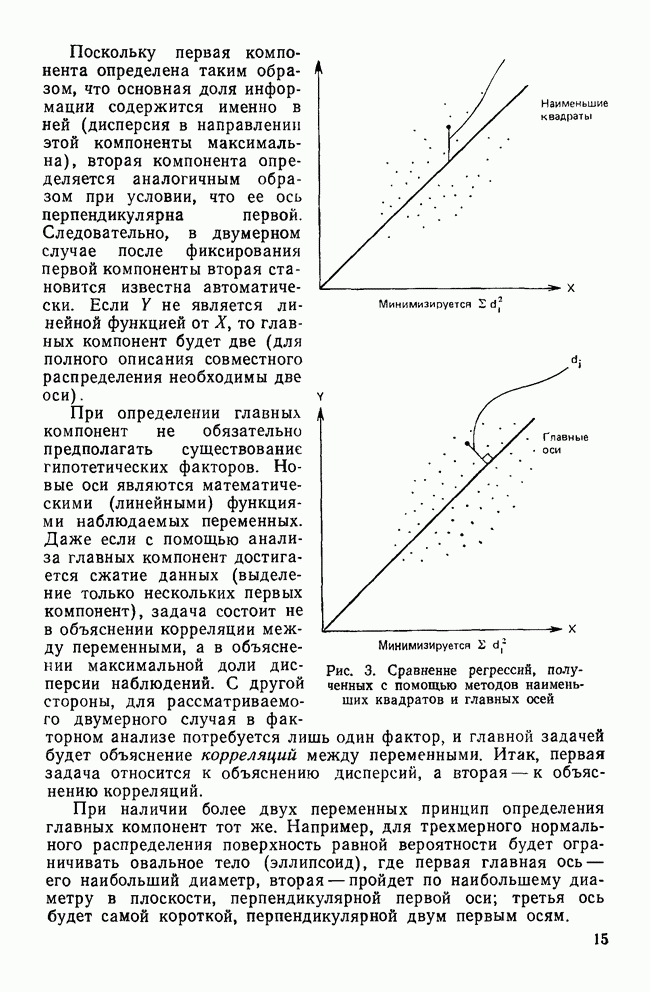
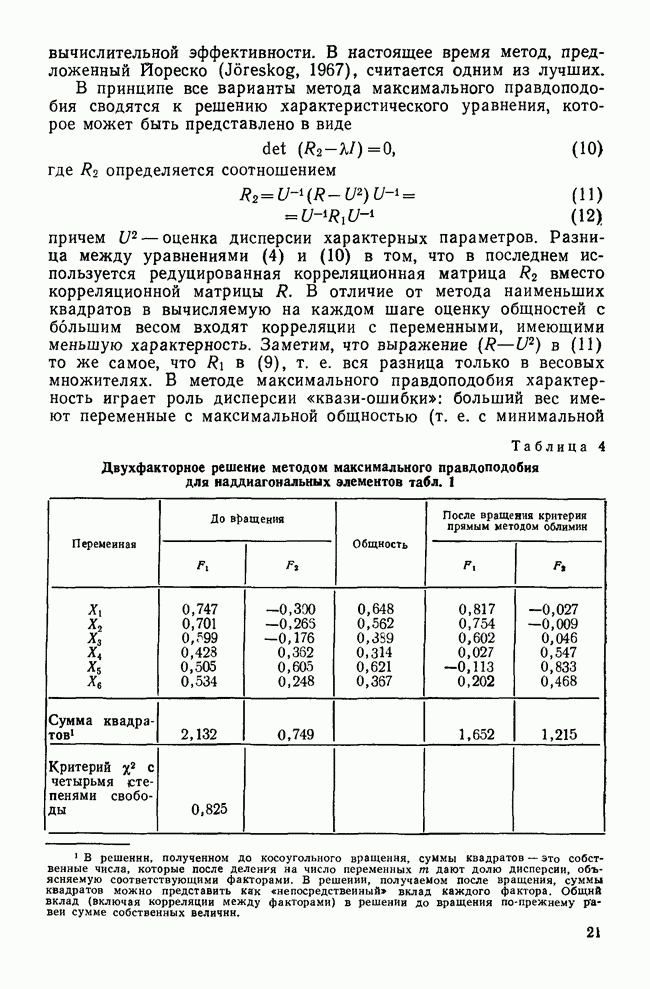
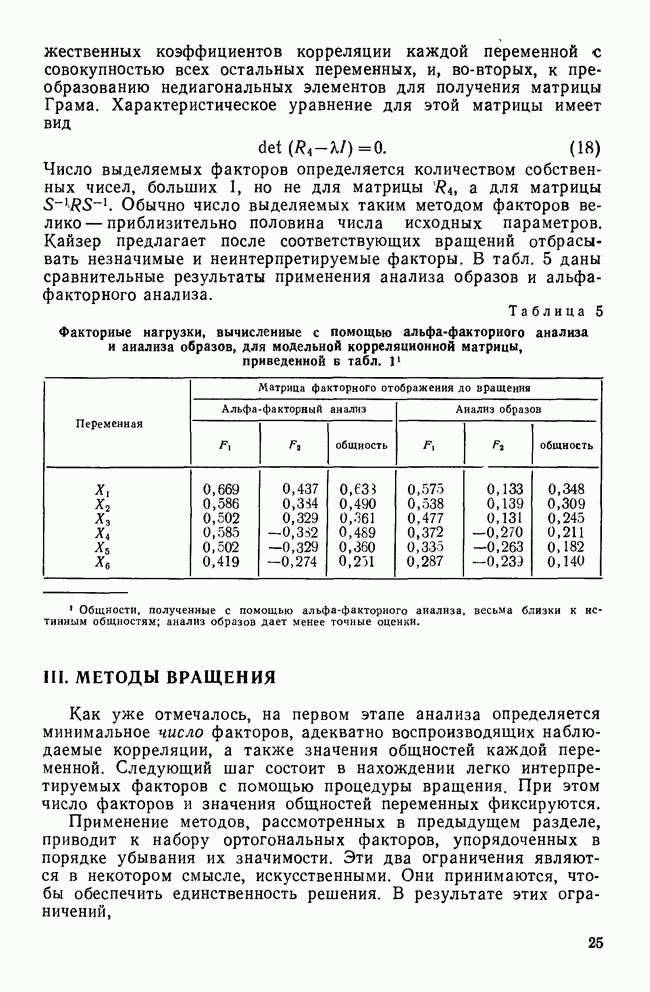
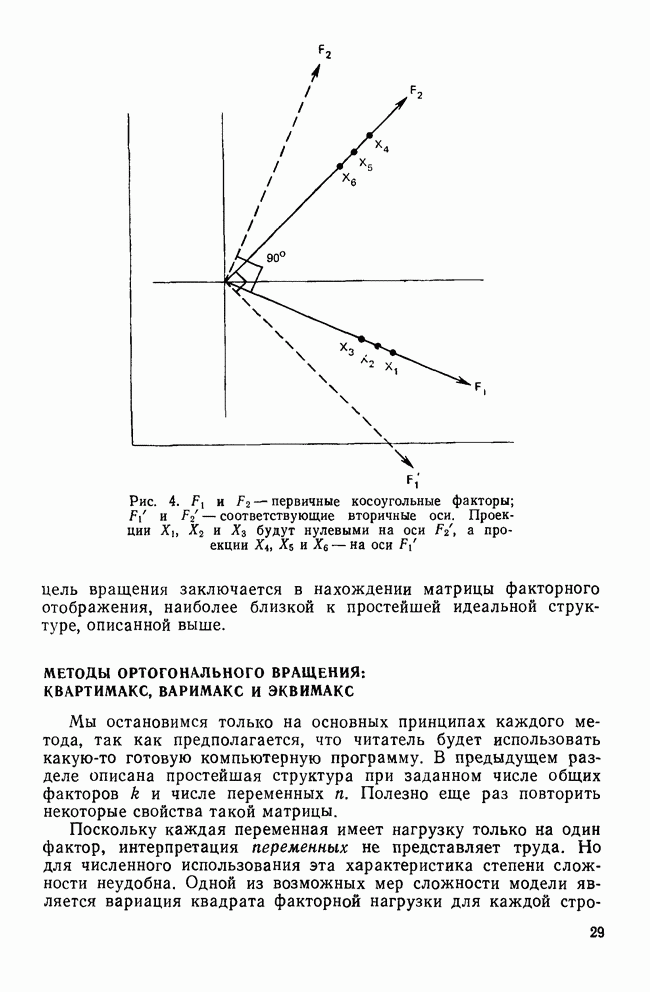
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
ВЫБОР ПЕРЕМЕННЫХПрежде чем приступить к описанию весьма распространенных коэффициентов, используемых при оценке сходства, необходимо сделать небольшое отступление и рассказать о выборе переменных и преобразовании данных, предшествующих оцениванию. Выбор переменных в кластерном анализе является одним из наиболее важных шагов в исследовательском процессе, но, к сожалению, и одним из наименее разработанных. Основная проблема состоит в том, чтобы найти ту совокупность переменных, которая наилучшим образом отражает понятие сходства. В идеале переменные должны выбираться в соответствии с ясно сформулированной теорией, которая лежит в основе классификации. Теория является базисом для разумного выбора переменных, необходимых в исследовании. На практике, однако, теория, обосновывающая классификационные исследования, часто не сформулирована, и поэтому бывает трудно оценить, насколько выбор переменных соответствует поставленной задаче. Важность наличия теории для руководства выбором переменных нельзя недооценивать. Искушение скатиться к наивному эмпиризму в использовании кластерного анализа очень сильно, так как метод специально создан для получения «объективной» группировки объектов. Под «наивным эмпиризмом» мы понимаем отбор и последующий анализ как можно большего количества переменных в надежде на то, что «структура» проявится, как только будет собрано достаточное количество данных. Хотя эмпирические исследования важны для любой науки, те из них, в основе которых лежит наивный эмпиризм, опасны при применении кластерного анализа ввиду эвристической природы метода и большого числа нерешенных проблем, которые компрометируют приложения (Everitt, 1979). В большинстве видов статистического анализа данные обычно подвергаются нормировке некоторым подходящим способом. При проверке, имеет ли переменная нормальное распределение, часто производится логарифмическое или какое-нибудь другое преобразование. В том случае, если данные измерены в разных масштабах, нормировка обычно проводится таким образом, чтобы среднее равнялось нулю, а дисперсия — единице. Имеются, однако, некоторые разногласия относительно того, должна ли нормировка быть стандартной процедурой в кластерном анализе. Как указывает Эверитт (1980), нормировка к единичной дисперсии и нулевому среднему уменьшает различия между группами по тем переменным, по которым наилучшим образом обнаруживались групповые различия. Более целесообразно проводить нормировку переменных внутри групп (т. е. внутри кластеров), но, очевидно, этого нельзя сделать, пока объекты не разнесены по группам. Эдельброк (1979) отметил, что переменные многомерных данных могут менять значения параметров распределения от группы к группе; таким образом, нормировка может не быть равносильным преобразованием для этих переменных и даже может изменять соотношения между ними. Однако, исследовав методом Монте-Карло воздействие нормировки на последующий анализ с использованием коэффициента корреляции и различных иерархических кластерных методов, Эдельброк не обнаружил существенных различий в результатах классификации по нормированным и ненормированным переменным. Миллиган (1980) также показал, что нормировка, по-видимому, оказывает незначительное воздействие на результаты кластерного анализа. Другие, особенно Мэттьюз (1979), продемонстрировали, что нормировка отрицательно сказывается на адекватности результатов кластерного анализа по сравнению с «оптимальной» классификацией объектов исследования. Ситуация относительно нормировки не совсем ясна. Пользователи, имеющие данные с существенно различными измерениями, без сомнения, захотят стандартизировать их, особенно если применяется такая мера сходства, как евклидово расстояние. Решение о проведении нормировки должно приниматься с учетом специфики решаемой задачи, при этом пользователь должен понимать, что результаты могут различаться в зависимости от принятого решения, хотя величина воздействия будет меняться от одного множества данных к другому. Возможны и другие виды преобразования данных, многие из которых применяются одновременно с кластерным анализом. Факторный анализ и метод главных компонент часто используются в том случае, когда известно, что переменные, взятые для исследования, сильно коррелированы. Наличие сильно коррелированных переменных при вычислении меры сходства приводит, по существу, к взвешиванию этих переменных. Так, если есть три сильно коррелированные переменные, то их совместное действие эквивалентно действию лишь одной переменной, которая имеет вес, в три раза превышающий вес каждой из первоначальных переменных. Метод главных компонент и факторный анализ могут применяться для уменьшения размерности данных, тем самым создавая новые, некоррелированные переменные, которые будут употребляться в качестве первичных данных при вычислении сходства между объектами. Использование процедуры преобразования данных вызывает много споров. В факторном анализе существует тенденция к ослаблению связей между кластерами, поскольку предполагается, что факторные переменные нормально распределены. Действие факторного анализа приводит к такому преобразованию данных, при котором зависимые переменные сливаются в одну, нормально распределенную. Рольф (1970) отметил, что метод главных компонент стремится к такому преобразованию данных, при котором хорошо разделенные кластеры остаются таковыми и в редуцированном пространстве, но при этом уменьшается расстояние (и тем самым ослабляются связи) между кластерами или группами, которые были разделены слабо. Полемика ведется и вокруг вопроса о необходимости взвешивания переменных. Особенно много таких дискуссий в области биологии. Взвешивание — это манипулирование значением переменной, позволяющее ей играть большую или меньшую роль в измерении сходства между объектами (Williams, 1971). Хотя идея взвешивания и проста, ее практическое применение затруднительно. Уильямс описывает пять видов взвешивания, из которых чаще всего использует выбор весов априори. Снит и Сокэл (1973) решительно возражают против априорного взвешивания и считают, что наиболее подходящий способ измерения сходства состоит в присвоении всем переменным равных весов. Однако необходимо учитывать, что Снит и Сокэл рассматривают кластеризацию как чисто эмпирический подход к созданию классификаций. Во многих случаях имеет смысл взвешивать некоторые переменные априори, если для этого есть хорошее теоретическое обоснование и процедура, позволяющая осуществить взвешивание. Поскольку вопрос взвешивания еще не стал предметом обсуждения в общественных науках, исследователи, пользующиеся кластерными методами, должны знать о существовании разногласий.
|
 |
Оглавление
|