Пред.
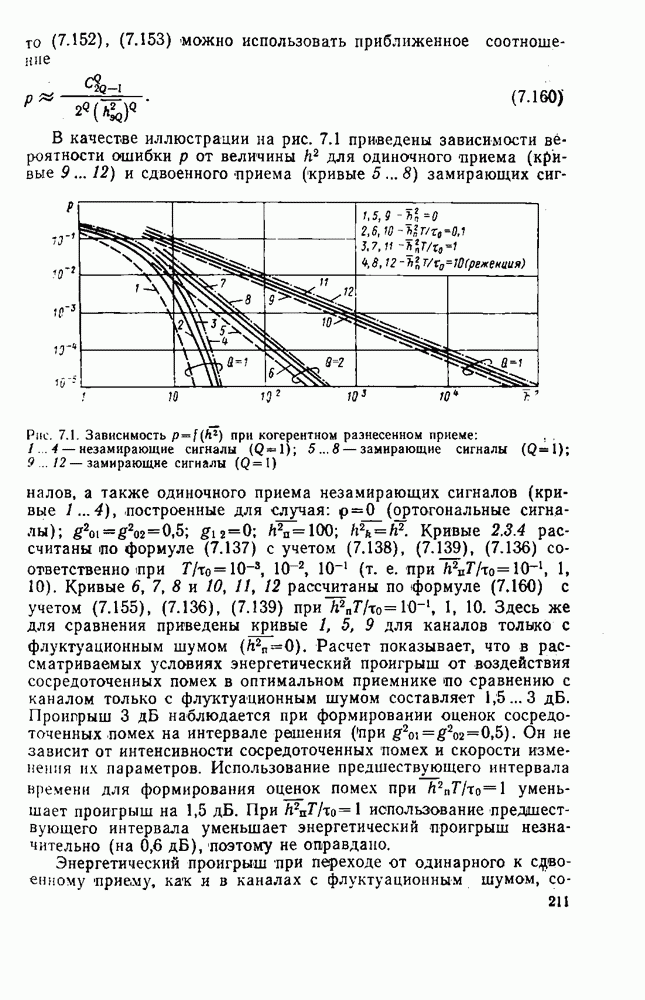
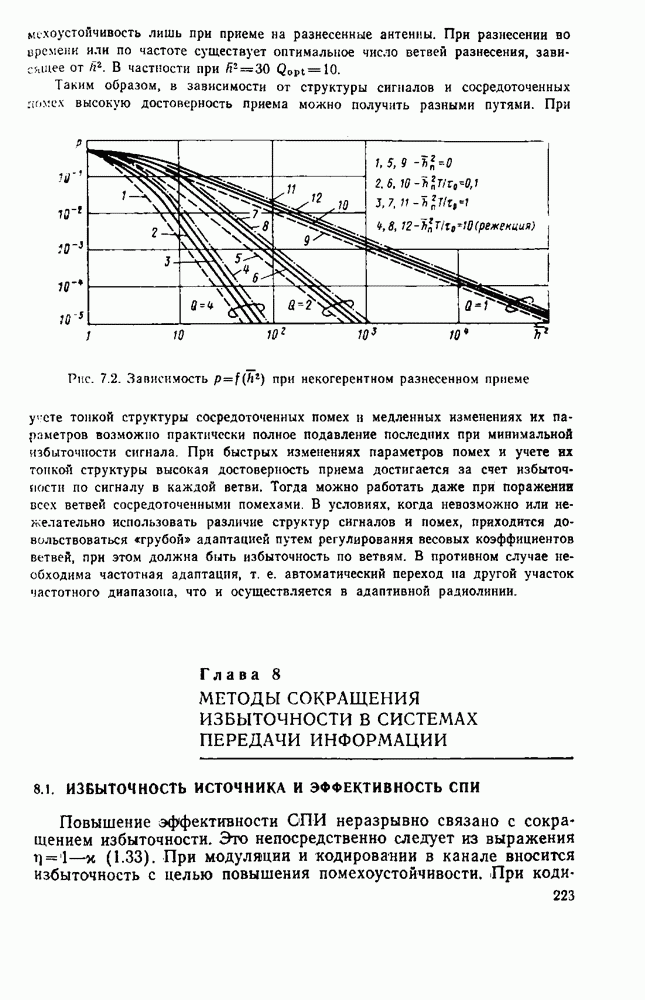
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
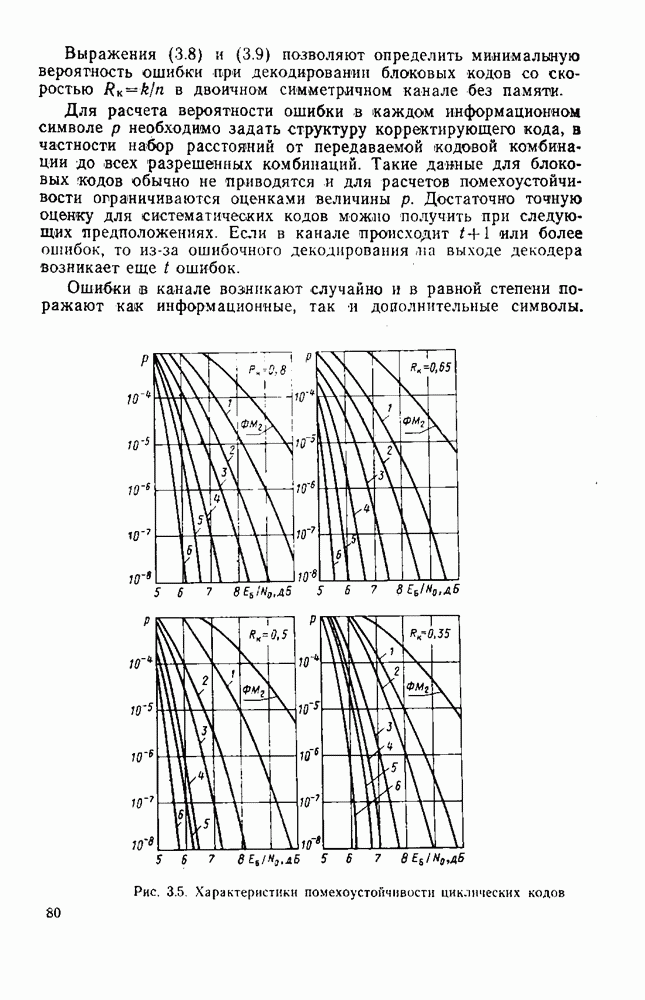
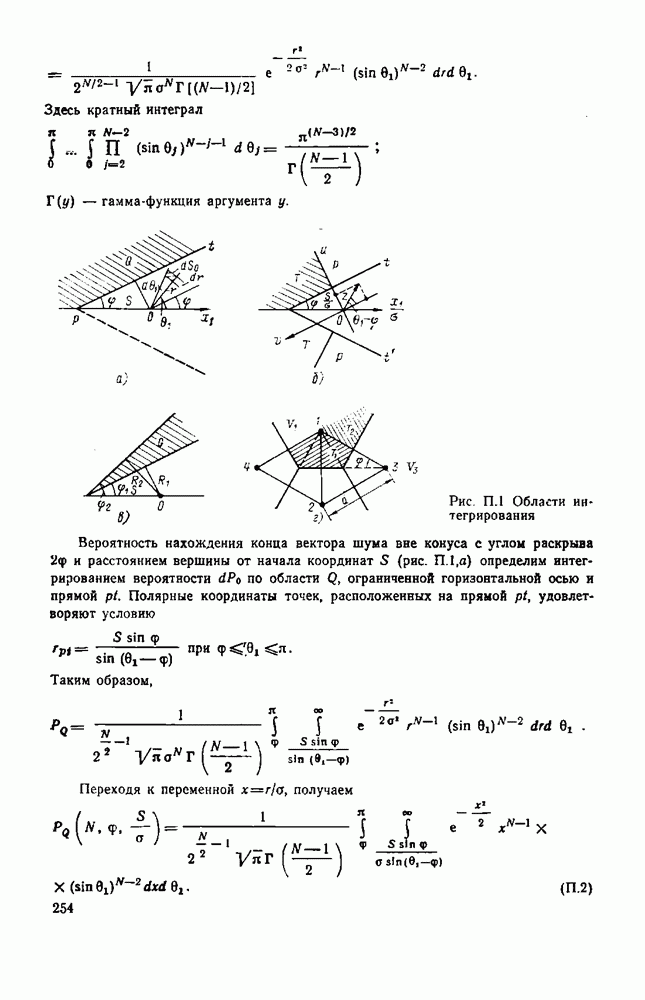
ГЛАВА 3. ЭФФЕКТИВНОСТЬ СПДС С ПОМЕХОУСТОЙЧИВЫМ КОДИРОВАНИЕМ3.1. МЕТОДЫ ПОМЕХОУСТОЙЧИВОГО КОДИРОВАНИЯ ПРИ ПЕРЕДАЧЕ ДИСКРЕТНЫХ СООБЩЕНИИПомехоустойчивое кодирование является эффективным средством повышения верности передаваемых сообщений. Принципы построения корректирующих кодов и их классификация изложены в ряде монографий [34, 73, 74]. В настоящее время предложено много кодов, обладающих различными свойствами и применяемых в тех или иных каналах. Ниже мы ограничимся анализом корректирующих кодов, используемых в каналах с независимыми ошибками. Некоторые реальные каналы хорошо описываются моделью двоичного симметричного канала без памяти. Кроме того, при наличии эффективного перемеження многие каналы с памятью могут рассматриваться как каналы с независимыми ошибками. Кодирование в каналах со случайной структурой подробно рассмотрено в книге [30]. Все известные коды можно разделить на две группы: блоковые коды, в которых кодирование и декодирование осуществляются в пределах блока (кодовой комбинации) длиной Математическое описание циклических кодов основано на представлении кодовой комбинации в виде многочлена [73]:
где Построение циклических кодов основано на использовании неприводимых многочленов. В теории циклических кодов их используют в качестве порождающих многочленов. Подробная таблица неприводимых многочленов приведена в монографии [73]. Пусть задана
Здесь Умножив левую и правую части равенства (3.1) на
Таким образом, можно указать два способа построения кодовых комбинаций циклического кода. 1. Кодовые комбинации систематического циклического кода значности 2. Кодовые комбинации несистематического циклического кода значности Кодирование и декодирование циклических кодов производится с использованием регистров сдвига. Подробное описание алгоритмов декодирования можно найти в [73, 74]. В классе циклических кодов особый интерес представляют коды Боуза-Чоудхури-Хоквингема (БЧХ), имеющие наилучшие характеристики декодирования в каналах с независимыми ошибками. Длина кодовой комбинации кода БЧХ находится из выражения
где m - любое целое число. Число проверочных символов кода
следовательно, число информационных символов кода
Здесь Поскольку код с расстоянием
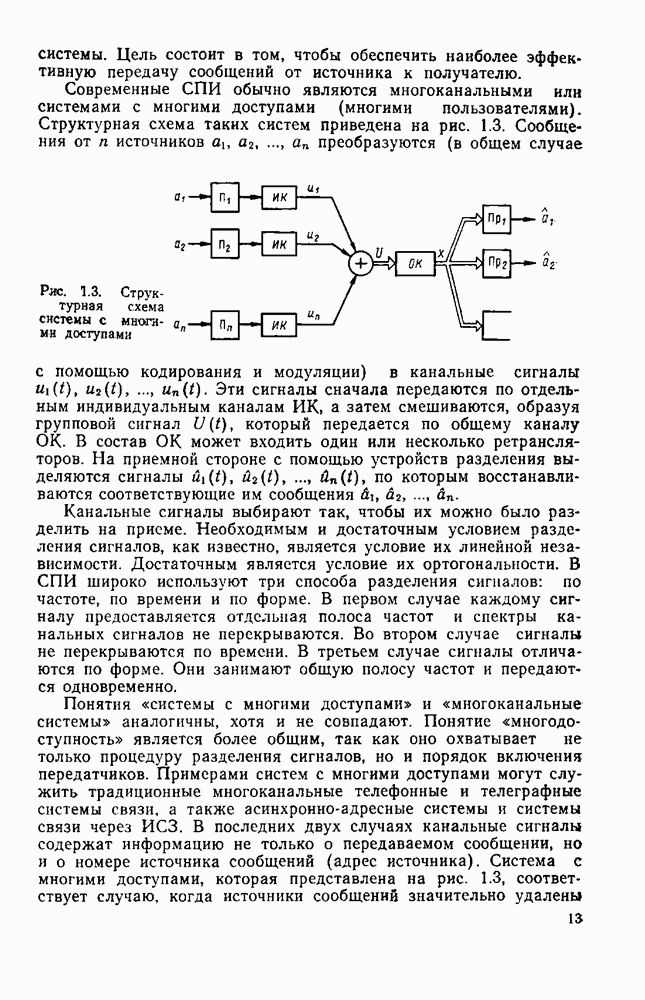
где Некоторые из линейных кодов (в том числе и циклических) допускают мажоритарное декодирование [75]. Возможность использования решения по большинству (мажоритарного принципа) гущественно упрощает процедуру декодирования в обмен на некоторое снижение эффективности алгоритма. Подробная таблица циклических кодов с мажоритарным декодированием приведена в [75]. Мажоритарный принцип декодирования применим и к сверточным кодам. Кодер сверточного кода, как и любое кодирующее устройство, имеет память для накопления определенного числа информационных символов и преобразователь информационной последовательности в кодовую последовательность. Схема простейшего кодера приведена на рис. 3.1 Информационные символы и поступают на вход регистра сдвига, имеющего К разрядов. На выходах сумматоров образуются кодовые символы
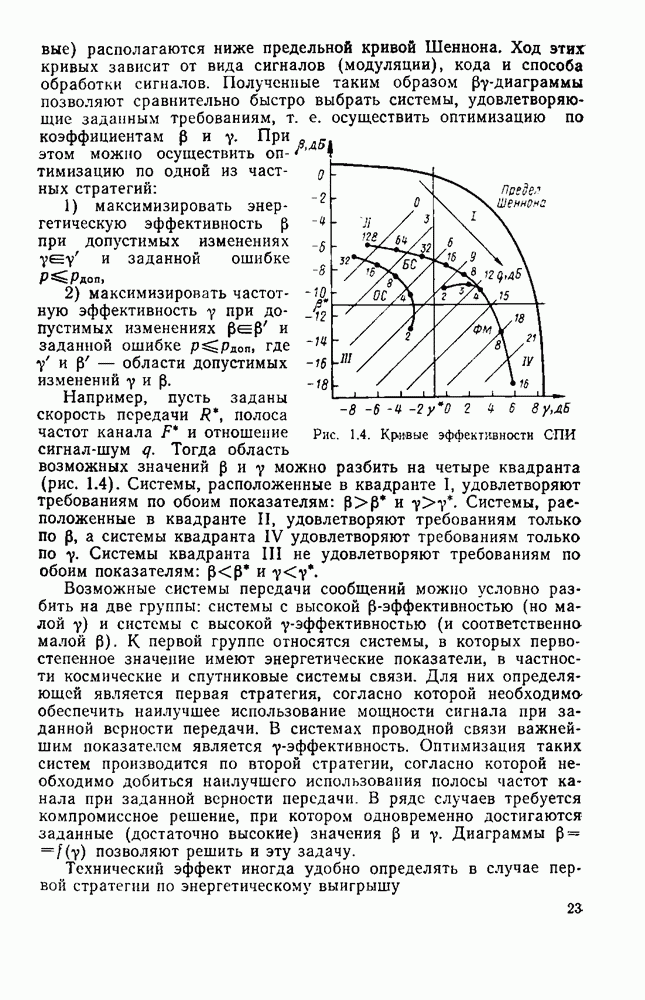
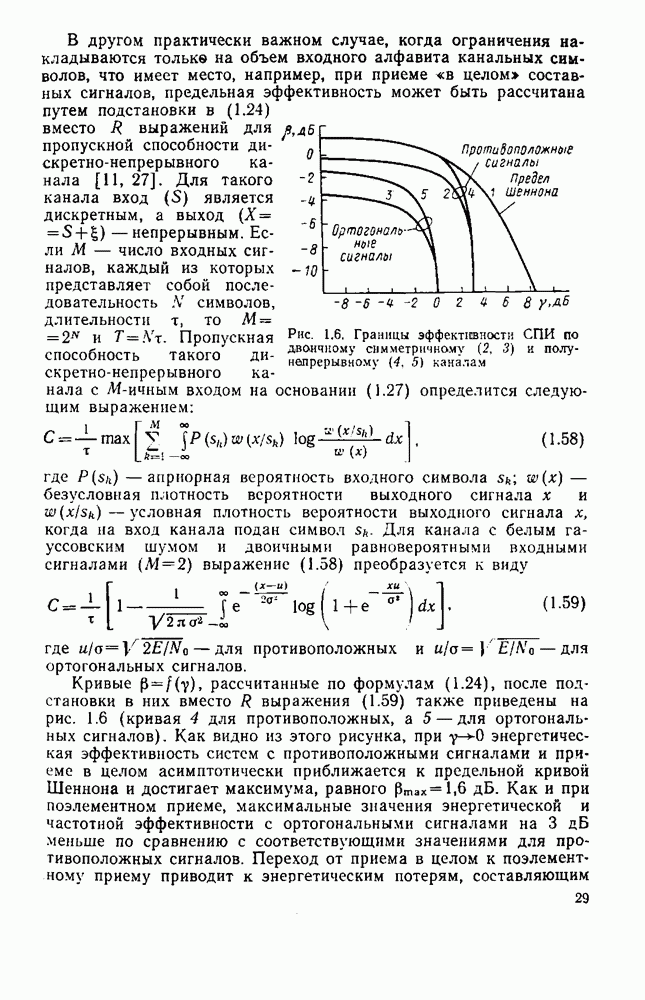
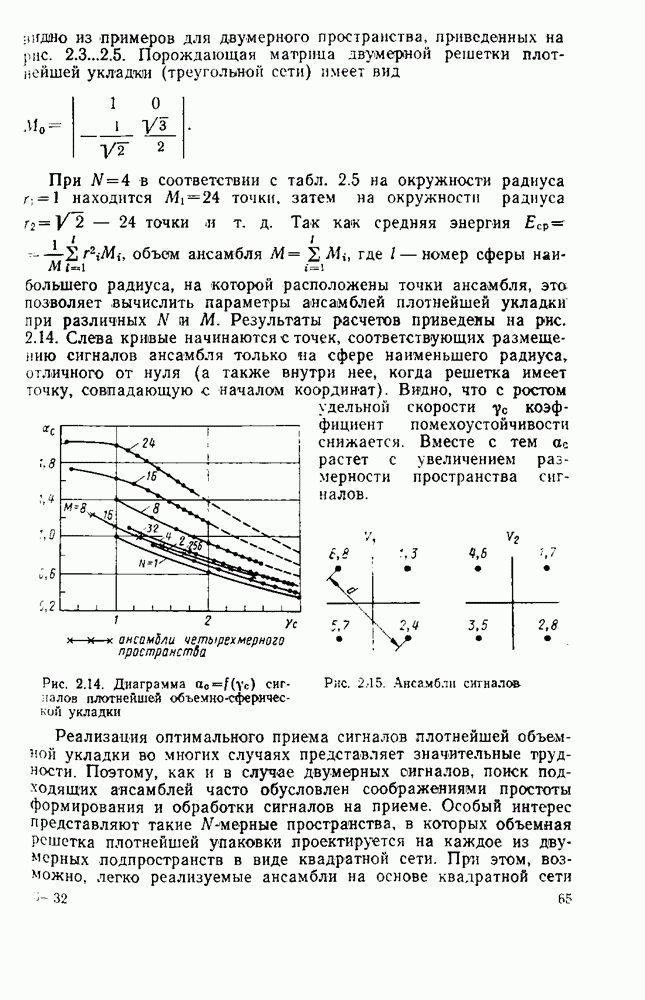
Рис. 3.1. Кодеры сверточных кодов: Сверточный кодер является дискретным автоматом с конечным числом состояний. Состоянием кодера, изображенного на рис. 3.1,а, называется содержимое двух первых разрядов регистра сдвига. В данном случае может быть четыре возможных состояния: Автомат с конечным числом состояний полностью описывается диаграммой состояний. Диаграмма содержит все возможные переходы кодера из одного состояния в другое. В качестве примера на рис. 3.2, а показана диаграмма состояний для кодера, изображенного на рис. 3.1, а. В кружках указаны четыре возможных состояния: поступлении символа 1. По диаграмме состояний можно проследить процесс кодирования. Решетчатая диаграмма оверточного кода является разверткой диаграммы состояний во времени. В качестве примера дан рис. 3.3. На решетке состояния показаны узлами, а переходы — соединяющими их линиями. После каждого перехода из одного состояния в другое происходит смещение на один шаг вправо. Решетчатая диаграмма дает наглядное представление всех разрешенных путей, по которым может продвигаться код
Рис. 3.3. Решетчатая диаграмма
Рис. 3.2. Исходная (а) и модифицированная (б) диаграммы состояний сверточного кодера Сверточный код будет полностью задан, если известна схема кодера. Скорость кода
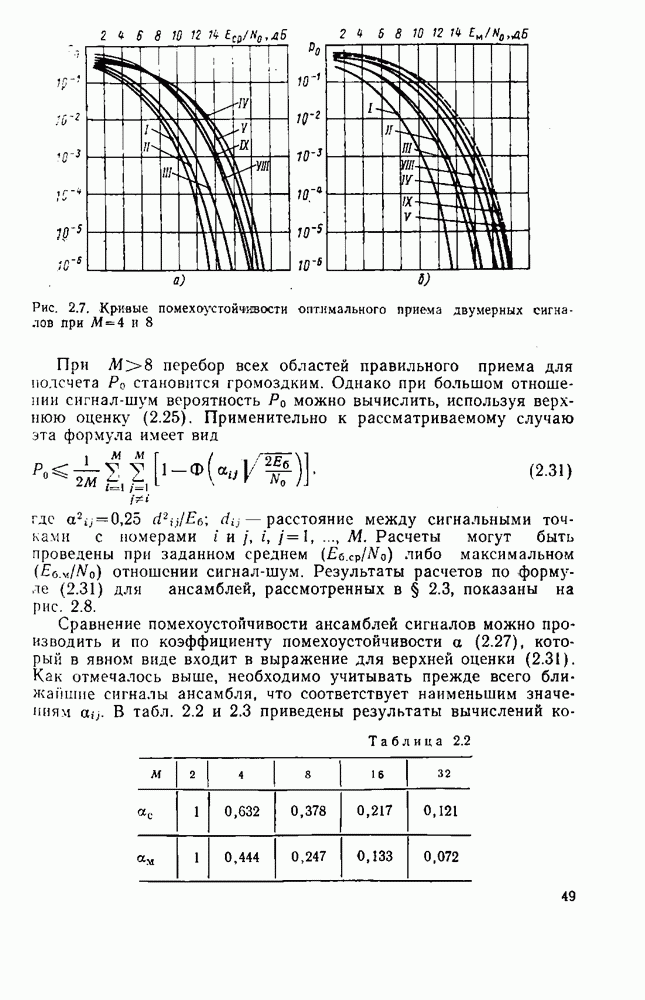
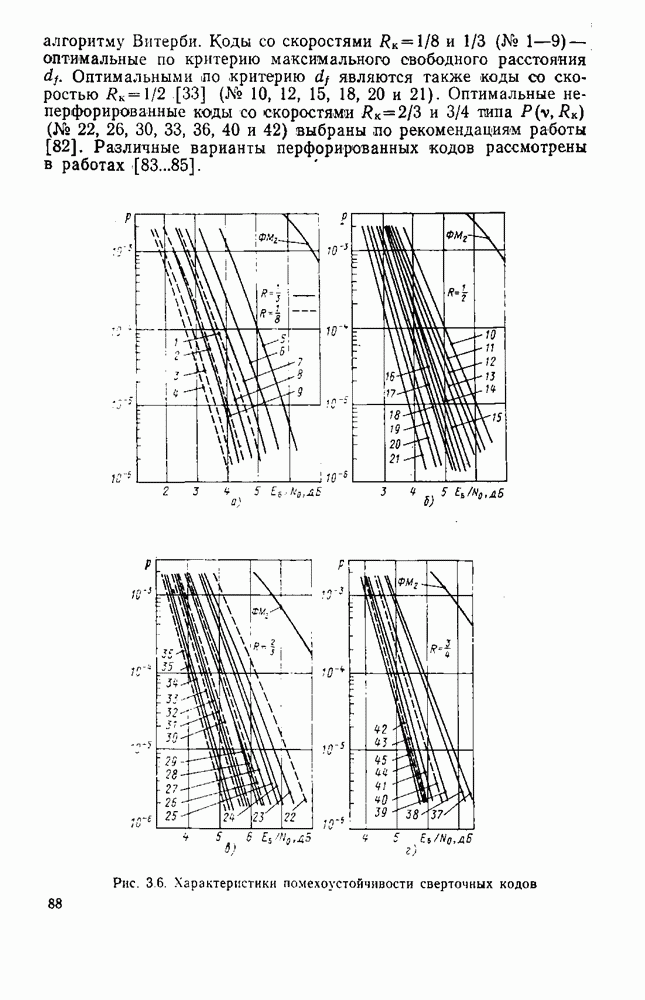
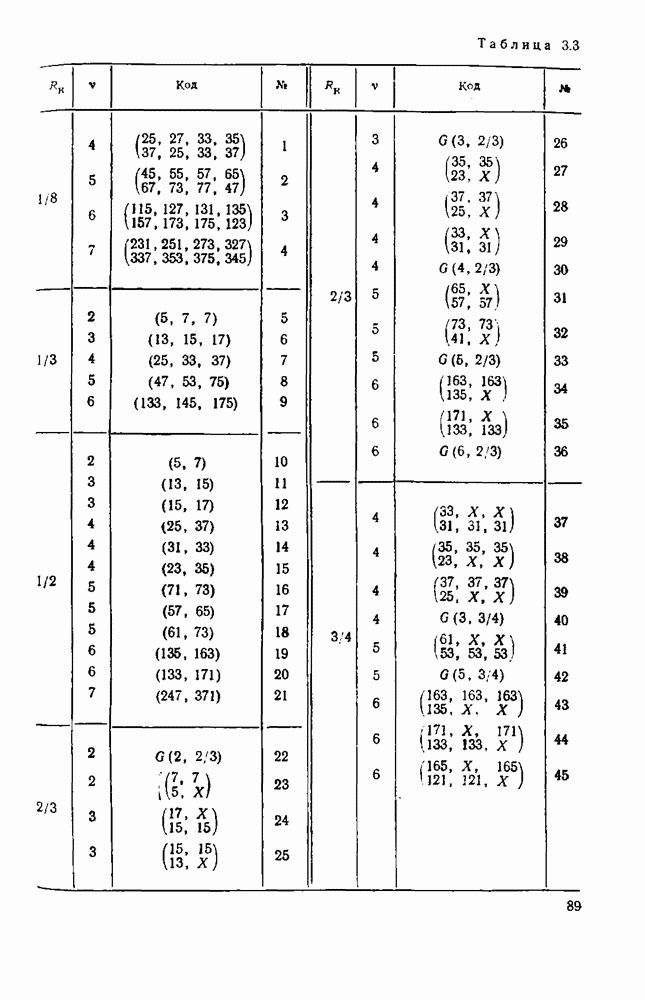
причем если связь Кодеры с несколькими входами матрицы кодера, показанного на рис. 3.1, б, имеют вид: Помехоустойчивость систем с корректирующими кодами зависит как от свойств используемого кода, так и от алгоритма декодирования. Оптимальные алгоритмы декодирования позволяют полностью «использовать корректирующие свойства кода, однако их программная либо аппаратная реализация является, как правило, сложной. Известны и субоптимальные алгоритмы, реализация которых проще. По способу согласования декодера с выходом канала (выходом демодулятора) различают декодирование с жестким решением в демодуляторе и с мягким решением. В первом случае в демодуляторе по принимаемой сумме сигнала и помехи выносится двоичное («жесткое») решение, которое поступает на вход декодера. При этом кодированию подвергается двоичный дискретный канал. При мягком решении на выходе демодулятора реализация сигнала и помехи квантуется на определенное число уровней и результат квантования подается на вход декодера. В этом случае рассматривается задача кодирования в дискретном канале с расширенным по сравнению с входным алфавитом символов на выходе. Наилучшие результаты декодирования получаются, если число уровней квантования Известны три основных алгоритма декодирования сеерточных кодов. Алгоритм максимального правдоподобия является оптимальным и позволяет полностью реализовать корректирующую способность кода. Для кодов малой длины отыскание максимально правдоподобной последовательности можио организовать путем перебора всех возможных вариантов. Однако с ростом длины кода объем вычислений резко возрастает. Декодирование максимального правдоподобия реализуется обычно с использованием алгоритма Витерби, основанного на принципе динамического программирования. При этом осуществляется динамический перебор всех возможных путей по кодовой решетке (см. рис. 3.3) с одновременным отбрасыванием маловероятных отрезков путей. Алгоритм Витерби подробно описал в монографиях [34, 73], в обзорах [76, 77] даны сведения по вопросам его реализации. Алгоритмы последовательного декодирования [29] основаны на поиске наиболее вероятного пути на кодовом дереве путем последовательных проб с возможностью возвращения назад. С ростом числа ошибок в канале число таких проб резко возрастает, и для декодирования в реальном масштабе времени на входе последовательного декодера необходима буферная память. Переполнение буферной памяти ведет к отказу от декодирования и стиранию части сообщений. Это обстоятельство ограничивает применение последовательных декодеров в системах связи, где стирания сообщений, направляемых к получателю, нежелательны. Алгоритм порогового декодирования основан на алгебраической структуре кода и применении мажоритарного принципа вынесения решения о каждом информационном символе [74]. Он заведомо неоптимален, однако по сравнению с оптимальными алгоритмами значительно проще в реализации. Алгоритм используется в основном при работе с жестким решением на выходе демодулятора. Однако возможна реализация порогового декодера и в варианте с гибким решением [77, 200]. В работе [78] описана перспективная модификация этого алгоритма — многопороговый алгоритм декодирования с в Сравнение сверточных кодов с различными скоростями показывает, что наиболее простыми по структуре и реализации являются коды со скоростью
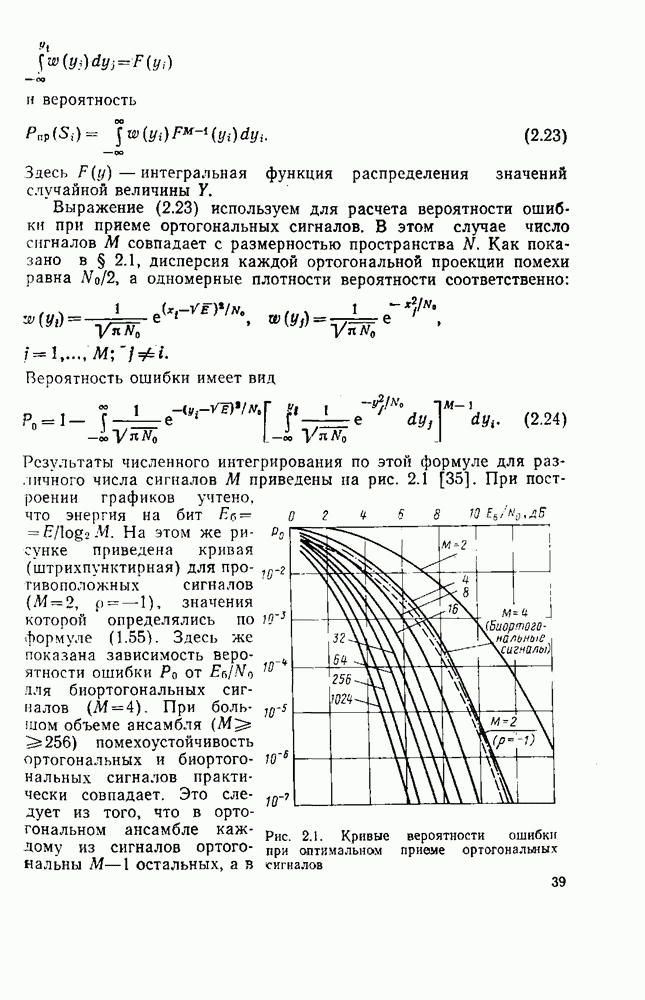
Рис. 3.4. Решетчатые диаграммы стандартного (а) и перфорированного (б) сверточных кодов со скоростью Если скорость кода возрастает в 1,7 раз. Вместе с тем кодирование сообщений со скоростью Повышение скорости кода возможно путем периодического вычеркивания (перфорации) символов на выходе кодера. Если из последовательности символов а на выходе кодера (см. рис. 3.1, а) вычеркивать (не передавать в канал) каждый четвертый символ, то скорость кода возрастет и будет Решетчатая диаграмма рассмотренного перфорированного кола представлена на рис. 3.4, б. Она состоит из двух различных периодических повторяющихся шагов. Первый шаг образуют ветви, состоящие из символов, порождаемых генераторами
|
 |
Оглавление
|






































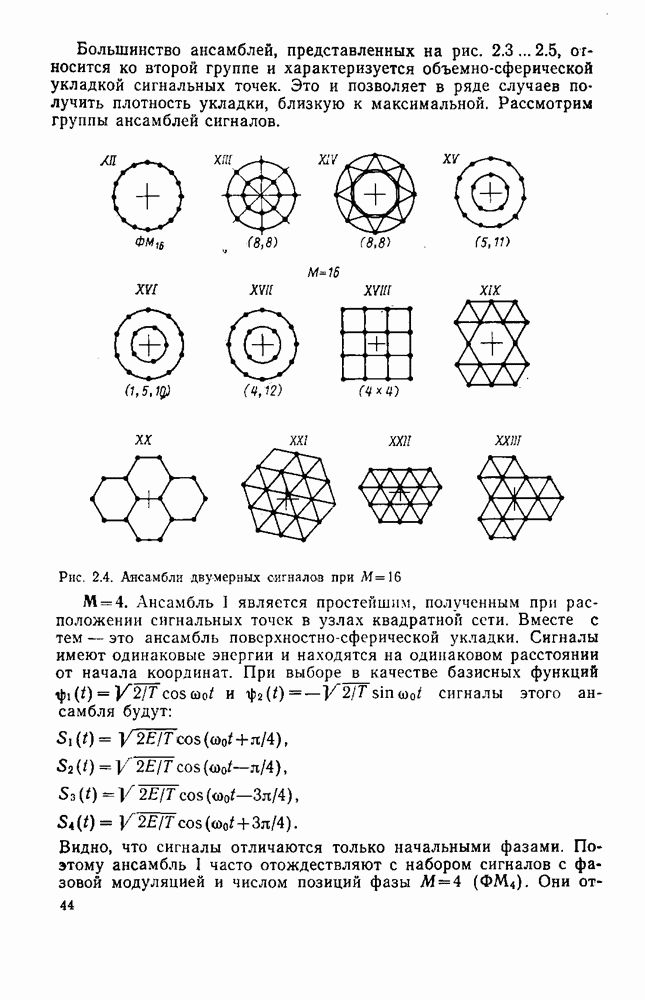
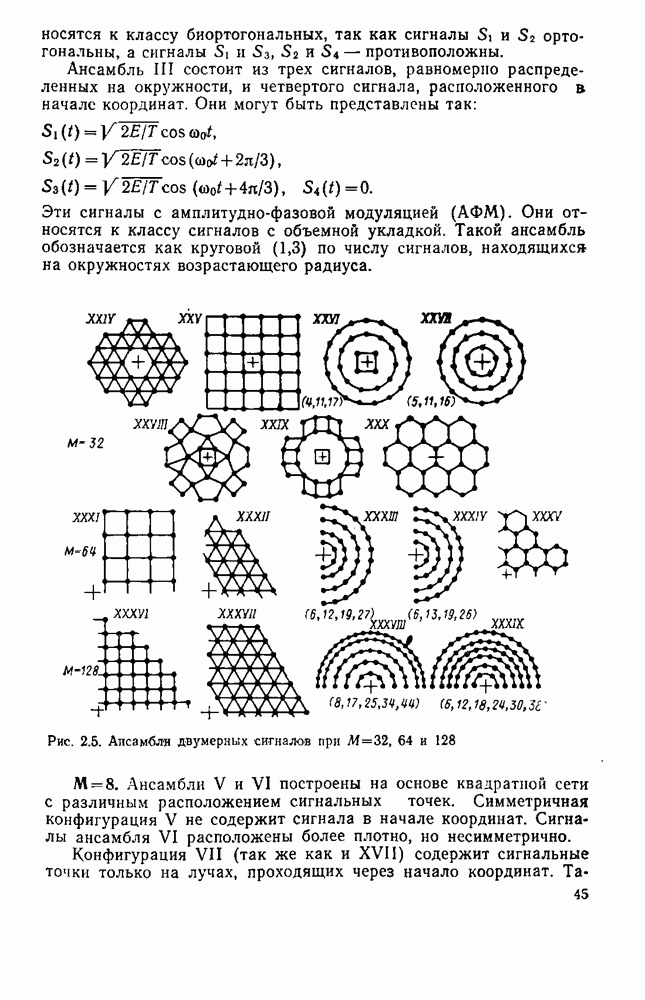

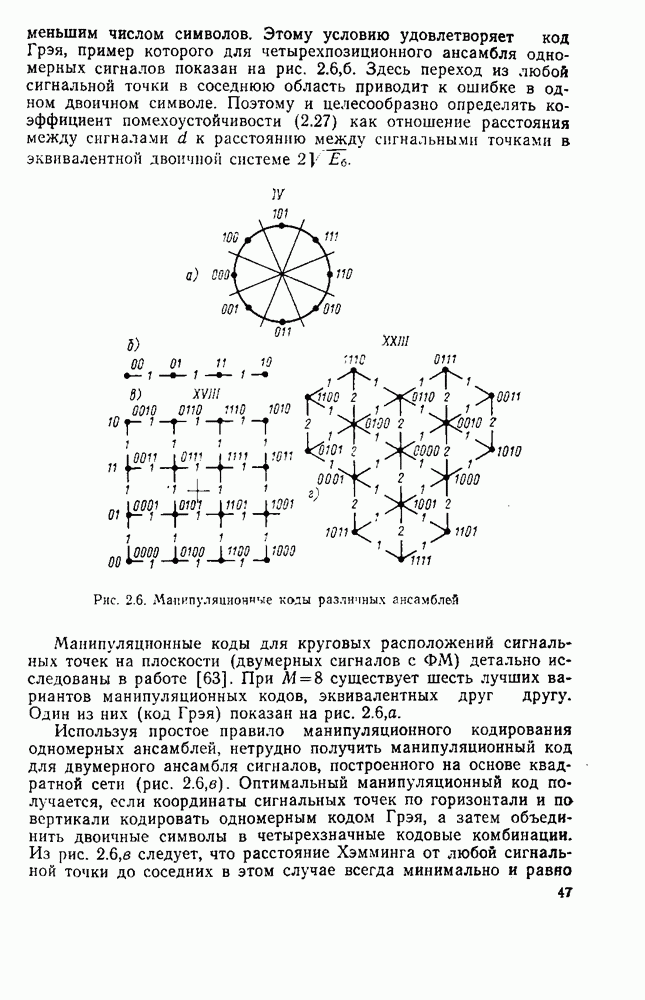

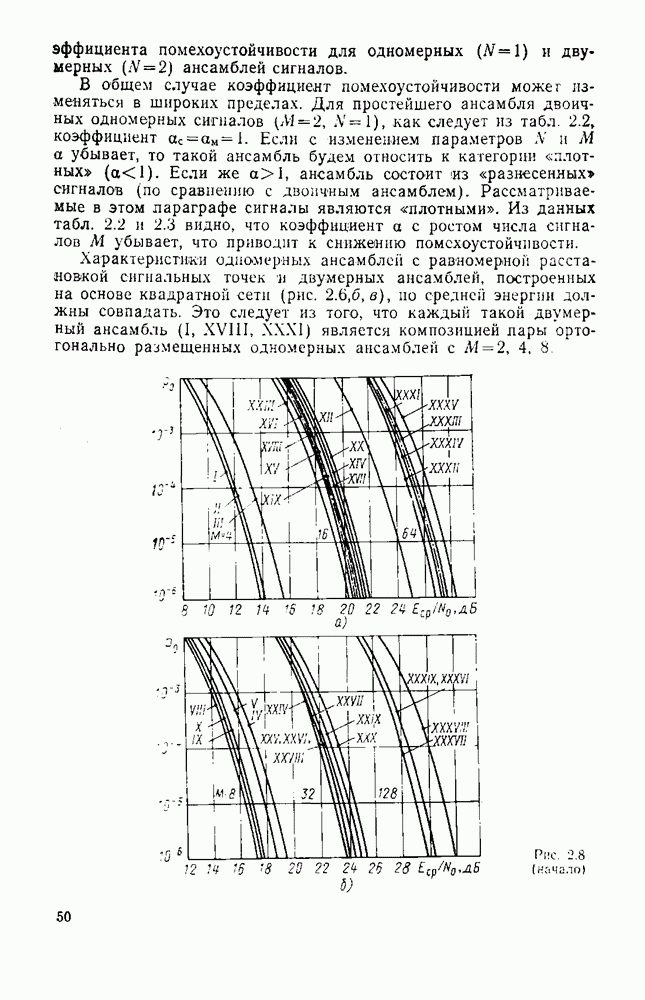
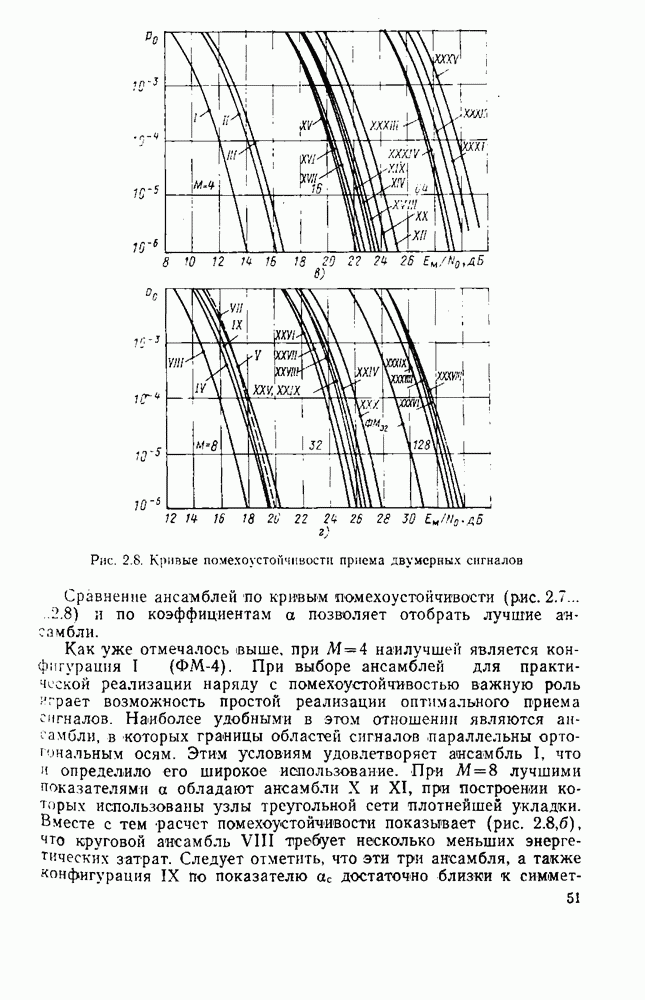




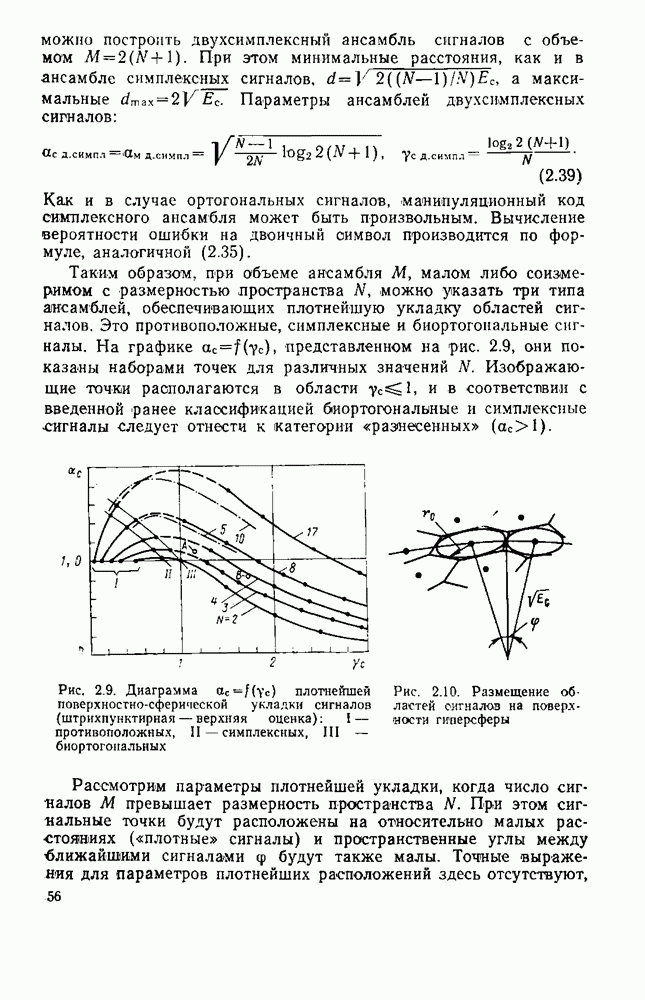



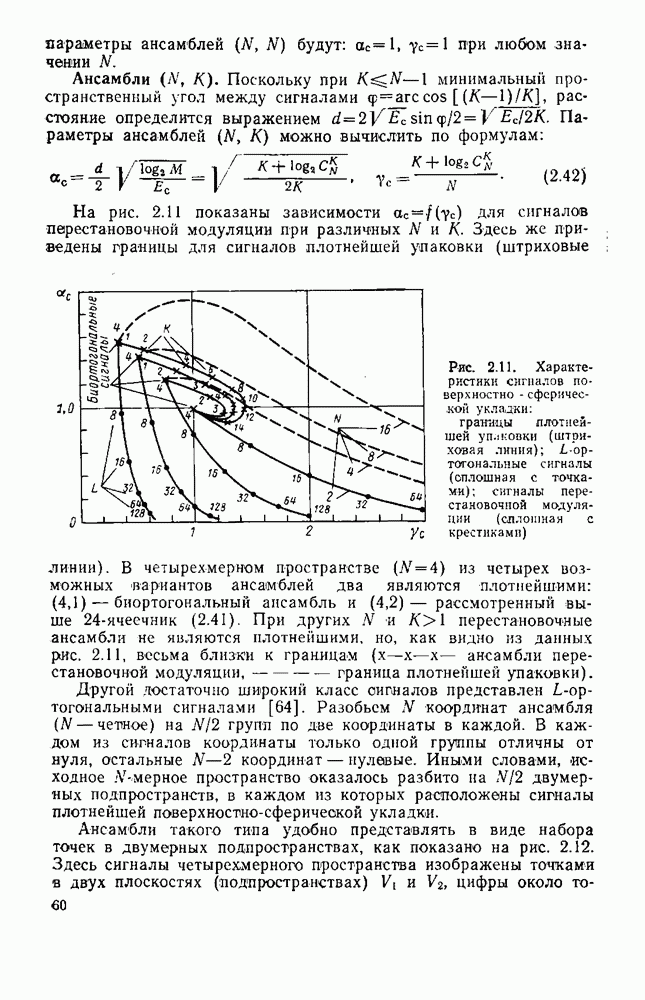























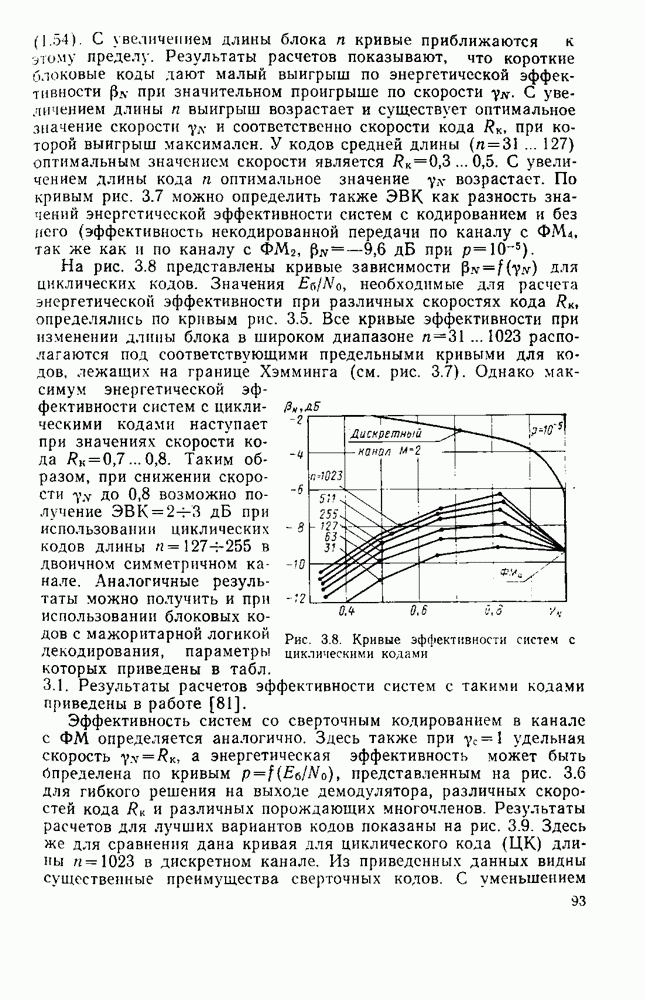
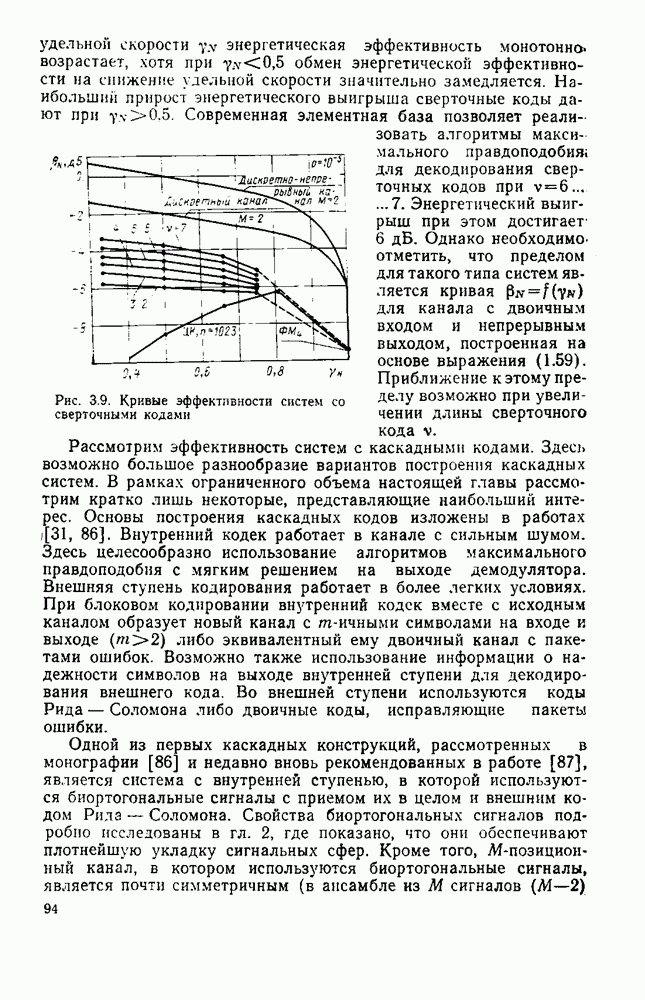
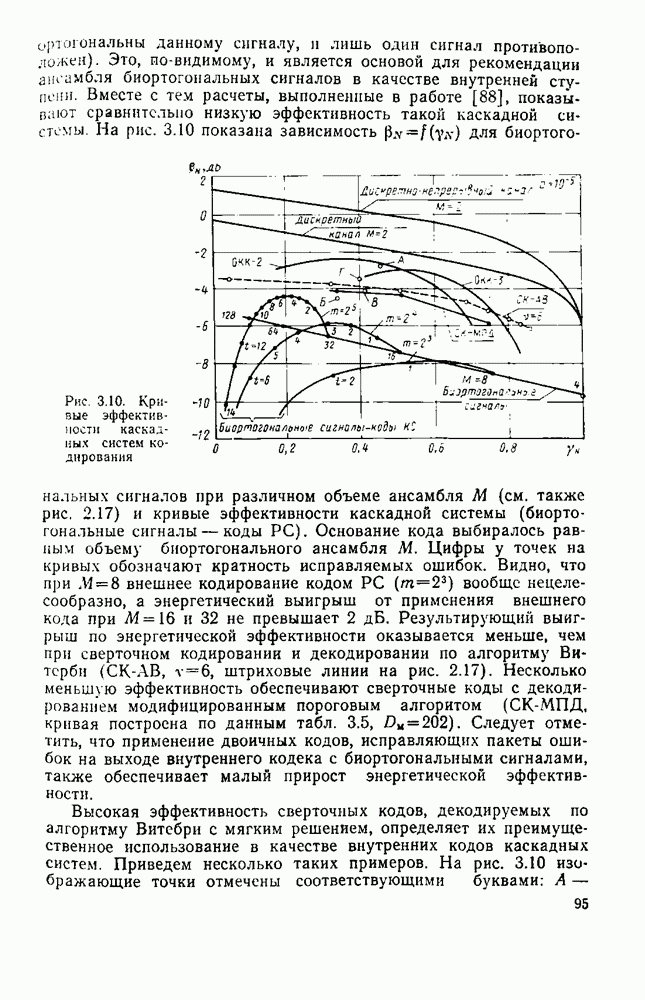









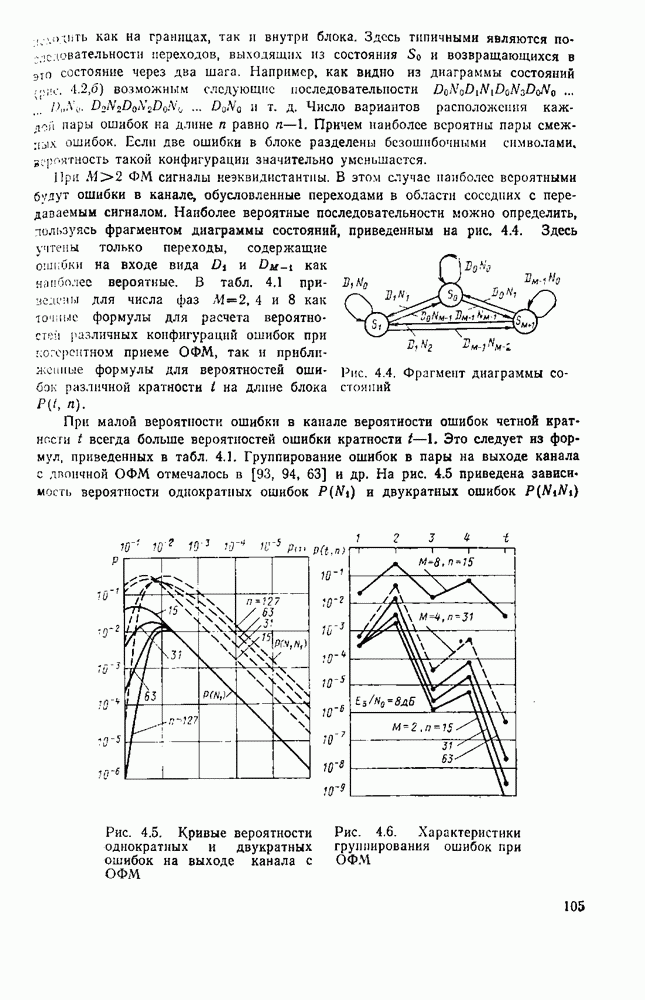



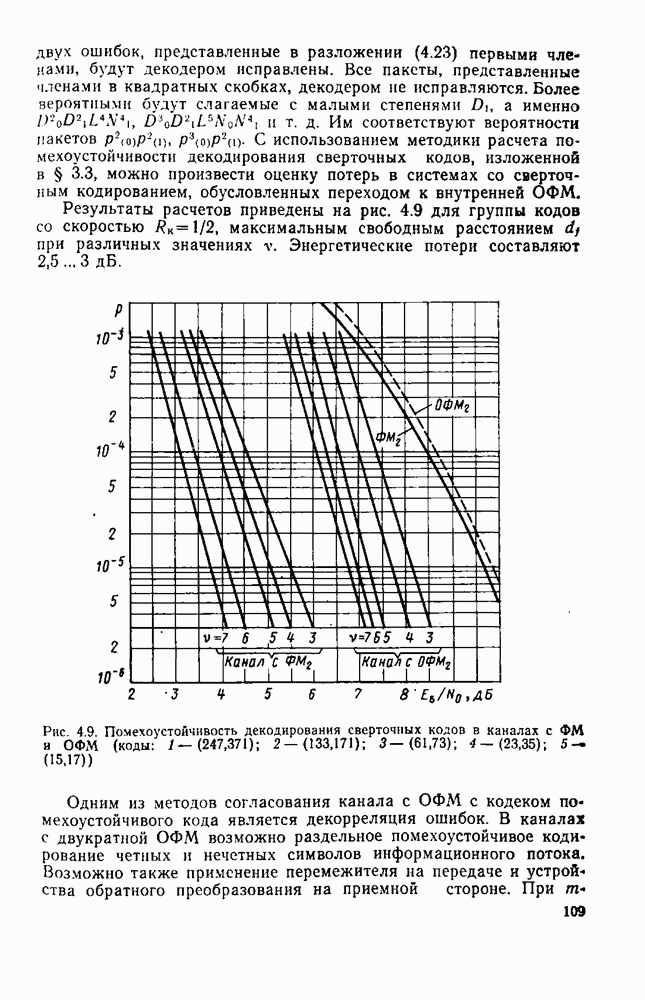




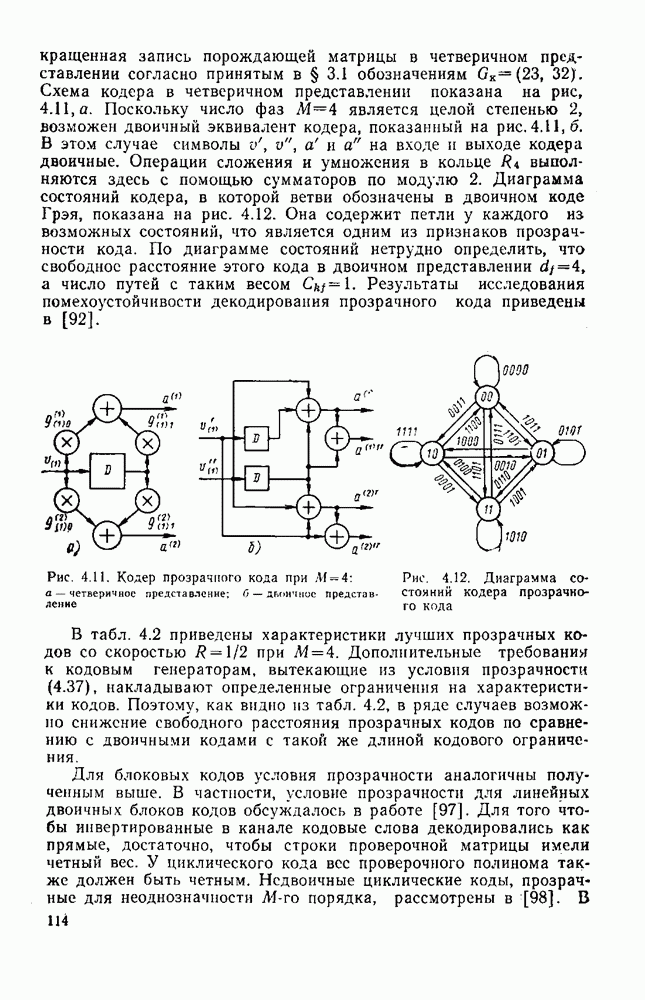



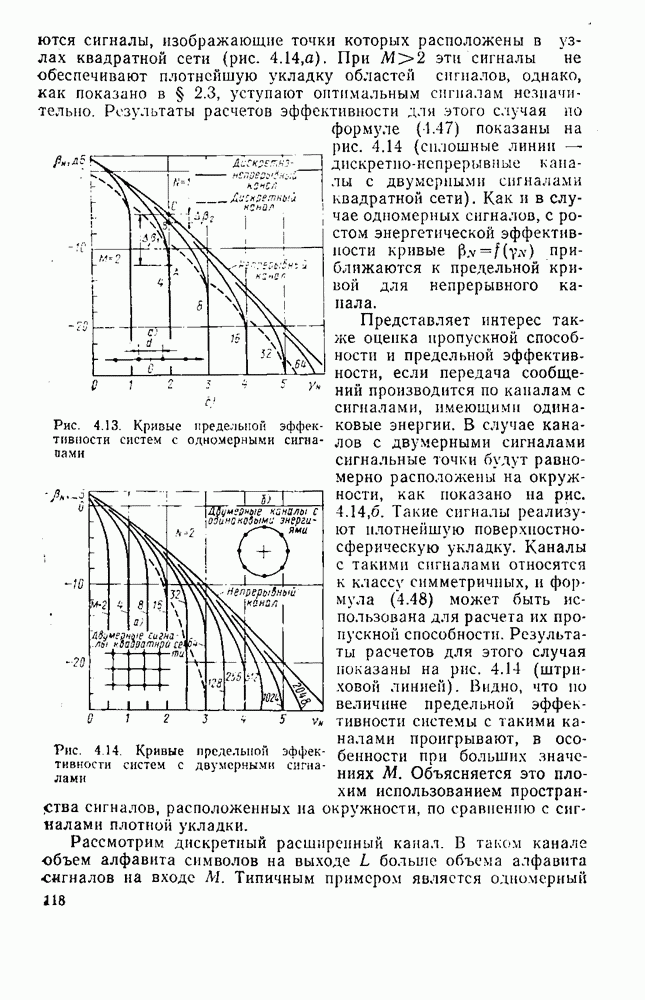




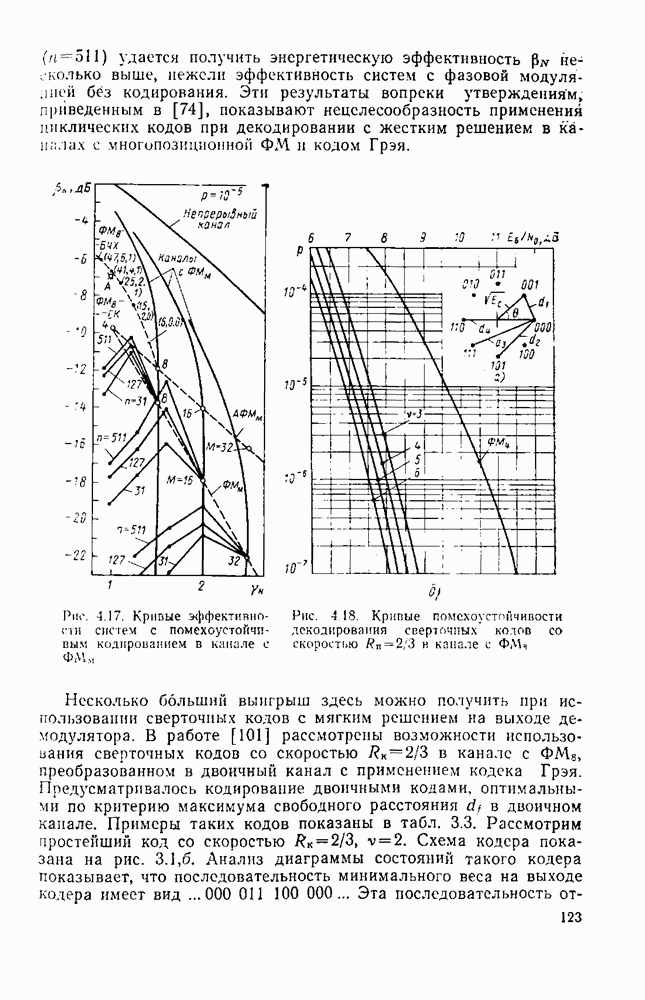




















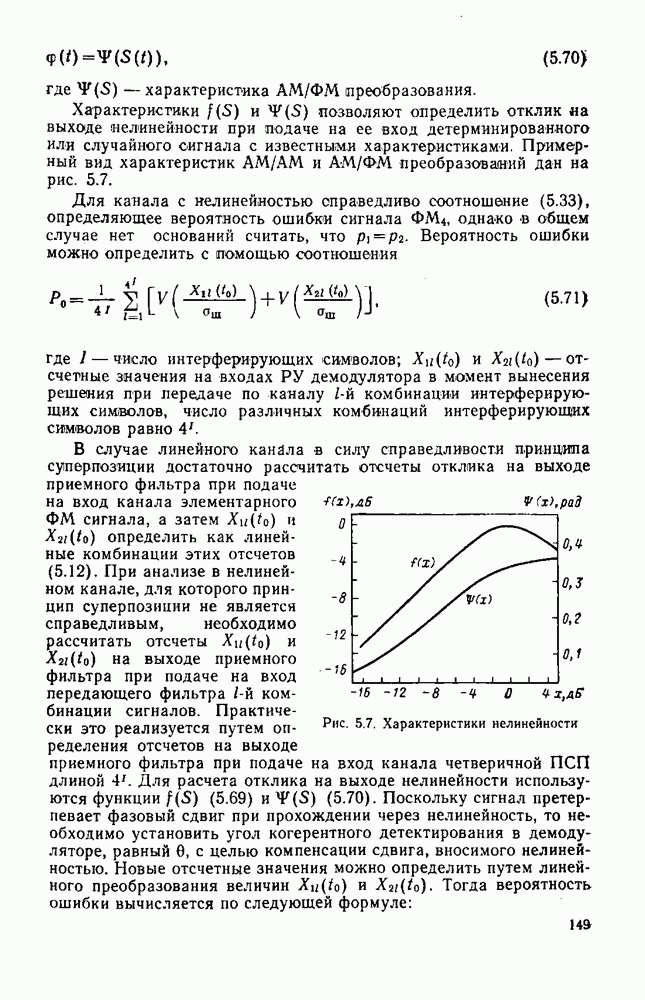


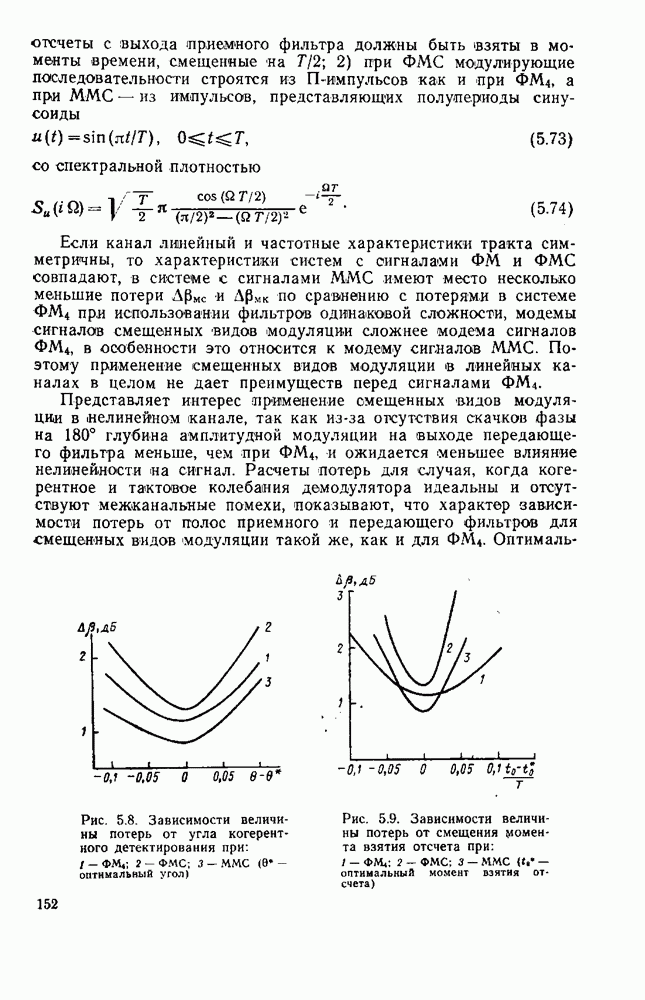








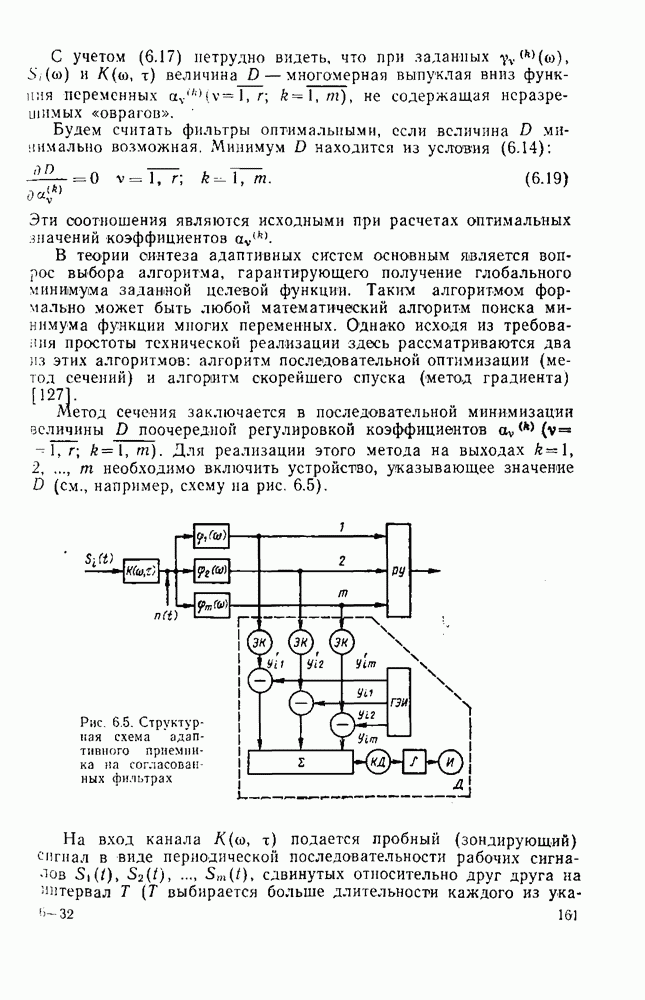

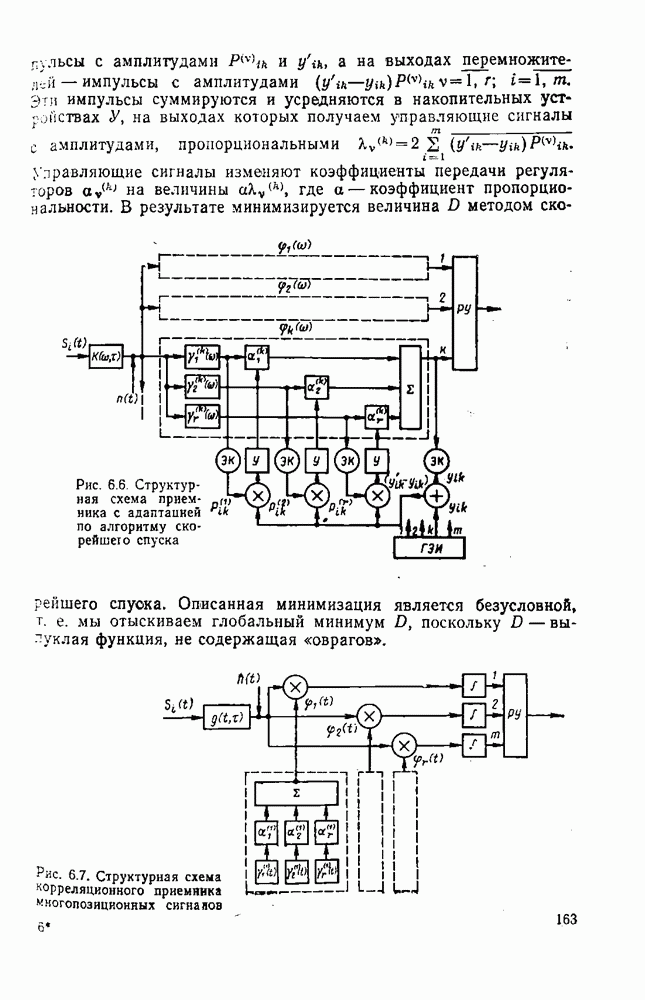

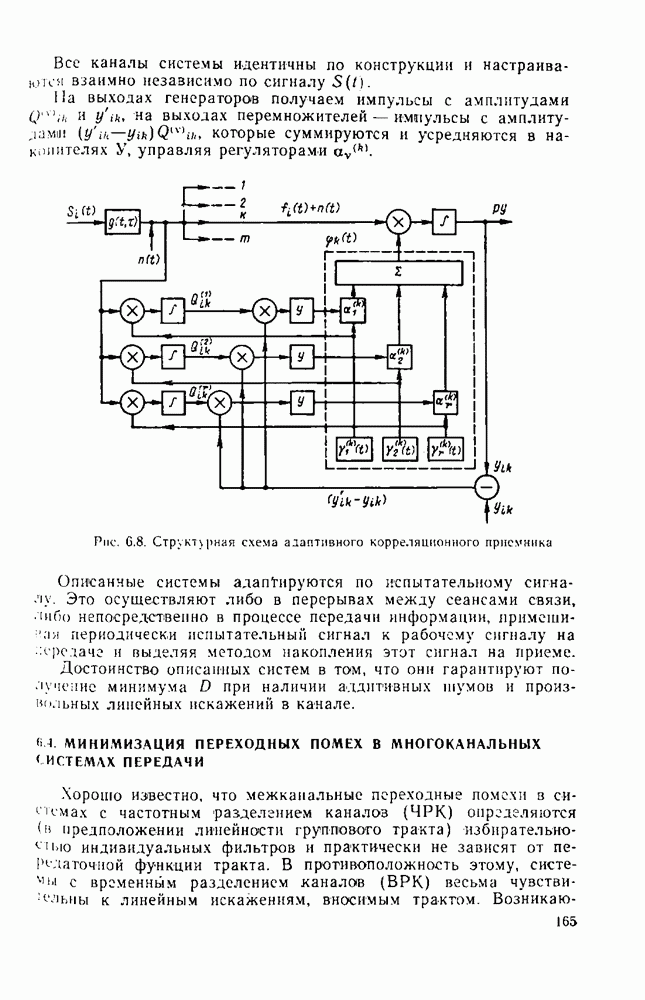



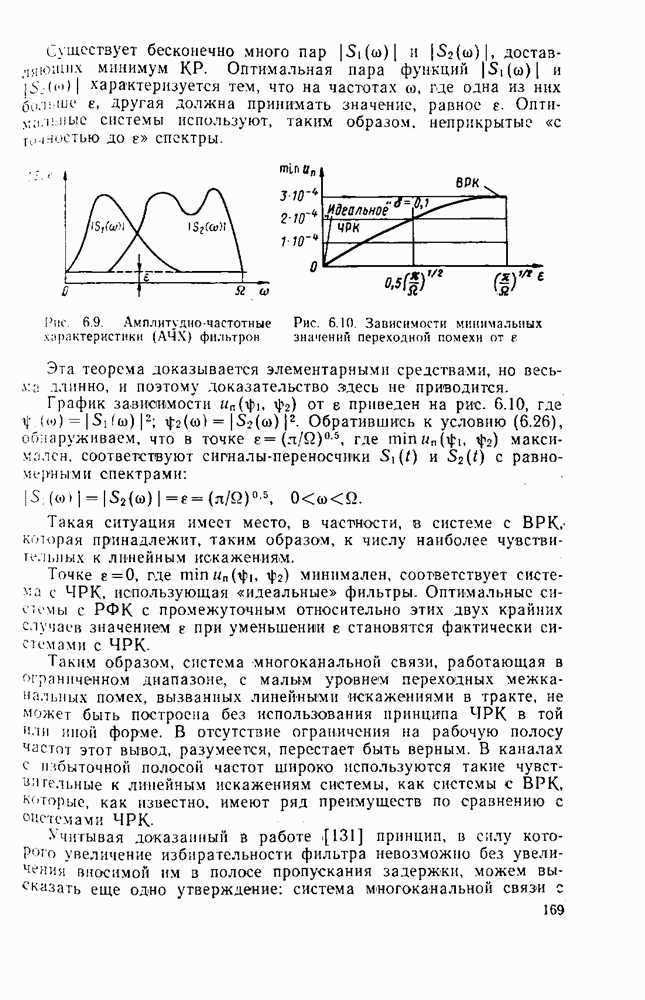




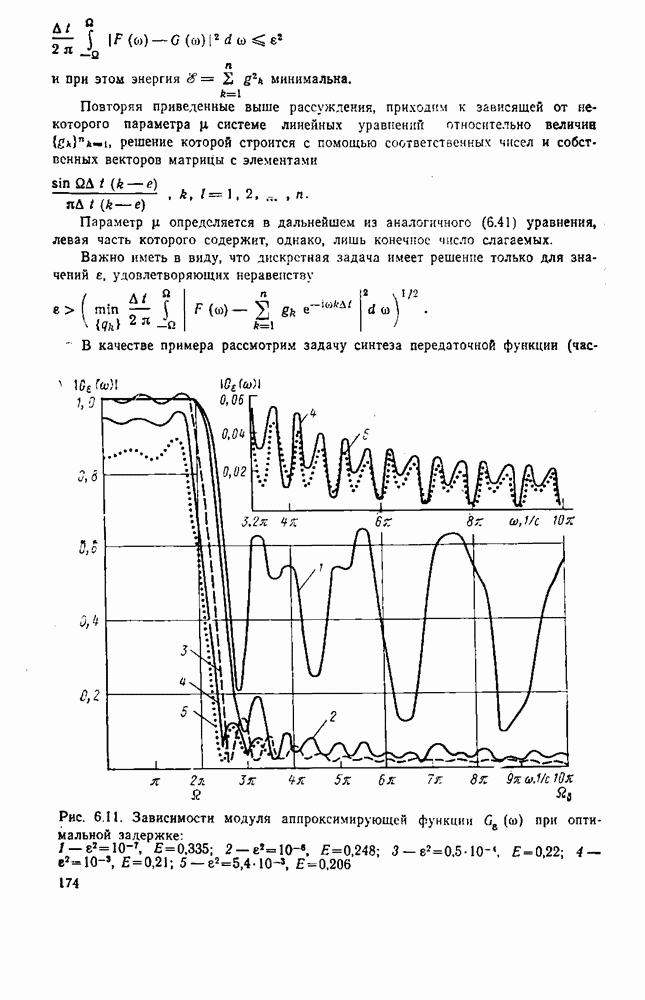
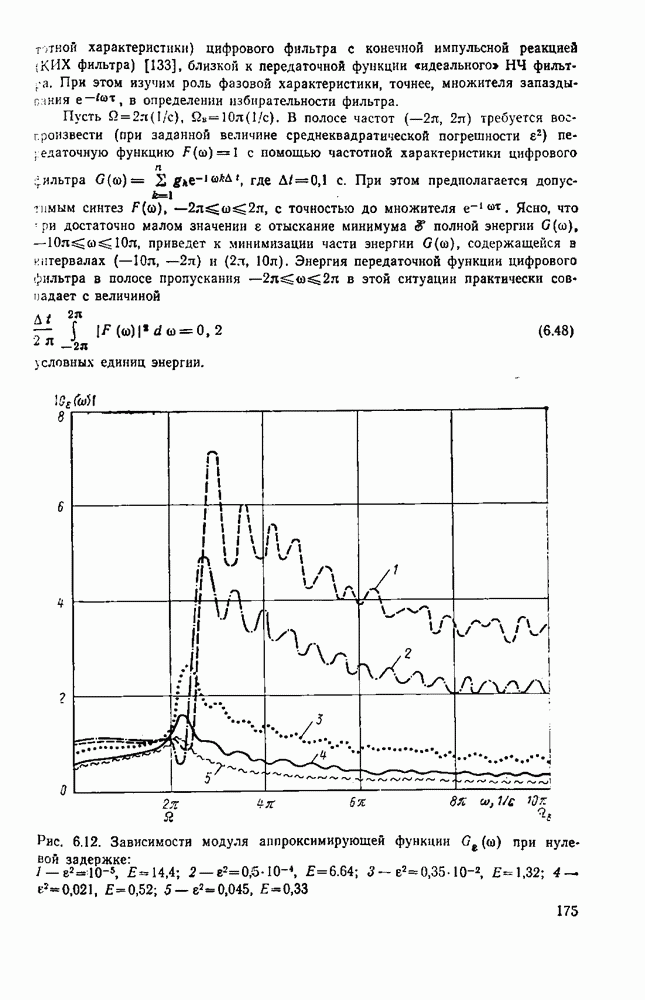






















































































 символов, и непрерывные коды, при использовании которых кодирование и декодирование производятся непрерывно, без разделения на блоки. Среди непрерывных большой интерес представляют сверточные коды. В классе блоковых кодов широко используют циклические коды.
символов, и непрерывные коды, при использовании которых кодирование и декодирование производятся непрерывно, без разделения на блоки. Среди непрерывных большой интерес представляют сверточные коды. В классе блоковых кодов широко используют циклические коды.

 вспомогательная переменная;
вспомогательная переменная;  — символы кодовой комбинации. При таком представлении действия над кодовыми комбинациями заменяются действиями над многочленами.
— символы кодовой комбинации. При таком представлении действия над кодовыми комбинациями заменяются действиями над многочленами.
 -значная информационная комбинация
-значная информационная комбинация  Рассмотрим способы формирования
Рассмотрим способы формирования  -значной комбинации циклического кода
-значной комбинации циклического кода  . Умножим комбинацию
. Умножим комбинацию  на одночлен
на одночлен  где
где  , а затем разделим на порождающий многочлен
, а затем разделим на порождающий многочлен 

 -частное от деления, имеющее такую же степень, как и исходный многочлен
-частное от деления, имеющее такую же степень, как и исходный многочлен  Остаток имеет наибольшую степень, равную
Остаток имеет наибольшую степень, равную 
 и переставив слагаемые, получим
и переставив слагаемые, получим

 получают, умножая исходные комбинации значности
получают, умножая исходные комбинации значности  на одночлен
на одночлен  и добавляя затем остаток от деления произведения
и добавляя затем остаток от деления произведения  на порождающий многочлен
на порождающий многочлен 
 получают умножением исходной кодовой комбинации на порождающий многочлен
получают умножением исходной кодовой комбинации на порождающий многочлен  Кодовая комбинация систематического кода значности
Кодовая комбинация систематического кода значности  состоит из информационной части, содержащей
состоит из информационной части, содержащей  символов и
символов и  дополнительных символов. Систематические коды обозначают как
дополнительных символов. Систематические коды обозначают как  где
где  кодовое расстояние. В несистематическом коде разделение комбинации кода на информационную и дополнительную части невозможно.
кодовое расстояние. В несистематическом коде разделение комбинации кода на информационную и дополнительную части невозможно.



 кодовое расстояние кода БЧХ. Порождающий многочлен кода БЧХ является наименьшим общим кратным минимальных многочленов
кодовое расстояние кода БЧХ. Порождающий многочлен кода БЧХ является наименьшим общим кратным минимальных многочленов  где
где 
 гарантированно исправляет
гарантированно исправляет  ошибок в кодовой комбинации, из выражений (3.3) и (3.5) можно получить формулу для определения скорости кода:
ошибок в кодовой комбинации, из выражений (3.3) и (3.5) можно получить формулу для определения скорости кода:


 За время одного информационного символа на выходе такого кодера образуется два канальных символа. Таким образом, скорость кода в рассматриваемом примере равна
За время одного информационного символа на выходе такого кодера образуется два канальных символа. Таким образом, скорость кода в рассматриваемом примере равна  Возможно кодирование и с другими скоростями. При скорости
Возможно кодирование и с другими скоростями. При скорости  при одновременном поступлении на вход кодера
при одновременном поступлении на вход кодера  информационных символов на выходе кодера будет
информационных символов на выходе кодера будет  канальных символа. Схема кодера показана на рис. 3.1,б.
канальных символа. Схема кодера показана на рис. 3.1,б.


 . В процессе кодирования кодер переходит из одного состояния
. В процессе кодирования кодер переходит из одного состояния  другое. При этом на выходе появляются определенные наборы кодовых символов
другое. При этом на выходе появляются определенные наборы кодовых символов  . В общем случае число состояний кодера равно
. В общем случае число состояний кодера равно  где
где  число элементов задержки в минимальной реализации кодера. Для схем на рис. 3.1
число элементов задержки в минимальной реализации кодера. Для схем на рис. 3.1  . Объем памяти кодера характеризуется величиной К, называемой длиной кодового ограничения сверточного кода (ДКО).
. Объем памяти кодера характеризуется величиной К, называемой длиной кодового ограничения сверточного кода (ДКО).
 стрелками — возможные переходы. Надписи около стрелок показывают значения символов
стрелками — возможные переходы. Надписи около стрелок показывают значения символов  на выходе кодера, соответствующих данному переходу. Сплошными линиями отмечены переходы, совершаемые при поступлении на вход кодера информационного символа 0, штриховыми — при
на выходе кодера, соответствующих данному переходу. Сплошными линиями отмечены переходы, совершаемые при поступлении на вход кодера информационного символа 0, штриховыми — при
 при кодировании.
при кодировании.


 определяется как отношение
определяется как отношение  Для кодов со скоростью
Для кодов со скоростью  связи
связи  сумматора
сумматора  с ячейками регистра сдвига описываются путем задания порождающего многочлена (кодового генератора):
с ячейками регистра сдвига описываются путем задания порождающего многочлена (кодового генератора):

 сумматора с
сумматора с  ячейкой регистра существует,
ячейкой регистра существует,  если такой связи нет. К примеру, кодер рис. 3.1,а характеризуется кодовыми генераторами
если такой связи нет. К примеру, кодер рис. 3.1,а характеризуется кодовыми генераторами  или, записывая последовательность коэффициентов
или, записывая последовательность коэффициентов  в виде двоичных комбинаций,
в виде двоичных комбинаций,  Для длинных кодов используют восьмиричную форму записи. В этом случае кодовые генераторы будут представлены так:
Для длинных кодов используют восьмиричную форму записи. В этом случае кодовые генераторы будут представлены так:  либо
либо 
 удобнее задавать базисной порождающей матрицей
удобнее задавать базисной порождающей матрицей  состоящей из набора матриц размером
состоящей из набора матриц размером  [73]. Элементы этих матриц характеризуют связи
[73]. Элементы этих матриц характеризуют связи  разрядов каждого из
разрядов каждого из  регистров сдвига с
регистров сдвига с  сумматорами кодера. К примеру, элементы базисной
сумматорами кодера. К примеру, элементы базисной

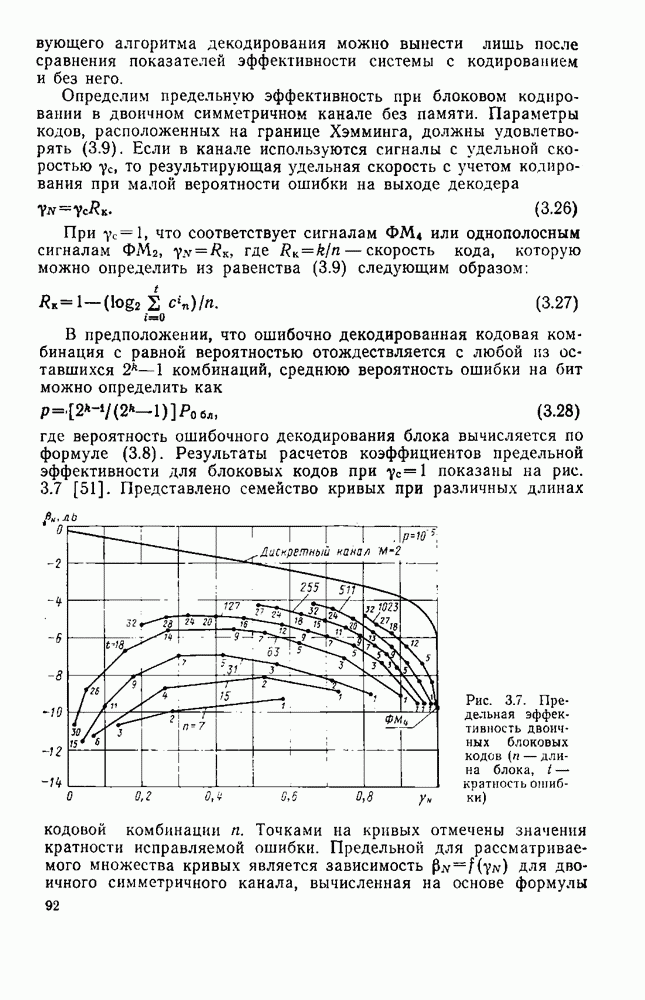
 . Однако, как показало в гл. 4, даже при
. Однако, как показало в гл. 4, даже при  характеристики декодирования близки к предельным.
характеристики декодирования близки к предельным.
 точных кодов. Решение о передаваемых информационных последовательностях в этом случае формируется на основе многоэтапной пороговой обработки кодовых символов. Результаты исследований этого алгоритма приведены в работе [79]. Сравнение алгоритмов имеется также в работе [80].
точных кодов. Решение о передаваемых информационных последовательностях в этом случае формируется на основе многоэтапной пороговой обработки кодовых символов. Результаты исследований этого алгоритма приведены в работе [79]. Сравнение алгоритмов имеется также в работе [80].
 . В то же время во многих случаях применение кодов со скоростями
. В то же время во многих случаях применение кодов со скоростями  является более желательным. Сложность алгоритма Витерби определяется в основном структурой решетчатой диаграммы сверточного кода. Фрагменты решетчатых диаграмм приведены на рис. 3,4.
является более желательным. Сложность алгоритма Витерби определяется в основном структурой решетчатой диаграммы сверточного кода. Фрагменты решетчатых диаграмм приведены на рис. 3,4.


 то число состояний кодера (узлов решетчатой диаграммы)
то число состояний кодера (узлов решетчатой диаграммы)  а число ветвей, выходящих (входящих) из каждого состояния,
а число ветвей, выходящих (входящих) из каждого состояния,  Декодирование состоит в прослеживании по решетчатой диаграмме предполагаемых путей и выборе максимально правдоподобного пути. При этом в начале каждого шага метрики ветвей складываются с метриками узлов, образуя метрики конкурирующих путей. Число сложений равно общему числу ветвей на шаге
Декодирование состоит в прослеживании по решетчатой диаграмме предполагаемых путей и выборе максимально правдоподобного пути. При этом в начале каждого шага метрики ветвей складываются с метриками узлов, образуя метрики конкурирующих путей. Число сложений равно общему числу ветвей на шаге  Далее в каждом узле производится сравнение метрик входящих путей, после чего менее правдоподобные пути отбрасываются. Число сравнений (вычитаний), выполняемых на каждом шаге декодирования,
Далее в каждом узле производится сравнение метрик входящих путей, после чего менее правдоподобные пути отбрасываются. Число сравнений (вычитаний), выполняемых на каждом шаге декодирования,  Общее число арифметических операций
Общее число арифметических операций  а число операций на один декодируемый бит
а число операций на один декодируемый бит  Видно, что удельное число операций возрастает не только с увеличением длины кода
Видно, что удельное число операций возрастает не только с увеличением длины кода  но и с ростом числителя окорости Так, при переходе от кода со скоростью
но и с ростом числителя окорости Так, при переходе от кода со скоростью  к коду
к коду  число арифметических операций на один декодируемый бит, выполняемых в процессоре декодера,
число арифметических операций на один декодируемый бит, выполняемых в процессоре декодера,
 предпочтительнее, так как требует меньшего расширения полосы занимаемых частот.
предпочтительнее, так как требует меньшего расширения полосы занимаемых частот.
 Генераторы такого кода обозначим
Генераторы такого кода обозначим  где знак указывает положение вычеркнутого симвбла.
где знак указывает положение вычеркнутого симвбла.
 и На втором шаге при декодировании вычеркнутый символ в каждой ветви может быть заменен произвольным символом (0 либо 1). Свойства кода от этого не меняются. Таким образом, декодирование кодов, полученных путем перфорации исходного кода со скоростью
и На втором шаге при декодировании вычеркнутый символ в каждой ветви может быть заменен произвольным символом (0 либо 1). Свойства кода от этого не меняются. Таким образом, декодирование кодов, полученных путем перфорации исходного кода со скоростью  возможно декодером, рассчитанным на эту скорость. Необходимо лишь предусмотреть правильную расстановку символов перфорации.
возможно декодером, рассчитанным на эту скорость. Необходимо лишь предусмотреть правильную расстановку символов перфорации.