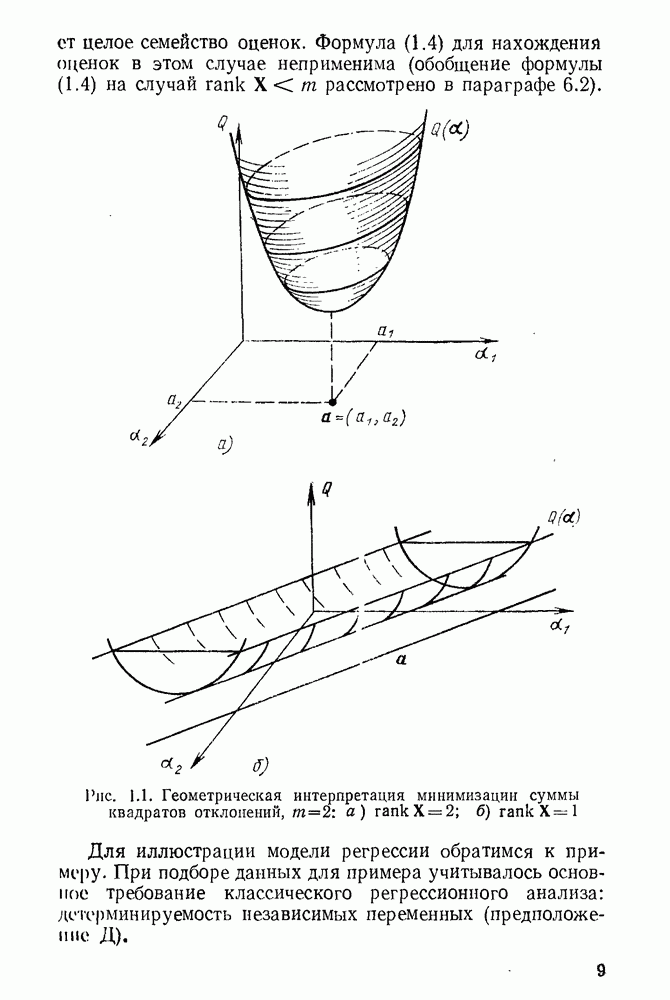
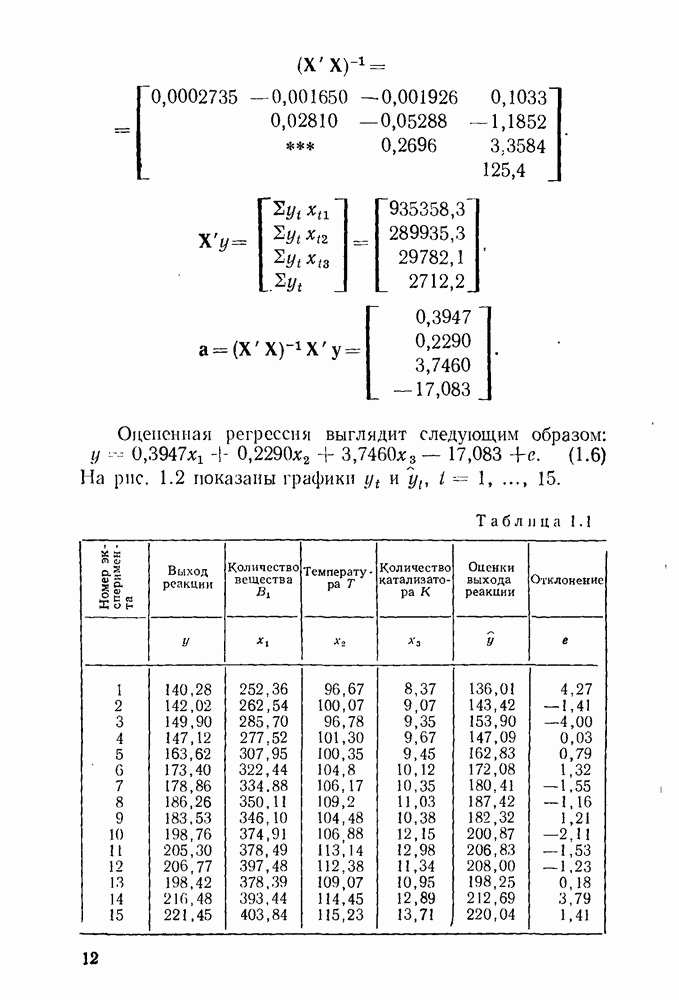
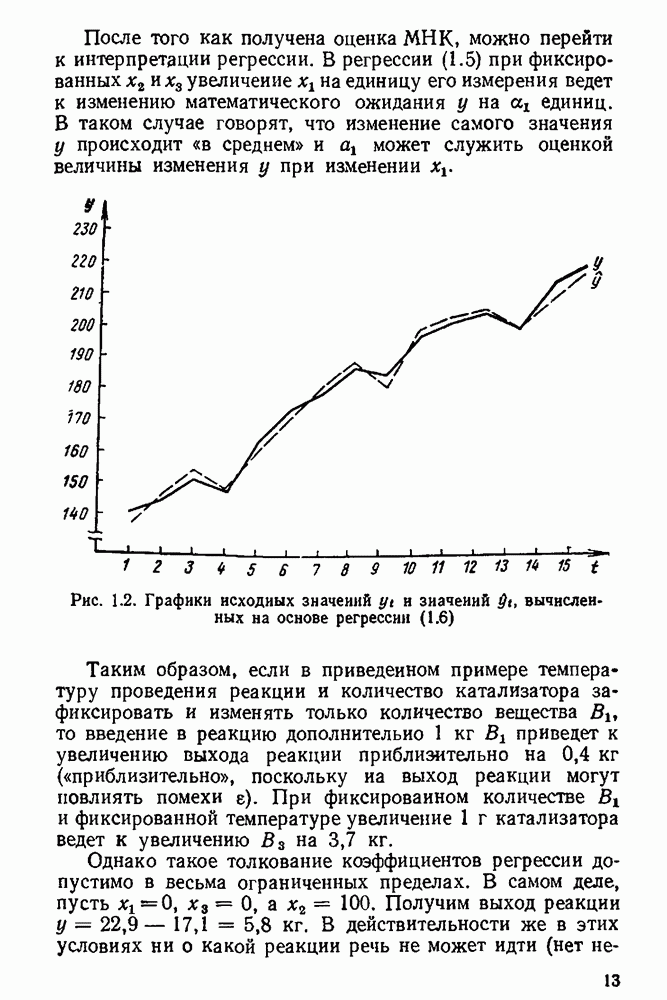
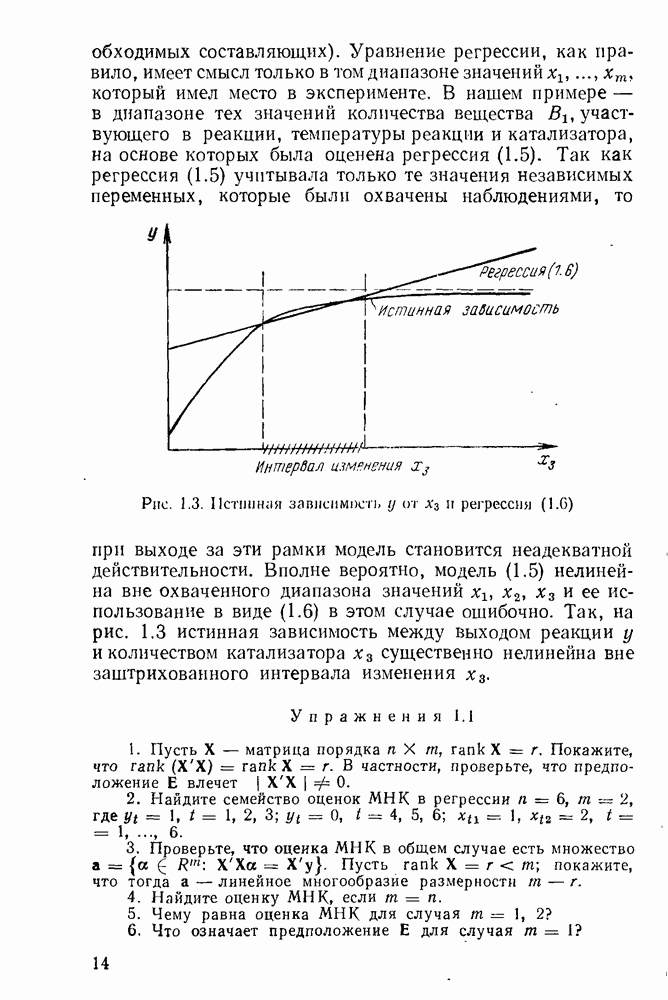
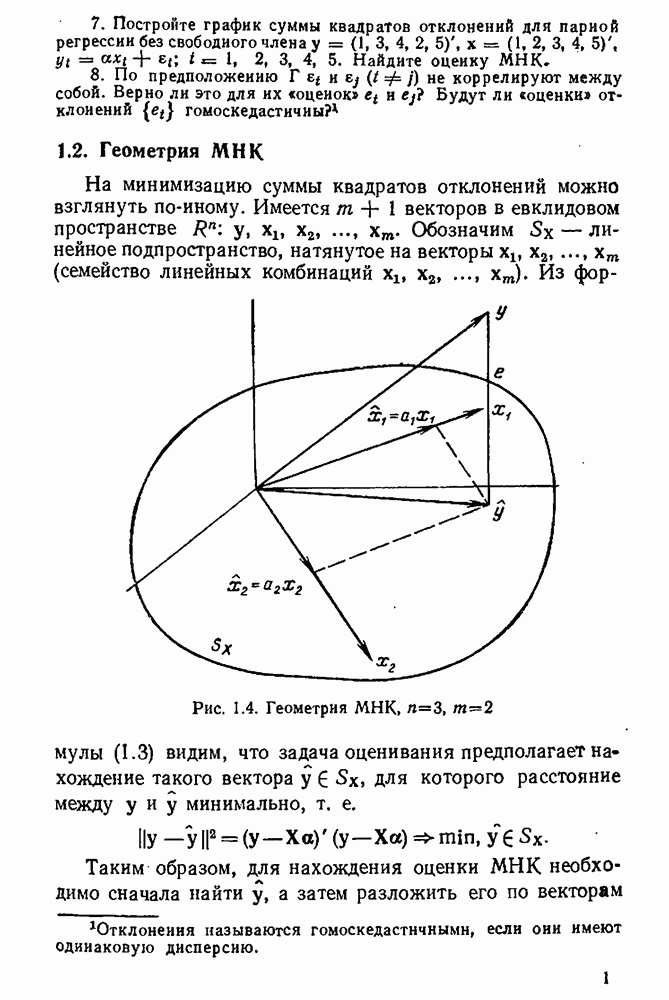
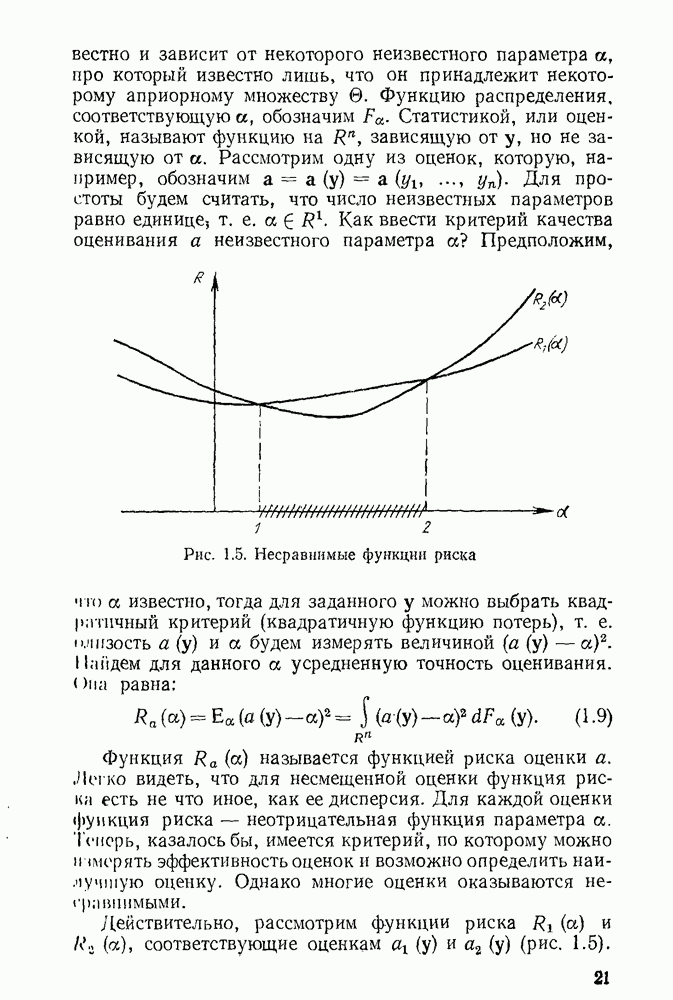
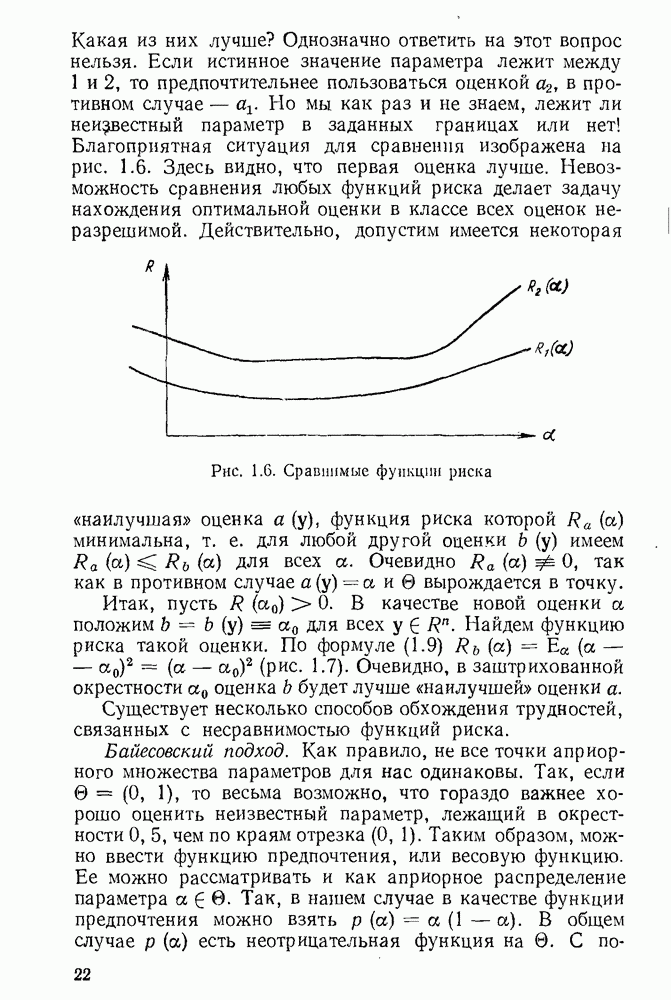
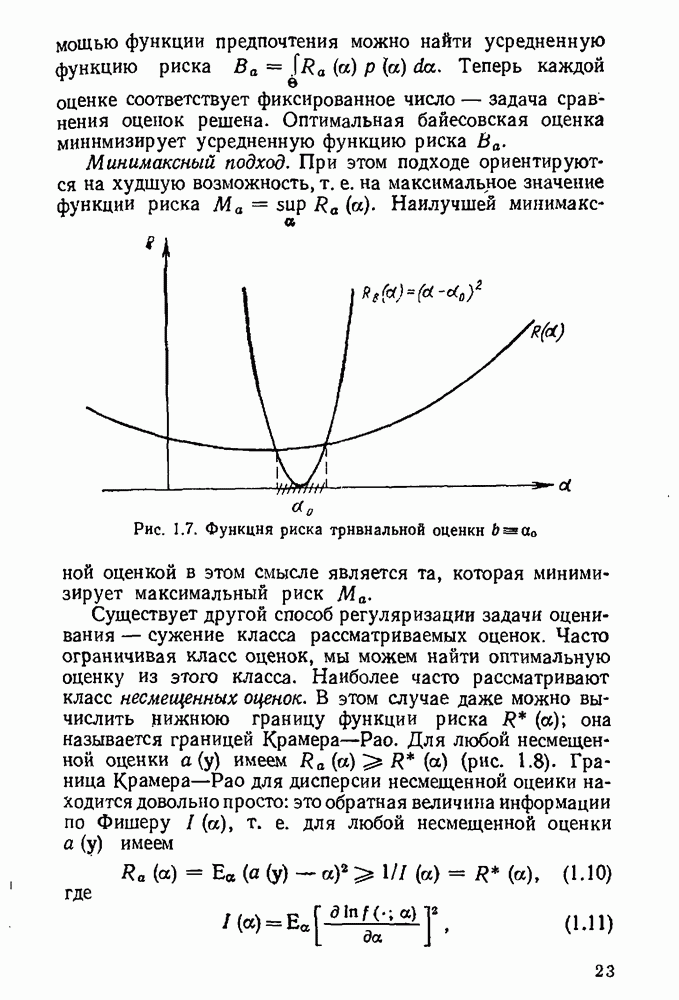
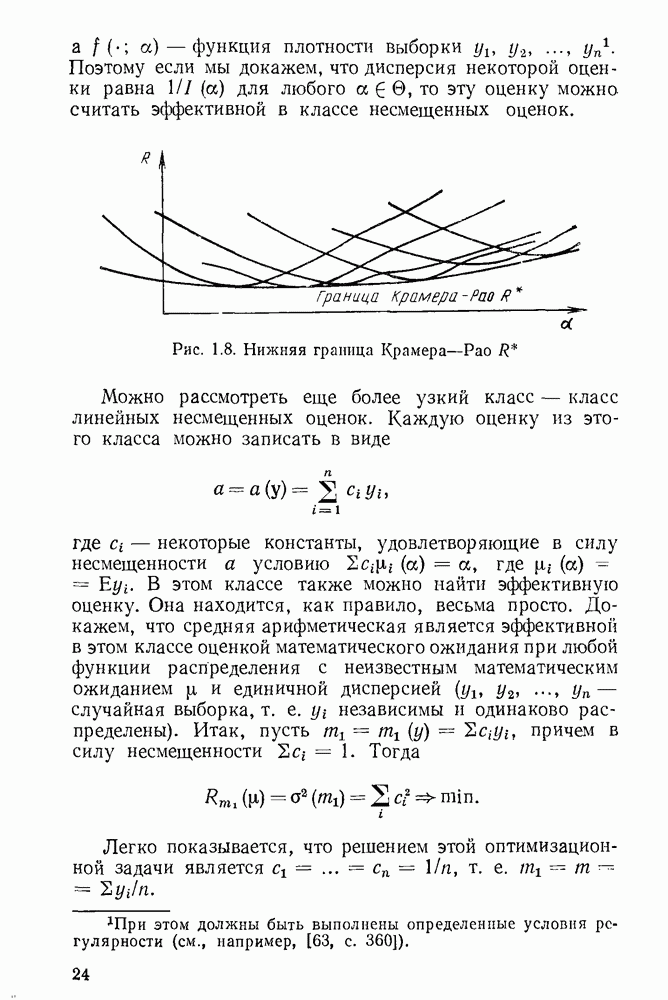
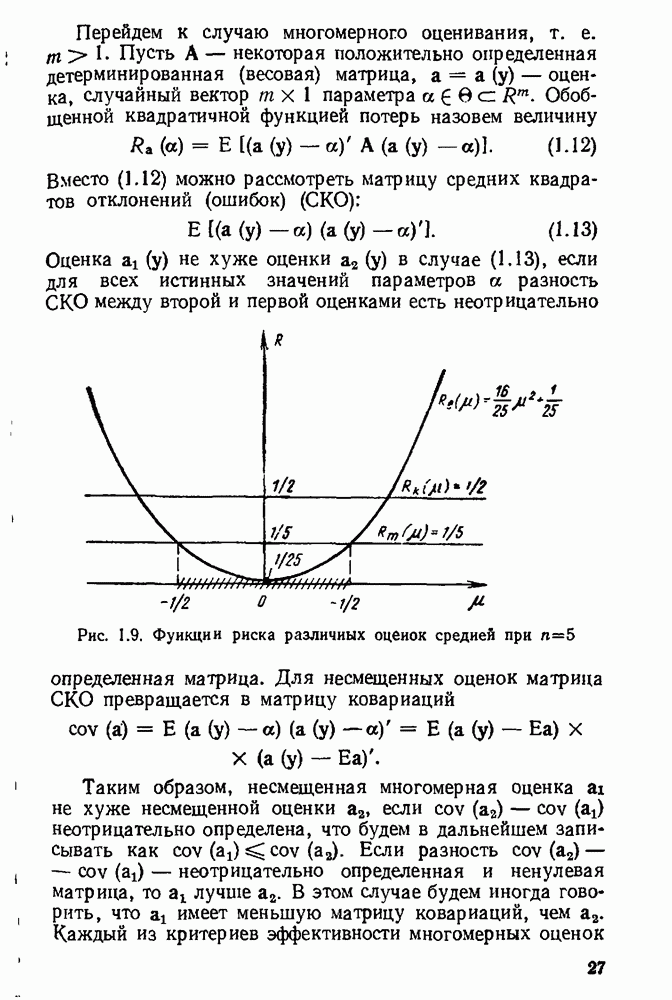
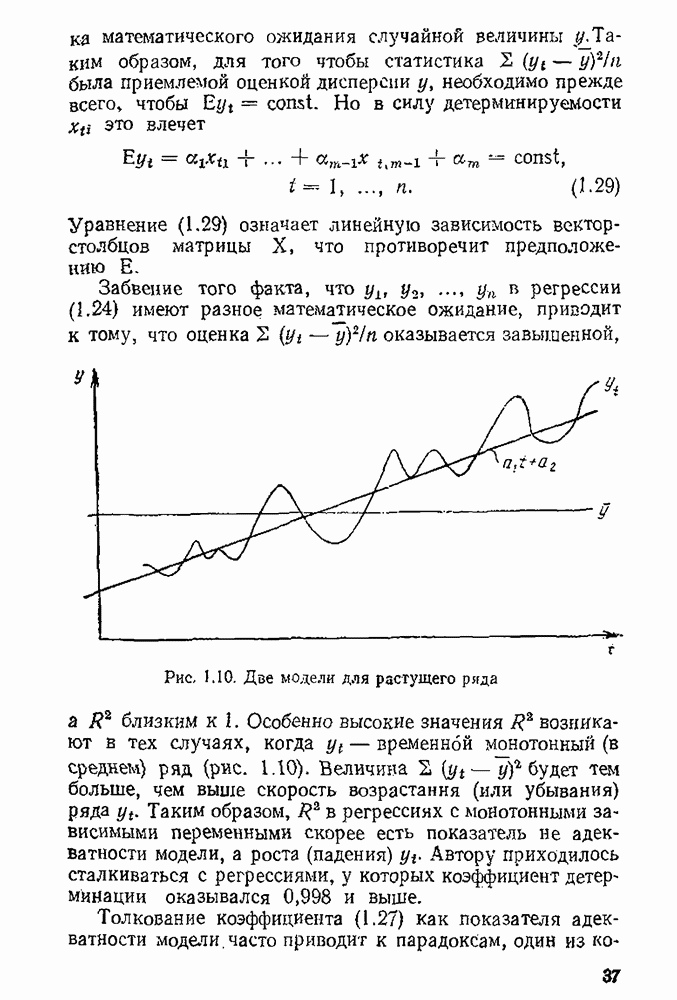
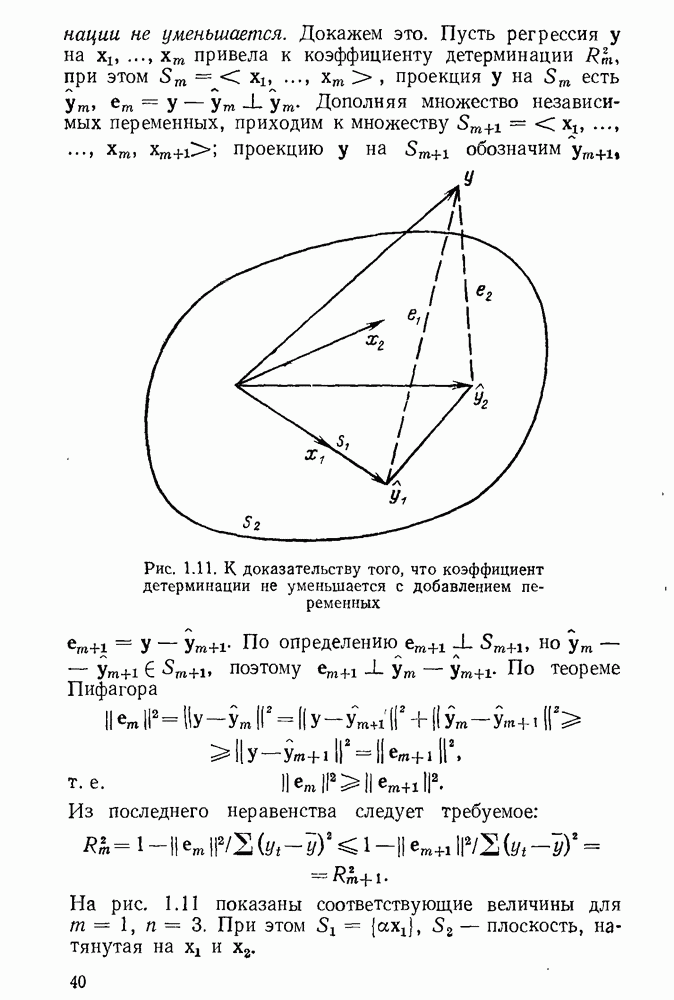
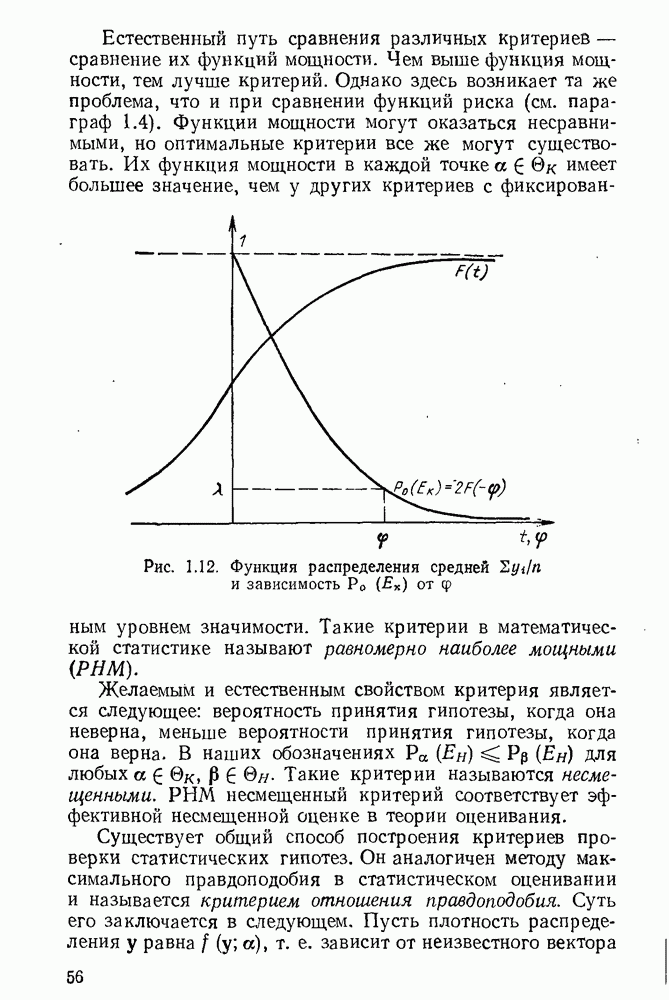
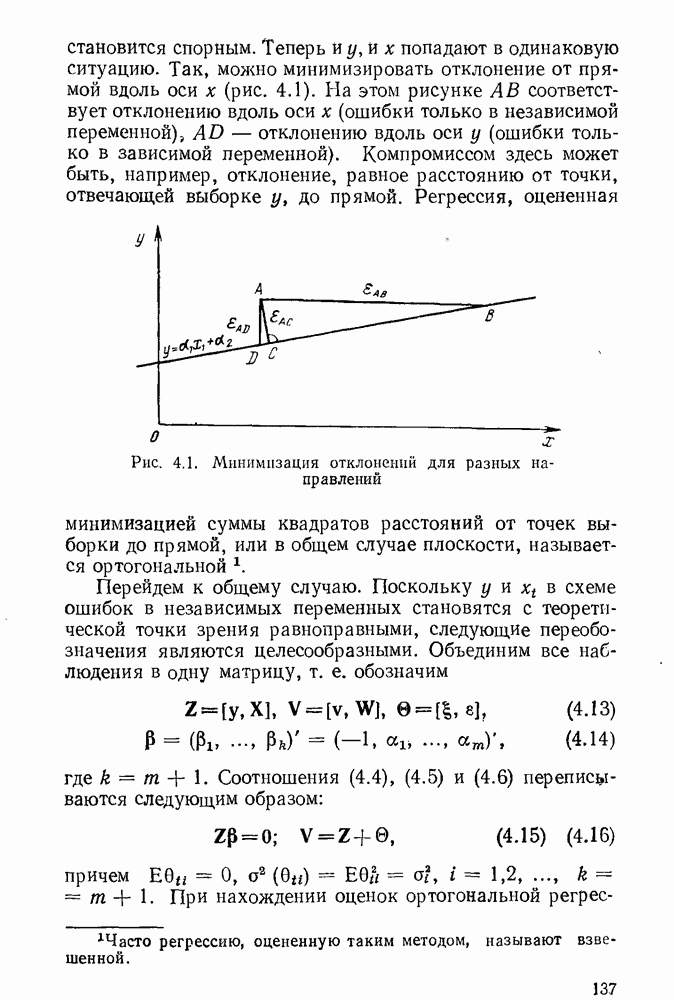
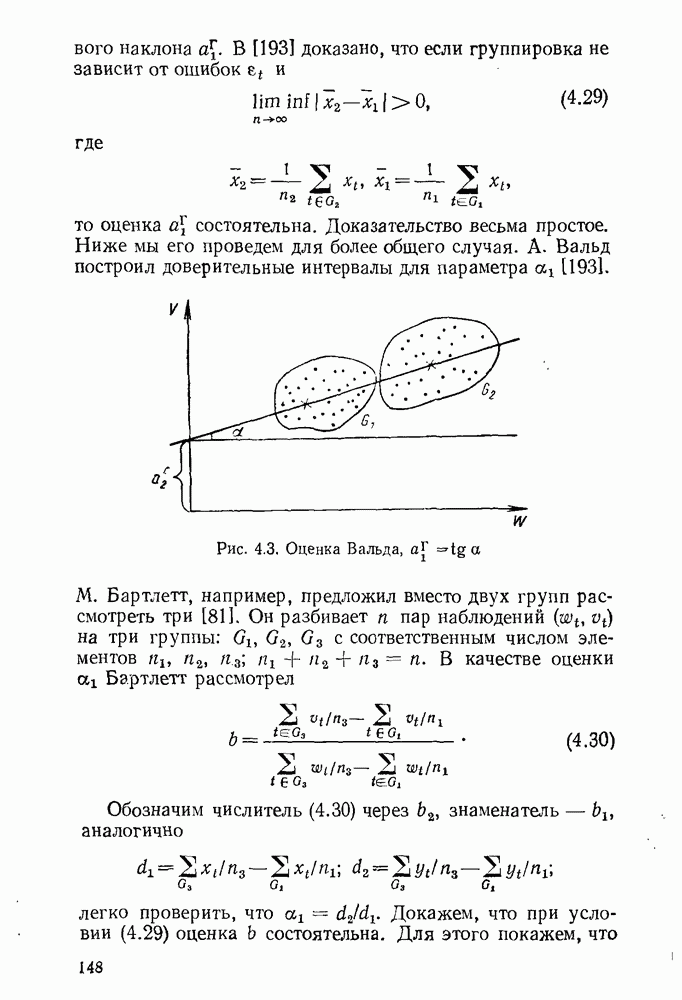
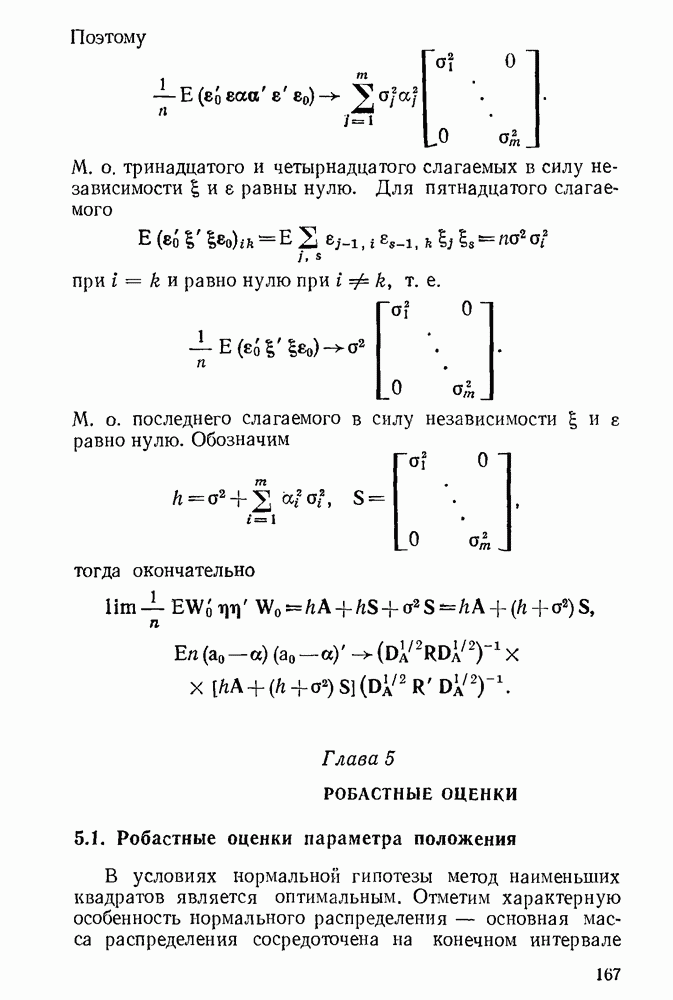
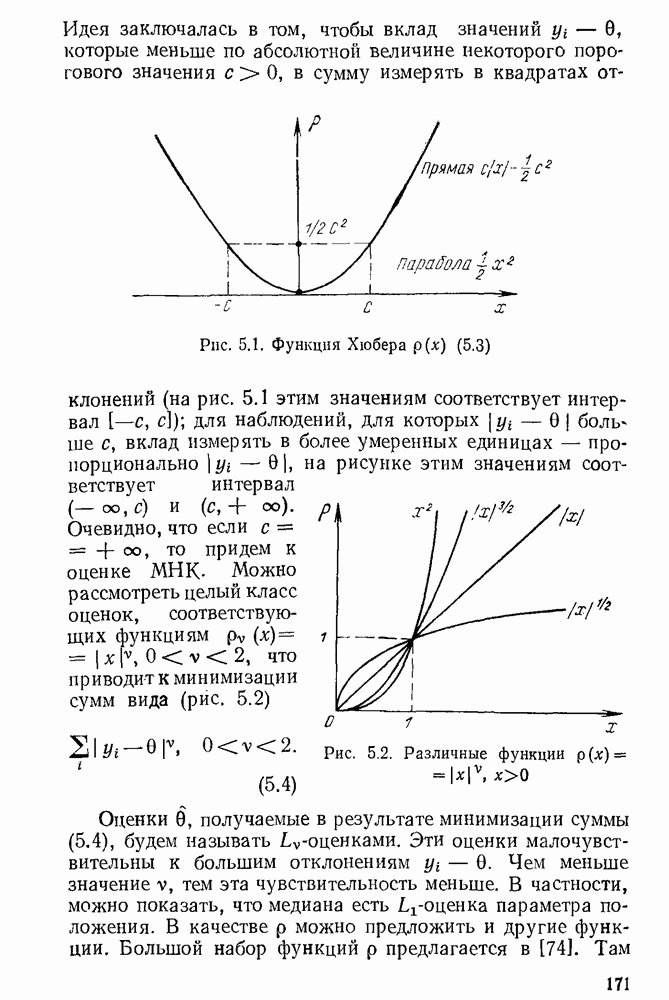
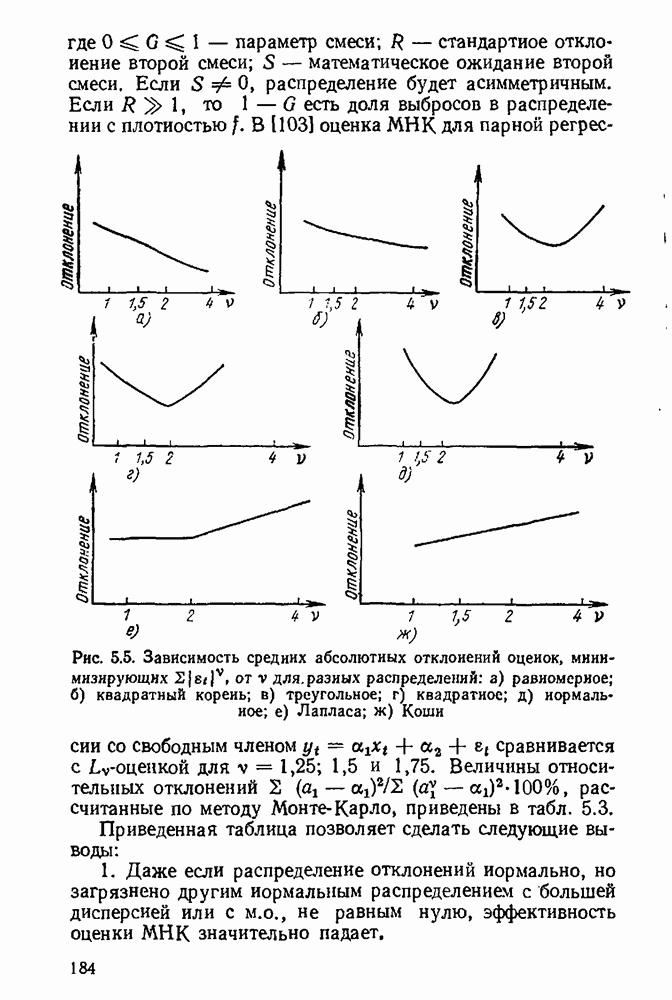
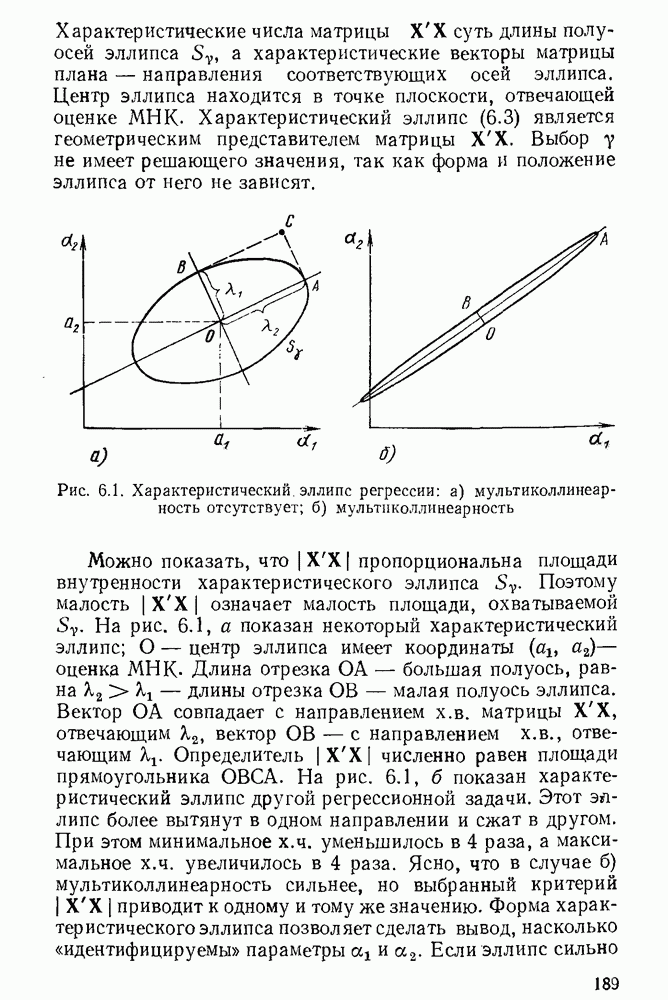
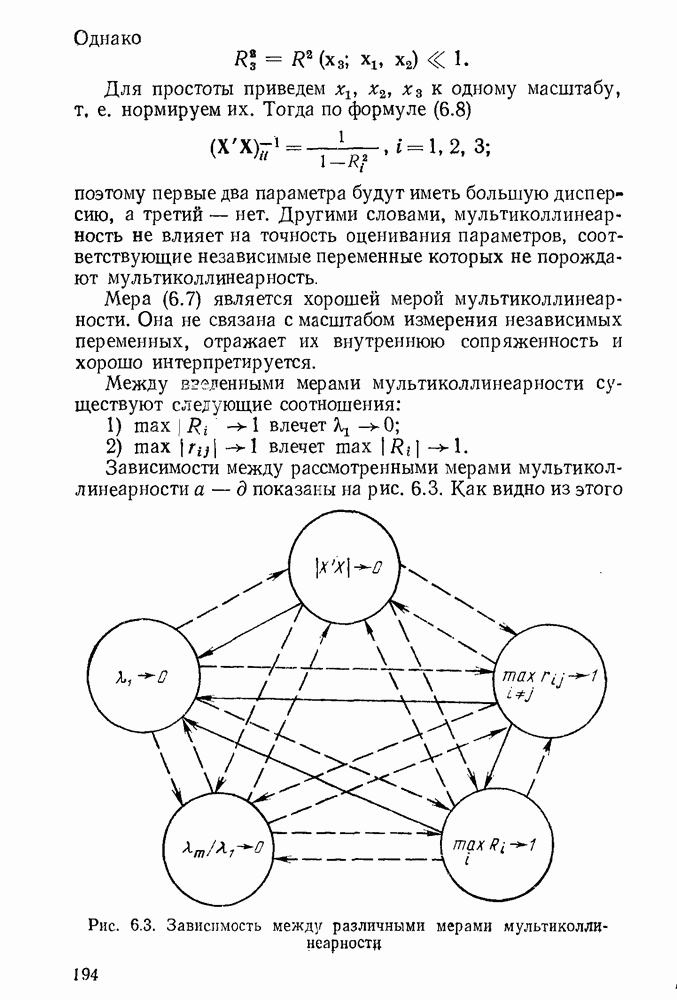
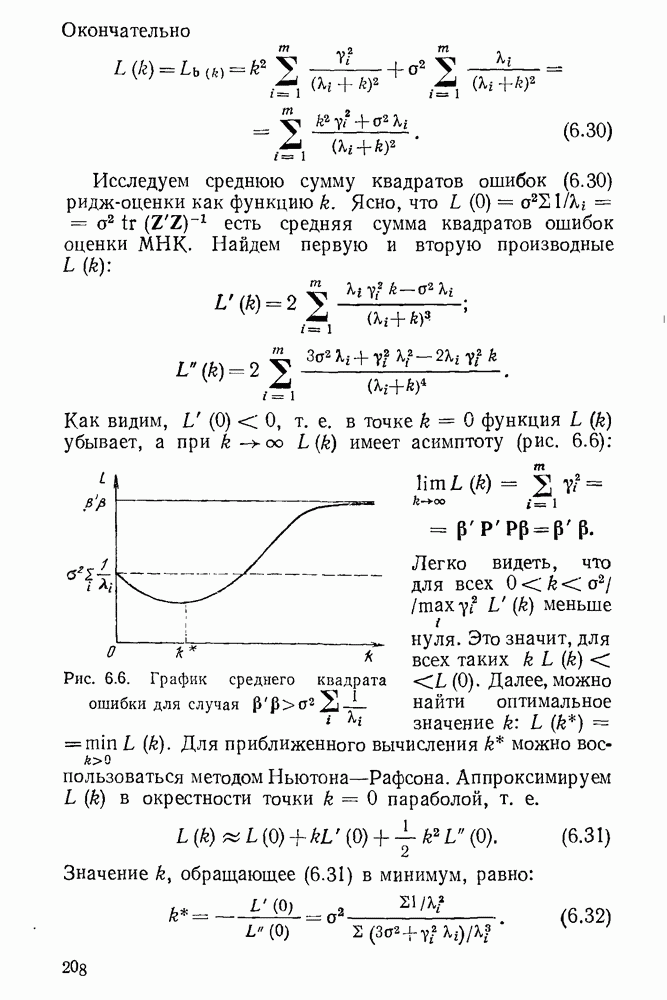
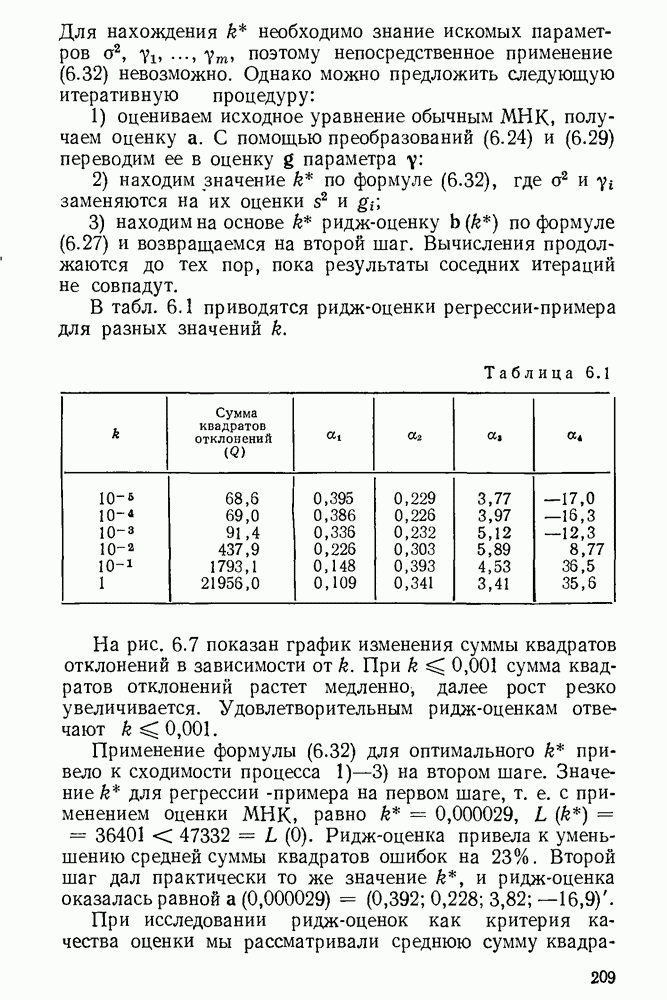
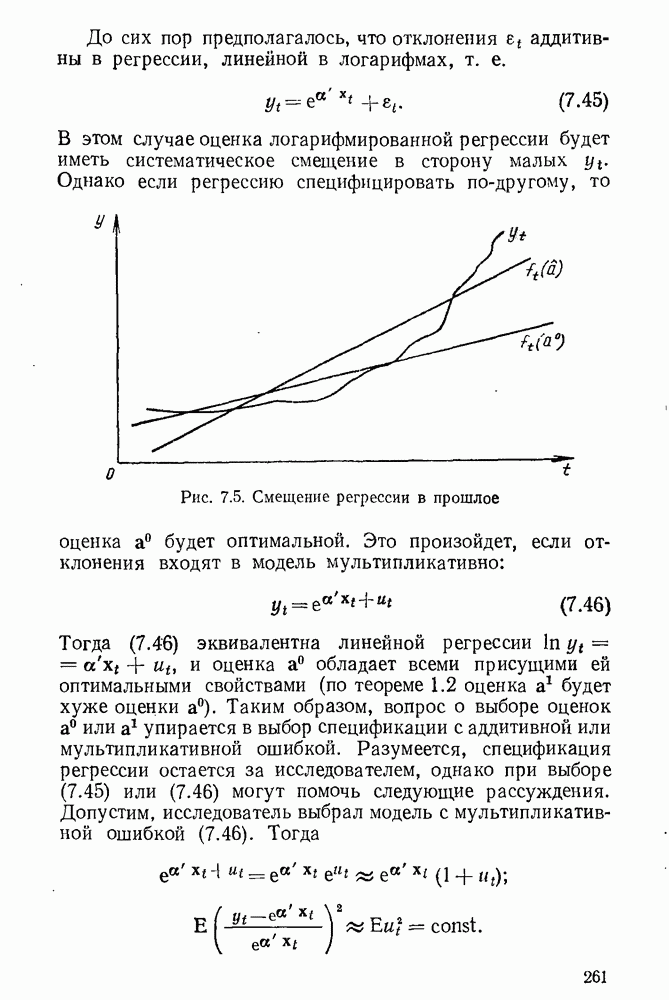
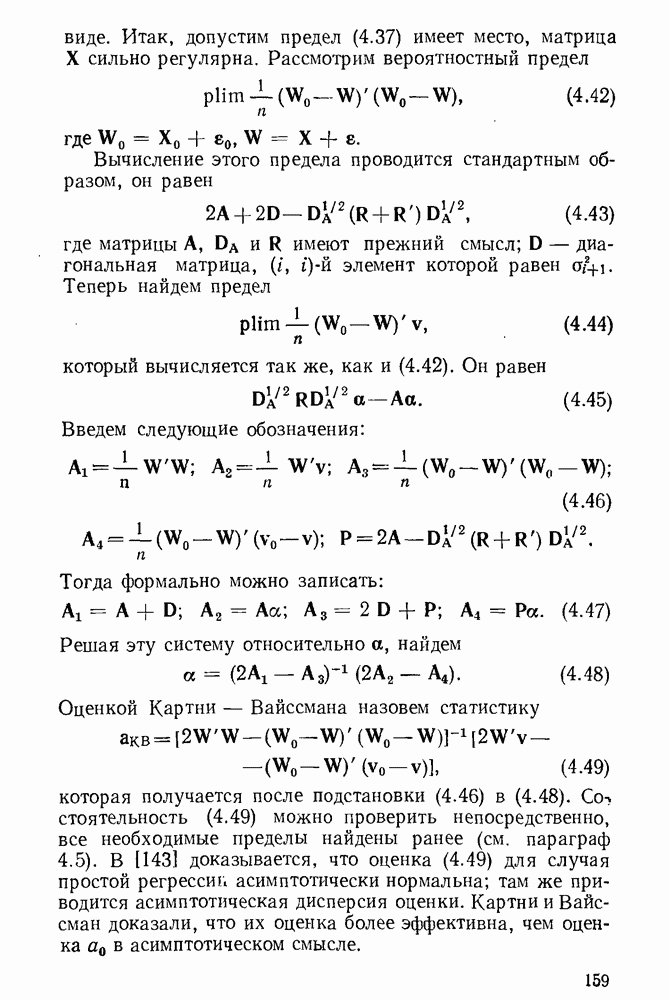5.3. Lv-оценки
Перейдем к  -оценкам регрессий, являющимся частным случаем оценок ММП Хюбера. Прежде всего заметим, что функция плотности
-оценкам регрессий, являющимся частным случаем оценок ММП Хюбера. Прежде всего заметим, что функция плотности

имеет более тяжелые хвосты, чем функция плотности нормального распределения  При
При  распределение (5.6) называется распределением Лапласа.
распределение (5.6) называется распределением Лапласа.
Предположим,  независимы, одинаково распределены с функцией плотности (5.6). В силу независимости функция плотности выборки
независимы, одинаково распределены с функцией плотности (5.6). В силу независимости функция плотности выборки  равна:
равна:

Максимум функции  соответствует оценкам ММП. Легко видеть, что оценка ММП минимизирует сумму
соответствует оценкам ММП. Легко видеть, что оценка ММП минимизирует сумму

Оценки, минимизирующие (5.7), назовем  -оценками.
-оценками.
Устойчивость суммы (5.7) относительно больших отклонений по сравнению с соответствующей суммой квадратов отклонений Ее очевидна. Действительно, допустим,  и основная масса отклонений сосредоточена на отрезке
и основная масса отклонений сосредоточена на отрезке  а одно отклонение равно 3, тогда этот член в сумме квадратов отклонений соответствует 9, а в сумме (5.7) — 3. Поэтому при нахождении оценки в сумме (5.7) это слагаемое не должно произвести значительного эффекта, тогда как при
а одно отклонение равно 3, тогда этот член в сумме квадратов отклонений соответствует 9, а в сумме (5.7) — 3. Поэтому при нахождении оценки в сумме (5.7) это слагаемое не должно произвести значительного эффекта, тогда как при  эффект будет весьма существенным. В этом смысле
эффект будет весьма существенным. В этом смысле  можно интерпретировать как фильтр больших отклонений (выбросов).
можно интерпретировать как фильтр больших отклонений (выбросов).
Остановимся на существовании и единственности минимума функции (5.7). Можно легко убедиться, что функция действительного переменного  для
для  выпукла вниз, для
выпукла вниз, для  выпукла вверх. Как сумма выпуклых вниз функций, таковой будет и функция
выпукла вверх. Как сумма выпуклых вниз функций, таковой будет и функция  а значит, и (5.7) как функция, совпадающая
а значит, и (5.7) как функция, совпадающая  на подмножестве
на подмножестве  линейном многообразии размерности
линейном многообразии размерности  Таким образом, для функции (5.7) при
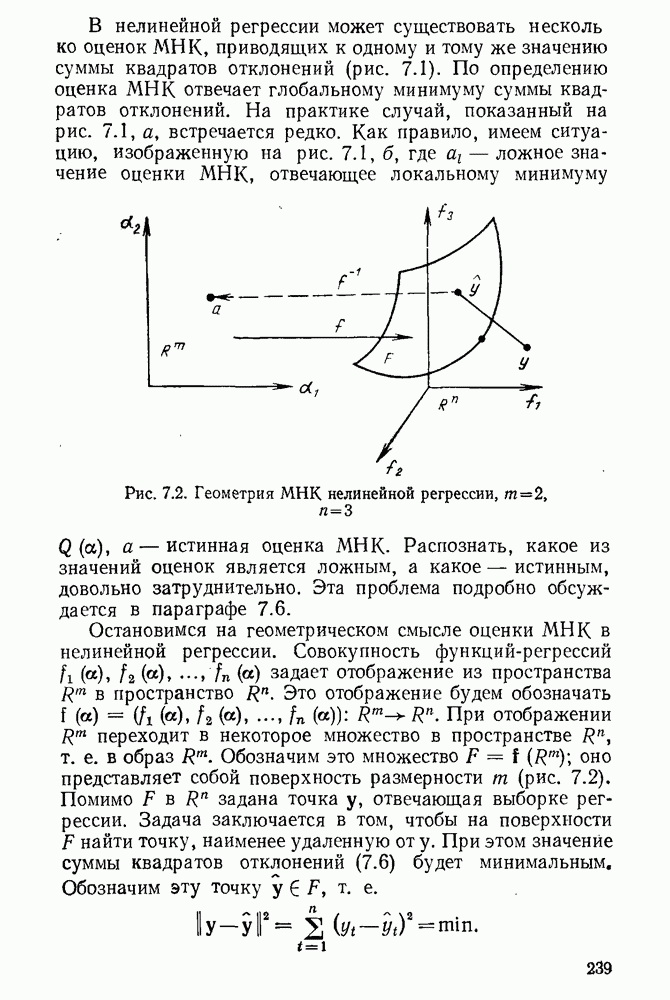
Таким образом, для функции (5.7) при  существует единственный локальный минимум, который совпадает с глобальным. Для
существует единственный локальный минимум, который совпадает с глобальным. Для  это неверно, и минимизируемая функция может иметь несколько локальных минимумов (см., например, [51]).
это неверно, и минимизируемая функция может иметь несколько локальных минимумов (см., например, [51]).
При  необходимо минимизировать сумму абсолютных модулей отклонений (невязок)
необходимо минимизировать сумму абсолютных модулей отклонений (невязок)

Минимизация (5.8) сводится к задаче линейного программирования (см., например, 1192], 1187]). Решение ее намного упростится, если перейти к двойственной задаче линейного программирования. Число ограничений задачи будет равно числу оцениваемых параметров,  Таким образом, при нахождении параметров регрессии, которые минимизируют сумму абсолютных отклонений, можно воспользоваться стандартными программами линейного программирования. В [31] предложен простой итеративный метод минимизации (5.8), который основан на том, что регрессия, минимизирующая (5.8), проходит через
Таким образом, при нахождении параметров регрессии, которые минимизируют сумму абсолютных отклонений, можно воспользоваться стандартными программами линейного программирования. В [31] предложен простой итеративный метод минимизации (5.8), который основан на том, что регрессия, минимизирующая (5.8), проходит через  точек выборки
точек выборки 
Для нахождения минимума функции  для
для  можно, разумеется, применить общие методы оптимизации: градиентный, метод Ньютона, метод сопряженных градиентов и т. д. Однако существует более простой метод минимизации
можно, разумеется, применить общие методы оптимизации: градиентный, метод Ньютона, метод сопряженных градиентов и т. д. Однако существует более простой метод минимизации  опирающийся на обычный МНК. Этот метод впервые был предложен
опирающийся на обычный МНК. Этот метод впервые был предложен  Флетчером, Дж. Грантом и X. Хебленом [102] и получил название «итеративного
Флетчером, Дж. Грантом и X. Хебленом [102] и получил название «итеративного  Идея его заключается в следующем. Найдем частные производные функции
Идея его заключается в следующем. Найдем частные производные функции  по параметру а и приравняем их к нулю. Поскольку
по параметру а и приравняем их к нулю. Поскольку  то решение соответствующей системы уравнений приведет к точке глобального минимума. Имеем
то решение соответствующей системы уравнений приведет к точке глобального минимума. Имеем

откуда

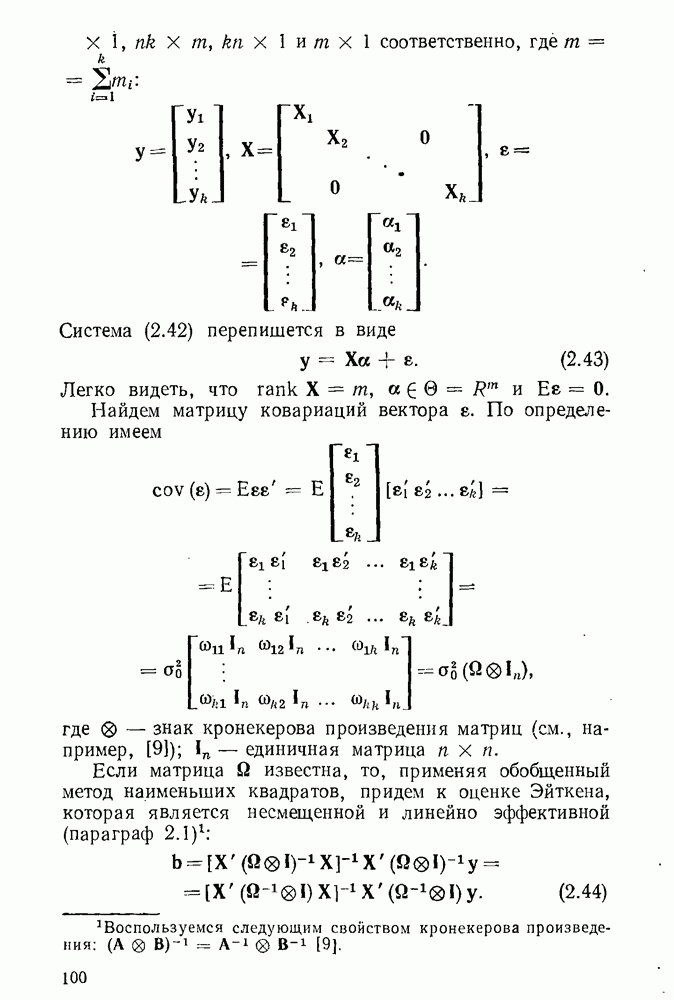
где  Данная система приводит нас к системе линейных нормальных уравнений относительно
Данная система приводит нас к системе линейных нормальных уравнений относительно 

Нетрудно заметить, что эта система линейных уравнений соответствует схеме взвешенного МНК с весами  при этом веса могут быть «оценены» на основе параметров, полученных из предыдущей итерации. Таким образом, на
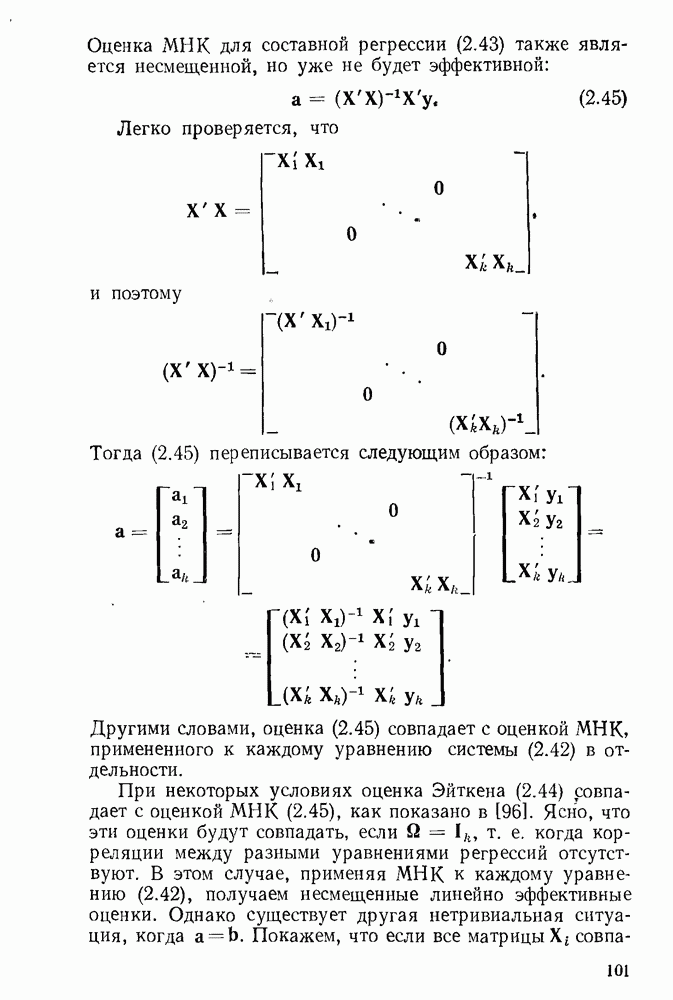
при этом веса могут быть «оценены» на основе параметров, полученных из предыдущей итерации. Таким образом, на
нулевой итерации оцениваем регрессию каким-либо методом (например, МНК), получаем вектор оценок  Исходя из этого вектора «оцениваем» веса
Исходя из этого вектора «оцениваем» веса

Решая систему линейных уравнений (5.9), т. е. применяя взвешенный МНК с весами  находим следующее значение вектора оценок
находим следующее значение вектора оценок  Этот же способ предлагают В. И. Мудров и В. Л. Кушко 1511, называя его методом вариационно-взвешенных квадратических приближений. Аргументация применения итеративного МНК здесь намного проще. Сумму (5.7) перепишем следующим образом:
Этот же способ предлагают В. И. Мудров и В. Л. Кушко 1511, называя его методом вариационно-взвешенных квадратических приближений. Аргументация применения итеративного МНК здесь намного проще. Сумму (5.7) перепишем следующим образом:

что опять приводит к взвешенному МНК с весами  В [51] доказана сходимость итеративного МНК для
В [51] доказана сходимость итеративного МНК для 
Найдем оценки по этому методу для  и 1,5 нашей регрессии-примера (табл. 5.1). Метод сходится уже на первой итерации. Это говорит о высокой эффективности его. Наиболее мобильной оказалась оценка второго параметра. Легко заметить также, что для
и 1,5 нашей регрессии-примера (табл. 5.1). Метод сходится уже на первой итерации. Это говорит о высокой эффективности его. Наиболее мобильной оказалась оценка второго параметра. Легко заметить также, что для  оценки ближе к оценкам МНК, чем для
оценки ближе к оценкам МНК, чем для  что вполне естественно. Даже при уменьшении чувствительности к большим отклонениям оценка параметра
что вполне естественно. Даже при уменьшении чувствительности к большим отклонениям оценка параметра  увеличивается, а
увеличивается, а  уменьшаются (по абсолютной величине).
уменьшаются (по абсолютной величине).
Таблица 5.1 (см. скан)
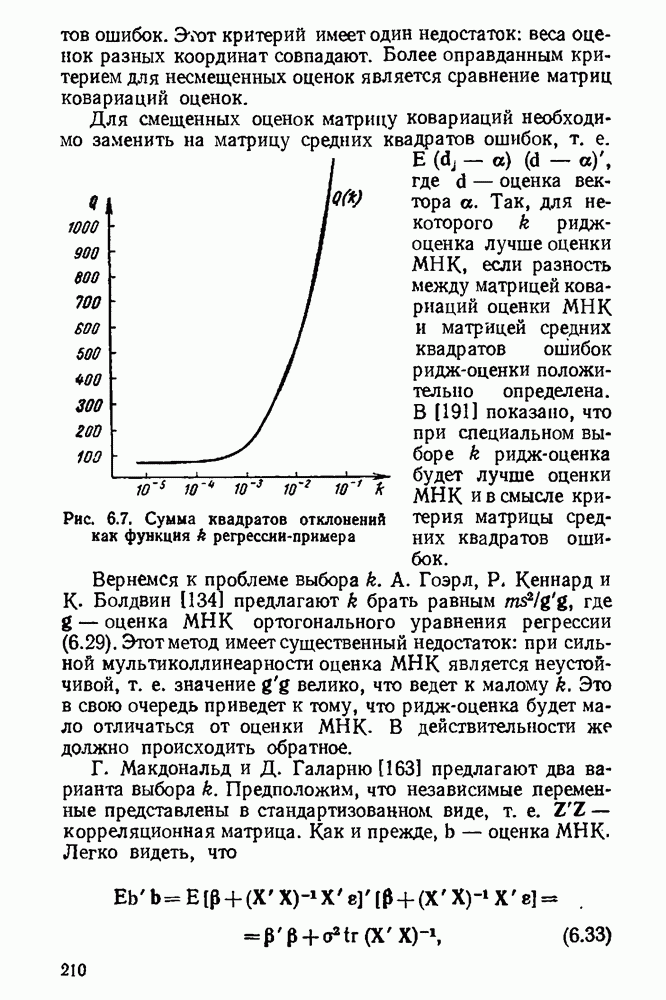
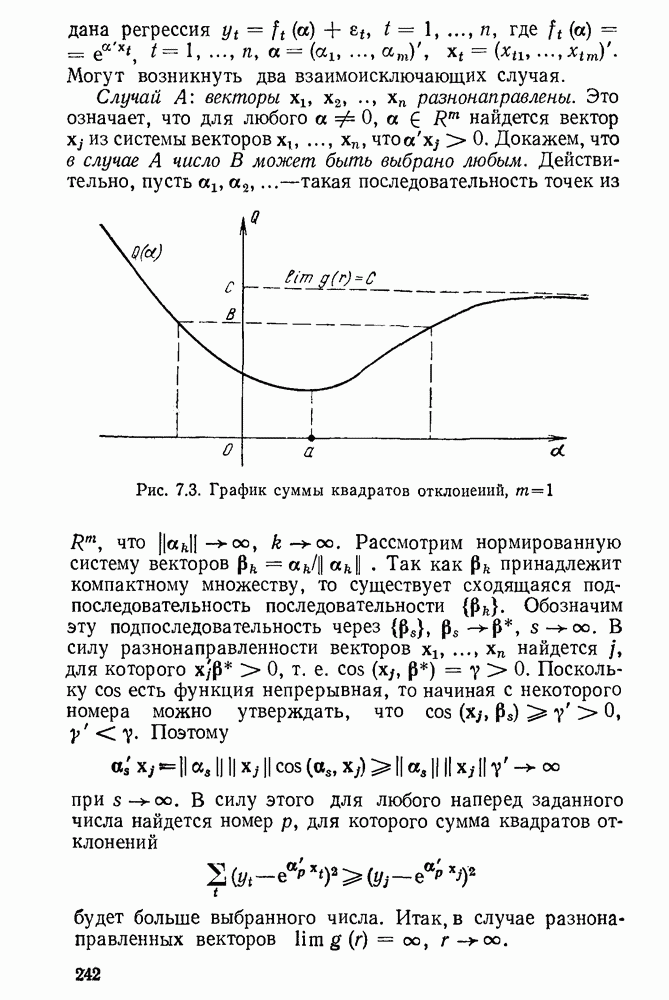
Иногда полезно выяснить, что происходит с оценкой, если, наоборот, ориентироваться на большие отклонения, в частности найти оценку, которая минимизирует максимальное отклонение. Такую оценку вправе назвать антиробастной. Подобным оценкам отвечают большие значения 
 Остановимся на минимизации (5.7) для
Остановимся на минимизации (5.7) для  При этих значениях Мудрову и Кушко не удалось доказать сходимость итеративного МНК. Однако Флетчером, Грантом и Хебленом было предложено в этом случае поправку к новому вектору оценок брать не полностью, а только ее часть [102]. Пусть
При этих значениях Мудрову и Кушко не удалось доказать сходимость итеративного МНК. Однако Флетчером, Грантом и Хебленом было предложено в этом случае поправку к новому вектору оценок брать не полностью, а только ее часть [102]. Пусть  значение вектора оценок на
значение вектора оценок на  итерации. Применяя итеративный МНК, можно найти следующий вектор
итерации. Применяя итеративный МНК, можно найти следующий вектор  при этом поправка
при этом поправка  Следующее значение а полагается равным:
Следующее значение а полагается равным:

где  Оказалось, что модифицированный итеративный МНК уже является сходящимся с квадратичной скоростью сходимости для
Оказалось, что модифицированный итеративный МНК уже является сходящимся с квадратичной скоростью сходимости для  Там же показано, что метод (5.10) совпадает с методом Ньютона.
Там же показано, что метод (5.10) совпадает с методом Ньютона.
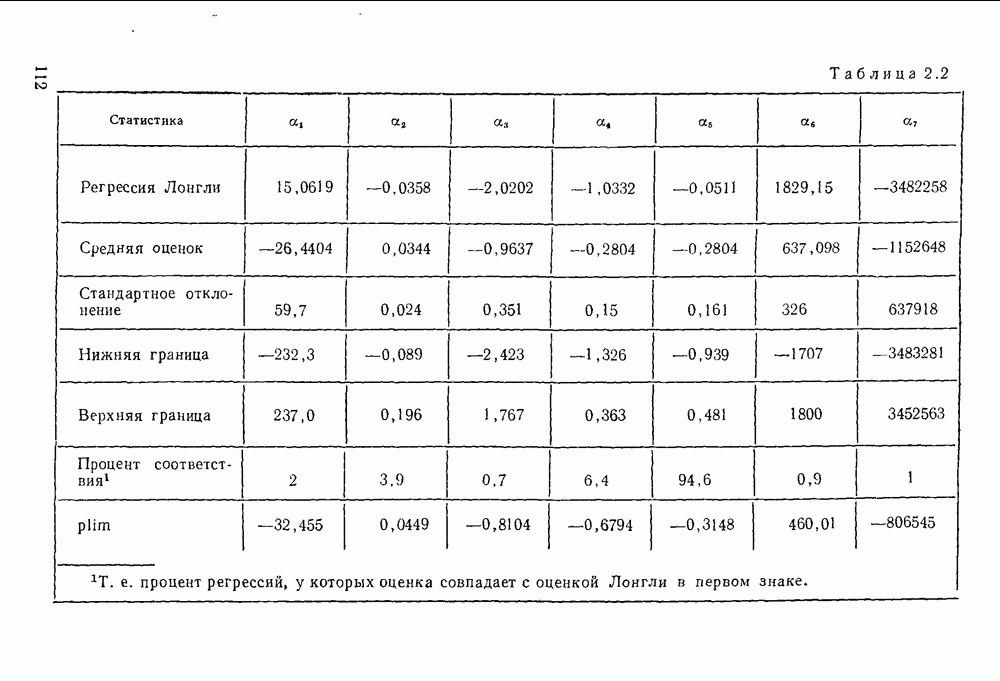
В табл. 5.2 приведены  -оценки регрессии-примера для
-оценки регрессии-примера для  . Отметим равномерное снижение значений оценки параметра
. Отметим равномерное снижение значений оценки параметра  -оценки для
-оценки для  и 20 параметров
и 20 параметров  сильно отличаются от предыдущих значений. Число итераций, необходимых для получения
сильно отличаются от предыдущих значений. Число итераций, необходимых для получения  -оценок при
-оценок при  и 20, намного больше, чем для
и 20, намного больше, чем для  и 4.
и 4.
Таблица 5.2 (см. скан)
К идее минимизации суммы (5.7) можно подойти с другой точки зрения. Естественным методом оценивания параметров регрессии является следующий. Обозначим оценку параметров а, тогда  является оценкой, приближением вектора данных (выборки)
является оценкой, приближением вектора данных (выборки)  Поэтому минимизация расстояния между
Поэтому минимизация расстояния между  приведет нас к соответствующей оценке. Метод оценивания будет различным в зависимости от того, как мы будем измерять расстояние в
приведет нас к соответствующей оценке. Метод оценивания будет различным в зависимости от того, как мы будем измерять расстояние в  В частности, если брать евклидово расстояние, то придем
В частности, если брать евклидово расстояние, то придем
к МНК. Большую группу составляют  -метрики, где расстояние между
-метрики, где расстояние между  задается по формуле
задается по формуле

Если  приходим к минимизации (5.8), в общем случае получаем
приходим к минимизации (5.8), в общем случае получаем  -оценки.
-оценки.
В. Хоганом была доказана несмещенность  -оценки при некоторых условиях на распределение вектора
-оценки при некоторых условиях на распределение вектора  [135]. Условие регулярности, которое накладывается на распределение отклонений, является следующим: математическое ожидание
[135]. Условие регулярности, которое накладывается на распределение отклонений, является следующим: математическое ожидание  при условии, что
при условии, что  -линейному подпространству
-линейному подпространству  равно нулю для любого
равно нулю для любого  короче говоря,
короче говоря,  Хоган доказал, что если
Хоган доказал, что если  удовлетворяют условию регулярности, то
удовлетворяют условию регулярности, то  -оценка для
-оценка для  несмещена, т. е.
несмещена, т. е.  Проанализируем условие регулярности Хогана. Ясно, что для
Проанализируем условие регулярности Хогана. Ясно, что для  оно совпадает с условием
оно совпадает с условием  Для
Для  это условие сильнее
это условие сильнее  Однако нетрудно проверить, что если
Однако нетрудно проверить, что если  независимы и одинаково распределены с симметричной функцией плотности, то
независимы и одинаково распределены с симметричной функцией плотности, то  удовлетворяет условию регулярности. Действительно, тогда функция плотности 8 равна
удовлетворяет условию регулярности. Действительно, тогда функция плотности 8 равна  и также симметрична, значит и
и также симметрична, значит и  для любого
для любого  Таким образом,
Таким образом,  -оценки с распределениями Коши, Лапласа, Гаусса (нормальное), равномерным и т. д. будут несмещенными.
-оценки с распределениями Коши, Лапласа, Гаусса (нормальное), равномерным и т. д. будут несмещенными.
Упражнения 5.3
(см. скан)