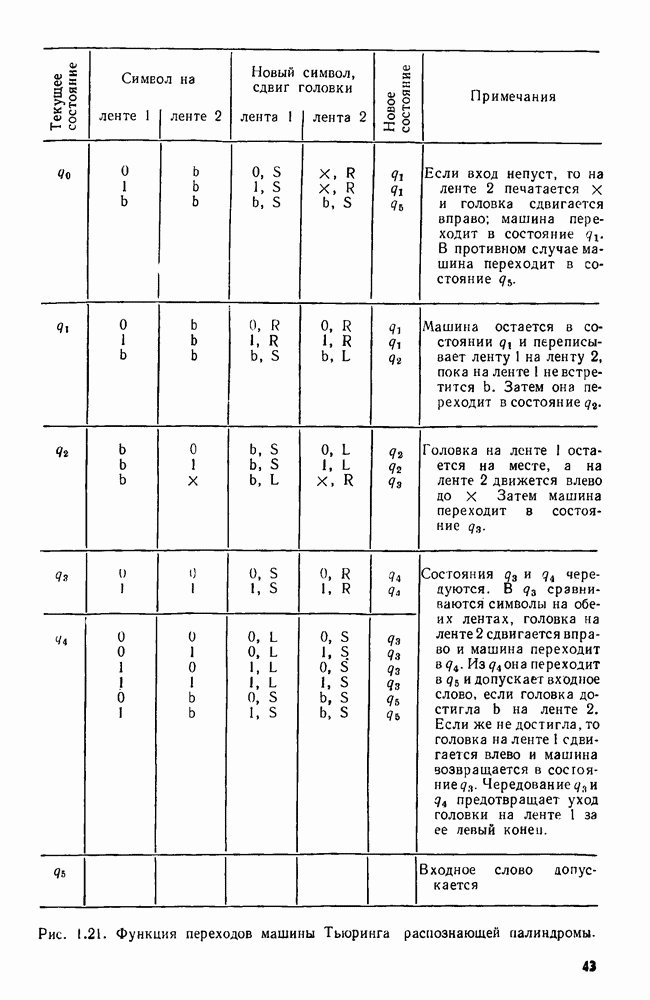
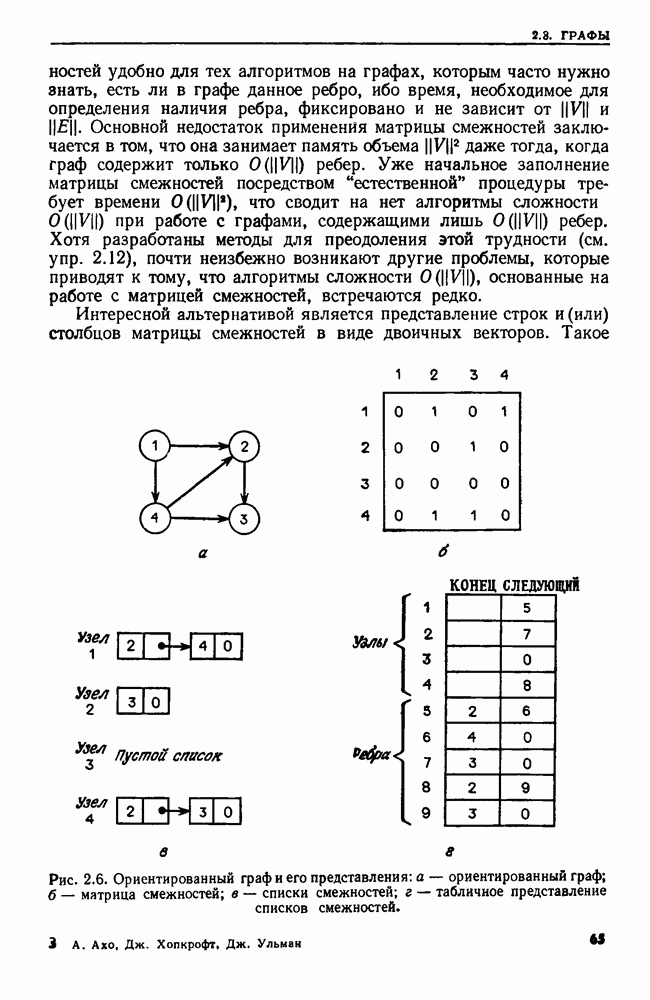
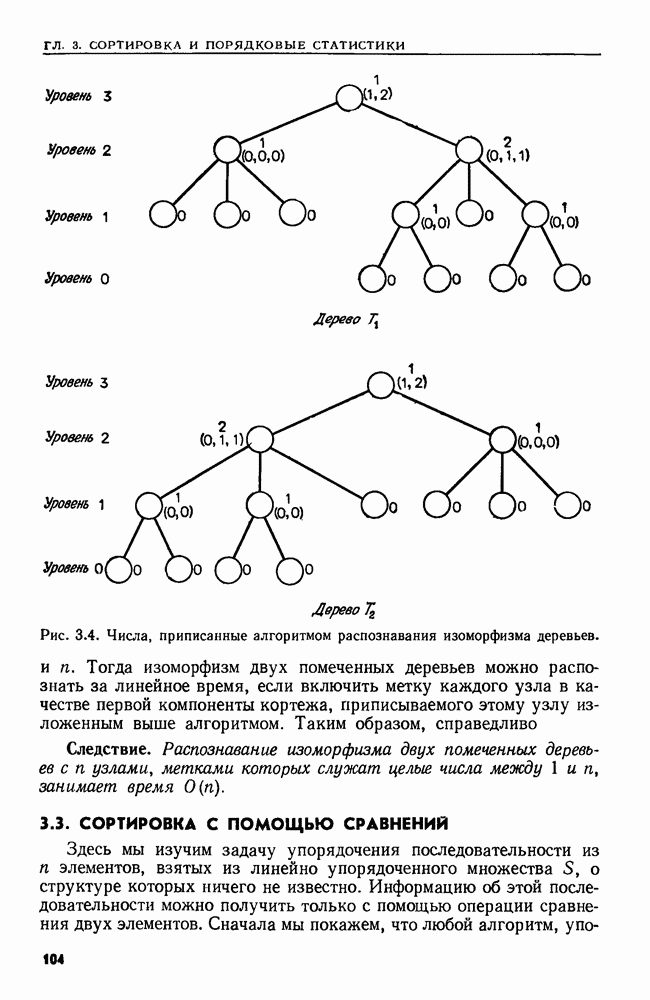
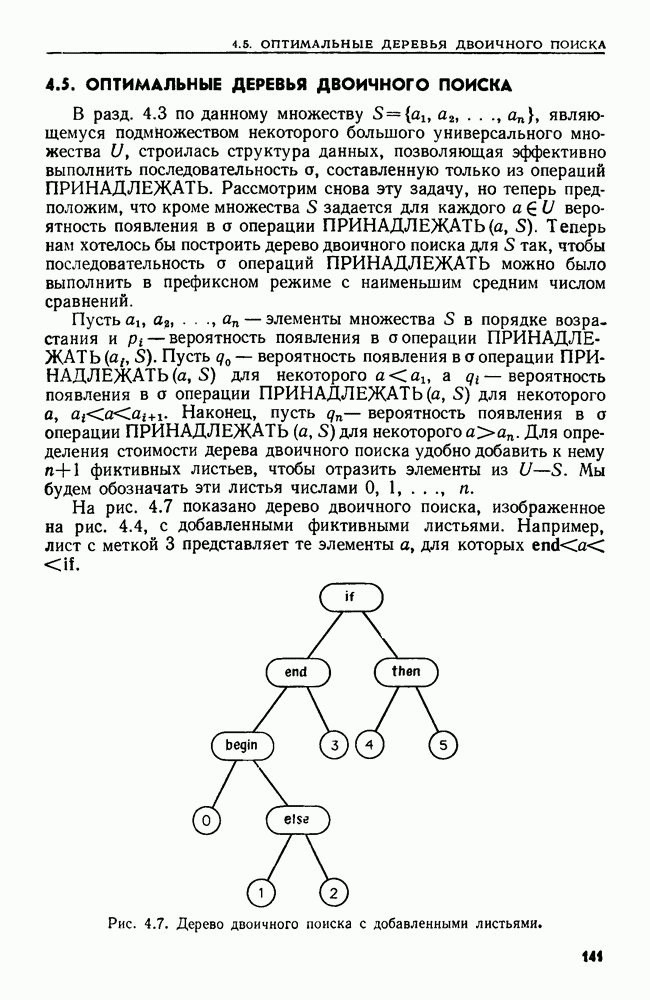
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
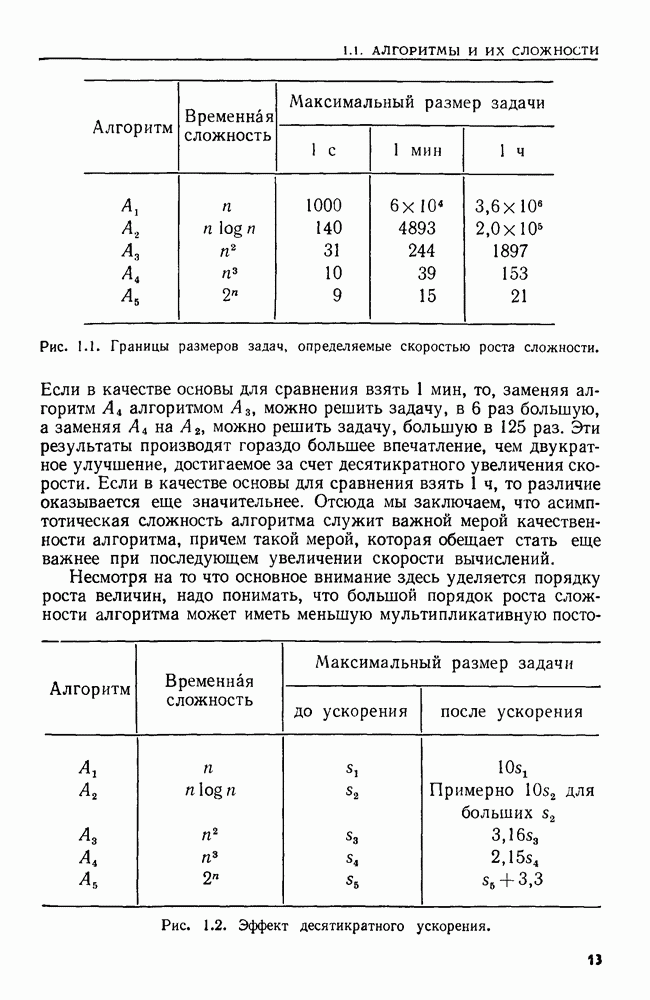
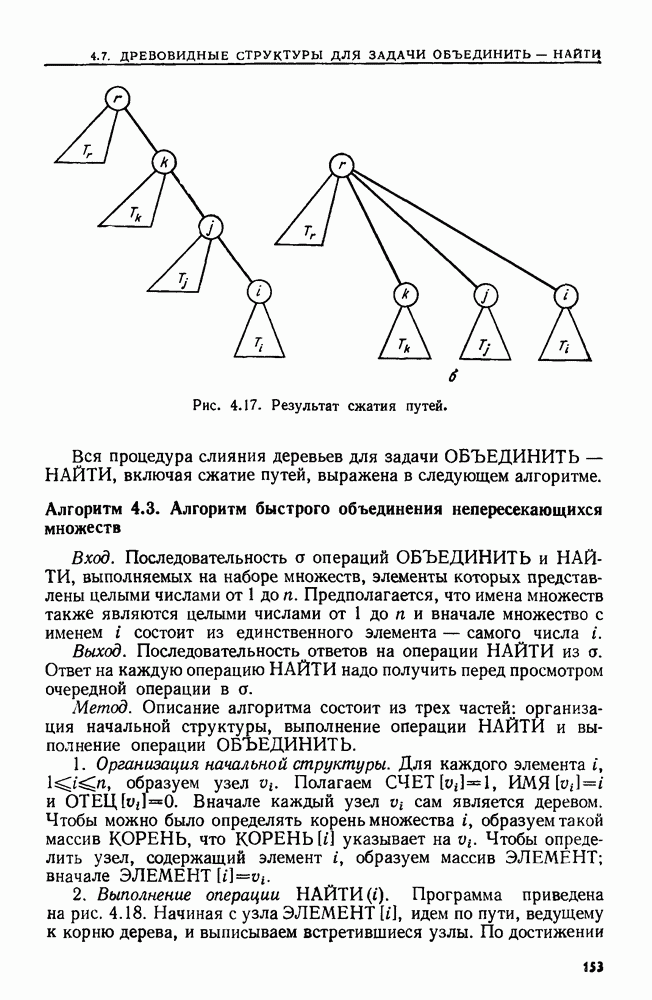
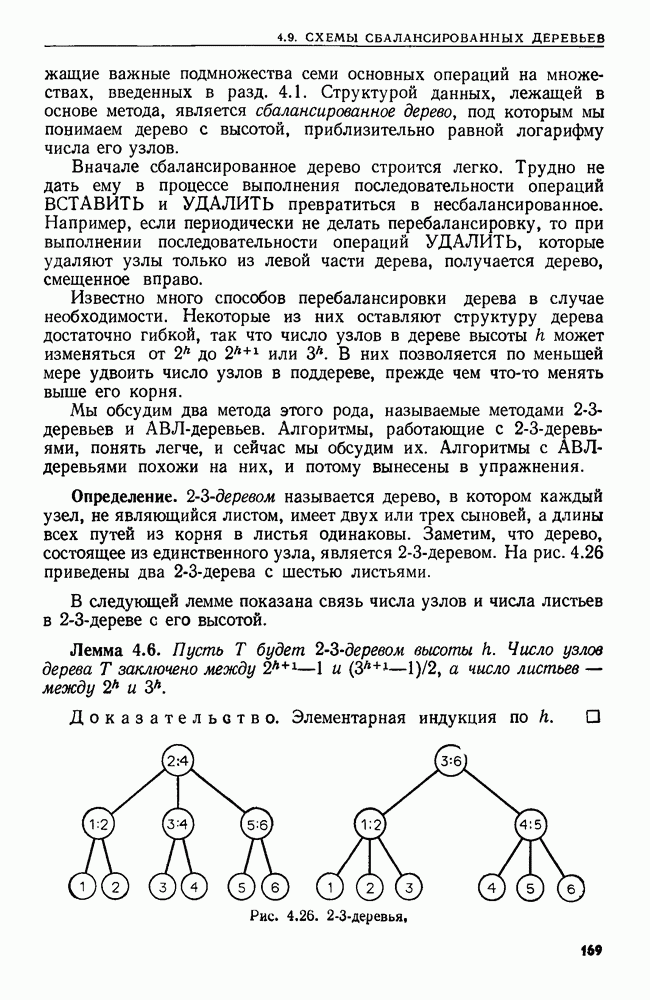
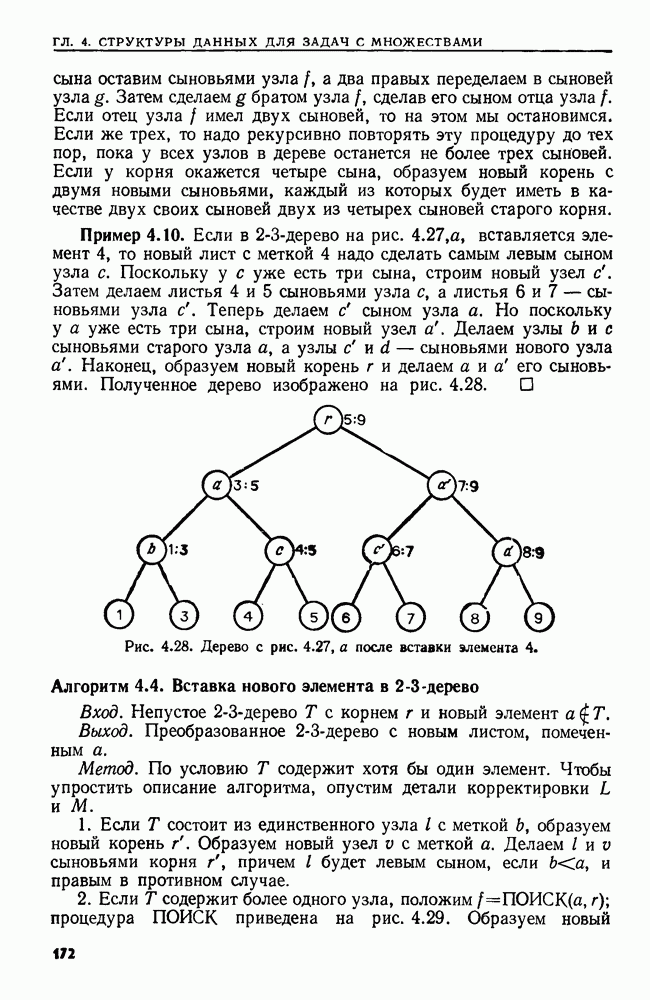
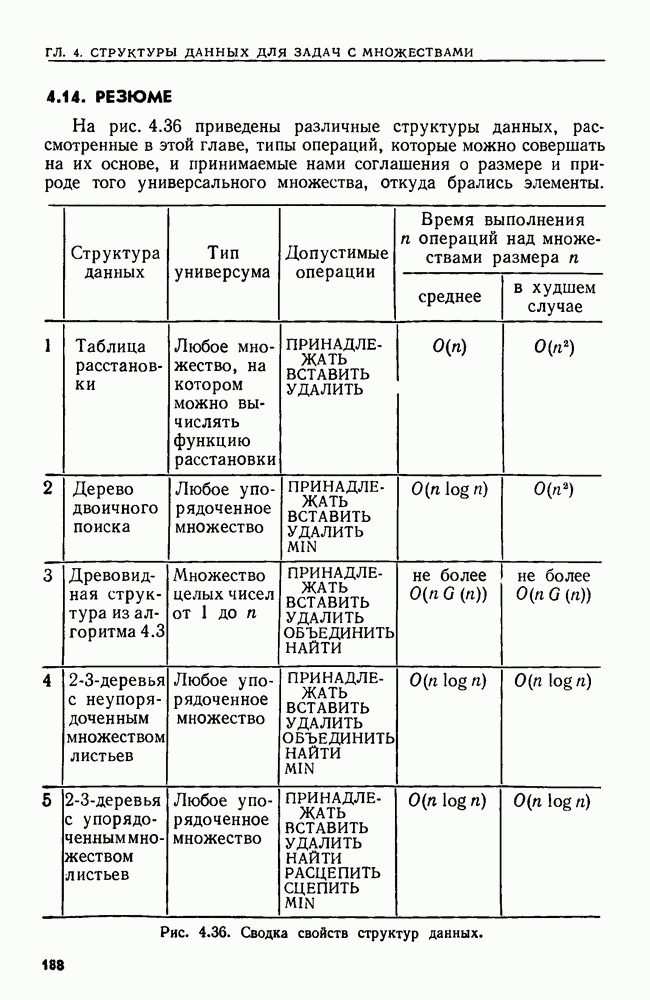
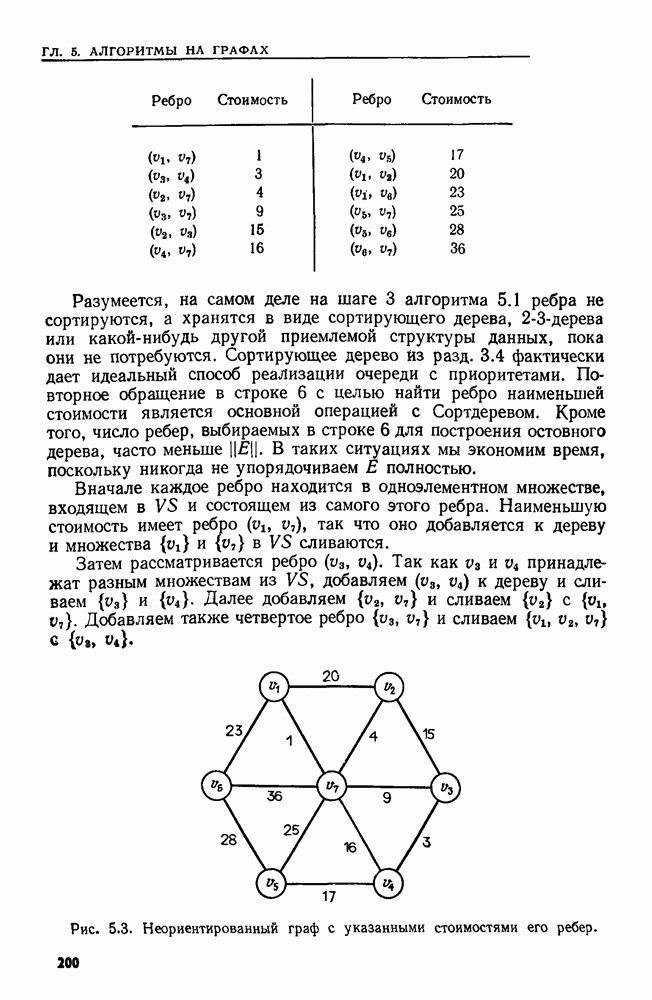
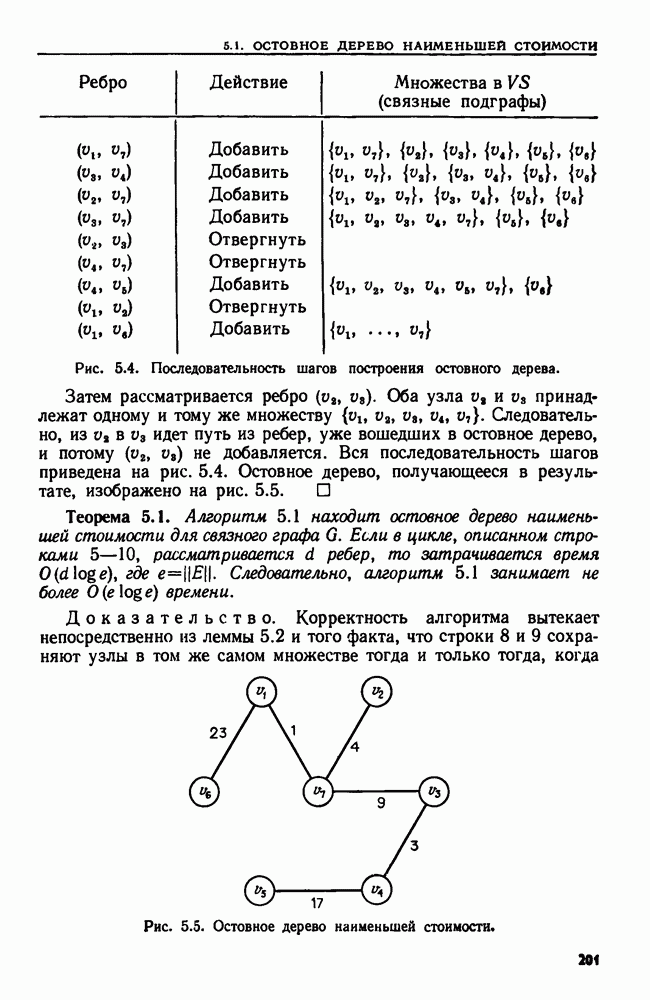
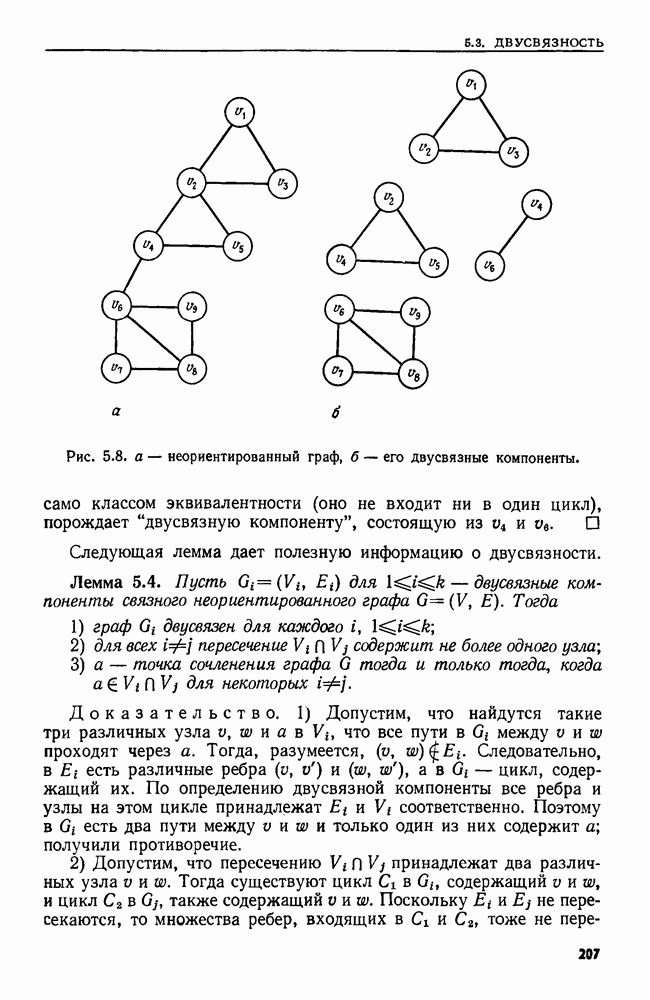
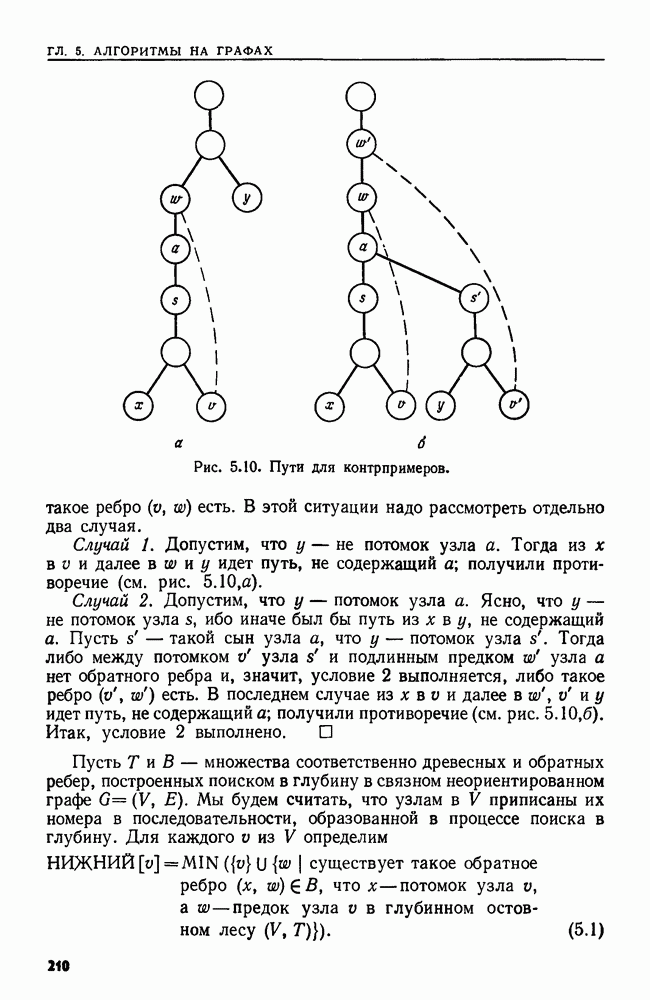
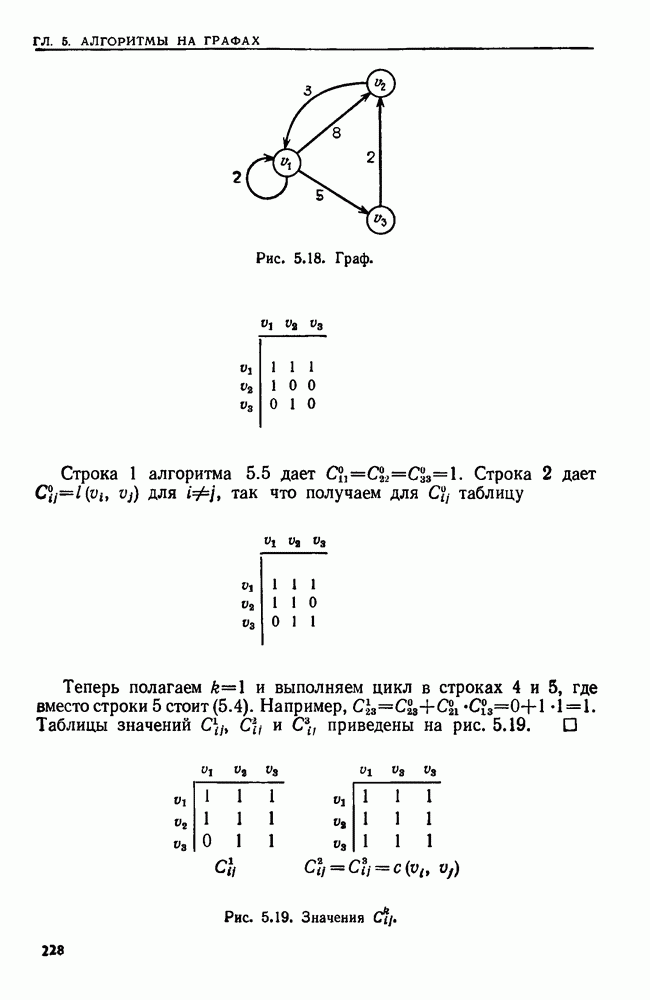
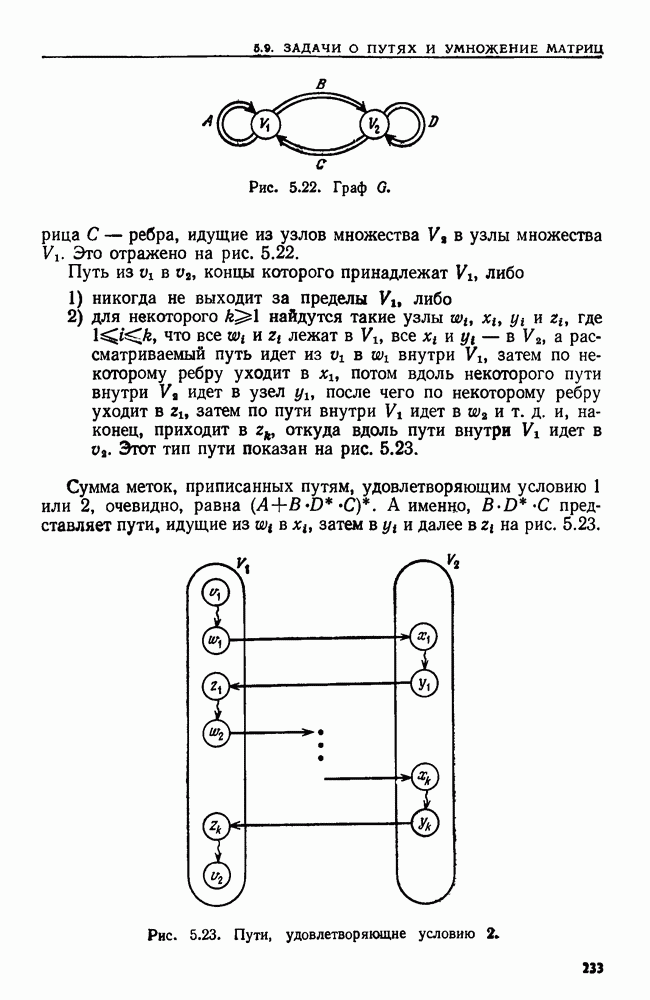
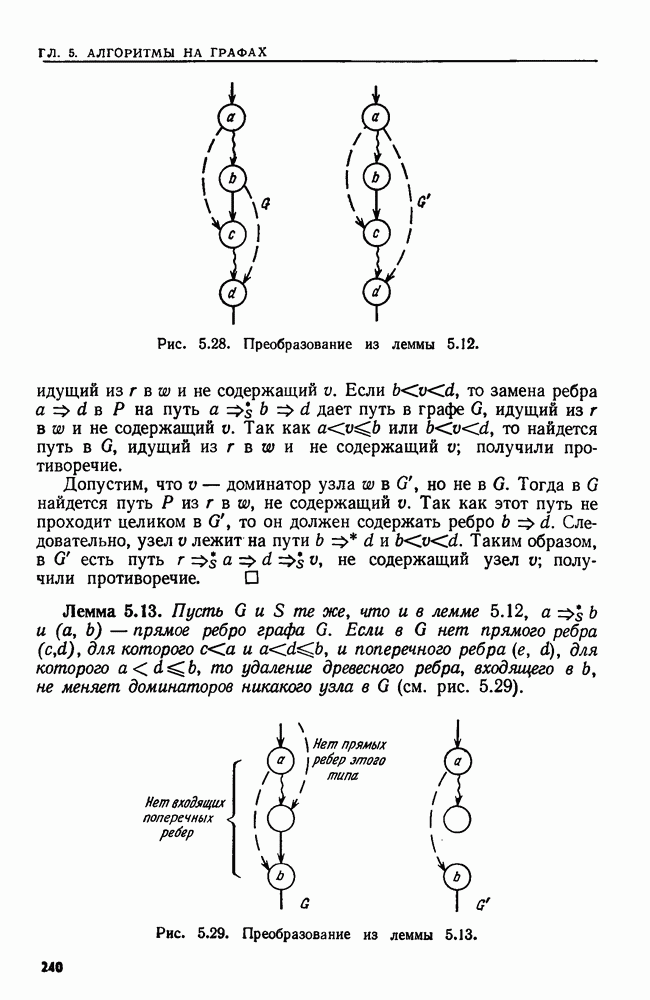
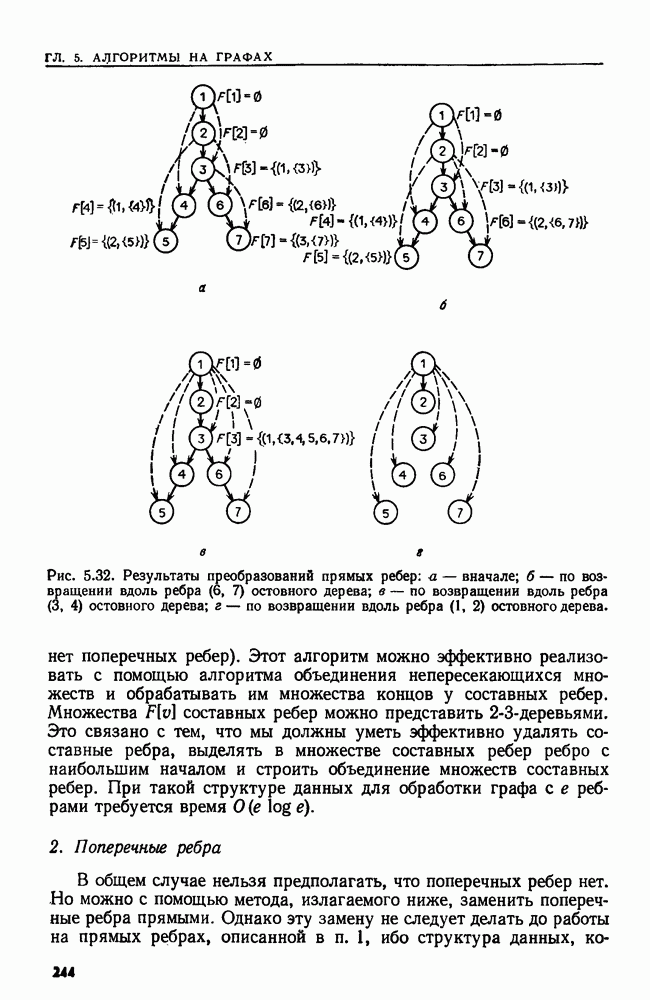
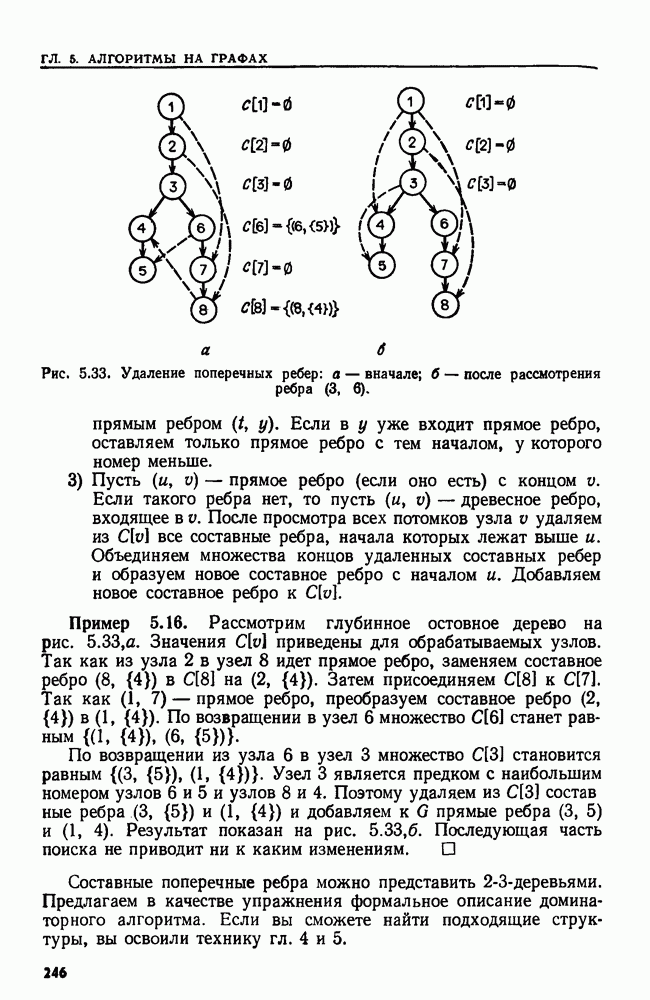
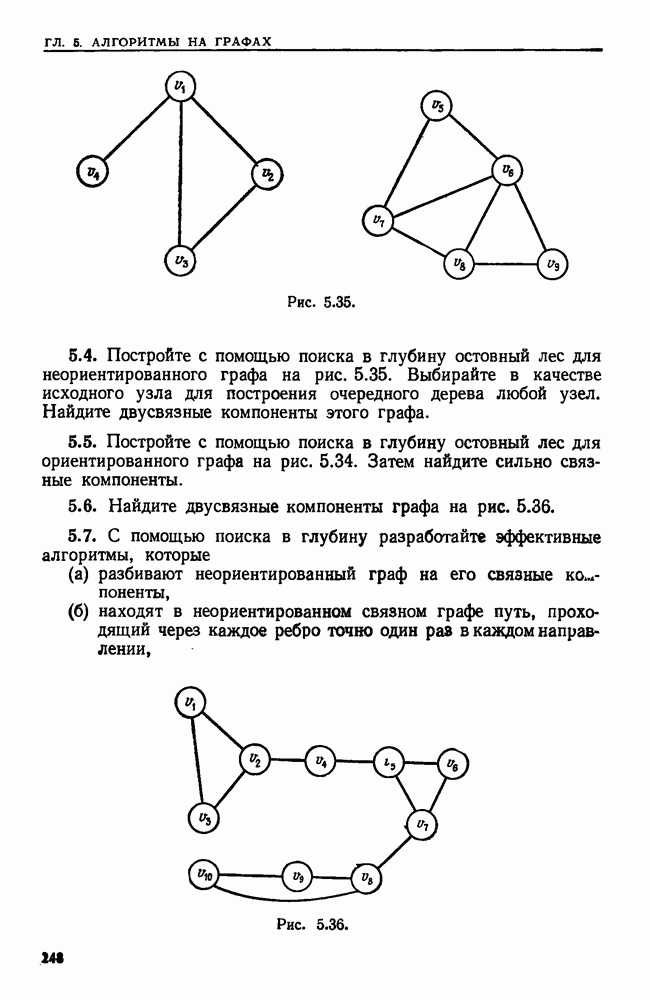
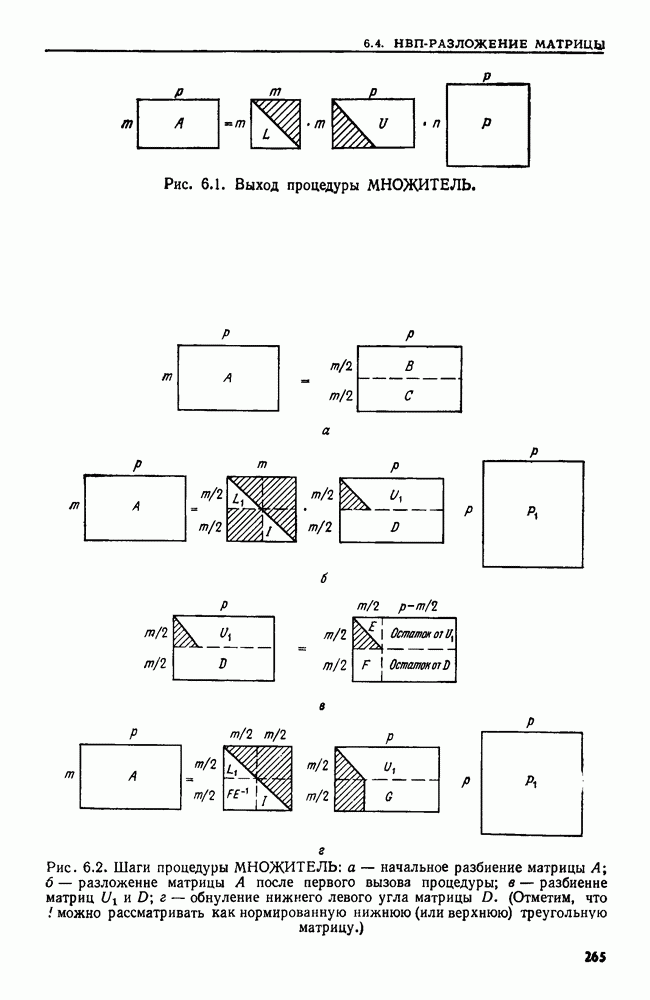
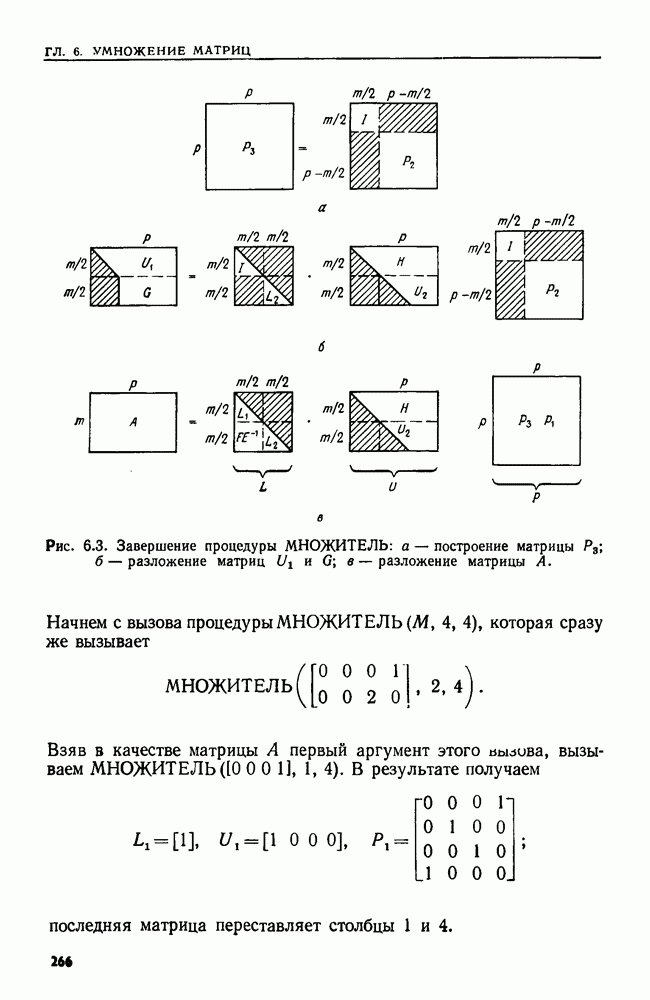
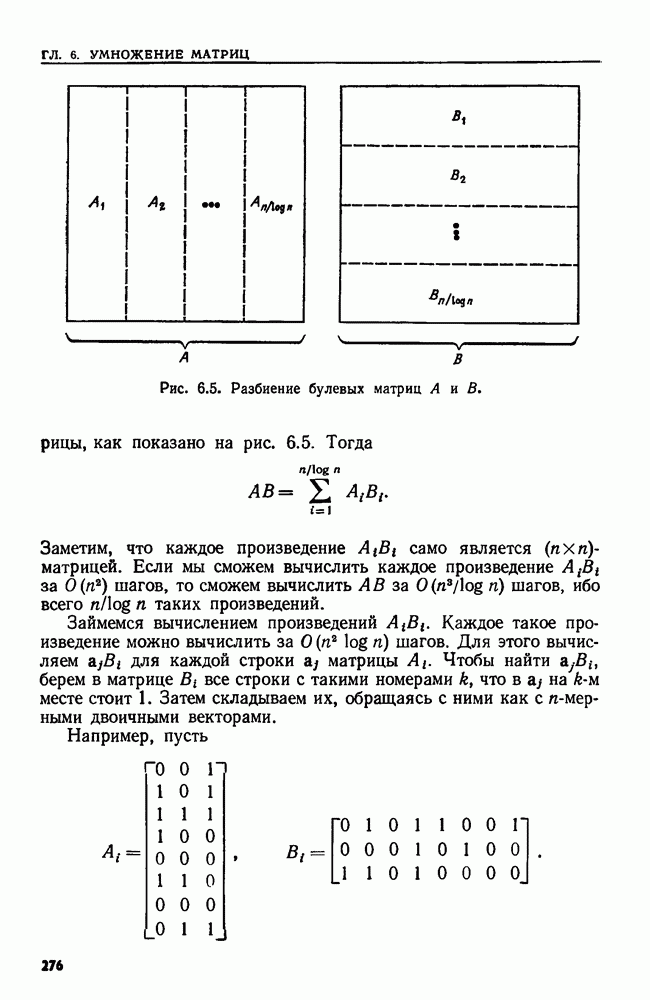
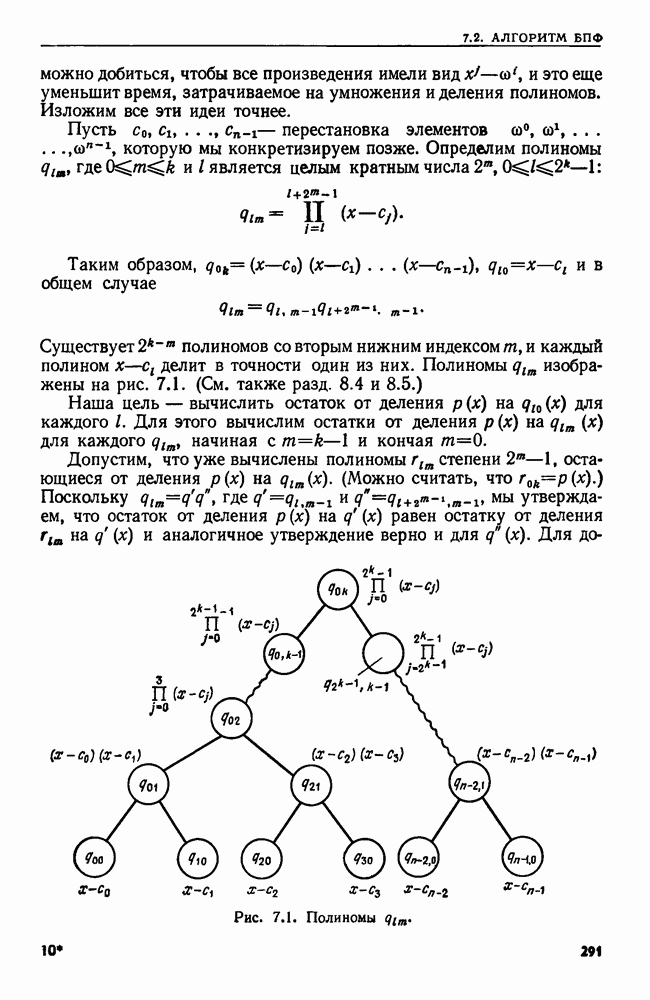
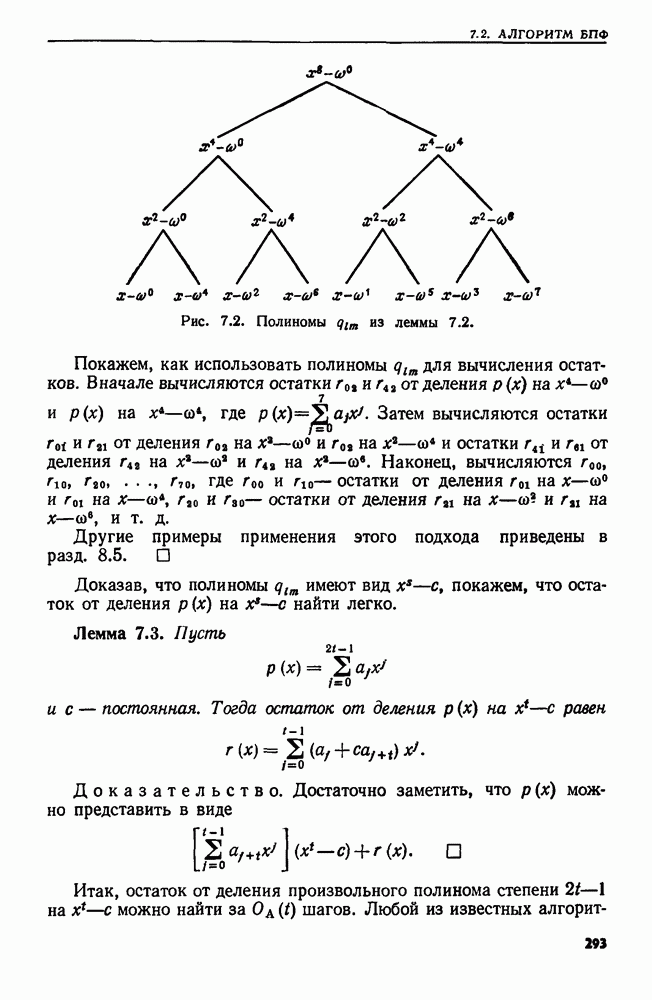
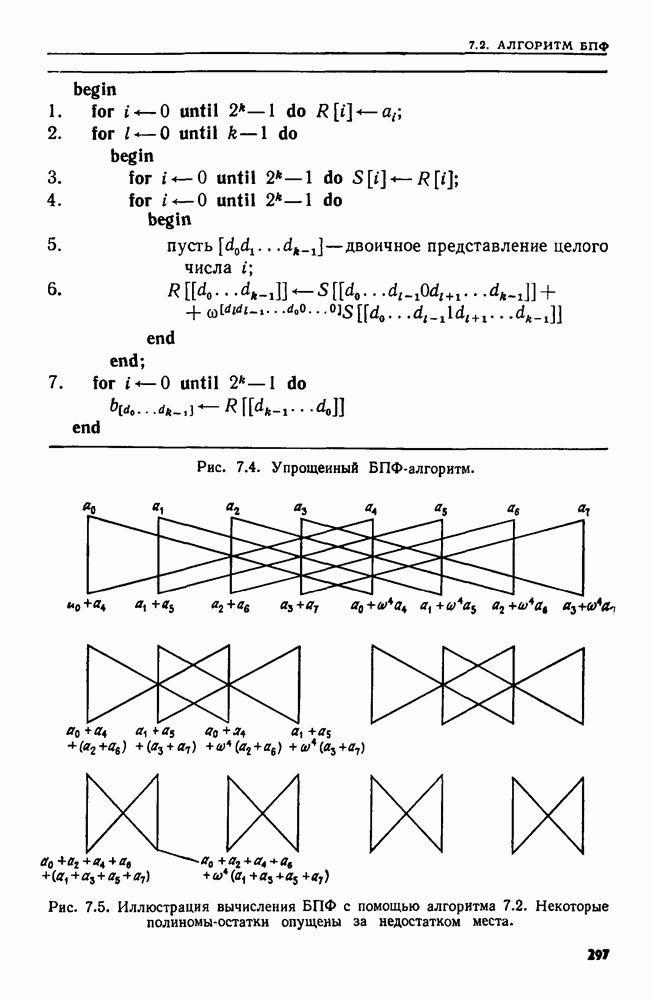
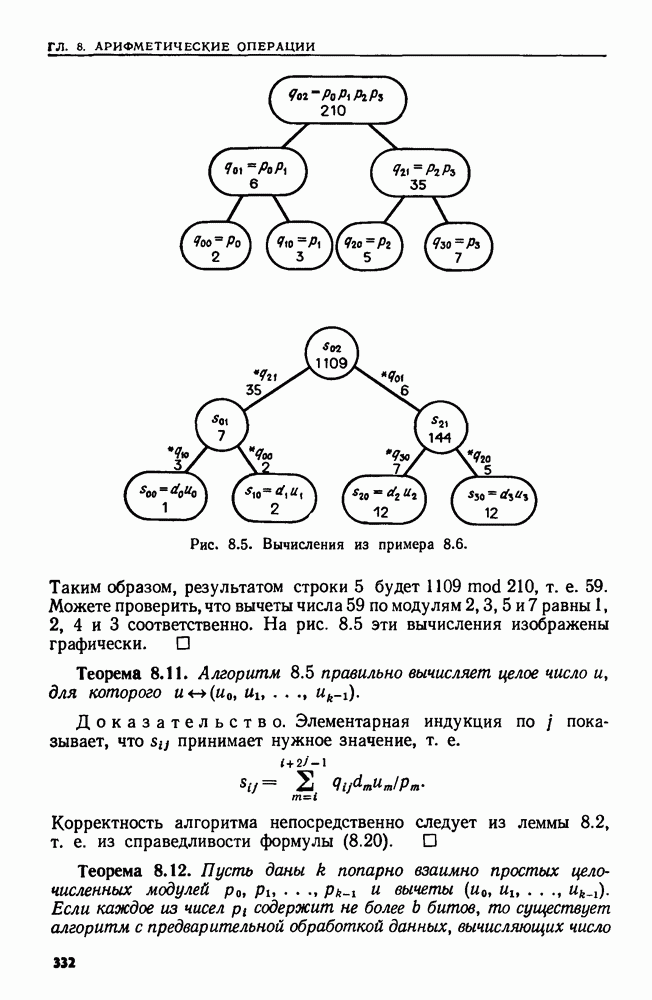
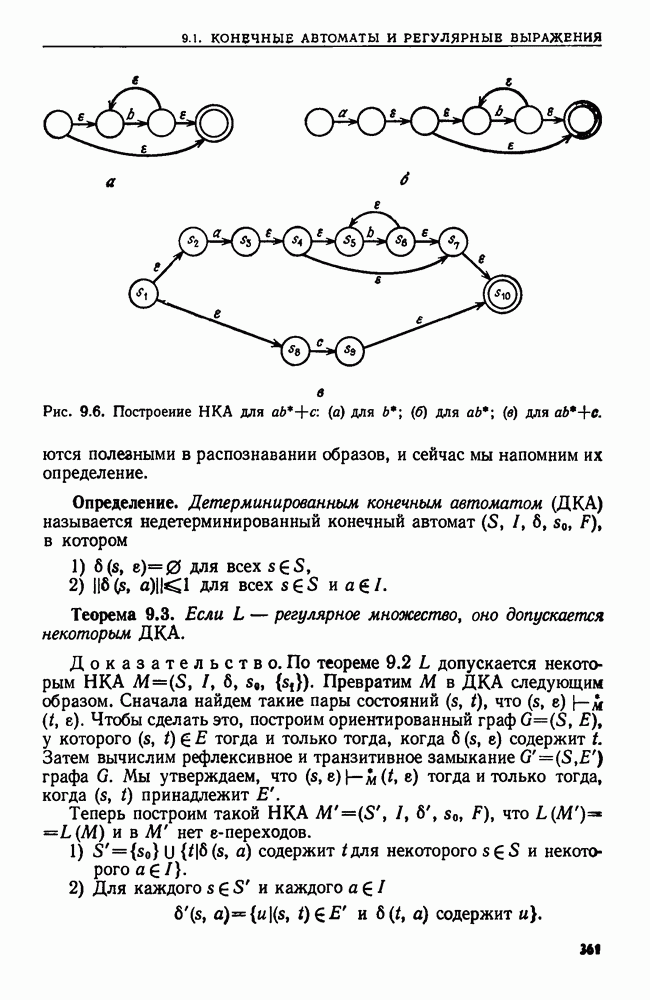
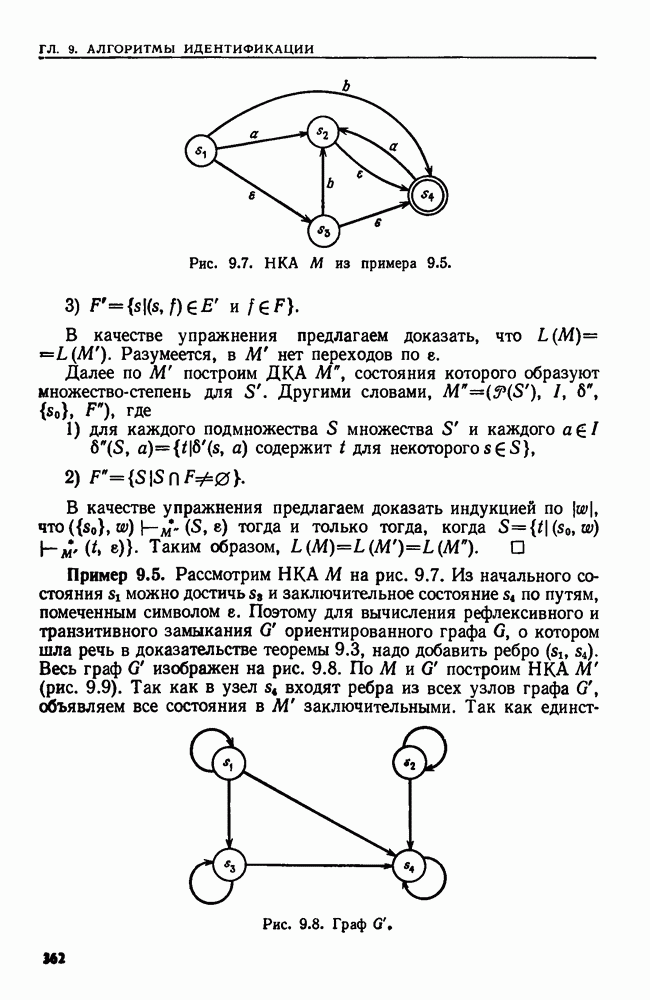
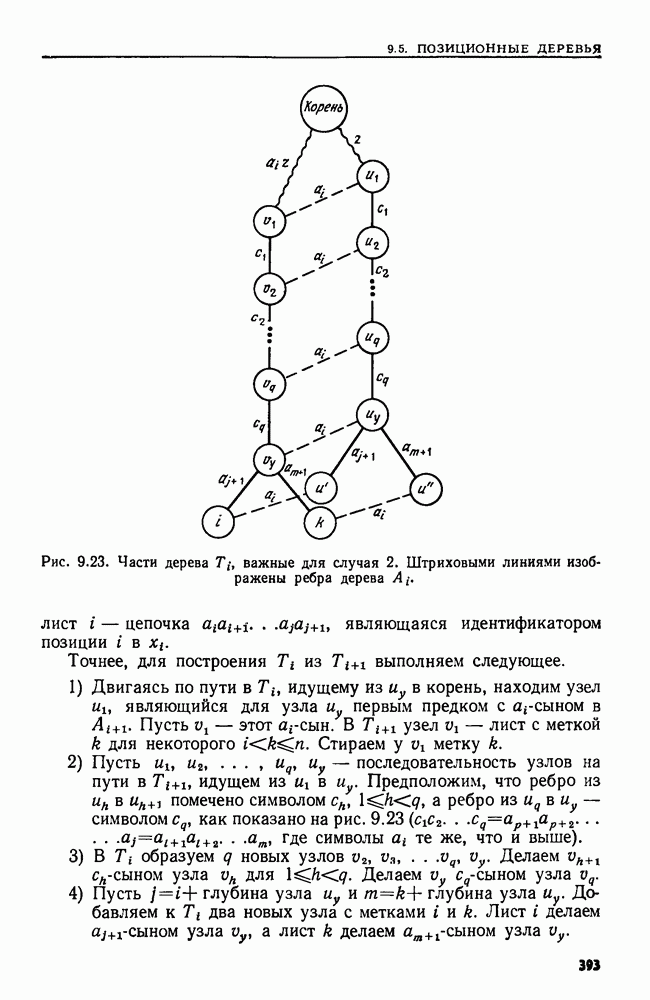
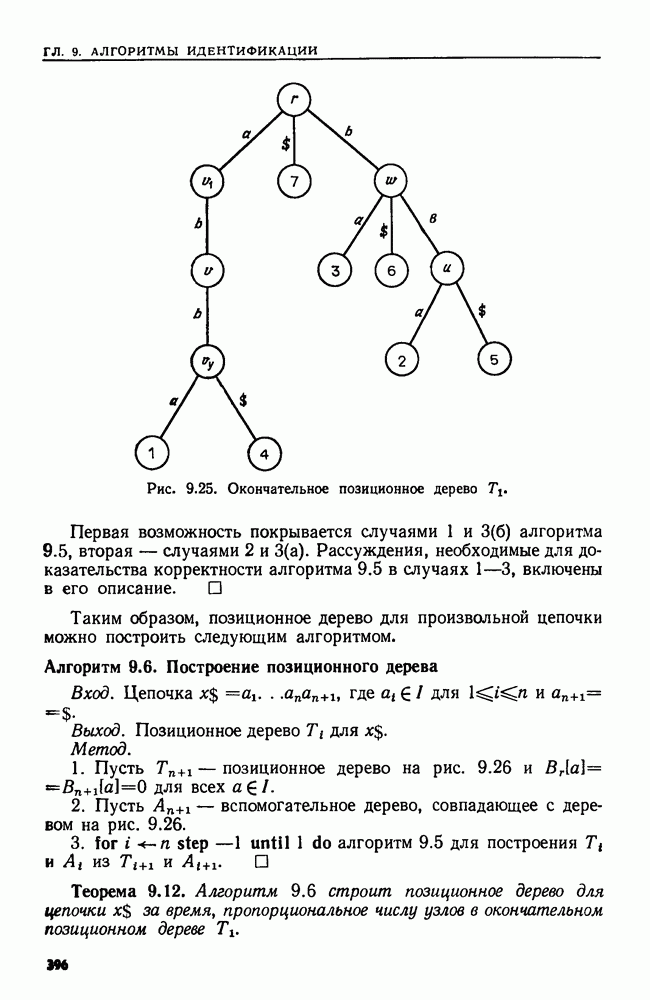
4.6. ПРОСТОЙ АЛГОРИТМ ДЛЯ НАХОЖДЕНИЯ ОБЪЕДИНЕНИЯ НЕПЕРЕСЕКАЮЩИХСЯ МНОЖЕСТВРассмотрим обработку узлов в алгоритме для нахождения остовного дерева (пример 4.1). Возникающая здесь задача преобразования множеств обладает следующими тремя особенностями. 1. Всякий раз сливаются только непересекающиеся множества. 2. Элементы множеств можно считать целыми числами от 1 до 3. Операциями над множествами являются ОБЪЕДИНИТЬ и НАЙТИ В этом и следующем разделах мы изучим структуры данных для задач такого типа. Пусть даны Эту задачу позволяют решить несколько интересных структур данных. Здесь мы познакомимся со структурой данных, благодаря которой можно выполнить за время Заметим, что в алгоритмах поиска, изложенных в разд. 4.2-4.5, предполагалось, что элементы выбираются из универсального множества, много большего, чем множество выполняемых операций. В этом разделе универсальное множество будет приблизительно того же размера, что и длина последовательности выполняемых операций. По-видимому, простейшей структурой данных для задачи типа Операция Чтобы выполнить операцию Этот безыскусный алгоритм можно улучшить несколькими способами. Для одного улучшения можно воспользоваться преимуществом связанных списков. Для другого — понять, что всегда эффективнее влить меньшее множество в большее. Чтобы сделать это, надо отличать "внутренние имена", используемые для идентификации множеств в массиве Рассмотрим следующую структуру данных для этой задачи. Как и ранее, возьмем такой массив Кроме того, возьмем еще массив, называемый РАЗМЕР, такой, что
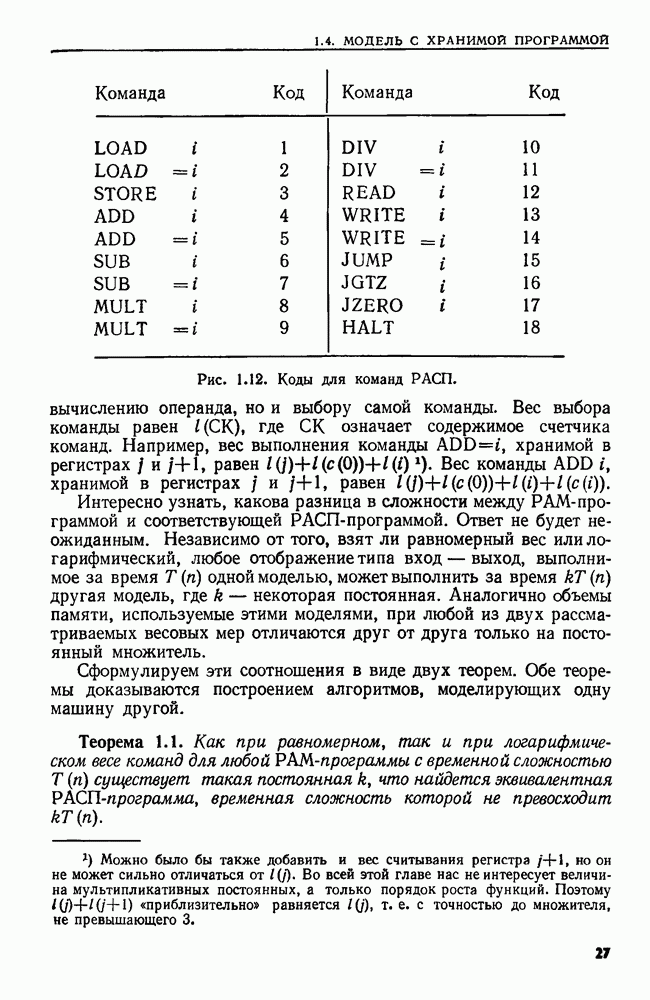
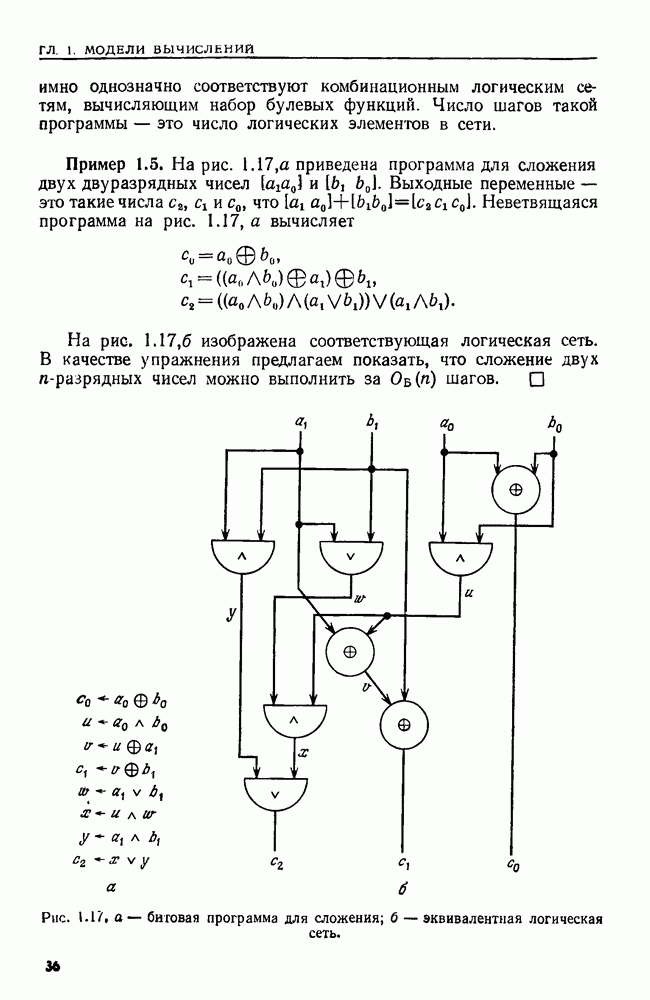
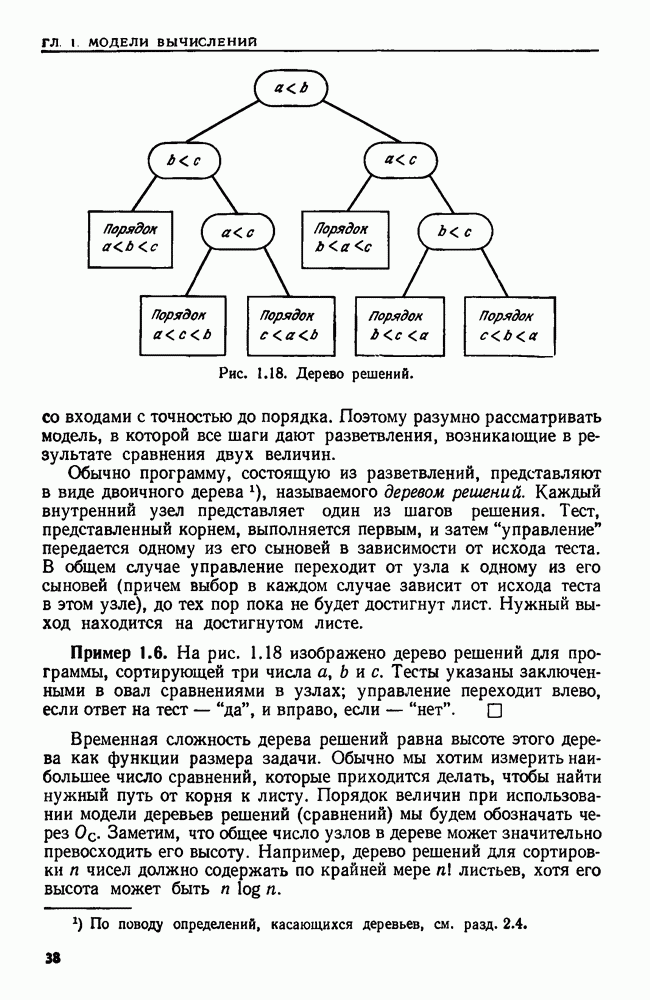
(кликните для просмотра скана) Пример 4.6. Пусть Операция Операцию объединения вида 1. Определяем внутренние имена для множеств 2. Сравниваем относительные размеры множеств 3. Проходим список элементов меньшего множества и изменяем соответствующие компоненты в массиве 4. Вливаем меньшее множество в большее, добавляя список элементов меньшего множества к началу списка для большего множества (строки 10—12). 5. Присваиваем полученному множеству внешнее имя К (строки 13, 14). Вливая меньшее множество в большее, мы делаем время выполнения операции ОБЪЕДИНИТЬ пропорциональным мощности меньшего множества. Все детали приведены в процедуре на Пример 4.7. После выполнения операции Теорема 4.3. С помощью алгоритма рис. 4.14 можно выполнить Доказательство. За каждое выполнение операции ОБЪЕДИНИТЬ будем налагать на перемещаемые элементы одинаковые штрафы, в сумме равные сложности этого выполнения. Так как сложность пропорциональна числу перемещаемых элементов, то величина штрафа, налагаемого на один элемент, будет всегда одна и та же. Основное здесь — это заметить, что всякий раз, когда элемент перемещается из списка, он оказывается в списке, по крайней мере в два раза длиннее прежнего. Поэтому никакой элемент нельзя переместить более чем
Рис. 4.15. Структура данных после выполнения операции ОБЪЕДИНИТЬ. Общая сложность получается суммированием штрафов, наложенных на отдельные элементы. Таким образом, общая сложность есть Из теоремы 4.3 вытекает, что если выполняется
|
 |
Оглавление
|

























































































































































































































































































































































































































































































 элементов, которые мы будем считать целыми числами
элементов, которые мы будем считать целыми числами  Предположим, что вначале каждый элемент образует одноэлементное множество. Пусть надо выполнить последовательность операций ОБЪЕДИНИТЬ и НАЙТИ. Напомним, что операция ОБЪЕДИНИТЬ имеет вид
Предположим, что вначале каждый элемент образует одноэлементное множество. Пусть надо выполнить последовательность операций ОБЪЕДИНИТЬ и НАЙТИ. Напомним, что операция ОБЪЕДИНИТЬ имеет вид  указывающий, что два непересекающихся множества с именами
указывающий, что два непересекающихся множества с именами  надо заменить их объединением и назвать это объединение С. В приложениях часто неважно, что выбирается в качестве имени множества, так что мы будем предполагать, что множества можно именовать целыми числами от 1 до
надо заменить их объединением и назвать это объединение С. В приложениях часто неважно, что выбирается в качестве имени множества, так что мы будем предполагать, что множества можно именовать целыми числами от 1 до  Кроме того, мы будем предполагать, что никакие два множества ни в один момент не названы одинаково.
Кроме того, мы будем предполагать, что никакие два множества ни в один момент не названы одинаково.
 последовательность, содержащую до
последовательность, содержащую до  операций ОБЪЕДИНИТЬ и до
операций ОБЪЕДИНИТЬ и до  операций НАЙТИ. В следующем разделе опишем структуру данных, позволяющую обрабатывать последовательность из
операций НАЙТИ. В следующем разделе опишем структуру данных, позволяющую обрабатывать последовательность из  операций ОБЪЕДИНИТЬ и НАЙТИ в худшем случае за время, почти линейное по
операций ОБЪЕДИНИТЬ и НАЙТИ в худшем случае за время, почти линейное по  Эти структуры данных могут обрабатывать последовательности операций ВСТАВИТЬ, УДАЛИТЬ и ПРИНАДЛЕЖАТЬ с той же вычислительной сложностью.
Эти структуры данных могут обрабатывать последовательности операций ВСТАВИТЬ, УДАЛИТЬ и ПРИНАДЛЕЖАТЬ с той же вычислительной сложностью.
 служит массив, представляющий набор множеств в данный момент. Пусть
служит массив, представляющий набор множеств в данный момент. Пусть  массив размера
массив размера  , а
, а  имя множества содержащего элемент
имя множества содержащего элемент  Так как вид имен множеств не существен, можно вначале взять
Так как вид имен множеств не существен, можно вначале взять  и выразить тем самым факт, что перед началом работы набором множеств является
и выразить тем самым факт, что перед началом работы набором множеств является  и множество
и множество  имеет имя
имеет имя 
 выполняется путем печати значения в данный момент. Поэтому сложность выполнения операции НАЙТИ постоянна, а это лучшее, на что можно надеяться.
выполняется путем печати значения в данный момент. Поэтому сложность выполнения операции НАЙТИ постоянна, а это лучшее, на что можно надеяться.
 надо последовательно просмотреть массив
надо последовательно просмотреть массив  и заменить каждую его компоненту, равную А или В, на С. Поэтому сложность выполнения такой операции есть
и заменить каждую его компоненту, равную А или В, на С. Поэтому сложность выполнения такой операции есть  Последовательность из
Последовательность из  операций ОБЪЕДИНИТЬ могла бы потребовать
операций ОБЪЕДИНИТЬ могла бы потребовать  времени, что нежелательно.
времени, что нежелательно.
 от "внешних имен", упоминаемых в операциях ОБЪЕДИНИТЬ. И те, и другие предполагаются числами от 1 до
от "внешних имен", упоминаемых в операциях ОБЪЕДИНИТЬ. И те, и другие предполагаются числами от 1 до  , но не обязательно одинаковыми.
, но не обязательно одинаковыми.
 что
что  содержит "внутреннее" имя множества, которому принадлежит элемент
содержит "внутреннее" имя множества, которому принадлежит элемент  Но теперь для каждого множества А мы построим связанный список
Но теперь для каждого множества А мы построим связанный список  содержащий его элементы. Для реализации этого связанного списка применяются два массива СПИСОК и
содержащий его элементы. Для реализации этого связанного списка применяются два массива СПИСОК и  представляет собой целое число
представляет собой целое число  указывающее, что
указывающее, что  первый элемент в множестве с внутренним именем
первый элемент в множестве с внутренним именем  дает следующий элемент в
дает следующий элемент в  следующий за ним элемент, и т. д.
следующий за ним элемент, и т. д.
 число элементов в множестве
число элементов в множестве  Множества будут переименовываться по внутренним именам, а два массива
Множества будут переименовываться по внутренним именам, а два массива  будут устанавливать соответствие между внутренними и внешними именами. Иными словами,
будут устанавливать соответствие между внутренними и внешними именами. Иными словами,  это настоящее имя (диктуемое операциями
это настоящее имя (диктуемое операциями  множества с внутренним именем
множества с внутренним именем  это внутреннее имя множества с внешним именем
это внутреннее имя множества с внешним именем  Внутренние имена — это имена, используемые в массиве
Внутренние имена — это имена, используемые в массиве 

 нас есть набор из трех множеств
нас есть набор из трех множеств  с внешними именами 1, 2 и 3 соответственно. Структуры данных для этих трех множеств показаны на рис. 4.13, где 2,3 и 1 — внутренние имена для 1,2 и 3 соответственно.
с внешними именами 1, 2 и 3 соответственно. Структуры данных для этих трех множеств показаны на рис. 4.13, где 2,3 и 1 — внутренние имена для 1,2 и 3 соответственно.
 выполняется, как и раньше, обращением к
выполняется, как и раньше, обращением к  для установления внутреннего имени множества, содержащего элемент
для установления внутреннего имени множества, содержащего элемент  в данный момент. Затем
в данный момент. Затем  дает настоящее имя множества, которому принадлежит
дает настоящее имя множества, которому принадлежит 
 выполняем следующим образом. (Номера строк относятся к рис. 4.14.)
выполняем следующим образом. (Номера строк относятся к рис. 4.14.)
 (строки 1,2).
(строки 1,2).
 справляясь в массиве РАЗМЕР (строки 3, 4).
справляясь в массиве РАЗМЕР (строки 3, 4).
 на внутреннее имя большего множества (строки 5—9).
на внутреннее имя большего множества (строки 5—9).

 структура данных рис. 4.13 превратится в структуру данных, изображенную на рис. 4.15.
структура данных рис. 4.13 превратится в структуру данных, изображенную на рис. 4.15.
 (максимально возможное число) операций ОБЪЕДИНИТЬ за
(максимально возможное число) операций ОБЪЕДИНИТЬ за  шагов.
шагов.
 раз и, значит, суммарный штраф, налагаемый на один элемент, составляет
раз и, значит, суммарный штраф, налагаемый на один элемент, составляет 


 операций НАЙТИ и до
операций НАЙТИ и до  операций ОБЪЕДИНИТЬ, то тратится время
операций ОБЪЕДИНИТЬ, то тратится время  Если
Если  имеет порядок
имеет порядок  или больше, то этот алгоритм действительно оптимален с точностью до постоянного множителя. Однако во многих ситуациях
или больше, то этот алгоритм действительно оптимален с точностью до постоянного множителя. Однако во многих ситуациях  есть
есть  а в таком случае, как мы увидим в следующем разделе, можно добиться лучшего времени, нежели
а в таком случае, как мы увидим в следующем разделе, можно добиться лучшего времени, нежели 