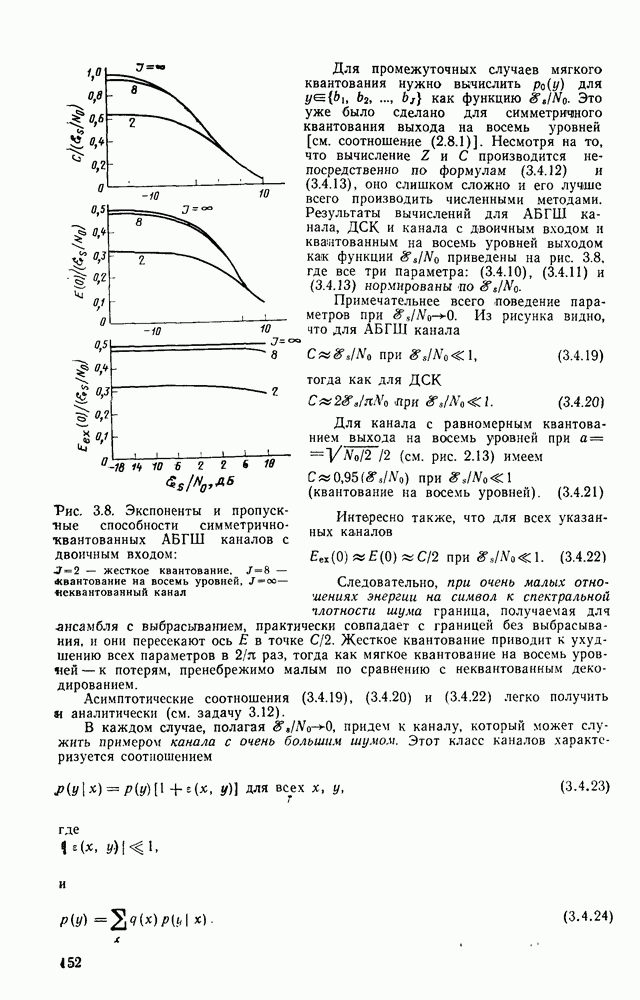
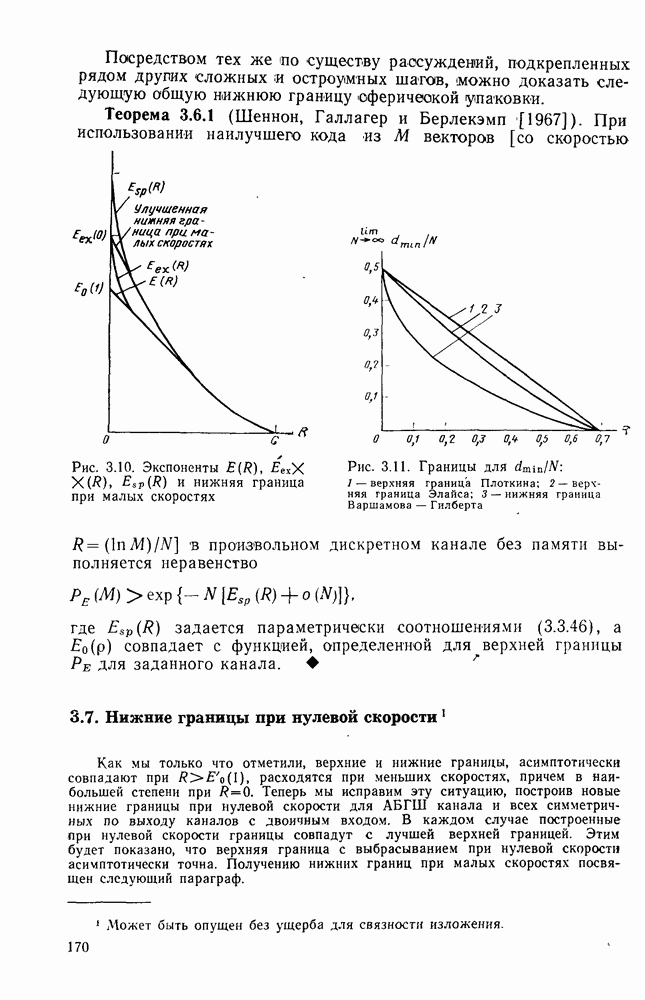
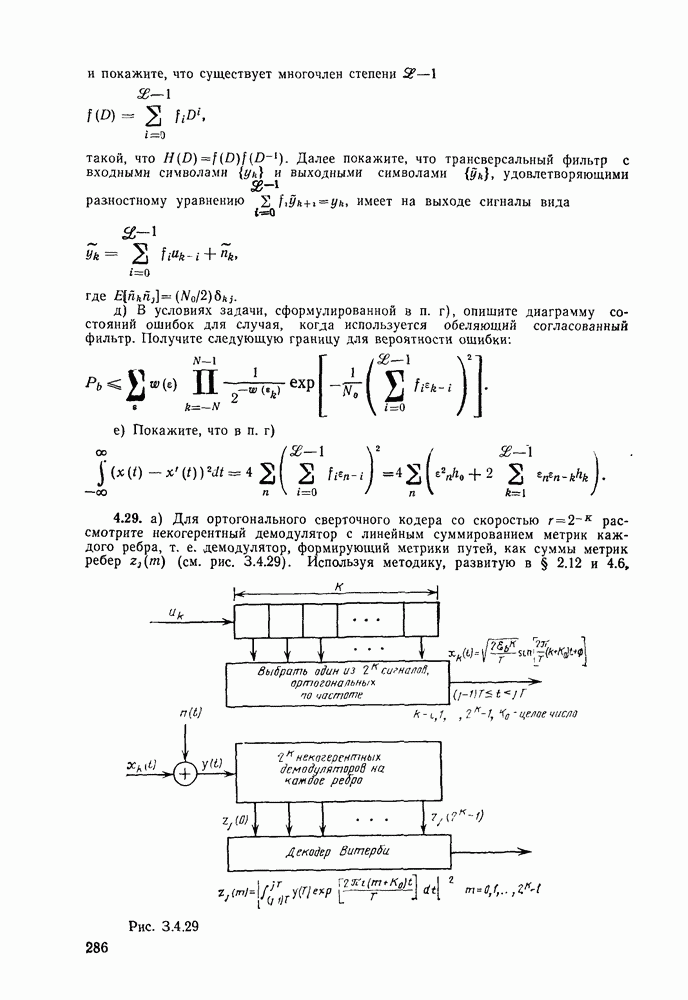
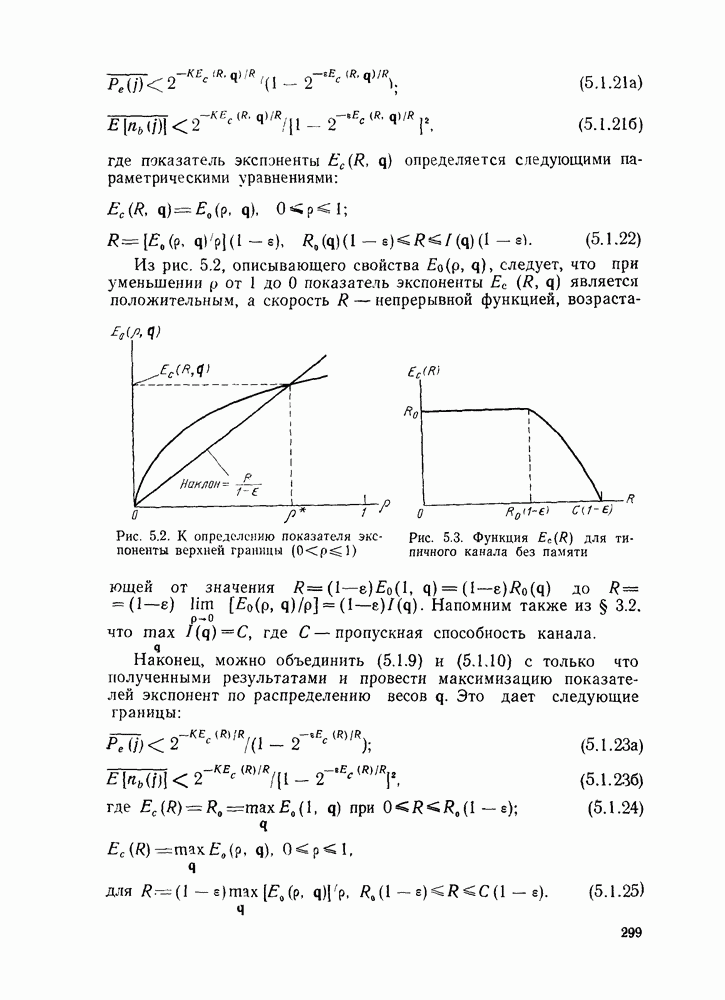
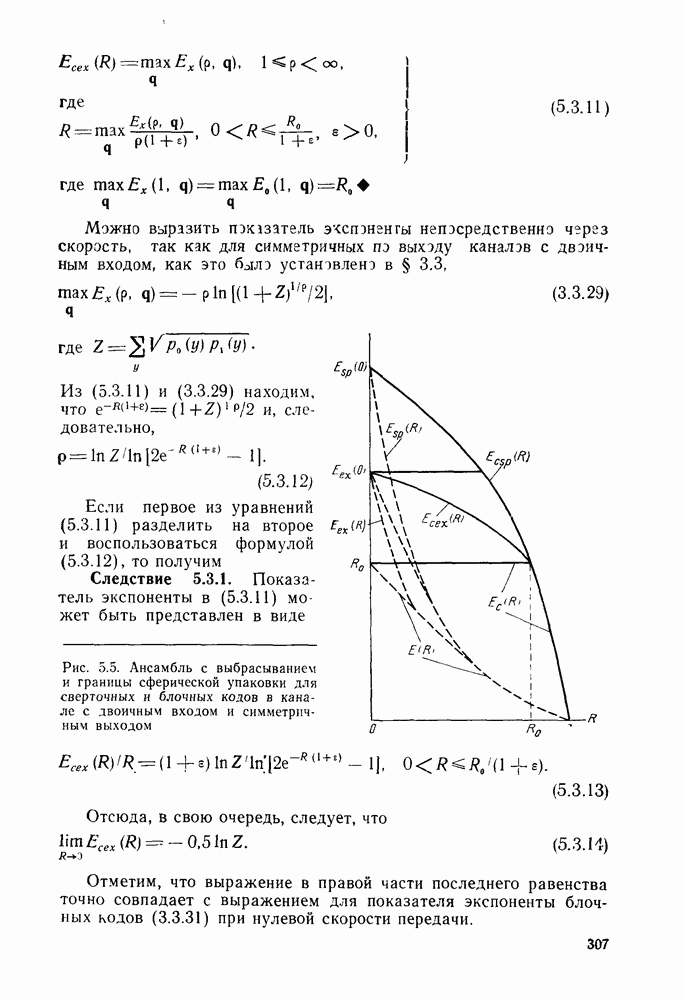
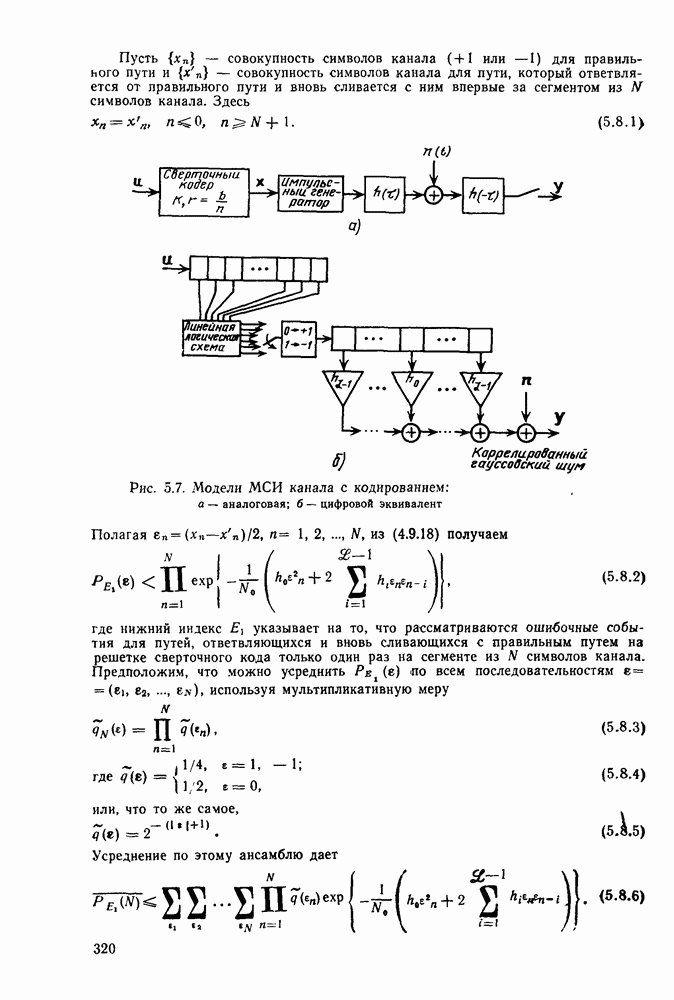
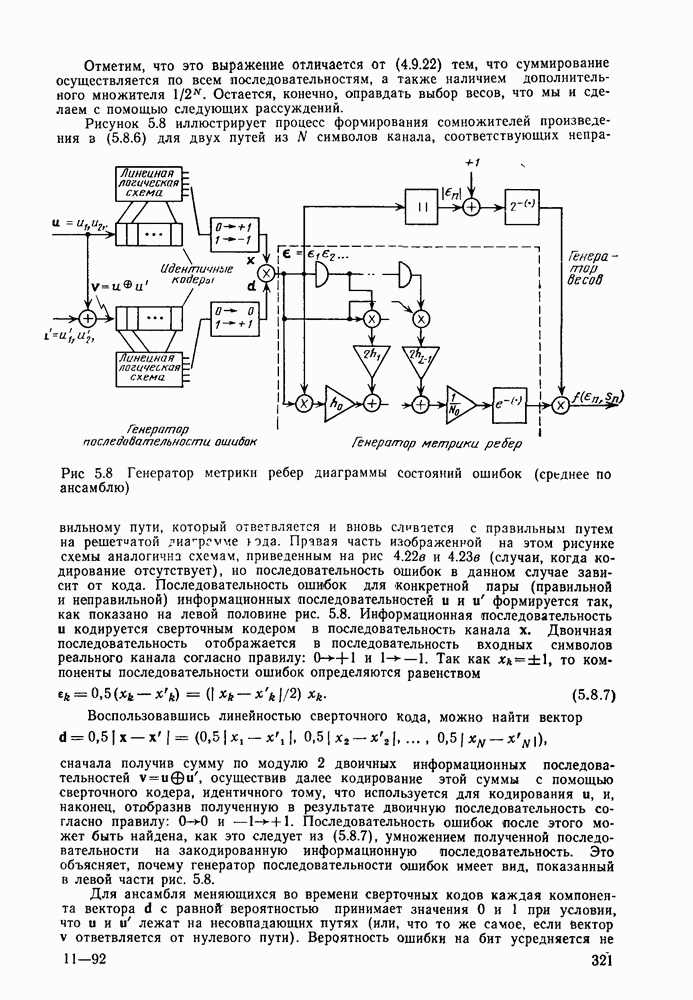
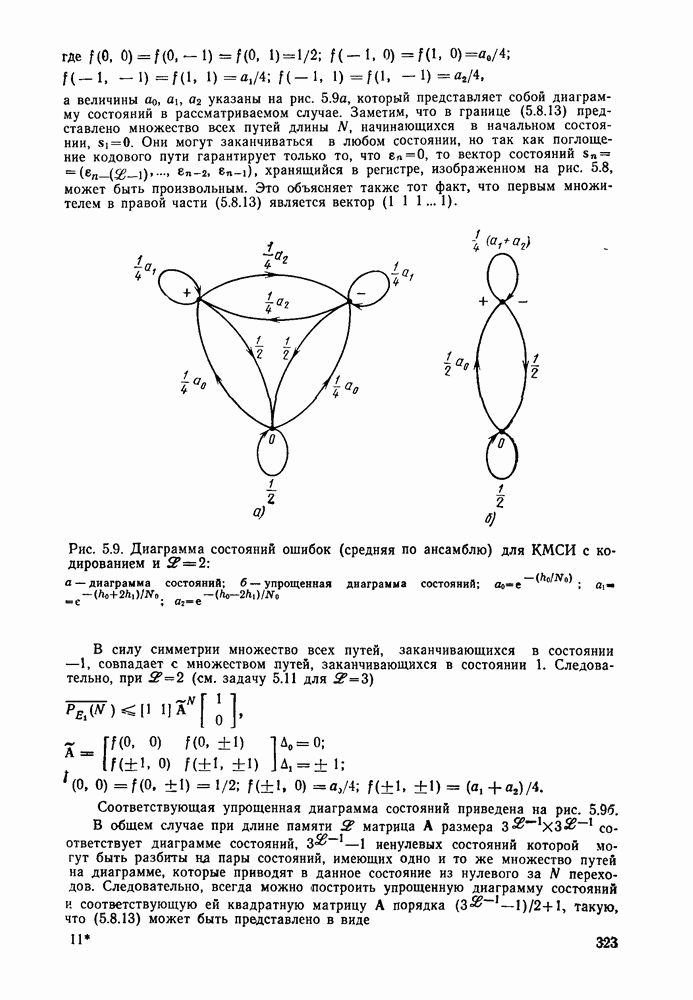
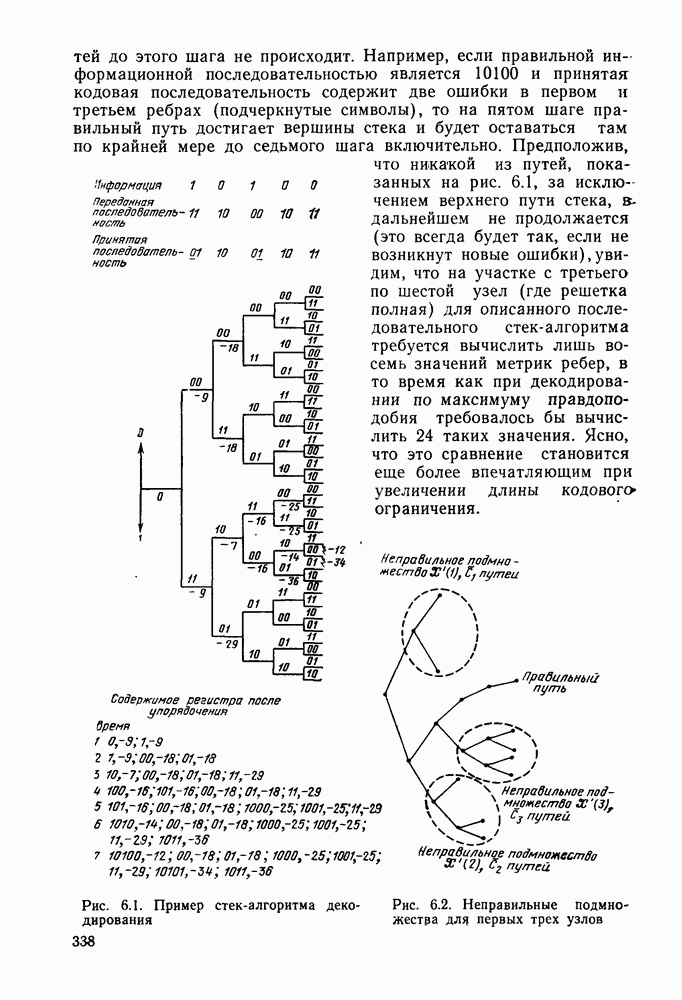
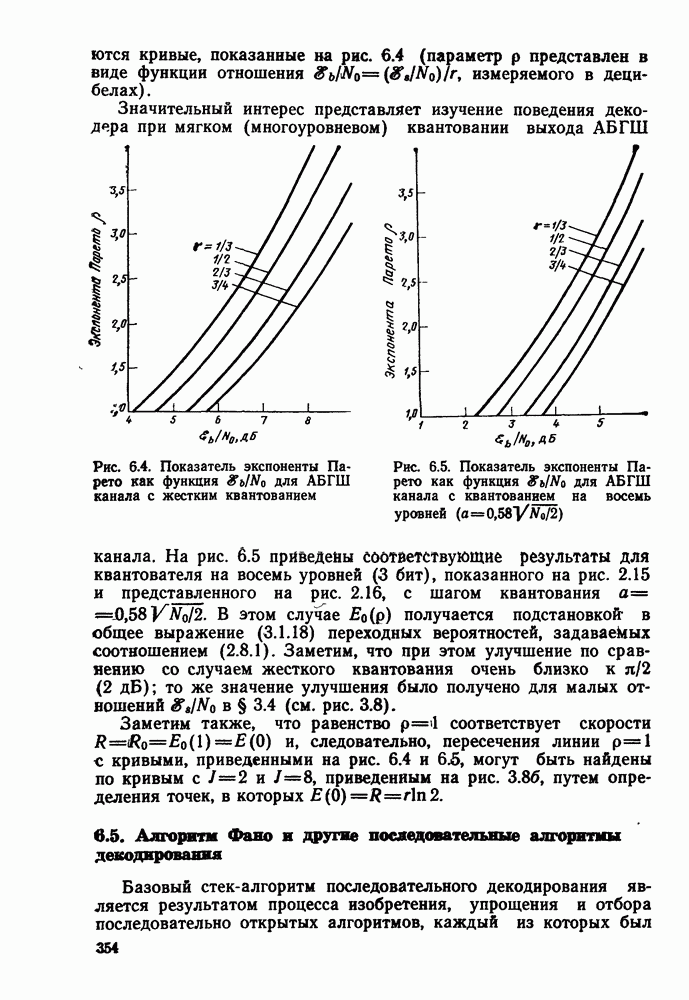
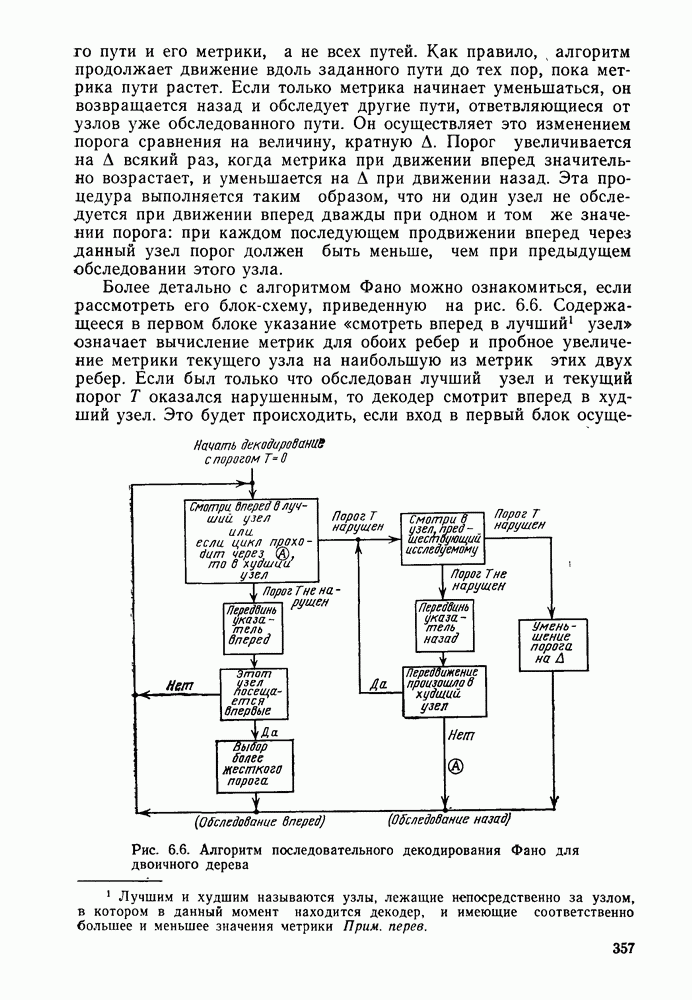
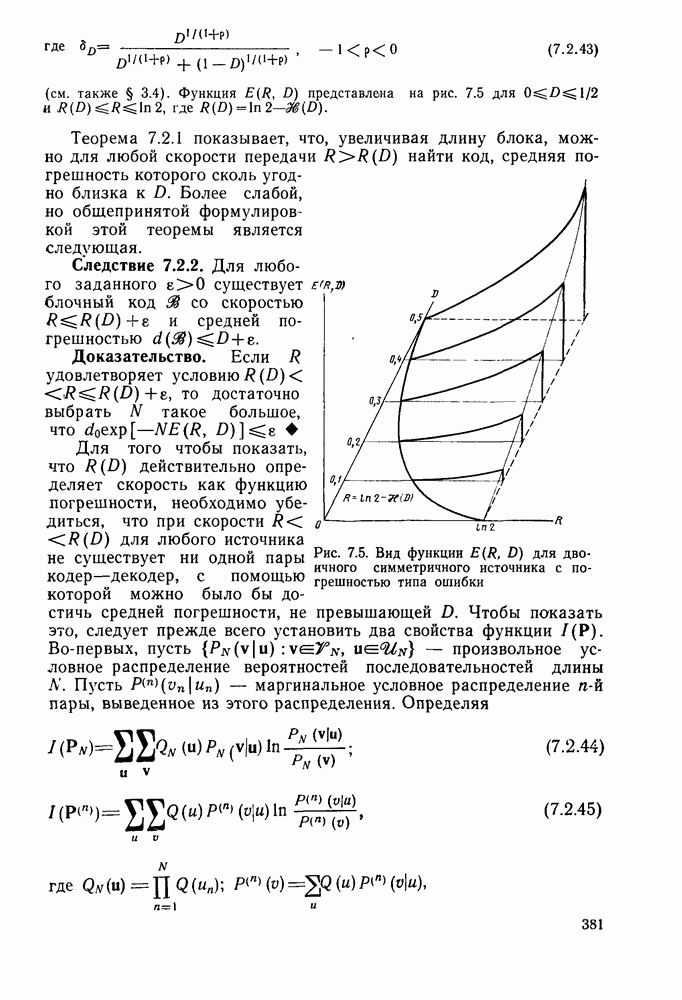
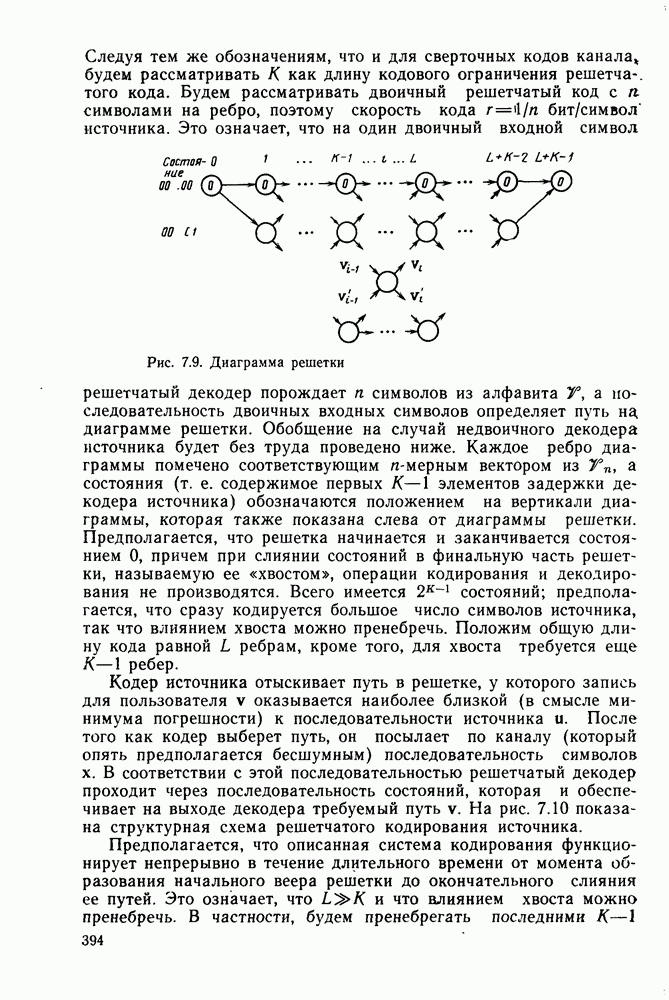
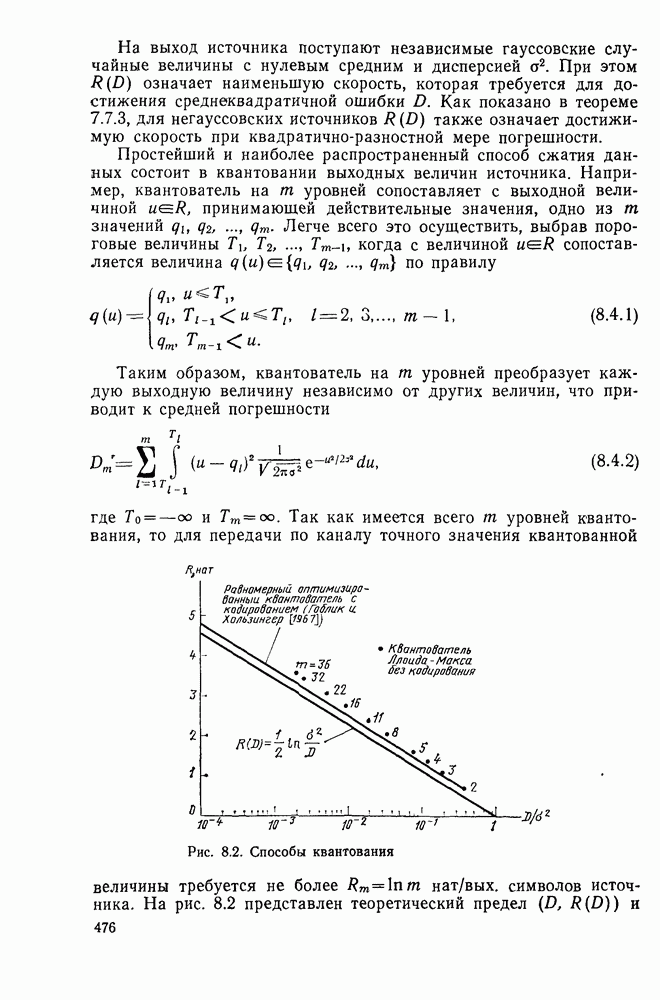
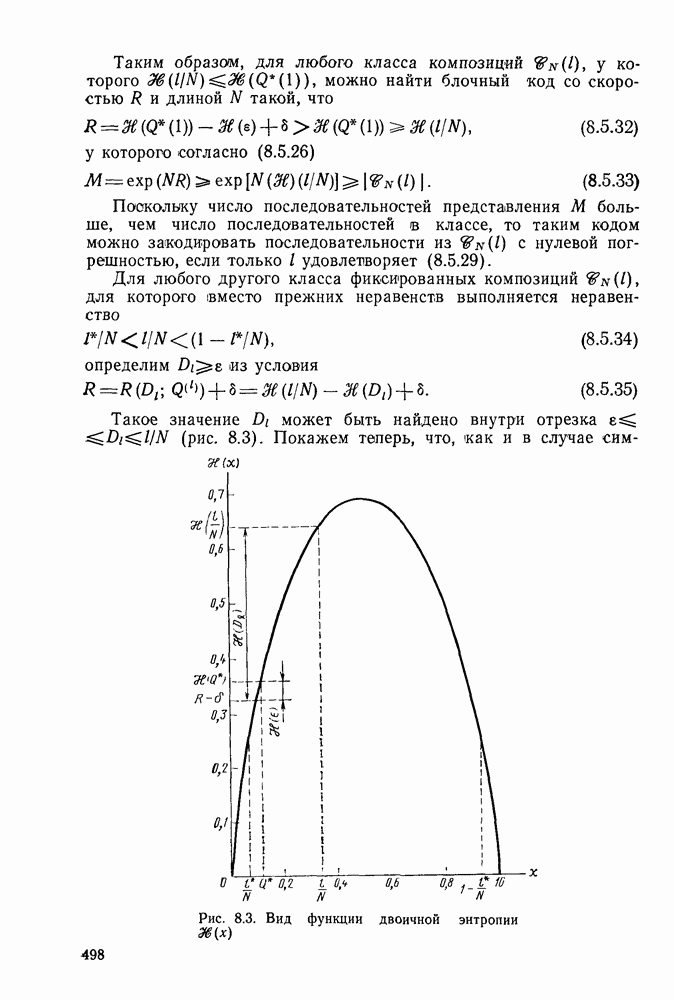
7.4. Дискретные источники без памяти. Решетчатые коды
Мы показали, что для блочных кодов существует дуальность между кодированием источников и кодированием каналов, согласно которой кодер источника работает подобно декодеру канала, а декодер канала работает подобно кодеру источника (см. рис. 7.6). Эта дуальность справедлива и для решетчатых кодов. Теперь покажем, что решетчатые коды могут быть использованы для такого кодирования источников, при котором кодер источника выполняет операции, которые, по сути дела, являются операциями алгоритма решетчатого декодирования канала по методу максимального правдоподобия, а решетчатый декодер источника выполняет операции решетчатого кодирования канала. В частности, покажем, что, используя решетчатые коды, имеющие вид обобщенных сверточных кодов, можно получить предельные значения скорости передачи и погрешности  достижимые для дискретных источников без памяти.
достижимые для дискретных источников без памяти.
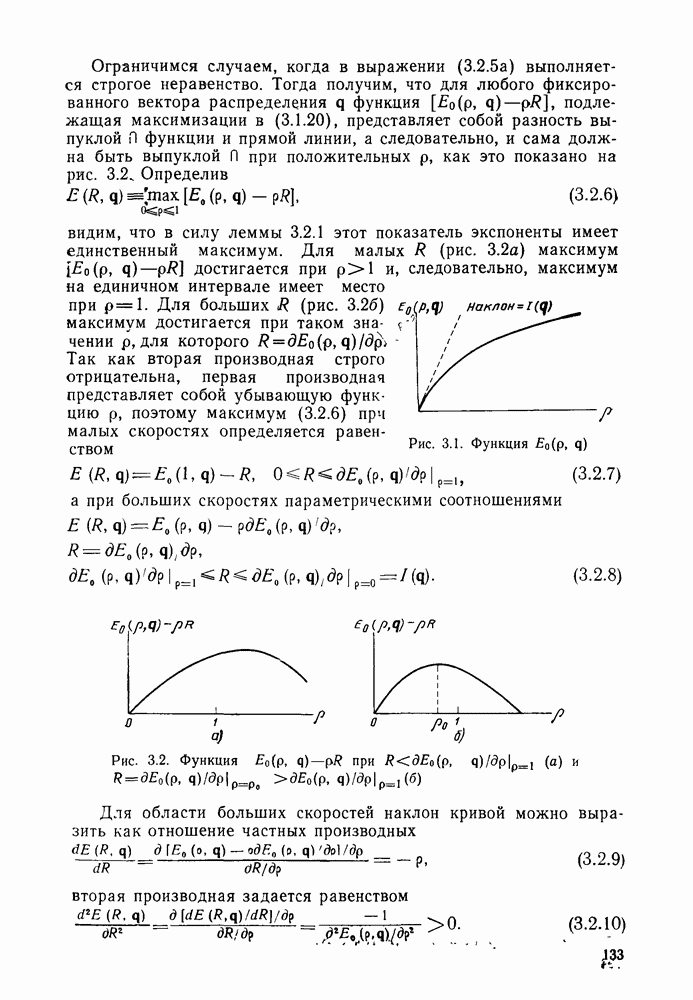
Более того, тот же алгоритм, который позволил достичь границы сверточного кодирования для каналов (Витерби [1967а]), достигает также границы решетчатого (обобщенного сверточного) кодирования источников. Термин «максимальное правдоподобие» в этом контексте уже неприменим.
Вновь рассмотрим дискретный источник без памяти с алфавитом  и с положительными вероятностями букв
и с положительными вероятностями букв  Пусть алфавит пользователя обозначается через
Пусть алфавит пользователя обозначается через  и используется неотрицательная ограниченная мера погрешности
и используется неотрицательная ограниченная мера погрешности  удовлетворяющая условию
удовлетворяющая условию

для всех  при некотором
при некотором 
Решетчатые коды — это обобщенные сверточные коды, порождаемые тем же самым кодером с регистром сдвигов, что и сверточные коды, но с произвольными нелинейными операциями, производимыми без задержки и заменяющими линейную комбинаторную логику этих кодов. Как в фиксированной, так и в переменной во времени модификации удобнее всего описывать и исследовать их с помощью уже известной решетчатой диаграммы (см. гл. 4). На рис. 7.8 показан решетчатый декодер источника, а на рис.  соответствующая диаграмма двоичного решетного кода с
соответствующая диаграмма двоичного решетного кода с  элементами задержки, производящего преобразования мгновенно.
элементами задержки, производящего преобразования мгновенно.

Рис. 7.8. Решетчатый декодер источника
Следуя тем же обозначениям, что и для сверточных кодов канала будем рассматривать К как длину кодового ограничения решетчатого кода. Будем рассматривать двоичный решетчатый код с  символами на ребро, поэтому скорость кода
символами на ребро, поэтому скорость кода  бит/символ источника.
бит/символ источника.

Рис. 7.9. Диаграмма решетки
Это означает, что на один двоичный входной символ решетчатый декодер порождает  символов из алфавита
символов из алфавита  а последовательность двоичных входных символов определяет путь на, диаграмме решетки. Обобщение на случай недвоичного декодера источника будет без труда проведено ниже. Каждое ребро диаграммы помечено соответствующим «
а последовательность двоичных входных символов определяет путь на, диаграмме решетки. Обобщение на случай недвоичного декодера источника будет без труда проведено ниже. Каждое ребро диаграммы помечено соответствующим « -мерным вектором из
-мерным вектором из  а состояния (т. е. содержимое первых
а состояния (т. е. содержимое первых  элементов задержки декодера источника) обозначаются положением на вертикали диаграммы, которая также показана слева от диаграммы решетки. Предполагается, что решетка начинается и заканчивается состоянием 0, причем при слиянии состояний в финальную часть решетки, называемую ее «хвостом», операции кодирования и декодирования не производятся. Всего имеется
элементов задержки декодера источника) обозначаются положением на вертикали диаграммы, которая также показана слева от диаграммы решетки. Предполагается, что решетка начинается и заканчивается состоянием 0, причем при слиянии состояний в финальную часть решетки, называемую ее «хвостом», операции кодирования и декодирования не производятся. Всего имеется  состояний; предполагается, что сразу кодируется большое число символов источника, так что влиянием хвоста можно пренебречь. Положим общую длину кода равной
состояний; предполагается, что сразу кодируется большое число символов источника, так что влиянием хвоста можно пренебречь. Положим общую длину кода равной  ребрам, кроме того, для хвоста требуется еще
ребрам, кроме того, для хвоста требуется еще  ребер.
ребер.
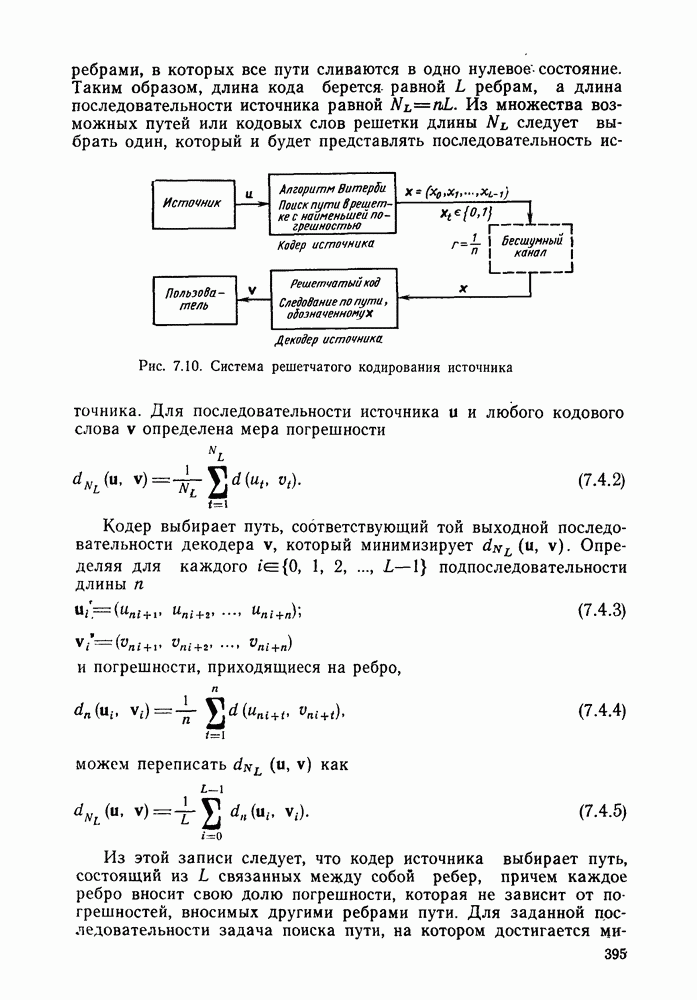
Кодер источника отыскивает путь в решетке, у которого запись для пользователя  оказывается наиболее близкой (в смысле минимума погрешности) к последовательности источника и. После того как кодер выберет путь, он посылает по каналу (который опять предполагается бесшумным) последовательность символов х. В соответствии с этой последовательностью решетчатый декодер проходит через последовательность состояний, которая и обеспечивает на выходе декодера требуемый путь
оказывается наиболее близкой (в смысле минимума погрешности) к последовательности источника и. После того как кодер выберет путь, он посылает по каналу (который опять предполагается бесшумным) последовательность символов х. В соответствии с этой последовательностью решетчатый декодер проходит через последовательность состояний, которая и обеспечивает на выходе декодера требуемый путь  На рис. 7.10 показана структурная схема решетчатого кодирования источника.
На рис. 7.10 показана структурная схема решетчатого кодирования источника.
Предполагается, что описанная система кодирования функционирует непрерывно в течение длительного времени от момента образования начального веера решетки до окончательного слияния ее путей. Это означает, что  и что влиянием хвоста можно пренебречь. В частности, будем пренебрегать последними
и что влиянием хвоста можно пренебречь. В частности, будем пренебрегать последними 
ребрами, в которых все пути сливаются в одно нулевое состояние. Таким образом, длина кода берется равной  ребрам, а длина последовательности источника равной
ребрам, а длина последовательности источника равной  Из множества возможных путей или кодовых слов решетки длины
Из множества возможных путей или кодовых слов решетки длины  следует выбрать один, который и будет представлять последовательность источника.
следует выбрать один, который и будет представлять последовательность источника.

Рис. 7.10. Система решетчатого кодирования источника
Для последовательности источника и и любого кодового слова  определена мера погрешности
определена мера погрешности

Кодер выбирает путь, соответствующий той выходной последовательности декодера  который минимизирует
который минимизирует  Определяя для каждого
Определяя для каждого  подпоследовательности длины
подпоследовательности длины 

и погрешности, приходящиеся на ребро,

можем переписать  как
как

Из этой записи следует, что кодер источника выбирает путь, состоящий из  связанных между собой ребер, причем каждое ребро вносит свою долю погрешности, которая не зависит от погрешностей, вносимых другими ребрами пути. Для заданной последовательности задача поиска пути, на котором достигается
связанных между собой ребер, причем каждое ребро вносит свою долю погрешности, которая не зависит от погрешностей, вносимых другими ребрами пути. Для заданной последовательности задача поиска пути, на котором достигается
минимум  равносильна задаче поиска, возникающей при декодировании в канале, при котором для нахождения пути, который минимизирует отрицательную логарифмическую функцию правдоподобия, используется алгоритм Витерби. Таким образом, решетчатое кодирование источника может быть реализовано на основе алгоритма Витерби.
равносильна задаче поиска, возникающей при декодировании в канале, при котором для нахождения пути, который минимизирует отрицательную логарифмическую функцию правдоподобия, используется алгоритм Витерби. Таким образом, решетчатое кодирование источника может быть реализовано на основе алгоритма Витерби.
В § 7.2 показано, что для данных источника и меры погрешности скорость как функция погрешности  задается соотношением (7.2.53). Независимо от типа рассматриваемой системы кодирования обратная теорема кодирования источников (теорема 7.2.3) показывает, что невозможно достичь средней погрешности
задается соотношением (7.2.53). Независимо от типа рассматриваемой системы кодирования обратная теорема кодирования источников (теорема 7.2.3) показывает, что невозможно достичь средней погрешности  или меньше, ведя передачу со скоростью, меньшей чем
или меньше, ведя передачу со скоростью, меньшей чем  Эта обратная теорема применима к решетчатому кодированию так же успешно, как и к блочному (§ 7.2). Было показано также, что в пределе с ростом длины блока блочная система кодирования может достичь средней погрешности
Эта обратная теорема применима к решетчатому кодированию так же успешно, как и к блочному (§ 7.2). Было показано также, что в пределе с ростом длины блока блочная система кодирования может достичь средней погрешности  при скорости
при скорости  нат на символ источника, определяя тем самым скорость как функции погрешности
нат на символ источника, определяя тем самым скорость как функции погрешности  В этом параграфе покажем, что в пределе, с ростом длины кодового ограничения К, решетчатые коды также способны приближаться к предельным значениям скорости как, функции погрешности. Вновь воспользуемся техникой кодирования в ансамбле, для чего рассмотрим ансамбль двоичных решетчатых кодов с длиной кодового ограничения К и скоростью передачи, равной
В этом параграфе покажем, что в пределе, с ростом длины кодового ограничения К, решетчатые коды также способны приближаться к предельным значениям скорости как, функции погрешности. Вновь воспользуемся техникой кодирования в ансамбле, для чего рассмотрим ансамбль двоичных решетчатых кодов с длиной кодового ограничения К и скоростью передачи, равной  бит. Ансамбль и распределение на нем выбираются так, что каждому ребру решетки соответствует воспроизводящая последовательность, состоящая из независимых символов, появляющихся с вероятностями
бит. Ансамбль и распределение на нем выбираются так, что каждому ребру решетки соответствует воспроизводящая последовательность, состоящая из независимых символов, появляющихся с вероятностями  Для любой последовательности источника и и любого заданного решетчатого кода последовательность с минимальной погрешностью обозначим через
Для любой последовательности источника и и любого заданного решетчатого кода последовательность с минимальной погрешностью обозначим через  Таким образом, по определению для любой последовательности V, принадлежащей решетчатому коду, справедлива граница
Таким образом, по определению для любой последовательности V, принадлежащей решетчатому коду, справедлива граница  Выберем
Выберем  согласно следующему правилу.
согласно следующему правилу.
1. Для заданного решетчатого кода и заданной последовательности источника и заменим последовательность, соответствующую нулевым состояниям, последовательностью  случайно выбранной в соответствии с условной вероятностью
случайно выбранной в соответствии с условной вероятностью 

При этом получится новый решетчатый код, который отличается от исходного в ребрах, соответствующих пути нулевых состояний. Будем называть этот модифицированный решетчатый код запрещенным кодом, так как, вообще говоря, нам не разрешается выбирать части решетчатого кода после наблюдения выходной последовательности источника и. Заметим, что исходный код и соответствующий ему запрещенный код различаются только запрещенным кодовым путем, соответствующим пути нулевых состояний.
2. При заданной последовательности источника и и заданном запрещенном коде обозначим через  последовательность с наименьшей погрешностью. Это значит, что
последовательность с наименьшей погрешностью. Это значит, что  соответствует той выходной последовательности запрещенного решетчатого кода, которая представляет и с наименьшей погрешностью.
соответствует той выходной последовательности запрещенного решетчатого кода, которая представляет и с наименьшей погрешностью.
3. Последовательность  определяет некоторый путь на запрещенной решетке. Тогда соответствующий ему путь на исходной решетке обозначим
определяет некоторый путь на запрещенной решетке. Тогда соответствующий ему путь на исходной решетке обозначим  Таким образом,
Таким образом,  и V совпадают, за исключением тех ребер, которые принадлежат последовательности нулевых состояний.
и V совпадают, за исключением тех ребер, которые принадлежат последовательности нулевых состояний.
Заметим, что  является последовательностью исходного решетчатого кода, а запрещенный код был введен только как способ построения этой последовательности. На практике никогда не будем использовать запрещенный код для кодирования последовательностей источника, а будем использовать его только для получения нужных границ. Так как
является последовательностью исходного решетчатого кода, а запрещенный код был введен только как способ построения этой последовательности. На практике никогда не будем использовать запрещенный код для кодирования последовательностей источника, а будем использовать его только для получения нужных границ. Так как  последовательность решетчатого кода, то по определению
последовательность решетчатого кода, то по определению

Выведем границу для  где
где  означает среднее по всем последовательностям и решетчатым кодам ансамбля. Сделаем это, оценивая сверху
означает среднее по всем последовательностям и решетчатым кодам ансамбля. Сделаем это, оценивая сверху 
Лемма 7.4.1, Справедливо неравенство

где

Доказательство. Пусть для заданной последовательности источника и и для последовательности  определенной выше, множество
определенной выше, множество  определяется соотношением
определяется соотношением  есть ребро, принадлежащее пути нулевых состояний}. Тогда
есть ребро, принадлежащее пути нулевых состояний}. Тогда

Для применим границу  для справедливо равенство
для справедливо равенство  Тогда найдем, что
Тогда найдем, что


где  ребро пути нулевых состояний запрещенного кода. Это последнее неравенство следует из того, что по определению
ребро пути нулевых состояний запрещенного кода. Это последнее неравенство следует из того, что по определению  в запрещенном коде
в запрещенном коде

где  путь нулевых состояний. Из (7.4.7) и (7.4.12) получаем неравенство
путь нулевых состояний. Из (7.4.7) и (7.4.12) получаем неравенство

Если усреднить (7.4.14) по всем последовательностям источника и всем решетчатым кодам в ансамбле, то первый член обратится в  Применяя ко второму члену аддитивную границу для вероятности суммы событий в силу определения величины
Применяя ко второму члену аддитивную границу для вероятности суммы событий в силу определения величины  данного в (7.4.9), приходим к искомому результату
данного в (7.4.9), приходим к искомому результату
Остается только получить наиболее строгую границу для Р. Это достигается с помощью вычислений в ансамбле запрещенных  решетчатых кодов, в каждом из которых путь нулевых состояний
решетчатых кодов, в каждом из которых путь нулевых состояний  выбирается для заданной последовательности источника и согласно (7.4.6). Заметим, что когда
выбирается для заданной последовательности источника и согласно (7.4.6). Заметим, что когда  сливается с путем нулевых состояний в узле
сливается с путем нулевых состояний в узле  и остается слившимся с ним на протяжении
и остается слившимся с ним на протяжении  ребер, последовательность
ребер, последовательность  в соответствующем запрещенном коде также сливается с путем нулевых состояний на том же самом участке. Следовательно, вероятность
в соответствующем запрещенном коде также сливается с путем нулевых состояний на том же самом участке. Следовательно, вероятность  равна также вероятности того, что в запрещенном решетчатом коде путь минимальной погрешности
равна также вероятности того, что в запрещенном решетчатом коде путь минимальной погрешности  сливается с путем нулевых состояний в узле
сливается с путем нулевых состояний в узле  и остается слившимся с ним на протяжении
и остается слившимся с ним на протяжении  ребер.
ребер.
Пусть  двоичная последовательность, поступающая на вход решетчатого запрещенного декодера и соответствующая кодовому слову с минимальной погрешностью
двоичная последовательность, поступающая на вход решетчатого запрещенного декодера и соответствующая кодовому слову с минимальной погрешностью  Если
Если  сливается с путем нулевых состояний на участке длиной
сливается с путем нулевых состояний на участке длиной  ребер, начинающемся в узле
ребер, начинающемся в узле  то двоичная последовательность х имеет вид
то двоичная последовательность х имеет вид

Предположим, что в узле  запрещенный решетчатый декодер находится в состоянии
запрещенный решетчатый декодер находится в состоянии  а в узле
а в узле  в состоянии
в состоянии  Следом за узлом
Следом за узлом  должен идти символ 1, так как в противном случае соединение могло бы начаться не в узле
должен идти символ 1, так как в противном случае соединение могло бы начаться не в узле  Точно так же 1 должна следовать сразу за узлом
Точно так же 1 должна следовать сразу за узлом  так как в противном случае участок слияния был бы длиннее
так как в противном случае участок слияния был бы длиннее  Участок слияния показан на рис.
Участок слияния показан на рис.
7.11. Заметим, что на состояния а и  никаких ограничений не накладывается, так что одно из них или оба могут быть нулевыми состояниями.
никаких ограничений не накладывается, так что одно из них или оба могут быть нулевыми состояниями.
Предположим на время, что состояния а и  фиксированы. Это значит, что путь
фиксированы. Это значит, что путь  воспроизведенный декодером в запрещенном коде, должен соответствовать состоянию а в
воспроизведенный декодером в запрещенном коде, должен соответствовать состоянию а в  вершине и состоянию
вершине и состоянию  вершине.
вершине.

Рис. 7.11. Слияние с путем, соответствующим нулевому состоянию
Найдем вероятность того, что подпуть, воспроизводимый декодером по входной последовательности

есть путь (подпоследовательность последовательности х, ведущий из состояния а в состояние  с минимальной погрешностью. Любой другой путь из а в
с минимальной погрешностью. Любой другой путь из а в  соответствует входной последовательности
соответствует входной последовательности

где  Так как вероятность того, что путь
Так как вероятность того, что путь  есть путь наименьшей погрешности среди всех путей вида
есть путь наименьшей погрешности среди всех путей вида  ограничена сверху вероятностью того, что путь
ограничена сверху вероятностью того, что путь  есть путь наименьшей погрешности среди всех путей вида
есть путь наименьшей погрешности среди всех путей вида  то можно рассматривать пути только этого, более ограниченного вида. Пусть
то можно рассматривать пути только этого, более ограниченного вида. Пусть  выходная последовательность запрещенного решетчатого декодера, состоящая из
выходная последовательность запрещенного решетчатого декодера, состоящая из  ребер, идущих из состояния а в состояние
ребер, идущих из состояния а в состояние  и соответствующая входной последовательности
и соответствующая входной последовательности  Обозначим через и случайную подпоследовательность источника длиной
Обозначим через и случайную подпоследовательность источника длиной  пользуясь ансамблем запрещенных решетчатых кодов, оценим вероятность
пользуясь ансамблем запрещенных решетчатых кодов, оценим вероятность  Для этого оценим сначала вероятность
Для этого оценим сначала вероятность

Ограничиваясь при этом только подпутями, идущими из состояния а в состояние  можно сформулировать нашу задачу как
можно сформулировать нашу задачу как
задачу блочного кодирования источников. Нужную границу для величины  получим способом, схожим со способом получения границы блочного кодирования в § 7.2.
получим способом, схожим со способом получения границы блочного кодирования в § 7.2.
Лемма 7.4.2. В определенном выше ансамбле решетчатых кодов

где

Доказательство. Потребуются специальные обозначения, чтобы отличать ребра пути нулевых состояний от других ребер запрещенной решетки. Как отмечалось выше, нас интересуют только ребра, относящиеся к путям вида  Поэтому наши обозначения
Поэтому наши обозначения  использовать элементы только этих путей:
использовать элементы только этих путей:
 означает подпоследовательность источника, расположенную над
означает подпоследовательность источника, расположенную над  центральными ребрами;
центральными ребрами;
 означает подпоследовательность источника, расположенную над К первыми и К последними ребрами рассматриваемой подрешетки,
означает подпоследовательность источника, расположенную над К первыми и К последними ребрами рассматриваемой подрешетки,
 означает векторы ребер пути нулевых состояний, расположенные над
означает векторы ребер пути нулевых состояний, расположенные над  центральными ребрами;
центральными ребрами;
 означает множество всех ребер, расположенных на
означает множество всех ребер, расположенных на  центральных позициях, но не принадлежащих пути нулевых состояний.
центральных позициях, но не принадлежащих пути нулевых состояний.
Пусть и — подпоследовательность источника, соответствующая участку пути из состояния а в состояние  тогда
тогда  так как все компоненты и независимы и одинаково распределены. Точно так же отрезок
так как все компоненты и независимы и одинаково распределены. Точно так же отрезок  представляет собой относящуюся к данному распределению часть пути нулевых состояний запрещенной решетки, выбранной случайным образом в соответствии с распределением
представляет собой относящуюся к данному распределению часть пути нулевых состояний запрещенной решетки, выбранной случайным образом в соответствии с распределением  независимо от
независимо от  Векторы
Векторы  включают в себя все ребра запрещенной решетки, соответствующие двоичным последовательностям вида
включают в себя все ребра запрещенной решетки, соответствующие двоичным последовательностям вида  Следовательно, все интересующие нас величины имеют совместное распределение
Следовательно, все интересующие нас величины имеют совместное распределение

Определим индикаторную функцию

Тогда


где при  применяется неравенство Гельдера. Для дальнейшей оценки применяется неравенство Иенсена
применяется неравенство Гельдера. Для дальнейшей оценки применяется неравенство Иенсена

Заметим, что последнее выражение, заключенное в квадратные скобки, симметрично по отношению ко всем входящим в него путям, так как отрезок пути нулевых состояний  имеет вероятность
имеет вероятность  определяемую из (7.4.6), но эту же самую вероятность имеют и все ребра, составляющие
определяемую из (7.4.6), но эту же самую вероятность имеют и все ребра, составляющие  Поэтому все
Поэтому все  путей вида
путей вида  имеют одинаковые статистические свойства, откуда находим, что независимо от и
имеют одинаковые статистические свойства, откуда находим, что независимо от и

Таким образом,

Здесь использовался тот факт, что все компоненты векторов статистически независимы. Полученная граница для  не зависит от состояний а и
не зависит от состояний а и  откуда и следует искомый результат
откуда и следует искомый результат
С помощью этой же границы из (7.4.8) находим

при условии, что  Напомним, что
Напомним, что  функция Галлагера, свойства которой были установлены леммой
функция Галлагера, свойства которой были установлены леммой
7.2.2. Из (7.2.58) имеем

где 
Для  получаем границу (см. задачу 7.3)
получаем границу (см. задачу 7.3)

из которой следует, что

С помощью этого неравенства находим границу 

Выберем

Тогда нижняя граница в (7.4.28) принимает вид

Определяя  находим
находим

где
Напомним, что согласно (7.2.53) скорость как функция погрешности определяется соотношением  где
где

Выберем  при котором
при котором  и определим
и определим  Тогда придем к следующей теореме кодирования источников.
Тогда придем к следующей теореме кодирования источников.
Теорема 7.4.1. Теорема решетчатого кодирования источников.
Если задана погрешность  то для любой заданной длины кодового ограничения К и скорости передачи
то для любой заданной длины кодового ограничения К и скорости передачи  при любом целом
при любом целом  существует двоичный решетчатый код Тк со средней погрешностью, ограниченной неравенством
существует двоичный решетчатый код Тк со средней погрешностью, ограниченной неравенством

где

Доказательство. Из (7.4.31) следует, что хотя бы один код имеет погрешность, меньшую или равную погрешности, усредненной по ансамблю?
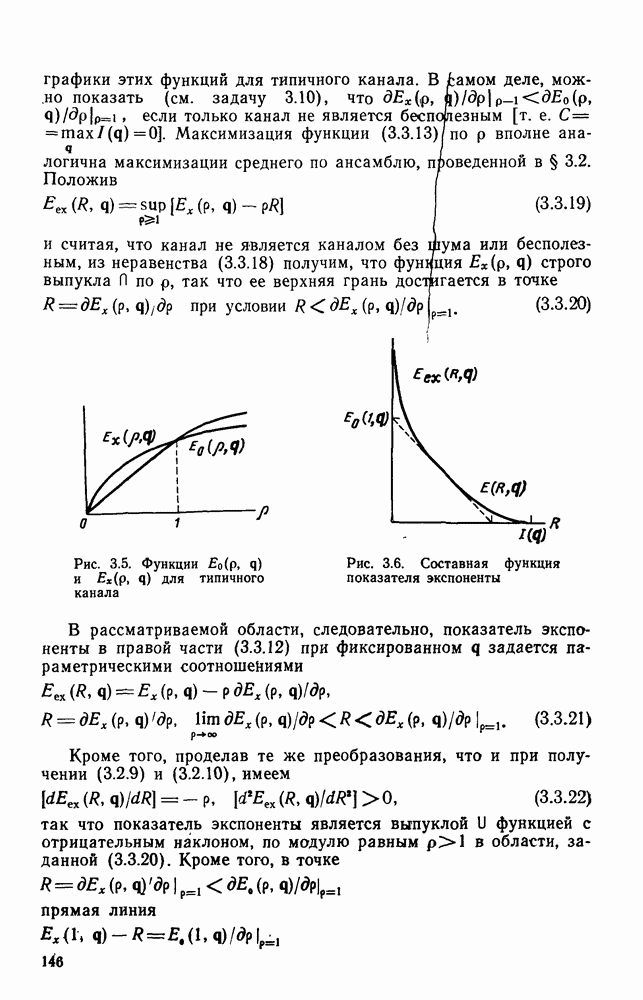
Эта теорема показывает, что в пределе, с ростом длины кодового ограничения К, можно с помощью схемы решетчатого кодирования, показанной на рис. 7.10, достичь предельных значений скорости и погрешности  Более того, теорема позволяет найти оценку средней погрешности, достижимой при конечной длине кодового ограничения.
Более того, теорема позволяет найти оценку средней погрешности, достижимой при конечной длине кодового ограничения.
До сих пор рассматривались решетчатые декодеры с двоичным (ходом, что соответствует решетке, из каждой вершины которой тсходят только два ребра. Нетрудно перейти к случаю декодеров  -ичным входом, что соответствует решетке, у которой из каждой вершины исходит
-ичным входом, что соответствует решетке, у которой из каждой вершины исходит  ребер. На каждые
ребер. На каждые  символов источника (одер посылает
символов источника (одер посылает  -ичный символ, так что скорость для этих кодов
-ичный символ, так что скорость для этих кодов  бит/символ источника, или
бит/символ источника, или

На каждое ребро по-прежнему приходится по  представляющих его символов. Доказательство остается таким же, как и при
представляющих его символов. Доказательство остается таким же, как и при  но требует введения условий, связанных с состояниями
но требует введения условий, связанных с состояниями  и двумя ненулевыми символами, один из которых следует за а,
и двумя ненулевыми символами, один из которых следует за а,
а другой предшествует  Для произвольного целого
Для произвольного целого  выражения (7.4.8) — (7.4.10) остаются теми же, но величина
выражения (7.4.8) — (7.4.10) остаются теми же, но величина  оценивается неравенством
оценивается неравенством 

Таким образом, для этого более общего случая получаем ту же самую теорему кодирования источников с той разницей, что неравенство (7.4.32) заменяется на неравенство

где
Чтобы оценить скорость сходимости к пределу  с ростом длины кодового ограничения, подставим
с ростом длины кодового ограничения, подставим  в границу (7.4.36) и перепишем ее в виде
в границу (7.4.36) и перепишем ее в виде 

где  эквивалентная длина блока. Сравнивая эту" границу с границей при блочном кодировании источников, определяемой теоремой 7.2.4, видим, что найденная здесь граница погрешности имеет показатель экспоненты, пропорциональный
эквивалентная длина блока. Сравнивая эту" границу с границей при блочном кодировании источников, определяемой теоремой 7.2.4, видим, что найденная здесь граница погрешности имеет показатель экспоненты, пропорциональный  тогда как показатель экспоненты блочного кодирования пропорционален
тогда как показатель экспоненты блочного кодирования пропорционален  Аналогичное превосходство сверточных кодов над блочными уже наблюдалось при изучении кодирования в каналах.
Аналогичное превосходство сверточных кодов над блочными уже наблюдалось при изучении кодирования в каналах. 
В этом параграфе описана и разобрана схема решетчатого кодирования, реализуемая с помощью алгоритма Витерби. Как и в случае кодирования в канале, вычислительная сложность оптимального кодера источника растет экспоненциально с ростом длины кодового ограничения. Естественно попытаться найти субоптимальные алгоритмы поиска пути, подобные тем, которые применяются для последовательного декодирования сверточных кодов в каналах. Эти алгоритмы способны уменьшить объем вычислений, приходящихся на символ источника.
Изучение алгоритмов последовательного кодирования источников лучше всего проводить, используя древовидные коды, представляющие собой решетчатые коды с бесконечной длиной кодового ограничения  Соответствующие им случайные решетки не имеют узлов слияния, а лишь ветвятся, порождая независимые случайные ребра. При древовидной схеме кодирования оптимальный декодер отыскивает в дереве путь, представляющий последовательность источника с наименьшей погрешностью. Джелинек [1969], используя теорию ветвящихся процессов (см. задачи 7.10 и
Соответствующие им случайные решетки не имеют узлов слияния, а лишь ветвятся, порождая независимые случайные ребра. При древовидной схеме кодирования оптимальный декодер отыскивает в дереве путь, представляющий последовательность источника с наименьшей погрешностью. Джелинек [1969], используя теорию ветвящихся процессов (см. задачи 7.10 и
7.11), первым показал, что древовидные коды позволяют достичь предельного значения скорости при заданном значении погрешности  Тот же результат получим из (7.4.37), полагая
Тот же результат получим из (7.4.37), полагая 
Наконец заметим, что нет никакой необходимости в том, чтобы кодер источника (решетчатый или древовидный) находил тот единственный путь, который представлял бы последовательность источника с минимальной погрешностью. Может быть много путей, которые представляют последовательность источника с требуемой точностью  поэтому естественно рассмотреть различные алгоритмы последовательного поиска, с помощью которых можно выбирать путь, удовлетворяющий заданному критерию точности. Андерсон и Джелинек [1973] и Галлагер [1974] предложили и исследовали такие алгоритмы, показав их сходимость к предельному значению скорости при заданном значении погрешности для различных источников. Последовательные алгоритмы этого типа, оставаясь подоптимальными, обеспечивают меньшую сложность решетчатых и древовидных кодеров и в то же время позволяют достичь предельные значения скорости при заданном значении погрешности.
поэтому естественно рассмотреть различные алгоритмы последовательного поиска, с помощью которых можно выбирать путь, удовлетворяющий заданному критерию точности. Андерсон и Джелинек [1973] и Галлагер [1974] предложили и исследовали такие алгоритмы, показав их сходимость к предельному значению скорости при заданном значении погрешности для различных источников. Последовательные алгоритмы этого типа, оставаясь подоптимальными, обеспечивают меньшую сложность решетчатых и древовидных кодеров и в то же время позволяют достичь предельные значения скорости при заданном значении погрешности.