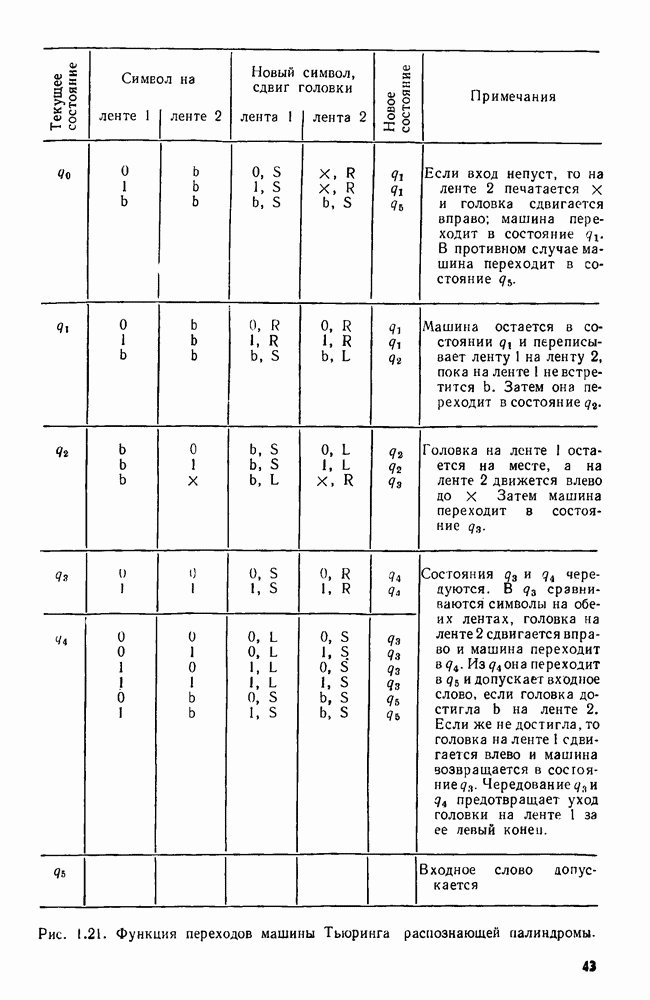
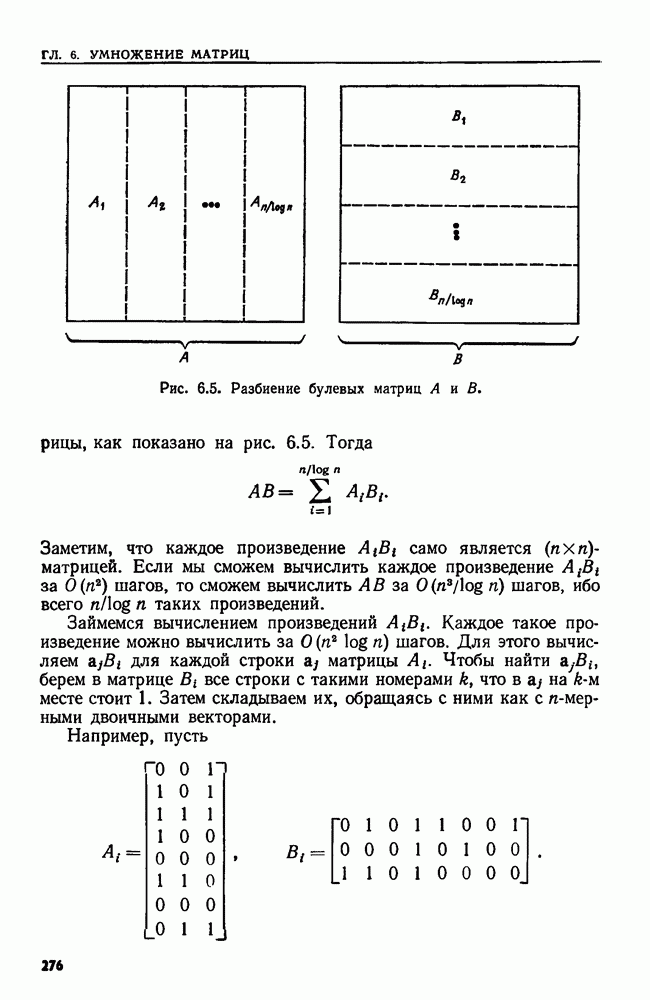
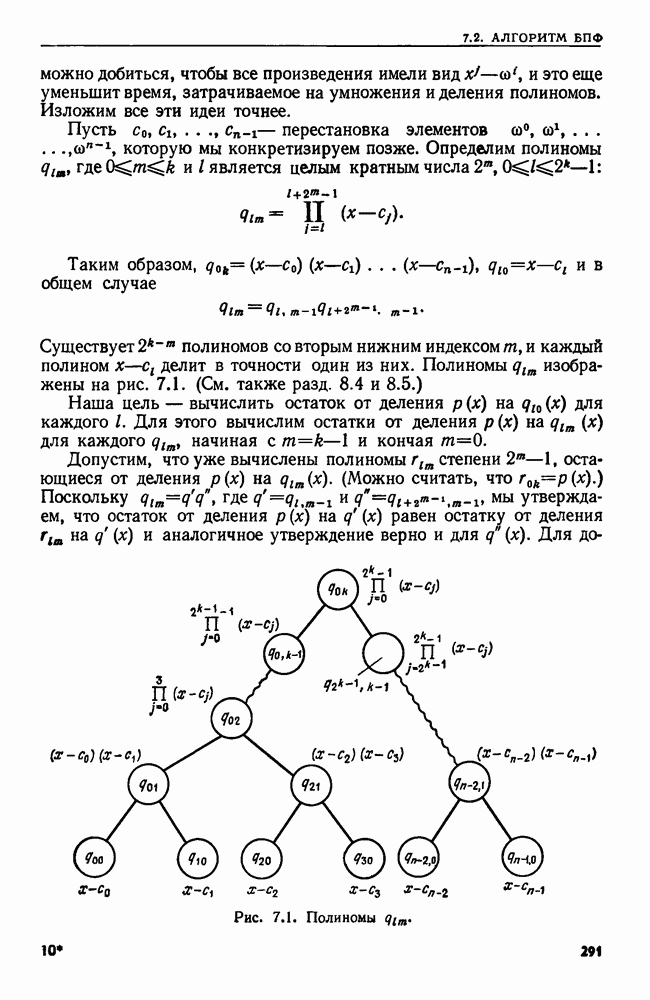
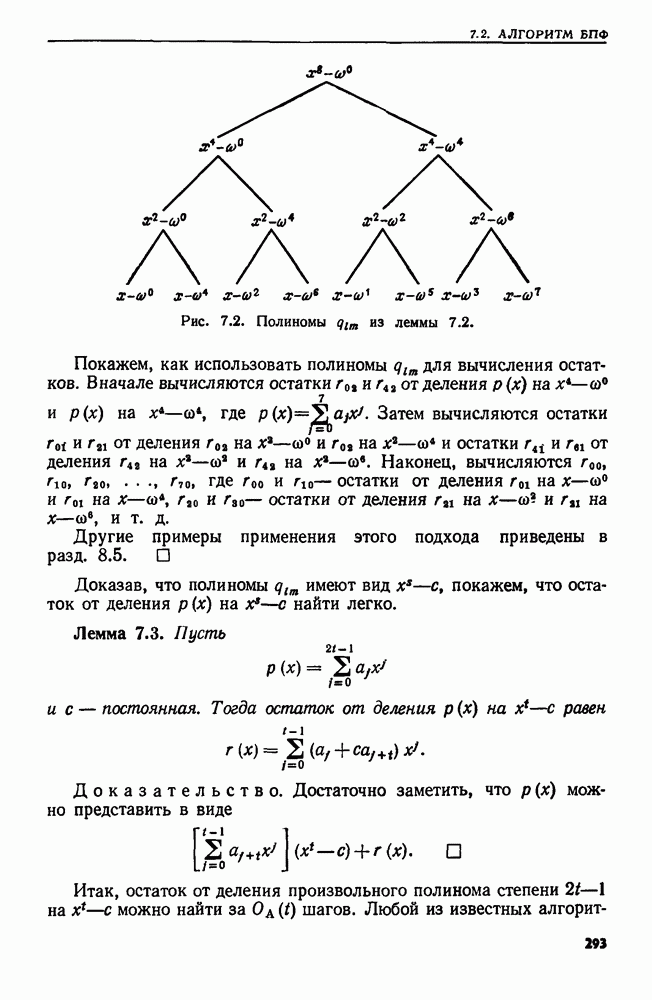
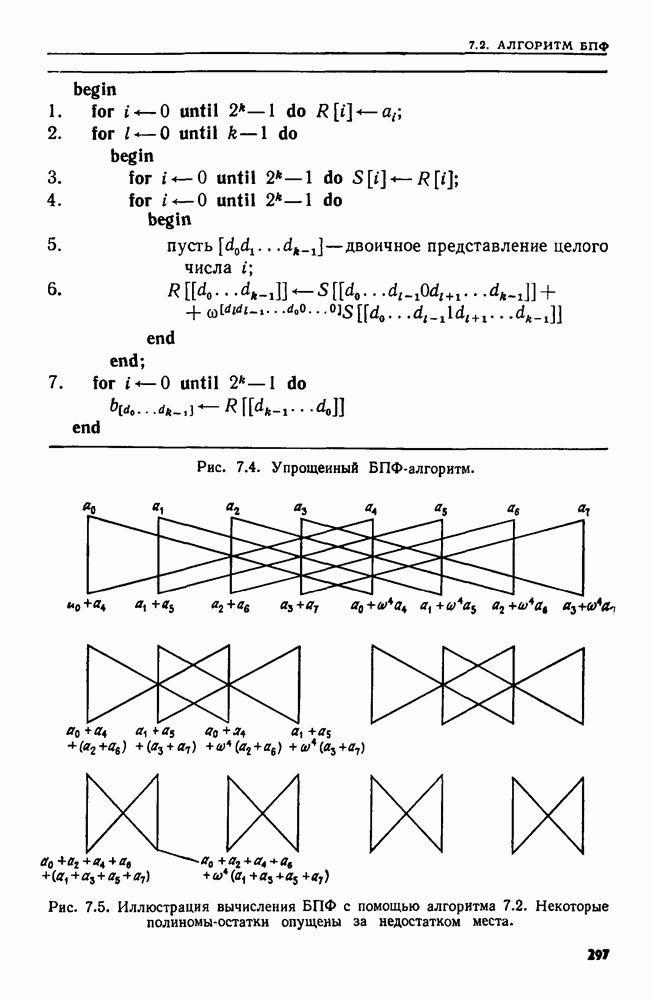
4.8. ПРИЛОЖЕНИЯ И ОБОБЩЕНИЯ АЛГОРИТМА ОБЪЕДИНИТЬ — НАЙТИ
Мы уже видели, как в задаче построения остовного дерева, описанной в примере 4.1, естественно возникает последовательность основных операций ОБЪЕДИНИТЬ и НАЙТИ. В этом разделе мы познакомимся с несколькими другими задачами, которые приводят к последовательностям операций ОБЪЕДИНИТЬ и НАЙТИ. В нашей первой задаче надо осуществить вычисления в свободном режиме, т. е. прочесть всю последовательность операций перед выдачей каких бы то ни было ответов.
Приложение 1. MIN-задача в свободном режиме
Даны два типа операций:  Начнем с множества
Начнем с множества  вначале пустого. Каждый раз, когда встречается операция
вначале пустого. Каждый раз, когда встречается операция  целое число
целое число  помещается в
помещается в  Каждый раз, когда выполняется операция
Каждый раз, когда выполняется операция  разыскивается и удаляется наименьший элемент в 5.
разыскивается и удаляется наименьший элемент в 5.
Пусть  такая последовательность операций ВСТАВИТЬ и
такая последовательность операций ВСТАВИТЬ и  что для каждого
что для каждого  операция
операция  встречается не более одного раза. По данной последовательности
встречается не более одного раза. По данной последовательности  надо найти последовательность целых чисел, удаляемых операцией
надо найти последовательность целых чисел, удаляемых операцией  Задача решается в свободном режиме, поскольку предполагается, что вся последовательность
Задача решается в свободном режиме, поскольку предполагается, что вся последовательность  известна до того, как надо вычислить даже первый элемент выходной последовательности.
известна до того, как надо вычислить даже первый элемент выходной последовательности.
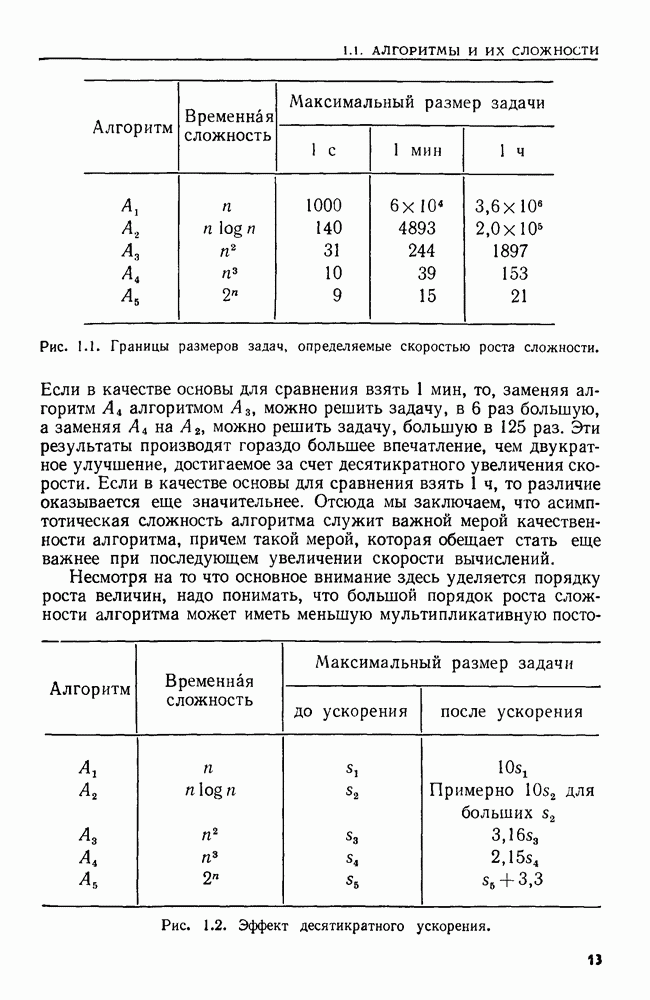
MIN-задачу в свободном режиме можно решить следующим методом. Пусть  число операций
число операций  Можно записать
Можно записать  в виде
в виде  где каждая подпоследовательность
где каждая подпоследовательность  состоит только из операций ВСТАВИТЬ,
состоит только из операций ВСТАВИТЬ,

Рис. 4.23. Программа для решения MIN-задачи в свободном режиме.
а  обозначает операцию
обозначает операцию  Промоделируем а с помощью алгоритма 4.3. Начальная последовательность множеств для работы алгоритма объединения строится так: если в последовательности
Промоделируем а с помощью алгоритма 4.3. Начальная последовательность множеств для работы алгоритма объединения строится так: если в последовательности  встречается операция
встречается операция  то считаем, что множество с именем
то считаем, что множество с именем  содержит элемент
содержит элемент  Для того чтобы для тех значений
Для того чтобы для тех значений  для которых существует множество с именем
для которых существует множество с именем  образовать дважды связанный упорядоченный список, пользуемся двумя массивами ПРЕД и
образовать дважды связанный упорядоченный список, пользуемся двумя массивами ПРЕД и  Вначале
Вначале  для и
для и  для Затем выполняется программа, приведенная на рис. 4.23.
для Затем выполняется программа, приведенная на рис. 4.23.
Легко видеть, что время выполнения этой программы ограничено временем работы алгоритма объединения множеств. Следовательно, MIN-задача в свободном режиме имеет временную сложность 
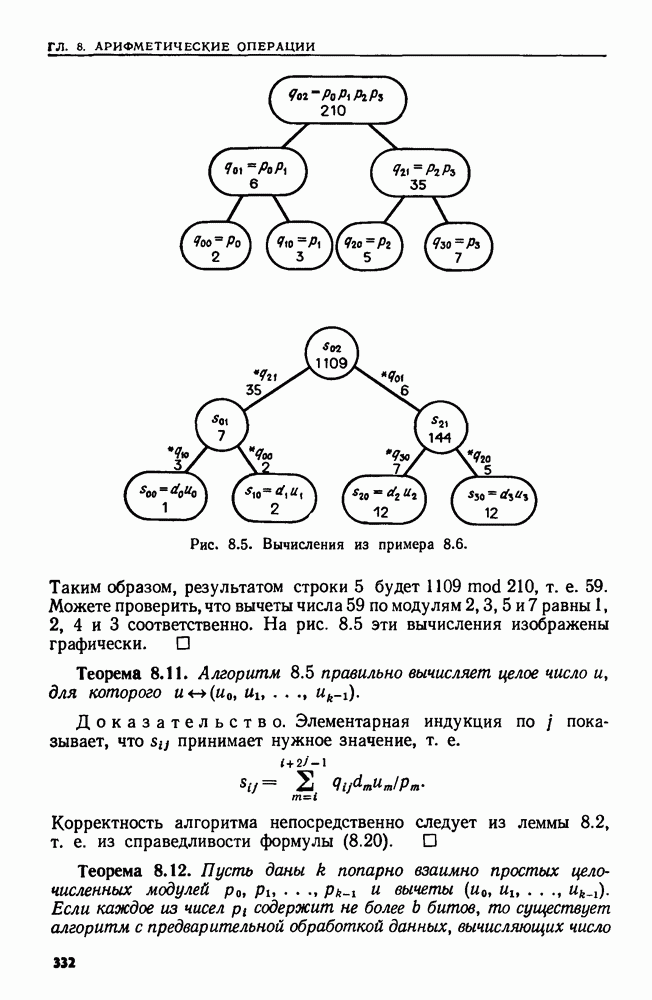
Пример 4.8. Рассмотрим последовательность операций  где
где  означает
означает  Тогда
Тогда  пустая последовательность. Начальная структура данных представляет собой последовательность множеств
пустая последовательность. Начальная структура данных представляет собой последовательность множеств

При первом выполнении  -цикла выясняется, что
-цикла выясняется, что  Следовательно, ответом на третью операцию в а
Следовательно, ответом на третью операцию в а  будет 1. Последовательность множеств превращается в
будет 1. Последовательность множеств превращается в

В этот момент  поскольку множества с именами 3 и 4 были слиты в одно множество с именем 4.
поскольку множества с именами 3 и 4 были слиты в одно множество с именем 4.
При следующем прохождении с  выясняется, что
выясняется, что  Таким образом, ответом на вторую операцию
Таким образом, ответом на вторую операцию  будет 2. Множество с именем 2 сливается со следующим множеством (с именем 4) и получается последовательность множеств
будет 2. Множество с именем 2 сливается со следующим множеством (с именем 4) и получается последовательность множеств

Два последних прохождения устанавливают, что ответ на первую операцию  есть 3 и что 4 никогда не извлекается.
есть 3 и что 4 никогда не извлекается.
Рассмотрим другое приложение — задачу определения глубины. В частности, она возникает при "приравнивании" идентификаторов в программе на языке ассемблера. Во многих языках ассемблера есть операторы, описывающие, что два идентификатора представляют одну и ту же ячейку памяти. Как только ассемблер встречает оператор, приравнивающий два идентификатора  он должен найти два множества
он должен найти два множества  идентификаторов,
идентификаторов,
эквивалентных соответственно  и заменить эти два множества их объединением. Очевидно, задачу можно смоделировать последовательностью операций ОБЪЕДИНИТЬ и НАЙТИ.
и заменить эти два множества их объединением. Очевидно, задачу можно смоделировать последовательностью операций ОБЪЕДИНИТЬ и НАЙТИ.
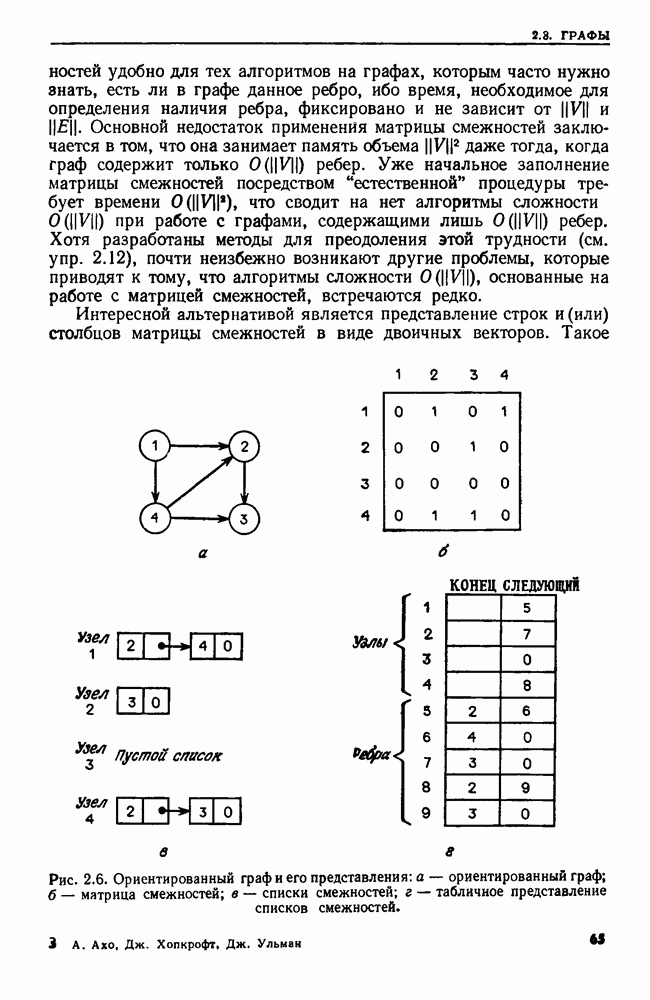
Однако если внимательнее проанализировать эту задачу, можно по-другому применить структуры данных из предыдущего раздела. Каждому идентификатору соответствует графа таблицы символов, и, если несколько идентификаторов эквивалентны, удобно хранить данные о них только в одной графе таблицы символов. Это означает, что для каждого множества эквивалентных идентификаторов есть начало отсчета, т. е. место в таблице символов, где хранится информация об этом множестве, и каждый элемент этого множества имеет смешение от начала. Чтобы найти положение идентификатора в таблице символов, надо прибавить его смещение к началу отсчета множества, которому принадлежит данный идентификатор. Но когда два множества идентификаторов становятся эквивалентными, надо изменить смещение. Эта задача корректировки смещений в абстрактном виде решается в приложении 2.
Приложение 2. Задача определения глубины
Дана последовательность операций двух типов:  Начнемся неориентированных корневых деревьев, каждое из которых состоит из единственного узла
Начнемся неориентированных корневых деревьев, каждое из которых состоит из единственного узла  Операция
Операция  где
где  корень дерева,
корень дерева,  узел другого дерева, делает корень
узел другого дерева, делает корень  сыном узла
сыном узла  Условия о том, что
Условия о том, что  принадлежат различным деревьям и что
принадлежат различным деревьям и что  корень, гарантируют, что получаемый в результате граф также будет лесом. Операция
корень, гарантируют, что получаемый в результате граф также будет лесом. Операция  состоит в том, чтобы найти и напечатать глубину узла
состоит в том, чтобы найти и напечатать глубину узла  в текущий момент.
в текущий момент.
Если при работе с лесом использовать обычное представление в виде списков смежностей и вычислять глубину узлов очевидным образом, то сложность алгоритма будет  Вместо этого мы представим исходный лес другим лесом, который будем называть
Вместо этого мы представим исходный лес другим лесом, который будем называть  -лесом. Он нужен нам только для того, чтобы можно было быстро вычислять глубины. Каждому узлу в
-лесом. Он нужен нам только для того, чтобы можно было быстро вычислять глубины. Каждому узлу в  -лесу приписывается целочисленный вес так, чтобы сумма весов вдоль пути в
-лесу приписывается целочисленный вес так, чтобы сумма весов вдоль пути в  -лесу от узла
-лесу от узла  к корню равнялась глубине узла
к корню равнялась глубине узла  в исходном лесу. Для каждого дерева в
в исходном лесу. Для каждого дерева в  -лесу хранится счетчик числа узлов в этом дереве.
-лесу хранится счетчик числа узлов в этом дереве.
Вначале  -лес состоит из
-лес состоит из  деревьев, каждое из которых содержит единственный узел, соответствующий целому числу
деревьев, каждое из которых содержит единственный узел, соответствующий целому числу  Начальный вес каждого узла равен нулю.
Начальный вес каждого узла равен нулю.
Для выполнения операции  мы проходим путь из узла
мы проходим путь из узла  в корень
в корень  Пусть
Пусть  узлы на этом пути
узлы на этом пути  Тогда
Тогда

Крометого, применяем сжатие путей. Каждый узел  делается сыном корня
делается сыном корня  Чтобы сохранялось сформулированное выше свойство весов, новый
Чтобы сохранялось сформулированное выше свойство весов, новый  узла
узла  должен равняться
должен равняться  для 1 Так как новые веса можно вычислить за время
для 1 Так как новые веса можно вычислить за время  то операция
то операция  имеет ту же временную сложность, что и операция НАЙТИ.
имеет ту же временную сложность, что и операция НАЙТИ.
Чтобы выполнить операцию  соединим деревья, содержащие узлы
соединим деревья, содержащие узлы  снова вливая меньшее дерево в большее. Пусть
снова вливая меньшее дерево в большее. Пусть  деревья в
деревья в  -лесу, содержащие
-лесу, содержащие  соответственно, а
соответственно, а  их корни. Деревья в
их корни. Деревья в  -лесу не обязательно изоморфны деревьям в исходном лесу, так что, в частности,
-лесу не обязательно изоморфны деревьям в исходном лесу, так что, в частности,  может не быть корнем для
может не быть корнем для  Пусть
Пусть  обозначает число узлов в дереве
обозначает число узлов в дереве  Рассмотрим отдельно два случая.
Рассмотрим отдельно два случая.
Случай  Делаем
Делаем  сыном узла
сыном узла  Мы должны также скорректировать вес старого корня
Мы должны также скорректировать вес старого корня  дерева
дерева  так, чтобы глубина каждого узла
так, чтобы глубина каждого узла  правильно вычислялась при прохождении пути из
правильно вычислялась при прохождении пути из  в объединенном дереве. Чтобы сделать это, выполняем операцию
в объединенном дереве. Чтобы сделать это, выполняем операцию  а затем
а затем

Таким образом, глубина каждого узла в  эффективно увеличена на глубину узла
эффективно увеличена на глубину узла  плюс 1. Наконец, полагаем счетчик числа узлов объединенного дерева равным сумме счетчиков для
плюс 1. Наконец, полагаем счетчик числа узлов объединенного дерева равным сумме счетчиков для 
Случай  Здесь вычисляется
Здесь вычисляется  преобразуется узел
преобразуется узел  в сына узла
в сына узла  и
и

Итак,  операций
операций  и
и  можно выполнить за время
можно выполнить за время 
Приложение 3. Эквивалентность конечных автоматов
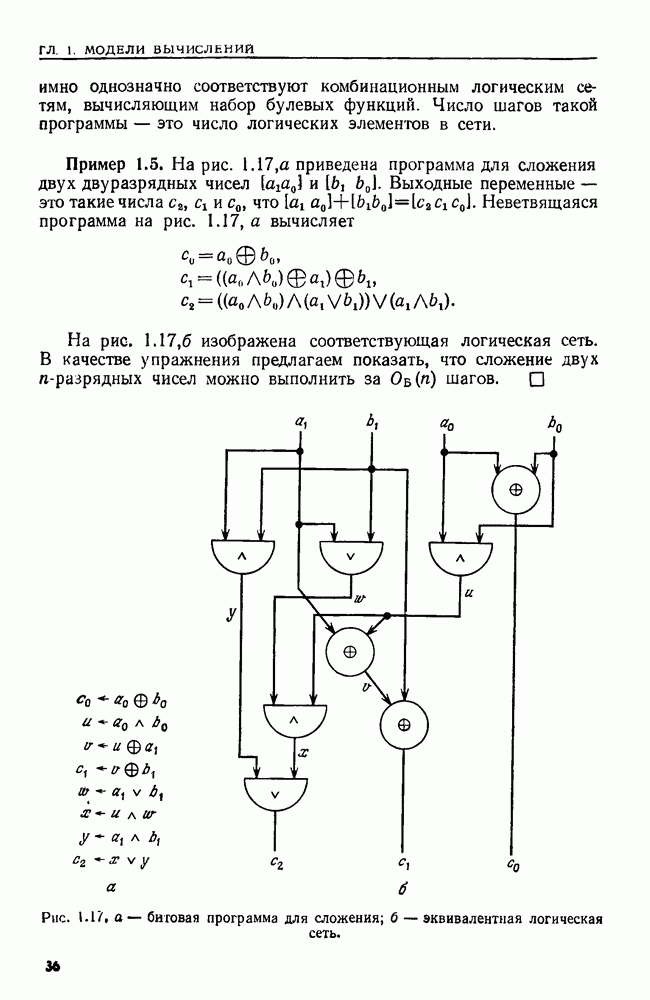
Детерминированным конечным автоматом называется машина, распознающая цепочки символов. Она имеет входную ленту, разбитую на клетки, головку на входной ленте (входную головку) и управляющее устройство с конечным числом состояний (рис. 4.24). Конечный автомат  можно представить в виде пятерки
можно представить в виде пятерки  где
где
1) S - множество состояний управляющего устройства,
2)  - входной алфавит (каждая клетка входной ленты содержит символ из
- входной алфавит (каждая клетка входной ленты содержит символ из 

Рис. 4.24. Конечный автомат.
3)  - отображение из
- отображение из  в 5 (если
в 5 (если  то всякий раз, когда
то всякий раз, когда  находится в состоянии
находится в состоянии  а входная головка обозревает символ
а входная головка обозревает символ  сдвигает входную головку вправо и переходит в состояние s),
сдвигает входную головку вправо и переходит в состояние s),
4)  — выделенное состояние в
— выделенное состояние в  называемое начальным,
называемое начальным,
5) F - подмножество в  называемое множеством допускающих (или заключительных) состояний.
называемое множеством допускающих (или заключительных) состояний.
Пусть  множество цепочек (слов) конечной длины, состоящих из символов алфавита
множество цепочек (слов) конечной длины, состоящих из символов алфавита  включается и пустая цепочка
включается и пустая цепочка  Продолжим
Продолжим  до отображения из
до отображения из 

Входная цепочка х допускается автоматом  если
если  Языком
Языком  допускаемым автоматом
допускаемым автоматом  называется множество всех цепочек, допускаемых
называется множество всех цепочек, допускаемых  Более подробное введение в теорию конечных автоматов изложено в разд. 9.1.
Более подробное введение в теорию конечных автоматов изложено в разд. 9.1.
Два состояния  считаются эквивалентными, если для каждого
считаются эквивалентными, если для каждого  состояние
состояние  будет допускающим тогда и только тогда, когда
будет допускающим тогда и только тогда, когда  допускающее состояние.
допускающее состояние.
Два конечных автомата  считаются эквивалентными, если
считаются эквивалентными, если  Мы покажем здесь, что с помощью алгоритма
Мы покажем здесь, что с помощью алгоритма  можно распознать эквивалентность двух конечных автоматов
можно распознать эквивалентность двух конечных автоматов  за
за  шагов, где
шагов, где 
Отношение эквивалентности двух состояний обладает важным свойством: если два состояния  эквивалентны, то для всех входных символов а состояния
эквивалентны, то для всех входных символов а состояния  и
и  также эквивалентны. Кроме того, благодаря наличию пустой цепочки, никакое допускающее состояние не может оказаться эквивалентным недопускающему. Таким образом, если допустить, что начальные состояния
также эквивалентны. Кроме того, благодаря наличию пустой цепочки, никакое допускающее состояние не может оказаться эквивалентным недопускающему. Таким образом, если допустить, что начальные состояния  автоматов
автоматов  эквивалентны, то можно вывести другие пары эквивалентных состояний. Если в одну из таких пар попадет допускающее состояние вместе с недопускающим, то
эквивалентны, то можно вывести другие пары эквивалентных состояний. Если в одну из таких пар попадет допускающее состояние вместе с недопускающим, то  были неэквивалентными. Если же это не произойдет, то верно обратное
были неэквивалентными. Если же это не произойдет, то верно обратное

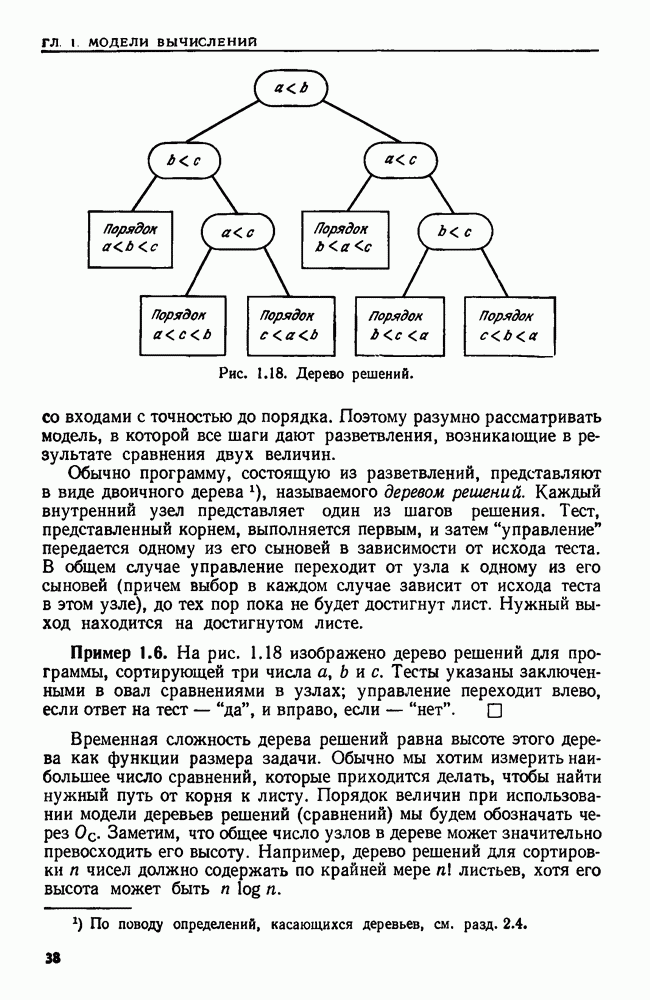
Рис. 4.25. Алгоритм для нахождения множеств эквивалентных состояний в предположении, что  эквивалентны.
эквивалентны.
Чтобы узнать, эквивалентны ли два конечных автомата  мы поступаем так:
мы поступаем так:
1. С помощью программы на рис. 4.25 находим все множества состояний, которые должны быть эквивалентными, если эквивалентны  содержит такие пары состояний
содержит такие пары состояний  что
что  оказались эквивалентными, а следующие за ними состояния
оказались эквивалентными, а следующие за ними состояния  еще не рассматривались. Вначале СПИСОК содержит только пару
еще не рассматривались. Вначале СПИСОК содержит только пару  Чтобы найти множества эквивалентных состояний, программа применяет алгоритм объединения непересекающихся множеств.
Чтобы найти множества эквивалентных состояний, программа применяет алгоритм объединения непересекающихся множеств.  представляет некоторое семейство множеств. Вначале каждое состояние из
представляет некоторое семейство множеств. Вначале каждое состояние из  образует одноэлементное множество. (Без потери общности можно считать, что множества
образует одноэлементное множество. (Без потери общности можно считать, что множества  не пересекаются.) Затем всякий раз, когда
не пересекаются.) Затем всякий раз, когда  оказываются эквивалентными, содержащие их множества
оказываются эквивалентными, содержащие их множества  входящие в НАБОР, сливаются, и новое множество получает имя А.
входящие в НАБОР, сливаются, и новое множество получает имя А.
2. После выполнения этой программы множества, входящие в НАБОР, представляют разбиение множества  на блоки
на блоки















































































































































































































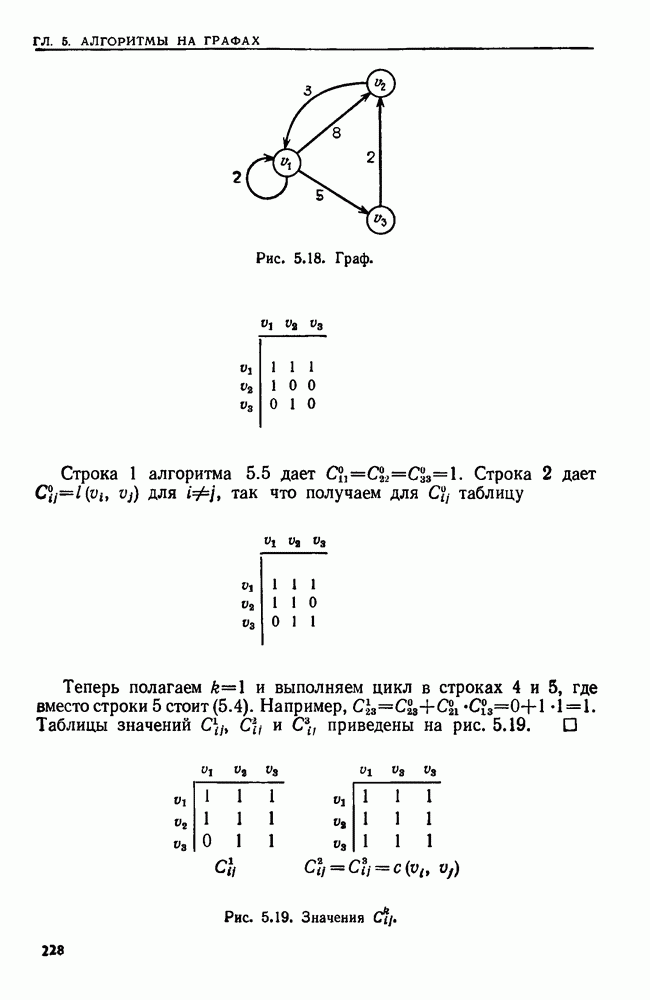




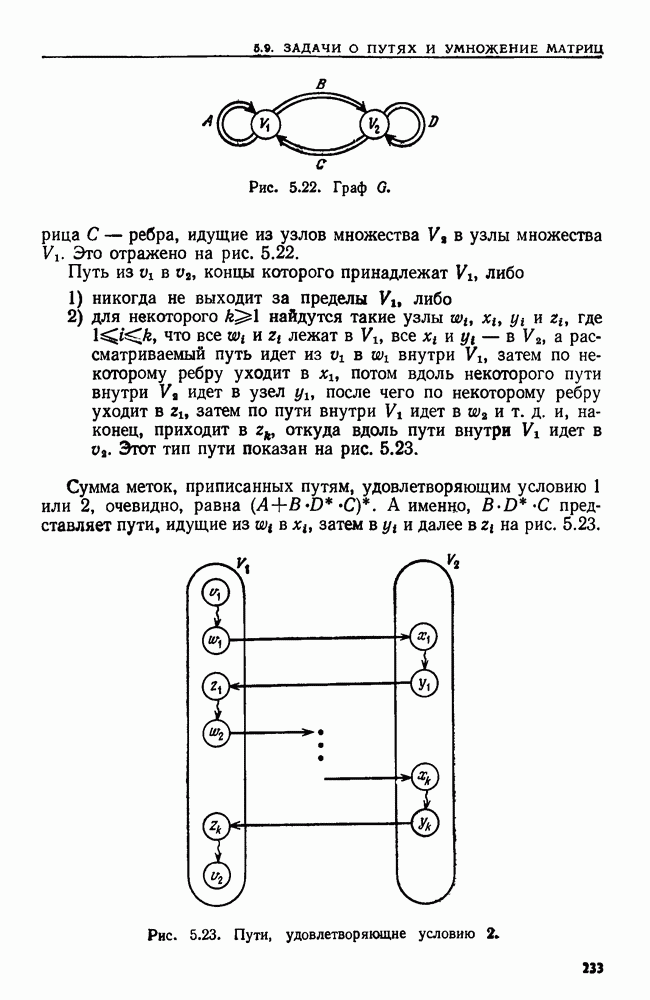






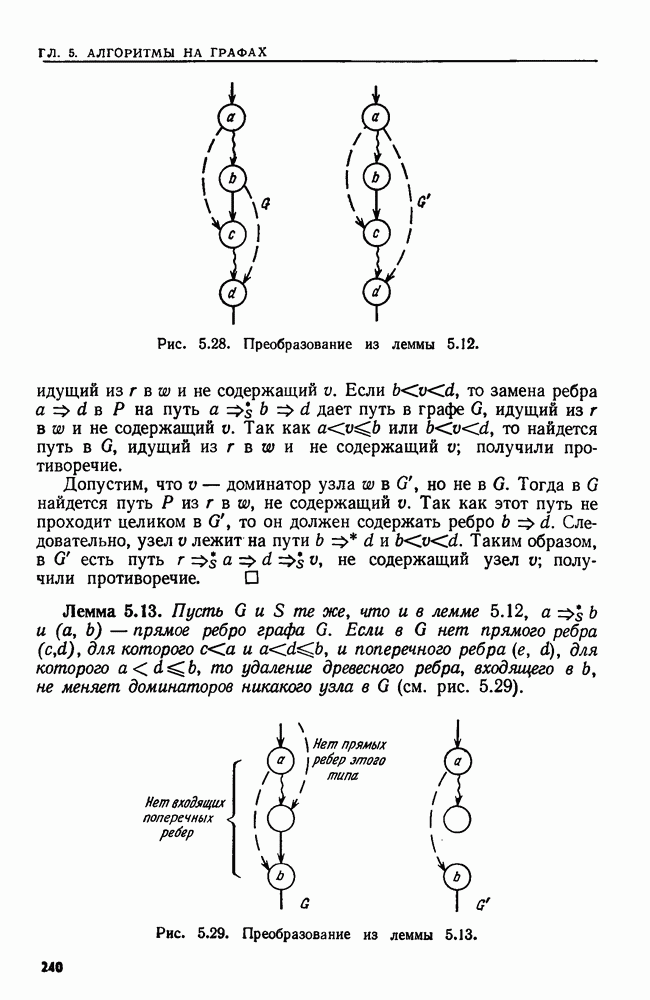



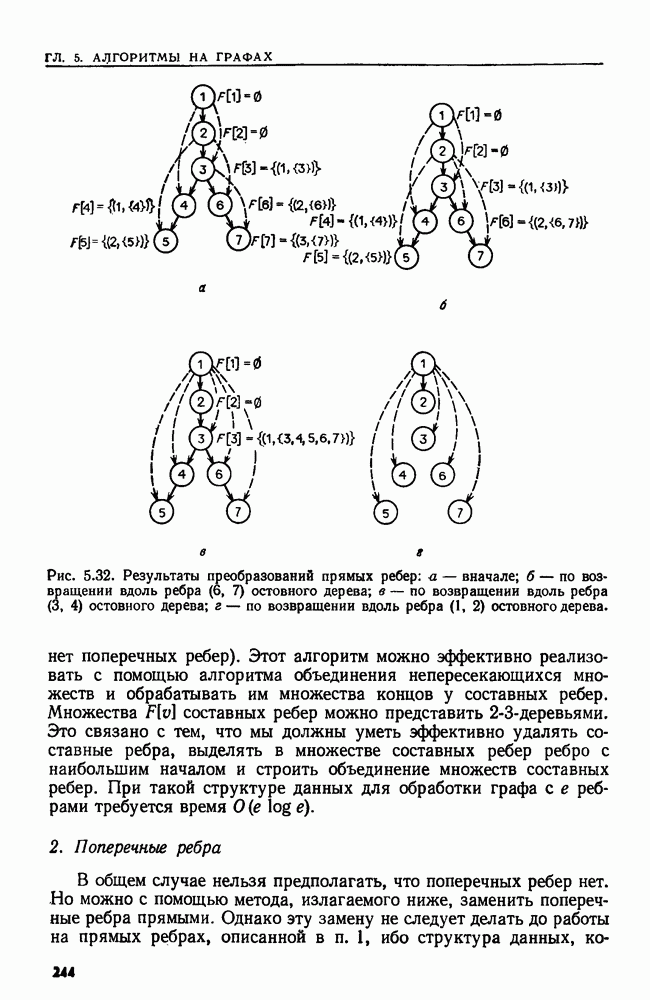

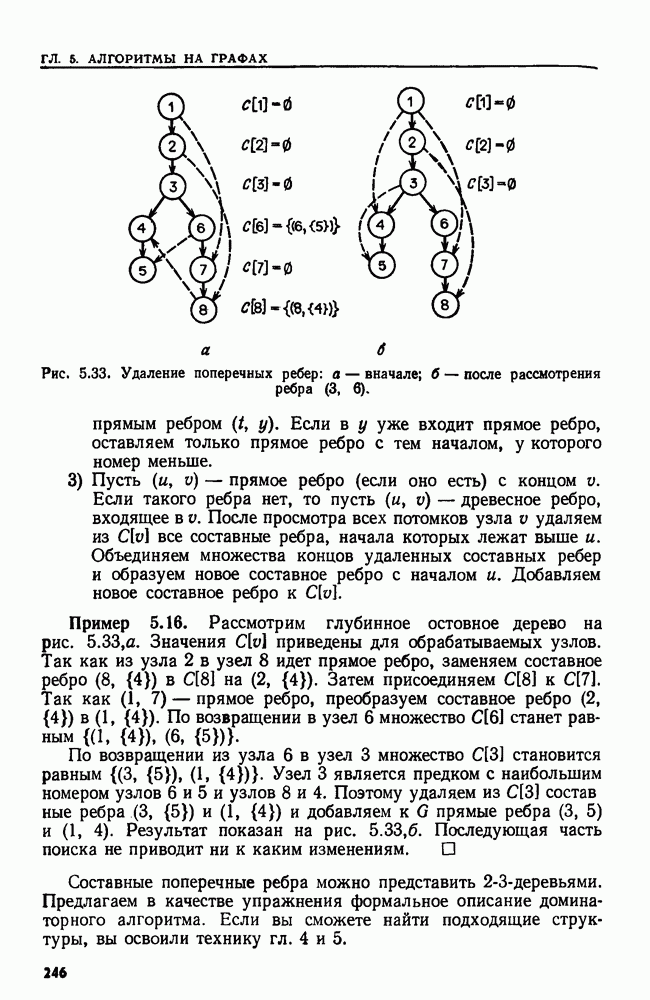




























































































































































































































































 эквивалентны тогда и только тогда, когда никакой блок не содержит допускающего состояния вместе с недопускающим.
эквивалентны тогда и только тогда, когда никакой блок не содержит допускающего состояния вместе с недопускающим.
 определяется в основном работой алгоритма объединения множеств. Операций ОБЪЕДИНИТЬ может быть не более
определяется в основном работой алгоритма объединения множеств. Операций ОБЪЕДИНИТЬ может быть не более  поскольку каждая такая операция уменьшает на единицу число множеств, входящих в НАБОР, а вначале было только
поскольку каждая такая операция уменьшает на единицу число множеств, входящих в НАБОР, а вначале было только  множеств. Число операций НАЙТИ пропорционально числу пар, помещенных в СПИСОК. Это число не больше
множеств. Число операций НАЙТИ пропорционально числу пар, помещенных в СПИСОК. Это число не больше  так как всякая пара, кроме начальной
так как всякая пара, кроме начальной  попадает в СПИСОК только после операции ОБЪЕДИНИТЬ. Таким образом, при постоянном размере входного алфавита на распознавание эквивалентности конечных автоматов и
попадает в СПИСОК только после операции ОБЪЕДИНИТЬ. Таким образом, при постоянном размере входного алфавита на распознавание эквивалентности конечных автоматов и  тратится время
тратится время 