Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
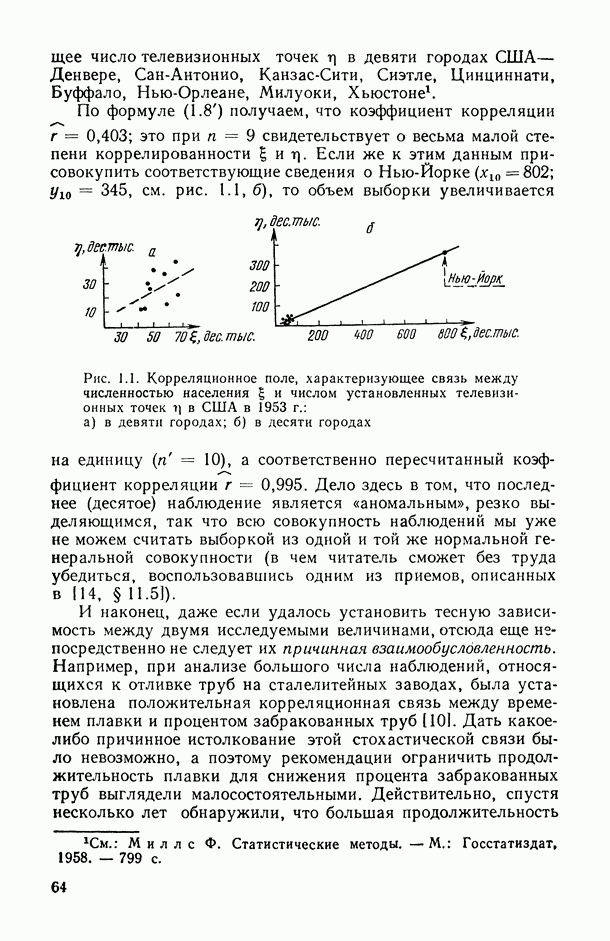
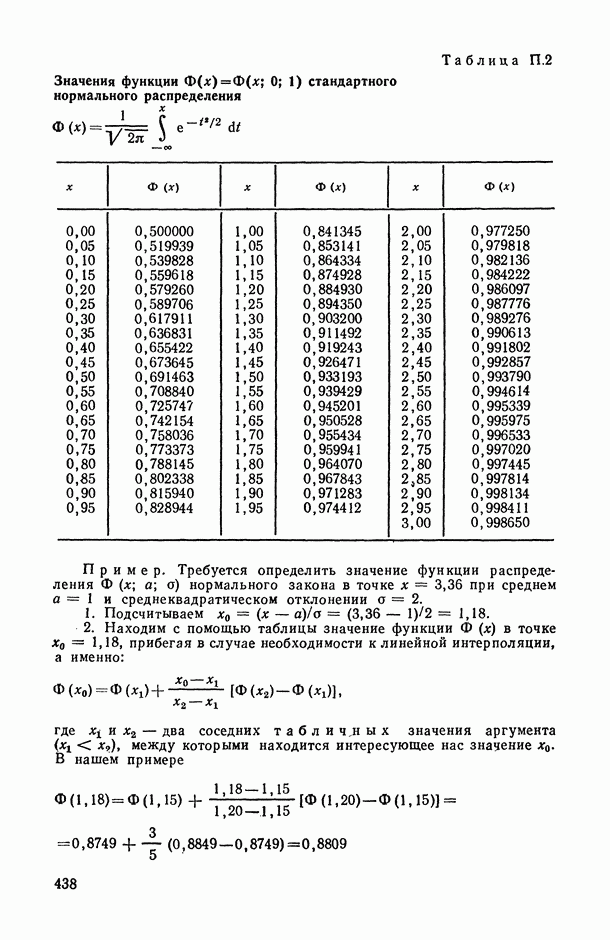
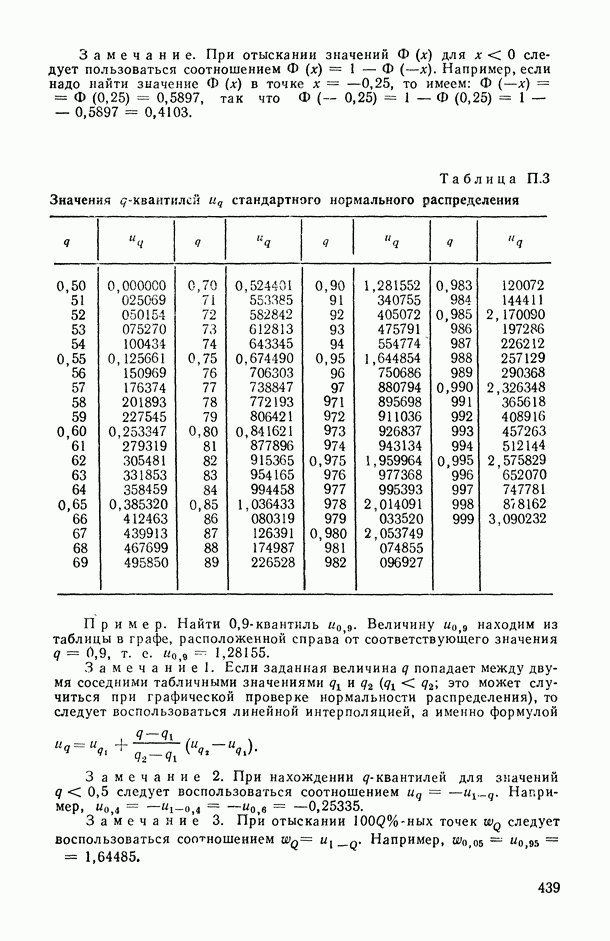
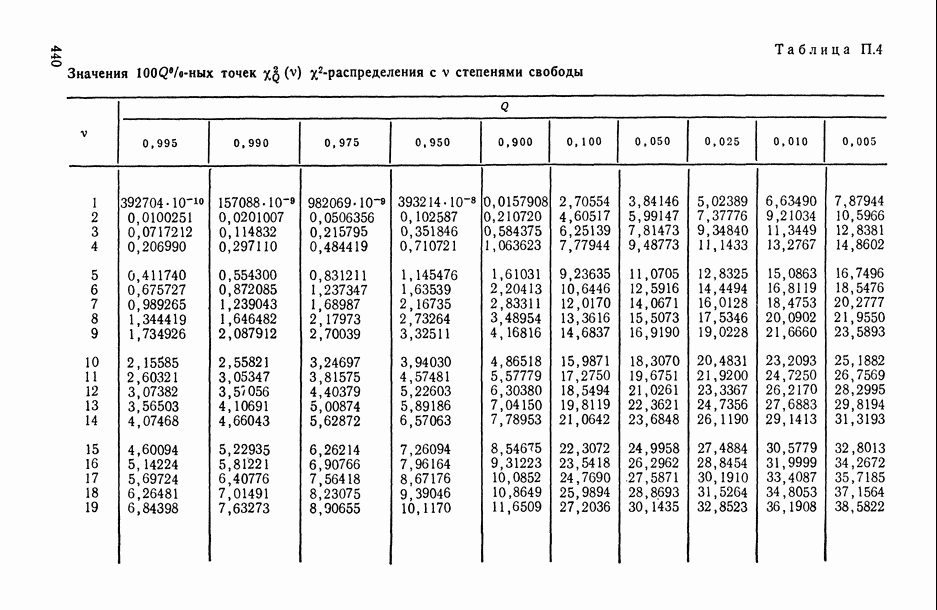
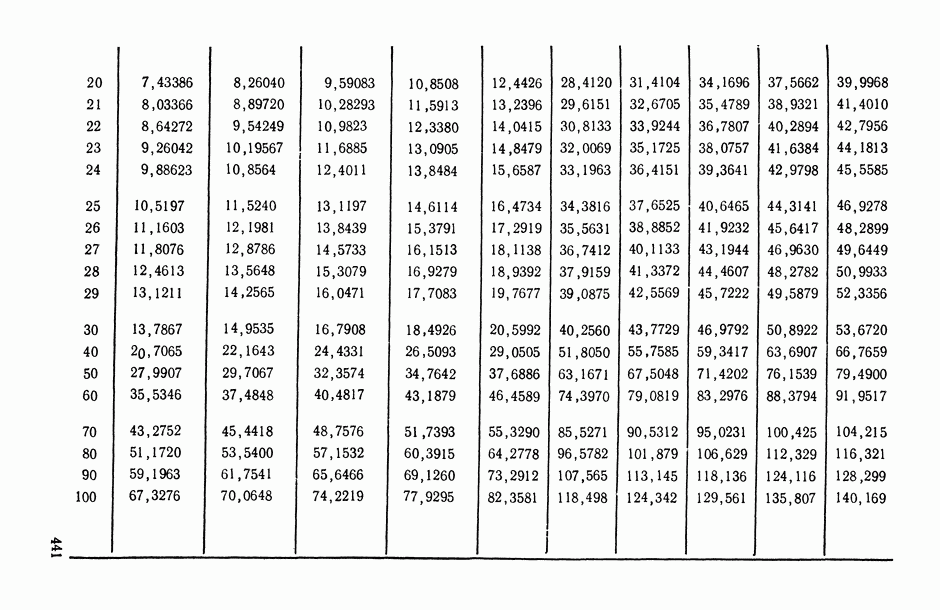
В.6. Основные этапы статистического исследования зависимостейВесь процесс статистического исследования интересующих нас зависимостей удобно разложить на основные этапы. Эти этапы ниже описаны в соответствии с хронологией их реализации, однако некоторые из них находятся, в плане хронологическом, в соотношении итерационного взаимодействия: результаты реализации более поздних этапов могут содержать выводы о необходимости повторной «прогонки» (с учетом добытой на предыдущих этапах новой информации) уже пройденных этапов (см., например, схему взаимодействия этапов 3,4, 5 и 6 на рис. В.8). Излагаемая ниже схема приспособлена в основном для исследования зависимостей между количественными переменными, однако с минимальными (и очевидными) модификациями она «работает» и при статистическом анализе связей между неколичественными и разнотипными переменными.
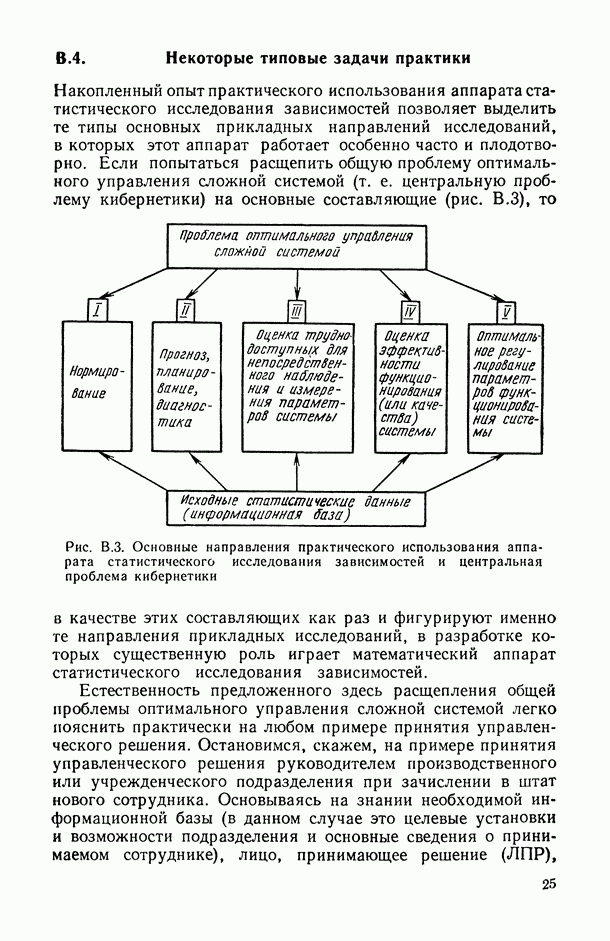
Рис. В.8. Схема хронологически-итерационных взаимосвязей основных этапов статистического исследования зависимостей Этап 1 (постановочный). Прежде всего исследователь должен определить: 1) элементарную единицу статистического обследования, или элементарный объект исследования О (это может быть страна, город, отрасль, предприятие, семья, индивидуум, пациент, технологический процесс, сложное техническое изделие и т. д.); 2) набор показателей
3) конечные прикладные цели исследования (см. § В.2), тип исследуемых зависимостей (см. § В.5) и желательную форму статистических выводов (а иногда и степень их точности); 4) совокупность элементарных объектов исследования, на которую мы хотим распространить справедливость действия выявленных в результате анализа статистических зависимостей (если, например, элементарная единица — семья, то анализируемой совокупностью могут быть семьи определенной социальной группы населения или семьи определенной республики и т. д.); 5) общее время и трудозатраты, отведенные на планируемое исследование и коррелированные с ними временная протяженность и объем необходимого статистического обследования (какую часть анализируемой совокупности подвергнуть статистическому обследованию, производить статистическое обследование в статическом или динамическом режиме и т. д.). Заметим, что именно на этом этапе решаются задачи в) и 1, описанные в § В. 1. В решении всех перечисленных вопросов первого этапа исследования главную роль, бесспорно, должен играть «заказчик», т. е. специалист той предметной области, для которой планируется проведение этого исследования. Этап 2 (информационный). Он состоит в проведении сбора необходимой статистической информации вида (В.1). При этом возможны две принципиально различные ситуации: 1) исследователь имеет возможность заранее спланировать выборочное обследование части анализируемой совокупности — выбрать способ отбора элементарных единиц статистического обследования (случайный, пропорциональный, расслоенный и т. д., см., например, [14, п. 5.4.3]), хотя бы по части объясняющих переменных 2) исследователь получает исходные данные такими, какими они были собраны без его участия (условия пассивного эксперимента). В любом случае «на выходе» этого этапа исследователь располагает исходными статистическими данными вида (В.1), т. е. каждому (t-му) из статистически обследованных элементарных объектов исследования О поставлен в соответствие конкретный вектор характеризующих его «входных» и «выходных» показателей:
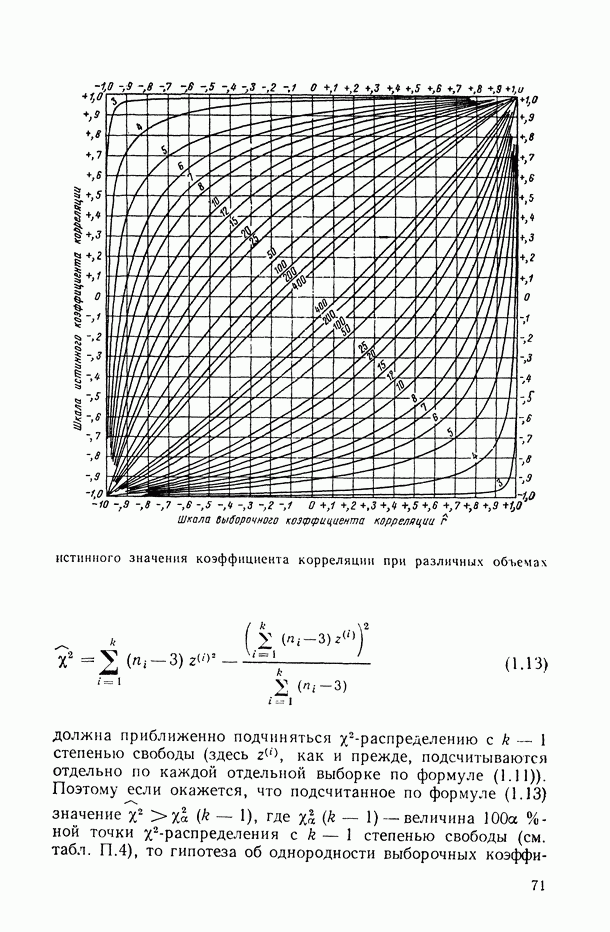
(здесь Говоря о проведении сбора статистических данных, мы не включаем сюда разработку методологии и системы показателей отображаемого объекта: эта работа предполагает профессионально-предметное (экономическое, техническое, медицинское и т. д.) изучение сущности решаемых задач статистического исследования зависимостей, поэтому относится к компетенции соответствующей предметной статистики (экономической и т. д.) и входит в задачи 1-го этапа исследований. Этап 3 (корреляционный анализ). Этот этап нацелен на решение задачи 2 (см. § В.1), он позволяет ответить на вопросы, имеется ли вообще какая-либо связь между исследуемыми переменными, какова структура этих связей и как измерить их тесноту? Описанию методов, с помощью которых проводится такой статистический анализ, посвящены гл. 1—4. Поскольку перечисленные выше вопросы решаются с помощью вычисления и анализа соответствующих корреляционных характеристик, содержание этапа можно определить как проведение корреляционного анализа. Этап достаточно полно оснащён необходимым математическим аппаратом и программным обеспечением, поэтому может быть почти полностью автоматизирован. Этап 4 (определение класса допустимых решений). Главной целью исследователя на этом этапе является определение общего вида, структуры искомой связи между Y и X, или, другими словами, описание класса функций F, в рамках которого он будет производить дальнейший поиск конкретного вида интересующей его зависимости (см. задачи а) и 3 в § В.1). Чаще всего это описание дается в форме некоторого параметрического семейства функций Следует отметить, что, являясь узловым, в определенной мере решающим звеном во всем процессе статистического Существует подход к исследованию моделей регрессии, не требующий предварительного выбора параметрического семейства функций F в рамках которого проводится дальнейший анализ. Речь идет о так называемых непараметрических (или частично-параметрических) методах исследования регрессионных зависимостей, которым посвящена гл. 10. Однако возникающие при их реализации проблемы (необходимость иметь очень большие объемы исходных статистических данных, выбор сглаживающих функций — «окон» и параметров масштаба, выбор порядка сплайна, числа и положения «узлов» и т. п.) сопоставимы по своей сложности с проблемами, возникающими при реализации этапа 4. Следующие два этапа — 5-й и 6-й — связаны с проведением определенного объема вычислений на ЭВМ и реализуются, по существу, параллельно. Этап 5 (анализ мультиколлинеарности предсказывающих переменных и отбор наиболее информативных из них.) Под явлением мультиколлинеарности в регрессионном анализе понимается наличие тесных статистических связей между предсказывающими переменными а) в реализации на ЭВМ необходимых вычислительных процедур и, в частности, в крайней неустойчивости получаемых при этом числовых характеристик анализируемых моделей (так, коэффициенты при объясняющих переменных в моделях типа (В. 12), (В. 13) и др. могут изменяться в несколько раз и даже менять знак при добавлении (или исключении) к массиву исходных статистических данных одного-двух объектов или одной-двух объясняющих переменных); б) в содержательной интерпретации параметров анализируемой модели, что играет решающую роль в ситуациях, когда конечной целью исследования является цель типа 3 («выявление причинных связей» и т. д., см. § В.2, соотношения (В.9) и Поэтому исследователь старается перейти к такой новой системе предсказывающих переменных (отобранных из числа исходных переменных Этап проводится в основном силами математиков-статистиков с подключением (в самом его конце) специалистов соответствующей предметной области для выбора из нескольких предложенных вариантов набора объясняющих переменных, наиболее легко и естественно интерпретируемого. Рекомендации по проведению этого этапа даны в гл. 8. Этап 6 (вычисление оценок неизвестных параметров, входящих в исследуемое уравнение статистической связи). Итак, в результате проведения предыдущих этапов были решены, в частности, следующие задачи: а) определены результирующие и объясняющие переменные и тип исследуемой зависимости (В, С или D, см. § В.5); б) собрана и подготовлена к счету на ЭВМ исходная статистическая информация вида (В.1); в) изучены характер и теснота статистических (корреляционных) связей между исследуемыми переменными; г) выбран класс допустимых решений F, т. е. класс (или параметрическое семейство) функций f (X), в рамках которого будет подбираться наилучшая (в определенном смысле) аппроксимация Теперь можно приступать к определению этой наилучшей аппроксимации
где функционал Эта часть исследования хорошо оснащена необходимым математическим аппаратом и соответствующим программным обеспечением (см. гл. 7—10). Этап 7 (анализ точности полученных уравнений связи). Исследователь должен отдавать себе отчет в том, что найденная им в соответствии с (В.24) аппроксимация Соответственно на данном этапе приходится решать следующие основные задачи анализа точности полученной регрессионной зависимости: 1) в случае
с вероятностью, не меньшей, чем Р (здесь 2) при заданных доверительной вероятности Р, объеме выборки
с вероятностью, не меньшей, чем Р (здесь 3) при заданных доверительной вероятности
с вероятностью, не меньшей, чем Р (здесь Описанию методов анализа точности исследуемых регрессионных моделей посвящена гл. 11 настоящего издания. Заметим в заключение, что часть исследования, объединяющая этапы 4, 5, 6 и 7, принято называть регрессионным анализом.
|
 |
Оглавление
|








































































































































































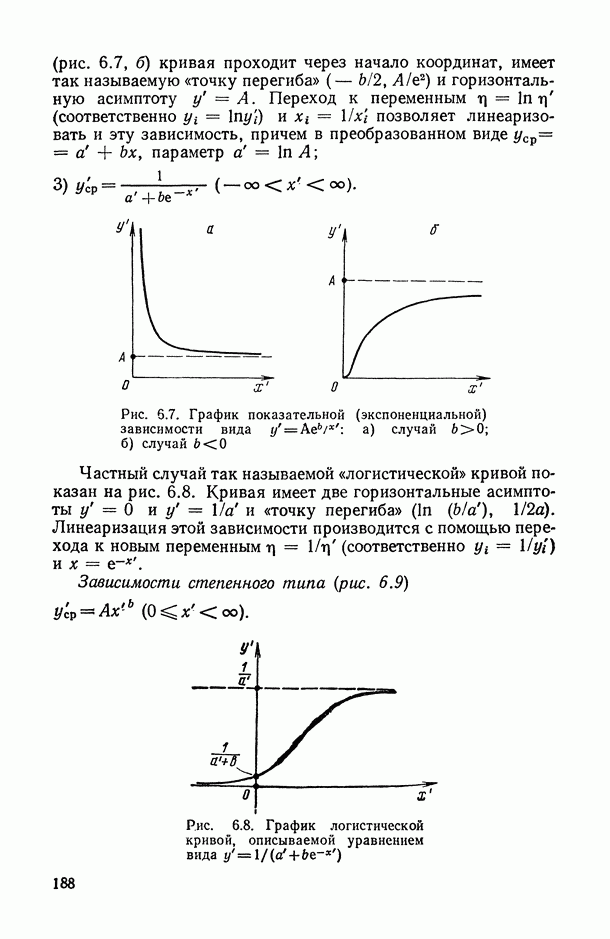
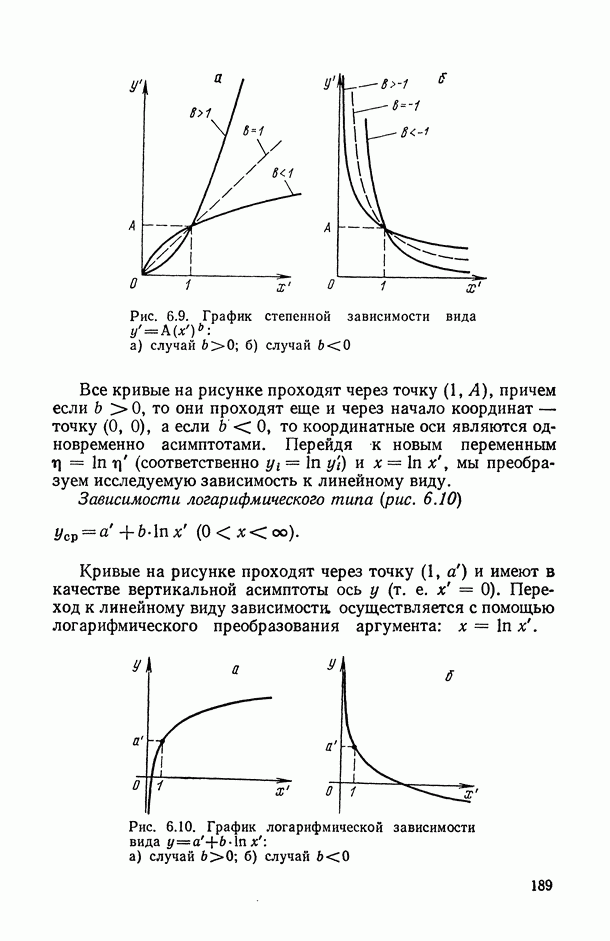


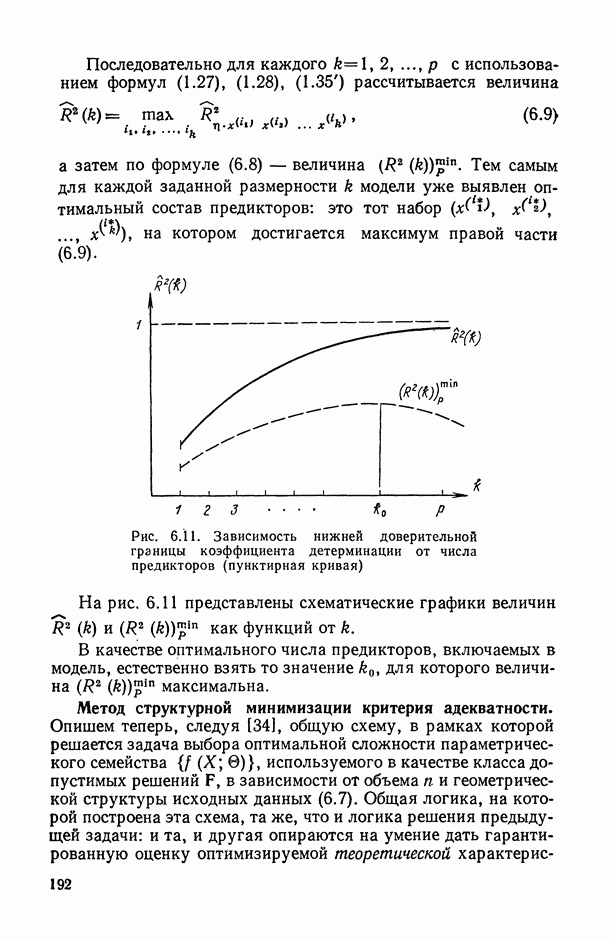




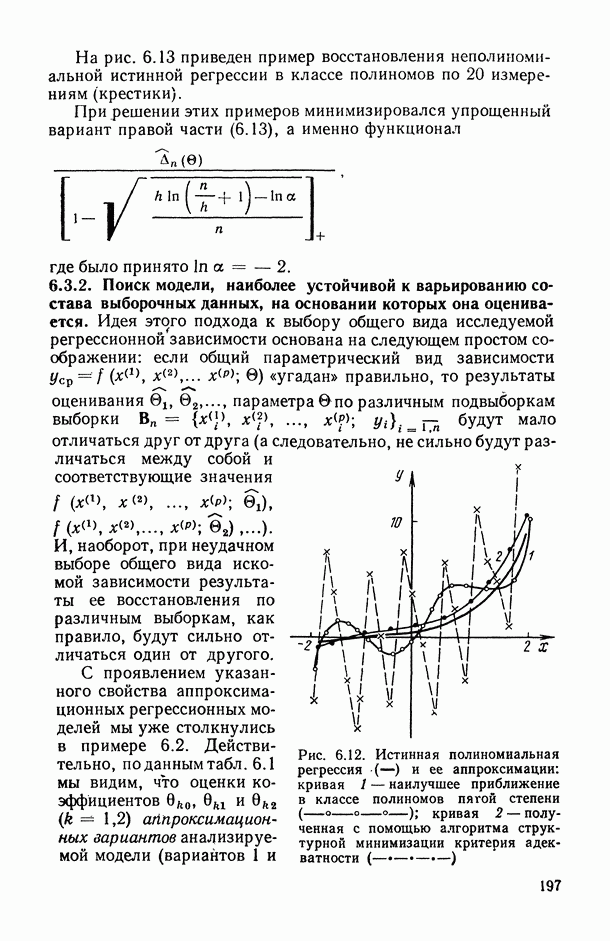
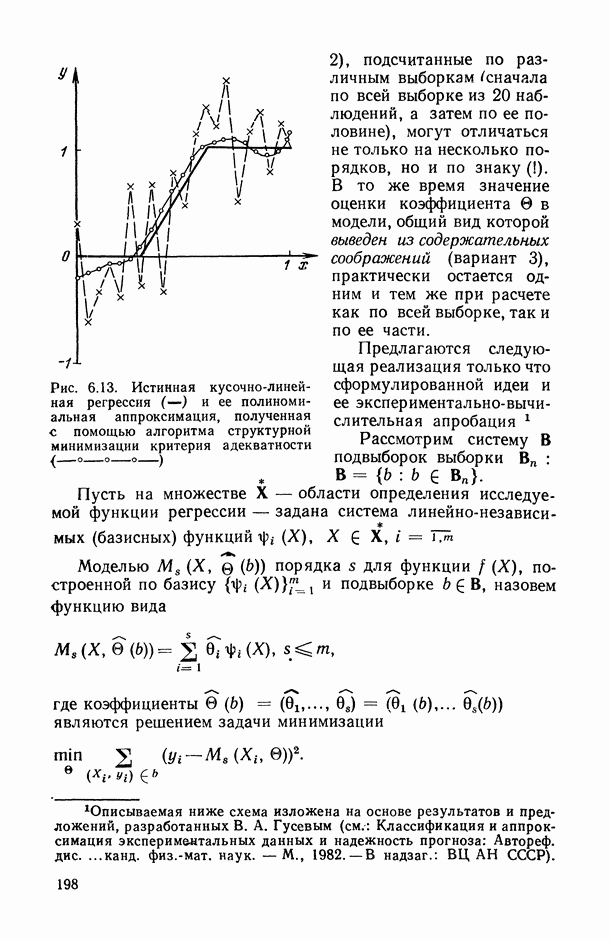


















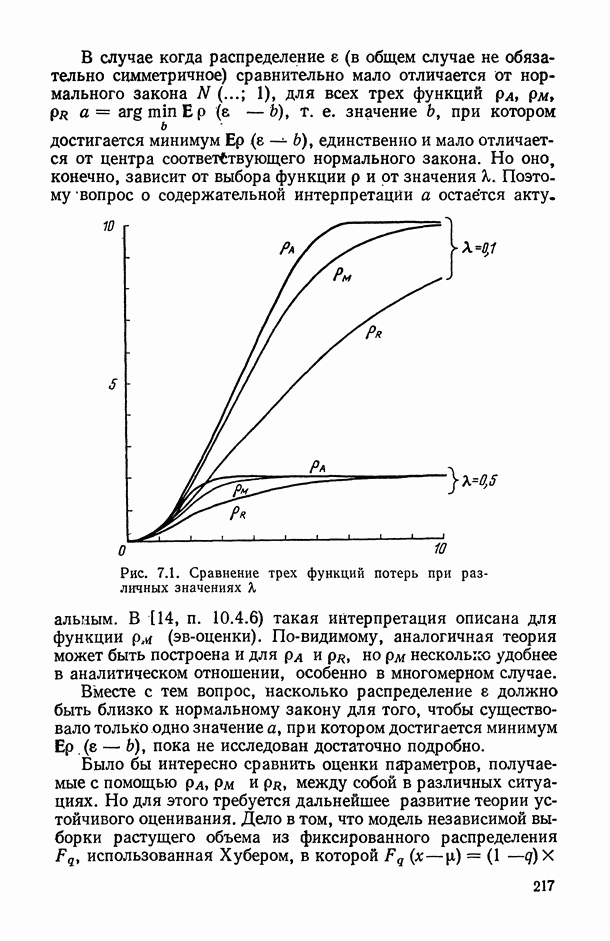


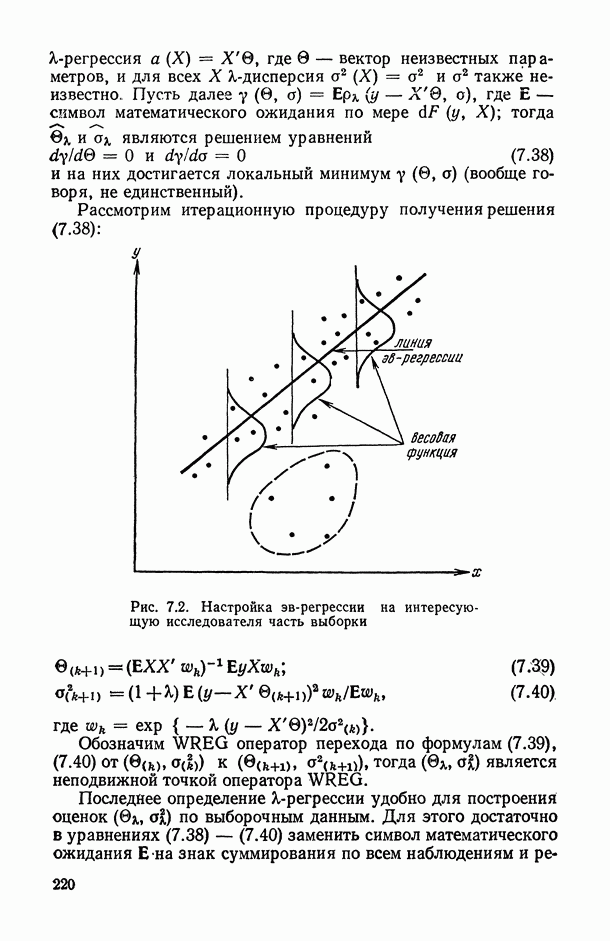










































































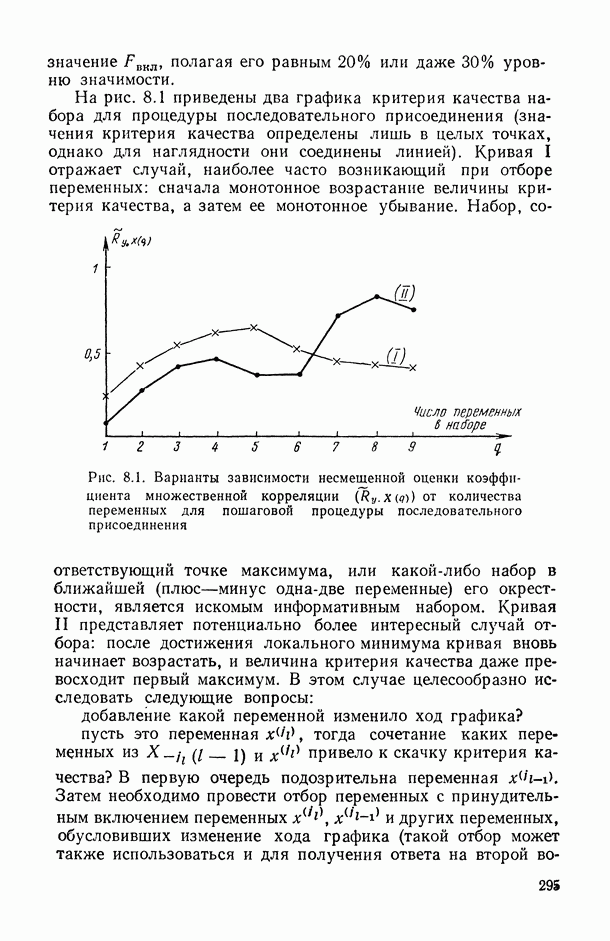






















































































































































 , регистрируемых на каждом из статистически обследованных объектов, с подразделением их на «входные» (объясняющие) и «выходные» (результирующие) и, если это необходимо, с четким определением способа их измерения; таким образом, на этом этапе каждому элементарному объекту исследования ставится в соответствие перечень анализируемых показателей, т. е.
, регистрируемых на каждом из статистически обследованных объектов, с подразделением их на «входные» (объясняющие) и «выходные» (результирующие) и, если это необходимо, с четким определением способа их измерения; таким образом, на этом этапе каждому элементарному объекту исследования ставится в соответствие перечень анализируемых показателей, т. е.

 назначить уровни их значений, при которых желательно произвести эксперимент или наблюдения (условия активного эксперимента);
назначить уровни их значений, при которых желательно произвести эксперимент или наблюдения (условия активного эксперимента);

 — общее число статистически обследованных элементарных объектов, т. е. объем выборки). Таким образом, на этом этапе решается, в частности, задача 7 из § В 1.
— общее число статистически обследованных элементарных объектов, т. е. объем выборки). Таким образом, на этом этапе решается, в частности, задача 7 из § В 1.
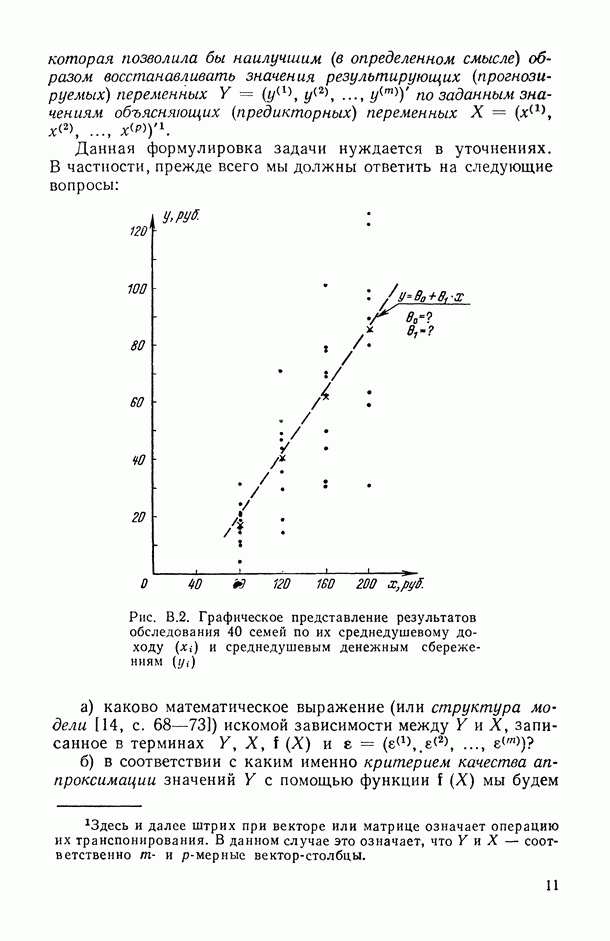
 , поэтому и этап этот называют также этапом параметризации модели. Так, определив в примере В.1, что поиск зависимости среднедушевых семейных сбережений
, поэтому и этап этот называют также этапом параметризации модели. Так, определив в примере В.1, что поиск зависимости среднедушевых семейных сбережений  от величины их среднедушевого дохода
от величины их среднедушевого дохода  мы будем производить в классе
мы будем производить в классе  линейных функций, мы тем самым завершили четвертый этап исследования (но конкретных числовых значений параметров
линейных функций, мы тем самым завершили четвертый этап исследования (но конкретных числовых значений параметров  мы к этому моменту еще не знаем).
мы к этому моменту еще не знаем).
 иследования зависимостей, этот этап в то же время находится в наименее выгодном положении по сравнению с другими этапами (с позиций наличия строгих и законченных математических рекомендаций по его реализации). Поэтому его реализация требует совместной работы специалиста соответствующей предметной области (экономики, техники, медицины и т. д.) и математика-статистика, направленной на как можно более глубокое проникновение в «физический механизм» исследуемой связи. Подходам и методам проведения этого этапа исследований посвящена гл. 6 данного издания.
иследования зависимостей, этот этап в то же время находится в наименее выгодном положении по сравнению с другими этапами (с позиций наличия строгих и законченных математических рекомендаций по его реализации). Поэтому его реализация требует совместной работы специалиста соответствующей предметной области (экономики, техники, медицины и т. д.) и математика-статистика, направленной на как можно более глубокое проникновение в «физический механизм» исследуемой связи. Подходам и методам проведения этого этапа исследований посвящена гл. 6 данного издания.
 , что, в частности, проявляется в близости к нулю (слабой обусловленности) определителя их корреляционной матрицы, т. е. матрицы размера
, что, в частности, проявляется в близости к нулю (слабой обусловленности) определителя их корреляционной матрицы, т. е. матрицы размера  , составленной из парных коэффициентов корреляции
, составленной из парных коэффициентов корреляции  ([14, с. 155], а также гл. 1—3 данного издания). Поскольку этот определитель входит в знаменатель выражений для ряда важных характеристик анализируемых моделей (см. гл. 7-И), то мультиколлинеарность создает трудности и неудобства при статистическом исследовании зависимостей по меньшей мере в двух направлениях:
([14, с. 155], а также гл. 1—3 данного издания). Поскольку этот определитель входит в знаменатель выражений для ряда важных характеристик анализируемых моделей (см. гл. 7-И), то мультиколлинеарность создает трудности и неудобства при статистическом исследовании зависимостей по меньшей мере в двух направлениях:
 ).
).
 ) или представленных в виде некоторых их комбинаций), в которой эффект мультиколлинеарности уже не имел бы места.
) или представленных в виде некоторых их комбинаций), в которой эффект мультиколлинеарности уже не имел бы места.
 искомой зависимости типа (В. 14), (В.16) или (В.20).
искомой зависимости типа (В. 14), (В.16) или (В.20).
 , которая является решением оптимизационной задачи вида
, которая является решением оптимизационной задачи вида

 задает критерий качества аппроксимации результирующего показателя
задает критерий качества аппроксимации результирующего показателя  (или Y) с помощью функции
(или Y) с помощью функции  из класса F. Выбор конкретного вида этого функционала опирается на знание вероятностной природы остатков
из класса F. Выбор конкретного вида этого функционала опирается на знание вероятностной природы остатков  в моделях типа (В. 14), (В. 16) и (В.21), причем он строится, как правило, в виде некоторой функции от невязок
в моделях типа (В. 14), (В. 16) и (В.21), причем он строится, как правило, в виде некоторой функции от невязок  , где
, где  (один из распространенных вариантов такого функционала, а именно функционал метода наименьших квадратов, упоминается в примере В.1, см. соотношение (В.7)). Если в качестве класса F задаются некоторым параметрическим семейством функций (
(один из распространенных вариантов такого функционала, а именно функционал метода наименьших квадратов, упоминается в примере В.1, см. соотношение (В.7)). Если в качестве класса F задаются некоторым параметрическим семейством функций ( то задача (В.24) сводится к подбору (статистическому оцениванию) значений параметров
то задача (В.24) сводится к подбору (статистическому оцениванию) значений параметров  , на которых достигается экстремум по
, на которых достигается экстремум по  функционала
функционала  )), а соответствующие модели называют параметрическими.
)), а соответствующие модели называют параметрическими.
 неизвестной теоретической функции
неизвестной теоретической функции  из соотношений типа (В.14), (В.16) или (В.21) (называемая эмпирической функцией регрессии, см. гл. 5) является лишь некоторым приближением истинной зависимости
из соотношений типа (В.14), (В.16) или (В.21) (называемая эмпирической функцией регрессии, см. гл. 5) является лишь некоторым приближением истинной зависимости  При этом погрешность
При этом погрешность  в описании неизвестной истинной функции
в описании неизвестной истинной функции  с помощью
с помощью  в общем случае состоит из двух составляющих: а) ошибки аппроксимации
в общем случае состоит из двух составляющих: а) ошибки аппроксимации  и б) ошибки выборки
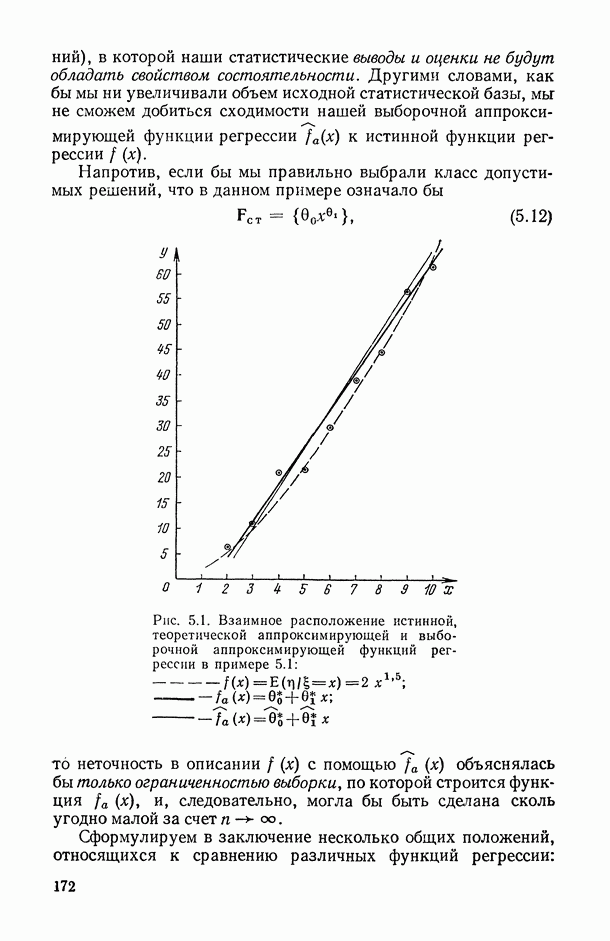
и б) ошибки выборки  Величина первой зависит от успеха в реализации этапа 4, т. е. от правильности выбора класса допустимых решений F. В частности, если класс F выбран таким образом, что включает в себя и неизвестную истинную функцию f (т. е.
Величина первой зависит от успеха в реализации этапа 4, т. е. от правильности выбора класса допустимых решений F. В частности, если класс F выбран таким образом, что включает в себя и неизвестную истинную функцию f (т. е.  ), то ошибка аппроксимации
), то ошибка аппроксимации  Но даже в этом случае остается случайная составляющая (ошибка выборки)
Но даже в этом случае остается случайная составляющая (ошибка выборки)  обусловленная ограниченностью выборочных данных вида (В.1), на основании которых мы подбираем функцию f(X) (оцениваем ее параметры). Очевидно, уменьшить ошибку выборки мы можем за счет увеличения объема
обусловленная ограниченностью выборочных данных вида (В.1), на основании которых мы подбираем функцию f(X) (оцениваем ее параметры). Очевидно, уменьшить ошибку выборки мы можем за счет увеличения объема  обрабатываемых выборочных данных, так как при
обрабатываемых выборочных данных, так как при  (т. е. при
(т. е. при  и правильно выбранных методах статистического оценивания (т. е. при правильном выборе оптимизируемого функционала качества модели
и правильно выбранных методах статистического оценивания (т. е. при правильном выборе оптимизируемого функционала качества модели  ) ошибка выборки
) ошибка выборки  (по вероятности) при
(по вероятности) при  (свойство состоятельности используемой процедуры статистического оценивания неизвестной функции
(свойство состоятельности используемой процедуры статистического оценивания неизвестной функции 
 , т. е. когда класс допустимых решений задается параметрическим семейством функций и включает в себя неизвестную теоретическую функцию регрессии
, т. е. когда класс допустимых решений задается параметрическим семейством функций и включает в себя неизвестную теоретическую функцию регрессии  , при заданных доверительной вероятности Р и объеме выборки
, при заданных доверительной вероятности Р и объеме выборки  указать такую предельную (гарантированную) величину погрешности
указать такую предельную (гарантированную) величину погрешности  для любой компоненты неизвестного векторного параметра
для любой компоненты неизвестного векторного параметра  , что
, что

 — истинное значение
— истинное значение  компоненты неизвестного параметра
компоненты неизвестного параметра  , а
, а  — его статистическая оценка);
— его статистическая оценка);
 и значениях объясняющих переменных X указать такую предельную (гарантированную) величину погрешности
и значениях объясняющих переменных X указать такую предельную (гарантированную) величину погрешности  ), что
), что

 )
)  — неизвестное условное среднее значение исследуемого результирующего показателя при значениях объясняющих переменных, равных X, a
— неизвестное условное среднее значение исследуемого результирующего показателя при значениях объясняющих переменных, равных X, a  — построенная в соответствии с
— построенная в соответствии с  эмпирическая функция регрессии);
эмпирическая функция регрессии);
 , объеме выборки
, объеме выборки  и значениях объясняющих переменных X указать такую предельную (гарантированную) величину погрешности
и значениях объясняющих переменных X указать такую предельную (гарантированную) величину погрешности  ), что
), что

 — прогнозируемое индивидуальное значение исследуемого результирующего показателя при значениях объясняющих переменных, равных X).
— прогнозируемое индивидуальное значение исследуемого результирующего показателя при значениях объясняющих переменных, равных X).