Пред.
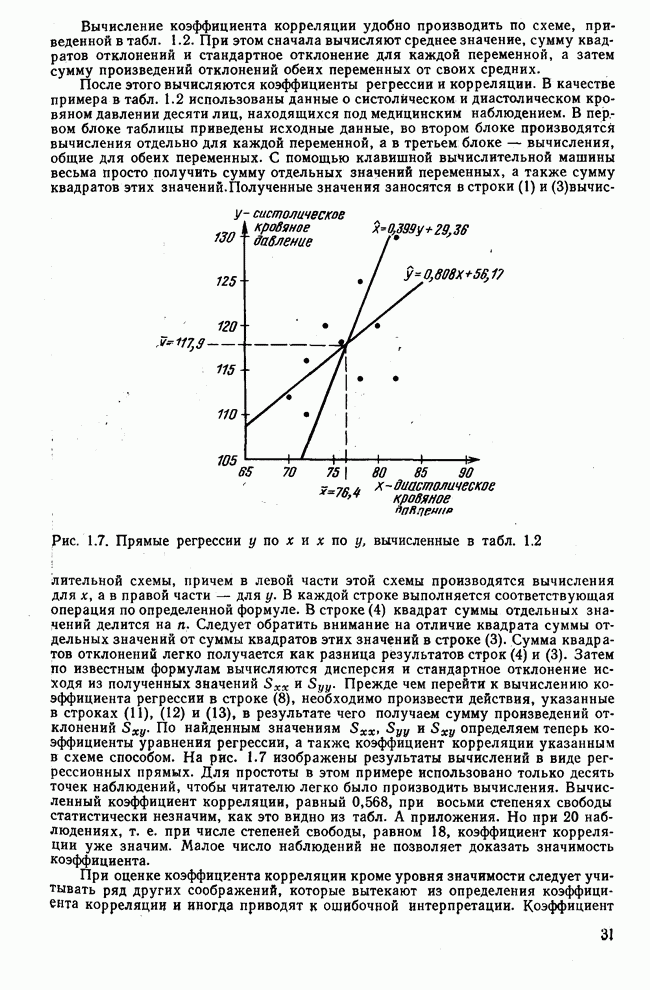
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
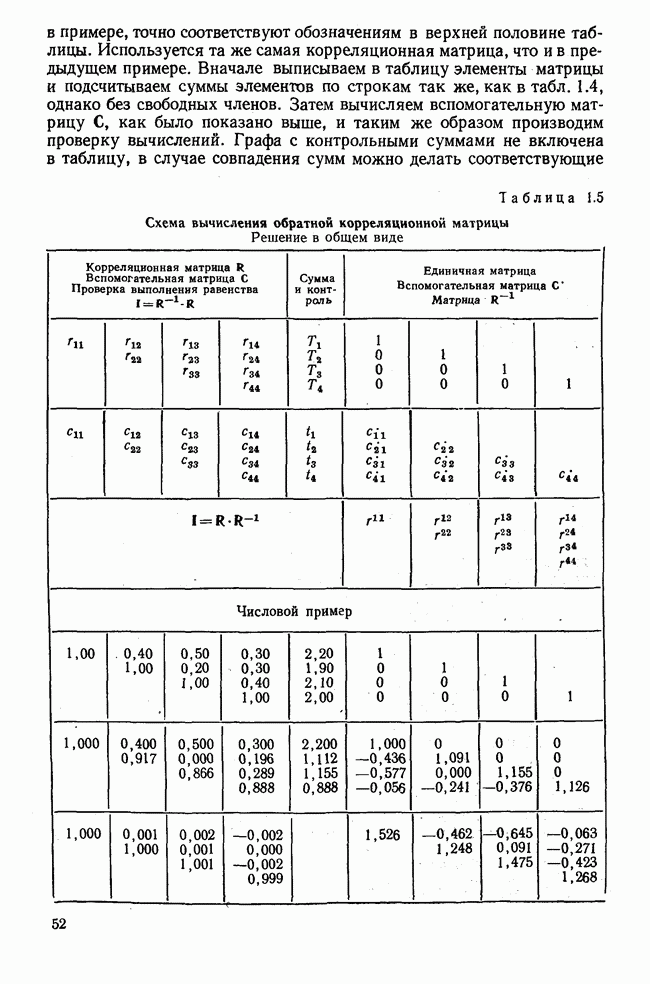
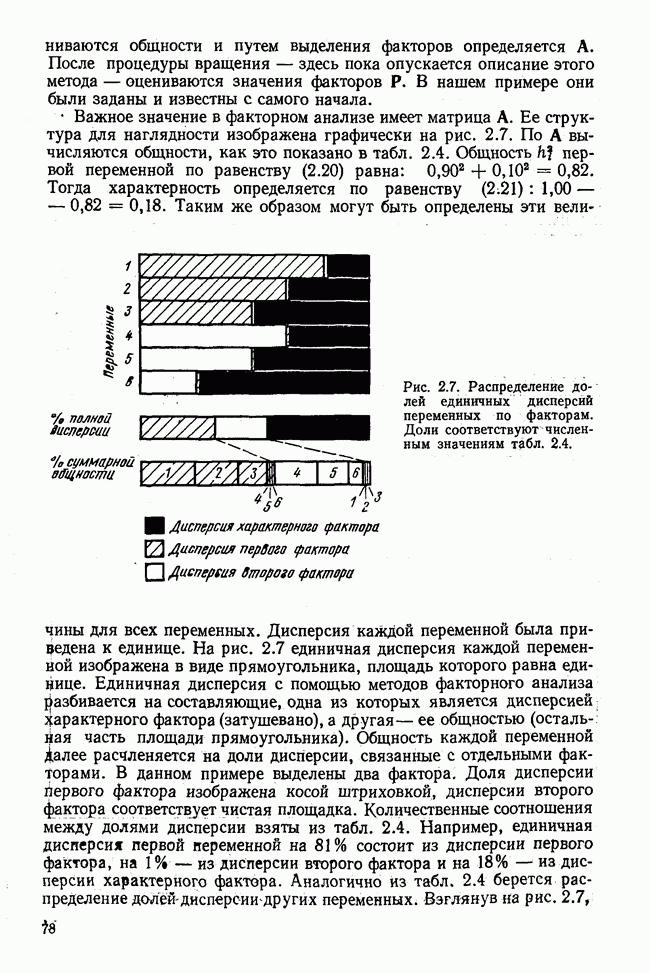
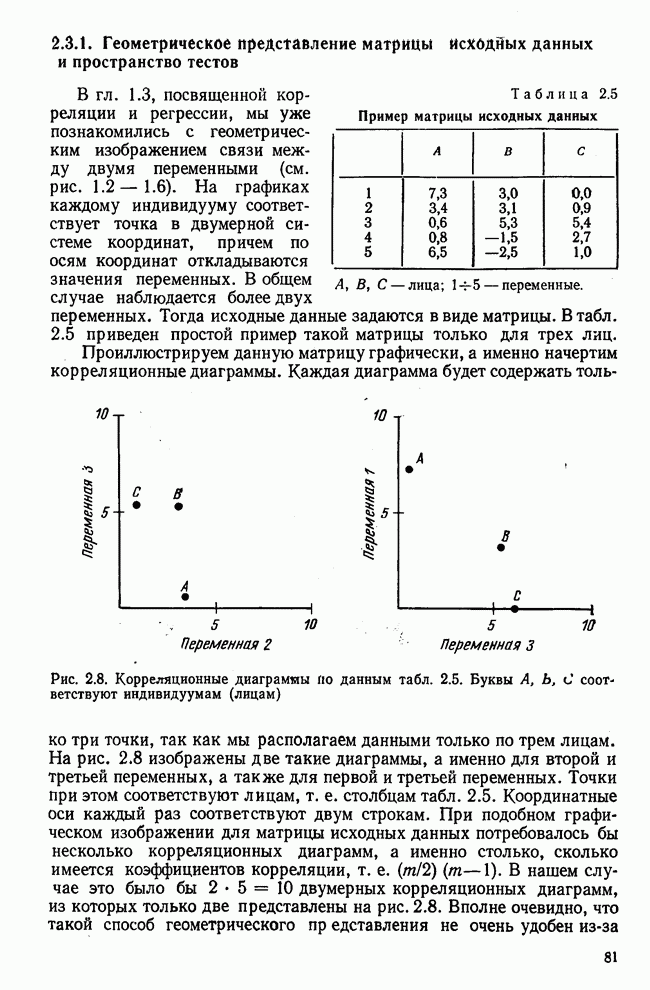
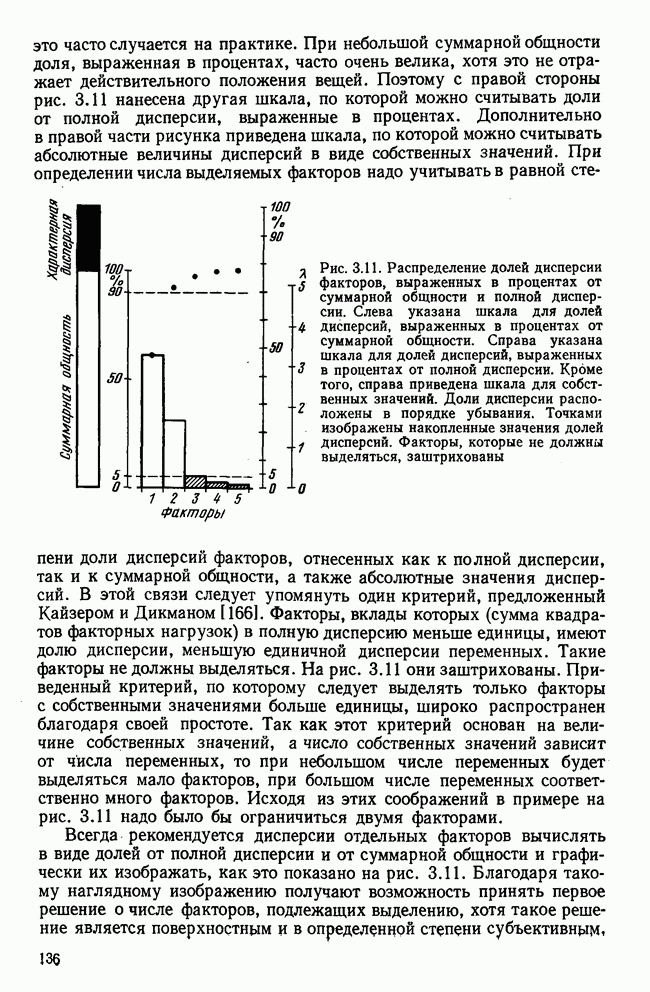
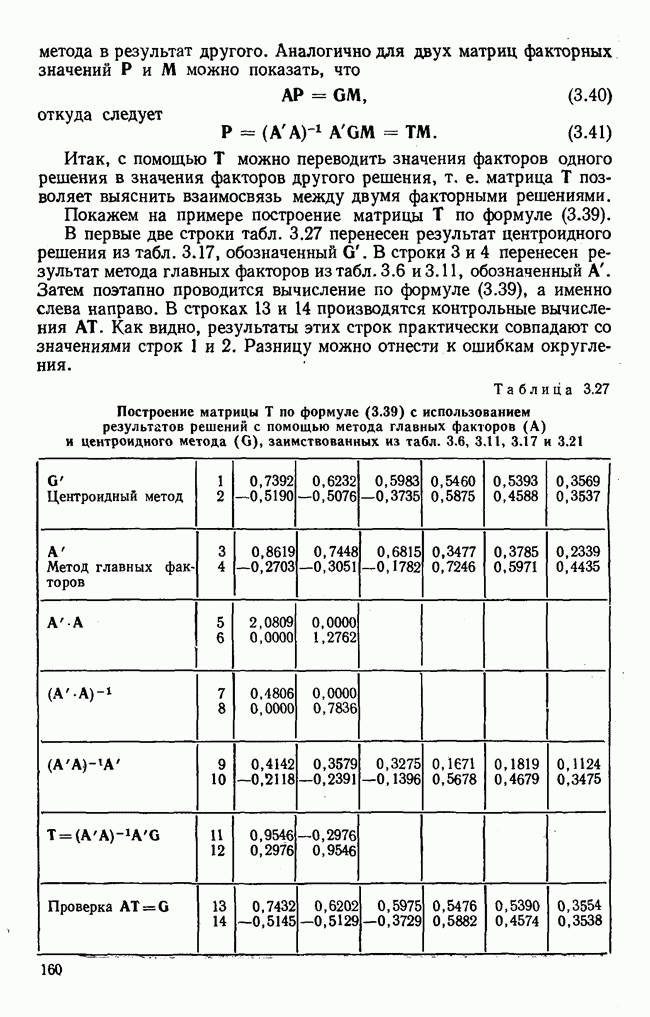
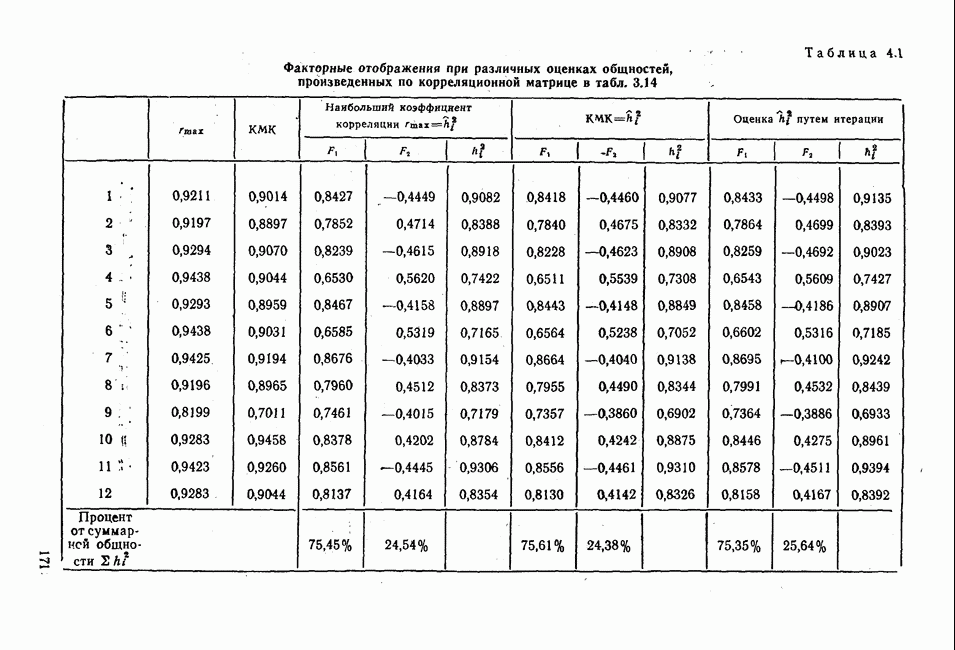
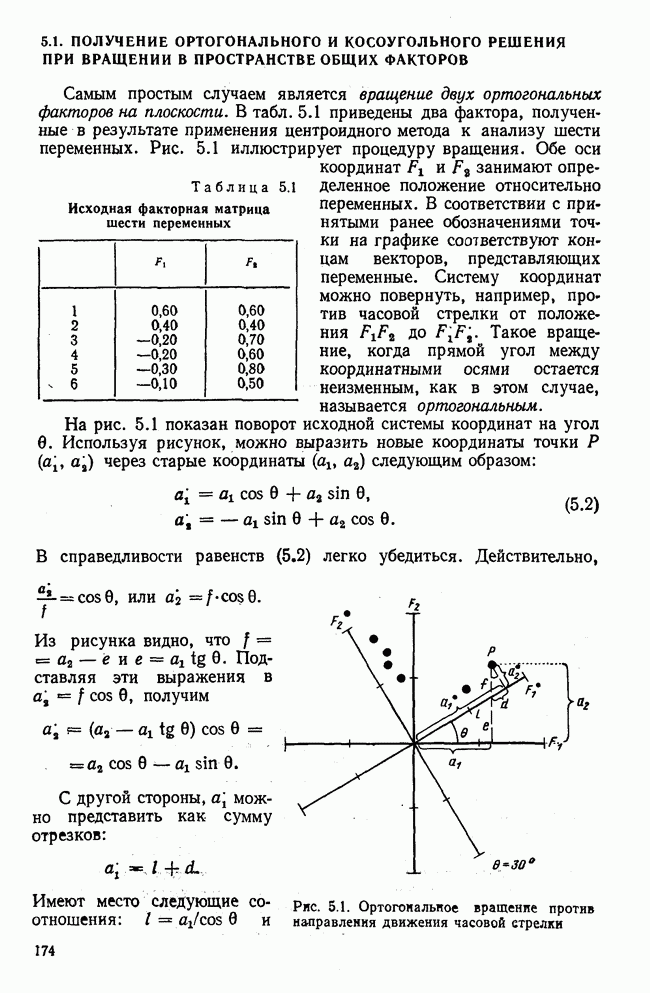
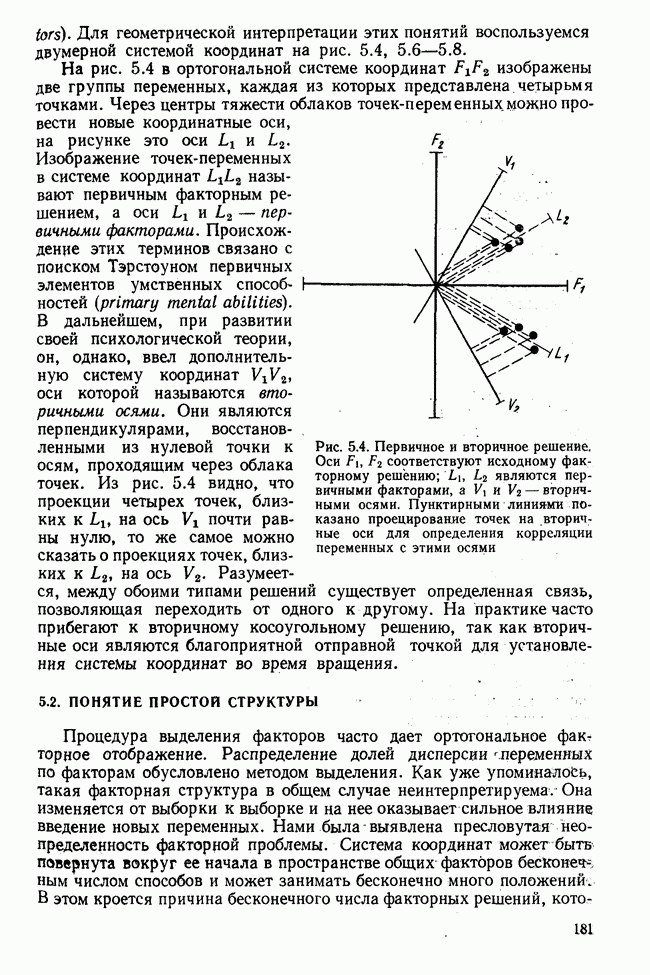
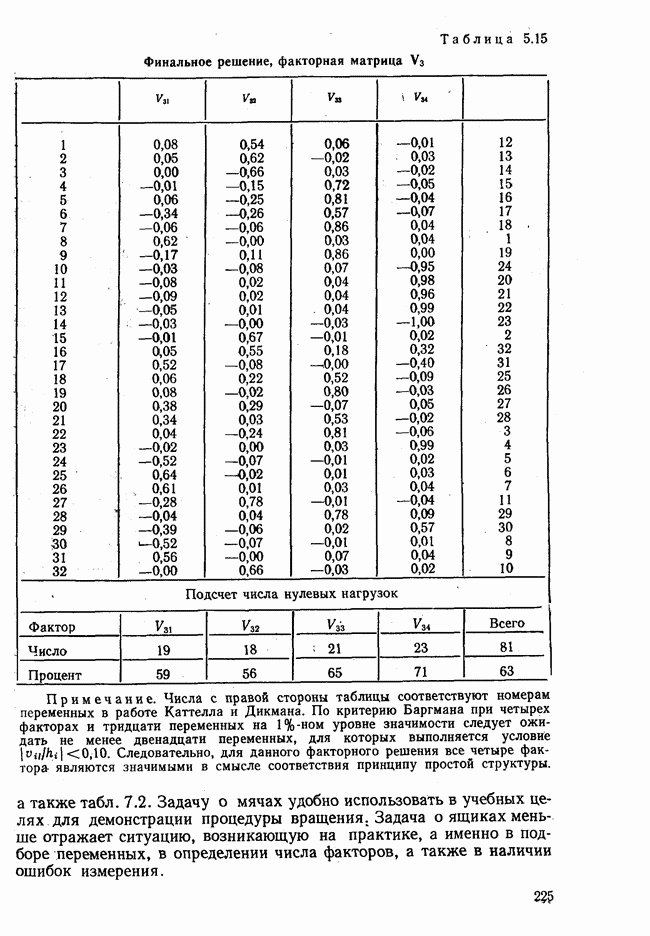
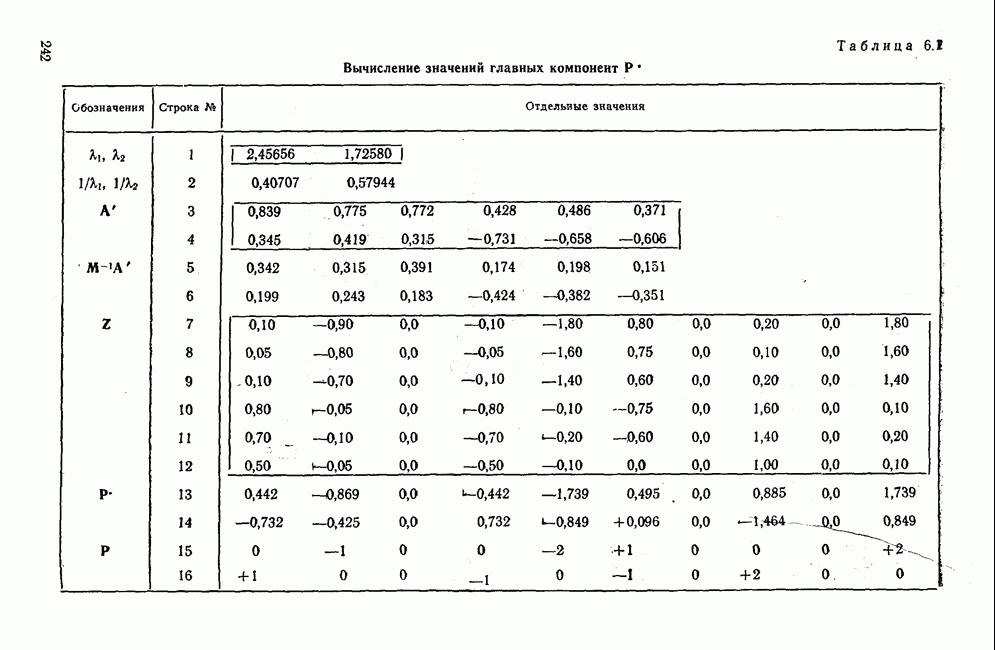
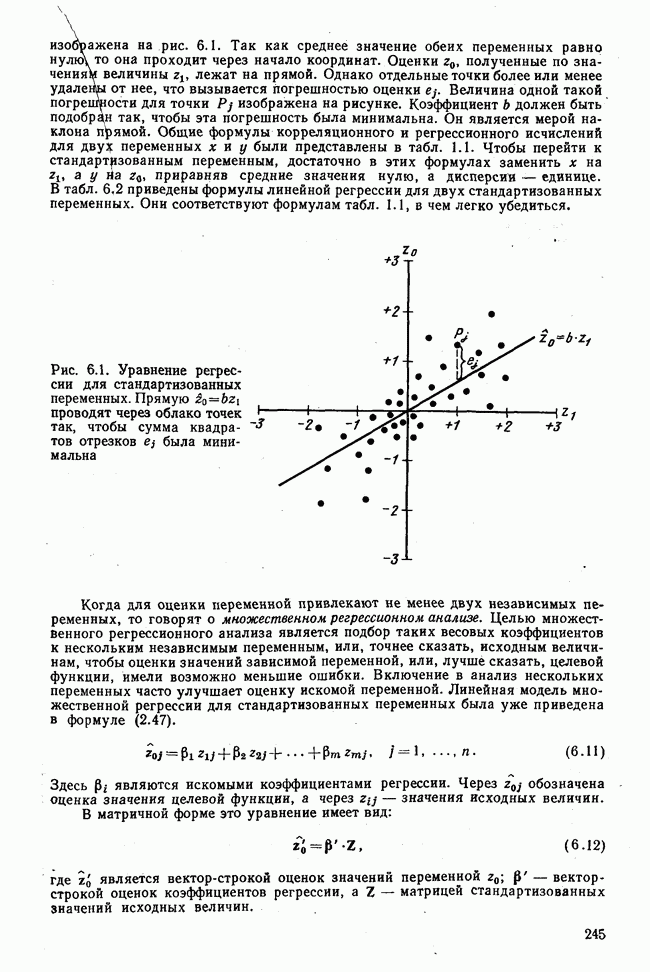
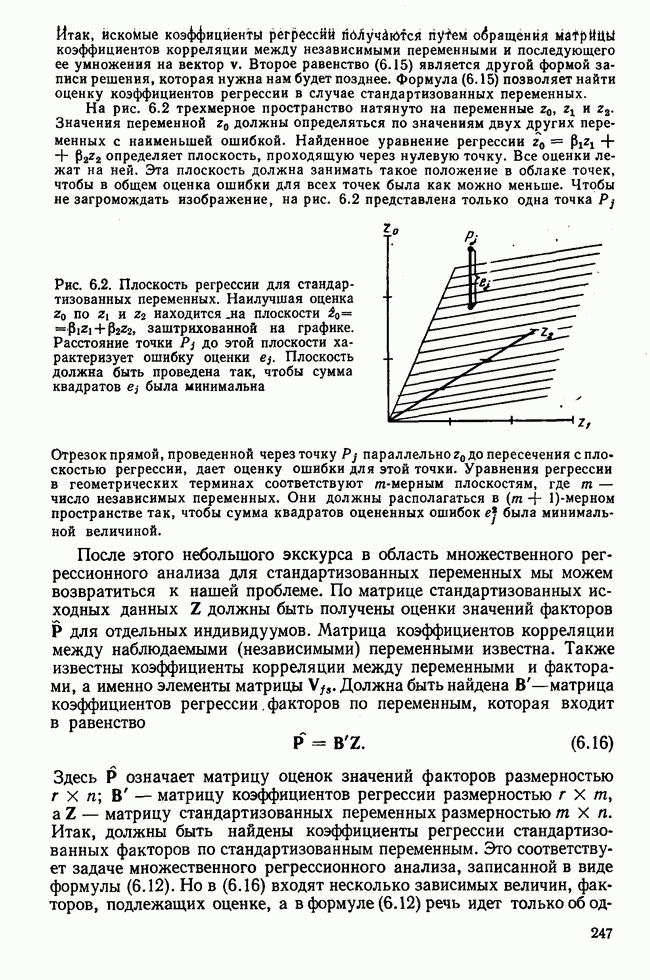
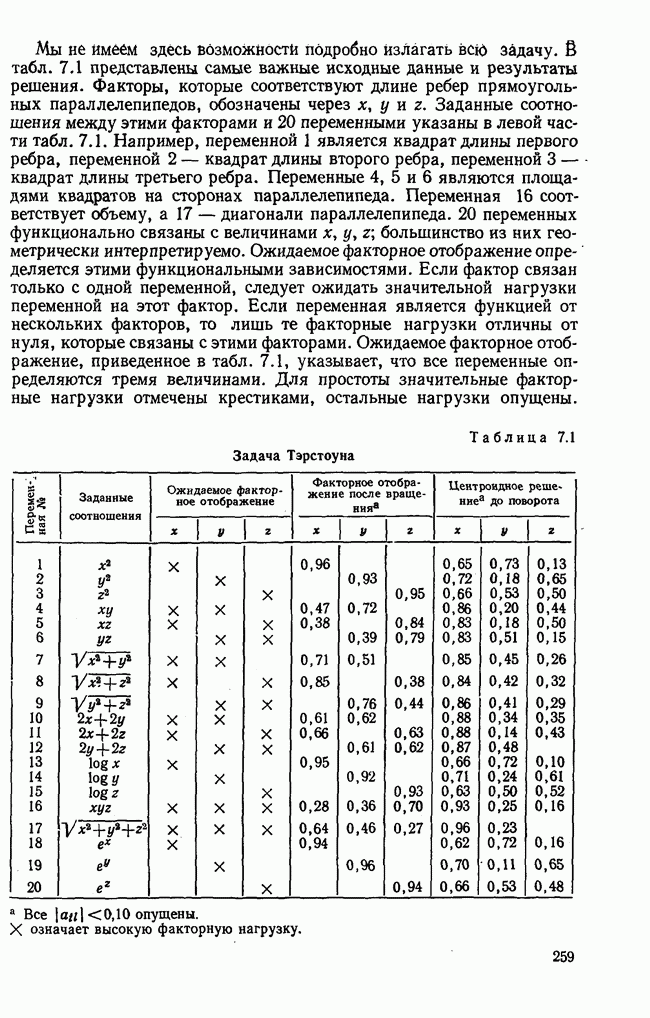
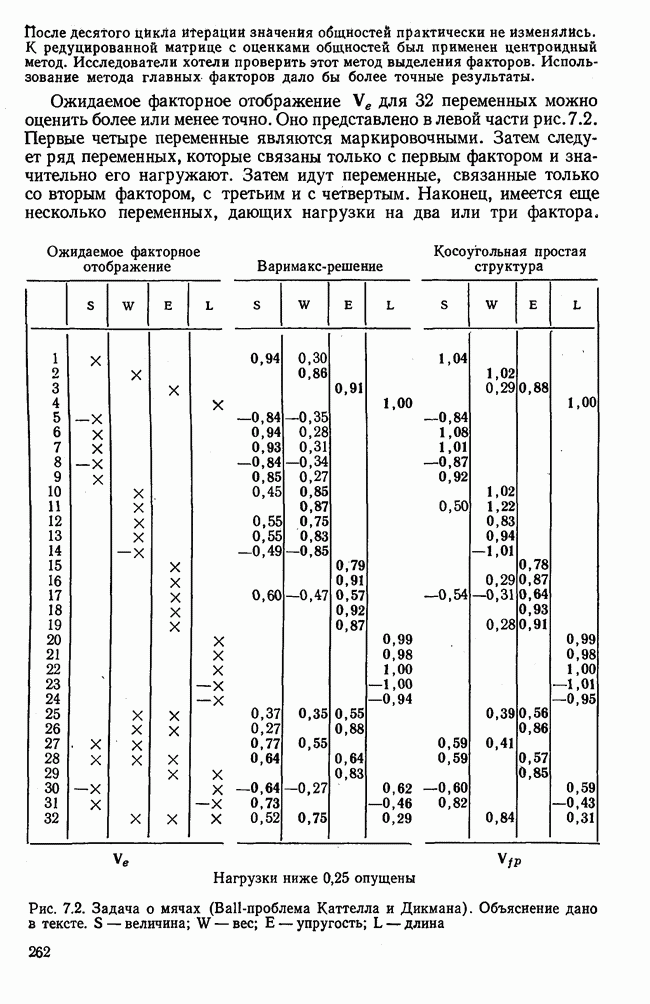
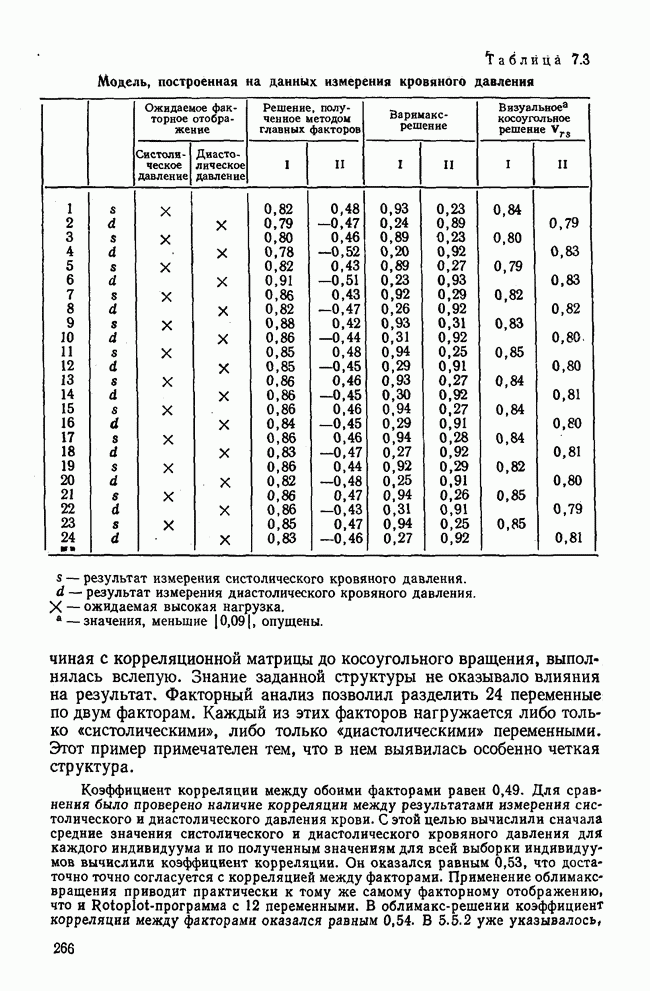
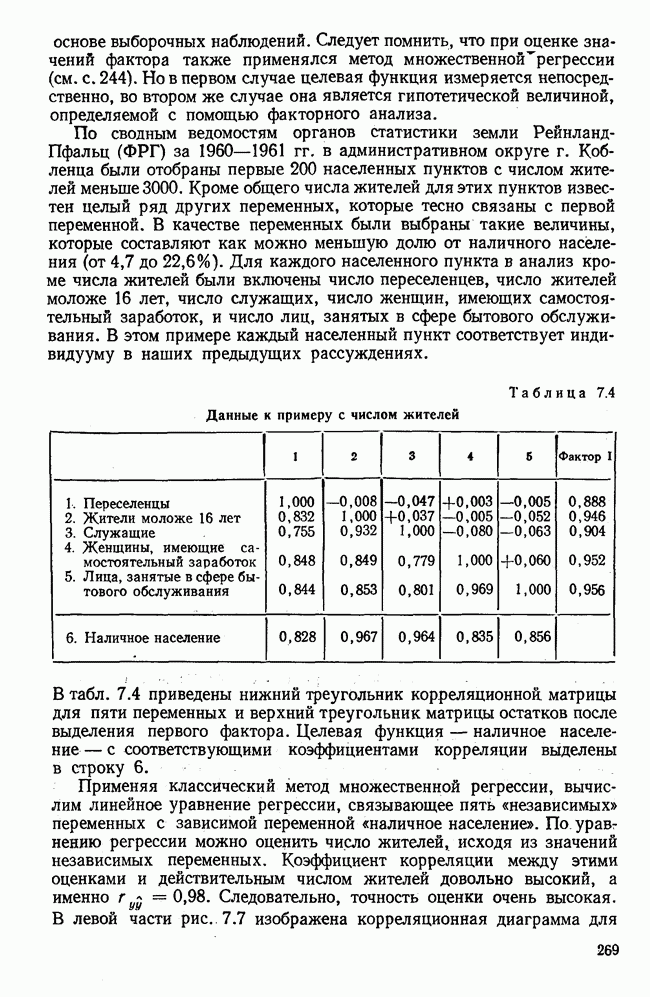
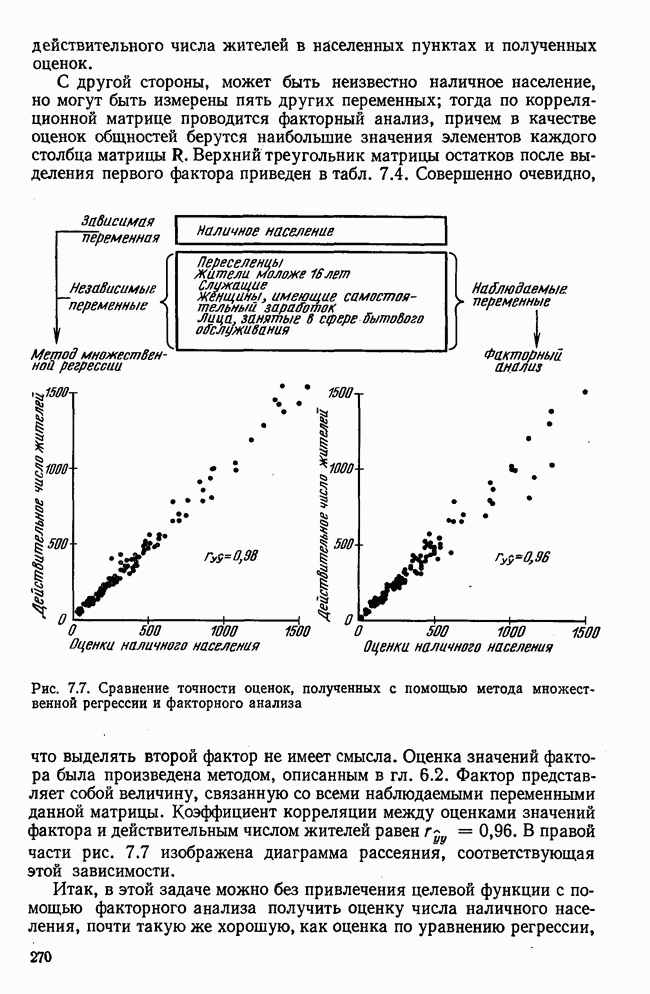
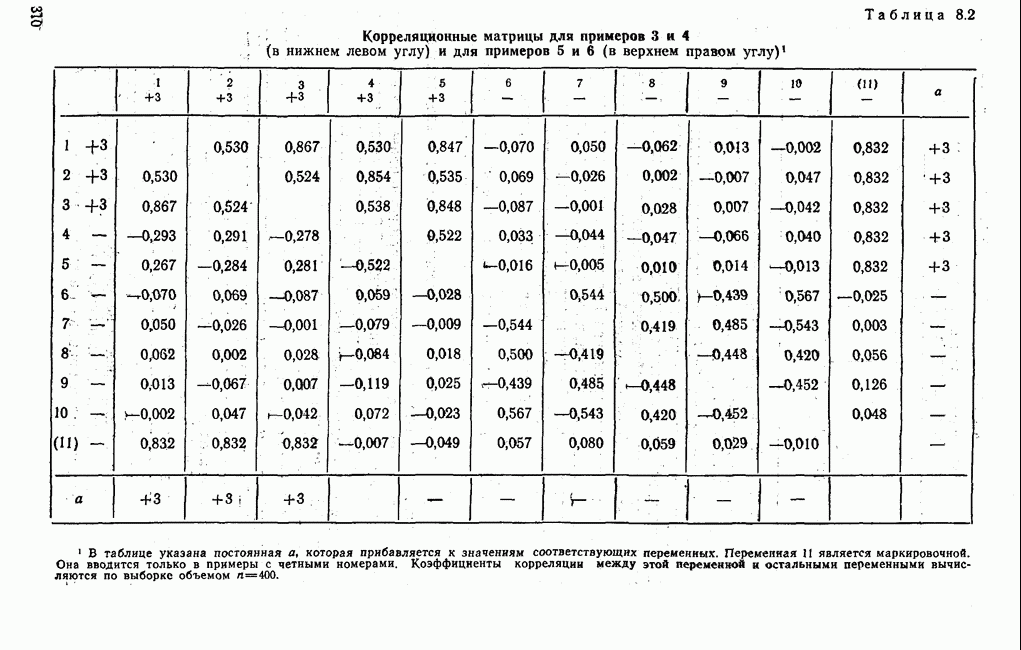
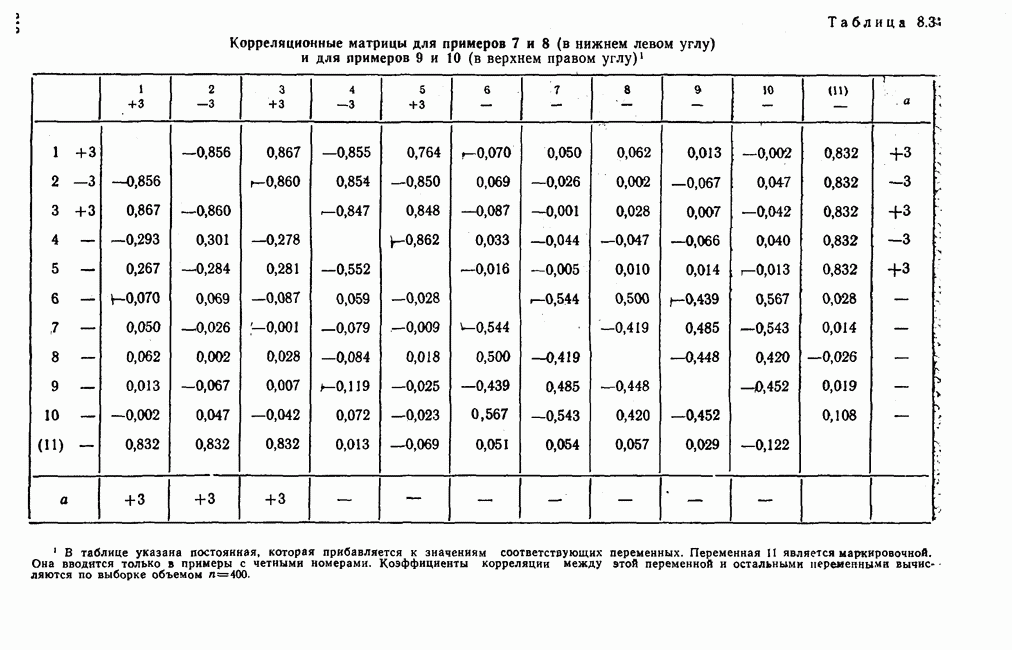
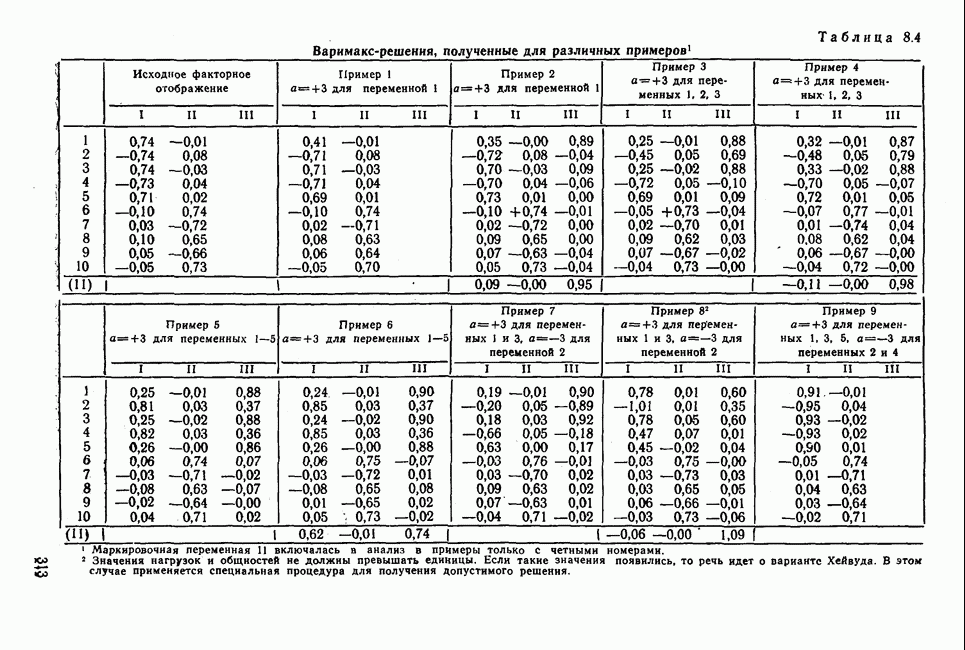
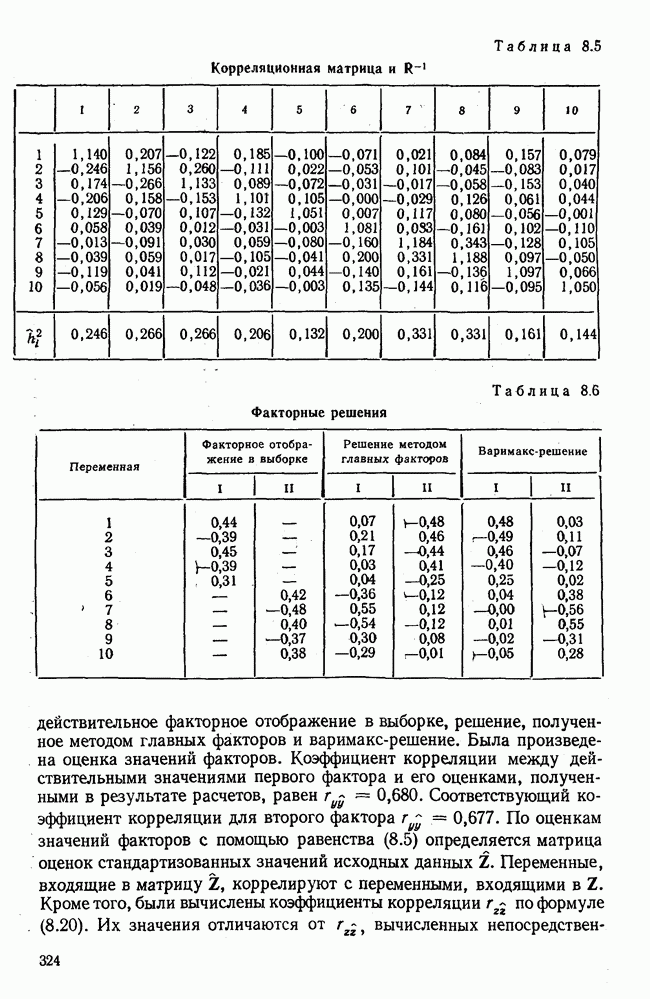
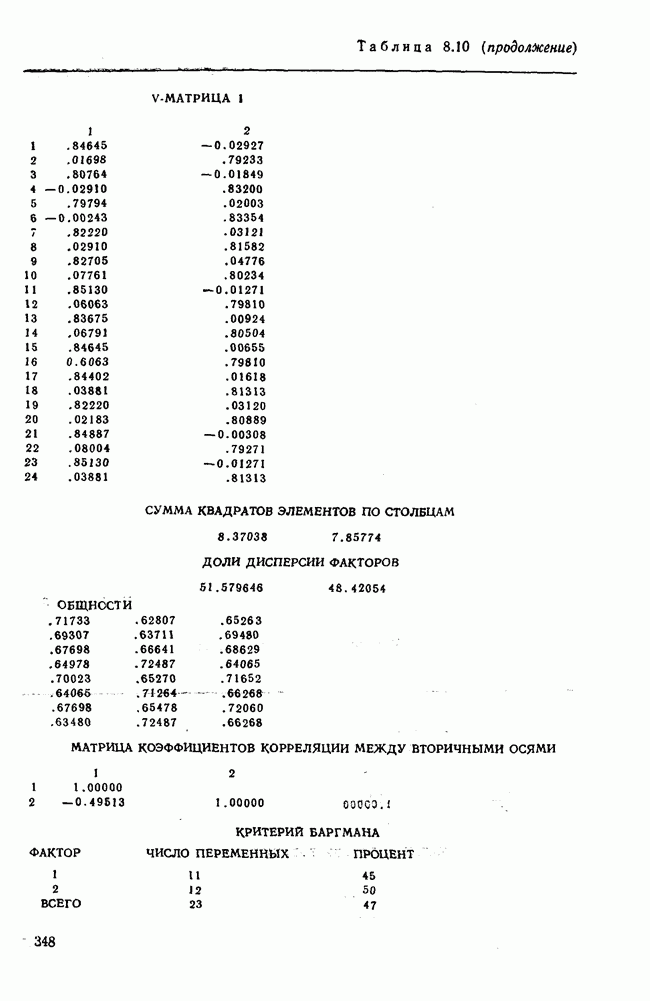
3.1.3. Процедура вычисленияКомпонентный анализ можно провести с любой корреляционной матрицей с единицами на главной диагонали. Вычисление собственных значений и собственных векторов на КВМ довольно затруднительно и его имеет смысл проводить только в дидактических целях или при небольшой корреляционной матрице. Вообще для вычисления собственных значений и собственных векторов матрицы R привлекается ЭВМ. Разработан ряд машинных способов решения, отличных от вычислительной процедуры на КВМ. Вычисление главных факторов на КВМ.Далее изложен итерационный метод определения собственных значений и собственных векторов корреляционной матрицы и приводится способ вычисления факторных нагрузок в такой же форме, как указано у Хармана [117]. Как и во многих подобных случаях, процедура вычисления не связана непосредственно с определениями, которые были приведены выше для собственных значений и векторов. Но можно показать, что результаты согласуются с этими определениями. Метод особенно пригоден при использовании КВМ, так как факторы вычисляются последовательно друг за другом и число факторов ограничивается требованиями соответствующей проблемы. Итеративный процесс начинается с выбора вектора
Процесс повторяется до тех пор, пока не добиваются сходимости к первому собственному значению В качестве элементов вектора Если в качестве множителя для итерации в (3.8) вместо R брать Поэтому при возведении В соответствующую степень остаточной матрицы пользуются соотношением (3.11), позволяющим избежать последовательного умножения этой матрицы.
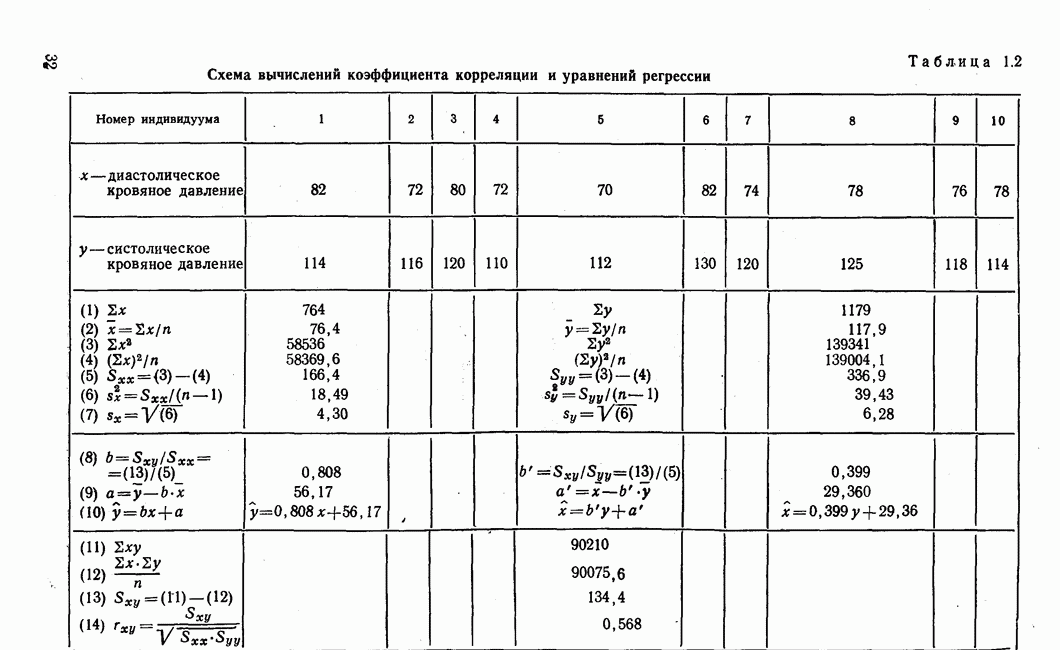
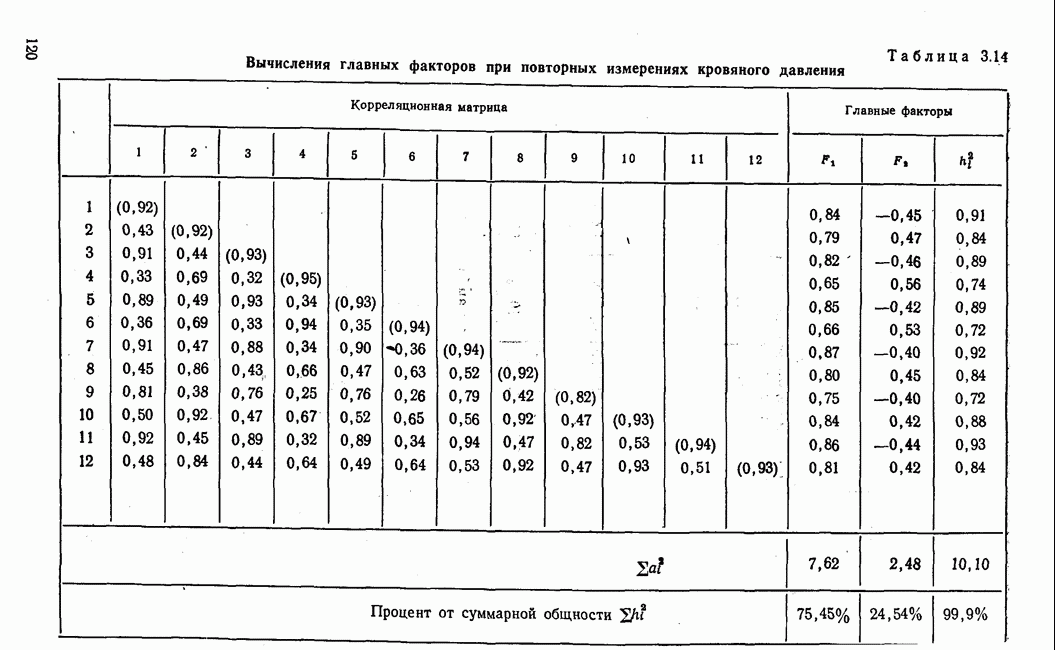
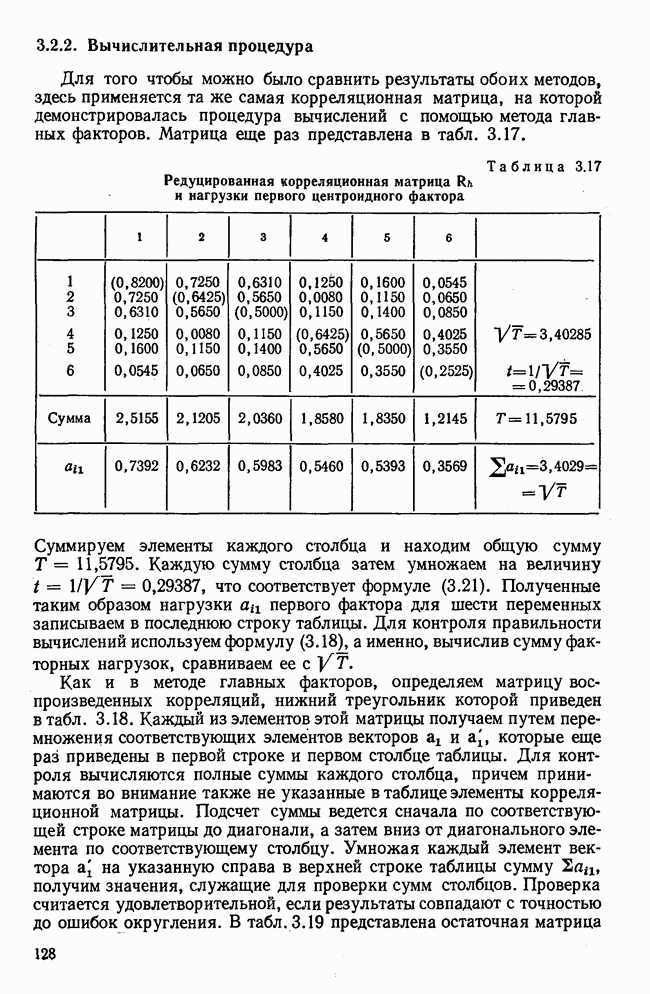
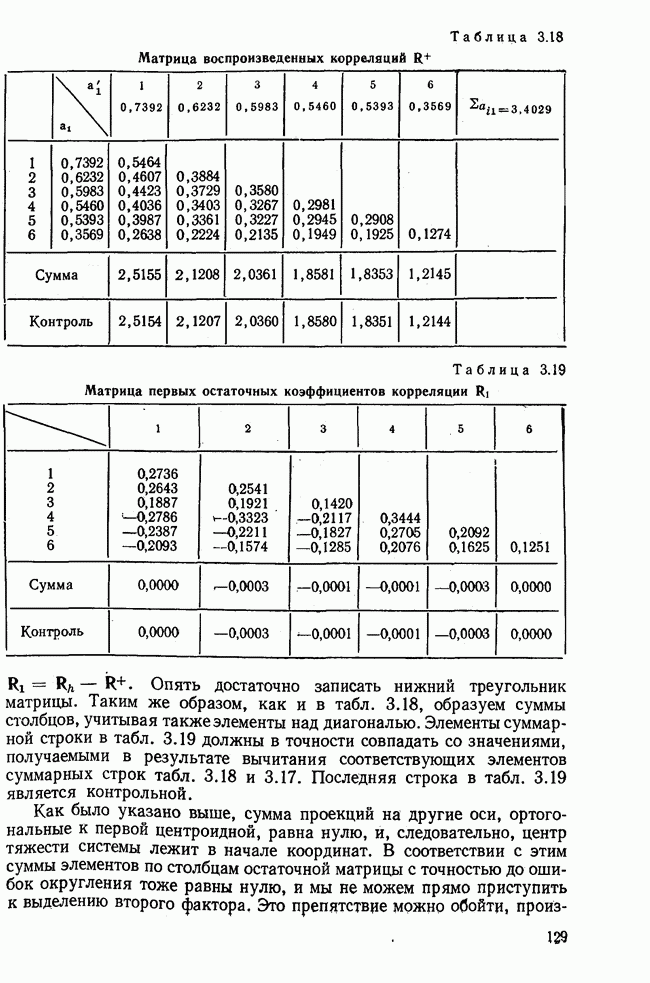
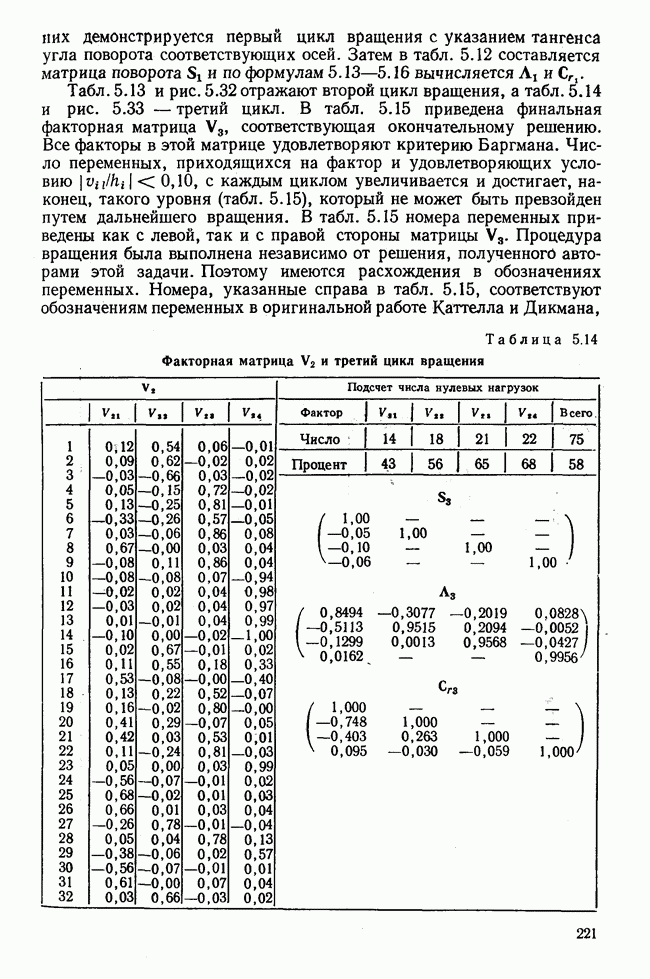
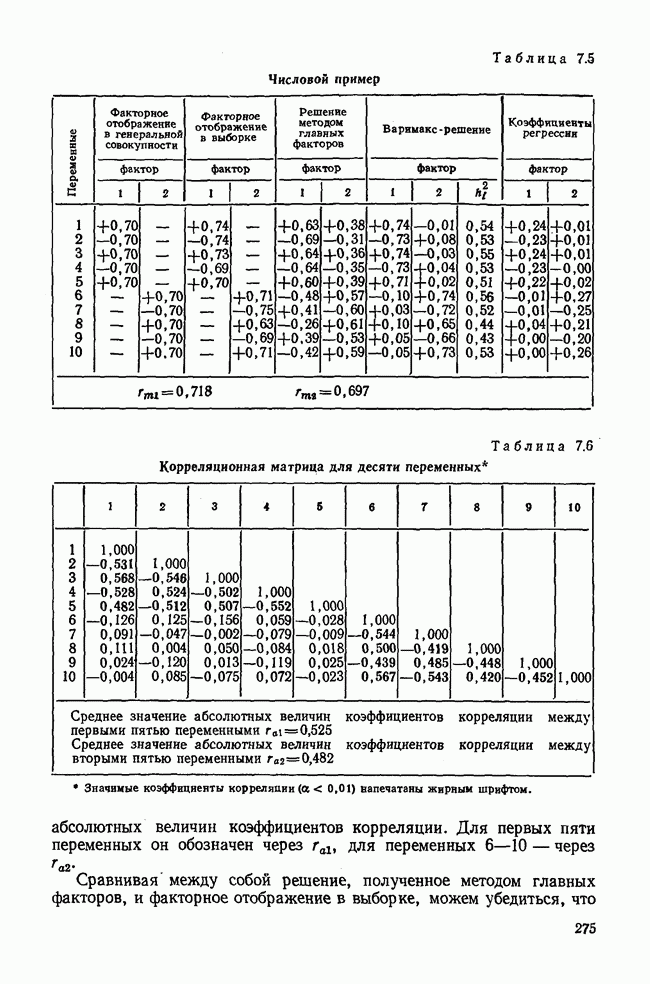
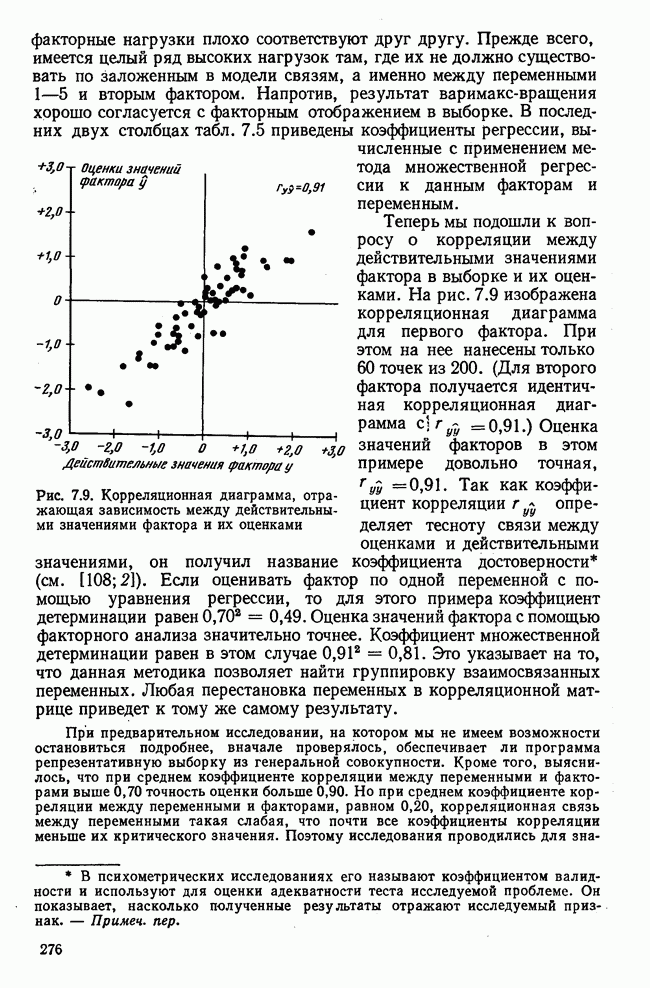
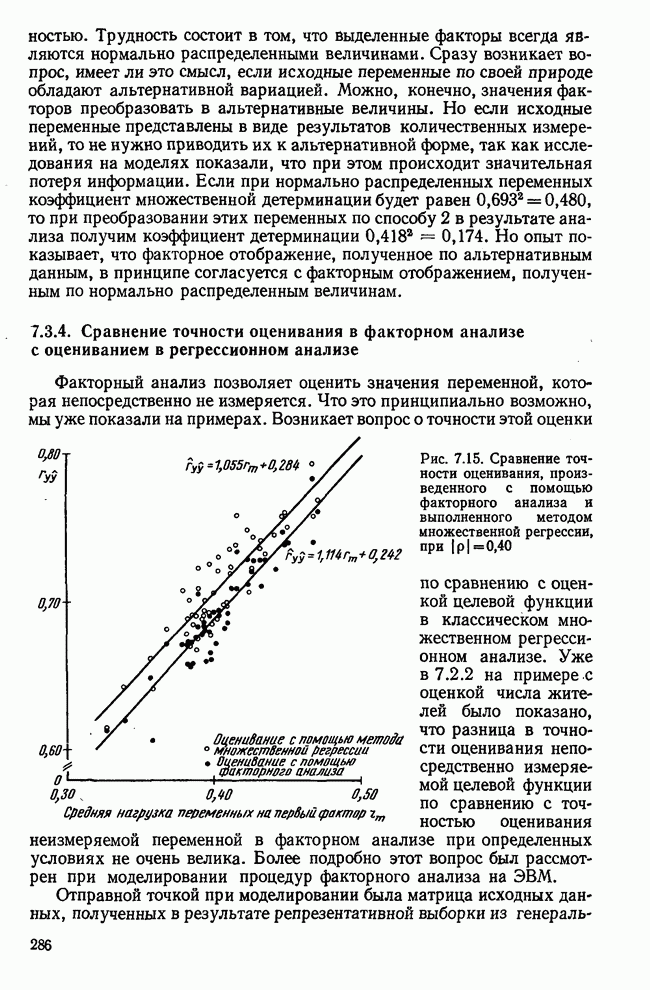
Далее в примере показан порядок вычислений при работе с КВМ. Время, необходимое для расчета этого примера, составляет примерно одну рабочую неделю. В табл. 3.1 приведена корреляционная матрица для 6 переменных. Общности уже известны. Матрица заимствована из табл. 2.3. К ней будет применяться описанная процедура вычисления для выделения главных факторов. Вычислив суммы элементов строк матрицы R и разделив их на максимальную из этих сумм (в данном случае она равна сумме элементов первой строки: 2,5155), получим элементы первого вектора Таблица 3.1. Исходная редуцированная корреляционная матрица
В качестве следующего приближения берется вектор Таблица 3.2. Квадрат корреляционной матрицы и первый цикл итерации
И наконец, в последнем столбце вычисляется абсолютная величина разности Этот новый цикл проводится не с Совершенно аналогично по табл. 3.3 вычисляем табл. 3.4. Здесь разницы Если бы требовалась большая точность, можно было бы выполнить еще один цикл, определив для этого Вычисления нагрузок первого фактора приведены в табл. 3.6, в первом столбце которого записан первый собственный вектор Таблица 3.3. Четвертая степень корреляционной матрицы и второй цикл итерации
Таблица 3.4. Восьмая степень корреляционной матрицы и третий цикл итерации
Таблица 3.5. Последний цикл итераций
Таблица 3.6. Вычисление нагрузок первого фактора
Таблица 3.7. Матрица воспроизведенных корреляций
Таблица 3.8. Матрица первых остаточных коэффициентов корреляции
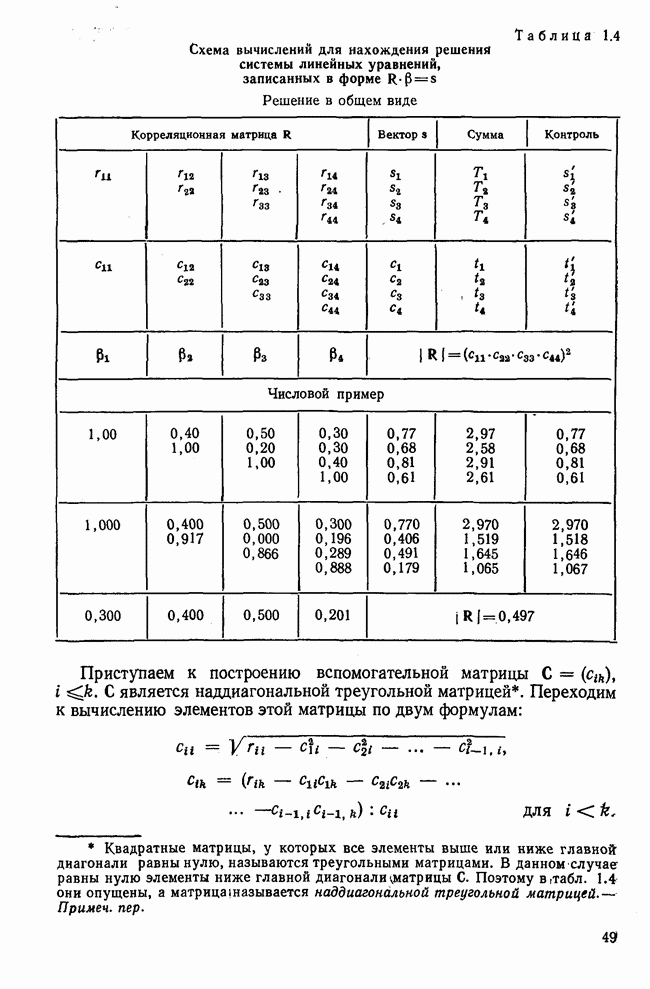
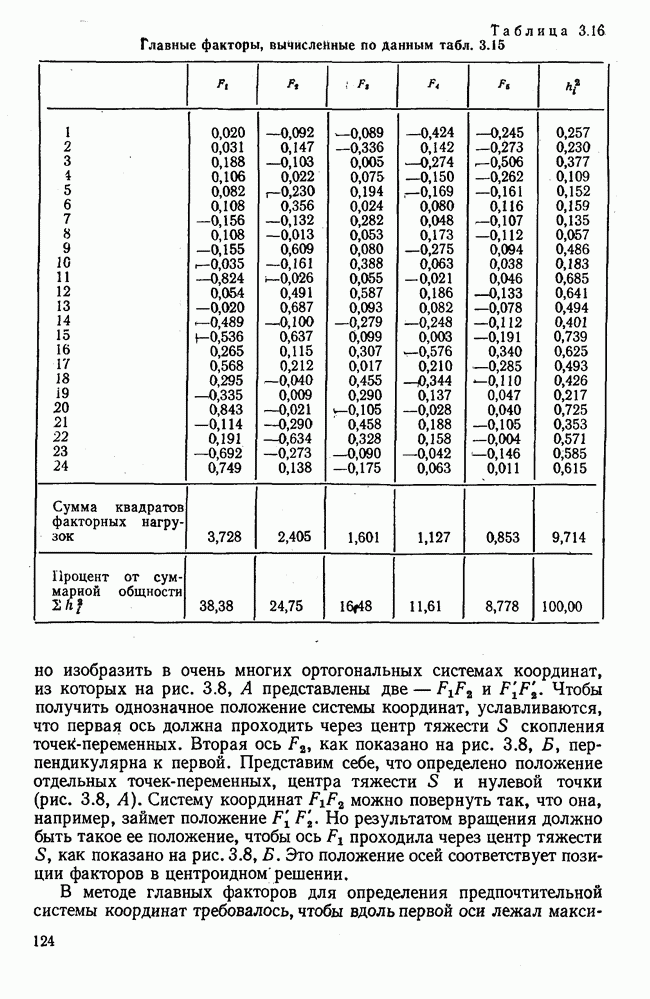
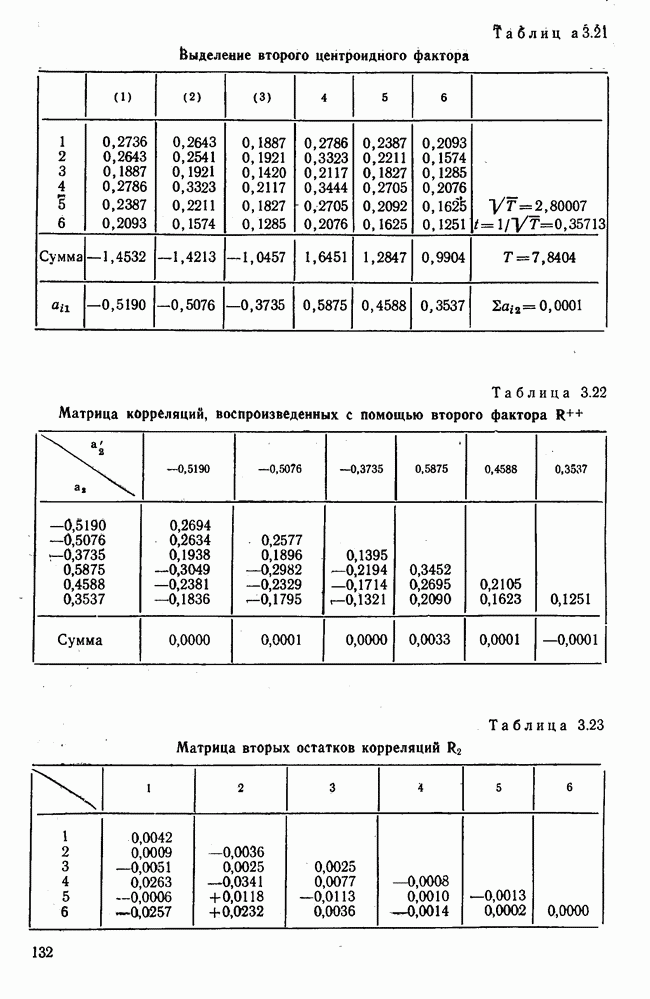
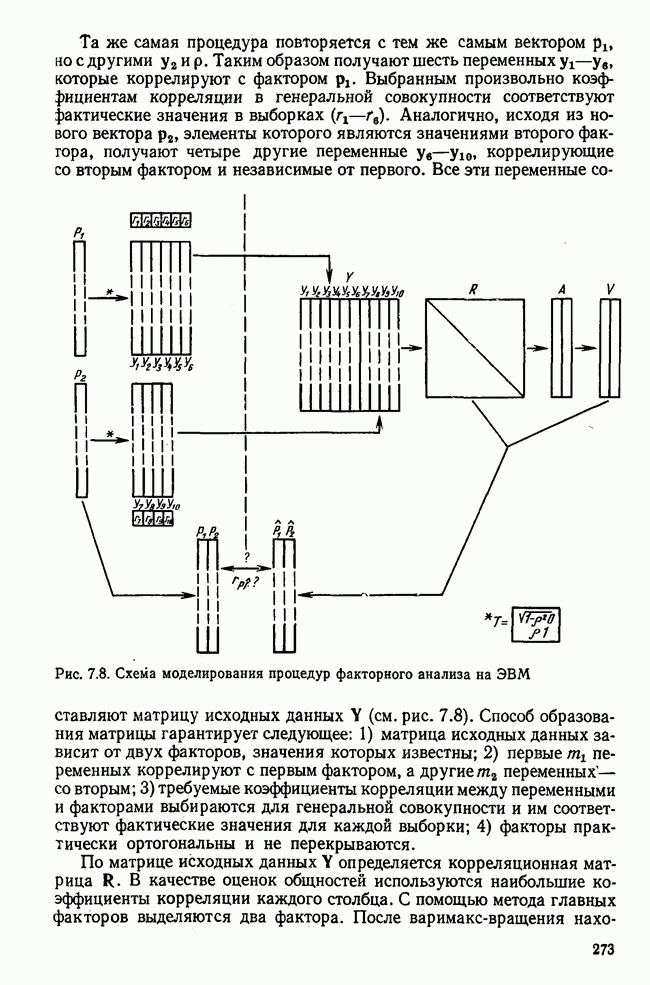
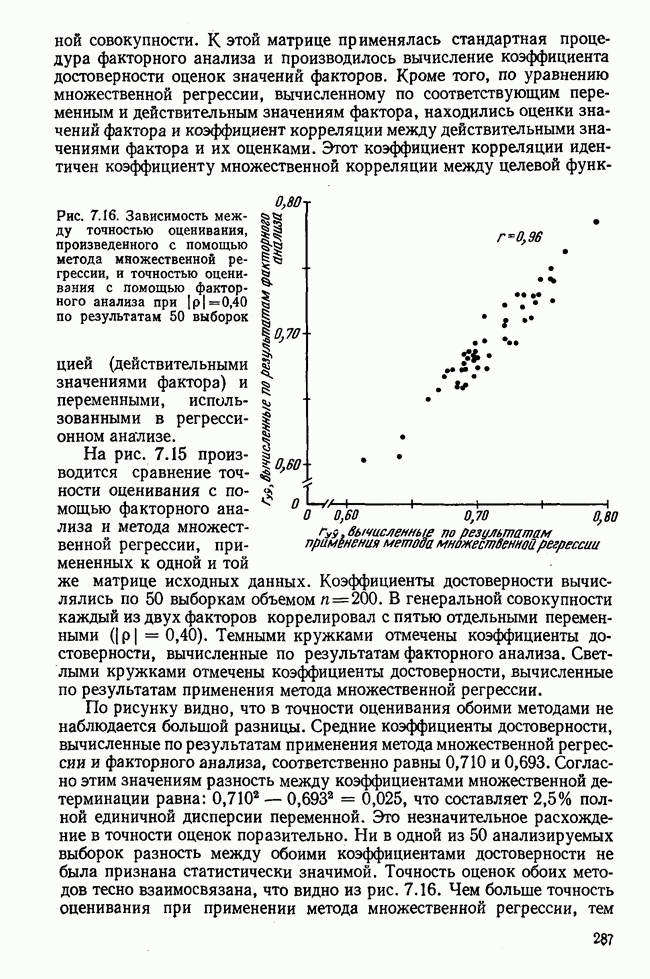
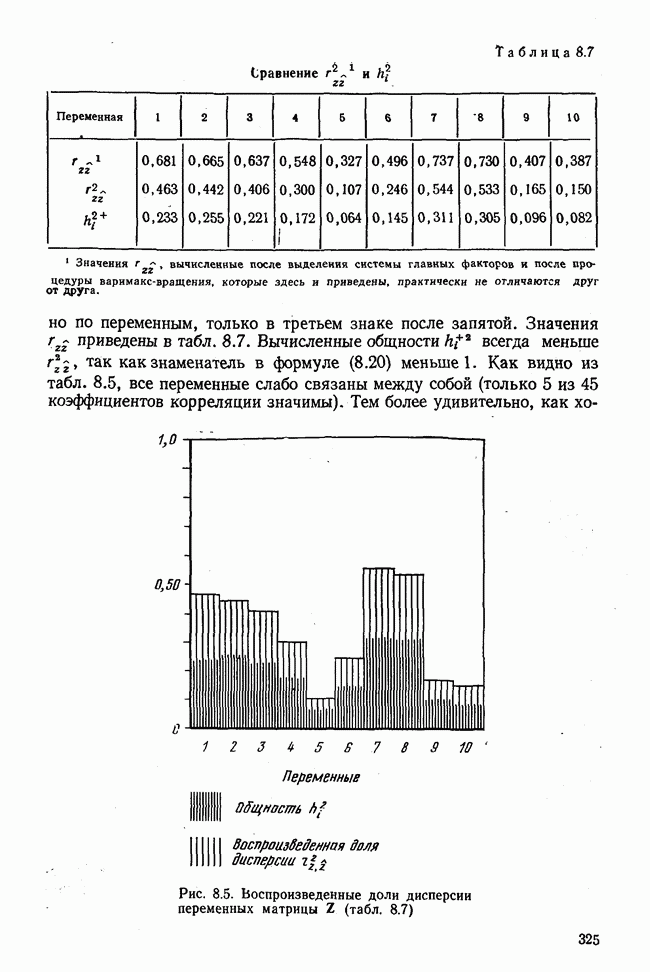
Вычисление второго собственного значения и нагрузок второго фактора исходя из остаточной матрицы менее объемно. Можно воспользоваться формулой (3.10), как это показано в схеме вычислений у Хармана [117]. Ради простоты вычисления здесь производятся по предыдущей схеме, хотя объем работы потребуется больший. Но мы исходим из того, что пример должен иллюстрировать принцип. При проведении анализа главных факторов практически не пользуются КВМ и в данном случае воспроизведение полной процедуры вычислений преследует единственную цель — лучшее усвоение материала; ради этого мы позволяем себе пойти по пути увеличения объема работы. Табл. 3.9 с определением Результаты вычислений элементов вектора По элементам остаточной матрицы видно, что не имеет смысла производить выделение других факторов. Если бы в ней были еще достаточно большие значения остаточных коэффициентов корреляции, то аналогичным путем определили бы следующий фактор. Ограничимся этим примером с двумя выделенными факторами, выбранным для иллюстрации процедуры вычислений на КВМ по методу главных факторов. Таблица 3.9. Квадрат матрицы остатков и первый цикл итерации
Таблица 3.10. Последний цикл итерации
Таблица 3.11. Вычисление нагрузок второго фактора
Таблица 3.12. Матрица вторых остаточных коэффициентов корреляции
|
 |
Оглавление
|



















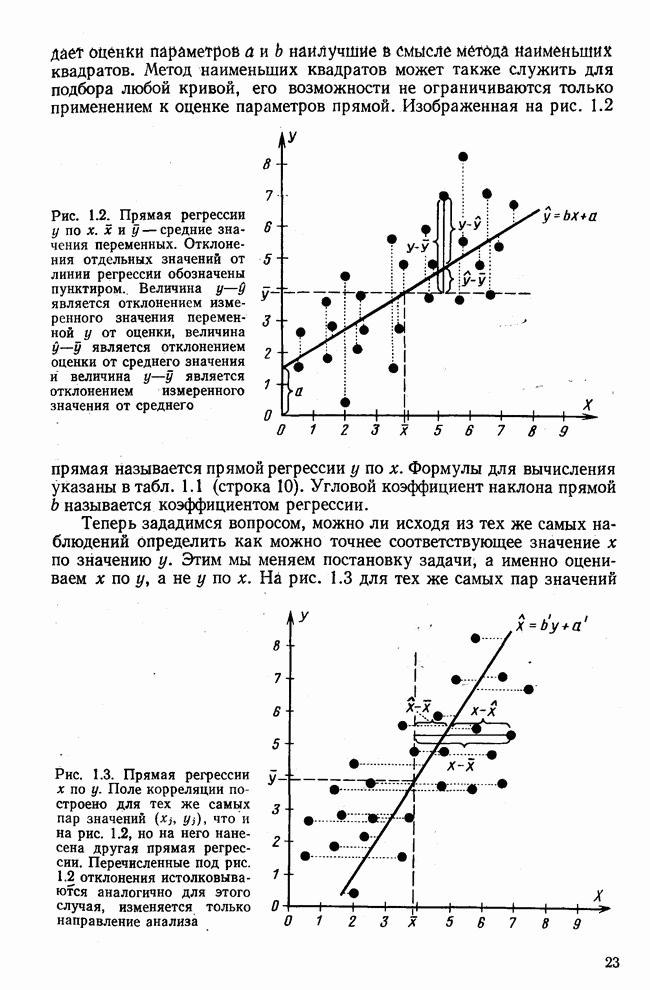













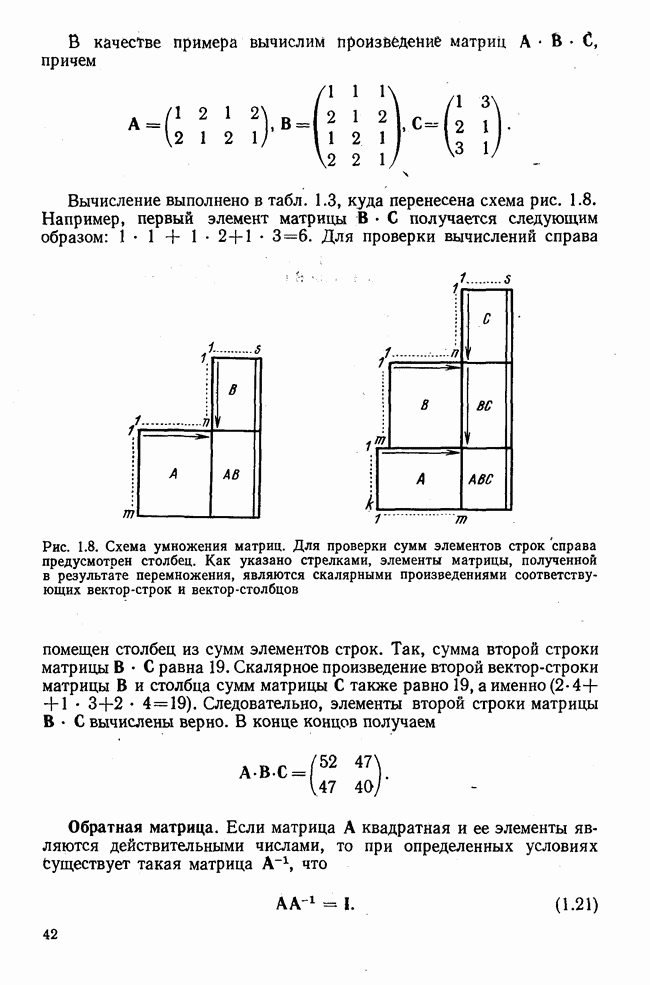


































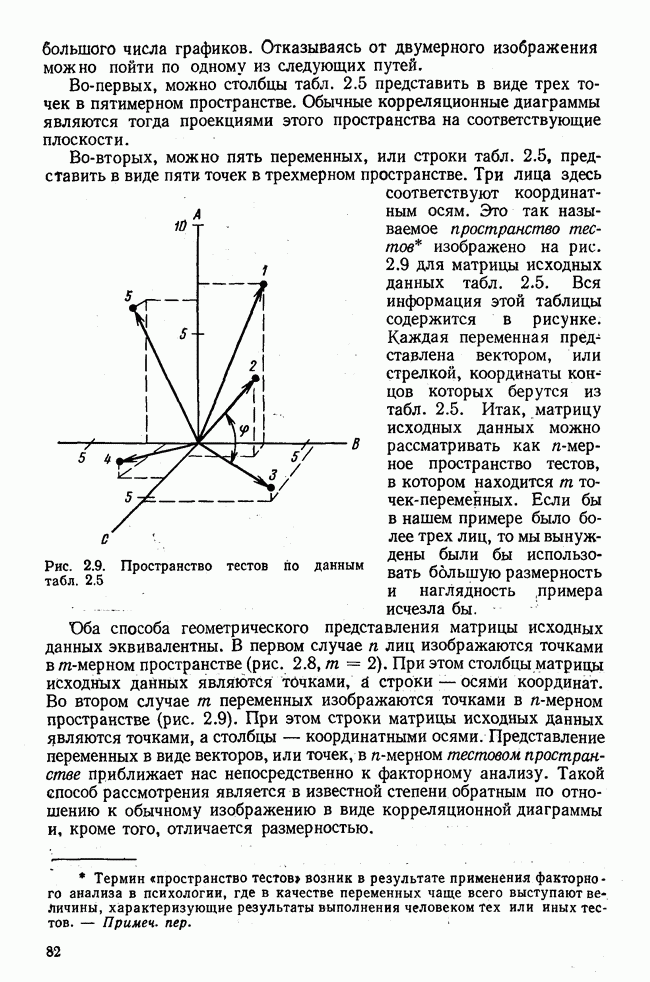






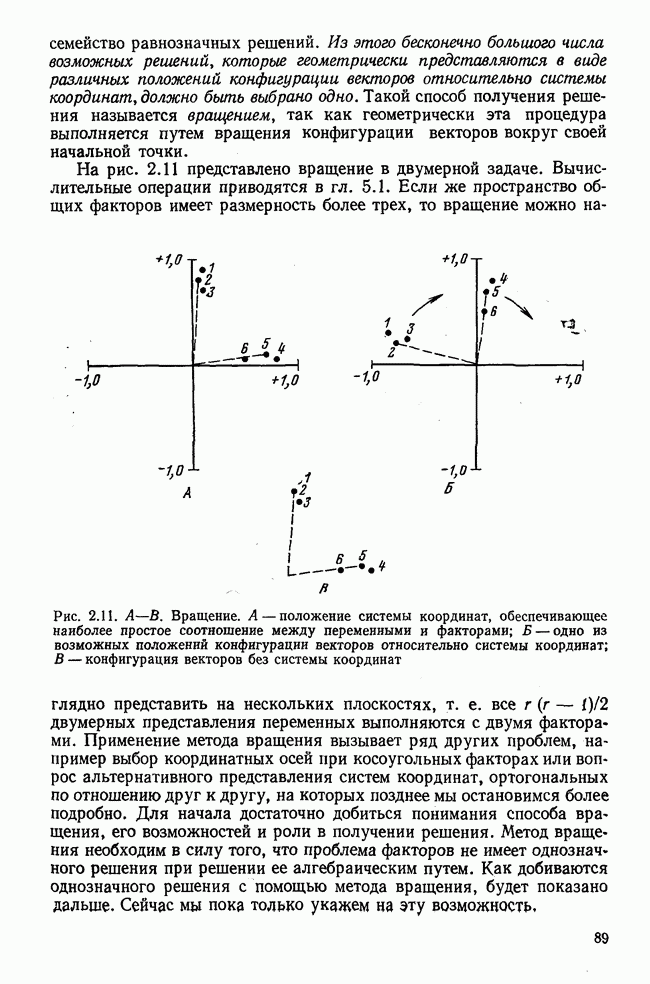














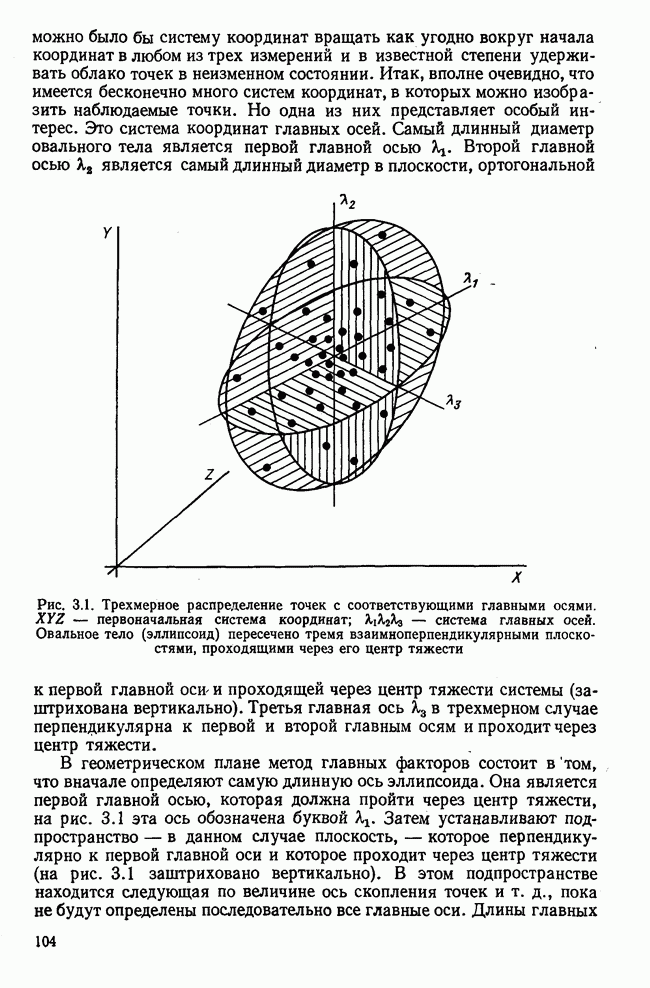


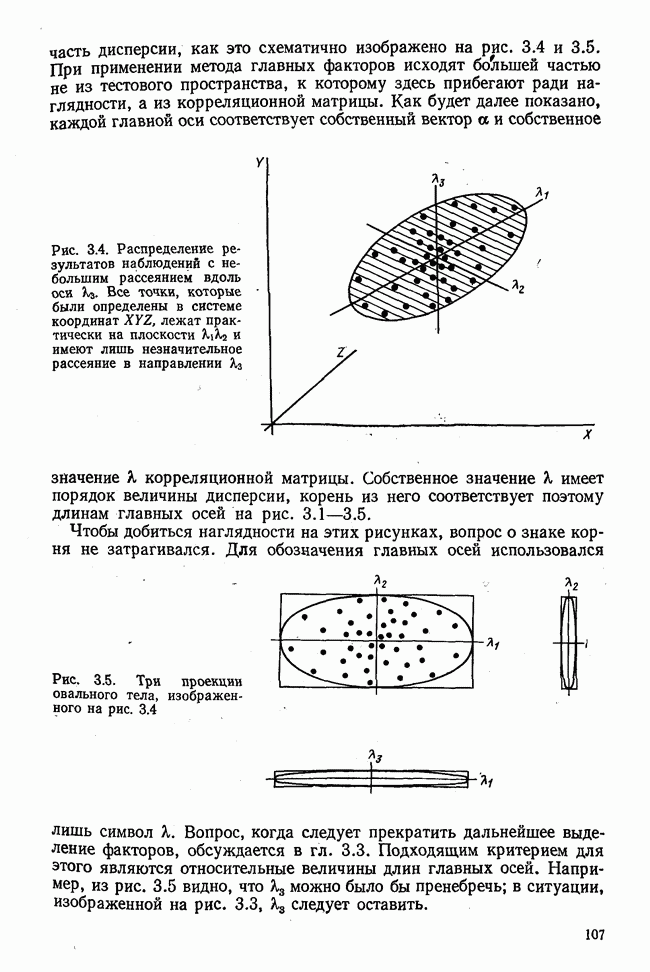





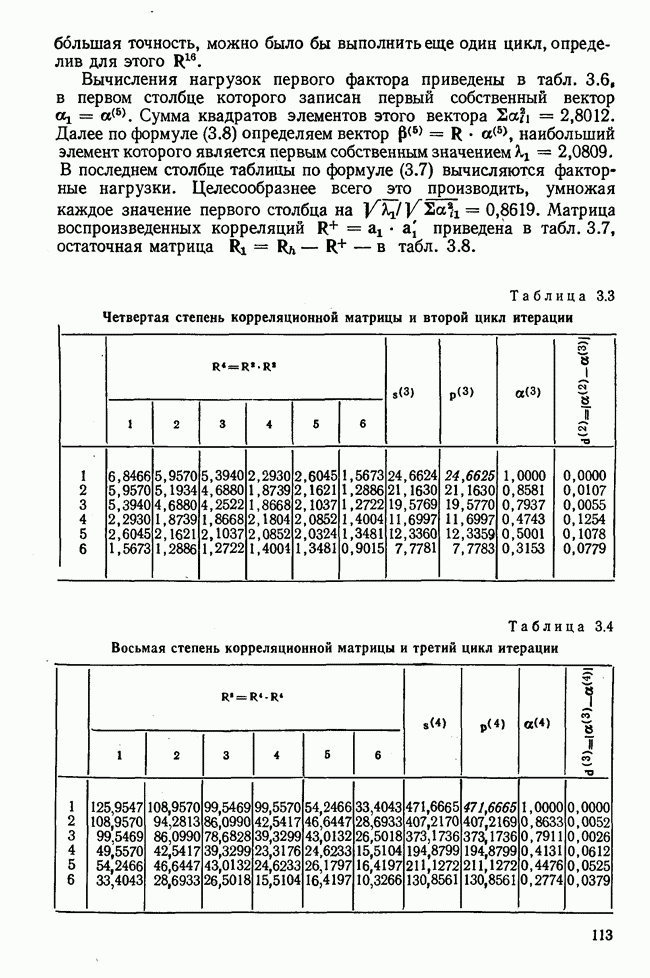





























































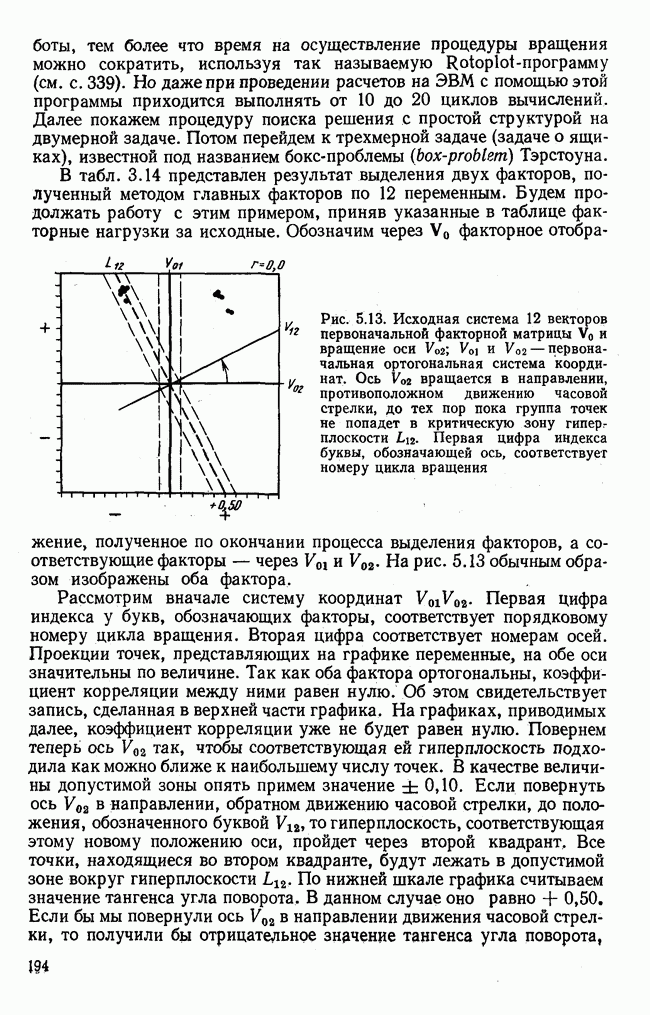


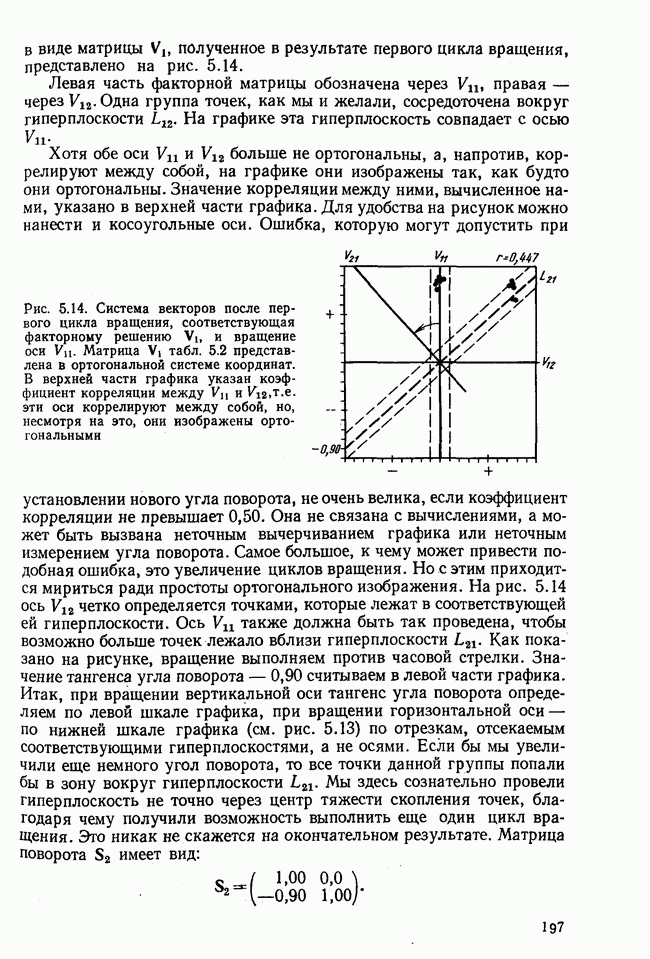

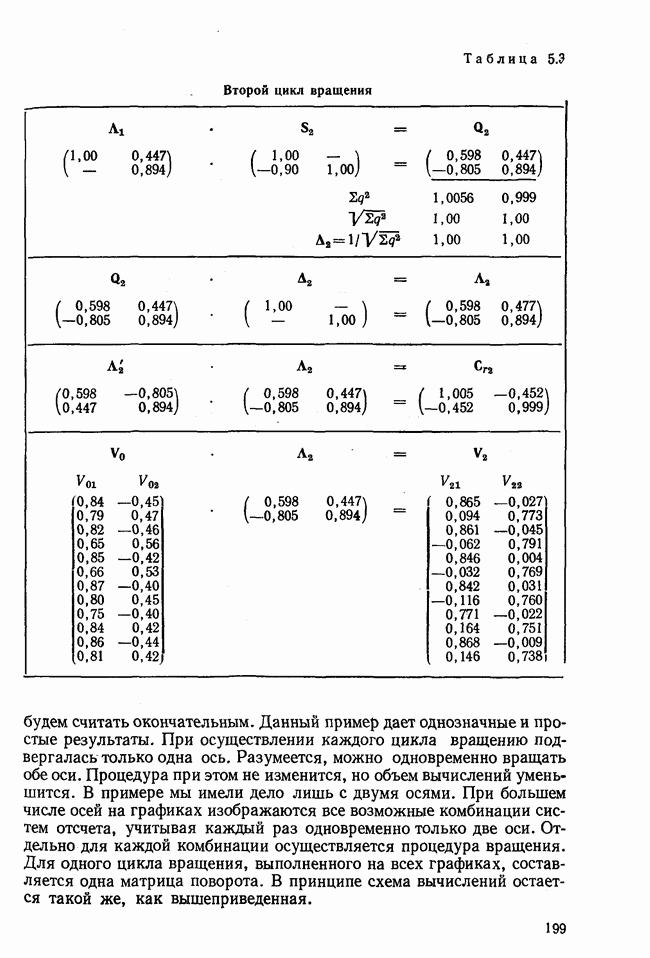





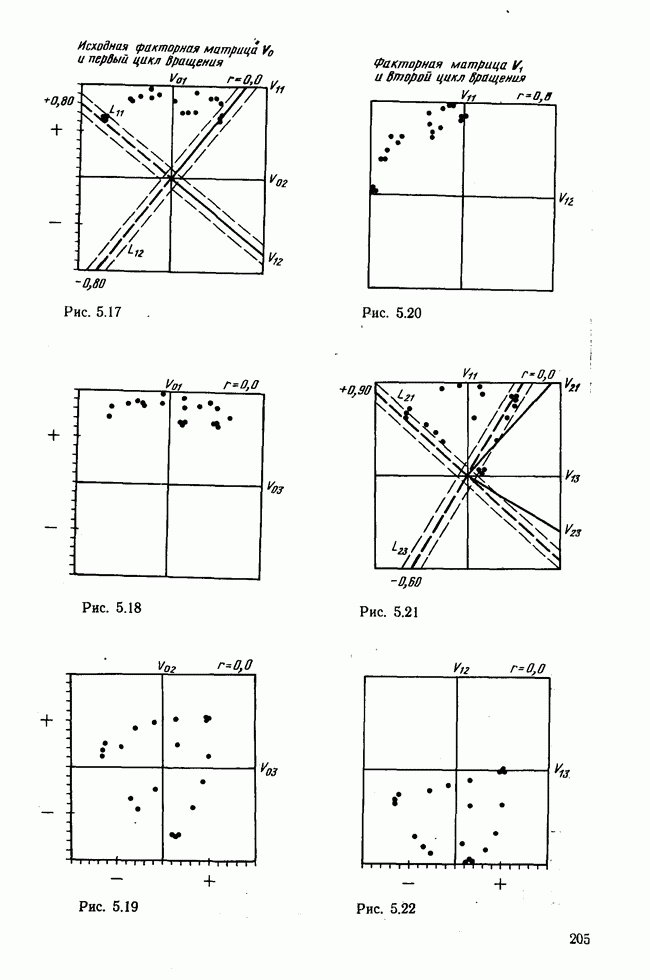




















































































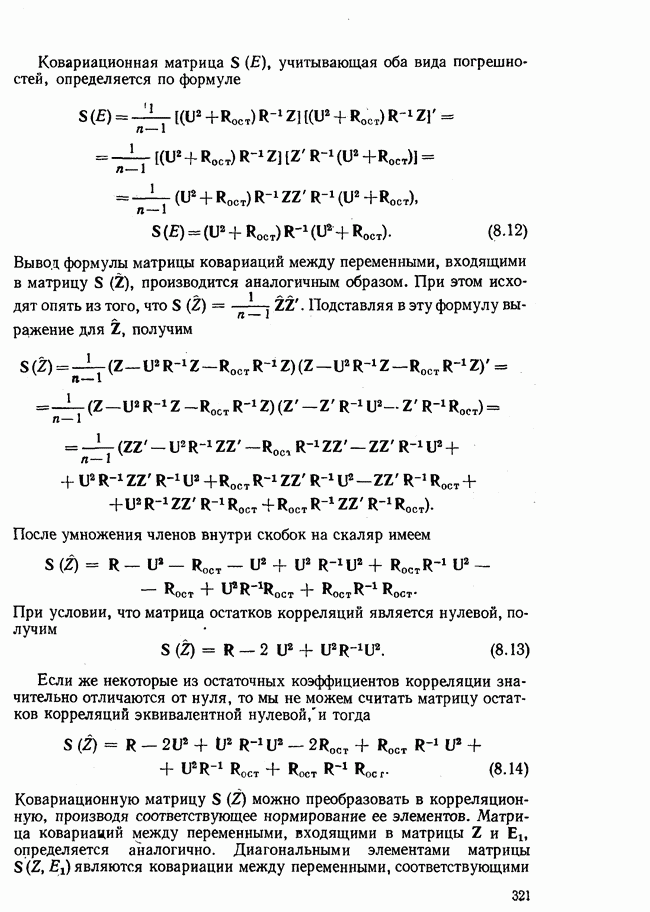






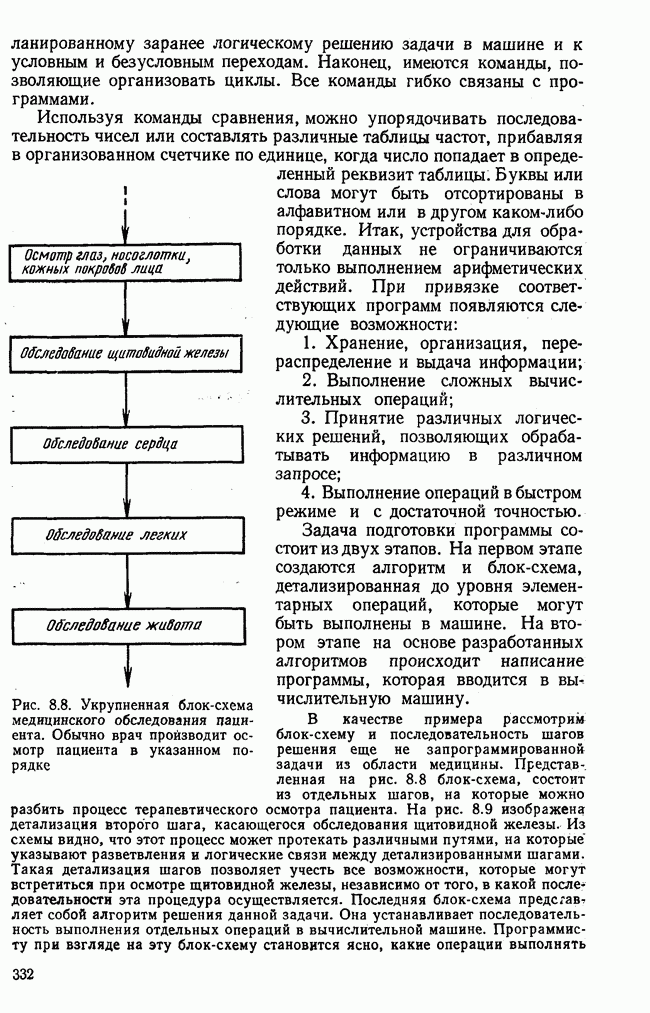
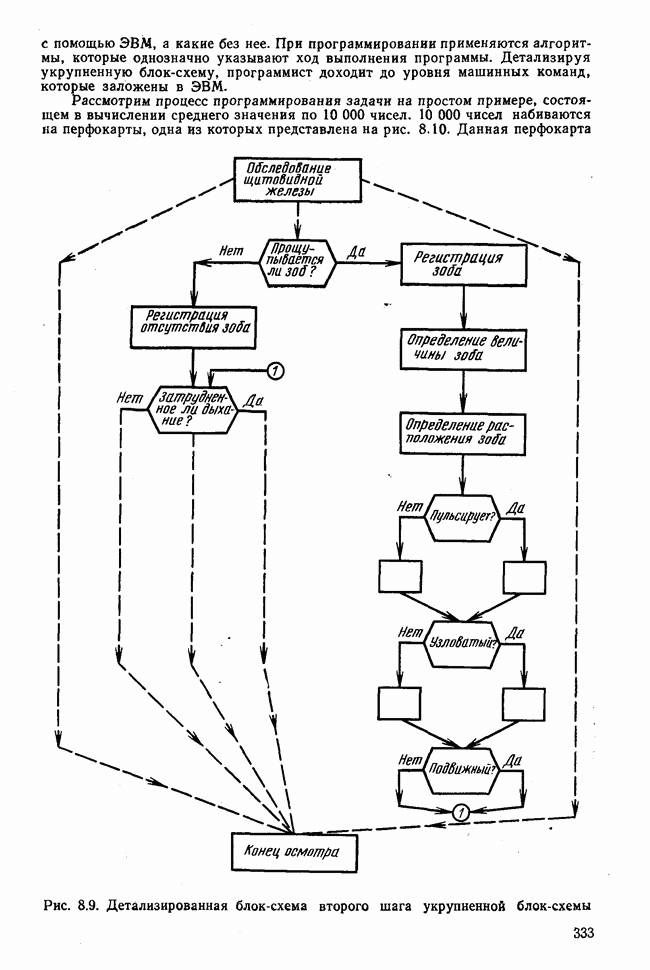

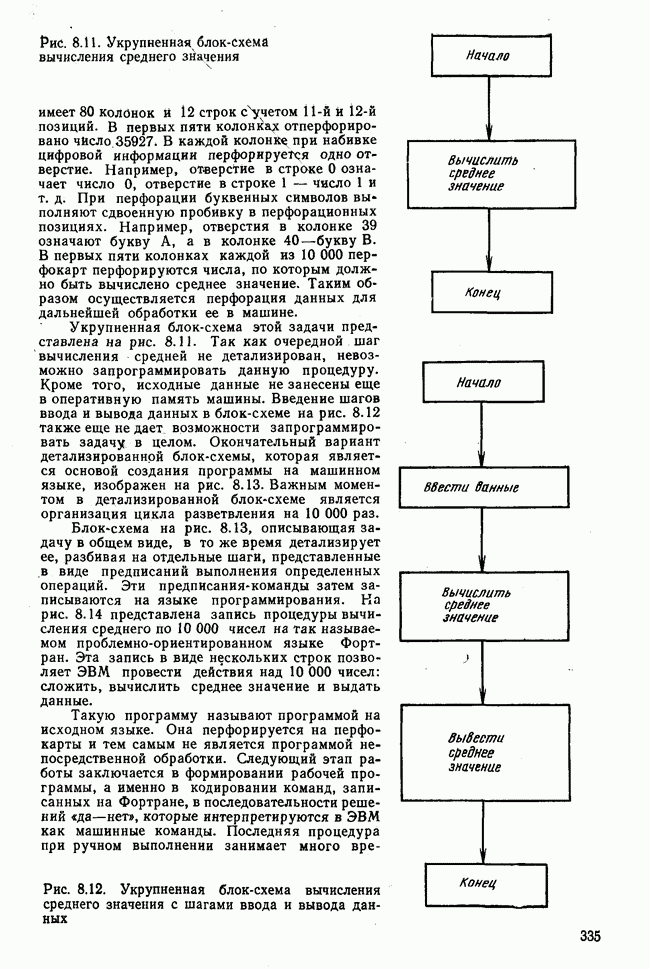
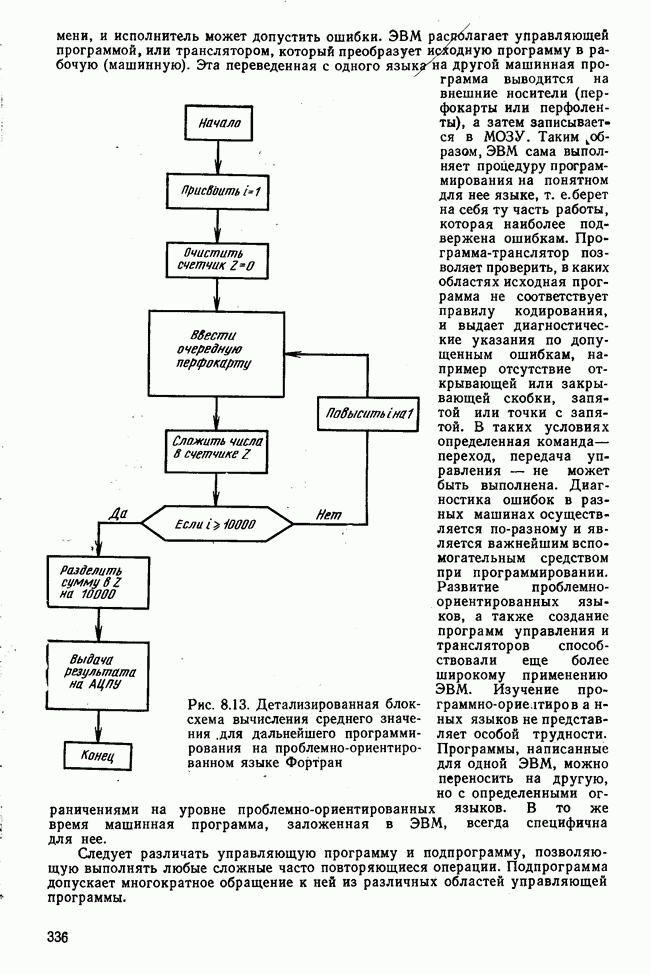















































 элементы которого являются первыми приближениями значений элементов собственных векторов. Вектор
элементы которого являются первыми приближениями значений элементов собственных векторов. Вектор  перемножается с матрицей R по формуле (3.8). Разделив элементы результирующего вектора
перемножается с матрицей R по формуле (3.8). Разделив элементы результирующего вектора  на наибольший по величине элемент этого же вектора (формула (3.9)), получаем новый вектор
на наибольший по величине элемент этого же вектора (формула (3.9)), получаем новый вектор  с которым опять повторяется процедура (3.8). Верхние индексы в скобках означают здесь шаг итерации.
с которым опять повторяется процедура (3.8). Верхние индексы в скобках означают здесь шаг итерации.

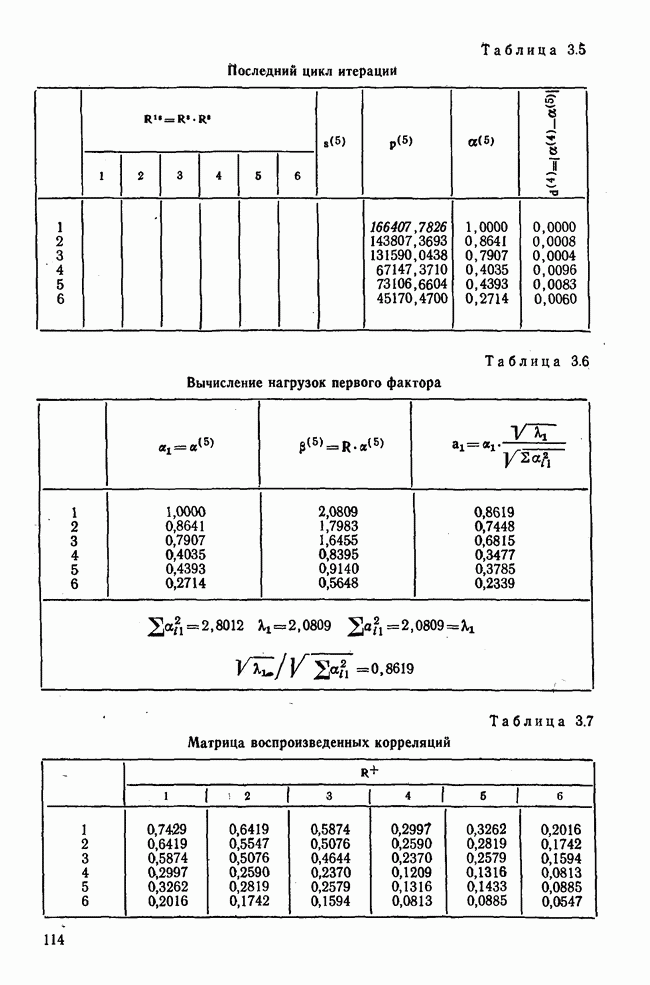
 ) и соответствующему первому собственному вектору
) и соответствующему первому собственному вектору  Формула (3.10) является общей формулой для k шагов. Итеративный процесс заканчивается, когда
Формула (3.10) является общей формулой для k шагов. Итеративный процесс заканчивается, когда  и с достаточной точностью совпадают друг с другом.
и с достаточной точностью совпадают друг с другом.
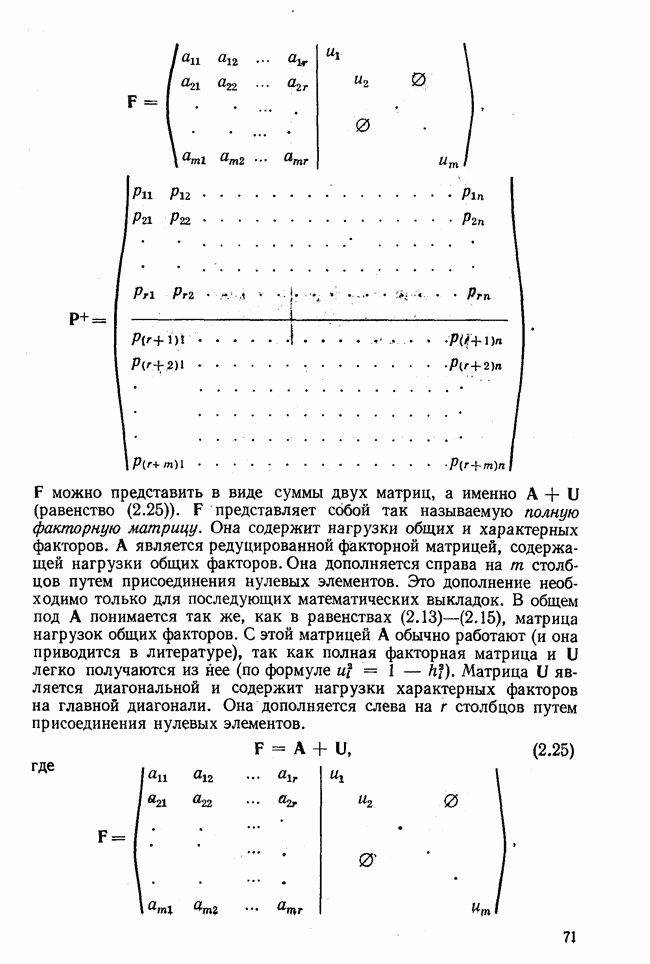
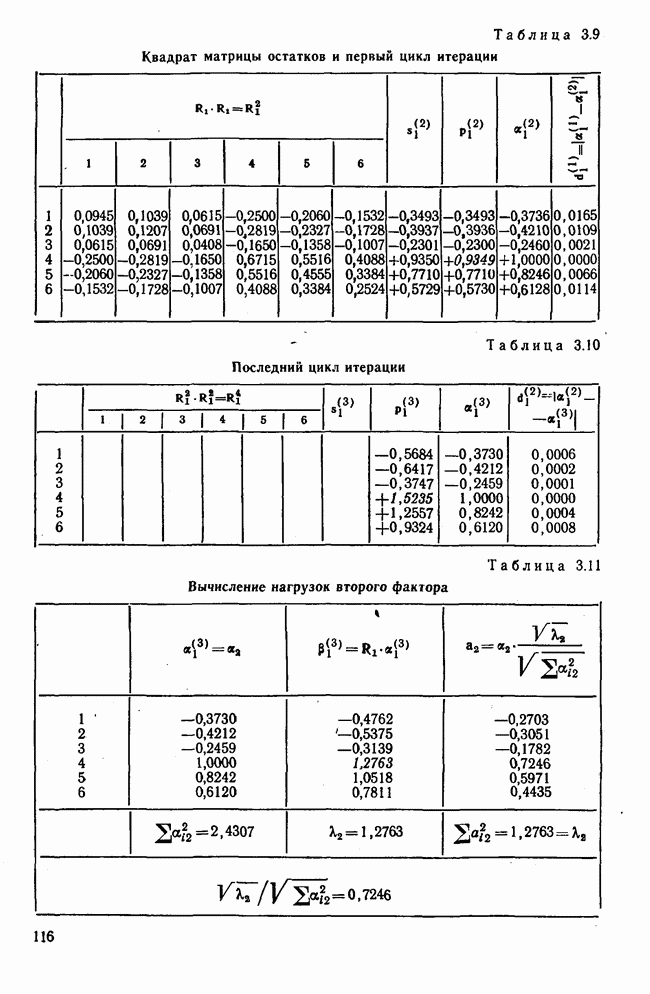
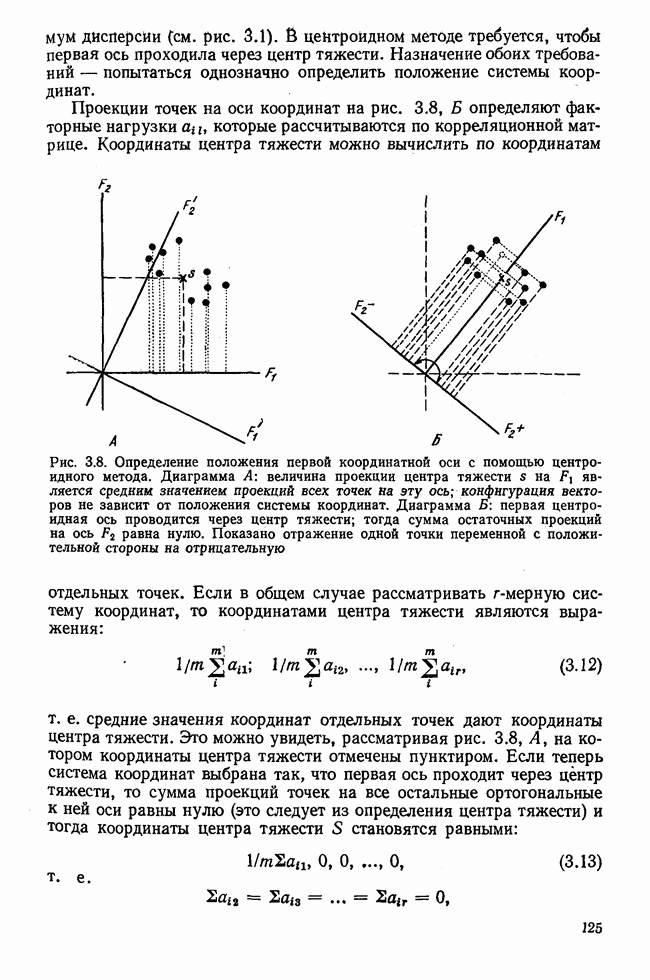
 используются величины, пропорциональные суммам элементов строк матрицы R. Исходя из полученных значений элементов собственного вектора и собственного значения по формуле (3.7) вычисляются нагрузки первого фактора
используются величины, пропорциональные суммам элементов строк матрицы R. Исходя из полученных значений элементов собственного вектора и собственного значения по формуле (3.7) вычисляются нагрузки первого фактора  которые затем служат для определения
которые затем служат для определения  Матрица
Матрица  является матрицей коэффициентов корреляции, вычисленных с учетом только первого фактора. Остаточная матрица в общем виде определяется так:
является матрицей коэффициентов корреляции, вычисленных с учетом только первого фактора. Остаточная матрица в общем виде определяется так:  Если принимают решение вычислять нагрузки второго фактора, то повторяется аналогичная процедура с
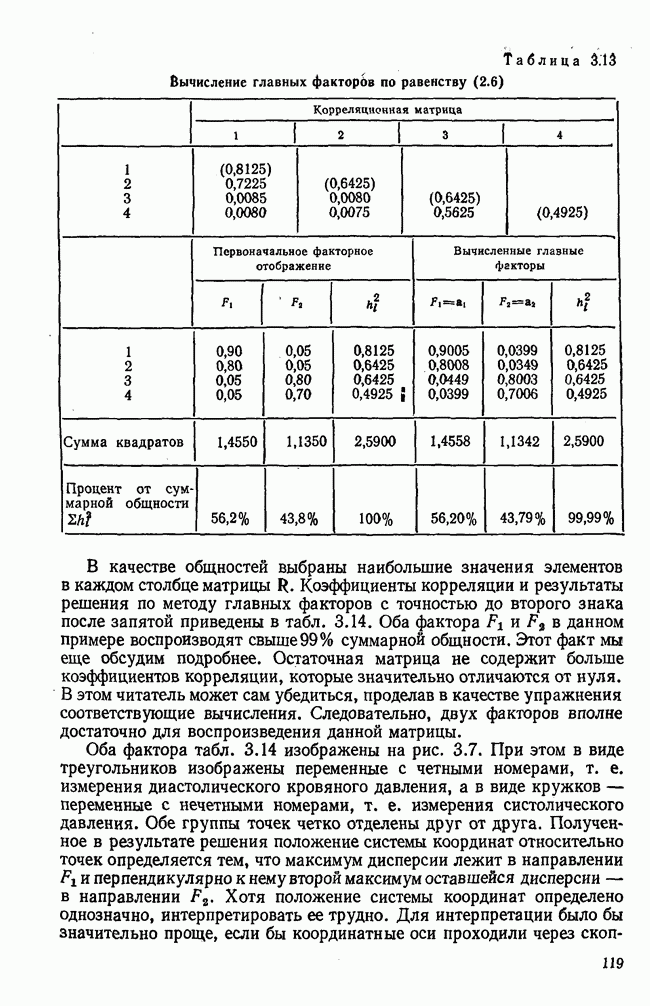
Если принимают решение вычислять нагрузки второго фактора, то повторяется аналогичная процедура с  до получения второго собственного значения и второго собственного вектора. Процесс выделения факторов можно продолжить и дальше.
до получения второго собственного значения и второго собственного вектора. Процесс выделения факторов можно продолжить и дальше.
 или
или  то скорость сходимости повышается соответственно в два, четыре или восемь раз, что равносильно сокращению числа итераций в такое же
то скорость сходимости повышается соответственно в два, четыре или восемь раз, что равносильно сокращению числа итераций в такое же  раз. При этом
раз. При этом  означает четырехкратное перемножение матрицы, а именно
означает четырехкратное перемножение матрицы, а именно  а не возведение в четвертую степень ее элементов. Это трудоемкая работа.
а не возведение в четвертую степень ее элементов. Это трудоемкая работа.

 Затем мы не сразу приступаем к выполнению операции (3.8). Сначала для ускорения процесса сходимости умножаем матрицу R саму на себя, что отражено в табл. 3.2. В силу симметрии матрицы
Затем мы не сразу приступаем к выполнению операции (3.8). Сначала для ускорения процесса сходимости умножаем матрицу R саму на себя, что отражено в табл. 3.2. В силу симметрии матрицы  приходится вычислять только диагональные элементы и элементы выше или ниже главной диагонали. Далее опять образуем суммы из элементов строк
приходится вычислять только диагональные элементы и элементы выше или ниже главной диагонали. Далее опять образуем суммы из элементов строк  . Для проверки правильности вычислений заполняется столбец
. Для проверки правильности вычислений заполняется столбец  элементы которого с точностью до ошибок округления должны равняться соответствующим суммам
элементы которого с точностью до ошибок округления должны равняться соответствующим суммам  Таким образом, элементы контрольного столбца
Таким образом, элементы контрольного столбца  в табл. 3.2 определяются по данным табл. 3.1 путем перемножения R с
в табл. 3.2 определяются по данным табл. 3.1 путем перемножения R с  . В нашем примере
. В нашем примере  хорошо согласуются друг с другом, следовательно, квадрат корреляционной матрицы вычислен верно.
хорошо согласуются друг с другом, следовательно, квадрат корреляционной матрицы вычислен верно.

 , элементы которого получаются делением элементов
, элементы которого получаются делением элементов  на наибольший из них (следующий столбец табл. 3.2).
на наибольший из них (следующий столбец табл. 3.2).

 . Различие между двумя векторами еще относительно велико. Если бы разница между приближениями значений элементов собственного вектора не превышала 0,005, дальнейшие вычисления можно было бы прекратить. Но в данном случае требуется следующий цикл итерации.
. Различие между двумя векторами еще относительно велико. Если бы разница между приближениями значений элементов собственного вектора не превышала 0,005, дальнейшие вычисления можно было бы прекратить. Но в данном случае требуется следующий цикл итерации.
 . В принципе повторяется процедура вычислений, приведенных в табл. 3.1 и 3.2. Однако лучше начинать с вычисления контрольного столбца. Вектор
. В принципе повторяется процедура вычислений, приведенных в табл. 3.1 и 3.2. Однако лучше начинать с вычисления контрольного столбца. Вектор  в табл. 3.3 определяется по данным табл. 3.2 как
в табл. 3.3 определяется по данным табл. 3.2 как  Разделив значения элементов вектора
Разделив значения элементов вектора  на наибольшее из них, получим вектор следующего приближения
на наибольшее из них, получим вектор следующего приближения  Разница
Разница  вычислена в последнем столбце табл. 3.3. Разница все
вычислена в последнем столбце табл. 3.3. Разница все  велика, следовательно, требуется следующий цикл. Если бы не это обстоятельство, можно было обойтись без определения
велика, следовательно, требуется следующий цикл. Если бы не это обстоятельство, можно было обойтись без определения  . Итак, по табл. 3.2 вычисляем
. Итак, по табл. 3.2 вычисляем  и заносим
и заносим  в табл. 3.3. Получив первый столбец и строку матрицы
в табл. 3.3. Получив первый столбец и строку матрицы  вычисляем сумму элементов первой строки. Если эта сумма не согласуется с первым элементом вектора
вычисляем сумму элементов первой строки. Если эта сумма не согласуется с первым элементом вектора  , то это свидетельствует об арифметической ошибке и нужно ее устранить. Затем приступают к вычислению второго столбца и строки матрицы
, то это свидетельствует об арифметической ошибке и нужно ее устранить. Затем приступают к вычислению второго столбца и строки матрицы  . При этом нужно вычислить только пять новых элементов. Если и обнаруживается ошибка в вычислении (при сравнении с элементом
. При этом нужно вычислить только пять новых элементов. Если и обнаруживается ошибка в вычислении (при сравнении с элементом  ), то она может быть допущена не более, чем в пяти скалярных произведениях. Так, последовательно, строка за строкой, определяется и одновременно проверяется вся матрица
), то она может быть допущена не более, чем в пяти скалярных произведениях. Так, последовательно, строка за строкой, определяется и одновременно проверяется вся матрица  причем возможности допущения ошибок все больше и больше сужаются и тем самым экономится время на поиск этих ошибок. Ни в коем случае нельзя производить дальнейшие вычисления, если разница в и
причем возможности допущения ошибок все больше и больше сужаются и тем самым экономится время на поиск этих ошибок. Ни в коем случае нельзя производить дальнейшие вычисления, если разница в и  превосходит ошибку округления.
превосходит ошибку округления.
 уже довольно малы. Контрольный столбец в табл. 3.5 получаем как
уже довольно малы. Контрольный столбец в табл. 3.5 получаем как  . Все элементы вектора
. Все элементы вектора  меньше 0,01, так что на этом мы прекратим вычисления.
меньше 0,01, так что на этом мы прекратим вычисления.

 . Сумма квадратов элементов этого вектора
. Сумма квадратов элементов этого вектора  Далее по формуле (3.8) определяем вектор
Далее по формуле (3.8) определяем вектор  наибольший элемент которого является первым собственным значением
наибольший элемент которого является первым собственным значением  . В последнем столбце таблицы по формуле (3.7) вычисляются факторные нагрузки. Целесообразнее всего это производить, умножая каждое значение первого столбца на
. В последнем столбце таблицы по формуле (3.7) вычисляются факторные нагрузки. Целесообразнее всего это производить, умножая каждое значение первого столбца на  Матрица воспроизведенных корреляций
Матрица воспроизведенных корреляций  приведена в табл. 3.7, остаточная матрица
приведена в табл. 3.7, остаточная матрица  - в табл. 3.8.
- в табл. 3.8.






 построена так же, как предыдущие таблицы. Нижний индекс векторов
построена так же, как предыдущие таблицы. Нижний индекс векторов  указывает на то, что они относятся к остаточной матрице первого фактора. В остальном процедура вычислений аналогична выделению первого фактора. Разницы между приближениями двух векторов, приведенные в последнем столбце, малы.
указывает на то, что они относятся к остаточной матрице первого фактора. В остальном процедура вычислений аналогична выделению первого фактора. Разницы между приближениями двух векторов, приведенные в последнем столбце, малы.
 заносятся в табл. 3.10. Вектор
заносятся в табл. 3.10. Вектор  определяется также, как было показано выше. Различие между
определяется также, как было показано выше. Различие между  так мало, что нецелесообразно повторять цикл. Поэтому не имеет смысла определять
так мало, что нецелесообразно повторять цикл. Поэтому не имеет смысла определять  в табл. 3.10 и предусмотренная для этого часть таблицы остается не заполненной. Со вторым собственным вектором
в табл. 3.10 и предусмотренная для этого часть таблицы остается не заполненной. Со вторым собственным вектором  входим в табл. 3.11, совершенно аналогичную табл. 3.6, для определения факторных нагрузок. Опять определяем сумму квадратов элементов первого столбца. Наибольший элемент вектора является вторым собственным значением
входим в табл. 3.11, совершенно аналогичную табл. 3.6, для определения факторных нагрузок. Опять определяем сумму квадратов элементов первого столбца. Наибольший элемент вектора является вторым собственным значением  . В третьем столбце вычисляются нагрузки второго фактора. И наконец, в табл. 3.12 приведена матрица вторых остаточных коэффициентов корреляции
. В третьем столбце вычисляются нагрузки второго фактора. И наконец, в табл. 3.12 приведена матрица вторых остаточных коэффициентов корреляции  после выделения второго фактора, которая определяется как разность
после выделения второго фактора, которая определяется как разность  а.
а.




