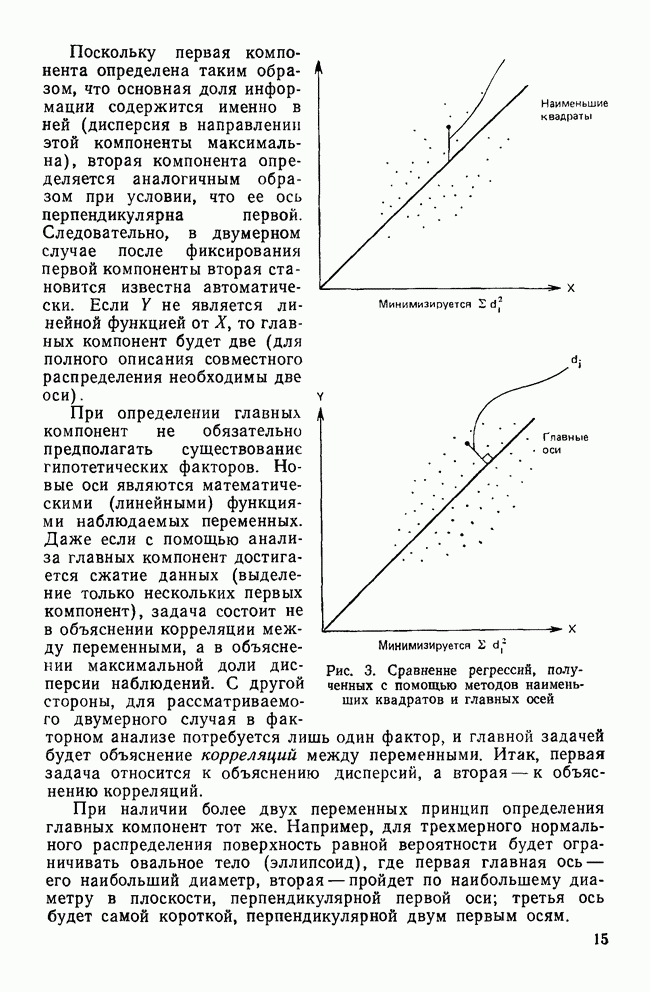
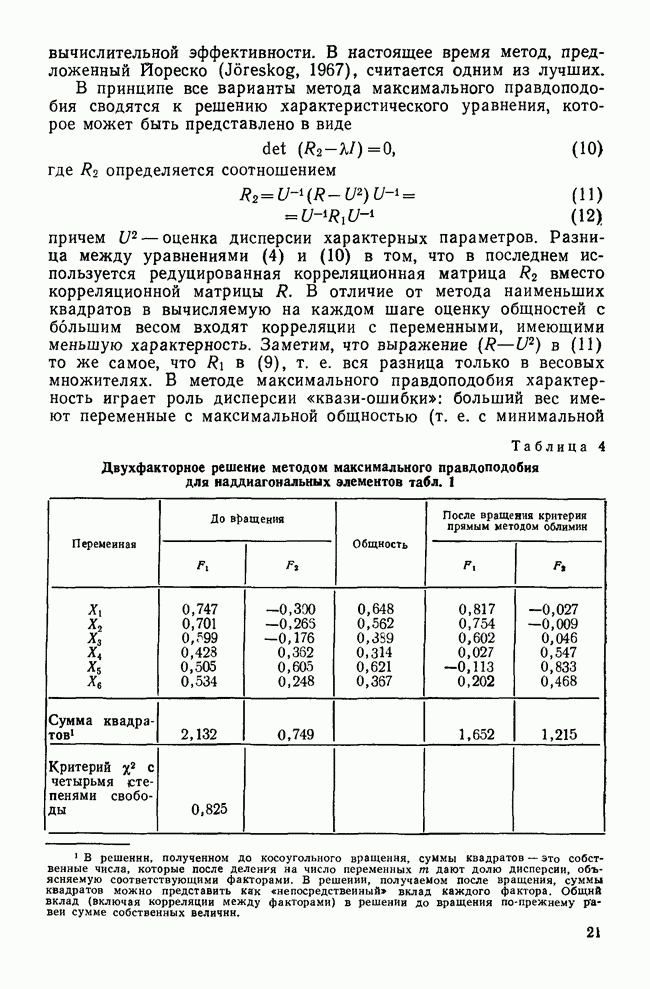
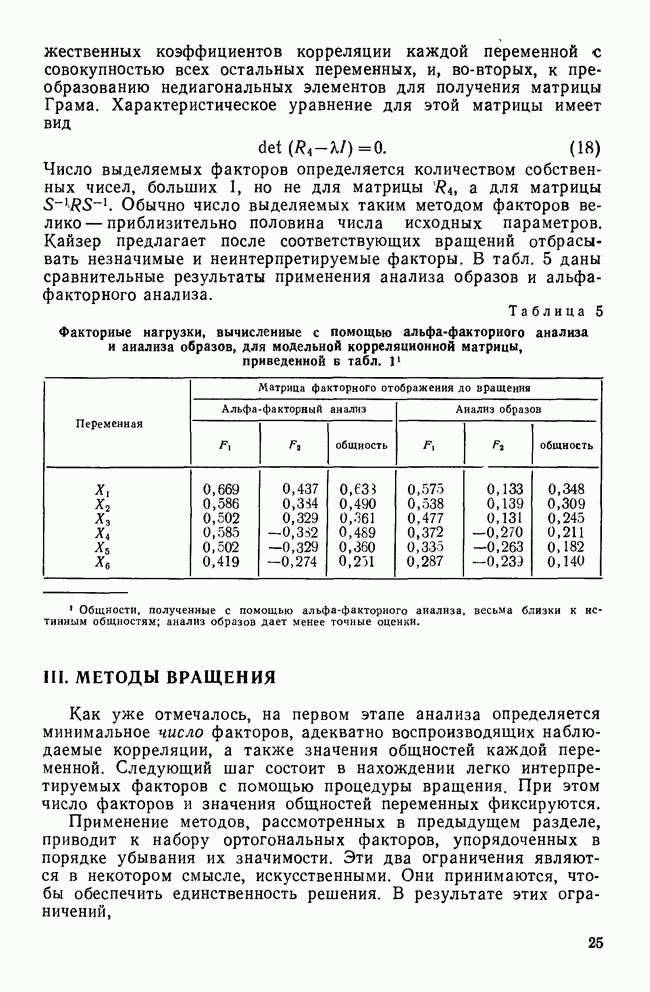
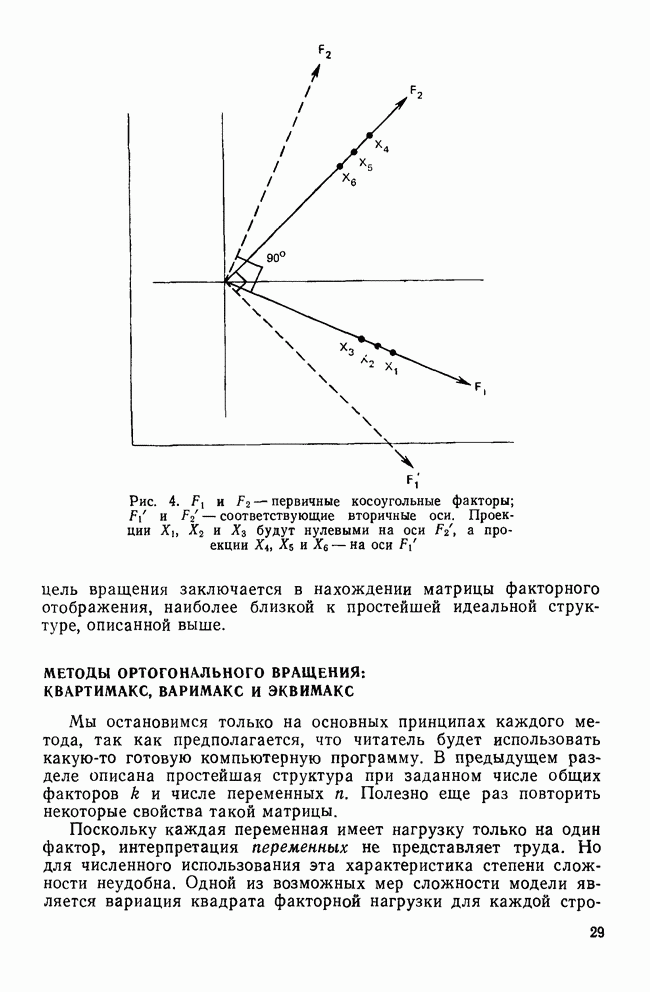
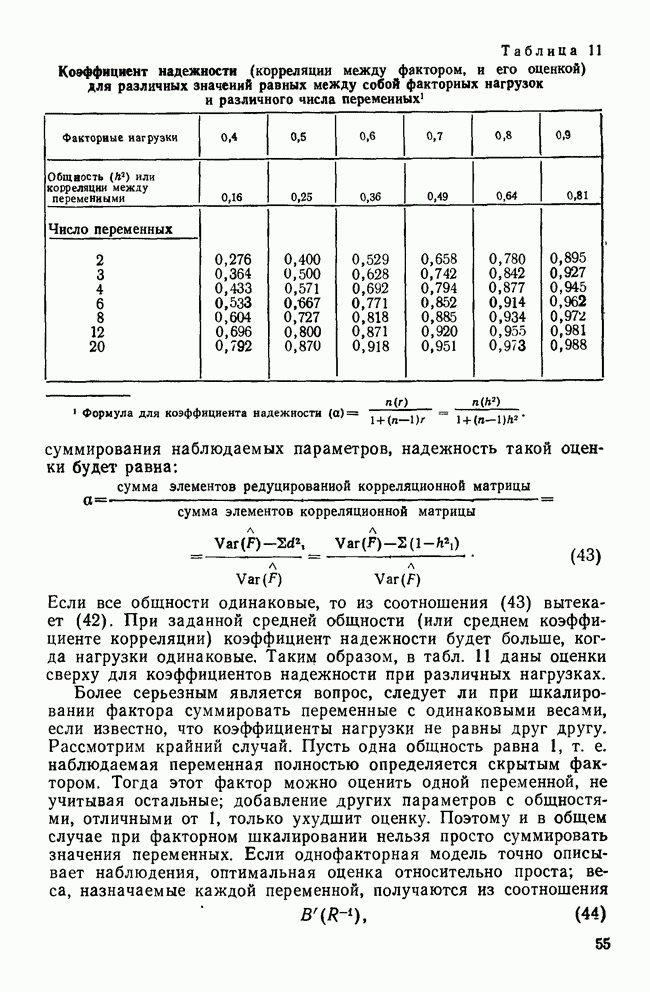
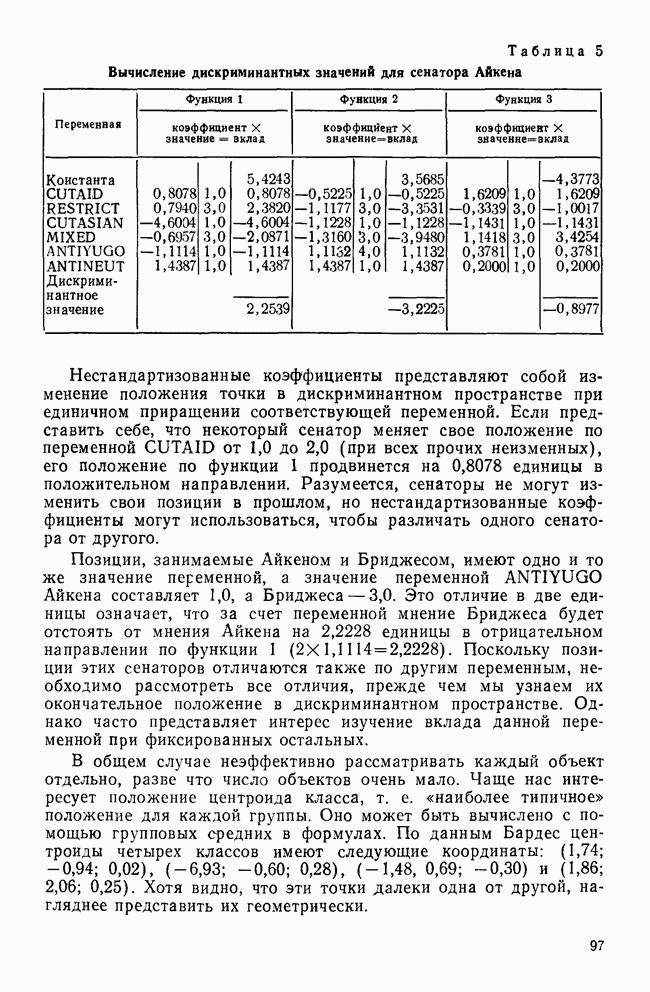
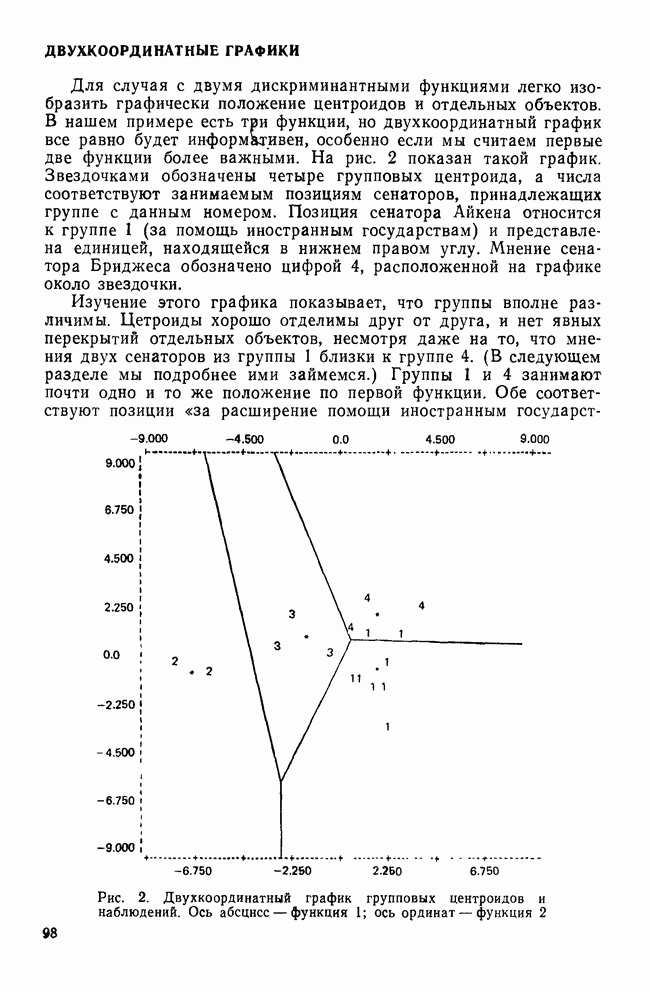
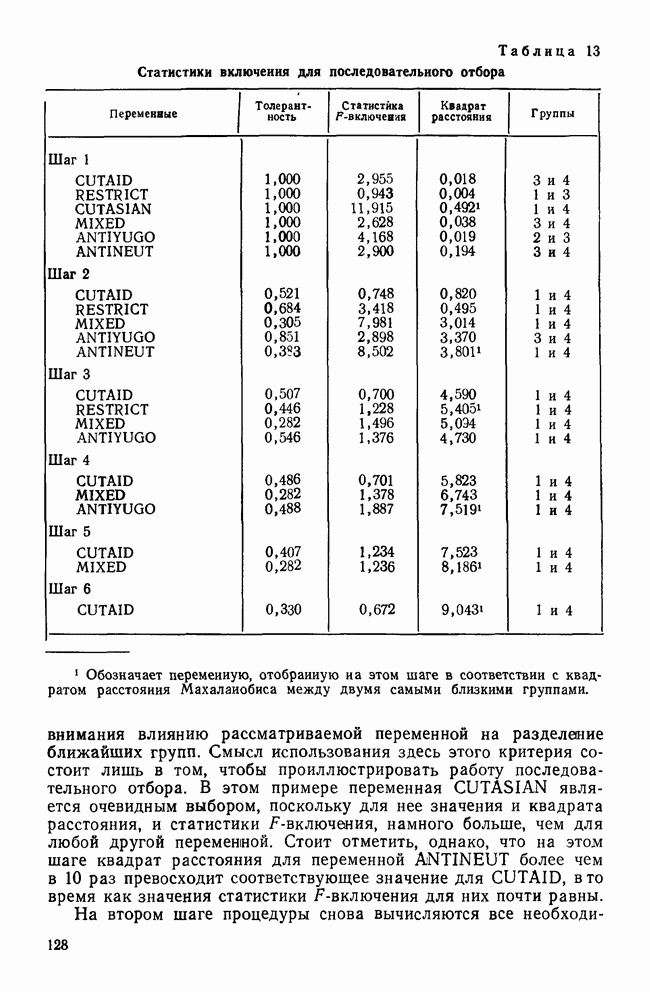
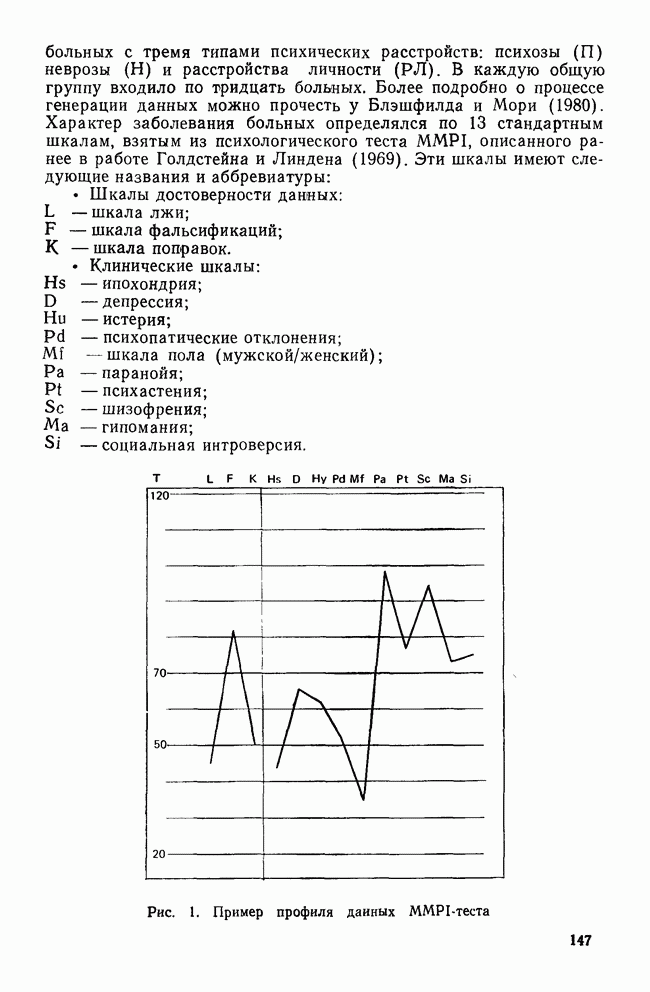
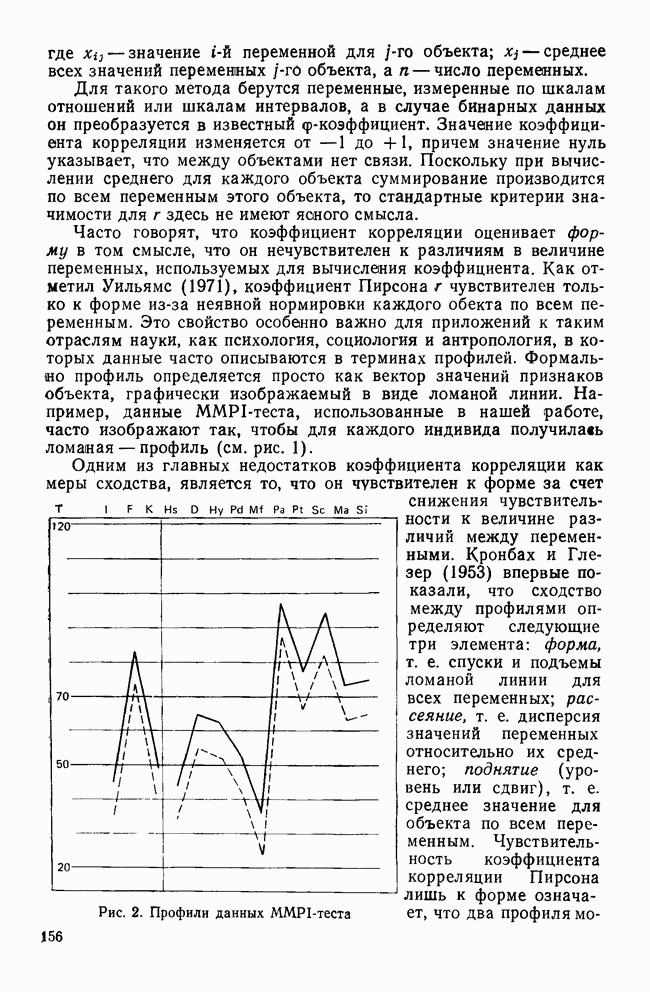
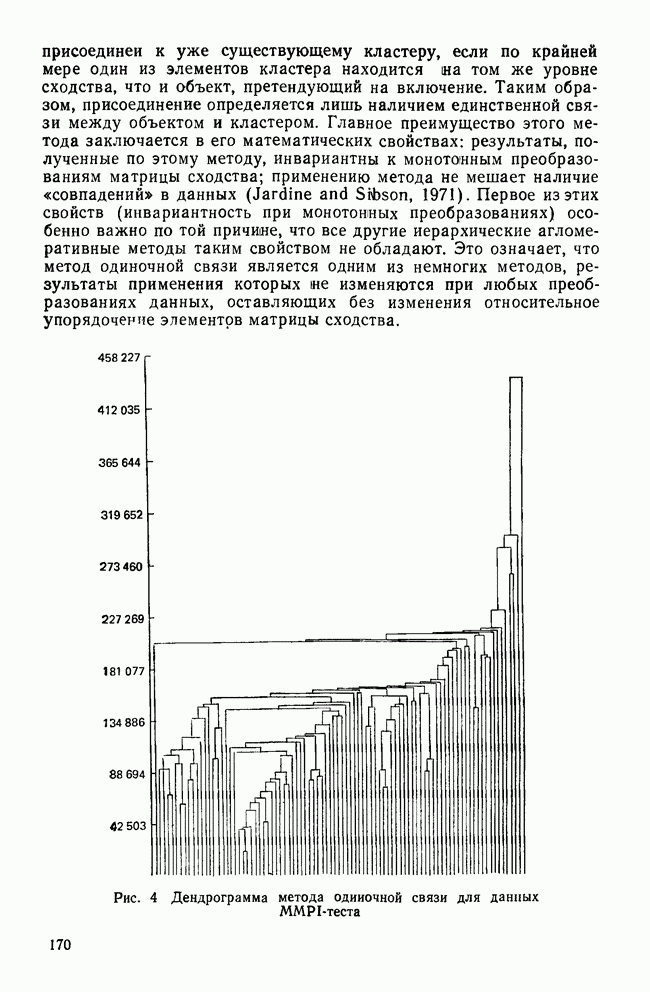
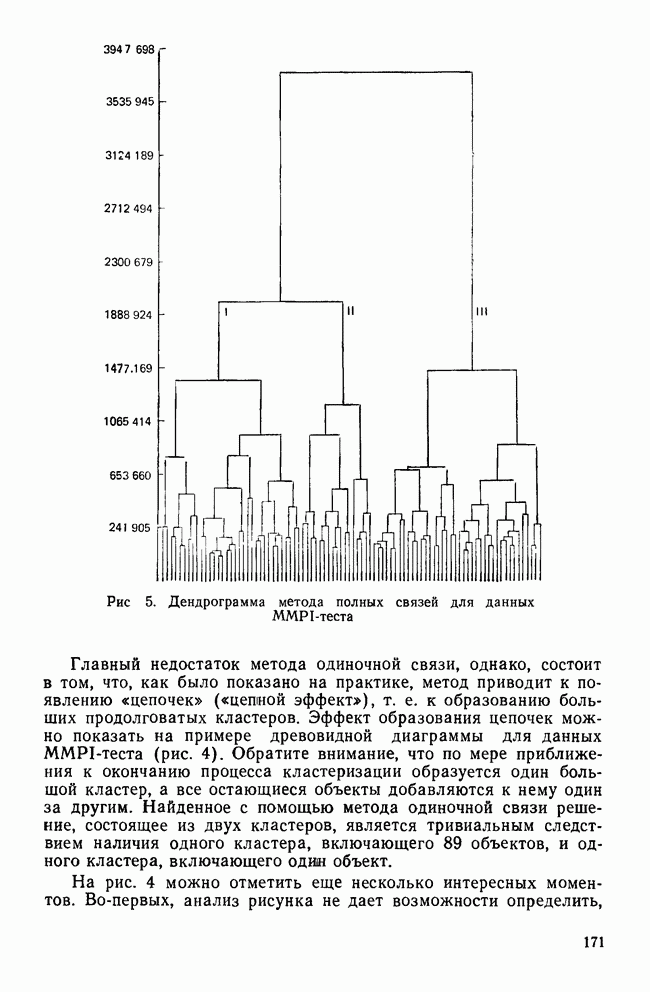
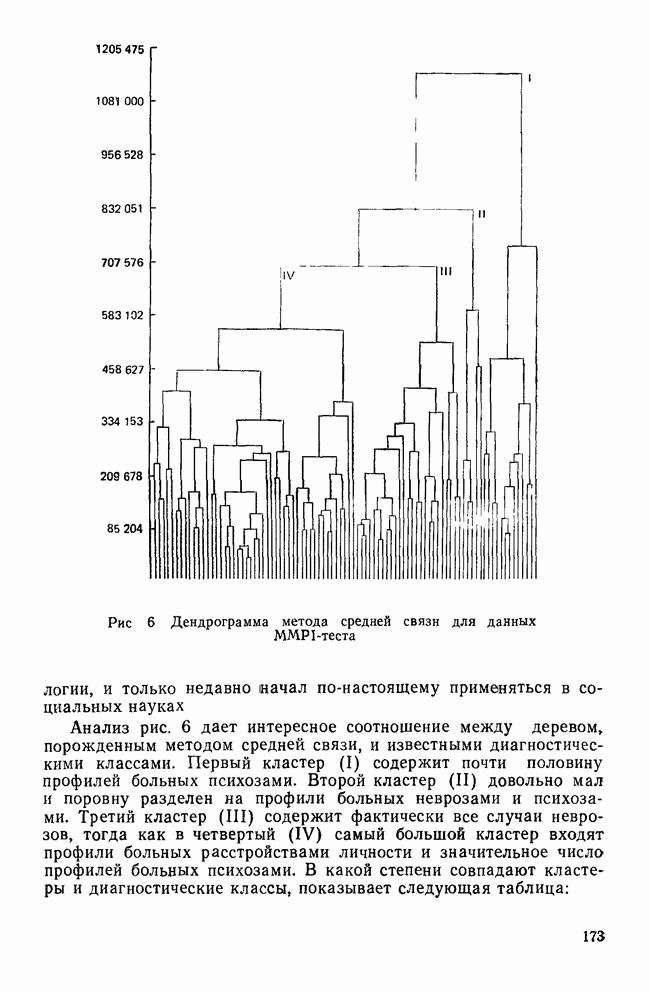
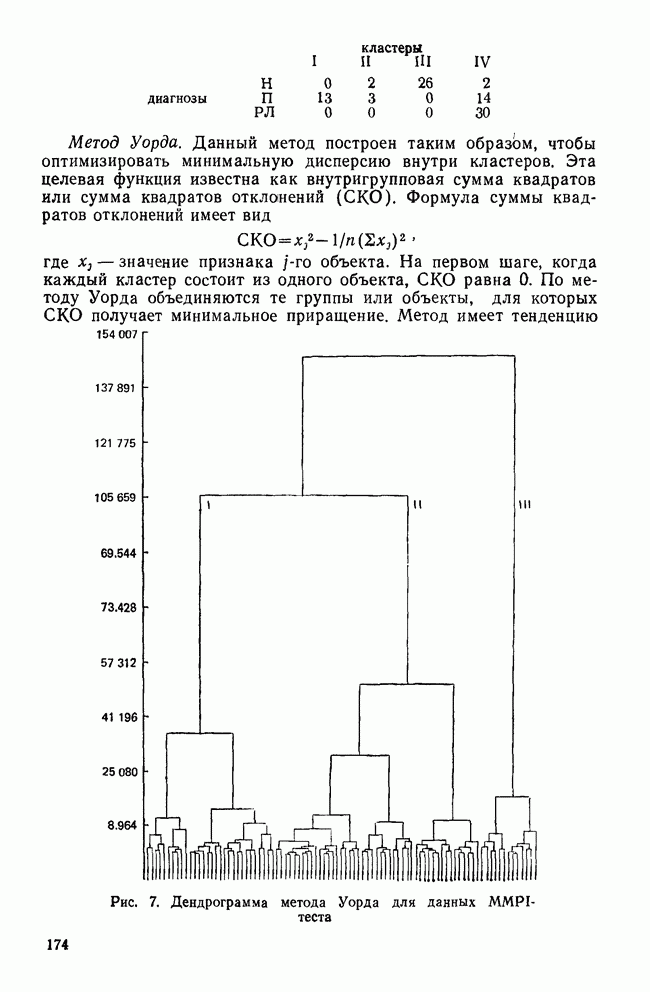
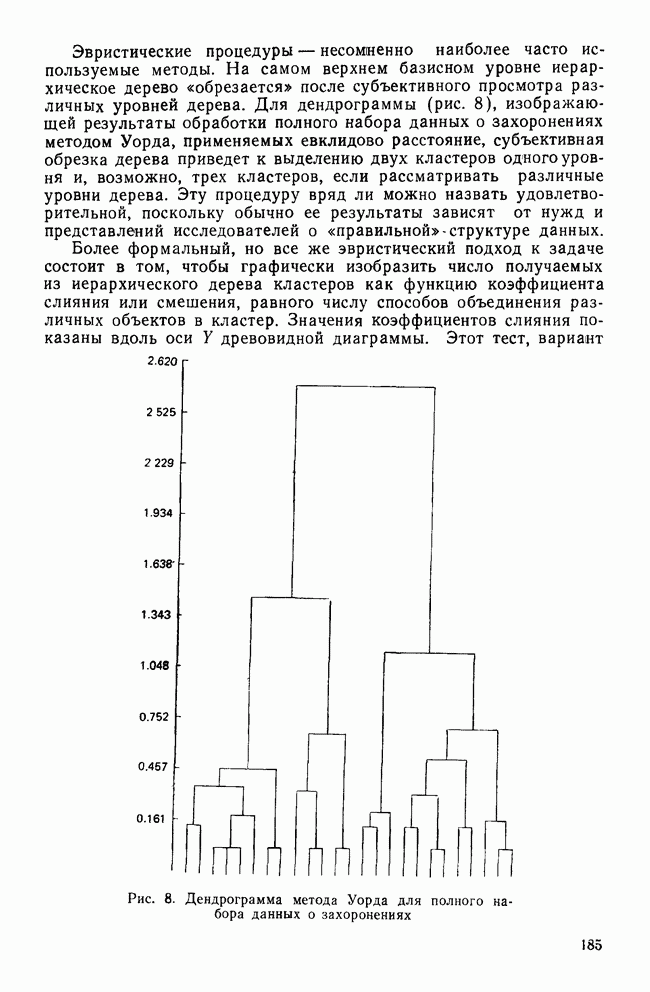
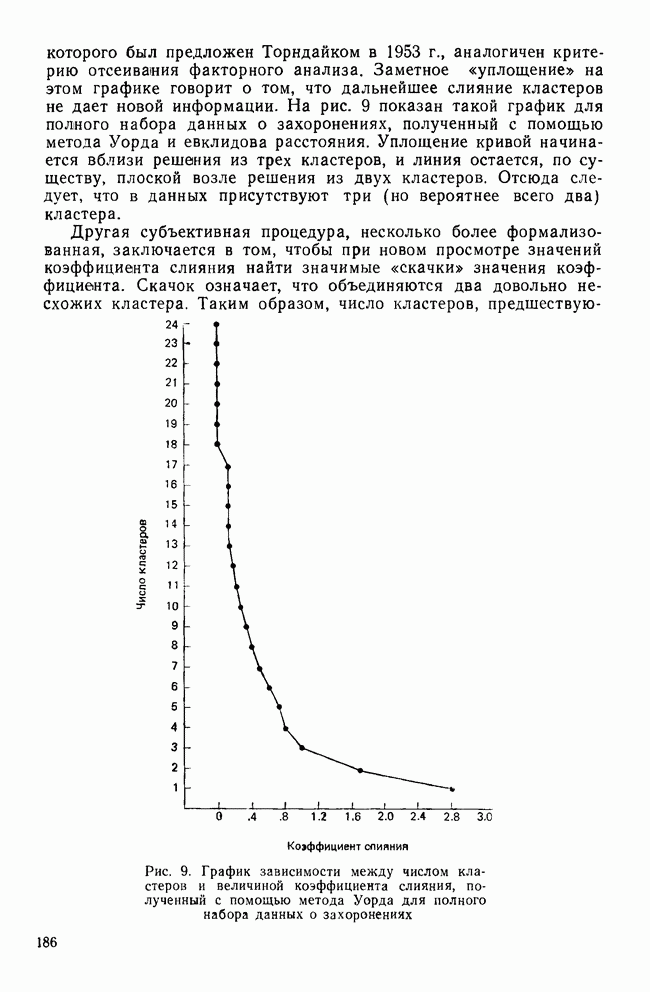
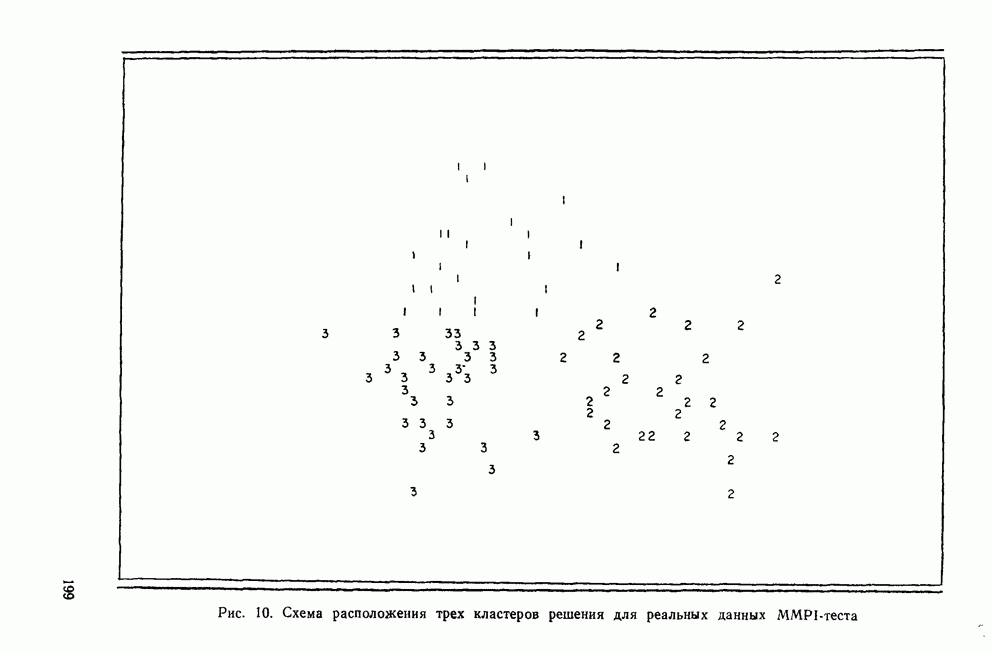
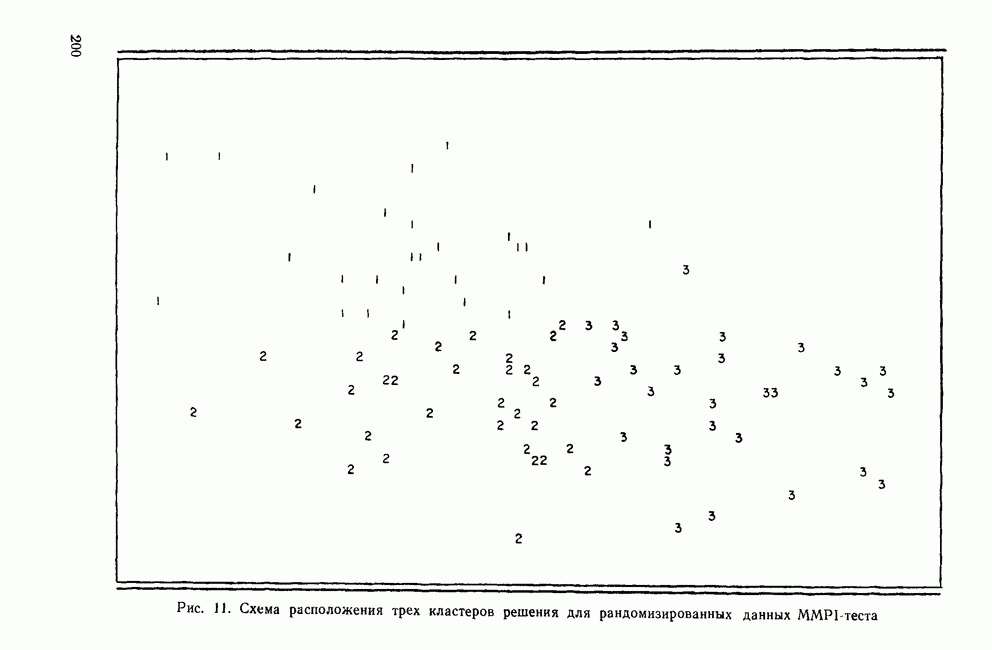
УЧЕТ АПРИОРНЫХ ВЕРОЯТНОСТЕЙ, ИЛИ ЦЕНА ОШИБОЧНОЙ КЛАССИФИКАЦИИ
До сих пор при обсуждении классификации предполагалось, что все классы равноправны. На практике это не всегда так. Рассмотрим, например, случай двух классов, когда 90% генеральной совокупности содержится в классе 1. Еще до вычислений ясно, что с очень большой вероятностью любой заданный объект принадлежит классу 1. Следовательно, он будет отнесен к классу 2 только при наличии очень сильных свидетельств в пользу такого решения. Это можно сделать, вычисляя апостериорные вероятности с учетом априорных знаний о вероятной принадлежности к классу.
Другая ситуация, в которой желательно использование апостериорных вероятностей, возникает, когда «стоимость» неправильной классификации существенно меняется от класса к классу. Типичный пример — применение классифицирующих функций для определения на основе различных симптомов, является ли опухоль злокачественной или доброкачественной. Вероятно, больному придется перенести много страданий при любой ошибке в диагнозе (классификации). Но больной со злокачественной опухолью, которому поставлен диагноз «доброкачественная опухоль», будет страдать больше, чем больной с доброкачественной опухолью, которому поставили диагноз «злокачественная опухоль». Если бы эти издержки неправильной классификации могли быть выражены в виде отношения, то их следовало бы использовать тем же способом, что и априорные вероятности.
В обоих примерах было бы желательно включить априорные вероятности в классифицирующую функцию, чтобы улучшить точность предположения или уменьшить «стоимость» совершения ошибок. Это можно сделать для простых классифицирующих функций с помощью добавления натурального логарифма от априорной вероятности к постоянному члену.
Или же будем модифицировать расстояние  дважды вычитая натуральный логарифм от априорной вероятности. Это изменение в расстоянии математически идентично умножению
дважды вычитая натуральный логарифм от априорной вероятности. Это изменение в расстоянии математически идентично умножению  на априорную вероятность для этого класса. Татсуока (1971; 217—232), Кули и Лохнес (1971; 262—270) дают более полное обсуждение этих модификаций.
на априорную вероятность для этого класса. Татсуока (1971; 217—232), Кули и Лохнес (1971; 262—270) дают более полное обсуждение этих модификаций.
Если классы очень различаются, то привлечение априорных вероятностей вряд ли повлияет на результат, поскольку вблизи границы между классами будет находиться очень мало объектов. Таким образом, априорные вероятности будут оказывать наибольшее воздействие, когда классы перекрываются и, следовательно, многие объекты с большой вероятностью могут принадлежать к нескольким классам. Конечно, в основе решения об использовании априорных вероятностей должны лежать теоретические соображения. Если же таких соображений нет, то лучше этого не делать. Следует также помнить, что априорные вероятности вычислены на основе генеральной совокупности и будут отличаться от вычисленных на основе выборки.