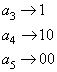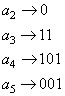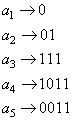Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
1. Коды ХаффманаРабота алгоритма начинается с
составления списка символов (чисел) алфавита в порядке убывания их частоты
(вероятности). Лучше всего продемонстрировать этот алгоритм на простом примере.
Пусть имеется пять символов:
Символы
Далее, условно объединяем все три символа, в символ
Аналогично, получаем для последнего символа
В итоге получаем коды Хаффмана, но записанные в обратном
порядке, т.е. для кодирования символа 01011111011100 В этой последовательности первым встречается битовый ноль, но
с нуля начинается только один код – код символа Построенные таким образом однозначные коды будут в среднем тратить 2,2 бита на символ:
Для сравнения, обычный двоичный код потребовал бы 3 бита для представления одного символа, т.е. в этом случае последовательность можно было бы сжать в 3/2,2=1,36 раза. Однако чтобы произвести декодирование данных необходимо знать построенные коды. Самый лучший способ передать декодеру частоты появления символов в потоке, т.е. в данном случае дополнительно пять чисел. На основе этих частот декодер строит коды, а затем применяет их для декодирования последовательности. Поэтому, чем длиннее кодированная последовательность, тем меньше удельный вес служебной информации переданной декодеру. И здесь возникает вопрос: а как можно численно определить степень статистической избыточности в заданной цифровой последовательности? Ведь тогда, зная эту характеристику мы могли бы определять максимально возможную степень сжатия этой последовательности и сравнивать конкретный алгоритм с этой нижней границей, т.е. мы могли бы объективно оценивать качество работы алгоритма сжатия. Оказывается, что такой величиной является энтропия, которая определяет минимальное число бит, необходимое для представления заданной последовательности чисел с последующей возможностью полного восстановления информации. В 1948 г. сотрудник лаборатории Bell Labs Клод Шеннон показал, что минимальное число бит, которое необходимо затратить для представления одного символа той или иной информации можно найти с помощью формулы
где
Сравнивая полученный результат с ранее полученным для кодов Хаффмана (2,2 бит/символ), видим, что коды Хаффмана оказываются более близкими к нижней границе, чем равномерный код, которому необходимо 3 бита/символ. Также можно посчитать и степень сжатия последовательности. Если равномерный код будет расходовать 3 бита на символ, то потенциальное сжатие будет равно
а с помощью неравномерных кодов Хаффмана получим
Следовательно, представленный алгоритм сжатия не является
лучшим. Кроме того, с помощью энтропии можно показать, что если
последовательность содержит случайный набор чисел (не имеет закономерностей),
то вероятности
|
 |
Оглавление
|