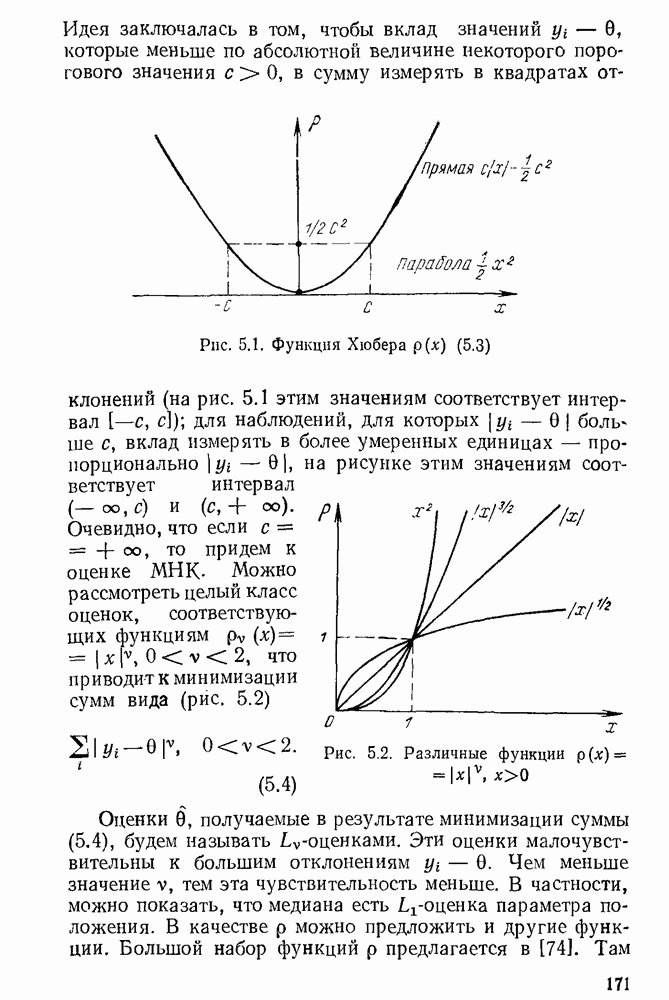
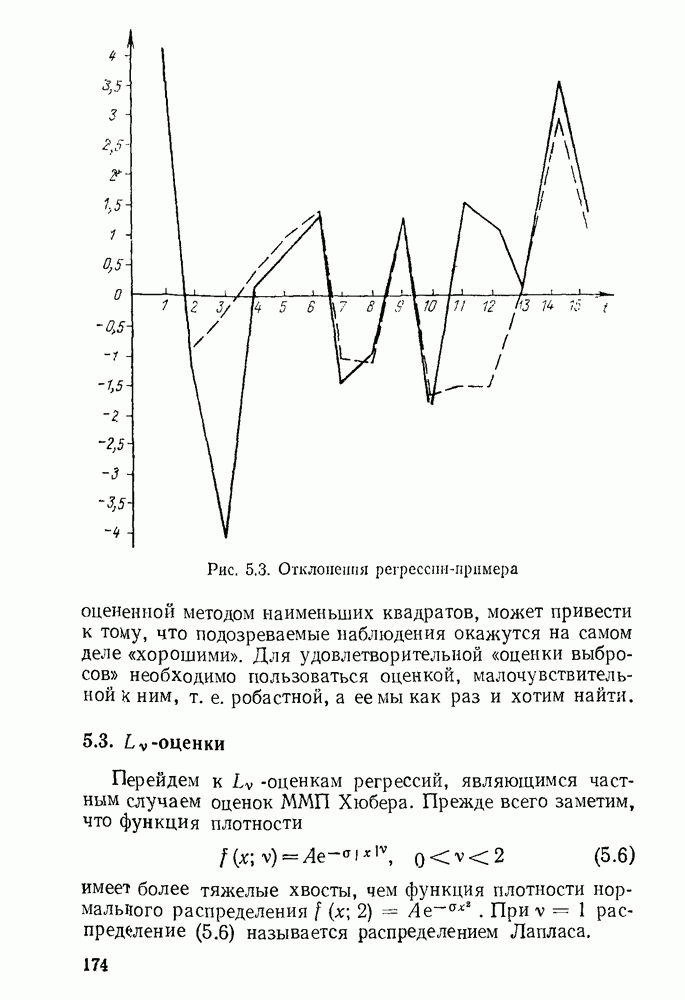
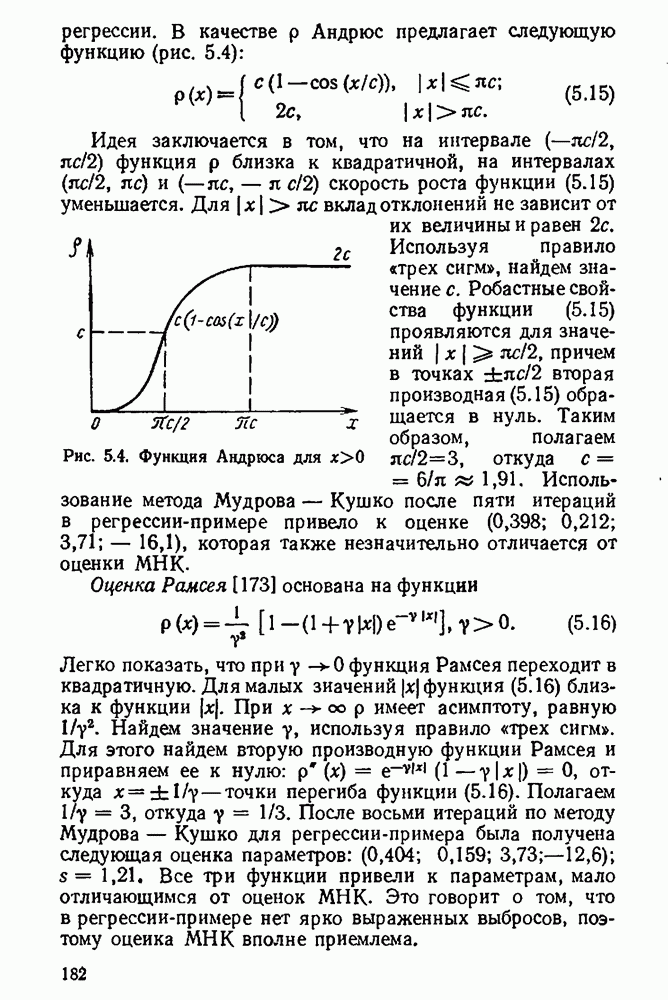
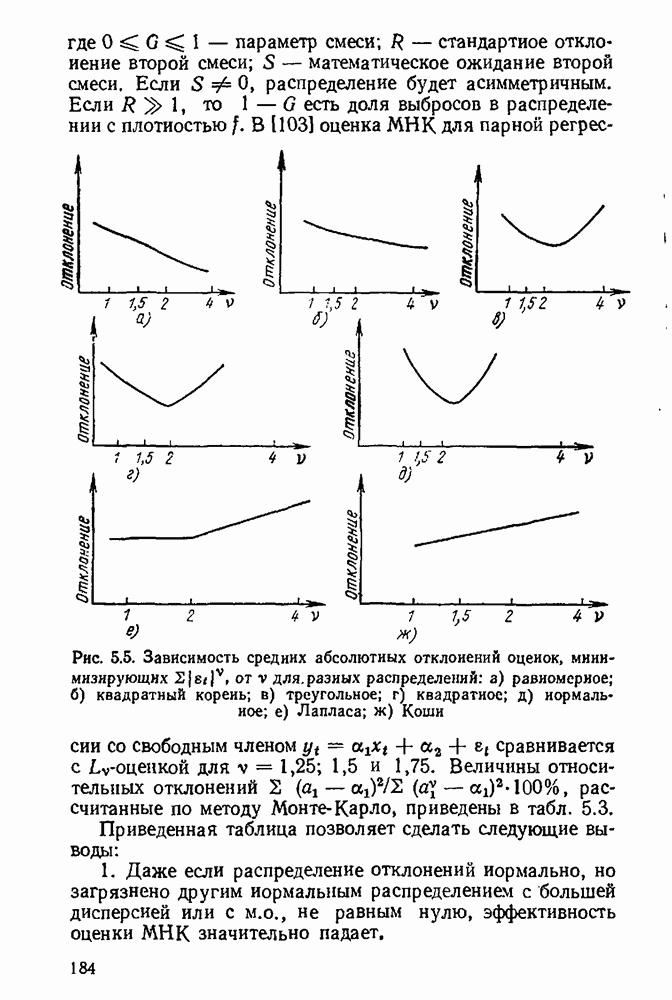
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
1.9. Общие принципы проверки статистических гипотез и построения доверительных интерваловДопустим, распределение заданному множеству Ошибки могут иметь разные последствия. Например, если гипотеза
где а — истинное значение параметра, принадлежащее
где а
Множество
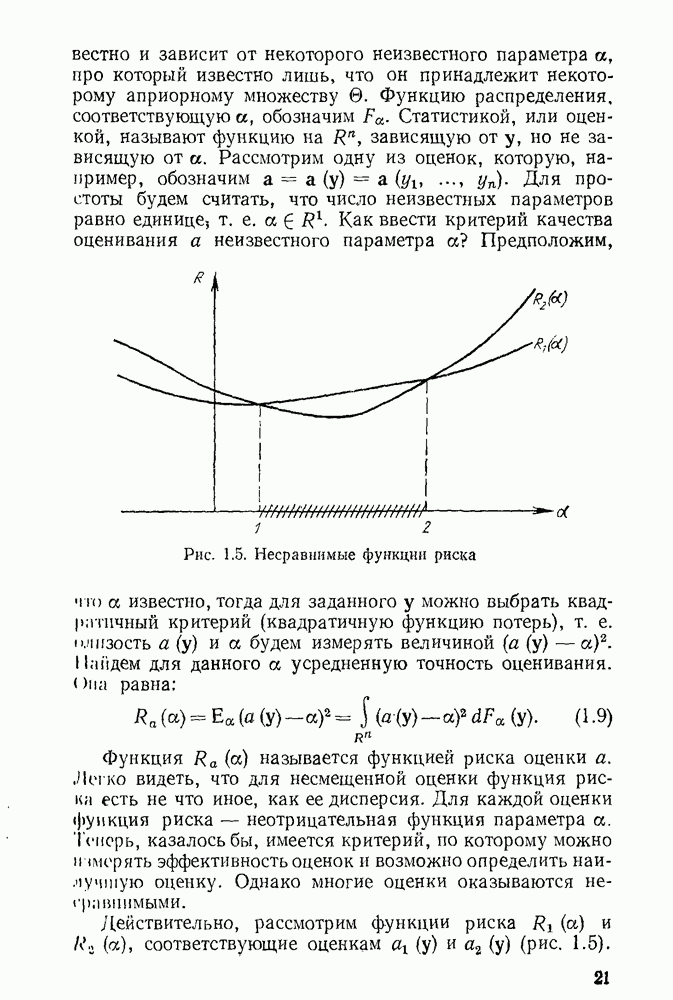
называют функцией мощности. Таким образом, критерий проверки гипотезы Пример. Рассмотрим пример из параграфа 1.4. Допустим, мы хотим проверить простую гипотезу
В точке
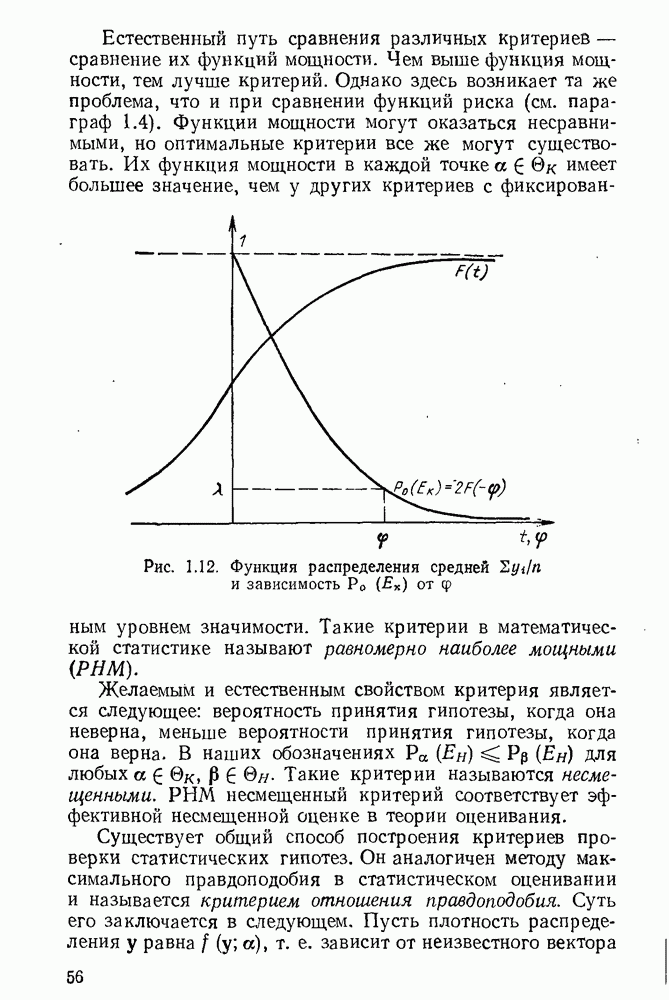
Обозначим функцню распределения статистики при Естественный путь сравнения различных Критериев — сравнение их функций мощности. Чем выше функция мощности, тем лучше критерий. Однако здесь возникает та же проблема, что и при сравнении функций риска (см. параграф 1.4). Функции мощности могут оказаться несравнимыми, но оптимальные критерии все же могут существовать. Их функция мощности в каждой точке а
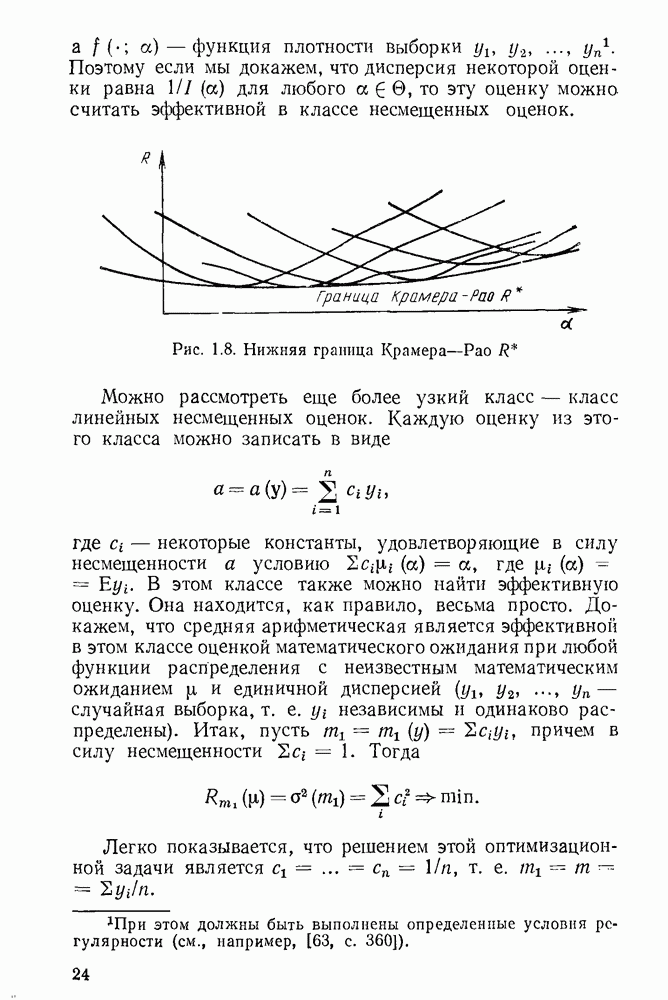
Рис. 1.12. Функция распределения средней Такие критерии в математической статистике называют равномерно наиболее мощными РИМ). Желаемым и естественным свойством критерия является следующее: вероятность принятия гипотезы, когда она неверна, меньше вероятности принятия гипотезы, когда она верна. В наших обозначениях Существует общий способ построения критериев проверки статистических гипотез. Он аналогичен методу максимального правдоподобия в статистическом оценивании и называется критерием отношения правдоподобия. Суть его заключается в следующем. Пусть плотность распределения у равна параметров а В качестве критического множества при проверке гипотезы
где Продолжение примера. Применим критерий отношения правдоподобия для проверки гипотезы
далее
Последнее выражение следует из того, что минимальное значение
Как видим, это множество совпадает с найденным ранее. Значение Перейдем к построению доверительных интервалов. Пусть распределение случайного вектора
Слева записана вероятность того, что Вероятность ошибки, т. е. вероятность того, что доверительное множество не накроет истинное значение параметра, равна:
Таким образом, можно трактовать как максимальную вероятность ошибки накрытия. Можно ввести понятие несмещенности доверительного множества, аналогичное несмещенности статистического критерия. Допустим, а — истинное значение параметра, Мы же ошибочно предполагаем, что именно
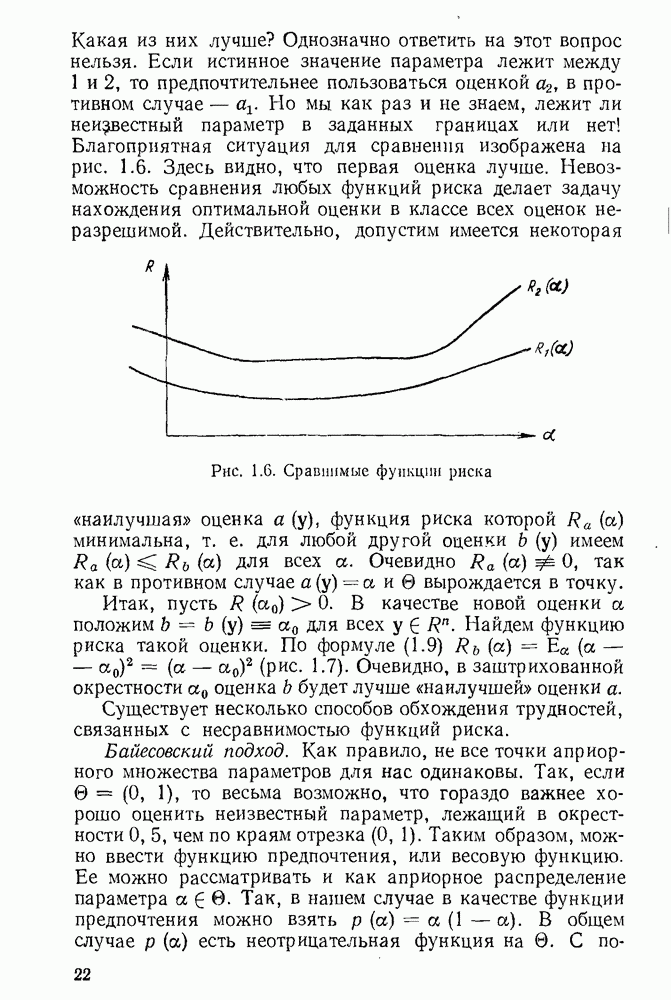
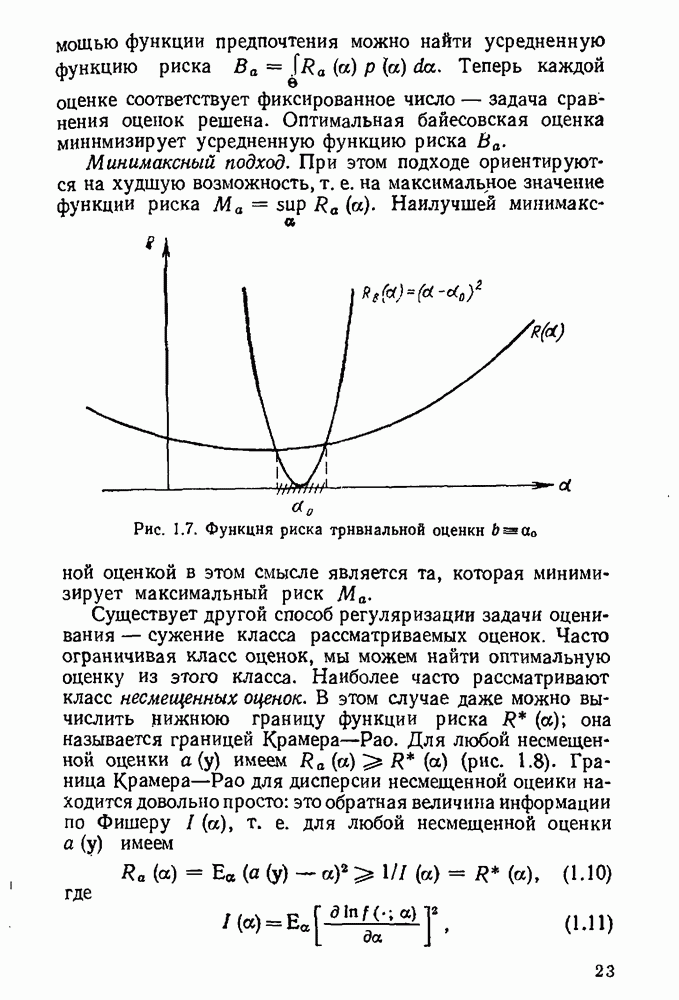
Теперь дадим определение наиболее точного доверительного множества. Представим себе ситуацию, когда истинное значение параметра а нам неизвестно и мы ошибочно оцениваем
В частном случае, когда
Задача доверительного оценивания теснейшим образом связана с проверкой простой гипотезы. Будем проверять простую гипотезу
Как объяснить выбор
Основная связь между проверкой гипотез и доверительным оцениванием выражается в виде следующей теоремы, доказательство которой весьма просто. Теорема 1.14. Пусть имеется РИМ несмещенный критерий проверки простой статистической гипотезы Сформулированная теорема предлагает нам большие возможности в построении доверительных множеств. Задачи построения гипотез и доверительного оценивания можно считать эквивалентными. Пример. Несколько обобщим предыдущий пример. Предположим, мы хотим проверить простую гипотезу Н: истинное значение
Тогда
Значение Упражнения 1.9(см. скан)
|
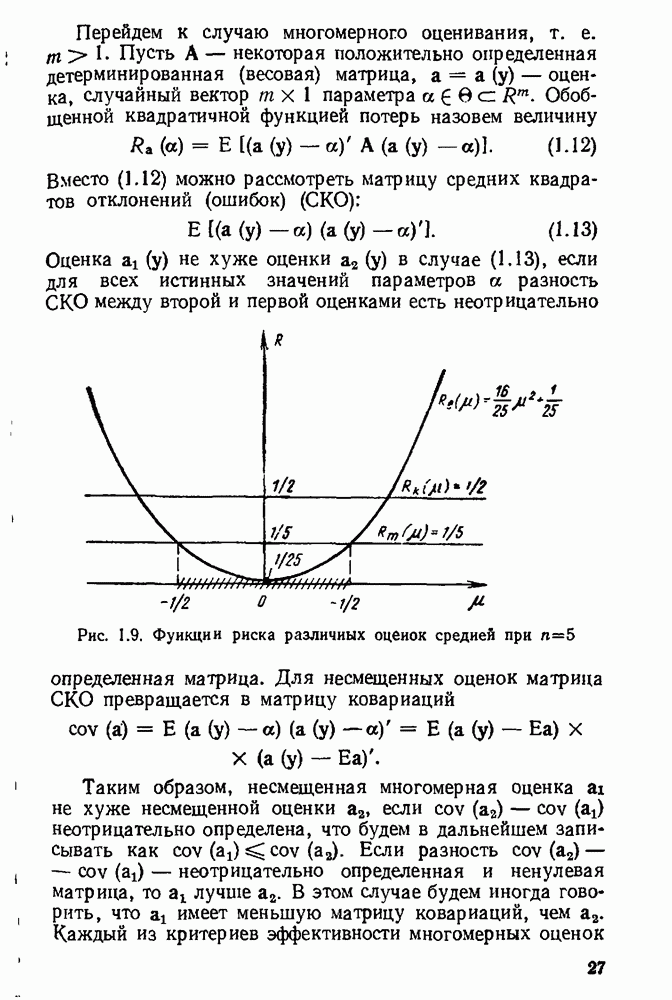
 |
Оглавление
|







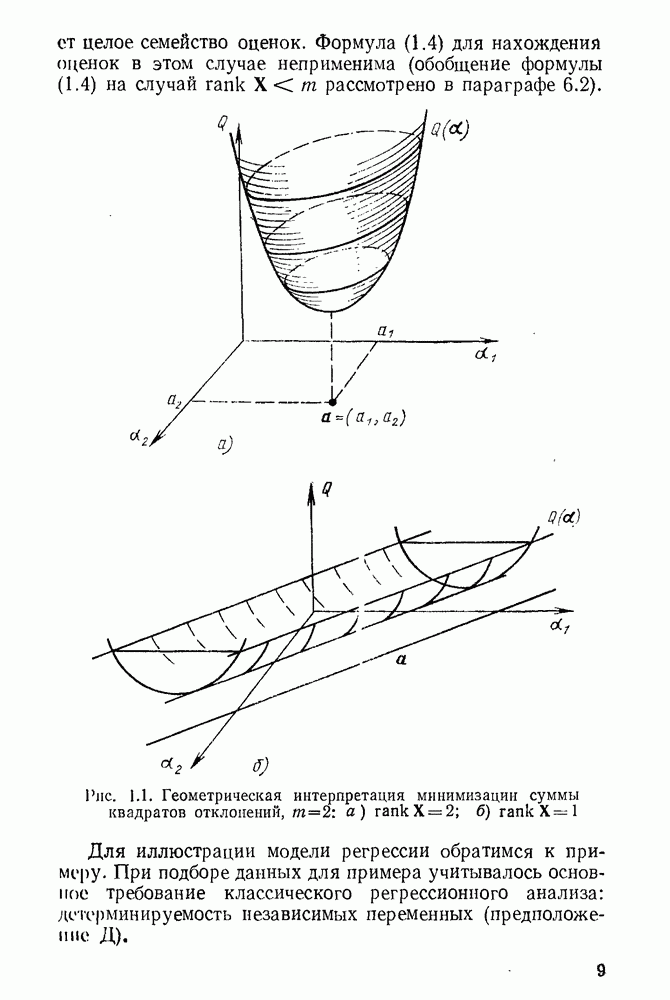


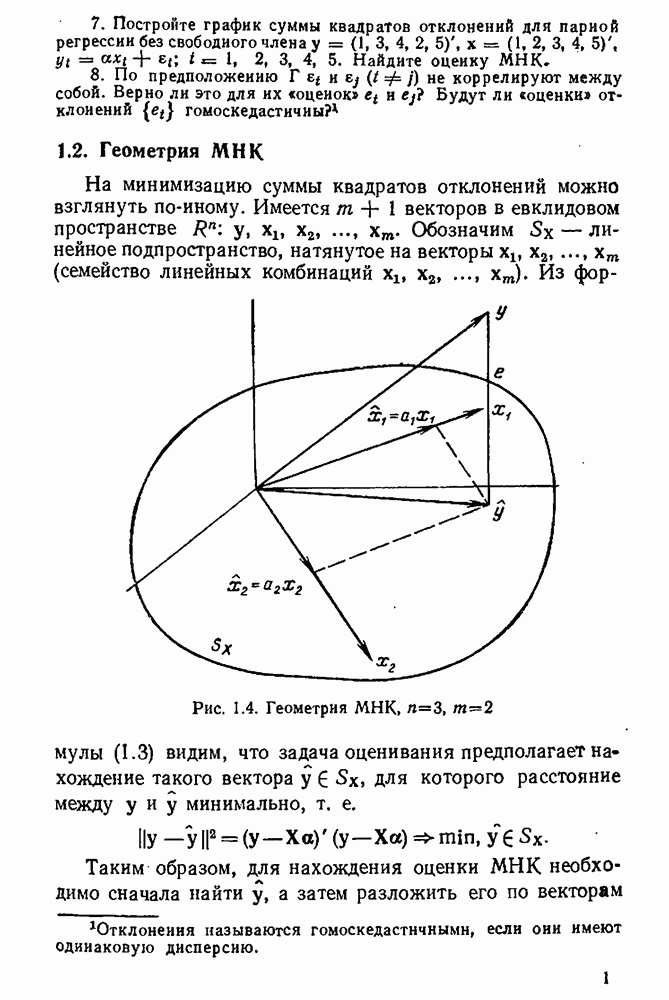
































































































































































































































































 -мерной случайной величины у зависит от некоторого (может быть многомерного) неизвестного параметра а, который принадлежит априори
-мерной случайной величины у зависит от некоторого (может быть многомерного) неизвестного параметра а, который принадлежит априори
 Далее, задано разбиение множества В на два подмножества
Далее, задано разбиение множества В на два подмножества  Выдвигаем гипотезу
Выдвигаем гипотезу  которую мы впоследствии будем проверять: истинное значение параметра а принадлежит множеству
которую мы впоследствии будем проверять: истинное значение параметра а принадлежит множеству  Если
Если  состоит из одной точки, гипотезу
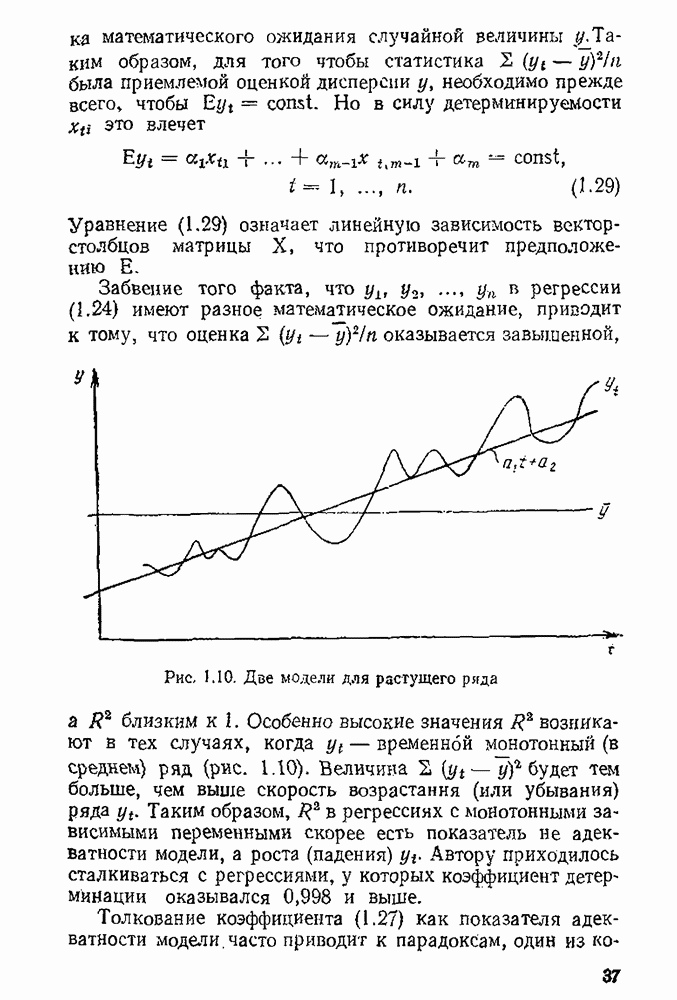
состоит из одной точки, гипотезу  называют простой. Каждый раз, когда значение случайной величины у известно (т. е. имеется выборка), мы должны определенно ответить, верна наша гипотеза или нет. Таким образом, выборочное пространство
называют простой. Каждый раз, когда значение случайной величины у известно (т. е. имеется выборка), мы должны определенно ответить, верна наша гипотеза или нет. Таким образом, выборочное пространство  разбивается в свою очередь на два подмножества
разбивается в свою очередь на два подмножества  Если у попадает в
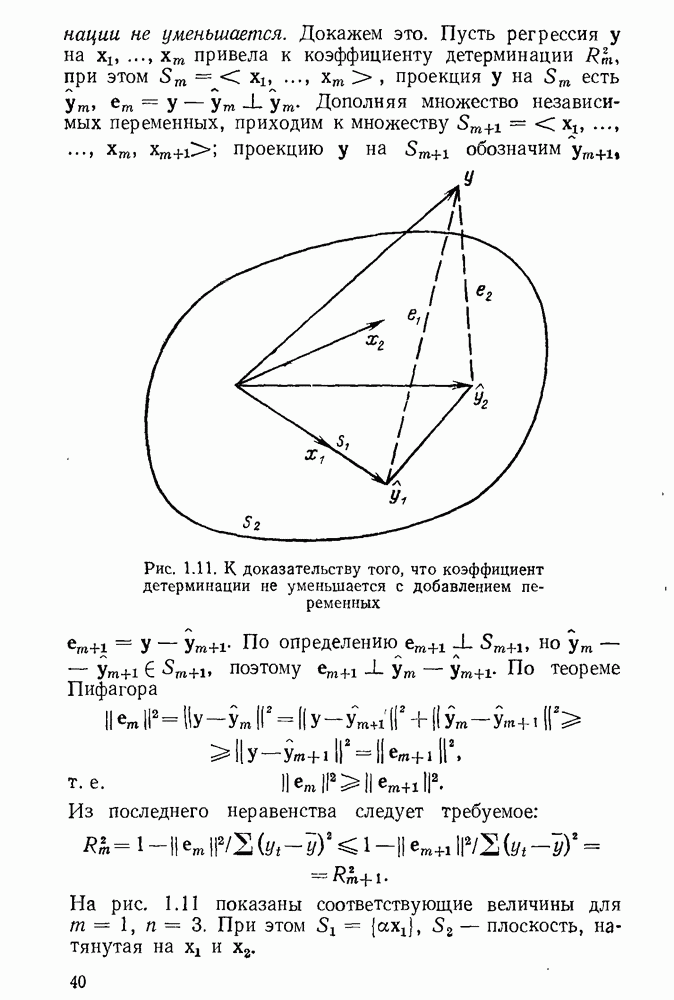
Если у попадает в  то гипотезу
то гипотезу  принимаем, если
принимаем, если  отвергаем. При этом мы можем совершить ошибку двух родов: 1) гипотеза
отвергаем. При этом мы можем совершить ошибку двух родов: 1) гипотеза  верна, а мы ее отвергаем, 2) гипотеза
верна, а мы ее отвергаем, 2) гипотеза  неверна, а мы ее принимаем.
неверна, а мы ее принимаем.
 состоит в наличии у пациента некоторой тяжелой болезни, то ошибка 2) не так существенна, как 1). Одновременно свести обе ошибки к минимуму невозможно. Целесообразно поступить следующим образом. Зададим верхнюю границу К максимальной ошибки первого рода и при этом условии будем минимизировать ошибку второго рода;
состоит в наличии у пациента некоторой тяжелой болезни, то ошибка 2) не так существенна, как 1). Одновременно свести обе ошибки к минимуму невозможно. Целесообразно поступить следующим образом. Зададим верхнюю границу К максимальной ошибки первого рода и при этом условии будем минимизировать ошибку второго рода;  называют уровнем значимости. Как же подсчитать ошибку, совершаемую нами для каждого
называют уровнем значимости. Как же подсчитать ошибку, совершаемую нами для каждого  Разумеется, в такой постановке ответить на такой вопрос невозможно. Однако мы можем подсчитать вероятность совершения ошибок первого и второго родов. Вероятность ошибки первого рода:
Разумеется, в такой постановке ответить на такой вопрос невозможно. Однако мы можем подсчитать вероятность совершения ошибок первого и второго родов. Вероятность ошибки первого рода:

 (гипотеза на самом деле верна). Вероятность ошибки второго рода:
(гипотеза на самом деле верна). Вероятность ошибки второго рода:

 (гипотеза на самом деле неверна). Минимизация предыдущего выражения эквивалентна максимизации вероятности отвергнуть гипотезу, когда она на самом деле неверна, т. е.
(гипотеза на самом деле неверна). Минимизация предыдущего выражения эквивалентна максимизации вероятности отвергнуть гипотезу, когда она на самом деле неверна, т. е.

 называют критической областью критерия, или критическим множеством. Функцию
называют критической областью критерия, или критическим множеством. Функцию

 полностью определяется подмножеством
полностью определяется подмножеством  выборочного пространства
выборочного пространства  Множество
Множество  разумеется, не должно зависеть от неизвестного параметра а.
разумеется, не должно зависеть от неизвестного параметра а.
 В наших обозначениях
В наших обозначениях  Допустим, мы задались некоторым уровнем значимости X (как правило, выбирают
Допустим, мы задались некоторым уровнем значимости X (как правило, выбирают  или
или  В качестве критического множества рассмотрим множество
В качестве критического множества рассмотрим множество  где
где  некоторое фиксированное число, зависящее от
некоторое фиксированное число, зависящее от  Найдем функцию мощности предложенного критерия
Найдем функцию мощности предложенного критерия

 Заметим, что
Заметим, что  поэтому
поэтому

 функция мощности имеет минимум. Это очевидно, так как если истинное значение
функция мощности имеет минимум. Это очевидно, так как если истинное значение  близко к нулю, то мы легко можем совершить ошибку второго рода (т. е. принять гипотезу
близко к нулю, то мы легко можем совершить ошибку второго рода (т. е. принять гипотезу  тогда как
тогда как  Вероятность ошибки первого рода равна:
Вероятность ошибки первого рода равна:

 через
через  тогда
тогда  Для заданного
Для заданного  является решением уравнения
является решением уравнения  (рис. 1.12). Значение
(рис. 1.12). Значение  находится из таблиц нормального распределения.
находится из таблиц нормального распределения.
 имеет большее значение, чем у других критериев с фиксированным уровнем значимости.
имеет большее значение, чем у других критериев с фиксированным уровнем значимости.

 и зависимость
и зависимость  от
от 
 для любых а
для любых а  Такие критерии называются несмещенными. РНМ несмещенный критерий соответствует эффективной несмещенной оценке в теории оценивания.
Такие критерии называются несмещенными. РНМ несмещенный критерий соответствует эффективной несмещенной оценке в теории оценивания.
 т. е. зависит от неизвестного вектора
т. е. зависит от неизвестного вектора
 Для каждого у найдем
Для каждого у найдем  и
и  (считаем, что максимум достигается).
(считаем, что максимум достигается).
 выбираем
выбираем

 фиксированное число, зависящее от
фиксированное число, зависящее от  , которое в свою очередь задает верхнюю границу вероятности совершения ошибки первого рода
, которое в свою очередь задает верхнюю границу вероятности совершения ошибки первого рода  для всех а
для всех а  -Статистика
-Статистика  называется статистикой критерия отношения правдоподобия. В случае простой случайной выборки, т. е. когда
называется статистикой критерия отношения правдоподобия. В случае простой случайной выборки, т. е. когда  независимы и одинаково распределены, известны асимптотические оптимальные статистические свойства критерия отношения правдоподобия [63].
независимы и одинаково распределены, известны асимптотические оптимальные статистические свойства критерия отношения правдоподобия [63].
 Функция плотности у равна:
Функция плотности у равна:


 достигается при
достигается при  Критическим множеством будет:
Критическим множеством будет:

 находится, как и раньше, из решения уравнения
находится, как и раньше, из решения уравнения 
 известно с точностью до
известно с точностью до  Оценим а с помощью доверительного интервала или в общем случае с помощью доверительного множества. Доверительное множество каждый раз зависит от наблюдения у, т. е. является его функцией. Обозначим его через
Оценим а с помощью доверительного интервала или в общем случае с помощью доверительного множества. Доверительное множество каждый раз зависит от наблюдения у, т. е. является его функцией. Обозначим его через  Важно, с какой вероятностью доверительное множество
Важно, с какой вероятностью доверительное множество  накрывает истинный параметр. Аналогично проверке гипотез можно ввести коэффициент доверия доверительного множества.
накрывает истинный параметр. Аналогично проверке гипотез можно ввести коэффициент доверия доверительного множества.  является доверительным множеством с коэффициентом доверия не менее
является доверительным множеством с коэффициентом доверия не менее  если для каждого а
если для каждого а 

 накроет а. Эта вероятность вычисляется при условии, что истинное значение параметра также равно а.
накроет а. Эта вероятность вычисляется при условии, что истинное значение параметра также равно а.

 является истинным, и поэтому наше доверительное множество
является истинным, и поэтому наше доверительное множество  направлено на оценивание параметра
направлено на оценивание параметра  Вероятность такого (ошибочного) оценивания равна
Вероятность такого (ошибочного) оценивания равна  Естественно считать, что эта вероятность будет меньше, чем если бы мы не делали ошибки и
Естественно считать, что эта вероятность будет меньше, чем если бы мы не делали ошибки и  тогда вероятность накрытия равна
тогда вероятность накрытия равна  (по условию (1.50)). Говорим, что
(по условию (1.50)). Говорим, что  является несмещенным доверительным множеством, если для любых
является несмещенным доверительным множеством, если для любых  имеем
имеем

 вместо
вместо  Пусть имеются два метода доверительного оценивания, т. е. два доверительных множества
Пусть имеются два метода доверительного оценивания, т. е. два доверительных множества  и
и  будет точнее
будет точнее  если
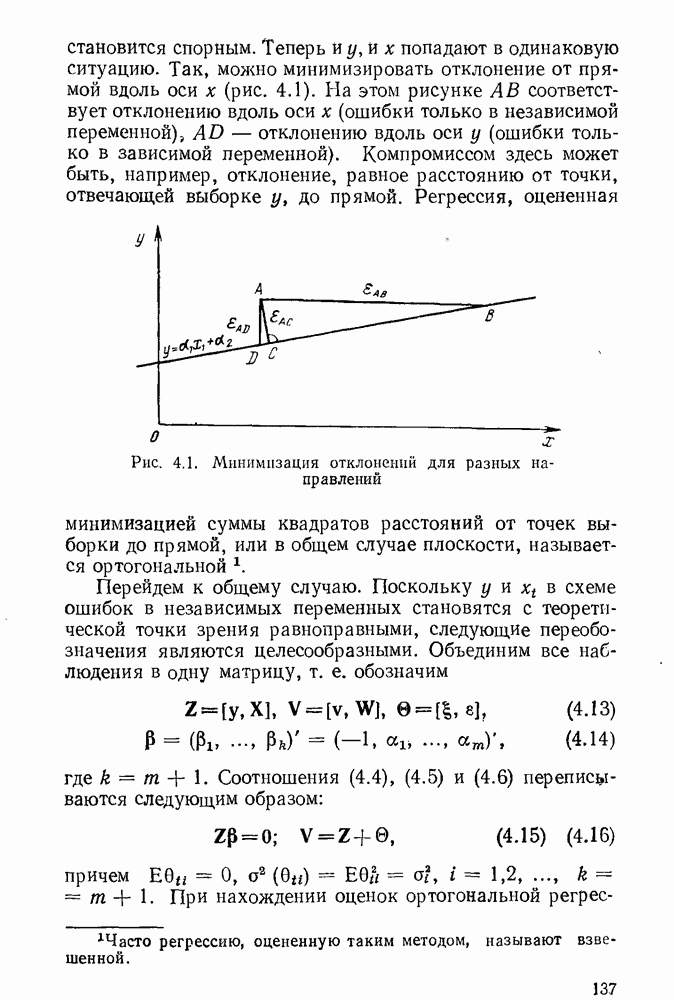
если  накрывает ошибочное значение
накрывает ошибочное значение  реже, чем
реже, чем 

 естественно вместо произвольных доверительных множеств рассматривать доверительные интервалы. Такой интервал будет характеризоваться парой статистик
естественно вместо произвольных доверительных множеств рассматривать доверительные интервалы. Такой интервал будет характеризоваться парой статистик  причем
причем  Для любых у. Вероятность накрытия равна:
Для любых у. Вероятность накрытия равна:

 где
где  фиксированное значение из В. Допустим, имеется некоторый критерий проверки этой гипотезы. Область принятия гипотезы обозначим
фиксированное значение из В. Допустим, имеется некоторый критерий проверки этой гипотезы. Область принятия гипотезы обозначим  или
или  Предположим, что критерий имеет уровень значимости X, причем
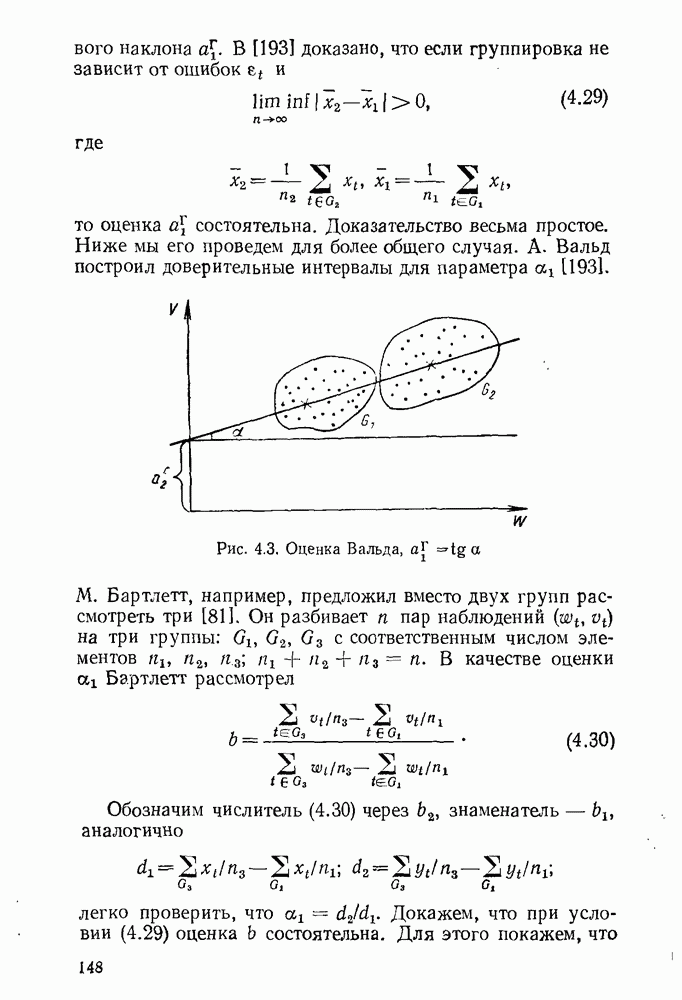
Предположим, что критерий имеет уровень значимости X, причем  для всех а
для всех а  На основе
На основе  построим доверительное множество для оценивания
построим доверительное множество для оценивания  которое обозначим
которое обозначим  Положим
Положим  тогда и только тогда, когда
тогда и только тогда, когда  ; другими словами,
; другими словами,

 Множество
Множество  есть множество тех возможных наблюдений у, которые «скорее всего» получаются, если в качестве неизвестного параметра выступает параметр
есть множество тех возможных наблюдений у, которые «скорее всего» получаются, если в качестве неизвестного параметра выступает параметр  Поэтому множество всех параметров, которые «порождают» это множество
Поэтому множество всех параметров, которые «порождают» это множество  будет «близко расположенным» к
будет «близко расположенным» к  и будет хорошей доверительной оценкой этого параметра. Легко убедиться в том, что если критерий имеет уровень значимости X, то построенное доверительное множество
и будет хорошей доверительной оценкой этого параметра. Легко убедиться в том, что если критерий имеет уровень значимости X, то построенное доверительное множество  имеет коэффициент доверия
имеет коэффициент доверия 

 с уровнем значимости
с уровнем значимости  Тогда доверительное множество
Тогда доверительное множество  является несмещенным, имеет коэффициент доверия
является несмещенным, имеет коэффициент доверия  и является равномерно наиболее точным (РНТ), т. е. эффективным. Обратно, РНТ несмещенные доверительные множества приводят к РИМ несмещенным критериям.
и является равномерно наиболее точным (РНТ), т. е. эффективным. Обратно, РНТ несмещенные доверительные множества приводят к РИМ несмещенным критериям.
 равно
равно  Легко проверить, что область принятия гипотезы будет
Легко проверить, что область принятия гипотезы будет


 как и раньше, является решением уравнения
как и раньше, является решением уравнения  Множество
Множество  имеет коэффициент доверия
имеет коэффициент доверия  Можно показать, что критерий (1.54) является несмещенным РНМ. Отсюда вытекает, что доверительный интервал
Можно показать, что критерий (1.54) является несмещенным РНМ. Отсюда вытекает, что доверительный интервал  для оценивания
для оценивания  где
где  является несмещенным РНТ.
является несмещенным РНТ.