Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
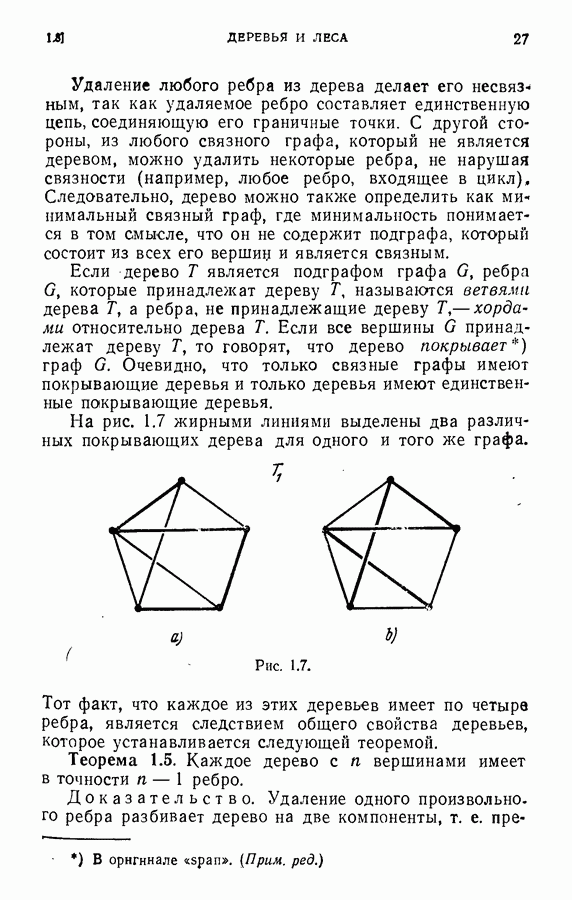
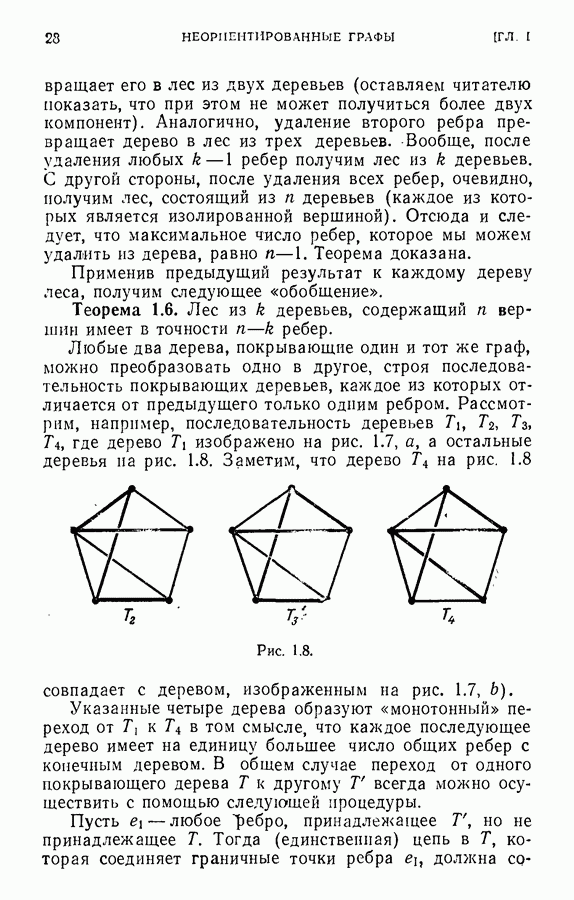
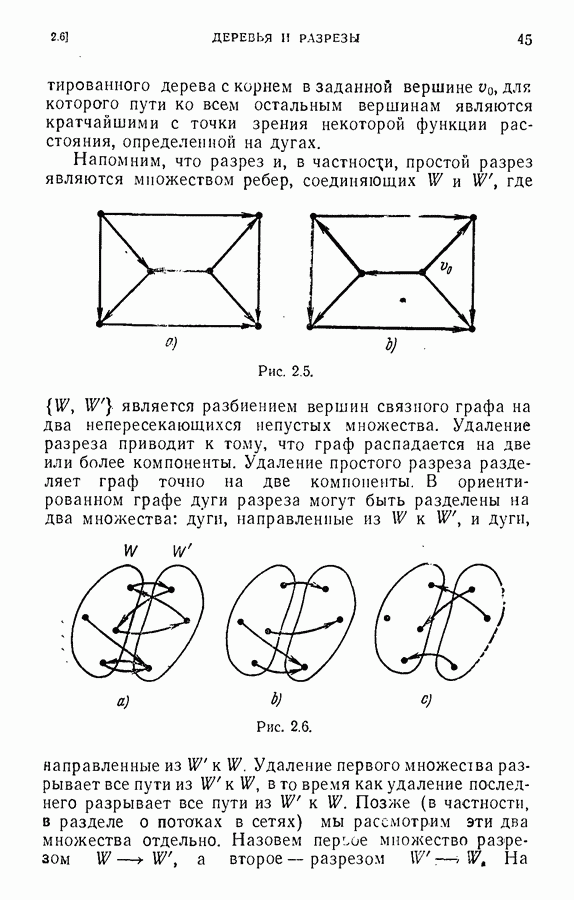
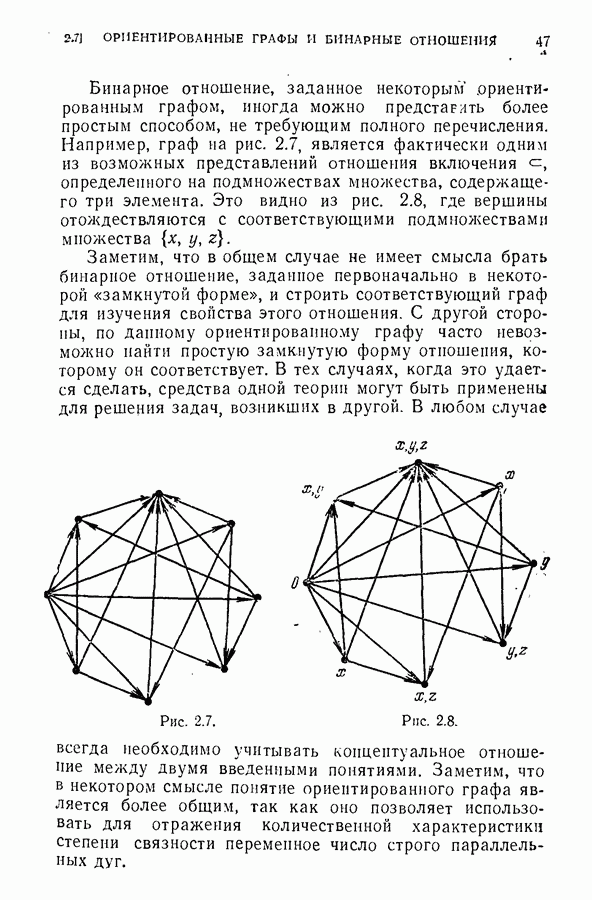
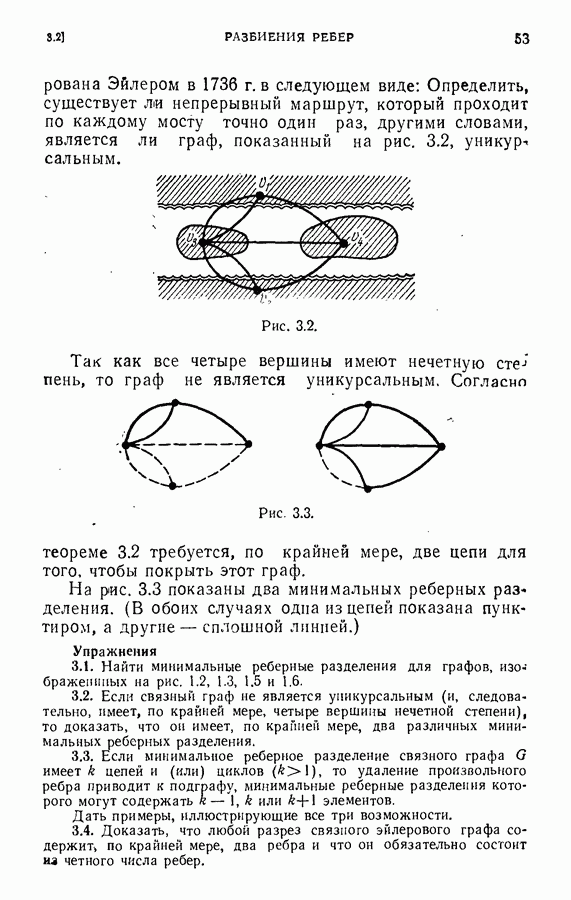
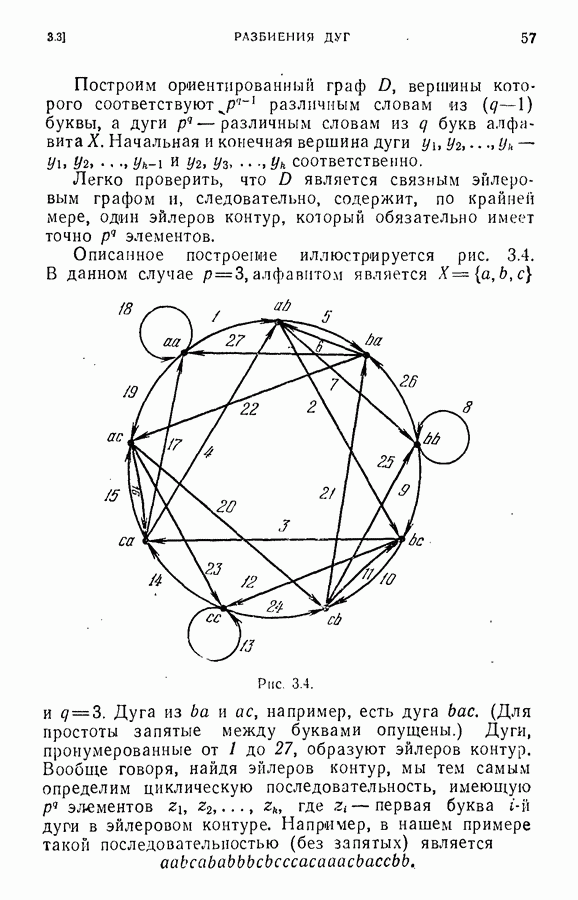
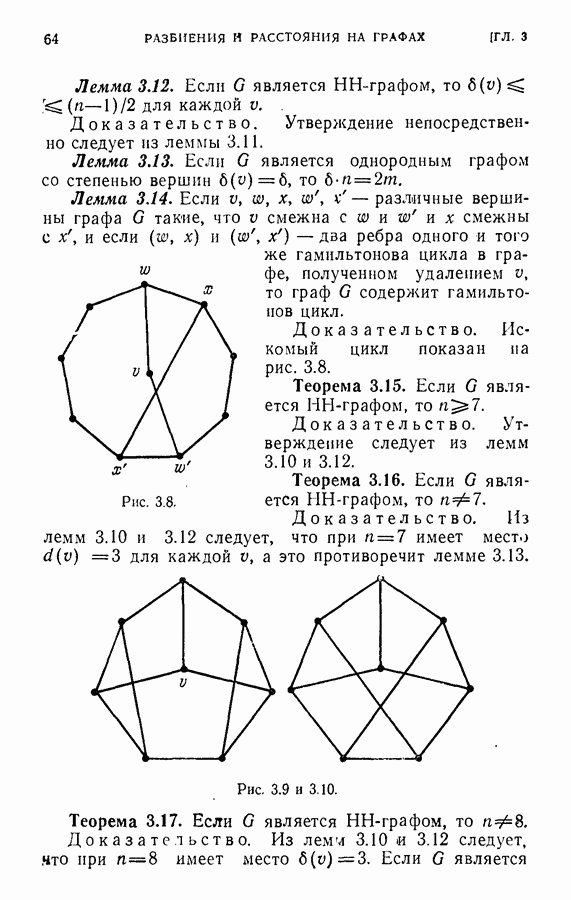
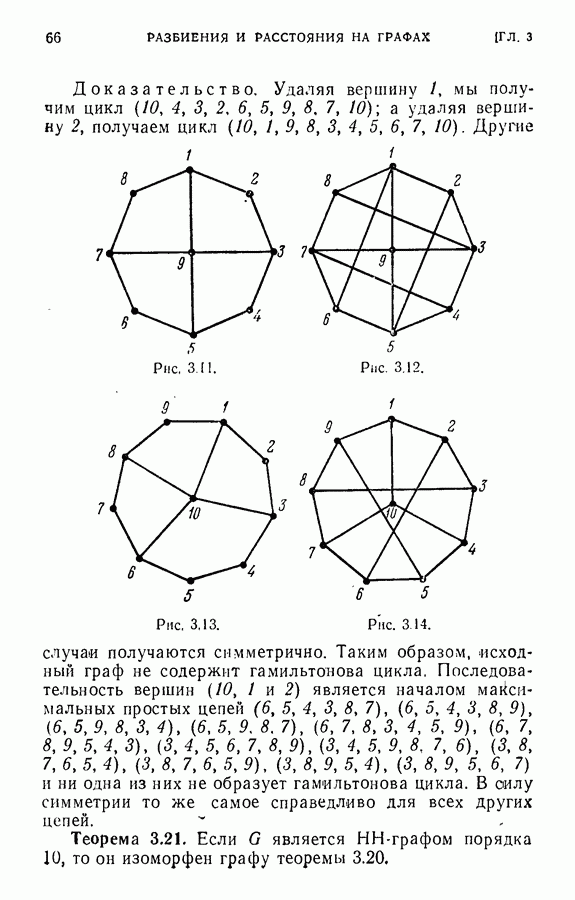
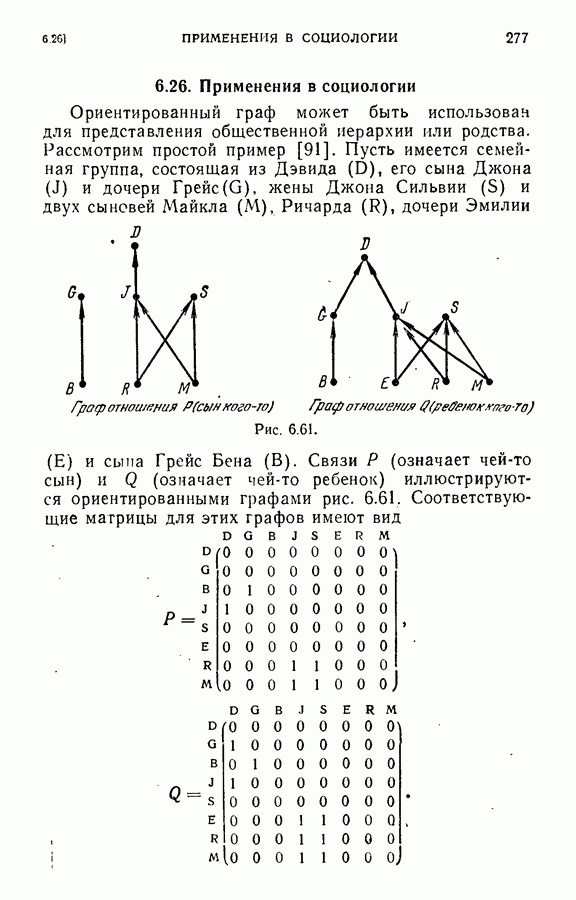
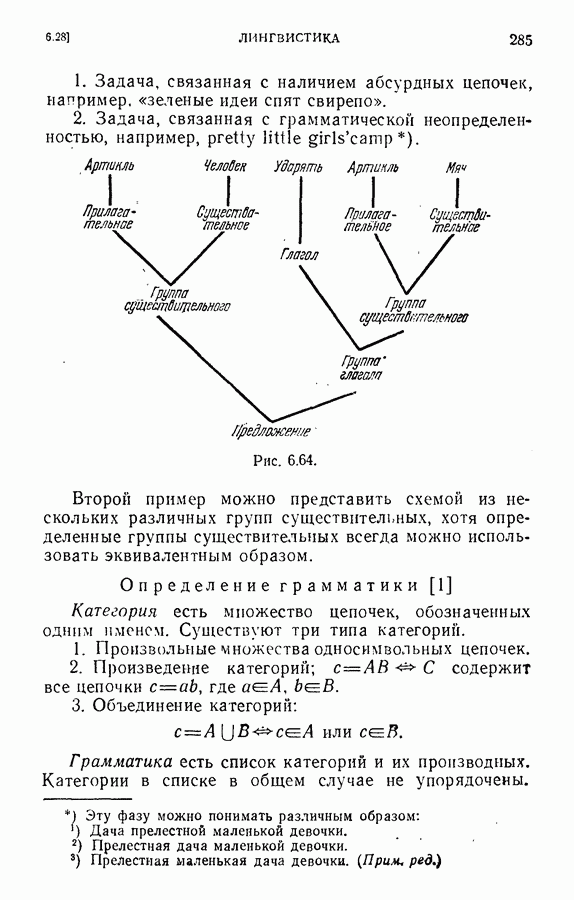
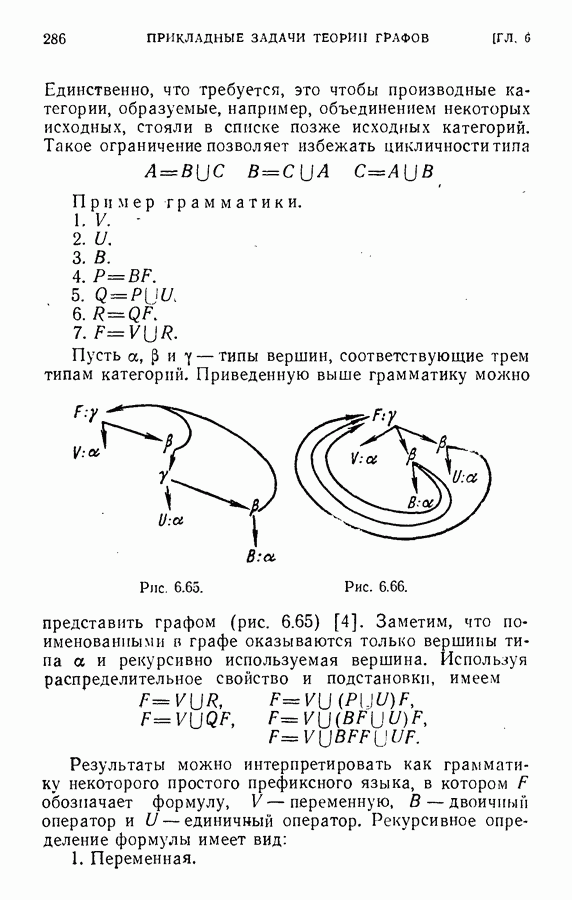
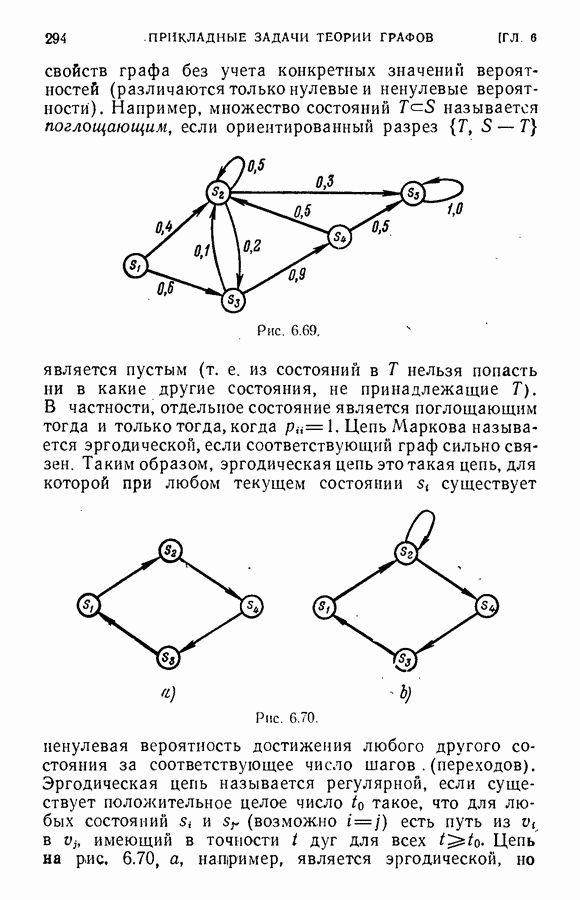
ЕСТЕСТВЕННЫЕ НАУКИ6.21. Идентификация в химииОдна из основных задач теории графов состоит в нахождении хорошего алгоритма для определения того, являются ли два конечных графа одинаковыми в абстрактном смысле или, в более общем случае, является ли один граф подграфом другого. Первая задача называется задачей идентификации графа, а вторая — задачей идентификации подграфа. Чтобы формулировка задачи была более четкой, слову «хороший» нужно придать некоторый математический смысл. Будем считать, что алгоритм является «хорошим», если объем вычислений связанных с его применением для любой пары графов, растет в худшем случае как степенная функция, а не экспоненциально с ростом числа ребер в выбранной паре графов. Хороший алгоритм идентификации деревьев (но не поддеревьев) разработал Эдмондс. Этот алгоритм мы рассмотрим ниже. Эдмондс считает, что хорошего алгоритма идентификации произвольных подграфов или даже произвольных графов в общем случае не существует. С практической точки зрения задачи индентификации графов и подграфов важны в органической химии, где молекулы представляются в виде графов. Вершины соответствуют атомам, а ребра — связям между атомами. Существование нескольких видов атомов не вносит серьезных трудностей в задачу идентификации. В настоящее время много внимания уделяется разработке «эвристических» алгоритмов химической идентификации — алгоритмов, не являющихся «хорошими» в нашем смысле, но хорошо работающих на практике. Для химиков важно не только решить задачу идентификации структур, но гораздо более интересно найти удобную систему каталогизации химических препаратов так, чтобы любой препарат можно было легко найти в каталоге или внести туда. (Поиск химических патентов в настоящее время является довольно сложной задачей.) Алгоритм идентификации деревьев использует каталожную систему, построенную на основе линейного упорядочения множества всех конечных деревьев. Однако наличие такой системы совершенно не обязательно. Например, существует хороший алгоритм для определения идентичности (в комбинаторном смысле) любых двух поверхностных карт. Карты обладают свойством комбинаторной «жесткости» — так, что если карты и Упомянутое выше свойство «жесткости» можно использовать для определения идентичности деревьев Можно считать (хотя мы и не будем придерживаться такой точки зрения), что алгоритм идентификации деревьев есть процедура приведения деревьев к каноническому виду. Напомним, что корневым деревом является дерево, в котором одна из вершин, в отличие от других, называется корнем. Алгоритм идентификации фактически применяется к корневым деревьям. Поэтому опишем сначала хороший алгоритм приведения любого дерева В случае, когда получена вершина, будем считать, что она и есть корень дерева Каждому корневому дереву будет соответствовать определенная конечная последовательность целых чисел. Не существует двух разных корневых деревьев, которые имели бы одинаковые последовательности. Алгоритм определения идентичности двух корневых деревьев основан на вычислении соответствующих последовательностей и их сравнении. Для сравнения последовательностей существует хороший алгоритм, так как число членов в последовательности и наибольший ее член равны числу вершин в дереве, соответствующем последовательности. Как это будет видно из определения, хороший алгоритм вычисления последовательности для данного дерева всегда существует. Ранг корневых деревьев устанавливается в соответствии с лексикографическим упорядочением соответствующих последовательностей. Таким образом, ранг Если удалить из корневого дерева Последовательность для корневого дерева Заметим, что существует единственное взаимно однозначное соответствие между членами словами, Важнейшей характеристикой последовательности Осталось проверить достаточность идентичности соответствующих последовательностей. Это легко сделать, убедившись, что из последовательности Если Определенные таким образом После построения Рассмотренный метод идентификации деревьев вряд ли может дать хороший алгоритм решения более общей задачи определения того, содержит ли данное корневое дерево подграф, идентичный другому заданному корневому дереву при совпадении их корней. Такой алгоритм было бы очень интересно получить. Упражнение 6.25. Показать, что последовательности, полученные удалением всех членов, равных 1, из последовательностей
|
 |
Оглавление
|






















































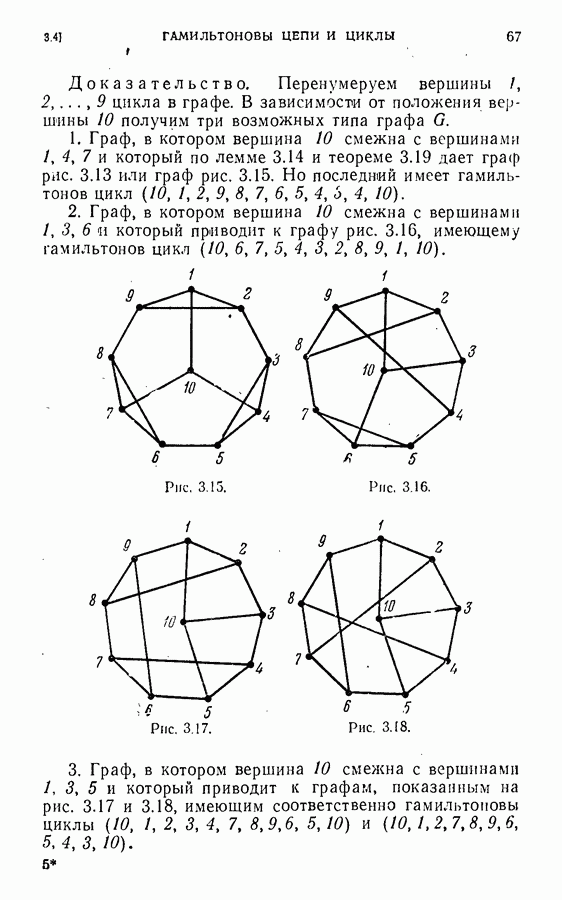















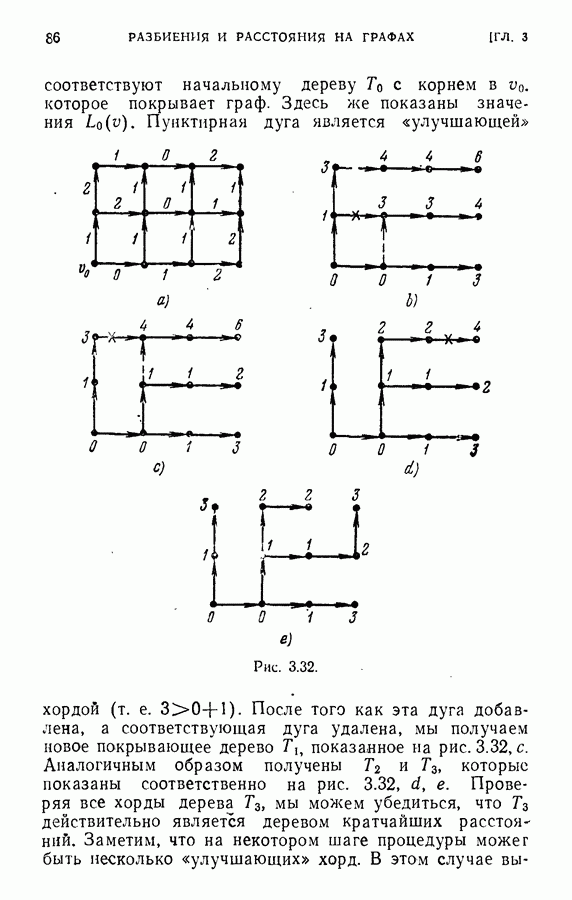



























































































































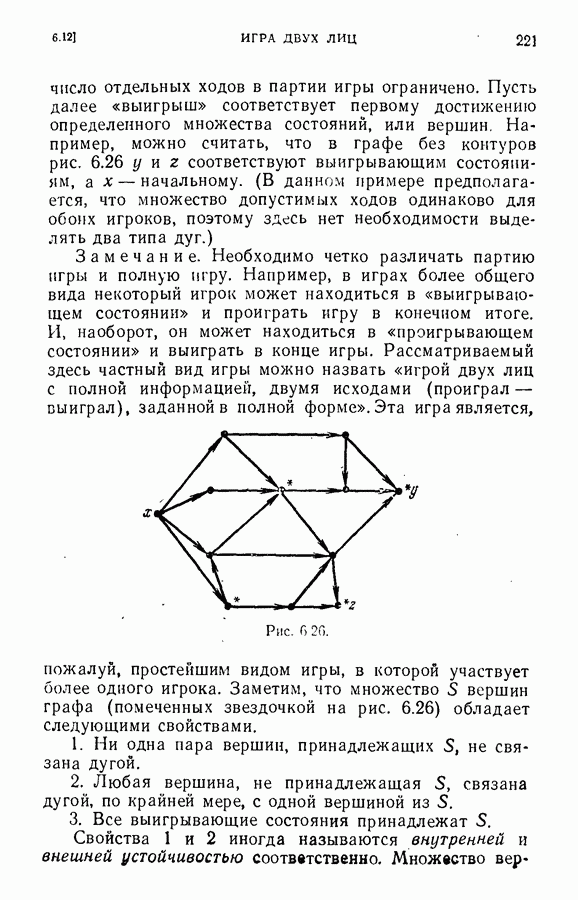




































































































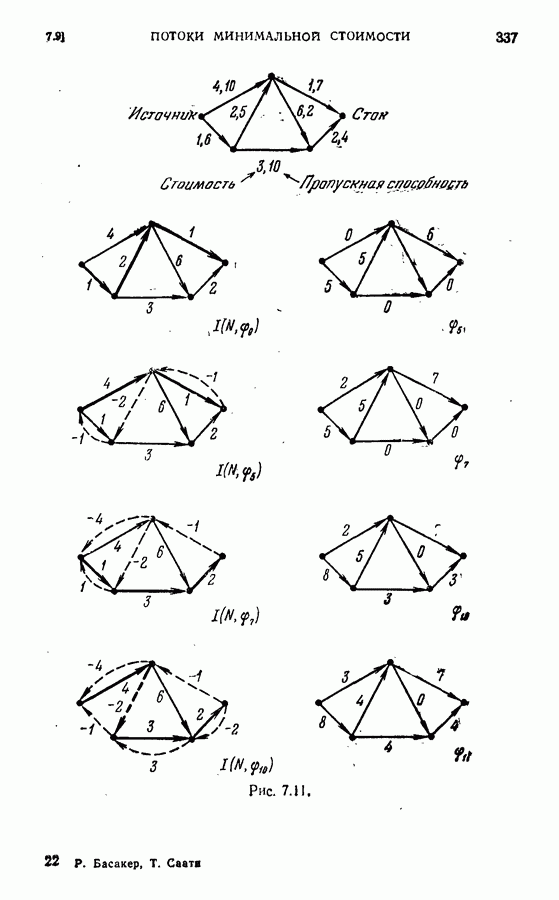




























 идентичны и установлено, что ребро
идентичны и установлено, что ребро  идентично ребру
идентично ребру  конечная точка
конечная точка  ребра
ребра  идентична с конечной точкой
идентична с конечной точкой  ребра
ребра  и грань
и грань  содержащая
содержащая  идентична с гранью
идентична с гранью  содержащей
содержащей  идентификация оставшихся частей
идентификация оставшихся частей  однозначна и легко устанавливается. Таким образом, для того чтобы установить идентичность карт
однозначна и легко устанавливается. Таким образом, для того чтобы установить идентичность карт  необходимо только идентифицировать ребро
необходимо только идентифицировать ребро  с каждым ребром
с каждым ребром  четырьмя способами, соответствующими каждому возможному способу идентификации вершины
четырьмя способами, соответствующими каждому возможному способу идентификации вершины  и грани
и грани  Из такой процедуры, конечно, непосредственно не следует система каталогизации карт.
Из такой процедуры, конечно, непосредственно не следует система каталогизации карт.
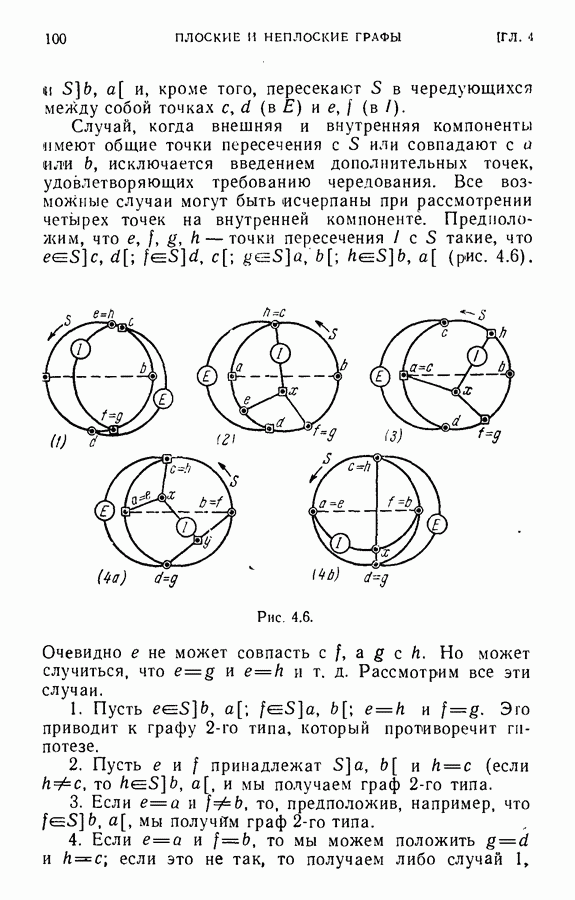
 а также идентичности их способа изображения на плоскости. Под идентичностью способа изображения мы будем понимать, что для каждой пары взаимно идентичных вершин
а также идентичности их способа изображения на плоскости. Под идентичностью способа изображения мы будем понимать, что для каждой пары взаимно идентичных вершин  ребра, которые пересекаются в в изображении
ребра, которые пересекаются в в изображении  располагаются вокруг
располагаются вокруг  в том же самом порядке, в каком идентичные ребра расположены вокруг
в том же самом порядке, в каком идентичные ребра расположены вокруг  в изображении дерева
в изображении дерева  Различные способы изображения одинаковых деревьев
Различные способы изображения одинаковых деревьев  обычно усложняют проверку на идентичность, а число различных способов изображения дерева, вообще говоря, растет экспоненциально с числом ребер в дереве.
обычно усложняют проверку на идентичность, а число различных способов изображения дерева, вообще говоря, растет экспоненциально с числом ребер в дереве.
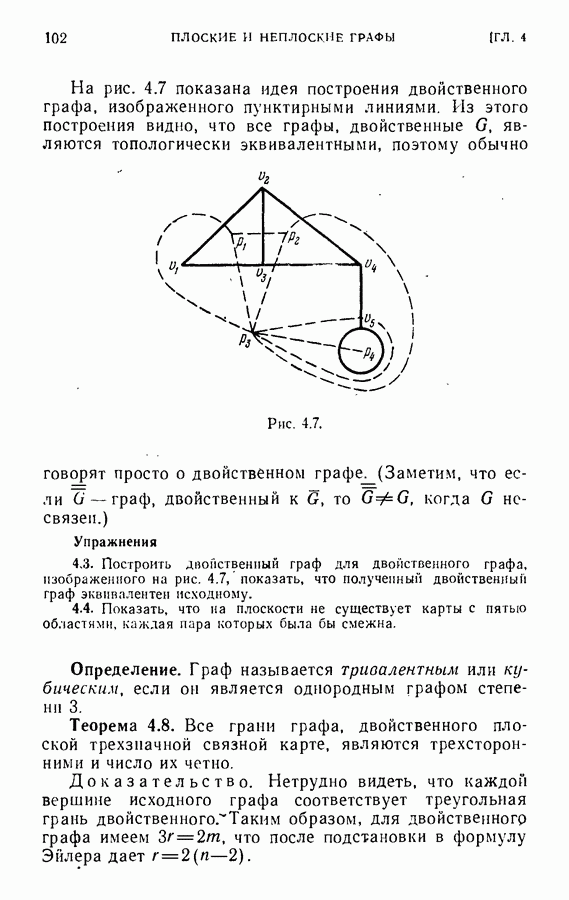
 к канонической корневой форме. Пусть
к канонической корневой форме. Пусть  есть дерево
есть дерево  Будем формировать
Будем формировать  из
из  вычеркивая из
вычеркивая из  все вершины степени 1 и инцидентные им ребра. Такой процесс продолжим до тех пор, пока не получим
все вершины степени 1 и инцидентные им ребра. Такой процесс продолжим до тех пор, пока не получим  которое состоит только из одной вершины или одного ребра и его конечных точек. Процесс оказывается конечным для любого исходного дерева
которое состоит только из одной вершины или одного ребра и его конечных точек. Процесс оказывается конечным для любого исходного дерева  Вершина или ребро, получаемые по окончании процесса, называются центром
Вершина или ребро, получаемые по окончании процесса, называются центром 
 В случае получения ребра примем за корень одну из его конечных точек, например, вершину, которая дает корневое дерево более низкого ранга (или любую конечную точку в случае, когда они дают одинаковые корневые деревья). Упорядочим все корневые деревья так, чтобы из любых двух неодинаковых деревьев одно имело меньший ранг. (При другом подходе в качестве корня дерева
В случае получения ребра примем за корень одну из его конечных точек, например, вершину, которая дает корневое дерево более низкого ранга (или любую конечную точку в случае, когда они дают одинаковые корневые деревья). Упорядочим все корневые деревья так, чтобы из любых двух неодинаковых деревьев одно имело меньший ранг. (При другом подходе в качестве корня дерева  можно выбрать одну из вершин, которая образует корневое дерево с минимальным рангом. Выбор вершины в этом случае не однозначен, а результирующее корневое дерево определяется однозначно. Независимо от метода определения корня два дерева идентичны тогда и только тогда, когда соответствующие им корневые деревья одинаковы. Первый метод кажется более простым.)
можно выбрать одну из вершин, которая образует корневое дерево с минимальным рангом. Выбор вершины в этом случае не однозначен, а результирующее корневое дерево определяется однозначно. Независимо от метода определения корня два дерева идентичны тогда и только тогда, когда соответствующие им корневые деревья одинаковы. Первый метод кажется более простым.)
 меньше, чем
меньше, чем  если существует целое число
если существует целое число  такое, что для
такое, что для  члены двух последовательностей равны
члены двух последовательностей равны  кроме того,
кроме того,  член в последовательности
член в последовательности  либо меньше
либо меньше  члена в последовательности
члена в последовательности  либо больше.
либо больше.
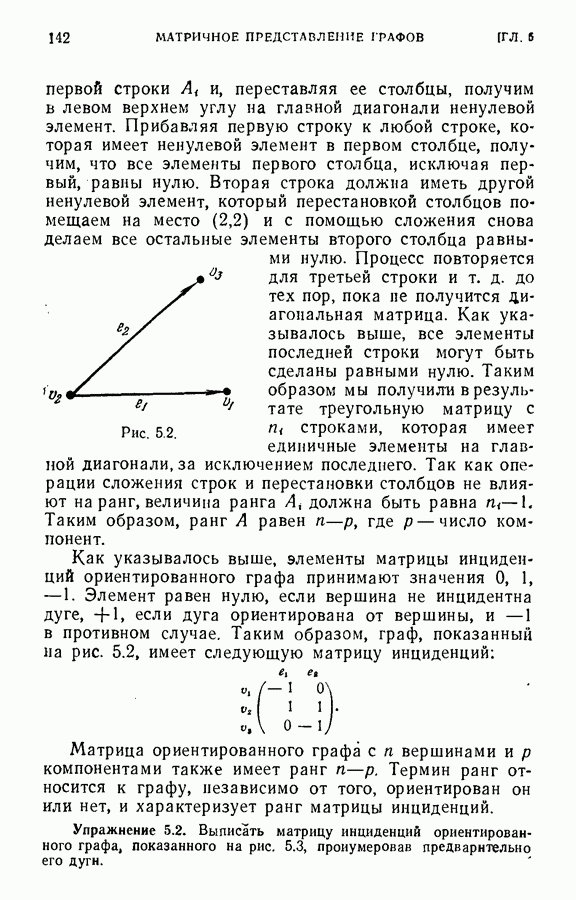
 корень
корень  и ребра, которые инцидентны ему, то получится несколько деревьев, каждое из которых соответствует одному из удаленных ребер. Эти деревья называются факторами корневого дерева
и ребра, которые инцидентны ему, то получится несколько деревьев, каждое из которых соответствует одному из удаленных ребер. Эти деревья называются факторами корневого дерева  Каждый фактор
Каждый фактор  содержит точно одну вершину, которая соединяется с
содержит точно одну вершину, которая соединяется с  в
в  Эта вершина рассматривается как корень фактора. Таким образом, корневое дерево
Эта вершина рассматривается как корень фактора. Таким образом, корневое дерево  если оно не является просто единственной вершиной, однозначно разбивается на один пли несколько факторов, которые представляют собой также корневые деревья.
если оно не является просто единственной вершиной, однозначно разбивается на один пли несколько факторов, которые представляют собой также корневые деревья.
 состоящего из единственной вершины, имеет один член, равный 1. Для любого другого корневого дерева
состоящего из единственной вершины, имеет один член, равный 1. Для любого другого корневого дерева  все члены последовательности
все члены последовательности  соответствующей
соответствующей  кроме первого, получаются из последовательностей
кроме первого, получаются из последовательностей  соответствующих факторам
соответствующих факторам  дерева
дерева  упорядочением
упорядочением  по возрастанию ранга. Конечно, в случае совпадения некоторых
по возрастанию ранга. Конечно, в случае совпадения некоторых  их порядок не имеет значения, важно только, чтобы все они присутствовали в
их порядок не имеет значения, важно только, чтобы все они присутствовали в  Таким образом, совокупность членов всех
Таким образом, совокупность членов всех  содержит все члены
содержит все члены  кроме первого. Первый член
кроме первого. Первый член  равен единице плюс сумма первых членов
равен единице плюс сумма первых членов  числу вершин в
числу вершин в 
 и вершинами
и вершинами  при котором первый член
при котором первый член  соответствует корню
соответствует корню  а другие члены
а другие члены  соответствуют тем же самым вершинам, что и члены
соответствуют тем же самым вершинам, что и члены  из которых они были получены. Каждая вершина
из которых они были получены. Каждая вершина  в
в  является корнем только одного корневого дерева (обозначим его через
является корнем только одного корневого дерева (обозначим его через  которое включается в индуктивное определение
которое включается в индуктивное определение  Другими
Другими
 является фактором фактора... фактора
является фактором фактора... фактора  Величина члена
Величина члена  который соответствует
который соответствует  равна числу вершин в
равна числу вершин в 
 с точки зрения идентификации корневого дерева является единсггенность упорядочения ее членов даже при отсутствии заранее заданного упорядочения вершин дерева
с точки зрения идентификации корневого дерева является единсггенность упорядочения ее членов даже при отсутствии заранее заданного упорядочения вершин дерева  Из определения
Из определения  следует, что для идентичности двух деревьев необходимо, чтобы были идентичны соответствующие им последовательности.
следует, что для идентичности двух деревьев необходимо, чтобы были идентичны соответствующие им последовательности.
 действительно получается дерево
действительно получается дерево  с помощью следующей однозначной процедуры.
с помощью следующей однозначной процедуры.
 состоит из единственного члена, то он равен 1 и
состоит из единственного члена, то он равен 1 и  состоит из одной вершины. Если членов несколько, то, отбрасывая первый член
состоит из одной вершины. Если членов несколько, то, отбрасывая первый член  все остальные члены можно разбить на несвязанные подпоследовательности
все остальные члены можно разбить на несвязанные подпоследовательности  состоящие из следующих друг за другом членов
состоящие из следующих друг за другом членов  так, что там, где
так, что там, где  обозначает первый член
обозначает первый член  есть второй член
есть второй член  Кроме того,
Кроме того,  есть ближайший к
есть ближайший к  член
член  величина которого не меньше
величина которого не меньше  После
После  нет члена, величина которого была бы
нет члена, величина которого была бы  меньше
меньше 
 являются последовательностями, соответствующие факторам
являются последовательностями, соответствующие факторам  дерева
дерева  Это следует из двух фактов: (1) первый член последовательности, соответствующей корневому дереву, больше всех остальных членов; 2) последовательности, соответствующие факторам
Это следует из двух фактов: (1) первый член последовательности, соответствующей корневому дереву, больше всех остальных членов; 2) последовательности, соответствующие факторам  располагаются в
располагаются в  в порядке возрастания их рангов.
в порядке возрастания их рангов.
 соответствующих
соответствующих  строится корневое дерево
строится корневое дерево  Оно получается путем соединения дополнительной вершины (корня
Оно получается путем соединения дополнительной вершины (корня  с корнями всех
с корнями всех  Описание процедуры построения корневого дерева по соответствующей ему последовательности завершается индукцией по размеру последовательности.
Описание процедуры построения корневого дерева по соответствующей ему последовательности завершается индукцией по размеру последовательности.
 соответствующих корневым деревьям, так же могут использоваться для идентификации деревьев, как и исходные последовательности
соответствующих корневым деревьям, так же могут использоваться для идентификации деревьев, как и исходные последовательности 