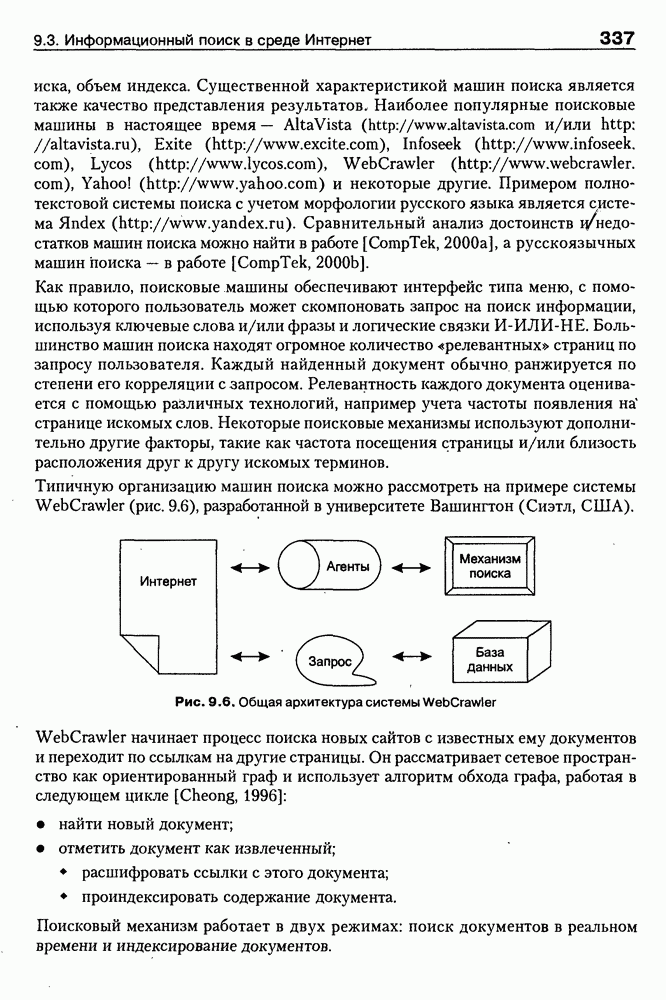
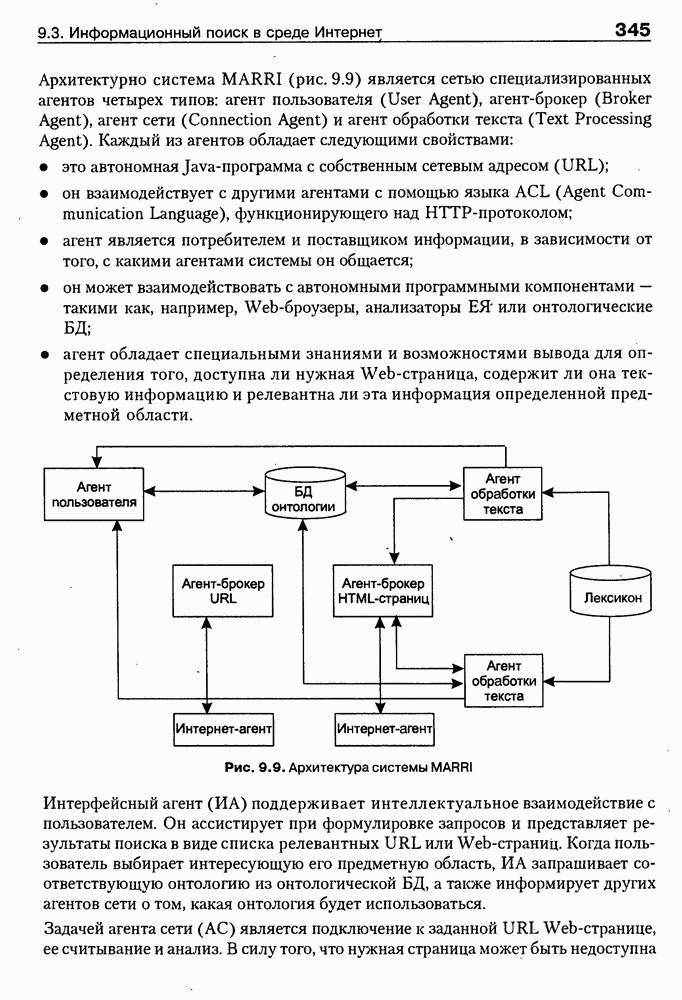
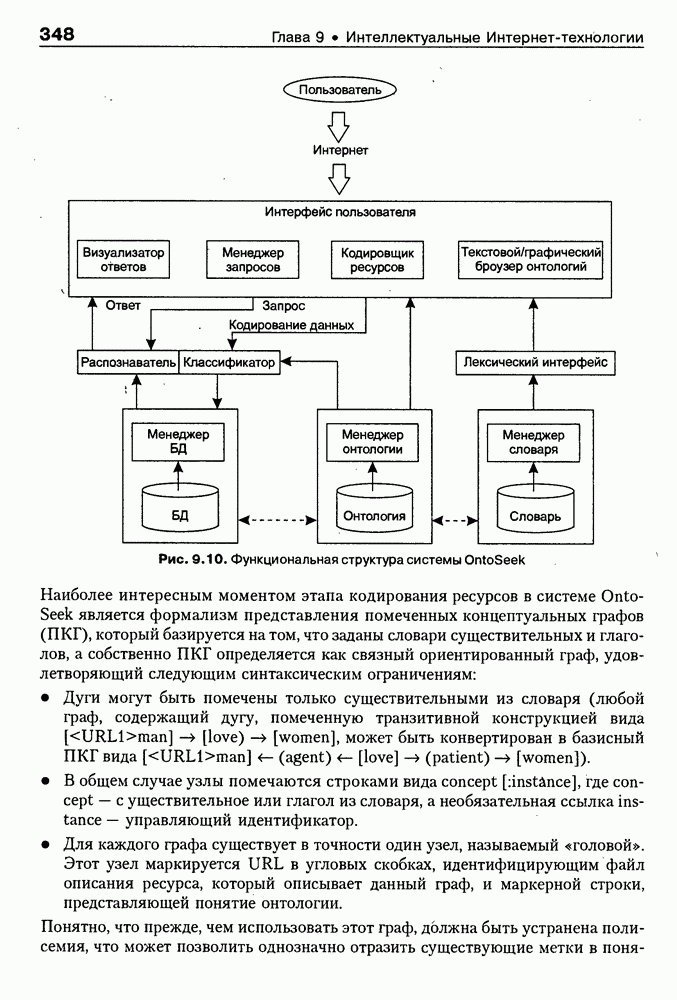
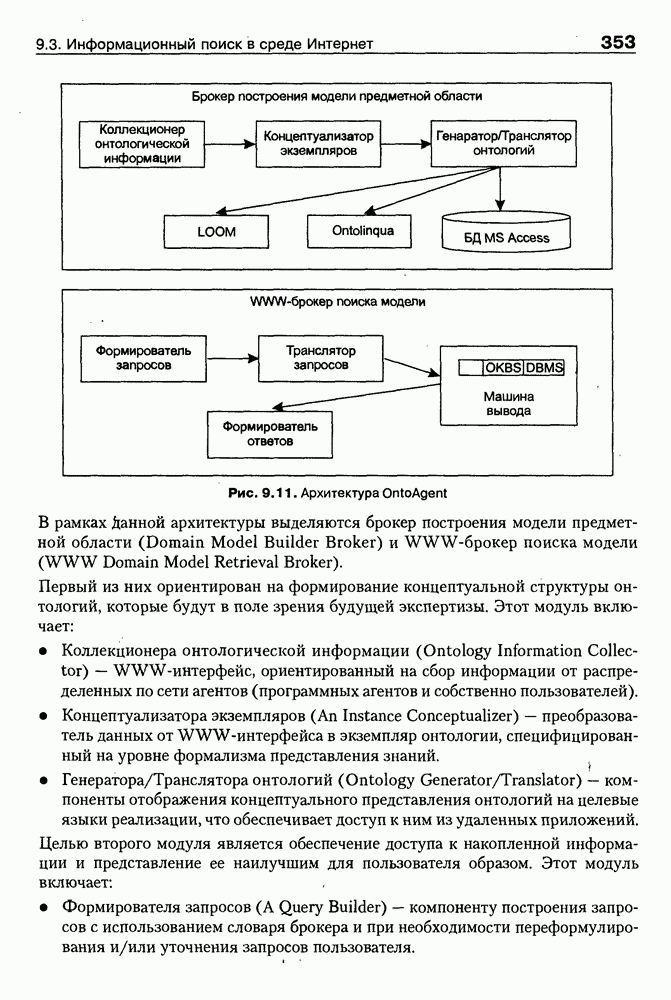
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
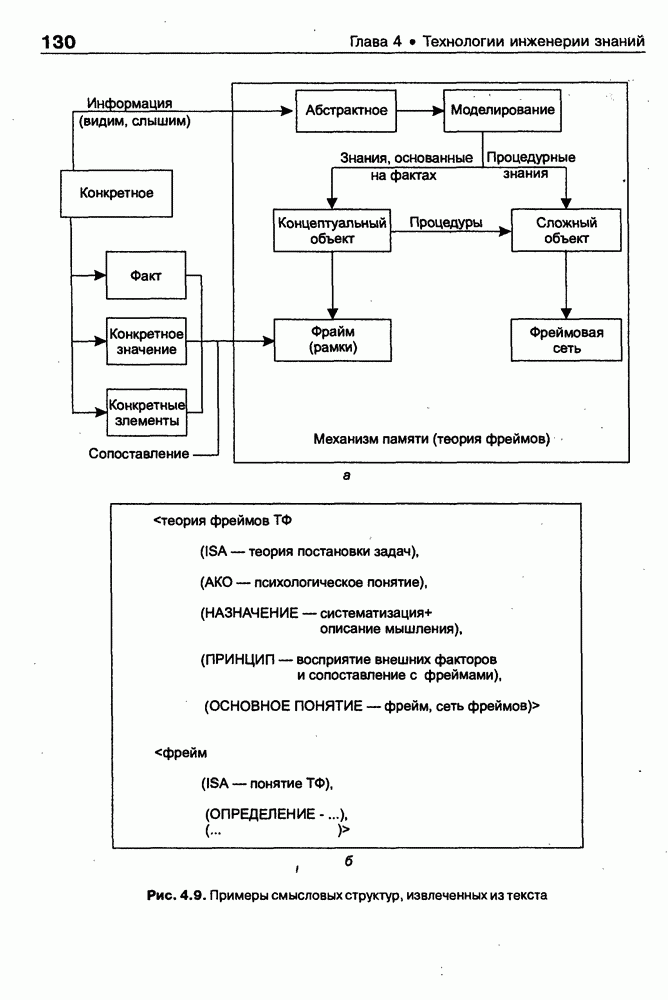
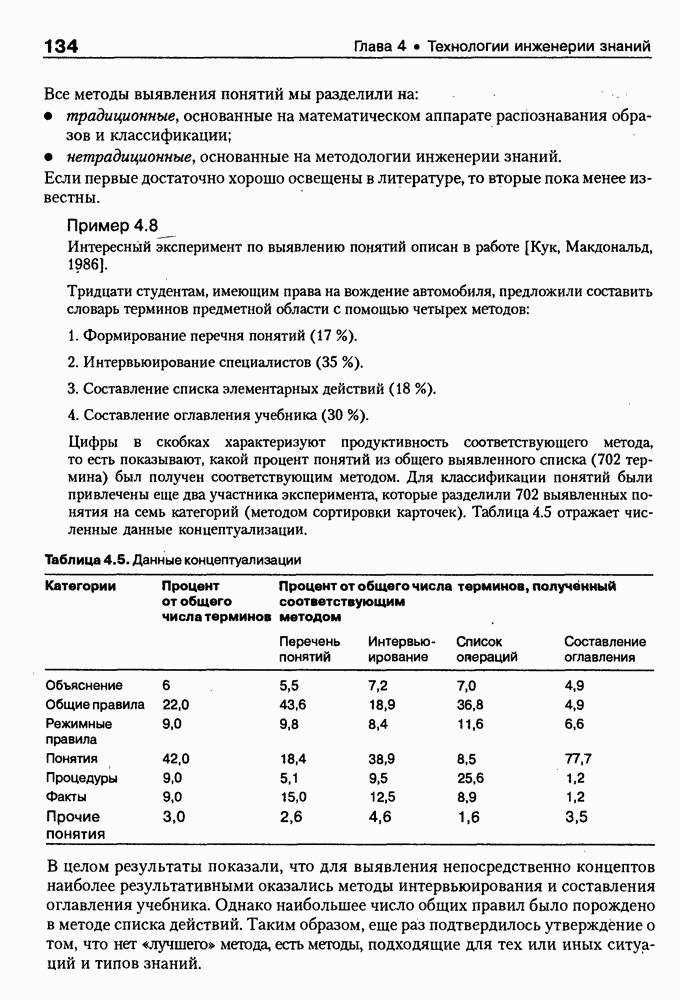
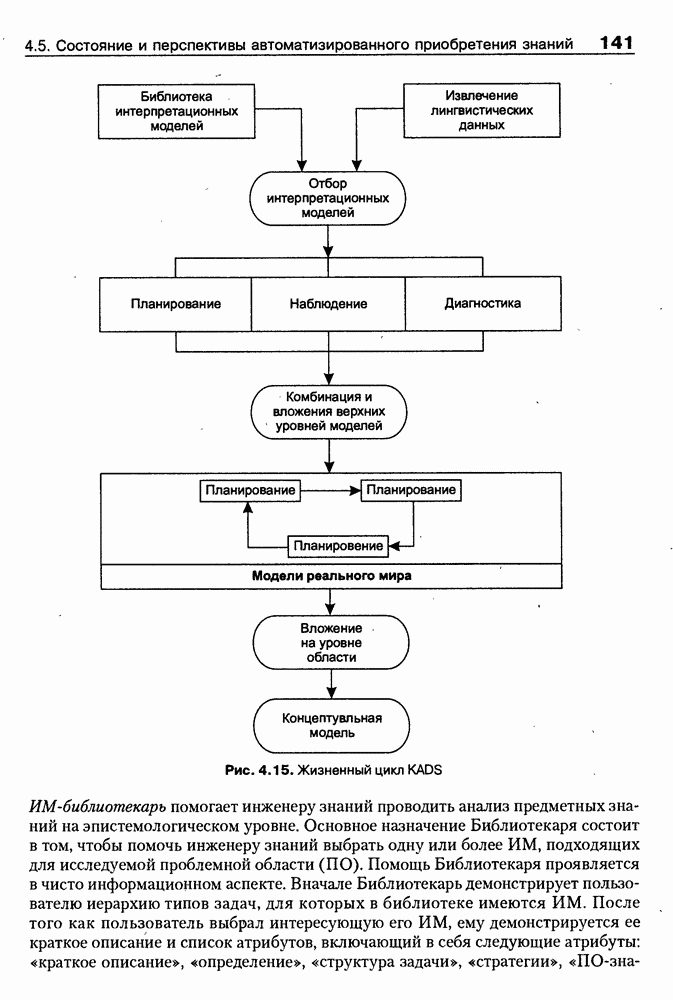
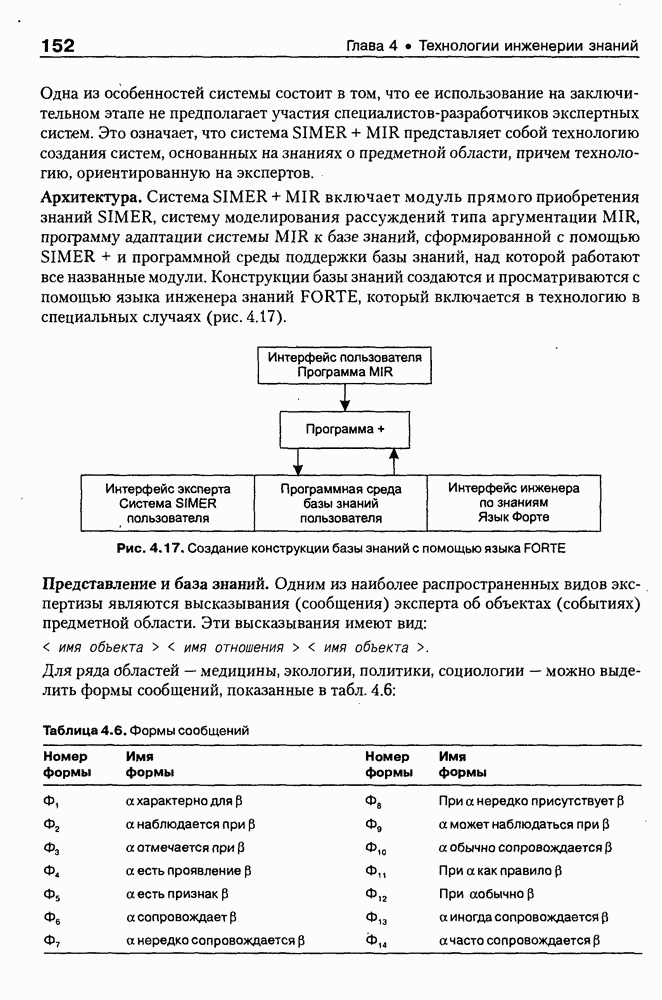
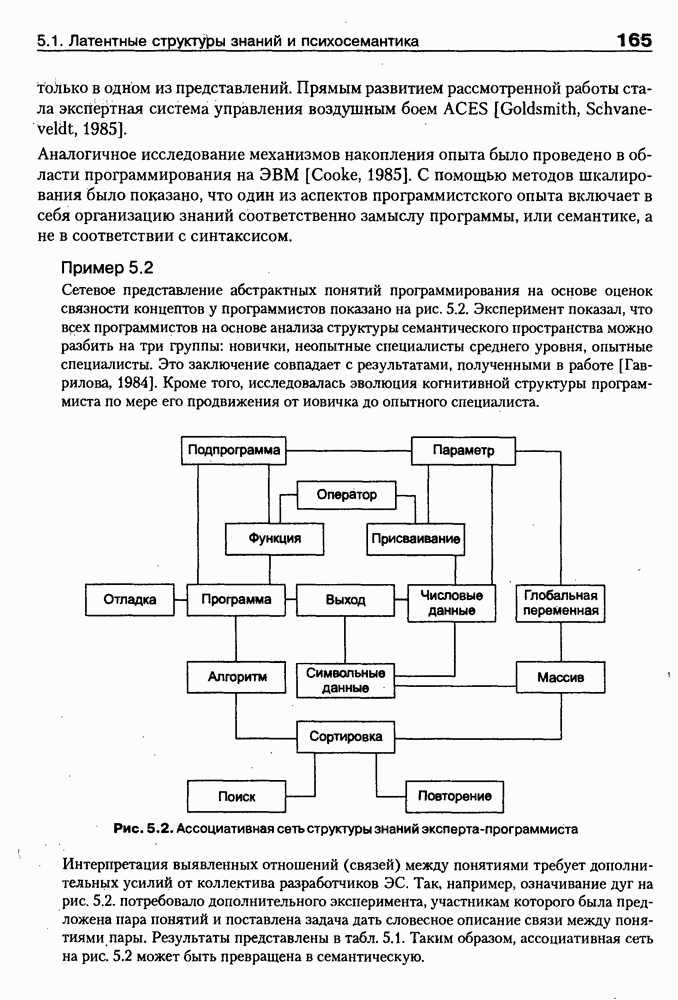
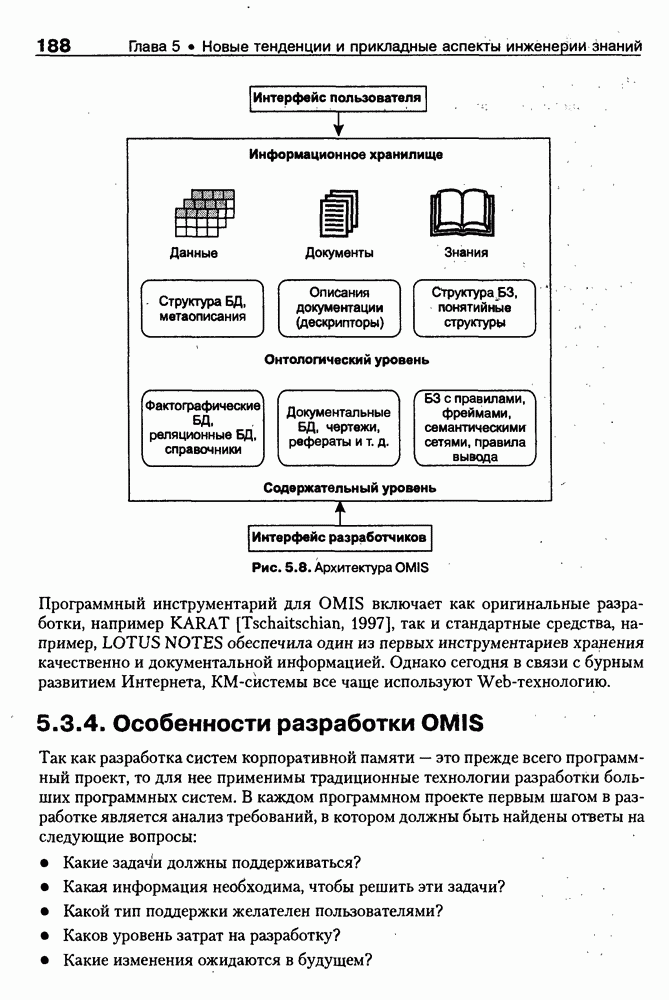
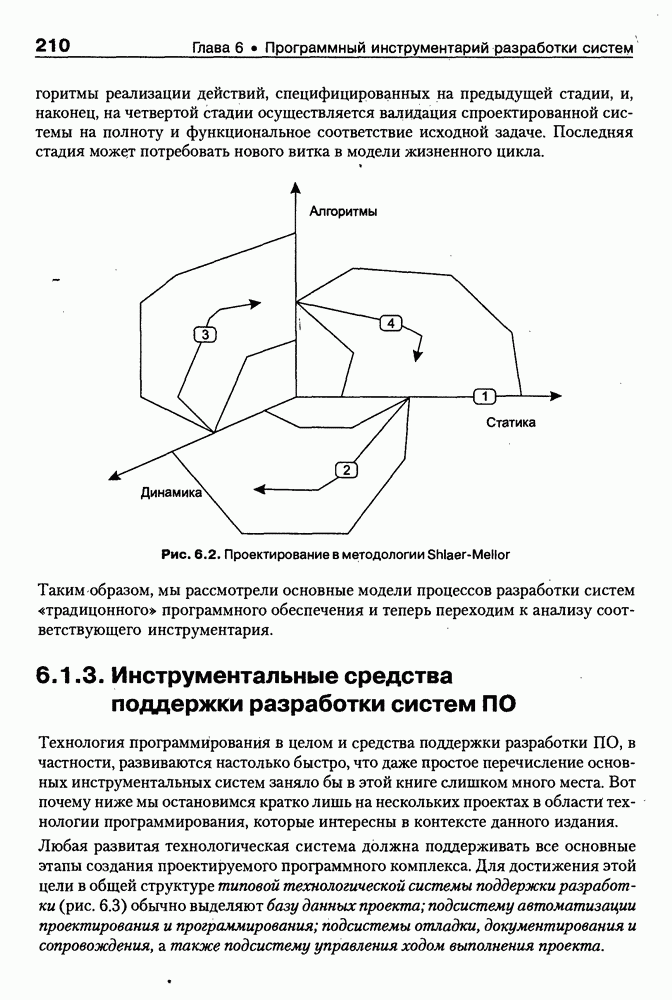
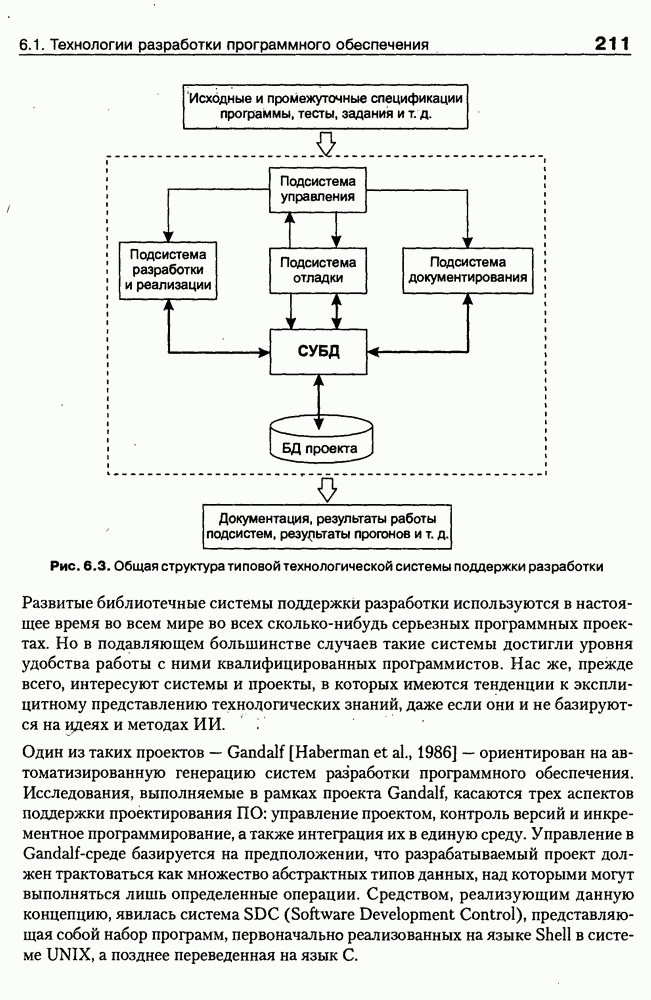
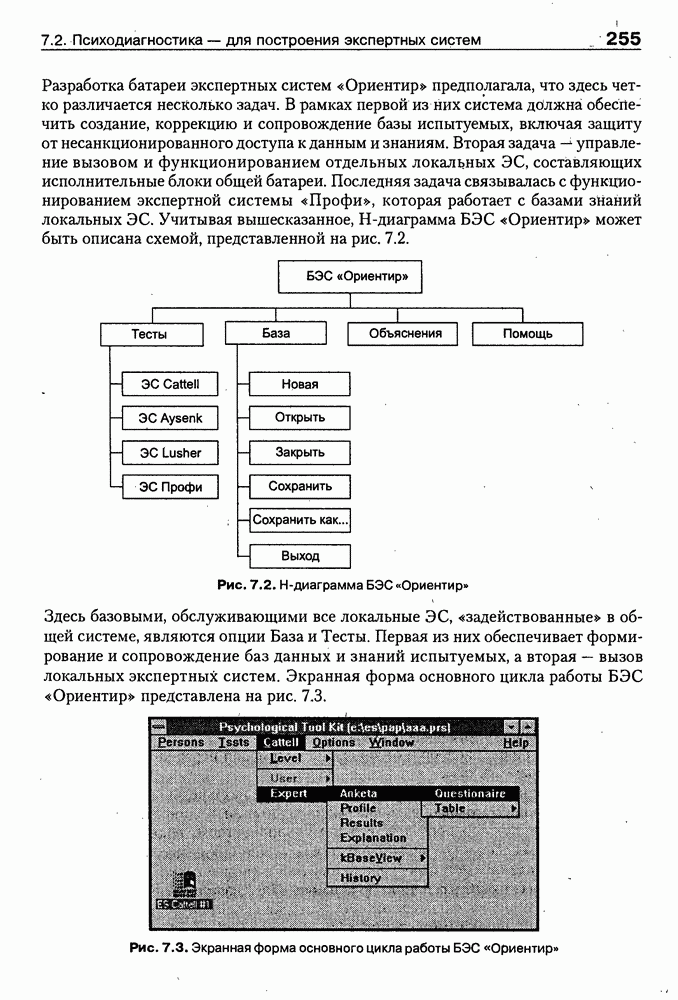
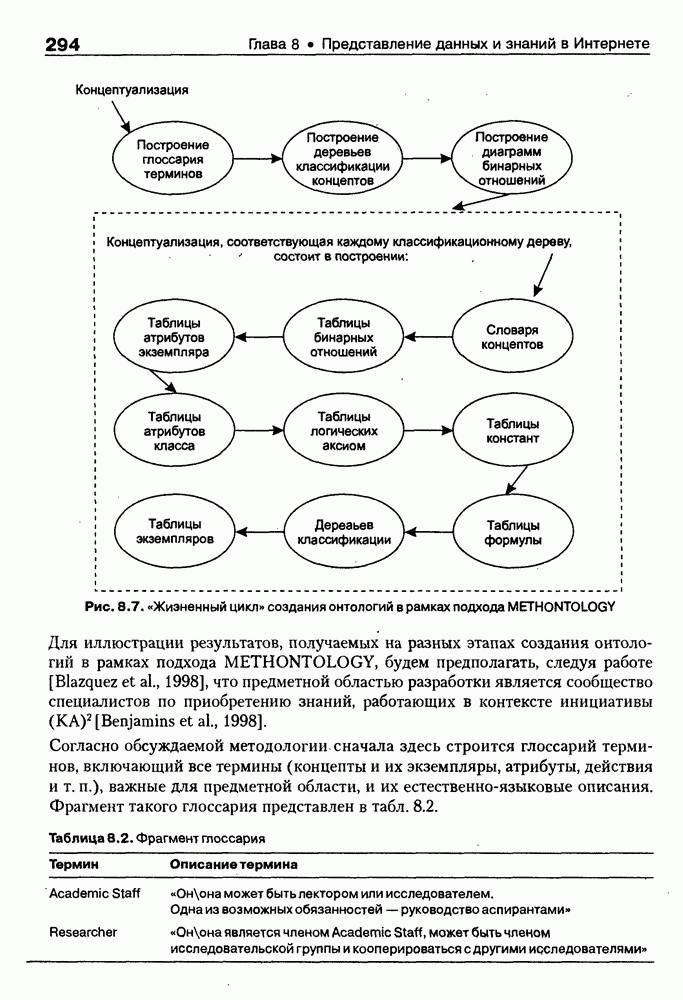
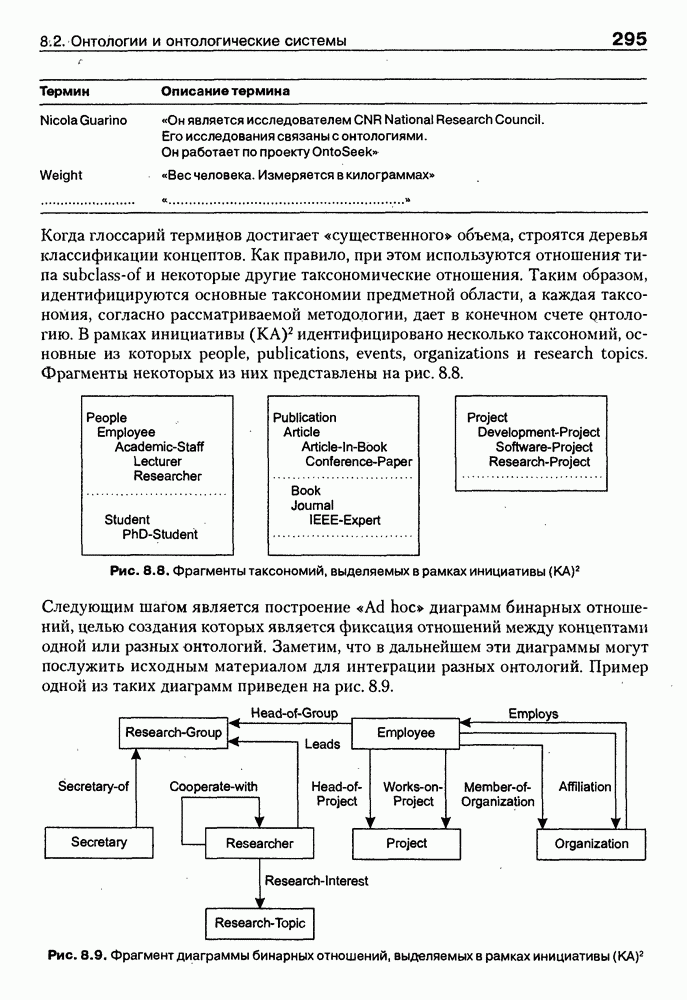
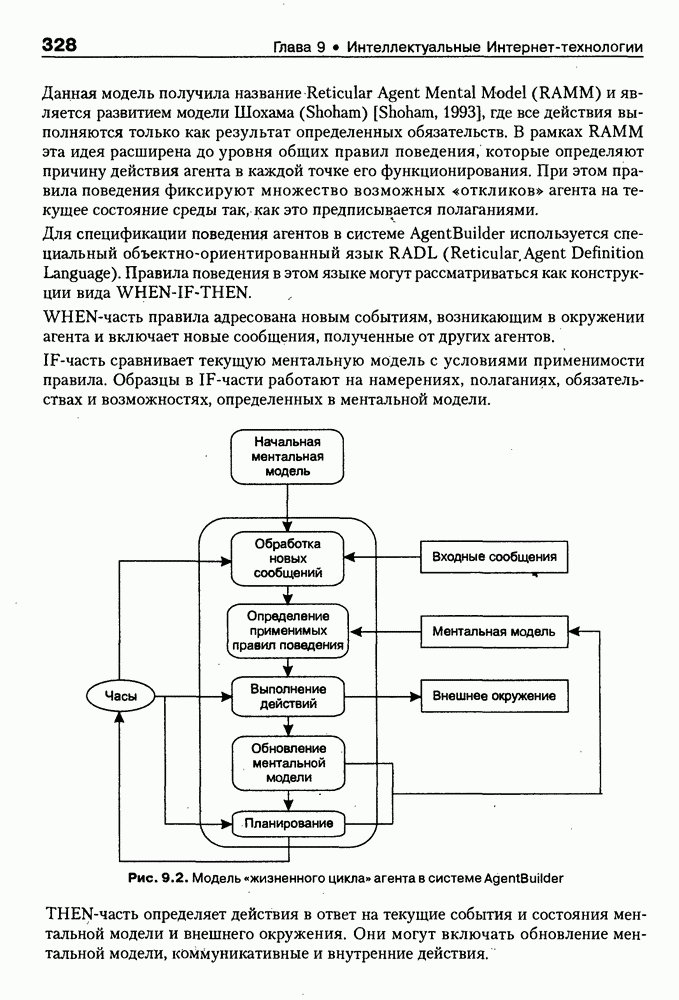
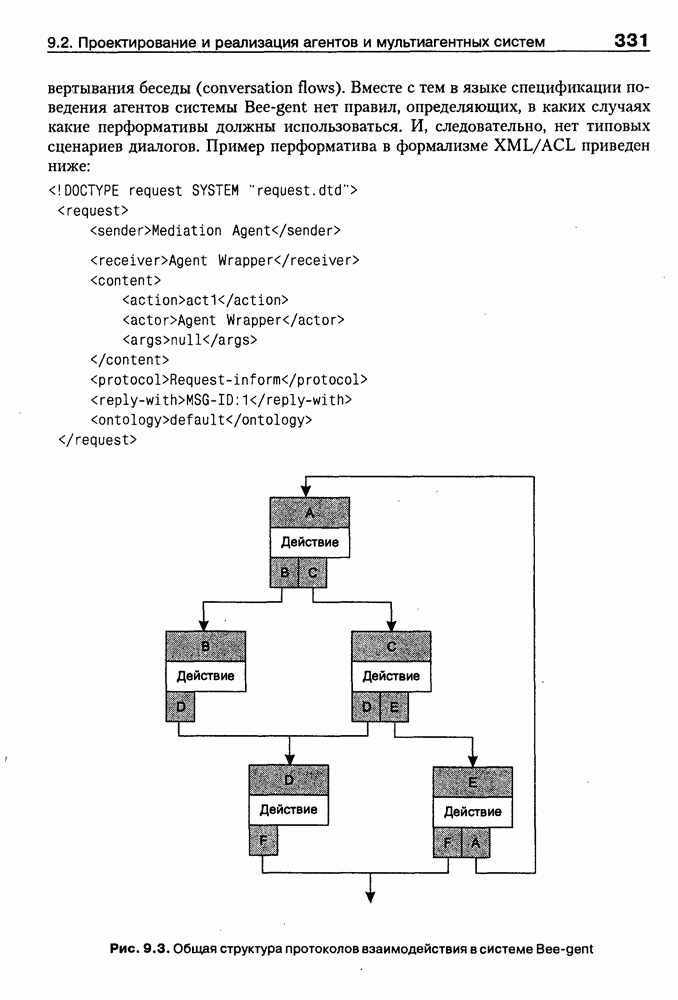
8.1.3. Возможности представления знаний на базе языка HTMLВыше были рассмотрены основные конструкции HTML. Теперь обсудим, каким образом они могут быть использованы для семантической разметки Интернет-документов и насколько это вообще возможно и эффективно. Для этого выделим те конструкции языка, которые могут быть полезными для решения данной задачи. Очевидно, что к их числу, прежде всего, относятся теги типа Первый важен для фиксации семантики всего HTML-документа, так как текст, заключенный между тегами Теги типа Но если теги типа Из других конструкций HTML полезными для последующей обработки на предмет эксплицитного представления семантики соответствующих частей документа могут быть заголовки разделов и подразделов (тексты между тегами Но в целом можно отметить, что выделение значимых для семантической интерпретации конструкций является экспертной задачей, решаемой каждый раз автором соответствующей Интернет-публикации по-своему. Правда, уже существуют определенные стереотипы, особенно заметные на коммерческих сайтах. Так, например, при анализе сайтов Интернет-магазинов, проведенном Н. В. Майкевич, было зафиксировано, что каталоги товаров в настоящее время в большинстве случаев представляются таблицами и/или списками либо «зашиты» в чувствительные для щелчка мышью графические образы. Аналогичная ситуация характерна и для индексов на сайтах машин поиска. Для примера на рис. 8.2 приведена экранная форма известного электронного магазина, функционирующего в сети по адресу http://amazon.com/. Рис. 8.2. (см. скан) Экранная форма секции «Электроника» магазина Amazon.com Фрагмент соответствующего HTML-текста представлен ниже:
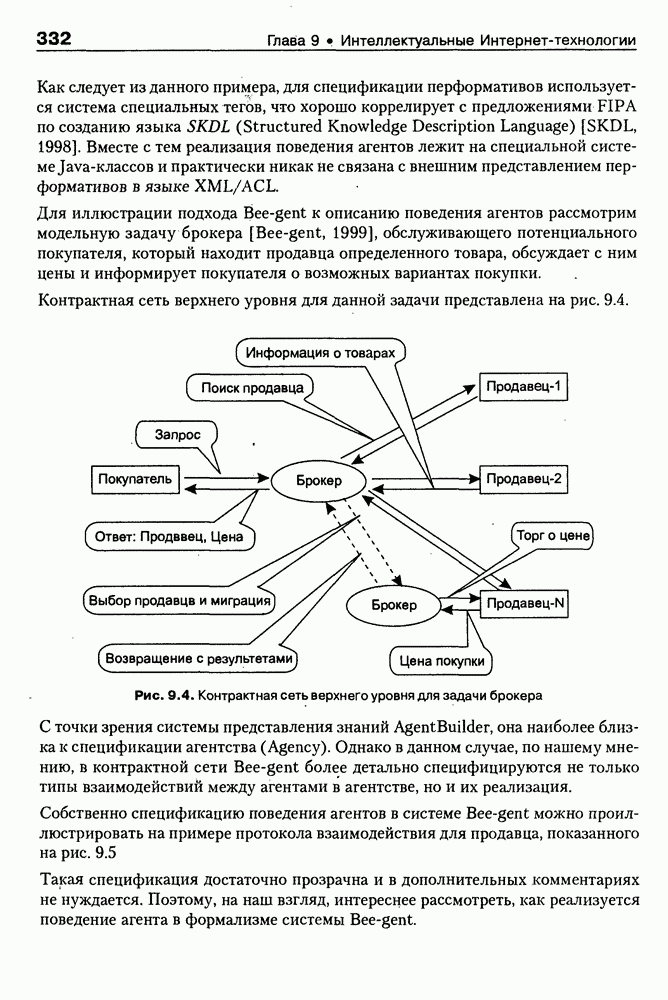
(см. скан) Как следует из сравнения экранной формы (см. рис. 8.2) и приведенного HTML-текста, каталог товаров организован в виде таблицы Решение проблемы семантического анализа Интернет-документов в настоящее время связывается с использованием двух подходов. В рамках первого из них предполагается, что семантическая разметка HTML-текста выполняется вручную (или полуавтоматически, с применением соответствующих инструментальных средств) его автором на основе специальных метатегов. По существу, результатом такой разметки является семантическая сеть, отражающая знания, представленные в документе. Второй подход связан с автоматическим и/или полуавтоматическим преобразованием исходного текста в специальное семантическое представление, как правило, в онтологию или ее фрагмент. Подробнее эти подходы обсуждаются ниже. Но и в том и в другом случае для выполнения указанных преобразований целесообразно конвертирование HTML-текстов в более удобное для дальнейшей обработки представление. Для иллюстрации возможностей применения к решению этой задачи средств представления знаний, описанных в предыдущих главах, рассмотрим интеллектуальный HTML-конвертор [Maikevich et al., 1998]. Для сокращения объема материала обсудим подмножество языка HTML, которое может быть задано следующими BNF-определениями:
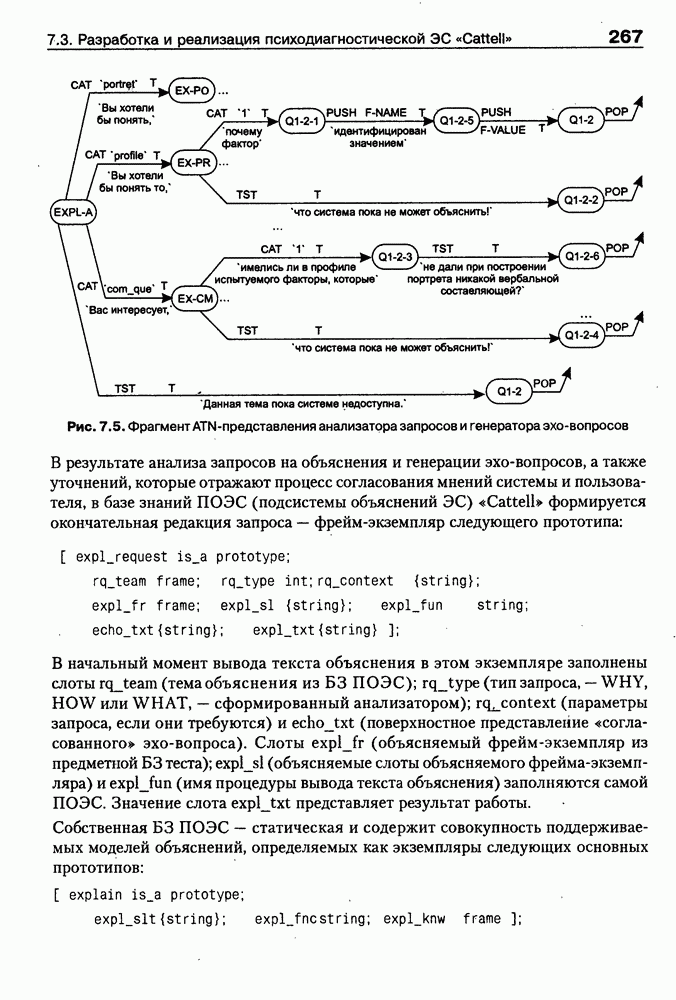
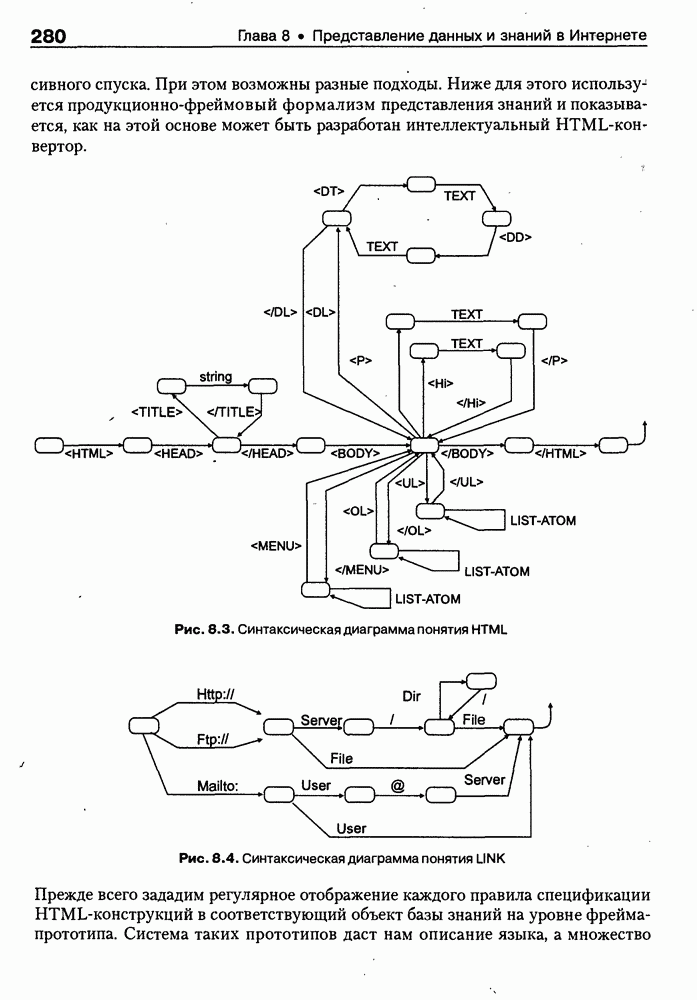
Некоторые из синтаксических диаграмм, соответствующих приведенным выше правилам, представлены на рис. 8.3 и 8.4. Как следует из приведенных правил и диаграмм, с теоретической точки зрения HTML — это простой язык программирования с контекстно-свободной грамматикой. Нетрудно показать, что для анализа HTML-текстов можно использовать, например, нисходящие распознаватели, реализуемые на базе метода рекурсивного спуска. При этом возможны разные подходы. Ниже для этого используй ется продукционно-фреймовый формализм представления знаний и показывается, как на этой основе может быть разработан интеллектуальный HTML-конвертор. Рис. 8.3. (см. скан) Синтаксическая диаграмма понятия HTML Рис. 8.4. (см. скан) Синтаксическая диаграмма понятия LINK Прежде всего зададим регулярное отображение каждого правила спецификации HTML-конструкций в соответствующий объект базы знаний на уровне фрейма-прототипа. Система таких прототипов даст нам описание языка, а множество фреймов-экземпляров — спецификацию конкретных и синтаксически правильных HTML-текстов. Основные правила такого отображения следующие: • каждому концепту из левой части BNF-определения поставим в соответствие имя фрейма-прототипа; • альтернативам из правой части BNF-определения при этом должны соответствовать имена слотов этого фрейма; • для концептов-нетерминалов соответствующий слот должен иметь тип frame; • для концептов-терминалов соответствующие слоты будут, как правило, иметь типы • рекурсия в BNF-определениях заменяется итерацией, а соответствующие слоты становятся множественными. Применение сформулированных выше правил к BNF-определениям языка HTML приводит нас к следующему множеству фреймов-прототипов: (см. скан)
Теперь, в соответствии с приведенными фреймами-прототипами и синтаксическими диаграммами, можно специфицировать процедурную часть конвертора как систему демонов, присоединенных к фреймам и/или их слотам. Для примера ниже приводится спецификация одного из таких демонов на языке Java [Нортон и др., 1998]:
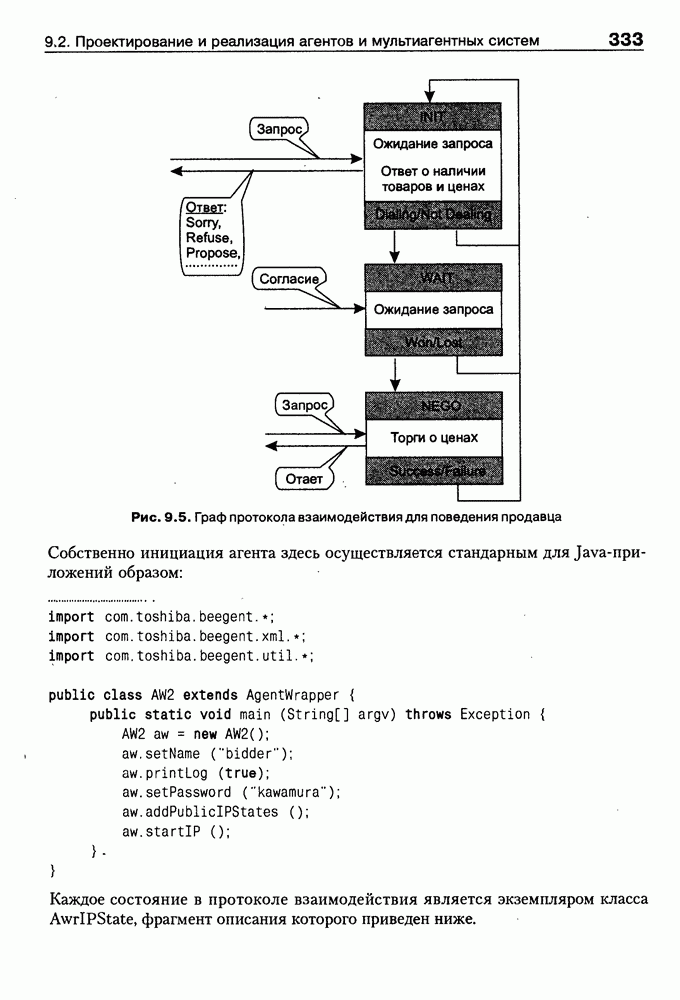
По существу, такой демон не что иное, как конструктор класса HTML, а запуск конвертора осуществляется с помощью оператора создания нового объекта этого класса:
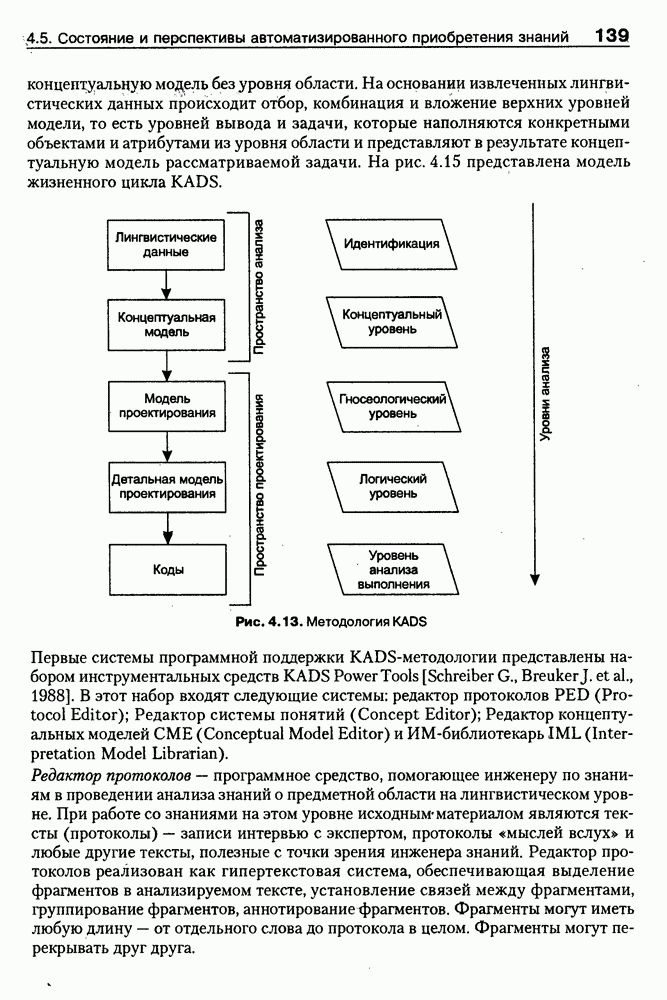
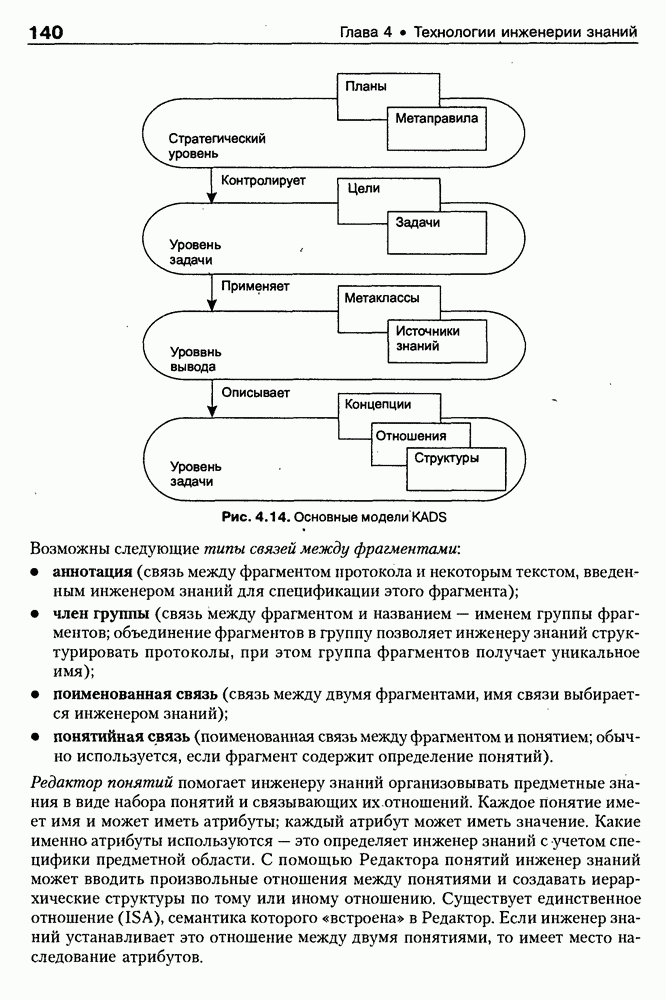
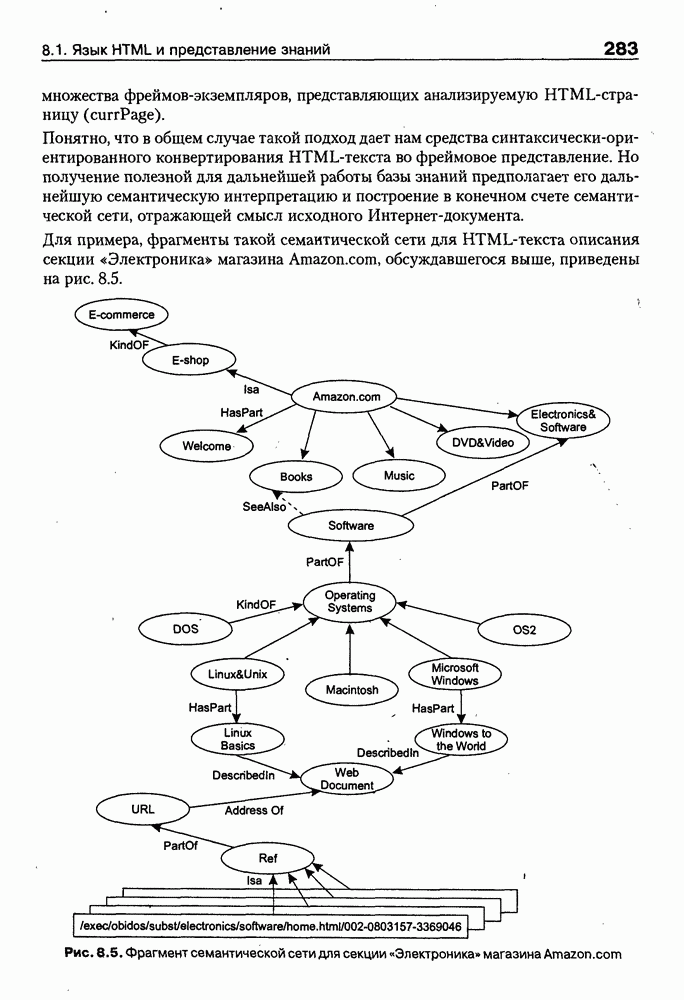
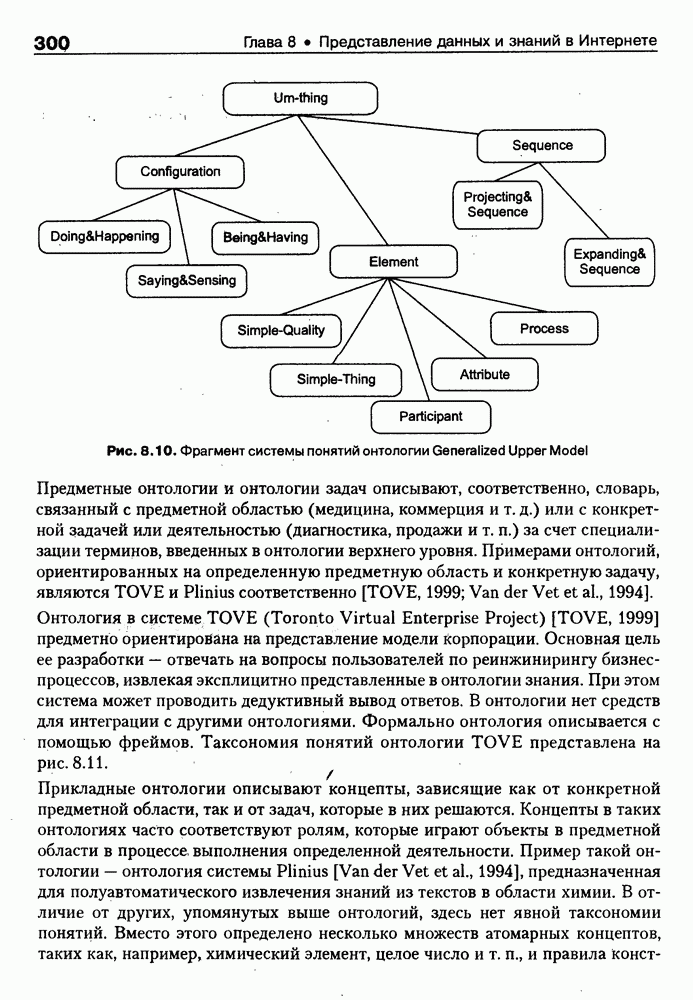
При этом будут рекурсивно вызываться конструкторы других классов (на верхнем уровне это HEAD и BODY), что, в конечном счете, приведет к построению множества фреймов-экземпляров, представляющих анализируемую HTML-страницу (currPage). Понятно, что в общем случае такой подход дает нам средства синтаксически-ори-ентированного конвертирования HTML-текста во фреймовое представление. Но получение полезной для дальнейшей работы базы знаний предполагает его дальнейшую семантическую интерпретацию и построение в конечном счете семантической сети, отражающей смысл исходного Интернет-документа. Для примера, фрагменты такой семантической сети для HTML-текста описания секции «Электроника» магазина Amazon.com, обсуждавшегося выше, приведены на рис. 8.5. Рис. 8.5. (см. скан) фрагмент семантической сети для секции «Электроника» магазина Amazon.com По сути дела, эта семантическая сеть представляет фрагмент онтологии предметной области «Электронная коммерция», которая может быть базйсом для решения разнообразных практических задач. Так, например, с ее помощью могут решаться задачи поиска определенных товаров по запросу пользователя, осуществляться маркетинговый анализ запросов и т. п. Во всех этих и многих других случаях онтологии играют ключевую роль как один из перспективных подходов к представлению знаний в среде Интернет. Вместе с тем, несмотря на важность понятия онтологии для теории и практики современных интеллектуальных систем, общепринятого понимания этого термина нет, хотя различные определения, предложенные разными авторами и научными коллективами [Gruber, 1991; Guarino, 1996; Fridman et al., 1997], распространяются и медленно конвергируют. Поэтому в следующем параграфе обсуждается само понятие онтологии и вводится соответствующая система моделей [Maikevich et al., 1999], затем приводится классификация онтологий, полезная для последующего сравнения известных в зтой области проектов. В заключительных разделах главы обсуждаются примеры онтологий и специальные системы аннотирования Интернет-ресурсов на основе онтологий.
|
 |
Оглавление
|


























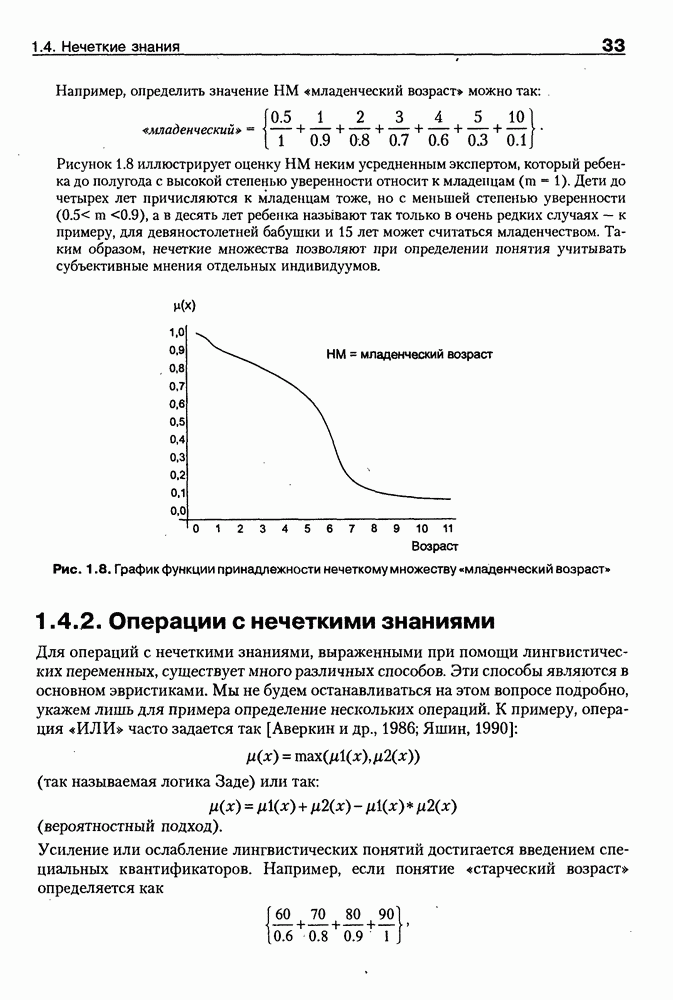
















































































































































































































































































































 чаще всего отражает его назначение и/или содержание.
чаще всего отражает его назначение и/или содержание.
 по существу, вводят имена атрибутов и их значения с помощью параметров
по существу, вводят имена атрибутов и их значения с помощью параметров  а ссылки и якоря фиксируют отношения между частями одного документа и/или отдельными документами.
а ссылки и якоря фиксируют отношения между частями одного документа и/или отдельными документами.
 явно вводят семантику значений атрибутов, одинаково интерпретируемых броузерами за счет ключевых слов (например, keywords, author и др.), которые могут быть значениями параметра
явно вводят семантику значений атрибутов, одинаково интерпретируемых броузерами за счет ключевых слов (например, keywords, author и др.), которые могут быть значениями параметра  то теги типа
то теги типа  лишь фиксируют факт наличия отношения между ссылкой и ее якорем. В некоторых случаях этому отношению можно «приписать» имя
лишь фиксируют факт наличия отношения между ссылкой и ее якорем. В некоторых случаях этому отношению можно «приписать» имя  в других —
в других —  или иное подходящее имя, но в целом семантика данной конструкции имплицитна, а встроенная интерпретация ее связана лишь с переходом по ссылке и визуализацией начала соответствующего фрагмента документа или загрузкой нового документа для просмотра.
или иное подходящее имя, но в целом семантика данной конструкции имплицитна, а встроенная интерпретация ее связана лишь с переходом по ссылке и визуализацией начала соответствующего фрагмента документа или загрузкой нового документа для просмотра.
 списки, таблицы и другие элементы языка.
списки, таблицы и другие элементы языка.

 в ячейках которой
в ячейках которой  с помощью конструкции списка
с помощью конструкции списка  перечислены продукты (в данном случае это операционные системы DOS, Linux & Unix, Macintosh, Microsoft Windows и OS2). Собственно описания этих продуктов и их характеристики заданы в виде ссылок на отдельные документы (теги
перечислены продукты (в данном случае это операционные системы DOS, Linux & Unix, Macintosh, Microsoft Windows и OS2). Собственно описания этих продуктов и их характеристики заданы в виде ссылок на отдельные документы (теги  При этом из анализа HTML-текста следует, что его семантически значимые характеристики могут быть «закопаны» достаточно глубоко. И более того, разбросаны по разным частям одного документа и даже разным документам. Все вышесказанное существенно затрудняет семантический анализ Интернет-документов, независимо от того, выполняется ли он людьми-экспертами или специальными программами.
При этом из анализа HTML-текста следует, что его семантически значимые характеристики могут быть «закопаны» достаточно глубоко. И более того, разбросаны по разным частям одного документа и даже разным документам. Все вышесказанное существенно затрудняет семантический анализ Интернет-документов, независимо от того, выполняется ли он людьми-экспертами или специальными программами.

 или string,
или string,


