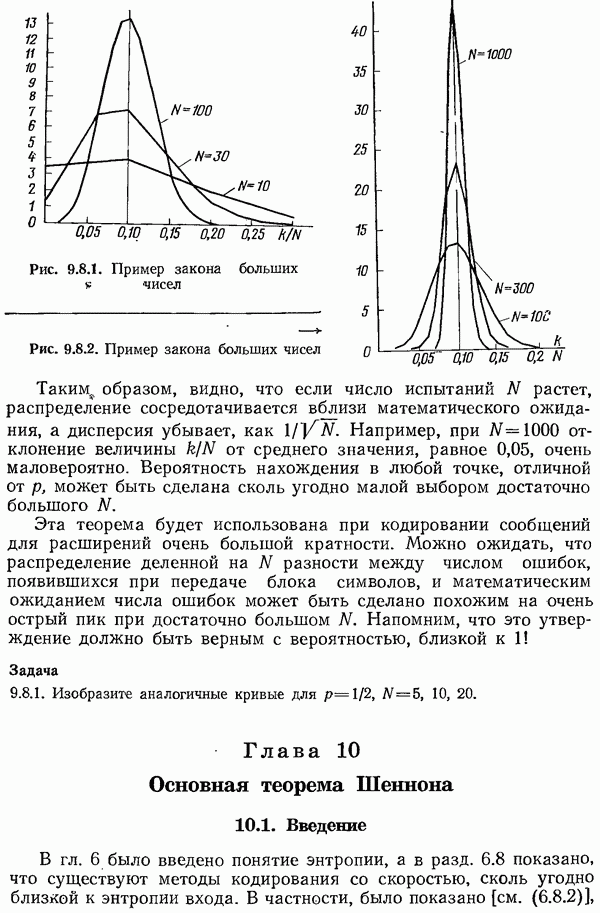
Перейдем к обратным величинам и получим  Поскольку
Поскольку  то, суммируя эти неравенства, получаем
то, суммируя эти неравенства, получаем

что дает неравенство Крафта. Поэтому существуют мгновенно декодируемые коды, имеющие кодовые слова указанных длин.
Для определения энтропии распределения  умножим (6.6.1) на
умножим (6.6.1) на  и проведем суммирование по
и проведем суммирование по 

В терминах средней длины  кода (6.5.4) имеем
кода (6.5.4) имеем

Таким образом, для кодирования Шеннона — Фано энтропия снова дает нижнюю границу средней длины кода. Энтропия входит также в верхнюю границу. Верхнюю границу для кодов Хаффмена (см. гл. 4) получить нелегко, однако вследствие своей оптимальности коды Хаффмена не могут быть хуже кодов Шеннона — Фано.
Как фактически найти кодовые слова? Следует просто сопоставить их одно за другим. Например, из вероятностей  получаем длины Шеннона — Фано
получаем длины Шеннона — Фано
После этого строим кодовые слова: 
Неравенство Крафта, выполненное для кодирования Шеннона — Фано, гарантирует, что кодовых слов хватит для построения мгновенного кода. Такое упорядоченное сопоставление сразу дает дерево декодирования.
Это показывает, что кодирование Шеннона — Фано является достаточно хорошим. Интересно посмотреть, как возникает левое изнеравенств в выражении (6.6.3). Прежде всего, если каждая из вероятностей  является некоторой отрицательной целой степенью основания
является некоторой отрицательной целой степенью основания  то при указанном распределении длин кодовых слов неравенство переходит в равенство, т. е. средняя длина кодовых слов совпадает с энтропией. Для получения кодовых слов следует просто сопоставить символам возрастающие
то при указанном распределении длин кодовых слов неравенство переходит в равенство, т. е. средняя длина кодовых слов совпадает с энтропией. Для получения кодовых слов следует просто сопоставить символам возрастающие  -ичные числа нужных длин.
-ичные числа нужных длин.































































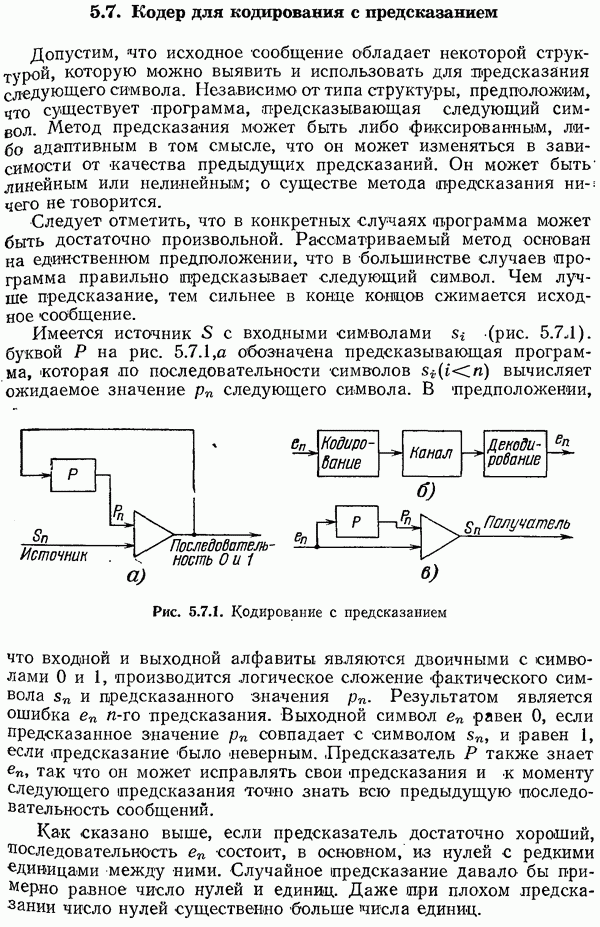


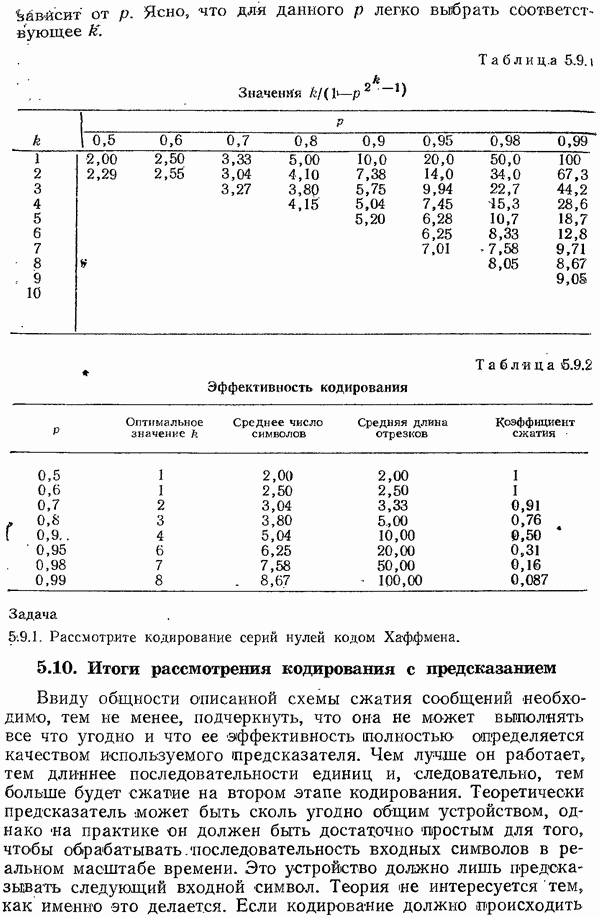










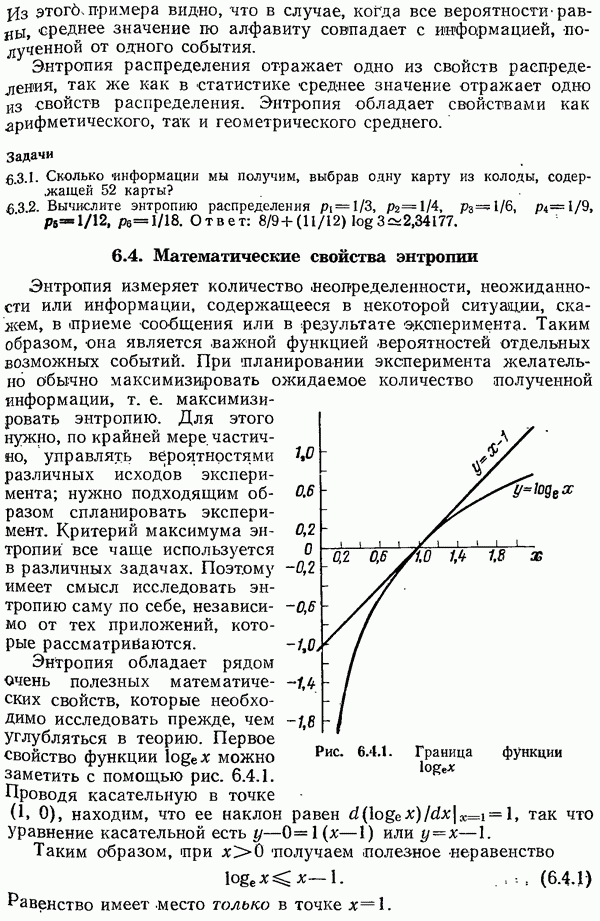

































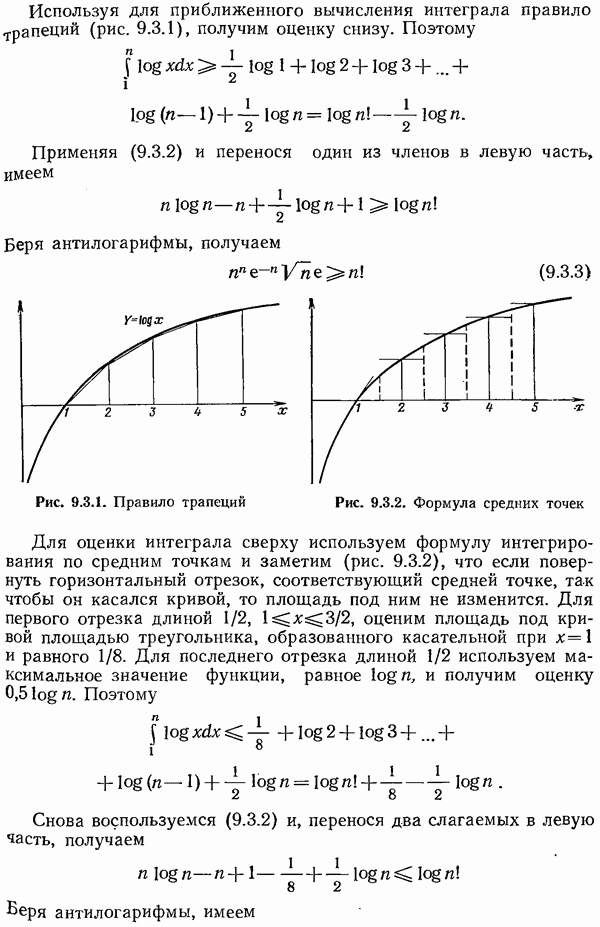



















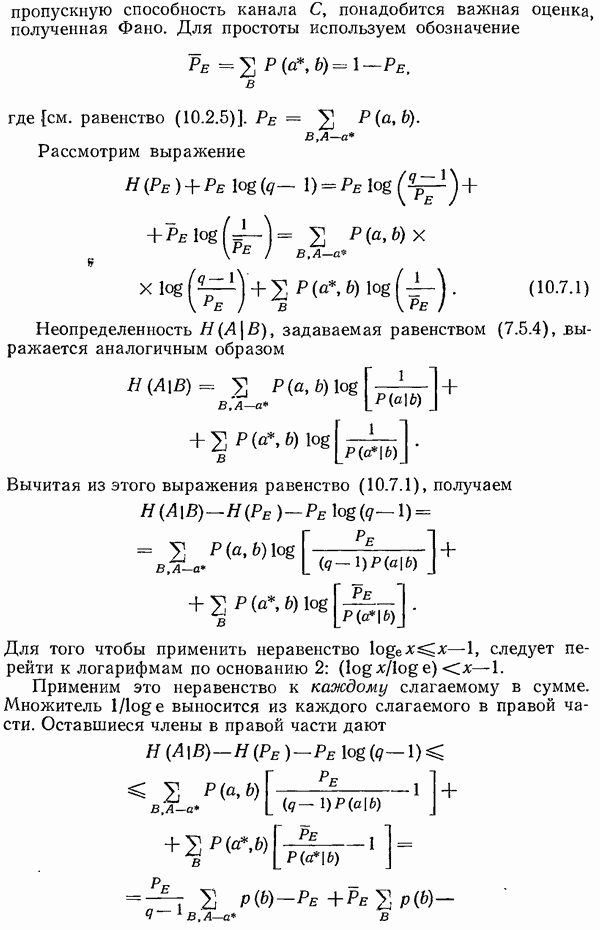


























 Кодирование Хаффмена дает длины кодовых слов, причем каждая длина зависит от всего набора вероятностей.
Кодирование Хаффмена дает длины кодовых слов, причем каждая длина зависит от всего набора вероятностей.
 можно непосредственно найти длину
можно непосредственно найти длину  соответствующего кодового слова. Пусть даны символы. источника
соответствующего кодового слова. Пусть даны символы. источника  и соответствующие вероятности.
и соответствующие вероятности.  каждого
каждого  найдется такое целое число
найдется такое целое число  что
что


