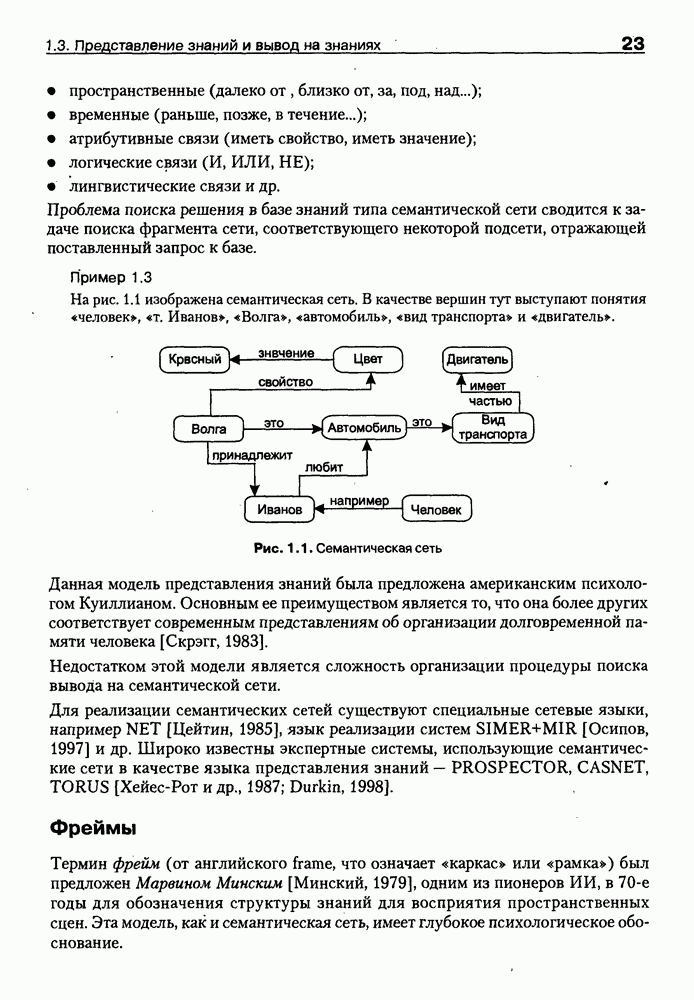
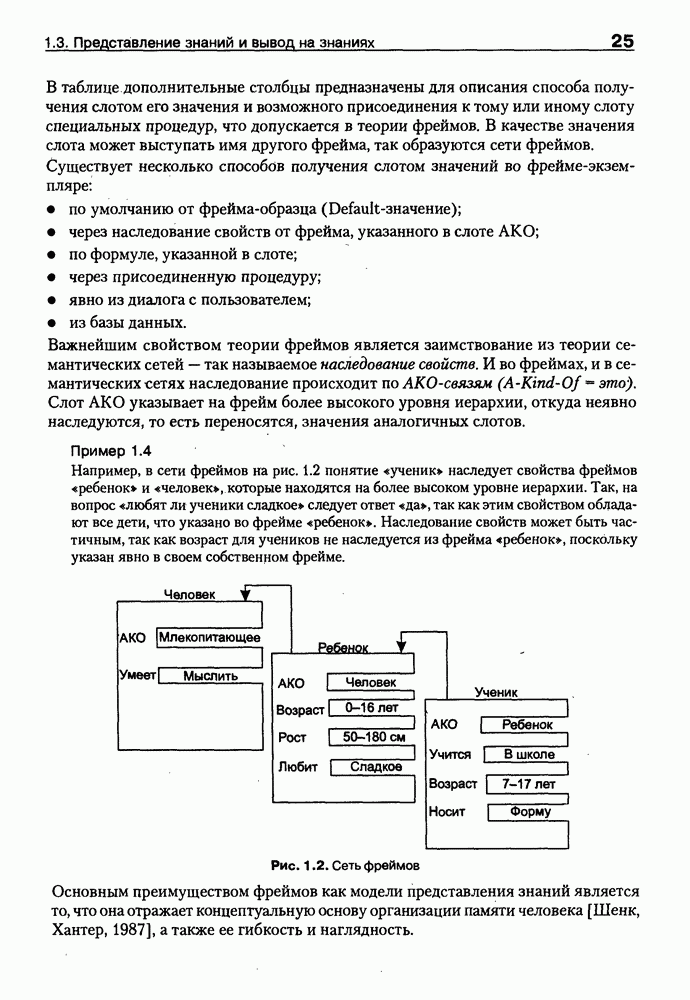
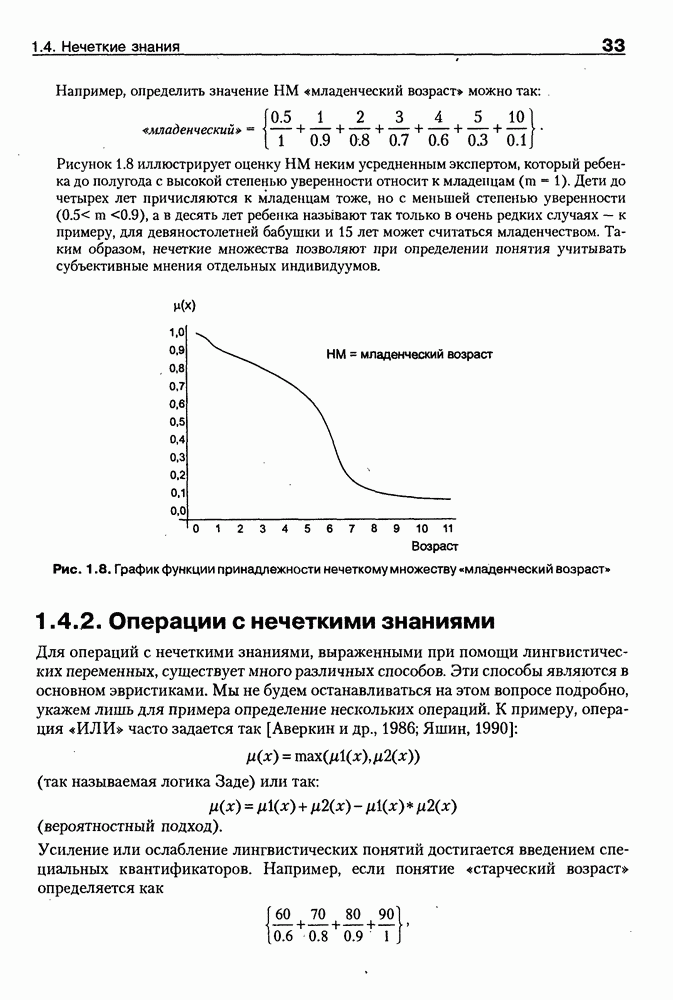
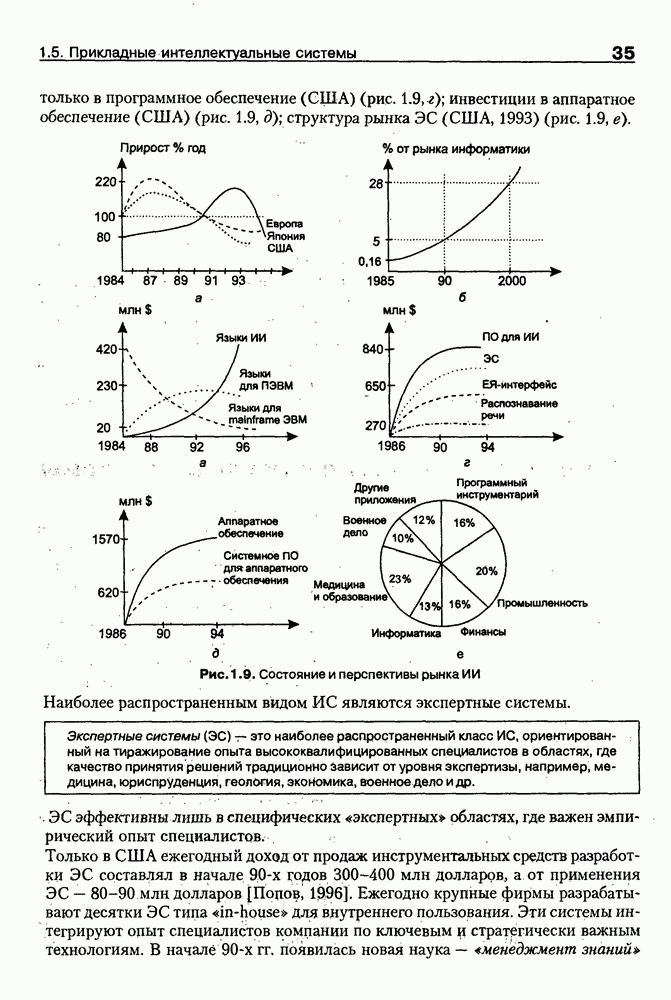
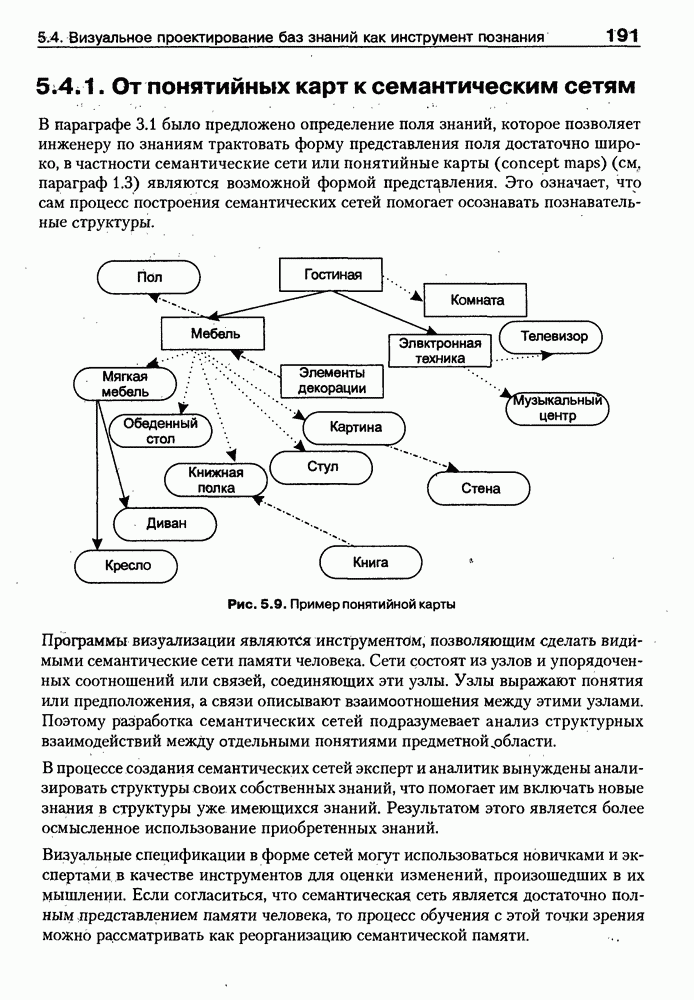
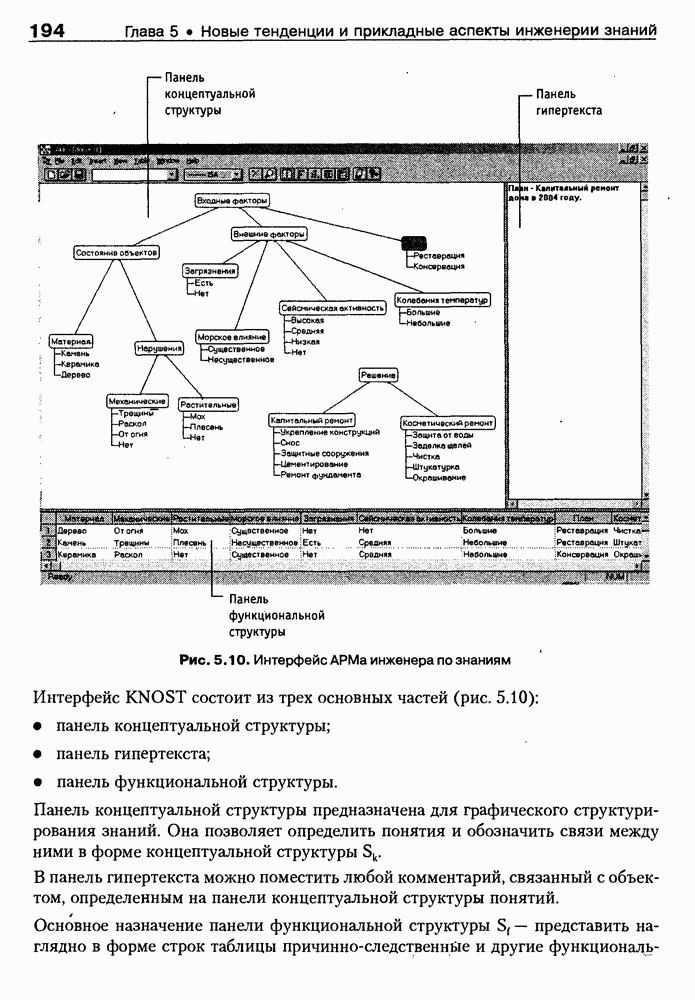
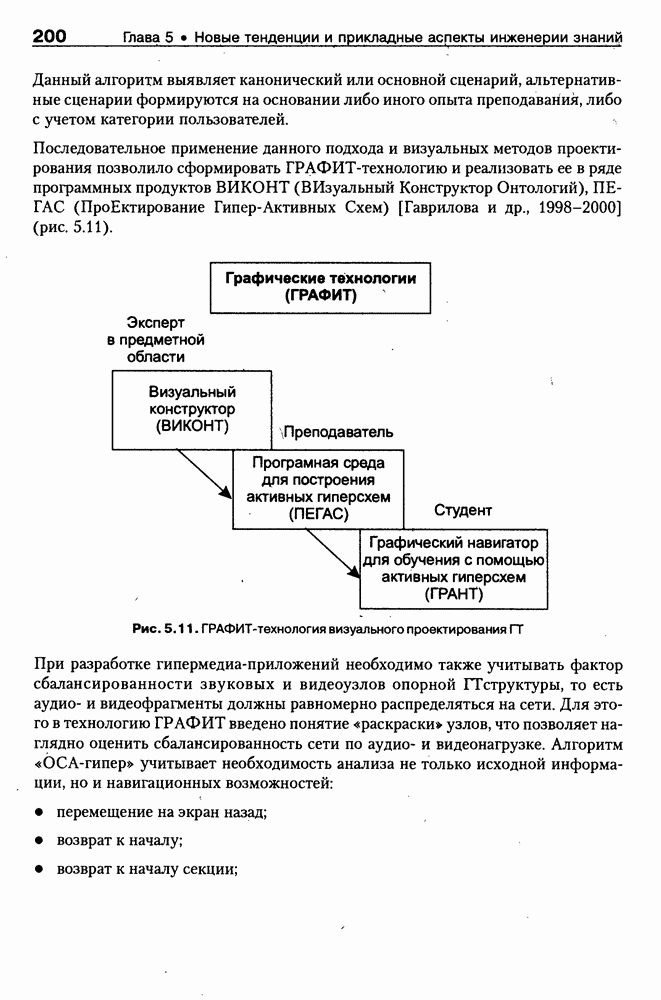
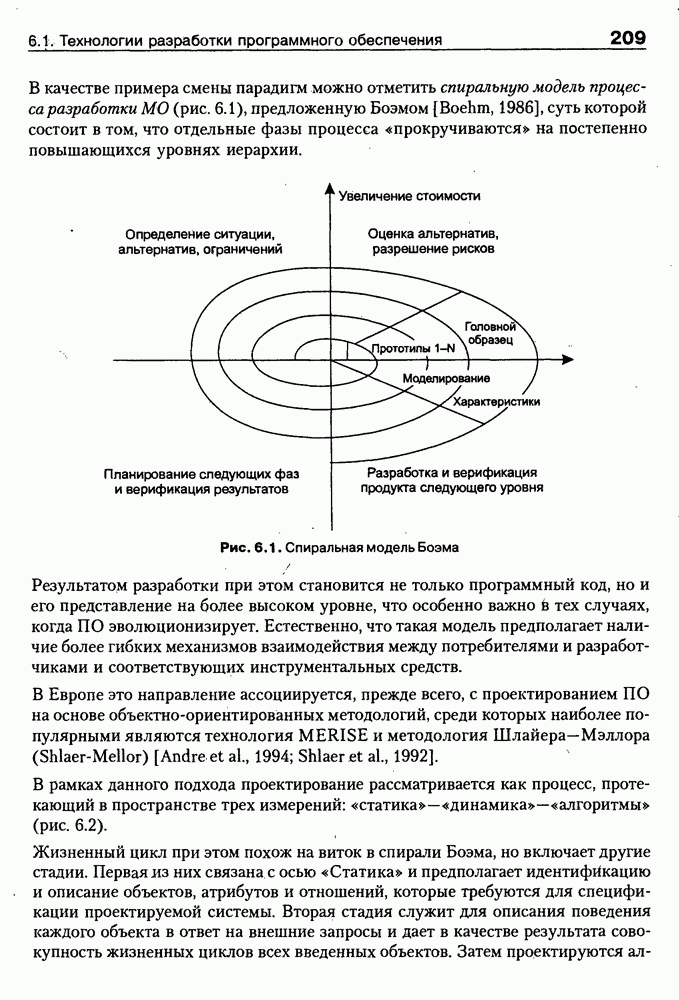
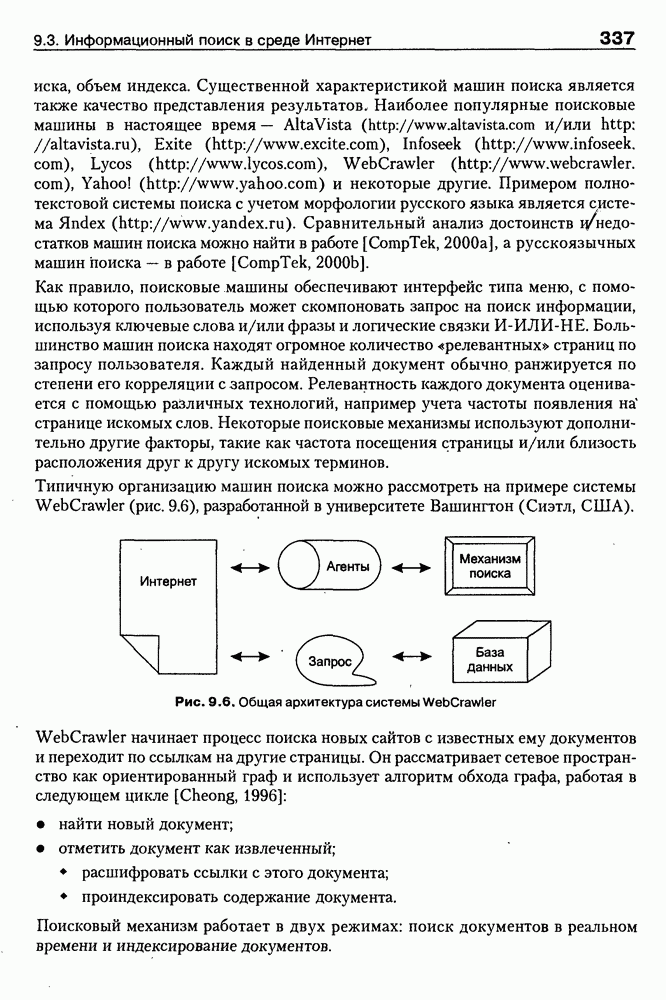
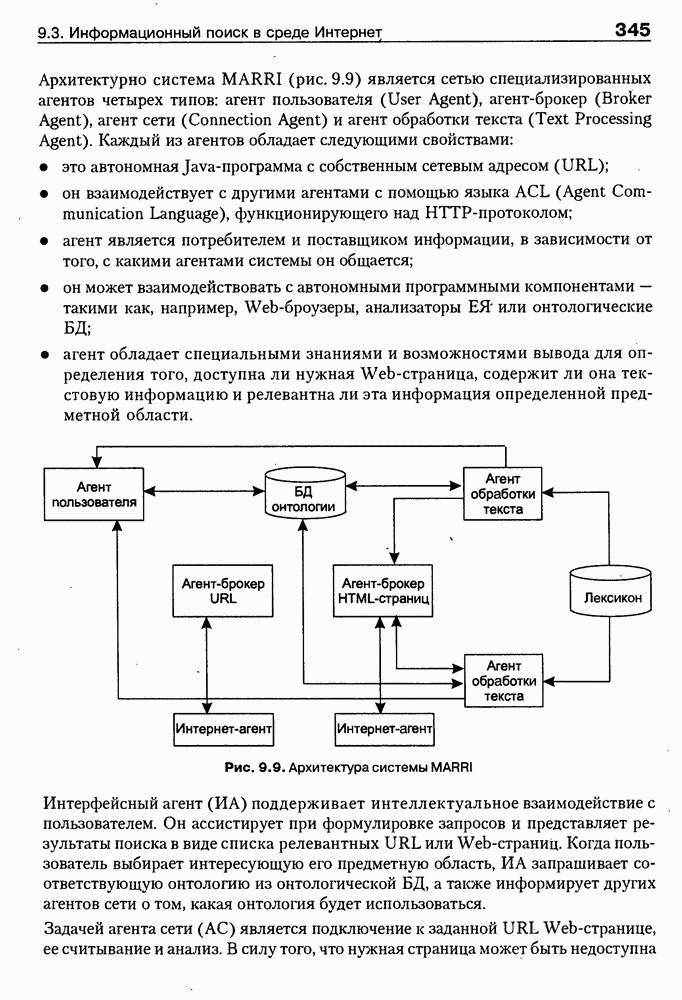
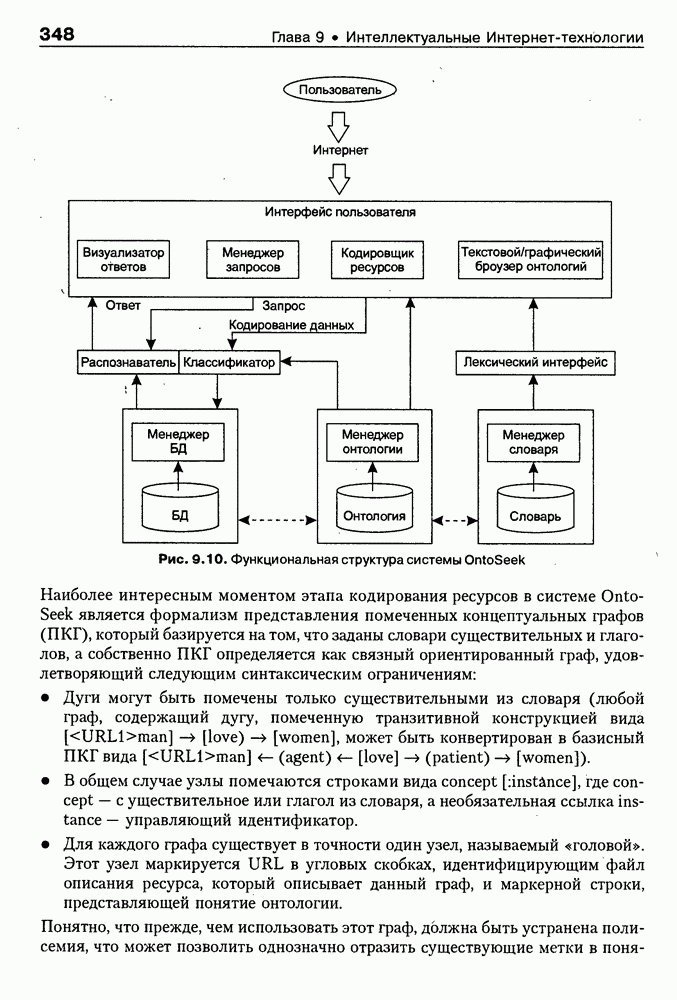
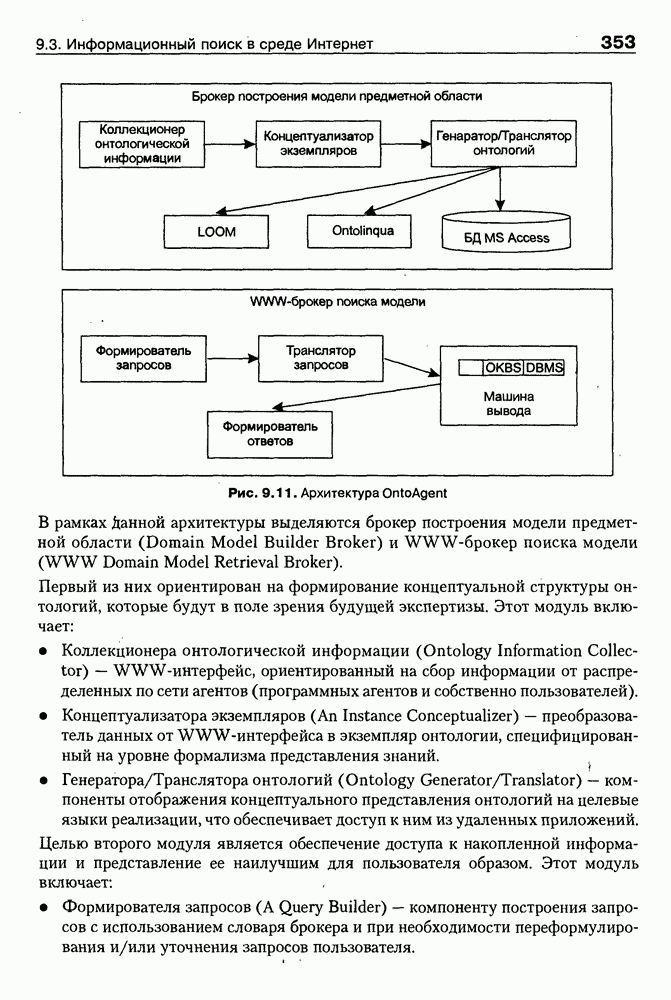
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
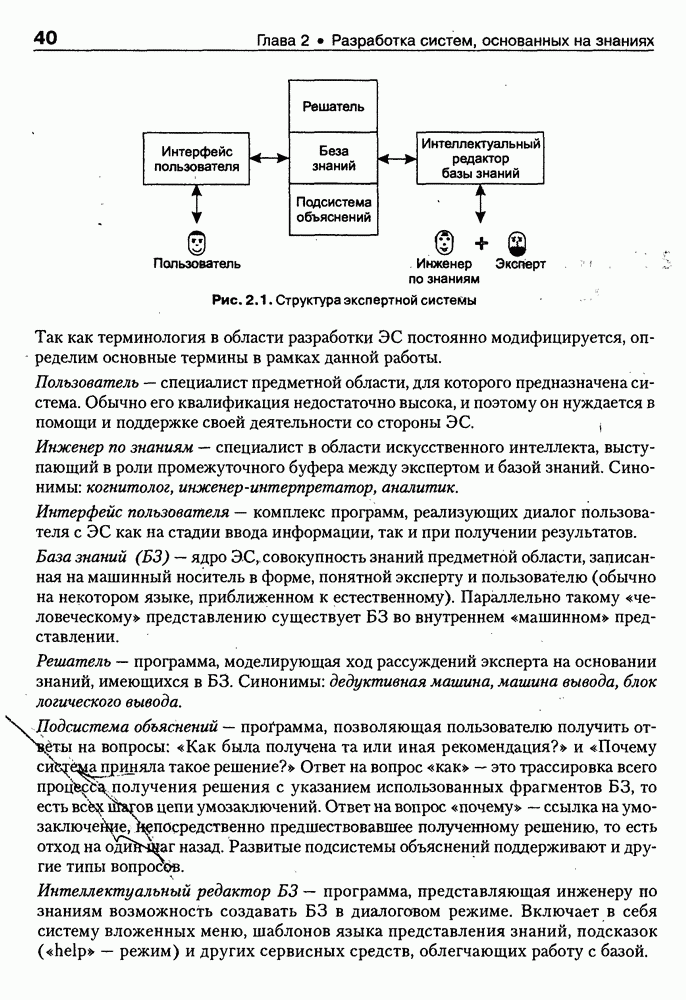
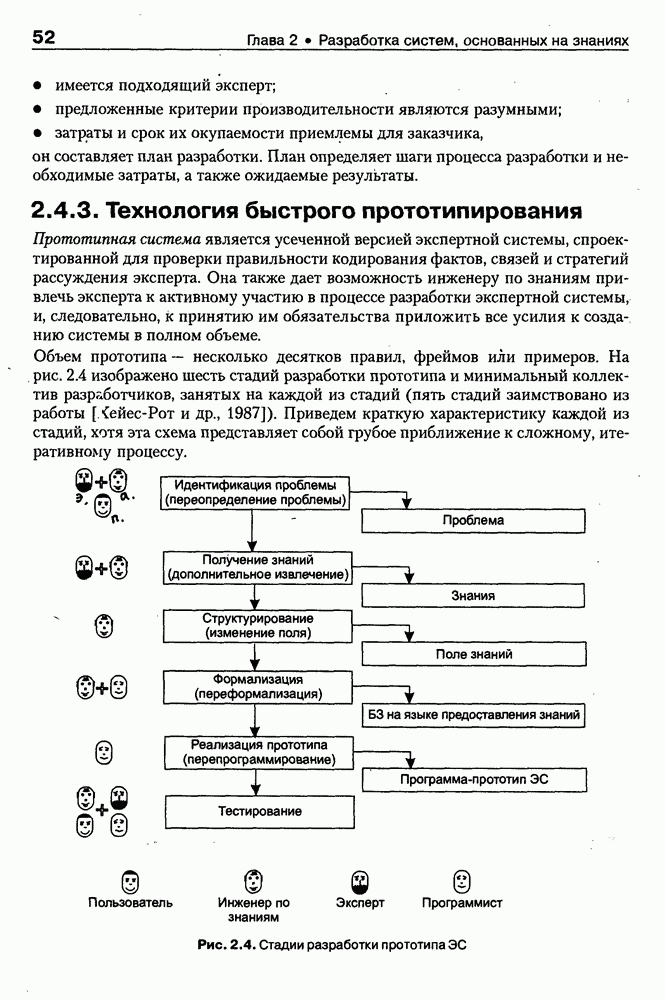
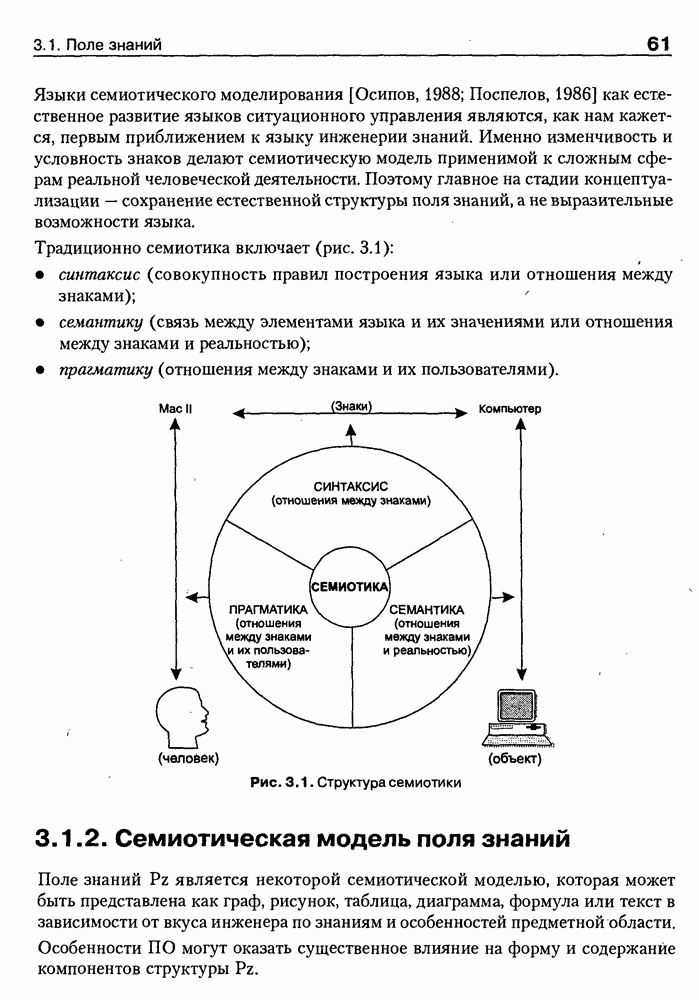
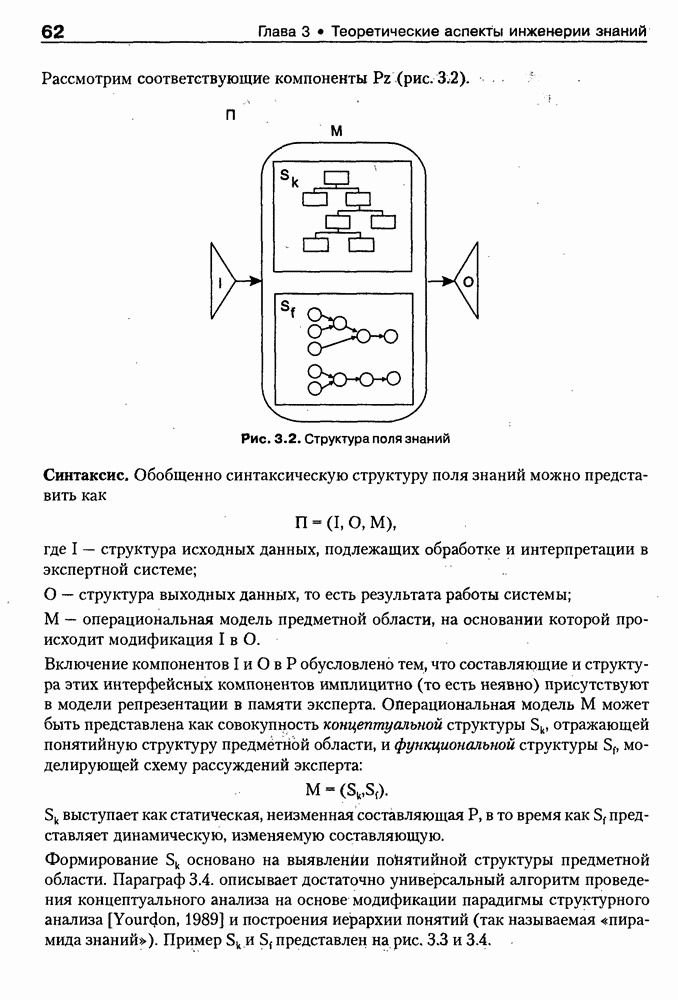
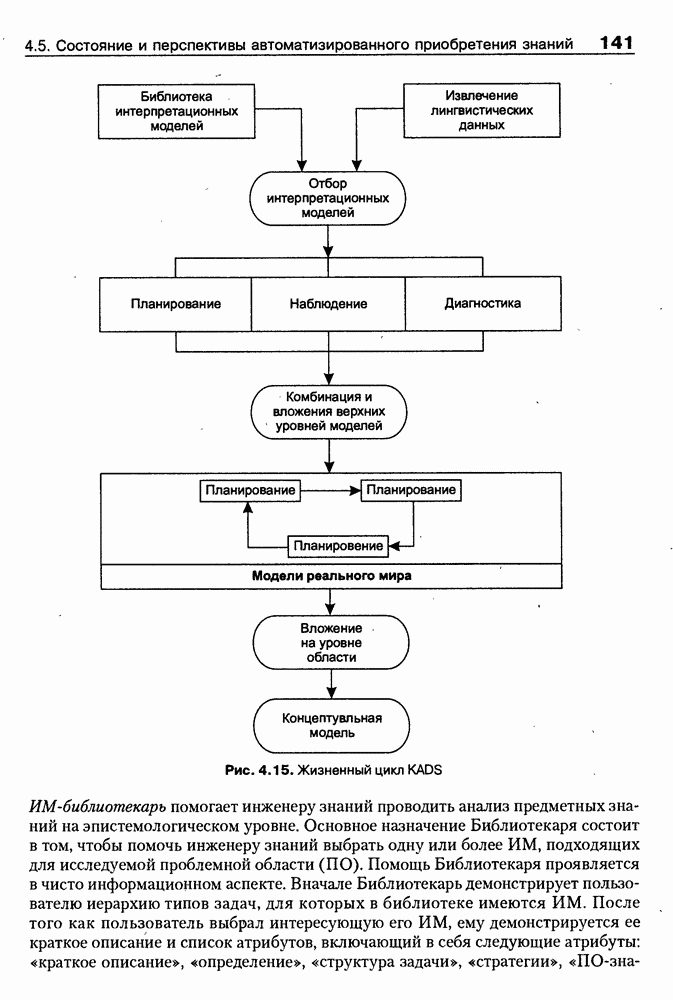
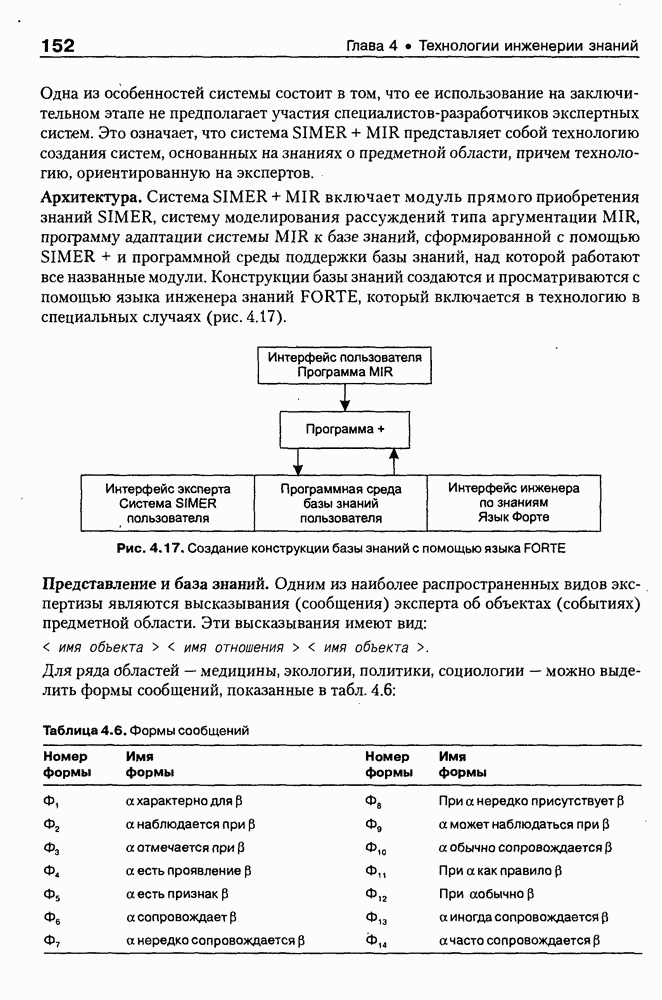
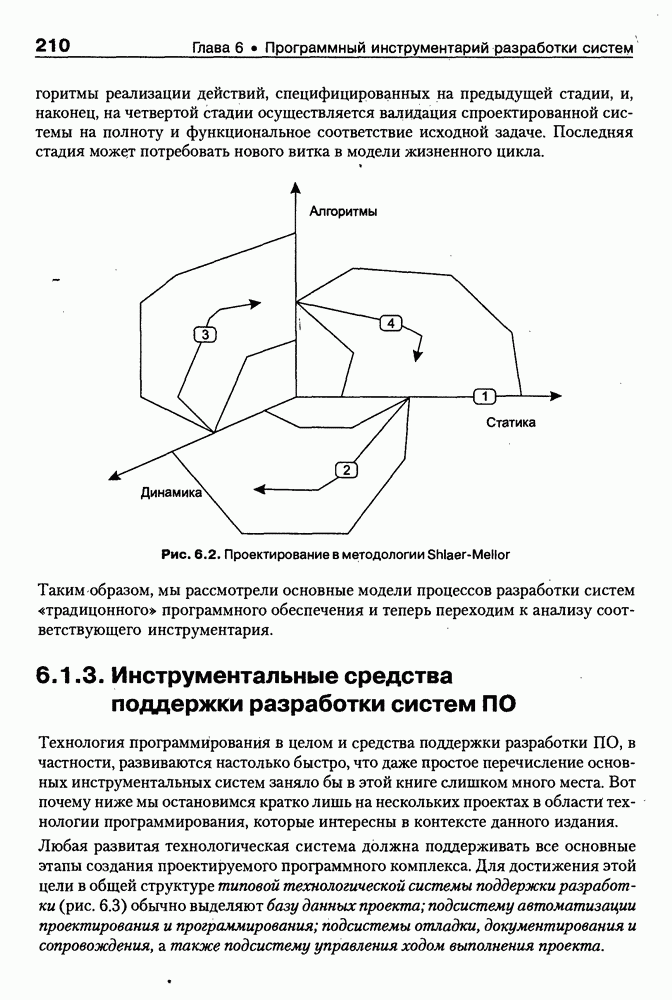
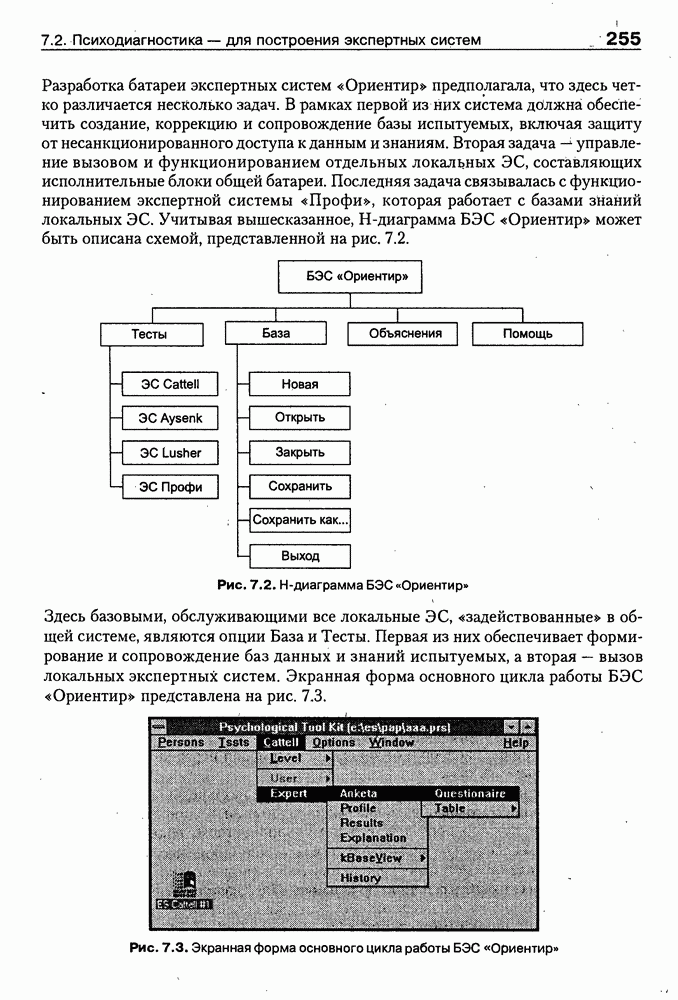
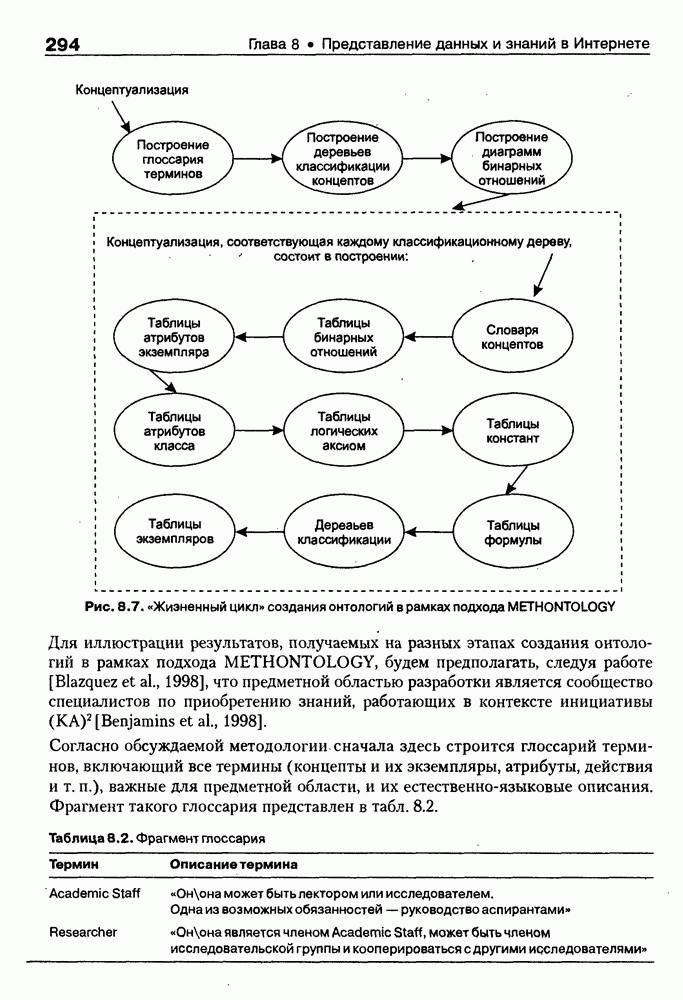
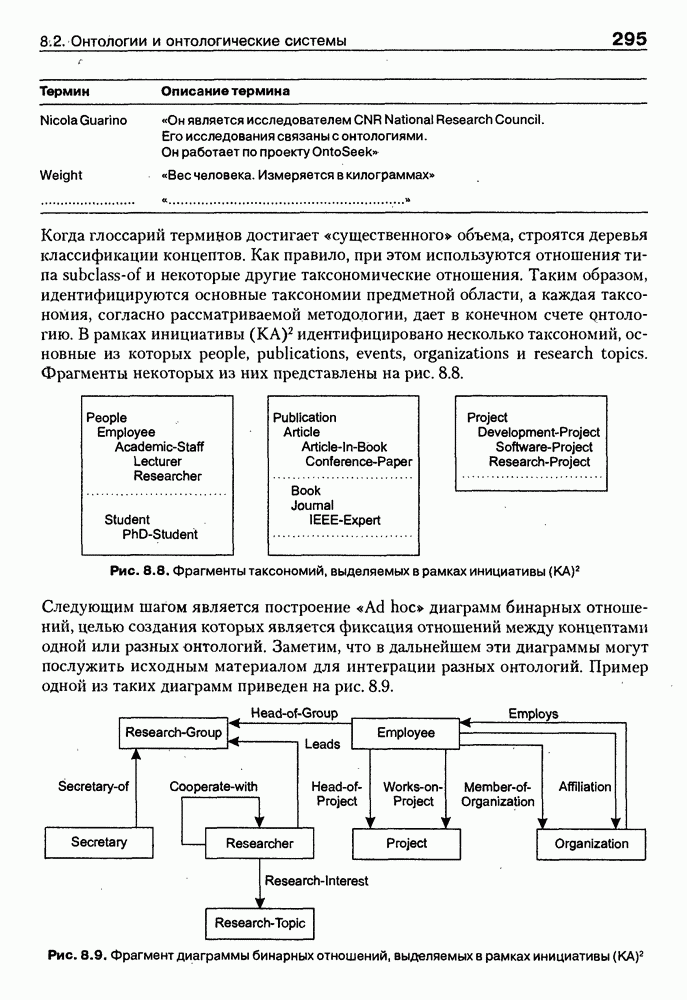
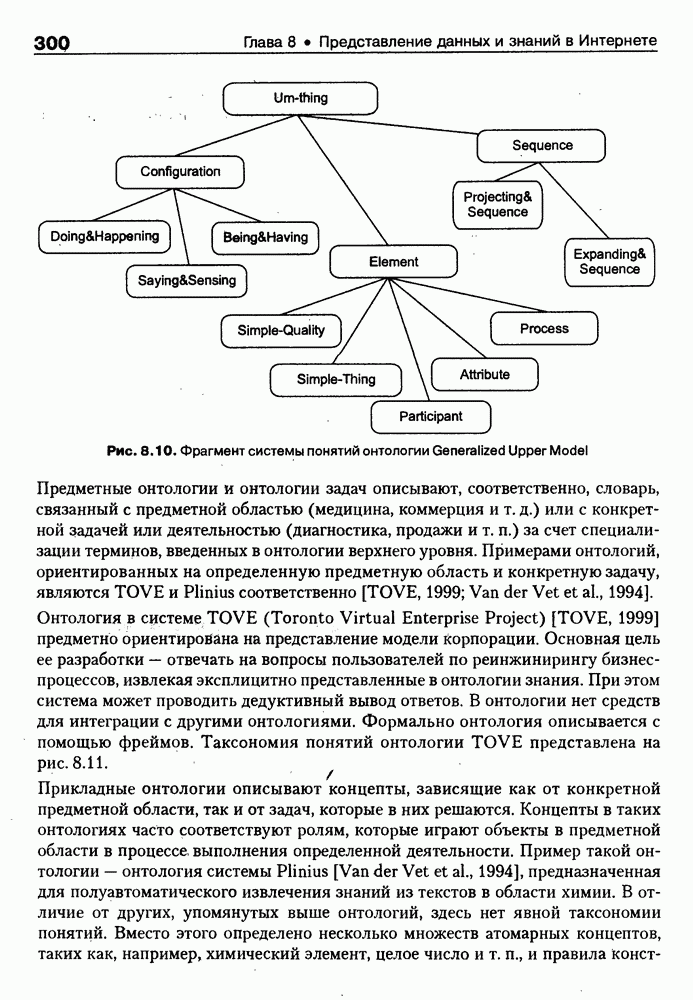
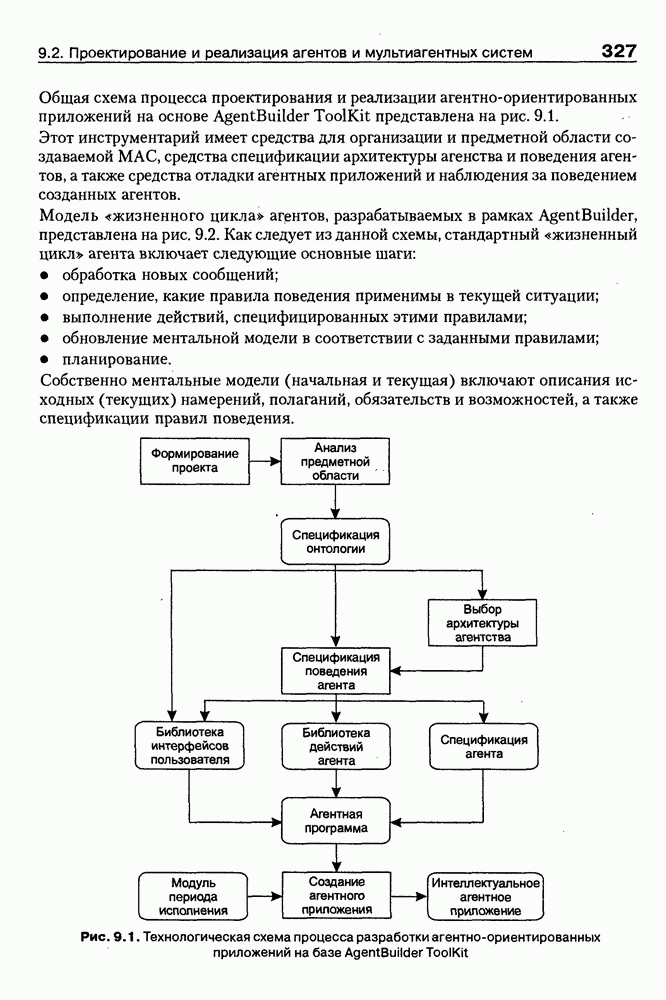
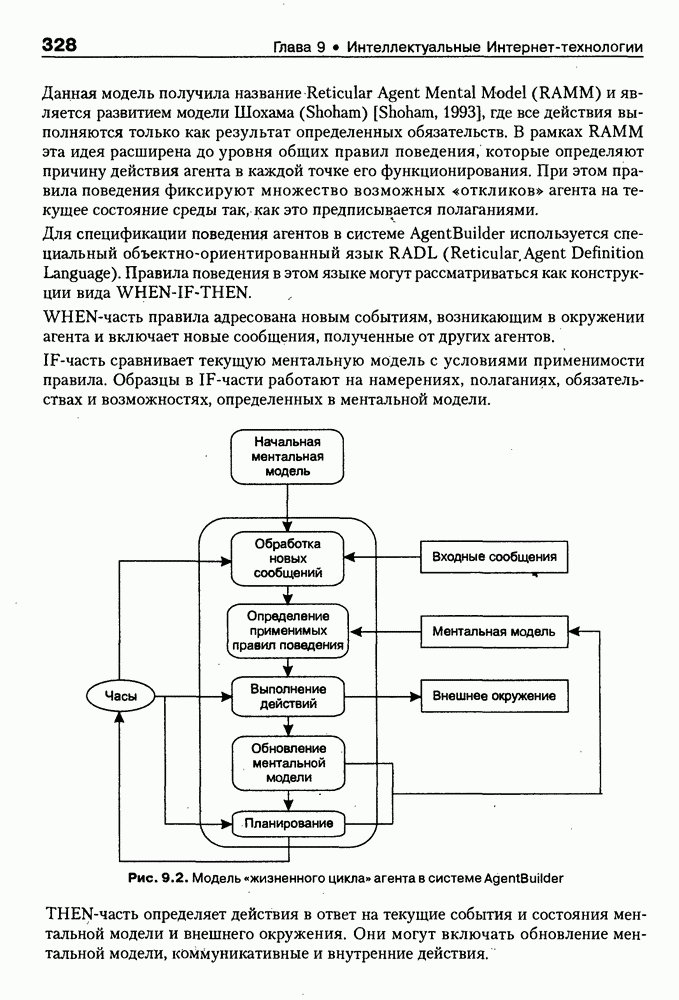
4.6.5. Инструментарий прямого приобретения знаний SIMER + MIRПрограммная система SIMER + MIR, разработанная в ИПС РАН под руководством Осипова Г. С. [Осипов, 1997], представляет собой совокупность программных Одна из особенностей системы состоит в том, что ее использование на заключительном этапе не предполагает участия специалистов-разработчиков экспертных систем. Это означает, что система SIMER + MIR представляет собой технологию создания систем, основанных на знаниях о предметной области, причем технологию, ориентированную на экспертов. Архитектура. Система SIMER + MIR включает модуль прямого приобретения знаний SIMER, систему моделирования рассуждений типа аргументации MIR, программу адаптации системы MIR к базе знаний, сформированной с помощью SIMER + и программной среды поддержки базы знаний, над которой работают все названные модули. Конструкции базы знаний создаются и просматриваются с помощью языка инженера знаний FORTE, который включается в технологию в специальных случаях (рис. 4.17).
Рис. 4.17. Создание конструкции базы знаний с помощью языка FORTE Представление и база знаний. Одним из наиболее распространенных видов экспертизы являются высказывания (сообщения) эксперта об объектах (событиях) предметной области. Эти высказывания имеют вид: (см. скан) Для ряда областей — медицины, экологии, политики, социологии — можно выделить формы сообщений, показанные в табл. 4.6: Таблица 4.6. Формы сообщений
Этот список не является исчерпывающим, однако дает представление о тех когнитивных структурах, которые необходимо представлять и обрабатывать в базе знаний. Каждая из этих форм может иметь различный смысл; уточнение смысла можно получить при рассмотрении «прямого» сообщения с «обращенным». Иными словами, если для некоторых фиксированных а или 3 справедливо сообщение формы С каждым типом сообщения из табл. 4.7 связывается формальная конструкция базы знаний, то есть бинарное отношение на множестве объектов (событий). Эти конструкции можно проиллюстрировать следующим образом: если каждый объект (событие) представить в виде «двухмерного» множества, по первому измерению которого можно откладывать атрибуты этого объекта, а по второму — множества значений соответствующих атрибутов, то каждый объект представляется в виде фигуры:
Теблица 4.7. Типы сообщений
Таблица 4.7. (продолжение) Если считать множества всех атрибутов равновеликими, то можно рисовать прямоугольники. Тогда типу сообщения Т, можно поставить в соответствие диаграмму (пересечение
В качестве примера приведем интерпретации некоторых диаграмм. Так, диаграмму, соответствующую сообщению типа Для остальных типов сообщений получим диаграммы, представленные в табл. 4.8. Таблица 4.8. Диаграммы для различных типов сообщений
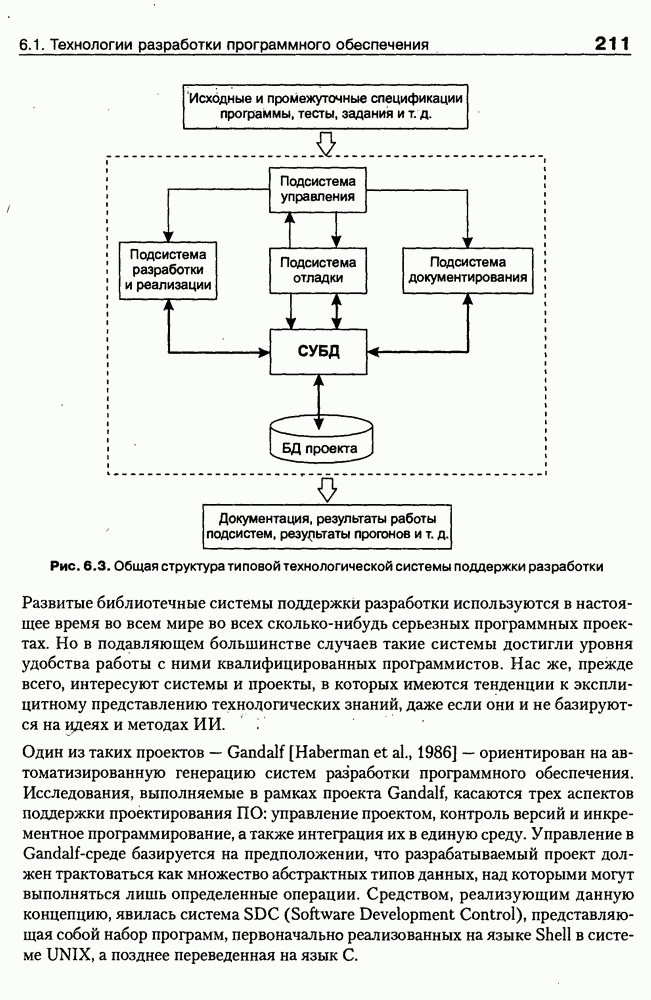
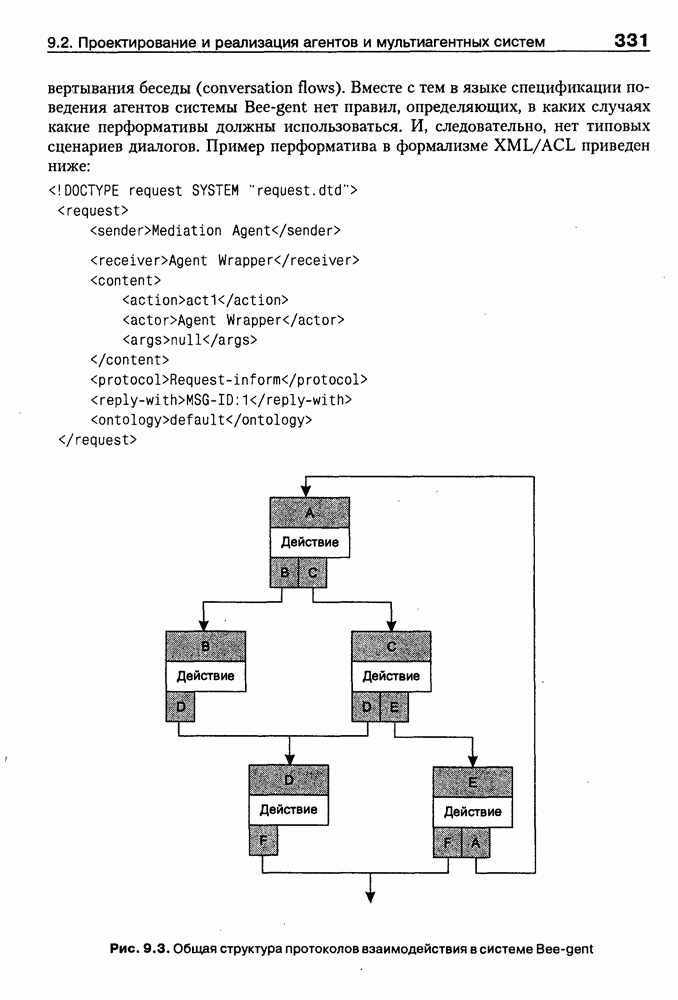
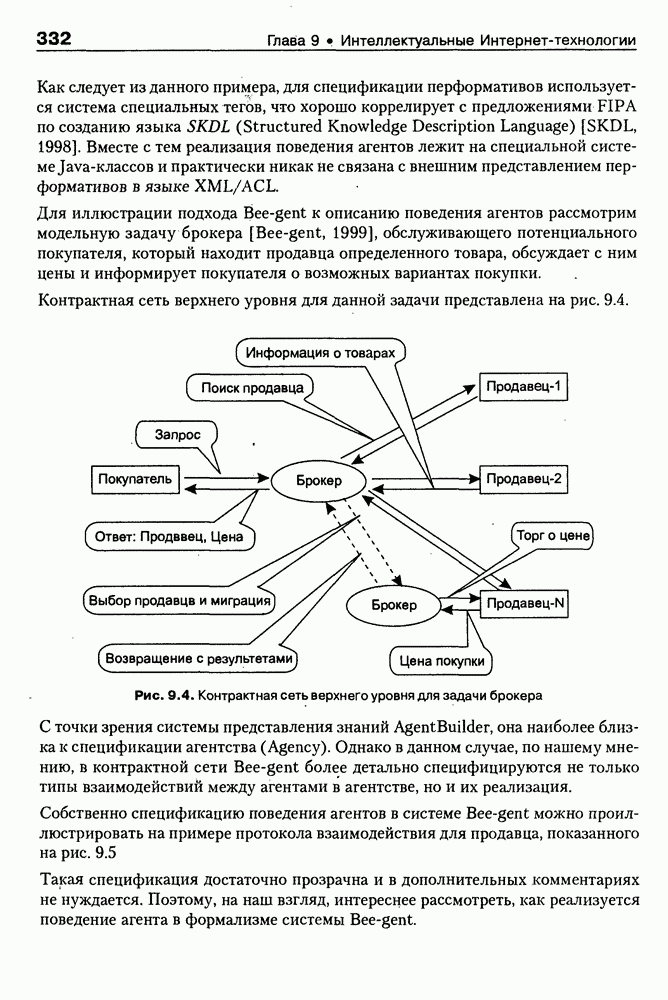
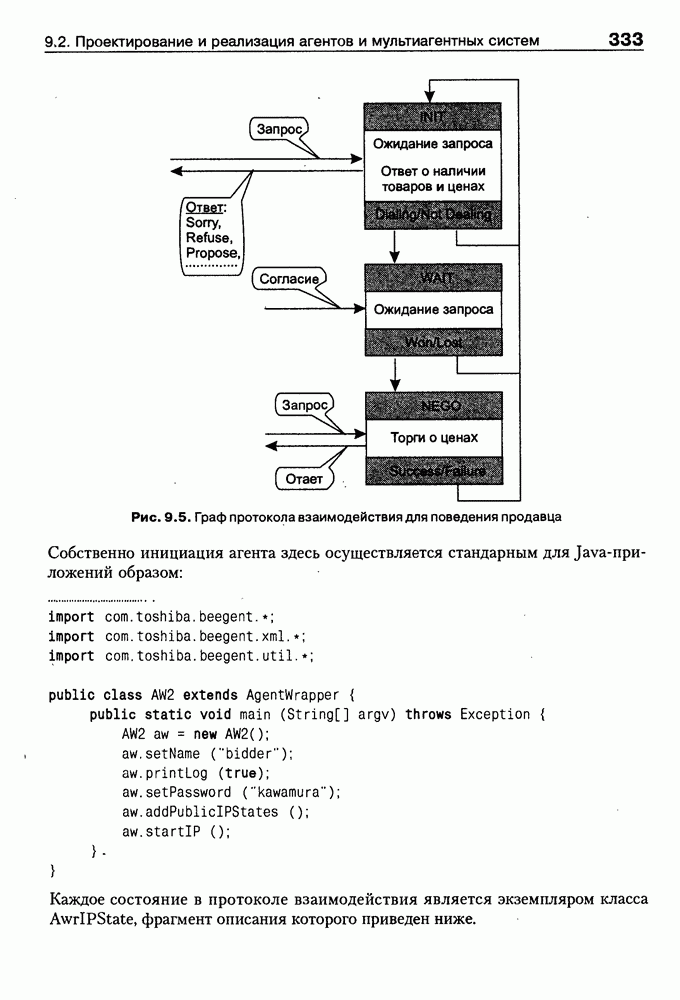
(см. скан) Для сообщения типа Каждой из изображенных диаграмм можно дать такую теоретико-множественную интерпретацию, связав с каждым из типов сообщений некоторое бинарное отношение Способ представления с определенными так отношениями называется неоднородной семантической сетью. В реализации базы знаний основными элементами структур данных являются элементы «вершина», «элемент кортежа», «атрибут», «цепь», «стрелка». Элемент «вершина» соответствует объекту (событию), он содержит имя, списки входных и выходных «стрелок» и список типа «элемент кортежа». Список «элементов кортежа» соответствует совокупности атрибутов события. Для обеспечения простого способа определения указателя «вершины» существуют элементы типа «цепь». Элемент типа «цепь» содержит указатель на «вершину» и указатель на следующий элемент типа «цепь». Указатель на первый элемент списка «цепь» входит в описание элемента типа «атрибут». «Атрибут» характеризуется также именем, множеством значений и единицей измерения. Отношения на множестве объектов реализованы в элементах типа «стрелка». Каждый такой элемент содержит имя, сорт, вес, тип веса, указатель на «вершину» и указатель на следующий элемент типа «стрелка». Отношения на двух объектах описываются парой элементов типа «стрелка», один из которых входит в список входящих стрелок одного объекта, другой — в список входящих стрелок другого объекта. Процедурная компонента системы содержит функции создания структур данных, поддержки корректности базы знаний, наследования свойств и ряд других функций. Для обеспечения поиска по именам элементов типа «вершина» и «атрибут» в системе реализовано В-дерево. Доступ ко всем элементам базы осуществляется через виртуальную память. Каждый элемент имеет внутренний идентификатор, по значению которого однозначно определяется его размещение в оперативной или внешней памяти. Для работы с объектами, отсутствующими в оперативной памяти, осуществляется их динамический перенос из внешней памяти в оперативную. Это позволяет системе работать на компьютере с ограниченным объемом оперативной памяти. Прямое приобретение знаний в системе SIMER Для выявления структурных знаний о предметной области используются стратегии разбиения на ступени и репертуарных решеток. Подробнее о репертуарных решетках см. параграф 5.2. Стратегия разбиения на ступени направлена на выявление структурных и классификационных свойств событий (понятий, объектов), области и таксонометрической структуры событий предметной области. Стратегия разбиения на ступени реализуется в одном из двух сценариев, который выбирается экспертом 1. «Имя - свойство». 2. «Множество имен — свойство». Сценарий «Имя — свойство» 1. Вопрос системы об имени события. 2. Сообщение эксперта об имени события. 3. Вопрос системы об имени свойства. 4. Сообщение эксперта об имени свойства. 5. Вопрос системы о существовании множества значений свойства. 6. Ответ эксперта (Да/Нет). 7. В случае отрицательного ответа имя свойства воспринимается как имя события. 8. Если имя события, образованного на шаге 3, отсутствует в базе знаний, то это событие рассматривается как новое, и для него выполняются шаги 2-7. 9. Вопрос системы о типе множества значений свойства (непрерывноб/дис-кретное). 10. Ответ эксперта. 11. Вопрос системы о единице измерения свойства. 12. Сообщение эксперта о единице измерения. 13. Вопрос системы о множестве значений свойства. 14. Сообщения эксперта о множестве значений свойства. 15. В процессе выполнения шагов 2—6 создается глобальный объект «имя свойства» и область его значений. Совокупность таких объектов будем называть базисом свойств области. 16. Вопрос системы о подмножестве значений свойства, характерного для описываемого события. 17. Сообщение эксперта о подмножестве значений свойства. В результате выполнения шага 7 один из элементов базиса свойств связывается с описываемым событием (с указанием подмножества области значений элемента базиса, характеризующего описываемое событие). Сценарий «Множество имен — свойство» При работе сценария шаг 1 многократно повторяется, а затем выполняются шаги 2—7 для каждого имени события. Стратегия репертуарных решеток направлена на преодоление когнитивной защиты эксперта. Механизм преодоления основан на выявлении его личностных конструктов. Каждый конструкт описывается некоторой совокупностью шкал, а каждая шкала образуется оппозицией свойств. Наиболее эффективный способ выявления противоположных свойств — предъявление эксперту триад семантически связанных событий с предложением назвать свойство, отличающее одно событие от двух других [Kelly, 1955]. На следующем шаге эксперту предлагается назвать противоположное свойство. Таким способом выявляются элементы множества личностных психологических конструктов конкретного эксперта. С другой стороны, свойства, различающие события, — это те свойства, которые влияют на формирование решения. Так как при этом не ставится задача выявления когнитивной организации индивидуального сознания эксперта, то описанная процедура используется для формирования базиса свойств области, а не для построения личностных конструктов. Пополнение базиса свойств области осуществляется путем повторения этой процедуры с другими триадами. Пример 4.9 Например, эксперту в области представления знаний предъявляется триада понятий, описывающих способы представления: семантические сети, фреймы, системы продукций. Эксперту предлагается ответить на следующие вопросы: Какой из указанных способов представления отличается от двух других? системы продукций; Какое свойство отличает системы продукций от семантических сетей и фреймов? легкость описания динамики; Назовите противоположное свойство свойству легкость описания динамики»? трудность описания динамики; Дайте имя свойству, имеющему значения легкость описания динамики» и трудность описания динамики»? возможность описания динамики. В результате формируется шкала с именем «возможность описания динамики» и со значением «легкость описания динамики» для объекта «системы продукций»; «трудность описания динамики» для объектов «семантические сети» и «фреймы». Предлагая эксперту аналогичные вопросы об отличии семантических сетей от систем продукций и фреймов, можно выявить и другие свойства базиса областй. Еще один пример — выявление каузальных знаний о предметной области. К каузальным знаниям о предметной области в соответствии с работой [Поспелов, 1986] относятся: • связи между следствиями и необходимыми и достаточными причинами; • связи между следствиями и достаточными причинами; • связи между следствиями и необходимыми co-причинами; связи между следствиями и возможными со-причинами. Будем понимать каузальные знания несколько шире, включив в рассмотрение, кроме связей событий настоящего с будущим и событий прошлого с настоящим, и связи между событиями настоящего. В соответствии с этим отнесем к каузальным знаниям все типы сообщений из табл. 4.6. Тогда задача выявления каузальных знаний сведется к установлению соответствия между множеством типов сообщений и множеством отношений Пример 4.10 Например, относительно двух событий: «рост заработной платы» и «повышение уровня жизни» эксперт сообщил, что «рост заработной платы» обычно сопровождается «повышением уровня жизни». Тогда возникают вопросы: а) повышение уровня жизни всегда сопровождается ростом заработной платы? б) повышение уровня жизни обычно сопровождается ростом заработной платы? в) повышение уровня жизни может сопровождаться ростом заработной платы? Ответ эксперта а) будет свидетельствовать о том, что исходное сообщёнйе относится к типу Стратегия подтверждения сходства является комбинированной, основанной на взаимодействии стратегий разбиения на ступени и выявления сходства, а также на анализе свойств событий (если они определены). Например, в результате работы стратегии выявления сходства установлена принадлежность предыдущего примера отношению Моделирование рассуждений в системе MIRВведем следующие обозначения: • О — опрос признаков из множества S; • П — порождение множества гипотез Г; • И — исключение множества гипотез Г. Элементы данных типа «стрелка», соответствующие отношению Работа системы MIR начинается с работы модуля О, затем модуль П строит множество гипотез Г на основе анализа положительных связей неподтвержденных признаков, отсутствие которых имеет большее значение для принятия решения, чем их присутствие. Если в результате выполнения модуля И во множестве гипотез осталось более одной гипотезы, то выполняется поиск дифференциальных признаков для подмножеств множества гипотез (дифференциальным признаком для некоторого множества гипотез называется значение свойства, характерное для одной гипотезы из множества и нехарактерное для других, или событие, связанное положительной связью с одной гипотезой из множества и не связанное таковой с другими). В результате этого процесса происходит исключение соответствующих гипотез. При необходимости процедура повторяется для оставшегося множества гипотез до его стабилизации. После выполнения еще нескольких модулей осуществляется анализ полученного множества гипотез с целью поиска его минимального подмножества, связанного положительными связями со всеми подтвержденными признаками и тем самым объясняющего их. Это последнее множество и считается окончательным результатом.
|
 |
Оглавление
|












































































































































































































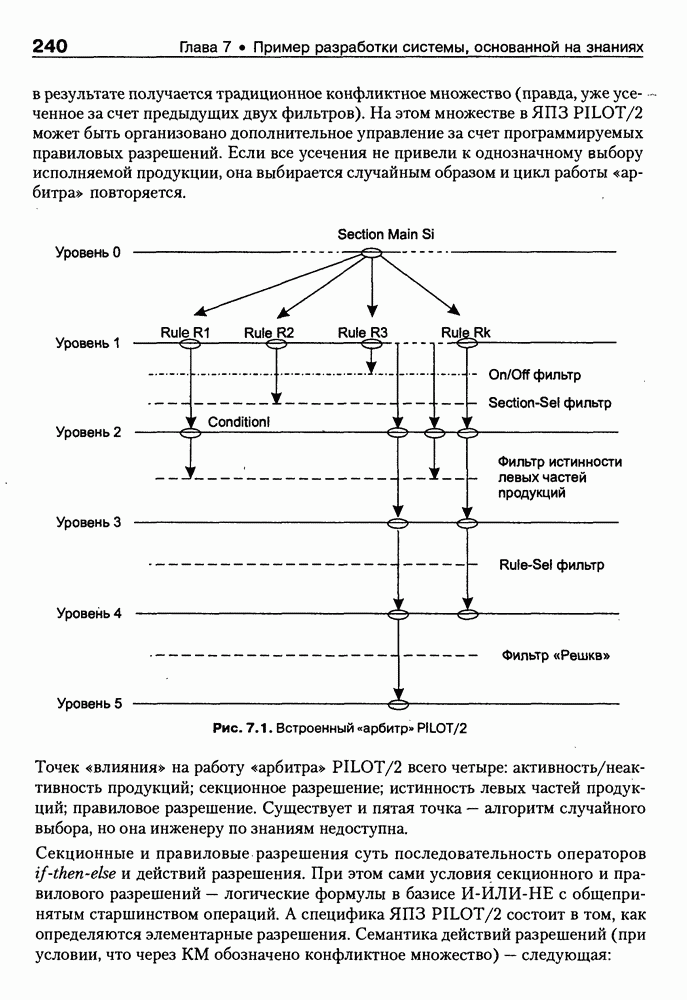





























































































































 средств для формирования модели и базы знаний предметной области. Система ориентирована преимущественно на области с неясной структурой объектов, с неполно описанным множеством свойств объектов и богатым набором связей различной «связывающей силы» между объектами.
средств для формирования модели и базы знаний предметной области. Система ориентирована преимущественно на области с неясной структурой объектов, с неполно описанным множеством свойств объектов и богатым набором связей различной «связывающей силы» между объектами.



 то необходимо попытаться установить, какое из сообщений
то необходимо попытаться установить, какое из сообщений  справедливо при замене а на
справедливо при замене а на  ,
,  на а. Так, для сообщения «Гром наблюдается при грозе» справедливо «обращенное» сообщение «Гроза сопровождается громом», а для сообщения «Воспалительный процесс может наблюдаться при повышенной температуре» справедливо сообщение «Повышенная температура характерна для воспалительного процесса». Таким образом, смысл сообщений уточняется построением «конъюнкций» форм
на а. Так, для сообщения «Гром наблюдается при грозе» справедливо «обращенное» сообщение «Гроза сопровождается громом», а для сообщения «Воспалительный процесс может наблюдаться при повышенной температуре» справедливо сообщение «Повышенная температура характерна для воспалительного процесса». Таким образом, смысл сообщений уточняется построением «конъюнкций» форм  Такие «конъюнкции» форм сообщений будут называться типами сообщений. Возможные типы сообщений приведены в табл. 4.7.
Такие «конъюнкции» форм сообщений будут называться типами сообщений. Возможные типы сообщений приведены в табл. 4.7.


 всюду далее заштриховано).
всюду далее заштриховано).

 можно интерпретировать следующим образом: для всякого примера объекта Р качестве примера приведем интерпретации некоторых диаграмм. Так, диаграмму, соответствующую сообщению типа
можно интерпретировать следующим образом: для всякого примера объекта Р качестве примера приведем интерпретации некоторых диаграмм. Так, диаграмму, соответствующую сообщению типа  можно интерпретировать следующим образом: для всякого примера объекта Р найдутся такие примеры объекта а, в которых равны совпадающие имена и значения атрибутов.
можно интерпретировать следующим образом: для всякого примера объекта Р найдутся такие примеры объекта а, в которых равны совпадающие имена и значения атрибутов.

 для всякого имени атрибута примера объекта а найдется совпадающее с ним имя атрибута из примера объекта
для всякого имени атрибута примера объекта а найдется совпадающее с ним имя атрибута из примера объекта  , и наоборот; при этрм соответствующие значения атрибутов равны. Найдутся такие примеры объекта а, в которых равны совпадающие имена и значения атрибутов.
, и наоборот; при этрм соответствующие значения атрибутов равны. Найдутся такие примеры объекта а, в которых равны совпадающие имена и значения атрибутов.
 примеров объектов (при
примеров объектов (при  ).
).
 то есть к поиску отображения Т в
то есть к поиску отображения Т в  Для поиска этого отображения используется стратегия выявления сходства [Осипов, 1989]. Она основана на выявлении в интерактивном режиме алгебраических свойств сообщений
Для поиска этого отображения используется стратегия выявления сходства [Осипов, 1989]. Она основана на выявлении в интерактивном режиме алгебраических свойств сообщений  (таких как симметричность — ассимметричность, рефлексивность — иррефлексивность и других) и появлении на основании этого гипотез о принадлежности сообщений тем или иным отношениям
(таких как симметричность — ассимметричность, рефлексивность — иррефлексивность и других) и появлении на основании этого гипотез о принадлежности сообщений тем или иным отношениям  (именно эти свойства оказываются нужными при работе механизма рассуждений).
(именно эти свойства оказываются нужными при работе механизма рассуждений).
 табл. 4.6; ответ в) — исходное сообщение относится к типу
табл. 4.6; ответ в) — исходное сообщение относится к типу  той же таблицы. Далее появляются гипотезы о том, что сообщение эксперта интерпретируется отношением
той же таблицы. Далее появляются гипотезы о том, что сообщение эксперта интерпретируется отношением  или
или  в зависимости от ответа а) или в). Повышение степени достоверности такой гипотезы возможно при использовании стратегии подтверждения сходства [Осипов, 1989].
в зависимости от ответа а) или в). Повышение степени достоверности такой гипотезы возможно при использовании стратегии подтверждения сходства [Осипов, 1989].
 На основании определения отношения
На основании определения отношения  для всякого свойства первого события найдется единственное свойство второго события, и наоборот, так что область значения свойства первого события является подобластью области значений соответствующего свойства второго события. В случае выполнения этого условия гипотеза о принадлежности предыдущего примера отношению
для всякого свойства первого события найдется единственное свойство второго события, и наоборот, так что область значения свойства первого события является подобластью области значений соответствующего свойства второго события. В случае выполнения этого условия гипотеза о принадлежности предыдущего примера отношению  считается достоверным утверждением, в противном случае запускается стратегия разбиения на ступени с целью выявления новых свойств событий, для которых было бы верно это условие. Если, несмотря на это, условие достоверности не выполняется, то статус гипотезы сохраняется, однако в базе знаний системы появляется информация о некорректности соответствующей связи между событиями. Эта информация ограничивает возможность использования построенной связи, например, с точки зрения механизма наследования свойств. При работе стратегий выявления и подтверждения сходства сценарий работы называется системой.
считается достоверным утверждением, в противном случае запускается стратегия разбиения на ступени с целью выявления новых свойств событий, для которых было бы верно это условие. Если, несмотря на это, условие достоверности не выполняется, то статус гипотезы сохраняется, однако в базе знаний системы появляется информация о некорректности соответствующей связи между событиями. Эта информация ограничивает возможность использования построенной связи, например, с точки зрения механизма наследования свойств. При работе стратегий выявления и подтверждения сходства сценарий работы называется системой.
 будем называть отрицательными связями, остальные — положительными.
будем называть отрицательными связями, остальные — положительными.
 с Г для подтвержденных признаков
с Г для подтвержденных признаков  Множество гипотез Г используется модулем О для порождения нового множества признаков
Множество гипотез Г используется модулем О для порождения нового множества признаков  связанных с гипотезами из Г положительными связями, и осуществления их тестирования. К подтвержденным признакам из
связанных с гипотезами из Г положительными связями, и осуществления их тестирования. К подтвержденным признакам из  применяется модуль П для порождения нового множества гипотез
применяется модуль П для порождения нового множества гипотез  Выполняются операции
Выполняются операции  Этот процесс продолжается итеративно до стабилизации множества
Этот процесс продолжается итеративно до стабилизации множества  и Г. Затем выполняется модуль И исключения гипотез из Г на основе анализа отрицательных связей для подтверждения симптомов и анализа положительных связей для обусловленных признаков, то есть таких
и Г. Затем выполняется модуль И исключения гипотез из Г на основе анализа отрицательных связей для подтверждения симптомов и анализа положительных связей для обусловленных признаков, то есть таких