Пред.
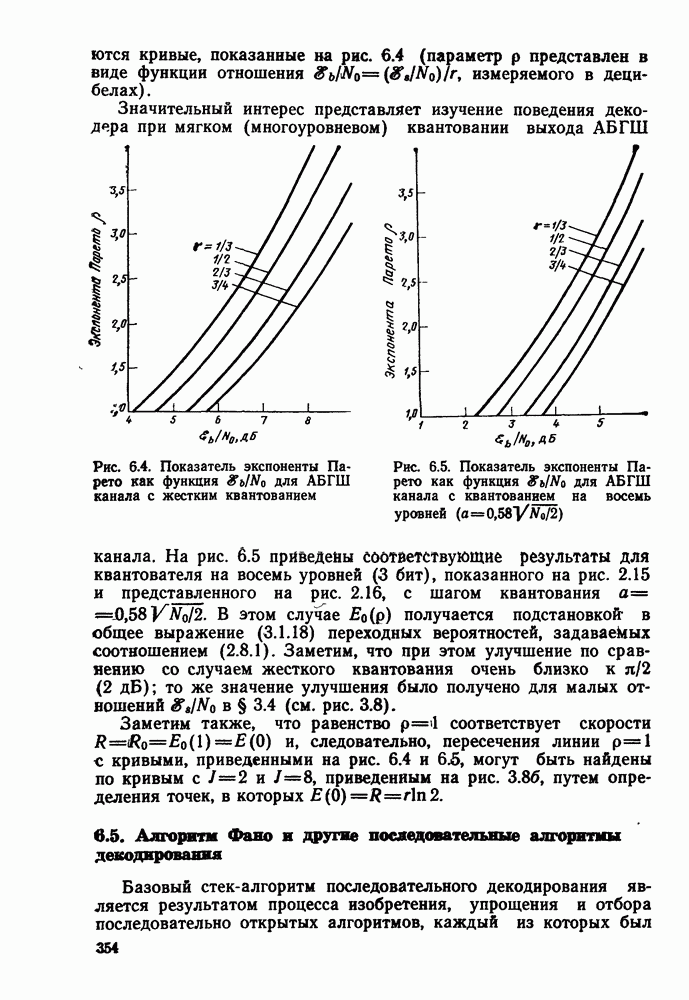
След.
Макеты страниц
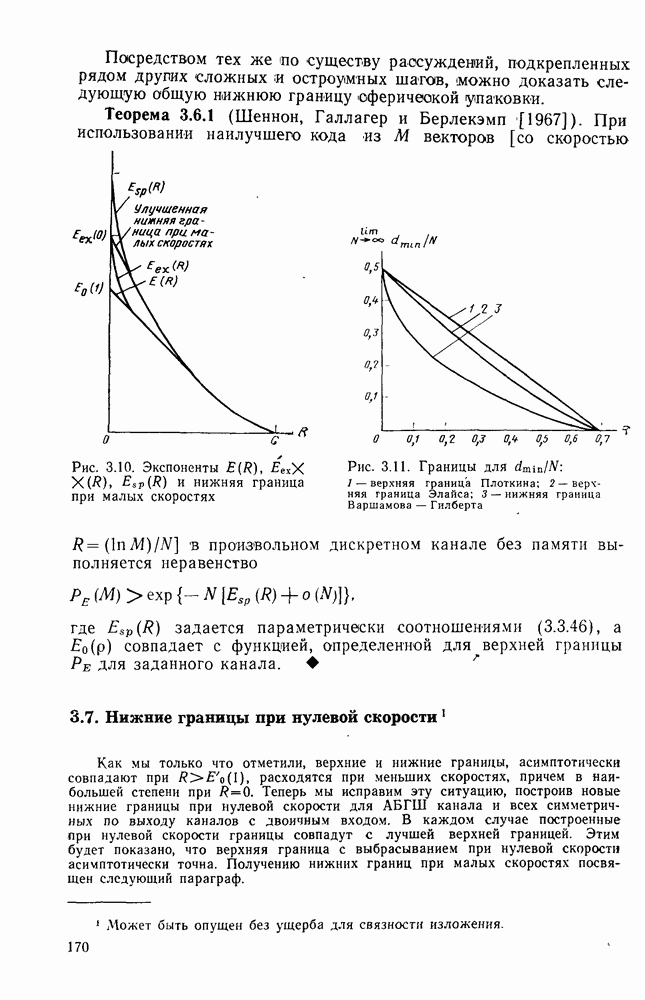
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
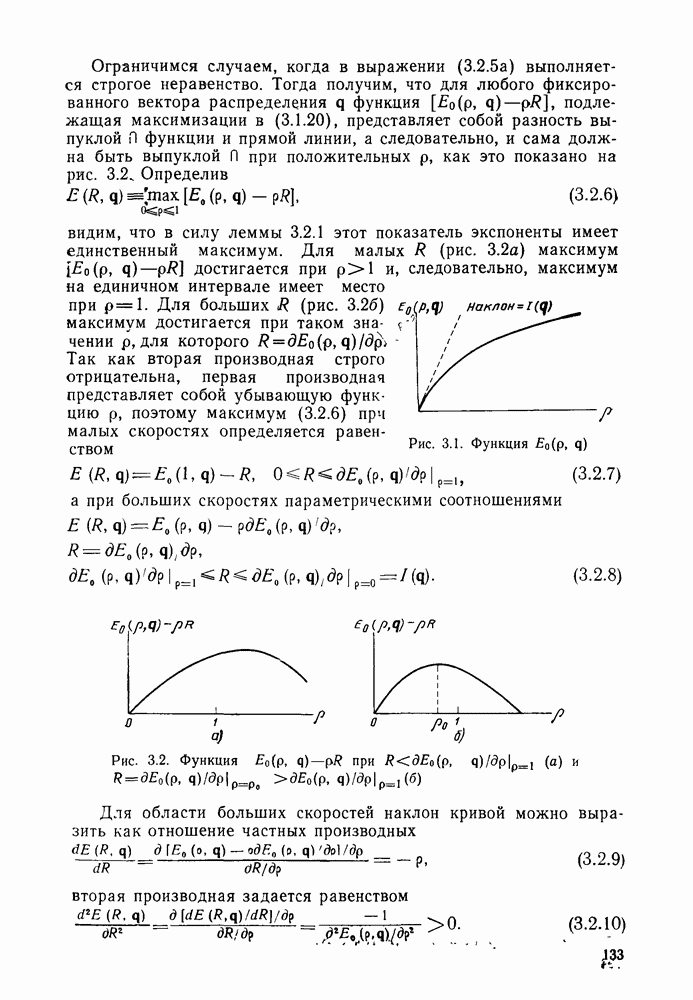
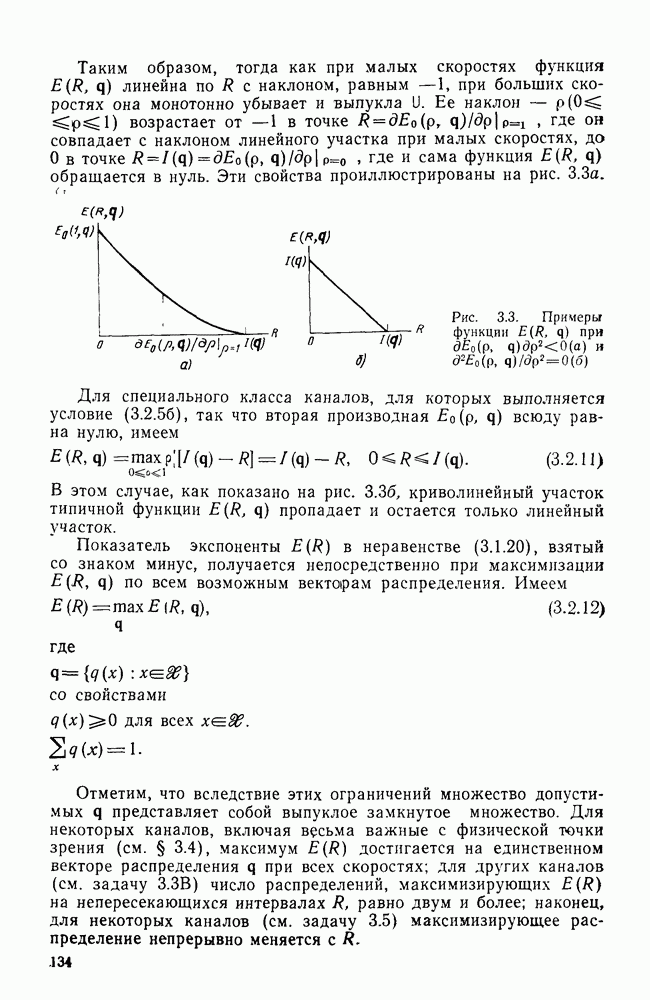
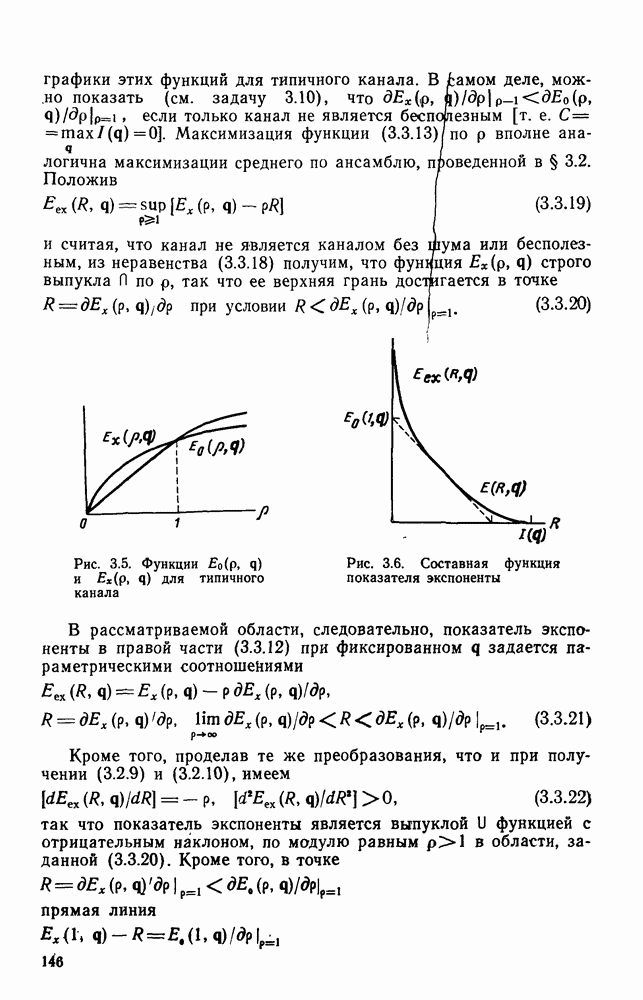
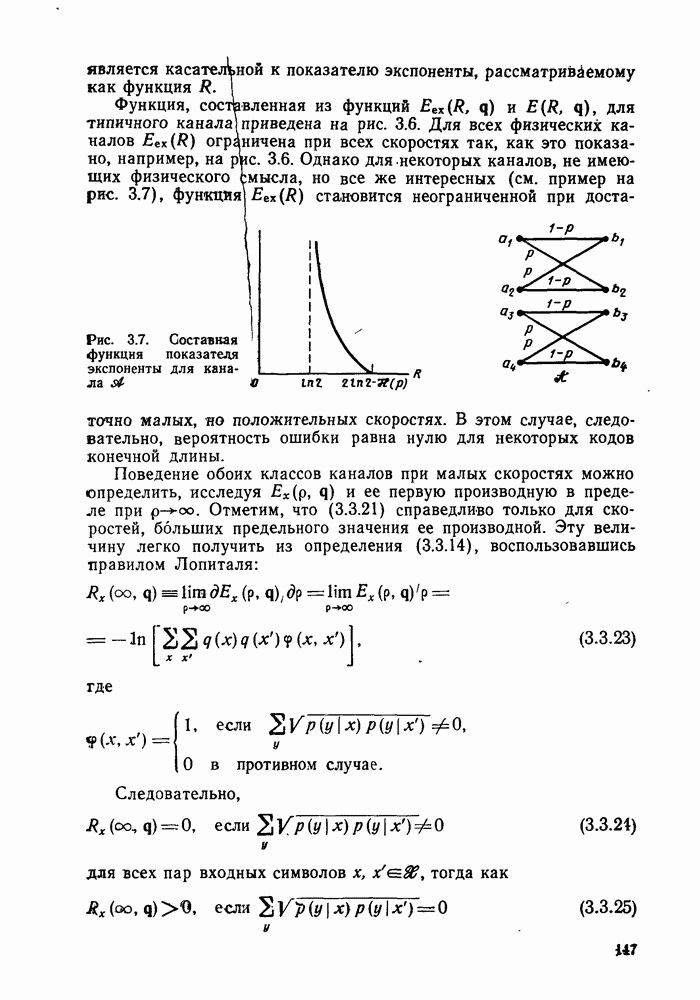
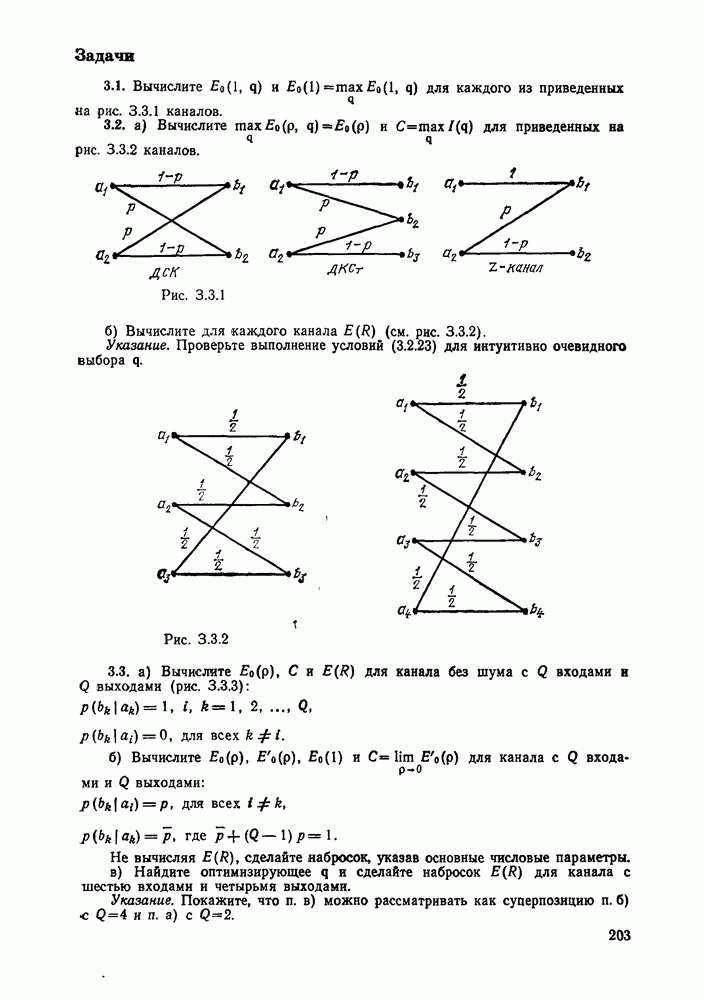
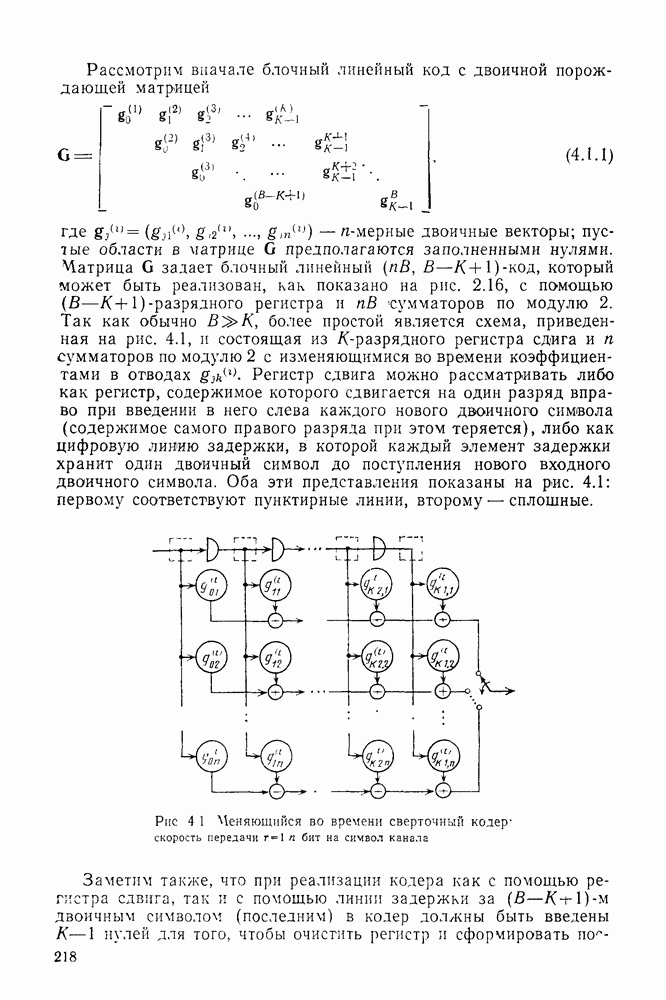
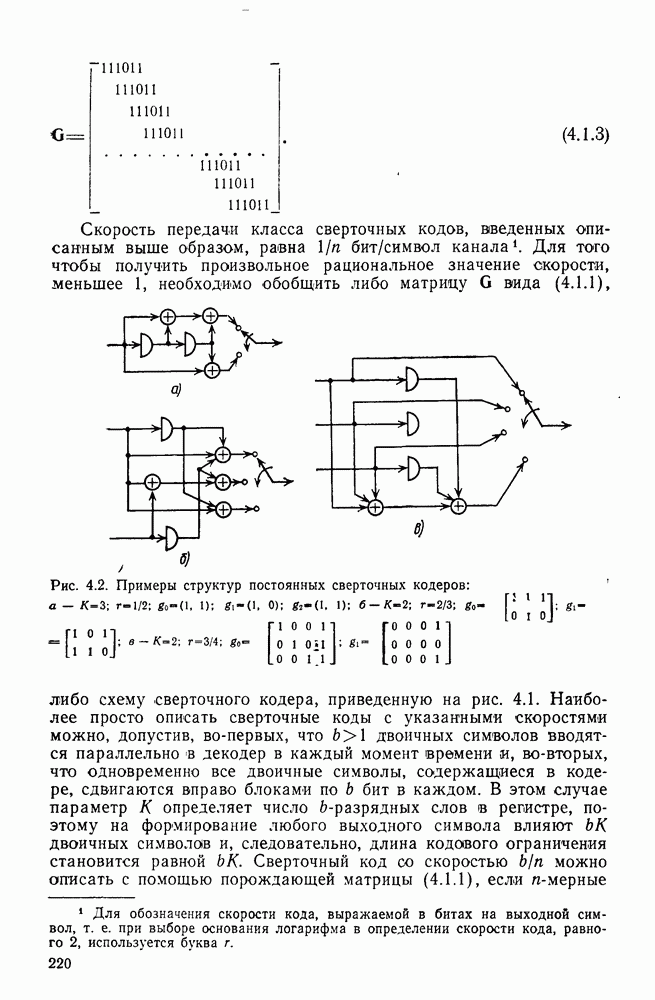
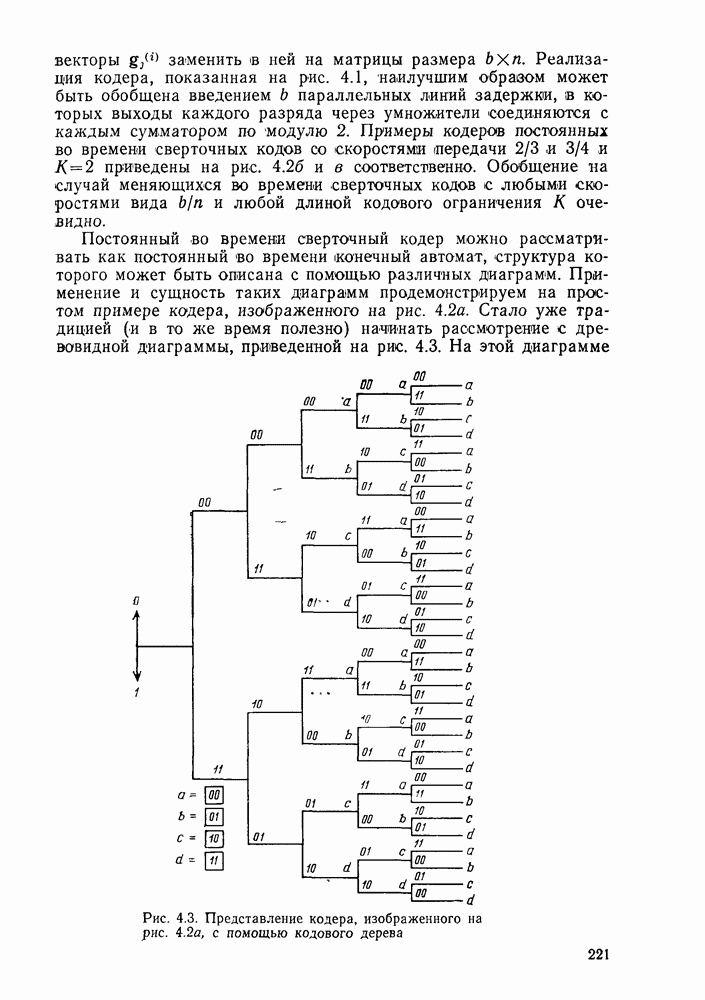
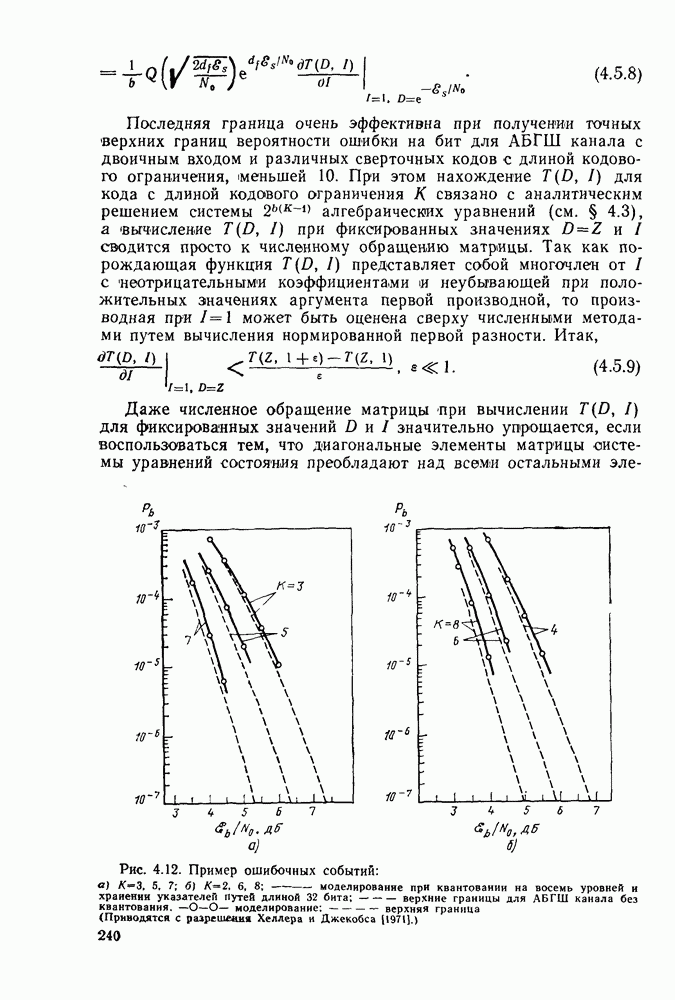
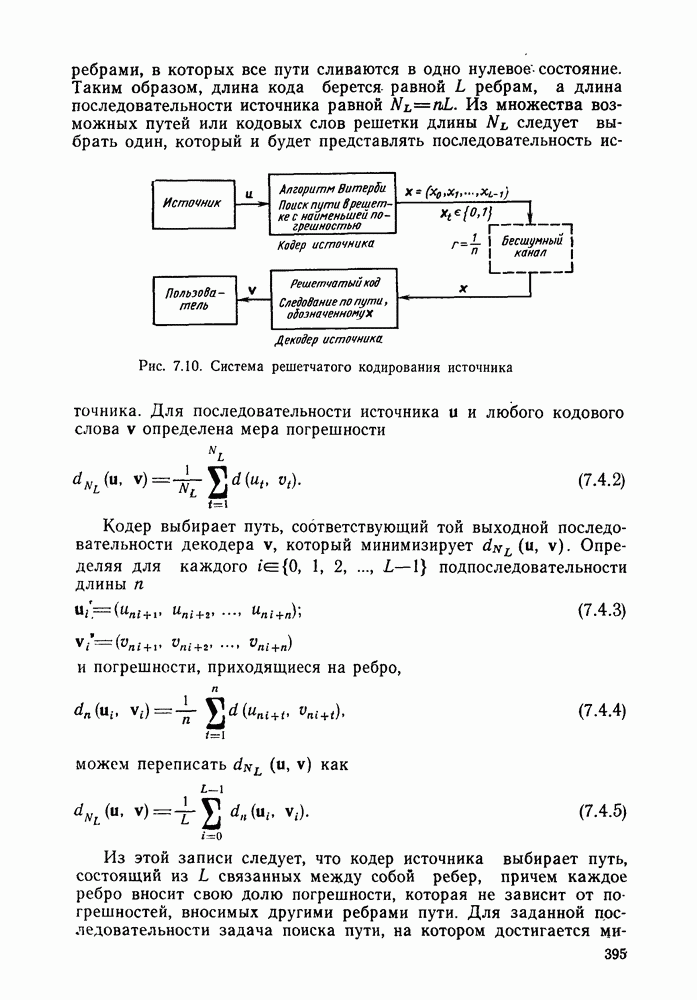
4.2. Декодер максимального правдоподобия для сверточных кодов — алгоритм ВитербиКак было показано выше, сверточные коды можно рассматривать как частный случай блочных кодов. Отсюда следует, что декодер максимального правдоподобия сверточного кода, задаваемого проверочной матрицей вида (4.1.1), может быть реализован так же, как описанный в гл. 2 декодер максимального правдоподобия блочного кода с которого изображен на рис. 4.2а, предполагая, что передача ведется по двоичному симметричному каналу (ДСК). После того как основные понятия будут проиллюстрированы на этом простом примере, можно легко описать декодер максимального правдоподобия минимальной сложности и для произвольного сверточного кода и произвольного канала без памяти. В § 2.8 было показано, что в случае ДСК, в котором символы 0 и 1 кодовых векторов с вероятностью Обращаясь к представлению кода с помощью дерева, видим, что декодер максимального правдоподобия должен выбирать тот путь на дереве, у которого соответствующая кодовая последовательность отличается от принятой последовательности в наименьшем числе символов. Однако, так как пути, соответствующие передаваемым кодовым векторам, постоянно сливаются, можно с тем же успехом ограничиться в поиске лишь множеством путей на решетчатой диаграмме, показанной на рис. 4.4. Исследование этой диаграммы показывает, что для принятия решения о начальных сегментах наиболее вероятной переданной последовательности (наиболее близкой к принятой последовательности) нет необходимости рассматривать всю принятую последовательность длины следующем уровне сравнивать в каждом узле два пути, выжившие на предыдущем уровне. Так, в узле а после четвертого ребра в сравнении будут участвовать пути, выжившие при сравнениях в узлах а и с после третьего ребра. Например, если принята последовательность 01000111 (рассматриваем первые четыре ребра), то путем, выжившим в узле на третьем урсзне, будет путь 00000000 с расстоянием 2, а в узле с — 110101 с расстоянием также 2. При переходе от третьего уровня узлов к четвертому символы принятой последовательности в точности совпадают с продолжением пути, выжившего в узле с, и находятся на расстоянии 2 от продолжения пути, выжившего в узле а. Следовательно, на четвертом уровне в узле а выживает информационная последовательность 1100, которой соответствует кодовая последовательность 11010111, находящаяся на (минимальном) расстоянии 2 от принятой последовательности. Таким образом, можно двигаться по решетчатой диаграмме, запоминая на каждом ее уровне в каждом состоянии только один выживший путь и расстояние от него до принятой последовательности; это расстояние является метрикой рассматриваемого канала. Единственная трудность, которая может возникнуть при этом, связана с тем, что при сравнении сходящихся путей расстояния (метрики) могут совпадать. В этом случае можно просто бросить монету, чтобы выбрать один из них, как это делалось ранее для кодовых слов блочных кодов, находящихся на одинаковом расстоянии от принятой последовательности. Если сохранить оба одинаково правдоподобных пути, то последующие принятые символы будут влиять на изменение их метрик абсолютно идентично, так что это не улучшит окончательный выбор. Алгоритм декодирования, описанный выше, был впервые предложен Витерби [1967а]. Для того чтобы он мог быть лучше понят и оценен, на рис. 4.7 приведена решетчатая диаграмма рассмотренного выше кода с растущими значениями расстояний и соответствующими им выжившими путями в случае, когда принята последовательность 0100010000. Также очевидно, что при принятии последних решений по полной решетчатой диаграмме, приведенной на рис. 4.4, из четырех возможных состояний решетки при поступлении хвоста декодера будут вначале рассматриваться лишь два и затем одно состояние. На первый взгляд описанный алгоритм декодирования является очень привлекательным, но на практике он неприемлем, так как приводит к задержке декодирования, равной В, и кроме того, к необходимости для каждого состояния иметь память для записи путей длины В (для хранения последовательностей входных двоичных символов, ведущих в множество, наиболее вероятное из четырех состояний на каждом уровне узлов). В § 4.7 и 5.6 будет показано, что характеристики не сильно ухудшаются при соответствующем уменьшении задержки и памяти до величины в несколько длин кодового ограничения. Однако пока будем игнорировать эту проблему и довольствоваться тем, что число вычислений метрики, приходящихся на один информационный символ, снизилось до величины, растущей экспоненциально по
Рис. 4.7 Пример декодирования для кодера, изображенного на рис. 4.2а, и ДСК (метрики состояний декодера приведены в кружочках) Другое описание алгоритма можно получить, воспользовавшись представлением кода с помощью диаграммы состояний, приведенной на рис. 4.5. Предположим, что найден путь на направленной диаграмме состояний, достигающий узла а после Таким образом, оказывается, что диаграмма состояний также является системной диаграммой этого декодера. С каждым узлом (состоянием) связаны регистр памяти, в котором запоминается ближайший к принятой последовательности путь, ведущий в данное состояние после каждого перехода, и регистр метрики, в котором хранится (минимальное) расстояние между этим путем и принятой последовательностью. Дальнейшие сравнения выполняются на каждом шаге между двумя путями, ведущими в каждый узел. Таким образом, для каждого состояния должно быть предусмотрено отдельное устройство сравнения, т. е. всего в предыдущем примере необходимы четыре тамих устройства. Обобщение описанного выше алгоритма на случай сверточных кодов с произвольной длиной кодового ограничения К и произвольной рациональной скоростью Обобщение этого алгоритма на случай произвольного канала без памяти также почти очевидно. Во-первых, следует заметить, что можно отобразить так же, как в § 2.9 векторы путей
где
где
Максимизация этой величины эквивалентна максимизации выражения
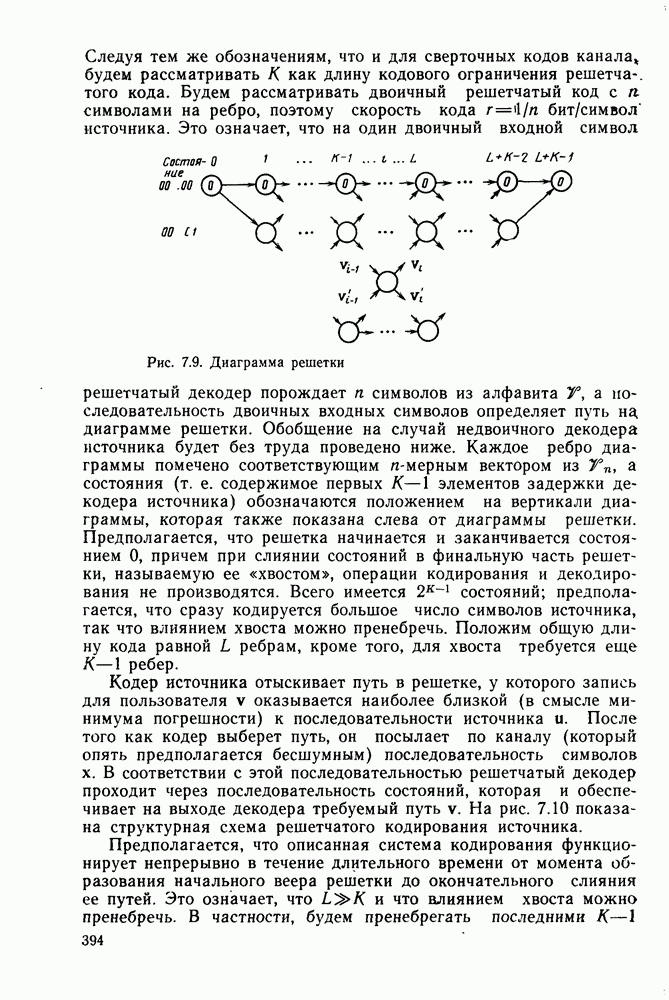
где Декодирование по максимуму правдоподобия произвольных решетчатых «одов осуществляется точно так же, как декодирование сверточных кодов с помощью алгоритма Витерби. Таким образом, лишь кодер решетчатых кодов существенно отличается от кодера сверточных кодов, как уже указывалось в § 4.1. Конечно, было бы желательным порождать кодовые символы с помощью более простых сверточных кодеров, если бы характеристика были одними и теми же. В гл. 5 будет показано, что в большинстве приложений это действительно так.
|
 |
Оглавление
|








































































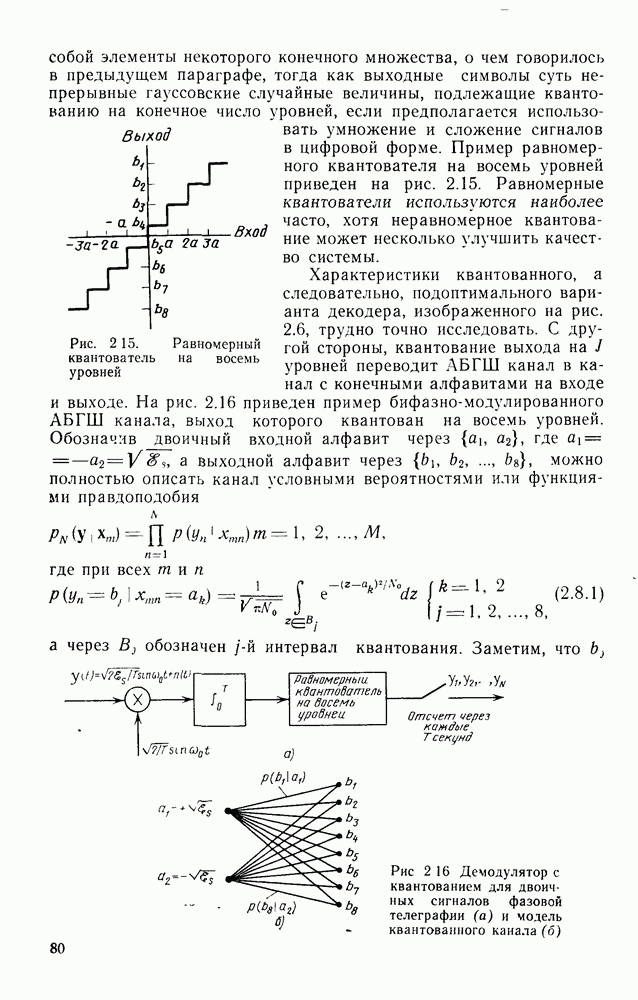



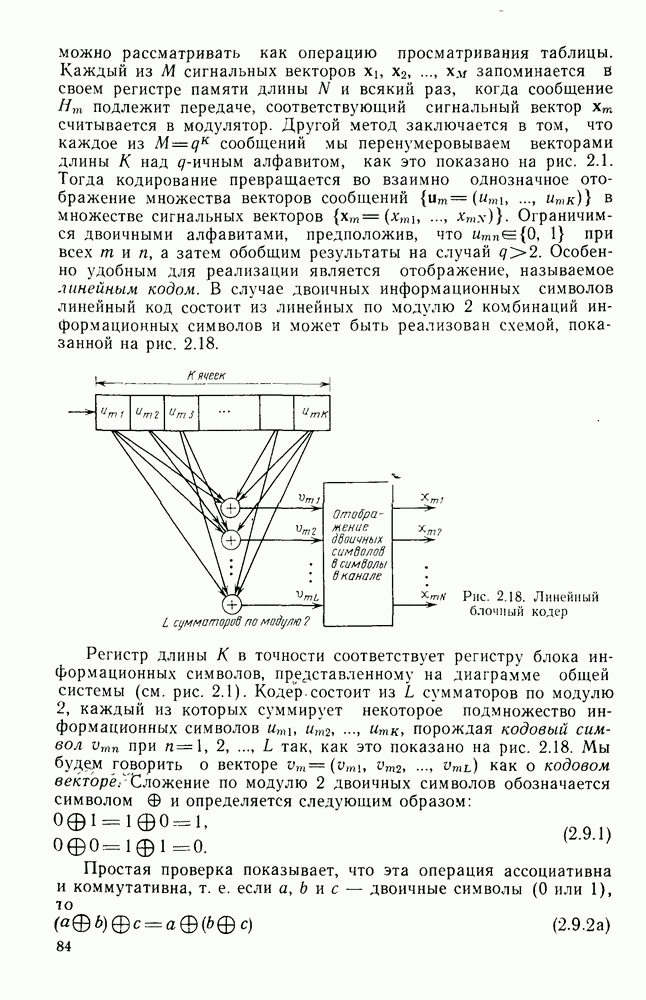













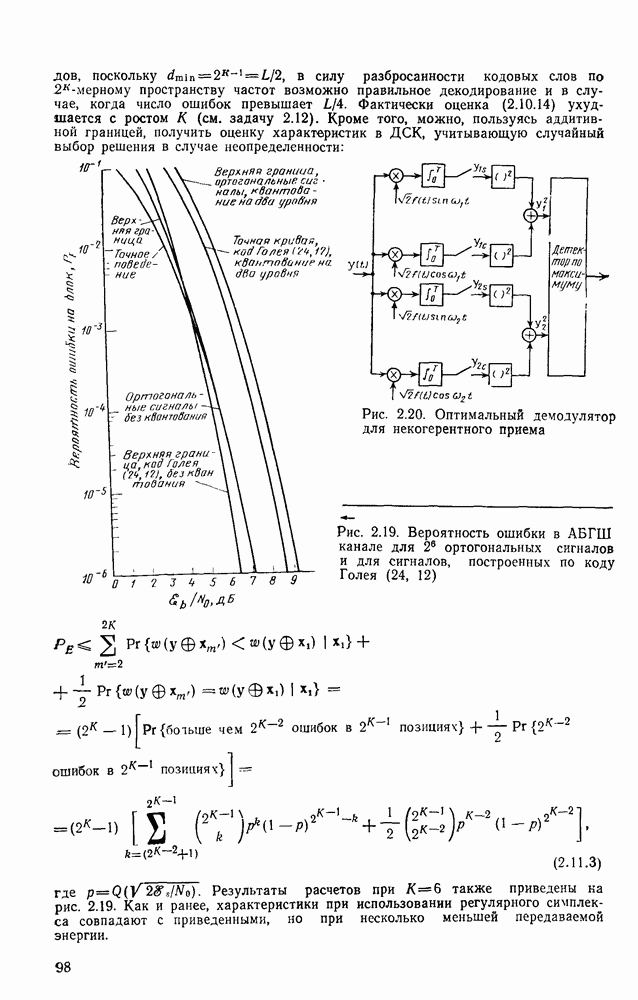












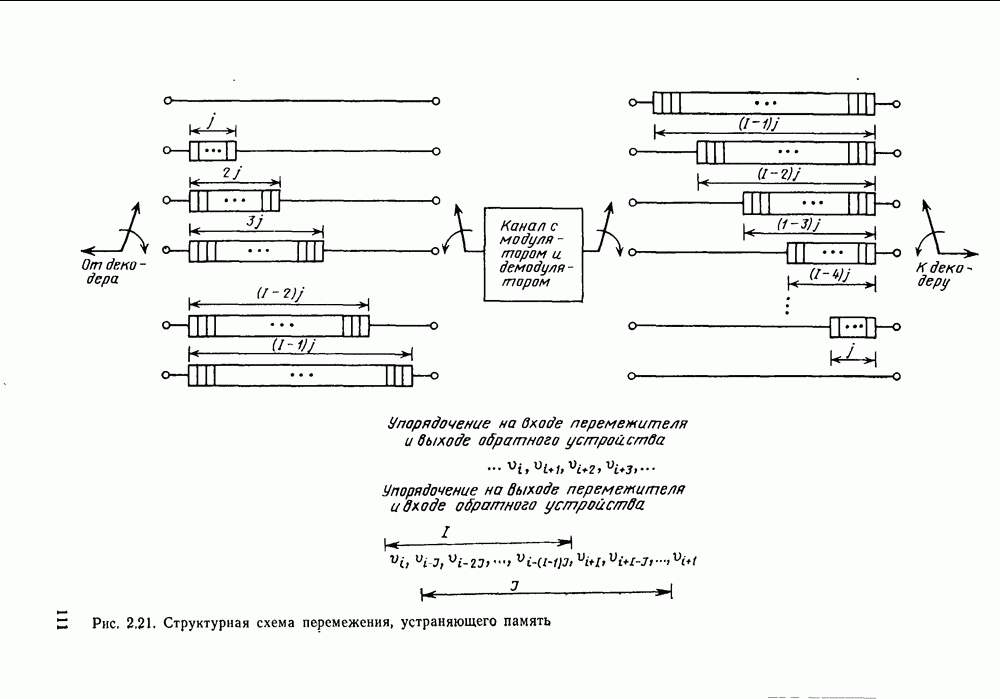




























































































































































































































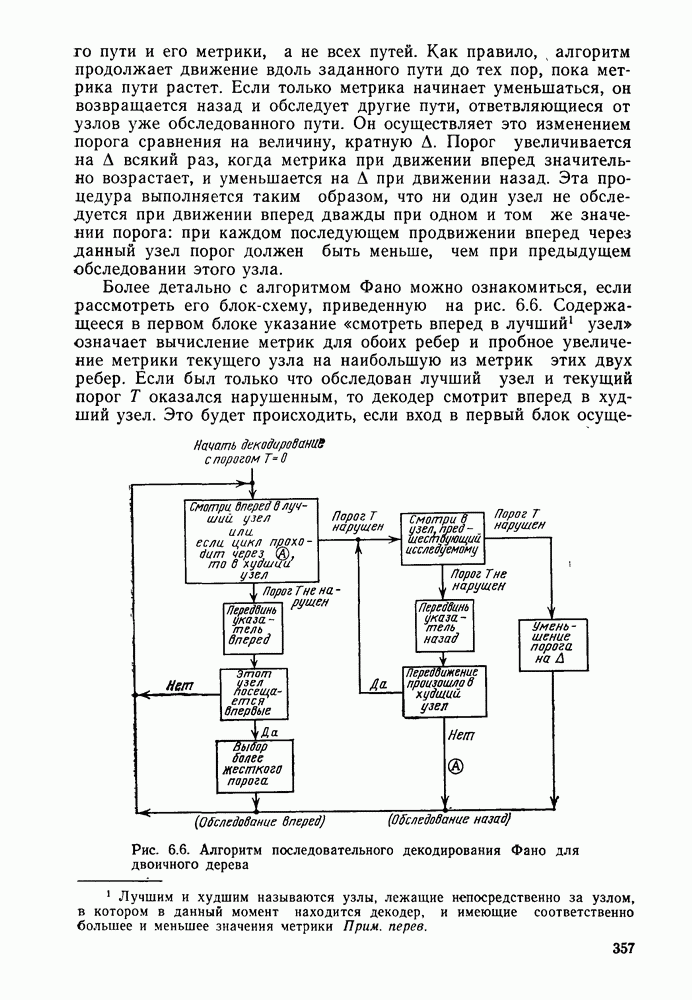






































































































































































 информационными символами: при этом он обеспечивает минимальную вероятность ошибки на блок при равновероятных входных последовательностях. Трудность реализации, конечно, связала с тем, что эффективные сверточные коды, как указывалось в предыдущем параграфе, имеют очень большую по сравнению с длиной кодового ограничения длину блока. Действительно, редко когда В бывает меньше нескольких сотен и очень часто кодируемая информация состоит из полного сообщения (плюс завершающий хвост). Так как число кодовых векторов или, другими словами, кодовых путей на дереве (решетке) равно
информационными символами: при этом он обеспечивает минимальную вероятность ошибки на блок при равновероятных входных последовательностях. Трудность реализации, конечно, связала с тем, что эффективные сверточные коды, как указывалось в предыдущем параграфе, имеют очень большую по сравнению с длиной кодового ограничения длину блока. Действительно, редко когда В бывает меньше нескольких сотен и очень часто кодируемая информация состоит из полного сообщения (плюс завершающий хвост). Так как число кодовых векторов или, другими словами, кодовых путей на дереве (решетке) равно  то обычный блочный декодер максимального правдоподобия, в котором используется отдельный декодирующий элемент на каждый кодовый вектор, оказывается чрезвычайно сложным. С другой стороны, так же, как было показано, что кодер может быть реализован со сложностью, зависящей от параметра
то обычный блочный декодер максимального правдоподобия, в котором используется отдельный декодирующий элемент на каждый кодовый вектор, оказывается чрезвычайно сложным. С другой стороны, так же, как было показано, что кодер может быть реализован со сложностью, зависящей от параметра  , а не от В, в дальнейшем покажем, что в действительности сложность декодера растет, как экспонента от К, а не от В. Для простоты и наглядности рассмотрим вначале код со скоростью 1/2 с
, а не от В, в дальнейшем покажем, что в действительности сложность декодера растет, как экспонента от К, а не от В. Для простоты и наглядности рассмотрим вначале код со скоростью 1/2 с  кодер
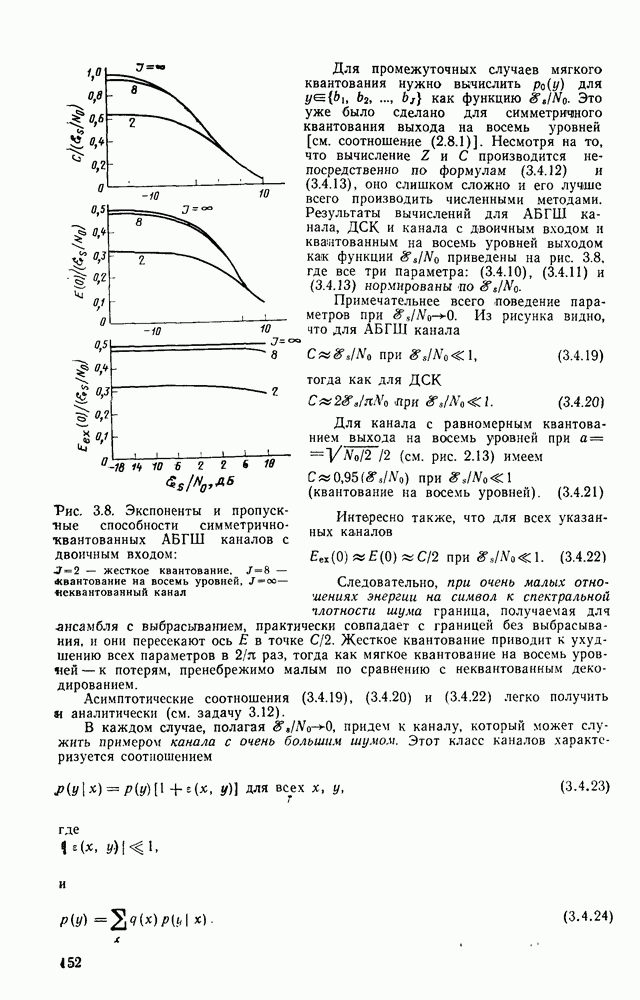
кодер
 переходят соответственно в символы 1 и 0, декодер максимального правдоподобия сводится к декодеру минимального расстояния. Последний вычисляет расстояние Хэмминга между принятым, быть может с ошибками, вектором
переходят соответственно в символы 1 и 0, декодер максимального правдоподобия сводится к декодеру минимального расстояния. Последний вычисляет расстояние Хэмминга между принятым, быть может с ошибками, вектором  каждым из возможных кодовых векторов
каждым из возможных кодовых векторов  и принимает решение в пользу того кодового вектора (или соответствующего ему информационного вектора), который оказывается ближайшим к принятому.
и принимает решение в пользу того кодового вектора (или соответствующего ему информационного вектора), который оказывается ближайшим к принятому.
 (в данном случае
(в данном случае  так как сегменты сливающихся путей, находящихся не на минимальном расстоянии, можно исключить из рассмотрения. В частности, непосредственно после третьего ребра можно определить, какой из двух путей, ведущих в узел (состояние) а, имеет большую вероятность оказаться действительно переданным. Например, если принята последовательность
так как сегменты сливающихся путей, находящихся не на минимальном расстоянии, можно исключить из рассмотрения. В частности, непосредственно после третьего ребра можно определить, какой из двух путей, ведущих в узел (состояние) а, имеет большую вероятность оказаться действительно переданным. Например, если принята последовательность  то она будет находиться на расстоянии 2 от кодовой последовательности 000000 и на расстоянии 3 от кодовой последовательности 111011 и, следовательно, можно исключить из рассмотрения нижний путь, ведущий в узел а. Это связано с тем, что независимо от того, какими будут последующие принятые символы, они будут увеличивать расстояние лишь через посредство следующих за слиянием ребер путей, т. е. абсолютно идентично. То же самое можно сказать и о парах путей, сходящихся после третьего ребра в любом другом из оставшихся трех узлов
то она будет находиться на расстоянии 2 от кодовой последовательности 000000 и на расстоянии 3 от кодовой последовательности 111011 и, следовательно, можно исключить из рассмотрения нижний путь, ведущий в узел а. Это связано с тем, что независимо от того, какими будут последующие принятые символы, они будут увеличивать расстояние лишь через посредство следующих за слиянием ребер путей, т. е. абсолютно идентично. То же самое можно сказать и о парах путей, сходящихся после третьего ребра в любом другом из оставшихся трех узлов  с и
с и  Тот из двух ведущих в данный узел путей, который находится на минимальном расстоянии от принятой последовательности, будет называться ниже выжившим путем. Таким образом, в каждом узле необходимо помнить, какой из путей является выжившим (т. е. путем, находящимся на минимальном расстоянии от принятой последовательности), и значение этого минимального расстояния. Последнее необходимо для того, чтобы на
Тот из двух ведущих в данный узел путей, который находится на минимальном расстоянии от принятой последовательности, будет называться ниже выжившим путем. Таким образом, в каждом узле необходимо помнить, какой из путей является выжившим (т. е. путем, находящимся на минимальном расстоянии от принятой последовательности), и значение этого минимального расстояния. Последнее необходимо для того, чтобы на
 в данном случае), а не по В.
в данном случае), а не по В.

 переходов, последовательность кодовых символов вдоль которого находится на минимальном расстоянии от принятой последовательности. Ясно, что этим ближайшим путем, достигающим узла а в момент
переходов, последовательность кодовых символов вдоль которого находится на минимальном расстоянии от принятой последовательности. Ясно, что этим ближайшим путем, достигающим узла а в момент  может быть продолжение лишь одного .из двух путей, заканчивающихся в момент
может быть продолжение лишь одного .из двух путей, заканчивающихся в момент  соответственно в узлах а и с и находящихся на минимальном расстоянии от принятой последовательности. В момент
соответственно в узлах а и с и находящихся на минимальном расстоянии от принятой последовательности. В момент  эти пути сравниваются по минимальным расстояниям, определяемым сложением их минимальных расстояний в момент
эти пути сравниваются по минимальным расстояниям, определяемым сложением их минимальных расстояний в момент  с приращениями, которые они получают при
с приращениями, которые они получают при  переходе.
переходе.
 очевидно Число состояний становится равным
очевидно Число состояний становится равным  и каждое ребро, как и раньше, содержит
и каждое ребро, как и раньше, содержит  кодовых символов. Единственное изменение, которое необходимо внести при
кодовых символов. Единственное изменение, которое необходимо внести при  связано с тем, что на каждом уровне, следующем за
связано с тем, что на каждом уровне, следующем за  сливаются
сливаются  путей и сравниваться должны каждый раз расстояния или метрики уже не двух, а
путей и сравниваться должны каждый раз расстояния или метрики уже не двух, а  путей, и только один из этих путей выживает. Таким образом, на каждом уровне слияния множество потенциальных путей сокращается в
путей, и только один из этих путей выживает. Таким образом, на каждом уровне слияния множество потенциальных путей сокращается в  раз, но это число вновь возрастает в
раз, но это число вновь возрастает в  раз перед следующим уровнем ветвления, сохраняя, таким образом, число состояний постоянным и равным
раз перед следующим уровнем ветвления, сохраняя, таким образом, число состояний постоянным и равным 
 в недвоичные сигнальные векторы
в недвоичные сигнальные векторы  (произвольной размерности вплоть до
(произвольной размерности вплоть до  с компонентами из произвольного конечного алфавита (состоящего, например, из значений амплитуд, фаз и т. д.). Канал без памяти (включающий демодулятор, см. рис. 2.1) преобразует эти символы в зашумленные выходные векторы у, размерности вплоть до
с компонентами из произвольного конечного алфавита (состоящего, например, из значений амплитуд, фаз и т. д.). Канал без памяти (включающий демодулятор, см. рис. 2.1) преобразует эти символы в зашумленные выходные векторы у, размерности вплоть до  Декодер Витерби при этом основан на метрике
Декодер Витерби при этом основан на метрике  или, что то же самое, на логарифме последнего выражения:
или, что то же самое, на логарифме последнего выражения:

 подблок кодовой последовательности, соответствующей
подблок кодовой последовательности, соответствующей  сообщению на
сообщению на  уровне ветвления. В случае рассмотренного выше ДСК последнее выражение имеет вид
уровне ветвления. В случае рассмотренного выше ДСК последнее выражение имеет вид

 расстояние между
расстояние между  -мерным принятым вектором и кодовым подблоком, соответствующим
-мерным принятым вектором и кодовым подблоком, соответствующим  ребру
ребру  пути. Логарифм этой метрики для конкретного пути имеет вид в в
пути. Логарифм этой метрики для конкретного пути имеет вид в в

 где а — положительная константа (при
где а — положительная константа (при  , а величина
, а величина  произвольна. Необходимо выбирать пути с максимальными значениями метрики или, что то же самое, минимизировать расстояние Хэмминга, как это делалось ранее. При этом, как было показано в разделе 2.1.15, в АБГШ канале с двоичным входом и постоянной энергией
произвольна. Необходимо выбирать пути с максимальными значениями метрики или, что то же самое, минимизировать расстояние Хэмминга, как это делалось ранее. При этом, как было показано в разделе 2.1.15, в АБГШ канале с двоичным входом и постоянной энергией

 символ
символ  ребра,
ребра,  символ
символ  ребра
ребра  возможного кодового пути,
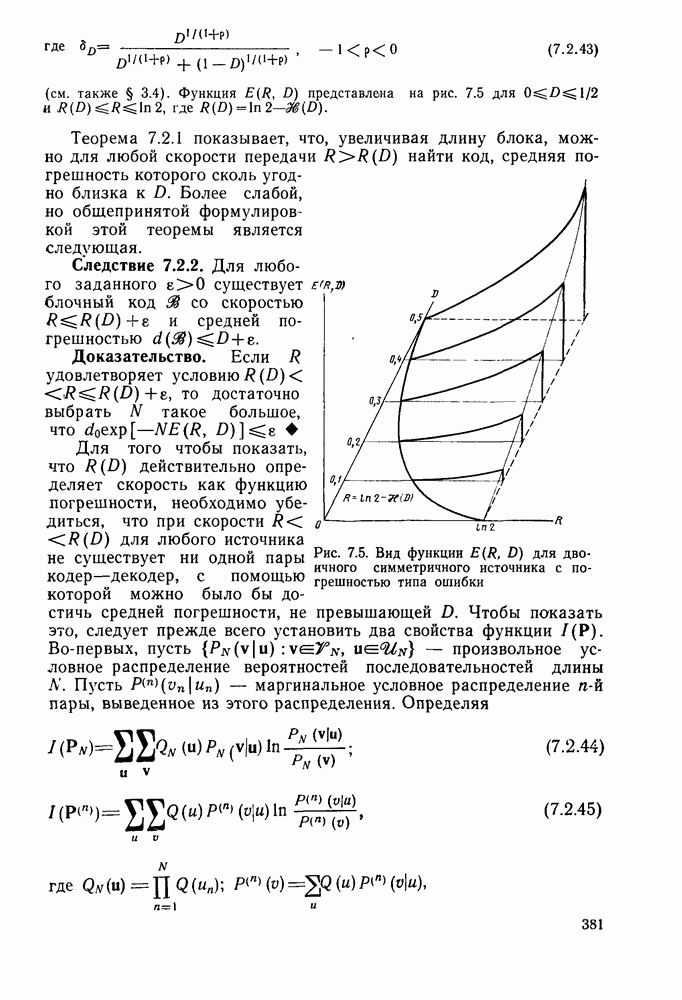
возможного кодового пути,  постоянная. Максимизация этой метрики эквивалентна максимизации накопленного внутреннего произведения принятого вектора с сигнальным вектором для каждого пути. Сравнение выполняется точно так же, как и в случае двоичного симметричного канала, за исключением того, что в данном случае выживающий путь определяется по максимальному внутреннему произведению, а не по минимальному расстоянию, как ранее. В случае произвольного канала без памяти с коммулятивной метрикой, задаваемой соотношением (4.2.1), рассуждения аналогичны.
постоянная. Максимизация этой метрики эквивалентна максимизации накопленного внутреннего произведения принятого вектора с сигнальным вектором для каждого пути. Сравнение выполняется точно так же, как и в случае двоичного симметричного канала, за исключением того, что в данном случае выживающий путь определяется по максимальному внутреннему произведению, а не по минимальному расстоянию, как ранее. В случае произвольного канала без памяти с коммулятивной метрикой, задаваемой соотношением (4.2.1), рассуждения аналогичны.