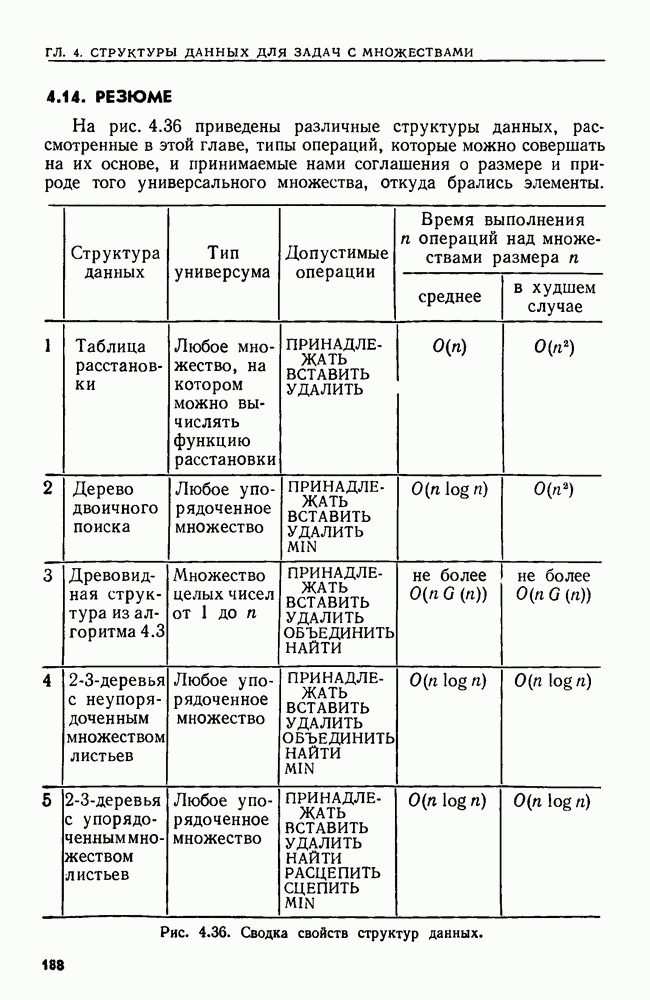
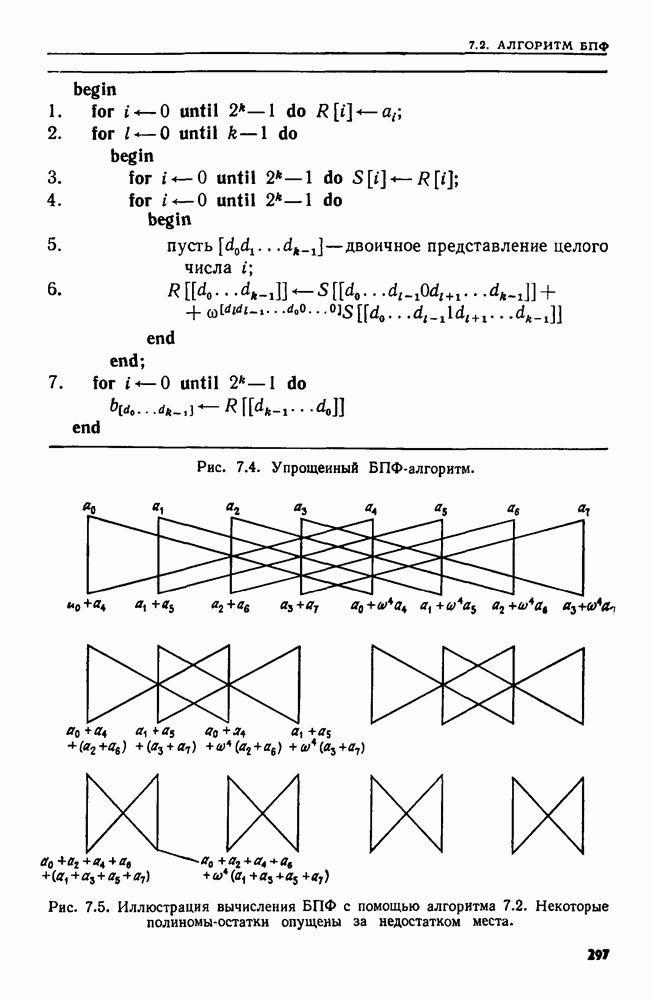
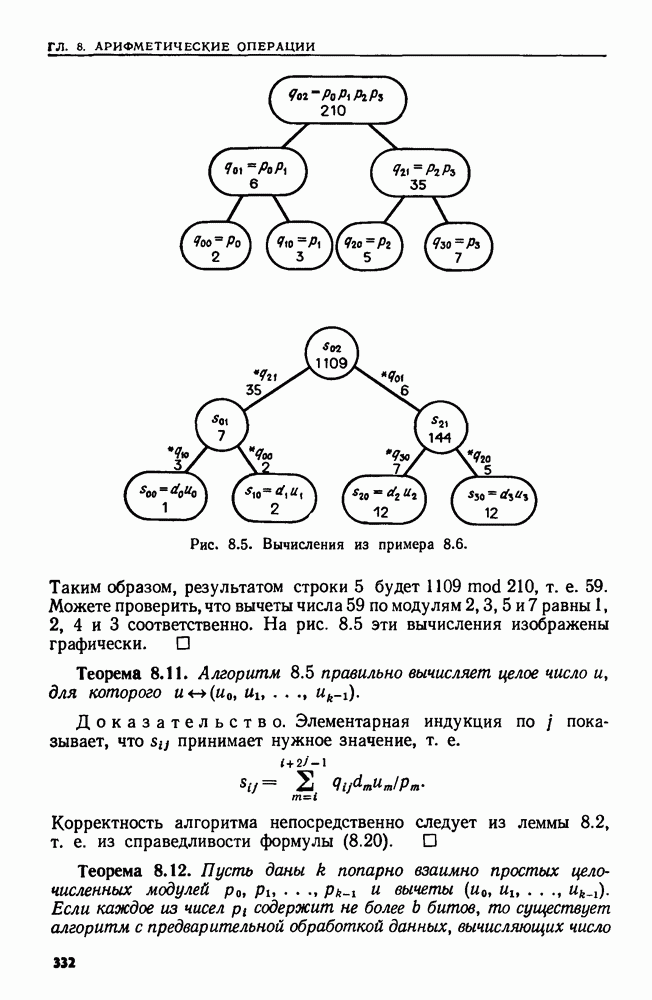
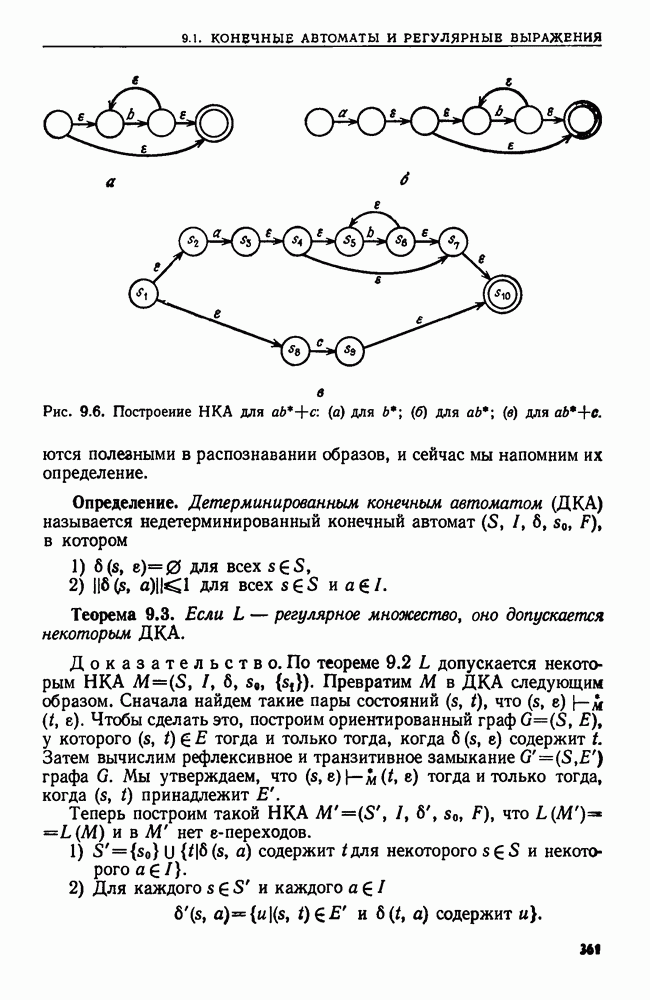
9.5. ПОЗИЦИОННЫЕ ДЕРЕВЬЯ И ИДЕНТИФИКАТОРЫ ПОЗИЦИЙ
В предыдущем разделе мы показали, что если задачу идентификации образов можно сформулировать как задачу распознавания языка, для которой можно найти решающий ее 2ДМА, то исходную задачу идентификации образов можно решить за линейное время. Можно было бы взять прямо алгоритм 9.4 как алгоритм линейной сложности, решающий исходную задачу. Но мультипликативная постоянная, возникающая при таком моделировании, сделала бы этот подход в лучшем случае непривлекательным. В настоящем разделе мы изучим структуру данных, которую можно использовать для идентификации образов с помощью более практичных алгоритмов, работающих линейное время. Эта структура данных применима, в частности, к следующим задачам.
1. По данным цепочке-тексту х и цепочке-образу у найти все вхождения у в х.
2. По данной цепочке-тексту х найти самую длинную повторяющуюся подцепочку в х.
3. По данным двум цепочкам х и у найти самую длинную подцепочку, входящую как в х, так 
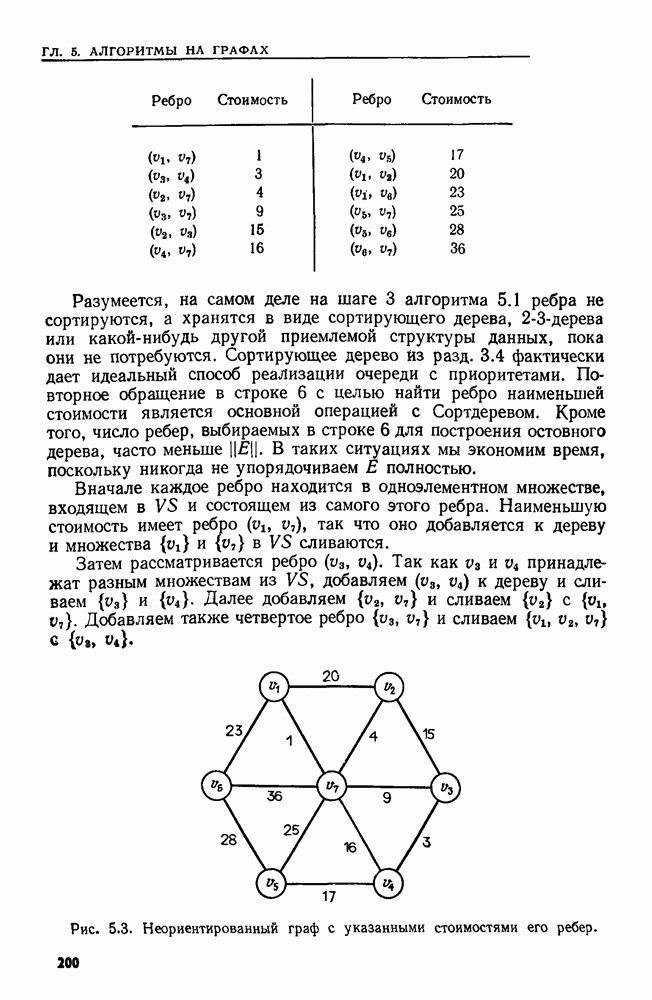
Определение. Позицией в цепочке длины  считается любое число от 1 до
считается любое число от 1 до  Говорят, что символ а входит в цепочку х в позиции
Говорят, что символ а входит в цепочку х в позиции  если
если  Говорят, что подцепочка и идентифицирует позицию
Говорят, что подцепочка и идентифицирует позицию  в цепочке х, если
в цепочке х, если  где
где  и цепочку х можно представить в виде
и цепочку х можно представить в виде  только при
только при  т. е. в позиции
т. е. в позиции  начинается единственное вхождение цепочки и в х. Например, подцепочка
начинается единственное вхождение цепочки и в х. Например, подцепочка  идентифицирует позицию 2 в цепочке
идентифицирует позицию 2 в цепочке  Подцепочка
Подцепочка  не идентифицирует позицию 2.
не идентифицирует позицию 2.
В оставшейся части этой главы положим  цепочка в некотором алфавите
цепочка в некотором алфавите  Тогда каждая позиция
Тогда каждая позиция  цепочки
цепочки  идентифицируется по крайней мере одной цепочкой, а именно
идентифицируется по крайней мере одной цепочкой, а именно  Кратчайшая цепочка, идентифицирующая позицию
Кратчайшая цепочка, идентифицирующая позицию  называется идентификатором (для) позиции
называется идентификатором (для) позиции  и обозначается через
и обозначается через 
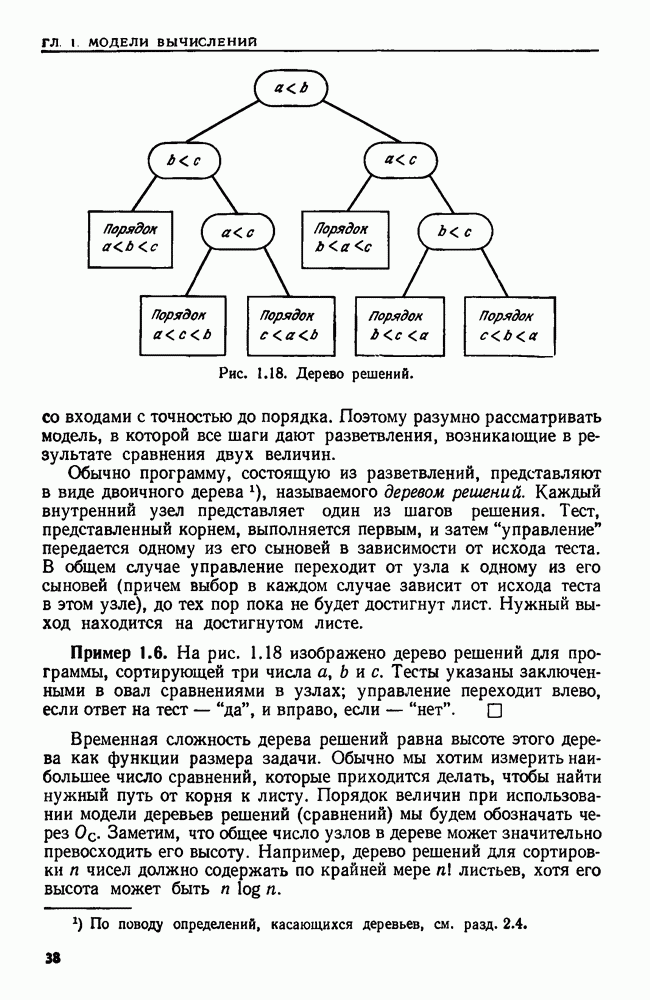
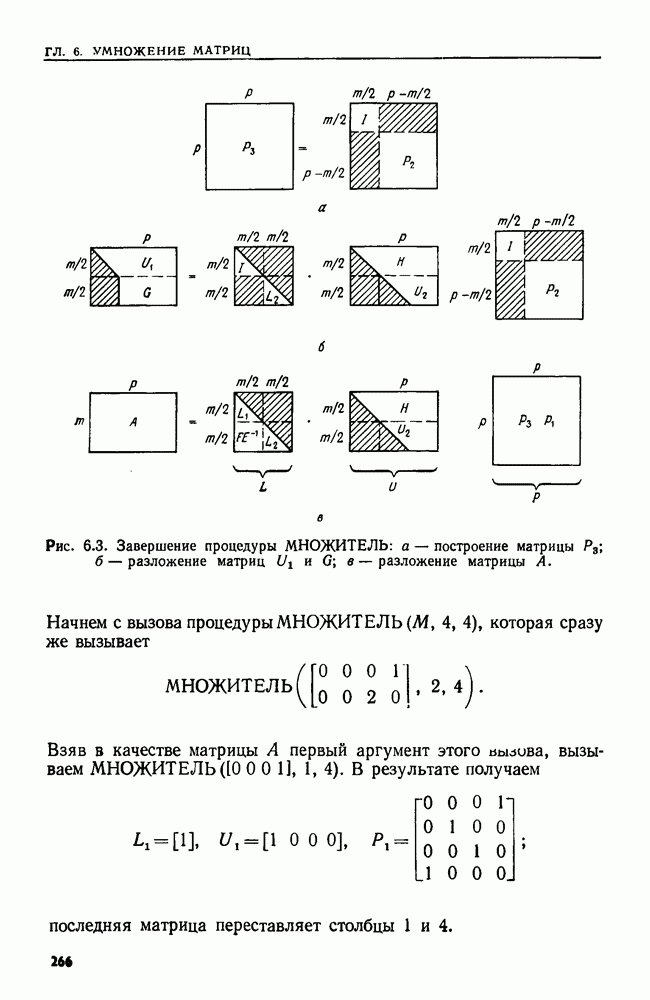
Пример 9.16. Рассмотрим цепочку  Идентификаторы позиций от 1 до 7 приведены на рис. 9.19.
Идентификаторы позиций от 1 до 7 приведены на рис. 9.19.
Идентификаторы позиций в цепочке удобно представлять с помощью дерева, называемого  -деревом, в котором помечены ребра и некоторые узлы.
-деревом, в котором помечены ребра и некоторые узлы.
Определение.  -деревом называют помеченное дерево
-деревом называют помеченное дерево  ребра которого, выходящие из любого внутреннего узла, помечены различными символами из
ребра которого, выходящие из любого внутреннего узла, помечены различными символами из  Если ребро
Если ребро  помечено символом а, то
помечено символом а, то  называют
называют  -сыном узла
-сыном узла 

Рис. 9.19. Идентификаторы для 
С помощью позиционных деревьев можно решить многие задачи идентификации образов, включая те, что были упомянуты в начале раздела.
Пример 9.18. Исследуем основную задачу идентификации образов: "Является ли  подцепочкой цепочки
подцепочкой цепочки  Допустим, что мы уже построили для позиционное дерево
Допустим, что мы уже построили для позиционное дерево  Чтобы узнать, входит ли
Чтобы узнать, входит ли  рассмотрим его как граф переходов некоторого детерминированного конечного автомата. Иными словами, отправляясь из корня дерева
рассмотрим его как граф переходов некоторого детерминированного конечного автомата. Иными словами, отправляясь из корня дерева  проследим максимально длинный возможный путь в позиционном дереве, которому приписана цепочка
проследим максимально длинный возможный путь в позиционном дереве, которому приписана цепочка  для некоторого
для некоторого  Пусть этот путь оканчивается в узле
Пусть этот путь оканчивается в узле  Возможны несколько случаев.
Возможны несколько случаев.
1. Если  не лист, то ответом будет "нет". В этом случае
не лист, то ответом будет "нет". В этом случае  подцепочка цепочки
подцепочка цепочки  нет.
нет.
2. Если  лист с меткой
лист с меткой  то
то  совпадает с
совпадает с  символами цепочки х, начиная с позиции
символами цепочки х, начиная с позиции  Тогда надо сравнить
Тогда надо сравнить  Если они не совпадают, то ответом будет "нет"; в противном случае "да", причем у входит в х, начиная с позиции
Если они не совпадают, то ответом будет "нет"; в противном случае "да", причем у входит в х, начиная с позиции 
3. Если  не лист, то ответом будет "да". В этом случае у — подцепочка с двумя или более вхождениями в х. Начальные позиции этих вхождений — метки листьев, принадлежащих поддереву узла
не лист, то ответом будет "да". В этом случае у — подцепочка с двумя или более вхождениями в х. Начальные позиции этих вхождений — метки листьев, принадлежащих поддереву узла  позиционного дерева.
позиционного дерева.
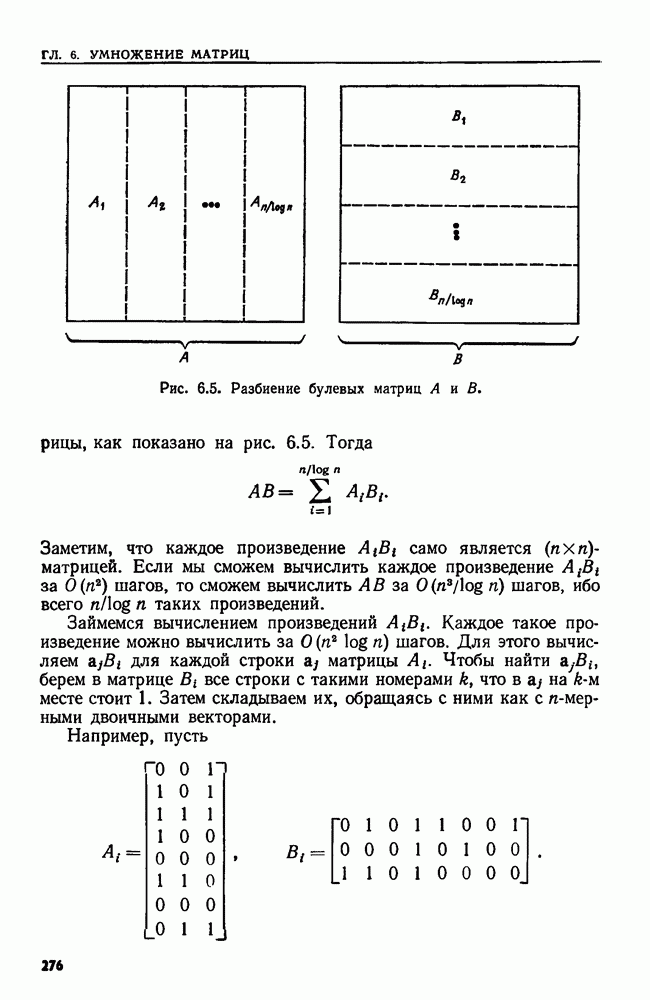
Пример 9.19. С помощью позиционного дерева можно найти самую длинную повторяющуюся подцепочку данной цепочки  (два вхождения этой подцепочки могут перекрываться). Длиннейшая повторяющаяся подцепочка соответствует внутреннему узлу позиционного дерева с наибольшей глубиной. Такой узел можно обнаружить очевидным способом.
(два вхождения этой подцепочки могут перекрываться). Длиннейшая повторяющаяся подцепочка соответствует внутреннему узлу позиционного дерева с наибольшей глубиной. Такой узел можно обнаружить очевидным способом.
Рассмотрим нахождение длиннейшей повторяющейся подцепочки в  В позиционном дереве для
В позиционном дереве для  (рис. 9.20) есть один внутренний узел глубины 3 и ни одного внутреннего узла большей глубины. Поэтому соответствующая этому узлу цепочка
(рис. 9.20) есть один внутренний узел глубины 3 и ни одного внутреннего узла большей глубины. Поэтому соответствующая этому узлу цепочка  самая длинная повторяющаяся подцепочка в
самая длинная повторяющаяся подцепочка в  Узлы с метками 1 и 4 указывают, где начинаются два вхождения цепочки
Узлы с метками 1 и 4 указывают, где начинаются два вхождения цепочки  В нашем случае они не перекрываются.
В нашем случае они не перекрываются.
Изучим подробно задачу построения позиционного дерева. В оставшейся части этой главы будет цепочкой  где
где  единственный правый концевой маркер
единственный правый концевой маркер  Через
Через  будем обозначать суффикс
будем обозначать суффикс  а через
а через  идентификатор позиции
идентификатор позиции  Все позиции нумеруются по исходной цепочке
Все позиции нумеруются по исходной цепочке 
Мы изложим алгоритм построения позиционного дерева для  за время, пропорциональное числу узлов окончательного
за время, пропорциональное числу узлов окончательного
дерева. Заметим, что позиционное дерево для  может содержать
может содержать  узлов. Например, позиционное дерево для
узлов. Например, позиционное дерево для  содержит
содержит  узлов, в чем легко убедиться самим. Но при разумных предположениях о том, что такое "случайная" цепочка (например, символы выбираются из алфавита с равной вероятностью и независимо), можно показать, что "среднее" позиционное дерево для цепочки длины
узлов, в чем легко убедиться самим. Но при разумных предположениях о том, что такое "случайная" цепочка (например, символы выбираются из алфавита с равной вероятностью и независимо), можно показать, что "среднее" позиционное дерево для цепочки длины  содержит
содержит  узлов. Мы не будем показывать это здесь. Отметим лишь, что существует алгоритм сложности
узлов. Мы не будем показывать это здесь. Отметим лишь, что существует алгоритм сложности  в худшем случае, который строит компактную форму позиционного дерева прямо по данной цепочке. Работы, обсуждающие этот алгоритм, указаны в замечаниях по литературе.
в худшем случае, который строит компактную форму позиционного дерева прямо по данной цепочке. Работы, обсуждающие этот алгоритм, указаны в замечаниях по литературе.
Рассмотрим различия между множествами  идентификаторов для
идентификаторов для  соответственно, поскольку в алгоритме, описываемом ниже,
соответственно, поскольку в алгоритме, описываемом ниже,  строится из
строится из  Одно очевидное различие состоит в том, что
Одно очевидное различие состоит в том, что  содержит идентификатор
содержит идентификатор  первой позиции в
первой позиции в  Из-за того, что
Из-за того, что  содержит эту дополнительную цепочку, может оказаться, что идентификатор некоторой позиции
содержит эту дополнительную цепочку, может оказаться, что идентификатор некоторой позиции  содержащийся в
содержащийся в  не является идентификатором позиции
не является идентификатором позиции  Это происходит тогда и только тогда, когда идентификатор
Это происходит тогда и только тогда, когда идентификатор  позиции
позиции  служит префиксом для
служит префиксом для  В этой ситуации надо удлинить цепочку
В этой ситуации надо удлинить цепочку  чтобы сделать из нее
чтобы сделать из нее  т. е. идентификатор позиции
т. е. идентификатор позиции  Два идентификатора из
Два идентификатора из  удлинять не придется. В самом деле, если бы надо было удлинять цепочки
удлинять не придется. В самом деле, если бы надо было удлинять цепочки  то они обе были бы префиксами цепочки
то они обе были бы префиксами цепочки  значит, одна из них была бы префиксом другой вопреки лемме
значит, одна из них была бы префиксом другой вопреки лемме 
Пример 9.20. Пусть  Идентификаторы для
Идентификаторы для  приведены на рис. 9.21. Заметим, что
приведены на рис. 9.21. Заметим, что  получается из
получается из  добавлением одной цепочки
добавлением одной цепочки  . С другой стороны, для построения
. С другой стороны, для построения  из
из  потребовалось два изменения. Мы добавили
потребовалось два изменения. Мы добавили  и дописали
и дописали  к концу
к концу  чтобы получить
чтобы получить  Чтобы построить
Чтобы построить  добавили
добавили  и дописали
и дописали  чтобы получить
чтобы получить 
Рассмотрим, что же нужно для построения позиционного дерева Тпредставляющего  по позиционному дереву
по позиционному дереву  представляющему
представляющему  Пусть
Пусть  построено. Надо добавить к
построено. Надо добавить к  лист с меткой
лист с меткой  соответствующий цепочке
соответствующий цепочке  Если для некоторого
Если для некоторого  цепочка
цепочка  служит префиксом цепочки
служит префиксом цепочки  то надо также удлинить путь в
то надо также удлинить путь в  идущий из корня в лист с меткой
идущий из корня в лист с меткой  чтобы новый лист с меткой
чтобы новый лист с меткой  соответствовал цепочке
соответствовал цепочке  Таким образом, ключом к эффективному построению по
Таким образом, ключом к эффективному построению по  позиционного дерева
позиционного дерева  для
для  является умение быстро находить такую цепочку у, что
является умение быстро находить такую цепочку у, что  самый длинный префикс цепочки
самый длинный префикс цепочки  входящий также в
входящий также в

Рис. 9.21. Идентификаторы некоторых суффиксов цепочки 
и, кроме того, умение узнавать, служит ли  префиксом идентификатора из
префиксом идентификатора из 
Такое построение требует добавления к позиционному дереву трех новых структур. Первая из них — двоичный вектор (массив), который приписывается каждому узлу позиционного дерева  Вектор, приписываемый узлу и, будет обозначаться
Вектор, приписываемый узлу и, будет обозначаться  Для каждого символа из
Для каждого символа из  в этом векторе будет своя компонента. Если
в этом векторе будет своя компонента. Если  узел в
узел в  соответствующий цепочке у, и а
соответствующий цепочке у, и а  то
то  если
если  подцепочка в
подцепочка в  . В противном случае
. В противном случае 
Далее каждому узлу приписывается его глубина в позиционном дереве. Эту информацию легко корректировать по мере роста дерева, и впредь мы будем предполагать, не оговаривая это особо, что она вычисляется.
Последнее добавление к позиционному дереву — новая древовидная структура, расположенная на его узлах. Мы будем называть ее "вспомогательным деревом", но на самом деле это будет всего лишь другое множество ребер, соединяющих узлы нашего позиционного дерева.
Определение. Пусть  позиционное дерево для
позиционное дерево для  Вспомогательным деревом для позиционного дерева
Вспомогательным деревом для позиционного дерева  назовем
назовем  и
и  -дерево
-дерево  обладающее следующими свойствами:
обладающее следующими свойствами:
1) A имеет то же множество узлов, что и 
2) узел  является
является  -сыном узла
-сыном узла  если
если  цепочка, соответствующая
цепочка, соответствующая  — цепочка, соответствующая
— цепочка, соответствующая  Таким образом, пути в
Таким образом, пути в  идущему из корня в
идущему из корня в  приписана цепочка
приписана цепочка  а пути в
а пути в  идущему из корня в
идущему из корня в  приписана цепочка
приписана цепочка 

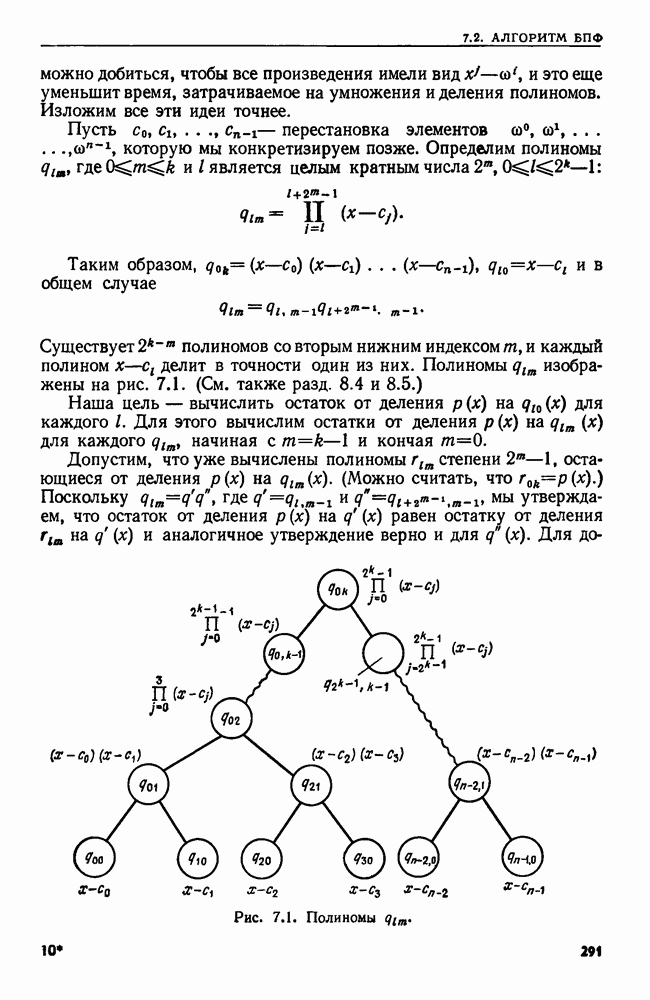
Рис. 9.22. Позиционное (а) и вспомогательное (б) деревья для 
Пример 9.21. Позиционное и вспомогательное деревья для  изображены на рис. 9.22. (Числа на листьях указывают позиции относительно
изображены на рис. 9.22. (Числа на листьях указывают позиции относительно  Заметим, что листья вспомогательного дерева не обязательно являются листьями позиционного дерева, хотя множество узлов у обоих деревьев одно и то же.
Заметим, что листья вспомогательного дерева не обязательно являются листьями позиционного дерева, хотя множество узлов у обоих деревьев одно и то же.
Из определения не видно, всегда ли у позиционного дерева есть вспомогательное; действительно, произвольное  -дерево может не иметь вспомогательного. В следующей теореме сформулированы условия, при которых
-дерево может не иметь вспомогательного. В следующей теореме сформулированы условия, при которых  -дерево имеет вспомогательное дерево.
-дерево имеет вспомогательное дерево.
Теорема 9.11. Для того чтобы у данного  -дерева
-дерева  было вспомогательное дерево, необходимо и достаточно, чтобы
было вспомогательное дерево, необходимо и достаточно, чтобы  обладало таким свойством: если в
обладало таким свойством: если в  есть узел, соответствующий цепочке
есть узел, соответствующий цепочке  где
где  то в нем есть также узел, соответствующий цепочке х.
то в нем есть также узел, соответствующий цепочке х.
Доказательство. Упражнение. 
Следствие. Всякое позиционное дерево имеет вспомогательное дерево.
Доказательство. Если  префикс идентификатора позиции
префикс идентификатора позиции  то в силу леммы
то в силу леммы  префикс идентификатора позиции
префикс идентификатора позиции 
Теперь мы готовы описать алгоритм, который строит позиционное дерево  для
для  из позиционного дерева
из позиционного дерева  для
для 
Алгоритм 9.5. Построение из 
Вход. Цепочка  позиционное
позиционное  и вспомогательное
и вспомогательное  деревья для
деревья для 
Выход. Позиционное  и вспомогательное
и вспомогательное  деревья для
деревья для 
Метод.
1. Находим лист с меткой  (Это последний добавленный к
(Это последний добавленный к  лист.)
лист.)
2. Проходим по пути, ведущему из этого листа в корень дерева  до такого узла
до такого узла  что
что  (Узел
(Узел  соответствует такой самой длинной цепочке у, что
соответствует такой самой длинной цепочке у, что  префикс цепочки
префикс цепочки  и подцепочка в начинающаяся в некоторой позиции
и подцепочка в начинающаяся в некоторой позиции  Если такого узла нет, доходим до корня.
Если такого узла нет, доходим до корня.
3. Полагаем  для каждого узла
для каждого узла  на пути, идущем из узла с меткой
на пути, идущем из узла с меткой  в сына узла
в сына узла  расположенного на том же пути, или в корень, если такого
расположенного на том же пути, или в корень, если такого  нет. (Каждый узел
нет. (Каждый узел  на этом пути соответствует некоторому префиксу
на этом пути соответствует некоторому префиксу  цепочки
цепочки  Поэтому ясно, что
Поэтому ясно, что  подцепочка цепочки
подцепочка цепочки 
4. 1) Если узла 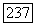 нет, переходим к случаю 1 (ниже).
нет, переходим к случаю 1 (ниже).
2) Если узел 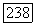 существует, но у него нет агсына во вспомогательном дереве
существует, но у него нет агсына во вспомогательном дереве 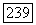 переходим к случаю 2.
переходим к случаю 2.
3) Если 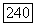 есть
есть 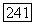 -сын
-сын 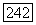 во вспомогательном дереве, переходим к случаю 3. Узел
во вспомогательном дереве, переходим к случаю 3. Узел 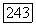 соответствует цепочке
соответствует цепочке  в позиционном дереве
в позиционном дереве 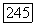
Случай 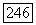 символ, не входящий в
символ, не входящий в 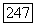 Тогда идентификатором позиции
Тогда идентификатором позиции 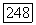 и будет
и будет 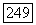 Чтобы построить
Чтобы построить 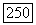 из
из 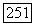 выполняем следующее:
выполняем следующее:
(а) образуем новый лист с меткой 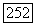 являющийся
являющийся 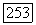 -сыном корня дерева
-сыном корня дерева 
полагаем  для всех а
для всех а 
Чтобы построить  из
из  делаем новый узел с меткой
делаем новый узел с меткой  сыном корня дерева
сыном корня дерева 
Случай  входит в
входит в  но в
но в 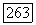 есть лишь собственный префикс цепочки
есть лишь собственный префикс цепочки 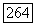 (приписанный пути из корня дерева
(приписанный пути из корня дерева 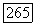 в некоторый лист
в некоторый лист 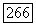 Эта ситуация возникает тогда, когда нужно удлинять идентификатор некоторой позиции
Эта ситуация возникает тогда, когда нужно удлинять идентификатор некоторой позиции 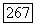 чтобы он стал идентификатором позиции
чтобы он стал идентификатором позиции 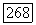 Допустим, что
Допустим, что 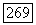 и узел
и узел 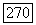 соответствует цепочке
соответствует цепочке 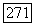 для некоторого
для некоторого 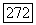 Тогда
Тогда 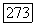 метка листа и
метка листа и 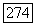 идентификатор позиции
идентификатор позиции 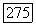 (т. е.
(т. е. 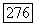
Чтобы построить 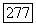 из
из 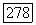 добавляем к узлу
добавляем к узлу 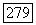 поддерево с двумя новыми листьями, помеченными числами
поддерево с двумя новыми листьями, помеченными числами 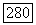 Пути, идущему из
Пути, идущему из 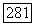 в этом добавленном поддереве, приписана цепочка
в этом добавленном поддереве, приписана цепочка 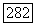 а пути из
а пути из 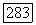 цепочка
цепочка  при этом
при этом 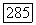 Таким образом, пути из корня дерева
Таким образом, пути из корня дерева 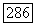 в лист
в лист 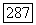 будет приписана цепочка
будет приписана цепочка  являющаяся новым идентификатором позиции
являющаяся новым идентификатором позиции  а пути из корня в
а пути из корня в
б) Для всех полагаем для каждого 
6) Полагаем  для всех
для всех 
Чтобы построить  из
из  выполняем следующее.
выполняем следующее.
7) Делаем  узла
узла 
8) Пусть и будет  -сыном узла
-сыном узла  Новый лист с меткой
Новый лист с меткой  делаем агсыном узла и в
делаем агсыном узла и в 
9) Пусть  будет
будет  -сыном узла
-сыном узла  Новый лист с меткой
Новый лист с меткой  делаем агсыном узла
делаем агсыном узла  в
в 
10) Делаем  узла
узла  для
для
Случай 3. Узел  имеет
имеет  В этом случае надо рассмотреть две ситуации.
В этом случае надо рассмотреть две ситуации.
(а)  - лист с меткой
- лист с меткой  Такая ситуация возникает, когда
Такая ситуация возникает, когда  причем
причем
 это частный вид случая 2, когда
это частный вид случая 2, когда  Чтобы построить
Чтобы построить  из
из  удаляем метку из узла и образуем для узла -сына с меткой и -сына с меткой Детали этого построения те же, что и в случае 2 (без шагов 3, 7 и 10).
удаляем метку из узла и образуем для узла -сына с меткой и -сына с меткой Детали этого построения те же, что и в случае 2 (без шагов 3, 7 и 10).
(б) - внутренний узел дерева Такая ситуация возникает, когда Чтобы построить из просто образуем для узла -сына (которого у него нет) и помечаем этот лист меткой Подробный алгоритм таков:
1 Пусть глубина узла
2. Новый узел с меткой делаем -сыном узла (Заметим, что не может быть -сына в в силу максимальности у.)
3. Полагаем для всех Поскольку не является подцепочкой цепочки то, разумеется, не является подцепочкой цепочки ни для какого а.
4. Чтобы построить из берем узел и, являющийся -сыном узла узел и соответствует Новый узел делаем -сыном узла и в узел будет соответствовать цепочке
Связи между узлами, упомянутыми в случае показаны на рис. 9.24.
Пример 9.22. Пусть и деревья с рис. 9.22. Алгоритмом 9.5 строим из Здесь
Прежде всего отыскиваем лист с меткой 2 и, поскольку полагаем и поднимаемся в узел, обозначенный и на рис.

Рис. 9.26. Начальное позиционное дерево.
Доказательство. На шаге 1 алгоритма 9.5 можно найти лист за фиксированное время с помощью указателя на этот лист, установленного в момент добавления листа к Когда к добавляется этот указатель переводится на
Работа, производимая при каждом выполнении шагов 2 и 3, очевидно, пропорциональна длине пути из а при каждом выполнении шага 1 постоянна. Легко проверить, что время, затрачиваемое на выполнение любого из случаев 1—3 алгоритма 9.5, пропорционально числу узлов, добавляемых к дереву. Таким образом, общее время, которое тратится всеми частями алгоритма 9.5, кроме шагов 2 и 3, пропорционально размеру дерева
Осталось показать, что сумма расстояний между узлами (или корнем, если узла нет) в для не превосходит размера дерева Обозначим эти расстояния через и пусть глубина узла Простой анализ случаев 1—3 показывает, что

Просуммируем обе части неравенства (9.1) по от 1 до

Из (9.2) непосредственно следует, что время, затрачиваемое шагами 2 и 3 алгоритма 9.5, составляет значит, по порядку не превосходит размера дерева
Как уже отмечалось, позиционное дерево для цепочки длины может содержать узлов. Поэтому любой алгоритм идентификации, в котором строится такое дерево, должен иметь временную сложность Однако можно "уплотнить" позиционное и вспомогательное деревья, сжав все цепи в позиционном дереве в один узел. Цепью называется путь, каждый узел которого обладает в точности одним сыном. Нетрудно показать, что уплотненное позиционное дерево для цепочек длины содержит не более узлов.
Уплотненное дерево может давать ту же информацию, что и исходное позиционное дерево, и потому его можно использовать в тех же алгоритмах идентификации.
Алгоритм 9.5 можно модифицировать так, чтобы он строил уплотненные позиционное и вспомогательное деревья за линейное время. Мы не приводим здесь этот модифицированный алгоритм потому, что он аналогичен алгоритму 9.5, а также потому, что во многих приложениях можно ожидать, что размер позиционного дерева будет пропорционален длине входной цепочки. В замечаниях по литературе указаны работы, в которых излагается алгоритм с уплотнением позиционного дерева и другие его приложения.
УПРАЖНЕНИЯ
(см. скан)
Замечания по литературе
Эквивалеитиость конечных автоматов и регулярных выражений установлена Клини [1956]. Недетерминированные конечные автоматы изучались Рабиным, Скоттом [1959], которые доказали их эквивалентность детерминированным. Алгоритм идентификации цепочек, задаваемых регулярным выражением (алгоритм 9.1), построен на основе алгоритма Томпсона [1968]. Эренфойхт, Цайгер [1974] обсуждают сложность НКА как устройства для классификации образов. Распознавание вхождения одной цепочки в другую за линейное время (алгоритм 9.3) взято у Морриса, Пратта [1970]. Моделирование 2ДМА за линейное время, а также обобщение в упр. 9.21 принадлежат Куку [1971а]. Свойства 2ДМА изучали Грей, Харрисон, Ибарра [1967]. Моделирование 2НМА за время (упр. 9.24) описано Хопкрофта, Ульмана [1968]. Упр. 9.15(6) принадлежит Честеру, а упр. 9.19(b) - Пратту. Решение упр. 9.19(b) приведено в работе Кнута, Пратта [1971].
Материал разд. 9.5, касающийся позиционных деревьев, а также понятие уплотненного позиционного дерева можно найти у Вайнера [1973]. Там же содержатся решения упр. 9.20 и 9.31-9.36 вместе с некоторыми другими приложениями; см. также Киут [19736]. Карп, Миллер, Розенберг [1972] дают несколько алгоритмов идентификации, касающихся повторяющихся цепочек. Упр. 9.9 и 9.10 о совпадении цепочек с несущественными символами принадлежат Фишеру, Патерсону [1974]. Вагнер, Фишер [1974] приводят решение упр. 9.38. В их статье и статье Хиршберга [1973] обсуждаются алгоритмы для задачи об общей подпоследовательности (см. упр. 9.37).






























































































































































































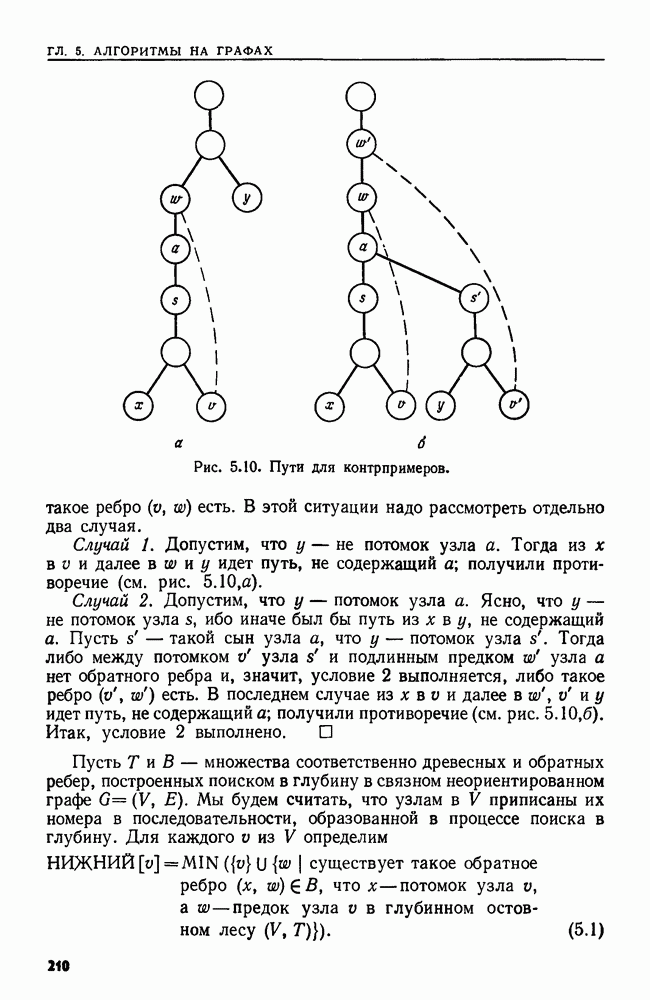







































































































































































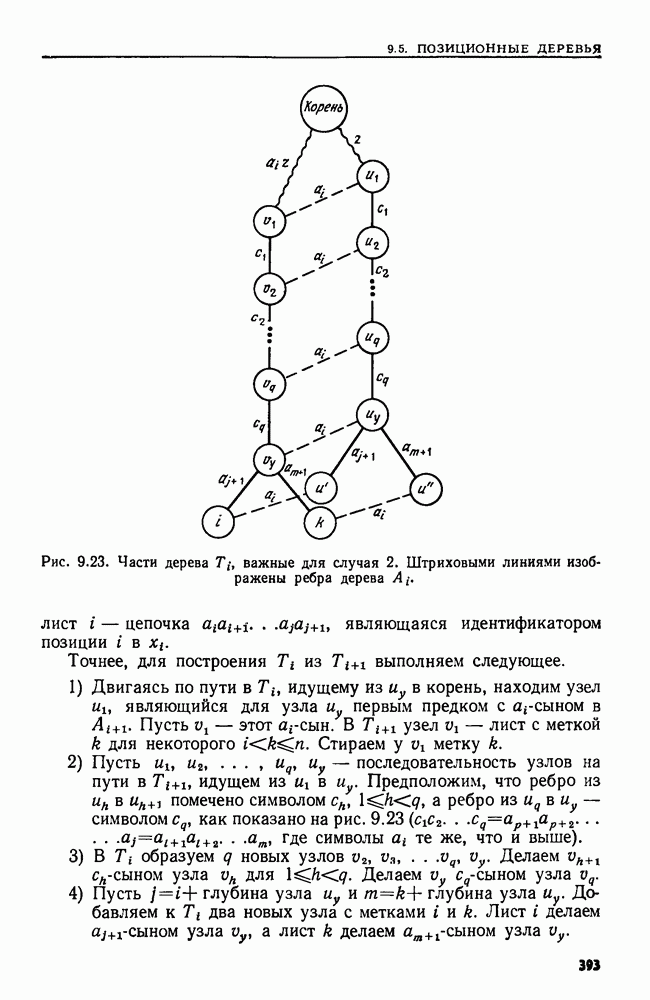





















































































































 важные для случая 2. Штриховыми линиями изображены ребра дерева
важные для случая 2. Штриховыми линиями изображены ребра дерева 
 цепочка
цепочка  являющаяся идентификатором позиции
являющаяся идентификатором позиции 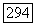
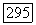 из
из 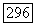 выполняем следующее.
выполняем следующее.
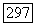 идущему из
идущему из  в корень, находим узел
в корень, находим узел  являющийся для узла
являющийся для узла  первым предком с агсыном в
первым предком с агсыном в 

