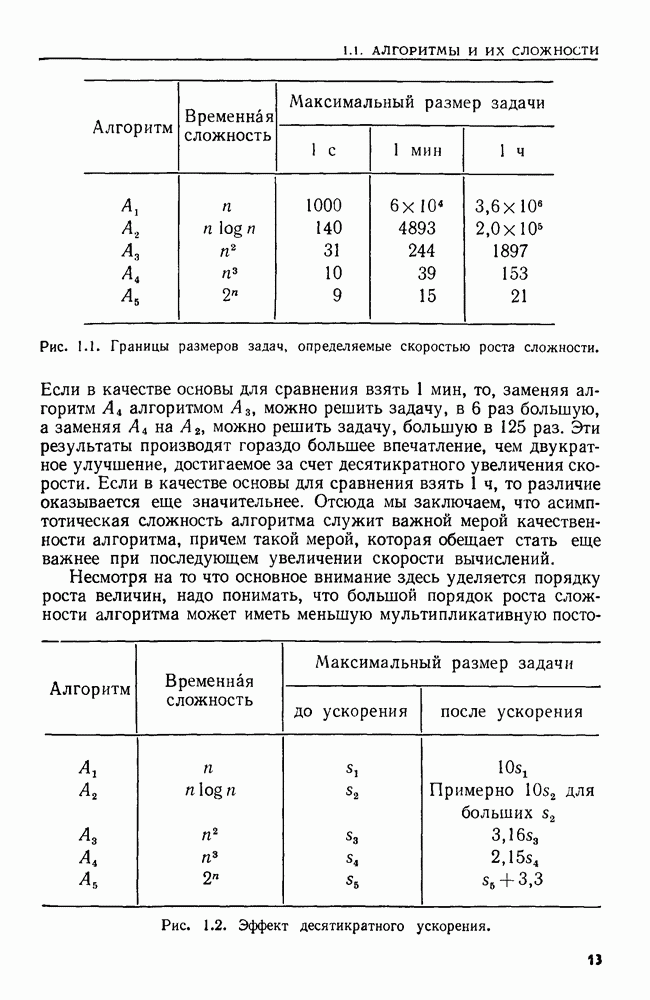
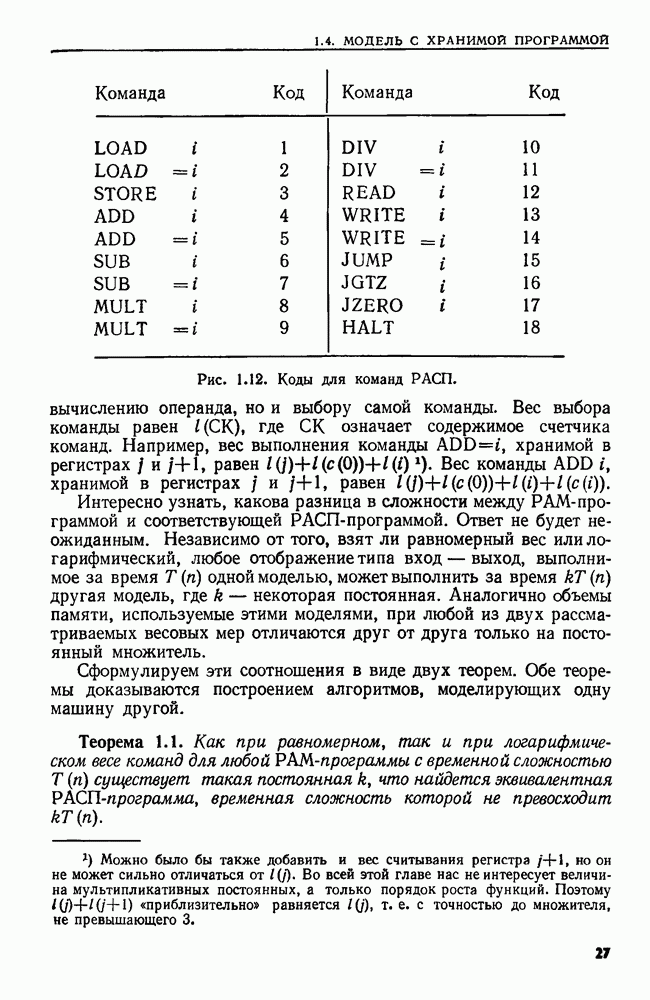
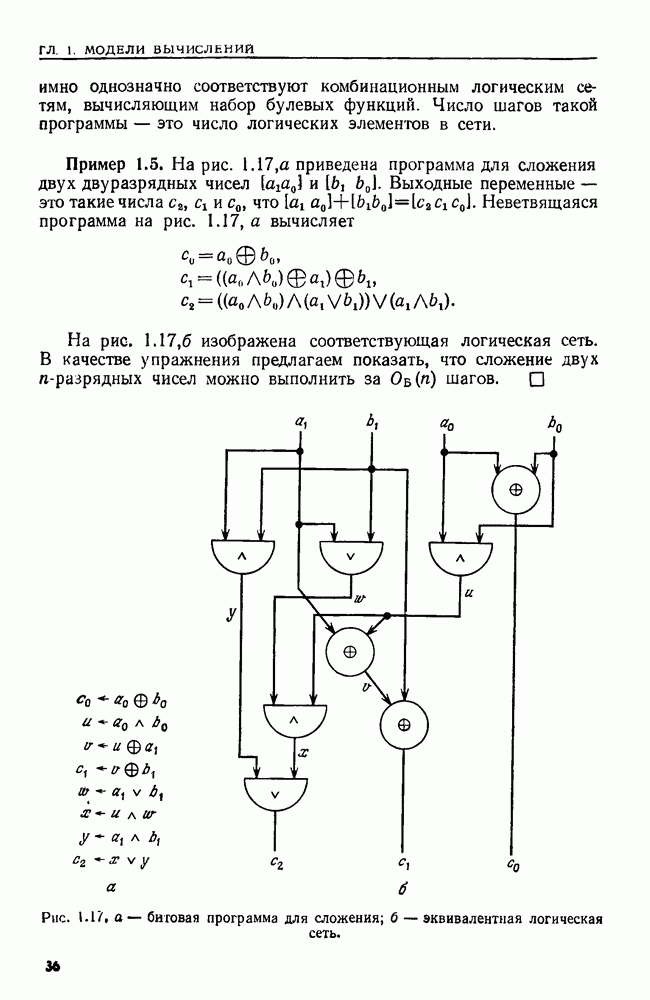
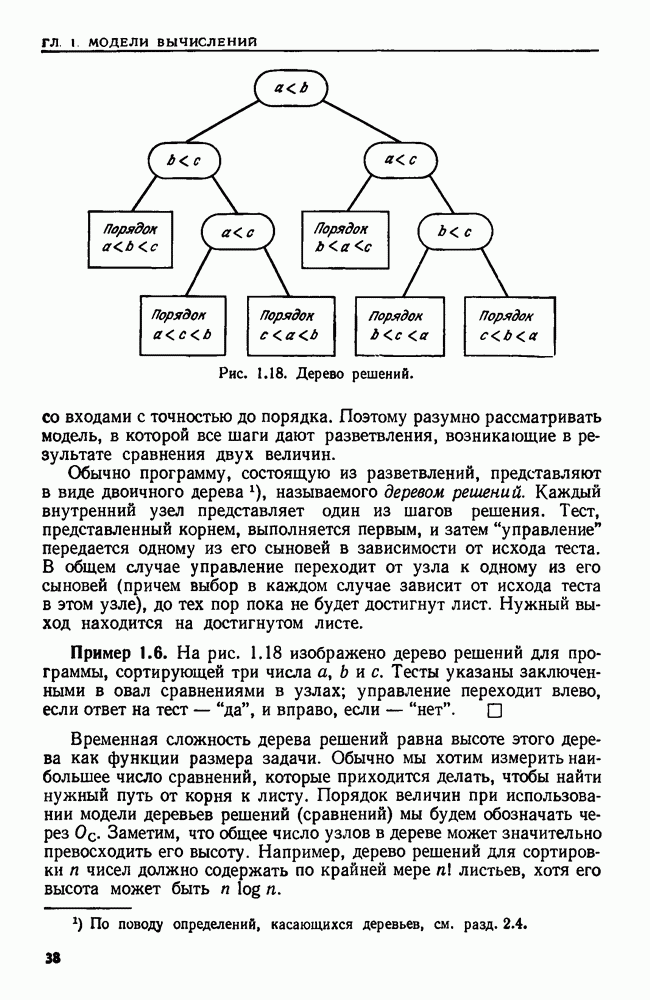
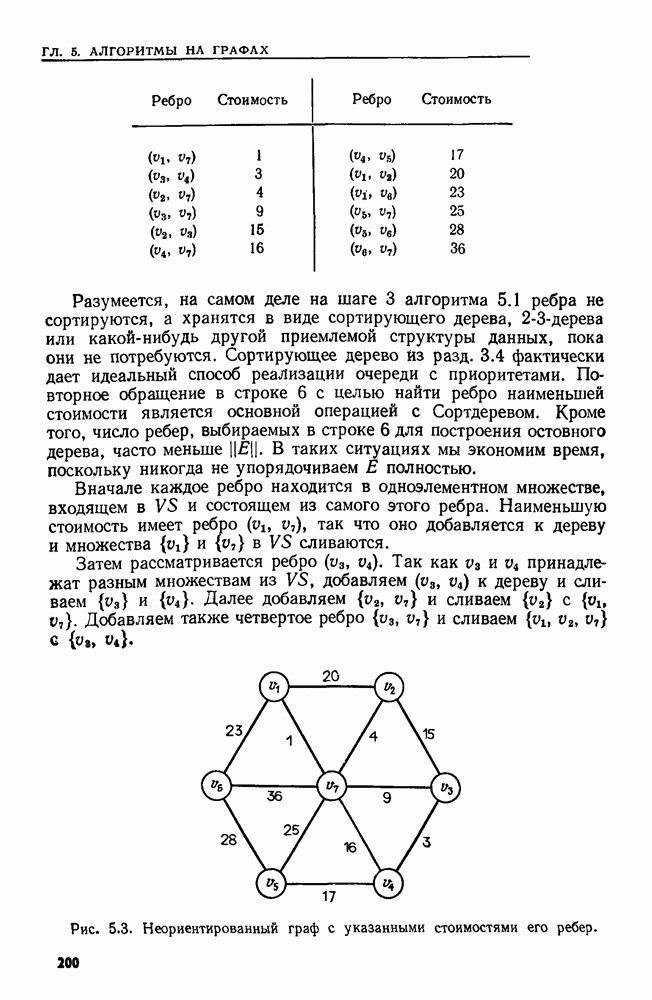
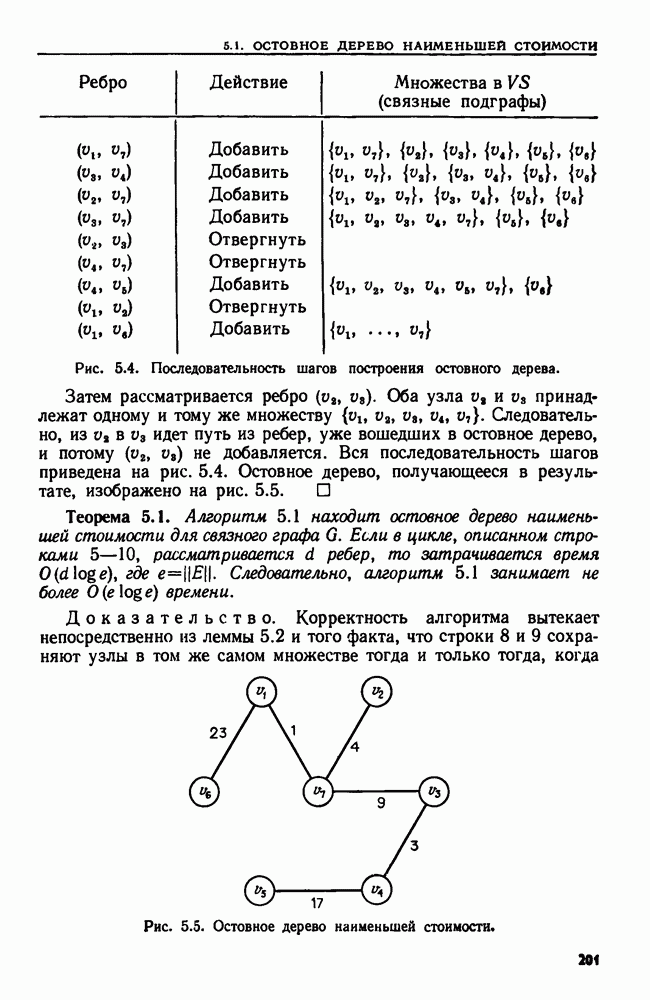
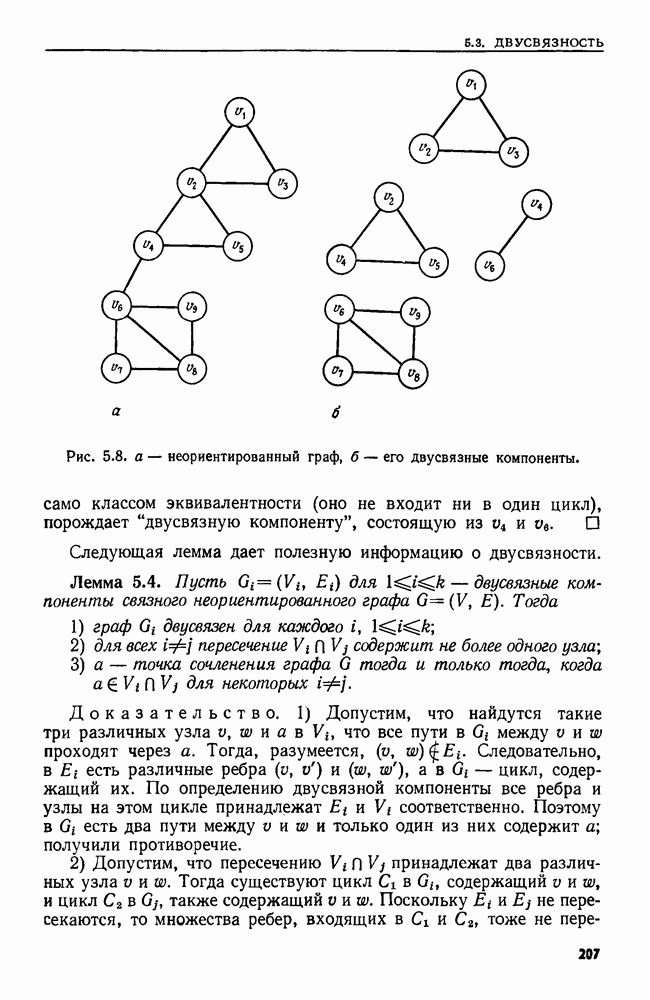
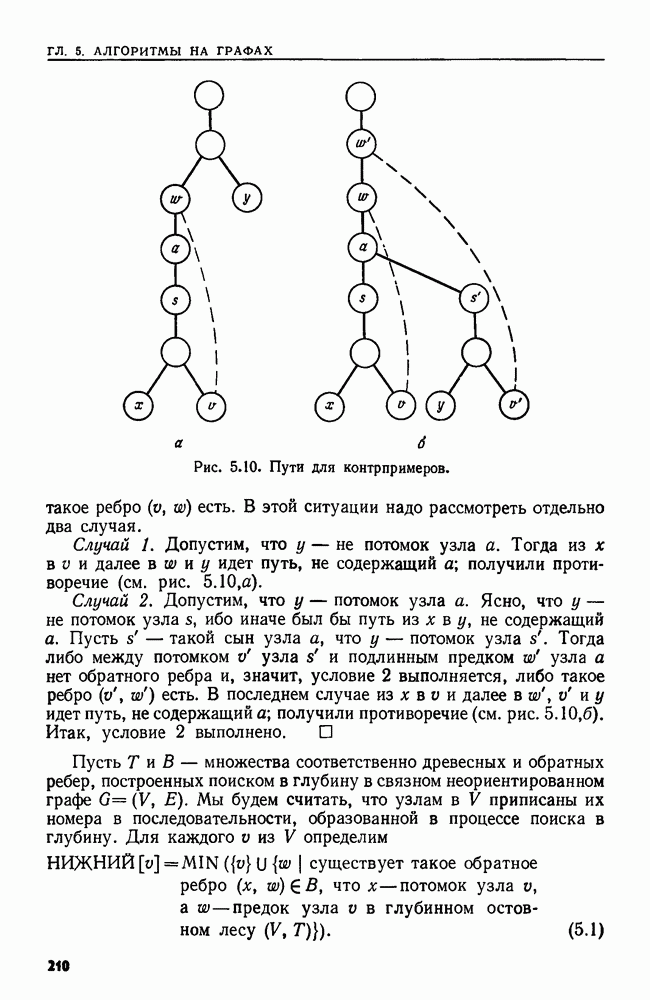
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
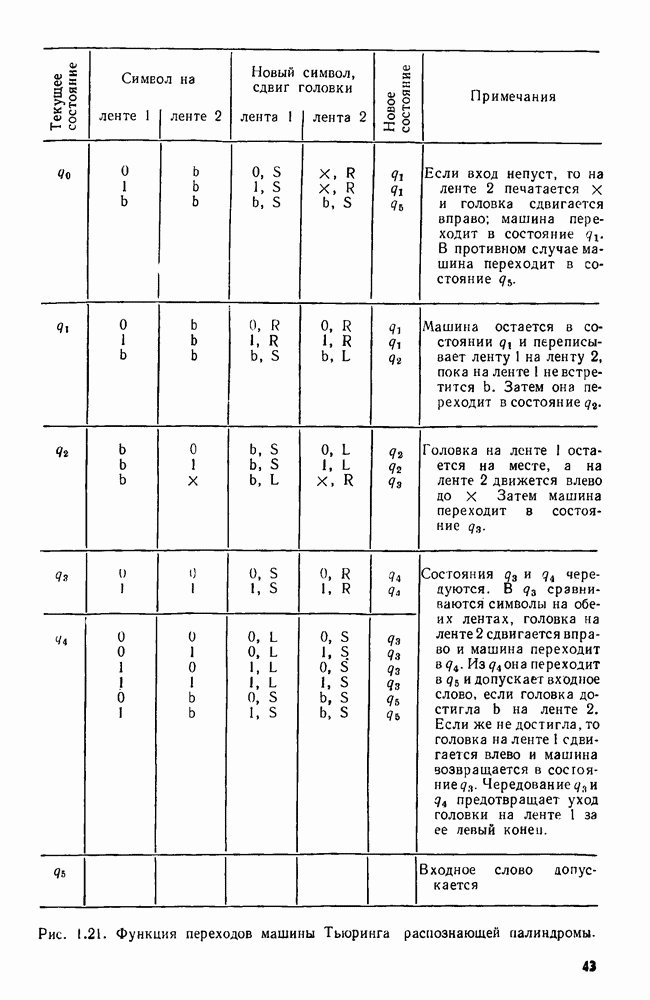
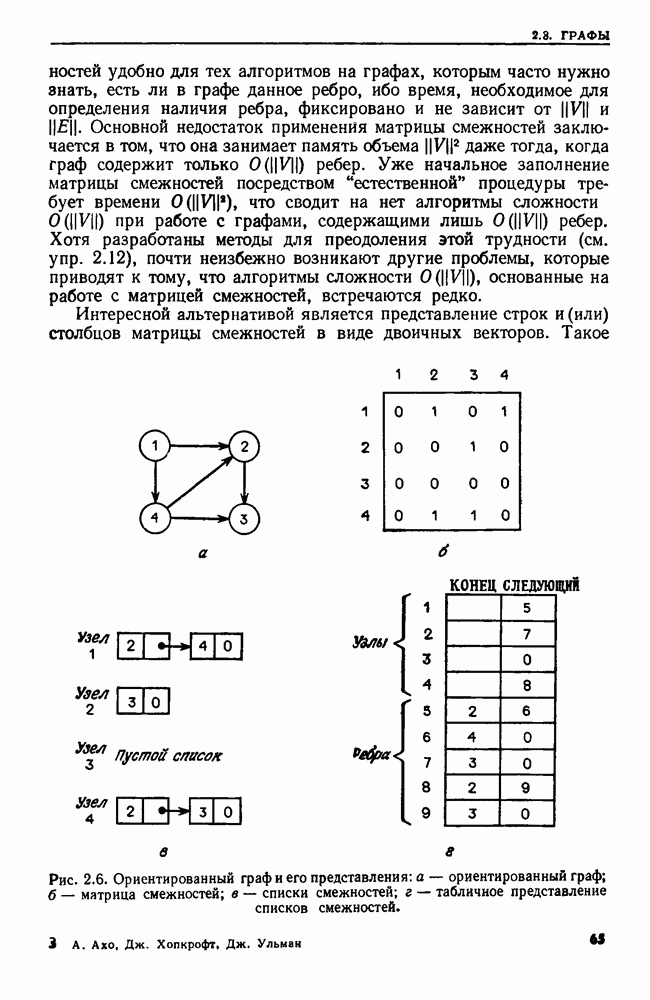
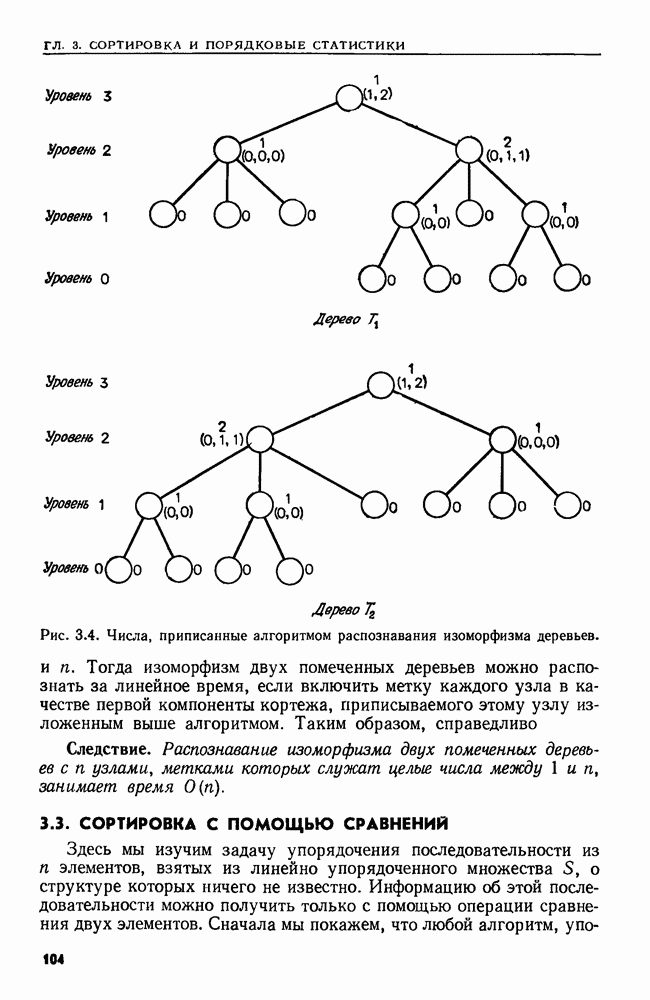
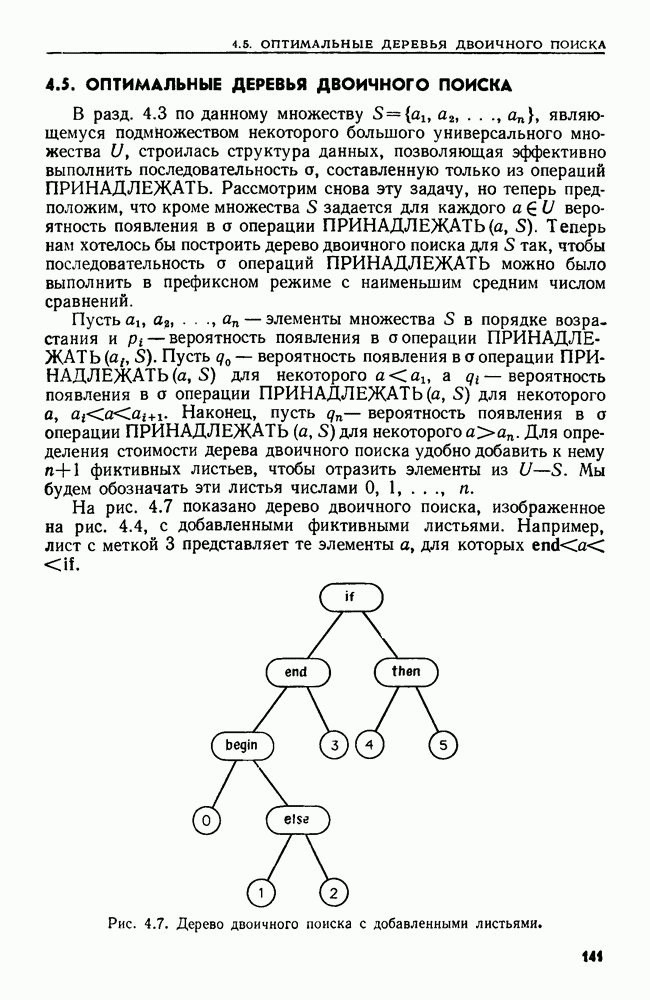
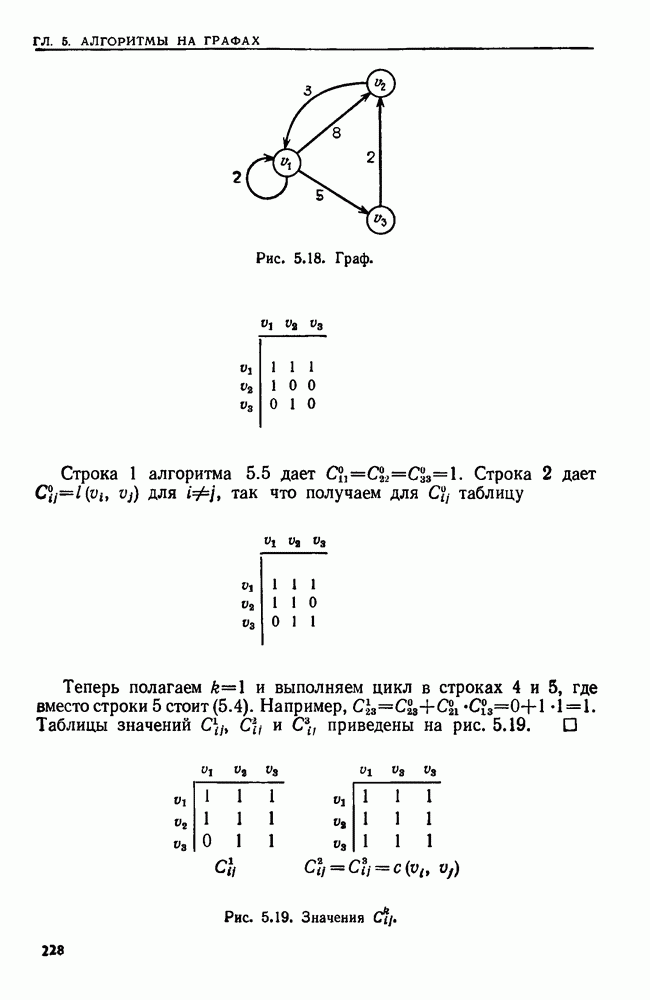
2.5. РЕКУРСИЯПроцедуру, которая прямо или косвенно обращается к себе, называют рекурсивной. Применение рекурсии часто позволяет давать более прозрачные и сжатые описания алгоритмов, чем это было бы возможно без рекурсии. В настоящем разделе мы приведем пример рекурсивного алгоритма и кратко опишем, как можно реализовать рекурсию на РАМ. Рассмотрим определение прохождения двоичного дерева во внутреннем порядке, данное в разд. 2.4. При создании алгоритма, который присваивает узлам номера в соответствии с внутренним порядком, хорошо было бы отразить в нем определение прохождения во внутреннем порядке. Один из таких алгоритмов приведен ниже. Заметим, что он рекурсивно обращается к себе для нумерации поддерева. Алгоритм 2.1. Нумерация узлов двоичного дерева в соответствии с внутренним порядком Вход. Двоичное дерево, представленное массивами Выход. Массив, называемый Метод. Кроме массивов Сам алгоритм таков:
Рекурсия дает несколько преимуществ и прежде всего простоту программ. Если бы приведенный выше алгоритм не был записан рекурсивно, надо было бы строить явный механизм для прохождения дерева. Двигаться вниз по дереву нетрудно, но чтобы обеспечить возможность вернуться к предку, надо запомнить всех предков в стеке, а операторы работы со стеком усложнили бы алгоритм.
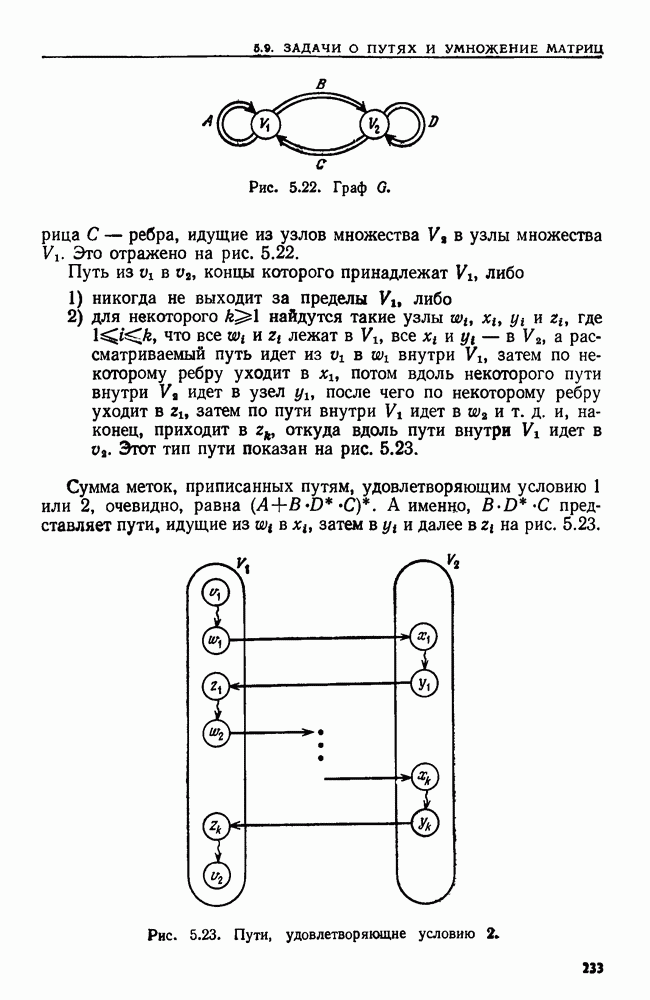
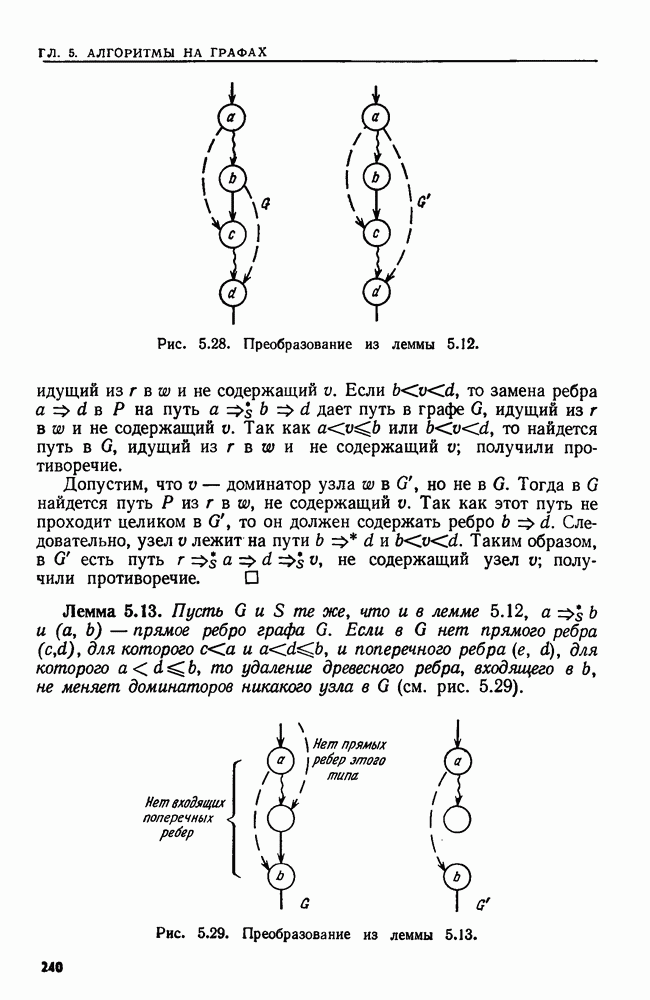
Рис. 2.9. Рекурсивная процедура для внутреннего порядка. Вариант того же алгоритма, не содержащий рекурсии, мог бы быть таким: Алгоритм 2.2. Вариант алгоритма 2.1 без рекурсии Вход. Тот же, что у алгоритма 2.1. Выход. Тот же, что у алгоритма 2.1. Метод. При прохождении дерева в стеке запоминаются все узлы, которые еще не были занумерованы и которые лежат на пути из корня в узел, рассматриваемый в данный момент. При переходе из узла При переходе из и к его правому сыну узел Рис. 2.10. (см. скан) Алгоритм без рекурсии для внутреннего порядка. узла Корректность варианта с рекурсией легко доказать индукцией по числу вершин в двоичном дереве. Корректность варианта без рекурсии также можно доказать, но здесь предположение индукции не столь прозрачно и возникают дополнительные трудности в связи с работой со стеком и правильным прохождением двоичного дерева. С другой стороны, платой за рекурсию может оказаться увеличение постоянных множителей у временной и емкостной сложностей. Естественно выяснить теперь, как перевести алгоритмы с рекурсией в команды РАМ. В свете теоремы 1.2 достаточно рассмотреть построение РАСП-программы, так как РАСП можно моделировать с помощью РАМ с замедлением не более чем в постоянное число раз. Обсудим довольно прямолинейный способ реализации рекурсии. Он пригоден для всех программ, о которых идет речь в этой книге, но не охватывает всех случаев, которые могут встретиться. В основе реализации процедуры о рекурсией лежит стек, где хранятся данные, участвующие во всех вызовах процедуры, при которых она еще не завершила свою работу. Иными словами, в стеке находятся все неглобальные данные. Стек разбит на фрагменты стека, представляющие собой блоки последовательных ячеек (регистров). Каждый вызов процедуры использует фрагмент стека, длина которого зависит от вызываемой процедуры. Пусть сейчас выполняется процедура А, а стек выглядит, как на рис. 2.11. Если А вызывает процедуру В, происходит следующее: 1. В вершину стека помещается фрагмент стека нужного размера. В него входят в порядке, известном процедуре В, (а) указатели фактических параметров этого вызова процедуры (б) пустое место для локальных переменных, участвующих в процедуре В, (в) адрес РАСП-команды в подпрограмме А, которую следует выполнить после того, как данный вызов В кончит работу (адрес возврата) а). Если В — функция, вырабатывающая некоторое значение, то во фрагмент стека для В также помещается указатель ячейки во фрагменте стека для А, в которую надлежит поместить это значение (адрес значения).
Рис. 2.11. Стек для вызовов рекурсивной процедуры. 2. Управление переходит к первой команде процедуры В. Адрес значения любого параметра или локального идентификатора, принадлежащего В, разыскивается с помощью индексации во фрагменте стека для В. 3. Когда процедура В кончает работу, управление передается процедуре А с помощью такой последовательности шагов: (а) адрес возврата извлекается из вершины стека, (б) если В — функция, то значение, обозначенное выражением из return-оператора, запоминается в ячейке, предписанной адресом значения в стеке, (в) фрагмент стека процедуры В выталкивается из стека (это ставит в вершину стека фрагмент процедуры А), (г) выполнение процедуры А возобновляется в ячейке, указанной в адресе возврата. Пример 2.5. Рассмотрим процедуру Описанную выше реализацию моделирует в некотором смысле соответствующий вариант без рекурсии (алгоритм 2.2). Однако там мы сделали так, что окончание выполнения вызова обязательно теперь хранить адрес возврата или УЗЕЛ в стеке, если фактическим параметром является Время, требуемое для вызова процедуры, пропорционально времени, требуемому для вычисления значений фактических параметров и запоминания указателей их значений в стеке. Время возвращения, разумеется, не превосходит этого времени. При подсчете времени, затрачиваемого несколькими рекурсивными процедурами, обычно легче всего оценить вес вызова процедуры, осуществляющей этот вызов. Тогда можно оценить сверху как функцию от размера входа разность времени, затрачиваемого на вызов каждой процедуры, и времени, затрачиваемого теми процедурами, которые она вызывает. Суммируя эти оценки по всем вызовам процедур, получаем верхнюю границу общего затраченного времени. Для подсчета времени работы алгоритма с рекурсией применяются рекуррентные уравнения. С t-й процедурой связывается функция Напомним, что здесь, как и в других местах, весь анализ сложности (веса) основан на равномерной весовой функции. Если брать логарифмическую весовую функцию, то на анализе временной сложности может сказаться длина стека, используемого для реализации процедур с рекурсией.
|
 |
Оглавление
|
























































































































































































































































































































































































































































































 и
и 
 такой, что
такой, что  номер узла
номер узла  во внутреннем порядке.
во внутреннем порядке.
 и
и  алгоритм использует глобальную переменную
алгоритм использует глобальную переменную  значение которой — номер очередного узла в соответствии с внутренним порядком. Начальным значением переменной
значение которой — номер очередного узла в соответствии с внутренним порядком. Начальным значением переменной  является 1. Параметр УЗЕЛ вначале равен корню. Процедура, изображенная на рис. 2.9, применяется рекурсивно.
является 1. Параметр УЗЕЛ вначале равен корню. Процедура, изображенная на рис. 2.9, применяется рекурсивно.


 к его левому сыну узел
к его левому сыну узел  запоминается в стеке. После нахождения левого поддерева для
запоминается в стеке. После нахождения левого поддерева для  узел
узел  нумеруется и выталкивается из стека. Затем нумеруется правое поддерево для
нумеруется и выталкивается из стека. Затем нумеруется правое поддерево для 
 не помещается в стек, поскольку после нумерации правого поддерева мы не хотим возвращаться в
не помещается в стек, поскольку после нумерации правого поддерева мы не хотим возвращаться в  более того, мы хотим вернуться к тому предку
более того, мы хотим вернуться к тому предку
 который еще не занумерован (т. е. к ближайшему предку
который еще не занумерован (т. е. к ближайшему предку  узла
узла  такому, что
такому, что  лежит в левом поддереве для
лежит в левом поддереве для  Этот алгоритм приведен на рис. 2.10.
Этот алгоритм приведен на рис. 2.10.


 из алгоритма 2.1. Когда, например, она вызывает себя с фактическим параметром
из алгоритма 2.1. Когда, например, она вызывает себя с фактическим параметром  она запоминает в стеке адрес нового значения параметра УЗЕЛ вместе с адресом возврата, указывающим, что по окончании работы этого вызова выполнение программы продолжается со строки 2. Таким образом, переменная УЗЕЛ эффективно заменяется на
она запоминает в стеке адрес нового значения параметра УЗЕЛ вместе с адресом возврата, указывающим, что по окончании работы этого вызова выполнение программы продолжается со строки 2. Таким образом, переменная УЗЕЛ эффективно заменяется на  где бы ни входил УЗЕЛ в это определение процедуры.
где бы ни входил УЗЕЛ в это определение процедуры.
 с фактическим параметром
с фактическим параметром  завершает выполнение и самой вызывающей процедуры. Поэтому нам не
завершает выполнение и самой вызывающей процедуры. Поэтому нам не

 обозначающая время выполнения и процедуры как функцию некоторого параметра
обозначающая время выполнения и процедуры как функцию некоторого параметра  рассматриваемого входа. Обычно рекуррентное уравнение для
рассматриваемого входа. Обычно рекуррентное уравнение для  можно записать в терминах времен выполнения процедур, вызываемых процедурой
можно записать в терминах времен выполнения процедур, вызываемых процедурой  Затем полученная система рекуррентных уравнений решается. Часто в алгоритме фигурирует только одна процедура, и
Затем полученная система рекуррентных уравнений решается. Часто в алгоритме фигурирует только одна процедура, и  зависит лишь от значений
зависит лишь от значений  для конечного числа аргументов
для конечного числа аргументов  меньших
меньших  В следующем разделе мы изучим решения некоторых часто встречающихся систем рекуррентных уравнений.
В следующем разделе мы изучим решения некоторых часто встречающихся систем рекуррентных уравнений.