5.4. Функционалы качества разбиения на классы и экстремальная постановка задачи кластер-анализа. Связь с теорией статистического оценивания параметров
Естественно попытаться определить сравнительное качество различных способов разбиения заданной совокупности элементов на классы, т. е. определить тот количественный критерий, следуя которому можно было бы предпочесть одно разбиение другому.
С этой целью в постановку задачи кластер-анализа часто вводится понятие так называемого функционала качества разбиения  , определенного на множестве всех возможных разбиений. Функционалом он называется потому, что чаще всего разбиение S задается, вообще говоря, набором дискриминантных функций
, определенного на множестве всех возможных разбиений. Функционалом он называется потому, что чаще всего разбиение S задается, вообще говоря, набором дискриминантных функций  . Тогда под наилучшим разбиением S понимается то разбиение, на котором достигается экстремум выбранного функционала качества. Выбор того или иного функционала качества, как правило, осуществляется весьма произвольно и опирается скорее на эмпирические и профессионально-интуитивные соображения, чем на какую-либо строгую формализованную систему.
. Тогда под наилучшим разбиением S понимается то разбиение, на котором достигается экстремум выбранного функционала качества. Выбор того или иного функционала качества, как правило, осуществляется весьма произвольно и опирается скорее на эмпирические и профессионально-интуитивные соображения, чем на какую-либо строгую формализованную систему.
Приведем примеры наиболее распространенных функционалов качества разбиения и попытаемся обосновать выбор некоторых из них в рамках одной из моделей статистического оценивания параметров.
5.4.1. Функционалы качества разбиения при заданном числе классов.
Пусть исследователем уже выбрана метрика d в пространстве  и пусть
и пусть  — некоторое фиксированное разбиение наблюдений
— некоторое фиксированное разбиение наблюдений  на заданное число k классов
на заданное число k классов 
За функционалы качества часто берутся следующие характеристики:
сумма («взвешенная») внутриклассовых дисперсий

весьма широко используется в задачах кластер-анализа в качестве критерийной оценки разбиения [268];
сумма попарных внутриклассовых расстояний между элементами

либо

в большинстве ситуаций приводит к тем же наилучшим разбиениям, что и  и тоже используется для сравнения кластер-процедур [228];
и тоже используется для сравнения кластер-процедур [228];
обобщенная внутриклассовая дисперсия  является, как известно [16, с. 231], одной из характеристик степени рассеивания многомерных наблюдений одного класса (генеральной совокупности) около своего «центра тяжести».
является, как известно [16, с. 231], одной из характеристик степени рассеивания многомерных наблюдений одного класса (генеральной совокупности) около своего «центра тяжести».
Следуя обычным правилам вычисления выборочной ковариационной матрицы W и отдельно по наблюдениям, попавшим в какой-то один класс  получаем
получаем

где под  понимается «определитель матрицы А», а элементы
понимается «определитель матрицы А», а элементы  выборочной ковариационной матрицы W класса
выборочной ковариационной матрицы W класса  подсчитываются по формуле
подсчитываются по формуле

где  компонента многомерного наблюдения
компонента многомерного наблюдения  — среднее значение
— среднее значение  компоненты, подсчитанное по наблюдениям
компоненты, подсчитанное по наблюдениям  класса.
класса.
Встречается и другой вариант использования понятия обобщенной дисперсии как характеристики качества разбиения, в котором операция суммирования  по классам заменена операцией умножения
по классам заменена операцией умножения

Как видно из формул (5.12) и (5.13), функционал  является средней арифметической (по всем классам) характеристикой обобщенной внутриклассовой дисперсии, в то время как функционал
является средней арифметической (по всем классам) характеристикой обобщенной внутриклассовой дисперсии, в то время как функционал  пропорционален средней геометрической характеристике тех же величин.
пропорционален средней геометрической характеристике тех же величин.
Использование функционалов  является особенно уместным в ситуациях, при которых исследователь в первую очередь задается вопросом: не сосредоточены ли наблюдения, разбитые на классы
является особенно уместным в ситуациях, при которых исследователь в первую очередь задается вопросом: не сосредоточены ли наблюдения, разбитые на классы  в пространстве размерности, меньшей, чем
в пространстве размерности, меньшей, чем  ?
?
Замечание. При теоретико-вероятностной модификации схем кластер-анализа соответственно видоизменится запись приведенных выше функционалов. Так, например,

где

или

5.4.2. Функционалы качества разбиения при неизвестном числе классов.
В ситуациях, когда исследователю заранее не известно, на какое число классов подразделяются исходные многомерные наблюдения  функционалы качества разбиения
функционалы качества разбиения  выбирают чаще всего в виде простой алгебраической комбинации (суммы, разности, произведения, отношения) двух функционалов
выбирают чаще всего в виде простой алгебраической комбинации (суммы, разности, произведения, отношения) двух функционалов  и
и  один из которых
один из которых  является убывающей (невозрастающей) функцией числа классов k и характеризует, как правило, внутриклассовый разброс наблюдений, а второй
является убывающей (невозрастающей) функцией числа классов k и характеризует, как правило, внутриклассовый разброс наблюдений, а второй  — возрастающей (неубывающей) функцией числа классов k. При этом интерпретация функционала
— возрастающей (неубывающей) функцией числа классов k. При этом интерпретация функционала  может быть различной. Под
может быть различной. Под  понимается иногда и некоторая мера взаимной удаленности (близости) классов, и мера тех потерь, которые приходится нести исследователю при излишней детализации рассматриваемого массива исходных наблюдений, и величина, обратная так называемой «мере концентрации» всей структуры точек, полученной при разбиении исследуемого множества наблюдений на k классов. В [218], например, предлагается брать
понимается иногда и некоторая мера взаимной удаленности (близости) классов, и мера тех потерь, которые приходится нести исследователю при излишней детализации рассматриваемого массива исходных наблюдений, и величина, обратная так называемой «мере концентрации» всей структуры точек, полученной при разбиении исследуемого множества наблюдений на k классов. В [218], например, предлагается брать

и

где  — число классов, получающихся при разбиении S, а с — некоторая положительная постоянная, характеризующая потери исследователя при увеличении числа классов на единицу.
— число классов, получающихся при разбиении S, а с — некоторая положительная постоянная, характеризующая потери исследователя при увеличении числа классов на единицу.
Другой вариант функционалов качества такого типа можно найти, например, в [57], где полагают

Здесь  — упомянутая выше потенциальная функция, а
— упомянутая выше потенциальная функция, а  — мера близости
— мера близости  классов, основанная на потенциальной функции (5.6).
классов, основанная на потенциальной функции (5.6).
Очевидно, в первом случае будем искать разбиение S, минимизирующее значение функционала

в то время как во втором случае требуется найти разбиение  которое максимизировало бы значение функционала
которое максимизировало бы значение функционала

Весьма [ибким и достаточно общим подходом, реализующим идею одновременного учета двух функционалов, является подход, основанный на схеме, предложенной А.Н. Колмогоровым. Эта схема опирается на понятия меры концентрации  точек, соответствующей разбиению S, и средней меры внутриклассового рассеяния
точек, соответствующей разбиению S, и средней меры внутриклассового рассеяния  , характеризующей то же разбиение
, характеризующей то же разбиение 
Под мерой концентрации  предлагается понимать степенное среднее (см. § 5.3) вида
предлагается понимать степенное среднее (см. § 5.3) вида

где  — число элементов в кластере, содержащем точку X, а выбор числового параметра
— число элементов в кластере, содержащем точку X, а выбор числового параметра  находится в распоряжении исследователя и зависит от конкретных целей разбиения. При выборе
находится в распоряжении исследователя и зависит от конкретных целей разбиения. При выборе  полезно иметь в виду следующие частные случаи
полезно иметь в виду следующие частные случаи 

где k — число различных кластеров в разбиении S;  — естественная информационная мера концентрации;
— естественная информационная мера концентрации;

Заметим, что при любом  предложенная мера концентрации имеет минимальное значение, равное
предложенная мера концентрации имеет минимальное значение, равное  при разбиении исследуемого множества на
при разбиении исследуемого множества на  одноточечных кластеров, и максимальное значение, равное
одноточечных кластеров, и максимальное значение, равное  , при объединении всех исходных наблюдений в один общий кластер.
, при объединении всех исходных наблюдений в один общий кластер.
При конструировании и сравнении различных кластер-процедур полезно иметь в виду, что объединение двух кластеров  в один дает прирост меры концентрации
в один дает прирост меры концентрации  равный
равный

Определение средней меры внутриклассового рассеяния  также опирается на понятие степенного среднего. В частности, полагают
также опирается на понятие степенного среднего. В частности, полагают

где

понимается обобщенная средняя мера рассеяния, характеризующая класс  Числовой параметр
Числовой параметр  здесь, как и прежде, выбирается по усмотрению исследователя. Полагая
здесь, как и прежде, выбирается по усмотрению исследователя. Полагая

где, как и прежде,  - кластер, в который входит наблюдение X, a
- кластер, в который входит наблюдение X, a  — число элементов в кластере
— число элементов в кластере  , формулу (5.18) можно переписать в виде
, формулу (5.18) можно переписать в виде

При конструировании и сравнении различных кластер-процедур полезно иметь в виду, что объединение двух кластеров  в один дает прирост величины
в один дает прирост величины  непосредственно характеризующей среднюю меру внутриклассового рассеяния, равный
непосредственно характеризующей среднюю меру внутриклассового рассеяния, равный

Очевидно, если ориентироваться на сокращение числа кластеров при наименьших потерях в отношении внутриклассового рассеивания, не обращая внимания на меру концентрации, то естественно объединять два кластера, для которых минимальна величина  . Если же одновременно ориентироваться и на рост взвешенной концентрации
. Если же одновременно ориентироваться и на рост взвешенной концентрации  то объединение кластеров следует подчинить требованию минимизации величины
то объединение кластеров следует подчинить требованию минимизации величины

5.4.3. Формулировка экстремальных задач разбиения исходного множества объектов на классы при неизвестном числе классов.
Возможно множество вариантов таких формулировок. Рассмотрим два из них, относящиеся к наиболее естественным и часто используемым.
Вариант 1: комбинирование функционалов качества. Требуется найти такое разбиение S, для которого некоторая алгебраическая комбинация функционала, характеризующего среднее внутриклассовое рассеяние (5.19), и функционала, характеризующего меру концентрации полученной структуры (5.17), достигала бы своего экстремума.
В качестве примеров можно привести комбинации  задаваемые формулами (5.15) и (5.16), а также более общие выражения вида
задаваемые формулами (5.15) и (5.16), а также более общие выражения вида

где  - некоторые положительные константы, например
- некоторые положительные константы, например 
Вариант 2: двойственная формулировка. Требуется найти разбиение S, которое, обладая концентрацией  не меньшей заданного порогового значения
не меньшей заданного порогового значения  давало бы наименьшее внутриклассовое рассеяние
давало бы наименьшее внутриклассовое рассеяние  или, в двойственной подстановке: при заданном пороговом значении
или, в двойственной подстановке: при заданном пороговом значении  найти разбиение S с внутриклассовым рассеянием
найти разбиение S с внутриклассовым рассеянием  и наибольшей концентрацией
и наибольшей концентрацией 
5.4.4. Общий вид функционала качества разбиения как функции ряда параметров, характеризующих межклассовую и внутриклассовую структуру наблюдений.
Зададимся вопросом, нельзя ли выделить такой достаточно полный набор величин их  характеризующих как межклассовую, так и внутриклассовую структуру наблюдений при каждом фиксированном разбиении на классы S, чтобы существовала некоторая функция
характеризующих как межклассовую, так и внутриклассовую структуру наблюдений при каждом фиксированном разбиении на классы S, чтобы существовала некоторая функция  от этих величин, которую мы могли бы считать в каком-то смысле универсальной характеристикой качества разбиения. В частности, в качестве таких величин
от этих величин, которую мы могли бы считать в каком-то смысле универсальной характеристикой качества разбиения. В частности, в качестве таких величин  можно рассмотреть, например, некоторые числовые характеристики: степени близости элементов внутри классов (их); степени удаленности классов друг от друга
можно рассмотреть, например, некоторые числовые характеристики: степени близости элементов внутри классов (их); степени удаленности классов друг от друга  ; степени «одинаковости» распределения многомерных наблюдений внутри классов
; степени «одинаковости» распределения многомерных наблюдений внутри классов  степени равномерности распределения общего числа классифицируемых наблюдений
степени равномерности распределения общего числа классифицируемых наблюдений  по классам
по классам 
Что касается установления общего вида функции  то без введения дополнительной априорной информации о наблюдениях
то без введения дополнительной априорной информации о наблюдениях  (характере и общем виде их закона распределения внутри классов и
(характере и общем виде их закона распределения внутри классов и  единственным возможным подходом в решении этой задачи, как нам представляется, является экспертно-экспериментальное исследование Именно с этих позиций в [63] сделана попытка определения общего вида функции Q. Чтобы определить рассмотренные в этой работе величины
единственным возможным подходом в решении этой задачи, как нам представляется, является экспертно-экспериментальное исследование Именно с этих позиций в [63] сделана попытка определения общего вида функции Q. Чтобы определить рассмотренные в этой работе величины  введем понятие кратчайшего незамкнутого пути (КНП), соединяющего все
введем понятие кратчайшего незамкнутого пути (КНП), соединяющего все  точек исходной совокупности в связный неориентированный граф с минимальной суммарной длиной
точек исходной совокупности в связный неориентированный граф с минимальной суммарной длиной 
Под длиной ребра понимается расстояние между соответствующими точками совокупности в смысле выбранной метрики. Построение такого графа можно начать с пары наиболее близких точек. Если таких пар несколько, то выбирается любая из этих пар. Пусть это будут наблюдения с номерами  Затем с помощью сравнения расстояний
Затем с помощью сравнения расстояний  , где
, где  определяются точки
определяются точки  наименее удаленные соответственно от точек
наименее удаленные соответственно от точек  и выбирается ближайшая из них
и выбирается ближайшая из них  если
если  если
если  Затем точка
Затем точка  «пристраивается» к той из точек
«пристраивается» к той из точек  к которой она ближе. Далее сравниваются расстояния
к которой она ближе. Далее сравниваются расстояния  и т. д. Очевидно, «разрубая» s ребер такого графа, будем делить совокупность на
и т. д. Очевидно, «разрубая» s ребер такого графа, будем делить совокупность на  классов.
классов.

Рис. 5.2. Графическое изображение кратчайшего незамкнутого пути
Пусть  ребро части графа, отнесенной к
ребро части графа, отнесенной к  классу. Всего таких ребер, как легко видеть, будет
классу. Всего таких ребер, как легко видеть, будет  . И пусть
. И пусть  — минимальное из ребер, непосредственно примыкающих к ребру
— минимальное из ребер, непосредственно примыкающих к ребру  и относящихся к
и относящихся к  классу, если таковое имеется. Пронумеруем в определенном порядке граничные, («разрубленные») ребра
классу, если таковое имеется. Пронумеруем в определенном порядке граничные, («разрубленные») ребра  , таким образом, чтобы имелось взаимно однозначное соответствие между номерами граничных ребер и номерами примыкающих к ним классов, за исключением одного, геометрически представленного одним из «хвостов» графа. Выбрасывая ребра I, II, III (рис. 5.2), получаем четыре связных графа, что соответствует разбиению совокупности на четыре группы.
, таким образом, чтобы имелось взаимно однозначное соответствие между номерами граничных ребер и номерами примыкающих к ним классов, за исключением одного, геометрически представленного одним из «хвостов» графа. Выбрасывая ребра I, II, III (рис. 5.2), получаем четыре связных графа, что соответствует разбиению совокупности на четыре группы.
Обозначим с помощью одно из таких ребер  класса.
класса.
Теперь, следуя [63], определим величины  таким образом:
таким образом:

где  — средняя длина ребер
— средняя длина ребер  класса;
класса;

Эмпирический перебор различных вариантов общего вида функции в сочетании с анализом результатов экспертных оценок качества всевозможных разбиений привели авторов [63] к следующей формуле для функционала:
 (5.21)
(5.21)
где a, b, с и d — некоторые неотрицательные параметры, оставляющие исследователю определенную свободу выбора в каждом конкретном случае. Авторы [63] отмечали хорошее согласие своих экспериментов с экспертными оценками при  .
.
Из смысла величин  следует, что лучшим разбиениям соответствуют большие численные значения функционала Q, так что в данном случае требуется найти такое разбиение S, при котором
следует, что лучшим разбиениям соответствуют большие численные значения функционала Q, так что в данном случае требуется найти такое разбиение S, при котором  .
.
Конечно, данный выбор количественного и качественного состава величин  и, в еще большей степени, их точное определение являются чисто эвристическими и подчас просто спорными. Это относится в первую очередь к величине
и, в еще большей степени, их точное определение являются чисто эвристическими и подчас просто спорными. Это относится в первую очередь к величине  Поэтому читатель должен принимать описанную здесь схему не как рекомендацию к универсальному использованию функционалов типа (5.21) в задачах кластер-анализа, а лишь как описание конкретного примера одного из возможных подходов при выборе функционалов качества пазбиения.
Поэтому читатель должен принимать описанную здесь схему не как рекомендацию к универсальному использованию функционалов типа (5.21) в задачах кластер-анализа, а лишь как описание конкретного примера одного из возможных подходов при выборе функционалов качества пазбиения.
5.4.5. Функционалы качества и необходимые условия оптимальности разбиения.
Естественно попытаться проследить, в какой мере выбор того или иного вида функционала качества определяет класс разбиений, в котором следует искать оптимальное. Приведем здесь некоторые результаты, устанавливающие такого рода соответствие.
Будем предполагать используемую метрику евклидовой. Обозначим через  группу из
группу из  -мерных векторов
-мерных векторов  ,
,  а через
а через  так называемое минимальное дистанционное разбиение, порождаемое точками
так называемое минимальное дистанционное разбиение, порождаемое точками  а именно
а именно

(Здесь и в дальнейшем  означает дополнение множества
означает дополнение множества  до всего пространства
до всего пространства  , т. е. совокупность всех наблюдений (элементов пространства
, т. е. совокупность всех наблюдений (элементов пространства  , не входящих в состав
, не входящих в состав  .) Таким образом, класс
.) Таким образом, класс  состоит из тех точек пространства
состоит из тех точек пространства  , которые ближе к
, которые ближе к  чем ко всем остальным
чем ко всем остальным  . Если для некоторых точек из
. Если для некоторых точек из  самыми близкими являются сразу несколько векторов
самыми близкими являются сразу несколько векторов  , то эти точки относим к классу с минимальным индексом.
, то эти точки относим к классу с минимальным индексом.
Разбиение  называется несмещенным, если это разбиение с точностью до множеств меры нуль совпадает с минимальным дистанционным разбиением, по рождаемым векторами средних
называется несмещенным, если это разбиение с точностью до множеств меры нуль совпадает с минимальным дистанционным разбиением, по рождаемым векторами средних 
Утверждение 1 (для функционалов типа (см. (5.11))). Минимальное значение функционала  достигается только на несмещенных разбиениях. Это означает, что оптимальное разбиение обязательно должно быть несмещенным [166].
достигается только на несмещенных разбиениях. Это означает, что оптимальное разбиение обязательно должно быть несмещенным [166].
Следующий результат относится к довольно широкому классу функционалов качества разбиения совокупности на два класса.
Разбиение на два класса может быть задано с помощью так называемой разделяющей функции. А именно точки пространства  , на которых разделяющая функция принимает неотрицательное значение, относятся к одному классу, а остальные — к другому. Поэтому поиск класса оптимальных разбиений в этом случае эквивалентен поиску класса оптимальных разделяющих функций.
, на которых разделяющая функция принимает неотрицательное значение, относятся к одному классу, а остальные — к другому. Поэтому поиск класса оптимальных разбиений в этом случае эквивалентен поиску класса оптимальных разделяющих функций.
Для иллюстрации дальнейшего изложения будем рассматривать вероятностную модификацию функционала  {см. (5.14)).
{см. (5.14)).
Пусть расстояние d (X, У) задается с помощью соотношения (5.3) потенциальной функцией вида

где  — некоторая система функций на
— некоторая система функций на  .
.
Функционал  через потенциальную функцию
через потенциальную функцию  выражается следующим образом:
выражается следующим образом:

Поскольку в правой части этого равенства первый интеграл не зависит от разбиения, то минимум функционала  достигается на тех разбиениях, на которых функционал
достигается на тех разбиениях, на которых функционал

достигает максимума.
Введем в рассмотрение спрямляющее пространство  координаты
координаты  векторов
векторов  которого определяются соотношениями
которого определяются соотношениями

В спрямляющем пространстве  вероятностной мерой Р, заданной в исходном пространстве
вероятностной мерой Р, заданной в исходном пространстве  , индуцируется своя вероятностная мера
, индуцируется своя вероятностная мера 
Однако в целях упрощения обозначений будем опускать верхний индекс Z у этой новой меры. Функционал  в спрямляющем пространстве примет вид
в спрямляющем пространстве примет вид

Пусть

Здесь  — числа,
— числа,  — векторы.
— векторы.
В работе [32] формулируется утверждение, устанавливающее класс функций в спрямляющем пространстве  среди которых следует искать разделяющую функцию, доставляющую экстремум функционалу качества разбиения. Показано, что если функционал качества Ф является дифференцируемой функцией от М;
среди которых следует искать разделяющую функцию, доставляющую экстремум функционалу качества разбиения. Показано, что если функционал качества Ф является дифференцируемой функцией от М;  , а вероятностное распределение
, а вероятностное распределение  сосредоточено на ограниченном множестве и обладает непрерывной плотностью, то в случае достижения функционалом Ф своего экстремума на некоторой разделяющей функции, этот же экстремум достигается на разделяющей функции, являющейся полиномом
сосредоточено на ограниченном множестве и обладает непрерывной плотностью, то в случае достижения функционалом Ф своего экстремума на некоторой разделяющей функции, этот же экстремум достигается на разделяющей функции, являющейся полиномом  степени вида:
степени вида:

где

а  означает при четном v произведение чисел
означает при четном v произведение чисел  а при нечетном v — скалярное произведение векторов
а при нечетном v — скалярное произведение векторов 
Утверждение 2 (для функционалов типа  ) и разбиений на два класса). Для функционала
) и разбиений на два класса). Для функционала  утверждение 1 означает, что класс разделяющих функций, среди которых надо искать наилучшее в спрямляющем пространстве разбиение, имеет вид
утверждение 1 означает, что класс разделяющих функций, среди которых надо искать наилучшее в спрямляющем пространстве разбиение, имеет вид

где

Класс разделяющих функций в спрямляющем пространстве очевидным образом определяет класс разделяющих функций в исходном пространстве  .
.
Если  является скалярным произведением векторов X и Y, то спрямляющее пространство
является скалярным произведением векторов X и Y, то спрямляющее пространство  совпадает с исходным пространством
совпадает с исходным пространством  , а метрика, задаваемая потенциальной функцией
, а метрика, задаваемая потенциальной функцией  , совпадает с обычной евклидовой метрикой. Функционалы
, совпадает с обычной евклидовой метрикой. Функционалы  рассматриваемые относительно этой метрики, совпадают с точностью до константы. В этом случае, как нетрудно видеть, разбиение, задаваемое разделяющей функцией
рассматриваемые относительно этой метрики, совпадают с точностью до константы. В этом случае, как нетрудно видеть, разбиение, задаваемое разделяющей функцией  является несмещенным разбиением.
является несмещенным разбиением.
5.4.6. Функционалы качества разбиения как результат применения метода максимального правдоподобия к задаче статистического оценивания неизвестных параметров.
Приведем пример, иллюстрирующий возможность обоснования выбора общего вида функционала качества разбиения на классы в ситуациях, в которых исследователю удается описать механизм генерирования анализируемых данных одной из классических моделей.
Пусть априорные сведения позволяют определить  однородный класс (кластер) как нормальную генеральную совокупность наблюдений с вектором средних
однородный класс (кластер) как нормальную генеральную совокупность наблюдений с вектором средних  и ковариационной матрицей
и ковариационной матрицей  . При этом
. При этом  , вообще говоря, неизвестны. Известно лишь, что каждое из наблюдений
, вообще говоря, неизвестны. Известно лишь, что каждое из наблюдений  извлекается из одной из k нормальных генеральных совокупностей
извлекается из одной из k нормальных генеральных совокупностей  . Задача исследователя — определить, какие
. Задача исследователя — определить, какие  , из
, из  исходных наблюдений извлечены из класса
исходных наблюдений извлечены из класса  какие
какие  наблюдений извлечены из класса
наблюдений извлечены из класса  и т. д. Очевидно, числа
и т. д. Очевидно, числа  вообще говоря, также неизвестны.
вообще говоря, также неизвестны.
Если ввести в рассмотрение вспомогательный вектор «параметр разбиения»  в котором компонента определяет номер класса, к которому относится наблюдение
в котором компонента определяет номер класса, к которому относится наблюдение  если
если  , то задачу разбиения на классы можно формулировать как задачу оценивания неизвестных параметров
, то задачу разбиения на классы можно формулировать как задачу оценивания неизвестных параметров  при «мешающих» неизвестных параметрах
при «мешающих» неизвестных параметрах 
Обозначив весь набор неизвестных параметров с помощью  , т. е.
, т. е.  и пользуясь известной [16] техникой, получаем логарифмическую функцию правдоподобия для наблюдений
и пользуясь известной [16] техникой, получаем логарифмическую функцию правдоподобия для наблюдений 

Как известно, оценка  параметра
параметра  по методу максимального правдоподобия находится из условия
по методу максимального правдоподобия находится из условия 
Поэтому естественно было бы попытаться найти такое значение «параметра разбиения» у, а также такие векторы средних  и ковариационные матрицы
и ковариационные матрицы  , при которых величина —
, при которых величина —  достигла бы своего абсолютного минимума.
достигла бы своего абсолютного минимума.
При известном разбиении у оценками максимального правдоподобия для  будут «центры тяжести» классов
будут «центры тяжести» классов

Подставляя их в (5.23) вместо  и воспользовавшись очевидными тождественными преобразованиями, приходим к эквивалентности задачи поиска минимума функции
и воспользовавшись очевидными тождественными преобразованиями, приходим к эквивалентности задачи поиска минимума функции  , определенной соотношением (5.23), и задачи поиска минимума выражения
, определенной соотношением (5.23), и задачи поиска минимума выражения

или, что то же, выражения

В последнем выражении  — выборочная ковариационная матрица, вычисленная по наблюдениям, входящим в состав
— выборочная ковариационная матрица, вычисленная по наблюдениям, входящим в состав  класса (см. (5.13)).
класса (см. (5.13)).
Анализ выражений (5.24) и (5.25) в некоторых частных случаях немедленно приводит к следующим интересным выводам:
если ковариационные матрицы исследуемых генеральных совокупностей равны между собой и известны, то задача оценивания неизвестного параметра  по методу максимального правдоподобия равносильна задаче разбиения наблюдений X, на классы, подчиненной функционалу качества разбиения вида
по методу максимального правдоподобия равносильна задаче разбиения наблюдений X, на классы, подчиненной функционалу качества разбиения вида  , в котором под расстоянием d подразумевается расстояние Махаланобиса;
, в котором под расстоянием d подразумевается расстояние Махаланобиса;
если ковариационные матрицы исследуемых генеральных совокупностей равны между собой, но неизвестны, то, подставляя в (5.25) вместо  ее оценку максимального правдоподобия
ее оценку максимального правдоподобия

убеждаемся в эквивалентности задачи оценивания (по методу максимального правдоподобия) параметра 0 и задачи поиска разбиення наблюдений X, на классы, наилучшего в смысле функционала качества 
если ковариационные матрицы исследуемых генеральных совокупностей не равны между собой и не известны, то, подставляя в (5.25) вместо 211 их оценки максимального правдоподобия W, убеждаемся в эквивалентности задачи оценивания по методу максимального правдоподобия параметра 0 и задачи поиска разбиения наблюдений Х; на классы, наилучшего в смысле функционала качества  .
.
В [303] авторы пытаются конструировать алгоритмы, реализующие идею получения оценок максимального правдоподобия для параметра  . Однако, нам представляется, главная ценность подобного подхода лишь в его методологической, качественной стороне, в том, что он позволяет строго осмыслить и формализовать некоторые функционалы качества разбиения, введенные ранее чисто эвристически. Конструктивная же сторона подобного подхода упирается в трудно преодолимые препятствия вычислительного плана, связанные с колоссальным количеством переборов вариантов уже при сравнительно небольших размерностях
. Однако, нам представляется, главная ценность подобного подхода лишь в его методологической, качественной стороне, в том, что он позволяет строго осмыслить и формализовать некоторые функционалы качества разбиения, введенные ранее чисто эвристически. Конструктивная же сторона подобного подхода упирается в трудно преодолимые препятствия вычислительного плана, связанные с колоссальным количеством переборов вариантов уже при сравнительно небольших размерностях  и объемах выборки.
и объемах выборки.
Роль функционалов качества разбиения в построении общей теории автоматической классификации и разнообразные примеры функционалов качества, используемых в конкретных (распространенных в статистической практике) алгоритмах автоматической классификации, описаны в гл. 10.
5.4.7. Функционалы качества классификации как показатели степени аппроксимации данных.
Поскольку формируемая классификационная структура является приближенным представлением имеющихся данных, естественно возникает идея формализации задачи классификации как задачи аппроксимации матрицы данных матрицей, характеризующей искомую классификацию. Для реализации этой идеи необходимо тем или иным образом выбрать, во-первых, матричный способ представления классификации и, во-вторых, меру близости между матрицами, соответствующими исходным данным и искомым классификациям. Рассмотрим некоторые возникающие при этом задачи для ситуаций, когда классификация рассматривается как а) иерархия классов, б) разбиение, в) совокупность непустых (возможно, пересекающихся) подмножеств, а в качестве меры близости матриц используется обычная евклидова метрика — сумма квадратов разностей их соответствующих элементов.
В одной из первых версий аппроксимационная постановка задачи была рассмотрена для классификации, представленной иерархической системой кластеров, т. е. совокупностью разбиений  множества объектов О, такой, что каждое последующее разбиение S получается из предыдущего разбиения
множества объектов О, такой, что каждое последующее разбиение S получается из предыдущего разбиения  объединением некоторых его классов
объединением некоторых его классов  , причем последнее разбиение
, причем последнее разбиение  состоит из единственного класса, совпадающего со всем множеством
состоит из единственного класса, совпадающего со всем множеством  Разбиение
Разбиение  соответствует
соответствует  уровню иерархии, характеризуемому также индексом уровня
уровню иерархии, характеризуемому также индексом уровня  монотонно зависящим от t (обычно полагают
монотонно зависящим от t (обычно полагают  ). Такая иерархическая система порождает, в частности, матрицу расстояний между объектами
). Такая иерархическая система порождает, в частности, матрицу расстояний между объектами  по следующему правилу: расстояние
по следующему правилу: расстояние  между ними равно индексу уровня
между ними равно индексу уровня  того разбиения
того разбиения  в котором они впервые попадают в один и тот же класс. Мера близости
в котором они впервые попадают в один и тот же класс. Мера близости  является ультраметрикой, т. е. удовлетворяет усиленному неравенству треугольника:
является ультраметрикой, т. е. удовлетворяет усиленному неравенству треугольника:  шах
шах  для любых i, j,
для любых i, j,  п. Имеет место и обратное утверждение: всякая ультраметрика порождает иерархическую систему кластеров, индексами уровня которой служат различающиеся значения ультраметрики. Таким образом, иерархические системы кластеров эквивалентно представимы ультраметрическими матрицами близости. Это позволяет формулировать задачу построения иерархической системы кластеров как задачу аппроксимации заданной матрицы расстояний
п. Имеет место и обратное утверждение: всякая ультраметрика порождает иерархическую систему кластеров, индексами уровня которой служат различающиеся значения ультраметрики. Таким образом, иерархические системы кластеров эквивалентно представимы ультраметрическими матрицами близости. Это позволяет формулировать задачу построения иерархической системы кластеров как задачу аппроксимации заданной матрицы расстояний  с помощью ультраметрических матриц [250].
с помощью ультраметрических матриц [250].
Оказалось, что если искомая ультраметрика удовлетворяет априорному ограничению  а критерий аппроксимации — сумма квадратов (или других монотонных функций) от разностей
а критерий аппроксимации — сумма квадратов (или других монотонных функций) от разностей  , то оптимальной будет система кластеров, получаемая по методу «ближайшего соседа».
, то оптимальной будет система кластеров, получаемая по методу «ближайшего соседа».
Иными словами, ультраметрическое расстояние  есть не что иное, как минимальное значение р, при котором
есть не что иное, как минимальное значение р, при котором  -граф
-граф  содержит последовательность ребер, соединяющую объекты
содержит последовательность ребер, соединяющую объекты  (или, что то же самое, максимальное ребро на той части кратчайшего незамкнутого пути, которая соединяет эти объекты).
(или, что то же самое, максимальное ребро на той части кратчайшего незамкнутого пути, которая соединяет эти объекты).
Из сказанного вытекает следующее свойство «компактности» оптимальных кластеров: любое «внутреннее» расстояние  для объектов
для объектов  принадлежащих одному и тому же кластеру S, меньше любого расстояния
принадлежащих одному и тому же кластеру S, меньше любого расстояния  «во вне», т. е. при любых
«во вне», т. е. при любых  из S и
из S и  не принадлежащих
не принадлежащих 
Задача аппроксимации с противоположным ограничением  приводит к методу «дальнего соседа» с аналогичными свойствами.
приводит к методу «дальнего соседа» с аналогичными свойствами.
Задача аппроксимации матрицы близости с помощью иерархической системы кластеров без ограничений не рассматривалась практически в литературе, в отличие от задач аппроксимации с помощью разбиений и подмножеств (задаваемых, впрочем, специальными типами ультраметрик). Рассмотрим некоторые результаты, полученные в [92] применительно к ситуации, когда элементы матрицы характеризуют не расстояние, а сходство (связь) между объектами.
Разбиение  множества объектов О представим матрицей связи вида
множества объектов О представим матрицей связи вида  где
где  если
если  содержатся в одном и том же классе разбиения S, и
содержатся в одном и том же классе разбиения S, и  в противном случае, а К — вещественное число, характеризующее уровень связи между объектами «внутри» классов S. Нетрудно видеть, минимизация суммы квадратов разностей величин
в противном случае, а К — вещественное число, характеризующее уровень связи между объектами «внутри» классов S. Нетрудно видеть, минимизация суммы квадратов разностей величин 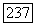 при заданном
при заданном 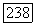 эквивалентна задаче отыскания такого разбиения S, которое максимизирует суммарные внутренние связи
эквивалентна задаче отыскания такого разбиения S, которое максимизирует суммарные внутренние связи

Величина 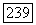 играет здесь, с одной стороны, роль порога существенности связей
играет здесь, с одной стороны, роль порога существенности связей 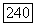 поскольку при
поскольку при 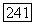 выгодно поместить
выгодно поместить 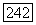 в один и тот же класс
в один и тот же класс 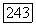 а при
а при  напротив, это невыгодно, и, с другой стороны, роль параметра компромисса двух противоречивых критериев — максимума суммы внутренних связей
напротив, это невыгодно, и, с другой стороны, роль параметра компромисса двух противоречивых критериев — максимума суммы внутренних связей 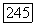 и минимума меры концентрации —
и минимума меры концентрации — 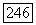
Оптимальное по данному критерию разбиение 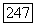 компактно в том смысле, что средняя связь
компактно в том смысле, что средняя связь 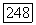 в каждом из его классов
в каждом из его классов 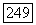 не меньше, чем средняя связь
не меньше, чем средняя связь 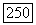 во вне и чем средняя связь между любыми классами
во вне и чем средняя связь между любыми классами 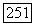 Точнее, для любых t, q, I справедливо неравенство
Точнее, для любых t, q, I справедливо неравенство 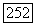
Разбиение, удовлетворяющее данному свойству, может быть найдено с помощью локально-оптимального агломеративного алгоритма, на каждом шаге которого объединяются те классы 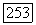 для которых сумма связей
для которых сумма связей 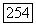 максимальна и положительна. Процесс объединений прекращается, когда такие суммы для всех
максимальна и положительна. Процесс объединений прекращается, когда такие суммы для всех  становятся неположительными. Таким образом, данная задача приводит к сумме всех связей (за вычетом порога) как мере близости классов.
становятся неположительными. Таким образом, данная задача приводит к сумме всех связей (за вычетом порога) как мере близости классов.
В том случае, когда величина К не фиксирована заранее, а подбирается в соответствии с квадратичным критерием аппроксимации, ее оптимальное значение (при данном S) равно среднему значению внутренних связей

В этой ситуации необходимое условие оптимальности S может быть уточнено следующим образом: средняя внутренняя связь 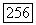 по крайней мере вдвое превышает средние связи между любыми двумя классами (
по крайней мере вдвое превышает средние связи между любыми двумя классами (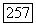 ) или во вне (
) или во вне (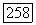 ). Данное условие также может использоваться в качестве критерия оптимизации и остановки в агломеративном методе последовательного объединения классов.
). Данное условие также может использоваться в качестве критерия оптимизации и остановки в агломеративном методе последовательного объединения классов.
К достоинствам рассмотренной аппроксимационной задачи классификации относится то, что, во-первых, она допускает интерпретацию в терминах порога существенности (он же показатель компромисса) 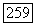 ; во-вторых, приводит к «компактным» в указанном смысле кластерам, число которых не задается заранее, и, в-третьих, при некоторых конкретных способах расчета связей
; во-вторых, приводит к «компактным» в указанном смысле кластерам, число которых не задается заранее, и, в-третьих, при некоторых конкретных способах расчета связей 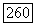 эквивалентна другим агшроксимационным критериям многомерной классификации по матрице «объект — свойство», содержащей как количественные, так и номинальные признаки [111].
эквивалентна другим агшроксимационным критериям многомерной классификации по матрице «объект — свойство», содержащей как количественные, так и номинальные признаки [111].
Особенностью данного критерия является наличие единого порога существенности для всех классов, что неудобно в тех нередких ситуациях, когда структура данных отражает наличие кластеров различных «диаметров».
Этот недостаток в значительной мере преодолевается в методике последовательной аппроксимации матрицы связи с помощью отдельных подмножеств множества объектов О. Подмножество 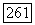 характеризуется
характеризуется 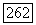 -матрицей где
-матрицей где 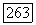 при
при 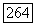 в противном случае. При фиксированном значении
в противном случае. При фиксированном значении 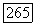 задача квадратичной аппроксимации матрицы
задача квадратичной аппроксимации матрицы 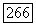 в множестве матриц такого вида эквивалентна задаче максимизации суммы внутренних связей
в множестве матриц такого вида эквивалентна задаче максимизации суммы внутренних связей

что представляет собой часть критерия (5.26), соответствующую одному классу. Здесь 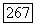 — число объектов в
— число объектов в 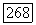
Необходимое условие оптимальности здесь принимает следующий вид. Оптимальное множество S является 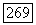 -кластером в том смысле, что для всякого объекта
-кластером в том смысле, что для всякого объекта 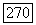 его средняя связь
его средняя связь 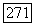 с S не меньше, чем
с S не меньше, чем 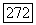 , тогда как для
, тогда как для 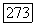 . Это свойство позволяет формировать локально-оптимальный
. Это свойство позволяет формировать локально-оптимальный 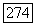 -кластер путем последовательного присоединения к S, начиная с
-кластер путем последовательного присоединения к S, начиная с 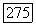 объектов, имеющих с «текущим» S максимальную среднюю связь
объектов, имеющих с «текущим» S максимальную среднюю связь 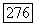 если
если 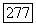
В том случае, когда величина К или 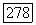 заранее не задана, ее выбор можно также подчинить аппроксимационному критерию, который, как нетрудно убедиться, равен в этом случае
заранее не задана, ее выбор можно также подчинить аппроксимационному критерию, который, как нетрудно убедиться, равен в этом случае 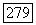 где
где

причем 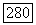 — не что иное, как оптимальное значение
— не что иное, как оптимальное значение 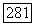 , равное средней внутренней связи.
, равное средней внутренней связи.
Оптимальное по данному критерию множество S является «сильным» кластером в том смысле, что его средняя внутренняя связь 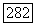 по крайней мере вдвое превышает среднюю связь
по крайней мере вдвое превышает среднюю связь 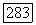 с S любого объекта
с S любого объекта  Отсюда вытекает алгоритм построения локально-оптимального сильного кластера
Отсюда вытекает алгоритм построения локально-оптимального сильного кластера 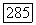 помощью последовательных присоединений к «текущему» S тех
помощью последовательных присоединений к «текущему» S тех 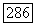 для которых
для которых 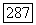 максимально (по
максимально (по  ), если
), если 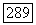 Подобные алгоритмы формирования отдельных кластеров развиваются в литературе довольно давно, правда, из чисто эвристических соображений, например метод Р-коэффициентов [161], алгоритм Спектр [34] и др.
Подобные алгоритмы формирования отдельных кластеров развиваются в литературе довольно давно, правда, из чисто эвристических соображений, например метод Р-коэффициентов [161], алгоритм Спектр [34] и др.
В случае, когда часть связей 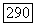 может быть отрицательна (если, например, матрица
может быть отрицательна (если, например, матрица  предварительно центрирована), аппроксимационный критерий
предварительно центрирована), аппроксимационный критерий 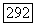 допускает решение, при котором
допускает решение, при котором 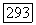 , а значит, и порог
, а значит, и порог 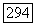 отрицательны. В этом случае оптимальное множество S является «антикластером», так как состоит из наиболее непохожих друг на друга объектов. До последнего времени задачи построения антикластеров в приложениях рассматривались редко.
отрицательны. В этом случае оптимальное множество S является «антикластером», так как состоит из наиболее непохожих друг на друга объектов. До последнего времени задачи построения антикластеров в приложениях рассматривались редко.
Описанный подход допускает естественное развитие, состоящее в многократном повторении аппроксимации применительно к «остаточным» матрицам связей, получаемым вычитанием из «объясненных» на данном шаге связей 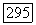 . Очевидно, на разных этапах процесса аппроксимируемые матрицы связи будут разными, так что конструируемые кластеры и их средние внутренние связи будут, вообще говоря, разными. Указанный метод последовательного исчерпания связей
. Очевидно, на разных этапах процесса аппроксимируемые матрицы связи будут разными, так что конструируемые кластеры и их средние внутренние связи будут, вообще говоря, разными. Указанный метод последовательного исчерпания связей 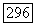 (качественный факторный анализ
(качественный факторный анализ 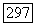 ) может рассматриваться как пошаговая процедура идентификации модели аддитивных кластеров, согласно которой заданная матрица связи
) может рассматриваться как пошаговая процедура идентификации модели аддитивных кластеров, согласно которой заданная матрица связи 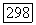 представляется (с некоторой погрешностью) в виде суммы матриц
представляется (с некоторой погрешностью) в виде суммы матриц 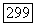 отвечающих искомым кластерам
отвечающих искомым кластерам 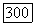

где  — минимизируемые невязки модели.
— минимизируемые невязки модели.
Согласно методу последовательного исчерпания сначала определяется и вычитается из  оптимальное
оптимальное  равное среднему значению
равное среднему значению  затем матрица
затем матрица  аппроксимируется матрицей вида после этого остаточная матрица
аппроксимируется матрицей вида после этого остаточная матрица  аппроксимируется матрицей
аппроксимируется матрицей  и т. д. Особенностью метода является декомпозиция
и т. д. Особенностью метода является декомпозиция

где

справедливая независимо от того, пересекаются кластеры  друг с другом или нет.
друг с другом или нет.
Разложение (5.29) позволяет трактовать величины  как характеристики значимости вклада отдельных кластеров в дисперсию исходных связей и на этой основе оценивать доли объясненной и необъясненной дисперсии данных, что включает кластер-анализ в традиционную методологию многомерного статистического анализа. Указанные свойства метода последовательного исчерпания (декомпозиция (5.29), «сильная компактность» кластеров, вычислительная эффективность) дают ему определенные преимущества по сравнению с другими подходами к оценке параметров модели (5.28) [111].
как характеристики значимости вклада отдельных кластеров в дисперсию исходных связей и на этой основе оценивать доли объясненной и необъясненной дисперсии данных, что включает кластер-анализ в традиционную методологию многомерного статистического анализа. Указанные свойства метода последовательного исчерпания (декомпозиция (5.29), «сильная компактность» кластеров, вычислительная эффективность) дают ему определенные преимущества по сравнению с другими подходами к оценке параметров модели (5.28) [111].
Рассмотрим некоторые критерии классификации, возникающие в задачах аппроксимации таблиц «объект — свойство». В этих задачах подмножества объектов S задаются  -мерными
-мерными  -векторами
-векторами  , где
, где  если
если  в противном случае. Разбиение
в противном случае. Разбиение  множества объектов задается (
множества объектов задается ( -матрицей
-матрицей  ) со столбцами
) со столбцами  характеризующими классы разбиения S. Очевидно, (
характеризующими классы разбиения S. Очевидно, ( -матрица
-матрица  совпадает с ранее определенной матрицей
совпадает с ранее определенной матрицей  -матрица
-матрица  — диагональная матрица величин
— диагональная матрица величин  Линейное пространство
Линейное пространство  )
)  при подходящем
при подходящем  является адекватным представлением разбиения S, поскольку всякий вектор
является адекватным представлением разбиения S, поскольку всякий вектор  выражает возможную кодировку классов
выражает возможную кодировку классов  величинами
величинами 
Аппроксимационные построения в терминах линейных пространств, ассоциированных с номинальными и количественными признаками, приводят к критериям вида (5.1), (5.11) и (5.26) при подходящих способах вычисления характеристик близости объектов [111]. Здесь рассмотрим только наиболее прозрачную схему метода главных кластеров [112]. Согласно этой схеме матрица данных  номера объектов,
номера объектов,  — номера признаков) аппроксимируется каким-либо элементом
— номера признаков) аппроксимируется каким-либо элементом  , где Z — (
, где Z — ( -матрица искомой классификации (с не обязательно непересекающимися классами), так что справедливо представление
-матрица искомой классификации (с не обязательно непересекающимися классами), так что справедливо представление

с «невязками» 
Смысл равенств (5.30): значения признаков j на объектах  с точностью до невязок гц совпадают с величинами
с точностью до невязок гц совпадают с величинами  которые задают, таким образом, «эталон» кластера
которые задают, таким образом, «эталон» кластера  в признаковом пространстве.
в признаковом пространстве.
Модель (5.30) является линейной моделью факторного анализа (см. гл. 14) с той особенностью, что величины  принимают не любые значения, а только нулеединичные.
принимают не любые значения, а только нулеединичные.
Аппроксимационная задача отыскания произвольных  и нулеединичных
и нулеединичных  по заданным
по заданным  в модели (5.30) с целью минимизации суммы квадратов невязок
в модели (5.30) с целью минимизации суммы квадратов невязок

как нетрудно показать, эквивалентна задаче построения классификации  (при непересекающихся классах), минимизирующей критерий (5.11) с
(при непересекающихся классах), минимизирующей критерий (5.11) с  или, что то же самое, максимизирующей критерии вида
или, что то же самое, максимизирующей критерии вида

где связи между объектами — их скалярные произведения 
Вид критерия (5.31) позволяет в какой-то мере уточнить характер предварительного преобразования данных, необходимого для адекватного применения критериев, эквивалентных (5.11) и (5.32). Действительно, в сумму (5.32) все невязки  входят равноправно, что подразумевает равноправие всех элементов матрицы данных Скажем, изменение масштаба
входят равноправно, что подразумевает равноправие всех элементов матрицы данных Скажем, изменение масштаба  признака в а раз вызовет а-кратное изменение «веса» соответствующих невязок в критерии (5.31) и соответствующее изменение решения. По-видимому, критерию (5.31) соответствует предварительное уравновешивание матрицы данных, приводящее к выполнению равенств
признака в а раз вызовет а-кратное изменение «веса» соответствующих невязок в критерии (5.31) и соответствующее изменение решения. По-видимому, критерию (5.31) соответствует предварительное уравновешивание матрицы данных, приводящее к выполнению равенств  .
.
Формулировка задачи классификации как задачи оценки параметров модели (5.30) позволяет распространить на нее принцип пошаговой аппроксимации. На первом шаге отыскиваются параметры первого кластера путем минимизации критерия  по произвольным а, и
по произвольным а, и  нулеединичным
нулеединичным  Полученное решение определяет эталонный вектор первого кластера
Полученное решение определяет эталонный вектор первого кластера  и его состав
и его состав  На общем
На общем  шаге исходя из полученного решения
шаге исходя из полученного решения  и «текущей» остаточной матрицы
и «текущей» остаточной матрицы  осуществляется переход к матрице следующего шага
осуществляется переход к матрице следующего шага 
Метод назван методом главных кластеров из-за аналогии с методом главных компонент, «простирающейся» вплоть до декомпозиции

где  — вклад
— вклад  кластера
кластера  в суммарный разброс данных, справедливой даже при пересекающихся главных кластерах.
в суммарный разброс данных, справедливой даже при пересекающихся главных кластерах.








































































































































































































































































































































































































































































































































































































 шаге аппроксимация сводится к максимизации величины
шаге аппроксимация сводится к максимизации величины  и соответственно каждый главный кластер является сильным кластером (относительно матрицы связей
и соответственно каждый главный кластер является сильным кластером (относительно матрицы связей  ).
).
 по максимуму средней связи
по максимуму средней связи  имеет здесь простой геометрический смысл: к S присоединяется тот объект
имеет здесь простой геометрический смысл: к S присоединяется тот объект  , длина проекции которого на радиус-вектор центра тяжести S превышает половину длины радиус-вектора.
, длина проекции которого на радиус-вектор центра тяжести S превышает половину длины радиус-вектора.

 и признаков
и признаков  применительно к данному конкретному кластеру.
применительно к данному конкретному кластеру.