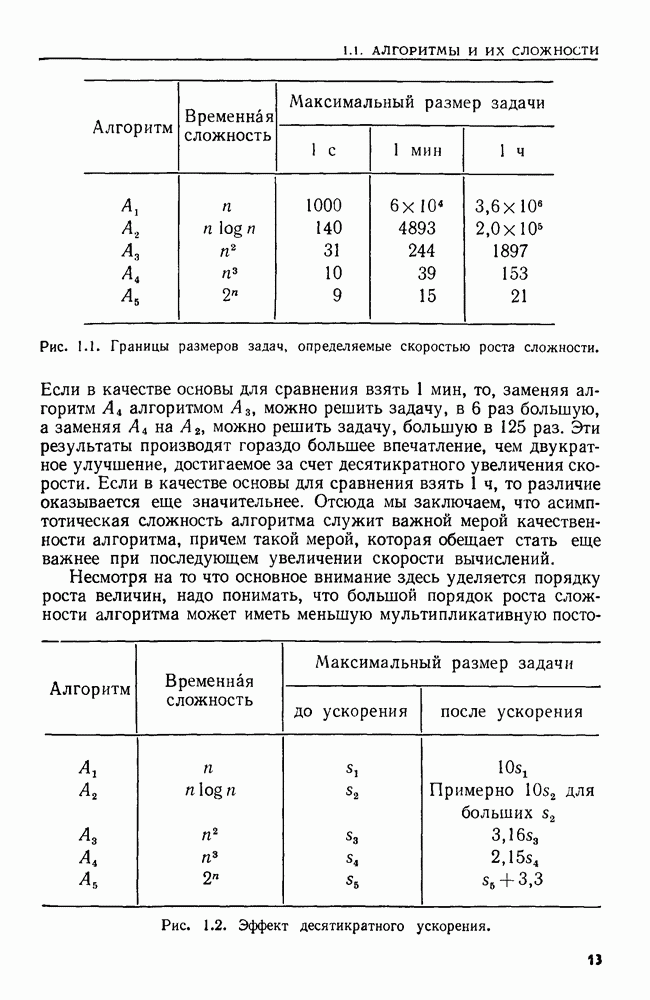
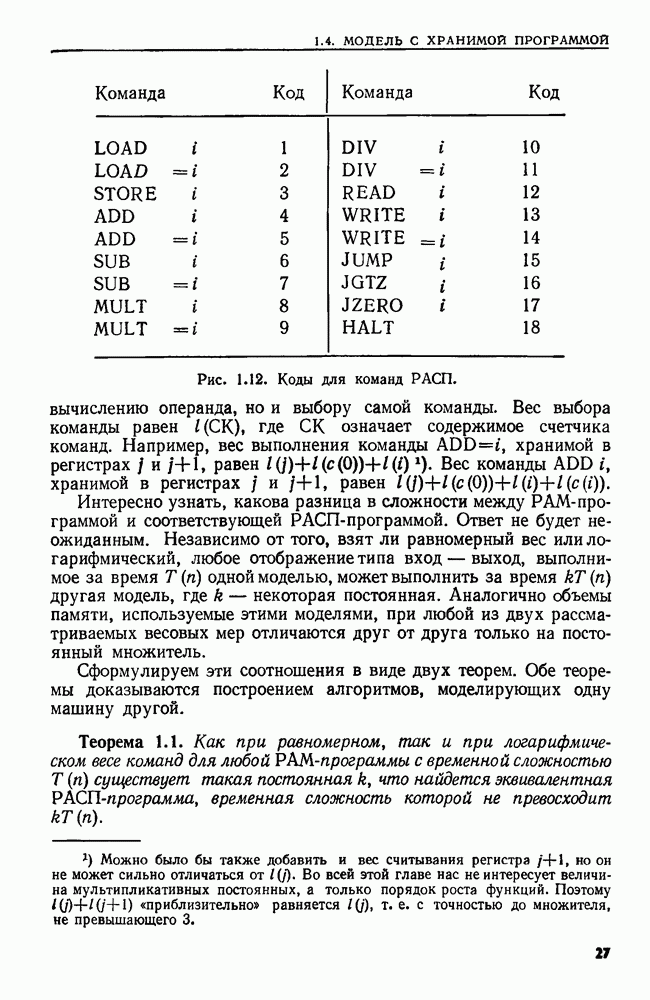
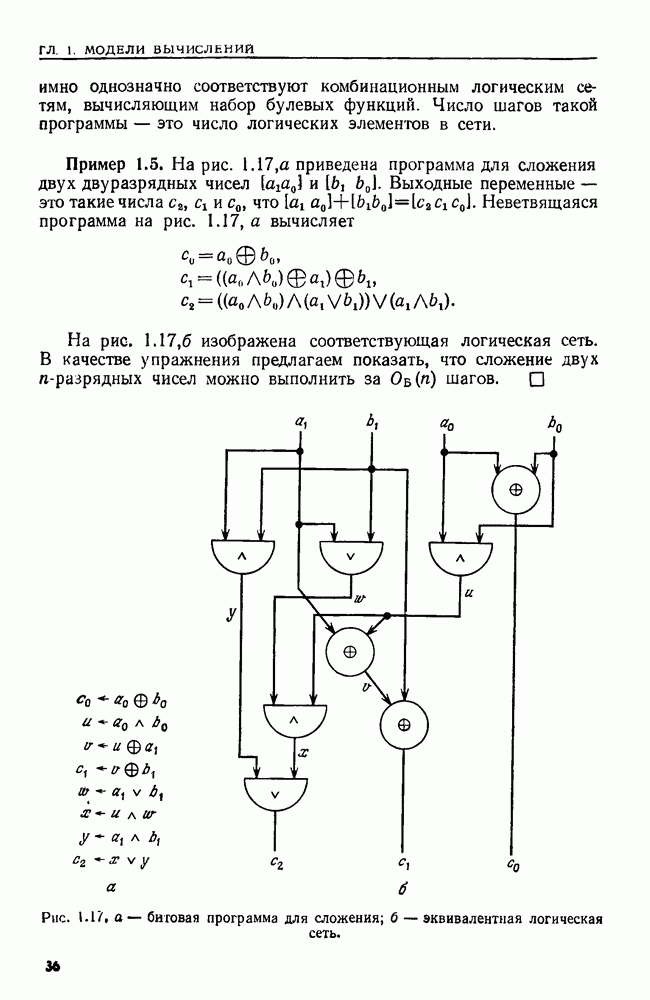
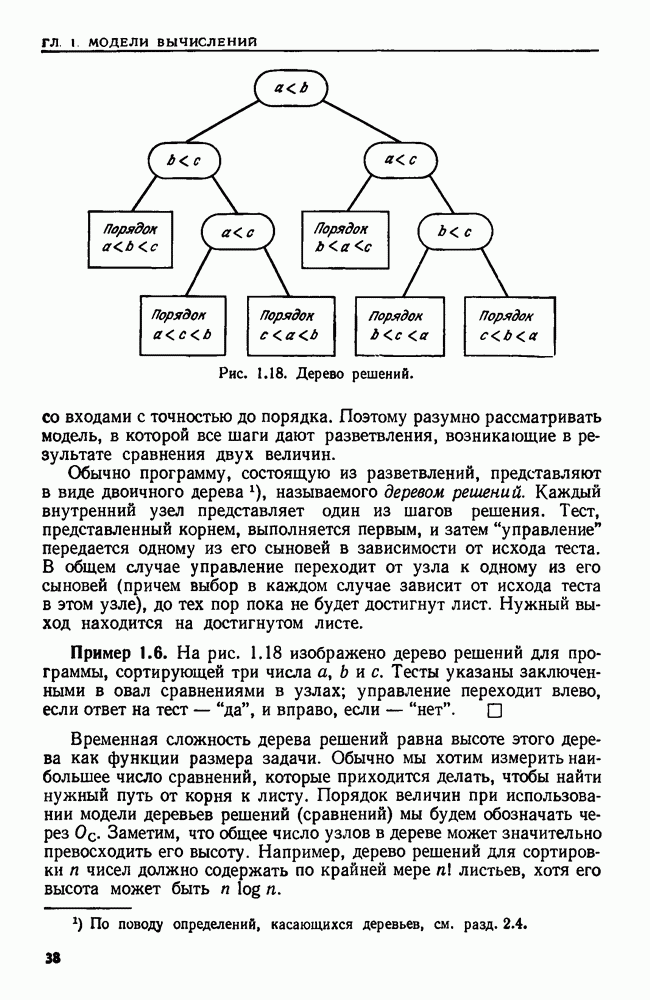
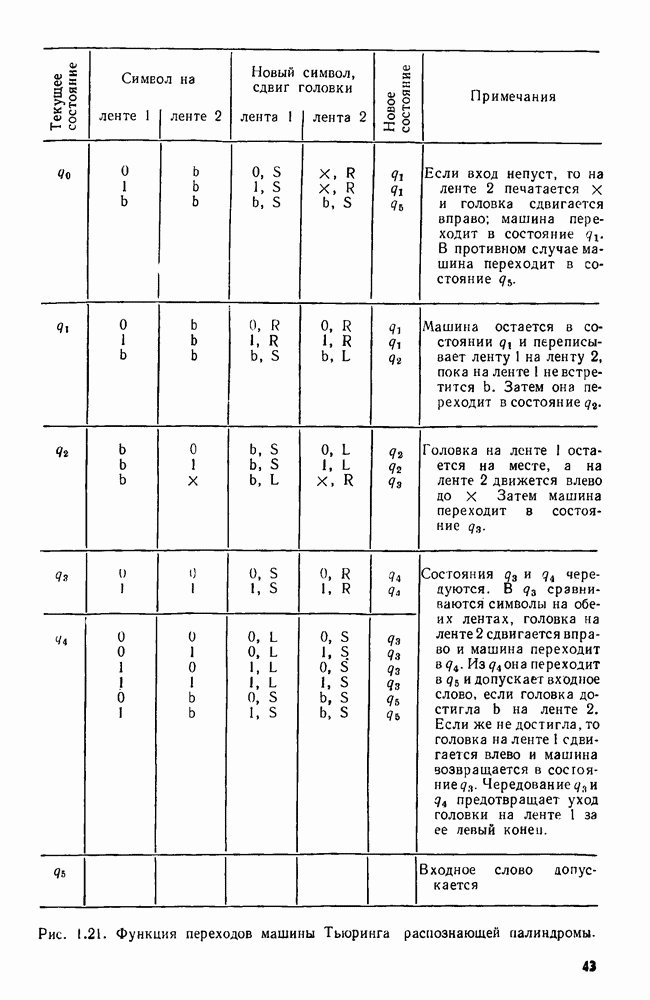
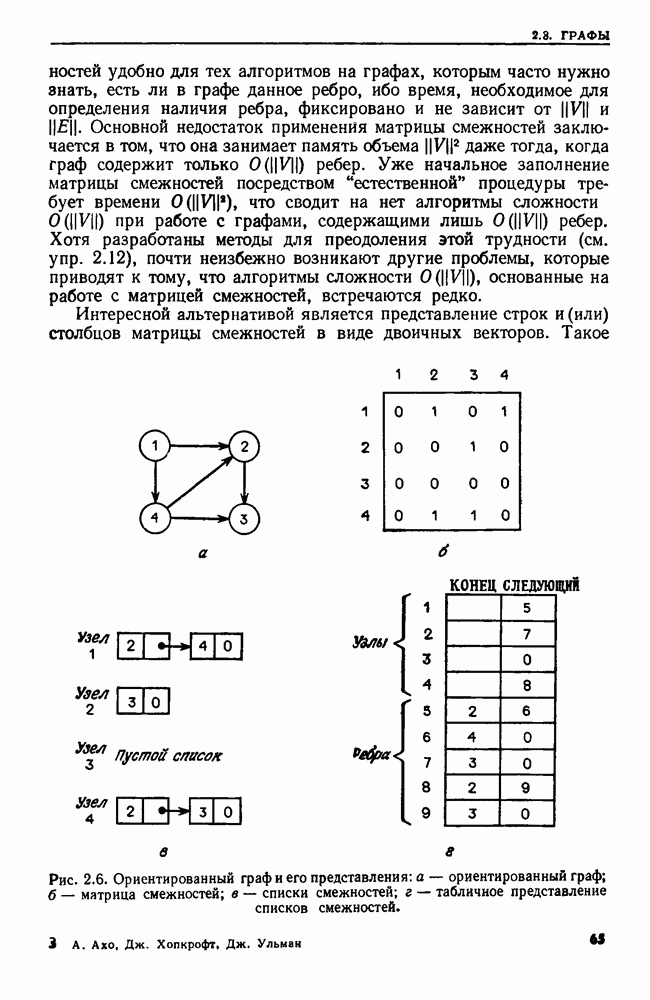
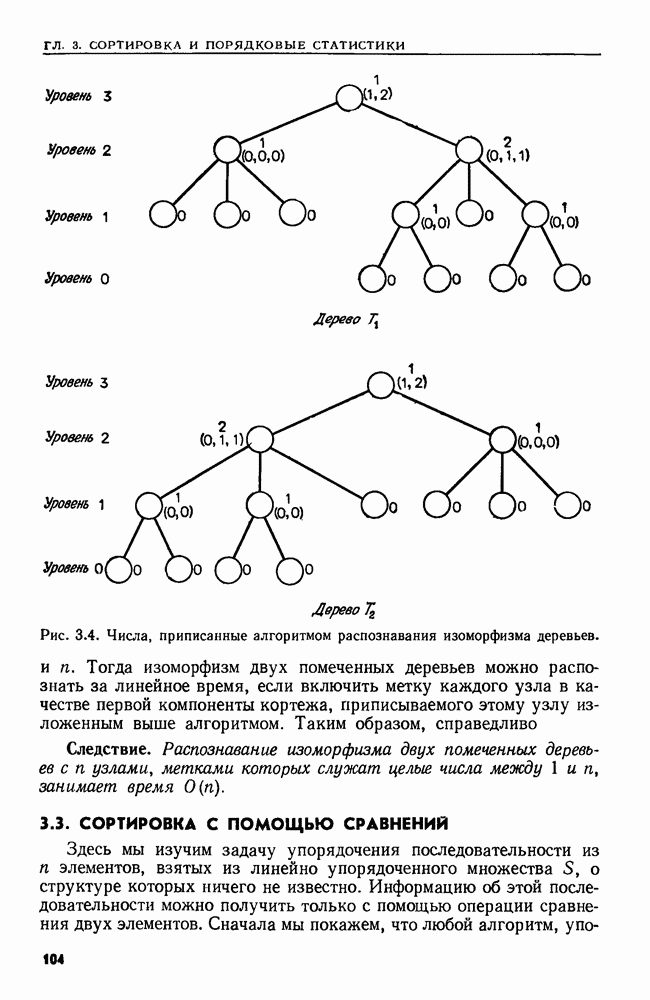
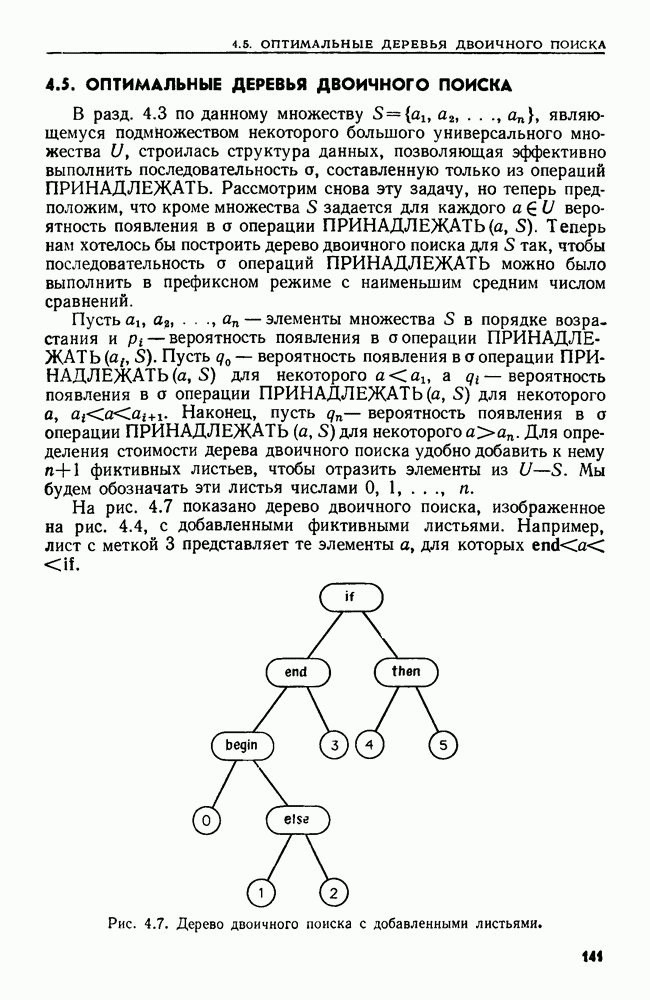
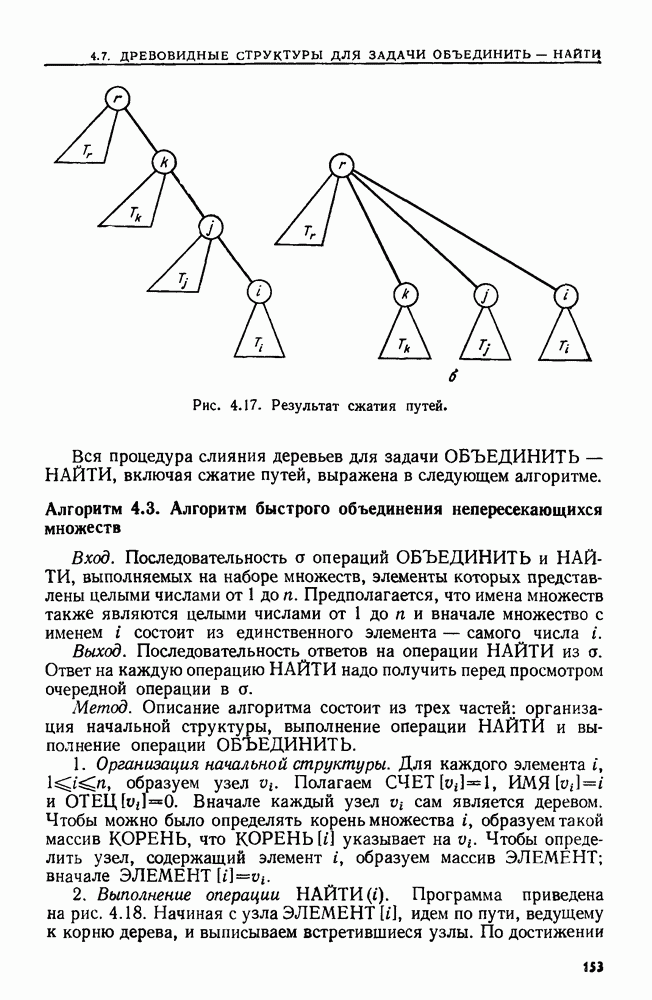
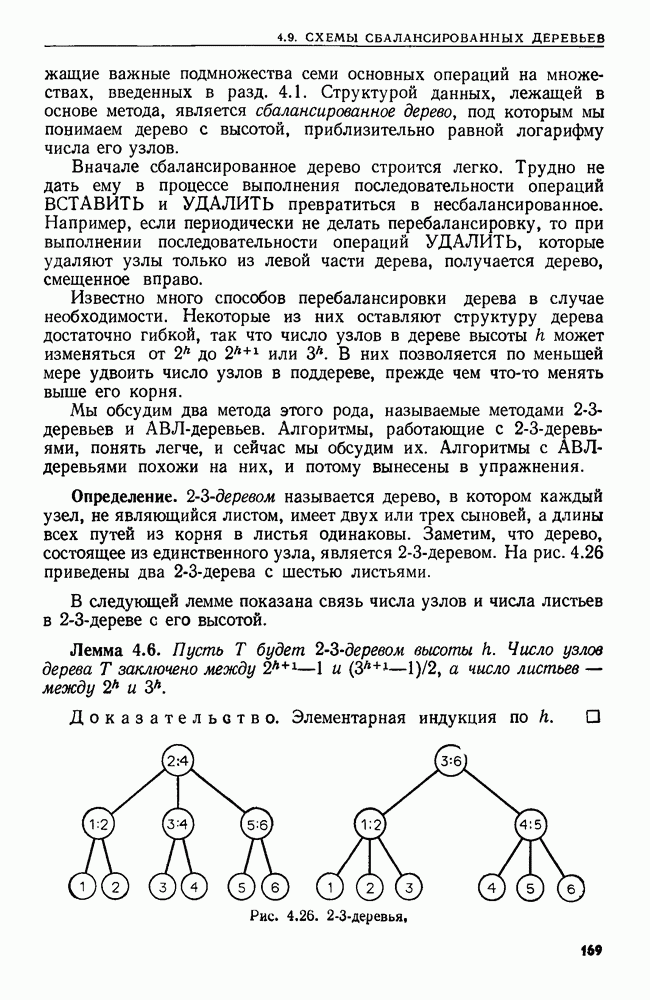
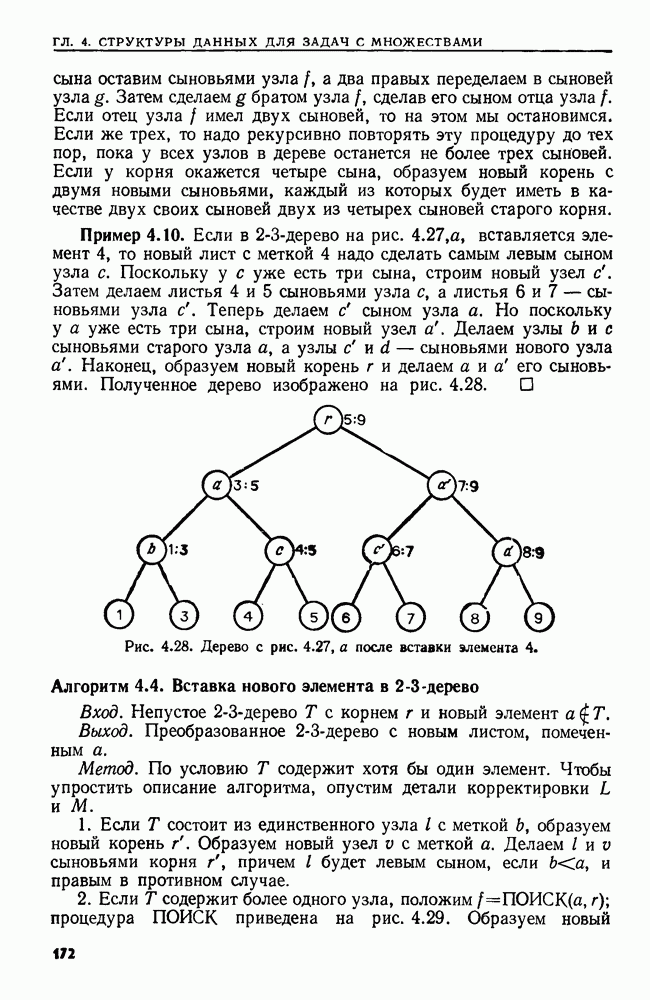
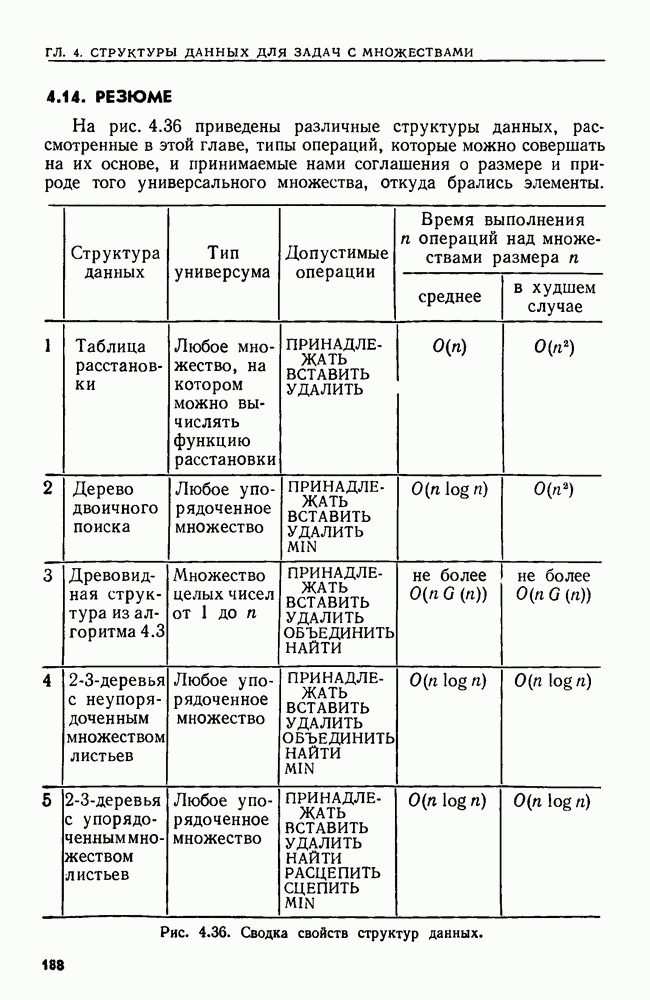
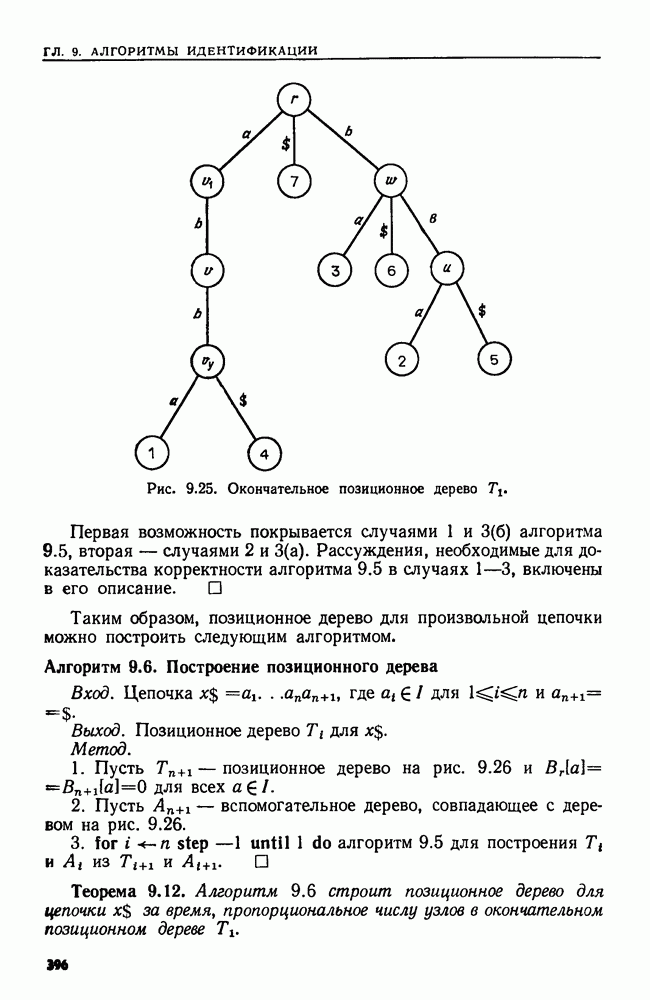
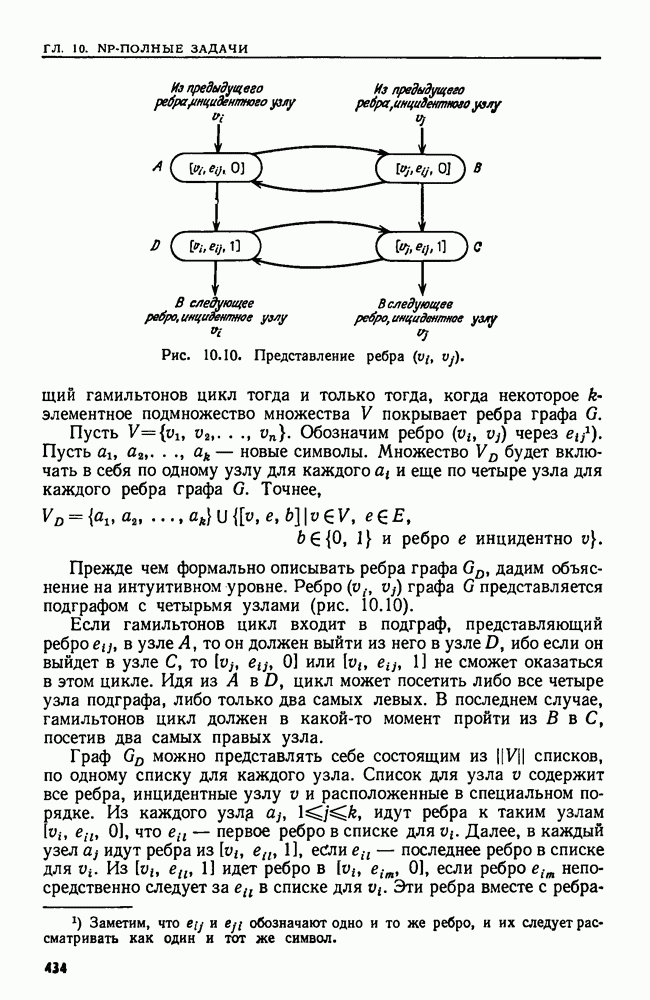
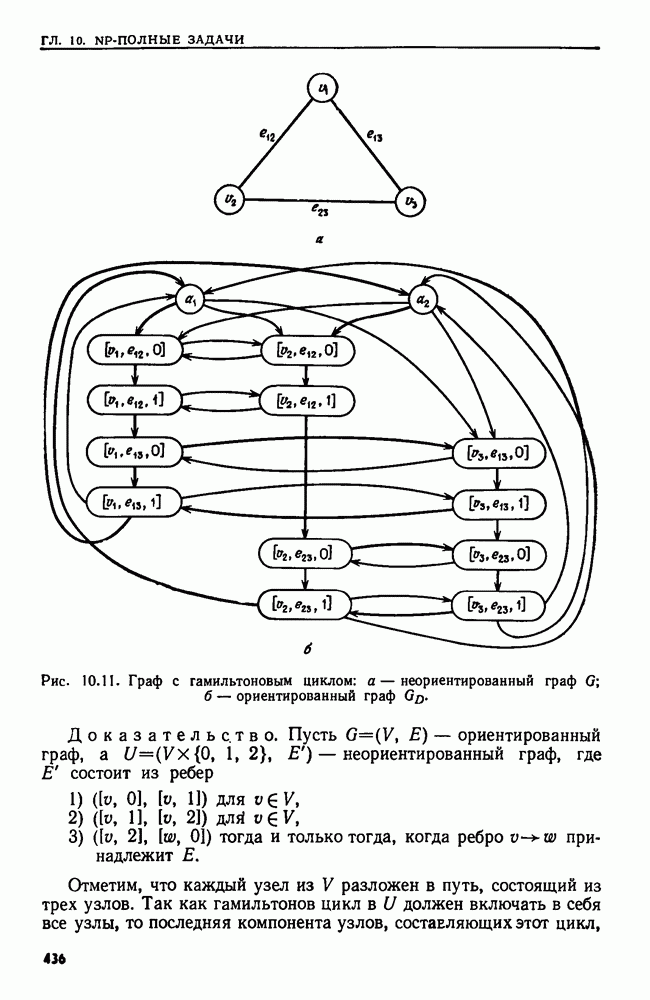
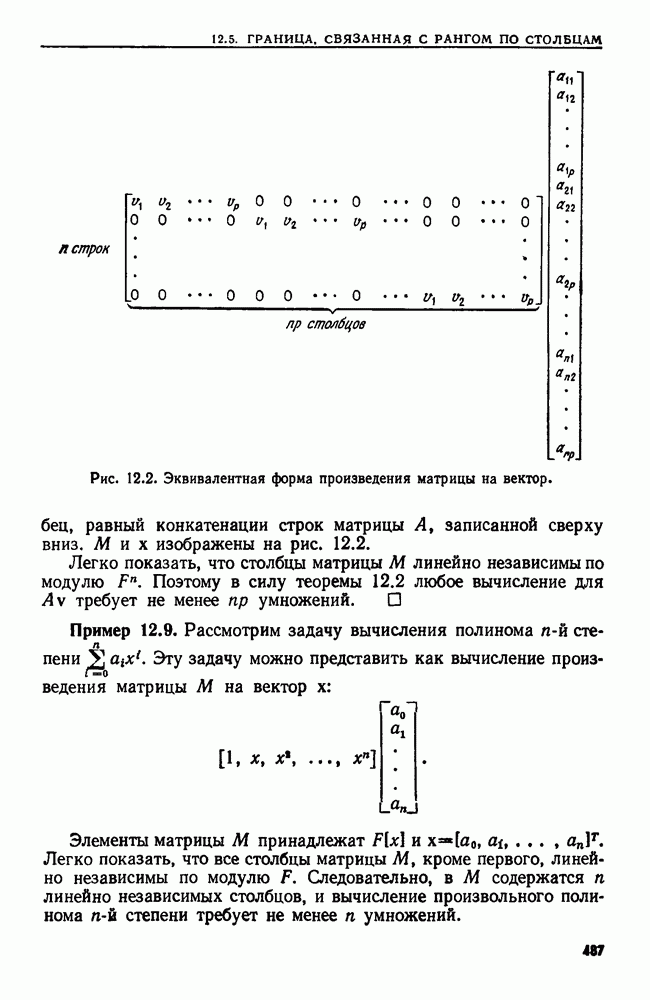
сказать: "Заменить  в х пустой цепочкой", имея в виду, что в х следует стереть пару квадратных скобок и символы между ними.
в х пустой цепочкой", имея в виду, что в х следует стереть пару квадратных скобок и символы между ними.
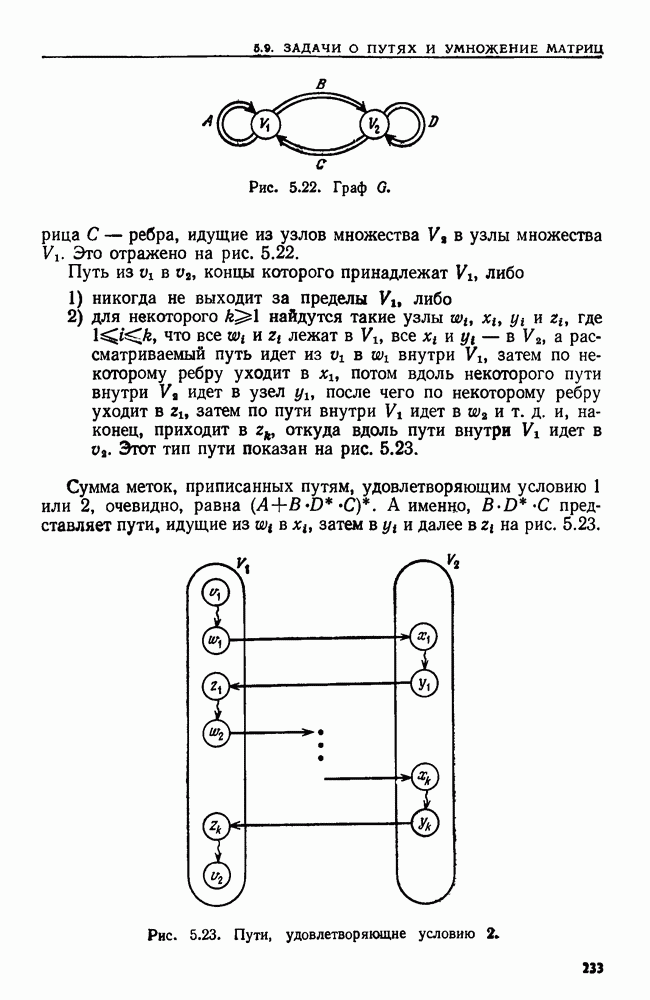
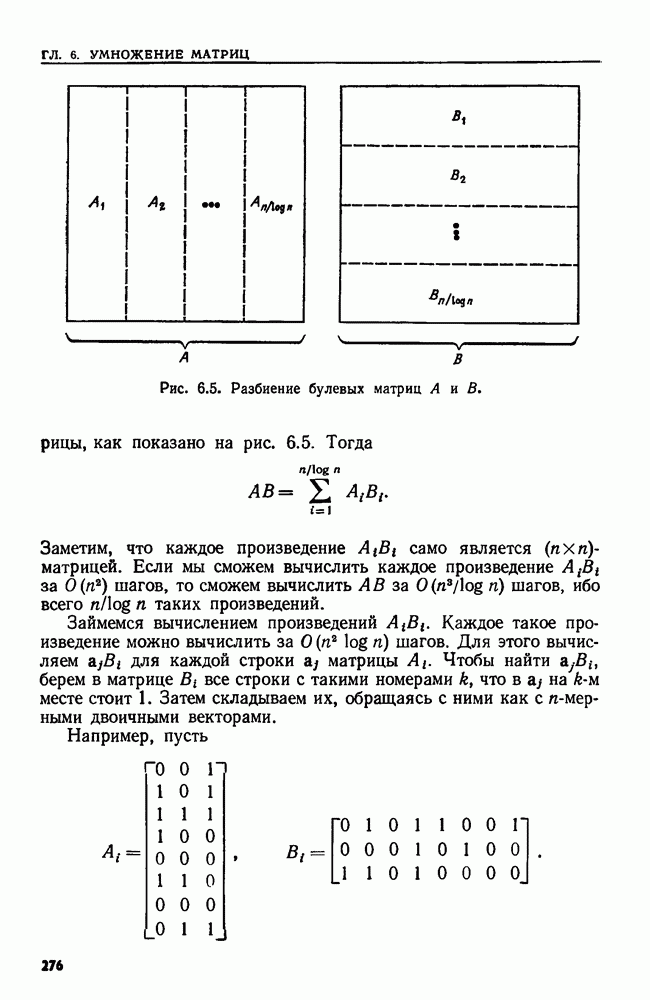
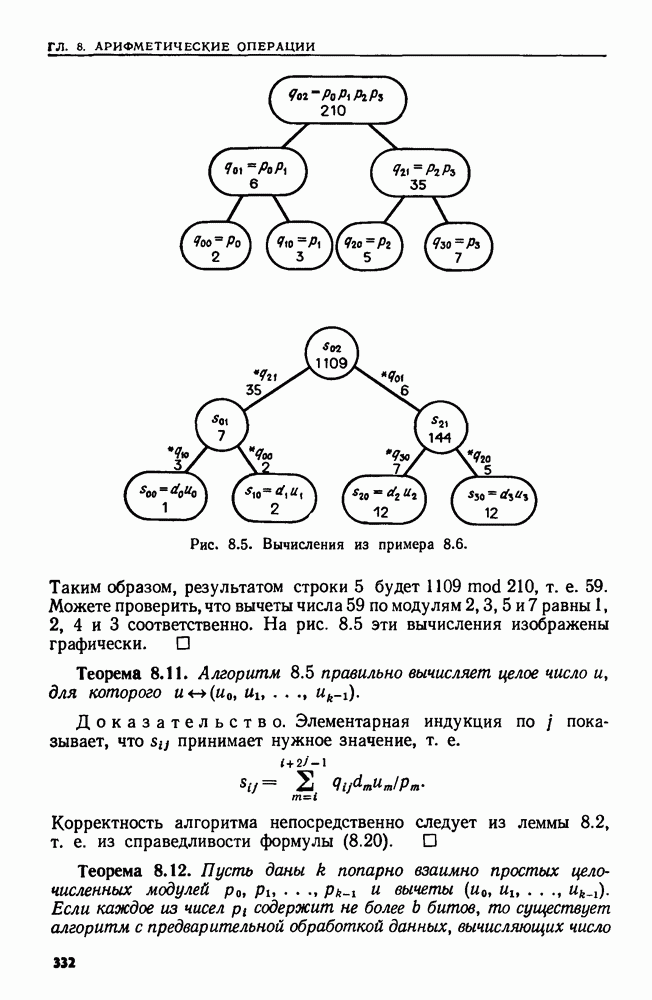
Поставленную выше задачу можно переформулировать, заменив данное регулярное выражение а выражением  где
где  алфавит цепочки-текста. Можно найти первое вхождение цепочки из
алфавит цепочки-текста. Можно найти первое вхождение цепочки из  обнаружив кратчайший префикс цепочки х, принадлежащий языку выражения
обнаружив кратчайший префикс цепочки х, принадлежащий языку выражения  Эту задачу можно решить, сначала построив НКА М для распознавания множества, представленного выражением
Эту задачу можно решить, сначала построив НКА М для распознавания множества, представленного выражением  а затем применив алгоритм 9.1 (см. ниже) для определения последовательности множеств состояний
а затем применив алгоритм 9.1 (см. ниже) для определения последовательности множеств состояний  в которые может перейти НКА М после прочтения цепочки
в которые может перейти НКА М после прочтения цепочки  при
при  Как только в
Как только в  попадает заключительное состояние, мы можем сказать, что у цепочки
попадает заключительное состояние, мы можем сказать, что у цепочки  есть такой суффикс
есть такой суффикс  что
что  принадлежит языку, представленному выражением а, при некотором
принадлежит языку, представленному выражением а, при некотором  Техника нахождения
Техника нахождения  т. е. левого конца образа, обсуждается в упр.
т. е. левого конца образа, обсуждается в упр. 
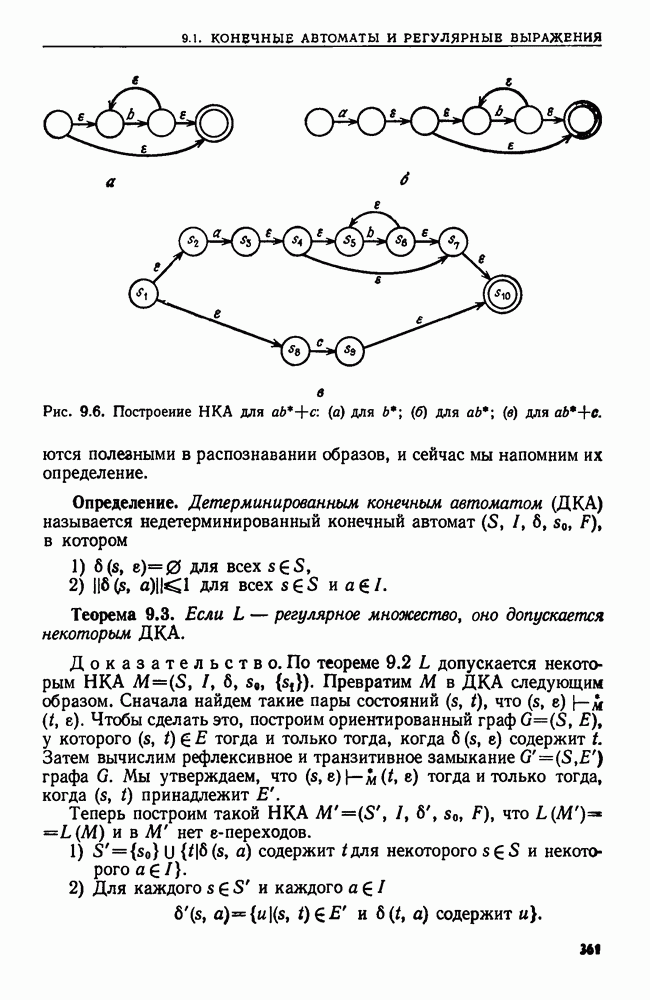
Один из способов моделирования поведения НКА М на цепочке-тексте  превратить
превратить  в детерминированный конечный автомат, как в теореме 9.3. Но такой путь может оказаться слишком дорогим, поскольку от регулярного выражения
в детерминированный конечный автомат, как в теореме 9.3. Но такой путь может оказаться слишком дорогим, поскольку от регулярного выражения  можно перейти к
можно перейти к  состояниями, а затем к ДКА с почти
состояниями, а затем к ДКА с почти  состояниями. Уже само построение ДКА может вызвать непреодолимые трудности.
состояниями. Уже само построение ДКА может вызвать непреодолимые трудности.
Другой способ моделирования поведения НКА М на цепочке  сначала исключить
сначала исключить  -переходы в
-переходы в  и тем самым построить
и тем самым построить  без
без  как это было сделано в теореме 9.3. Затем моделировать
как это было сделано в теореме 9.3. Затем моделировать  на входной цепочке
на входной цепочке  вычислив для каждого
вычислив для каждого  множество состояний
множество состояний  в которые мог бы попасть
в которые мог бы попасть  после прочтения
после прочтения  На самом деле каждое множество
На самом деле каждое множество  это то состояние, в которое пришел бы
это то состояние, в которое пришел бы  построенный в доказательстве теоремы 9.3, после прочтения
построенный в доказательстве теоремы 9.3, после прочтения 
Применяя эту технику, можно не строить автомат  а вычислить только те его состояния, которые появляются при обработке цепочки х. Чтобы объяснить, как найти множество
а вычислить только те его состояния, которые появляются при обработке цепочки х. Чтобы объяснить, как найти множество  надо показать, как построить
надо показать, как построить  по
по  Легко видеть, что
Легко видеть, что

где  — функция переходов автомата
— функция переходов автомата  Тогда
Тогда  объединение вплоть до
объединение вплоть до  множеств, каждое из которых содержит не больше
множеств, каждое из которых содержит не больше  членов. Так как при объединении надо исключить повторяющиеся члены (иначе представление множеств может стать громоздким), то очевидное моделирование автомата
членов. Так как при объединении надо исключить повторяющиеся члены (иначе представление множеств может стать громоздким), то очевидное моделирование автомата  занимает
занимает  шагов на входной символ, т. е. в общей сложности
шагов на входной символ, т. е. в общей сложности  шагов.
шагов.
Как это ни удивительно, но во многих практических ситуациях гораздо эффективнее не исключать  -переходы, а работать прямо с
-переходы, а работать прямо с  построенным по теореме 9.2 из регулярного выражения
построенным по теореме 9.2 из регулярного выражения 
вычислим "замыкание" множества  добавив к
добавив к  все такие состояния и, что
все такие состояния и, что  содержит и для некоторого
содержит и для некоторого  ранее оказавшегося в
ранее оказавшегося в  Это замыкание (оно и будет множеством
Это замыкание (оно и будет множеством  строится с помощью очереди состояний
строится с помощью очереди состояний  для которых множество
для которых множество  еще не рассматривалось. Алгоритм приведен на рис. 9.11.
еще не рассматривалось. Алгоритм приведен на рис. 9.11.
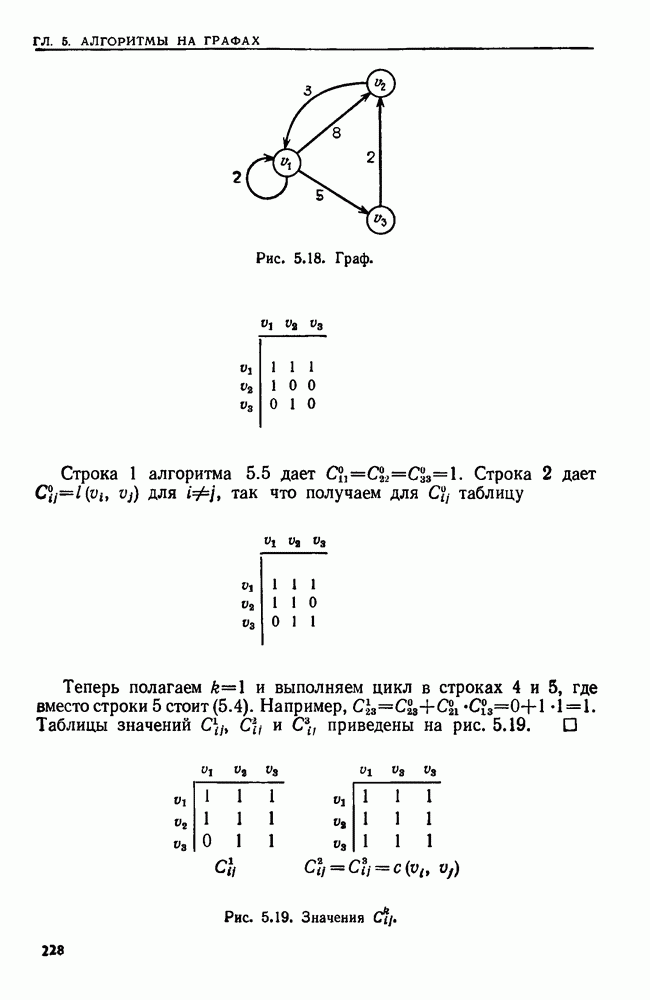
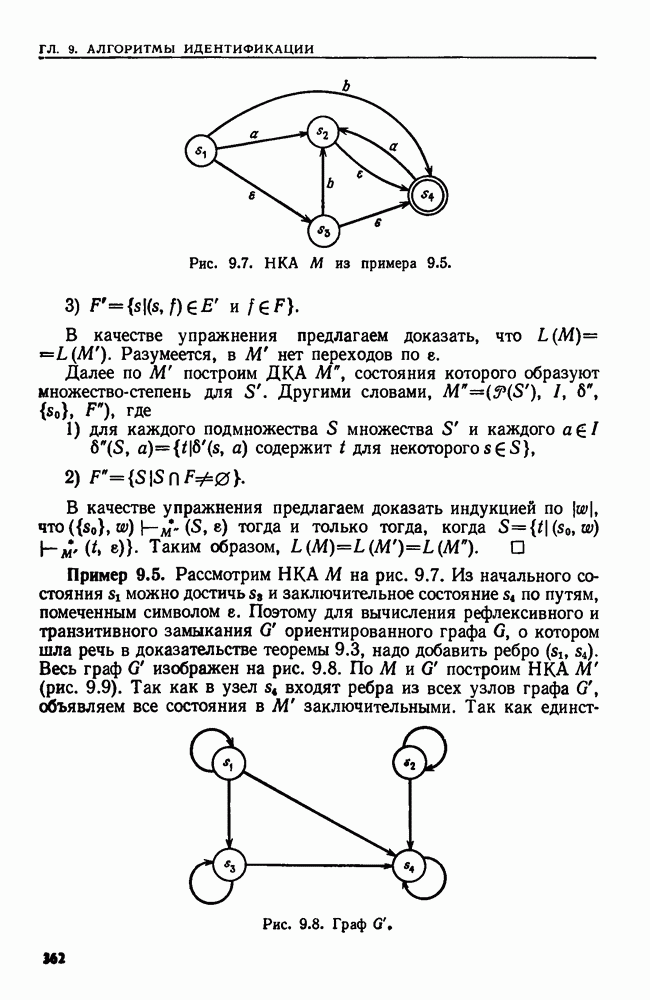
Пример 9.6. Пусть  изображенный на рис. 9.6, в. Допустим, что на вход подана цепочка
изображенный на рис. 9.6, в. Допустим, что на вход подана цепочка  Тогда
Тогда  в строке 2. В строках 9—12 рассмотрение состояния
в строке 2. В строках 9—12 рассмотрение состояния  приводит к добавлению
приводит к добавлению  в ОЧЕРЕДЬ и в
в ОЧЕРЕДЬ и в  Рассмотрение
Рассмотрение  не добавляет ничего, поэтому
не добавляет ничего, поэтому  Затем в строке
Затем в строке  Рассмотрение
Рассмотрение  добавляет
добавляет  а рассмотрение
а рассмотрение  добавляет
добавляет  Рассмотрение
Рассмотрение  не добавляет ничего, а рассмотрение
не добавляет ничего, а рассмотрение  добавляет
добавляет  Таким образом,
Таким образом,  Затем в строке
Затем в строке  Рассмотрение
Рассмотрение  добавляет
добавляет  Рассмотрение
Рассмотрение  добавляет
добавляет  Итак,
Итак, 
Теорема 9.4. Алгоритм 9.1 правильно вычисляет последовательность  где
где 
Доказательство. Простое упражнение на применение индукции, которое мы оставляем читателю. 
Теорема 9.5. Пусть в диаграмме автомата  состояниями из каждого узла выходит не более
состояниями из каждого узла выходит не более  ребер. Тогда на входной цепочке длины
ребер. Тогда на входной цепочке длины  алгоритм 9.1 тратит
алгоритм 9.1 тратит  шагов.
шагов.
Доказательство. Исследуем построение множества  для одного конкретного значения
для одного конкретного значения  Строки 8—12 на рис. 9.11 занимают
Строки 8—12 на рис. 9.11 занимают  шагов. Поскольку для данного
шагов. Поскольку для данного  никакое состояние не попадает в ОЧЕРЕДЬ дважды, то цикл в строках 7—12 требует
никакое состояние не попадает в ОЧЕРЕДЬ дважды, то цикл в строках 7—12 требует  времени. Поэтому легко показать, что тело основного цикла, т. е. строки 2—12, занимает
времени. Поэтому легко показать, что тело основного цикла, т. е. строки 2—12, занимает  времени. Таким образом, весь алгоритм занимает
времени. Таким образом, весь алгоритм занимает  времени.
времени.
Отсюда вытекает важный результат, связывающий распознавание вхождения элементов регулярного множества с алгоритмом 9.1.
Следствие. Если  произвольное регулярное выражение и
произвольное регулярное выражение и  цепочка длины
цепочка длины  то найдется
то найдется  допускающий язык, представленный выражением
допускающий язык, представленный выражением  причем алгоритм 9.1 тратит на построение последовательности
причем алгоритм 9.1 тратит на построение последовательности  где
где  для
для  время
время 
Доказательство. По теореме 9.2 можно построить автомат  которого не более
которого не более  состояний и из каждого из них выходит не более двух ребер. Поэтому
состояний и из каждого из них выходит не более двух ребер. Поэтому  в теореме 9.5 не превосходит 2.
в теореме 9.5 не превосходит 2.
Исходя из алгоритма 9.1, можно построить различные алгоритмы распознавания образов. Например, пусть даны регулярное выражение а и цепочка-текст  и надо найти наименьшее число
и надо найти наименьшее число  для которого существует такое
для которого существует такое  что
что  принадлежит множеству, представленному выражением а. С помощью теоремы 9.2 можно построить по а НКА М, допускающий язык
принадлежит множеству, представленному выражением а. С помощью теоремы 9.2 можно построить по а НКА М, допускающий язык  Чтобы найти наименьшее число
Чтобы найти наименьшее число  для которого
для которого  принадлежит
принадлежит  можно после блока, состоящего из строк 2—12 на рис. 9.11, вставить тест, проверяющий, содержит ли множество
можно после блока, состоящего из строк 2—12 на рис. 9.11, вставить тест, проверяющий, содержит ли множество  состояние из
состояние из  . В силу теоремы 9.2 можно сделать
. В силу теоремы 9.2 можно сделать  одноэлементным, так что такой текст не займет много времени; достаточно
одноэлементным, так что такой текст не займет много времени; достаточно  шагов, где
шагов, где  число состояний в
число состояний в  Если
Если  содержит состояние из
содержит состояние из  то прерываем основной цикл, поскольку обнаружено, что
то прерываем основной цикл, поскольку обнаружено, что  кратчайший префикс цепочки х, который входит в
кратчайший префикс цепочки х, который входит в 
Алгоритм 9.1 можно модифицировать и так, чтобы он для каждого упомянутого  находил такое наибольшее
находил такое наибольшее  (или наименьшее
(или наименьшее  что
что  входит в множество, представленное выражением а. Это делается приписыванием целого числа каждому состоянию из множеств
входит в множество, представленное выражением а. Это делается приписыванием целого числа каждому состоянию из множеств  Число, приписанное состоянию
Число, приписанное состоянию  указывает такое наибольшее (или наименьшее)
указывает такое наибольшее (или наименьшее)  что
что  Детали приписывания этих целых чисел с помощью алгоритма 9.1 оставляем в качестве упражнения.
Детали приписывания этих целых чисел с помощью алгоритма 9.1 оставляем в качестве упражнения.























































































































































































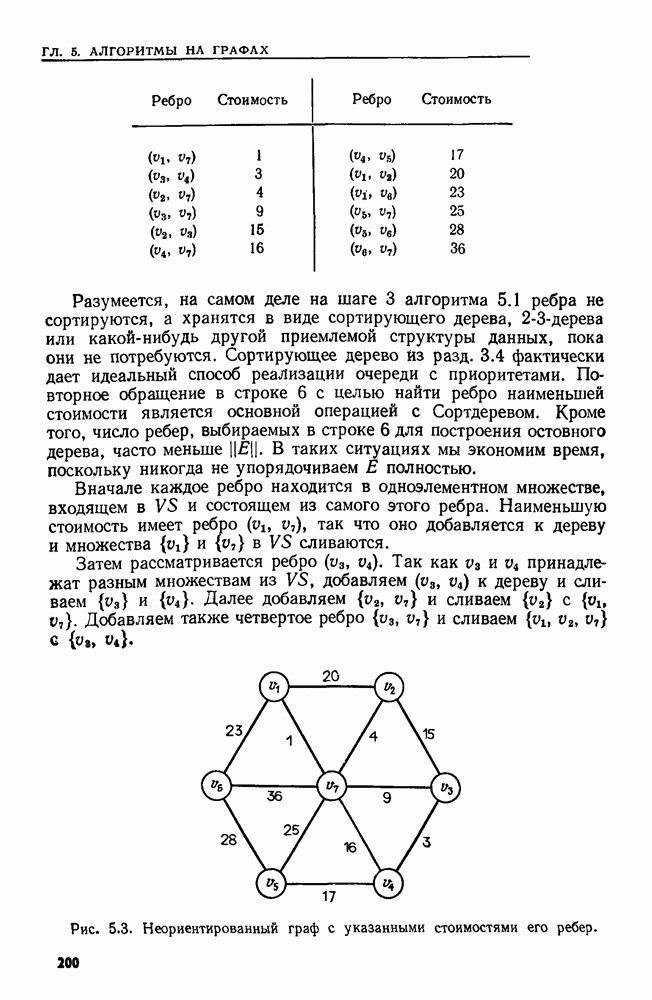
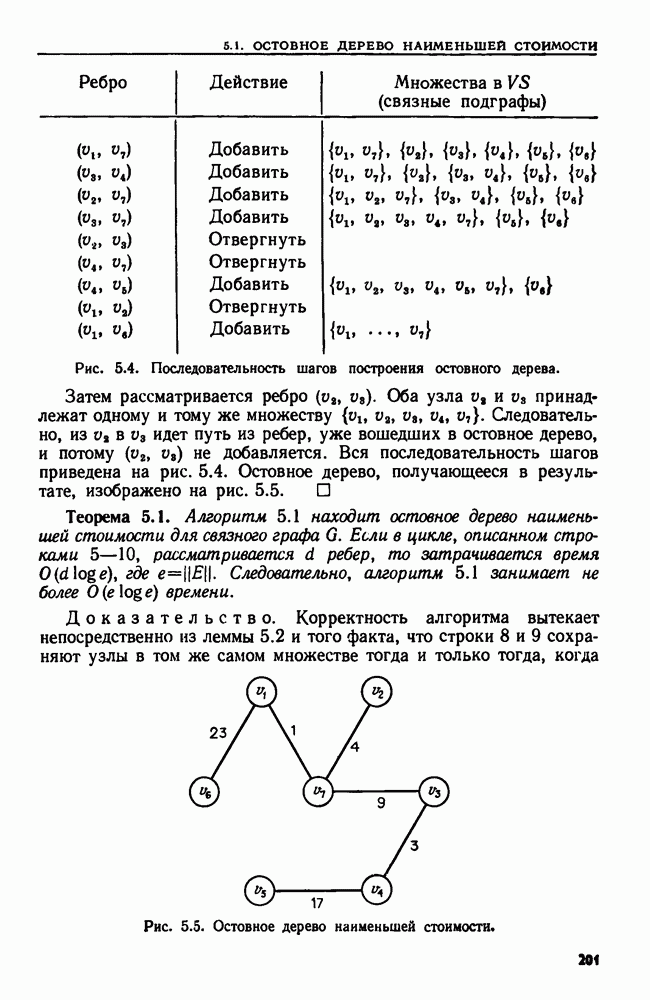





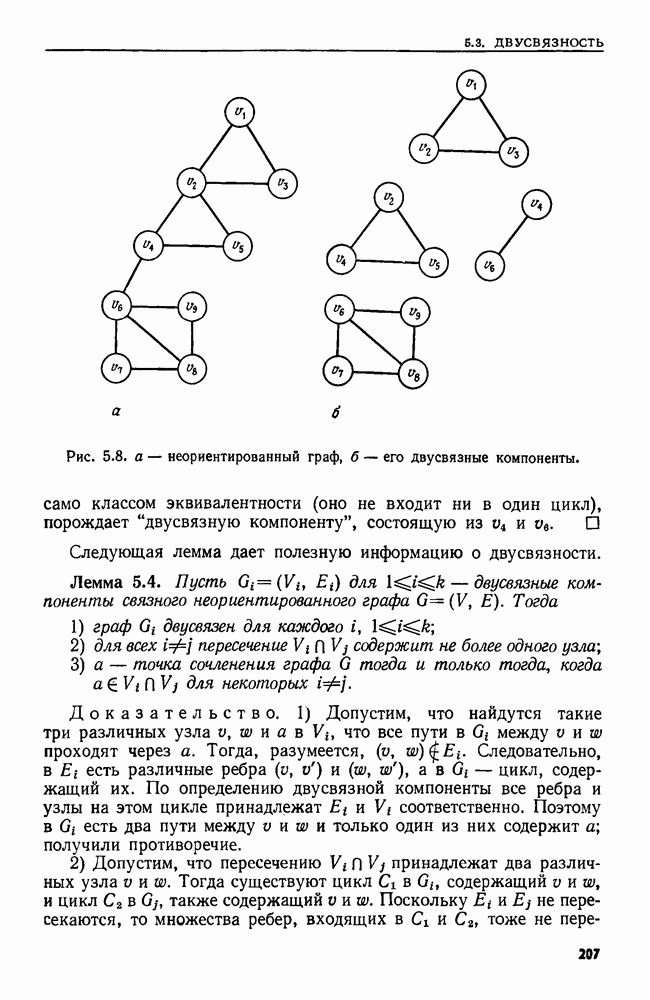


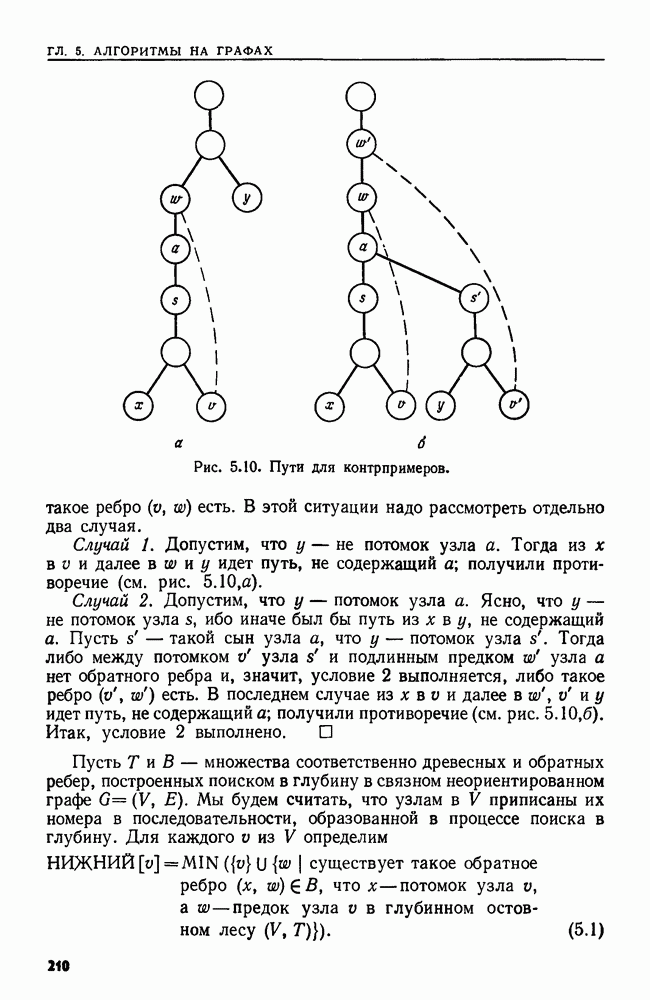































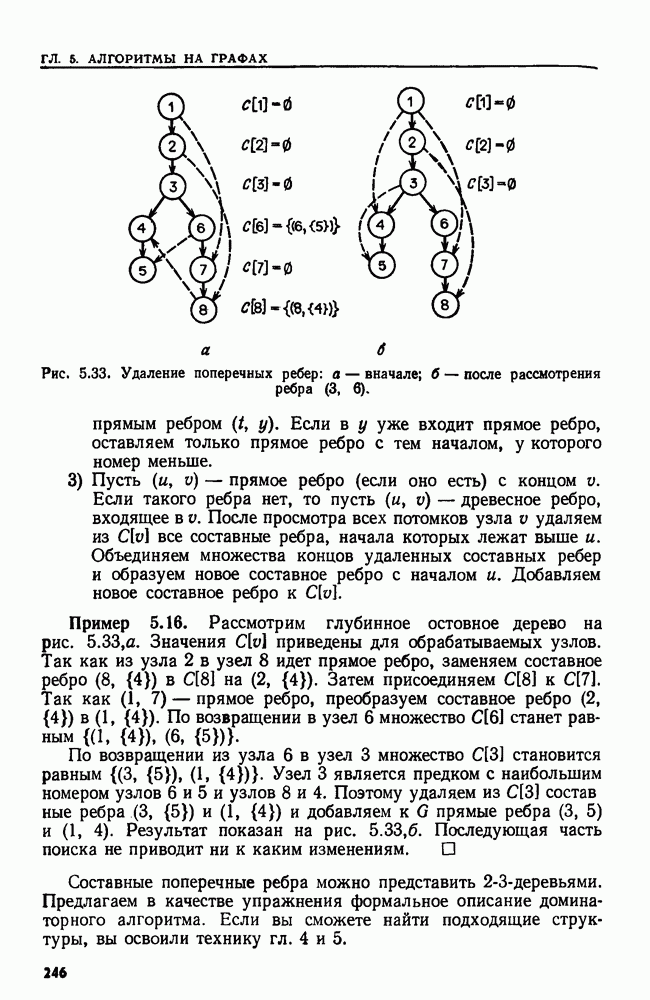




























































































































































































































































 и регулярное выражение а, называемое образом. Мы хотим найти такой наименьший индекс
и регулярное выражение а, называемое образом. Мы хотим найти такой наименьший индекс  что для некоторого
что для некоторого  подцепочка
подцепочка  цепочки х принадлежит языку, представленному выражением а.
цепочки х принадлежит языку, представленному выражением а.
 выходит не более двух ребер. Это свойство позволяет показать, что на входной цепочке
выходит не более двух ребер. Это свойство позволяет показать, что на входной цепочке  алгоритм 9.1 (см. ниже) тратит на моделирование НКА, построенного из
алгоритм 9.1 (см. ниже) тратит на моделирование НКА, построенного из  шагов.
шагов.
 и цепочка
и цепочка  из
из 
 где
где

 сначала найдем множество состояний
сначала найдем множество состояний  содержит
содержит  для некоторого
для некоторого  Затем
Затем