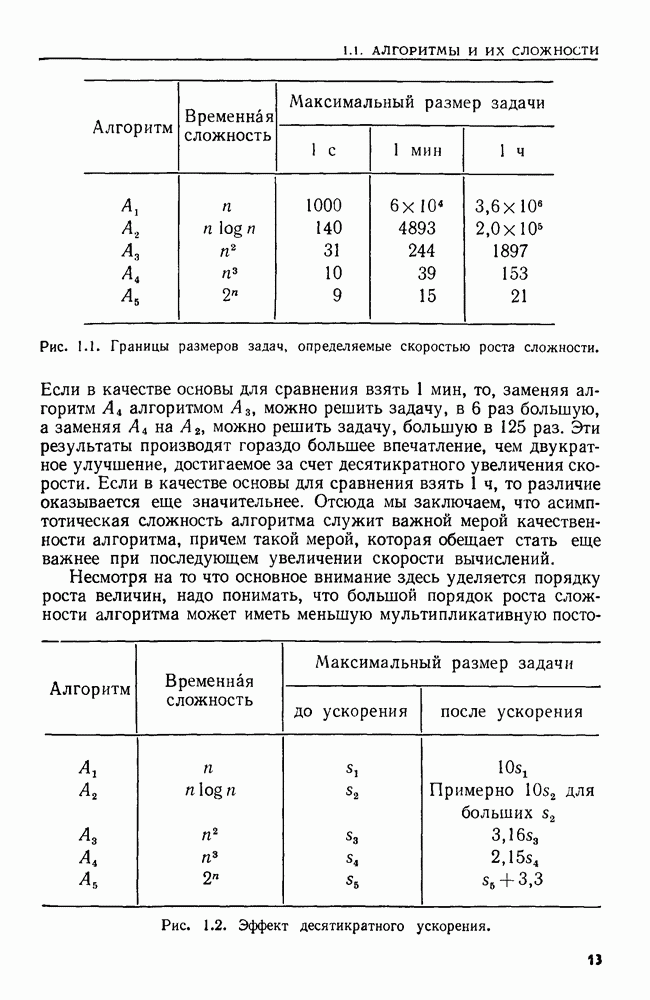
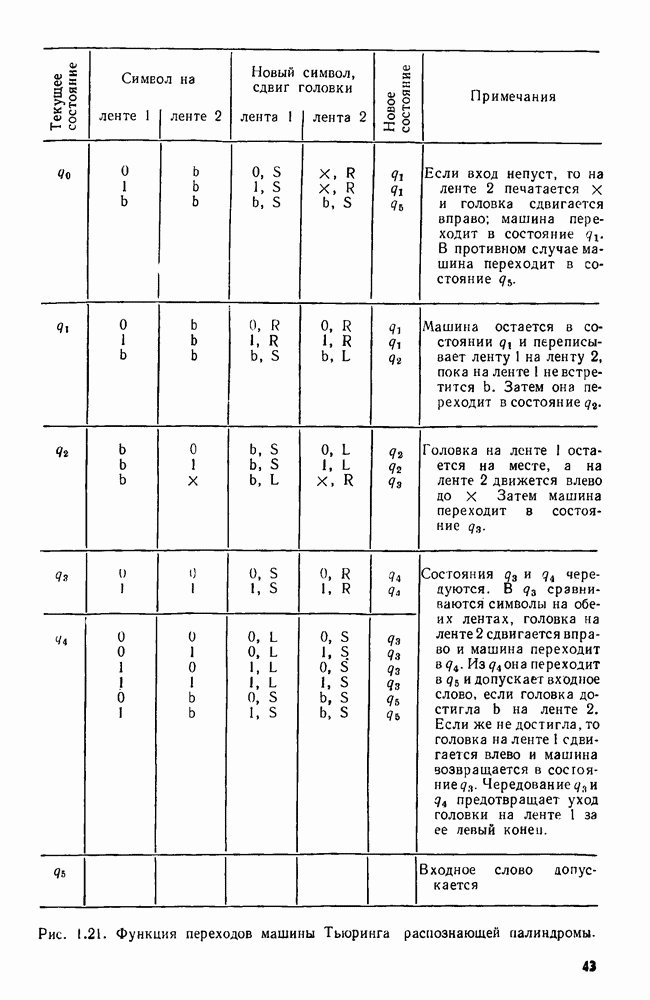
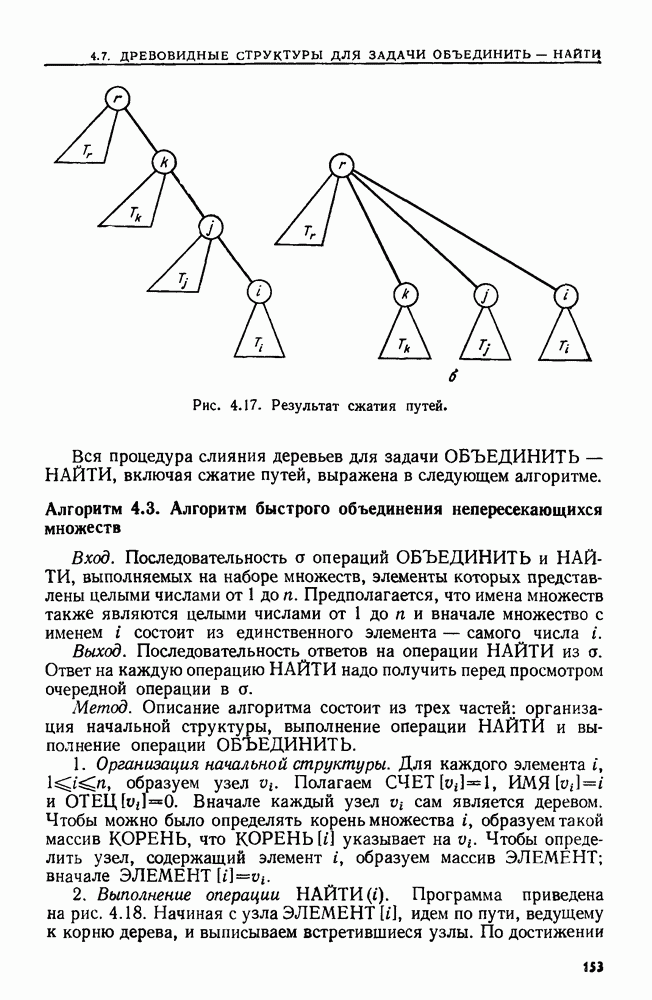
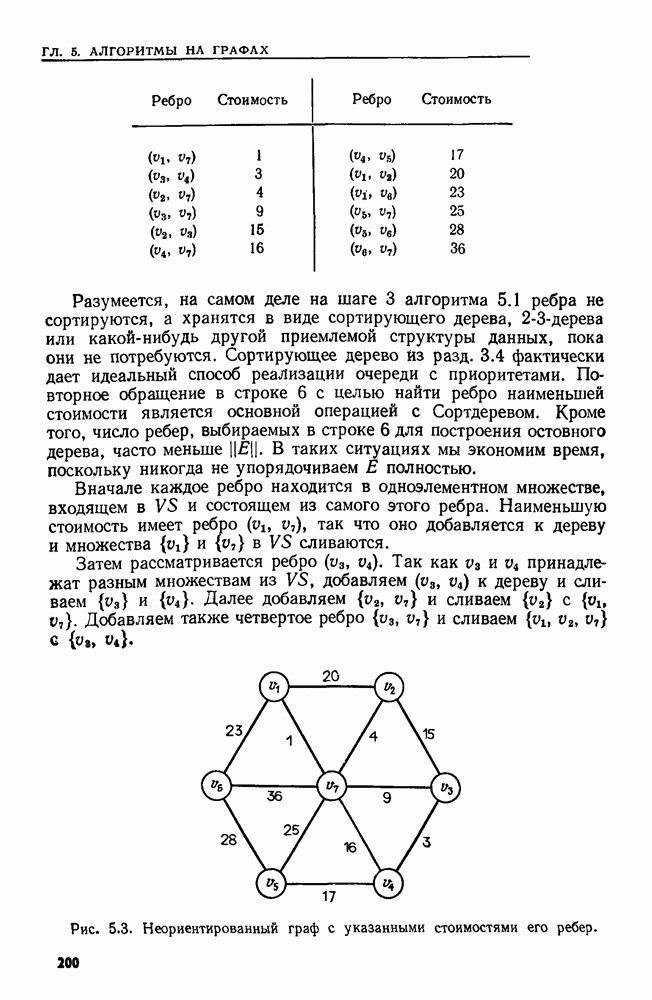
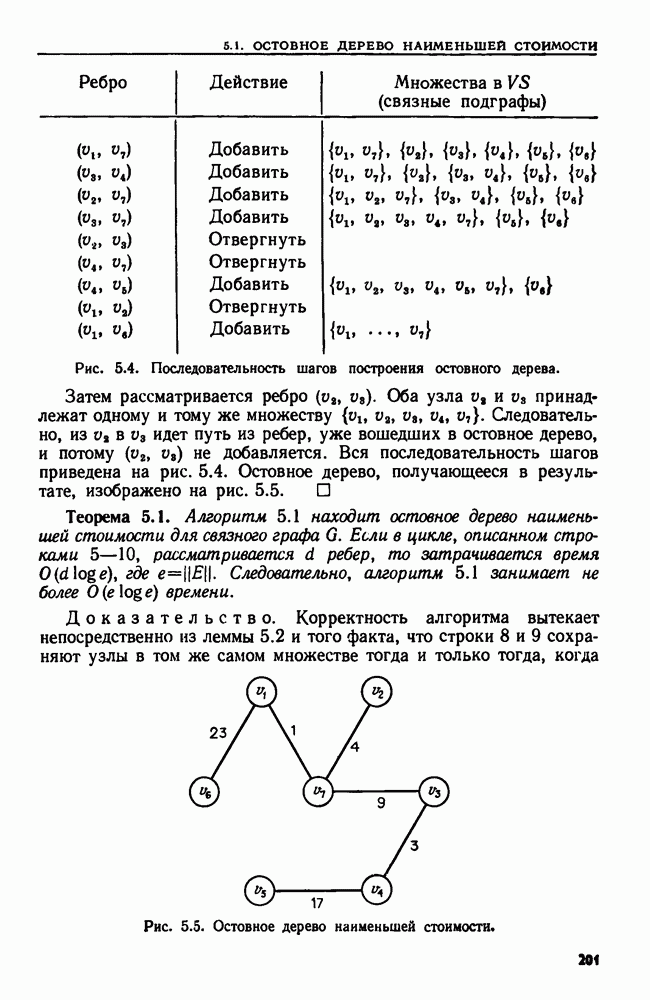
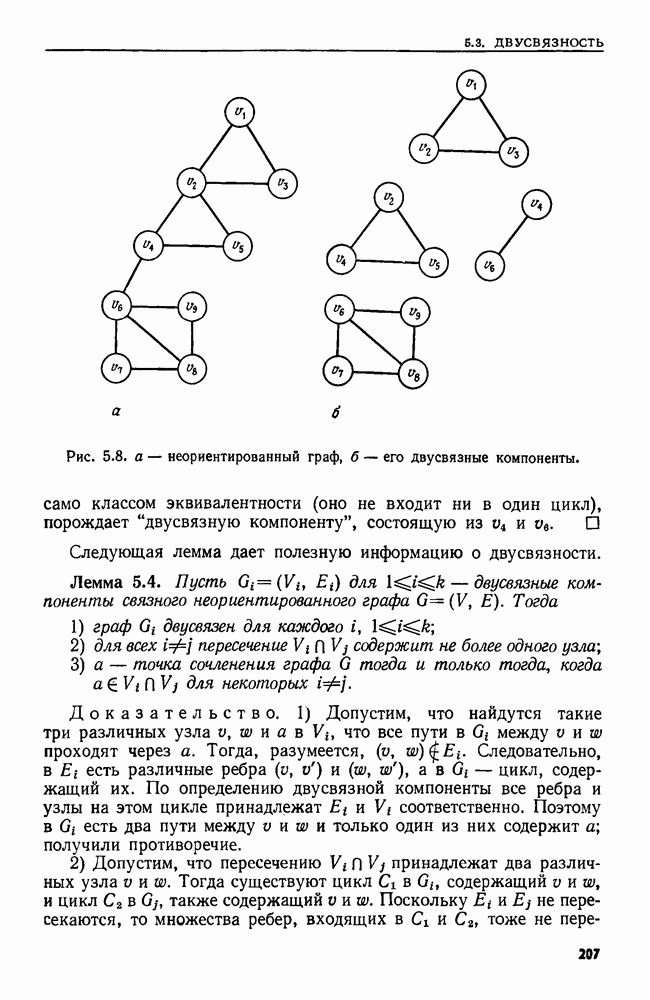
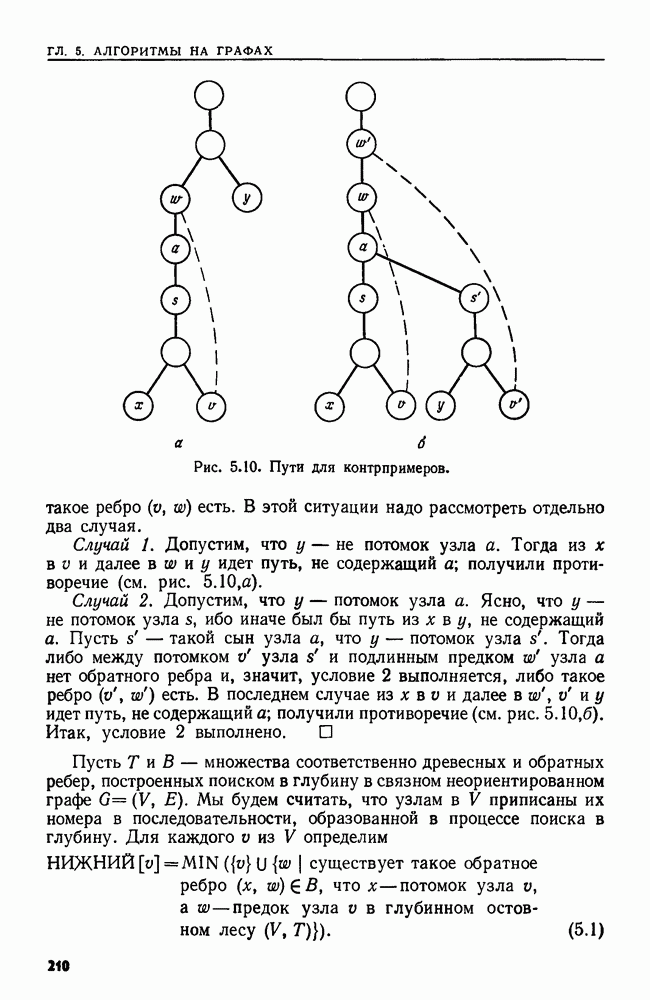
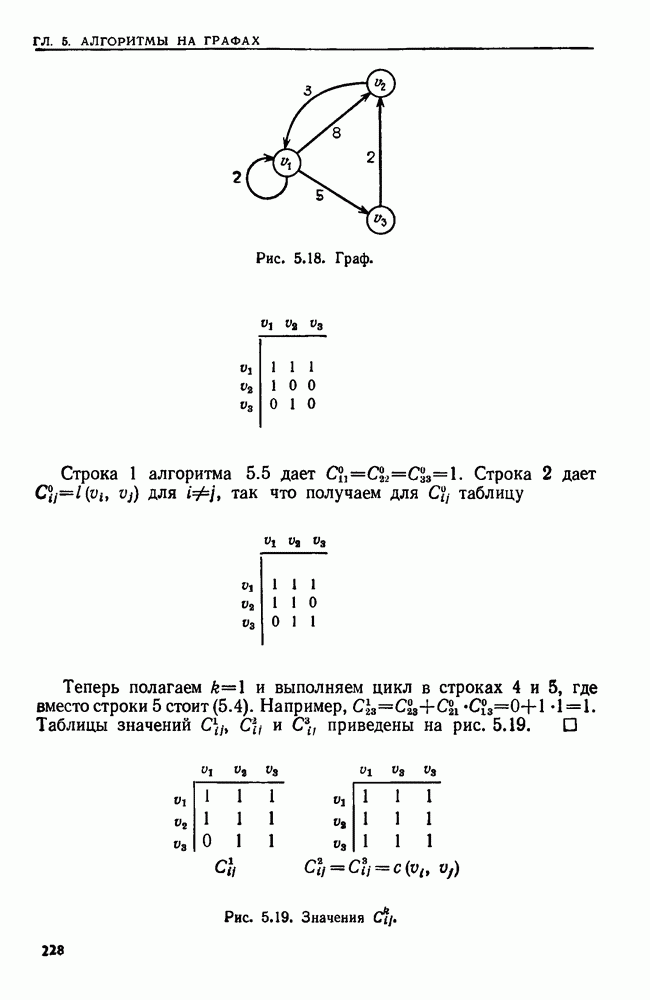
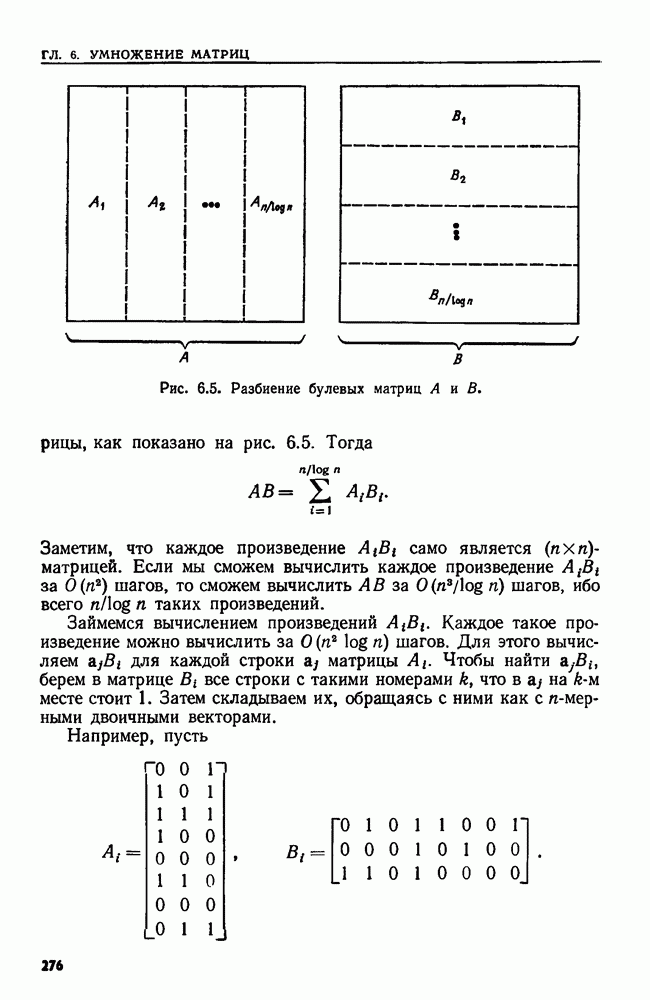
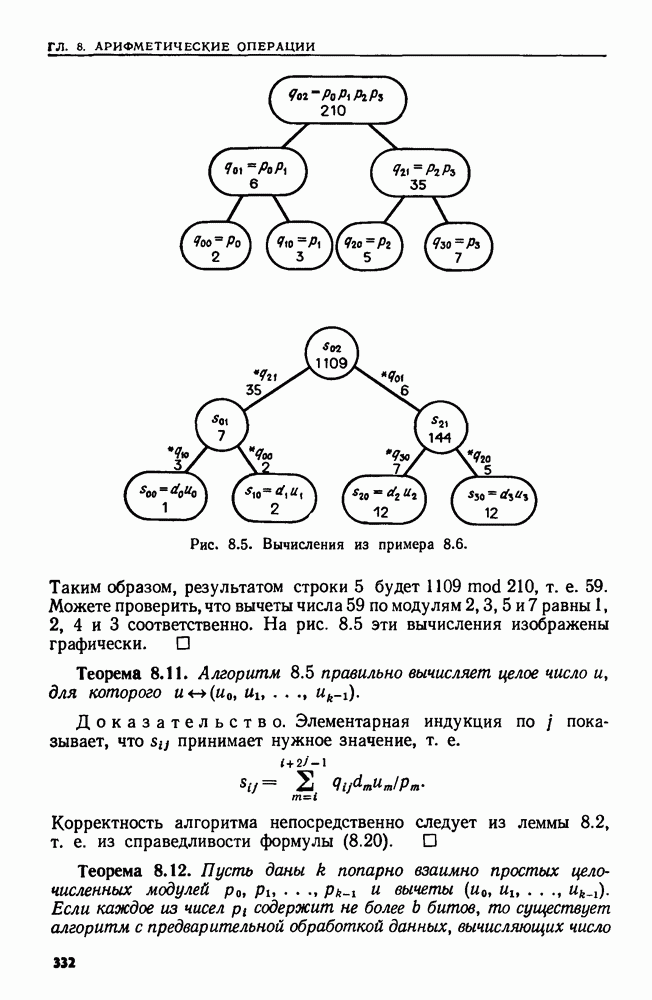
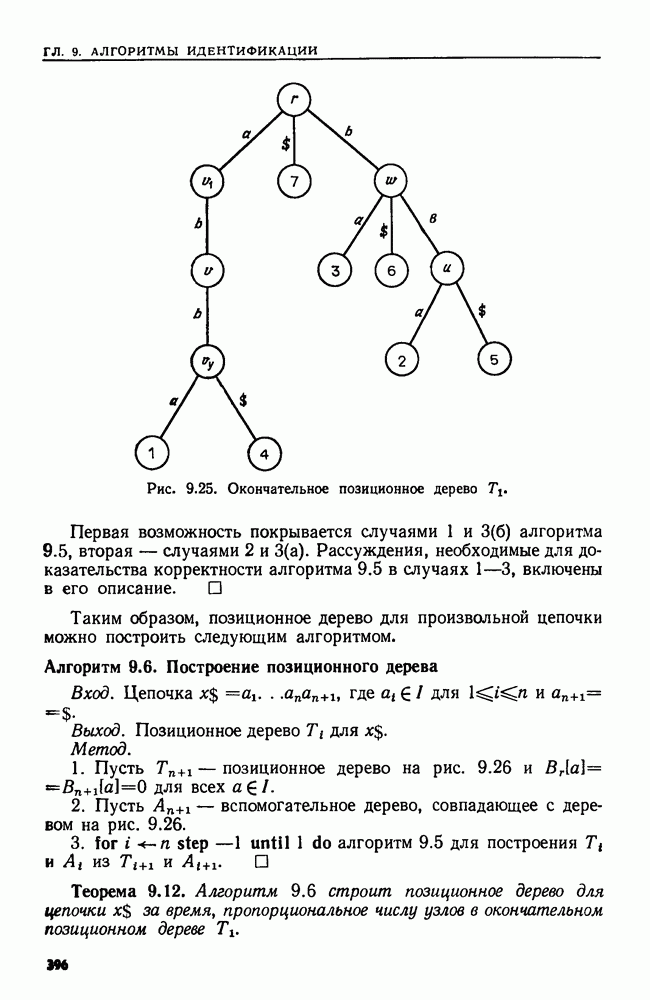
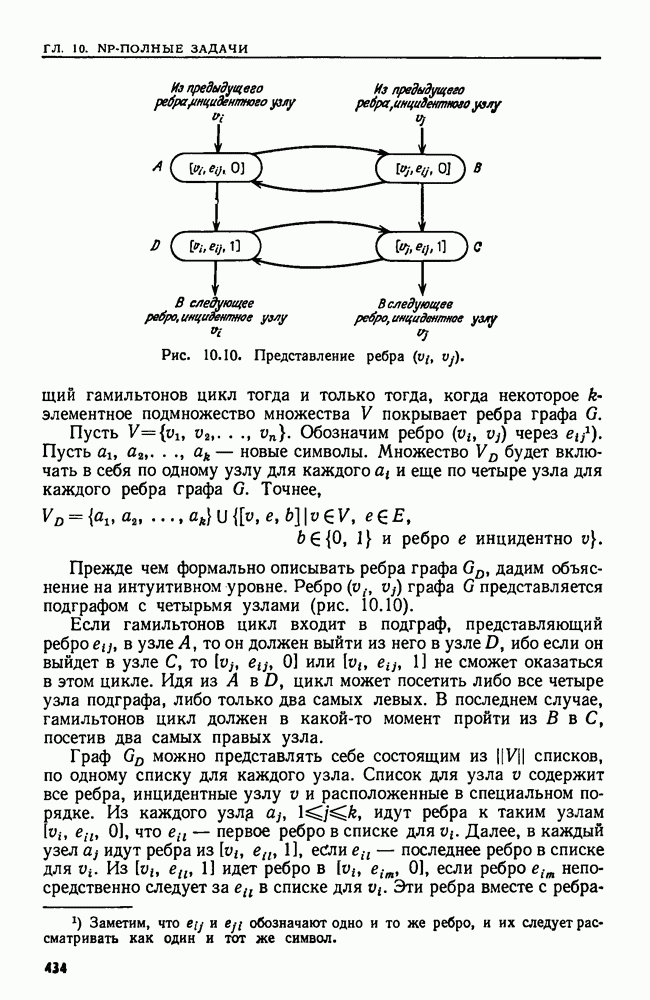
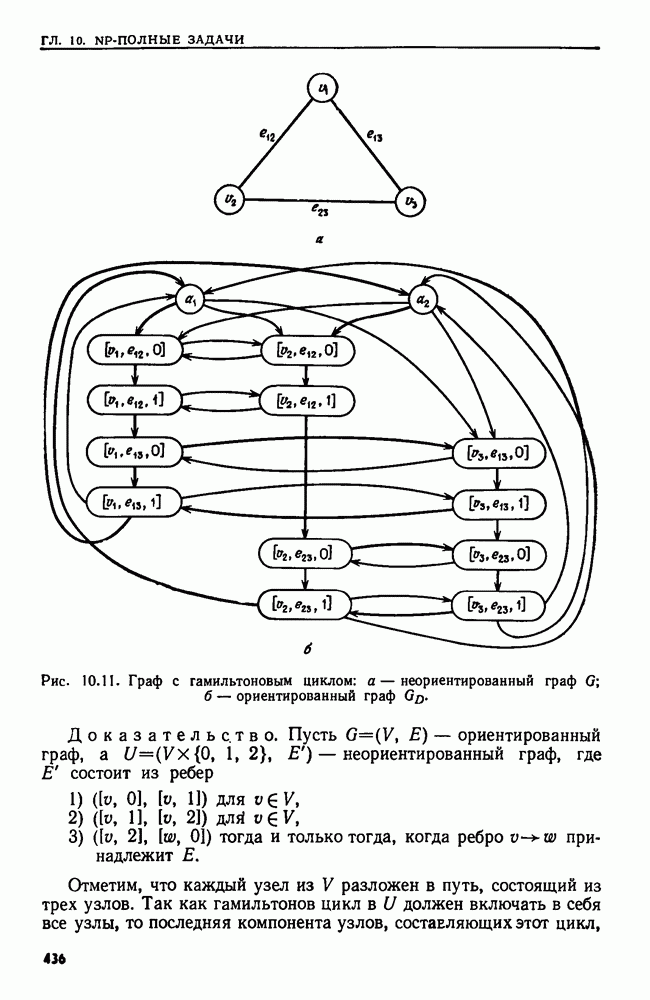
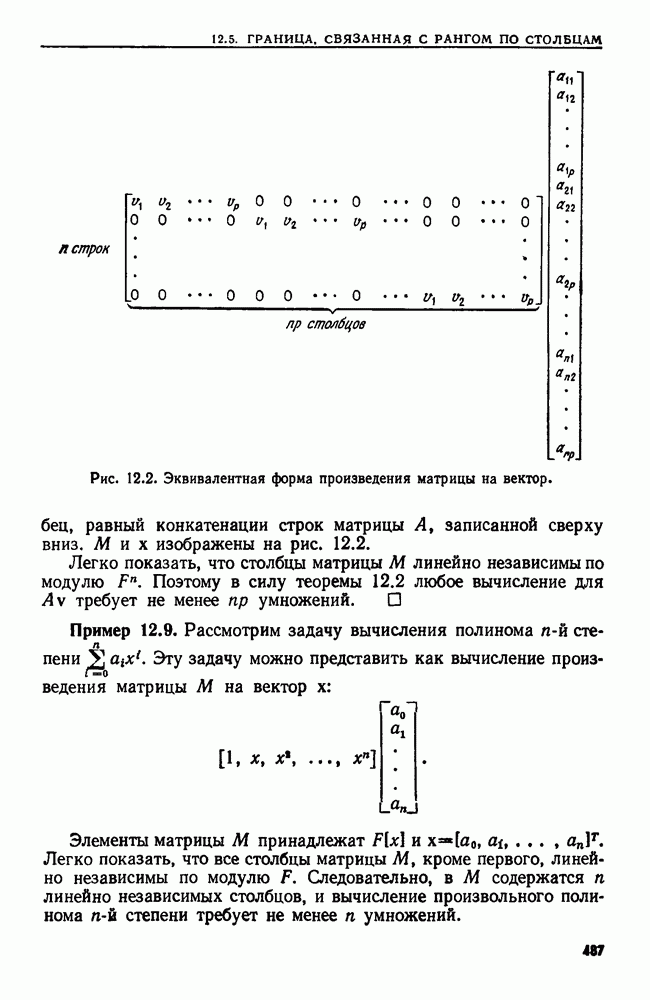
4.4. ДЕРЕВЬЯ ДВОИЧНОГО ПОИСКА
Рассмотрим следующую задачу. В множество  вставляются и из него удаляются элементы. Время от времени нам может понадобиться узнать, принадлежит ли данный элемент множеству
вставляются и из него удаляются элементы. Время от времени нам может понадобиться узнать, принадлежит ли данный элемент множеству  или, например, каков в данный момент наименьший элемент в 5. Мы считаем, что элементы добавляются в 5 из большого универсального множества, линейно упорядоченного отношением Эту задачу можно сформулировать в общем виде как выполнение последовательности, состоящей из операций ВСТАВИТЬ, УДАЛИТЬ, ПРИНАДЛЕЖАТЬ и MIN.
или, например, каков в данный момент наименьший элемент в 5. Мы считаем, что элементы добавляются в 5 из большого универсального множества, линейно упорядоченного отношением Эту задачу можно сформулировать в общем виде как выполнение последовательности, состоящей из операций ВСТАВИТЬ, УДАЛИТЬ, ПРИНАДЛЕЖАТЬ и MIN.
Мы уже видели, что для выполнения последовательности операций ВСТАВИТЬ, УДАЛИТЬ и ПРИНАДЛЕЖАТЬ хорошей структурой данных может служить таблица расстановки. Но нельзя найти наименьший элемент, не просмотрев всю таблицу. Структурой данных, пригодной для всех четырех операций, является дерево двоичного поиска.
Определение. Деревом двоичного поиска для множества  называется помеченное двоичное дерево, каждый узел
называется помеченное двоичное дерево, каждый узел  которого помечен элементом
которого помечен элементом  так, что
так, что

Рис. 4.4. Дерево двоичного поиска.
1)  для каждого узла и из левого поддерева узла v,
для каждого узла и из левого поддерева узла v,
2)  для каждого узла и из правого поддерева узла и,
для каждого узла и из правого поддерева узла и,
3) для каждого элемента  существует в точности один узел
существует в точности один узел  для которого
для которого 
Заметим, что из условий 1 и 2 вытекает, что метки этого дерева расположены в соответствии с внутренним порядком. Кроме того, условие 3 следует из условий 1 и 2.
Пример 4.3. На рис. 4.4 изображено возможное двоичное дерево для выделенных слов Алгола begin, else, end, if, then. Здесь линейным порядком является лексикографический порядок. 
Чтобы выяснить, принадлежит ли элемент а множеству  представленному деревом двоичного поиска, надо сравнить а с меткой корня. Если метка корня равна а, то очевидно, что
представленному деревом двоичного поиска, надо сравнить а с меткой корня. Если метка корня равна а, то очевидно, что  Если а меньше метки корня, то надо перейти к левому поддереву корня (если оно есть). Если а больше метки корня, то надо перейти к правому поддереву корня. Если а присутствует в дереве, его местоположение будет в конце концов обнаружено. В противном случае процесс окончится, когда надо будет найти несуществующее левое или правое поддерево.
Если а меньше метки корня, то надо перейти к левому поддереву корня (если оно есть). Если а больше метки корня, то надо перейти к правому поддереву корня. Если а присутствует в дереве, его местоположение будет в конце концов обнаружено. В противном случае процесс окончится, когда надо будет найти несуществующее левое или правое поддерево.
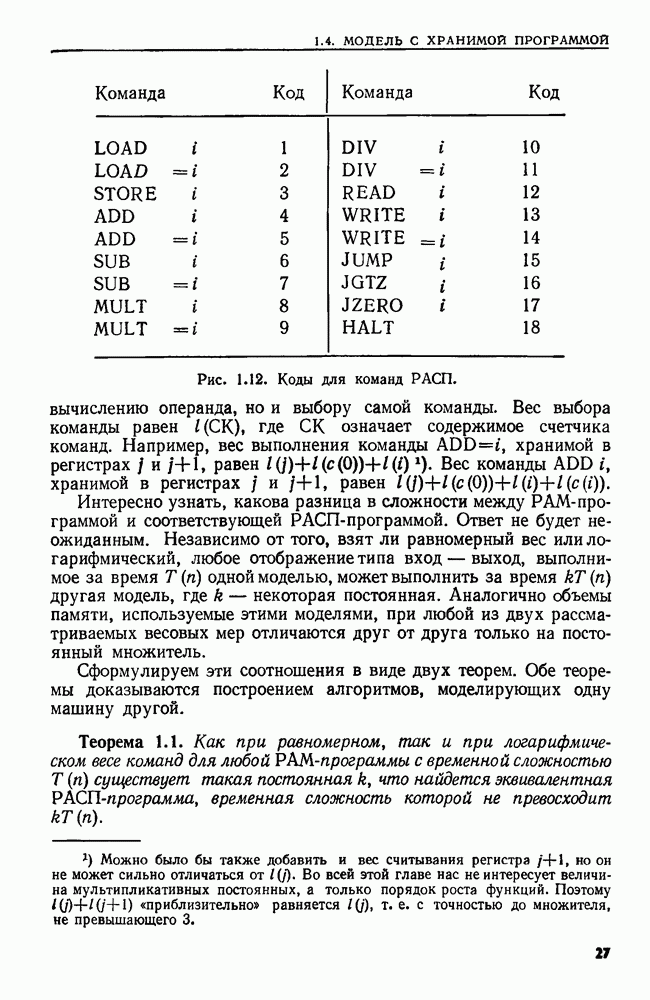
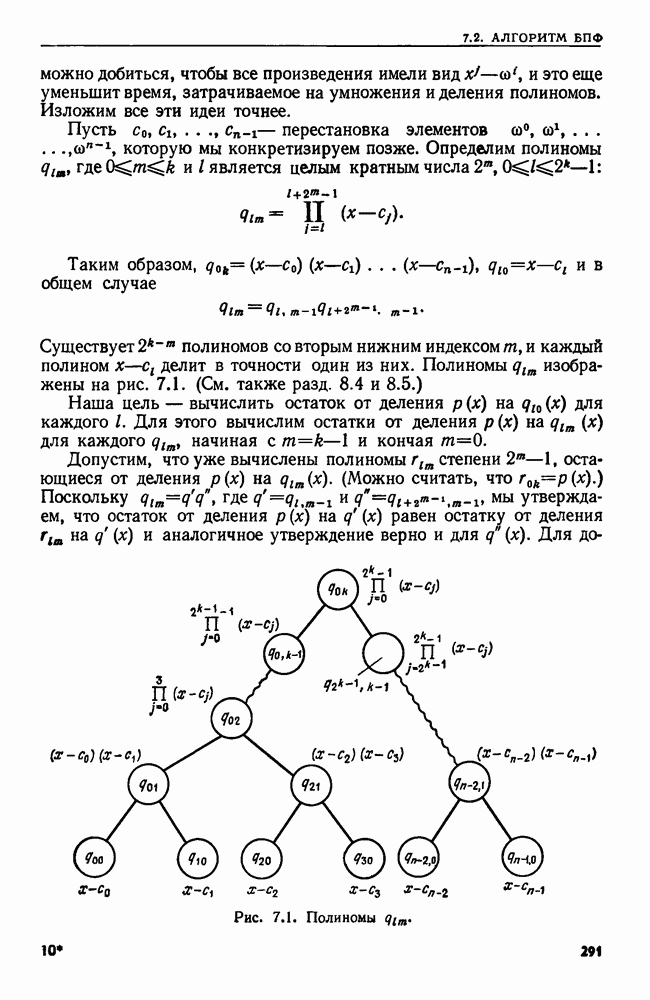
Алгоритм 4.1. Просмотр дерева двоичного поиска
Вход. Дерево  двоичного поиска для множества
двоичного поиска для множества  и элемент а.
и элемент а.
Выход. "Да", если  и "нет" в противном случае.
и "нет" в противном случае.
Метод. Если дерево  пусто, выдать
пусто, выдать  В противном
В противном

Рис. 4.5. Просмотр дерева двоичного поиска.
случае пусть  корень дерева
корень дерева  Тогда алгоритм состоит из единственного вызова
Тогда алгоритм состоит из единственного вызова  рекурсивной процедуры ПОИСК, приведенной на рис.
рекурсивной процедуры ПОИСК, приведенной на рис. 
Очевидно, что алгоритм 4.1 достаточен для выполнения операции  Более того, его легко модифицировать так, чтобы он выполнял операцию
Более того, его легко модифицировать так, чтобы он выполнял операцию  Если дерево пусто, строится корень с меткой а. Если дерево непусто, а элемент, который надлежит вставить, не обнаружен в дереве, то процедуре ПОИСК не удается найти сына в строке 3 или 5. Вместо того чтобы выдать "нет" в строке 4 или 6 соответственно, для этого элемента строится новый узел там, где должен был быть отсутствующий сын.
Если дерево пусто, строится корень с меткой а. Если дерево непусто, а элемент, который надлежит вставить, не обнаружен в дереве, то процедуре ПОИСК не удается найти сына в строке 3 или 5. Вместо того чтобы выдать "нет" в строке 4 или 6 соответственно, для этого элемента строится новый узел там, где должен был быть отсутствующий сын.
Деревья двоичного поиска также удобны для выполнения операций MIN и УДАЛИТЬ. Для нахождения наименьшего элемента в дереве двоичного поиска  просматривается путь
просматривается путь  где
где  -корень дерева
-корень дерева  -левый сын узла
-левый сын узла  узла
узла  нет левого сына. Метка в узле
нет левого сына. Метка в узле  является наименьшим элементом в
является наименьшим элементом в  В некоторых задачах может оказаться удобным иметь указатель на
В некоторых задачах может оказаться удобным иметь указатель на  чтобы обеспечить доступ к наименьшему элементу за постоянное время.
чтобы обеспечить доступ к наименьшему элементу за постоянное время.
Реализовать операцию  немного труднее. Допустим, что элемент а, подлежащий удалению, расположен в узле
немного труднее. Допустим, что элемент а, подлежащий удалению, расположен в узле  Возможны три случая:
Возможны три случая:
1) v - лист; в этом случае  удаляется из дерева;
удаляется из дерева;
2)  в точности один сын; в этом случае делаем отца узла
в точности один сын; в этом случае делаем отца узла  отцом его сына, тем самым удаляя
отцом его сына, тем самым удаляя  из дерева (если
из дерева (если  корень, то его сына делаем новым корнем);
корень, то его сына делаем новым корнем);
3)  два сына; в этом случае находим в левом поддереве узла
два сына; в этом случае находим в левом поддереве узла  наибольший элемент
наибольший элемент  рекурсивно удаляем из этого поддерева узел, содержащий
рекурсивно удаляем из этого поддерева узел, содержащий  и метим узел
и метим узел  элементом
элементом  (Заметим, что среди элементов, меньших
(Заметим, что среди элементов, меньших  будет наибольшим элементом всего дерева.)
будет наибольшим элементом всего дерева.)

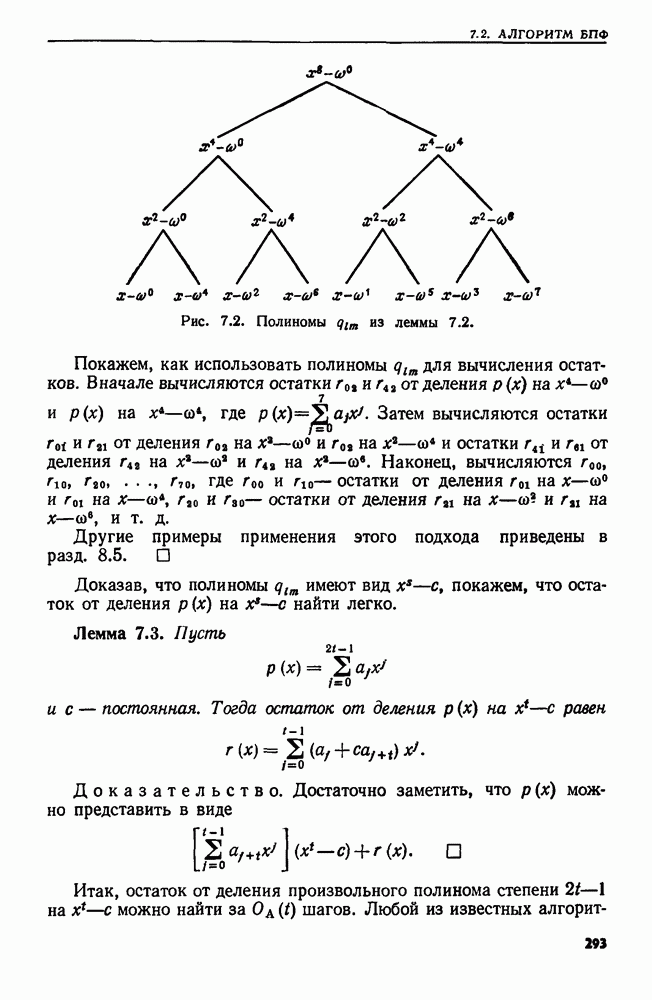
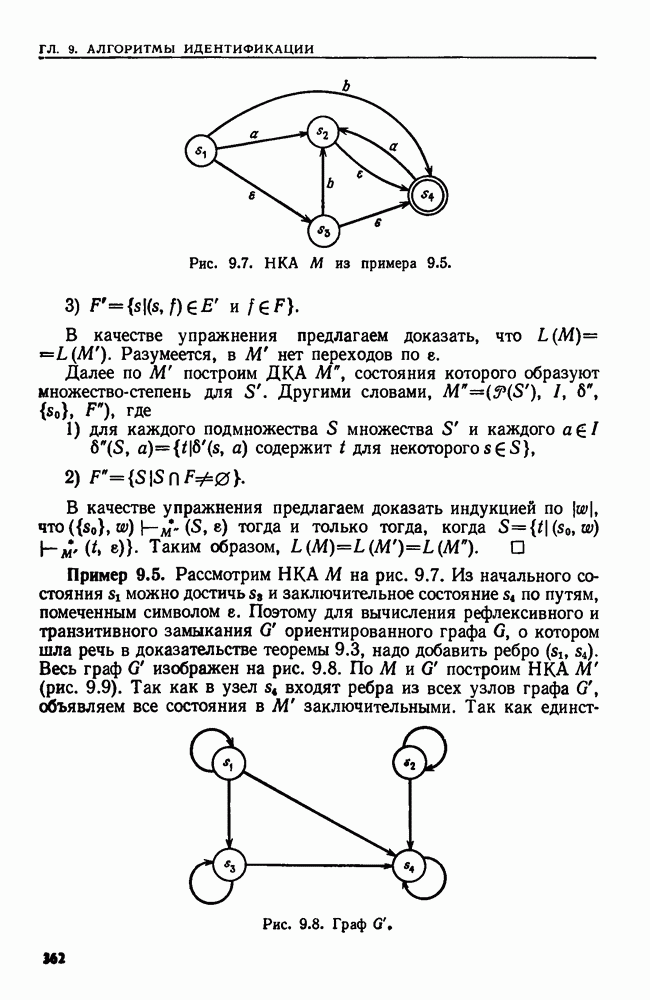
Рис. 4.6. Дерево двоичного поиска после выполнения операции УДАЛИТЬ.
В качестве упражнения предлагаем написать программу на Упрощенном Алголе для операции УДАЛИТЬ. Заметим, что одно выполнение любой из операций ПРИНАДЛЕЖАТЬ, ВСТАВИТЬ, УДАЛИТЬ и MIN можно осуществить за время 
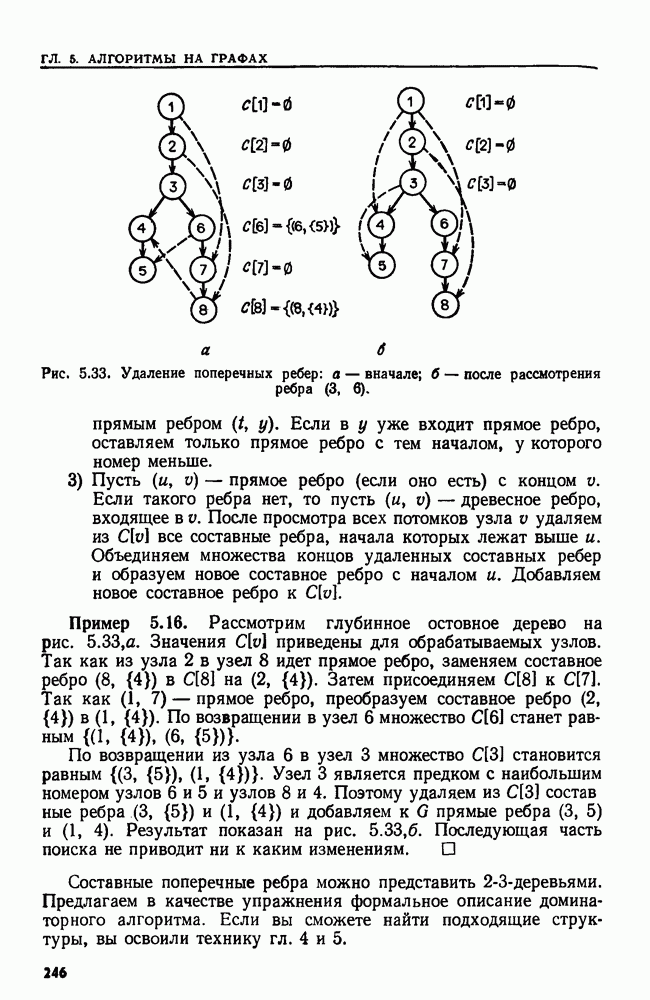
Пример 4.4. Предположим, что надо удалить слово  из дерева двоичного поиска, изображенного на рис. 4.4. Слово
из дерева двоичного поиска, изображенного на рис. 4.4. Слово  расположено в корне, у которого два сына. Наибольшее слово, меньшее
расположено в корне, у которого два сына. Наибольшее слово, меньшее  (лексикографически), расположенное в левом поддереве корня, — это
(лексикографически), расположенное в левом поддереве корня, — это  Удаляем из дерева узел с меткой end и заменяем
Удаляем из дерева узел с меткой end и заменяем  на end в корне. Затем, поскольку end имеет одного сына
на end в корне. Затем, поскольку end имеет одного сына  делаем begin сыном корня. Полученное дерево показано на рис. 4.6.
делаем begin сыном корня. Полученное дерево показано на рис. 4.6.
Подсчитаем временную сложность последовательности из  операций ВСТАВИТЬ, когда рассматриваемое множество представлено деревом двоичного поиска. Время, требуемое, чтобы в дерево двоичного поиска вставить элемент а, ограничено по порядку числом сравнений, производимых между а и элементами, уже находящимися в дереве. Поэтому время можно измерять числом производимых сравнений.
операций ВСТАВИТЬ, когда рассматриваемое множество представлено деревом двоичного поиска. Время, требуемое, чтобы в дерево двоичного поиска вставить элемент а, ограничено по порядку числом сравнений, производимых между а и элементами, уже находящимися в дереве. Поэтому время можно измерять числом производимых сравнений.
В худшем случае добавление к дереву  элементов может потребовать квадратичного времени. Например, допустим, что последовательность элементов, которые надлежит добавить, оказалась упорядоченной (в порядке возрастания). Тогда дерево поиска будет просто цепью правых сыновей. Но если вставляется
элементов может потребовать квадратичного времени. Например, допустим, что последовательность элементов, которые надлежит добавить, оказалась упорядоченной (в порядке возрастания). Тогда дерево поиска будет просто цепью правых сыновей. Но если вставляется  случайных элементов, то, как показывает следующая теорема, вставка потребует время
случайных элементов, то, как показывает следующая теорема, вставка потребует время 
Теорема 4.4. Среднее число сравнений, необходимых для вставки  случайных элементов в дерево двоичного поиска, пустое вначале, равно
случайных элементов в дерево двоичного поиска, пустое вначале, равно  для
для
Доказательство. Пусть  число сравнений, производимых между элементами последовательности
число сравнений, производимых между элементами последовательности  при построении дерева двоичного поиска,
при построении дерева двоичного поиска,  Пусть
Пусть  та же последовательность в порядке возрастания.
та же последовательность в порядке возрастания.
Если  случайная последовательность элементов, то
случайная последовательность элементов, то  с равной вероятностью совпадает с
с равной вероятностью совпадает с  для любого
для любого  Элемент
Элемент  становится корнем дерева двоичного поиска, и в окончательном дереве
становится корнем дерева двоичного поиска, и в окончательном дереве  элементов
элементов  будут находиться в левом поддереве корня и
будут находиться в левом поддереве корня и  элементов
элементов  в правом поддереве.
в правом поддереве.
Подсчитаем среднее число сравнений, необходимых для вставки элементов  в дерево. Каждый из этих элементов когда-нибудь сравнивается с корнем, и это дает
в дерево. Каждый из этих элементов когда-нибудь сравнивается с корнем, и это дает  сравнений с корнем. Затем по индукции получаем, что еще потребуется
сравнений с корнем. Затем по индукции получаем, что еще потребуется  сравнений, чтобы вставить
сравнений, чтобы вставить  в левое поддерево. Итак, необходимо
в левое поддерево. Итак, необходимо  сравнений, чтобы вставить
сравнений, чтобы вставить  в дерево двоичного поиска. Аналогично
в дерево двоичного поиска. Аналогично  сравнений потребуется, чтобы вставить в дерево элементы
сравнений потребуется, чтобы вставить в дерево элементы 
Поскольку  с равной вероятностью принимает любое значение от 1 до
с равной вероятностью принимает любое значение от 1 до  то
то

или, с учетом простых алгебраических преобразований,

Способом, описанным в разд. 3.5, можно показать, что

где  Таким образом, в среднем на вставку
Таким образом, в среднем на вставку  элементов в дерево двоичного поиска тратится
элементов в дерево двоичного поиска тратится  сравнений.
сравнений. 
Итак, методами этого раздела можно выполнить случайную последовательность из  операций ВСТАВИТЬ, УДАЛИТЬ, ПРИНАДЛЕЖАТЬ и MIN за среднее время
операций ВСТАВИТЬ, УДАЛИТЬ, ПРИНАДЛЕЖАТЬ и MIN за среднее время  Выполнение в худшем случае занимает квадратичное время. Однако даже это худшее время можно улучшить до
Выполнение в худшем случае занимает квадратичное время. Однако даже это худшее время можно улучшить до  с помощью одной из схем сбалансированных деревьев
с помощью одной из схем сбалансированных деревьев  АВЛ-деревьев или деревьев с ограниченной балансировкой), которые обсуждаются в разд. 4.9 и упр. 4.30-4.37.
АВЛ-деревьев или деревьев с ограниченной балансировкой), которые обсуждаются в разд. 4.9 и упр. 4.30-4.37.