Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
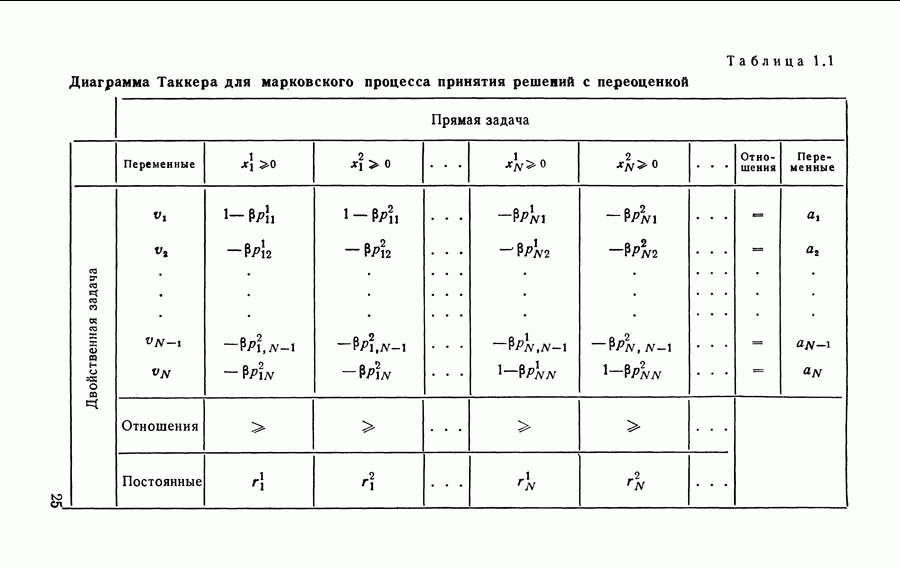
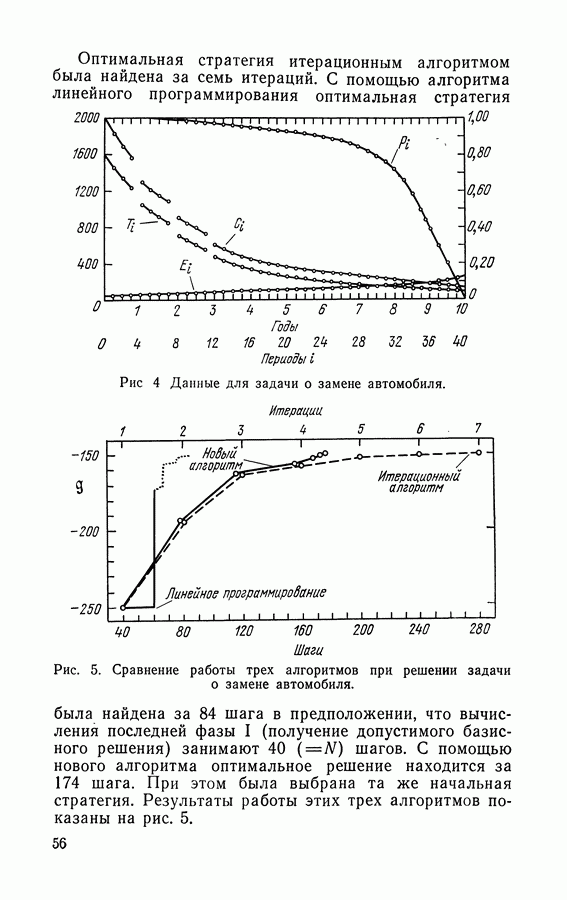
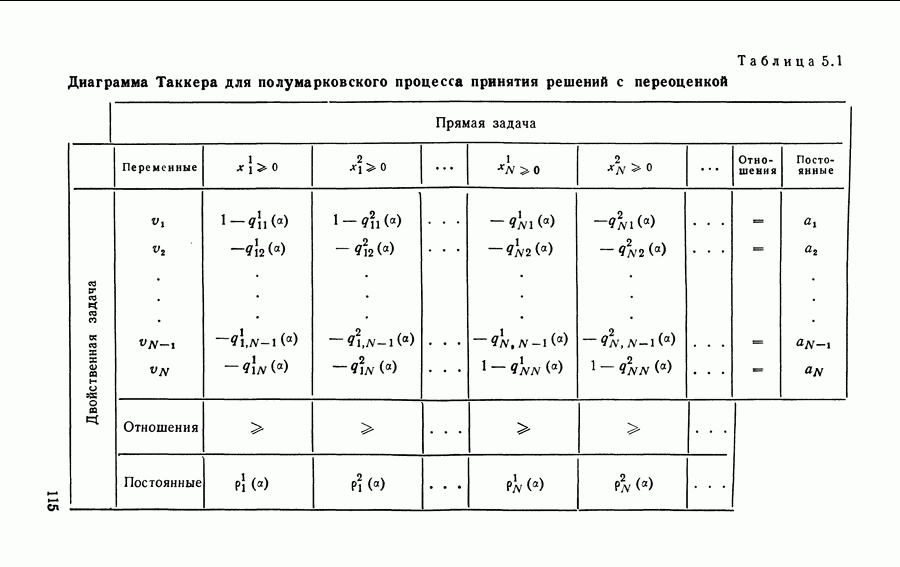
1.2. Итерационный алгоритм нахождения стратегийНиже мы приведем итерационный алгоритм нахождения стратегий для марковских процессов принятия решений с переоценкой, который был впервые предложен Ховардом [63] и поэтому иногда называется итерационным алгоритмом Ховарда. Он тесно связан с линейным программированием, и эта связь будет позднее обсуждена. Материал этого параграфа является основой для рассмотрения общих процессов принятия решений в гл. 7. Пусть
Стратегия Стационарная стратегия
обозначается При любой стратегии
где
Чтобы показать ограниченность этого вектора, положим
где Справедливы следующие равенства:
где Определим векторные неравенства следующим образом. Для любых векторов Определение 1.1. Стратегия Это определение означает, что оптимальная стратегия оптимальна одновременно для всех начальных состояний — факт, не являющийся тривиальным, как будет показано далее. Из определения следует, что Лемма 1.1. Оператор Доказательство. Пусть Отсюда получаем следующие теоремы. Теорема 1.1. Если Доказательство. По предположению теоремы при всех Неоднократное применение этого соотношения приводит к неравенству
справедливому при всех Доказательство. По предположению Следующая теорема является основной. Теорема 1.3. Пусть
где 1) Если 2) Если и б)
Доказательство, Следствие. Существует стационарная Доказательство. По теореме 1.3 любая стационарная стратегия Доказанные теоремы содержат описание метода нахождения оптимальной стационарной стратегии. Этот метод, называемый итерационным алгоритмом Ховарда, состоит из следующих двух процедур. Процедура определения весов. Выбирая произвольную политику
относительно Процедура улучшения решения. Используя найденные значения найдем при каждом
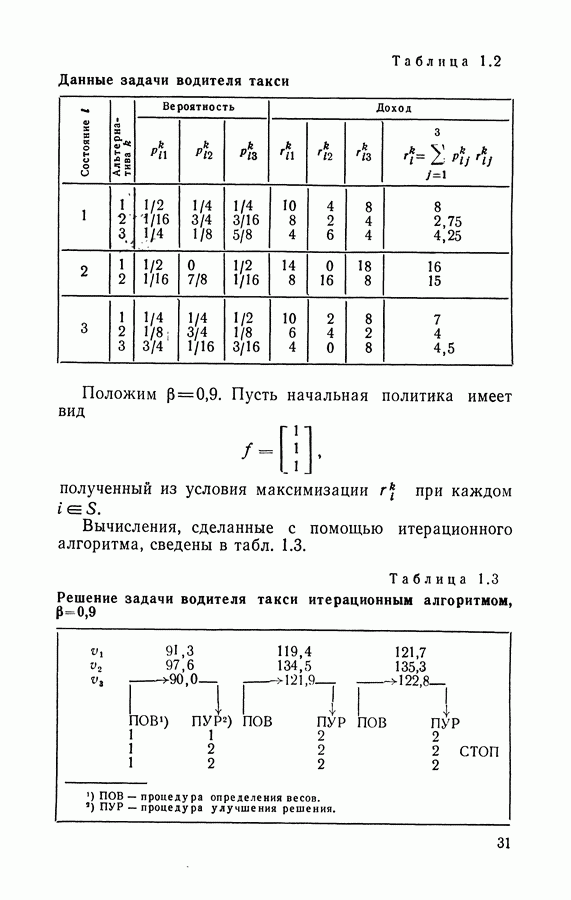
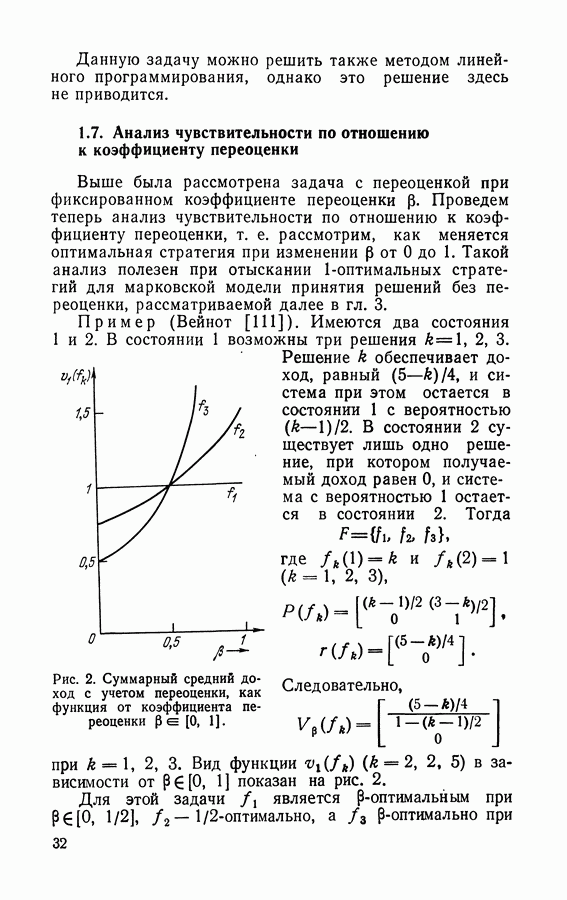
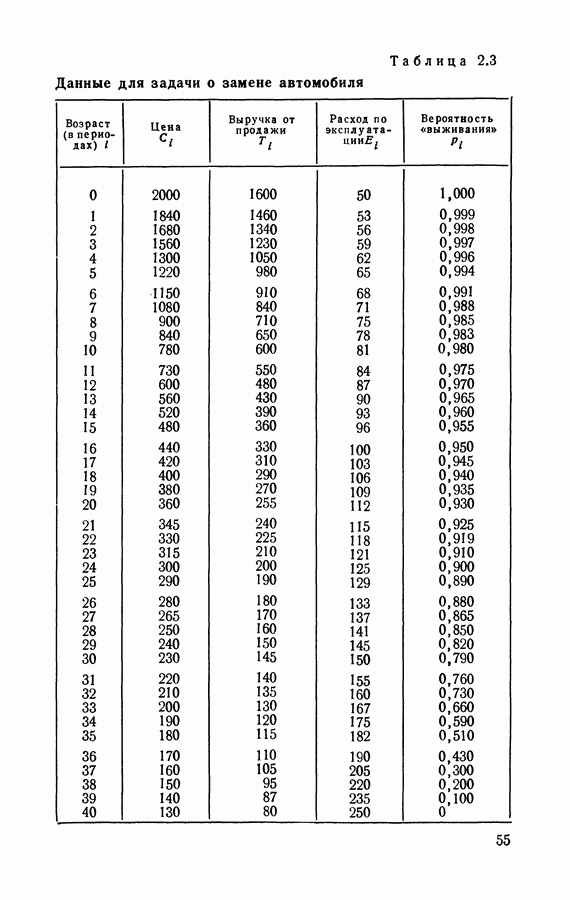
Если множества В качестве начальной стратегии можно взять, например, такую, в которой В разделе 1.6 будут даны численные примеры применения итерационного алгоритма.
|
 |
Оглавление
|





































































































































































 множество всевозможных векторов со значениями в пространстве политик
множество всевозможных векторов со значениями в пространстве политик  и
и  -элементы из
-элементы из  Тогда стратегия
Тогда стратегия  определяется, как последовательность
определяется, как последовательность  т. е.
т. е.

 вектор,
вектор,  элемент которого, обозначаемый
элемент которого, обозначаемый  является решением, принимаемым в состоянии
является решением, принимаемым в состоянии  в момент
в момент 
 обозначается
обозначается  где
где  Стратегия
Стратегия  обозначается
обозначается  где
где  и называется стационарной.
и называется стационарной.
 состоит из политик, не зависящих от времени. Стратегия вида
состоит из политик, не зависящих от времени. Стратегия вида

 где
где 
 изучаемый процесс является, вообще говоря, неоднородной цепью Маркова, для которой матрица вероятностей перехода за
изучаемый процесс является, вообще говоря, неоднородной цепью Маркова, для которой матрица вероятностей перехода за  шагов имеет вид
шагов имеет вид

 является матрицей перехода размера
является матрицей перехода размера  элемент которой равен
элемент которой равен  При
При  положим
положим  (единичная матрица размера
(единичная матрица размера  При любом
При любом  можно определить
можно определить  -мерный вектор доходов
-мерный вектор доходов  его
его  элемент обозначается
элемент обозначается  . В этих обозначениях
. В этих обозначениях  -мерный вектор суммарных средних доходов
-мерный вектор суммарных средних доходов  элемент которого отвечает начальному состоянию процесса
элемент которого отвечает начальному состоянию процесса  имеет вид
имеет вид

 Имеем
Имеем

 -мерный вектор с компонентами, равными 1.
-мерный вектор с компонентами, равными 1.

 стратегия, получающаяся из исходной сдвигом на один элемент. Для любого
стратегия, получающаяся из исходной сдвигом на один элемент. Для любого  -мерного вектора определим оператор
-мерного вектора определим оператор  который отображает
который отображает  в вектор
в вектор  Можно интерпретировать
Можно интерпретировать  как вектор средних одношаговых доходов при условии, что в момент завершения рассматриваемого перехода выплачивается сумма, равная
как вектор средних одношаговых доходов при условии, что в момент завершения рассматриваемого перехода выплачивается сумма, равная  компоненте вектора
компоненте вектора  если при этом процесс попадает в состояние у. Таким образом,
если при этом процесс попадает в состояние у. Таким образом, 
 будем писать
будем писать  если каждый элемент вектора
если каждый элемент вектора  не меньше, чем соответствующий элемент вектора
не меньше, чем соответствующий элемент вектора  и будем писать
и будем писать  если
если 
 называется
называется  -опти-калъной, если для всех
-опти-калъной, если для всех  при фиксированной величине
при фиксированной величине 
 любых
любых  и начального распределения а, т. е. оптимальная стратегия не зависит также от начального распределения а. Обратно, если стратегия, максимизирующая не зависит от начального распределения а, то
и начального распределения а, т. е. оптимальная стратегия не зависит также от начального распределения а. Обратно, если стратегия, максимизирующая не зависит от начального распределения а, то 
 является монотонным, т. е. если
является монотонным, т. е. если  то
то 
 Тогда
Тогда 
 при всех
при всех  , то
, то  -оптимальна.
-оптимальна.
 Для любой стратегии
Для любой стратегии  полагая
полагая  имеем
имеем  Применяя монотонный оператор
Применяя монотонный оператор  получаем
получаем 

 Полагая
Полагая  находим, что
находим, что  всех
всех  Теорема
Теорема  то
то 
 Применяя монотонный оператор
Применяя монотонный оператор  находим, что
находим, что  для всех
для всех  По индукции приходим к неравенству
По индукции приходим к неравенству  всех
всех  При
При  получаем
получаем 
 и для каждого
и для каждого  обозначим
обозначим  множество всех
множество всех  таких, что
таких, что

 элемент
элемент  Тогда
Тогда
 пусто при всех
пусто при всех  , то
, то  - оптимальна.
- оптимальна.
 непусто, то для любого
непусто, то для любого  такого, кто
такого, кто  некотором
некотором 
 если
если  имеет место неравенство
имеет место неравенство

 элемент вектора
элемент вектора  равен
равен  где
где  Он больше тогда и только тогда, когда
Он больше тогда и только тогда, когда  и равен
и равен  если
если  Таким образом, если
Таким образом, если  пусто при всех то
пусто при всех то  при всех
при всех  откуда следует, что является
откуда следует, что является  -оптимальной стратегией (по теореме 1.1). В то же время для любой
-оптимальной стратегией (по теореме 1.1). В то же время для любой  удовлетворяющей условиям а) и б), имеем
удовлетворяющей условиям а) и б), имеем  откуда
откуда  (по теореме 1.2).
(по теореме 1.2).
 -оптимальная стратегия.
-оптимальная стратегия.
 либо является
либо является  -оптимальной (случай, когда
-оптимальной (случай, когда  пусто при всех
пусто при всех  ), либо имеет стационарное улучшение
), либо имеет стационарное улучшение  (случай, когда
(случай, когда  не пусто при некотором S). Поскольку существует лишь конечное число стационарных стратегий, то за конечное число итераций найдется такая, которая не имеет стационарных улучшений. Следовательно, она должна быть
не пусто при некотором S). Поскольку существует лишь конечное число стационарных стратегий, то за конечное число итераций найдется такая, которая не имеет стационарных улучшений. Следовательно, она должна быть  -оптимальной.
-оптимальной.
 решим уравнения
решим уравнения

 где
где  соответствует выбранной стратегии
соответствует выбранной стратегии
 такой элемент
такой элемент  множества
множества  что
что

 пусты при всех
пусты при всех  то
то  -оптимальна и вектор
-оптимальна и вектор  является вектором суммарных средних доходов с учетом переоценки. Пусть теперь существует хотя бы одно состояние для которого множество
является вектором суммарных средних доходов с учетом переоценки. Пусть теперь существует хотя бы одно состояние для которого множество  непусто. И пусть
непусто. И пусть  множество всех таких состояний. Тогда образуем улучшенную стратегию
множество всех таких состояний. Тогда образуем улучшенную стратегию  по следующему правилу:
по следующему правилу:  произвольный элемент множества
произвольный элемент множества  при каждом а при полагаем
при каждом а при полагаем  После этого возвращаемся к процедуре определения весов.
После этого возвращаемся к процедуре определения весов.
 (при всех
(при всех  ) выбирается из условия максимизации величин доходов
) выбирается из условия максимизации величин доходов 