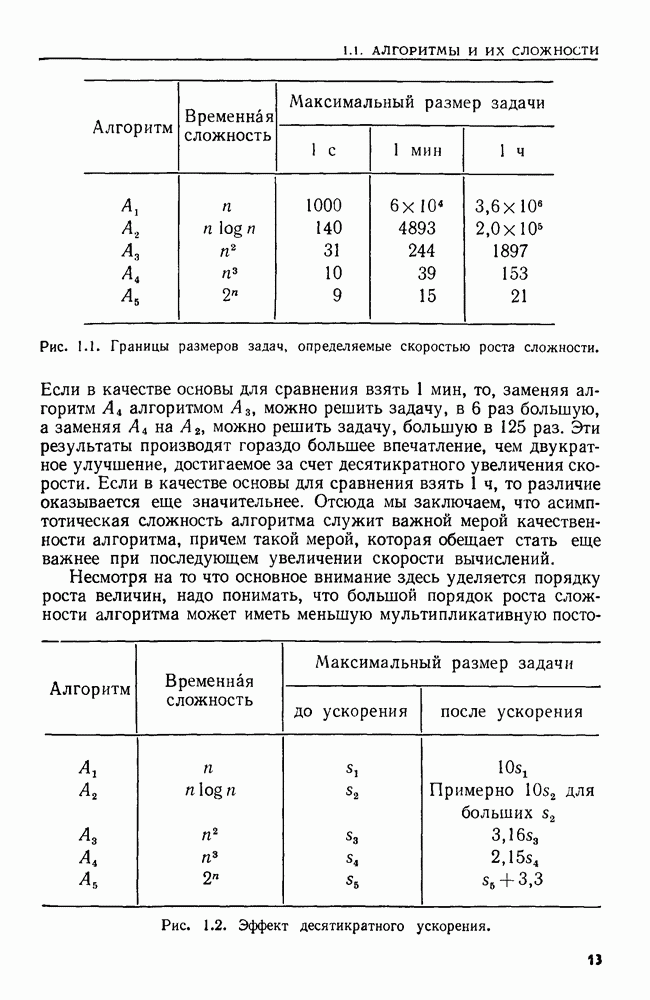
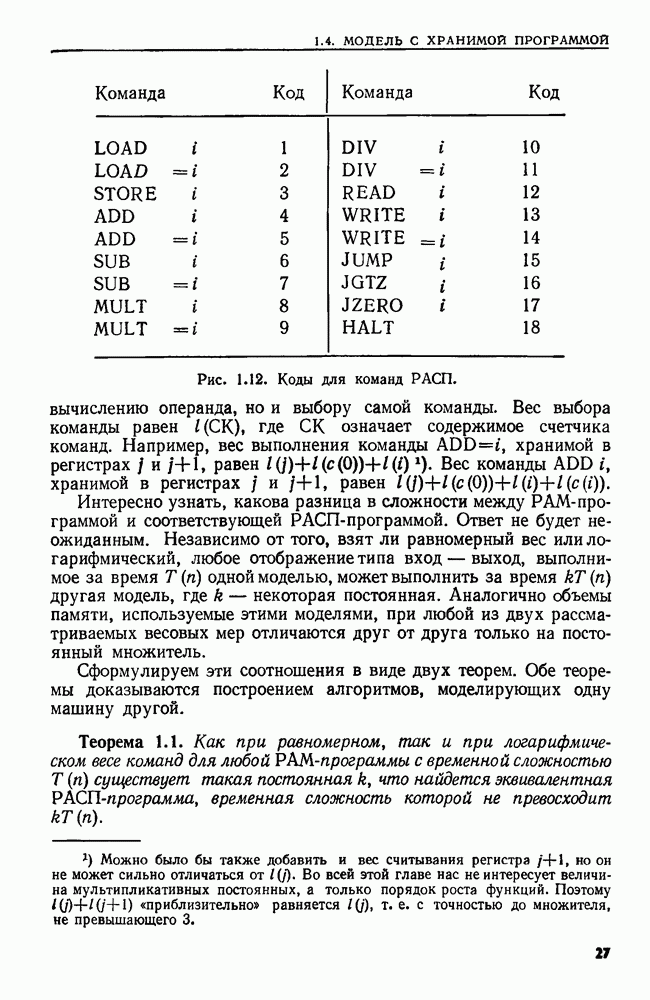
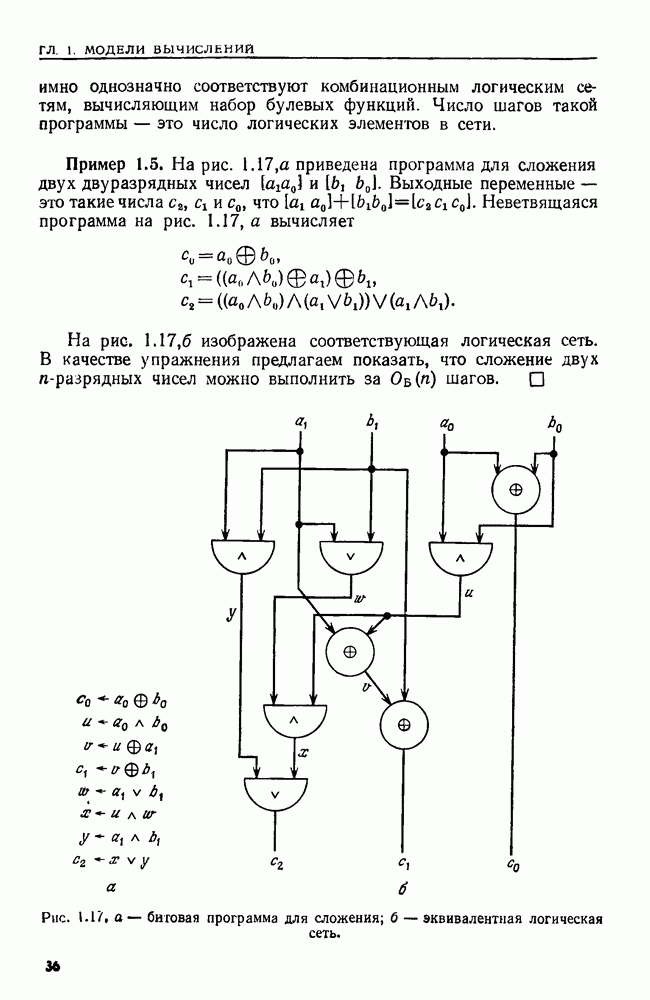
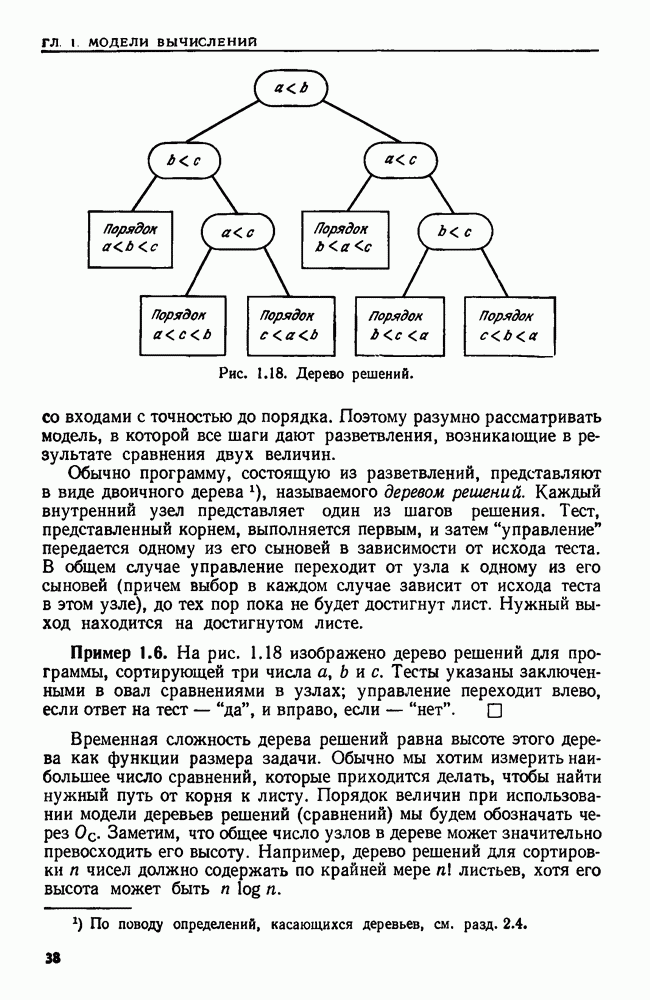
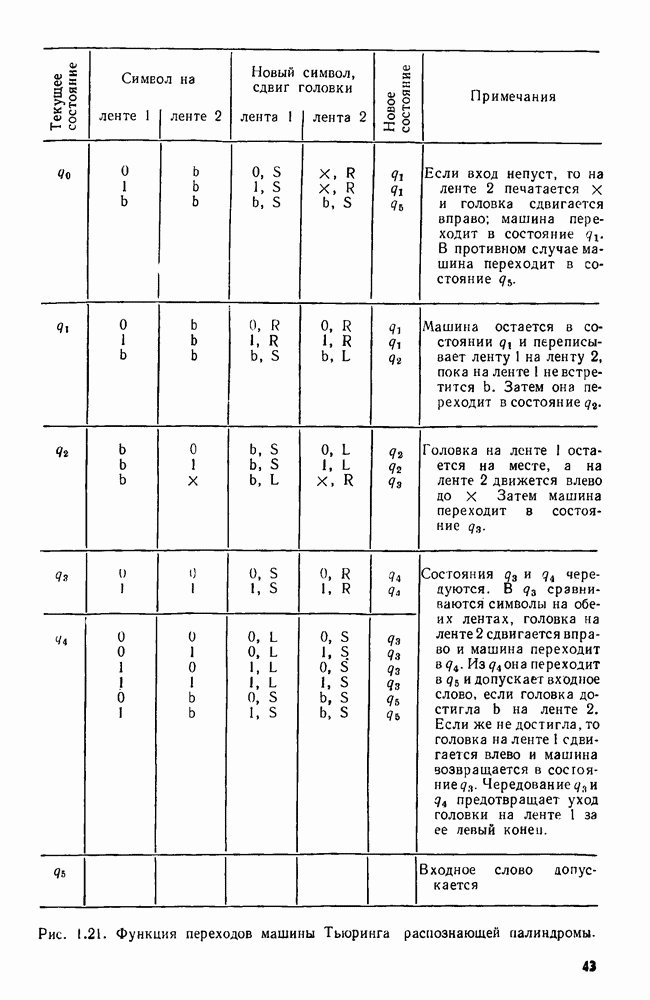
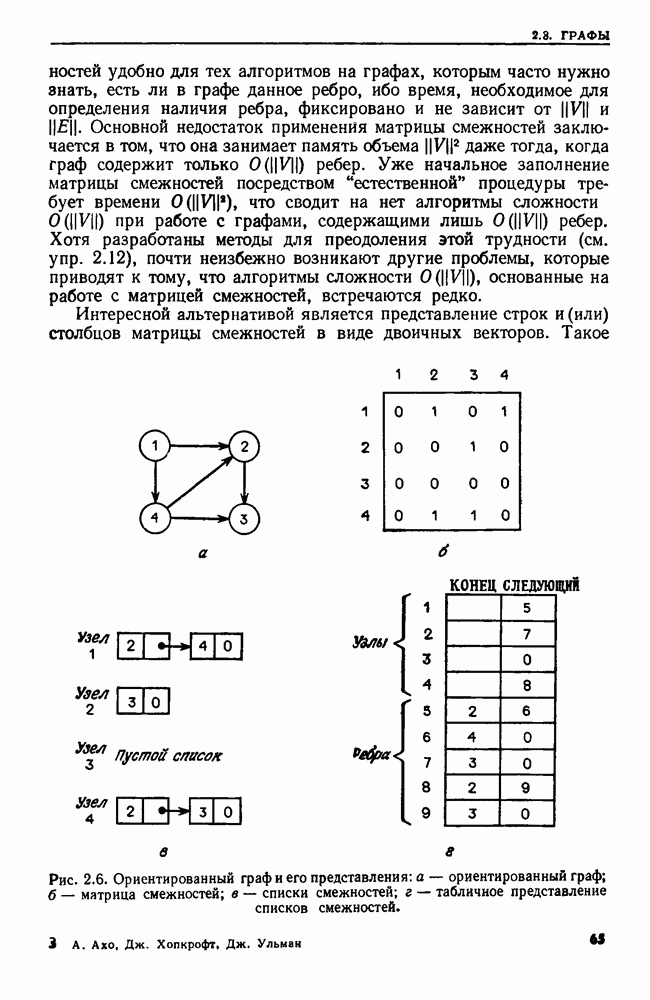
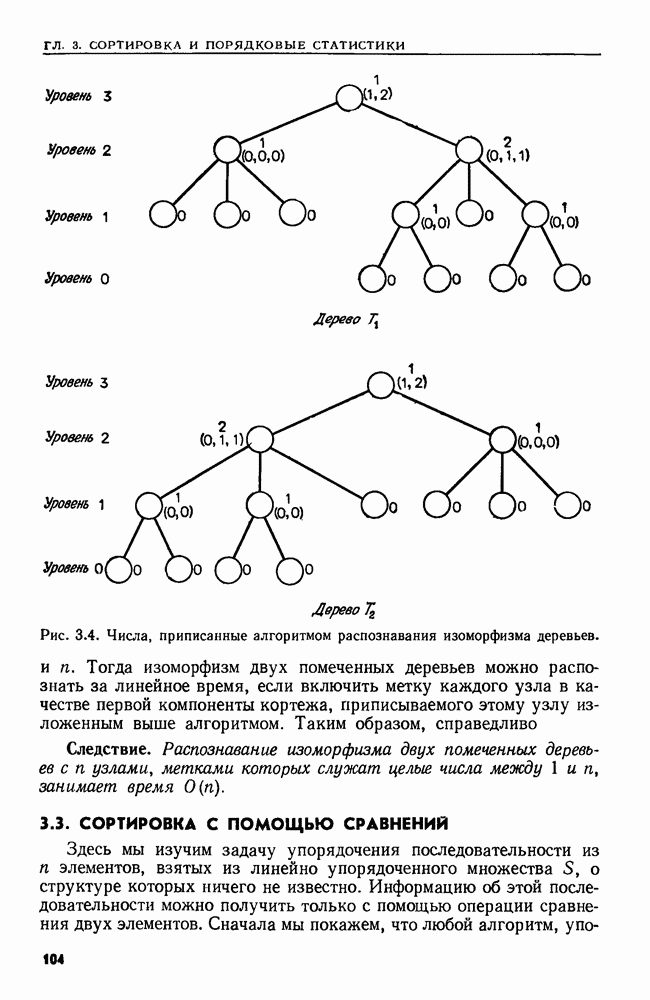
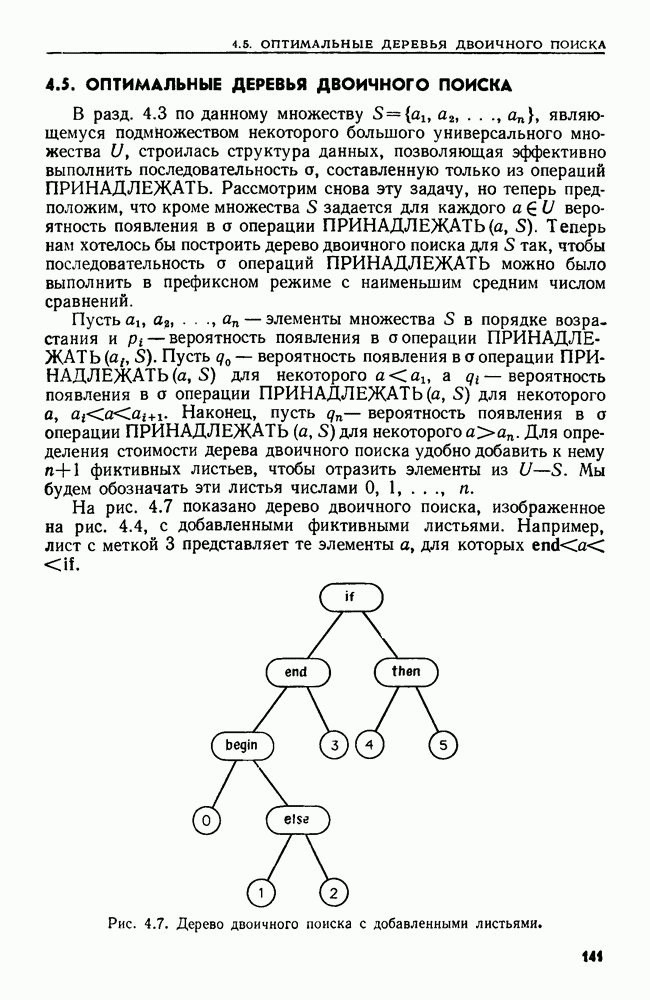
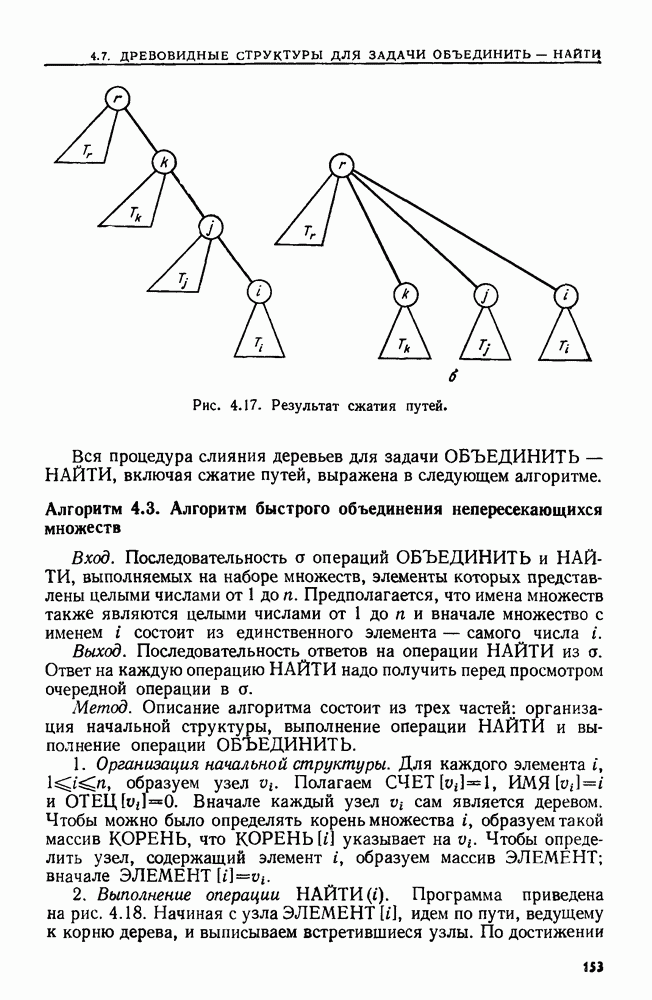
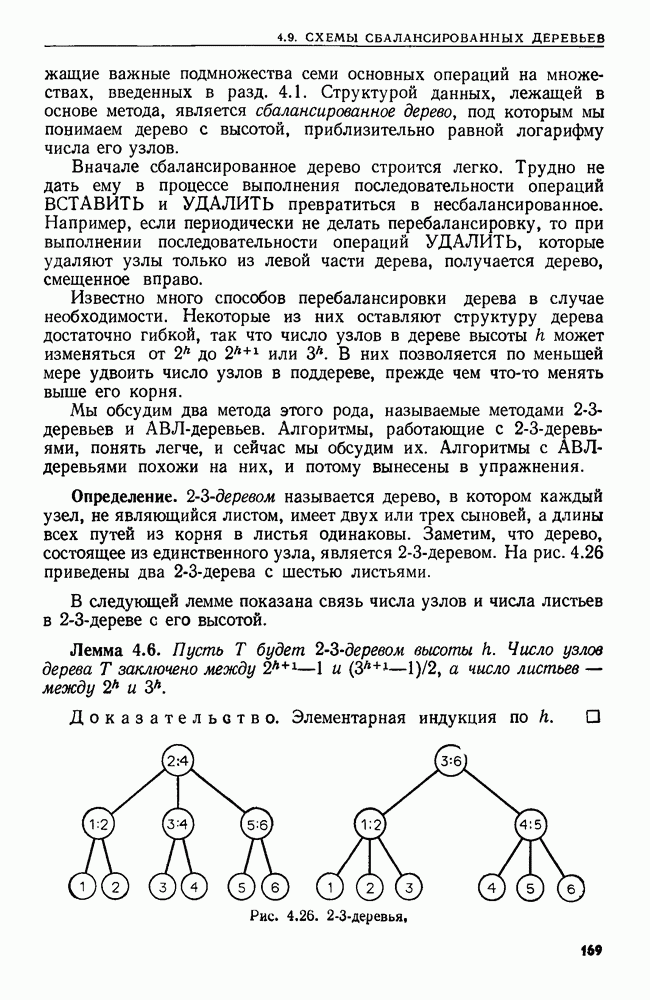
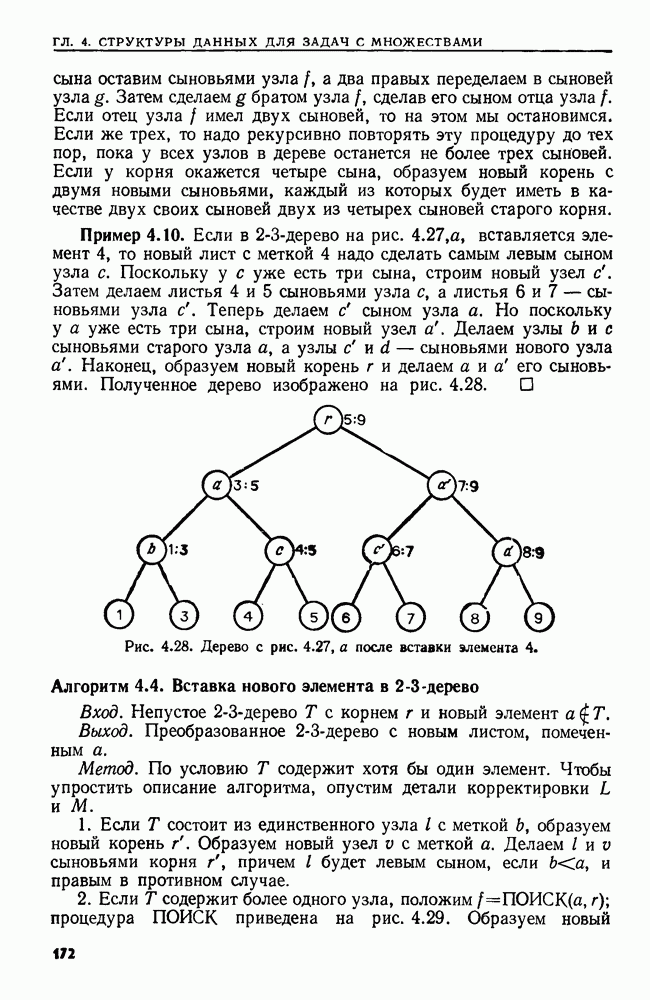
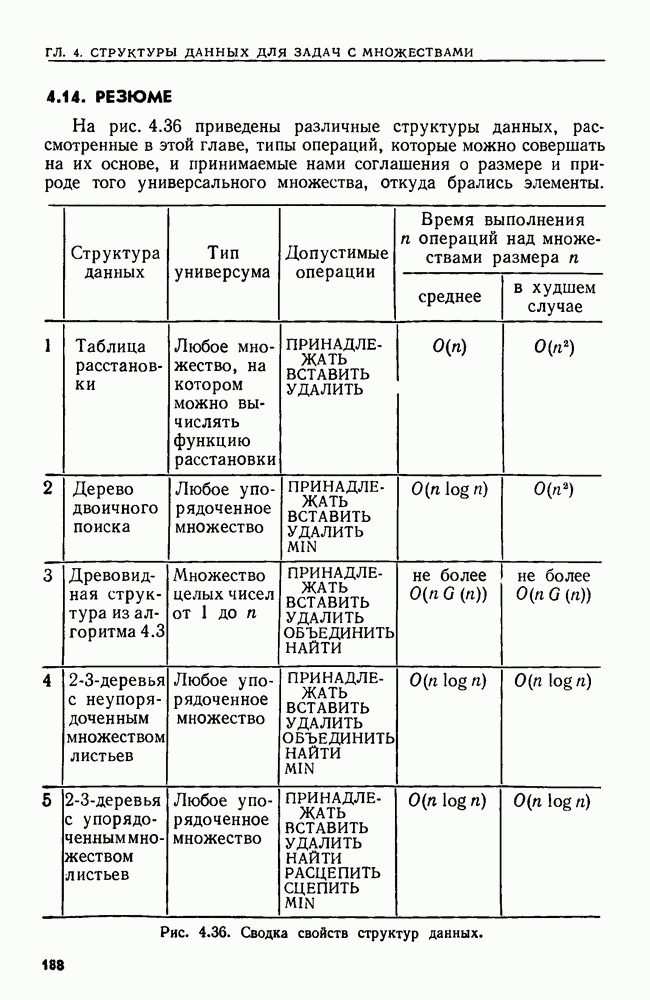
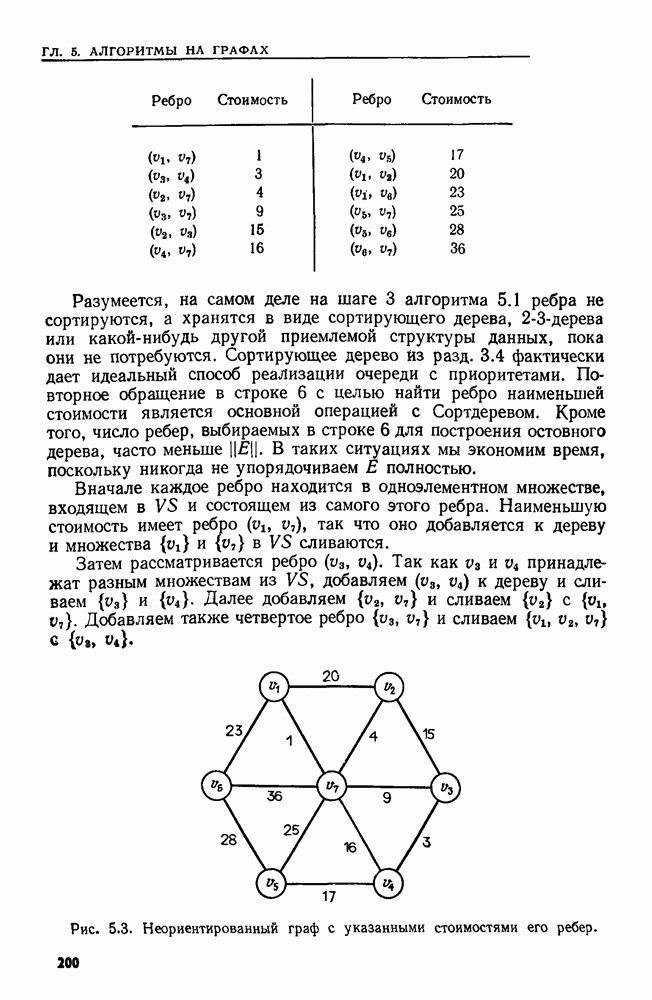
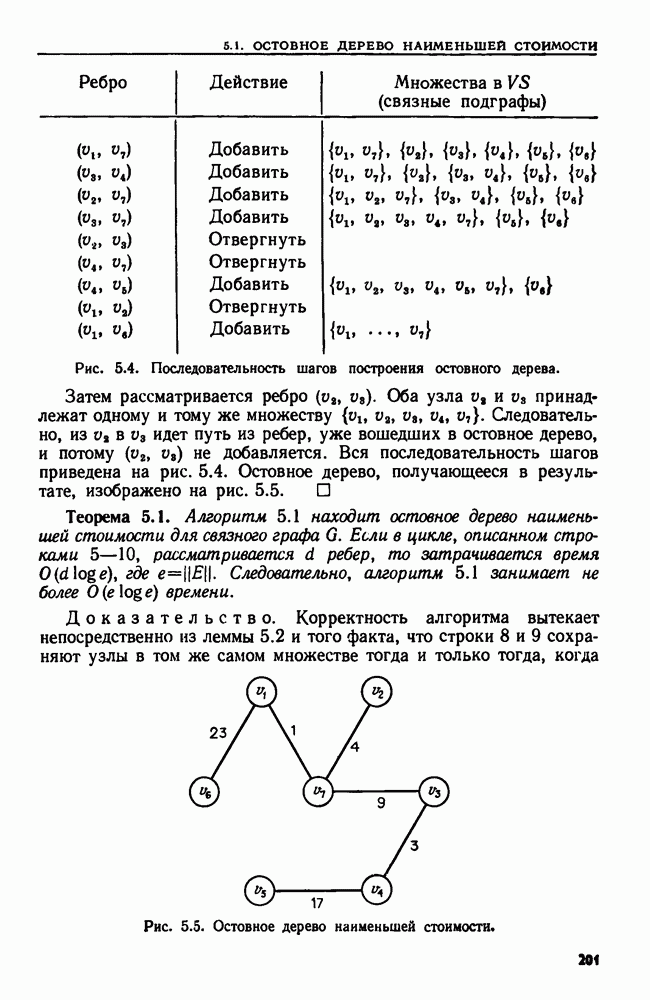
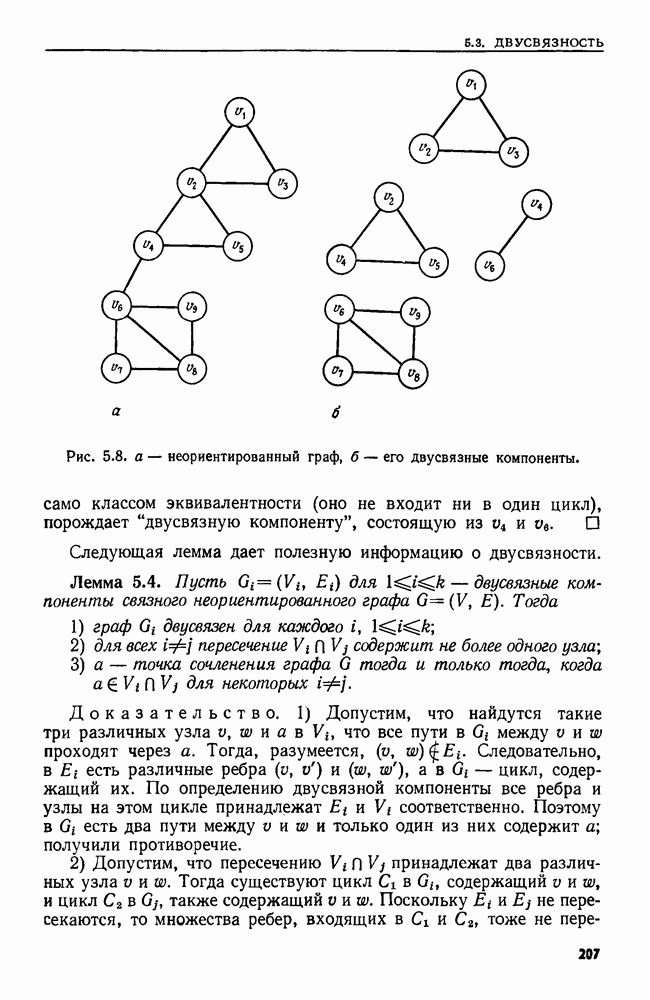
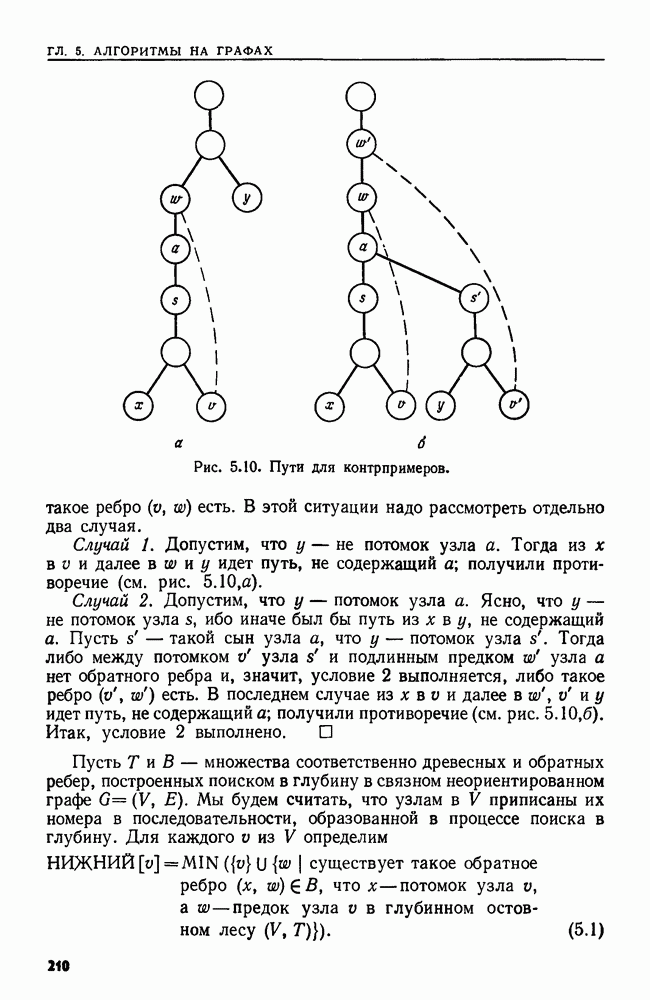
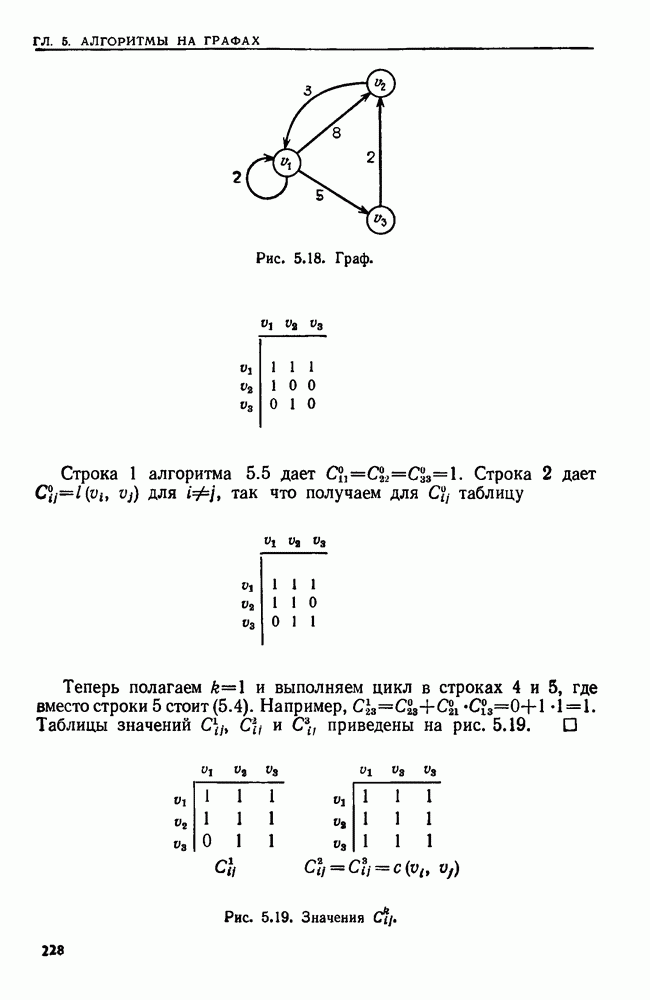
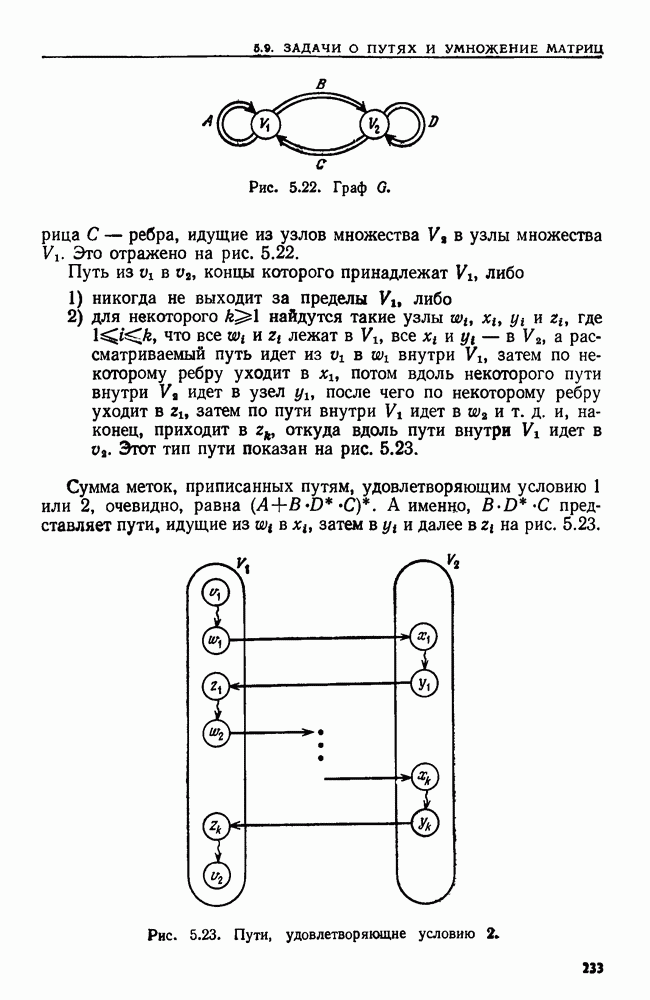
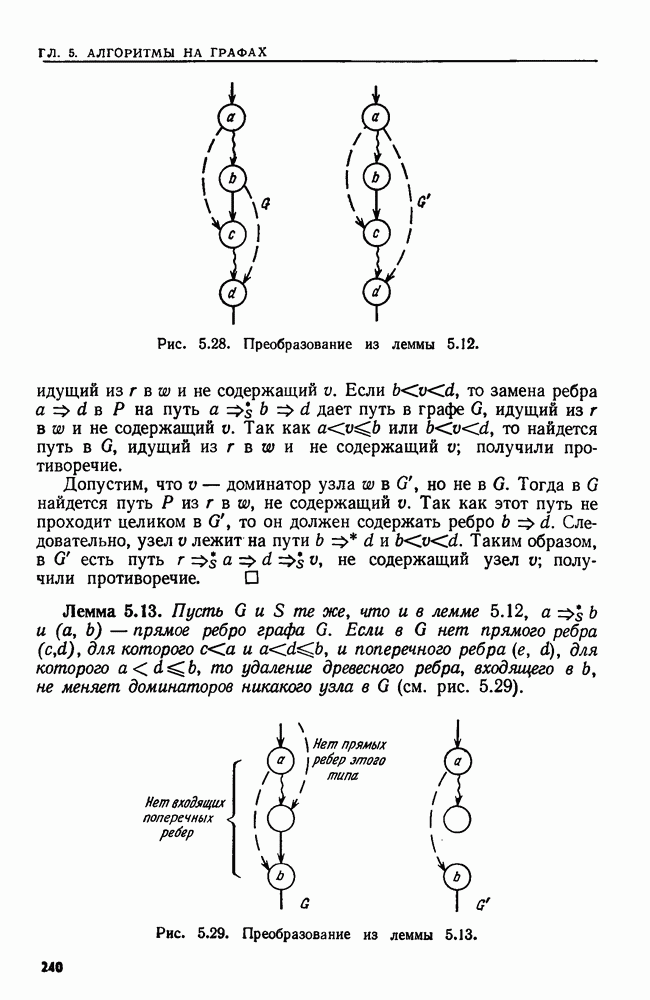
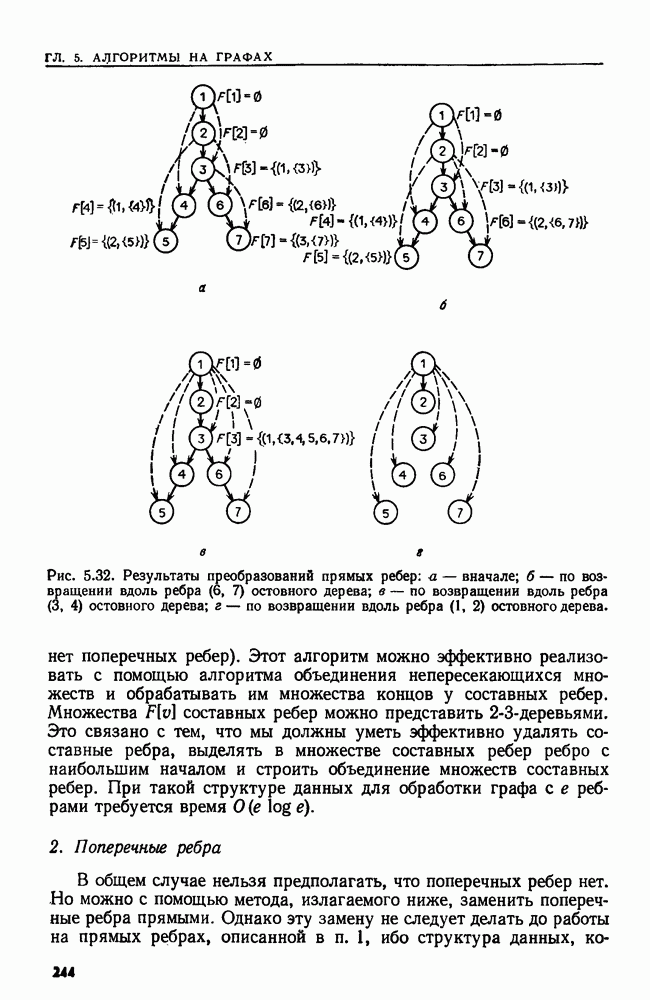
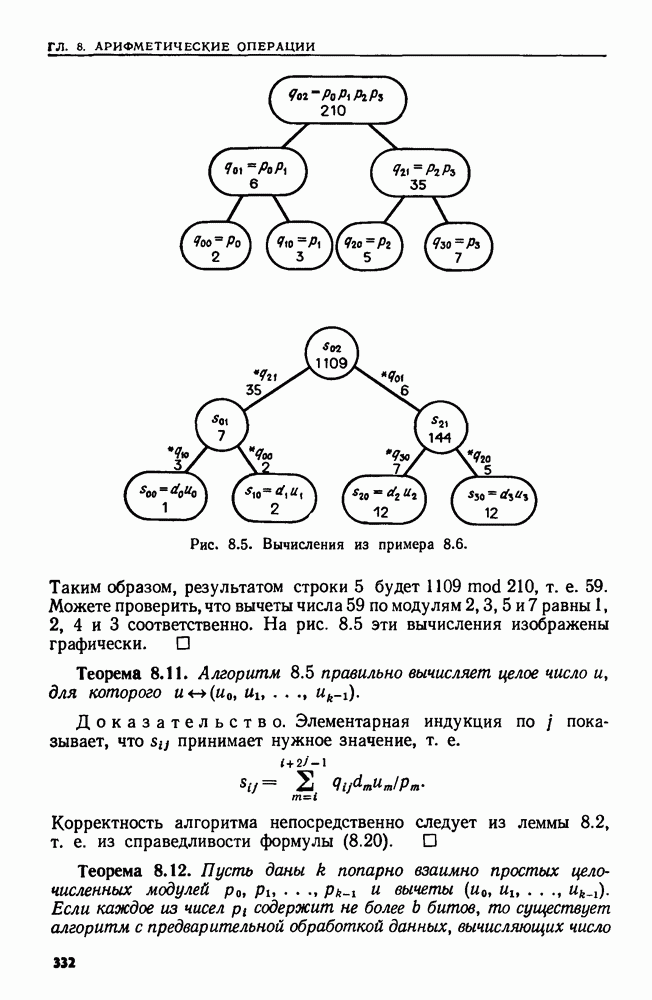
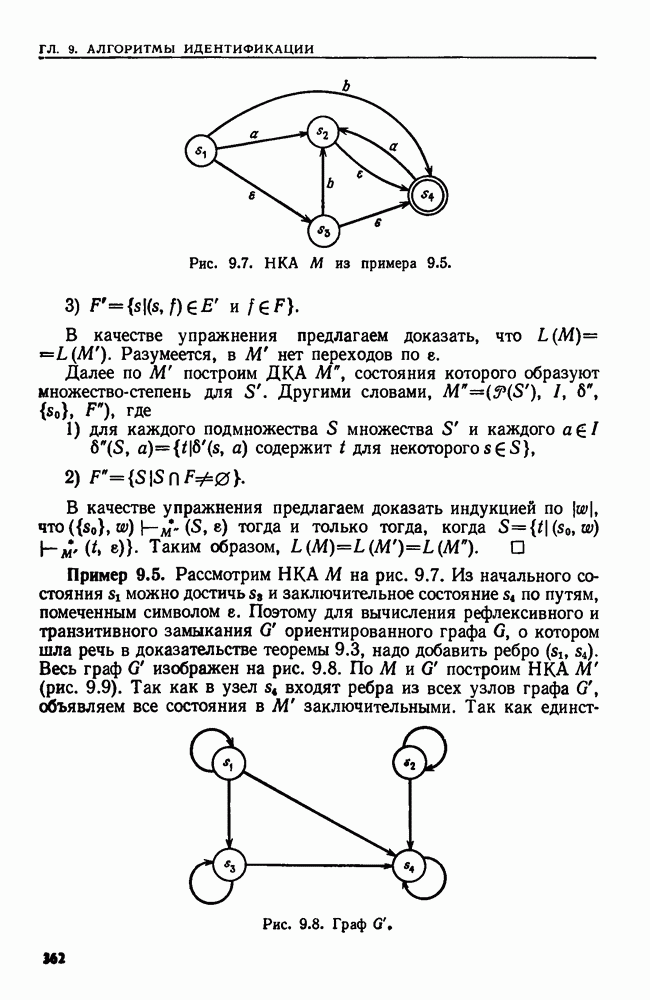
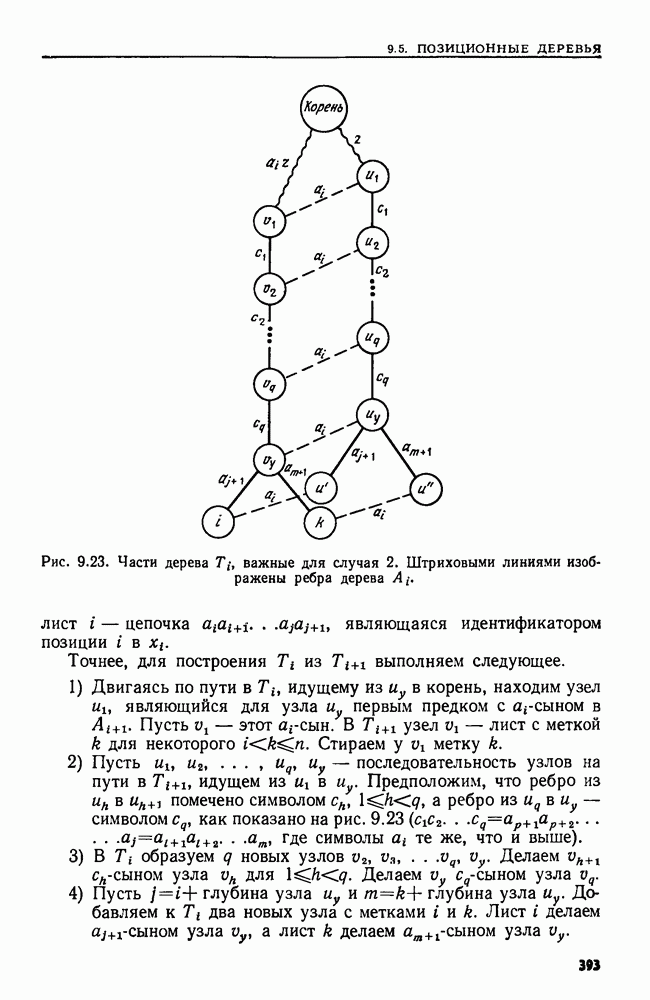
4.3. ДВОИЧНЫЙ ПОИСК
В данном разделе сравниваются три различных решения одной простой задачи поиска. Дано множество  из
из  элементов, взятых из большого универсального множества. Требуется выполнить последовательность
элементов, взятых из большого универсального множества. Требуется выполнить последовательность  состоящую только из операций ПРИНАДЛЕЖАТЬ.
состоящую только из операций ПРИНАДЛЕЖАТЬ.
Наиболее прямым путем решения было бы запомнить элементы множества  в некотором списке. Каждая операция ПРИНАДЛЕЖАТЬ
в некотором списке. Каждая операция ПРИНАДЛЕЖАТЬ  выполняется последовательными просмотрами этого списка до тех пор, пока не найдется данный элемент а или не будут просмотрены все элементы списка. Выполнение всех операций из о заняло бы тогда время порядка
выполняется последовательными просмотрами этого списка до тех пор, пока не найдется данный элемент а или не будут просмотрены все элементы списка. Выполнение всех операций из о заняло бы тогда время порядка  как в худшем случае, так и в среднем. Основное преимущество этой схемы в том, что предварительная работа здесь занимает очень мало времени.
как в худшем случае, так и в среднем. Основное преимущество этой схемы в том, что предварительная работа здесь занимает очень мало времени.
Другой путь — разместить элементы множества  в таблице расстановки размера
в таблице расстановки размера  Операция ПРИНАДЛЕЖАТЬ
Операция ПРИНАДЛЕЖАТЬ  выполняется поиском в списке
выполняется поиском в списке  Если можно найти хорошую функцию
Если можно найти хорошую функцию  то выполнение а займет время
то выполнение а займет время  в среднем и
в среднем и  в худшем случае. Основная трудность здесь связана с нахождением функции расстановки, равномерно распределяющей элементы из
в худшем случае. Основная трудность здесь связана с нахождением функции расстановки, равномерно распределяющей элементы из  в таблице расстановки.
в таблице расстановки.
Если на  задан линейный порядок то третьим решением будет двоичный поиск. Элементы из
задан линейный порядок то третьим решением будет двоичный поиск. Элементы из  хранятся в массиве А. Этот массив упорядочивается так, чтобы было
хранятся в массиве А. Этот массив упорядочивается так, чтобы было  Теперь, чтобы установить, принадлежит ли элемент а множеству
Теперь, чтобы установить, принадлежит ли элемент а множеству  надо сравнить его с элементом
надо сравнить его с элементом  который хранится в ячейке
который хранится в ячейке  Если
Если  то остановиться и ответить "да". В противном случае повторить эту процедуру на первой половине массива, если
то остановиться и ответить "да". В противном случае повторить эту процедуру на первой половине массива, если  и на второй, если
и на второй, если  Повторно разбивая область поиска пополам, можно не более чем за
Повторно разбивая область поиска пополам, можно не более чем за  сравнений либо найти а, либо установить, что его нет в
сравнений либо найти а, либо установить, что его нет в 
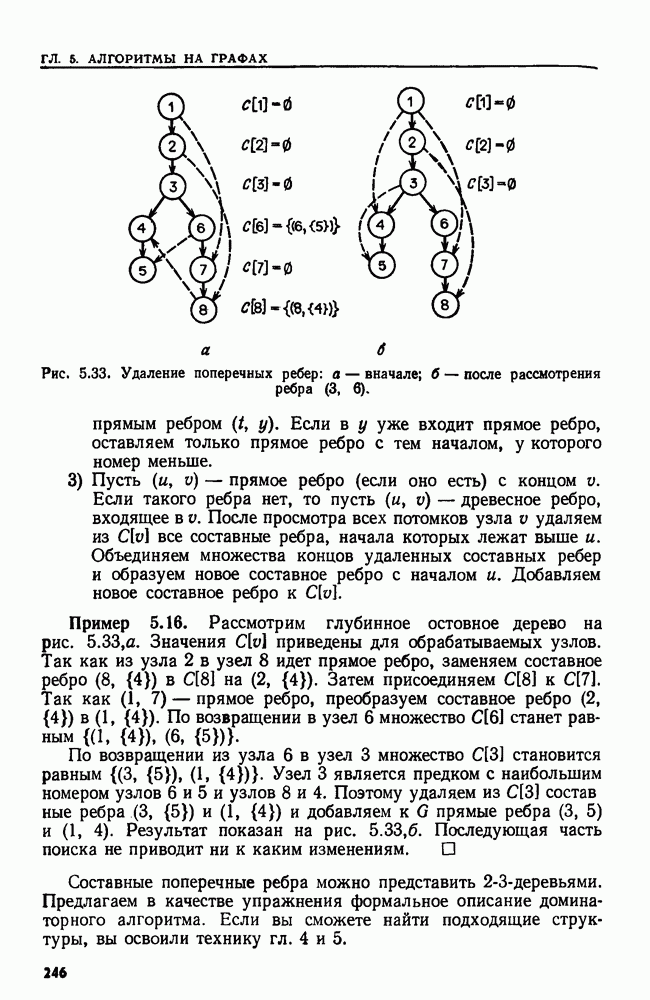
Рекурсивная процедура  приведенная на рис. 4.3, ищет элемент а в ячейках
приведенная на рис. 4.3, ищет элемент а в ячейках  массива А. Для установления принадлежности а множеству
массива А. Для установления принадлежности а множеству  вызывается
вызывается 
Чтобы понять, почему эта процедура работает, представим массив А в виде двоичного дерева. Корень находится в ячейке  а его левый и правый сыновья — в ячейках
а его левый и правый сыновья — в ячейках  соответственно, и т. д. Эта интерпретация двоичного поиска станет яснее в следующем разделе.
соответственно, и т. д. Эта интерпретация двоичного поиска станет яснее в следующем разделе.

Рис. 4.3. Процедура двоичного поиска.
Легко показать, что на розыск элемента в ПОИСК тратит не более  сравнений, так как никакой путь в рассматриваемом дереве не длиннее
сравнений, так как никакой путь в рассматриваемом дереве не длиннее  Если все элементы как цели для поиска равновероятны, то можно также показать (упр. 4.4), что ПОИСК дает оптимальное среднее число сравнений (а именно,
Если все элементы как цели для поиска равновероятны, то можно также показать (упр. 4.4), что ПОИСК дает оптимальное среднее число сравнений (а именно,  необходимое для Выполнения операций ПРИНАДЛЕЖАТЬ в последовательности а
необходимое для Выполнения операций ПРИНАДЛЕЖАТЬ в последовательности а