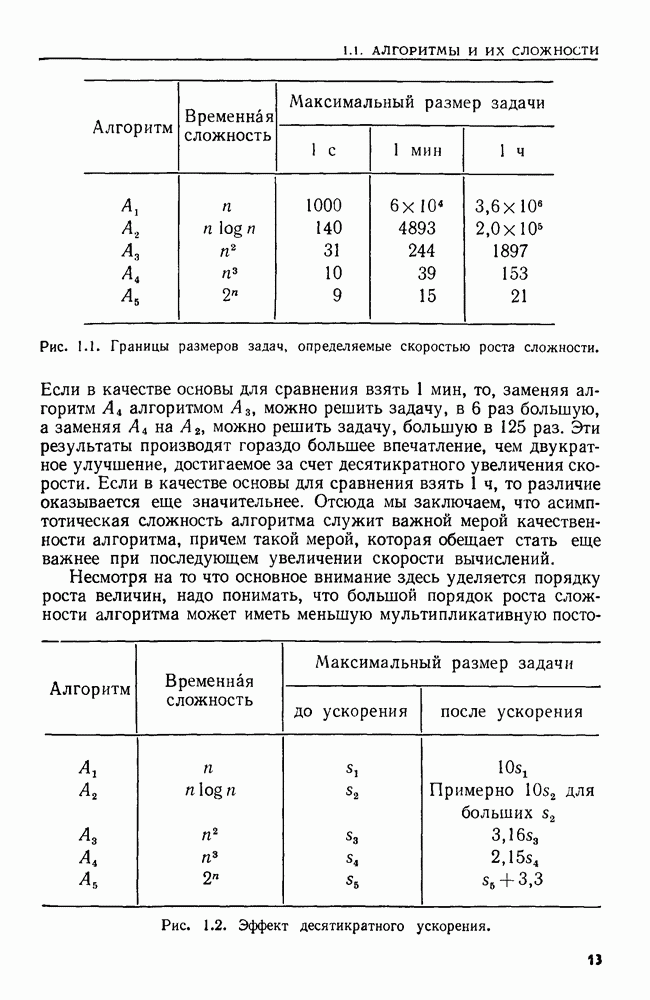
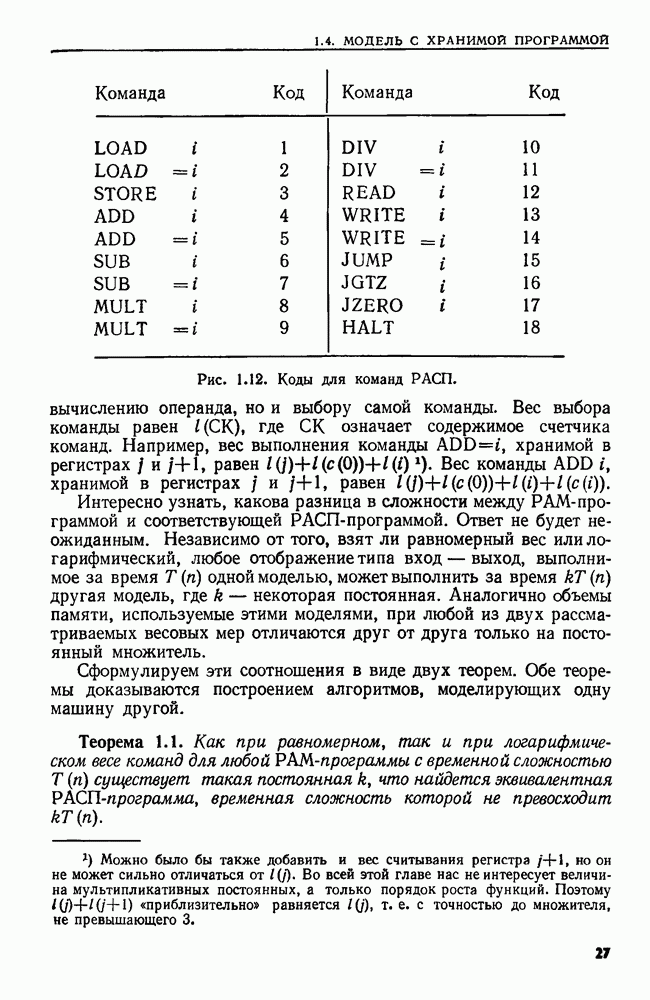
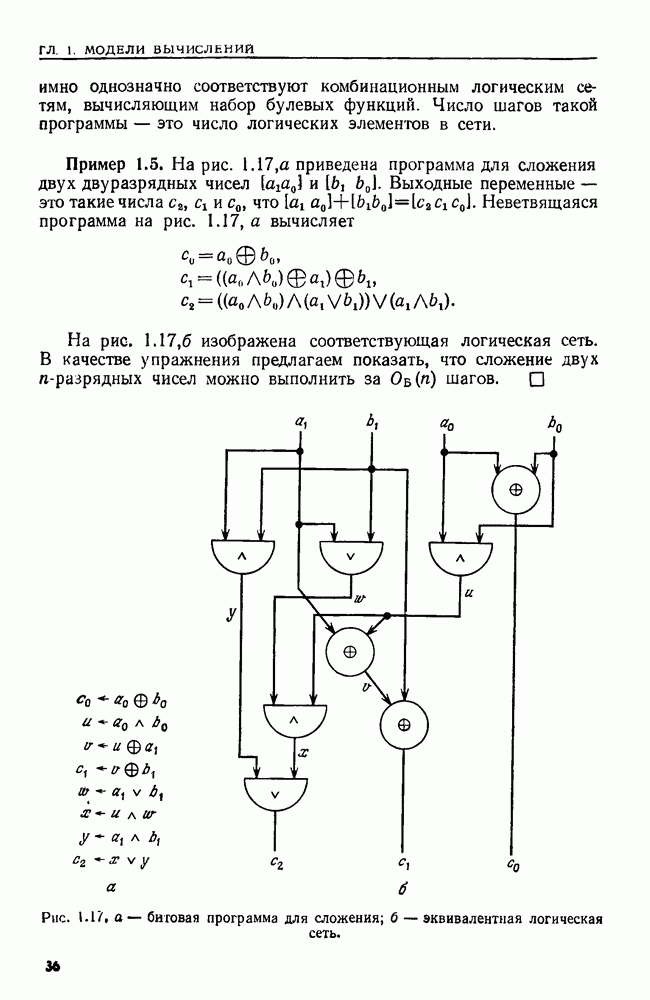
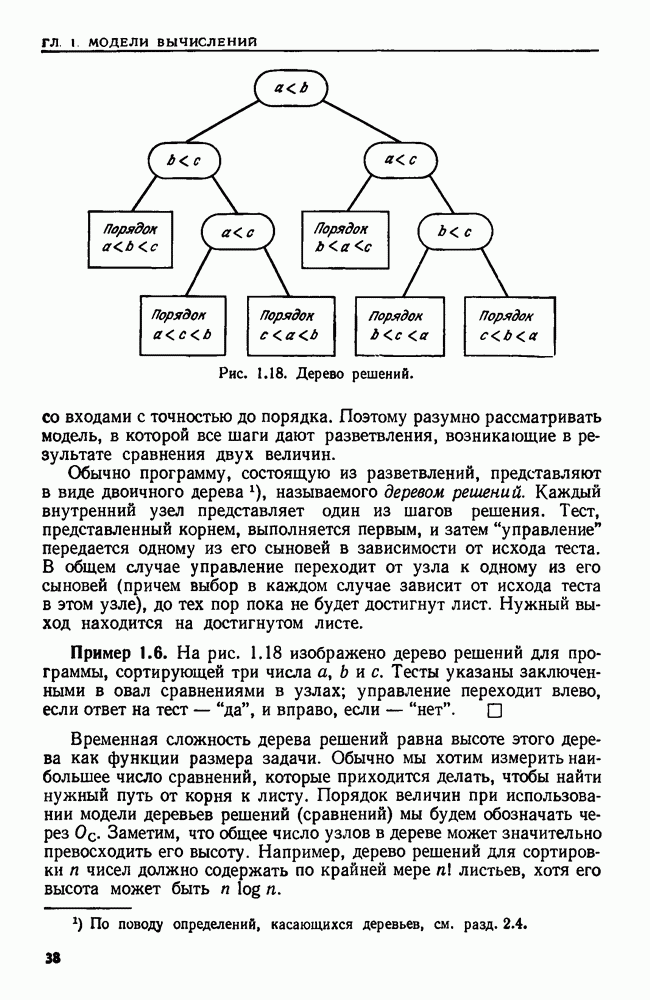
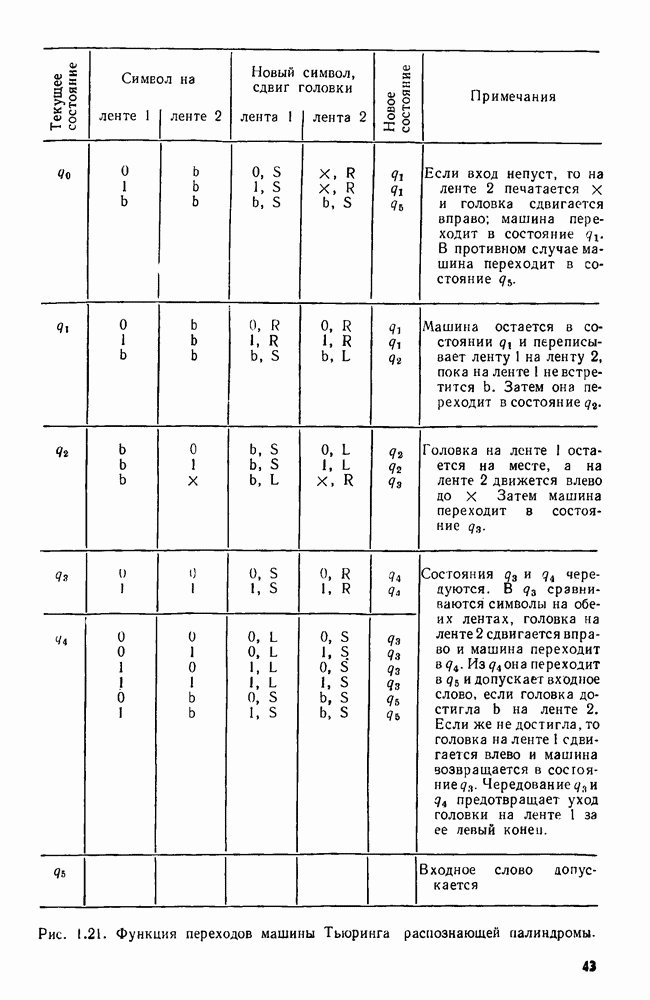
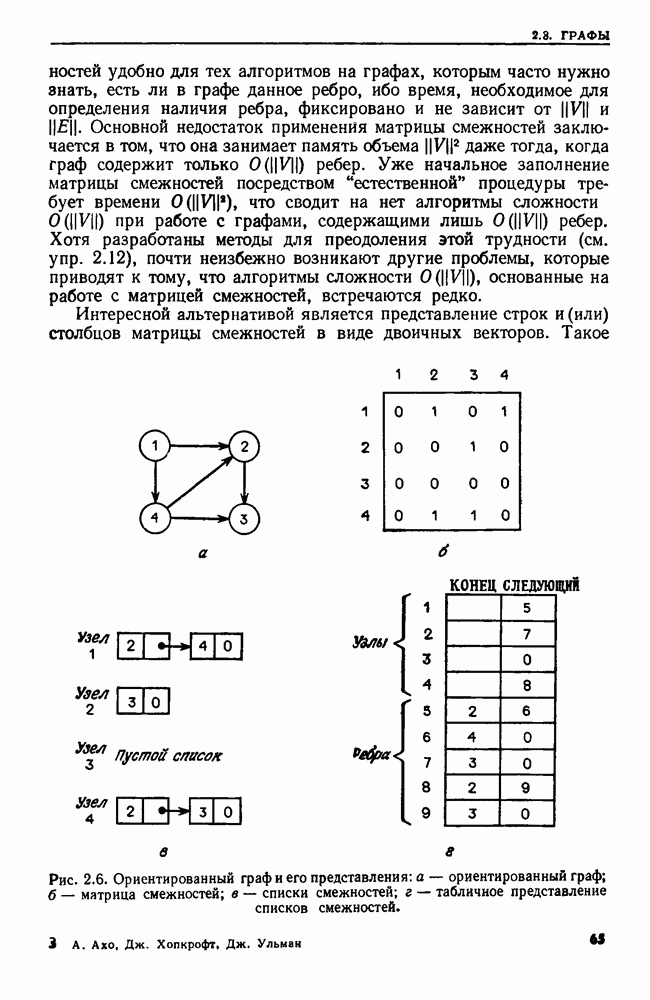
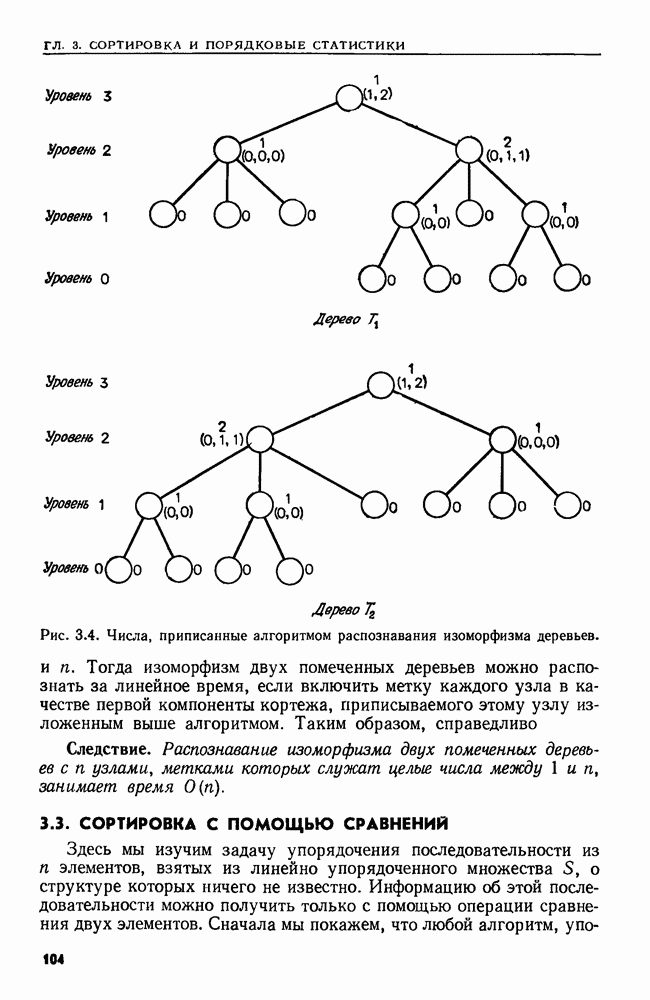
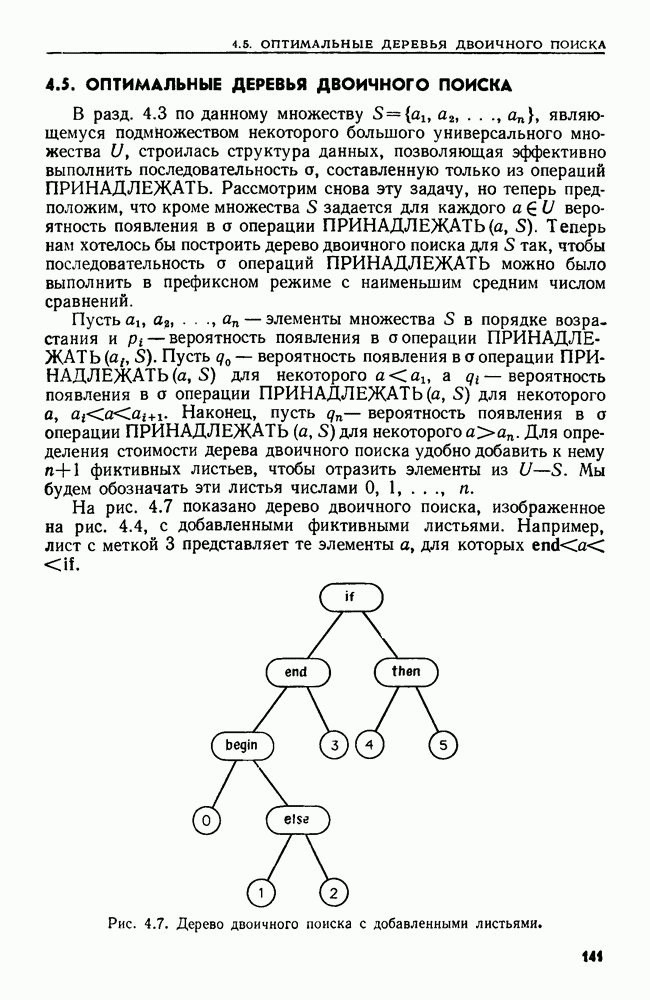
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
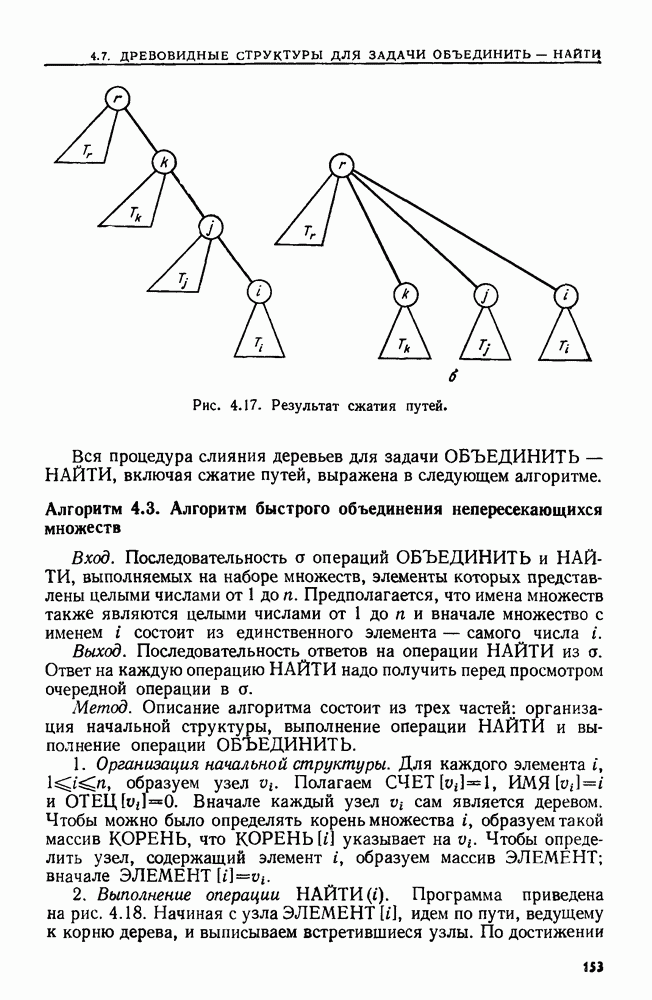
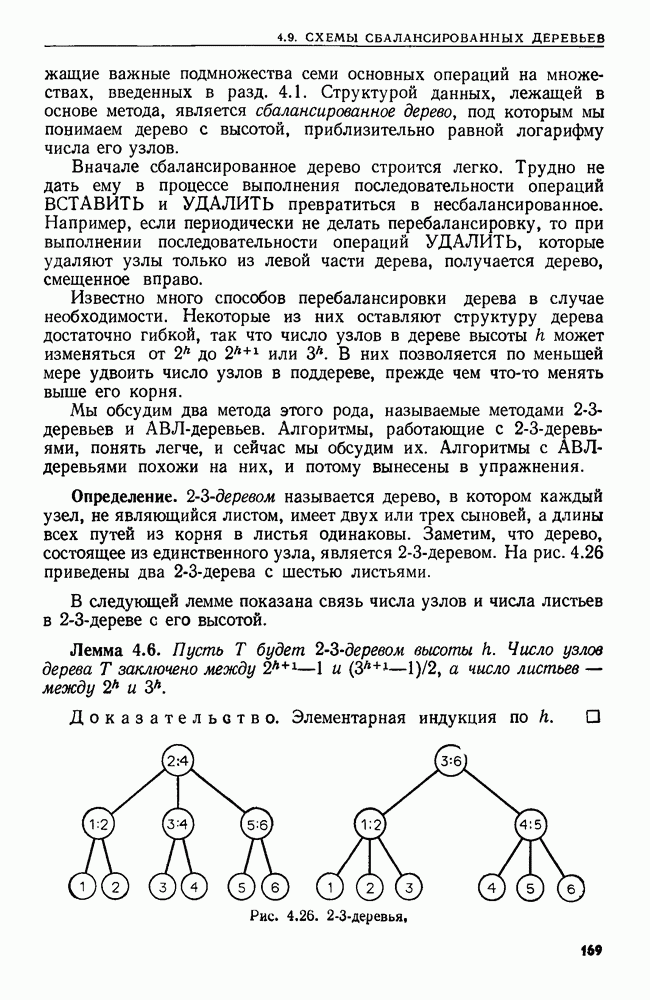
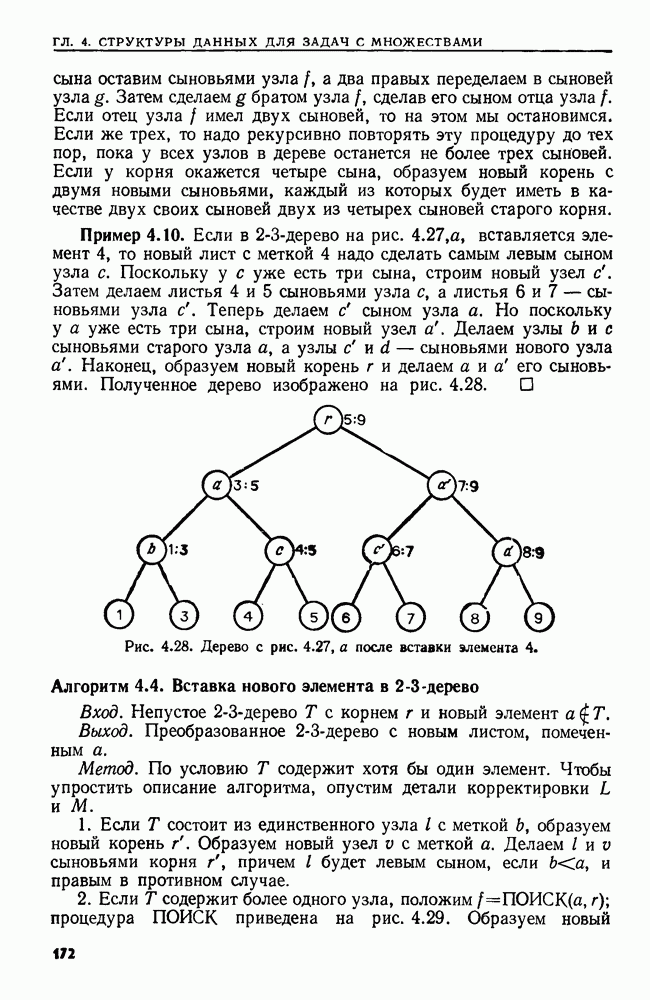
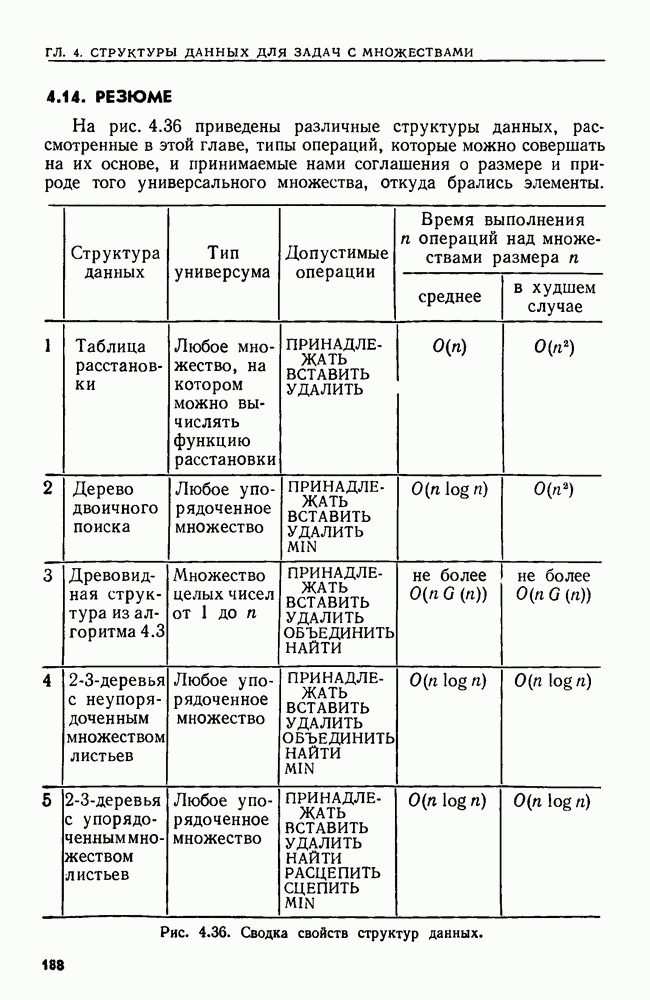
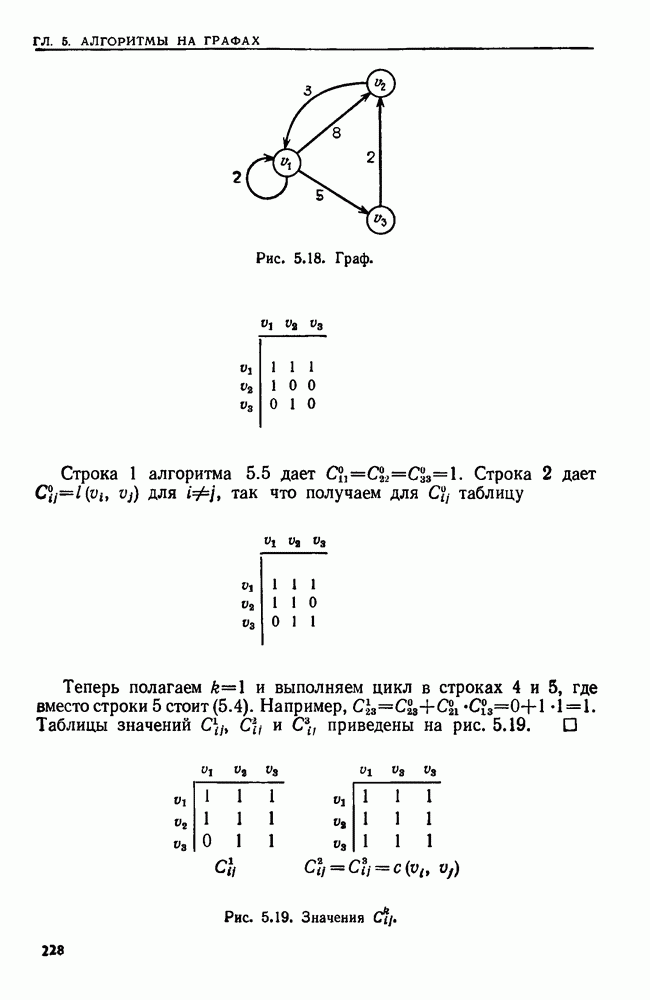
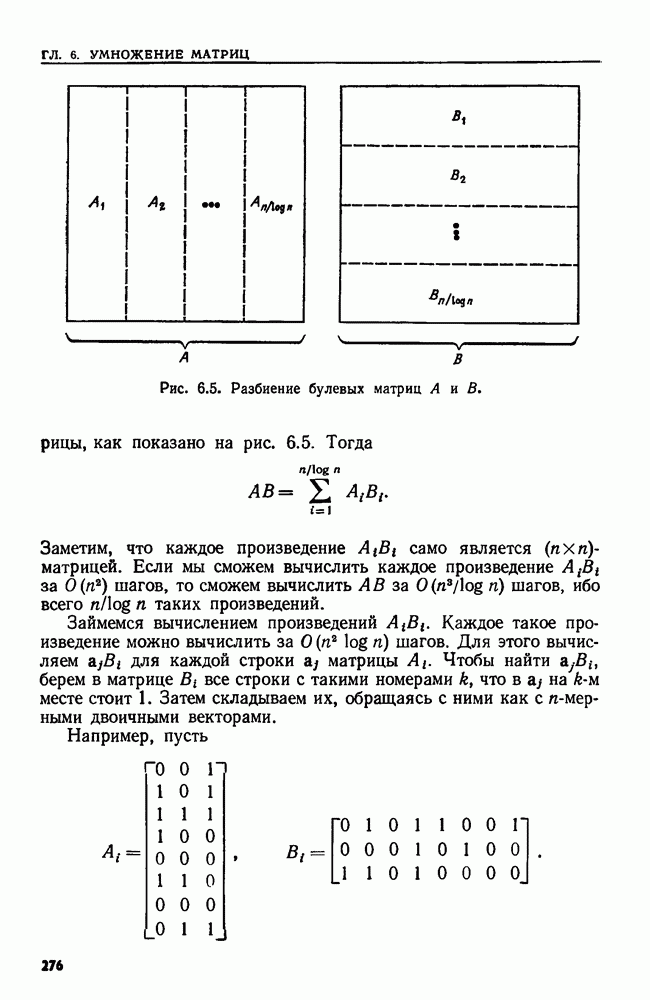
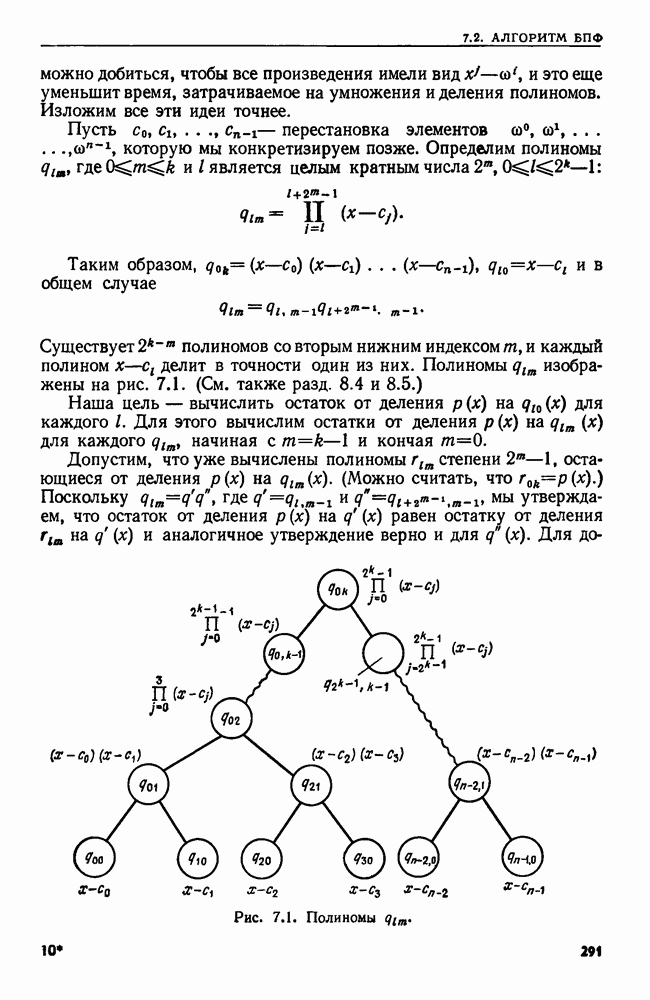
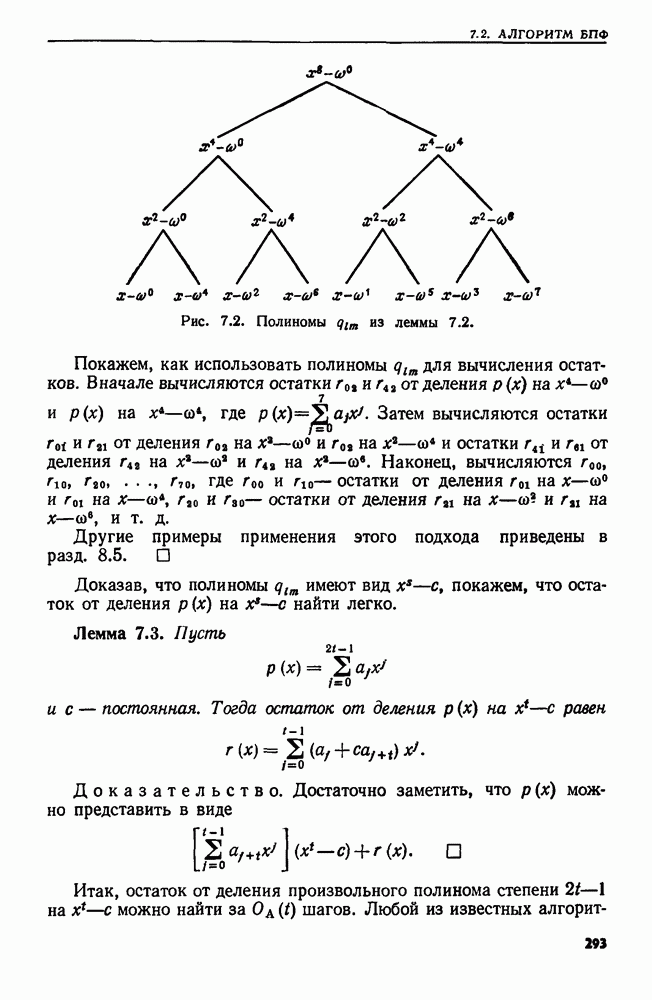
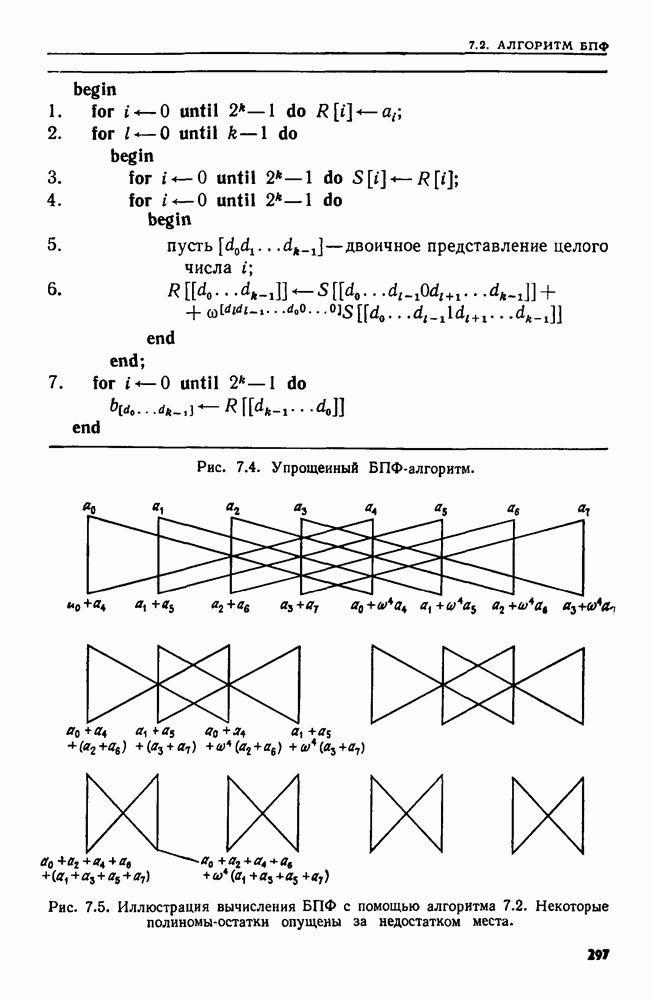
4. СТРУКТУРЫ ДАННЫХ ДЛЯ ЗАДАЧ, КАСАЮЩИХСЯ РАБОТЫ С МНОЖЕСТВАМИХороший подход к разработке эффективного алгоритма для данной задачи — изучить ее сущность. Часто задачу можно сформулировать на языке основных математических понятий, таких, как множество, и тогда алгоритм для нее можно изложить в терминах основных операций над основными объектами. Преимущество такой точки зрения в том, что можно проанализировать несколько различных структур данных и выбрать из них ту, которая лучше всего подходит для задачи в целом. Таким образом, разработка хорошей структуры данных идет рука об руку с разработкой хорошего алгоритма. В настоящей главе изучаются семь основных операций над множествами, типичных для многих задач информационного поиска. Мы приведем разнообразные структуры данных для представления множеств и рассмотрим пригодность каждой из них в ситуациях, когда выполняется та или иная последовательность операций различных типов. 4.1. ОСНОВНЫЕ ОПЕРАЦИИ НАД МНОЖЕСТВАМИБудем рассматривать следующие основные операции над множествами. 1. ПРИНАДЛЕЖАТЬ 2. ВСТАВИТЬ 3. УДАЛИТЬ 4. ОБЪЕДИНИТЬ 5. НАЙТИ (а). Печатает имя того множества, которому в данный момент принадлежит а. Если а принадлежит более чем одному множеству, то операция не определена. 6. РАСЦЕПИТЬ 7. Многие задачи, встречающиеся на практике, можно свести к одной или нескольким подзадачам, таким, что каждую подзадачу можно абстрактно сформулировать как последовательность основных команд, которые следует выполнить на некоторой базе данных (универсальном множестве элементов). В данной главе мы будем изучать последовательности а команд, каждая из которых является операцией одного из перечисленных выше семи типов. Например, выполнение последовательностей, состоящих из операций ПРИНАДЛЕЖАТЬ, ВСТАВИТЬ и Здесь возникает много интересных вопросов. Нас будет интересовать главным образом временная сложность выполнения операций в о, т. е. время как функция длины последовательности а и размера базы данных. Мы исследуем временную сложность в худшем случае и в среднем, а также сложность выполнения о в префиксном и свободном режимах. Определение. Выполнение последовательности операций а в префиксном режиме требует, чтобы операции в о выполнялись в порядке слева направо, причем Очевидно, что всякий префиксный алгоритм (т. е. работающий в префиксном режиме) может работать как свободный (т. е. в свободном режиме), но обратное верно не всегда. Мы увидим ситуации, когда свободный алгоритм работает быстрее любого из известных префиксных. Однако во многих приложениях приходится рассматривать только префиксные алгоритмы. Пусть дана последовательность операций, которую надлежит выполнить. Основной вопрос: какую структуру данных использовать для представления универсальной базы данных? Часто задача будет требовать осторожного взвешивания всех за и против каждого конкретного выбора. В типичной ситуации последовательность будет состоять из нескольких операций, подлежащих многократному выполнению, часто в неизвестном порядке. Может оказаться несколько структур данных, каждая из которых позволяет одну операцию выполнять легко, а другие — с большим трудом. Во многих случаях лучшим решением будет компромисс. Часто мы будем использовать структуру, которая не делает максимально легким выполнение ни одной из операций, но позволяет выполнить всю работу лучше, чем при любом очевидном подходе. Приведем пример, показывающий, как сформулировать задачу о построении остовного дерева для графа в терминах последовательности операций над множествами. Определение. Путь Функцией стоимости для графа Пример 4.1. Рассмотрим алгоритм, приведенный на рис. 4.1, для нахождения для данного графа В алгоритме на рис. 4.1 участвуют три множества Можно считать этот алгоритм последовательностью операций с тремя множествами
Рис. 4.1. Алгоритм для нахождения остовного дерева наименьшей стоимости. дерева сливаются, а в строке 9 ребро Строка 7 предполагает, что мы можем найти имя того множества в Отыскать структуру данных, на которой быстро выполняется операция ОБЪЕДИНИТЬ или НАЙТИ, довольно легко. Но здесь требуется, чтобы на одной структуре данных можно было легко реализовать обе операции ОБЪЕДИНИТЬ и НАЙТИ. Более того, поскольку выполнение операции ОБЪЕДИНИТЬ в строке 8 зависит от результата выполнения операций НАЙТИ в строке 7, требуемая последовательность операций ОБЪЕДИНИТЬ и НАЙТИ должна выполняться в префиксном режиме. Две такие структуры изучаются в разд. 4.6 и 4.7. Рассмотрим последовательность операций, выполняемых на множестве ребер сортирующее дерево из разд. 3.4. (Хотя там с помощью сортирующего дерева разыскивался наибольший элемент, должно быть ясно, что с его помощью можно также найти и наименьший элемент.) Наконец, множество
|
 |
Оглавление
|




























































































































































































































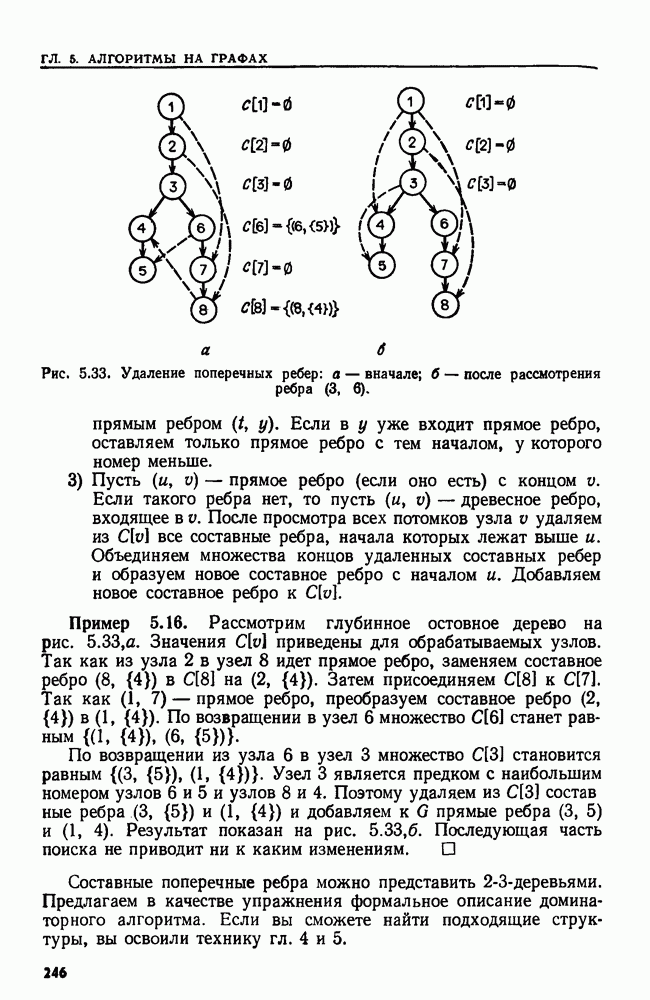




























































































































































































































































 . Устанавливает принадлежность а множеству
. Устанавливает принадлежность а множеству  если
если  печатается "да"; в противном случае —
печатается "да"; в противном случае — 
 . Заменяет
. Заменяет  на
на 
 . Заменяет
. Заменяет  на
на 
 . Строит множество
. Строит множество  Мы будем предполагать, что в тех случаях, когда применяется эта операция, множества
Мы будем предполагать, что в тех случаях, когда применяется эта операция, множества  не пересекаются; это делается для того, чтобы избежать необходимости удалять повторяющиеся экземпляры одного и того же элемента в
не пересекаются; это делается для того, чтобы избежать необходимости удалять повторяющиеся экземпляры одного и того же элемента в  и
и  .
.
 . Здесь предполагается, что множество
. Здесь предполагается, что множество  наделено линейным порядком Операция разбивает S на два множества и
наделено линейным порядком Операция разбивает S на два множества и  .
.
 Выдает наименьший (относительно элемент множества
Выдает наименьший (относительно элемент множества 
 составляет существенную часть многих задач поиска. Структура данных, которую можно использовать для выполнения последовательности этих операций, будет называться словарем. В настоящей главе рассматривается несколько структур данных (такие, как таблицы расстановки, деревья двоичного поиска и 2-3-деревья), которые могут быть словарями.
составляет существенную часть многих задач поиска. Структура данных, которую можно использовать для выполнения последовательности этих операций, будет называться словарем. В настоящей главе рассматривается несколько структур данных (такие, как таблицы расстановки, деревья двоичного поиска и 2-3-деревья), которые могут быть словарями.
 операция в о должна выполняться без просмотра какой бы то ни было последующей операции. При свободном режиме разрешается просматривать всю последовательность а в любой момент времени.
операция в о должна выполняться без просмотра какой бы то ни было последующей операции. При свободном режиме разрешается просматривать всю последовательность а в любой момент времени.
 неориентированный граф. Остовным деревом
неориентированный граф. Остовным деревом  графа
графа  называется неориентированное дерево вида
называется неориентированное дерево вида  Остовным лесом (для) графа
Остовным лесом (для) графа  называется множество неориентированных деревьев вида
называется множество неориентированных деревьев вида  в котором
в котором  образуют разбиение множества V, а каждое множество
образуют разбиение множества V, а каждое множество  является (возможно, пустым) подмножеством в
является (возможно, пустым) подмножеством в 
 называется отображение с из
называется отображение с из  в множество вещественных чисел. Стоимостью подграфа
в множество вещественных чисел. Стоимостью подграфа  графа
графа  считается
считается 
 остовного дерева
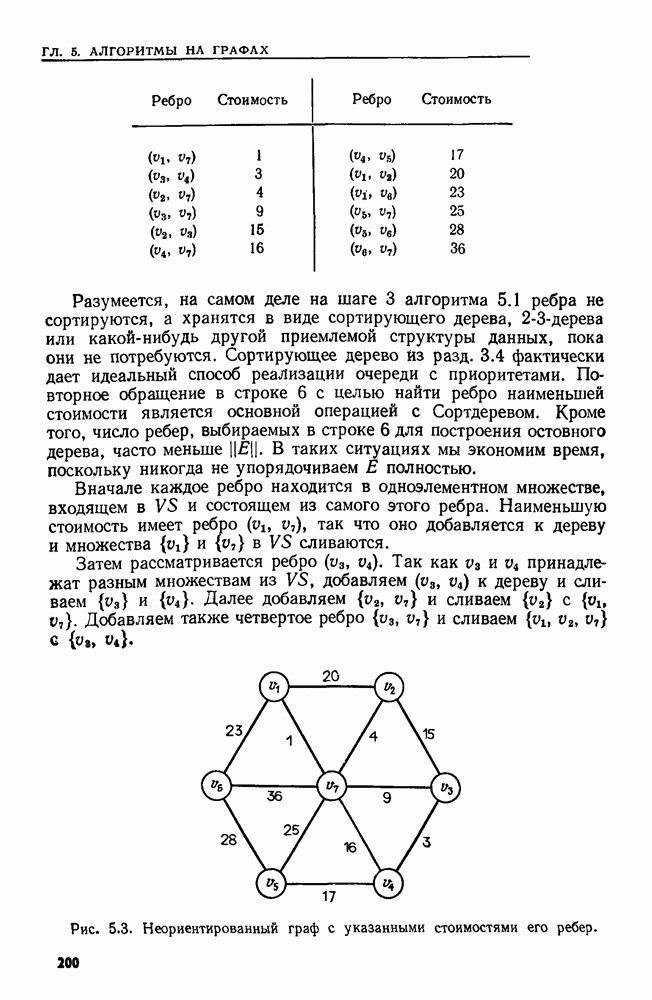
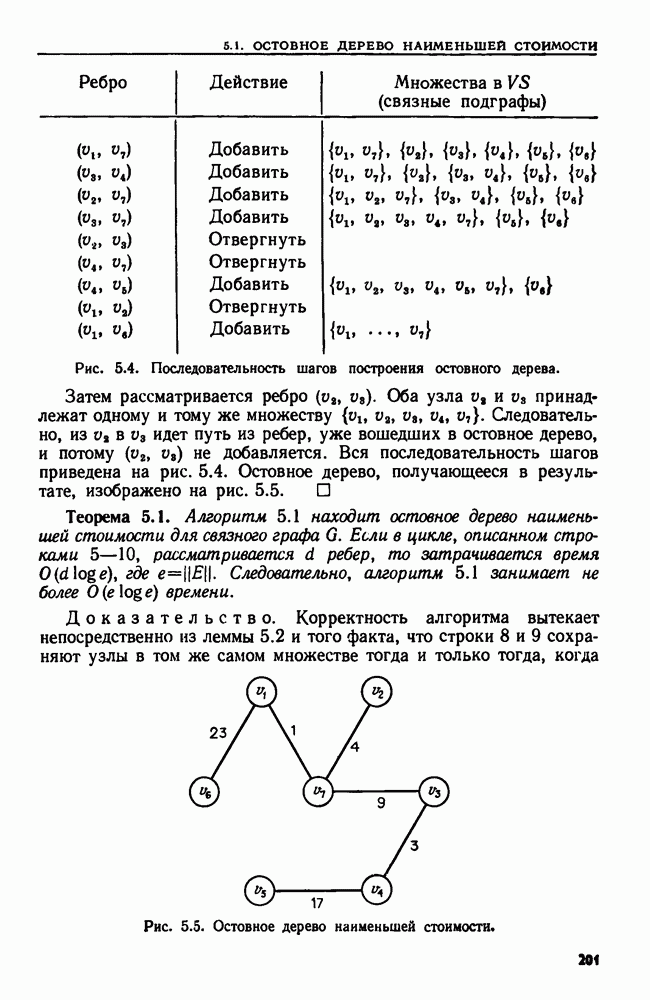
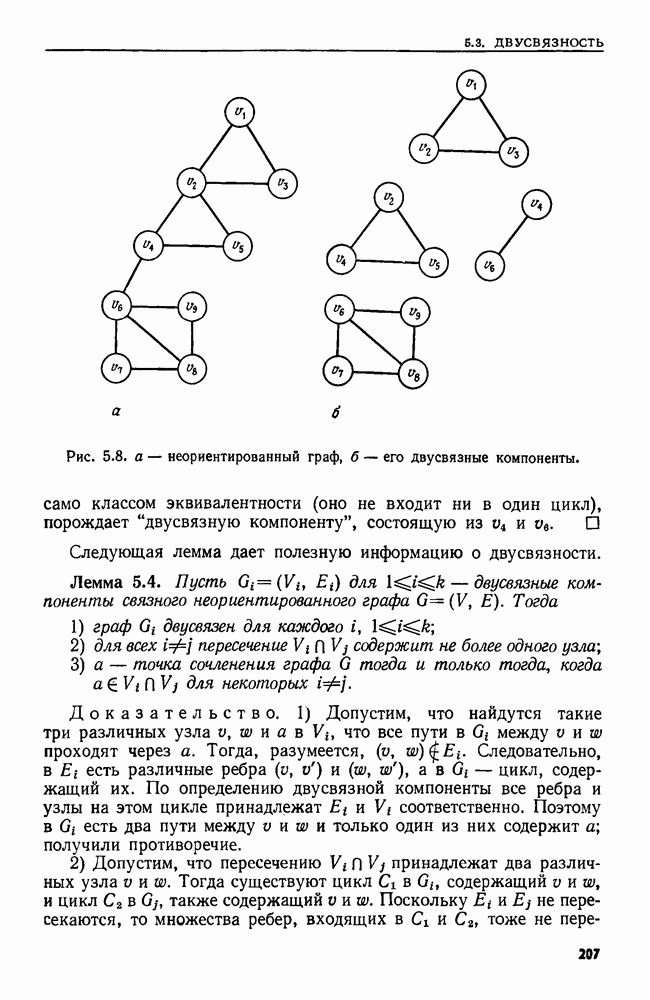
остовного дерева  наименьшей стоимости. Этот алгоритм построения остовного дерева наименьшей стоимости подробно обсуждается в разд. 5.1, а его применение проиллюстрировано в примере 5.1.
наименьшей стоимости. Этот алгоритм построения остовного дерева наименьшей стоимости подробно обсуждается в разд. 5.1, а его применение проиллюстрировано в примере 5.1.
 Множество
Множество  содержит ребра данного графа
содержит ребра данного графа  а
а  используется для сбора ребер окончательного остовного дерева. Работа алгоритма состоит в преобразовании остовного леса для
используется для сбора ребер окончательного остовного дерева. Работа алгоритма состоит в преобразовании остовного леса для  в единое остовное дерево. Множество
в единое остовное дерево. Множество  содержит множества узлов, входящих в деревья этого остовного леса. Вначале
содержит множества узлов, входящих в деревья этого остовного леса. Вначале  содержит каждый узел графа
содержит каждый узел графа  в виде одноэлементного множества.
в виде одноэлементного множества.
 В строке 1 формируется начальное значение для
В строке 1 формируется начальное значение для  в строках 2 и 3 — для
в строках 2 и 3 — для  (элементы множества
(элементы множества  сами являются множествами). В строке 3 добавляются исходные одноэлементные множества к
сами являются множествами). В строке 3 добавляются исходные одноэлементные множества к  Строка 4, управляющая основным циклом алгоритма, предполагает наличие счетчика множеств, составляющих
Строка 4, управляющая основным циклом алгоритма, предполагает наличие счетчика множеств, составляющих  В строке 7 выясняется, соединяет ли ребро
В строке 7 выясняется, соединяет ли ребро  два остовных дерева в остовном лесу. Если да, то в строке 8 эти два
два остовных дерева в остовном лесу. Если да, то в строке 8 эти два

 добавляется к окончательному остовному дереву.
добавляется к окончательному остовному дереву.
 которое содержит конкретный узел. (Вид имен, действительно используемых для множеств в
которое содержит конкретный узел. (Вид имен, действительно используемых для множеств в  не важен, так что можно употреблять произвольные имена.) По существу, строка 7 предполагает, что мы можем эффективно выполнить основную операцию НАЙТИ. Аналогично строка 8 предполагает, что над непересекающимися множествами узлов мы можем выполнить операцию ОБЪЕДИНИТЬ.
не важен, так что можно употреблять произвольные имена.) По существу, строка 7 предполагает, что мы можем эффективно выполнить основную операцию НАЙТИ. Аналогично строка 8 предполагает, что над непересекающимися множествами узлов мы можем выполнить операцию ОБЪЕДИНИТЬ.
 В строке 5 применяется основная операция MIN, а в строке 6 — операция УДАЛИТЬ. Хорошая структура данных для этих двух операций нам уже встречалась —
В строке 5 применяется основная операция MIN, а в строке 6 — операция УДАЛИТЬ. Хорошая структура данных для этих двух операций нам уже встречалась —
 ребер остовного дерева нуждается только в операции ВСТАВИТЬ в строке 9 для добавления к
ребер остовного дерева нуждается только в операции ВСТАВИТЬ в строке 9 для добавления к  нового ребра. Здесь достаточно простого списка.
нового ребра. Здесь достаточно простого списка.