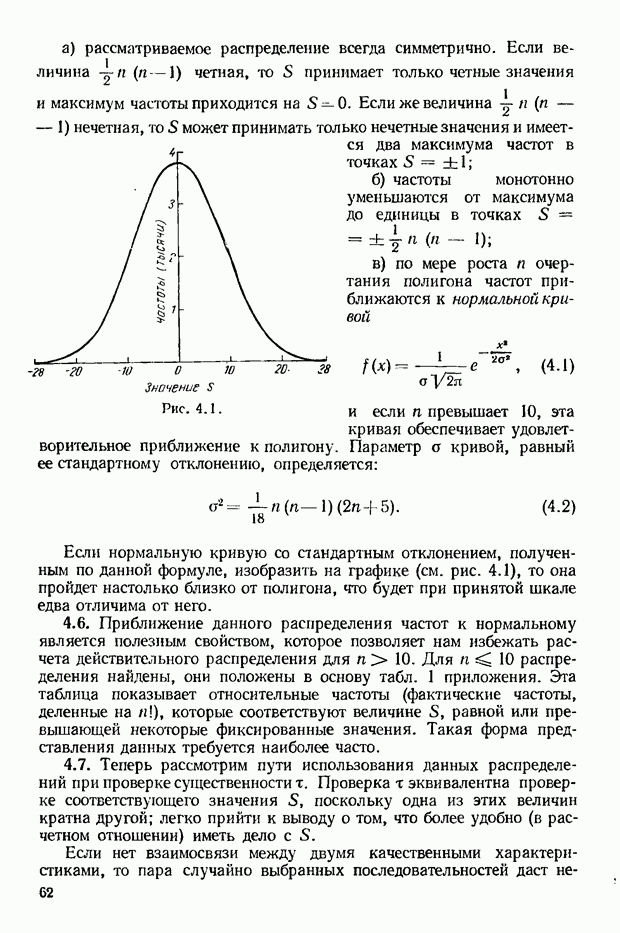
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
ГЛАВА 1. ИЗМЕРЕНИЕ РАНГОВОЙ КОРРЕЛЯЦИИВводные замечания1.1. Ряд объектов, расположенных в соответствии с некоторым признаком (в неодинаковой мере присущим этим объектам), называют упорядоченным. Сам процесс такого упорядочения называется ранжированием, а каждому члену ряда присваивается ранг. 1.2. Чаще всего ранги обозначаются порядковыми числительными 1.3. Предположим, например, что при ранжировании некоторого набора по признаку А ранг объекта оказался равен 5, тогда как при ранжировании по другому признаку В его ранг составил 8. Что выражает разница рангов, равная 3? Вычитание «пятого места» из «восьмого» не имеет смысла, и все-таки эта операция может иметь определенное содержание. Ведь когда мы говорим, что при упорядочении по признаку А ранг объекта равен 5, это эквивалентно следующему утверждению: при упорядочении по А четыре объекта оказались впереди, или, иными словами, данному объекту предпочли четыре других. Аналогично при ранжировании по признаку В данному объекту предпочли семь других. Следовательно, при ранжировании по критерию В количество предпочитаемых объектов на 3 превосходит число объектов, предпочитаемых при ранжировании по признаку Стоит ли в самом начале курса обращать внимание на столь тонкие различия? Если читатель полагает, что это не имеет смысла, он может отложить рассмотрение указанных вопросов до тех пор, пока это не потребуется по ходу изложения. Однако он должен с самого начала осознать, что связанные с ранжированием вычислительные процедуры чаще всего основываются на измерении количества объектов, а не их порядковых номеров. 1.4. Можно назвать много различных способов упорядочения; упомянем лишь некоторые из них. а. Задача может сводиться просто к упорядочению объектов по месту, которое они занимают в пространстве или во времени. Расположим, например, карты в колоде в некотором порядке, а затем перетасуем их. Новое расположение карт также характеризуется определенным порядком, ранжированием. Сравнив его со старым, можно увидеть, насколько тщательно были перетасованы карты. В этой задаче нас интересует только общее расположение карт в колоде, и мы не стремимся, скажем, упорядочить объекты в соответствии с «возрастанием» или «убыванием» того или иного присущего всем им признака. б. Упорядочить объекты можно и по некоторому качеству, для которого не существует объективной абсолютной шкалы измерения. Мы можем, например, ранжировать образцы горных пород по твердости исходя из следующего простого критерия: А тверже В, если А оставляет царапину на В, когда они соприкасаются. Если А оставляет царапину на В, а В - на С, то А будет оставлять царапину на С. Таким образом, прибегнув к ряду сопоставлений, мы сможем с достаточной точностью упорядочить рассматриваемые объекты (если только наш набор не включает такие два объекта, которые обладают одинаковой твердостью; (этот особый случай будет рассмотрен в гл. 3). Однако подобный способ не позволяет измерить абсолютную величину твердости горных пород. Мы всегда можем установить, что А тверже В. Однако до тех пор, пока не построена та или иная шкала измерения абсолютных величин, мы не можем утверждать, что А, скажем, вдвое тверже В. в. Упорядочение может проводиться в соответствии с измеряемой (или теоретически исчисляемой) величиной некоторого признака. Например, мы можем располагать людей в том или ином порядке в зависимости от их роста, а города — по численности населения. При этом не всегда требуется прибегать к самому процессу измерения: можно «на глаз» построить группу студентов по росту; однако в таких случаях критерий, по которому мы ранжируем, должен допускать возможность непосредственных сопоставлений. г. Можно упорядочивать объекты по некоторому признаку, величину которого, по нашему мнению, в принципе можно измерить, но на практике (или даже теоретически) не удается прибегнуть к такому измерению в силу тех или иных причин. Например, мы можем упорядочить ряд лиц по их интеллектуальным способностям, полагая, что такое качество действительно существует и что можно разместить людей в том или ином порядке в соответствии с интенсивностью этого признака. В гл. 11 мы рассмотрим метод, который в некоторых случаях позволяет дать ответ на вопрос о том, правомерны ли подобные предпосылки. Этот случай отличается от ситуации, упоминавшейся в пункте «б», поскольку в данном примере содержательные соображения убеждают нас в том, что ранжирование возможно, тогда как в ситуации пункта «б» мы просто выдвигаем гипотезу относительно возможности подобных измерений. 3 1.5. Количественную характеристику, которая может менять свое значение при переходе от одного из элементов совокупности к другому, в теоретической статистике назьюают случайной величиной. Так, значения того или иного признака, которые можно измерить, представляют собой, разумеется в рамках соответствующей шкалы измерения, случайную величину. Такой набор мы всегда можем упорядочить, руководствуясь местом, которое занимает на шкале измерения каждый объект, после чего имеем право сказать, что значения случайной величины представлены соответствующими рангами. Следовательно, можно рассматривать процесс упорядочения как не совсем точный способ выражения порядковых отношений между элементами — не совсем точный потому, что он не позволяет нам судить о том, насколько близко друг к другу расположены на шкале измерения различные элементы рассматриваемой совокупности. Per contra проигрывая в точности, процесс ранжирования выигрывает в общности подхода. Допустим, например, что мы «растянули» отрезок, характеризующий шкалу измерения; больше того, допустим, что мы с разной интенсивностью «растягивали» отдельные промежутки рассматриваемого отрезка. В любом случае порядок расположения элементов не изменится, или, выражаясь языком математики, такое упорядочение инвариантно относительно изменений масштаба шкалы. 1.6. Теория рангов впервые возникла как ответвление теории случайных процессов. На начальной стадии в рангах чаще всего видели просто удобный аппарат, благодаря которому удается обойтись без измерения абсолютной величины переменных и тем самым сэкономить время или усилия. Благодаря использованию рангов можно было избежать трудностей, связанных с построением объективной шкалы абсолютных значений. Позднее статистика рангов смогла завоевать признание благодаря своим собственным достоинствам. В начальных разделах книги наше внимание будет сосредоточено на самом процессе упорядочения, независимо от существования тех или иных шкал измерения абсолютных величин. Таким образом, предлагаемые методы обладают достаточно большой степенью общности. В гл. 9 и 10 будет рассмотрено соотношение между рангами и случайными величинами. Ранговая корреляция1.7. Предположим, что группу учеников ранжировали в соответствии с их способностями, обнаруженными на уроках музыки и математики. Обозначим детей буквами от
Рассмотрим теперь вопрос, существует ли зависимость между музыкальными и математическими способностями. Даже беглого взгляда на приведенные данные достаточно, для того чтобы увидеть, что четкого соответствия между ними не существует. Однако некоторые ученики занимают одинаковое или почти одинаковое место в обоих рядах. Наличие (или отсутствие) связи между этими показателями станет более очевидным, если мы расположим элементы первого ряда в порядке возрастания (в последовательности натуральных чисел):
Нужно определить степень соответствия между этими двумя последовательностями порядковых оценок, или, другими словами, измерить тесноту ранговой корреляции. Поэтому изложим методику построения соответствующего коэффициента корреляции, обозначив его буквой 1.8. Коэффициент корреляции должен обладать следующими тремя свойствами: а) если между последовательностями порядковых оценок имеется полное соответствие, т. е. если каждый объект занимает одно и то же место в обоих рядах, то б) если налицо полная отрицательная зависимость, т. е. если в одной последовательности оценки расположены в обратном порядке по сравнению с другой, в) в остальных ситуациях Первые два соображения просто вводят общепринятый масштаб измерения; как ни условен подобный масштаб, он в высшей степени полезен для практики. 1.9. В первой последовательности (1.1) выделим какую-нибудь пару рангов, например Перемножив значения, приписанные этим парам, в первой и во второй последовательностях, получим произведение, равное —1. Ясно, что для любой пары оно будет равно +1 в тех случаях, когда соответствующие ранги в обеих последовательностях расположены в одинаковом порядке, и —1, если эти ранги образуют различный порядок. Можно сказать, что мы приписываем значения +1 или —1 в зависимости от того, согласован или не согласован между собой порядок пары в обеих последовательностях. Проделаем все эти вычисления для каждой пары, полученной из
Сумма значений, равных +1 (назовем ее Если бы во всех парах наблюдался одинаковый порядок, то каждое из 45 приписываемых им значений было бы положительным; следовательно, максимальное значение
Эта величина близка к нулю; отсюда следует, что корреляция между двумя последовательностями рангов очень мала. Нулевое значение 1.10. Рассмотрим теперь общий случай, когда имеются две последовательности рангов, каждая из которых содержит предметов; эта величина равна
Пусть
1.11. Для того чтобы найти величину а. Рассмотрим формулу (1.2). В тех случаях, когда одна последовательность рангов представляет собой натуральный ряд
Рассмотрим сначала пары, которые с первым элементом, т. е. с 8, образуют остальные элементы последовательности; мы видим, что справа от элемента 8 расположены два члена, которые превосходят 8 по величине. Следовательно, первые слагаемые суммы что следующее слагаемое суммы
Следовательно, из (1.6) имеем: б. Допустим, что очень сложно так организовать последовательности, чтобы одна из них была расположена в строгом порядке. Тогда можно поступить следующим образом. Запишем друг под другом рассмотренные выше последовательности, а над ними выпишем числа натурального ряда от 1 до 10:
Элементу 1 ряда В соответствует элемент 6 в последовательности А. В натуральном ряду справа от 6 стоят 4 элемента. Включим в
которая совпадает с полученным выше значением Желая убедиться в правильности подобной вычислительной процедуры, перепишем наши последовательности рангов таким образом, чтобы элементы последовательности В совпадали с членами натурального ряда (в таком порядке мы рассматривали ранее элементы обоих рядов):
Легко видеть, что при использовании метода 1.12. Чтобы получить некоторое представление о тех значениях, которые может принимать соответствующие расчеты, сверив результаты своих вычислений с приведенными в таблице значениями:
«тау» как коэффициент неупорядоченности1.13. Введенный нами коэффициент может служить количественной характеристикой общего соответствия между отдельными парами элементов (слово «соответствие» здесь означает соответствие порядков рассматриваемых элементов). Благодаря этому он может быть использован при согласовании между собой двух последовательностей. Чтобы лучше разобраться в том, что означает этот коэффициент, прибегнем к следующему способу рассуждений. Рассмотрим две последовательности, каждая из которых содержит числа от 1 до 7:
Мы можем перейти от В к А, последовательно меняя местами стоящие рядом числа. Например, в последовательности В будем перемещать влево число 1; тогда после четырех перестановок мы получим:
Затем будем перемещать влево число 2, для этого потребуются еще четыре перестановки:
Поменяем местами числа 3 и 6:
Далее проведем трехкратную перестановку числа 4:
Наконец, поменяем местами числа 6 и 5. В результате нам удалось получить последовательность А, т. е. последовательность натурального ряда. Вся процедура перехода от В к А потребовала 13 перестановок, и мы не могли бы получить тот же результат, применяя меньшее число взаимных перемещений. Можно было бы проделать больше перестановок, например дважды поменять местами числа 1 и 2, а затем начать описанную выше процедуру перемещения. Покажем, что всегда существует некое минимальное число перестановок, необходимое для перехода от одной последовательности к другой, содержащей то же количество элементов. Обозначим это число буквой В следующей главе будут выведены две эквивалентные формулы:
и
которые устанавливают простое соотношение между числом перестановок
Из (1.5) и (1.7) следует, что
Таким образом, Коэффициент Спирмэна1.14. Рассмотрим еще один коэффициент ранговой корреляции, обозначаемый
Из ранга по математике мы вычли ранг по музыке и записали результат в строку, названную «разности d». Легко увидеть, что сумма этих разностей должна равняться нулю, поскольку речь идет о разности двух величин, каждая из которых представляет собой сумму числа от 1 до 10 (тем самым обеспечивается возможность арифметической проверки). Кроме того, мы выписали квадраты этих разностей. Обозначив их сумму через
Вычислим коэффициент Спирмэна для нашего примера:
1.15. Пусть заданы две одинаковые последовательности. Тогда все разности Пусть
Таким образом, сумма квадратов составляет:
Подставив это значение в (1.9), можно найти численное значение:
Допустим теперь, что
Следовательно,
Подставляя, как и в предшествующем случае, полученный результат в (1.9), мы найдем, что Таким образом, коэффициент 1.16. Читателю, знакомому с методикой расчета статистической оценки дисперсии и, в частности, с вычислением среднего квадратического отклонения, легче понять причины, побудившие нас возвести в квадрат разности рассматриваемых рангов, и лишь затем сложить их. Совершенно очевидно, что при построении коэффициента мы не можем воспользоваться суммой разностей, 1.17. Оценка
и, следовательно,
Этот результат будет доказан в следующей главе. Рассмотрим пример. Обратимся вновь к двум последовательностям, приведенным в 1.13.
Выпишем те пары рангов, которые образуют инверсию:
Как было показано в 1.13, общее число инверсий равно 13 и
Просуммировав вес, приходящийся на каждую инверсию, получим число 40, следовательно,
Нетрудно подсчитать, что для последовательности Сопряженные последовательности рангов1.18. Следует отметить, что коэффициенты тир обладают общим свойством. Рассмотрим сначала отношение между последовательностью А и последовательностью (
Переставим эти пары таким образом, чтобы элементы последовательности А были расположены в натуральном порядке:
Теперь легко найти значение
В таком случае корреляция рангов
Последовательности рангов 1.19. Аналогичные соотношения, но не столь простым способом, можно вывести для коэффициента 1.20. Таким образом, если мы пользуемся коэффициентами тир для измерения корреляции рангов, то шкала допустимых значений в определенном смысле симметрична относительно нуля. Она ограничена числами +1 и —1, и любому положительному значению коэффициентов 1.21. Не следует полагать, что численные значения тир будут одинаковы для любых двух последовательностей (если только не рассматриваются случаи полной согласованности и рассогласованности). Сопоставляя последовательности, приведенные в 1.12, с порядком натурального ряда, можно получить следующие значения коэффициентов:
На этом примере можно убедиться в том, что в практических задачах неизбежно приходится сталкиваться со следующей проблемой. Подобно паре термометров, один из которых измеряет температуру по Цельсию, а другой — по Фаренгейту, у наших коэффициентов разные масштабы, при этом они отличаются друг от друга не только шкалой измерения, но и тем, что при подсчете коэффициента Неравенство Дэниелса1.22. Если заданы последовательности ранговых оценок, можно установить неравенства, которые связывают между собой коэффициенты тир. Первое неравенство было выведено Дэниелсом:
где
Если
Найдем
Неравенство Дарбина-Стюарта1.23. Другие неравенства для
В некоторых случаях указанное выражение может превратиться в равенство. Используя соотношения (1.13) и (1.5), мы получаем
т. е., зная величину
При больших
причем При
В следующей главе будут приведены доказательства этих результатов. Описанные неравенства позволяют лучше осознать уже высказывавшееся выше соображение: хотя коэффициенты Некоторые замечания1.24. Вообще говоря, коэффициент достоинства этих коэффициентов, но все же здесь стоит упомянуть одно любопытное практическое соображение. Иногда, после того как ранжирование уже проведено, могут появиться новые элементы и возникает необходимость в дальнейшем упорядочении всей последовательности. Аналогичная ситуация может сложиться также при следующих обстоятельствах: предположим, что мы выписываем ранговые оценки множества неупорядоченных объектов, различающихся между собой по величине или отмеченных неодинаковыми условными значками; при этом легко допустить ошибки, которые обнаружатся при завершении процесса ранжирования, — некоторые элементы последовательности окажутся неучтенными. Это потребует вычисления коэффициента Пример 1.1. Нескольким фирмам были разосланы опросные листы, в которых содержалась просьба конфиденциально сообщить норму выплачиваемого дивиденда, которую компания предполагает огласить на ближайшем годовом собрании акционеров. Будем полагать, что все фирмы могут ответить на этот вопрос, однако не исключена следующая возможность: фирмы, предполагающие выплатить более высокие дивиденды, менее охотно станут отвечать на запрос, задерживая ответ, или вообще окажутся от заполнения опросного листа. Будем полагать, кроме того, что все нормы дивиденда различны. Подобные предположения, вероятно, не слишком реалистичны, однако они упростят построение числового примера. К некоторому сроку от фирм будет получено определенное число ответов; теперь необходимо завершить наше обследование и сформулировать полученные результаты. Насколько правомерно полагать, что присланные ответы могут служить репрезентативной характеристикой всей совокупности адресатов? Есть ли какое-либо основание полагать, что дивиденды в фирмах, которые ответили раньше, имеют систематические отличия от дивидендов в фирмах, ответивших позже? Допустим, что мы получили 15 ответов в следующем порядке:
Если действительно существует зависимость между временем получения ответа и величиной дивиденда, такая зависимость должна проявиться в корреляции рангов этих величин. При этом упорядочение нормы дивиденда проводится в порядке ее возрастания (соответствующие порядковые номера приведены в последней строке таблицы). Рассмотрим корреляцию рангов между последовательностями
Подсчитаем величину
Из приведенных расчетов следует, что между последовательностями Однако можно без особого труда учесть дополнительное влияние на
Используя эту методику, можно рассчитать новые значения Следует отметить, что в этом примере ранги, образующие последовательность С, определяются случайной величиной, указанной в ответах нормой дивиденда. В то же время ранги, характеризующие очередность получения ответов, не «опираются» на какую-то особую переменную величину (хотя, если мы запасемся терпением и будем в каждом случае измерять продолжительность времени до момента поступления каждого последующего ответа, можно считать, что ранги, которые будут указаны в строке А, определяются упорядочением соответствующих промежутков времени). 1.25. В заключение рассмотрим три примера, [иллюстрирующие возможности использования корреляции рангов. Пример 1.2 Имеется 12 одинаковых по размеру дисков, окраска которых отличается тоном — от светло-голубого до темно-синего. С помощью колориметрического испытания можно получить объективную оценку интенсивности цвета. Для того чтобы оценить, как тонко модельер одежды различает цветовые оттенки, ему показывают все эти диски и предлагают расположить их в определенном порядке — по степени интенсивности цвета. При этом получают, скажем, следующие результаты:
С помощью корреляции рангов мы стремимся дать количественную характеристику способности модельера различать оттенки синего цвета. Найдем сначала значение Р:
Налицо положительная корреляция рангов, степень соответствия довольно велика, но все же далека от полной эквивалентности. В гл. 3 мы покажем, как проверить существенность исчисленных коэффициентов. В этом примере измерялась степень согласованности порядка, установленного на основе объективных оценок, с порядком, определенным на основе субъективного выбора. Модельер не сумел достичь полного успеха, что может объясняться его неумением различать малозаметные оттенки, либо отсутствием сосредоточенности, либо какими-то другими факторами; однако, какова бы ни была действительная причина, в любом случае мы можем проверить, насколько субъективные оценки модельера отличаются от заранее заданных объективных оценок. Пример 1.3 Рассмотрим ситуацию, при которой некоторый ряд участниц конкурса красоты должен быть упорядочен тремя членами жюри. Их оценки распределились следующим образом:
В отличие от условий предыдущего примера в этом случае не существует объективных оценок. Нас интересует вопрос, в какой степени различаются между собой мнения членов жюри; в этом случае уже не может возникнуть проблема отклонения субъективных оценок от некоторых стандартных объективных значений. Выясним парную корреляционную зависимость между оценками членов жюри:
Отсюда следует, что мнения членов жюри Пример 1.4 В табл. 1.1 приведены данные об обороте внешней торговли (импорт плюс экспорт) и численности населения некоторых государств в 1938 г. В соответствующих столбцах указаны оценки рангов, полученные в результате упорядочения стран по этим двум признакам. Значение Таблица 1.1. Внешняя торговля и численность населения некоторых государств в 1938 г. (см. скан) При анализе такого рода данных часто встречается ситуация, когдапоказатели очень сильно отличаются друг от друга, например население Норвегии составляет 2,9 млн. человек, а население Китая — 410 млн. Следует иметь в виду, что при значительном различии исходных величин присутствие одной-двух переменных, характеризующихся большими значениями, может существенно исказить общую картину, поскольку колебания этих переменных могут просто «перекрыть» колебания многих малых величин. Ранжируя отдельные элементы, мы устанавливаем какой-то более приемлемый порядок, когда каждому государству отводится то или иное место в зависимости от размеров этой страны. Правильность подобного подхода зависит от предмета исследования; следует подчеркнуть, однако, что бывают ситуации, когда использование самих переменных величин, казалось бы, обеспечивает более точные результаты, и все же абсолютные величины могут в большей степени искажать картину, чем ранговые оценки, поскольку на самом деле такие абсолютные величины менее пригодны для описания зависимостей, которые мы стремимся измерить. Для читателя, знакомого с описываемой в обычном курсе статистики методикой расчета смешанных корреляционных моментов, добавим, что коэффициент корреляции между приведенными в табл. 1.1 величинами — оборотом торговли и численностью населения — равен 0,006. Включение в расчет стран, располагающих огромным населением, таких, как Китай, приводит к тому, что средняя теснота корреляционной взаимосвязи между объемом торговли и населением практически сводится к нулю. БиблиографияМетодика расчетов коэффициентов Методы использования коэффициента Вывод неравенств, связывающих коэффициенты
|
 |
Оглавление
|






























































































































































































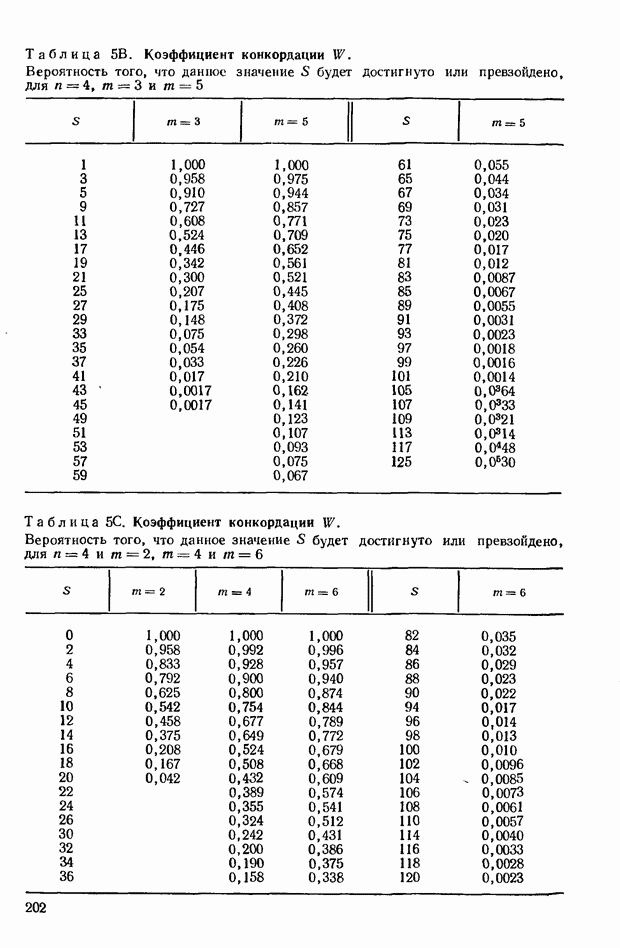
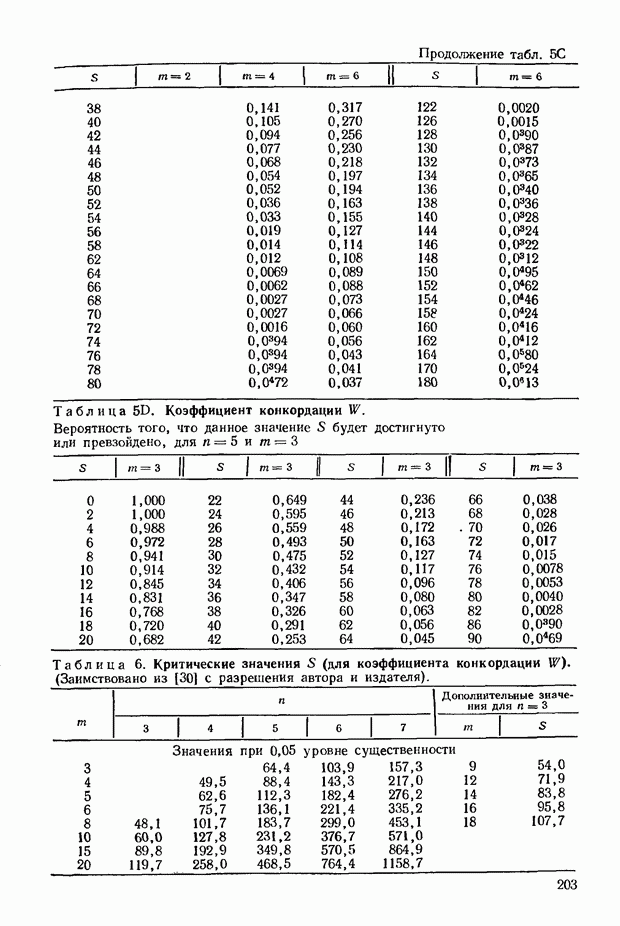
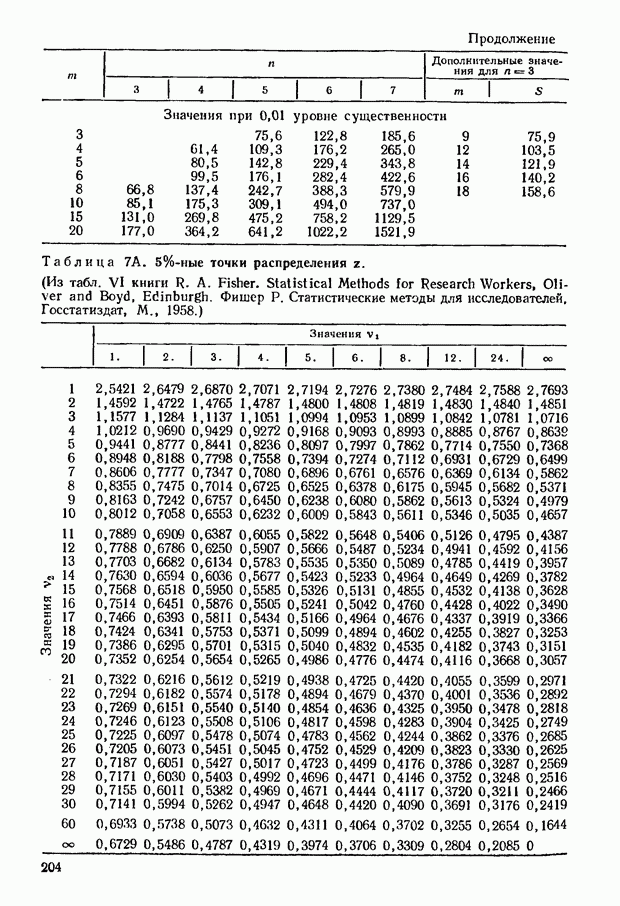

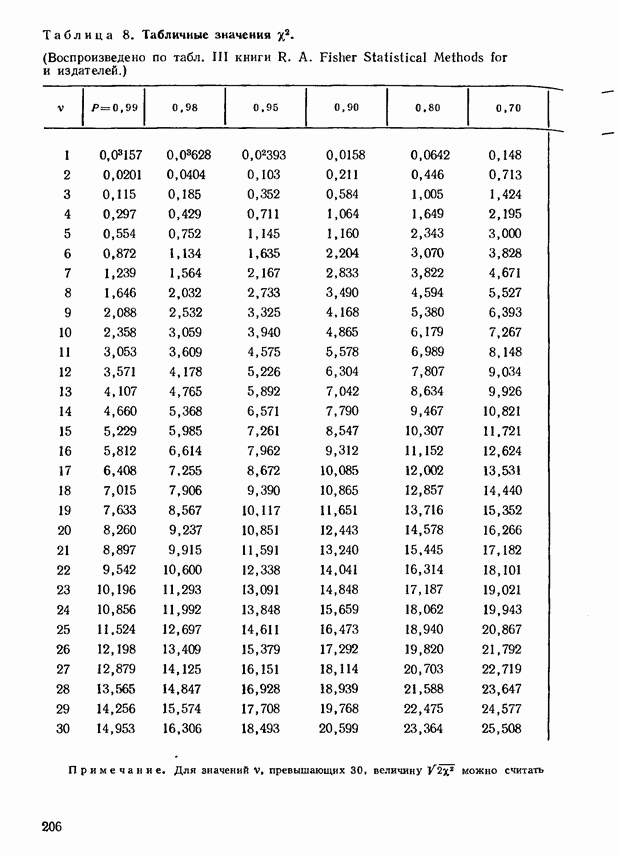
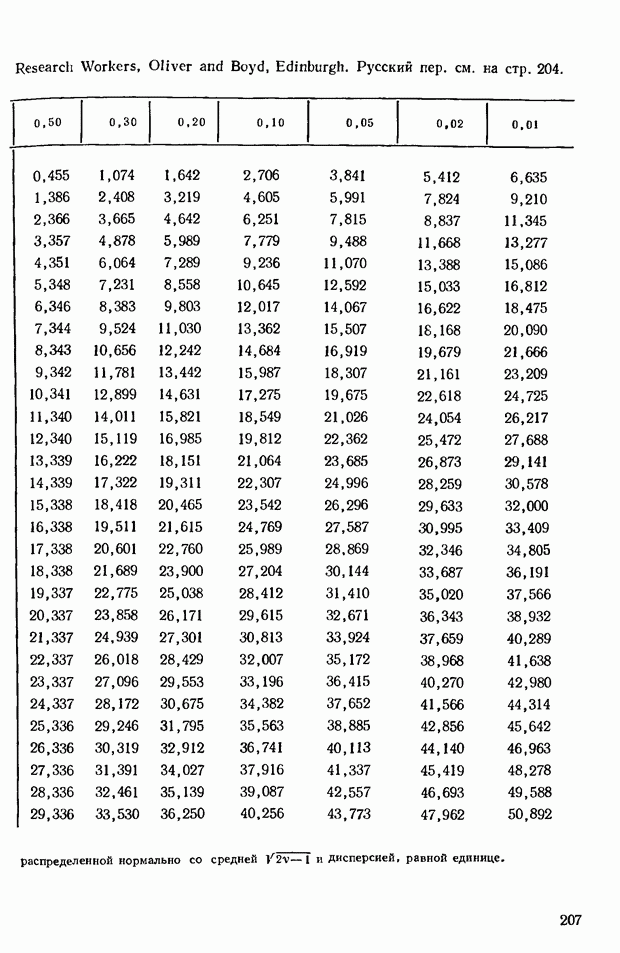
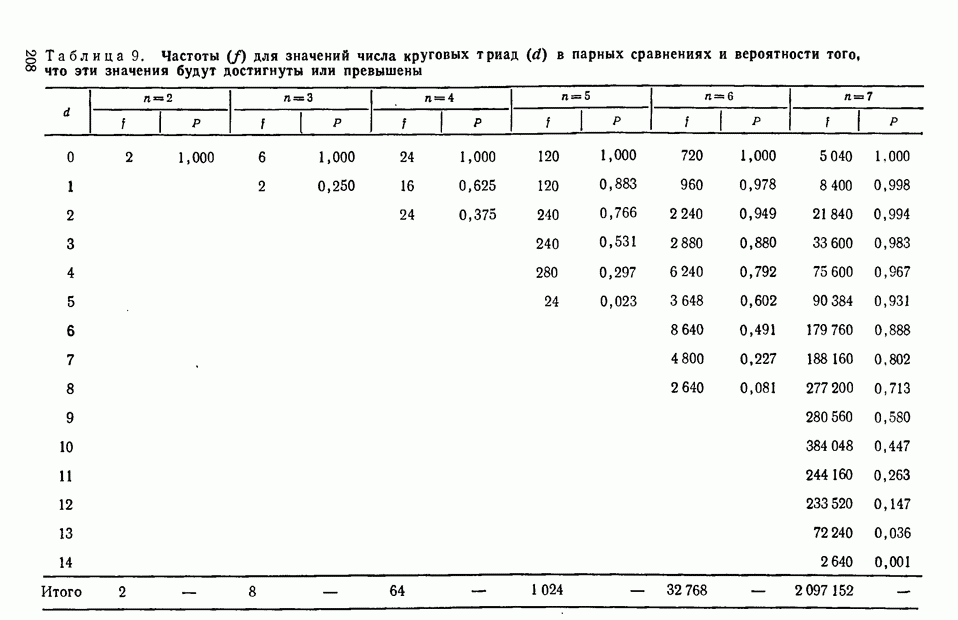
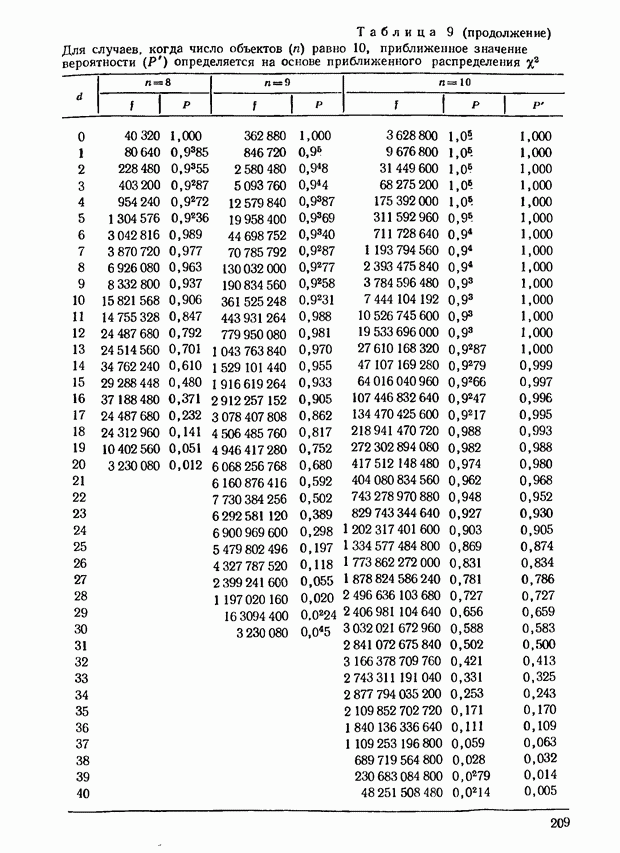
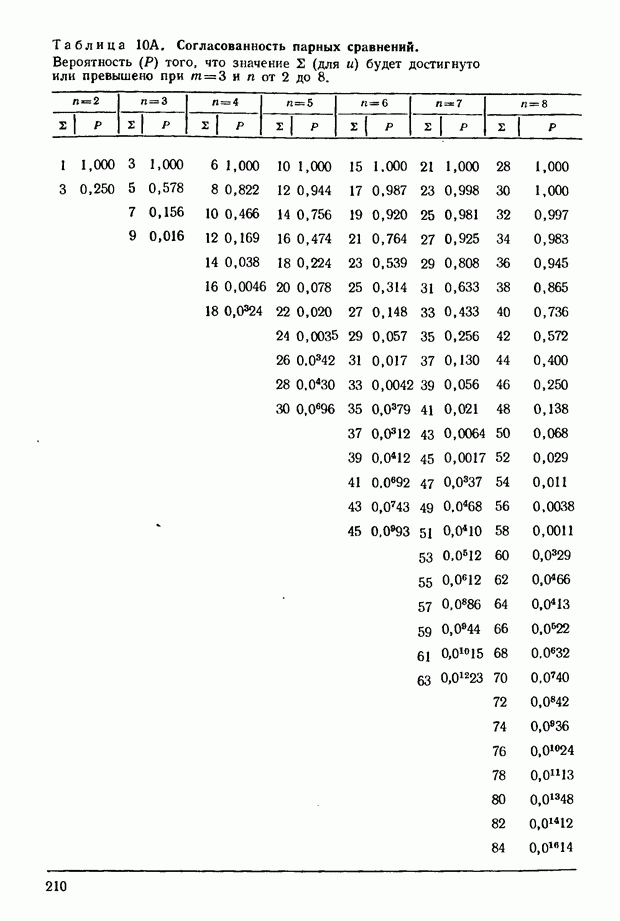

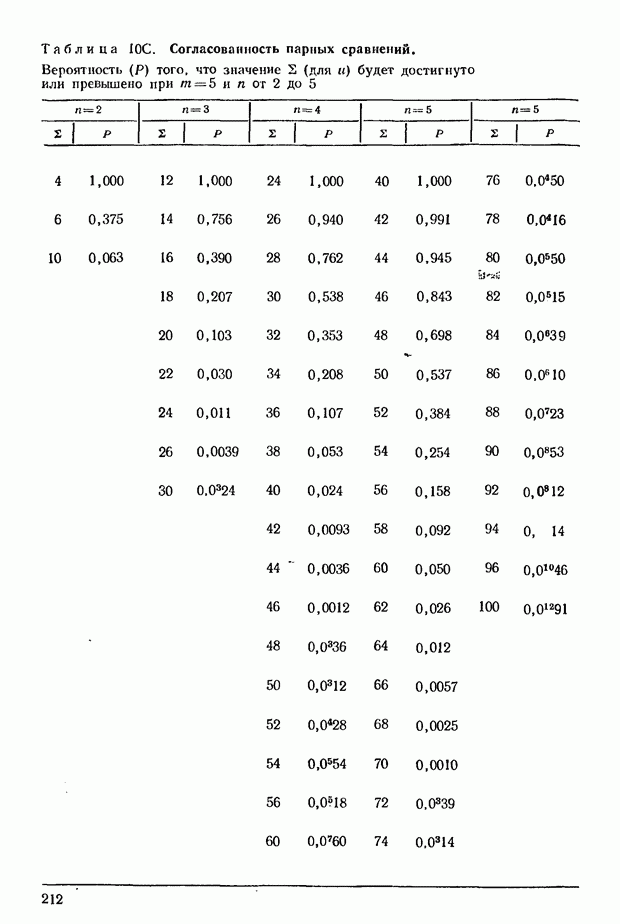
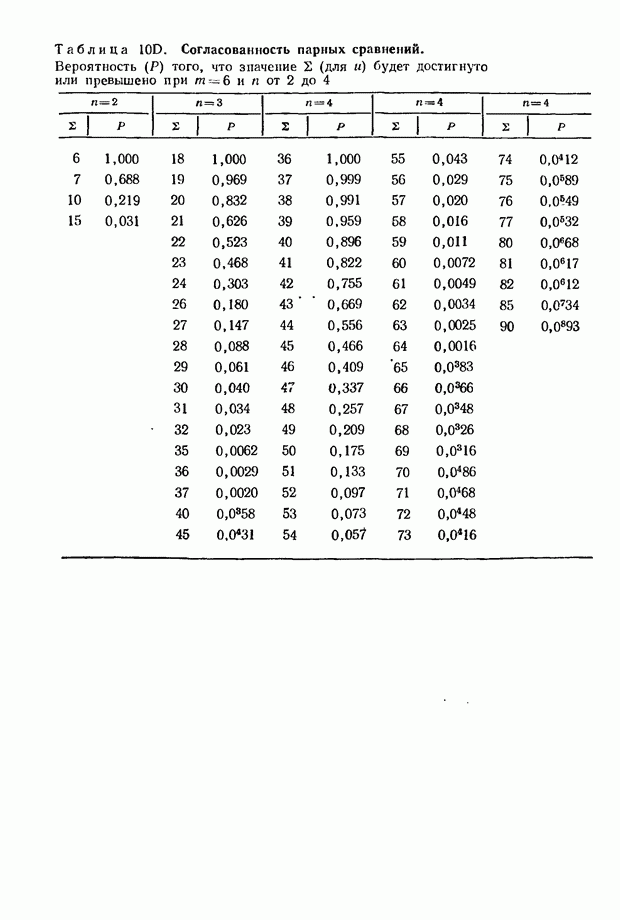
 где
где  количество объектов (хотя подобный выбор, вообще говоря, не столь существен). Таким образом, если какой-либо предмет или кто-либо после ранжирования будет занимать пятое место в ряду, его ранг равен 5. В дальнейшем этими числами часто будем оперировать так, как если бы они представляли собой количественные числительные, обычно фигурирующие в арифметике; будем складывать, вычитать и даже умножать эти числа. Поэтому следует разобраться в том, что означают подобные операции.
количество объектов (хотя подобный выбор, вообще говоря, не столь существен). Таким образом, если какой-либо предмет или кто-либо после ранжирования будет занимать пятое место в ряду, его ранг равен 5. В дальнейшем этими числами часто будем оперировать так, как если бы они представляли собой количественные числительные, обычно фигурирующие в арифметике; будем складывать, вычитать и даже умножать эти числа. Поэтому следует разобраться в том, что означают подобные операции.
 цифра 3 в данном случае представляет собой не порядковое, а количественное числительное.
цифра 3 в данном случае представляет собой не порядковое, а количественное числительное.
 и выпишем следующие Две последовательности рангов:
и выпишем следующие Две последовательности рангов:



 должен быть равен
должен быть равен  что означает полную положительную корреляцию;
что означает полную положительную корреляцию;
 что означает полную отрицательную корреляцию;
что означает полную отрицательную корреляцию;
 лежит между предельными значениями; можно утверждать, что возрастание
лежит между предельными значениями; можно утверждать, что возрастание  от —1 до +1 в некотором приемлемом для нас смысле характеризует увеличивающееся соответствие между двумя последовательностями порядковых оценок.
от —1 до +1 в некотором приемлемом для нас смысле характеризует увеличивающееся соответствие между двумя последовательностями порядковых оценок.
 Их значения 7 и 4 образуют обратный порядок величин (прямым порядком мы будем называть порядок натурального ряда
Их значения 7 и 4 образуют обратный порядок величин (прямым порядком мы будем называть порядок натурального ряда  ; парам, образующим обратный порядок, будем приписывать значения —1; парам, значения которых образуют прямой порядок,
; парам, образующим обратный порядок, будем приписывать значения —1; парам, значения которых образуют прямой порядок,  Во второй последовательности ранги А к В равны соответственно 5 и 7; они образуют прямой порядок, и, следовательно, в этой последовательности паре
Во второй последовательности ранги А к В равны соответственно 5 и 7; они образуют прямой порядок, и, следовательно, в этой последовательности паре  приписывается значение
приписывается значение 
 элементов. В результате придется взять 45 пар, каждой из которых будут приписаны следующие значения (запишем соответствующие цифры для каждой пары, с тем чтобы читатель мог непосредственно проследить за всеми расчетами; однако, как будет показано ниже, на практике можно обойтись и без столь громоздких вычислений):
элементов. В результате придется взять 45 пар, каждой из которых будут приписаны следующие значения (запишем соответствующие цифры для каждой пары, с тем чтобы читатель мог непосредственно проследить за всеми расчетами; однако, как будет показано ниже, на практике можно обойтись и без столь громоздких вычислений):

 составляет 21, а сумма значений, равных —1 (обозначим ее
составляет 21, а сумма значений, равных —1 (обозначим ее  составляет —24. Сложив эти два числа, получим общую сумму приписанных значений
составляет —24. Сложив эти два числа, получим общую сумму приписанных значений  равную —3.
равную —3.
 равно 45. Рассуждая аналогично, приходим к выводу, что минимальное значение
равно 45. Рассуждая аналогично, приходим к выводу, что минимальное значение  должно составлять —45. Таким образом, значение
должно составлять —45. Таким образом, значение  равно:
равно:

 может интерпретироваться как свидетельство независимости, которая лежит, так сказать, на полпути между полной положительной зависимостью и полной отрицательной зависимостью.
может интерпретироваться как свидетельство независимости, которая лежит, так сказать, на полпути между полной положительной зависимостью и полной отрицательной зависимостью.
 членов; количество пар, подлежащих сравнению, равно числу способов, с помощью которых можно выбрать два предмета из набора, содержащего
членов; количество пар, подлежащих сравнению, равно числу способов, с помощью которых можно выбрать два предмета из набора, содержащего 
 иногда ее обозначают также
иногда ее обозначают также  Указанное число характеризует наибольшую возможную сумму приписанных значений; такая величина может быть достигнута лишь тогда, когда порядок рангов в обеих последовательностях полностью совпадает. Обозначив общее количество приписанных значений буквой
Указанное число характеризует наибольшую возможную сумму приписанных значений; такая величина может быть достигнута лишь тогда, когда порядок рангов в обеих последовательностях полностью совпадает. Обозначив общее количество приписанных значений буквой  введем следующее определение коэффициента корреляции:
введем следующее определение коэффициента корреляции:

 означают соответственно суммы приписываемых положительных и отрицательных значений (так что
означают соответственно суммы приписываемых положительных и отрицательных значений (так что  тогда можно записать эквивалентные формулы для вычисления
тогда можно записать эквивалентные формулы для вычисления

 (или, что равносильно, значения
(или, что равносильно, значения  не требуется проделывать всю описанную выше вычислительную процедуру. Существуют и более простые методы. Наиболее легким из них, вероятно, является следующий.
не требуется проделывать всю описанную выше вычислительную процедуру. Существуют и более простые методы. Наиболее легким из них, вероятно, является следующий.
 оценки, приписываемые каждой паре значений этого ряда, положительны. Следовательно, значения
оценки, приписываемые каждой паре значений этого ряда, положительны. Следовательно, значения  входящие слагаемыми в сумму
входящие слагаемыми в сумму  будут приписываться только тем парам второго ряда, которые образуют прямой порядок. Требуется лишь пересчитать их. Вторая последовательность рангов имеет вид:
будут приписываться только тем парам второго ряда, которые образуют прямой порядок. Требуется лишь пересчитать их. Вторая последовательность рангов имеет вид:

 составляют
составляют  Рассмотрим теперь пары, которые образуют с элементом 9 остальные элементы (кроме пары 8 9, которая уже была учтена ранее); они увеличивают
Рассмотрим теперь пары, которые образуют с элементом 9 остальные элементы (кроме пары 8 9, которая уже была учтена ранее); они увеличивают  на
на  Аналогично, рассматривая пары, которые стоящие справа элементы образуют с цифрой 3, мы приходим к выводу,
Аналогично, рассматривая пары, которые стоящие справа элементы образуют с цифрой 3, мы приходим к выводу,
 равно
равно  Продолжая этот расчет находим:
Продолжая этот расчет находим:

 что совпадает с полученным ранее результатом.
что совпадает с полученным ранее результатом.

 слагаемое, равное
слагаемое, равное  и вычеркнем элемент 6 из процедуры ранжирования в соответствии с порядком натурального ряда. Далее, элементу 2 ряда В соответствует элемент 8 ряда
и вычеркнем элемент 6 из процедуры ранжирования в соответствии с порядком натурального ряда. Далее, элементу 2 ряда В соответствует элемент 8 ряда  а в натуральном ряду справа от 8 стоят два члена. Включаем в
а в натуральном ряду справа от 8 стоят два члена. Включаем в  еще одно слагаемое, равное
еще одно слагаемое, равное  и вычеркиваем 8 из верхнего ряда. Закончив этот расчет, мы найдем общую сумму.
и вычеркиваем 8 из верхнего ряда. Закончив этот расчет, мы найдем общую сумму.



 слагаемые
слагаемые  образуются согласно тому же закону, которым мы пользовались при сопоставлении рядов
образуются согласно тому же закону, которым мы пользовались при сопоставлении рядов  по методу
по методу  Например, в ряду А справа от 6 стоят 4 элемента, которые по величине превосходят 6, справа от 8 в ряду А — два члена, которые по величине превосходят 8, и т. д.
Например, в ряду А справа от 6 стоят 4 элемента, которые по величине превосходят 6, справа от 8 в ряду А — два члена, которые по величине превосходят 8, и т. д.
 в различных случаях, выпишем некоторые последовательности чисел от 1 до 10 и значения
в различных случаях, выпишем некоторые последовательности чисел от 1 до 10 и значения  характеризующие степень соответствия этих последовательностей порядку чисел натурального ряда. Читателю рекомендуется самостоятельно проделать
характеризующие степень соответствия этих последовательностей порядку чисел натурального ряда. Читателю рекомендуется самостоятельно проделать









 количеством отрицательных значений, или
количеством отрицательных значений, или  общим количеством значений, приписанных парам объектов. В рассматриваемом примере
общим количеством значений, приписанных парам объектов. В рассматриваемом примере  и, следовательно, мы вновь можем убедиться в том, что
и, следовательно, мы вновь можем убедиться в том, что


 представляет собой простую функцию минимального числа перестановок соседних элементов, необходимых для перехода от одного порядка элементов к другому; говоря короче,
представляет собой простую функцию минимального числа перестановок соседних элементов, необходимых для перехода от одного порядка элементов к другому; говоря короче,  может служить количественной характеристикой, мерой неупорядоченности.
может служить количественной характеристикой, мерой неупорядоченности.
 Его называют коэффициентом К. Спирмэна в честь автора, который впервые ввел такой показатель при исследованиях в области психологии. Вернемся теперь к нашим двум последовательностям рангов, состоящим из 10 элементов (см. (1.1)).
Его называют коэффициентом К. Спирмэна в честь автора, который впервые ввел такой показатель при исследованиях в области психологии. Вернемся теперь к нашим двум последовательностям рангов, состоящим из 10 элементов (см. (1.1)).

 определим коэффициент Спирмэна с помощью следующего соотношения:
определим коэффициент Спирмэна с помощью следующего соотношения:


 равны нулю; из (1.9) следует, что
равны нулю; из (1.9) следует, что  Предположим теперь, что элементы двух последовательностей расположены в обратном порядке. Покажем, что в этом случае
Предположим теперь, что элементы двух последовательностей расположены в обратном порядке. Покажем, что в этом случае 
 нечетное число, равное
нечетное число, равное  Без утраты общности одну из последовательностей можно расположить в натуральном порядке, тогда наши последовательности и соответствующие разности будут иметь следующий вид:
Без утраты общности одну из последовательностей можно расположить в натуральном порядке, тогда наши последовательности и соответствующие разности будут иметь следующий вид:



 четное число, скажем,
четное число, скажем,  Выпишем наши последовательности и соответствующие разности:
Выпишем наши последовательности и соответствующие разности:



 может принимать значения
может принимать значения  На стр. 32 будет показано, что коэффициент Спирмэна не может лежать вне этих границ и достигает экстремальных значений только при полной согласованности или полной рассогласованности между элементами двух последовательностей.
На стр. 32 будет показано, что коэффициент Спирмэна не может лежать вне этих границ и достигает экстремальных значений только при полной согласованности или полной рассогласованности между элементами двух последовательностей.
 поскольку она равна нулю. На это можно возразить, что просуммировав абсолютные величины разностей, можно было бы получить несколько более простой коэффициент; и к этому сводилось, между прочим, одно из первоначальных предложений Спирмэна. Но в таком случае возникли бы затруднения на последующих ступенях анализа, особенно усложнились бы проблемы выборочного обследования. Поэтому в дальнейшем изложении мы не будем пользоваться подобной методикой.
поскольку она равна нулю. На это можно возразить, что просуммировав абсолютные величины разностей, можно было бы получить несколько более простой коэффициент; и к этому сводилось, между прочим, одно из первоначальных предложений Спирмэна. Но в таком случае возникли бы затруднения на последующих ступенях анализа, особенно усложнились бы проблемы выборочного обследования. Поэтому в дальнейшем изложении мы не будем пользоваться подобной методикой.
 в уравнении (1.5) представляет собой просто число расположенных в неодинаковом порядке пар, образованных элементами двух последовательностей. Любое такое нарушение порядка мы будем называть «инверсией»; тем самым
в уравнении (1.5) представляет собой просто число расположенных в неодинаковом порядке пар, образованных элементами двух последовательностей. Любое такое нарушение порядка мы будем называть «инверсией»; тем самым  оказывается линейной функцией от количества инверсий. Любопытно, что
оказывается линейной функцией от количества инверсий. Любопытно, что  тоже можно считать коэффициентом инверсии, если только предположить, что каждая инверсия взвешена. В самом деле, предположим, что некоторая пара рангов
тоже можно считать коэффициентом инверсии, если только предположить, что каждая инверсия взвешена. В самом деле, предположим, что некоторая пара рангов  образует инверсию (пусть
образует инверсию (пусть  Припишем этой инверсии оценку
Припишем этой инверсии оценку  . Тогда общую сумму приписанных значений можно представить так:
. Тогда общую сумму приписанных значений можно представить так:






 а затем, воспользовавшись формулой (1.12), проверить значение
а затем, воспользовавшись формулой (1.12), проверить значение 
 в которой элементы расположены в натуральном порядке, а затем соотношение между А и такой последовательностью
в которой элементы расположены в натуральном порядке, а затем соотношение между А и такой последовательностью  в которой элементы расположены в порядке, обратном В. Тогда значения коэффициента
в которой элементы расположены в порядке, обратном В. Тогда значения коэффициента  окажутся равными по величине и противоположными по знаку. Это следует из самого определения
окажутся равными по величине и противоположными по знаку. Это следует из самого определения  ведь изменить порядок расположения элементов В на противоположный — значит изменить знак каждого слагаемого, входящего в сумму 5, и, следовательно, в конечном счете изменить знак
ведь изменить порядок расположения элементов В на противоположный — значит изменить знак каждого слагаемого, входящего в сумму 5, и, следовательно, в конечном счете изменить знак  Таким образом, справедливо следующее утверждение: если коэффициент корреляции рангов между последовательностями
Таким образом, справедливо следующее утверждение: если коэффициент корреляции рангов между последовательностями  (причем элементы в каждой из них не обязательно должны быть расположены в натуральном порядке) равен
(причем элементы в каждой из них не обязательно должны быть расположены в натуральном порядке) равен  то корреляция рангов между
то корреляция рангов между  измеряется величиной
измеряется величиной  Рассмотрим, например, такие две последовательности, содержащие по семь элементов:
Рассмотрим, например, такие две последовательности, содержащие по семь элементов:


 оно равно — 11/21, или —0,52. Переставив элементы верхней последовательности в обратном порядке, мы получим следующие пары:
оно равно — 11/21, или —0,52. Переставив элементы верхней последовательности в обратном порядке, мы получим следующие пары:

 измеряется величиной
измеряется величиной  Расположим теперь пары таким образом, чтобы порядок элементов в последовательности
Расположим теперь пары таким образом, чтобы порядок элементов в последовательности  совпадал с порядком
совпадал с порядком  В таком случае
В таком случае

 будем считать сопряженными. Рассматривая степень их корреляции с последовательностью В, мы получим одинаковые по величине, но противоположные по знаку коэффициенты
будем считать сопряженными. Рассматривая степень их корреляции с последовательностью В, мы получим одинаковые по величине, но противоположные по знаку коэффициенты 
 Значения
Значения  при сопоставлении последовательностей
при сопоставлении последовательностей  и при сопоставлении последовательностей
и при сопоставлении последовательностей  равны по величине и противоположны по знаку. В следующей главе эти результаты будут доказаны в общем виде. До тех пор читатель может самостоятельно убедиться, в частности, в том, что при сопоставлении между собой последовательностей
равны по величине и противоположны по знаку. В следующей главе эти результаты будут доказаны в общем виде. До тех пор читатель может самостоятельно убедиться, в частности, в том, что при сопоставлении между собой последовательностей  , а для
, а для  .
.
 или
или  соответствует равная ему по модулю и обратная по знаку величина. Отрицательное значение указанных коэффициентов характеризует корреляцию рангов в том случае, когда одна из исходных последовательностей расположена в обратном порядке, а другая сохраняет прежний порядок. Можно утверждать, что такие шкалы не имеют смещения.
соответствует равная ему по модулю и обратная по знаку величина. Отрицательное значение указанных коэффициентов характеризует корреляцию рангов в том случае, когда одна из исходных последовательностей расположена в обратном порядке, а другая сохраняет прежний порядок. Можно утверждать, что такие шкалы не имеют смещения.

 инверсиям более отдаленных (по величине) друг от друга элементов приписываются большие веса. На практике мы чаще всего сталкиваемся с такой ситуацией: если значения обоих коэффициентов не слишком близки к единице, то
инверсиям более отдаленных (по величине) друг от друга элементов приписываются большие веса. На практике мы чаще всего сталкиваемся с такой ситуацией: если значения обоих коэффициентов не слишком близки к единице, то  примерно на 50% превосходит
примерно на 50% превосходит  по своей абсолютной величине.
по своей абсолютной величине.

 количество членов в сопоставляемых последовательностях. При больших
количество членов в сопоставляемых последовательностях. При больших  можно пользоваться приближенным соотношением:
можно пользоваться приближенным соотношением:

 больше нуля, то может достигаться устанавливаемый неравенством верхний предел, а нижний предел недостижим; если
больше нуля, то может достигаться устанавливаемый неравенством верхний предел, а нижний предел недостижим; если  меньше нуля, может достигаться нижний предел, а верхний — недостижим. При
меньше нуля, может достигаться нижний предел, а верхний — недостижим. При  разность может принимать оба предельных значения. Следовательно, могут существовать и такие последовательности, у которых корреляция рангов характеризуется
разность может принимать оба предельных значения. Следовательно, могут существовать и такие последовательности, у которых корреляция рангов характеризуется  Но эти случаи носят довольно специфический характер. Рассмотрим, например, такие последовательности:
Но эти случаи носят довольно специфический характер. Рассмотрим, например, такие последовательности:


 были выведены Дарбином и Стюартом: они позволяют, зная величину
были выведены Дарбином и Стюартом: они позволяют, зная величину  установить верхний и нижний пределы, которыми ограничены значения
установить верхний и нижний пределы, которыми ограничены значения  . С помощью этих неравенств удается установить связь между V (см. 1.12) и
. С помощью этих неравенств удается установить связь между V (см. 1.12) и  для любых последовательностей:
для любых последовательностей:


 мы можем отыскать верхний предел для значений
мы можем отыскать верхний предел для значений  Из выражения (1.17) находим нижний предел значения
Из выражения (1.17) находим нижний предел значения 

 можно пользоваться приближенной формулой, имеющей вид:
можно пользоваться приближенной формулой, имеющей вид:

 может принимать два предельных значения. Пусть, например,
может принимать два предельных значения. Пусть, например,  тогда
тогда  Если
Если  при
при 


 связаны между собой, эта связь не столь элементарна.
связаны между собой, эта связь не столь элементарна.
 легче рассчитать, чем
легче рассчитать, чем  . И все же, как будет показано в последующих главах, в силу целого ряда практических и теоретических соображений больший интерес представляет коэффициент
. И все же, как будет показано в последующих главах, в силу целого ряда практических и теоретических соображений больший интерес представляет коэффициент  а не
а не  Важнейшие методы, приводимые в этой книге, также предполагают применение коэффициента
Важнейшие методы, приводимые в этой книге, также предполагают применение коэффициента  Мы не будем на данной стадии изложения сравнивать между собой относительные
Мы не будем на данной стадии изложения сравнивать между собой относительные
 с использованием всей совокупности данных, в то время как коэффициент
с использованием всей совокупности данных, в то время как коэффициент  при добавлении к последовательности новых элементов не требует полного пересчета данных. Поясним это соображение с помощью числового примера.
при добавлении к последовательности новых элементов не требует полного пересчета данных. Поясним это соображение с помощью числового примера.

 и
и  в таком случае
в таком случае 



 существует некоторая, хотя и слабая, положительная корреляция; в гл. 3 будет показано, как проверить существенность такой зависимости. Однако для нашего примера это не столь уж важно. Предположим, что после того, как коэффициенты тир были уже вычислены, получены еще два ответа, в которых указаны нормы дивиденда 7 и 23%. Чтобы включить эти числа в уже упорядоченную последовательность, нужно изменить величины почти всех рангов в строке С. Кроме этого, надо заново рассчитать значения разностей
существует некоторая, хотя и слабая, положительная корреляция; в гл. 3 будет показано, как проверить существенность такой зависимости. Однако для нашего примера это не столь уж важно. Предположим, что после того, как коэффициенты тир были уже вычислены, получены еще два ответа, в которых указаны нормы дивиденда 7 и 23%. Чтобы включить эти числа в уже упорядоченную последовательность, нужно изменить величины почти всех рангов в строке С. Кроме этого, надо заново рассчитать значения разностей  и сумму
и сумму  . А если ответы будут поступать и в последующий период, то всю эту работу придется проделывать еще раз.
. А если ответы будут поступать и в последующий период, то всю эту работу придется проделывать еще раз.
 оказываемое прибавлением двух новых элементов, если прибегнуть к следующему ходу рассуждений. Новый элемент последовательности В, равный 7% и имеющий ранг 16 в последовательности
оказываемое прибавлением двух новых элементов, если прибегнуть к следующему ходу рассуждений. Новый элемент последовательности В, равный 7% и имеющий ранг 16 в последовательности  может оказать влияние на корреляцию рангов лишь в силу того, что соответствующие ему числа вносят определенные изменения в порядок, образуемый остальными пятнадцатью парами. Норма дивиденда характеризуется наименьшей величиной, следовательно, новый элемент добавит в сумму
может оказать влияние на корреляцию рангов лишь в силу того, что соответствующие ему числа вносят определенные изменения в порядок, образуемый остальными пятнадцатью парами. Норма дивиденда характеризуется наименьшей величиной, следовательно, новый элемент добавит в сумму  слагаемое, равное — 15. Аналогичным образом новый элемент, представленный нормой дивиденда в 23%, вносит в сумму
слагаемое, равное — 15. Аналогичным образом новый элемент, представленный нормой дивиденда в 23%, вносит в сумму  слагаемое, равное 14. Следовательно, вновь полученная сумма
слагаемое, равное 14. Следовательно, вновь полученная сумма  будет на
будет на  превосходить старую, т. е. составит 24. Теперь можно вычислить новое значение
превосходить старую, т. е. составит 24. Теперь можно вычислить новое значение 

 не прибегая на каждом этапе к повторному упорядочению всего массива данных.
не прибегая на каждом этапе к повторному упорядочению всего массива данных.




 в большей степени совпадают между собой, чем суждения
в большей степени совпадают между собой, чем суждения  или
или  Привлекает внимание сравнительно слабая согласованность оценок
Привлекает внимание сравнительно слабая согласованность оценок 
 равно 72, следовательно,
равно 72, следовательно,  По-видимому, это число довольно точно отражает общую зависимость между переменными. В целом для государства с ббльшим населением характерен больший объем внешнеторговых операций; однако Китай представляет собой исключение, поэтому утверждение о положительной корреляционной зависимости нельзя считать строгим.
По-видимому, это число довольно точно отражает общую зависимость между переменными. В целом для государства с ббльшим населением характерен больший объем внешнеторговых операций; однако Китай представляет собой исключение, поэтому утверждение о положительной корреляционной зависимости нельзя считать строгим.
 при оценке корреляционных зависимостей между случайными величинами, характеризующимися нормальным распределением, описана в [33] и [24], см. гл. 9 и 10. Независимо от этих авторов коэффициент
при оценке корреляционных зависимостей между случайными величинами, характеризующимися нормальным распределением, описана в [33] и [24], см. гл. 9 и 10. Независимо от этих авторов коэффициент  использовал Кендэл [48], видевший в нем только характеристику степени соответствия ранговых оценок. Способы применения коэффициента
использовал Кендэл [48], видевший в нем только характеристику степени соответствия ранговых оценок. Способы применения коэффициента  при измерении степени неупорядоченности описаны в [36], [26] и [65].
при измерении степени неупорядоченности описаны в [36], [26] и [65].
 рассматриваются в работах [88 и 89], [75], [55].
рассматриваются в работах [88 и 89], [75], [55].
 можно найти в [11 и 12], а также [20].
можно найти в [11 и 12], а также [20].