Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
5.4. Полумарковские процессы принятия решений с переоценкойОпишем полумарковские процессы принятия решений с переоценкой следующим образом. Каждому состоянию распределение времени ее пребывания в состоянии
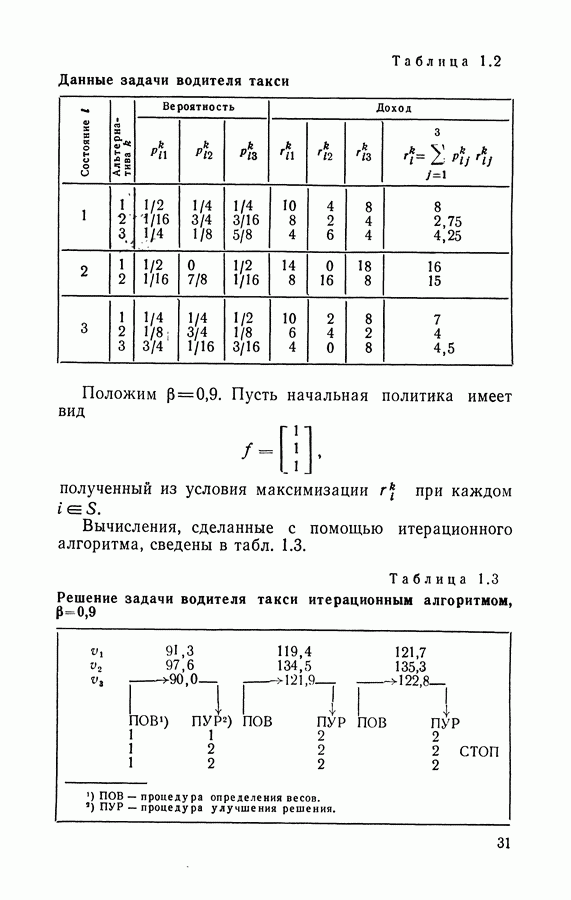
Нашей задачей является отыскание стратегии, т. е. последовательности решений, принимаемых в моменты переходов из состояния в состояние, максимизирующей суммарный средний доход (или средний доход за единицу времени) при произвольном начальном распределении процесса. Для процессов с переоценкой или поглощением суммарный средний доход является конечной величиной, а для процесса без переоценки, как правило, бесконечной. Будем считать целевой функцией суммарный средний доход, если он конечен, и средний доход за единицу времени в противном случае. Рассмотрение полумарковского процесса принятия решений при конечном времени планирования приводит к дополнительным трудностям, связанным с возможной остановкой процесса в момент, не совпадающий с моментом скачка. Поэтому здесь изучаются только модели с бесконечным временем планирования. Для таких моделей назовем стратегию стационарной, если решение, принимаемое в каждом состоянии, полностью определяется этим состоянием и не зависит ни от момента попадания в это состояние, ни от предыстории процесса (т. е. от предыдущих состояний, длительностей пребываний в них и принимавшихся решений). Пусть Определение 5.1. Стратегия Теорема 5.1. Существует стационарная Доказательство этой теоремы, основанное на принципе сжатых отображений, принадлежит Денардо [31] и будет приведено в примере 4 раздела 7.5. В силу теоремы 5.1 можно искать Сформулируем теперь задачу линейного программирования применительно к полумарковским процессам принятия решений с переоценкой. Из (5.41) для любой стационарной стратегии
Суммарный средний доход с учетом переоценки при начальном распределении а имеет вид
где
или
Для дальнейшего удобно расширить понятие решений и рассмотреть рандомизированные (или смешанные) стратегии. Пусть
Используя распределение
где
Отметим, что величины
Используя
Выполняя несложные преобразования, получаем
Последнее равенство справедливо в силу (5.67). Следовательно,
Таким образом, приходим к следующей задаче линейного программирования:
при ограничениях
Эта задача аналогична рассмотренной в разделе 1.3. Теорема 5.2. Если все Доказательство этой теоремы в точности совпадает с доказательством следствия теоремы 1.6. Теорема 5.2 играет важную роль в обосновании итерационного алгоритма нахождения стратегий. Рассмотрим теперь двойственную по отношению к (5.76) — (5.78) задачу. Она имеет смысл, поскольку ранг матрицы системы ограничений (5.77) равен
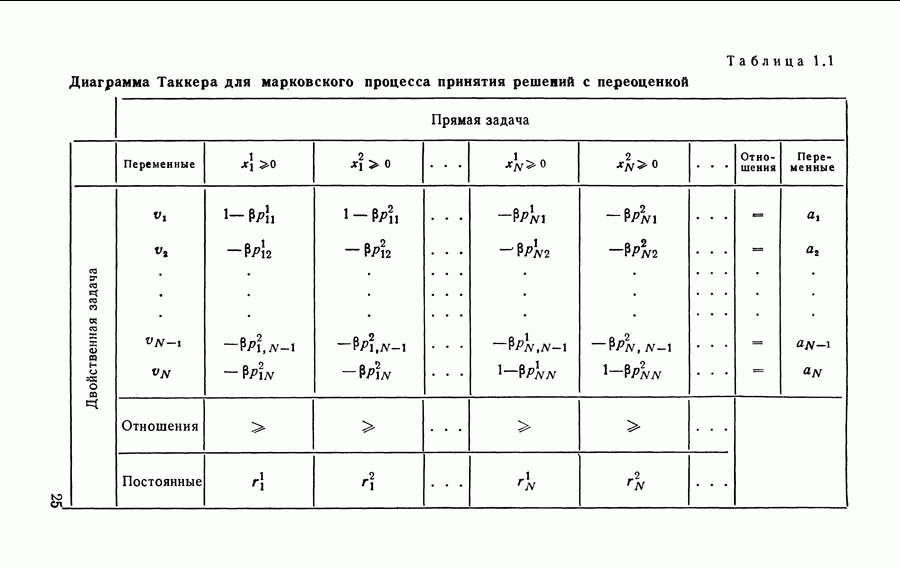
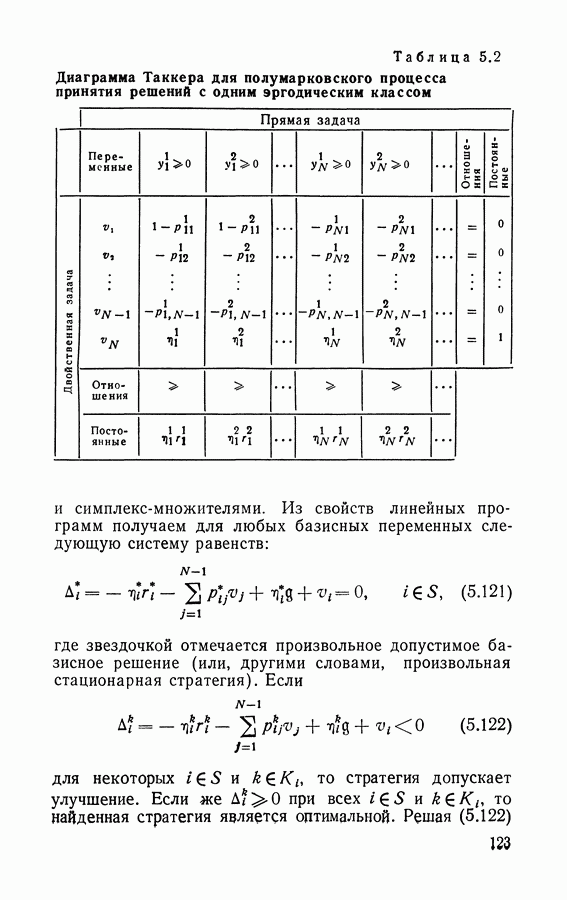
при ограничениях
где двойственная переменная Табл. 5.1 изображает диаграмму Таккера для прямой и двойственной задач. Используя результаты раздела 1.4 и теорему 5.2, немедленно получаем итерационный алгоритм нахождения стратегий для полумарковского процесса с переоценкой. Заметим, что двойственные переменные (5.81) являются одновременно симплекс-множителями для прямой задачи. Итерационный алгоритм нахождения стратегий состоит из двух последовательно выполняемых процедур. Таблица 5.1 (см. скан) Диаграмма Танкера для полумарковского процесса принятия решений с переоценкой Процедура определения весов. Выбирая произвольную стационарную стратегию решим уравнения
где индекс Процедура улучшения решения. Используя найденные значения
Если Пусть теперь существует хотя бы одно состояние В качестве начальной стратегии можно взять, например, такую, для которой С позиции линейного программирования процедура улучшения решения является таким расширением симплексного критерия, при котором последний используется одновременно во всех состояниях. Если хотя бы при одном Покажем теперь, что стратегия Теорема 5.3. Выберем произвольную стратегию Пусть хотя бы при одном множество Доказательство. Для двух стратегий
Вычитая (5.82) из (5.83), получаем
Определим
В силу условия теоремы
Решая уравнение (5.85) относительно
Так как элементы вектора у и матрицы Из теоремы 5.3 следует, что итерационный алгоритм нахождения стратегий сходится к
то все они
|
 |
Оглавление
|





































































































































































 поставим в соответствие конечное множество
поставим в соответствие конечное множество  решений, элементы которого обозначим
решений, элементы которого обозначим  Если система находится в состоянии
Если система находится в состоянии  и принимается решение
и принимается решение  то ее дальнейшее поведение определяется вероятностным законом
то ее дальнейшее поведение определяется вероятностным законом  где
где  вероятность перехода системы в состояние у, а
вероятность перехода системы в состояние у, а 
 при условии, что следующий переход произойдет в состояние у. Кроме того, за единицу времени пребывания в состоянии
при условии, что следующий переход произойдет в состояние у. Кроме того, за единицу времени пребывания в состоянии  в случае принятия решения
в случае принятия решения  выплачивается доход
выплачивается доход  Другими словами, в каждом состоянии
Другими словами, в каждом состоянии  имеются
имеются  решений; выбор
решений; выбор  решения
решения  означает задание величин
означает задание величин

 -мерный вектор суммарных средних доходов с учетом переоценки при произвольной стратегии
-мерный вектор суммарных средних доходов с учетом переоценки при произвольной стратегии  и норме переоценки а
и норме переоценки а 
 называется
называется  -оптимальной
-оптимальной  если
если  для любой стратегии
для любой стратегии  .
.
 -опти-мальная стратегия.
-опти-мальная стратегия.
 -оптимальные стратегии в классе стационарных стратегий, число которых конечно, и воспользоваться полученной ранее формулой (6.41).
-оптимальные стратегии в классе стационарных стратегий, число которых конечно, и воспользоваться полученной ранее формулой (6.41).
 имеем
имеем




 вероятность того, что в состоянии
вероятность того, что в состоянии  принимается решение
принимается решение  Эта вероятность не зависит от времени поскольку рассматриваются лишь стационарные стратегии. Ясно, что
Эта вероятность не зависит от времени поскольку рассматриваются лишь стационарные стратегии. Ясно, что

 получаем для произвольной стационарной стратегии следующее равенство:
получаем для произвольной стационарной стратегии следующее равенство:


 зависят от
зависят от  так как элементы матрицы
так как элементы матрицы  выражаются через
выражаются через  Определим новые переменные
Определим новые переменные

 перепишем (5.69) в виде
перепишем (5.69) в виде






 в правой части (5.77) положительны, то существует допустимое базисное решение, обладающее тем свойством, что для каждого
в правой части (5.77) положительны, то существует допустимое базисное решение, обладающее тем свойством, что для каждого  найдется ровно один элемент
найдется ровно один элемент  для которого
для которого  при остальных же
при остальных же 
 (см. раздел 1.3). Эту задачу можно записать в виде
(см. раздел 1.3). Эту задачу можно записать в виде


 свободны от ограничений, (5.81)
свободны от ограничений, (5.81)
 является
является  координатой вектора доходов
координатой вектора доходов  -оптимальная стратегия.
-оптимальная стратегия.

 соответствует выбранной стратегии
соответствует выбранной стратегии
 выберем при каждом
выберем при каждом  такой элемент
такой элемент  множества
множества  что
что

 пусто при всех 5, то стратегия оптимальна
пусто при всех 5, то стратегия оптимальна  является вектором суммарных средних доходов с учетом переоценки.
является вектором суммарных средних доходов с учетом переоценки.
 для которого множество
для которого множество  непусто, и пусть
непусто, и пусть  множество всех таких состояний. Тогда образуем улучшенную стратегию
множество всех таких состояний. Тогда образуем улучшенную стратегию  по следующему правилу:
по следующему правилу:  произвольный элемент множества
произвольный элемент множества  при каждом
при каждом  а при полагаем
а при полагаем  После этого возвращаемся к процедуре определения весов.
После этого возвращаемся к процедуре определения весов.
 элемент политики
элемент политики  выбирается из условия
выбирается из условия  при всех
при всех
 множество
множество  непусто, то процедура улучшения решения эквивалентна симплексному критерию основной задачи.
непусто, то процедура улучшения решения эквивалентна симплексному критерию основной задачи.
 полученная с помощью процедуры улучшения решения, удовлетворяет неравенству
полученная с помощью процедуры улучшения решения, удовлетворяет неравенству 
 непусто,
непусто,  такая политика, что
такая политика, что  если
если  непусто, и
непусто, и  если
если  пусто. Тогда и
пусто. Тогда и 
 имеем
имеем


 -мерный вектор у следующим образом:
-мерный вектор у следующим образом:

 если
если  непусто, и
непусто, и  если
если  пусто. Используя (5.85) и обозначая
пусто. Используя (5.85) и обозначая  преобразуем выражение (5.84) к виду
преобразуем выражение (5.84) к виду

 находим
находим

 неотрицательны, содержат хотя бы по одному положительному элементу и матрица
неотрицательны, содержат хотя бы по одному положительному элементу и матрица  то по крайней мере один из элементов вектора
то по крайней мере один из элементов вектора  строго положителен, т. е.
строго положителен, т. е. 
 -оптимальной стратегии за конечное число шагов, поскольку число всех стационарных стратегий конечно. Отметим, что если две или более стратегий удовлетворяют уравнению оптимальности
-оптимальной стратегии за конечное число шагов, поскольку число всех стационарных стратегий конечно. Отметим, что если две или более стратегий удовлетворяют уравнению оптимальности

 -оптимальны.
-оптимальны.