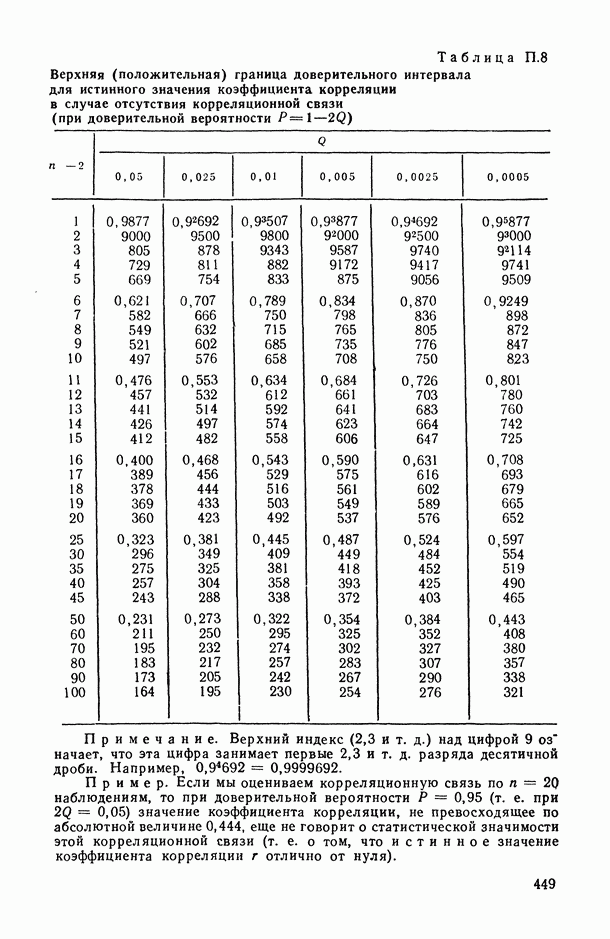
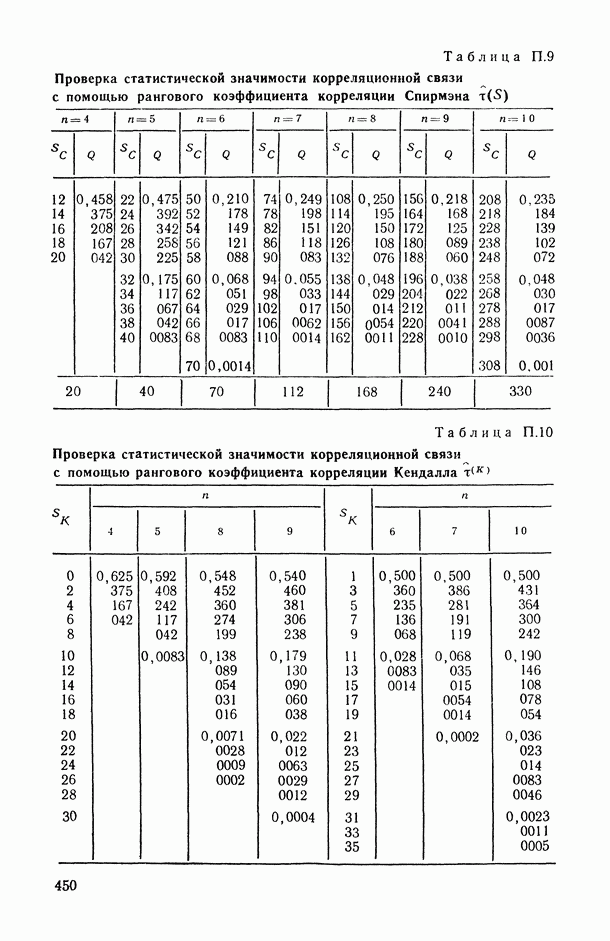
Пред.
След.
Макеты страниц
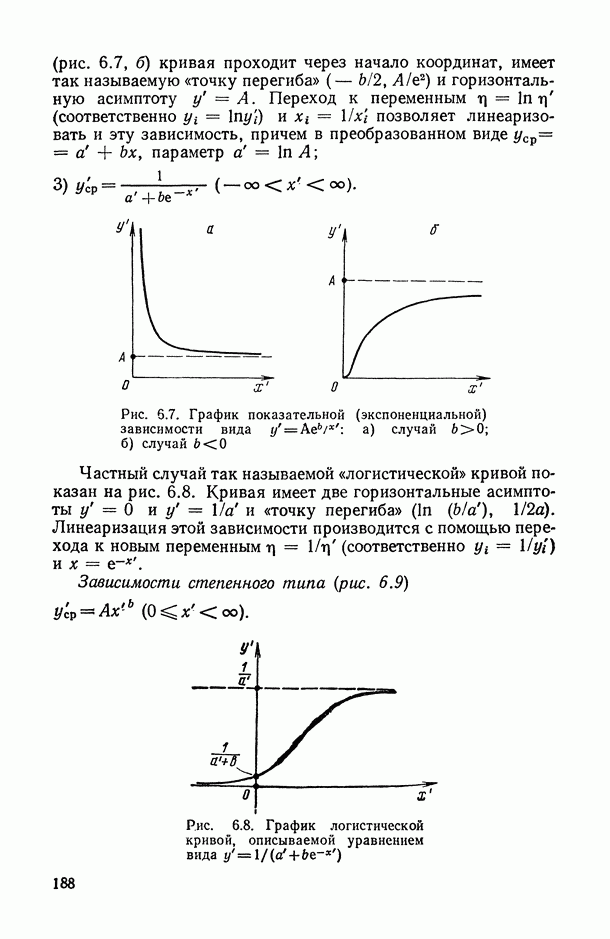
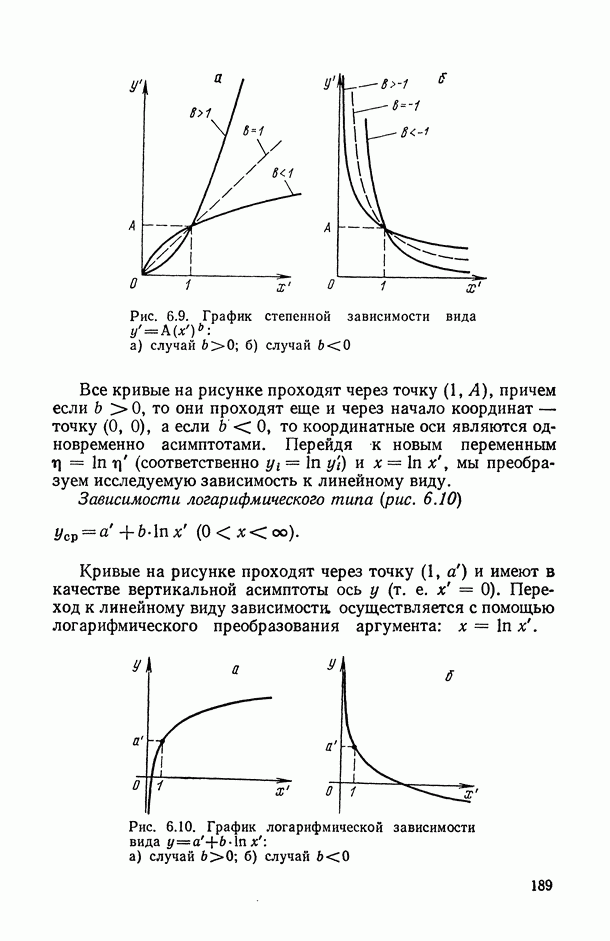
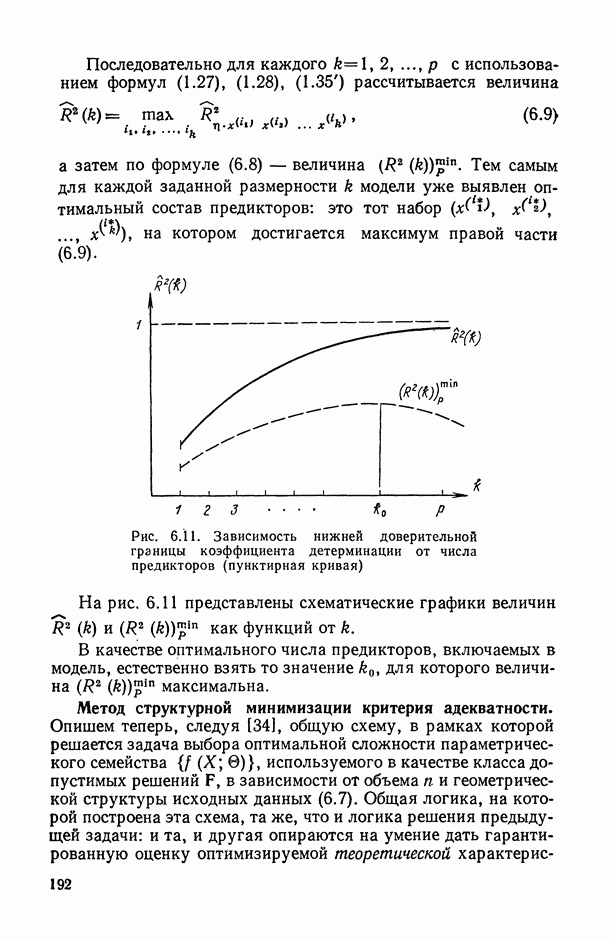
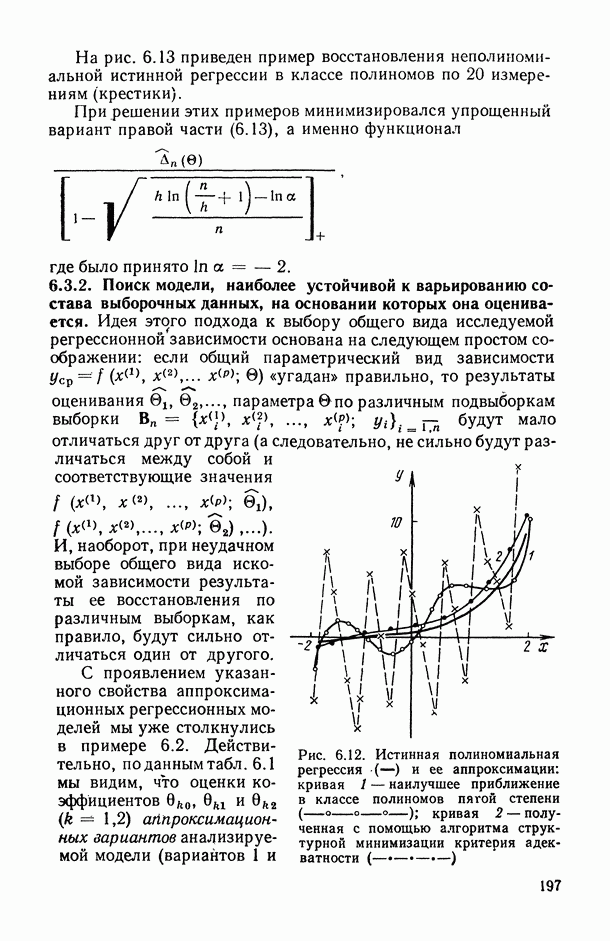
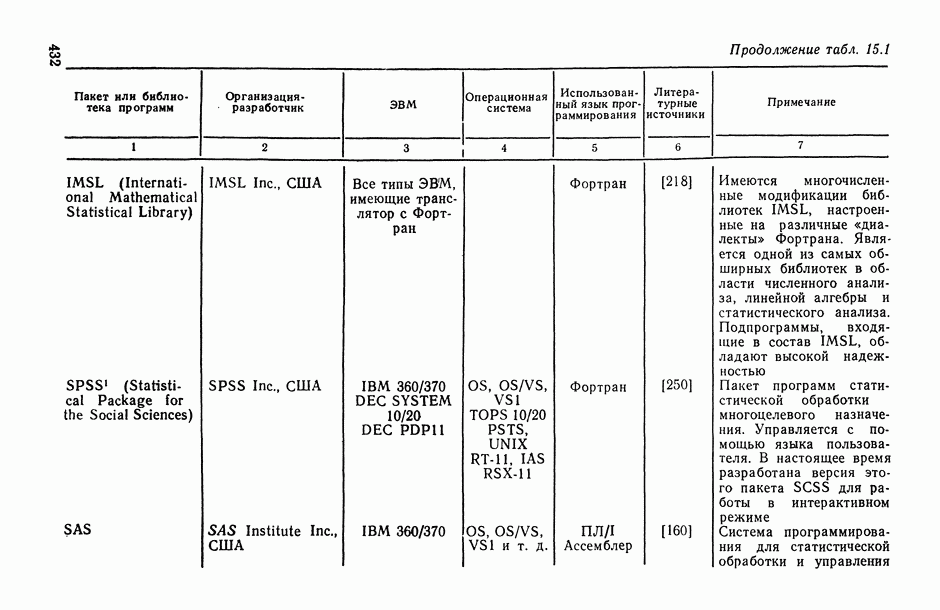
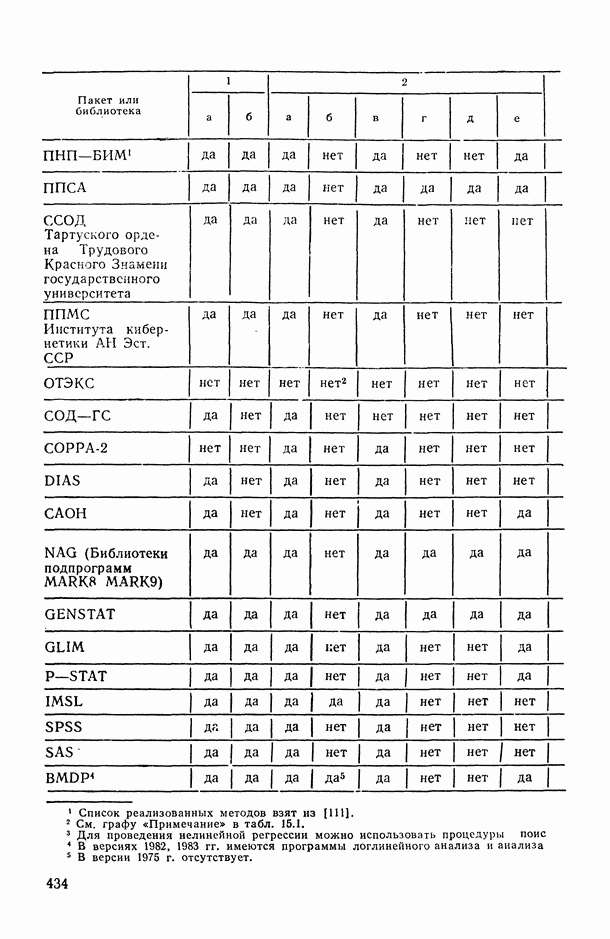
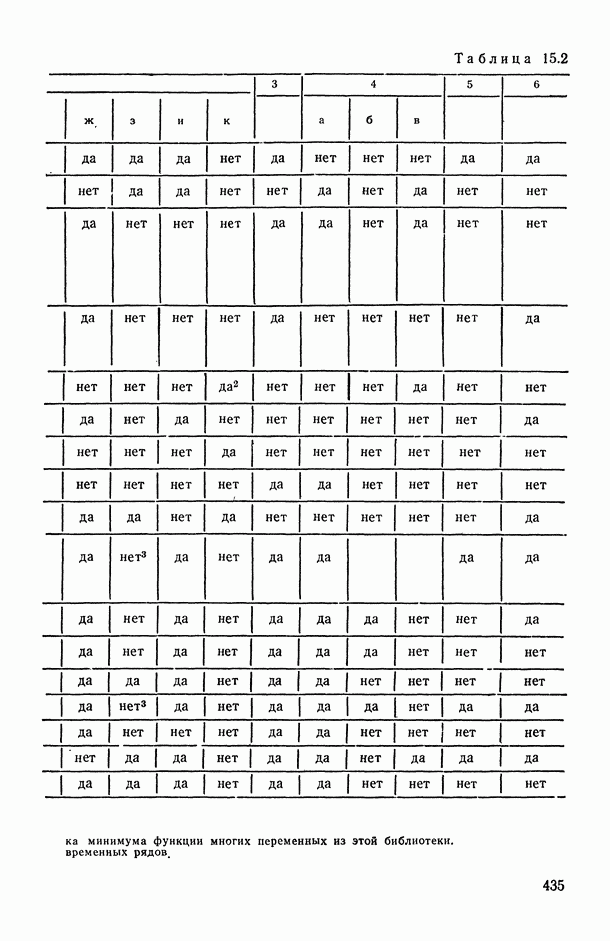
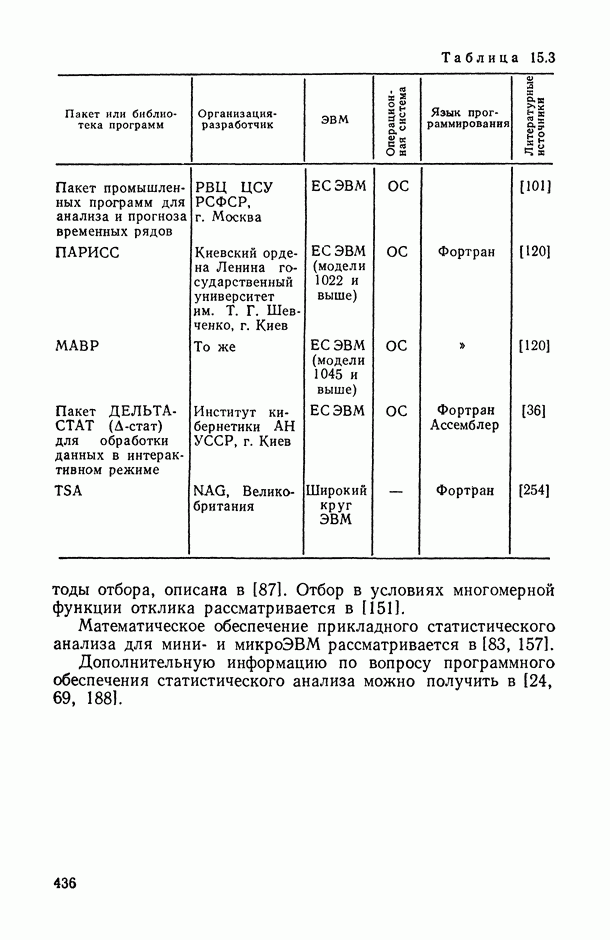
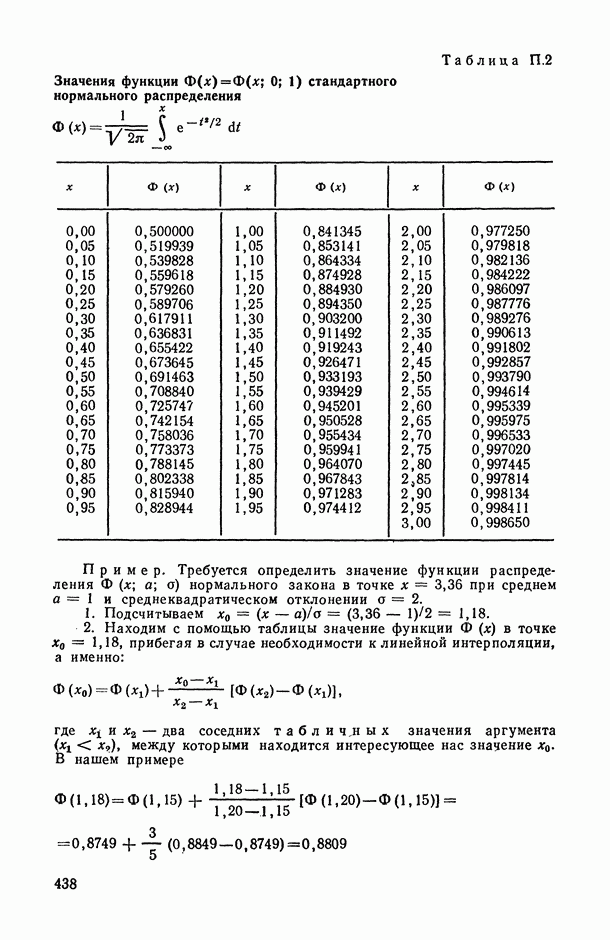
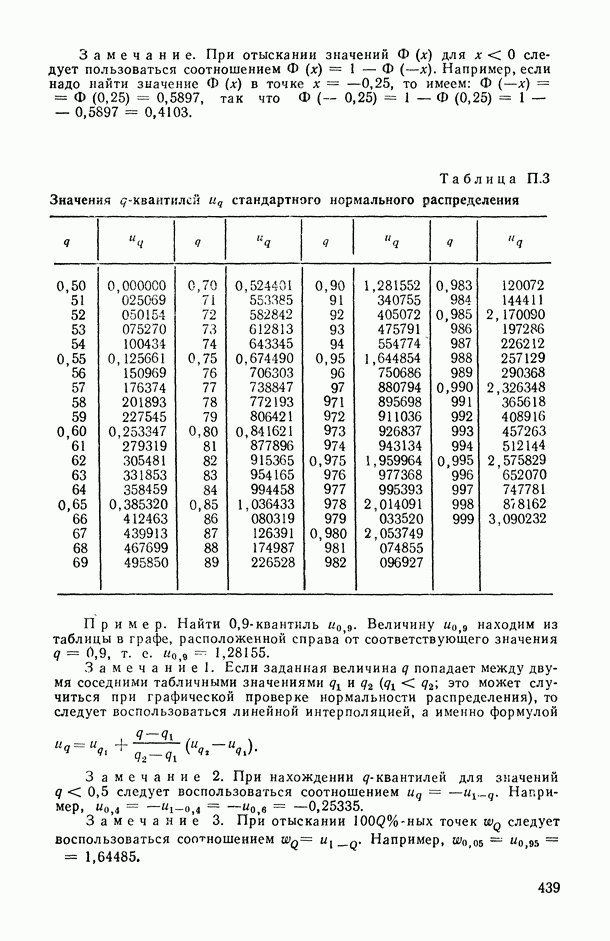
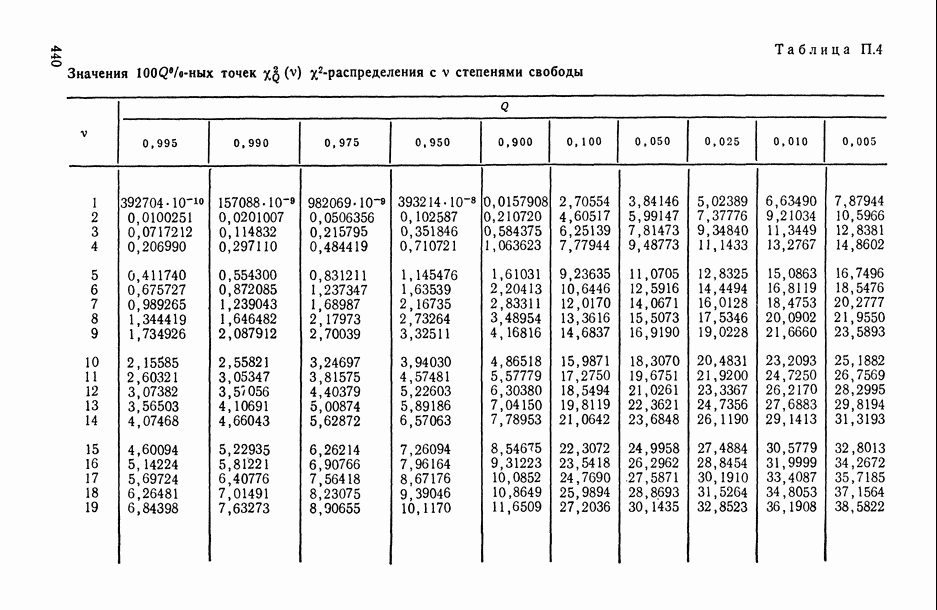
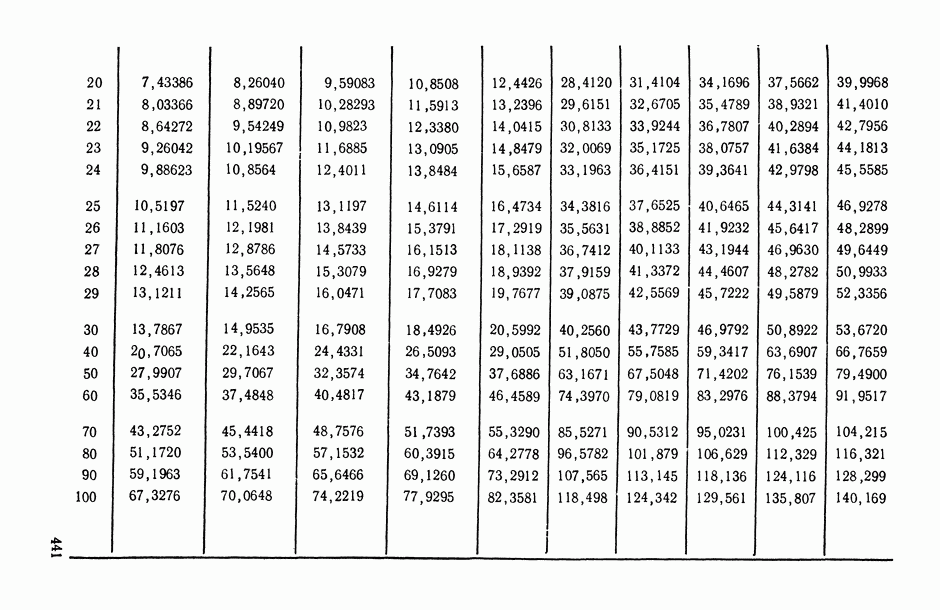
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
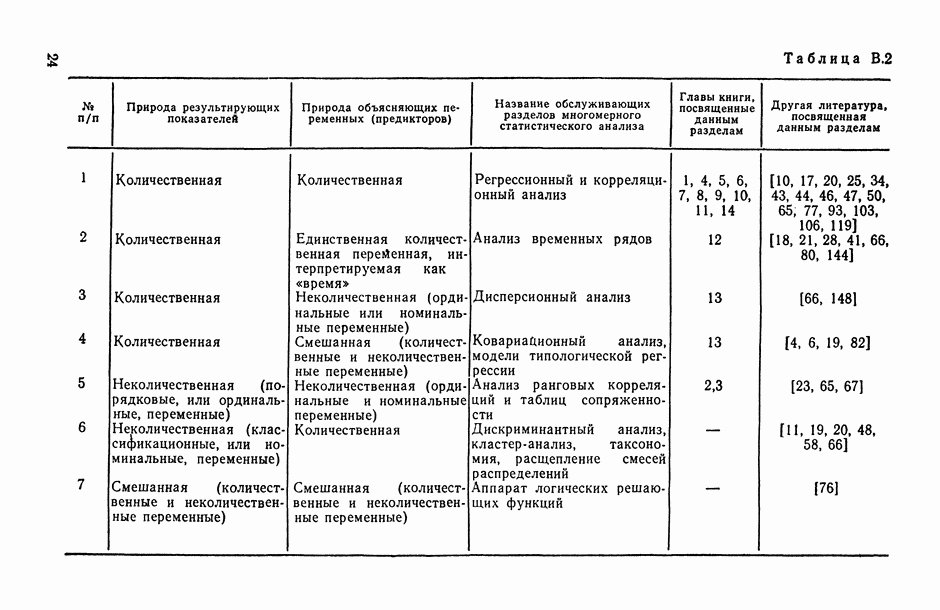
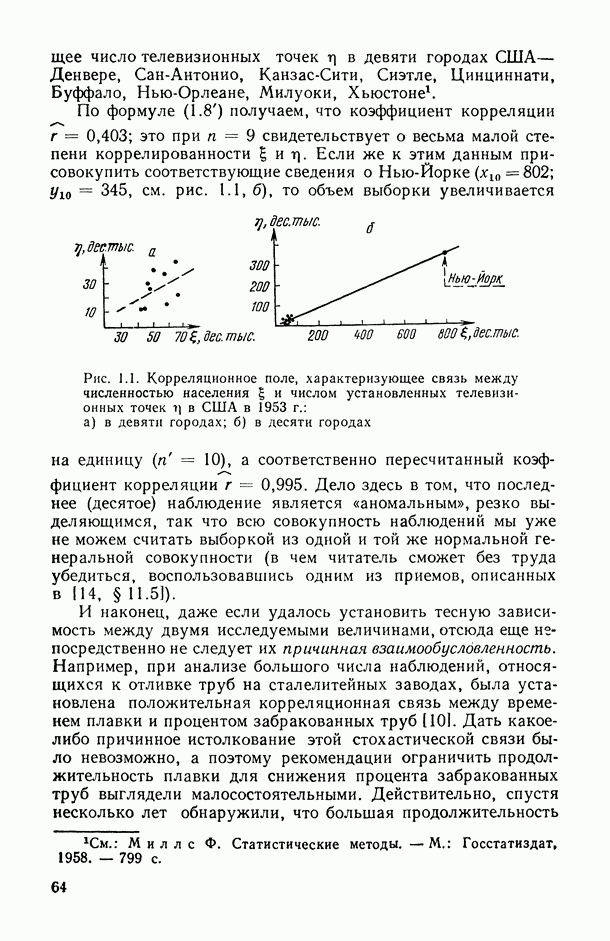
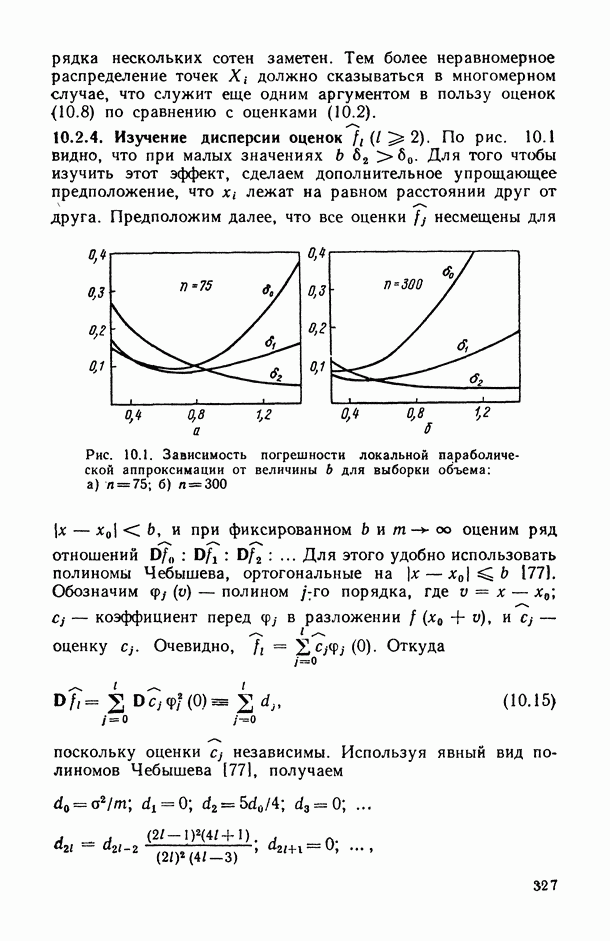
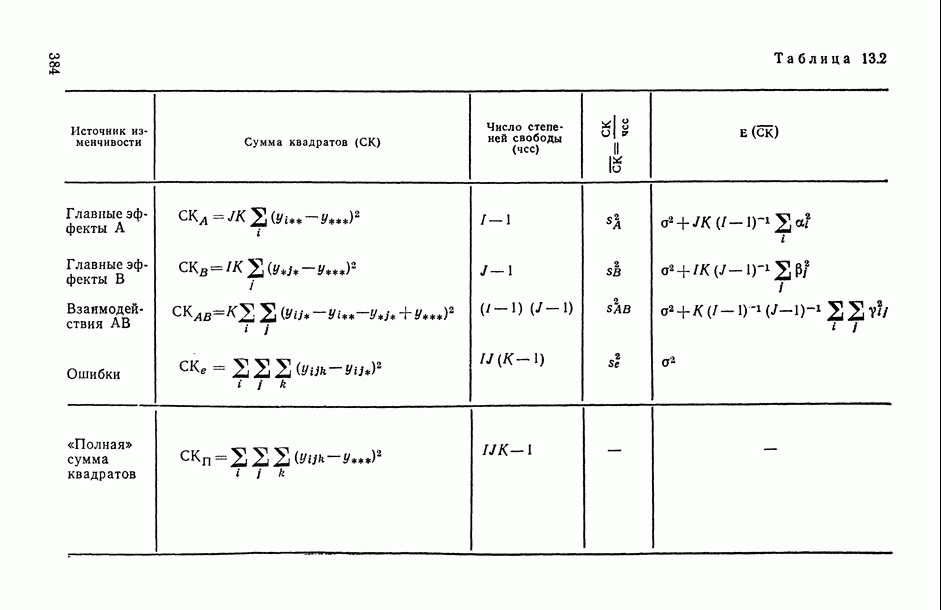
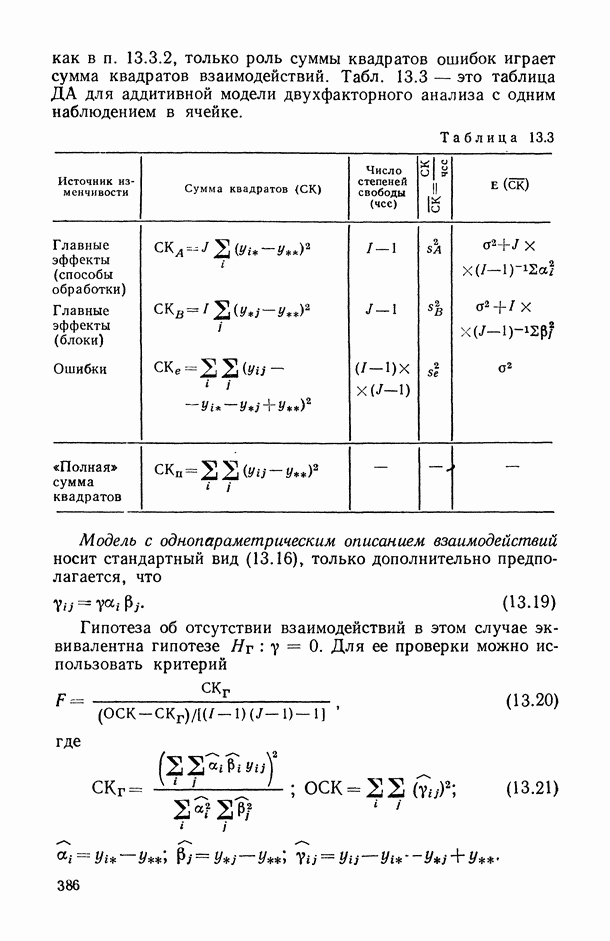
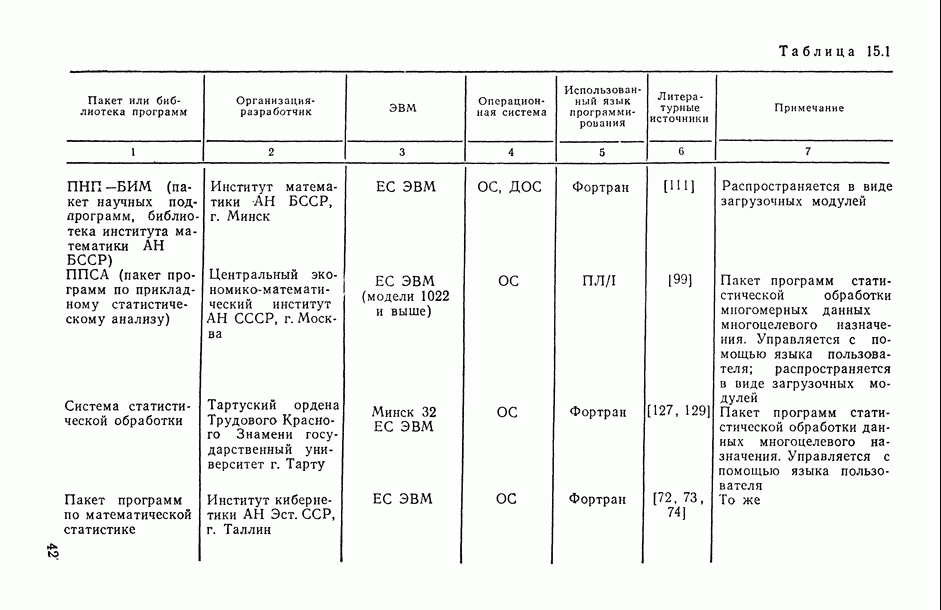
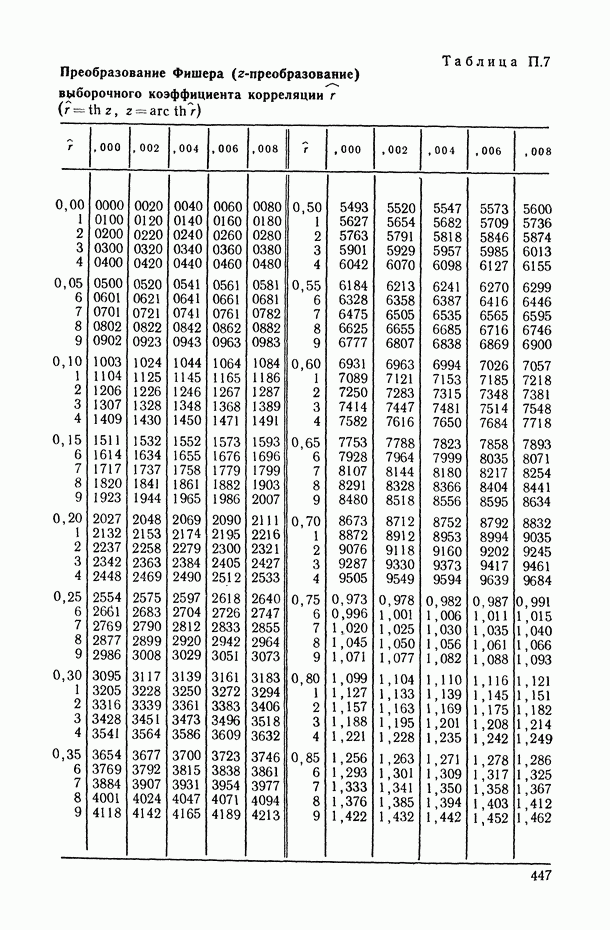
Введение. СТАТИСТИЧЕСКОЕ ИССЛЕДОВАНИЕ ЗАВИСИМОСТЕЙ СОДЕРЖАНИЕ, ЗАДАЧИ, ОБЛАСТИ ПРИМЕНЕНИЯВ.1. Предварительное обсуждение задачЛюбой закон природы или общественного развития может быть выражен в конечном счете в виде описания характера или структуры взаимосвязей (зависимостей), существующих между изучаемыми явлениями или показателями (переменными величинами или просто переменными). Если эти зависимости: а) сто-хаотичны по своей природе, т. е. позволяют устанавливать лишь вероятностные логические соотношения между изучаемыми событиями А и 5, а именно соотношения типа «из факта осуществления события А следует, что событие В должно произойти, но не обязательно, а лишь с некоторой (как правило, близкой к единице) вероятностью Р»; б) выявляются на основании статистического наблюдения за анализируемыми событиями или переменными, осуществляемого по выборке из интересующей нас генеральной совокупности [14, п. 5.4.2], то мы оказываемся в рамках проблемы статистического исследования зависимостей. Соответствующий математический аппарат, будучи таким образом нацеленным в первую очередь на решение основной проблемы естествознания: как по отдельным, частным наблюдениям выявить и описать интересующую нас общую закономерность? — занимает, бесспорно, центральное место во всем прикладном математическом анализе. Перед тем как перейти к формулировке общей и частных задач статистического исследования зависимостей, условимся описывать функционирование изучаемого реального объекта (системы, процесса, явления) набором переменных (рис. В.1), среди которых:
Рис. В.1. Общая схема взаимодействия переменных при статистическом исследовании зависимостей Тогда общая задача статистического исследования зависимостей (в терминах изучаемых показателей) может быть сформулирована следующим образом: по результатам
исследуемых переменных на объектах (системах, процессах) анализируемой совокупности построить такую (векторнозначную) функцию
которая позволила бы наилучшим (в определенном смысле) образом восстанавливать значения результирующих (прогнозируемых) переменных
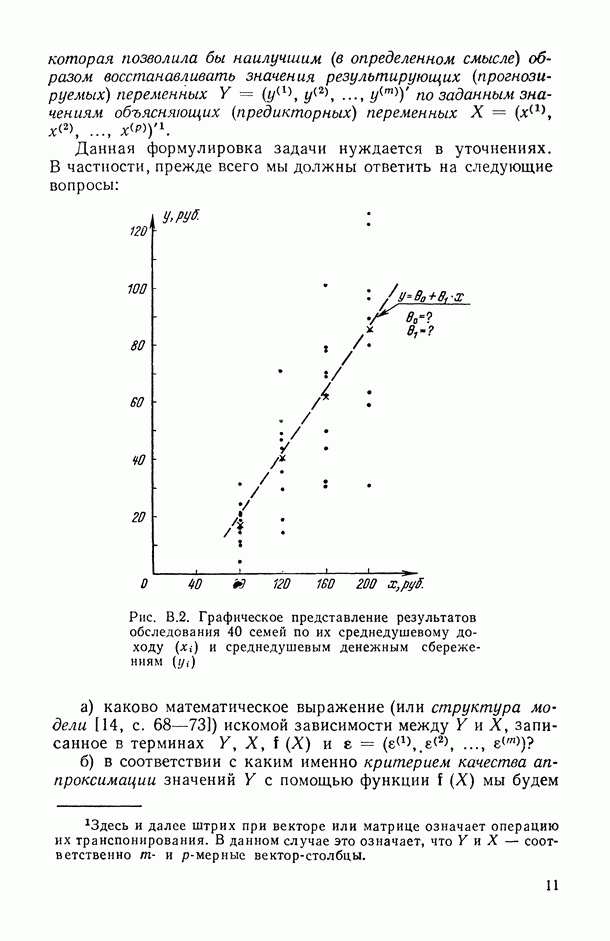
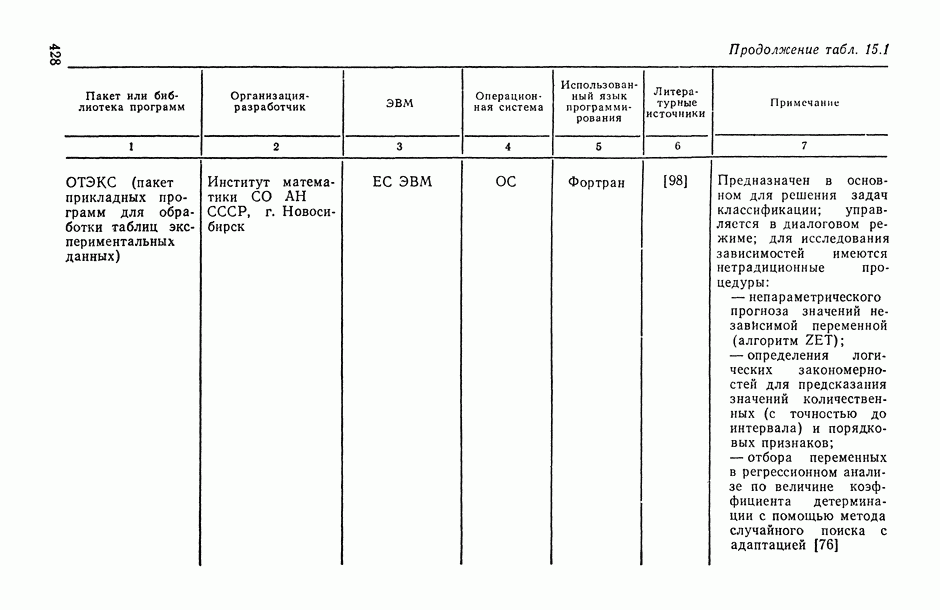
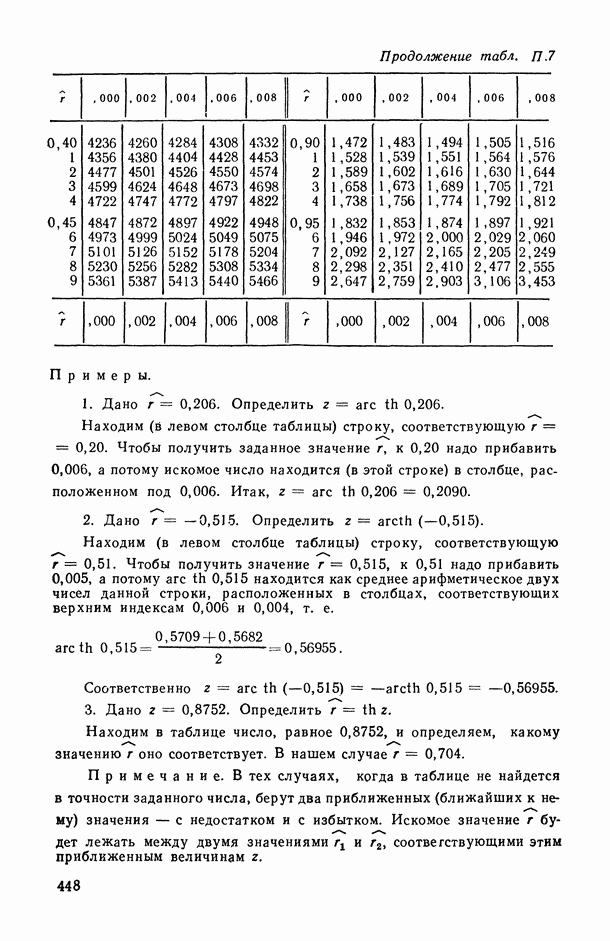
Рис. В.2. Графическое представление результатов обследования 40 семей по их среднедушевому доходу Данная формулировка задачи нуждается в уточнениях. В частности, прежде всего мы должны ответить на следующие вопросы: а) каково математическое выражение (или структура модели [14, с. 68—73]) искомой зависимости между Y и X, записанное в терминах Y, X, б) в соответствии с каким именно критерием качества аппроксимации значений У с помощью функции в) с какой именно прикладной целью мы проводим все наше исследование, т. е. для решения каких конкретных задач мы собираемся использовать построенную в результате исследования функцию Прежде чем обсуждать эти вопросы, рассмотрим пример. Пример В.1. Анализируется «поведение» двумерной случайной величины Мы видим, что даже в пределах каждой из этих групп величины среднедушевых сбережений семей подвержены некоторому неконтролируемому разбросу, обусловленному влиянием множества не поддающихся строгому учету и контролю факторов (т. е. налицо упомянутый выше стохастический характер зависимости между х и у). Однако это еще не значит, что расположение точек 1. Как исходя из конкретных прикладных целей исследования определить смысл, в котором понимается исследуемая зависимость? (В.2, § 5.3.) 2. Имеется ли вообще какая-либо связь между исследуемыми переменными (а в случае многих переменных — какова структура этих связей?) и как измерить тесноту этой связи? (Гл. 1-4.) 3. Каков общий математический вид искомой связи между 4. Как, отправляясь от принятой общей структуры модели, провести необходимую вычислительную обработку исходных данных (В.1) с целью получения конкретного вида зависимости 5. Поскольку наши выводы основаны на обработке ограниченного ряда наблюдений, то их количественные характеристики, естественно, подвержены (при повторениях соответствующих выборочных обследований) некоторому случайному разбросу. Как оценить степень точности наших выводов? (Гл. 11.) 6. Как решать все вопросы в ситуациях, когда среди объясняющих (предикторных) переменных могут быть и неколичественные? (Гл. 13.) 7. И наконец, если при сборе исходной статистической информации мы находимся в условиях активного эксперимента [14, с. 121, то как, при заданных затратах на наблюдения, оптимально выбрать матрицу плана [14, с. 26, 68], т. е. как определить те значения объясняющих (предикторных) переменных и то распределение заданного общего числа наблюдений между этими значениями, которые являются в некотором смысле наиболее выгодными с точки зрения достижения наивысшей точности наших статистических выводов? Вернемся к нашему примеру и попробуем ответить на некоторые из поставленных здесь вопросов, в том числе на принципиальные вопросы а), б) и в), ответы на которые позволяют уточнить общую формулировку задачи статистического исследования зависимостей, данную выше. Начнем «с конца», т. е. с уточнения конечных прикладных целей исследования (см. вопросы 1, а также а) и в)). Известно, что из двух анализируемых характеристик материальной сосостоятельности семьи характеристика денежных сбережений Таблица В.1
Поэтому главной конечной целью нашего исследования (опирающегося, как мы будем всегда предполагать, на достоверную и репрезентативную выборку исходных данных) является возможность восстановления (прогноза): удельной (т. е. в расчете на одного члена семьи за определенный отрезок времени) величины денежных сбережений в конкретной семье (у(x)) по заданному значению ее среднедушевого дохода удельной величины средних денежных сбережений Таблица B.l
Этой цели мы сможем достигнуть, если сумеем математически описать закономерность изменения условных теоретических средних значений Это естественным образом приводит нас к необходимости рассмотрения математической модели вида
в которой остаточная компонента Таким образом, из (В.3) мы непосредственно получаем
Чтобы покончить с вопросами 1, а) и в), остается уточнить общую структуру модели, т. е. определить, в каком классе F функций В нашем случае, учитывая однородный (по характеру потребительского поведения) состав исследуемой совокупности семей, естественно исходить из гипотезы об одинаковой (в среднем) склонности семей к сбережениям, выражающейся, в частности, в том, что все семьи начиная с некоторого «порогового» уровня дохода, склонны отделять в сбережения в среднем одинаковую долю дохода. Математически, как легко понять, это выразится в виде
где
где под Такой выбор «класса допустимых решений» И наконец, следует уточнить, в соответствии с каким именно критерием качества аппроксимации неизвестных величин среднедушевых семейных денежных сбережений у
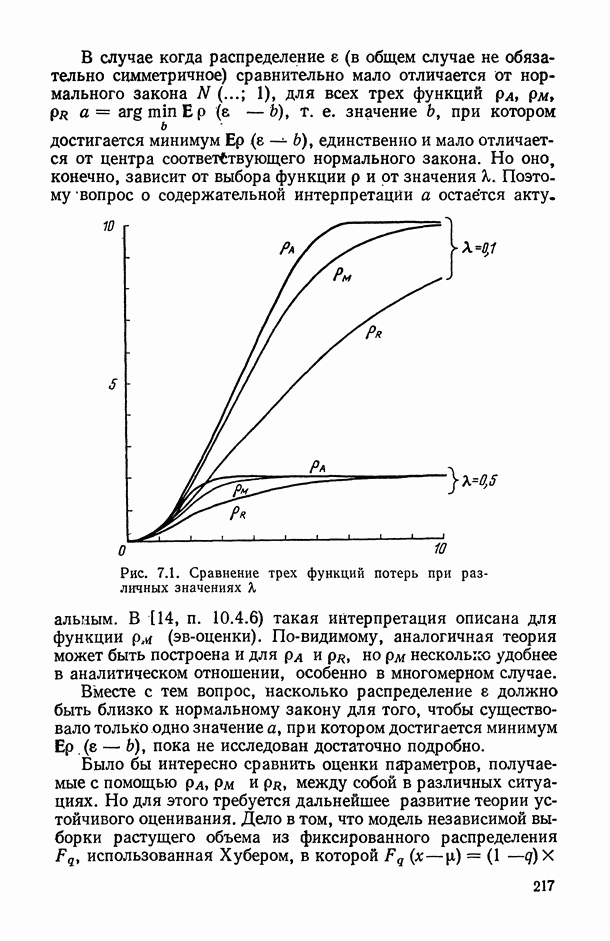
В нашем примере явно нарушено условие постоянства дисперсии остатков (см. табл. В.1), т. е. условная дисперсия Тогда можно показать (с помощью методов, описанных, например, в [14, § 11.1]), что гипотеза о
т. е. к системе из двух линейных уравнений с двумя неизвестными
Решение системы (В.7") дает нам в качестве оценок
Расчет по этим формулам с использованием данных табл. В.1 дает нам решение задачи 4:
так что статистическая оценка искомой зависимости средней величины среднедушевых семейных сбережений
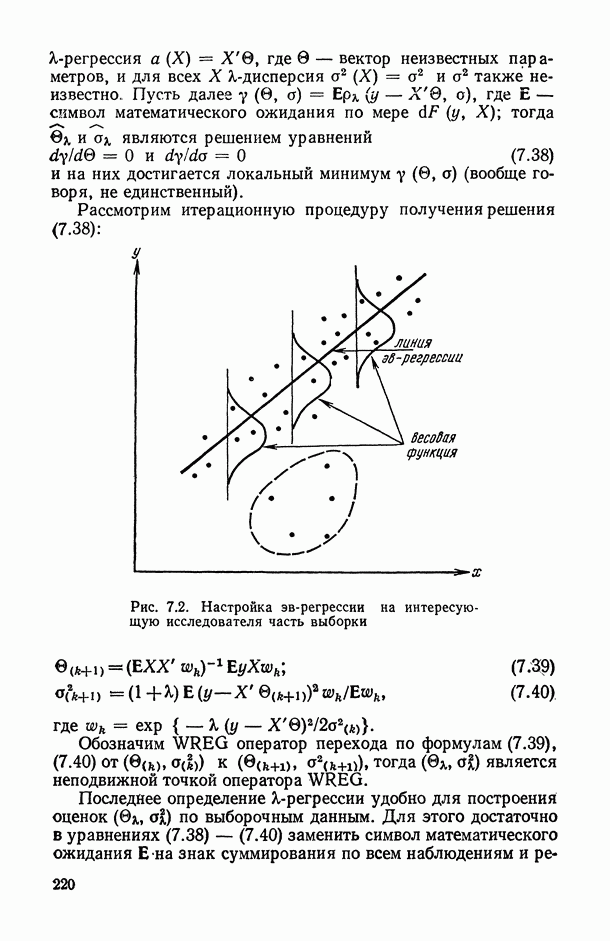
При другой статистической природе остатков 8 или при отсутствии достаточной информации о типе их вероятностного распределения возможен иной, чем по Заканчивая обсуждение примера
|
 |
Оглавление
|

































































































































































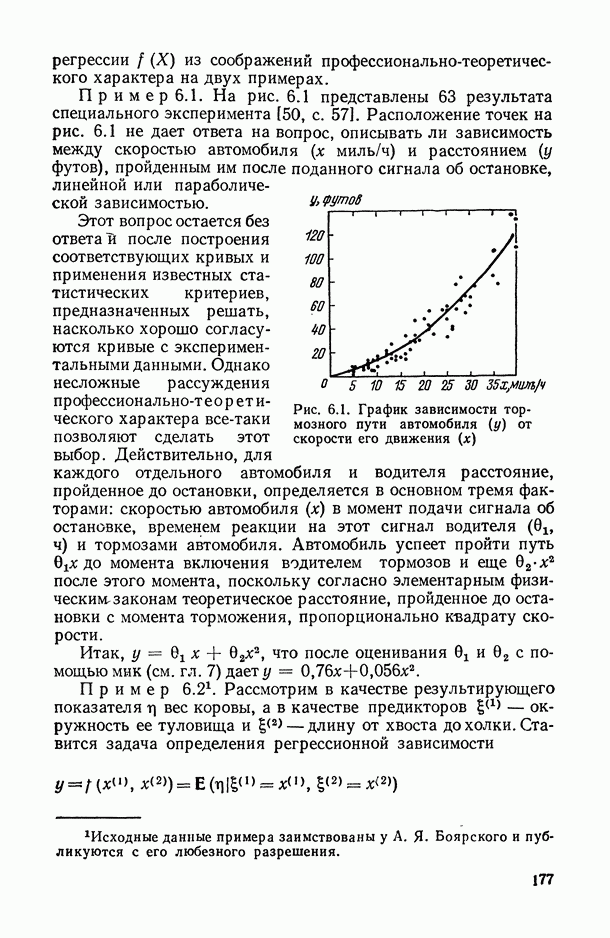




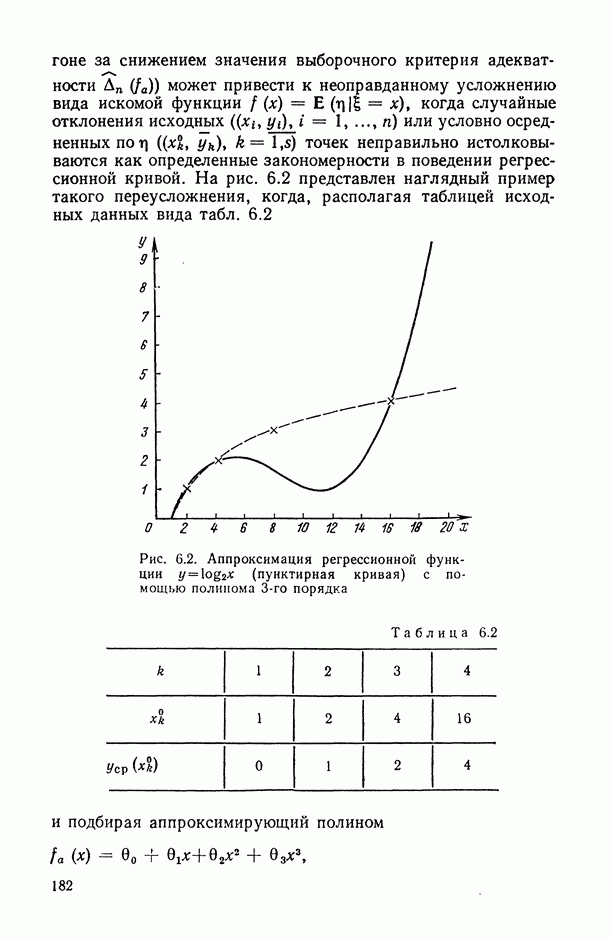



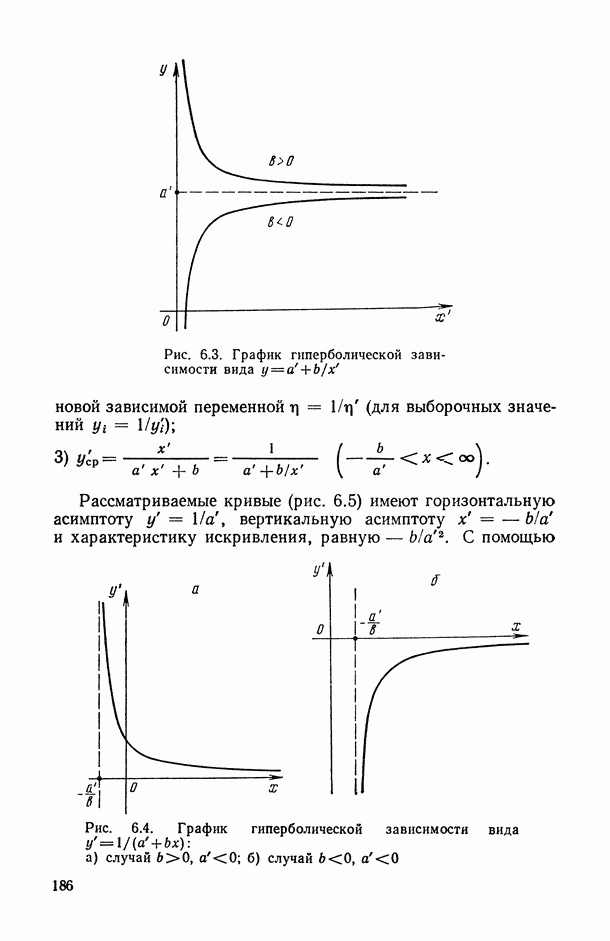
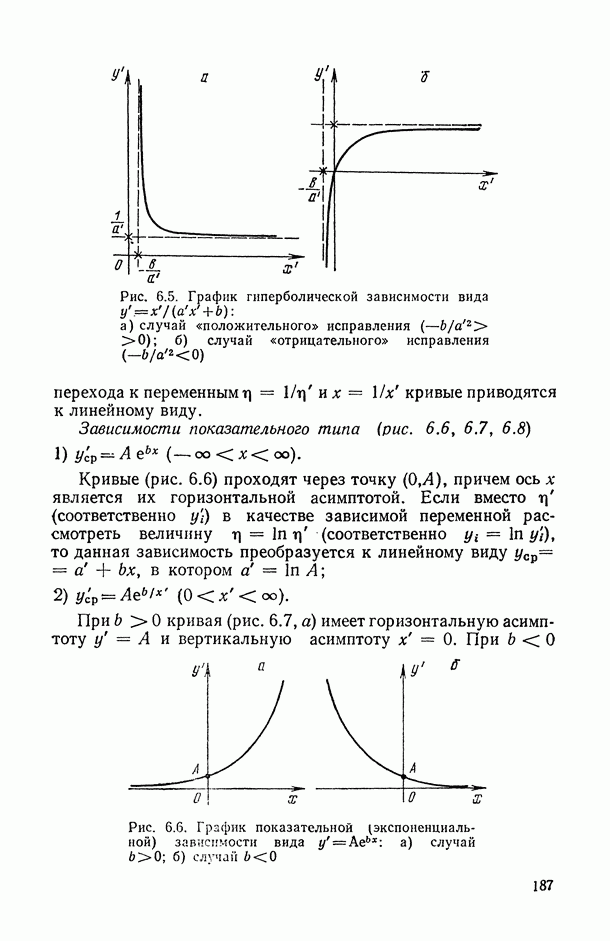






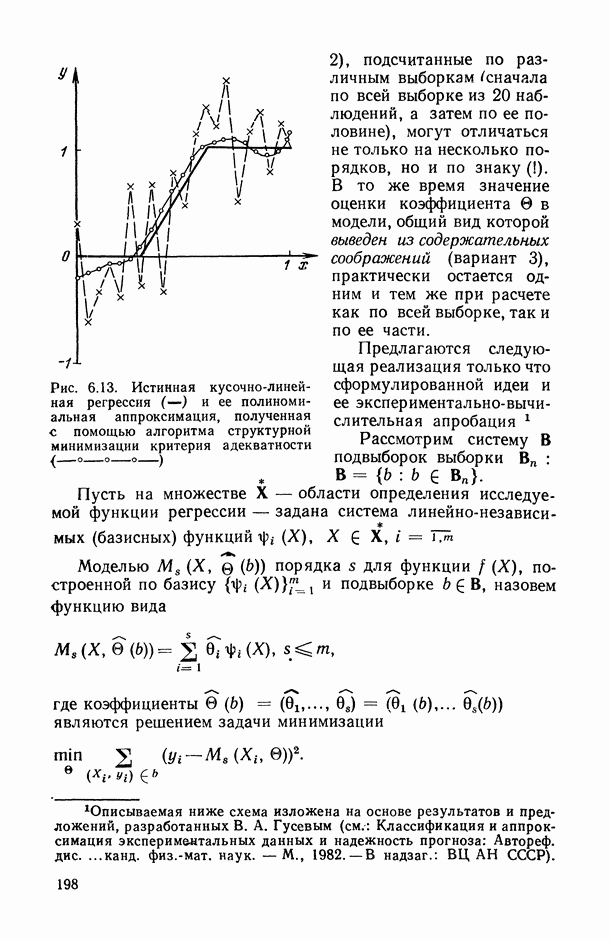

































































































































































































































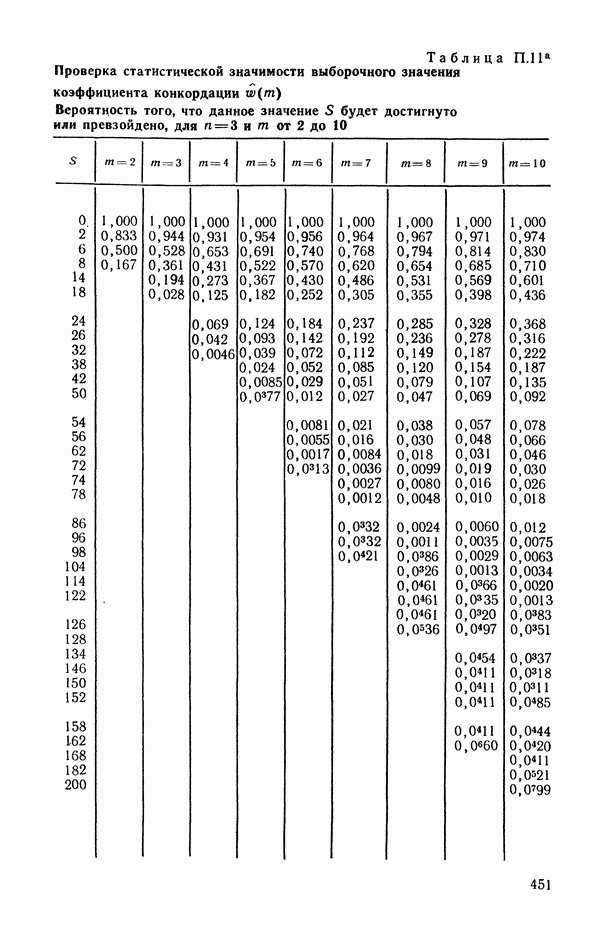
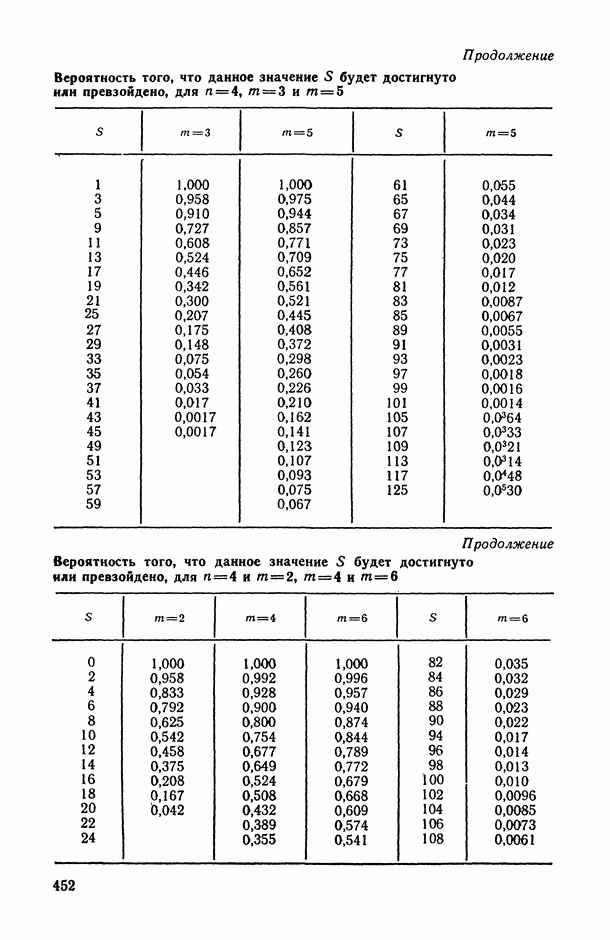
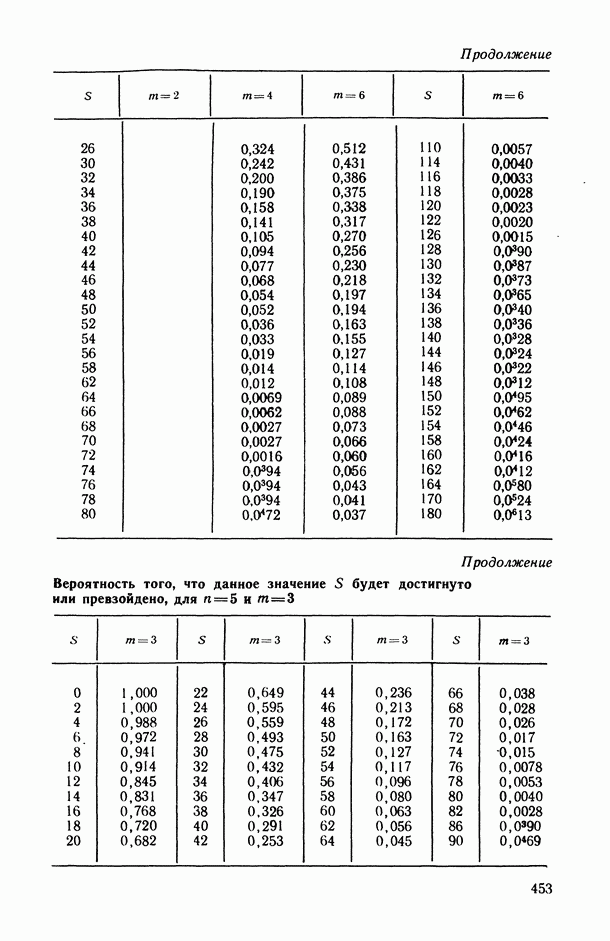


















 — так называемые «входные» переменные, описывающие условия функционирования (часть из них, как правило, поддается регулированию или частичному управлению); в соответствующих математических моделях их называют независимыми, факторами-аргументами, экзогенными, предикторными (или просто предикторами, т. е. предсказателями), объясняющими (в книге мы будем использовать в основном два последних термина);
— так называемые «входные» переменные, описывающие условия функционирования (часть из них, как правило, поддается регулированию или частичному управлению); в соответствующих математических моделях их называют независимыми, факторами-аргументами, экзогенными, предикторными (или просто предикторами, т. е. предсказателями), объясняющими (в книге мы будем использовать в основном два последних термина);
 — выходные переменные, характеризующие поведение или результат (эффективность) функционирования; в математических моделях их называют зависимыми, откликами, эндогенными, результирующими или объясняемыми (в книге используются в основном два последних термина);
— выходные переменные, характеризующие поведение или результат (эффективность) функционирования; в математических моделях их называют зависимыми, откликами, эндогенными, результирующими или объясняемыми (в книге используются в основном два последних термина);
 — латентные (т. е. скрытые, не поддающиеся непосредственному измерению) случайные «остаточные» компоненты, отражающие влияние (соответственно на
— латентные (т. е. скрытые, не поддающиеся непосредственному измерению) случайные «остаточные» компоненты, отражающие влияние (соответственно на  неучтенных «на входе» факторов, а также случайные ошибки в измерении анализируемых показателей (в математических моделях мы их, как правило, будем именовать просто «остатками»).
неучтенных «на входе» факторов, а также случайные ошибки в измерении анализируемых показателей (в математических моделях мы их, как правило, будем именовать просто «остатками»).

 измерений
измерений


 по заданным значениям объясняющих (предикторных) переменных
по заданным значениям объясняющих (предикторных) переменных 

 и среднедушевым денежным сбережениям
и среднедушевым денежным сбережениям 
 и
и 
 мы будем определять наилучший способ восстановления значений результирующих показателей по заданным значениям объясняющих переменных?
мы будем определять наилучший способ восстановления значений результирующих показателей по заданным значениям объясняющих переменных?
 ?
?
 где
где  — среднедушевой доход и
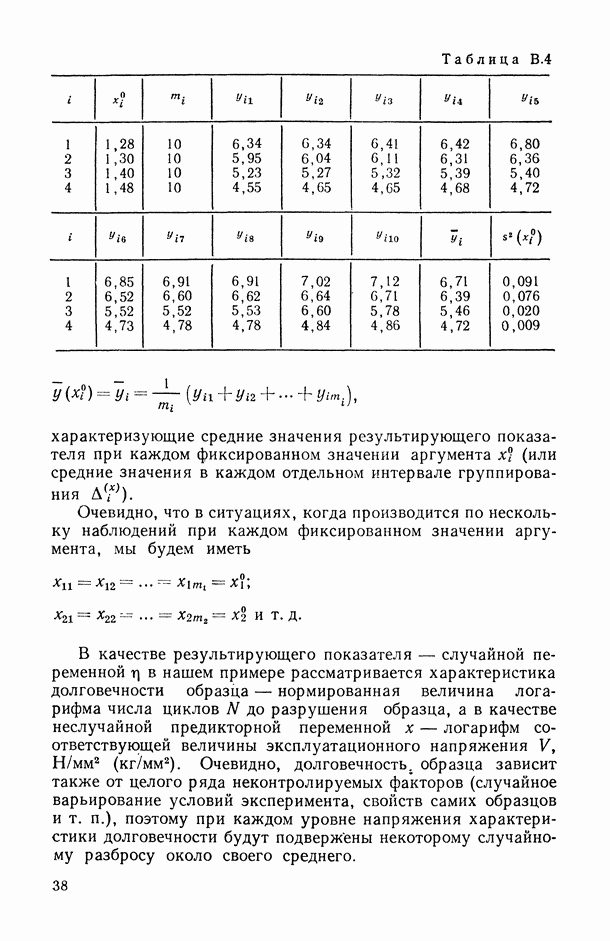
— среднедушевой доход и  — среднедушевые денежные сбережения в семье, случайно извлеченной из рассматриваемой совокупности семей, однородной по своему потребительскому поведению (см., например, [1281). В табл. В.1 и на рис. В.2 представлены исходные статистические данные вида (В.1), характеризующие среднедушевые величины дохода
— среднедушевые денежные сбережения в семье, случайно извлеченной из рассматриваемой совокупности семей, однородной по своему потребительскому поведению (см., например, [1281). В табл. В.1 и на рис. В.2 представлены исходные статистические данные вида (В.1), характеризующие среднедушевые величины дохода  и денежных сбережений
и денежных сбережений  за определенный отрезок времени, а именно за месяц, в каждой
за определенный отрезок времени, а именно за месяц, в каждой  обследованной семье рассматриваемой совокупности семей (в данном условном примере объем
обследованной семье рассматриваемой совокупности семей (в данном условном примере объем  статистически обследованной совокупности семей равнялся 40). В этом примере имелась возможность при отборе исходных данных (выборки) контролировать значения предикторной переменной Н (условия активного эксперимента [14, с. 1211), что позволило, в частности, разбить статистически обследованные семьи на четыре равные по объему группы по доходам.
статистически обследованной совокупности семей равнялся 40). В этом примере имелась возможность при отборе исходных данных (выборки) контролировать значения предикторной переменной Н (условия активного эксперимента [14, с. 1211), что позволило, в частности, разбить статистически обследованные семьи на четыре равные по объему группы по доходам.
 являющихся геометрическим изображением результатов обследования семей по доходу и сбережениям, должно быть совершенно хаотичным и не должно обнаруживать некоторой вполне определенной тенденции, характеризующей зависимость денежных сбережений в семье
являющихся геометрическим изображением результатов обследования семей по доходу и сбережениям, должно быть совершенно хаотичным и не должно обнаруживать некоторой вполне определенной тенденции, характеризующей зависимость денежных сбережений в семье  от ее среднедушевого дохода
от ее среднедушевого дохода  При исследовании подобных зависимостей встают следующие основные вопросы (в скобках после вопроса указываются главы, параграфы или пункты настоящей книги, ему посвященные).
При исследовании подобных зависимостей встают следующие основные вопросы (в скобках после вопроса указываются главы, параграфы или пункты настоящей книги, ему посвященные).
 и
и  , т. е. как определяется общая структура соответствующей математической модели? (Гл. 6.)
, т. е. как определяется общая структура соответствующей математической модели? (Гл. 6.)
 от
от  , что позволит в данном случае производить количественную оценку неизвестных денежных сбережений семьи по заданной величине ее среднедушевого дохода? (Гл. 7—10, 13, 14.)
, что позволит в данном случае производить количественную оценку неизвестных денежных сбережений семьи по заданной величине ее среднедушевого дохода? (Гл. 7—10, 13, 14.)
 относится к категории статистически труднодоступных: содержащиеся в ежегодных и единовременных выборочных семейных бюджетных обследованиях ЦСУ [85] сведения о сбережениях, как правило, непредставительны.
относится к категории статистически труднодоступных: содержащиеся в ежегодных и единовременных выборочных семейных бюджетных обследованиях ЦСУ [85] сведения о сбережениях, как правило, непредставительны.


 в семьях данной группы х по доходам.
в семьях данной группы х по доходам.

 в зависимости от
в зависимости от  а также изучить характер случайного разброса денежных сбережений
а также изучить характер случайного разброса денежных сбережений  отдельных семей данной группы
отдельных семей данной группы  по доходам относительно своего среднего значения
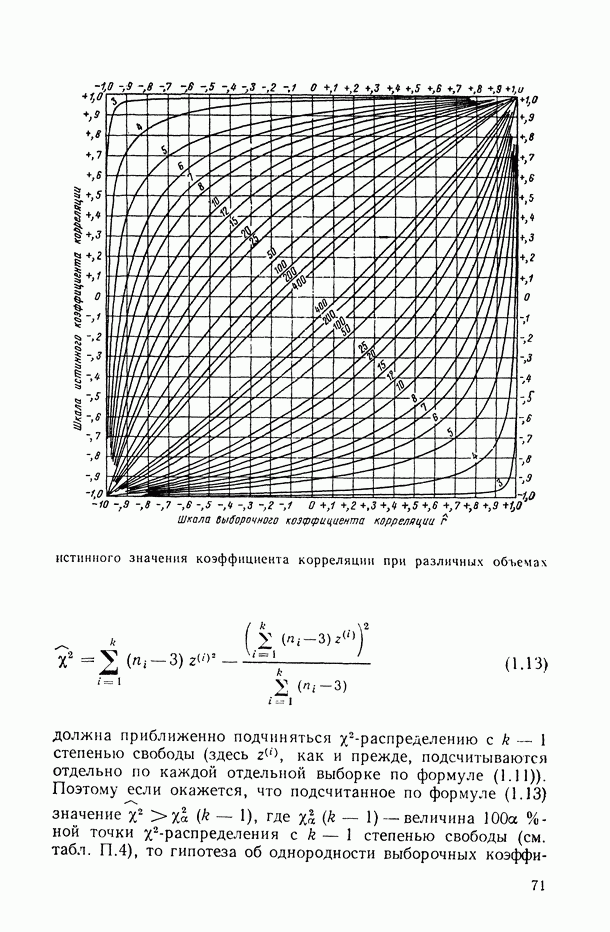
по доходам относительно своего среднего значения  (при любом интересующем нас значении среднедушевого дохода
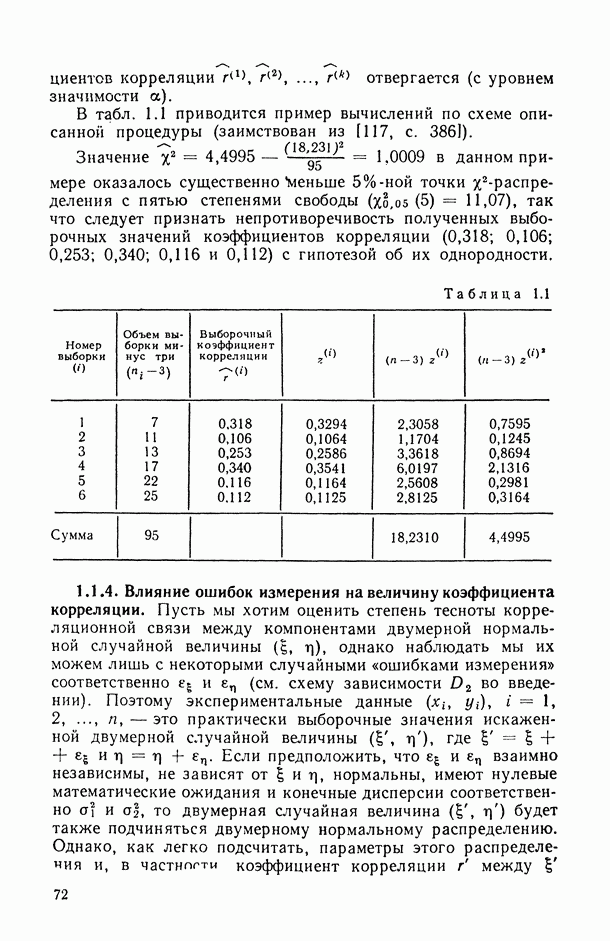
(при любом интересующем нас значении среднедушевого дохода  ).
).

 отражает случайное отклонение денежных сбережений наугад выбранной отдельной семьи с доходом
отражает случайное отклонение денежных сбережений наугад выбранной отдельной семьи с доходом  от среднего значения
от среднего значения  этих сбережений, подсчитанного по всем семьям данной группы по доходам, а функция
этих сбережений, подсчитанного по всем семьям данной группы по доходам, а функция  описывает характер изменения условного среднего
описывает характер изменения условного среднего  (при
(при  ) в зависимости от изменения
) в зависимости от изменения  если дополнительно прийти к соглашению, что характер случайного разброса величин
если дополнительно прийти к соглашению, что характер случайного разброса величин  относительно своих средних
относительно своих средних  таков, что
таков, что  при всех
при всех 

 мы будем производить аппроксимацию искомой зависимости
мы будем производить аппроксимацию искомой зависимости 

 и
и  — некоторые константы (неизвестные параметры модели). Так что
— некоторые константы (неизвестные параметры модели). Так что

 понимается семейство всех тех функций
понимается семейство всех тех функций  , которые могут быть получены при подстановке вместо
, которые могут быть получены при подстановке вместо  ее различных конкретных значений (
ее различных конкретных значений ( — векторный параметр).
— векторный параметр).
 подтверждается и характером расположения совокупности точек, являющихся геометрическим изображением исходных данных в нашлем примере (см. на рис. В.2 расположение «крестиков», ординаты которых определяются экспериментально подсчитанными, т. е. вычисленными на основании имеющихся выборочных данных, условными средними
подтверждается и характером расположения совокупности точек, являющихся геометрическим изображением исходных данных в нашлем примере (см. на рис. В.2 расположение «крестиков», ординаты которых определяются экспериментально подсчитанными, т. е. вычисленными на основании имеющихся выборочных данных, условными средними 
 с помощью функции
с помощью функции  мы будем определять наилучший способ прогноза
мы будем определять наилучший способ прогноза  по х. Наиболее обоснованное и точное решение этого вопроса опирается на знание вероятностной природы (а именно типа закона распределения вероятностей) остатков
по х. Наиболее обоснованное и точное решение этого вопроса опирается на знание вероятностной природы (а именно типа закона распределения вероятностей) остатков  в модели (В.3). Так, например, известно [14, с. 281], что если предположить, что при любых значениях х распределение вероятностей остатков
в модели (В.3). Так, например, известно [14, с. 281], что если предположить, что при любых значениях х распределение вероятностей остатков  описывается
описывается  - нормальным законом (т. е. нормальным законом со средним значением, равным нулю, и с некоторой, вообще говоря, неизвестной, но постоянной, т. е. не зависящей от х дисперсией
- нормальным законом (т. е. нормальным законом со средним значением, равным нулю, и с некоторой, вообще говоря, неизвестной, но постоянной, т. е. не зависящей от х дисперсией  ) и что остатки
) и что остатки  , характеризующие различные наблюдения, статистически независимы, то наименьшая ошибка прогноза
, характеризующие различные наблюдения, статистически независимы, то наименьшая ошибка прогноза  с помощью модели
с помощью модели  (т. е. функция
(т. е. функция  подбирается из класса F) обеспечивается требованием метода наименьших квадратов
подбирается из класса F) обеспечивается требованием метода наименьших квадратов

 существенно зависит от значения
существенно зависит от значения  Можно устранить это нарушение, поделив все анализируемые величины, откладываемые по оси
Можно устранить это нарушение, поделив все анализируемые величины, откладываемые по оси  , а следовательно, и остатки
, а следовательно, и остатки  на значения
на значения  (являющиеся статистическими оценками для
(являющиеся статистическими оценками для  ), т. е. перейдя к анализу остатков
), т. е. перейдя к анализу остатков 
 - нормальном характере распределения остатков (х не противоречит имею щимся в нашем распоряжении данным (представленным в табл. В.1) и, следовательно, требование (В.7) приводит к необходимости решения экстремальной задачи вида
- нормальном характере распределения остатков (х не противоречит имею щимся в нашем распоряжении данным (представленным в табл. В.1) и, следовательно, требование (В.7) приводит к необходимости решения экстремальной задачи вида



 для неизвестных параметров соответственно
для неизвестных параметров соответственно  выражения:
выражения:


 от значения среднедушевого дохода семей данной доходной группы
от значения среднедушевого дохода семей данной доходной группы  имеет в этом случае вид
имеет в этом случае вид

 выбор критерия качества аппроксимации
выбор критерия качества аппроксимации  (см. гл. 7). Отметим, однако, что наиболее широкое распространение в статистической практике именно критерия наименьших квадратов
(см. гл. 7). Отметим, однако, что наиболее широкое распространение в статистической практике именно критерия наименьших квадратов  подкреплено рядом исследований [15, 196]. В них обосновываются хорошие прогностические свойства моделей, полученных в соответствии с
подкреплено рядом исследований [15, 196]. В них обосновываются хорошие прогностические свойства моделей, полученных в соответствии с  и в ситуациях, характеризующихся различными отклонениями от нормальности и взаимной независимости остатков в
и в ситуациях, характеризующихся различными отклонениями от нормальности и взаимной независимости остатков в  .
.
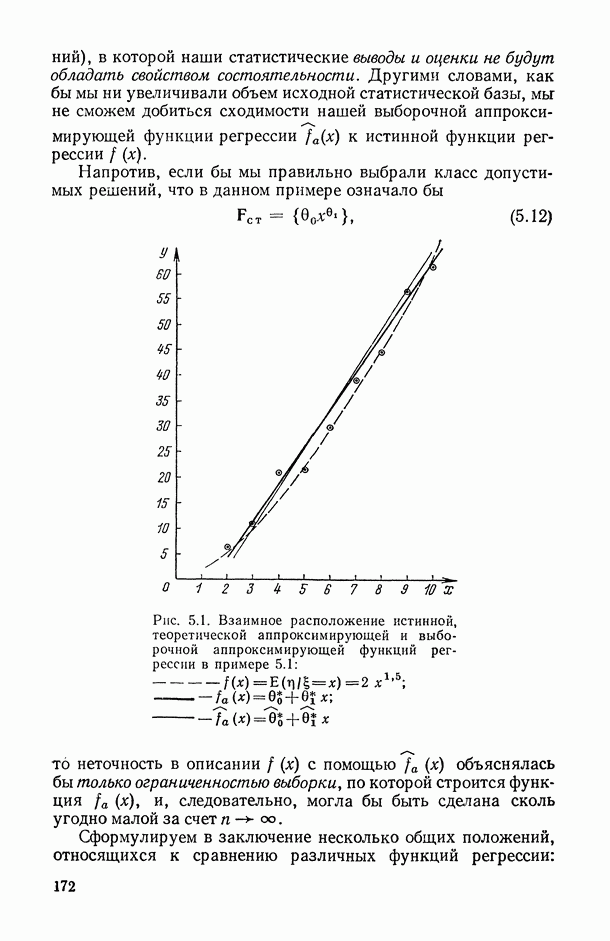
 и возвращаясь к общему описанию задач статистического исследования зависимостей, отметим, что функции
и возвращаясь к общему описанию задач статистического исследования зависимостей, отметим, что функции  описывающие поведение условных средних результирующего показателя
описывающие поведение условных средних результирующего показателя  (вычисленных при значениях предикторных переменных зафиксированных на уровне
(вычисленных при значениях предикторных переменных зафиксированных на уровне  в зависимости от изменения X, принято называть функциями регрессии (подробнее о различных определениях функции регрессии см. в гл. 5).
в зависимости от изменения X, принято называть функциями регрессии (подробнее о различных определениях функции регрессии см. в гл. 5).