Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
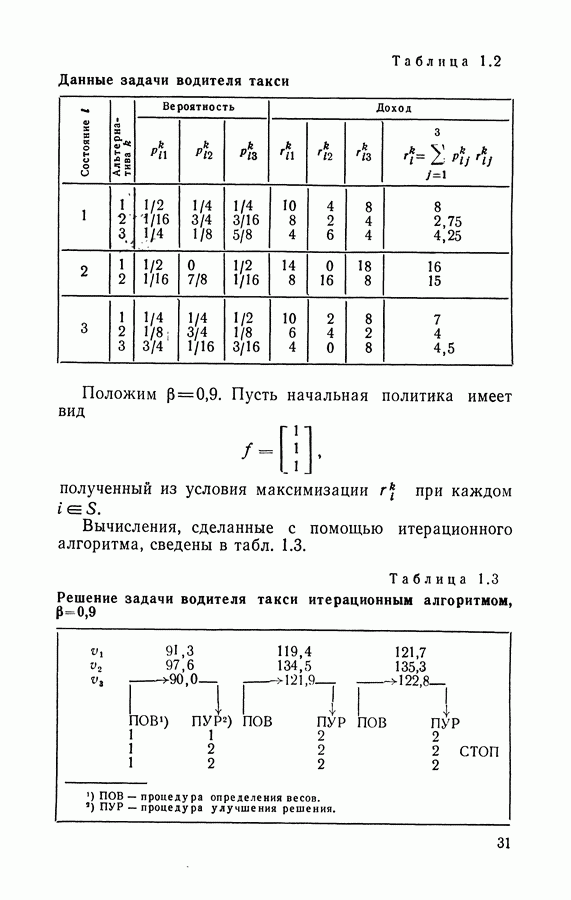
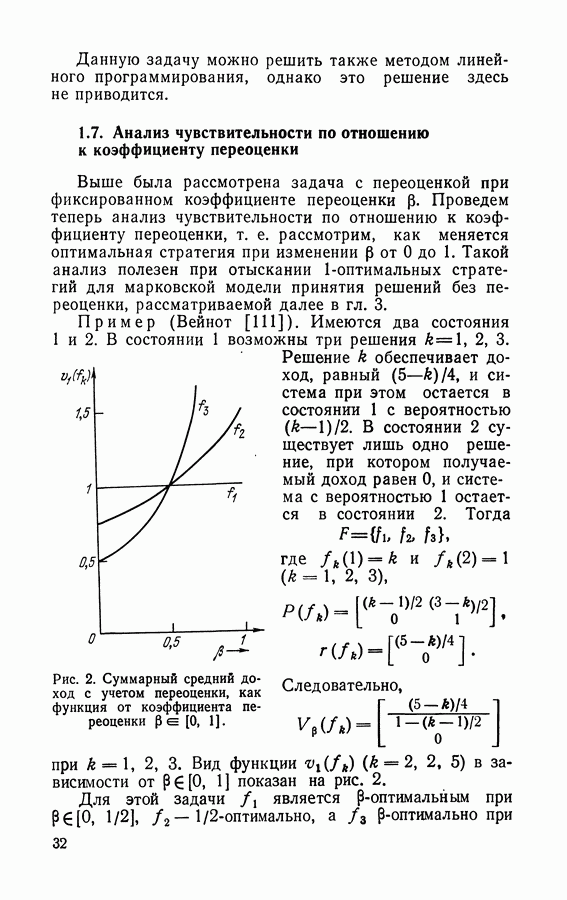
5.5. Полумарковские процессы принятия решений без переоценкиПерейдем теперь к изучению полумарковских процессов принятия решений без переоценки. В качестве критерия рассмотрим следующую функцию:
где Найдем стратегию, максимизирующую (5.88), т. е. оптимальную стратегию я, для которой Теорема 5.4. Существует стационарная оптимальная стратегия. Доказательство. В силу теоремы 5.1 существует стационарная Из (5.47) следует, что
для любой стационарной стратегии Применяя теорему Абеля и тауберову теорему
откуда следует, что В силу теоремы 5.4 можно искать оптимальные стратегии в классе стационарных, если в качестве критерия выбран средний доход в единицу времени. А тогда для нахождения дохода можно воспользоваться результатами раздела 5.3. Сформулируем задачу линейного программирования применительно к процессу с одним эргодическим классом и к процессу с поглощением. Рассмотрим вначале процесс с одним эргодическим классом. В этом случае стационарный средний доход за единицу времени имеет вид
где
где
Пусть
Целевая функция с учетом величин
Представим соотношения
Полагая
и используя тот факт, что
на основании соотношений (5.97)-(5.101), получаем следующую задачу математического программирования:
при ограничениях
Это так называемая задача дробно-линейного программирования (см., например, [21]), которую заменой переменных можно свести к задаче линейного программирования. Замечая, что
и
Тогда получаем следующую задачу линейного программирования:
при ограничениях
где дополнительное ограничение (5.111) получается простым преобразованием (5.106). Остановимся теперь на некоторых свойствах задачи (5.108) — (5.112). Теорема 5.5. У задачи (5.108)-(5.112) существует допустимое базисное решение, обладающее тем свойством, что для каждого найдется в точности одно Доказательство аналогично доказательству теоремы 2.3 и потому не приводится. Из теоремы 5.5 следует, что Теорема 5.6. Задача нахождения оптимального решения для рассматриваемого полумарковского процесса принятия решений эквивалентна следующей задаче линейного программирования:
при ограничениях
Доказательство. Как уже отмечалось, стационарная оптимальная стратегия и связанный с ней максимальный средний доход за единицу времени
не зависящими от у. В теореме 5.6 сформулирована задача линейного программирования (5.113)-(5.116), имеющая переменных и N ограничений (если не считать опущенного в (5.114) избыточного ограничения при Введем двойственные переменные
при ограничениях
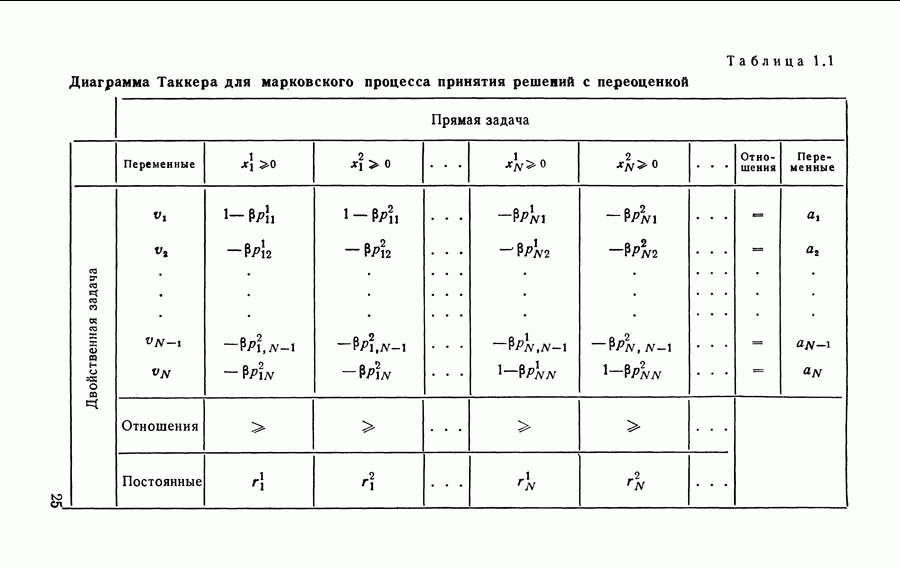
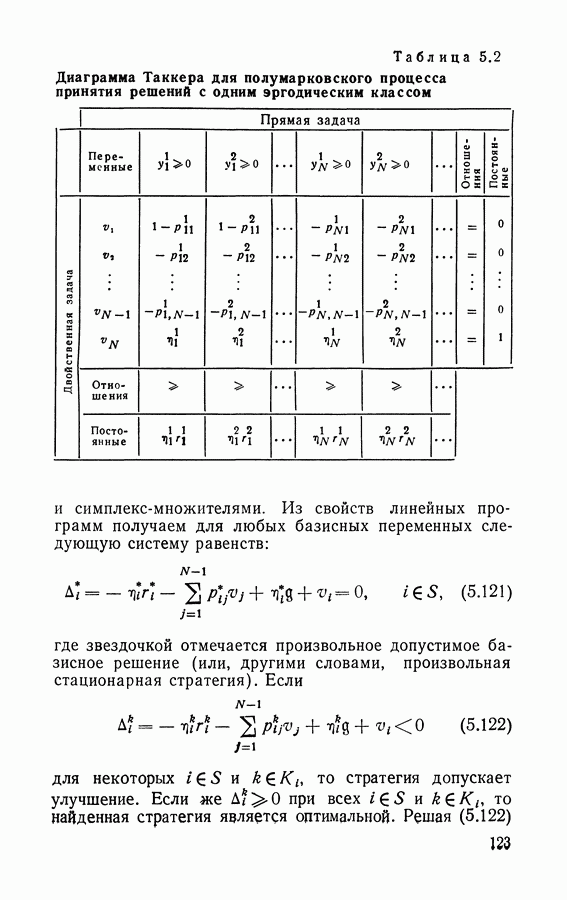
Отметим, что в Итерационный алгоритм нахождения стратегий для рассматриваемой задачи можно непосредственно получить из построений раздела 2.5. Отметим, что двойственные переменные Таблица 5.2 (см. скан) Диаграмма Таккера для полумарковского процесса принятия решений с одним эргодическим классом Из свойств линейных программ получаем для любых базисных переменных следующую систему равенств:
где звездочкой отмечается произвольное допустимое базисное решение (или, другими словами, произвольная стационарная стратегия). Если
для некоторых и относительно
порождающее процедуру улучшения решения. Таким образом, приходим к следующему итерационному алгоритму нахождения стратегий. Процедура определения весов. Выбирая любую стационарную стратегию решить уравнения
относительно Процедура улучшения решения. Используя полученные значения
Если множество Остается только показать, что процедура улучшения решения приводит к улучшенной стратегии (в смысле стационарного среднего дохода). Теорема 5.7. Пусть Доказательство. Для двух произвольных стратегий
где через
Определим
где Определим величины
Объединяя (5.126) и (5.127), получаем после несложных преобразований
Пусть Умножая обе части (5.128) на
которое положительно, так как финальная вероятность состояния
при всех а
Из теоремы 5.7 следует, что итерационный алгоритм приводит к оптимальной стационарной стратегии за конечное число итераций. Заметим, что если существуют две или более стратегий, удовлетворяющие уравнению оптимальности
то каждая из этих стратегий оптимальна и приносит одинаковый средний доход Тогда возникает задача отыскания оптимальной стратегии, максимизирующей члены Рассмотрим процесс с поглощением. Будем считать состояние 1 поглощающим. Предположение о поглощении. Поглощающее состояние может быть достигнуто с вероятностью 1 из любого состояния при любом принимаемом решении. При начальном распределении а суммарный средний доход, полученный к моменту поглощения, имеет вид
Найдем стратегию, максимизирующую этот дощд, Аналогичная задача уже рассматривалась при изучении модели с переоценкой, поэтому ограничимся только формулировкой соответствующей задачи линейного программирования
при ограничениях
Следующая теорема очевидна. Теорема 5.8. Если все Из сформулированной выше задачи линейного программирования и теоремы 5.8 немедленно вытекает итерационный алгоритм нахождения стратегии. Ссылки и комментарии Изложение теории полумарковских процессов или процессов марковского восстановления можно найти у Смита [107], Пайка [97], [98], Барлоу и Прошана [5], а также в обзорных статьях Цинлара [147], Королюка, Броди и Турбина [129] и в монографии Королюка и Турбина [130]. Теория восстановления излагается в работах Кокса [24] и Смита [108]. Полумарковские процессы принятия решений или управляемые процессы марковского восстановления были впервые рассмотрены Джевеллом [65], [66]. Итерационные алгоритмы нахождения стратегий для таких процессов изучались также Ховардом [64] и Де Кани [26]. Оптимальность стационарных стратегий была доказана Денардо [31] для модели с переоценкой и Фоксом [59] для модели без переоценки. Позднее Фокс доказал оптимальность стационарных стратегий для модели без переоценки при слабых ограничениях. Ховард [64], Фокс [59], Де Хелинк и Эпан [28], а также Осаки и Майн [94] сформулировали задачи линейного программирования применительно к таким процессам. Обобщенные полумарковские процессы изучали Денардо и Фокс [33]. Процесс принятия решений для марковской цепи с непрерывным временем был впервые рассмотрен Ховардом [63]. Рыков [103] доказал оптимальность стационарных стратегий для таких процессов с переоценкой. Эта модель в настоящей главе не обсуждалась. Более сильные результаты были получены Миллером [89], [90] для процессов с конечным и бесконечным временем планирования. Для процессов принятия решений применительно к периодическим цепям Маркова с непрерывным временем Мартин-Лефом доказано существование оптимальной (в смысле суммарного среднего дохода) периодической стратегии. Задачу нахождения оптимальных стратегий для полумарковских процессов среди класса немарковских стратегий исследовал Читгопекер [148].
|
 |
Оглавление
|
















































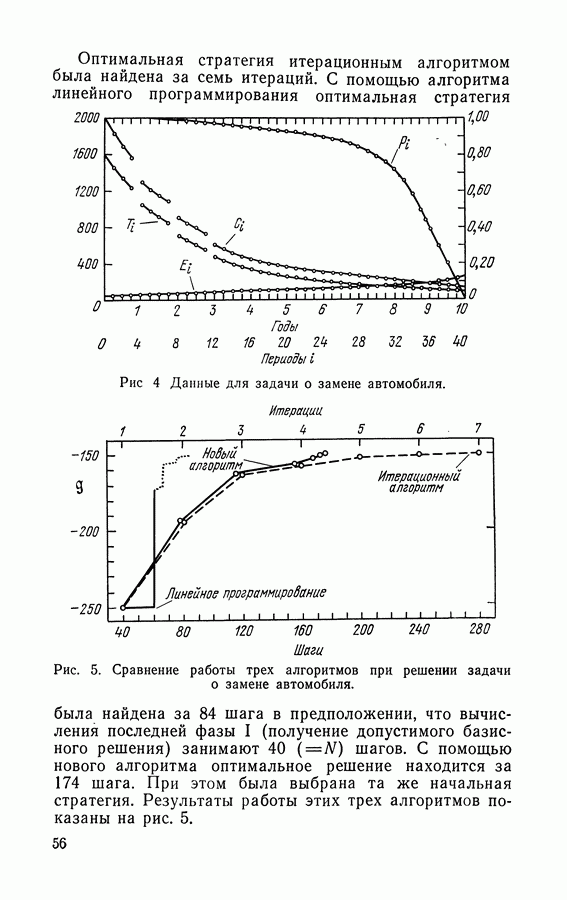


























































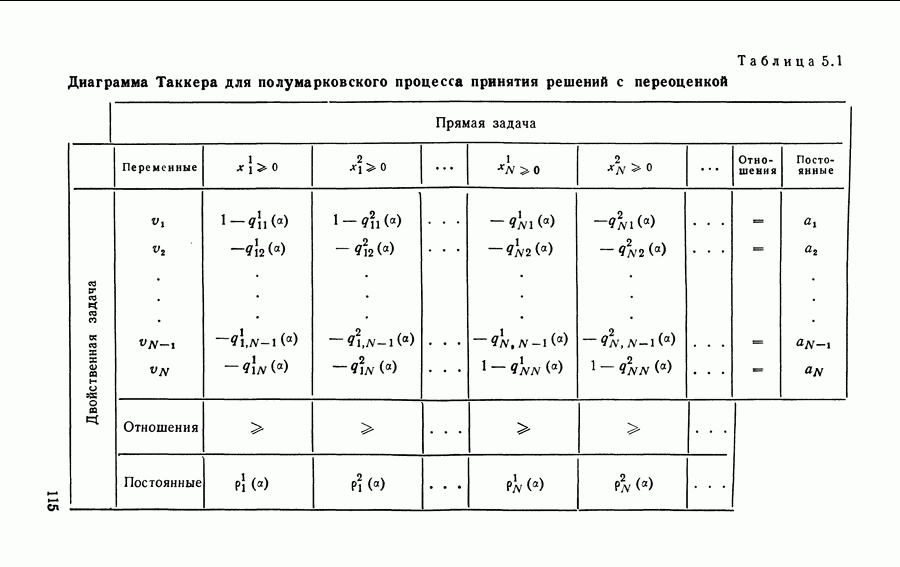




























































 -мерный вектор суммарных средних доходов, полученных за время
-мерный вектор суммарных средних доходов, полученных за время  при стратегии
при стратегии  Таким образом,
Таким образом,  можно интерпретировать как вектор средних доходов, получаемых за единицу времени при
можно интерпретировать как вектор средних доходов, получаемых за единицу времени при  Аналогом этой величины в случае дискретного времени является выражение (2.12). Для стационарной стратегии находим
Аналогом этой величины в случае дискретного времени является выражение (2.12). Для стационарной стратегии находим  решая уравнение (5.48) относительно
решая уравнение (5.48) относительно  Но для произвольной нестационарной стратегии получить
Но для произвольной нестационарной стратегии получить  в явном виде не удается.
в явном виде не удается.
 при всех стратегиях я.
при всех стратегиях я.
 -оптимальная стратегия. Поскольку число всех стационарных стратегий конечно, то можно выбрать сходящуюся к нулю последовательность
-оптимальная стратегия. Поскольку число всех стационарных стратегий конечно, то можно выбрать сходящуюся к нулю последовательность  такую, что
такую, что  где
где  стационарная стратегия.
стационарная стратегия.

 для произвольной стратегии
для произвольной стратегии  получаем
получаем

 — стационарная оптимальная стратегия.
— стационарная оптимальная стратегия. 

 финальная вероятность состояния
финальная вероятность состояния  вложенной цепи Маркова. Рассмотрим процесс принятия решений с целевой функцией
вложенной цепи Маркова. Рассмотрим процесс принятия решений с целевой функцией

 -соответствующая финальная вероятность процесса при стационарной стратегии соответственно безусловные средние значения времени пребывания процесса в состоянии
-соответствующая финальная вероятность процесса при стационарной стратегии соответственно безусловные средние значения времени пребывания процесса в состоянии  и дохода за единицу времени пребывания в состоянии
и дохода за единицу времени пребывания в состоянии  при выбранной стратегии Финальные вероятности удовлетворяют соотношениям
при выбранной стратегии Финальные вероятности удовлетворяют соотношениям

 вероятность того, что в состоянии
вероятность того, что в состоянии  принимается решение
принимается решение  Очевидно, что
Очевидно, что

 равна
равна

 в виде
в виде





 введем новые переменные
введем новые переменные  следующим образом:
следующим образом:




 такое, что
такое, что  Для остальных
Для остальных 
 при любом допустимом базисном решении.
при любом допустимом базисном решении.


 при любом допустимом базисном решении. Нас интересует
при любом допустимом базисном решении. Нас интересует
 Ясно, что оптимальное значение критерия (5.113) не зависит от у. Из формул замены переменных (5.106), (5.107) следует, что
Ясно, что оптимальное значение критерия (5.113) не зависит от у. Из формул замены переменных (5.106), (5.107) следует, что  при всех
при всех  Таким образом, оптимальная стратегия определяется соотношениями
Таким образом, оптимальная стратегия определяется соотношениями


 в виде равенств.
в виде равенств.
 и рассмотрим задачу, двойственную к задаче (5.113) — (5.116)
и рассмотрим задачу, двойственную к задаче (5.113) — (5.116)


 Поскольку ограничения (5.114) и (5.115) имеют ранг
Поскольку ограничения (5.114) и (5.115) имеют ранг  то у двойственной задачи существует решение, а в силу теоремы двойственности (см., например, [25]) стационарный средний доход за единицу времени
то у двойственной задачи существует решение, а в силу теоремы двойственности (см., например, [25]) стационарный средний доход за единицу времени  является целевой функцией двойственной задачи. Диаграмма Таккера для прямой и двойственной задач применительно к полумарковским процессам принятия решений с одним эргодическим классом приведена в табл. 5.2. Рассуждениями, аналогичными приведенным в разделе 2.4, можно показать, что двойственные переменные
является целевой функцией двойственной задачи. Диаграмма Таккера для прямой и двойственной задач применительно к полумарковским процессам принятия решений с одним эргодическим классом приведена в табл. 5.2. Рассуждениями, аналогичными приведенным в разделе 2.4, можно показать, что двойственные переменные  являются членами, характеризующими смещение, и вычисляются по формуле (5.46).
являются членами, характеризующими смещение, и вычисляются по формуле (5.46).
 являются еще и симплекс-множителями.
являются еще и симплекс-множителями.


 то стратегия допускает улучшение. Если же
то стратегия допускает улучшение. Если же  при всех
при всех  то найденная стратегия является оптимальной. Решая (5.122)
то найденная стратегия является оптимальной. Решая (5.122)
 получаем неравенство
получаем неравенство


 (полагая
(полагая  где верхний индекс
где верхний индекс  определяется выбранной стратегией
определяется выбранной стратегией
 найти для каждого
найти для каждого  элемент множества
элемент множества  такой, что
такой, что

 пусто для всех
пусто для всех  то стратегия оптимальна,
то стратегия оптимальна,  средний доход за единицу времени; тогда
средний доход за единицу времени; тогда  члены, характеризующие смещение. Если при некотором
члены, характеризующие смещение. Если при некотором  множество
множество  непусто, то рассмотреть улучшенную стратегию
непусто, то рассмотреть улучшенную стратегию  которая при таких
которая при таких  равна
равна  если
если  пусто. Далее перейти к процедуре определения весов.
пусто. Далее перейти к процедуре определения весов.
 произвольная стратегия, множество
произвольная стратегия, множество  непусто, хотя бы при одном стратегия
непусто, хотя бы при одном стратегия  такая, что
такая, что  если
если  непусто, и
непусто, и  если
если  Тогда
Тогда  где
где  стационарный средний доход за единицу времени при стратегии
стационарный средний доход за единицу времени при стратегии 
 имеем
имеем

 обозначены соответственно
обозначены соответственно  и
и  где
где  Разделив выражение (5.124) на
Разделив выражение (5.124) на  , а (5.125) на
, а (5.125) на  и вычитая первое из второго, получим
и вычитая первое из второго, получим

 -мерный вектор
-мерный вектор

 если
если  непусто, и
непусто, и  если
если  пусто (в силу условий теоремы). Заметим, что
пусто (в силу условий теоремы). Заметим, что  хотя бы для одного
хотя бы для одного 


 вектор финальных вероятностей вложенной цепи Маркова, задаваемой матрицей
вектор финальных вероятностей вложенной цепи Маркова, задаваемой матрицей  Очевидно, что
Очевидно, что 
 и суммируя по всем
и суммируя по всем  получаем выражение
получаем выражение

 равна
равна

 хотя бы для одного
хотя бы для одного  Таким образом, получаем
Таким образом, получаем



 характеризующие смещения, но ее решение здесь не приводится.
характеризующие смещения, но ее решение здесь не приводится.



 в правых частях (5.133) положительны, то существует базисное решение, обладающее тем свойством, что для каждого
в правых частях (5.133) положительны, то существует базисное решение, обладающее тем свойством, что для каждого  найдется ровно один элемент
найдется ровно один элемент  для которого при остальных же
для которого при остальных же 