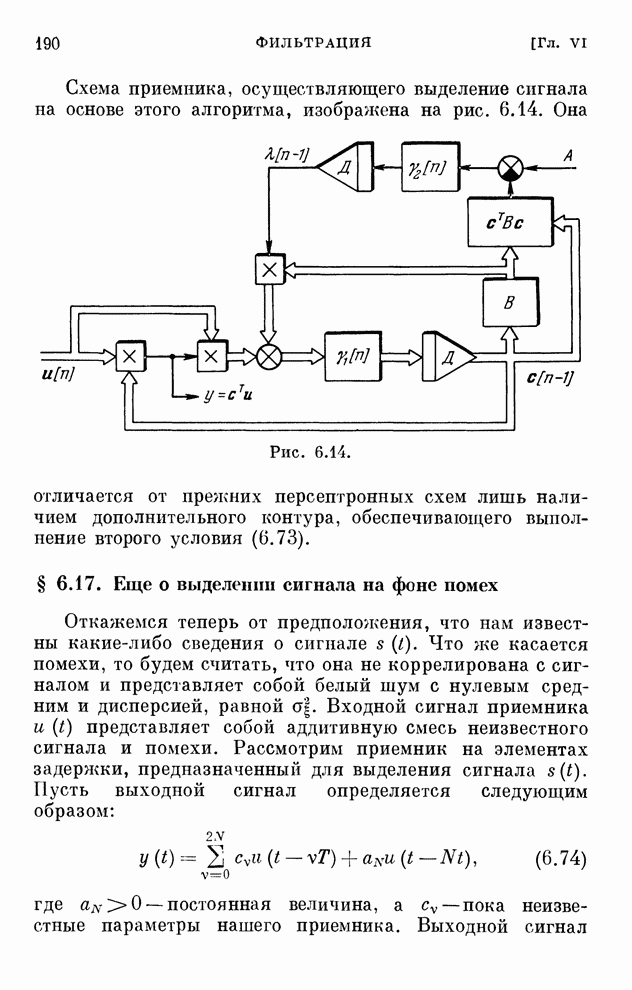
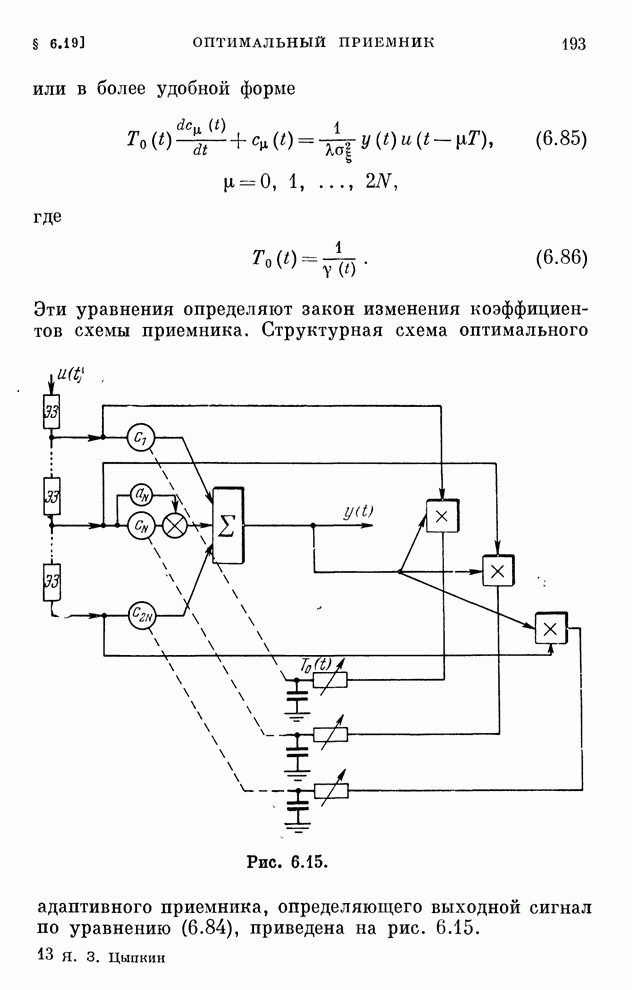
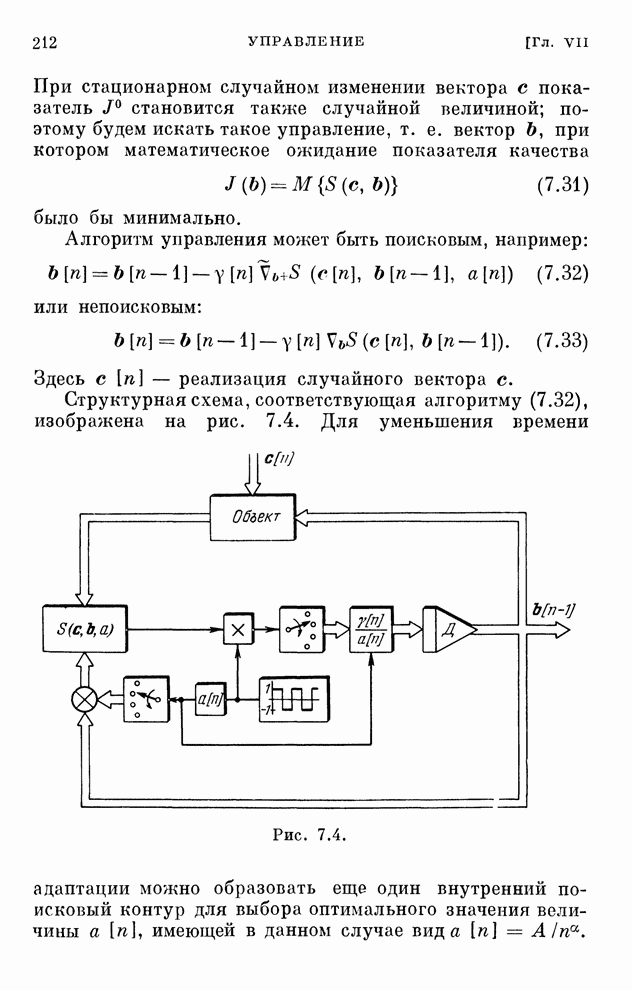
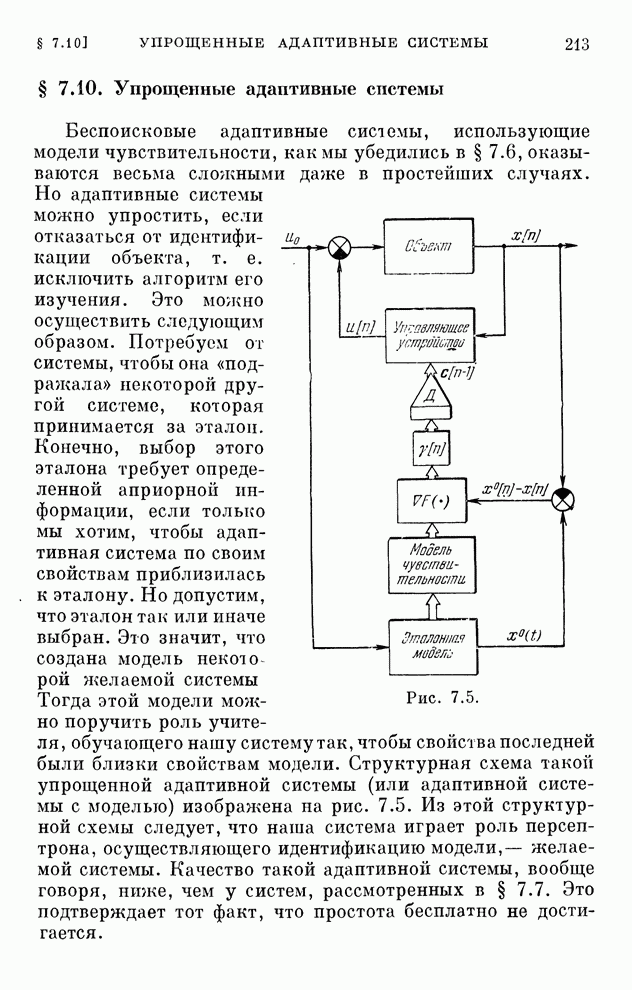
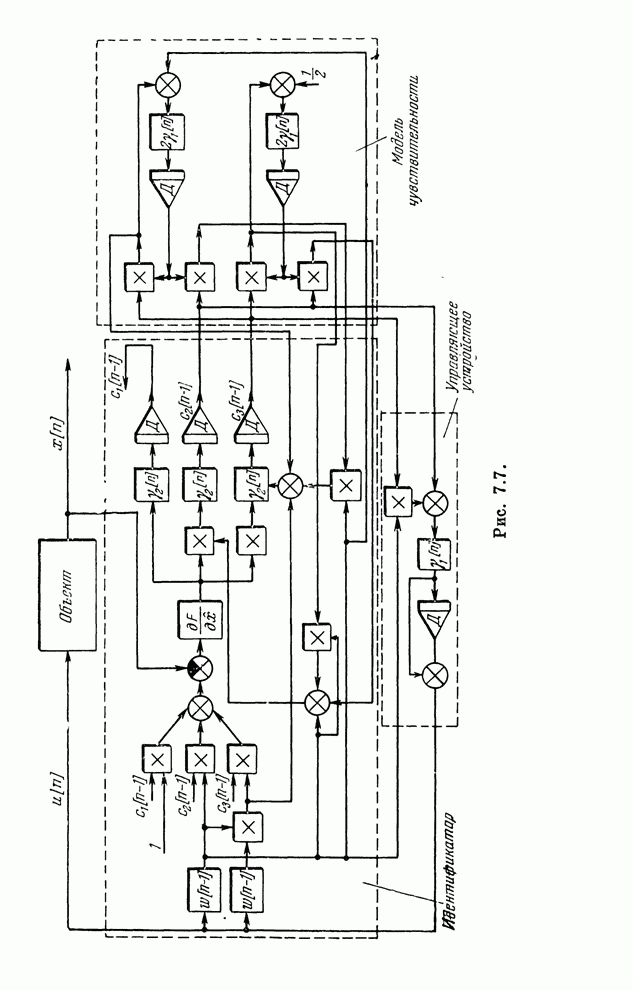
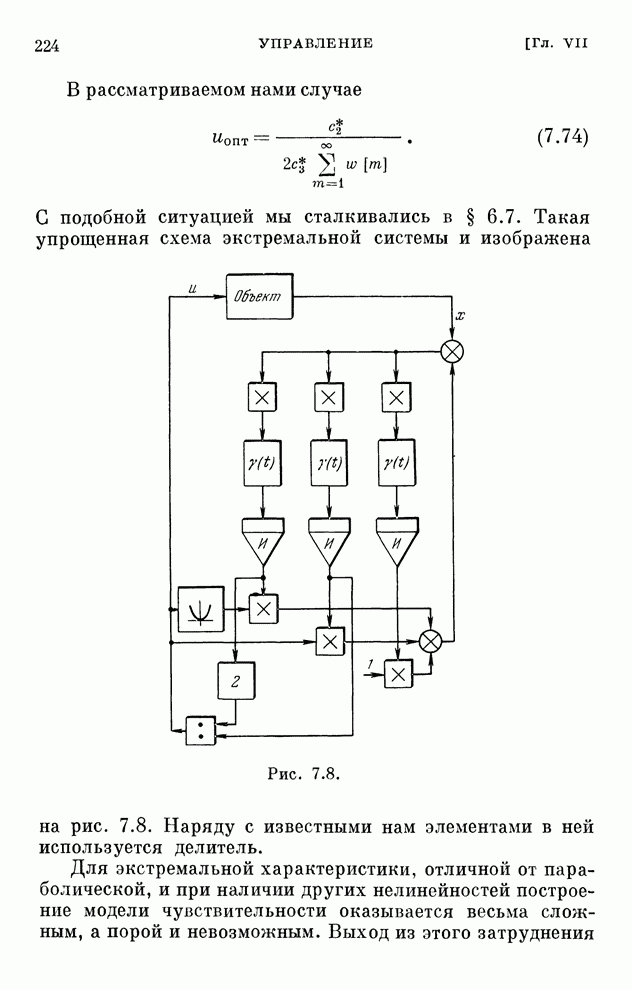
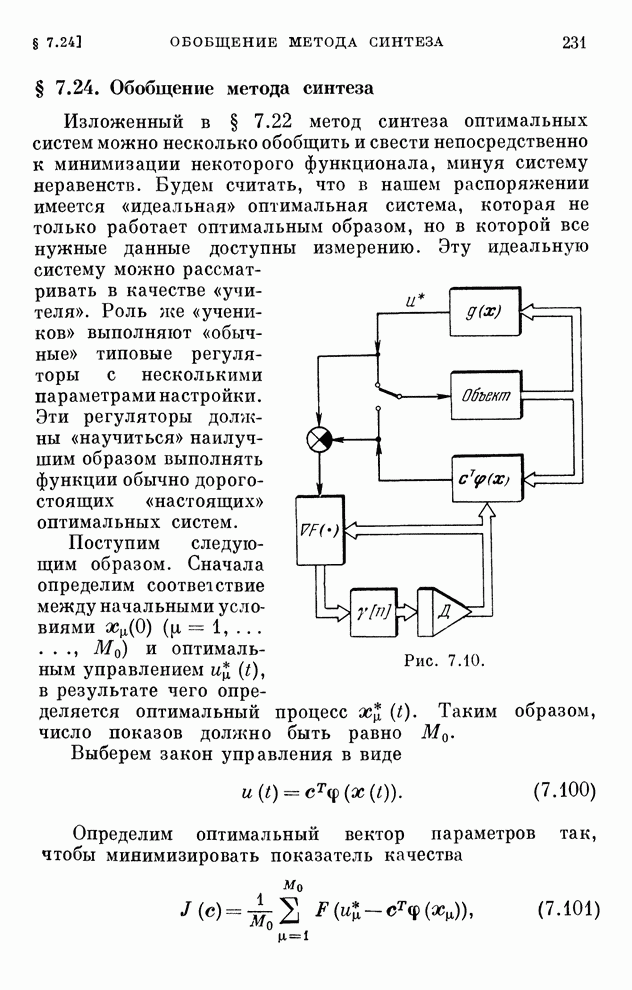
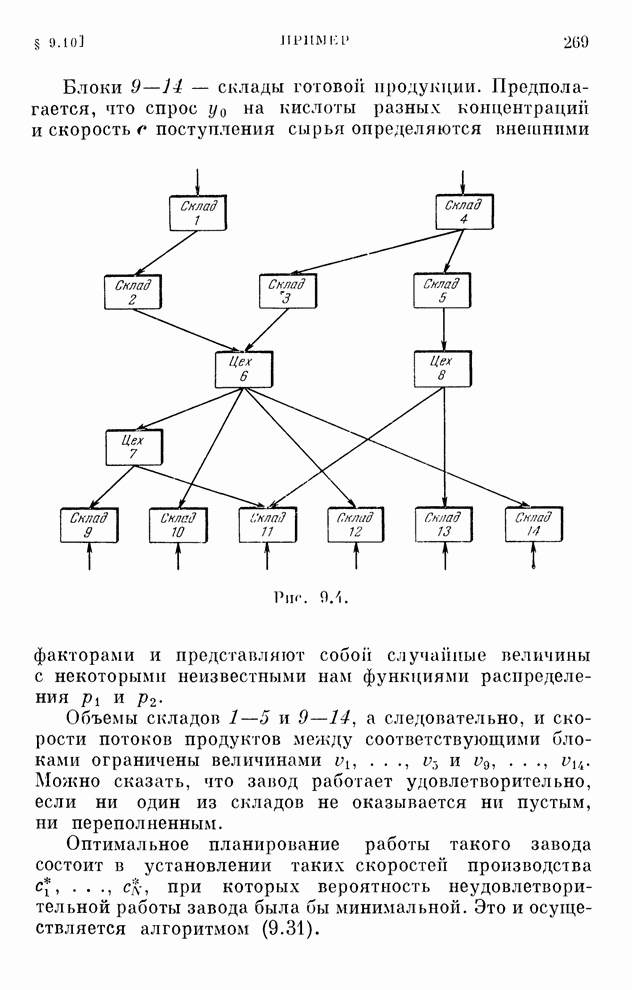
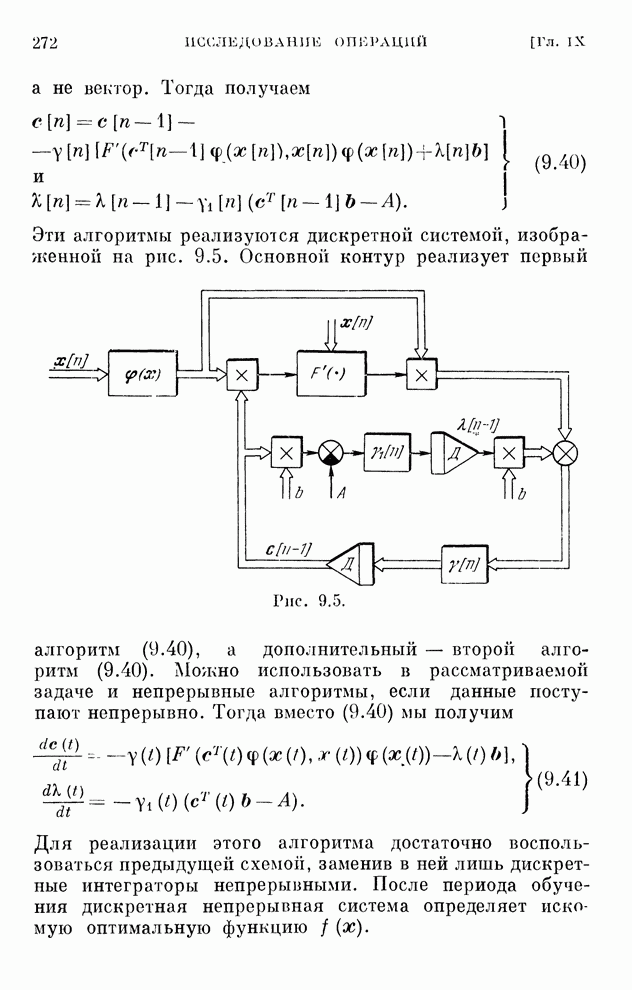
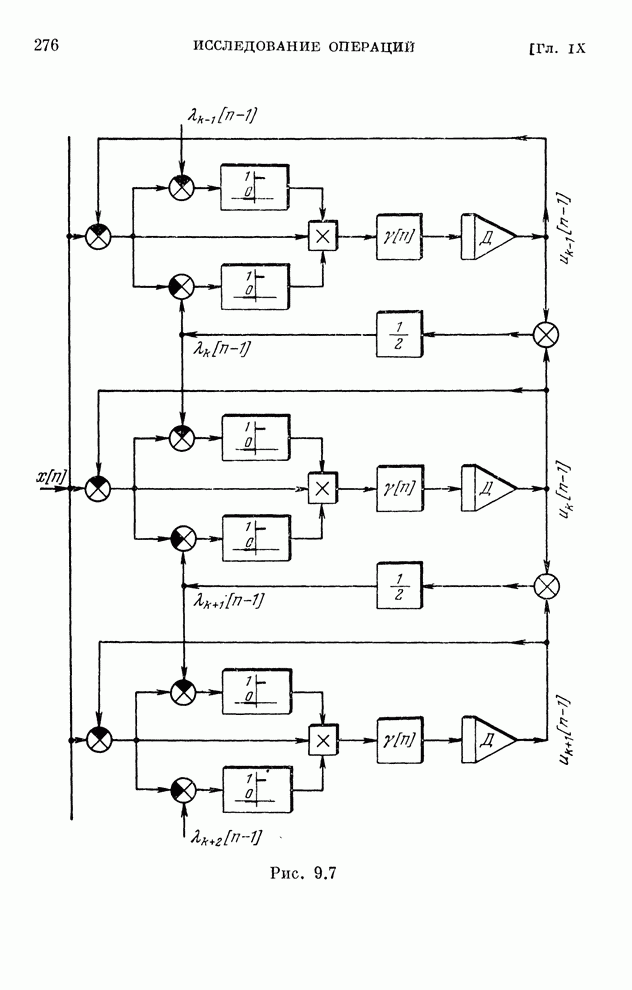
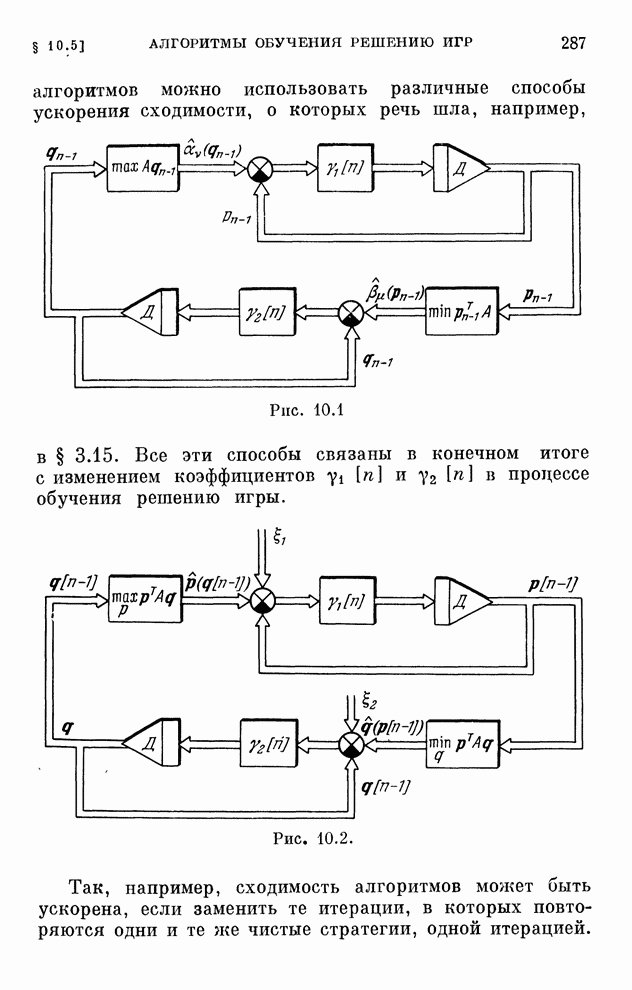
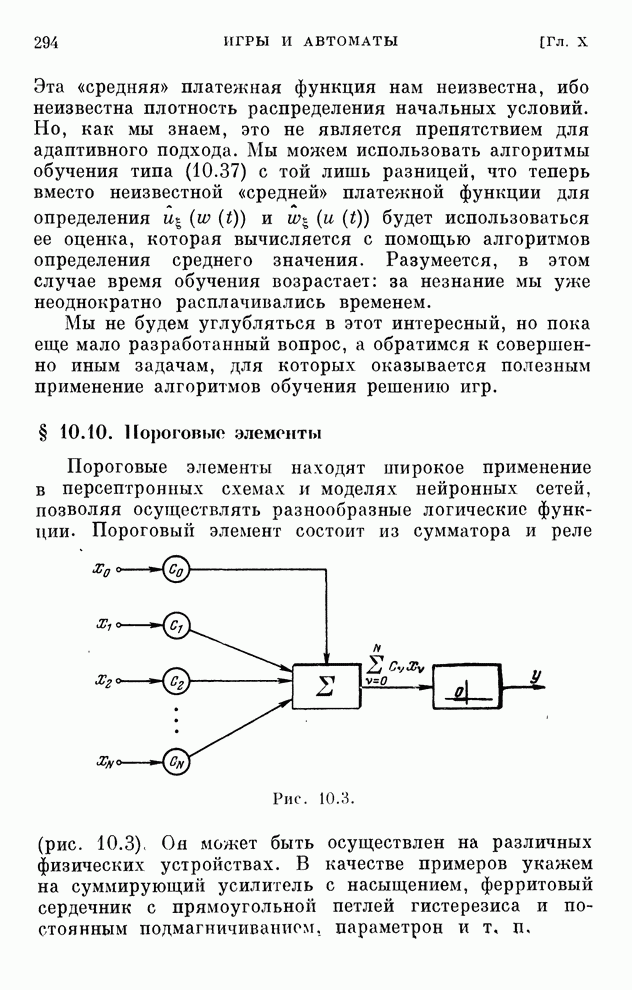
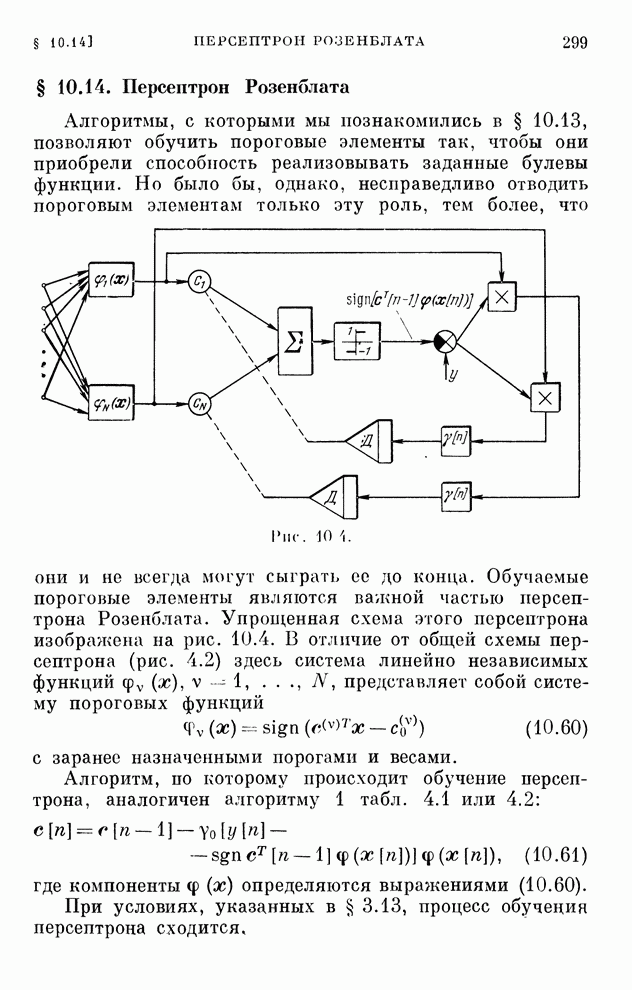
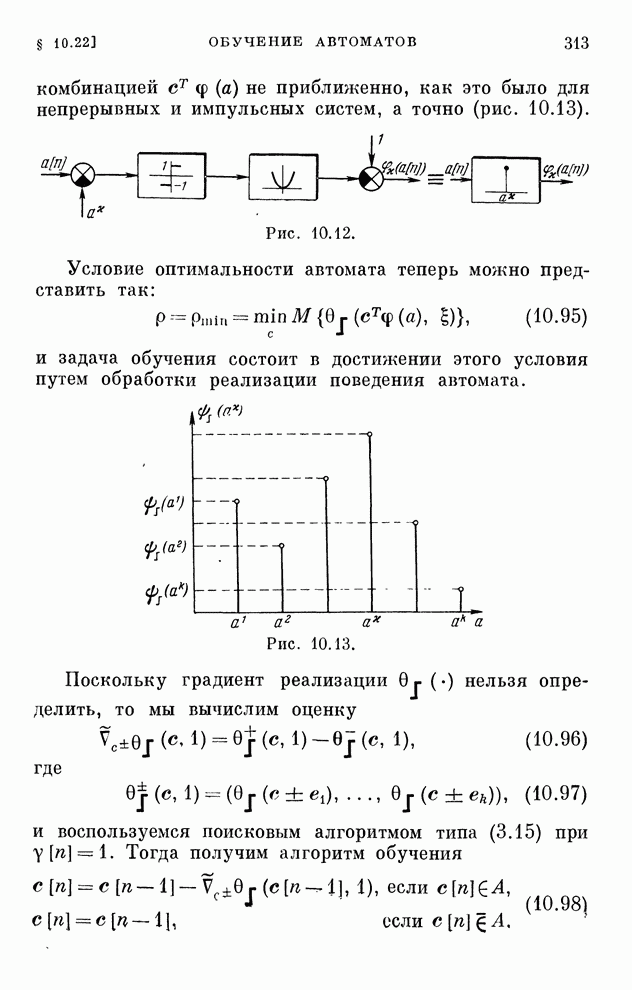
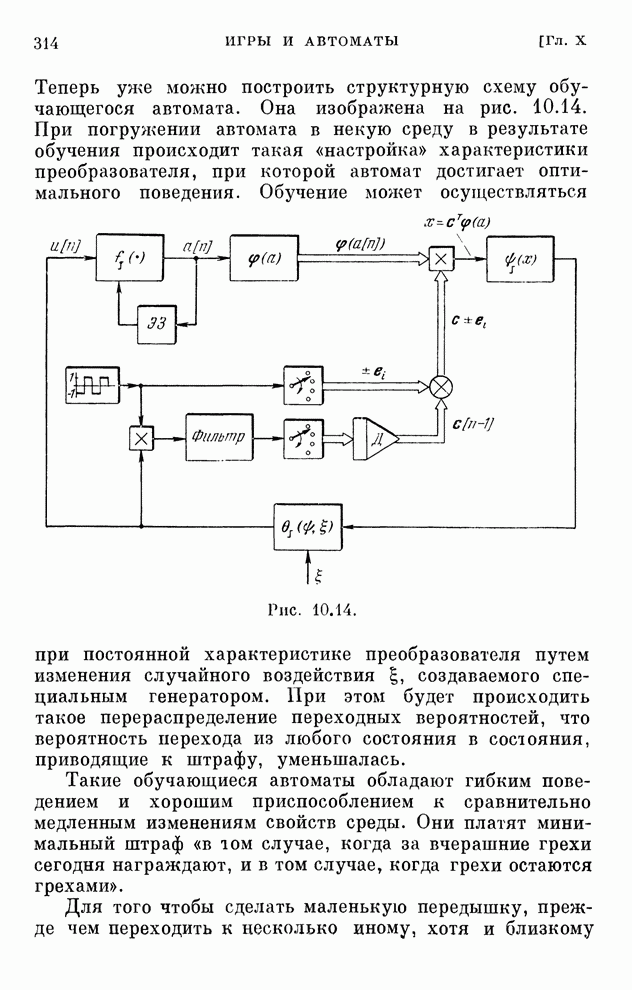
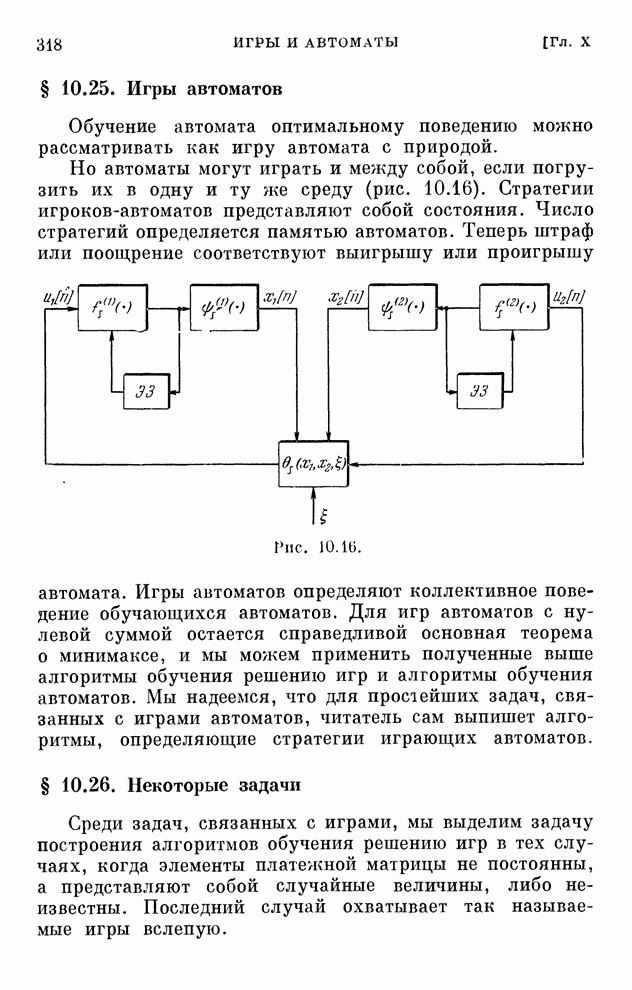
§ 4.8. Поисковые алгоритмы обучения
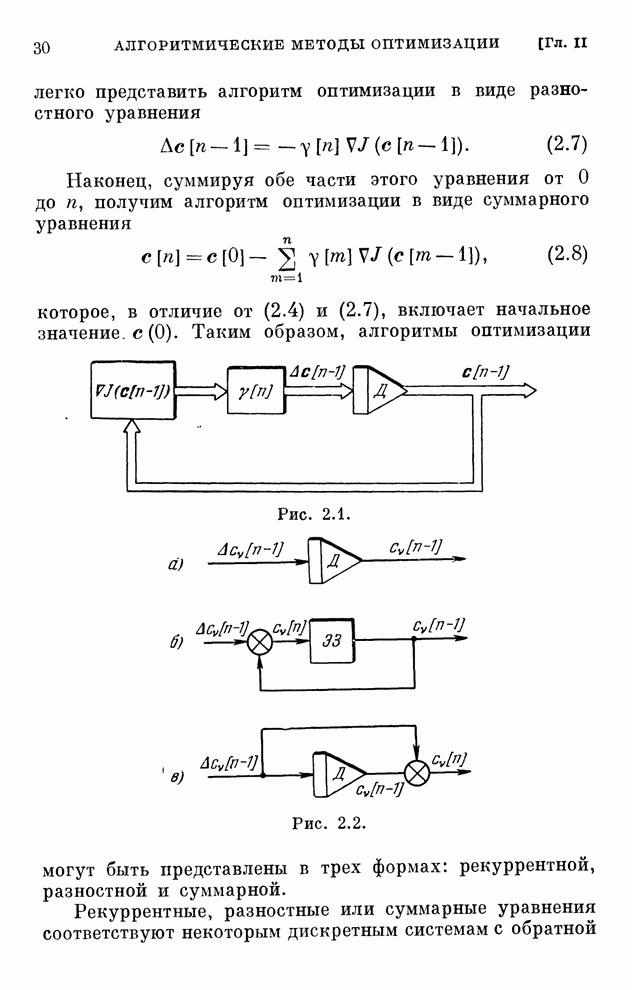
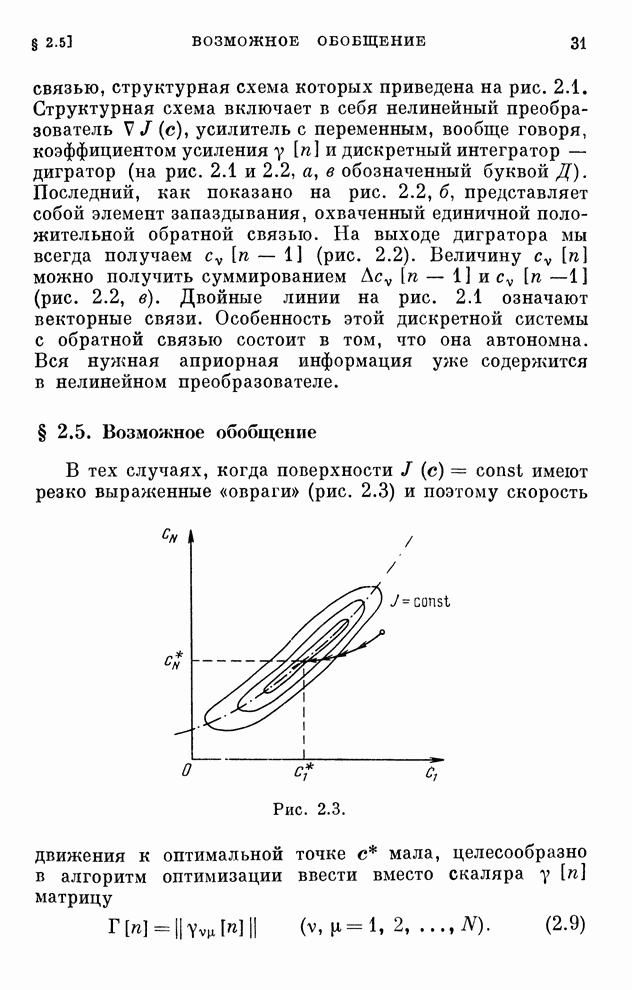
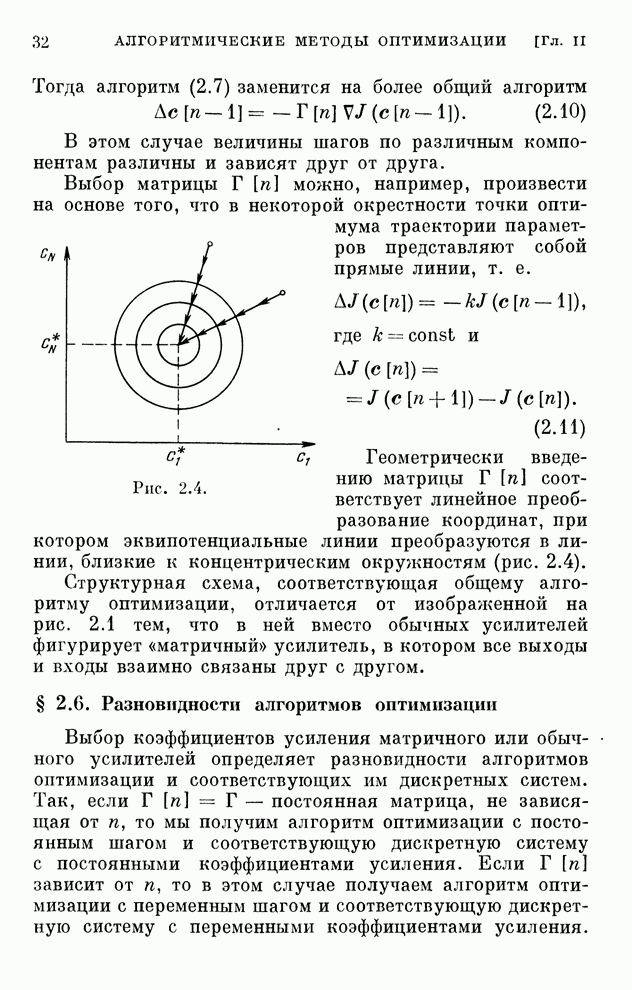
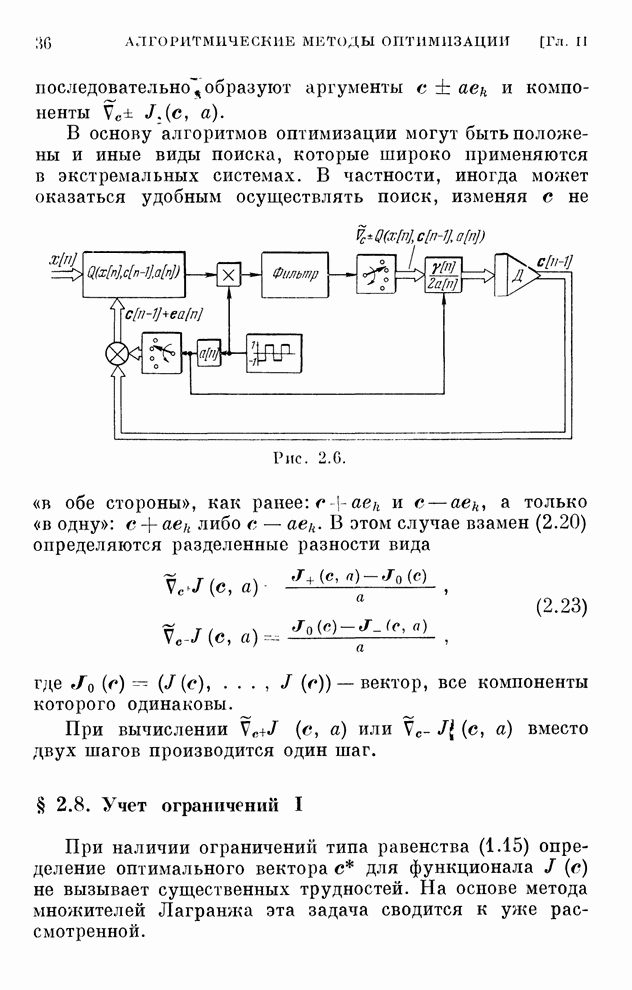
Хотя каждому дискретному алгоритму,
приведенному в табл. 4.1, можно поставить в соответствие поисковый алгоритм
обучения, вряд ли нужно в этих случаях отдавать какое-либо предпочтение поисковым
алгоритмам. Ведь для алгоритмов, с которыми мы познакомились в § 4.7, градиент
реализации вычисляется, как только выбрана функция  .
.
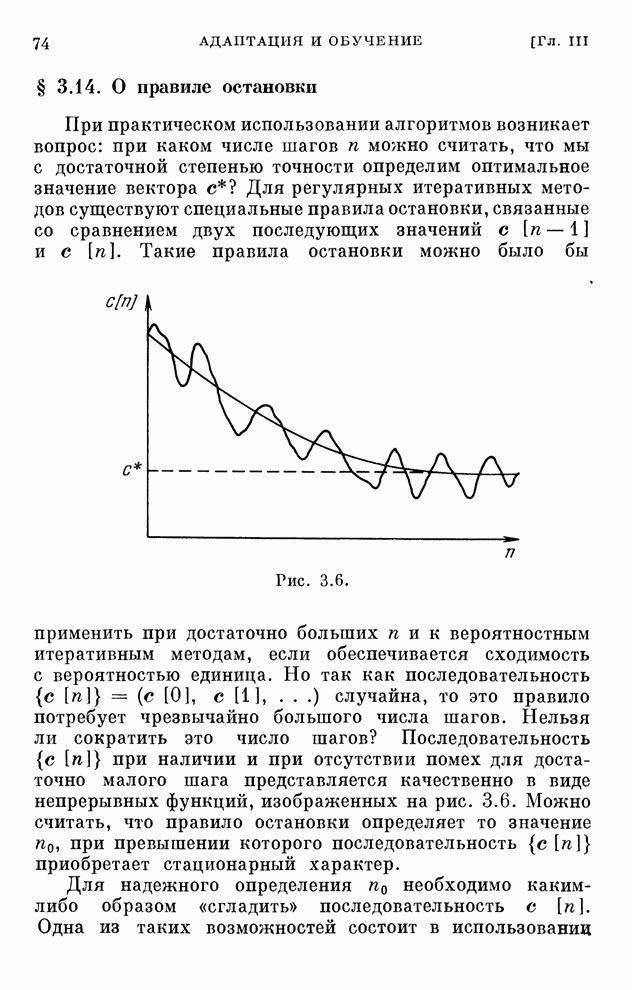
Тем не менее в ряде случаев (и при
несколько иной постановке задачи опознавания), по-видимому, единственно
возможными являются поисковые алгоритмы обучения. Вот эту постановку задачи
опознавания мы здесь и рассмотрим.
Рассмотрим два класса образов  и
и  , или, что эквивалентно, два
класса — 1 и 2. Если образ класса
, или, что эквивалентно, два
класса — 1 и 2. Если образ класса  мы отнесем к классу
мы отнесем к классу  , то эта ситуация оценивается
штрафом
, то эта ситуация оценивается
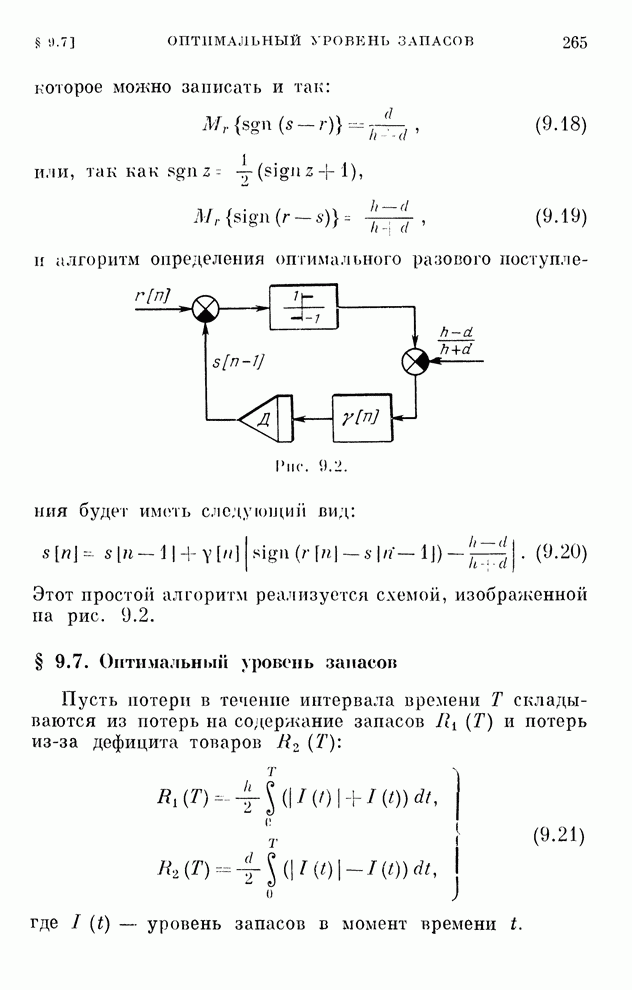
штрафом 
 . Величина этих
штрафов задается матрицей
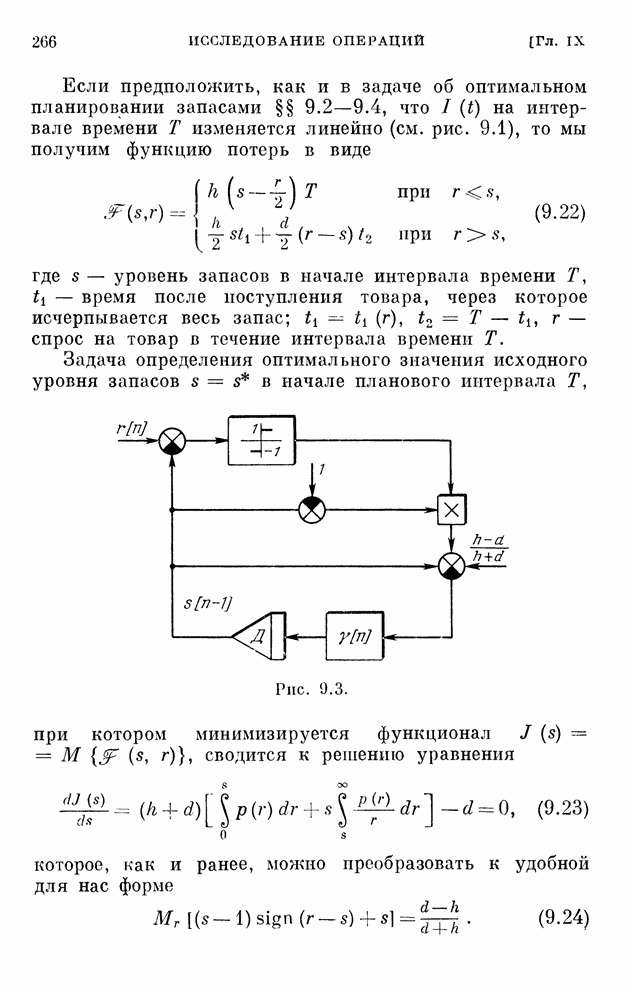
. Величина этих
штрафов задается матрицей  .
.
Средний риск, представляющий собой
математическое ожидание штрафов, можно представить в форме, которая является
частным случаем функционала (1.3):
 , (4.22)
, (4.22)
где
 —
вероятность появления образа 1-го класса,
—
вероятность появления образа 1-го класса,  — вероятность появления образа 2-го
класса,
— вероятность появления образа 2-го
класса,  —
условные плотности распределения образов обоих классов, a
—
условные плотности распределения образов обоих классов, a  — решающее правило:
— решающее правило: , если образ
, если образ  относится к 1-му
классу,
относится к 1-му
классу,  ,
если образ относится ко 2-му классу. Если бы плотности распределения
,
если образ относится ко 2-му классу. Если бы плотности распределения  были
известны, то для решения поставленной задачи можно было бы использовать все
могущество теории статистических решений, основаннойна байесовском подходе. Но
в нашем случае эти плотности распределения неизвестны, и мы не можем
непосредственно воспользоваться результатами этой изящной теории.
были
известны, то для решения поставленной задачи можно было бы использовать все
могущество теории статистических решений, основаннойна байесовском подходе. Но
в нашем случае эти плотности распределения неизвестны, и мы не можем
непосредственно воспользоваться результатами этой изящной теории.
Конечно, их можно применить, если
предварительно каким-либо путем определить плотности распределении. Так иногда
и поступают. Но не лучше ли не тратить время на этот «лишний» этап, а
воспользоваться алгоритмами обучения? Ведь риск  , выражаемый формулой (4.22),
представляет собой частный случай среднего риска (1.5). Поэтому можно представить в
виде
, выражаемый формулой (4.22),
представляет собой частный случай среднего риска (1.5). Поэтому можно представить в
виде
 , (4.23)
, (4.23)
где
 , если при
заданном решающем правиле мы этот образ отнесем к классу , тогда как на самом деле он
принадлежит классу .
, если при
заданном решающем правиле мы этот образ отнесем к классу , тогда как на самом деле он
принадлежит классу .
Решающее правило будем искать в виде известной
функции  с
неизвестным вектором параметров
с
неизвестным вектором параметров  . Поскольку
. Поскольку  зависит от вектора
зависит от вектора  лишь неявным образом, то для
определения оптимального вектора уместно воспользоваться поисковым алгоритмом
лишь неявным образом, то для
определения оптимального вектора уместно воспользоваться поисковым алгоритмом
 , (4.24)
, (4.24)
причем
 ,
,
где
 , если
, если  принадлежит к классу
принадлежит к классу
и  ,
,
 , если
, если  принадлежит классу
принадлежит классу
и  .
.
Поисковый алгоритм адаптации (4.24) и
решает задачу обучения. Этот алгоритм перебрасывает мост между алгоритмическим
подходом и теорией статистических решений, основанной на байесовском критерии.
С подобного рода связью мы еще встретимся в задачах фильтрации, точнее, в
задачах обнаружения и выделения сигналов, которые рассматриваются в гл. VI.