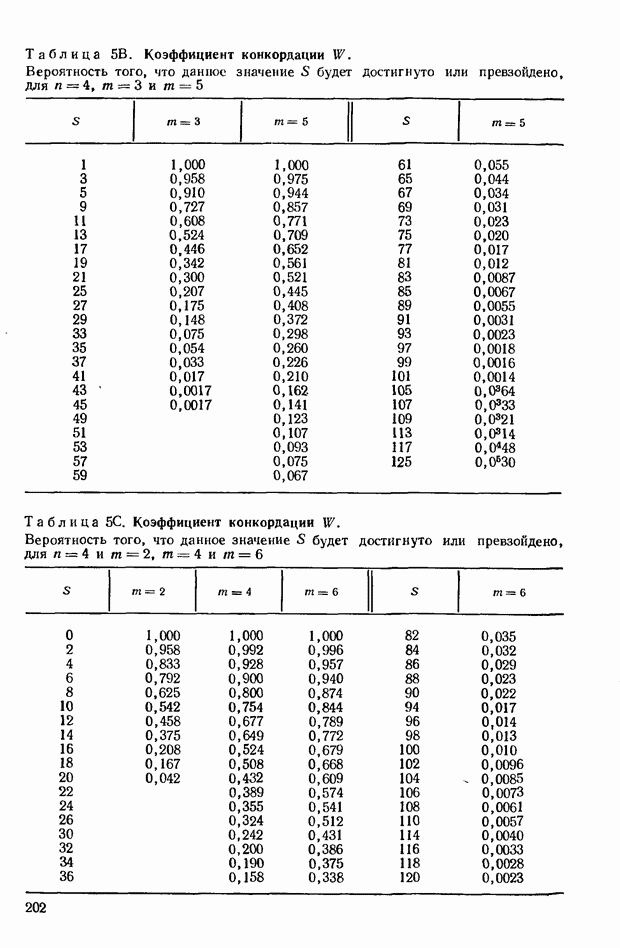
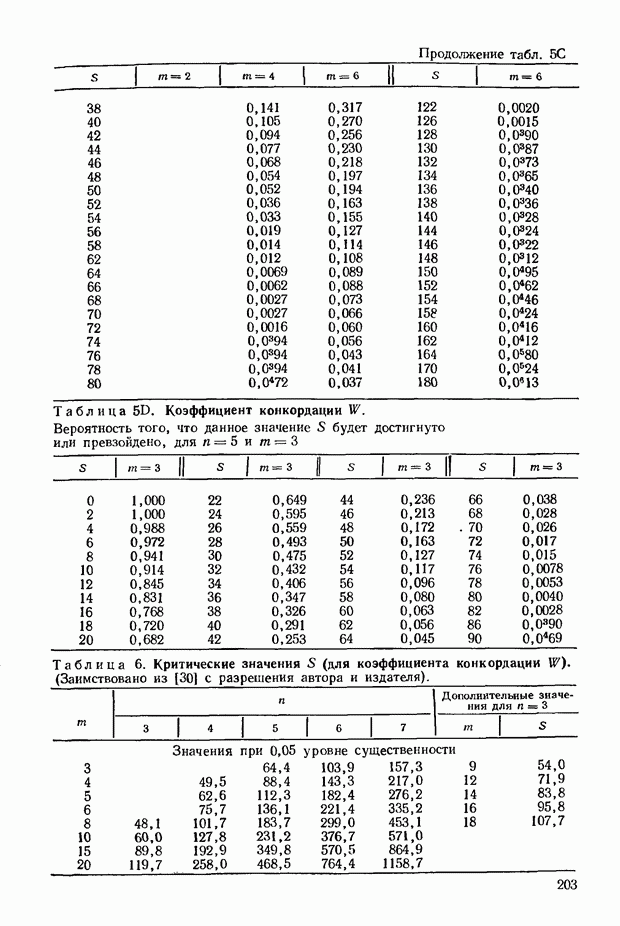
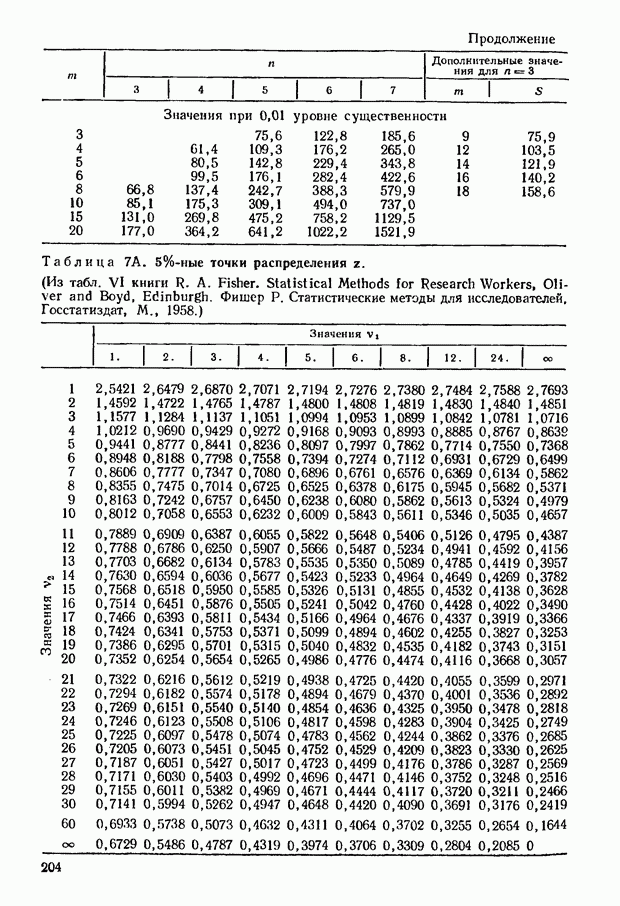
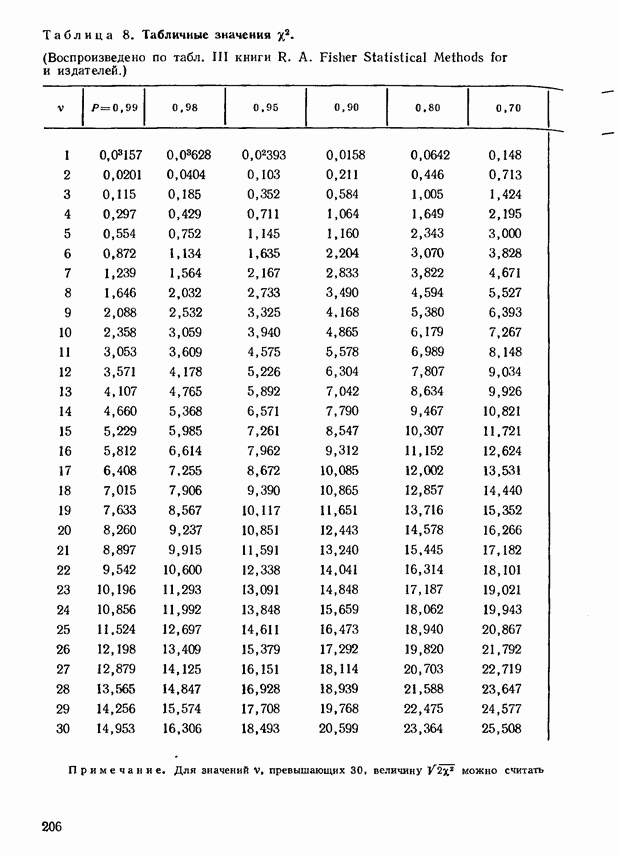
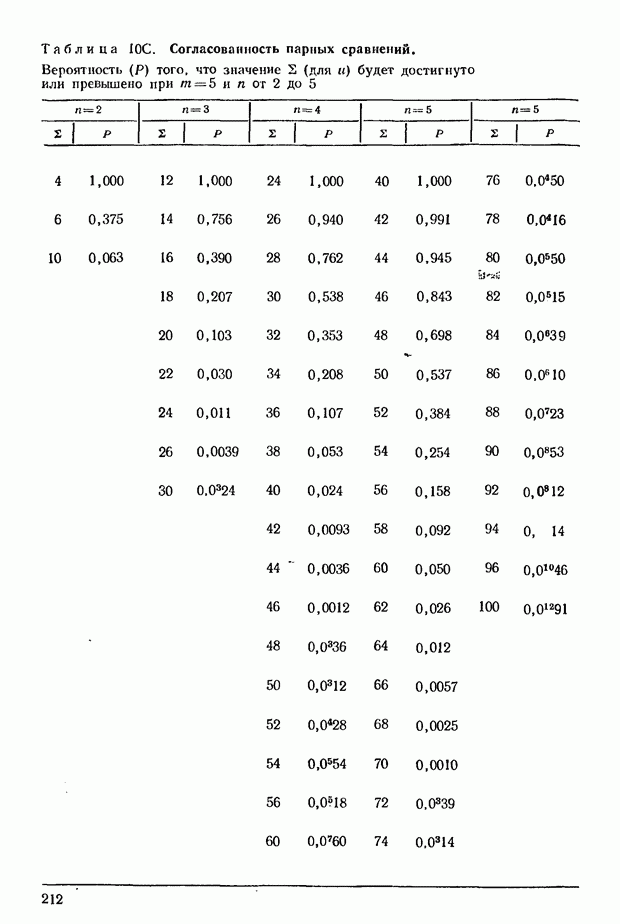
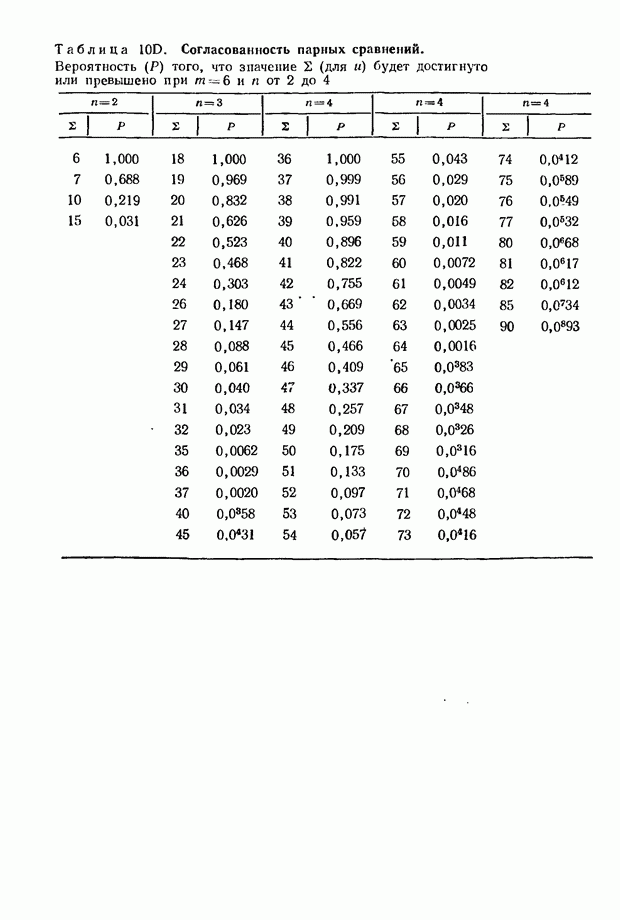
ГЛАВА 9. РАНГИ И ЗНАЧЕНИЯ ПРИЗНАКА
9.1. До сих пор мы рассматривали ранги как основные данные об имеющейся статистической ситуации, не связывая их со способами, которыми они были получены. Во многих таких ситуациях, однако, ранжирование производится (или можно предположить, что производится) в соответствии с величиной статистической переменной или признака.
Безусловно, интересно рассмотреть взаимосвязь между рангами и значениями соответствующих переменных или между измерителями корреляции, основанными на рангах, и измерителями, базой которых являются значения признака.
Конкордации
9.2. Нам будет нужно в общем рассмотреть непрерывную совокупность, иначе говоря, совокупность, значения признака которой могут находиться в любых точках непрерывного диапазона. Обратим внимание на одну деталь. Строго говоря, такая совокупность не может содержать ранговую корреляцию, поскольку существо ранжирования заключается в том, что объекты должны быть перечисляемыми, а совокупность значений непрерывного признака не может быть в этом смысле упорядочена.
9.3. Тем не менее мы можем соединить идеи ранговой корреляции и корреляции переменных при рассмотрении свойств упорядочения. Допустим, что из непрерывной совокупности в случайном порядке отобраны два члена:  Вероятность того, что они совпадают, равна нулю и, таким образом, допустимо не учитывать возможность
Вероятность того, что они совпадают, равна нулю и, таким образом, допустимо не учитывать возможность  Рассмотрим теперь вероятность того, что
Рассмотрим теперь вероятность того, что  и вероятность противоположного события, т. е. того, что
и вероятность противоположного события, т. е. того, что  Кроме того, если мы извлекли два члена
Кроме того, если мы извлекли два члена  из двумерной совокупности, то мы можем проанализировать вероятности конкордации типа 1:
из двумерной совокупности, то мы можем проанализировать вероятности конкордации типа 1:

иначе говоря, вероятность того, что  если
если  Вероятность противоположного события составит:
Вероятность противоположного события составит:

Число характеризует собой свойство совокупности.
9.4. Теперь предположим, что выборка, состоящая из  величин, случайным образом извлечена из совокупности и произведено
величин, случайным образом извлечена из совокупности и произведено
упорядочение  в порядке возрастания их значений. Из
в порядке возрастания их значений. Из  пар
пар  которые могли быть отобраны для сравнений, некоторым сопутствовали
которые могли быть отобраны для сравнений, некоторым сопутствовали  расположенные в порядке возрастания. Очевидно что число пар, у которых наблюдалось это соответствие, деленное на
расположенные в порядке возрастания. Очевидно что число пар, у которых наблюдалось это соответствие, деленное на  является оценкой
является оценкой  . Кроме того, как будет доказано в следующей главе, данная оценка является несмещенной. Если равно этой доле,
. Кроме того, как будет доказано в следующей главе, данная оценка является несмещенной. Если равно этой доле,  то сразу видно, что коэффициент
то сразу видно, что коэффициент  для данной выборки (обозначим его через
для данной выборки (обозначим его через  определяется как
определяется как

Теперь мы можем определить  как это уже было отмечено в 2.14, в терминах согласованности (конкордации) и перейти к коэффициенту, который имеет аналог в случае непрерывного распределения.
как это уже было отмечено в 2.14, в терминах согласованности (конкордации) и перейти к коэффициенту, который имеет аналог в случае непрерывного распределения.
9.5. Предположим теперь, что у нас имеется триада величин  и
и  Рассмотрим вероятность конкордации типа 2:
Рассмотрим вероятность конкордации типа 2:

иначе говоря, вероятность того, что  меньше
меньше  при условии, что
при условии, что  Определим выборочную величину
Определим выборочную величину  в виде числа конкордации типа 2, имеющихся в выборке, деленного на общее возможное их число. В отличие от
в виде числа конкордации типа 2, имеющихся в выборке, деленного на общее возможное их число. В отличие от  которое могло изменяться от
которое могло изменяться от  до
до  (как это будет показано в следующей главе) может варьировать только в пределах от
(как это будет показано в следующей главе) может варьировать только в пределах от  . В связи с некоторыми обстоятельствами, речь о которых будет идти ниже, мы не будем использовать в качестве другого коэффициента
. В связи с некоторыми обстоятельствами, речь о которых будет идти ниже, мы не будем использовать в качестве другого коэффициента  такой коэффициент менял бы свои значения от —1 до + 1). Вместо этого, следуя (2.35), определим выборочную величину
такой коэффициент менял бы свои значения от —1 до + 1). Вместо этого, следуя (2.35), определим выборочную величину

Величина  представляет собой коэффициент Спирмэна для выборки. Снова обнаруживаем, что коэффициент ранговой корреляции можно определять через конкордации. Заметим, что для больших
представляет собой коэффициент Спирмэна для выборки. Снова обнаруживаем, что коэффициент ранговой корреляции можно определять через конкордации. Заметим, что для больших  выражение (9.5) становится равным:
выражение (9.5) становится равным:

Данную величину можно интерпретировать как определение коэффициента Спирмэна для непрерывных совокупностей.
Отношение между рангами и значениями переменной
9.6. Предположим, что мы извлекли выборку из совокупности скалярных значений агов и ранжировали ее в порядке возрастания. Представляет некоторый интерес рассмотрение коэффициента корреляции между значениями  и рангами. Действительно, этот коэффициент иногда бывает удивительно высоким. А. Стюартом получены следующие основные результаты:
и рангами. Действительно, этот коэффициент иногда бывает удивительно высоким. А. Стюартом получены следующие основные результаты:
а) пусть коэффициент корреляции для совокупности из  единиц составляет
единиц составляет  а предельное его значение при
а предельное его значение при  равно С, тогда во всех случаях
равно С, тогда во всех случаях

б) если генеральная совокупность имеет равномерное распределение, иначе говоря, значения оказываются одинаковыми в некотором конечном диапазоне, то  и
и

в) если генеральная совокупность является нормальной и  то
то

г) если генеральная совокупность следует так называемому гамма-распределению, то

следовательно,

Например, при ранжировании 10 единиц, взятых из нормальной совокупности, коэффициент корреляции между рангами и значениями переменной составит:

9.7. Благодаря такой довольно тесной взаимосвязи между рангами и значениями переменной следует ожидать, что если бы мы заменили бы значения переменной числовыми рангами и затем оперировали с ними так, как если бы они были исходными переменными, то мы пришли бы во множестве случаев к тем же самым выводам. В большинстве
практических случаев именно так и бывает, однако следовать этой процедуре нужно с известной долей осторожности. Переход к рангам означает эффективное нормирование переменной и фиксирование средней величины; иногда эта процедура может вывести на ложный путь.
9.8. Некоторые авторы рекомендуют обратную процедуру. Соответственно ей в последовательности рангов, извлеченных из нормальной совокупности, ранги общим числом  единиц заменяются значениями переменной
единиц заменяются значениями переменной  Величина
Величина  есть средняя величина
есть средняя величина  члена в выборке объемом
члена в выборке объемом  Это, разумеется, не устраняет затруднения, которое было рассмотрено в 9.7. Однако, как было показано в [41], когда проверка связана с гипотезами о нормальном распределении, такая процедура обладает свойством оптимальности.
Это, разумеется, не устраняет затруднения, которое было рассмотрено в 9.7. Однако, как было показано в [41], когда проверка связана с гипотезами о нормальном распределении, такая процедура обладает свойством оптимальности.
Отношение между t и генеральным коэффициентом корреляции в случае нормального распределения
9.9. Теперь для того чтобы избежать путаницы, нам необходимо немного модифицировать и расширить систему обозначений:
1) будем, как и прежде, обозначать коэффициент  в выборке через
в выборке через 
2) обозначим выборочный коэффициент Спирмэна  как
как  а соответствующий параметр генеральной совокупности (9.6) — как
а соответствующий параметр генеральной совокупности (9.6) — как 
3) параметр двумерной нормальной совокупности, характеризующий коэффициент корреляции, обозначим через  а выборочный коэффициент корреляции — через
а выборочный коэффициент корреляции — через 
4) иногда оценки  будут рассчитываться на основе значений
будут рассчитываться на основе значений  или
или  их мы будем отмечать штрихом над
их мы будем отмечать штрихом над  т. е.
т. е. 
9.10. Можно показать, что для выборок из нормальной совокупности

Например, если

Поэтому мы можем сконструировать оценку для  скажем,
скажем,  приняв
приняв

Полученная величина не является несмещенной оценкой  поскольку Для этого необходимо, чтобы
поскольку Для этого необходимо, чтобы  Однако это не следует из (9.11). 1 ем не менее данная процедура представляется приемлемой.
Однако это не следует из (9.11). 1 ем не менее данная процедура представляется приемлемой.
Выражение (9.11) впервые было предложено в [33], а выражение (9.13) для ее дисперсии — в [24].
9.11. В следующей главе мы покажем, что для выборки, следующей нормальному распределению:

Нам известно, что у больших выборок  распределено нормально и, следовательно, этот результат можно использовать для проверки существенности наблюденных
распределено нормально и, следовательно, этот результат можно использовать для проверки существенности наблюденных  соотнося с интегралом нормального распределения. Однако, выполняя эту операцию, нам следует придать некоторое значение неизвестной величине
соотнося с интегралом нормального распределения. Однако, выполняя эту операцию, нам следует придать некоторое значение неизвестной величине  . В соответствии с обычной практикой, принятой в теории больших выборок, мы должны заменить
. В соответствии с обычной практикой, принятой в теории больших выборок, мы должны заменить  на
на  уравнения (9.12).
уравнения (9.12).
Если  характеризуют доли положительных и отрицательных вкладов в
характеризуют доли положительных и отрицательных вкладов в  то имеем:
то имеем:

и

Таким образом, на основе (9.13) получим для больших выборок

Можно также показать, что

и для 

Подставляя в (9.15), находим:

Верхний предел действительно достигается в целом ряде случаев, так что неравенство (9.18) дает нам достаточно хорошую оценку фактической дисперсии.
9.12. С той степенью приближения, которую мы здесь приняли, мы можем сравнить (9.18) с (4.9); последнее запишем как

Если не принимать во внимание разницу в сомножителях знаменателей, и  которая не играет роли для больших выборок, то при сравнении выражения (9.18) с (9.19) видно, что первое определяет предел, составляющий всего 0,278 от предела, рассчитываемого в соответствии с последним. Соответственно стандартная ошибка в первом случае будет равна 0,53 или чуть больше половины стандартной ошибки во втором случае. Этот выигрыш в точности достигается благодаря допущению, что совокупность имеет нормальное распределение. 9.13. Поскольку
которая не играет роли для больших выборок, то при сравнении выражения (9.18) с (9.19) видно, что первое определяет предел, составляющий всего 0,278 от предела, рассчитываемого в соответствии с последним. Соответственно стандартная ошибка в первом случае будет равна 0,53 или чуть больше половины стандартной ошибки во втором случае. Этот выигрыш в точности достигается благодаря допущению, что совокупность имеет нормальное распределение. 9.13. Поскольку

для небольших изменений имеем:

Возведя в квадрат и суммируя все такие изменения, получим:

Воспользуемся выражением (9.18). Тогда

Если мы взяли  в качестве оценки
в качестве оценки  дает нам оценку верхнего предела стандартной ошибки этой оценки. Интересно сравнить эту
дает нам оценку верхнего предела стандартной ошибки этой оценки. Интересно сравнить эту  ошибку со стандартной ошибкой выборочного коэффициента
ошибку со стандартной ошибкой выборочного коэффициента  которая определяется формулой
которая определяется формулой

Взяв верхний предел по (9.21), получим, пренебрегая разницей между 

Если генеральное  равно нулю, то
равно нулю, то  примерно равно
примерно равно  так что отношение стандартных ошибок, задаваемое (9.23), примерно равно 1,17. Если
так что отношение стандартных ошибок, задаваемое (9.23), примерно равно 1,17. Если  то приближенно можно положить, что
то приближенно можно положить, что

Отношение стандартных ошибок теперь равно примерно 1,88. Коэффициент корреляции  более точен, чем
более точен, чем  в том смысле, что он имеет меньшую стандартную ошибку и поэтому более вероятно, что он ближе к истинной величине
в том смысле, что он имеет меньшую стандартную ошибку и поэтому более вероятно, что он ближе к истинной величине 
Отношение между ps и р в случае нормального распределения
9.14. Если мы определяем  для непрерывной совокупности с помощью выражения, аналогичного (9.3), а именно
для непрерывной совокупности с помощью выражения, аналогичного (9.3), а именно

то  является несмещенной оценкой
является несмещенной оценкой  Процедура, подобная той, которая вытекает из (9.5), дает нам
Процедура, подобная той, которая вытекает из (9.5), дает нам

а если  определяется для совокупности с помощью (9.6), то это дает нам
определяется для совокупности с помощью (9.6), то это дает нам

Так подтверждается результат (5.76), согласно которому  не является несмещенной оценкой
не является несмещенной оценкой 
9.15. Рассмотрим теперь взаимосвязь между  в нормальной совокупности. Можно показать, что
в нормальной совокупности. Можно показать, что

и, следовательно, в качестве оценки  для больших выборок мы можем взять величину
для больших выборок мы можем взять величину 

Однако в связи с тем, что имеется смещение, обнаруживаем с помощью (9.25), по-видимому, лучше взять

Формула (9.26) принадлежит К. Пирсону [75]. Она была выведена им при рассмотрении корреляций степеней интенсивности следующим образом.
9.16. Определим степень интенсивности  связанную с конкретным значением переменной
связанную с конкретным значением переменной  как долю совокупности значений переменных меньших
как долю совокупности значений переменных меньших  или равных
или равных  Коэффициент корреляции между степенями интенсивности переменных х и у в двумерной взаимосвязи называется коэффициентом корреляции степеней интенсивности. Эта величина существует для непрерывной совокупности. Нетрудно убедиться, что она приводит к коэффициенту ранговой корреляции Спирмэна, когда применяется для конечной выборки. В следующей главе мы докажем, рассматривая коэффициенты конкордации, что коэффициент корреляции степеней интенсивности, определяемый таким путем, по существу является величиной
Коэффициент корреляции между степенями интенсивности переменных х и у в двумерной взаимосвязи называется коэффициентом корреляции степеней интенсивности. Эта величина существует для непрерывной совокупности. Нетрудно убедиться, что она приводит к коэффициенту ранговой корреляции Спирмэна, когда применяется для конечной выборки. В следующей главе мы докажем, рассматривая коэффициенты конкордации, что коэффициент корреляции степеней интенсивности, определяемый таким путем, по существу является величиной  найденной с помощью (9.6).
найденной с помощью (9.6).
9 17. Можно предположить, что имеется некоторая разумным образом интерпретируемая формула, подобная (9.13), дающая дисперсию  в случае нормального распределения. Однако в действительности это не так. Доказано, что такой формулы, выраженной с помощью элементарных функций, не существует.
в случае нормального распределения. Однако в действительности это не так. Доказано, что такой формулы, выраженной с помощью элементарных функций, не существует.
Для больших выборок на основе (9.26) имеем:

и, следовательно,

Эта формула поможет нам тогда, когда мы знаем  . В случае, когда
. В случае, когда  она сокращается до
она сокращается до  таким образом,
таким образом,

Когда  не равно нулю, необходимое выражение (имеющее практический смысл при больших
не равно нулю, необходимое выражение (имеющее практический смысл при больших  может быть выведено в виде бесконечного ряда следующим образом:
может быть выведено в виде бесконечного ряда следующим образом:

Уточненные варианты такой формулы см. в [27], [15] и [28]. В [28] вычислены некоторые таблицы и проверена формула с помощью выборочных экспериментов. Авторы также рассмотрели результаты нормализации  и пришли к выводу, что вполне достаточно испытать эти преобразованные величины в случае нормального распределения с помощью
и пришли к выводу, что вполне достаточно испытать эти преобразованные величины в случае нормального распределения с помощью

9.18. Если мы сопоставим стандартную ошибку  с ошибкой, определяемой (9.22), то находим при
с ошибкой, определяемой (9.22), то находим при  что это отношение равно 1,047, а при
что это отношение равно 1,047, а при  оно составит 1,137. Чаша весов склоняется в пользу коэффициента
оно составит 1,137. Чаша весов склоняется в пользу коэффициента  (как более точного), однако сказанное нельзя воспринимать очень строго. Оценка
(как более точного), однако сказанное нельзя воспринимать очень строго. Оценка  основанная на
основанная на  также достаточно хороша, если учитывать все обстоятельства. Это вытекает из замечания, приведенного в 9.7. Мы не можем вдаваться здесь в более подробные объяснения, но неслучайно дисперсия
также достаточно хороша, если учитывать все обстоятельства. Это вытекает из замечания, приведенного в 9.7. Мы не можем вдаваться здесь в более подробные объяснения, но неслучайно дисперсия  в (9.29) имеет множитель
в (9.29) имеет множитель  тогда как коэффициент С в (9.9) равен обратной величине корня четвертой степени из этой величины.
тогда как коэффициент С в (9.9) равен обратной величине корня четвертой степени из этой величины.
9.19. Интересно рассмотреть взаимосвязь между  в случае нормального распределения. Опять у нас нет точного выражения, однако Для больших выборок разложение, подобное тому, что было приведено в (9.30), дает нам
в случае нормального распределения. Опять у нас нет точного выражения, однако Для больших выборок разложение, подобное тому, что было приведено в (9.30), дает нам

Находим, например, что для  коэффициент корреляции между
коэффициент корреляции между  равен 1, как это уже известно из 5.14; для
равен 1, как это уже известно из 5.14; для  он равен 0,99955; для
он равен 0,99955; для  составляет 0,9981; хотя он и стремится к нулю при приближении
составляет 0,9981; хотя он и стремится к нулю при приближении  к единице, даже для
к единице, даже для  он равен 0,9843. Для больших
он равен 0,9843. Для больших  отношение
отношение  приближается к отношению их математических ожиданий, несмотря на то, что корреляция между ними может быть мала для больших
приближается к отношению их математических ожиданий, несмотря на то, что корреляция между ними может быть мала для больших  поскольку их дисперсии приближаются к нулю. Это отношение, равное
поскольку их дисперсии приближаются к нулю. Это отношение, равное  изменяется от 1,3 в окрестности
изменяется от 1,3 в окрестности  до 1,42, когда
до 1,42, когда  и до единицы, когда
и до единицы, когда  Это и является одной из причин, способствующих тому, что на практике значение
Это и является одной из причин, способствующих тому, что на практике значение  часто на 40 или 50% превосходит
часто на 40 или 50% превосходит  если только каждая из этих величин не близка к единице.
если только каждая из этих величин не близка к единице.
9.20. Может сложиться неправильное понимание оценок  основанных на
основанных на  связанное с относительными значениями стандартных ошибок
связанное с относительными значениями стандартных ошибок  Тот факт, что эти оценки различаются, указывает на действительную разницу в эффективности процессов оценивания. Процесс с меньшей дисперсией более эффективен.
Тот факт, что эти оценки различаются, указывает на действительную разницу в эффективности процессов оценивания. Процесс с меньшей дисперсией более эффективен.
Для больших выборок дисперсии  заданные (9.13) и (9.30), также различаются между собой. Однако это не означает, что
заданные (9.13) и (9.30), также различаются между собой. Однако это не означает, что  -лучшая или худшая оценка
-лучшая или худшая оценка  (по сравнению с тем, как
(по сравнению с тем, как  оценивает значение
оценивает значение  Различие в дисперсии связано с различием в самих шкалах измерения. Легко проверить, что для
Различие в дисперсии связано с различием в самих шкалах измерения. Легко проверить, что для  которое не близко к единице:
которое не близко к единице:

Последнее находится в соответствии с нашим общим результатом, согласно которому корреляция между  является высокой по крайней мере для случаев, когда
является высокой по крайней мере для случаев, когда  велико, а
велико, а  не близко к единице.
не близко к единице.
Библиография
О средней и дисперсии  см. [24] и [33]. О средней для
см. [24] и [33]. О средней для  см. [40], [66] и [67]; о дисперсии см. [53] и [16]. См. также библиографию к гл. 10. О корреляции степеней интенсивности см. [75].
см. [40], [66] и [67]; о дисперсии см. [53] и [16]. См. также библиографию к гл. 10. О корреляции степеней интенсивности см. [75].
О взаимосвязи между рангами и значениями признака см. [94]. Асимптотическое отношение для случая с нормальным распределением первоначально было получено (но не опубликовано) К. Бертом 
О конкордации первого и второго рода см. [97].