Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
§ 12.4. Алгоритм в некотором алфавите А.Нормальный алгоритм Маркова По аналогии с интуитивным определением алгоритма вообще (см. выше), мы могли бы и здесь интуитивно определить понятие «алгоритм в алфавите А» примерно так: I. Алгоритмом в алфавите А называется всякое общепонятное: точное предписание, определяющее потенциально осуществимый процесс над словами из А, допускающий любое слово в качестве исходного и последовательно определяющий новые слова в этом алфавите. Алгоритм применим к некоторому слову Например, следующее предписание удовлетворяет нашему определению. Перепиши заданное слово начиная с конца. Полученное слово есть результат. Остановка. Этот алгоритм предста? вляет собой совершенно точцое предписание, применимое к любому слову. Однако определение I слишком широко: уточнение понятия «алгоритм в алфавите А» связано II. Будем считать, что алгоритм в алфавите А задается в виде некоторой системы допустимых подстановок, дополненной общепонятным точным предписанием о том, в каком порядке и как нужно применять допустимые подстановки, и когда наступает остановка. Так как алфавит и система допустимых подстановок задают ассоциативное исчисление, которому, как мы знаем, можно поставить в соответствие бесконечный лабиринт, то вторую составную часть этого определения алгоритма (т. е. общепонятное и точное предписание о том, как пользоваться подстановками) можно понимать как точное предписание о способе движения в бесконечном лабиринте. Приведем пример алгоритма в алфавите А в смысле II. Пусть алфавит А содержит три буквы:
и следующего указания о способе применения этих подстановок: исходя из произвольного слова Итак, схема подстановок вместе с указанием, как ими пользоваться, определяет алгоритм в алфавите А. Этот алгоритм перерабатывает слово Наш алгоритм несколько напоминает такой способ задания движения в бесконечном лабиринте: выйдя на какую-либо площадку, иди в первый коридор направо и т. д. Остановка наступит, когда придешь в тупик. Ясно, что здесь также может быть три случая: отходя от данной площадки, мы можем либо попасть в тупик (сравни слово С первого взгляда можно решить, что определение алгоритма в смысле II уже, чем определение в смысле L. Однако оказывается, что на деле такого сужения нет, ибо для любого известного алгоритма в смысле I может быть построен эквивалентный ему алгоритм в смысле II. Это, конечно, не доказательство того, что определения I и II равносильны; такого доказательства не может существовать вообще в силу неточности и расплывчатости обоих определений (и там, и там фигурируют слова «общепонятное точное предписание»). Во всяком случае очевидно, что определение II — шаг вперед по пути уточнения понятия «алгоритм». Определим теперь понятие эквивалентности алгоритмов: два алгоритма Для того чтобы дать точное математическое определение алгоритма, потребовалось сделать еще один шаг по пути дальнейшего уточнения. Этот шаг был сделан А. А. Марковым. Построенный им нормальный алгоритм, так же как и алгоритм в смысле определения II, выражен в терминах системы подстановок; однако вместо расплывчатого «общепонятного указания» о том, как, пользоваться подстановками, Марков дал Задается алфавит А и фиксируется схема подстановок. Алгоритм предписывает, исходя из произвольного, слова Как мы видим, приведенный в определении II пример является примером «почти нормального» алгоритма. Вся разница состоит в том, что там остановка наступает лишь в одном случае, когда ни одна из подстановок неприменима, а здесь остановка может наступать в двух случаях. Различные нормальные алгоритмы отличаются друг от друга лишь алфавитами и системами допустимых подстановок. Чтобы задать какой-либо нормальный алгоритм, достаточно задать алфавит и систему подстановок. Примеры нормальных алгоритмов Пусть алфавит А и система подстановок имеют вид
(стрелками общепринято обозначать тот факт, что задано не ассоциативное исчисление обычного вида, а нормальный алгоритм Маркова). Посмотрим, во что переработает этот алгоритм слово
Процедура оканчивается применением заключительной подстановки Пусть теперь система подстановок в том же алфавите имеет вид ( Слово
Мы видим, что оба алгоритма суммируют количество единиц, т. е. осуществляют сложение. Нетрудно показать, что эти два нормальных алгоритма эквивалентны. Третий эквивалентный им обоим нормальный алгоритм можно было бы задать с помощью системы подстановок
Читателю предлагается убедиться, что следующий нормальный алгоритм
перерабатывает всякое слово вида
т. е. осуществляет умножение. Понятие алгоритма в некотором алфавите было уточнено Марковым следующим образом: Марков предположил, что всякий алгоритм в алфавите А эквивалентен некоторому нормальному алгоритму в этом же алфавите. Это утверждение является гипотезой; оно не может быть строго доказано, так как, с одной стороны, здесь фигурирует расплывчатое понятие «всякий алгоритм», а с другой стороны — точное понятие «нормальный алгоритм». На это утверждение можно смотреть как на закон, который не доказан, но который проверен и подтвержден всем нашим опытом. В пользу высказанной гипотезы говорит и тот факт, что никому еще не удалось сформулировать пример такого алгоритма в алфавите А, для которого нельзя было бы построить эквивалентный ему нормальный алгоритм. Возвращаясь к содержанию последних абзацев предыдущего параграфа, естественно рассматривать нормальный алгоритм Маркова как удобную «стандартную форму» для задания любого алгоритма, т. е. предположить, что вообще любой алгоритм может быть задан в форме нормального алгоритма Маркова. Разумеется, это не более чем гипотеза, и притом значительно менее ясная, чем гипотеза Маркова, о которой выше шла речь, так как она не может быть даже высказана в точных терминах, но интуитивный смысл ее очевиден. Как только мы примем эту гипотезу, сразу становится ясным один из путей, каким можно строго проводить доказательство алгоритмической неразрешимости того или иного круга проблем. Например, чтобы доказать алгоритмическую неразрешимость проблемы слов, т. е. доказать, что не существует алгоритма, позволяющего для любого ассоциативного исчисления и для произвольных заданных слов Р и Q ответить на вопрос: эквивалентны ли эти два слова, достаточно было построить пример ассоциативного исчисления и доказать, что для этого исчисления не существует нормального алгоритма, распознающего эквивалентность слов. Впервые такие примеры были построены А. А. Марковым в 1946 г. и Э, Постом в 1947 г. После того стало ясно, что и подавно не существует алгоритма для распознавания эквивалентности слов в любом ассоциативном исчислении. Примеры ассоциативных исчислений, приведенные Марковым и Постом, были весьма громоздкими, насчитывали сотни допустимых подстановок. Позже ленинградский математик Г. С. Цейтин привел пример ассоциативного исчисления, насчитывающего всего лишь семь допустимых подстановок, в котором проблема эквивалентности слов также алгоритмически неразрешима. В качестве иллюстрации приведем одну схему доказательства алгоритмической неразрешимости. Пусть в некотором алфавите Если алгоритм U перерабатывает это слово в некоторое иное слово, после чего наступает остановка, то это означает, что алгоритм U применим к собственной записи. Такой алгоритм назовем самоприменимым. В противном случае алгоритм будем называть несамоприменимым. Естественно, возникает задача распознавания самоприменимости: по записи данного алгоритма определить, самоприменим этот алгоритм или нет. Решение этой задачи мыслится в виде построения некоторого нормального алгоритма V, который, будучи применен ко всякой записи самоприменимого алгоритма и, перерабатывает эту запись в некоторое слово М, а примененный ко всякой записи несамоприменимого алгоритма U, перерабатывает эту запись в некоторое иное слово L. В этом случае по результату применения распознающего алгоритма V мы могли бы узнать, является ли заданный алгоритм U самоприменимым или нет. Доказано, что такого нормального алгоритма V не существует (см. Доказательство проводится от противного. Допустим, что нормальный алгоритм V распознавания построен и перерабатывает всякую запись самоприменимого алгоритма в слово М, а всякую запись несамоприменимого алгоритма в слово Тогда, путем некоторого изменения системы подстановок алгоритма Итак, 1. Пусть 2. Пусть Полученное противоречие доказывает алгоритмическую неразрешимость проблемы распознавания самоприменимости. Итак, решая какую-либо задачу, приходится считаться с тем, что алгоритм для ее решения может существовать, а может и не существовать. Поэтому одновременно с поиском нужного алгоритма приходится направлять усилия и на доказательство его несуществования. Отметим еще, что несуществование алгоритма для решения того или иного класса задач не означает неразрешимости вообще; это означает лишь, что рассматриваемый класс задач настолько широк, что единого эффективного метода для решения всех задач не существует. Так, хотя в ассоциативном исчислении Г. С. Цейтина общая проблема распознавания эквивалентности слов алгоритмически неразрешима, тем не менее для конкретных пар слов мы обычно тем или иным способом можем сделать вывод об их эквивалентности или неэквивалентности. До уточнения понятия «алгоритм» в математике было две точки зрения: 1) Все проблемы, для решения которых пока не удалось найти алгоритм, алгоритмически разрешимы, но искомый алгоритм еще не найден, потому что не хватает средств в современной математике для его построения. Иначе говоря, в наше время ситуация в ряде проблем похожа на ситуацию, когда пытались найти площадь круга с помощью циркуля и линейки или решить уравнение 2) Существуют классы задач, для решения которых не существует алгоритма вообще. Иначе говоря, есть такие проблемы, которые нельзя решать механически с помощью формальных рассуждений и вычислений и которые требуют творческого мышления. Утверждение это тем более сильно, что оно имеет характер прогноза на все будущие времена, применительно ко всем будущим средствам. Не тратьте сил зря на поиски несуществующих алгоритмов! Но как могли бы сторонники второго взгляда доказывать несуществование какого-либо алгоритма? До тех пор, пока в определении алгоритма так или иначе фигурируют слова «общепонятное точное предписание», о таком доказательстве нельзя и думать, так как невозможно вести доказательство путем перебора всех «общепонятных точных предписаний» и показа того, что ни одно из них не годится. Поэтому само существование второй точки зрения возможно только благодаря наличию смелых гипотез о существовании «стандартных форм» для любого алгоритма, например, нормального алгоритма Маркова, т. е. гипотез, делающих возможным сформулировать понятия «алгоритм» и «алгоритмически неразрешимая проблема» в точных терминах.
|
 |
Оглавление
|















































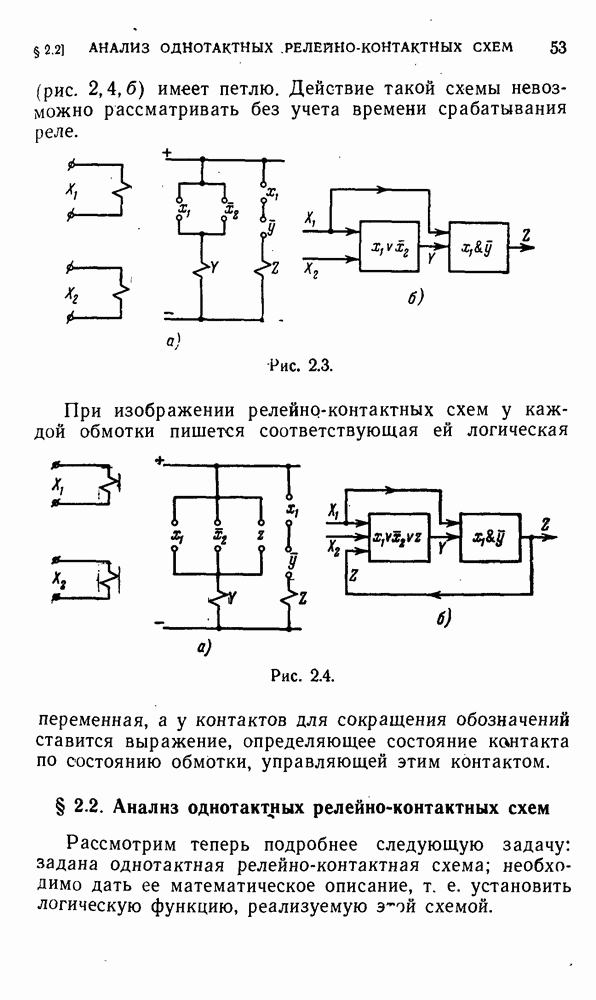


































































































































































































































































































































































































































































































 , если, отправляясь от этого слова и действуя согласно предписанию, мы получим в конце концов некоторое новое слово Q, на котором процесс оборвется. Будем тогда говорить, что алгоритм перерабатывает
, если, отправляясь от этого слова и действуя согласно предписанию, мы получим в конце концов некоторое новое слово Q, на котором процесс оборвется. Будем тогда говорить, что алгоритм перерабатывает  в
в  .
.
 , с использованием аппарата подстановок, т. е. с построением ассоциативного исчисления.
, с использованием аппарата подстановок, т. е. с построением ассоциативного исчисления.
 , а алгоритм определен с помощью системы подстановок
, а алгоритм определен с помощью системы подстановок

 , следует просмотреть схему подстановок в том порядке, в каком они выписаны, разыскивая первую формулу, левая часть которой входит в
, следует просмотреть схему подстановок в том порядке, в каком они выписаны, разыскивая первую формулу, левая часть которой входит в  . Если такой формулы не найдется, то процесс обрывается сразу же. В противном случае берется первая из найденных формул и делается подстановка ее правой части вместо первого вхождения ее левой части в слово
. Если такой формулы не найдется, то процесс обрывается сразу же. В противном случае берется первая из найденных формул и делается подстановка ее правой части вместо первого вхождения ее левой части в слово  , что дает новое слово
, что дает новое слово  в алфавите А. Затем слово
в алфавите А. Затем слово  играет роль
играет роль  , т. е. вновь берется в качестве исходного, и процесс повторяется. Остановка наступает в том случае, если на
, т. е. вновь берется в качестве исходного, и процесс повторяется. Остановка наступает в том случае, если на  шаге получено слово
шаге получено слово  , в которое не входит ни одна из левых частей формул схемы подстановок.
, в которое не входит ни одна из левых частей формул схемы подстановок.
 в слово
в слово  (применена
(применена  формула), слово
формула), слово  — последовательно в слова
— последовательно в слова  и, наконец, в
и, наконец, в  , на котором процесс обрывается; слово
, на котором процесс обрывается; слово  порождает бесконечно повторяющуюся последовательность слов
порождает бесконечно повторяющуюся последовательность слов  и т. д., т. е. остановка никогда не наступит, и следовательно, к слову
и т. д., т. е. остановка никогда не наступит, и следовательно, к слову  наш алгоритм неприменим.
наш алгоритм неприменим.
 ), либо бесконечно кружиться по циклу (сравни слово
), либо бесконечно кружиться по циклу (сравни слово  ), либо двигаться бесконечно долго, не попадая в циклы.
), либо двигаться бесконечно долго, не попадая в циклы.
 в некотором алфавите называются эквивалентными, если области их применимости совпадают и результаты переработки ими любого слова из их общей области применимости также совпадают. Иначе говоря, если алгоритм
в некотором алфавите называются эквивалентными, если области их применимости совпадают и результаты переработки ими любого слова из их общей области применимости также совпадают. Иначе говоря, если алгоритм  применим к некоторому слову
применим к некоторому слову  , то и
, то и  должен быть применим к этому слову, и наоборот; оба алгоритма должны перерабатывать слово
должен быть применим к этому слову, и наоборот; оба алгоритма должны перерабатывать слово  в некоторое слово Q. Если же один из алгоритмов неприменим к некоторому слову В, то и Другой алгоритм должен быть неприменим к нему.
в некоторое слово Q. Если же один из алгоритмов неприменим к некоторому слову В, то и Другой алгоритм должен быть неприменим к нему.
 раз и навсегда определенные точные указания о порядке использования подстановок. Определение нормального алгоритма Маркова таково:
раз и навсегда определенные точные указания о порядке использования подстановок. Определение нормального алгоритма Маркова таково:
 алфавите
алфавите  , просмотреть формулы подстановок в том порядке, в каком они заданы в схеме, разыскивая формулу с левой частью, входящей в
, просмотреть формулы подстановок в том порядке, в каком они заданы в схеме, разыскивая формулу с левой частью, входящей в  . Еслш такой формулы не найдется, то процесс обрывается., В противном случае берется первая из таких формул
. Еслш такой формулы не найдется, то процесс обрывается., В противном случае берется первая из таких формул  делается подстановка ее правой части вместо первого вхождения ее левой части в
делается подстановка ее правой части вместо первого вхождения ее левой части в  , что дает новое слово
, что дает новое слово  в алфавите А. После только что выполненного первого шага процесса приступают ко второму его шагу,
в алфавите А. После только что выполненного первого шага процесса приступают ко второму его шагу,  чающемуся от первого только тем, что роль
чающемуся от первого только тем, что роль  . Далее делают аналогичный третий шаг и т. д. да тех пор, пока не придется оборвать процесс. Оборваться же он может лишь двумя способами: во-первых, когда мы получим такое слово
. Далее делают аналогичный третий шаг и т. д. да тех пор, пока не придется оборвать процесс. Оборваться же он может лишь двумя способами: во-первых, когда мы получим такое слово  что ни одна из левых частей формул схемы подстановок не будет в него входить; во-вторых, когда при получении слова
что ни одна из левых частей формул схемы подстановок не будет в него входить; во-вторых, когда при получении слова  нам придется применить последнюю формулу. В обоих этих случаях мы считаем, что наш алгоритм перерабатывает слово
нам придется применить последнюю формулу. В обоих этих случаях мы считаем, что наш алгоритм перерабатывает слово  в слово
в слово  .
.

 . Последовательно получаем слова:
. Последовательно получаем слова:

 которая перерабатывает слово
которая перерабатывает слово  в себя.
в себя.
 — пустое слово).
— пустое слово).
 этот алгоритм переработает так:
этот алгоритм переработает так:





 задан с помощью системы подстановок нормальный алгоритм U. В записи этого алгоритма, кроме букв алфавита А, содержатся символы
задан с помощью системы подстановок нормальный алгоритм U. В записи этого алгоритма, кроме букв алфавита А, содержатся символы  . Приписав этим символам новые буквы
. Приписав этим символам новые буквы  , мы получим возможность изображать алгоритм U словом в расширенном алфавите
, мы получим возможность изображать алгоритм U словом в расширенном алфавите  . Применим теперь алгоритм U к слову, которое его изображает.
. Применим теперь алгоритм U к слову, которое его изображает.
 ); тем самым доказано, что проблема распознавания самоприменимости алгоритмически неразрешима.
); тем самым доказано, что проблема распознавания самоприменимости алгоритмически неразрешима.
 .
.
 можно построить иной алгоритм V, который всякую запись несамоприменимого алгоритма по-прежнему перерабатывает в слово X, а ко всякой записи самоприменимого алгоритма неприменим (остановка никогда не наступает).
можно построить иной алгоритм V, который всякую запись несамоприменимого алгоритма по-прежнему перерабатывает в слово X, а ко всякой записи самоприменимого алгоритма неприменим (остановка никогда не наступает).
 применим ко всякой записи несамоприменимого алгоритма (перерабатывая ее в слово L) и неприменим к записи самоприменимых алгоритмов (остановка не наступает). Однако это приводит к противоречию. Действительно:
применим ко всякой записи несамоприменимого алгоритма (перерабатывая ее в слово L) и неприменим к записи самоприменимых алгоритмов (остановка не наступает). Однако это приводит к противоречию. Действительно:
 самоприменим, т. е. он применим к собственной записи в виде слова (остановка наступает). Но это свидетельствует как раз о том, что V несамоприменим.
самоприменим, т. е. он применим к собственной записи в виде слова (остановка наступает). Но это свидетельствует как раз о том, что V несамоприменим.
 несамоприменим, тогда он применим к своей записи (так как он применим к любой записи несамоприменимого алгоритма); но это означает как раз, что
несамоприменим, тогда он применим к своей записи (так как он применим к любой записи несамоприменимого алгоритма); но это означает как раз, что  самоприменим.
самоприменим.
 степени в радикалах. Естественно, что решения найдено не было, так как для этого использовались недостаточные средства. Может быть и нам для решения проблем, которые мы называем алгоритмически неразрешимыми, просто не хватает средств современной математики, и построение искомых алгоритмов — дело завтрашнего дня?
степени в радикалах. Естественно, что решения найдено не было, так как для этого использовались недостаточные средства. Может быть и нам для решения проблем, которые мы называем алгоритмически неразрешимыми, просто не хватает средств современной математики, и построение искомых алгоритмов — дело завтрашнего дня?