Записывая это выражение в виде  получаем, что
получаем, что  можно сделать сколь угодно малым при достаточно большом
можно сделать сколь угодно малым при достаточно большом  Берем сколь угодно малую часть всех возможных сообщений. (При этом какие-то сообщения могут встретиться несколько раз.)
Берем сколь угодно малую часть всех возможных сообщений. (При этом какие-то сообщения могут встретиться несколько раз.)
Нарисуем эти последовательности в виде точек в подходящем  -мерном пространстве. Вероятность ошибки каждого символа равна
-мерном пространстве. Вероятность ошибки каждого символа равна  так что среднее число ошибок равно
так что среднее число ошибок равно  Рассмотрим шар радиуса
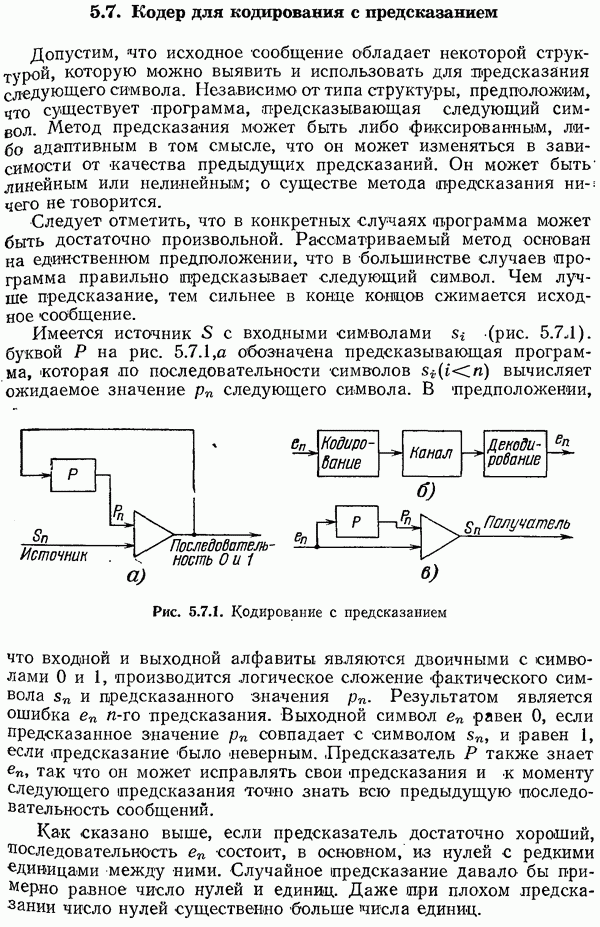
Рассмотрим шар радиуса  с центром в точке, соответствующей какому-нибудь выбранному сообщению. Рассмотрим несколько больший шар, увеличивая радиус на
с центром в точке, соответствующей какому-нибудь выбранному сообщению. Рассмотрим несколько больший шар, увеличивая радиус на  так что радиус становится равным (рис. 10.4.1)
так что радиус становится равным (рис. 10.4.1)  (здесь
(здесь  обозначает радиус, а не число символов или основание системы счисления;
обозначает радиус, а не число символов или основание системы счисления;  настолько мало, что
настолько мало, что  Фактическое значение
Фактическое значение  зависит от
зависит от  и будет определено позже.
и будет определено позже.

Рис. 10.4.1. Передающий конец

Рис. 10.4.2. Приемный конец
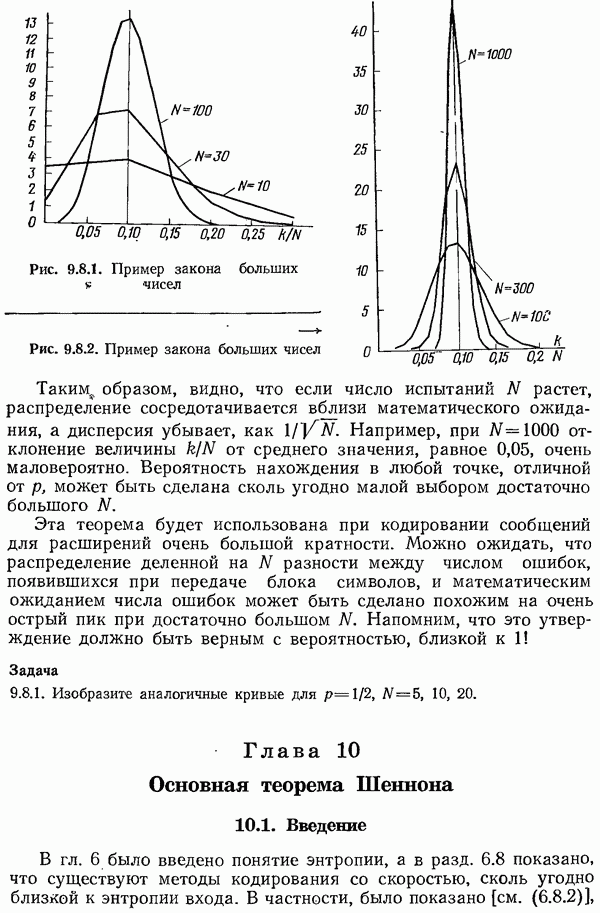
Закон больших чисел (см. разд. 9.8) показывает, что при достаточно больших  вероятность того, что принятое сообщение будет лежать вне этого нового шара, может быть сделана сколь угодно малой. (Поскольку почти весь объем
вероятность того, что принятое сообщение будет лежать вне этого нового шара, может быть сделана сколь угодно малой. (Поскольку почти весь объем  -мерного шара сосредоточен вблизи его поверхности, естественно интересоваться в основном сферической оболочкой толщиной
-мерного шара сосредоточен вблизи его поверхности, естественно интересоваться в основном сферической оболочкой толщиной  и радиуса
и радиуса  Таким образом, если использовать прием по максимуму правдоподобия и доказать, что с вероятностью, сколь угодно близкой к 1, никакие
Таким образом, если использовать прием по максимуму правдоподобия и доказать, что с вероятностью, сколь угодно близкой к 1, никакие  два шара не пересекаются, то можно будет доказать, что приемник почти наверное сможет определить, какое сообщение было послано. Скорость передачи будет при этом сколь угодно близкой к пропускной способности канала С, поскольку вероятность каждого сообщения равна
два шара не пересекаются, то можно будет доказать, что приемник почти наверное сможет определить, какое сообщение было послано. Скорость передачи будет при этом сколь угодно близкой к пропускной способности канала С, поскольку вероятность каждого сообщения равна  и количество посылаемой информации почти наверное равно
и количество посылаемой информации почти наверное равно

Таким образом,  определяется, исходя из того, насколько скорость передачи должна быть близкой к пропускной способности
определяется, исходя из того, насколько скорость передачи должна быть близкой к пропускной способности  канала.
канала.
Теперь рассмотрим ту же картину в  -мерном пространстве, но только со стороны приемного конца (рис. 10.4.2). Центр шара
-мерном пространстве, но только со стороны приемного конца (рис. 10.4.2). Центр шара
находится в точке, соответствующей принятому слову  Начнем с очевидного замечания о том, что ошибка возникает, если правильное сообщение не лежит в шаре или если в этом шаре имеется по крайней мере еще одно возможное сообщение. Поэтому вероятность ошибки
Начнем с очевидного замечания о том, что ошибка возникает, если правильное сообщение не лежит в шаре или если в этом шаре имеется по крайней мере еще одно возможное сообщение. Поэтому вероятность ошибки  задается равенством
задается равенством

где символ  означает «содержится в», а
означает «содержится в», а  «не содержится в». Поскольку
«не содержится в». Поскольку  равенство (10.4.3) можно упростить, отбрасывая этот сомножитель:
равенство (10.4.3) можно упростить, отбрасывая этот сомножитель:

Вероятность того, что по меньшей мере одно кодовое слово, отличное от  лежит в шаре, очевидно, не превосходит суммы вероятностей того, что каждое кодовое слово, отличное от
лежит в шаре, очевидно, не превосходит суммы вероятностей того, что каждое кодовое слово, отличное от  лежит в шаре. При этом по нескольку раз считаются те случаи, когда несколько родовых слов попадают в выбранный шар с центром в Если, например, в этом шаре оказалось два кодовых слова, отличных от
лежит в шаре. При этом по нескольку раз считаются те случаи, когда несколько родовых слов попадают в выбранный шар с центром в Если, например, в этом шаре оказалось два кодовых слова, отличных от  то произошла одна ошибка, однако в нашу сумму соответствующая вероятность входит дважды. Таким образом, можно написать (суммирование по
то произошла одна ошибка, однако в нашу сумму соответствующая вероятность входит дважды. Таким образом, можно написать (суммирование по  означает суммирование по всему множеству А, кроме точки
означает суммирование по всему множеству А, кроме точки 

где суммирование ведется по всем  кодовым словам, которые не были посланы. Из (10.4.4) имеем
кодовым словам, которые не были посланы. Из (10.4.4) имеем

Здесь первый член выражает вероятность того, что посланное слово не лежит в шаре с центром в принятом слове (другими словами, что принятое слово не лежит в шаре с центром в посланном слове). Второй член является суммой по всем непосланным кодовым словам, каждое из которых может оказаться в шаре радиуса  который (по отношению к
который (по отношению к  несколько больше расстояния Хэмминга, соответствующего среднему числу ошибок. Можно надеяться, что после случайного выбора сообщений они так распределятся по всему пространству, что вероятность того, что в шаре окажется другое сообщение, будет очень мала. Это происходит вследствие того, что
несколько больше расстояния Хэмминга, соответствующего среднему числу ошибок. Можно надеяться, что после случайного выбора сообщений они так распределятся по всему пространству, что вероятность того, что в шаре окажется другое сообщение, будет очень мала. Это происходит вследствие того, что  -мерное пространство очень просторно: вероятность того, что две случайные точки в пространстве большой размерности окажутся близкими друг к другу, очень мала.
-мерное пространство очень просторно: вероятность того, что две случайные точки в пространстве большой размерности окажутся близкими друг к другу, очень мала.

















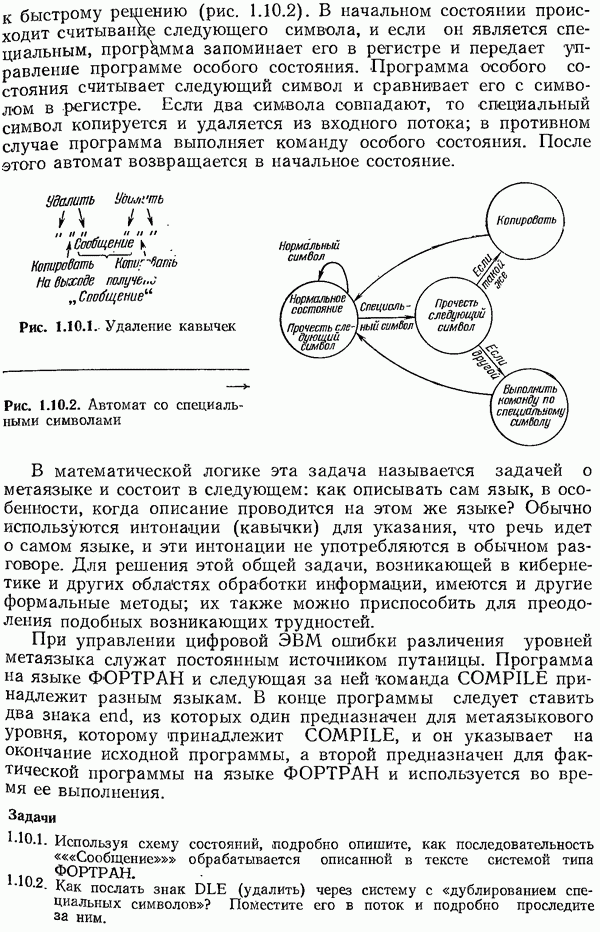































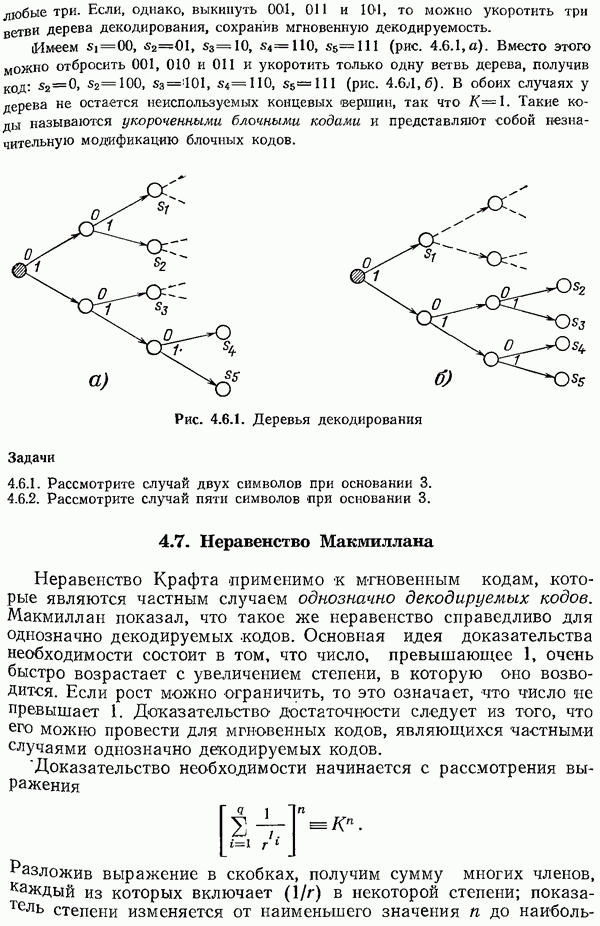
















































































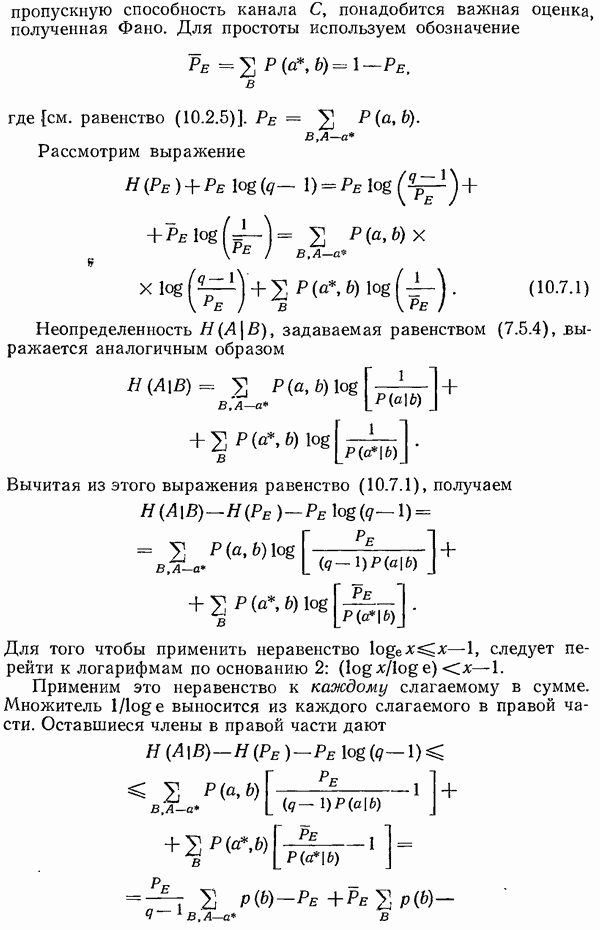


























 двоичных символов посылаются в виде блока. Число всех возможных сообщений равно
двоичных символов посылаются в виде блока. Число всех возможных сообщений равно  однако для того чтобы обеспечить защиту от большого числа одновременно появляющихся ошибок, допустимые сообщения следует выбирать возможно дальше друг от друга (относительно расстояния Хэмминга). Поскольку пока читателю неизвестно, как сделать это в общем случае, попробуем выбирать их случайно с возвращениями. Это эквивалентно тому, что для выбора каждого символа каждого кодового слова производится бросание монеты. Можно также представить себе урну, содержащую карточки со всеми
однако для того чтобы обеспечить защиту от большого числа одновременно появляющихся ошибок, допустимые сообщения следует выбирать возможно дальше друг от друга (относительно расстояния Хэмминга). Поскольку пока читателю неизвестно, как сделать это в общем случае, попробуем выбирать их случайно с возвращениями. Это эквивалентно тому, что для выбора каждого символа каждого кодового слова производится бросание монеты. Можно также представить себе урну, содержащую карточки со всеми  возможными наборами из
возможными наборами из  нулей и единиц. Из урны выбираются
нулей и единиц. Из урны выбираются  карточек, причем после каждого выбора карточка возвращается в урну. Так, производится выбор
карточек, причем после каждого выбора карточка возвращается в урну. Так, производится выбор  кодовых слов, где
кодовых слов, где

 может быть сделан меньшим, чем любое наперед заданное положительное число
может быть сделан меньшим, чем любое наперед заданное положительное число  (ввиду закона больших чисел), если выбрать длину блока
(ввиду закона больших чисел), если выбрать длину блока  настолько большой, что расширенный шар радиуса
настолько большой, что расширенный шар радиуса  будет содержать почти все наиболее вероятные точки. Таким образом, из (10.4.5) имеем, что
будет содержать почти все наиболее вероятные точки. Таким образом, из (10.4.5) имеем, что

 кодовым словам, отличным от посланного кодового слова.
кодовым словам, отличным от посланного кодового слова.