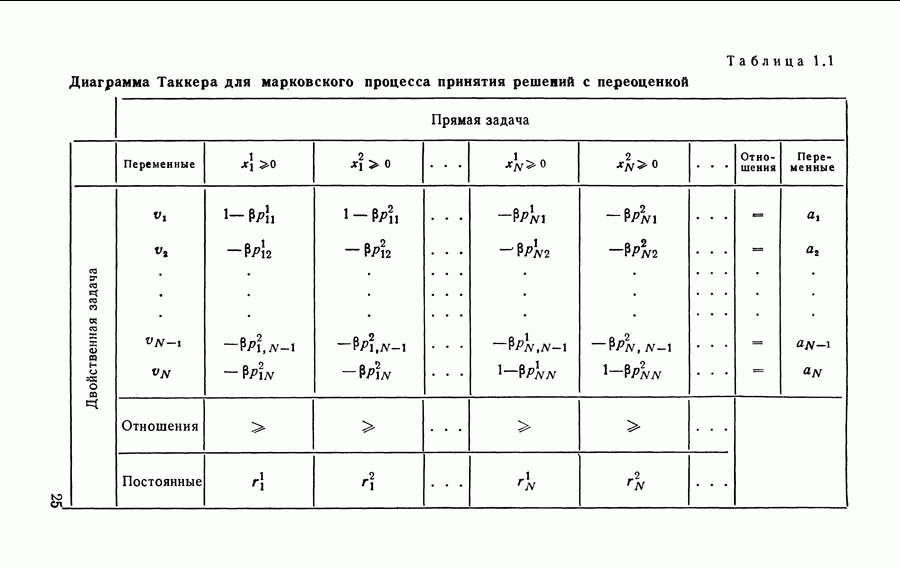
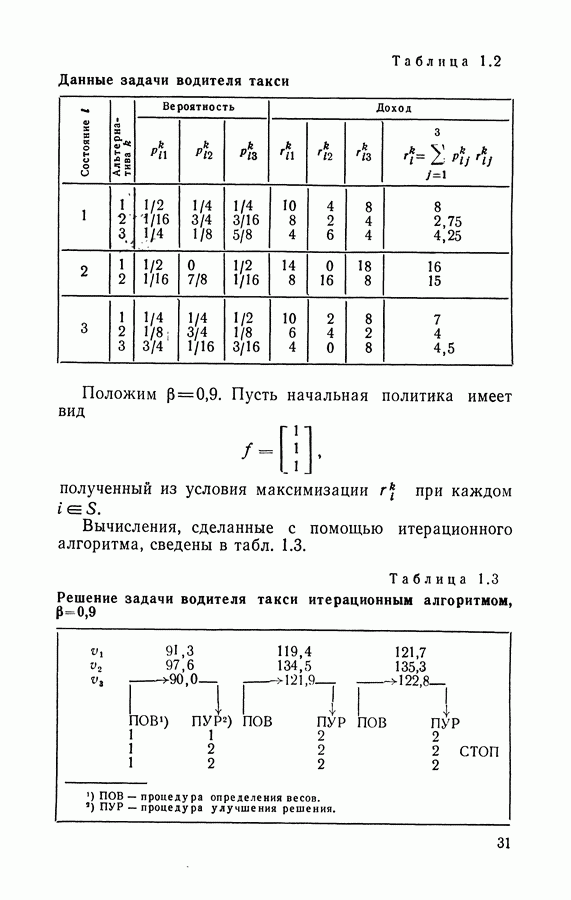
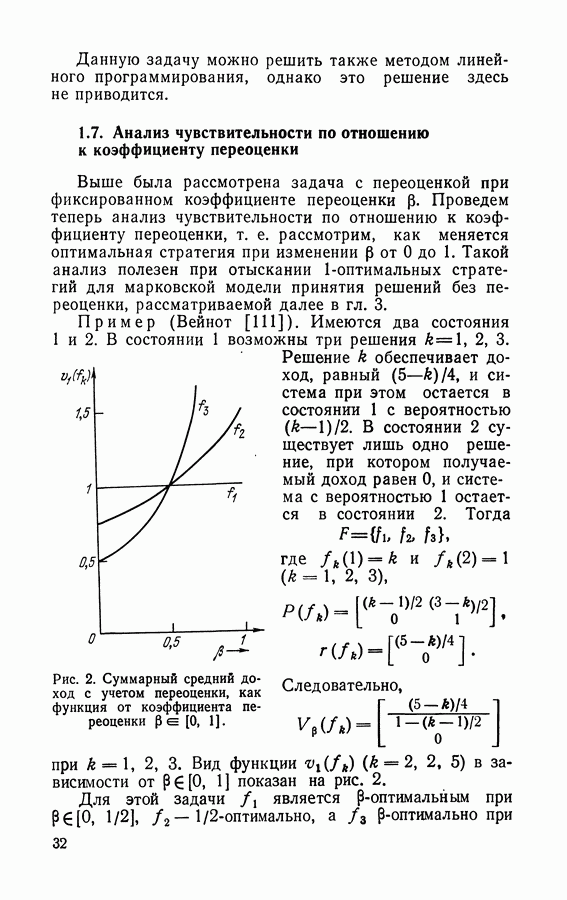
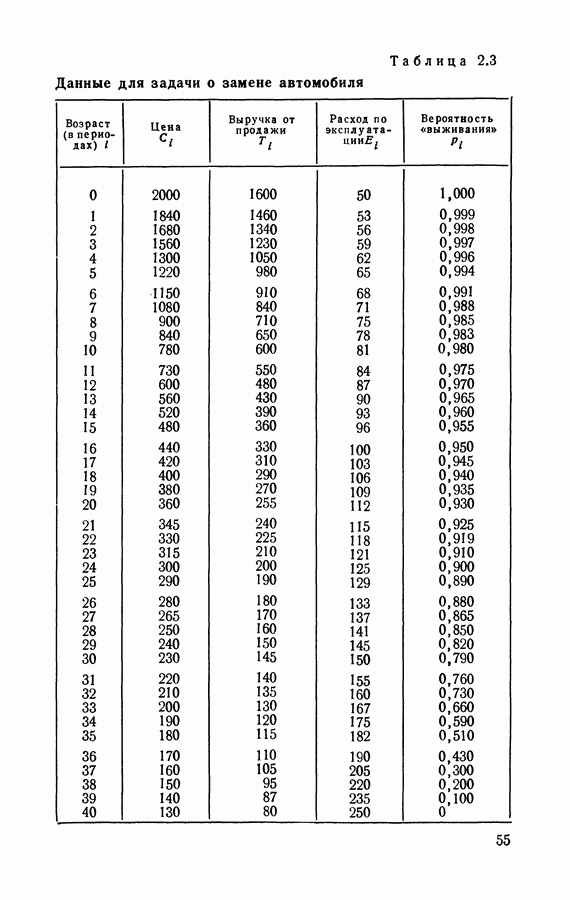
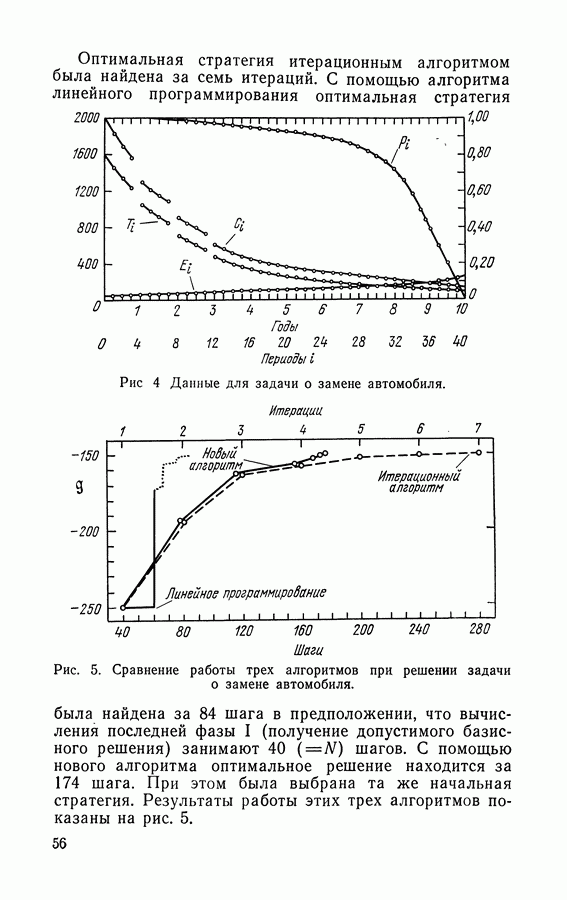
3.2. Итерационный алгоритм нахождения стратегий
Для модели с переоценкой вектор суммарных средних доходов с учетом переоценки равен

где  Пусть
Пусть  -оптимальна и
-оптимальна и 
Определение 3.1. Стратегия  называется 1-оптимальной, если
называется 1-оптимальной, если

Будет показано, что  -оптимальные стратегии играют важную роль для рассматриваемой задачи.
-оптимальные стратегии играют важную роль для рассматриваемой задачи.
Докажем теперь теорему, аналогичную лемме 2.4.
Теорема 3.1. Для любой стационарной стратегии  положим
положим

(см. лемму 2.3). Тогда

где  — единственное решение уравнений
— единственное решение уравнений

 — единственное решение уравнений
— единственное решение уравнений

Доказательство. Имеем

где  определены в (2.4). Таким образом, равенство (3.2) полупится, если положить
определены в (2.4). Таким образом, равенство (3.2) полупится, если положить

Из леммы 2.3 с очевидностью следует, что  являются единственными решениями (3.3) и (3.4) соответственно.
являются единственными решениями (3.3) и (3.4) соответственно.
Решения  уравнений (3.3) и (3.4) могут быть представлены в виде
уравнений (3.3) и (3.4) могут быть представлены в виде

Таким образом, задача заключается в нахождении стратегии, максимизирующей  (а также
(а также  ) на множестве всех стационарных стратегий. Для ее решения необходим эффективный алгоритм.
) на множестве всех стационарных стратегий. Для ее решения необходим эффективный алгоритм.
Из теоремы 2.1 следует, что существует стационарная оптимальная стратегия по критерию среднего дохода. Определим множество политик

Иначе говоря,  множество всех
множество всех  при которых достигается максимальный средний доход за единицу времени. Далее, определим множество политик
при которых достигается максимальный средний доход за единицу времени. Далее, определим множество политик

Очевидно, что  подмножество
подмножество  и является множеством всех
и является множеством всех  максимизирующих член
максимизирующих член  характеризующий смещение.
характеризующий смещение.
Для модели с переоценкой вектор  согласно (3.2) равен
согласно (3.2) равен

где

при 
Сравнивая правые части равенств (3.2) и  определим множество решений
определим множество решений

где  компоненты векторов
компоненты векторов  соответственно. Определим далее
соответственно. Определим далее

Теорема 3.2. Зафиксируем политику  Тогда
Тогда
а) Если  пусто, то
пусто, то 
б) Если  при некотором то для политики
при некотором то для политики  такой, что
такой, что  при всех
при всех  для которых
для которых  имеет место неравенство
имеет место неравенство  при всех
при всех  достаточно близких к 1.
достаточно близких к 1.
Доказательство, а) Если  пусто, т. е. если
пусто, т. е. если  пусто при всех
пусто при всех  то
то  или
или

Таким образом,  для всех
для всех  достаточно близких к 1. Из теоремы 1.1 следует, что
достаточно близких к 1. Из теоремы 1.1 следует, что  для всех
для всех  и всех
и всех  достаточно близких к 1. В силу (3.2) получаем, что
достаточно близких к 1. В силу (3.2) получаем, что 
б) Если  для некоторого
для некоторого  если
если  то
то  для всех
для всех  достаточно близких к 1. Из теоремы 1.2 получаем, что
достаточно близких к 1. Из теоремы 1.2 получаем, что  Для всех достаточно близких к
Для всех достаточно близких к  Эта теорема описывает итерационный алгоритм нахождения стратегий, позволяющий отыскать стационарную оптимальную стратегию
Эта теорема описывает итерационный алгоритм нахождения стратегий, позволяющий отыскать стационарную оптимальную стратегию  за конечное число итераций.
за конечное число итераций.
Следствие. Для любой политики  выберем
выберем  так, чтобы
так, чтобы  для некоторого
для некоторого 
и  Тогда или
Тогда или 
Доказательство. Из теоремы  и равенства (3.2) имеем
и равенства (3.2) имеем  а из равенства и
а из равенства и  следует, что
следует, что  Остается лишь показать, что
Остается лишь показать, что  Если предположить, что
Если предположить, что  то
то  пусто, а это противоречит условию.
пусто, а это противоречит условию.
Для каждого  определим множество решений
определим множество решений

зависящее лишь от значений  принимаемых на множестве решений в состоянии 5. Определим, далее,
принимаемых на множестве решений в состоянии 5. Определим, далее,

Очевидно, что  содержит по меньшей мере
содержит по меньшей мере 
Лемма 3.1. Если  то
то 
Если, кроме того,  то
то 
Доказательство. Включение  эквивалентно равенствам
эквивалентно равенствам

и

где для сокращения обозначено  Умножая (3.16) слева на
Умножая (3.16) слева на  получаем
получаем

Но в силу теоремы 3.1 уравнения (3.15) и (3.17) имеют единственное решение  такое, что
такое, что  Кроме того, из равенства
Кроме того, из равенства  имеем
имеем

так что если 

Поскольку  то единственное решение уравнений (3.16) и (3.18) равно
то единственное решение уравнений (3.16) и (3.18) равно  т. е.
т. е. 
Теорема 3.3. Пусть политика  такова, что
такова, что  пусто и для любой
пусто и для любой 

тогда  -оптимальна.
-оптимальна.
Доказательство. Пусть  удовлетворяет предположению теоремы. Выберем
удовлетворяет предположению теоремы. Выберем  настолько близким к 1, что если для некоторой пары
настолько близким к 1, что если для некоторой пары  выполняется неравенство
выполняется неравенство  при всех
при всех  Если
Если  не
не  -оптимальна, то пусть
-оптимальна, то пусть  последовательность
последовательность  -улучшений, где
-улучшений, где  -оптимальная стратегия, полученных аналогично тому, как это сделано в теореме 1.3. Тогда
-оптимальная стратегия, полученных аналогично тому, как это сделано в теореме 1.3. Тогда

для всех  Покажем с помощью индукции по
Покажем с помощью индукции по  что и
что и  Это равенство справедливо при
Это равенство справедливо при  Если оно справедливо при некотором
Если оно справедливо при некотором  то, поскольку
то, поскольку  зависят лишь от
зависят лишь от  и получаем, что
и получаем, что  пусто,
пусто,  т. е.
т. е.  при всех
при всех  Тогда
Тогда  удовлетворяют предположениям, сделанным относительно
удовлетворяют предположениям, сделанным относительно  в лемме 3.1, так что
в лемме 3.1, так что  Таким образом, обозначая
Таким образом, обозначая  -оптимальную стратегию
-оптимальную стратегию  через
через  имеем
имеем

Поскольку

то  при
при  и
и  -оптимальна.
-оптимальна.
Следствие. Если  пусто,
пусто,  содержит лишь
содержит лишь  то
то  -оптимальна.
-оптимальна.
Доказательство. Для любого 

что соответствует (3.19). Из теоремы 3.3 имеем, что  -оптимальна.
-оптимальна.
Следующая теорема раскрывает важное свойство  -оптимальных стратегий.
-оптимальных стратегий.
Теорема 3.4. Множество политик  непусто и состоит из всевозможных
непусто и состоит из всевозможных  таких, что стратегия
таких, что стратегия  -оптимальна.
-оптимальна.
Доказательство. Если  пусто, то для значений
пусто, то для значений  близких к 1, из (3.10) имеем неравенство
близких к 1, из (3.10) имеем неравенство

где  скалярная функция, равная максимальному элементу разности
скалярная функция, равная максимальному элементу разности

Обозначая  оператор
оператор  введенный в разделе 1.2, перепишем (3.24) в виде
введенный в разделе 1.2, перепишем (3.24) в виде  Индукцией по
Индукцией по  покажем, что для всех
покажем, что для всех 

для  близких к 1. Если (3.25) справедливо для данного
близких к 1. Если (3.25) справедливо для данного  то, применяя
то, применяя  получим
получим

где последнее неравенство получено с помощью (3.24). Таким образом,

при  близких к 1. Но из равенства (3.27) и
близких к 1. Но из равенства (3.27) и

следует, что 
Выберем любую  -оптимальную политику
-оптимальную политику  для некоторого множества значений
для некоторого множества значений  имеющего предельную точку 1. Из (3.28), полагая
имеющего предельную точку 1. Из (3.28), полагая  получаем, что
получаем, что 
 откуда и
откуда и  Имеем для любого
Имеем для любого 

так что, устремляя  по последовательности, для которой
по последовательности, для которой  -оптимальна, находим, что
-оптимальна, находим, что  всех
всех  Таким образом,
Таким образом, 
Доказанная теорема устанавливает, что при  -оптимальной стратегии получается не только максимальный средний доход
-оптимальной стратегии получается не только максимальный средний доход  но и максимальное слагаемое
но и максимальное слагаемое  характеризующее смещение, по всевозможным
характеризующее смещение, по всевозможным  . В предположениях следствия теоремы
. В предположениях следствия теоремы  -оптимальная стратегия получается автоматически. В общем случае найти
-оптимальная стратегия получается автоматически. В общем случае найти  -оптимальные стратегии не удается. Рассмотрим два численных примера (Блекуэлл [14]).
-оптимальные стратегии не удается. Рассмотрим два численных примера (Блекуэлл [14]).
1. Имеются два состояния 1 и 2, в каждом из которых могут приниматься два решения: 1 и 2. Принятие решения 1 в состоянии 1 приносит доход, равный 1, при этом с вероятностью  система остается в состоянии 1, а с вероятностью
система остается в состоянии 1, а с вероятностью  переходит в состояние 2. Принятие в состоянии 1 решения
переходит в состояние 2. Принятие в состоянии 1 решения  приносит доход, равный 2, а система при этом переходит в состояние 2. В состоянии 2 принятие любого решения приносит доход, равный 0, и система остается в состоянии 2. Пусть
приносит доход, равный 2, а система при этом переходит в состояние 2. В состоянии 2 принятие любого решения приносит доход, равный 0, и система остается в состоянии 2. Пусть  где
где  Тогда
Тогда

Находим

Итак,  и
и  -оптимальна. Очевидно, что
-оптимальна. Очевидно, что  удовлетворяет предположению леммы 3.1.
удовлетворяет предположению леммы 3.1.
2. Существуют два состояния, 1 и 2, и два решения. Принятие решения 1 в состоянии 1 приносит доход, равный 3, и система остается в состоянии 1 с вероятностью  Решение
Решение  приносит доход, равный 6, и система с вероятностью 1 переходит в состояние 2. В состоянии 2 любое решение приводит к расходу, равному 3, а система остается в состоянии 2 с вероятностью
приносит доход, равный 6, и система с вероятностью 1 переходит в состояние 2. В состоянии 2 любое решение приводит к расходу, равному 3, а система остается в состоянии 2 с вероятностью  и переходит в состояние 1 с вероятностью
и переходит в состояние 1 с вероятностью  Пусть
Пусть
 где
где  Тогда
Тогда

Таким образом, имеем

так что

при  не является
не является  -оптимальной. Очевидно, что
-оптимальной. Очевидно, что  -оптимальна. Если начать со стратегии
-оптимальна. Если начать со стратегии  то, как видно из теоремы
то, как видно из теоремы  -оптимальная стратегия не будет найдена. Но если начать с
-оптимальная стратегия не будет найдена. Но если начать с  -оптимальная стратегия будет найдена.
-оптимальная стратегия будет найдена.
Как показывают эти примеры, с помощью теоремы  -оптимальная стратегия может быть найдена не всегда. Следовательно, необходим алгоритм нахождения
-оптимальная стратегия может быть найдена не всегда. Следовательно, необходим алгоритм нахождения  -оптимальных стратегий. Такой алгоритм будет дан в разделе 3.3. Теперь же обсудим некоторые свойства элементов множеств
-оптимальных стратегий. Такой алгоритм будет дан в разделе 3.3. Теперь же обсудим некоторые свойства элементов множеств 
Лемма 3.2. Пусть при любой политике  марковская цепь, задаваемая матрицей
марковская цепь, задаваемая матрицей  не имеет невозвратных состояний и
не имеет невозвратных состояний и  -произвольный элемент множества
-произвольный элемент множества  Тогда а) если
Тогда а) если  то и
то и  если
если  пусто и
пусто и  то
то

Доказательство. Следствие теоремы 3.2 утверждает, что из соотношения  следует
следует  Из пункта а) теоремы 3.2 получим, что если множество
Из пункта а) теоремы 3.2 получим, что если множество  пусто, то выполняется неравенство
пусто, то выполняется неравенство  Таким образом, в каждом из этих случаев достаточно показать, что
Таким образом, в каждом из этих случаев достаточно показать, что 
Предположим противное, т. е. что  Тогда в силу (2.3)
Тогда в силу (2.3)

Но из предположения об отсутствии невозвратных состояний следует, что матрица  в каждом столбце имеет положительный элемент, а разность
в каждом столбце имеет положительный элемент, а разность  неотрицательна, если
неотрицательна, если  и неположительна, если
и неположительна, если  пусто. Таким образом,
пусто. Таким образом,

Учитывая (3.6) и (2.3), получаем 

Поскольку  имеет положительный элемент в каждом столбце, а сомножитель, заключенный в квадратные скобки в (3.32), неотрицателен, если
имеет положительный элемент в каждом столбце, а сомножитель, заключенный в квадратные скобки в (3.32), неотрицателен, если  и неположителен, если
и неположителен, если  пусто (см. (3.31)), то
пусто (см. (3.31)), то

Отсюда и из (3.31) следует, что  Это противоречит условиям леммы.
Это противоречит условиям леммы. 
Таким образом, если выполнено условие леммы 3.2, то итерационный алгоритм нахождения стратегий оказывается более эффективным. Другими словами, если при политике  нет невозвратных состояний, то всегда
нет невозвратных состояний, то всегда  при
при  или
или 
Следствие. Для любой  справедливо следующее.
справедливо следующее.

б) Если марковская цепь, определяемая матрицей  не имеет невозвратных состояний при всех
не имеет невозвратных состояний при всех  то
то  пусто и
пусто и 
Доказательство, а) Утверждение непосредственно следует из леммы 3.1.
б) Предположим сначала, что  Тогда
Тогда  в силу леммы
в силу леммы  Это противоречит предположению, что
Это противоречит предположению, что  Таким образом,
Таким образом,  пусто. Предположим теперь, что
пусто. Предположим теперь, что  Тогда в силу леммы
Тогда в силу леммы  Данное неравенство противоречит предположению, что
Данное неравенство противоречит предположению, что  Таким образом,
Таким образом,  Этот факт в совокупности с утверждением а) завершает доказательство.
Этот факт в совокупности с утверждением а) завершает доказательство. 
Если марковская цепь, определяемая матрицей  не имеет невозвратных состояний при каждом
не имеет невозвратных состояний при каждом 
то выполнены предположения а) теоремы 3.2 и б) следствия леммы 3.2, и итерационный алгоритм прекращает работу сразу же при нахождении элемента из  Более того,
Более того,  является множеством всех
является множеством всех  отвечающих максимальному среднему доходу за единицу времени. Таким образом, если алгоритм начинает работу с
отвечающих максимальному среднему доходу за единицу времени. Таким образом, если алгоритм начинает работу с  то он не приводит к
то он не приводит к  -оптимальной стратегии. В примере 2 мы рассмотрели этот случай.
-оптимальной стратегии. В примере 2 мы рассмотрели этот случай.
Лемма 3.3. Если  то
то 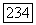 Более того,
Более того, 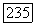
Доказательство. Множество 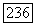 определяется только парой
определяется только парой 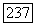 Аналогичное положение имеет место и для
Аналогичное положение имеет место и для 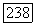 Но из включений
Но из включений 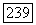 следует, что
следует, что 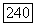 Следовательно,
Следовательно, 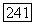 Кроме того, поскольку
Кроме того, поскольку 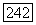 то
то 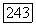 Наконец, включение
Наконец, включение  доказано в следствии леммы 3.2. Приведем пример того, что
доказано в следствии леммы 3.2. Приведем пример того, что 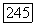 является собственным подмножеством
является собственным подмножеством 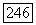
Пусть имеются два состояния, 1 и 2, и пять решений в состоянии 2. В состоянии 1 любое решение приносит доход, равный 2, а система переходит в состояние 2. В состоянии 2 решение 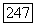 приносит доход, равный
приносит доход, равный 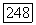 и система остается в состоянии 2 с вероятностью
и система остается в состоянии 2 с вероятностью 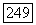 и переходит в состояние 1 с вероятностью
и переходит в состояние 1 с вероятностью 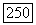 Далее,
Далее, 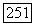 где
где 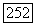 . Тогда
. Тогда

Политика 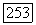 -оптимальна.
-оптимальна.