
матрица (размера  ) исходных данных по объясняющим (предикторным) переменным, матрица плана (здесь
) исходных данных по объясняющим (предикторным) переменным, матрица плана (здесь  ),
), 
 — известные базисные функции, по которым разложена функция регрессии
— известные базисные функции, по которым разложена функция регрессии  в частном случае линейной (по объясняющим переменным) модели регрессии матрица плана имеет вид:
в частном случае линейной (по объясняющим переменным) модели регрессии матрица плана имеет вид:

В гл. 3 X используется для обозначения матрицы исходных данных таблицы сопряженности (т. е. ее элемент  — это число объектов в двумерной выборке объема
— это число объектов в двумерной выборке объема  отнесенных по первой случайной компоненте к градации i, а по второй случайной компоненте — к градации
отнесенных по первой случайной компоненте к градации i, а по второй случайной компоненте — к градации  ), а в гл. 6 — для обозначения некоторого подмножества области определения исследуемой функции регрессии
), а в гл. 6 — для обозначения некоторого подмножества области определения исследуемой функции регрессии 
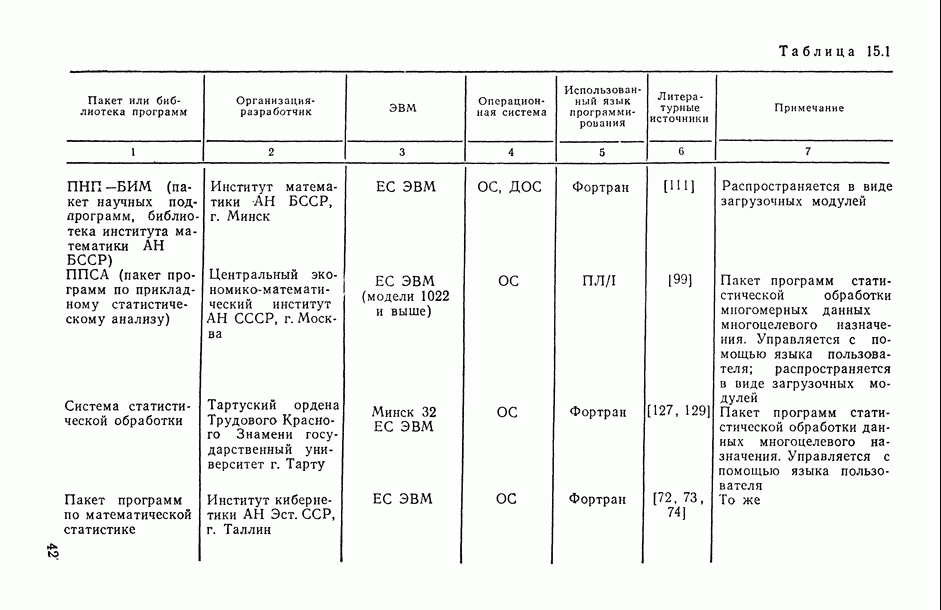
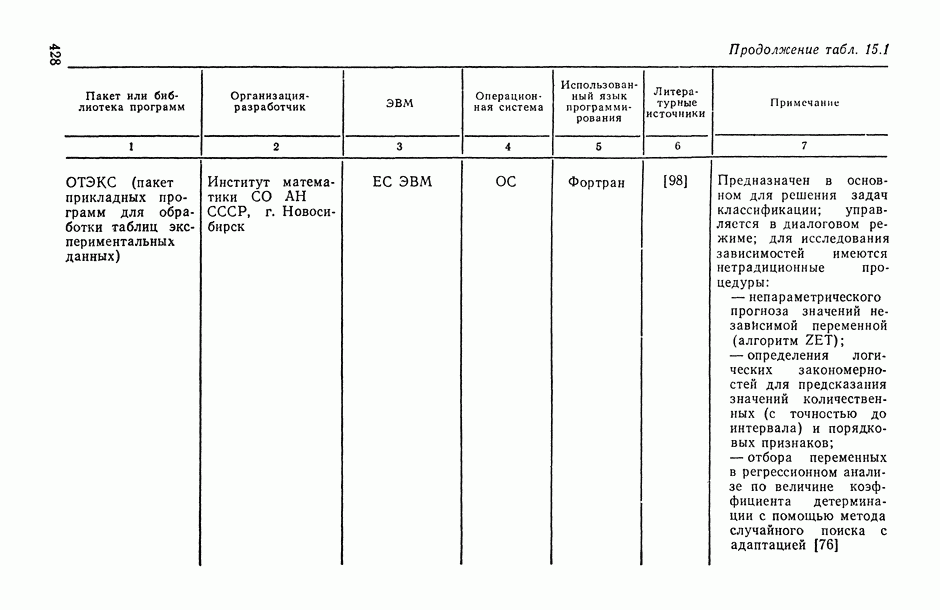
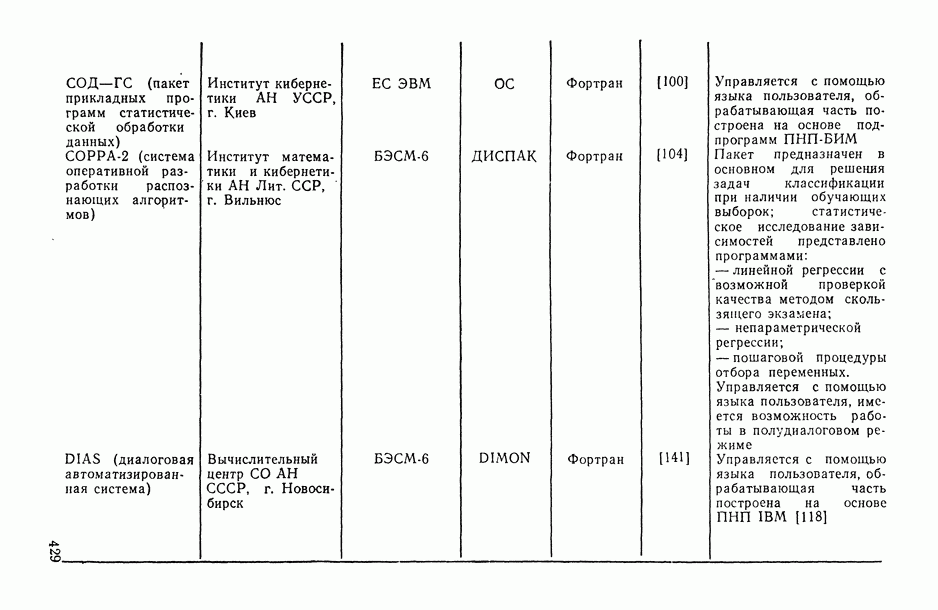
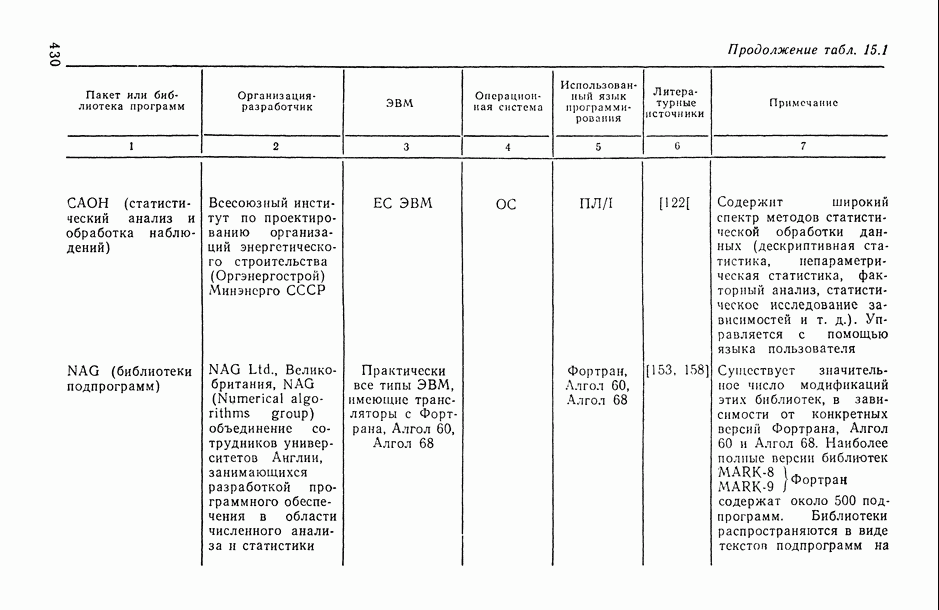
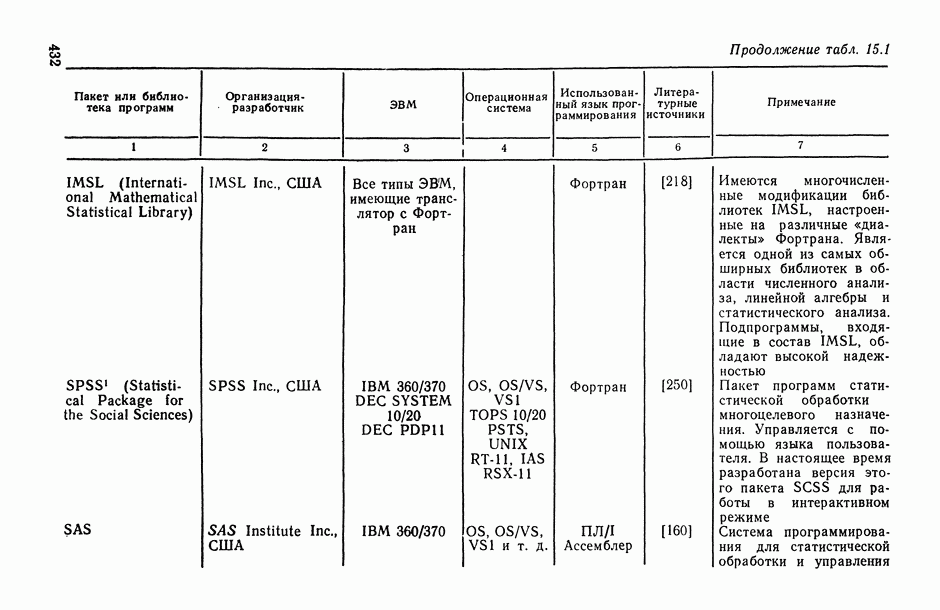
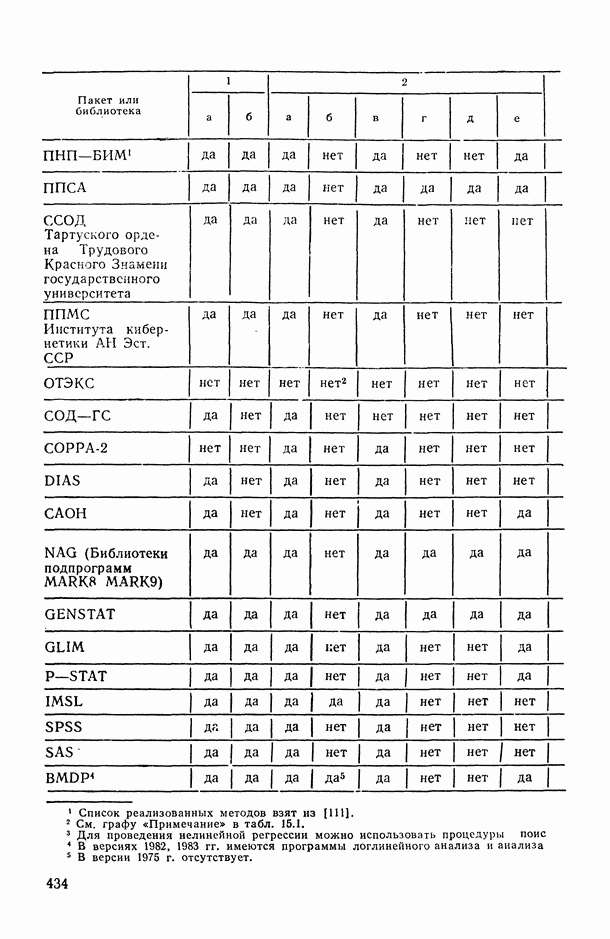
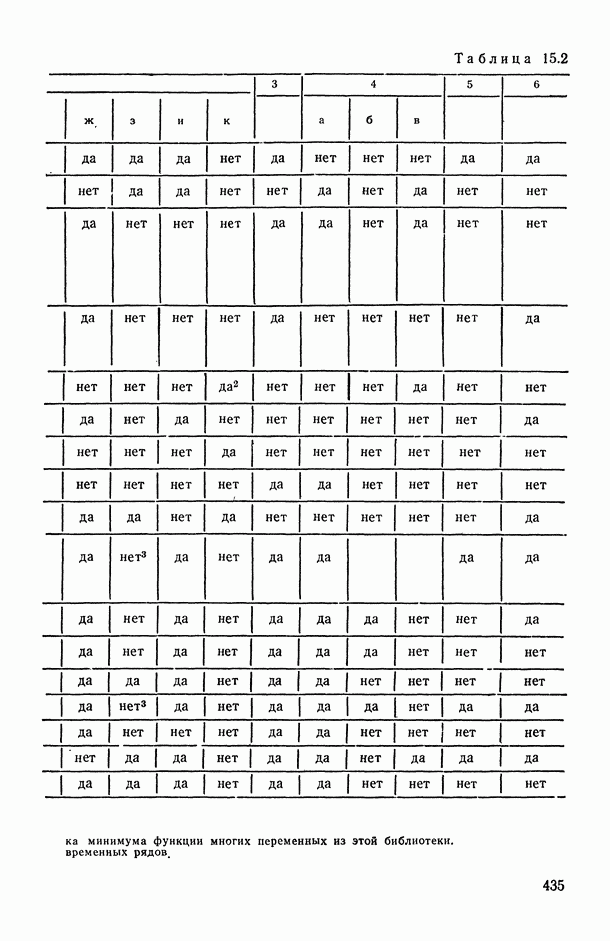
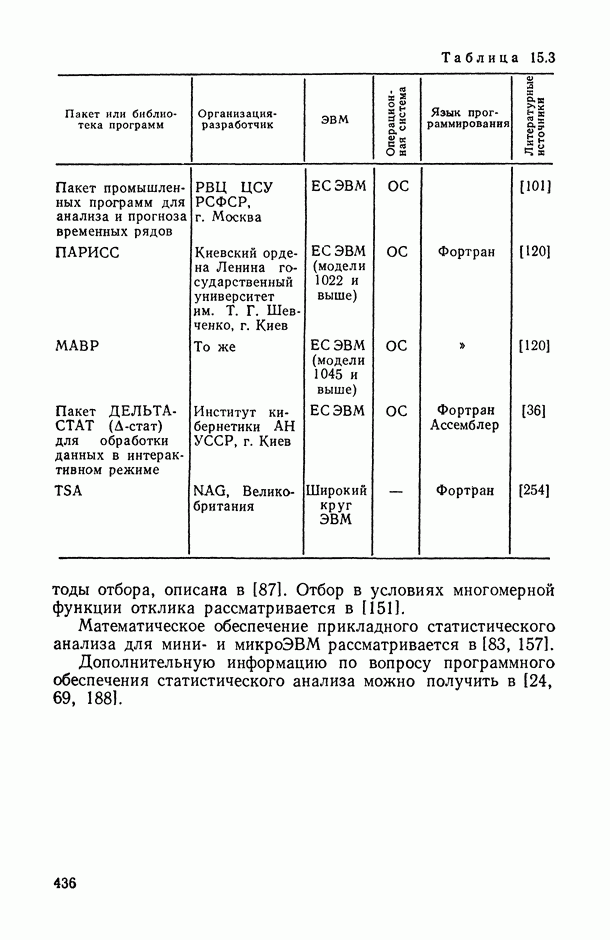
Законы распределения вероятностей и их числовые характеристики
 -мерный нормальный закон распределения вероятностей с вектором (столбцом) средних значений М и ковариационной матрицей
-мерный нормальный закон распределения вероятностей с вектором (столбцом) средних значений М и ковариационной матрицей  (если контекст не требует уточнения размерности закона, нижний индекс может быть опущен);
(если контекст не требует уточнения размерности закона, нижний индекс может быть опущен);
 — нецентральное
— нецентральное  -распределение с числами степеней свободы числителя и знаменателя соответственно и
-распределение с числами степеней свободы числителя и знаменателя соответственно и  и с параметром нецентральности
и с параметром нецентральности 
 — обозначение факта: «случайная величина Е, имеет распределение
— обозначение факта: «случайная величина Е, имеет распределение 
 — квантиль уровня
— квантиль уровня  квантиль) стандартного нормального распределения;
квантиль) стандартного нормального распределения;
 —
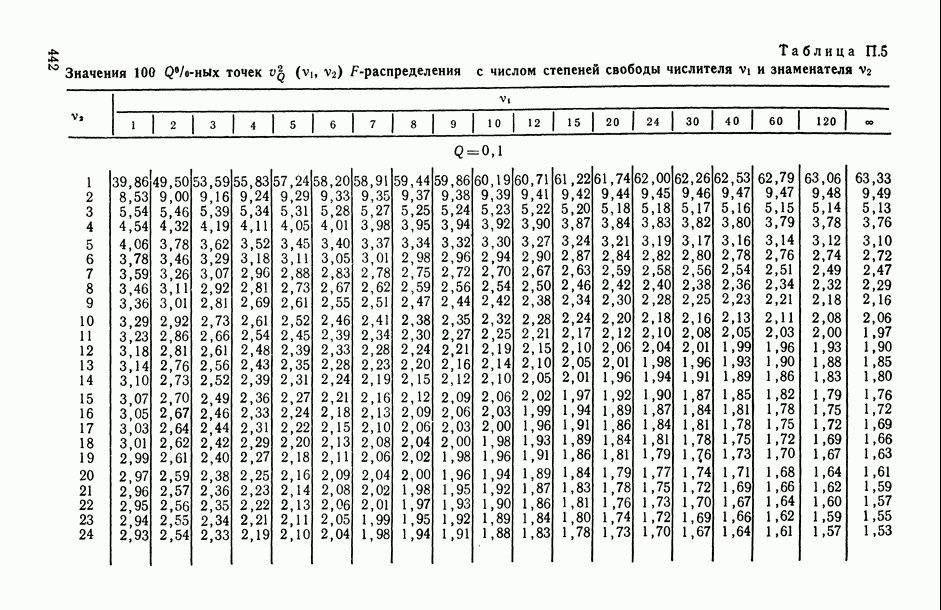
—  -ная точка
-ная точка  -распределения с v степенями свободы;
-распределения с v степенями свободы;  —
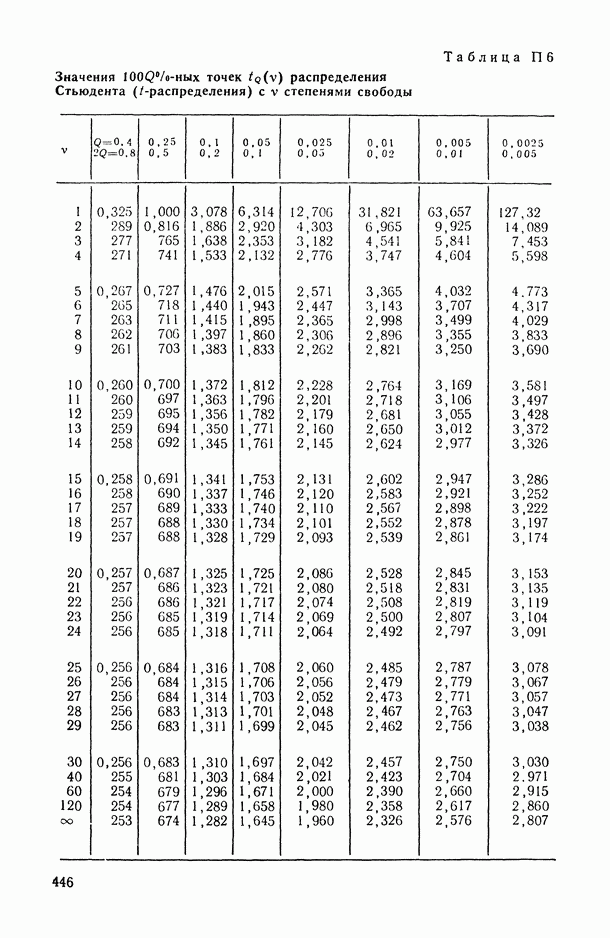
—  -ная точка распределения Стьюдента с v степенями свободы;
-ная точка распределения Стьюдента с v степенями свободы;
 —
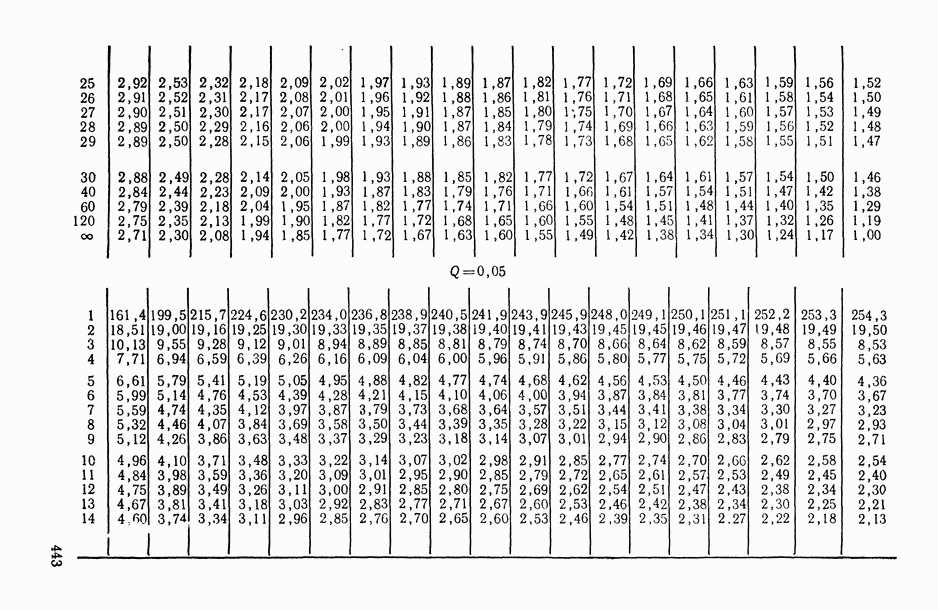
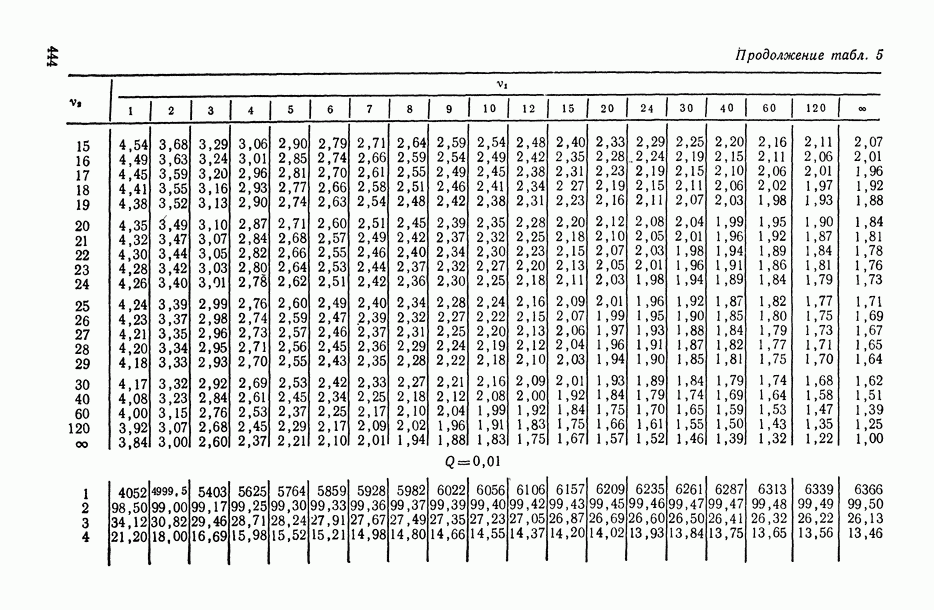
—  -ная точка центрального
-ная точка центрального  -распределения с числами степеней свободы числителя и знаменателя соответственно
-распределения с числами степеней свободы числителя и знаменателя соответственно 
 — элемент последовательности чисел, задающей двумерный (дискретный) закон распределения вероятностей: вероятность, что случайно извлеченный объект будет отнесен по первой компоненте к
— элемент последовательности чисел, задающей двумерный (дискретный) закон распределения вероятностей: вероятность, что случайно извлеченный объект будет отнесен по первой компоненте к  градации, а по второй — к
градации, а по второй — к 

 - случайная величина
- случайная величина  , анализируемая при условии, что значение другой случайной величины
, анализируемая при условии, что значение другой случайной величины  зафиксировано и равно X;
зафиксировано и равно X;
 — теоретическое среднее (математическое ожидание) случайной вели чины
— теоретическое среднее (математическое ожидание) случайной вели чины
 — корреляционное отношение, характеризующее тесноту статистической связи между
— корреляционное отношение, характеризующее тесноту статистической связи между  при разбиении диапазона изменения объясняющей (предикторной) переменной на k интервалов группирования (здесь
при разбиении диапазона изменения объясняющей (предикторной) переменной на k интервалов группирования (здесь  наблюденное значение результирующей переменной
наблюденное значение результирующей переменной  в
в  интервале группирования,
интервале группирования,  — средняя величина всех
— средняя величина всех  наблюденных значений
наблюденных значений  , оказавшихся в
, оказавшихся в  интервале группирования, а
интервале группирования, а  — общее среднее значение всех
— общее среднее значение всех  наблюденных значений случайной величины
наблюденных значений случайной величины  ;
;
 — информационная мера статистической связи между дискретными случайными величинами
— информационная мера статистической связи между дискретными случайными величинами  , где
, где  — энтропия случайной величины
— энтропия случайной величины  (здесь
(здесь  ), а суммирование производится по всем возможным значениям случайной величины
), а суммирование производится по всем возможным значениям случайной величины  );
);
 — частный (очищенный) коэффициент корреляции между компонентами
— частный (очищенный) коэффициент корреляции между компонентами  вектора
вектора  (вычислен при условии, что все остальные компоненты
(вычислен при условии, что все остальные компоненты  вектора X зафиксированы на некотором постоянном уровне);
вектора X зафиксированы на некотором постоянном уровне);
 — частный коэффициент корреляции между и при условии фиксации на постоянных уровнях компонент
— частный коэффициент корреляции между и при условии фиксации на постоянных уровнях компонент
 — множественный коэффициент корреляции между результирующей переменной
— множественный коэффициент корреляции между результирующей переменной  и объясняющими переменными
и объясняющими переменными 
 — коэффициент детерминации между
— коэффициент детерминации между  ;
;
 — ранговый коэффициент корреляции Спирмэна;
— ранговый коэффициент корреляции Спирмэна;
 — ранговый коэффициент корреляции Кендалла;
— ранговый коэффициент корреляции Кендалла;
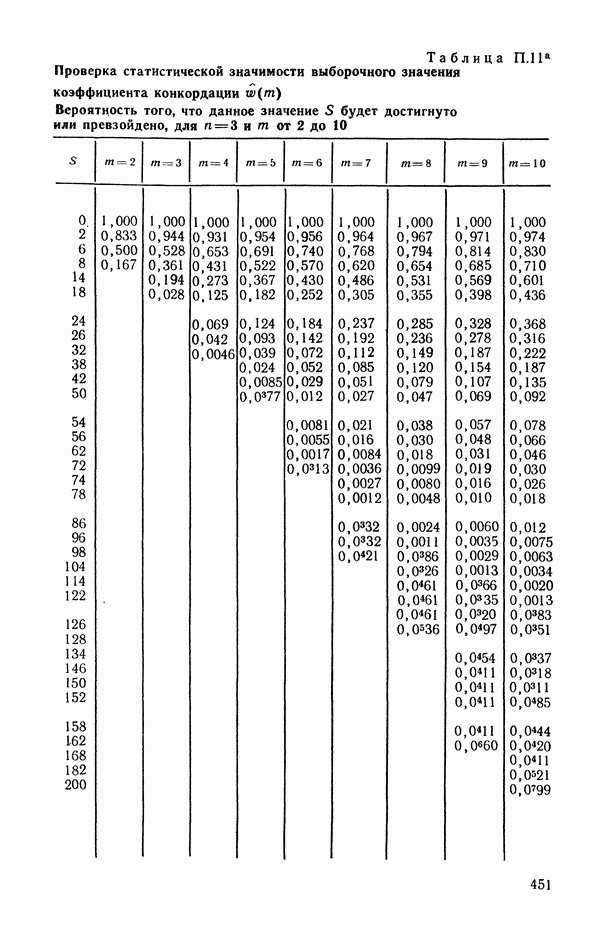
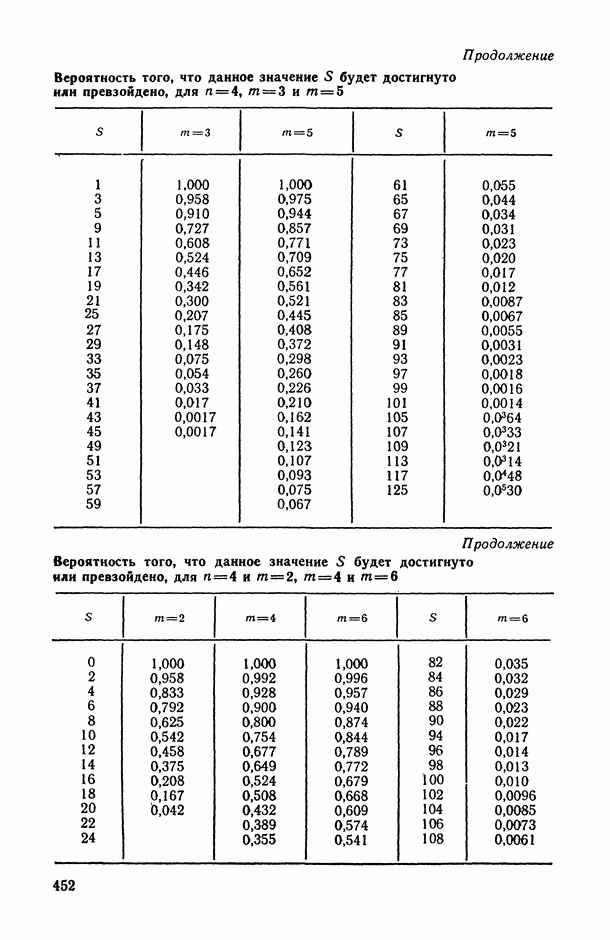
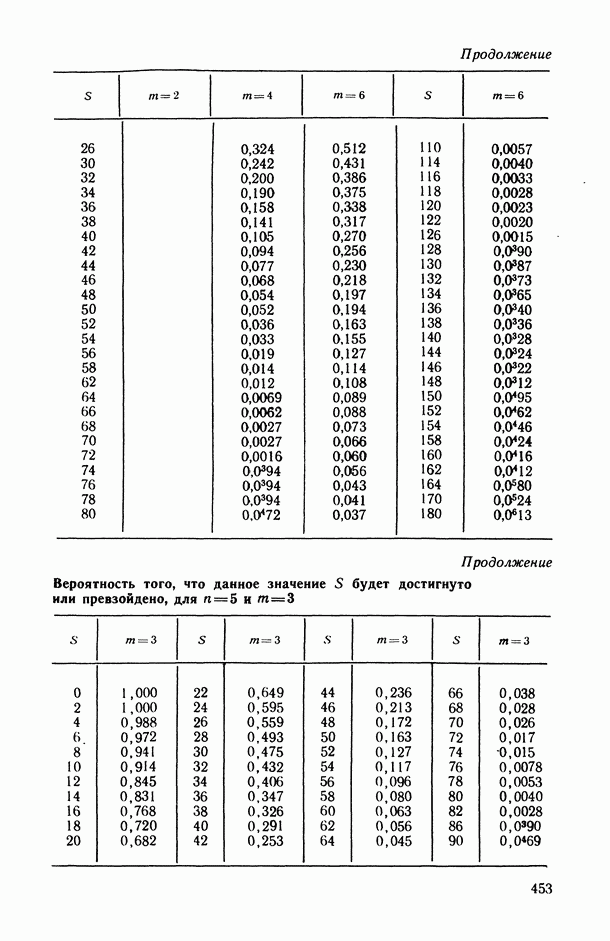
 — коэффициент конкордации (согласованности), измеряющий степень согласованности
— коэффициент конкордации (согласованности), измеряющий степень согласованности  различных ранжировок одних и тех же объектов.
различных ранжировок одних и тех же объектов.
Регрессионный, дисперсионный и ковариационный анализ
 - функция регрессии результирующей переменной
- функция регрессии результирующей переменной  по объясняющим переменным
по объясняющим переменным  (параметрическая запись):
(параметрическая запись):  — функция потерь, измеряющая убытки от неточности восстановления значения
— функция потерь, измеряющая убытки от неточности восстановления значения  с помощью функции
с помощью функции  где
где  — некоторая аппроксимация неизвестной функции регрессии
— некоторая аппроксимация неизвестной функции регрессии 







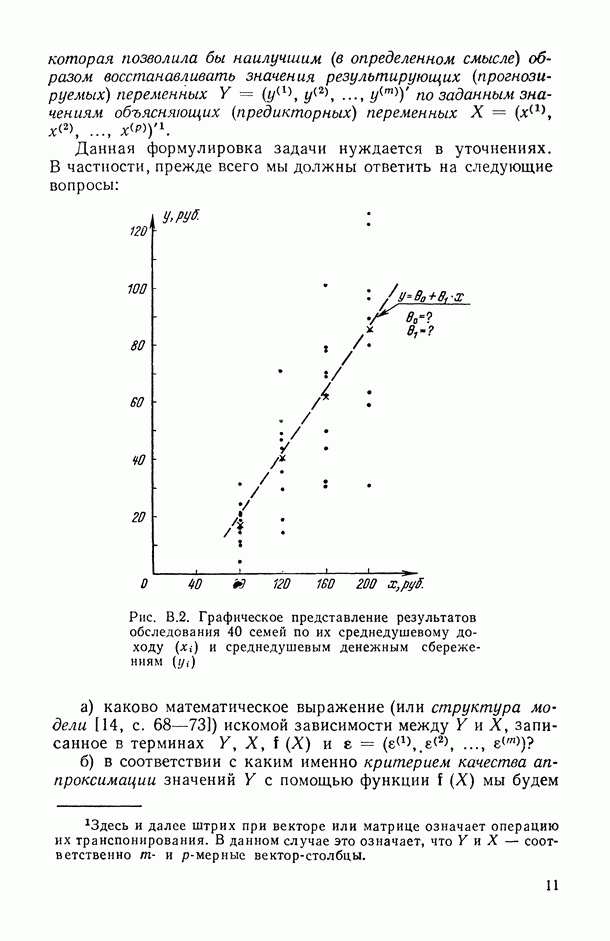












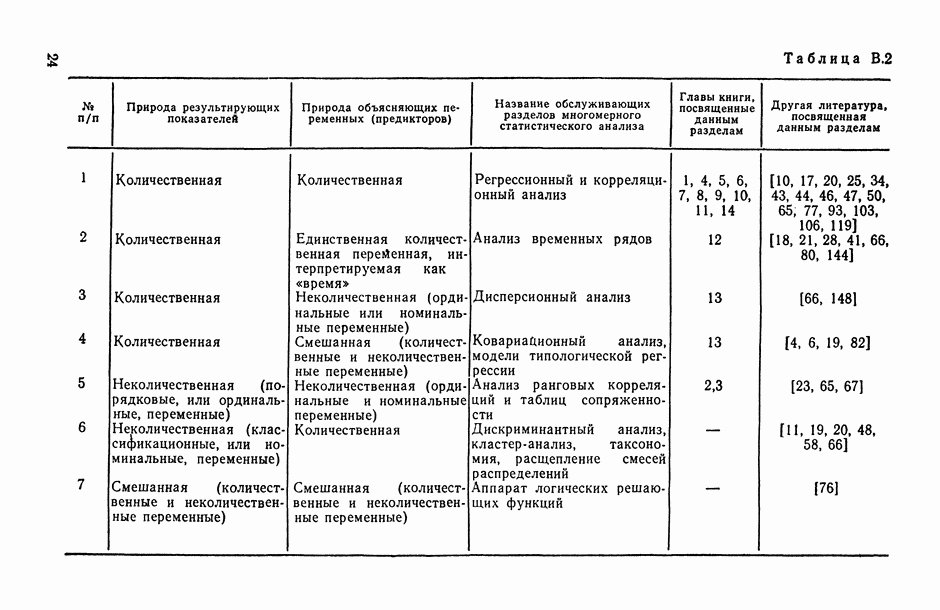
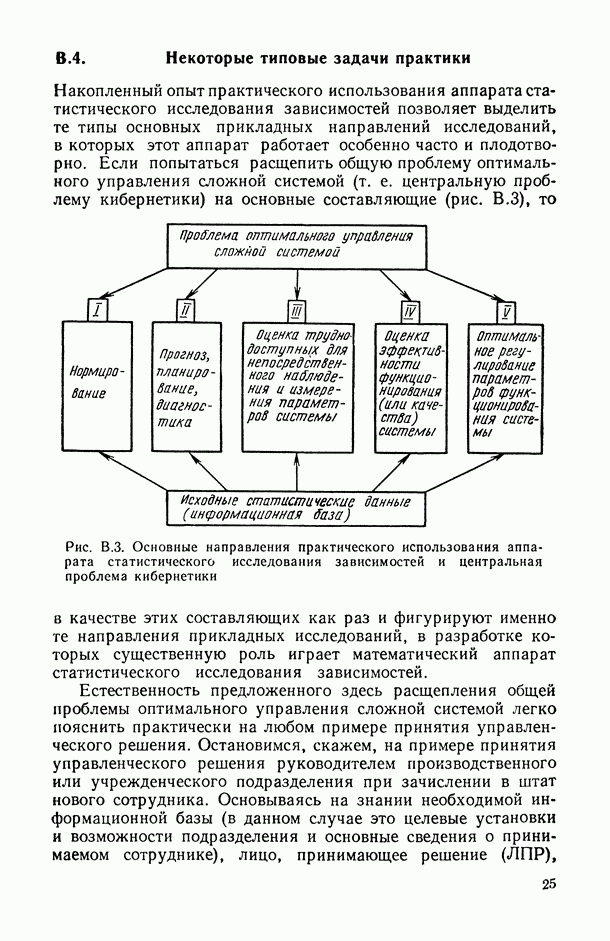





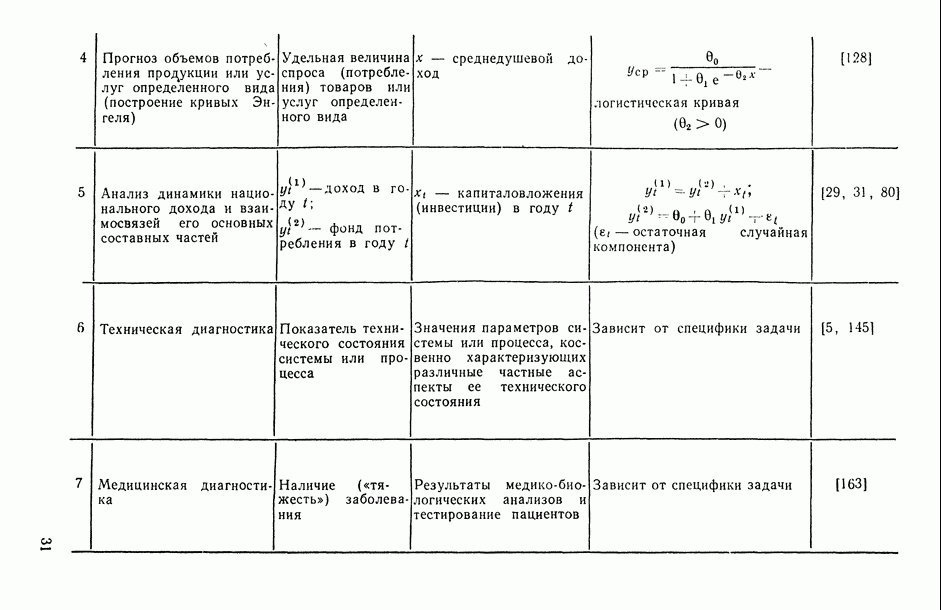





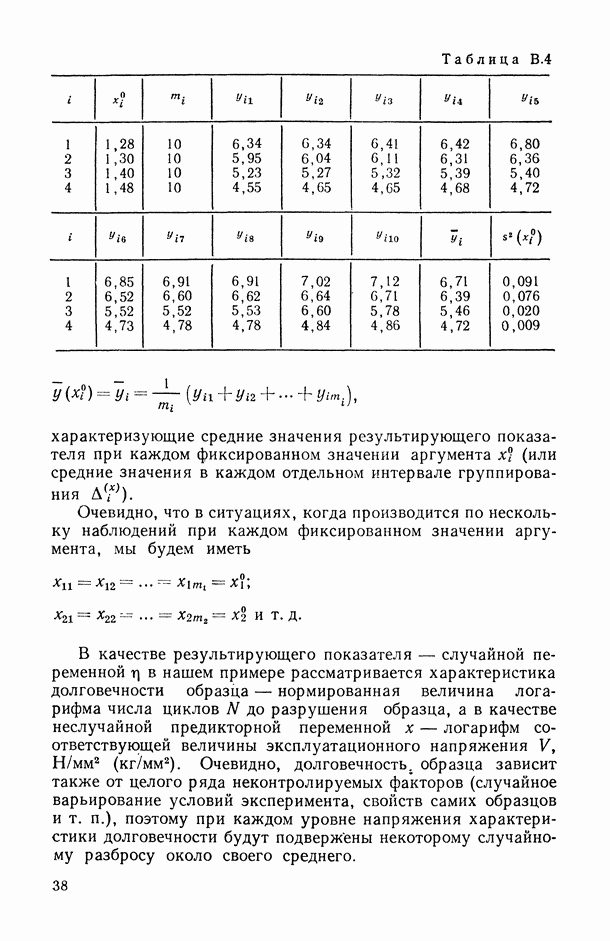




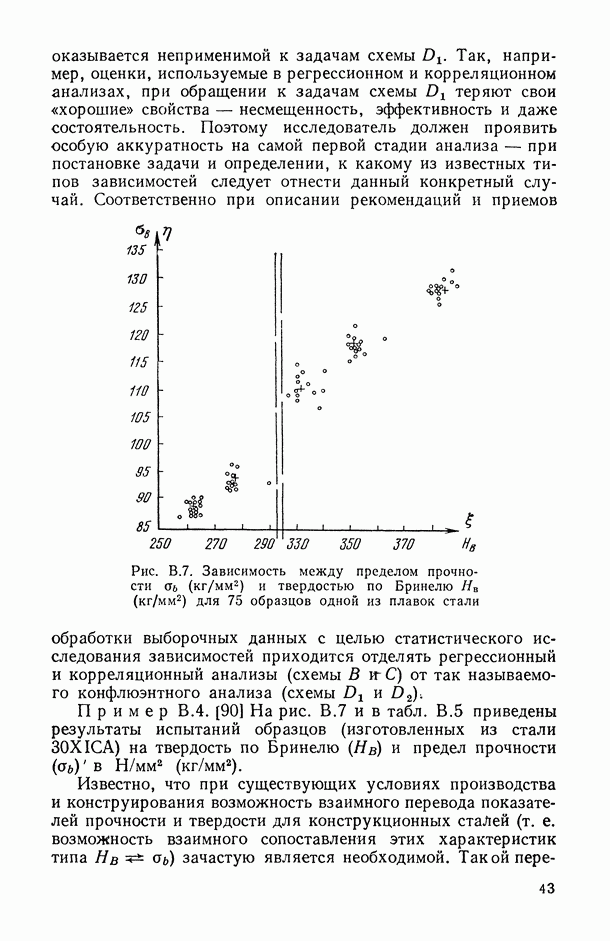
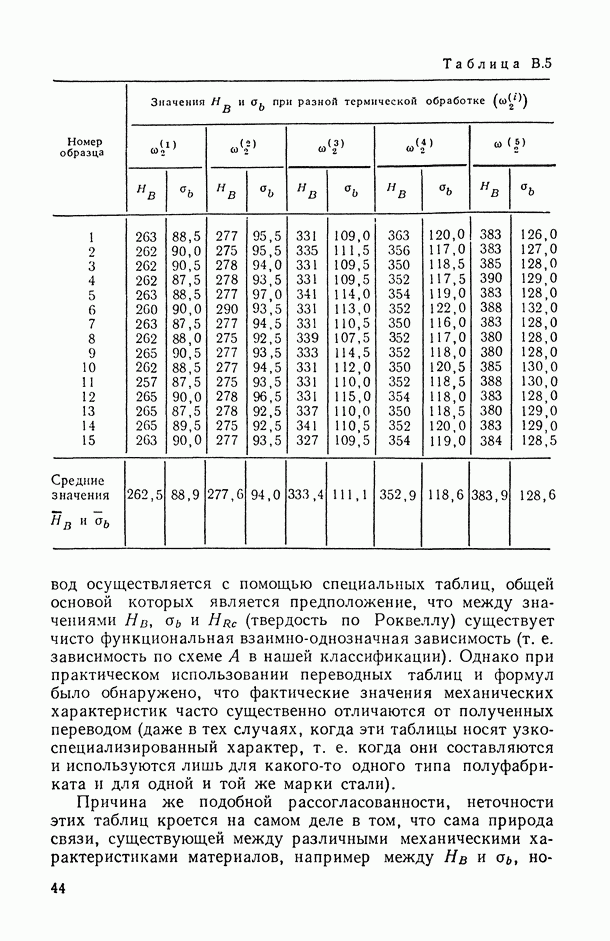
































































































































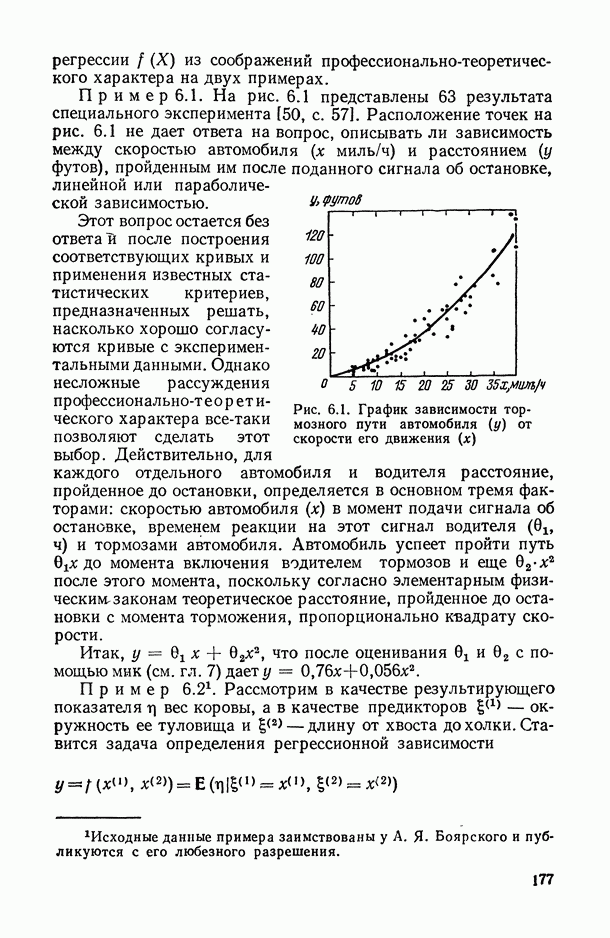




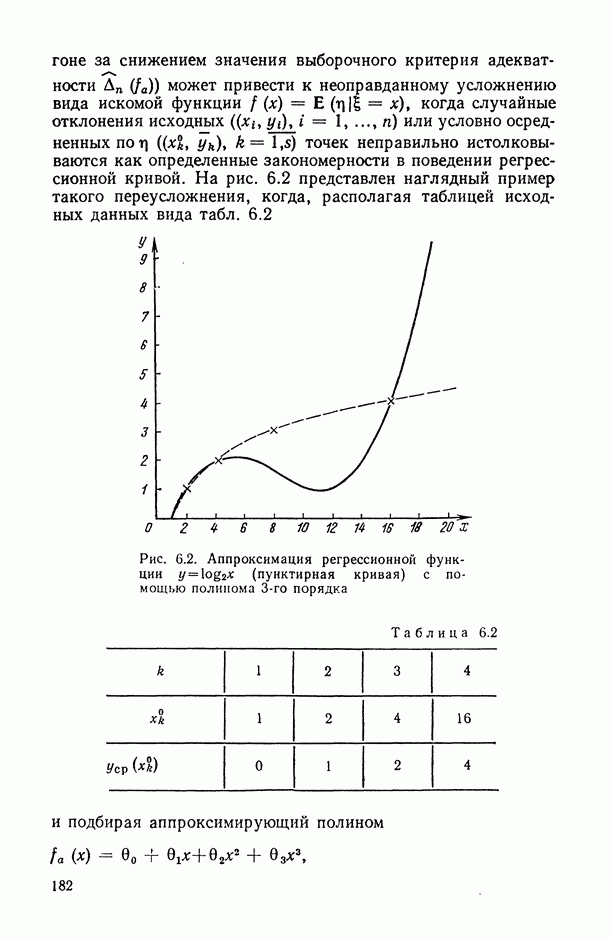



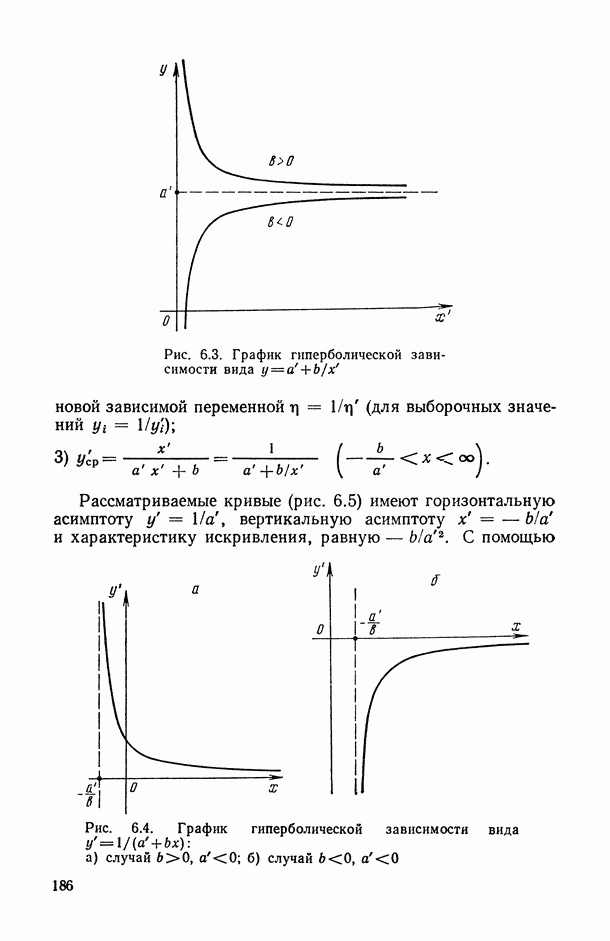
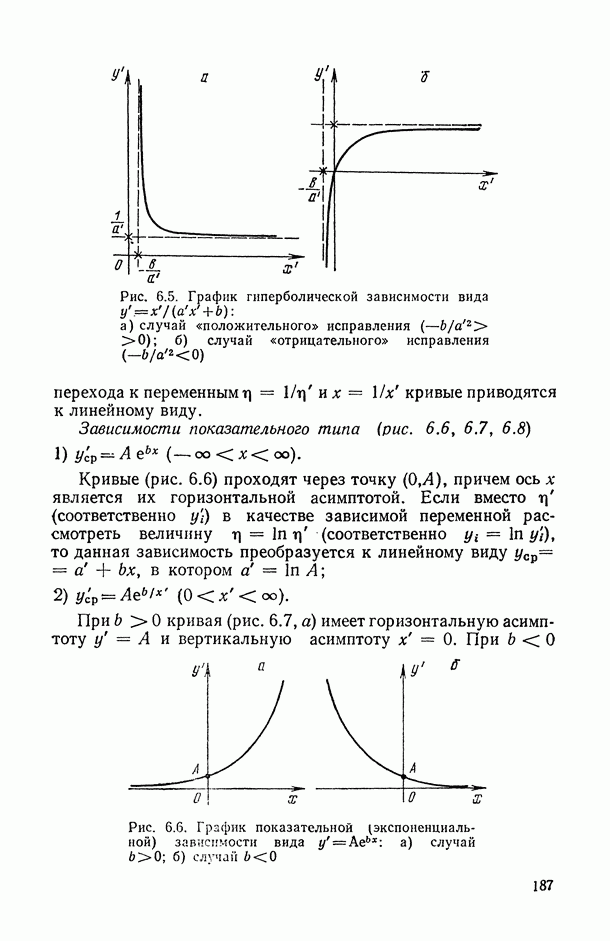






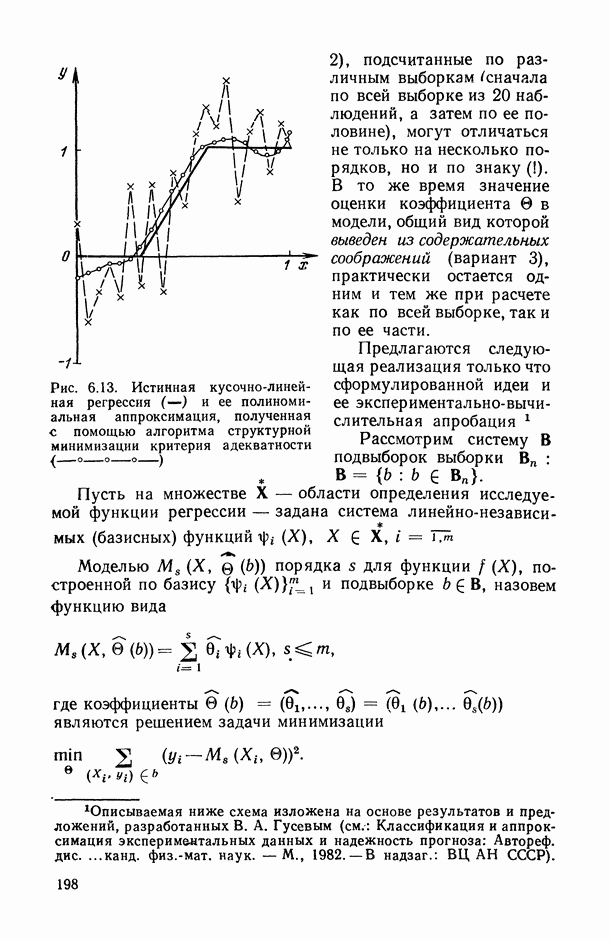


















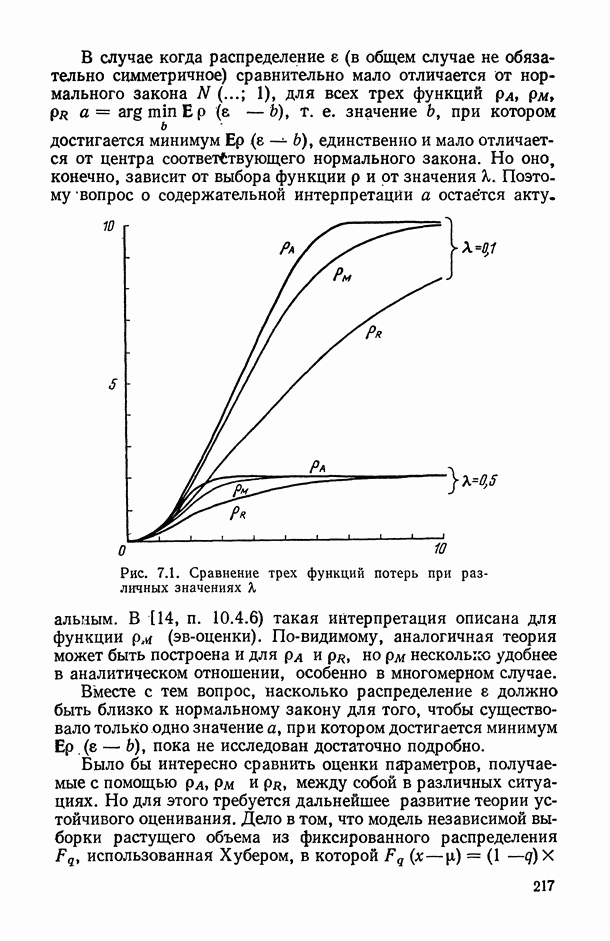


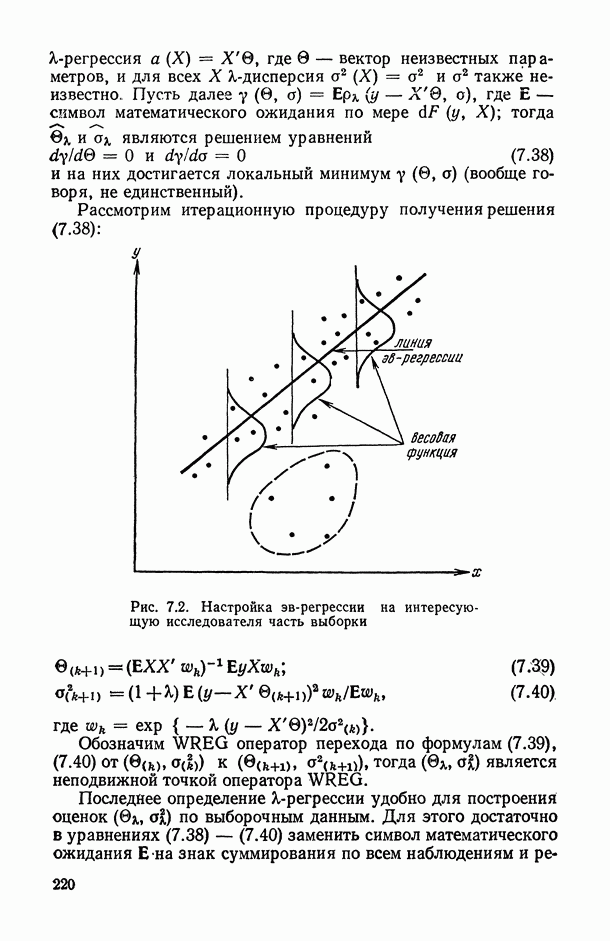










































































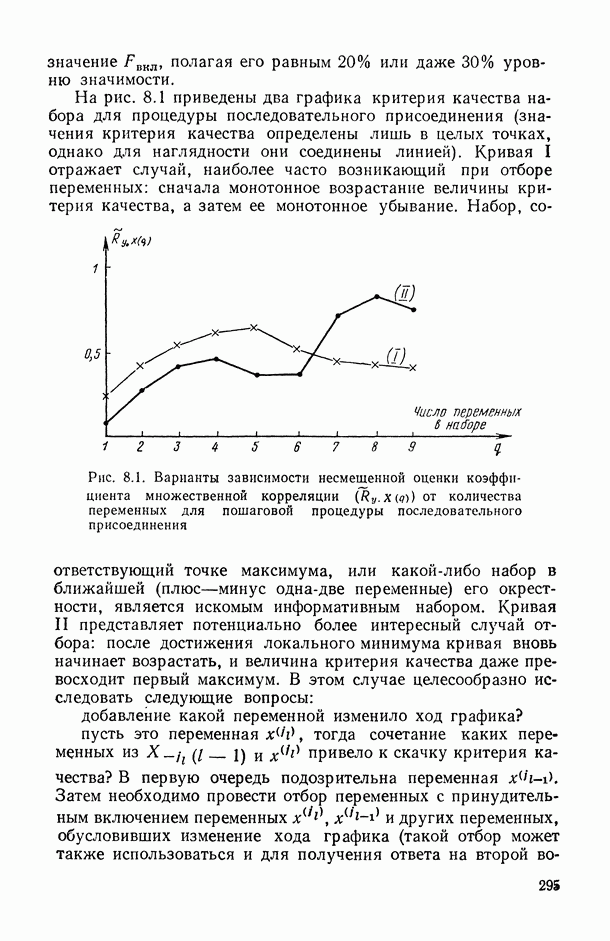































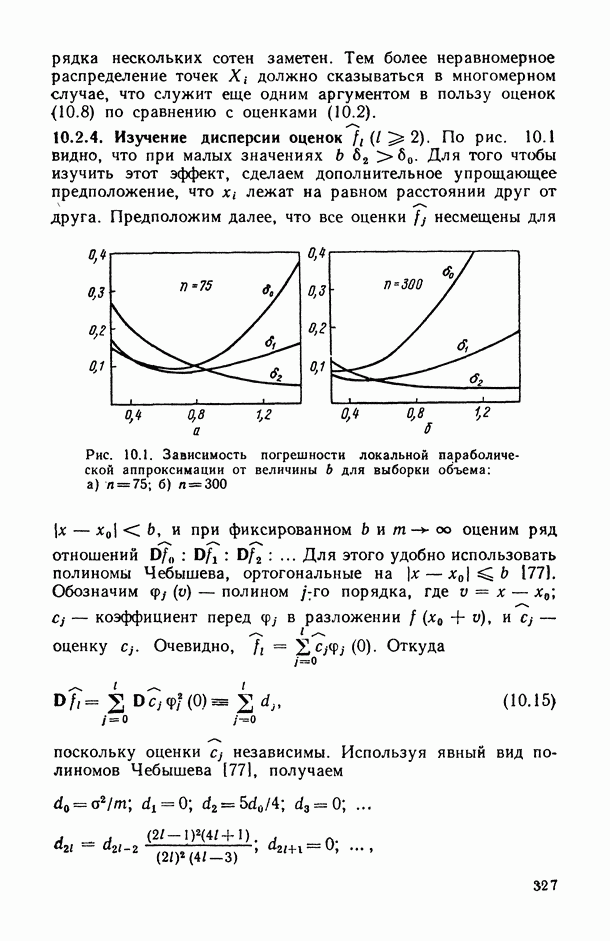
























































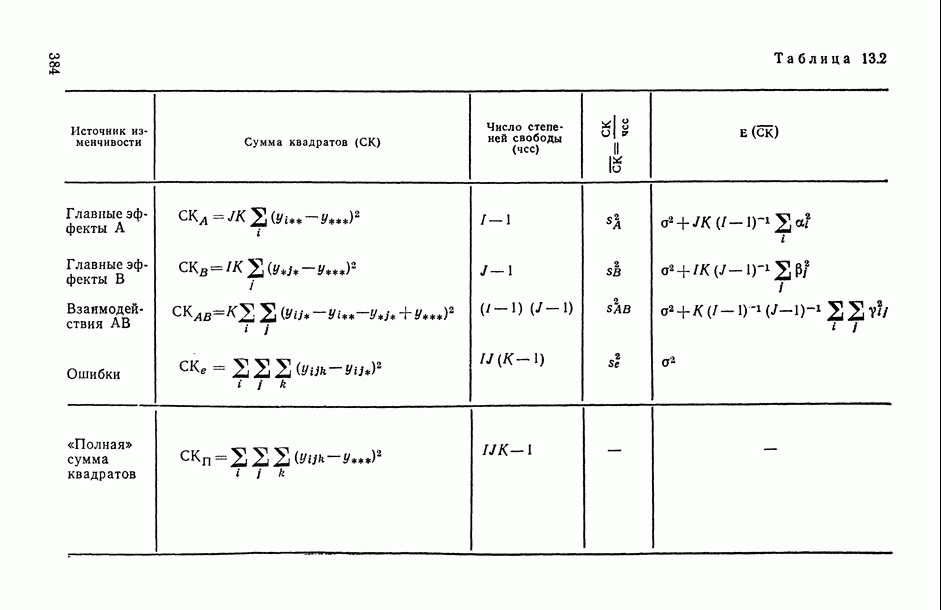

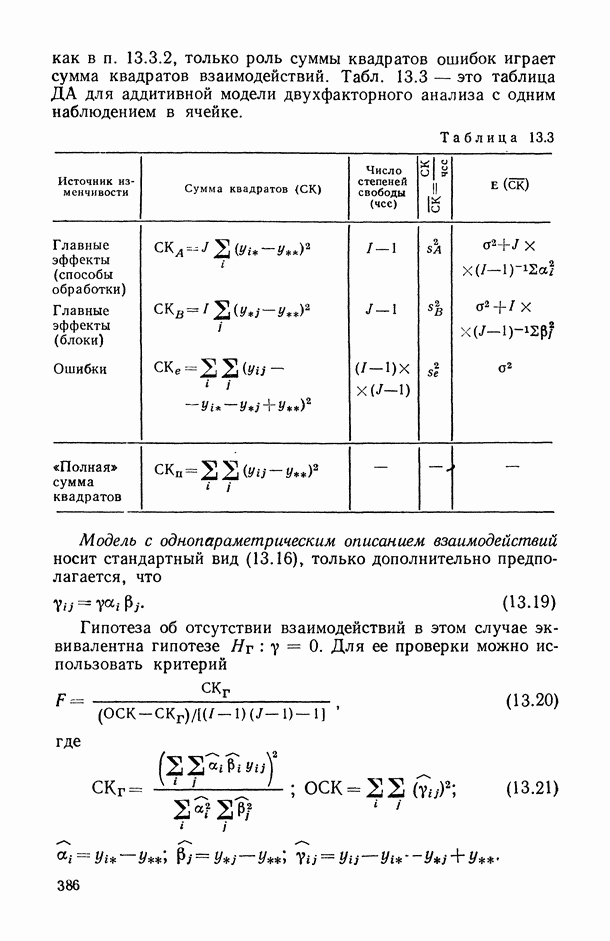









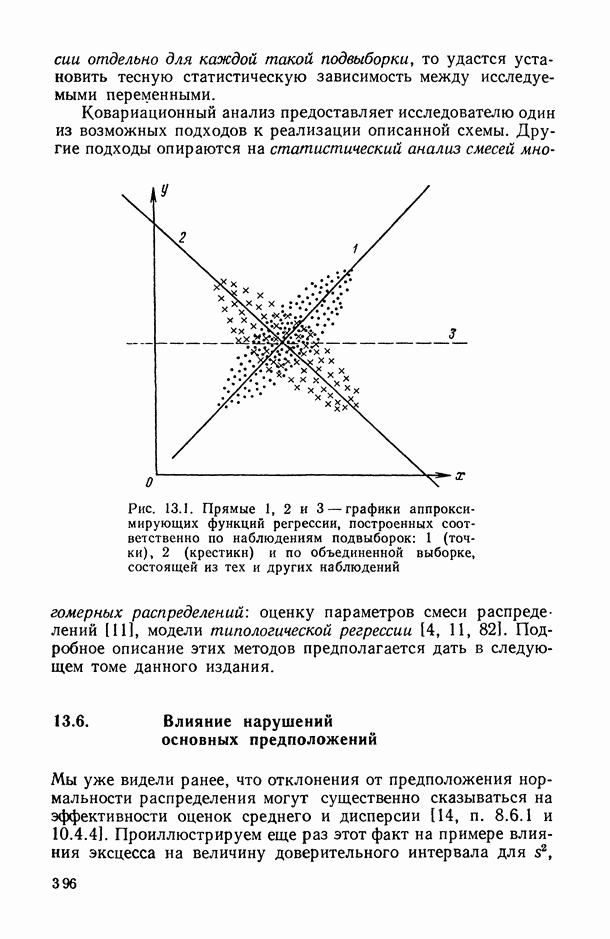




















































 — число статистически обследованных объектов, объем выборки из многомерной генеральной совокупности;
— число статистически обследованных объектов, объем выборки из многомерной генеральной совокупности;
 — число объясняющих (предикторных) переменных, регистрируемых на каждом из объектов;
— число объясняющих (предикторных) переменных, регистрируемых на каждом из объектов;
 — обозначение
— обозначение  объясняющей переменной на
объясняющей переменной на  обследуемом объекте;
обследуемом объекте;
 — значение исследуемого результирующего показателя («отклика») на
— значение исследуемого результирующего показателя («отклика») на  обследованном объекте;
обследованном объекте;
 — вектор-столбец значений
— вектор-столбец значений  объясняющих переменных зарегистрированных на
объясняющих переменных зарегистрированных на  обследованном объекте;
обследованном объекте;
 — значения входных («объясняющих»)
— значения входных («объясняющих»)  и выходных («результирующих»)
и выходных («результирующих»)  переменных, зарегистрированные в
переменных, зарегистрированные в  наблюдении (или на
наблюдении (или на  обследованном объекте);
обследованном объекте);  — выборка объема
— выборка объема  , исходные статистические данные;
, исходные статистические данные;
 — система подвыборок выборки
— система подвыборок выборки 
 - вектор-столбец наблюденных значений результирующей переменной («отклика»);
- вектор-столбец наблюденных значений результирующей переменной («отклика»);
 — дисперсия случайной величины
— дисперсия случайной величины  ;
;
 — условное среднее значение случайной величины
— условное среднее значение случайной величины  вычисленное при условии, что значение другой случайной величины
вычисленное при условии, что значение другой случайной величины  зафиксировано на уровне X;
зафиксировано на уровне X;
 — условная дисперсия случайной величины
— условная дисперсия случайной величины  , вычисленная при условии, что значение другой случайной величины
, вычисленная при условии, что значение другой случайной величины  зафиксировано на уровне X;
зафиксировано на уровне X;
 — ковариация случайных величин
— ковариация случайных величин 
 , то
, то
 — ковариационная матрица (размера
— ковариационная матрица (размера  ) вектора
) вектора  причем она в ряде мест книги разбита на подматрицы по следующей схеме:
причем она в ряде мест книги разбита на подматрицы по следующей схеме:

 имеют соответственно размеры
имеют соответственно размеры  .
.
 — коэффициент коорреляции между случайными величинами
— коэффициент коорреляции между случайными величинами 

 (здесь
(здесь  наблюденные значения случайных величин соответственно
наблюденные значения случайных величин соответственно 
 - индекс корреляции, характеризующий тесноту статистической связи между
- индекс корреляции, характеризующий тесноту статистической связи между  и в общем случае (здесь —
и в общем случае (здесь —  -безусловная дисперсия случайной величины
-безусловная дисперсия случайной величины  , а
, а  — усредненная по различным значениям X случайной величины
— усредненная по различным значениям X случайной величины  величина условной дисперсии
величина условной дисперсии  );
);
 — теоретический критерий адекватности модели
— теоретический критерий адекватности модели  ;
;
 - выборочный критерий адекватности модели
- выборочный критерий адекватности модели 
 — класс допустимых решений (класс функций, в рамках которого подыскивается наилучшая аппроксимация для
— класс допустимых решений (класс функций, в рамках которого подыскивается наилучшая аппроксимация для  )
)  — функция
— функция  -регрессии;
-регрессии;
 — вектор-столбец неизвестных параметров, от которых зависит уравнение искомой функции регрессии
— вектор-столбец неизвестных параметров, от которых зависит уравнение искомой функции регрессии 
 — статистическая оценка векторного параметра
— статистическая оценка векторного параметра  ;
;  — вектор-столбец базисных функций
— вектор-столбец базисных функций  , по которым разложена функция регрессии
, по которым разложена функция регрессии  — функция регрессии, разложенная в системе базисных функций
— функция регрессии, разложенная в системе базисных функций  линейная по параметрам;
линейная по параметрам;
 — ковариационная матрица оценок
— ковариационная матрица оценок  ;
;
 — общая (неявная) запись модели регрессии
— общая (неявная) запись модели регрессии  по X;
по X;
 — индикаторные переменные в схеме ковариационного анализа, соответствующие k возможным типам условий эксперимента (нижний индекс д показывает, что эти переменные относятся к «дисперсионной части» модели ковариационного анализа);
— индикаторные переменные в схеме ковариационного анализа, соответствующие k возможным типам условий эксперимента (нижний индекс д показывает, что эти переменные относятся к «дисперсионной части» модели ковариационного анализа);
 — параметры (неизвестные) модели ковариационного анализа, определяющие сравнительный эффект влияния каждого из k типов условий эксперимента на исследуемый результирующий показатель.
— параметры (неизвестные) модели ковариационного анализа, определяющие сравнительный эффект влияния каждого из k типов условий эксперимента на исследуемый результирующий показатель.
