Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
3.7. Введение дополнительных регрессоров3.7.7. Общая теорияПредположим, что уже после того, как подобрана модель регрессии
мы хотим включить в нее дополнительные регрессоры
(здесь мы обозначили
Во-вторых, можно уменьшить количество необходимых выкладок, используя те вычисления, которые были проведены в процессе подбора модели. Соответствующие результаты приведены в теореме 3.7. Геометрическое доказательство этой теоремы, допускающее неполноту ранга матрицы X, приведено в разд. 3.8.3. Лемма. Если Доказательство. Пусть
т. е. Теорема 3.7. Пусть
Тогда
Доказательство, (i) Пусть
поскольку
Из (3.29) вытекает, что
(ii) Подставляя (3.31) в (3.30), получаем
так что
Отсюда Имеем
так что
в силу симметричности и идемпотентности матрицы (iv) Из (iii) имеем
(в последнем равенстве мы использовали Прежде всего
Далее, в силу теоремы 1.4
поскольку
(последнее - в силу
(здесь мы опять использовали Из доказанной теоремы вытекает, что, обратив однажды (при подборе первоначальной модели) матрицу не требуется обращать матрицу 3.7.2. Одна дополнительная переменнаяОбозначим столбцы матрицы X символами
Предположим теперь, что мы намерены включить в подобранную модель еще один регрессор, скажем
и матрица легко находится с использованием матрицы Указанный метод включения одной дополнительной переменной впервые подробно рассмотрел Cochran (1938); на случай нескольких переменных его обобщил Quenouille (1950). 3.7.3. Двухшаговый метод наименьших квадратовУтверждения, содержащиеся в теореме 3.7, предполагают следующую последовательность шагов при намерении "расширить" матрицу плана: (1) Вычисляем (2) Для получения
Приравнивая производную
откуда находим искомую оценку наименьших квадратов для у:
(3) Остаточную сумму квадратов (4) Для получения
(5) Коэффициент при Мы называем приведенную процедуру двухшаговым методом наименьших квадратов. Этод метод широко используется в гл. 10 при рассмотрении моделей дисперсионного анализа. Интересно отметить, что указанный двухшаговый метод наименьших квадратов для подбора расширенной модели эквивалентен подбору "ортогонализованной" модели
или (обозначив
Здесь 3.7.4. Остатки в двухшаговой процедуреОстатки для расширенной модели имеют (с учетом (3.37)) вид
где Проведенные только что преобразования лежат в основе рекуррентного алгоритма для подбора моделей дисперсионного анализа регрессиоными методами. Этот алгоритм разработал Wilkinson G. N. (1970) (см. также James, Wilkinson (1971), Rogers, Wilkinson (1974); Pearce и др. (1974)). Основные этапы алгоритма таковы: (1) Вычисление остатков (2) Использование оператора (3) Повторное применение оператора Если столбцы матрицы Полагая, что матрица X образована первыми Упражнения 3g (см. скан)
|
 |
Оглавление
|




























































































































































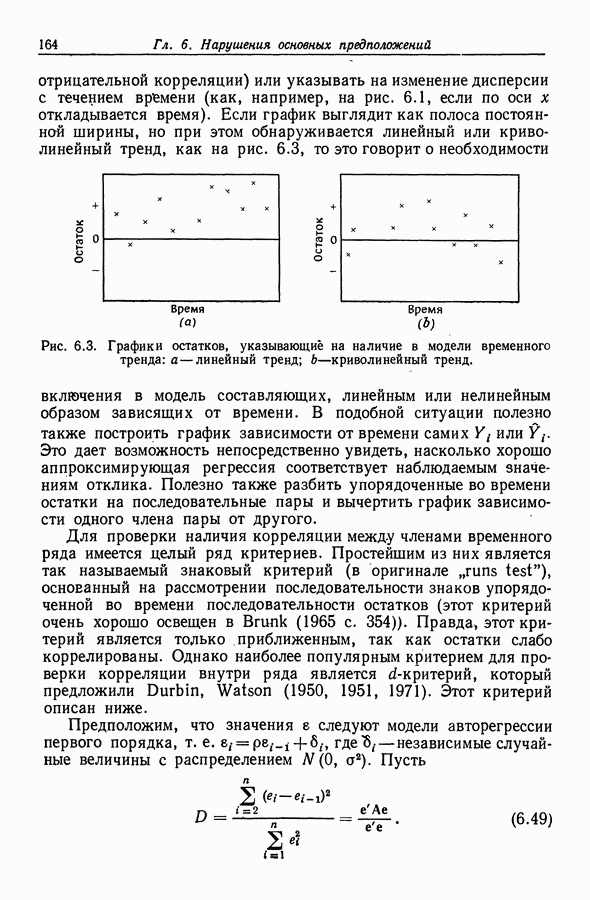
















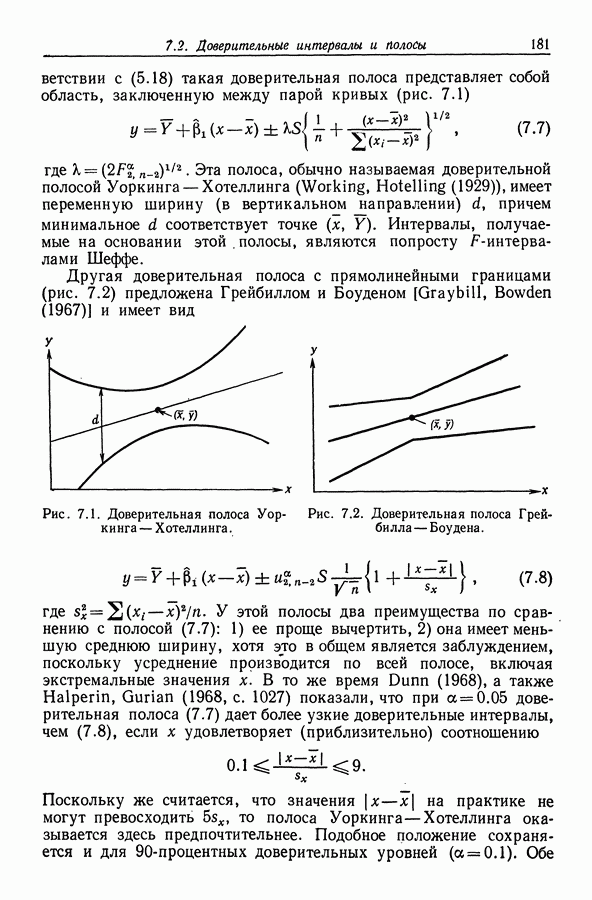

























































































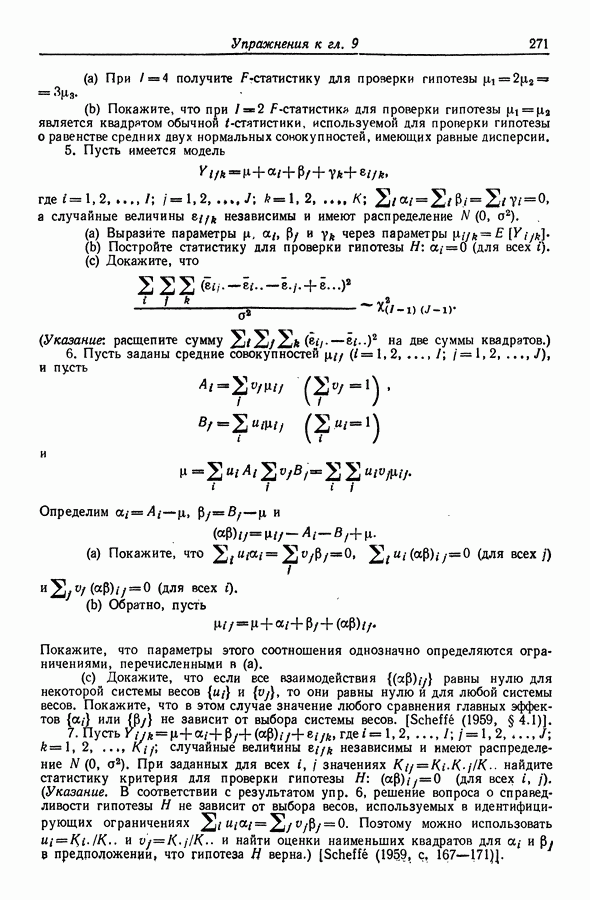





















































































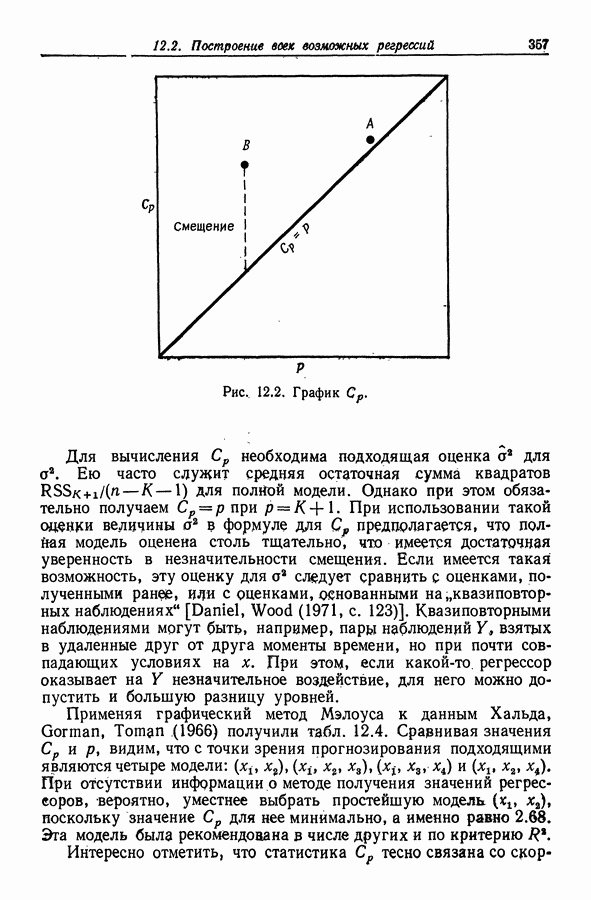






















































































 чтобы модель с введением этих регрессоров приняла вид
чтобы модель с введением этих регрессоров приняла вид

 и
и  где
где  - матрица размера
- матрица размера  ранга
ранга  -матрица размера
-матрица размера  ранга
ранга  и столбцы матрицы
и столбцы матрицы  линейно не зависят от столбцов матрицы X, т. е. матрица
линейно не зависят от столбцов матрицы X, т. е. матрица  размера
размера  имеет ранг
имеет ранг  Тогда имеются две возможности отыскания оценки наименьших квадратов
Тогда имеются две возможности отыскания оценки наименьших квадратов  вектора
вектора  . Во-первых, можно найти оценку
. Во-первых, можно найти оценку  и ее дисперсионную матрицу непосредственно из соотношений
и ее дисперсионную матрицу непосредственно из соотношений

 то матрица
то матрица  не вырождена.
не вырождена.
 Тогда по теореме 3.1 (i)
Тогда по теореме 3.1 (i)

 Поэтому
Поэтому  имеет вид
имеет вид  откуда при сделанном предположении о линейной независимости столбцов матрицы
откуда при сделанном предположении о линейной независимости столбцов матрицы  от столбцов матрицы X имеем
от столбцов матрицы X имеем  Следовательно, столбцы матрицы
Следовательно, столбцы матрицы  линейно независимы, и эта матрица является невырожденной.
линейно независимы, и эта матрица является невырожденной.
 и
и


 Тогда
Тогда

 и т. д. Чтобы найти
и т. д. Чтобы найти  разобьем систему нормальных уравнений
разобьем систему нормальных уравнений  на две части и решим отдельно уравнения
на две части и решим отдельно уравнения  Используя
Используя  получаем следующие уравнения:
получаем следующие уравнения:








 (теорема 3-1 (0).
(теорема 3-1 (0).




 (теорема 3.1 (iii)). Поэтому, используя n.(i), в соответствии с теоремами 1.5 и 1.4 имеем
(теорема 3.1 (iii)). Поэтому, используя n.(i), в соответствии с теоремами 1.5 и 1.4 имеем

 и
и


 можно найти оценку
можно найти оценку  (в расширенной модели) и ее дисперсионную матрицу, обращая только матрицу
(в расширенной модели) и ее дисперсионную матрицу, обращая только матрицу  размера
размера  При таком подходе уже
При таком подходе уже
 размера
размера  Ниже рассматривается случай
Ниже рассматривается случай 
 так что
так что

 так что в результате получится (в указанных выше обозначениях) модель с
так что в результате получится (в указанных выше обозначениях) модель с  . В соответствии с теоремой 3.7 оценки наименьших квадратов для этой расширенной модели вычисляются без затруднений, поскольку на сей раз матрица
. В соответствии с теоремой 3.7 оценки наименьших квадратов для этой расширенной модели вычисляются без затруднений, поскольку на сей раз матрица  равная
равная  состоит всего лишь из одного элемента, т. е. является скалярной величиной. Поэтому
состоит всего лишь из одного элемента, т. е. является скалярной величиной. Поэтому

 Простота, с которой производится "коррекция" оценок при переходе к модели с одной дополнительной переменной, наводит на мысль, что при необходимости включения в модель большего числа дополнительных переменных следует включать их в модель поочередно. Мы обратимся к такой ступенчатой процедуре в гл. 12.
Простота, с которой производится "коррекция" оценок при переходе к модели с одной дополнительной переменной, наводит на мысль, что при необходимости включения в модель большего числа дополнительных переменных следует включать их в модель поочередно. Мы обратимся к такой ступенчатой процедуре в гл. 12.

 вектор
вектор  заменяем в квадратичной форме
заменяем в квадратичной форме  на
на  и минимизируем соответствующую форму по отношению к у. После выполнения указанной подстановки приходим к квадратичной форме
и минимизируем соответствующую форму по отношению к у. После выполнения указанной подстановки приходим к квадратичной форме

 нулю, получаем
нулю, получаем


 для расширенной модели находим как минимальное значение квадратичной формы
для расширенной модели находим как минимальное значение квадратичной формы  по теореме
по теореме  равное
равное 
 заменяем
заменяем  на
на  в выражении для
в выражении для  т. е.
т. е.

 в уравнении
в уравнении  (соотношение (3.36)), равный
(соотношение (3.36)), равный  дает возможность легко вычислить дисперсионную матрицу
дает возможность легко вычислить дисперсионную матрицу 
 имеющей ортогональную структуру, описанную в § 3.5 (поскольку
имеющей ортогональную структуру, описанную в § 3.5 (поскольку  Чтобы убедиться в этом, используем теорему
Чтобы убедиться в этом, используем теорему  и получим
и получим



 - решение уравнения
- решение уравнения  т. е. уравнения
т. е. уравнения  (матрица R симметрична и идемпотентна), так что
(матрица R симметрична и идемпотентна), так что  является оценкой наименьших квадратов для
является оценкой наименьших квадратов для  Эта идея снова появляется в разд. 3.8.3 (формула (3.53)).
Эта идея снова появляется в разд. 3.8.3 (формула (3.53)).



 который Уилкинсон называет "выметающим" (не смешивать с методом "выметания" в разд. 12.2.2), для получения вектора "кажущихся остатков"
который Уилкинсон называет "выметающим" (не смешивать с методом "выметания" в разд. 12.2.2), для получения вектора "кажущихся остатков" 
 с целью получения значений истинных остатков
с целью получения значений истинных остатков 
 ортогональны столбцам матрицы X, то тогда
ортогональны столбцам матрицы X, то тогда  (в силу (3.39)), и этап (3) оказывается ненужным. В дальнейшем мы увидим (разд. 3.8.3), что рассмотренную процедуру можно использовать и в том случае, когда матрица X имеет неполный ранг.
(в силу (3.39)), и этап (3) оказывается ненужным. В дальнейшем мы увидим (разд. 3.8.3), что рассмотренную процедуру можно использовать и в том случае, когда матрица X имеет неполный ранг.
 столбцами некоторой исходной матрицы X, а матрица
столбцами некоторой исходной матрицы X, а матрица  столбцом исходной матрицы
столбцом исходной матрицы  , указанный алгоритм можно использовать для такого подбора регрессии, при котором подбор производится поочередно для каждого столбца исходной матрицы. Такая ступенчатая процедура вполне уместна при планировании эксперимента, поскольку в этом случае столбцы исходной матрицы X соответствуют различным компонентам модели, таким, как общее среднее значение, главные эффекты, блочные эффекты, взаимодействия, причем обычно некоторые из ее столбцов бывают ортогональными. Кроме того, элементы матрицы плана равны 0 или 1, так что для многих стандартных планов выметающий оператор
, указанный алгоритм можно использовать для такого подбора регрессии, при котором подбор производится поочередно для каждого столбца исходной матрицы. Такая ступенчатая процедура вполне уместна при планировании эксперимента, поскольку в этом случае столбцы исходной матрицы X соответствуют различным компонентам модели, таким, как общее среднее значение, главные эффекты, блочные эффекты, взаимодействия, причем обычно некоторые из ее столбцов бывают ортогональными. Кроме того, элементы матрицы плана равны 0 или 1, так что для многих стандартных планов выметающий оператор  сводится к простой операции вычитания средних или некоторого кратного средних из остатков.
сводится к простой операции вычитания средних или некоторого кратного средних из остатков.