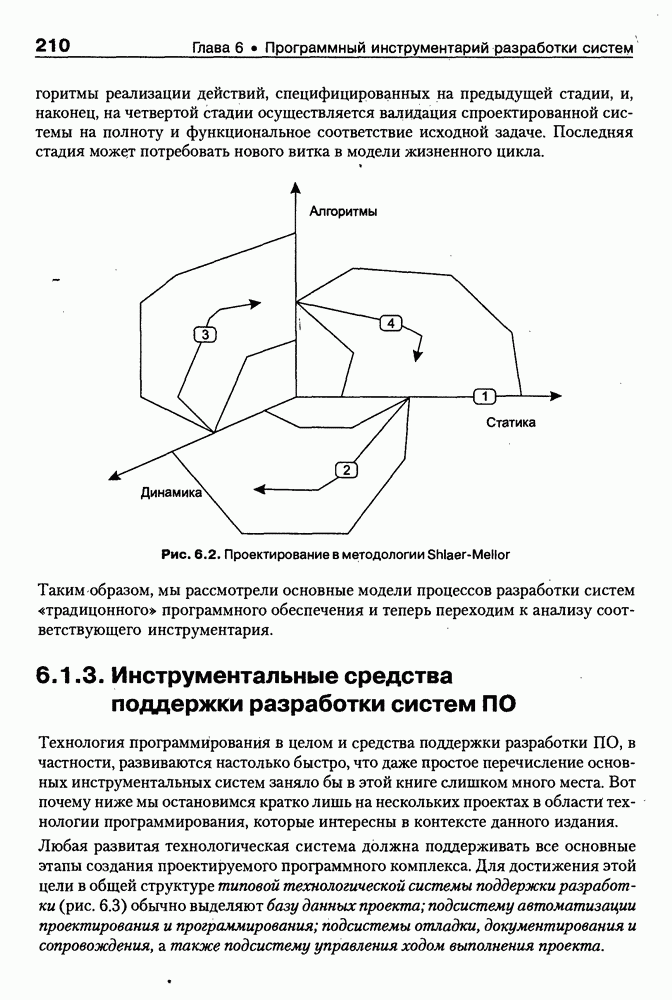
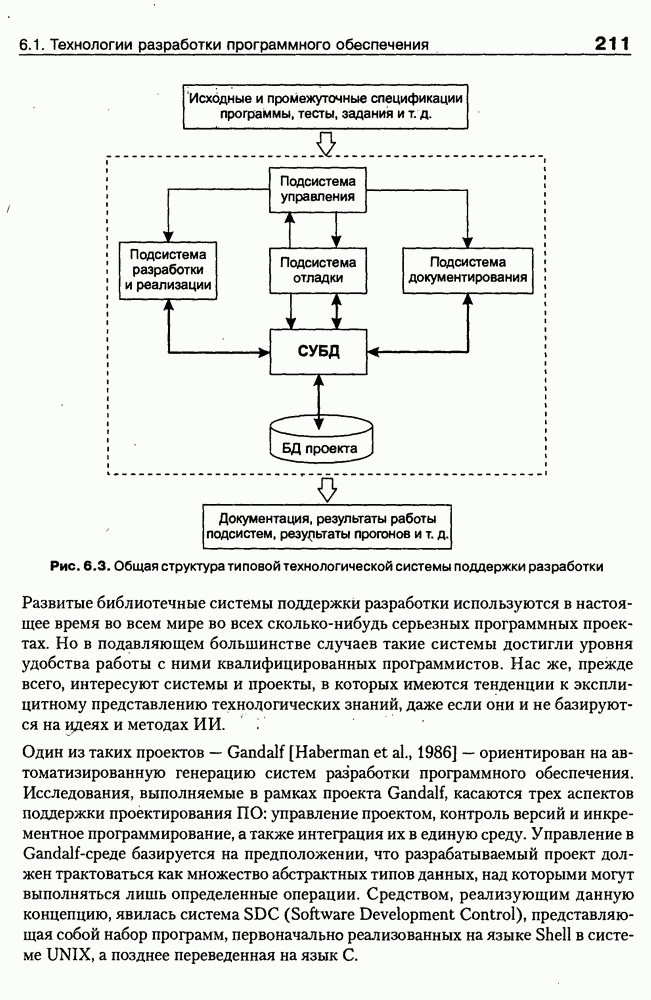
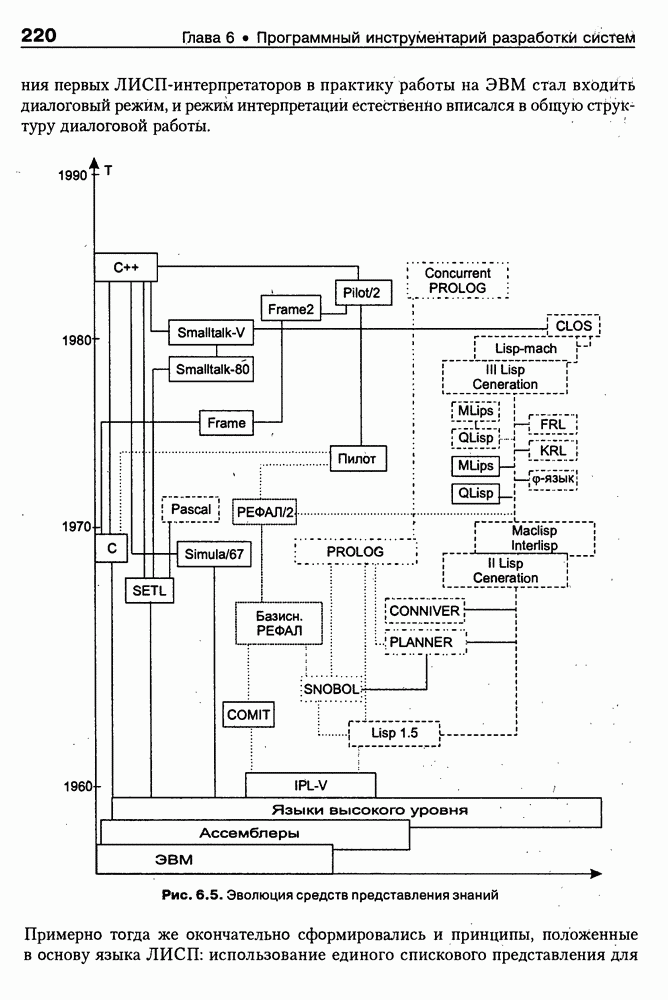
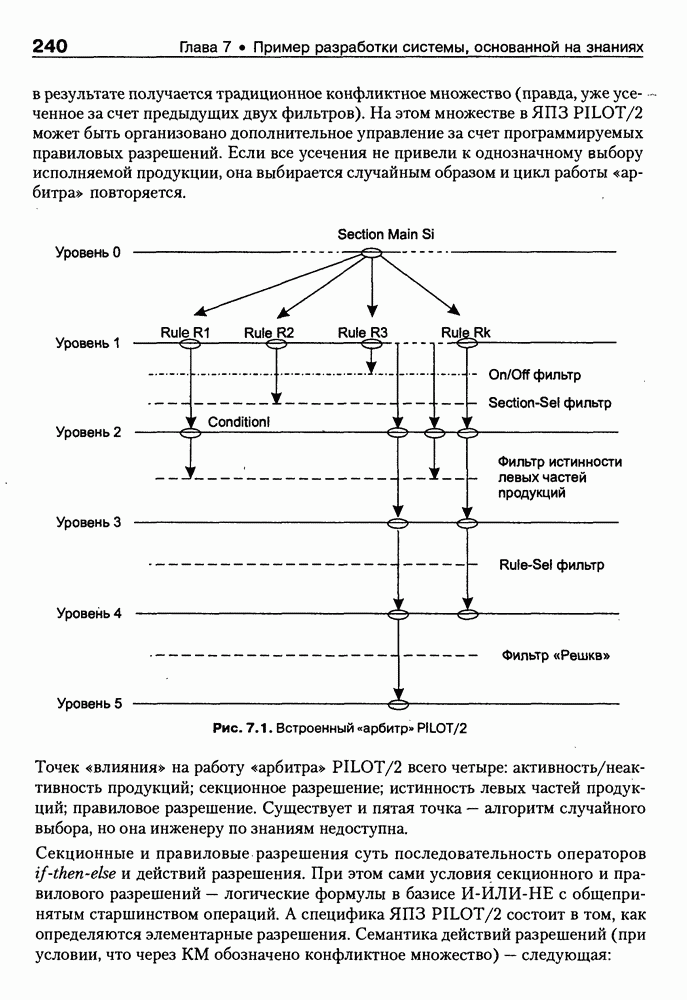
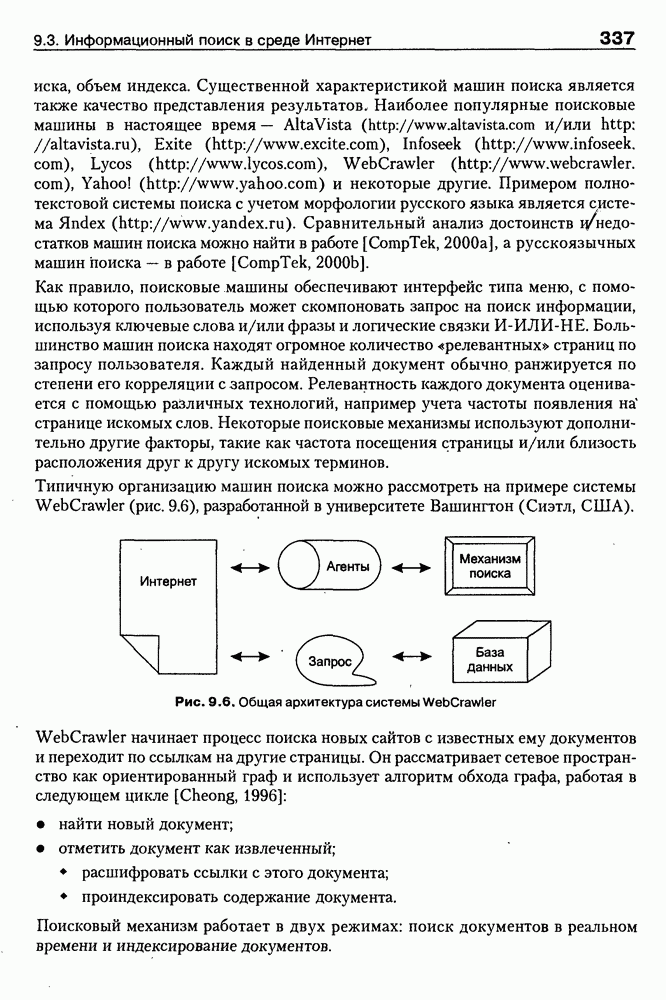
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
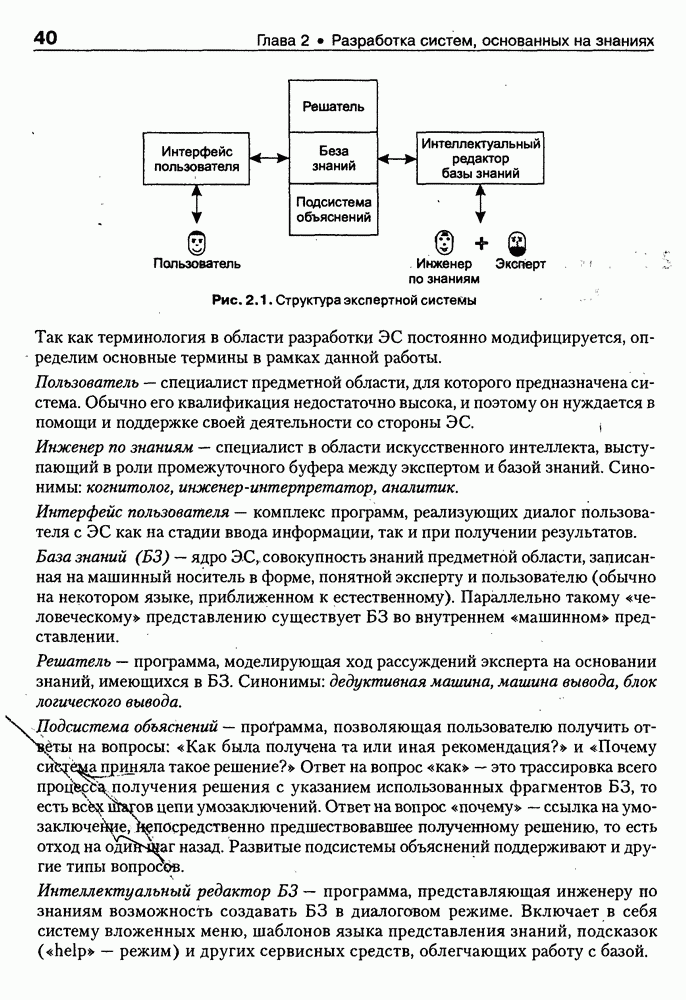
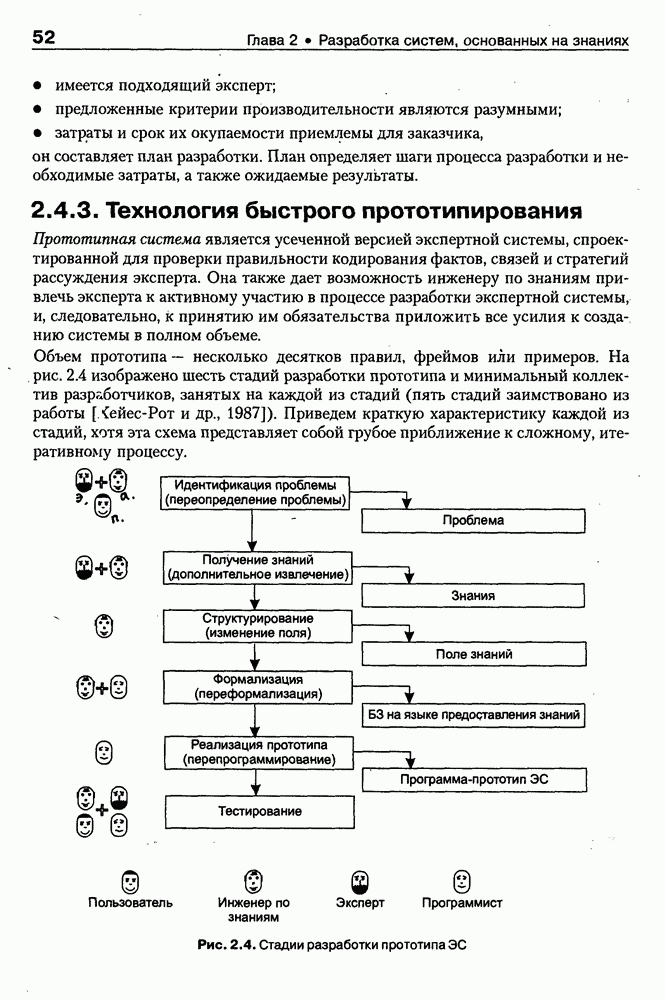
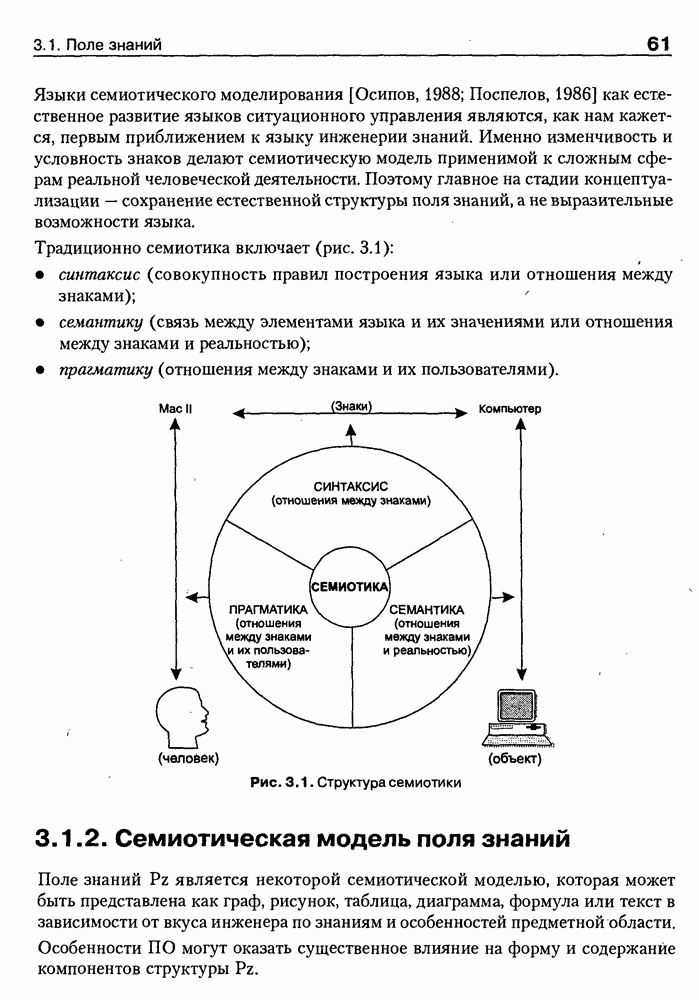
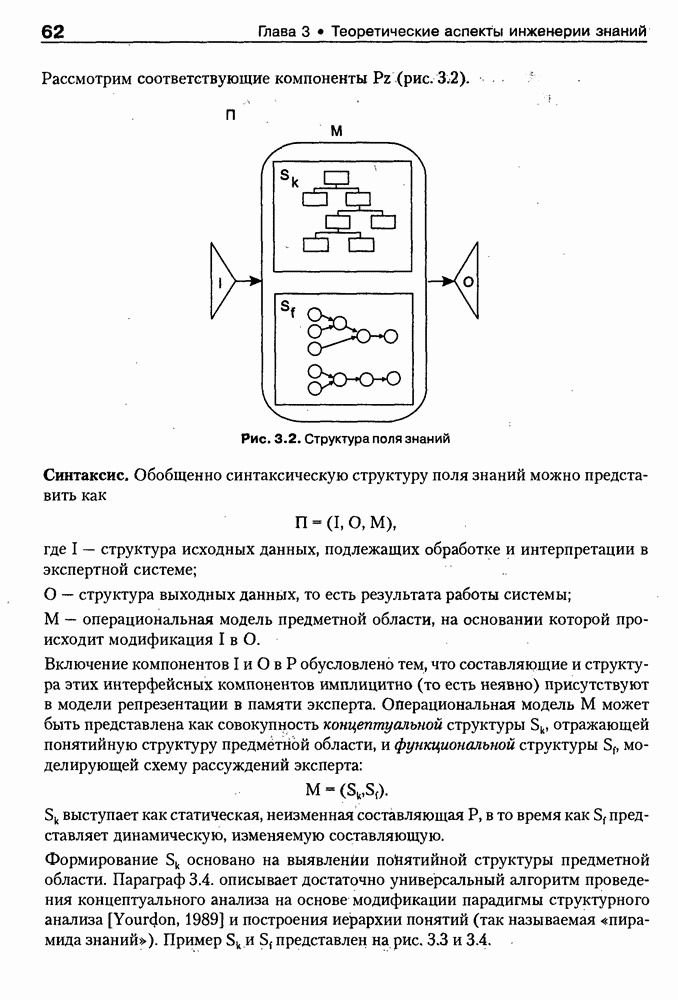
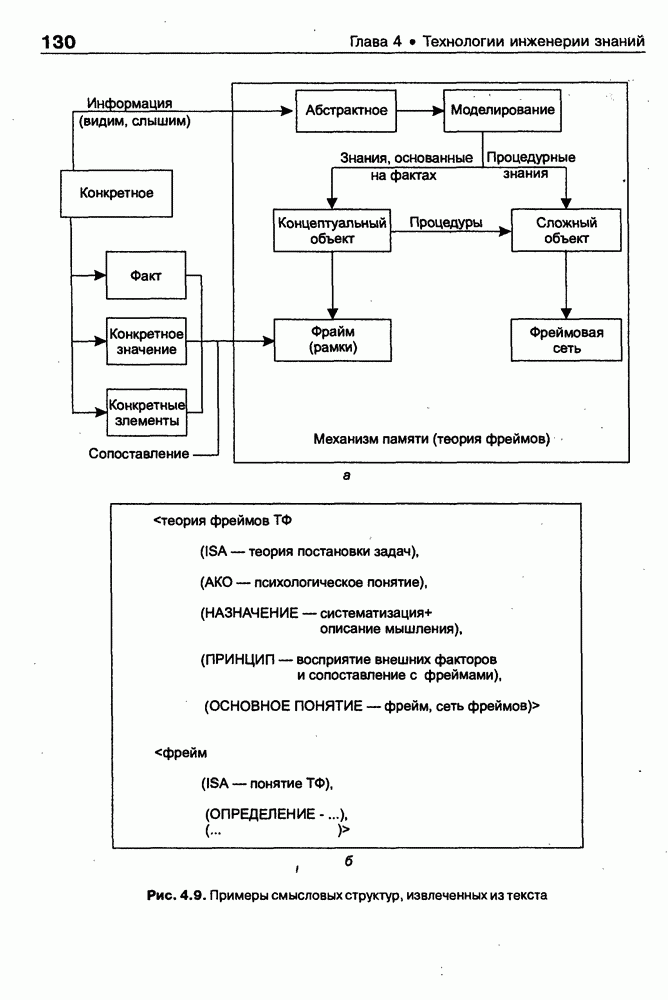
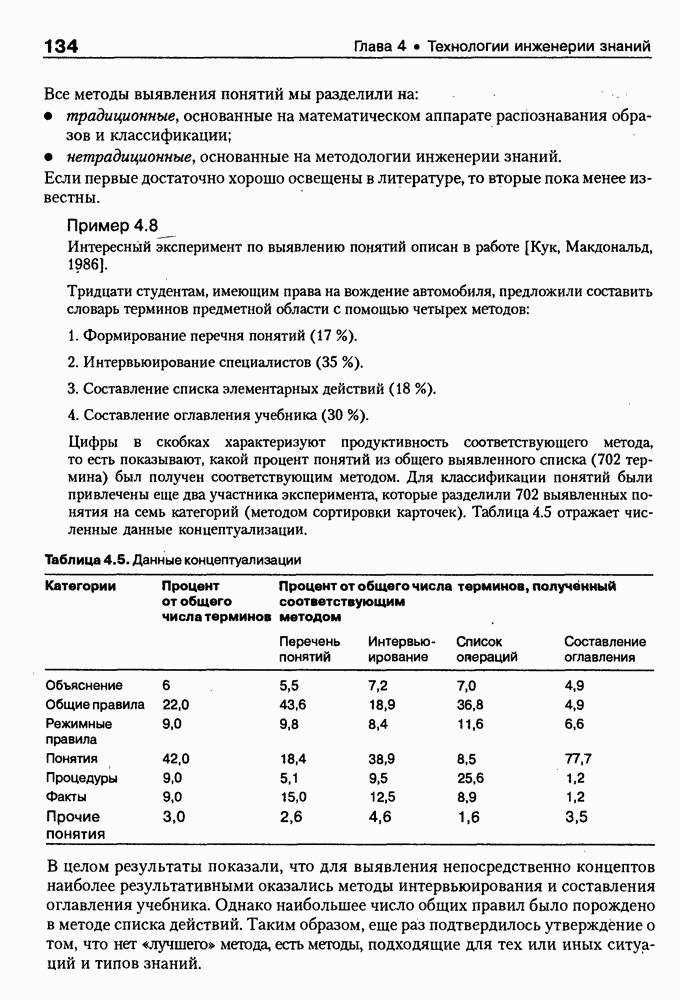
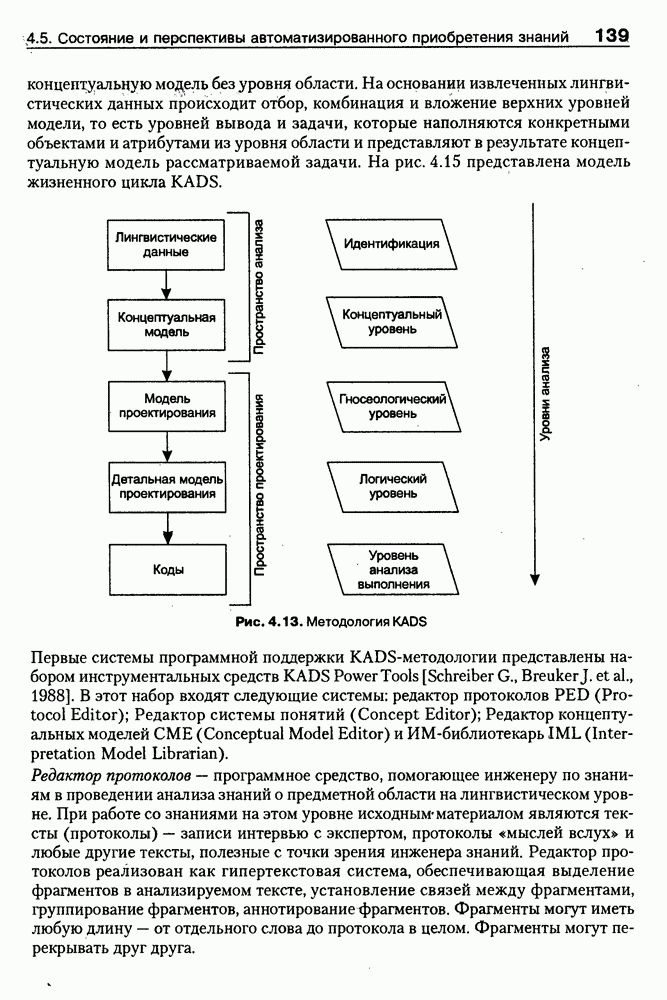
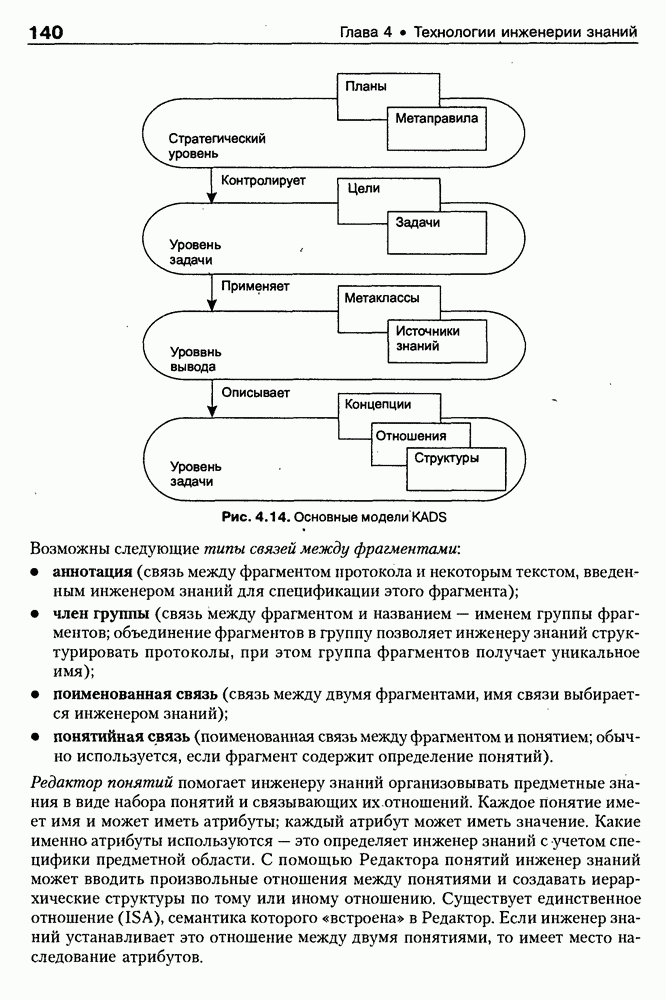
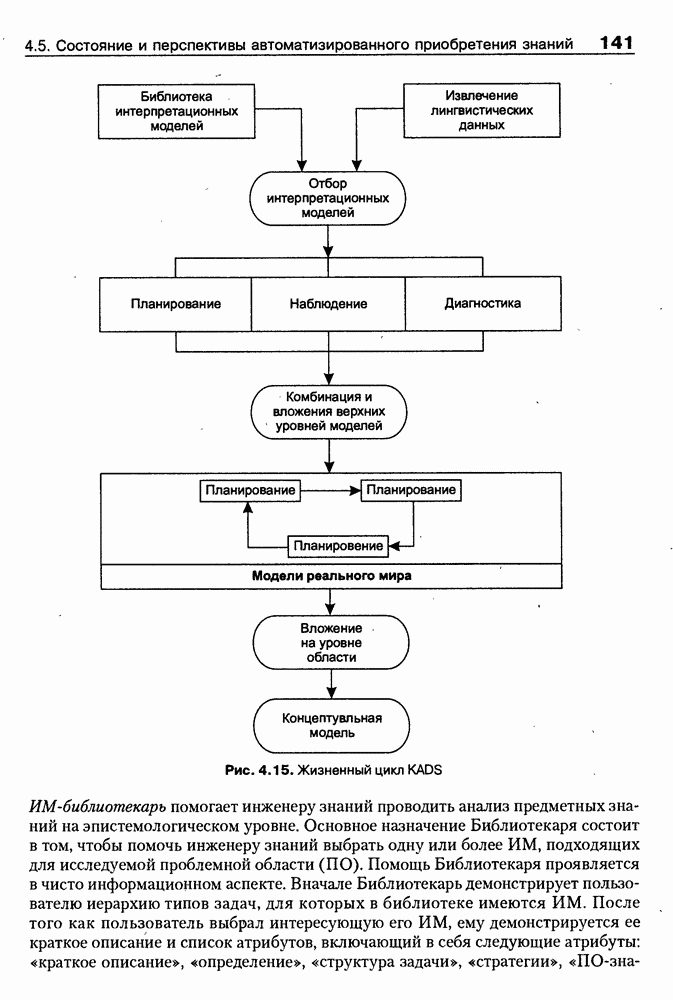
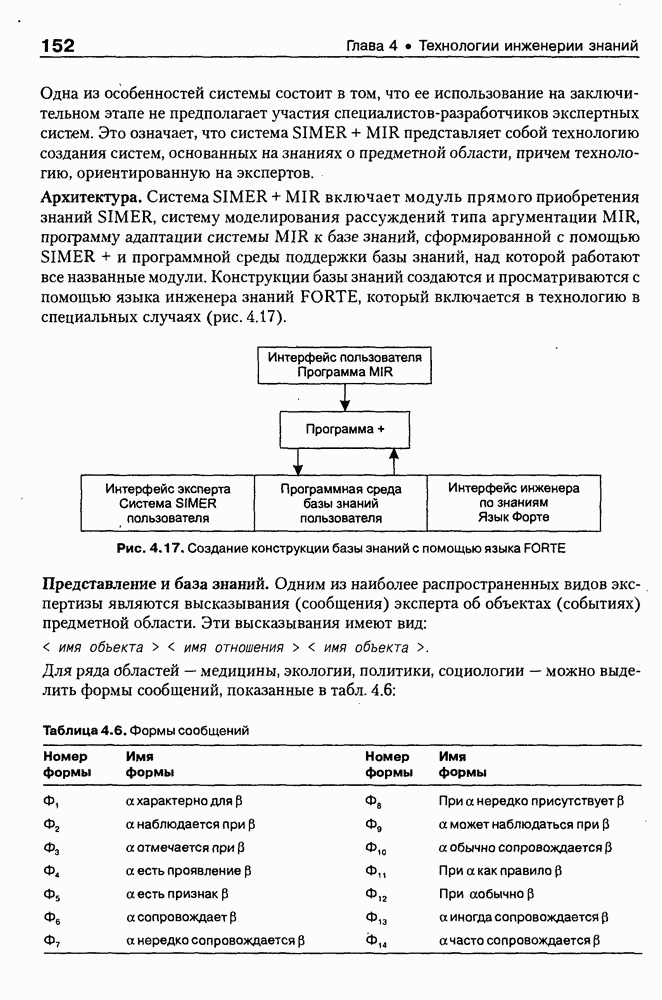
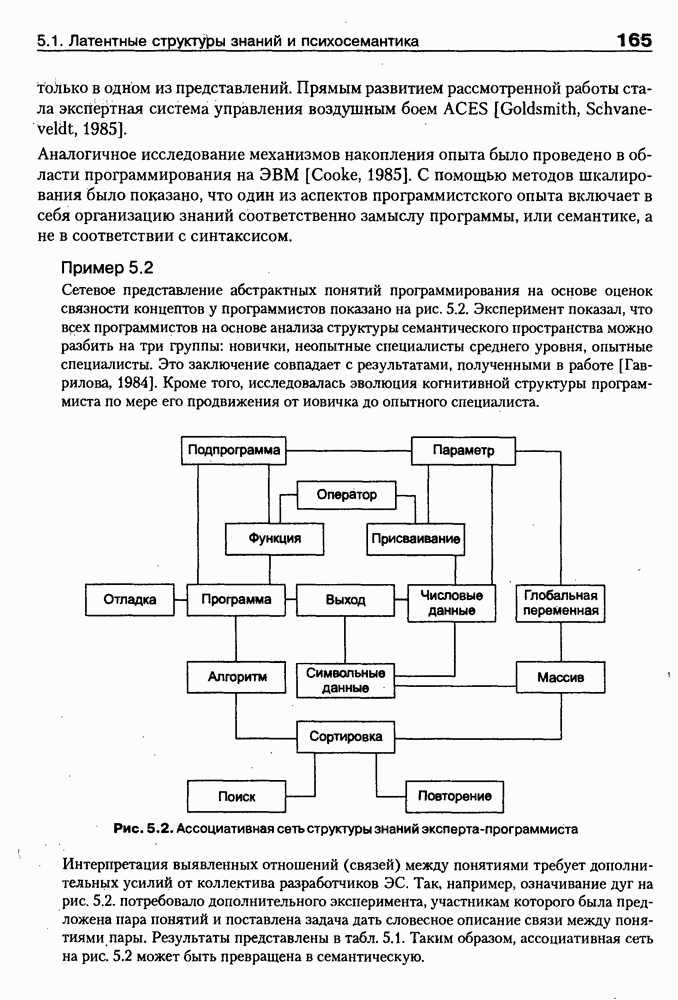
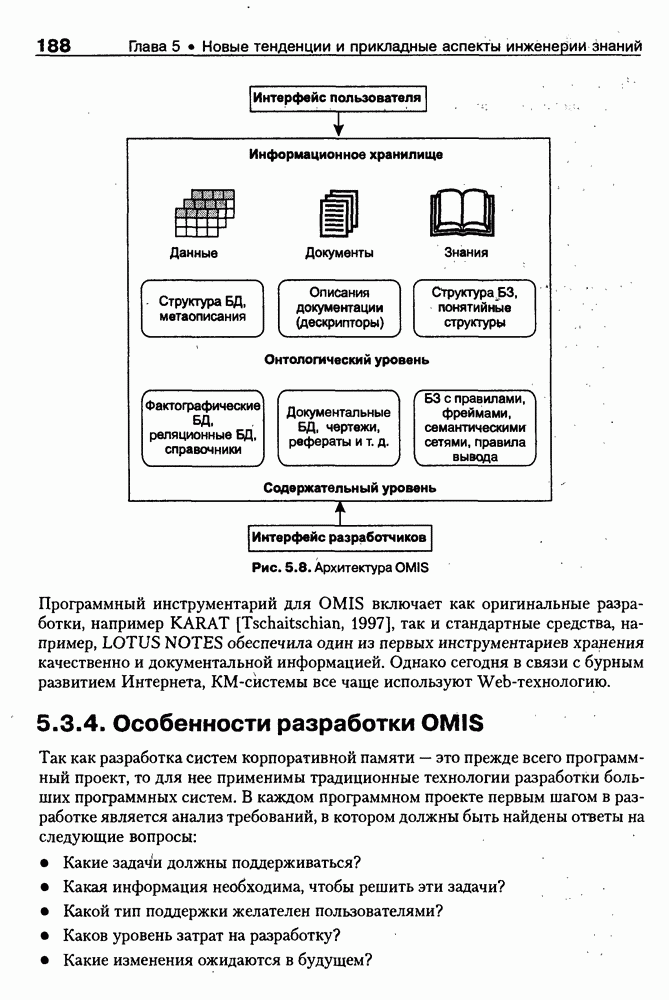
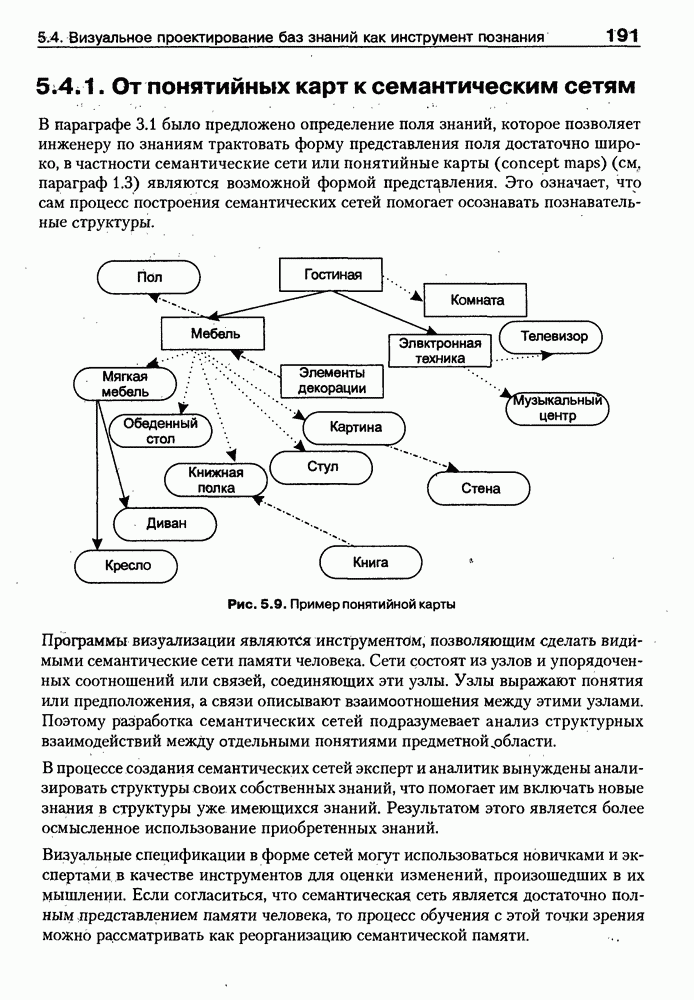
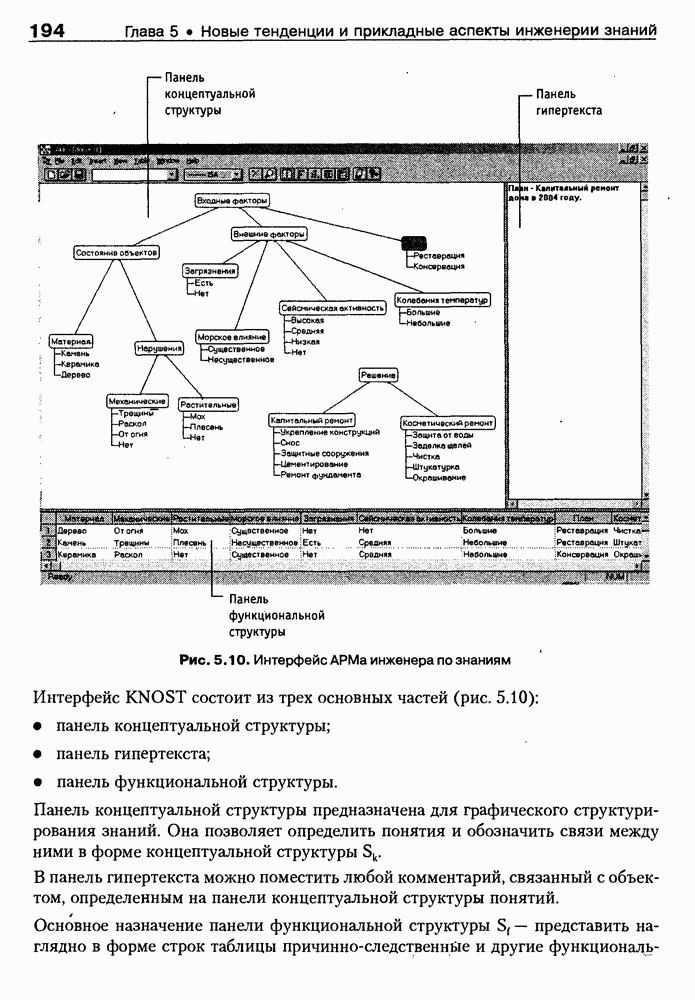
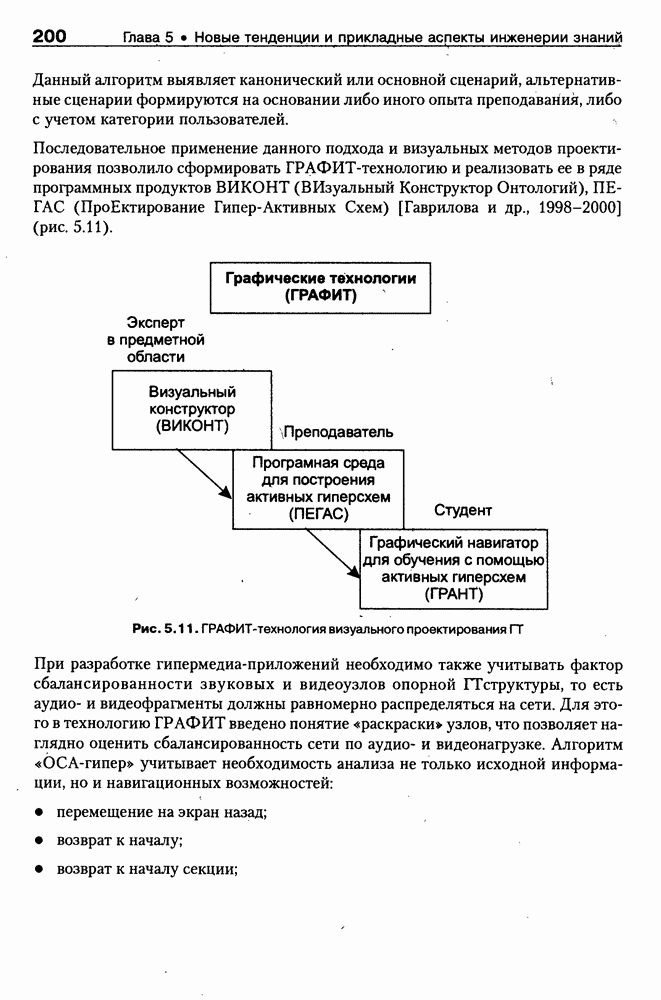
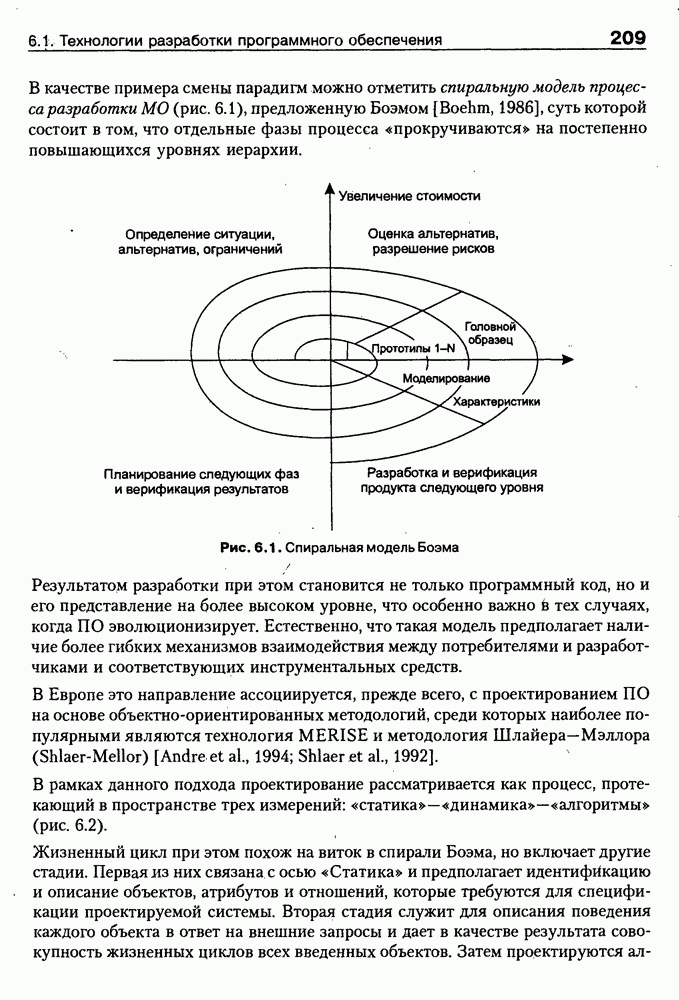
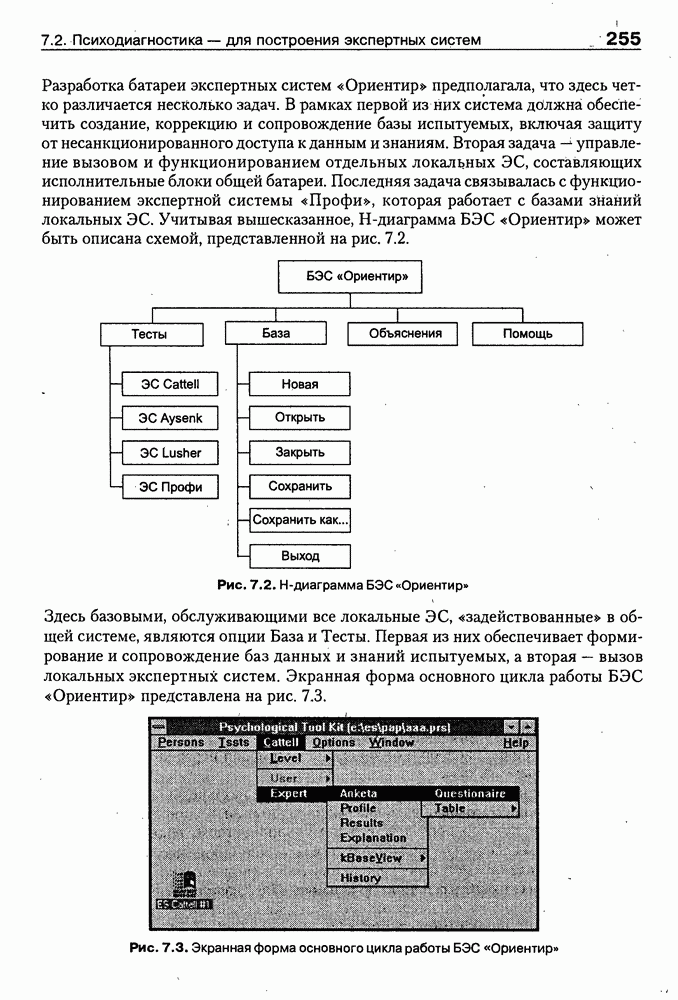
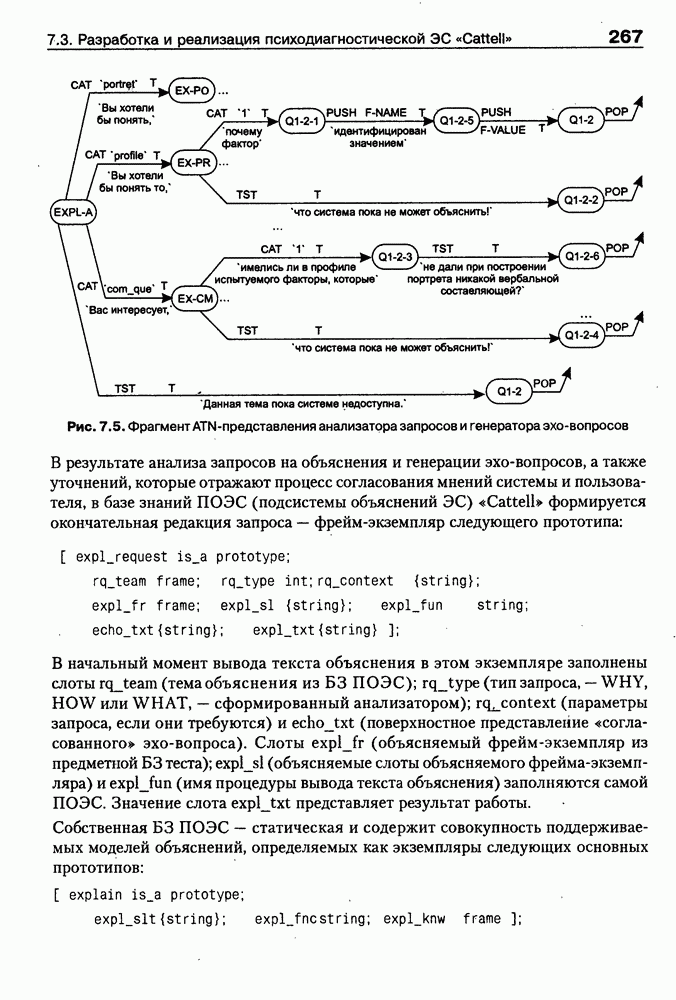
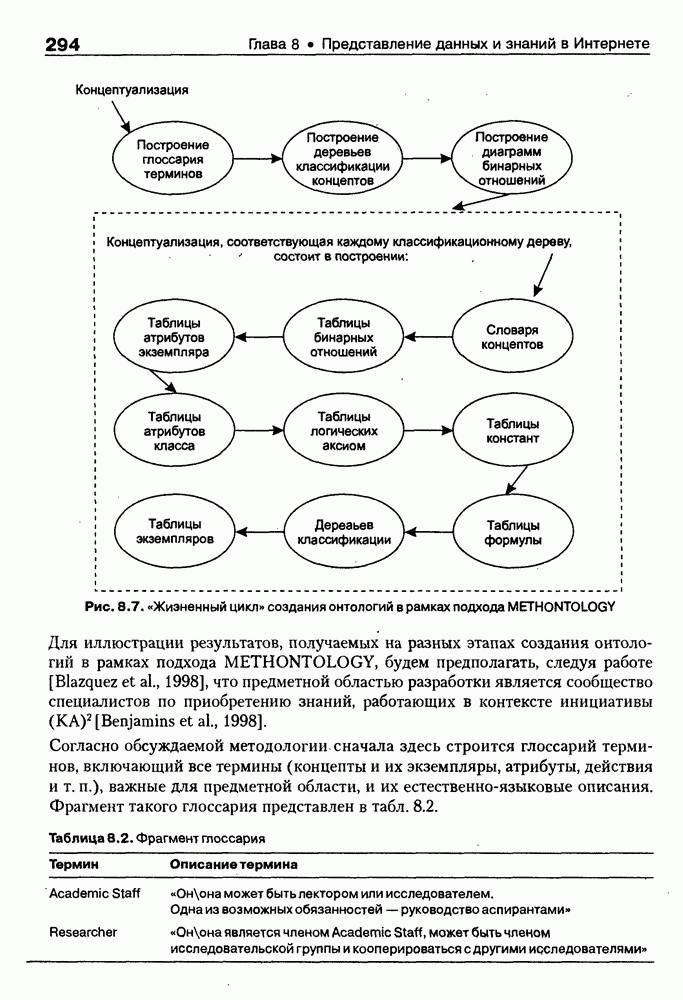
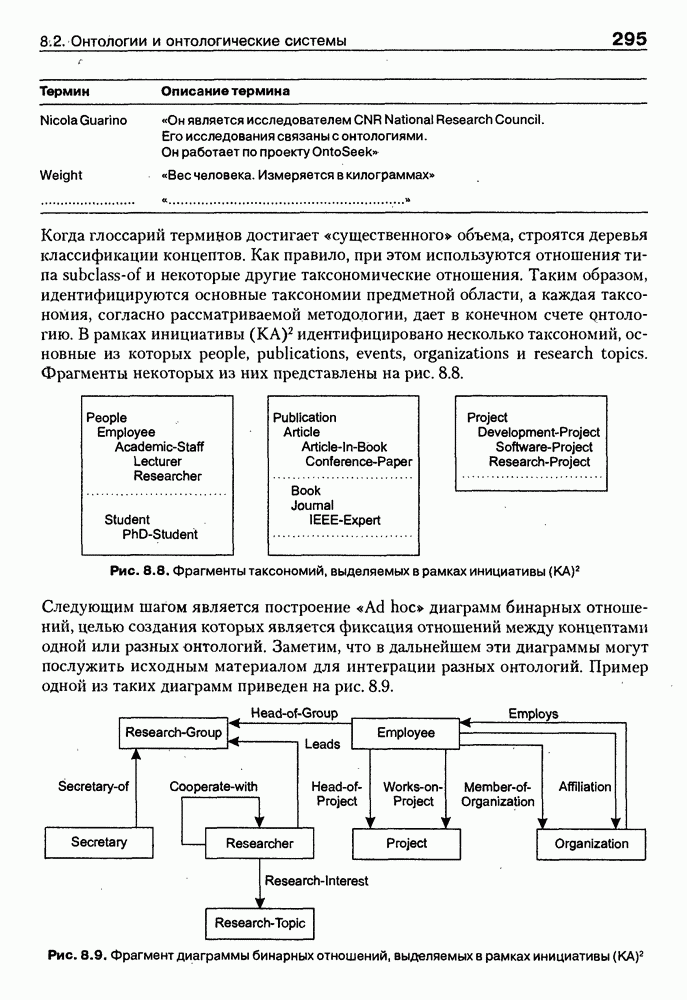
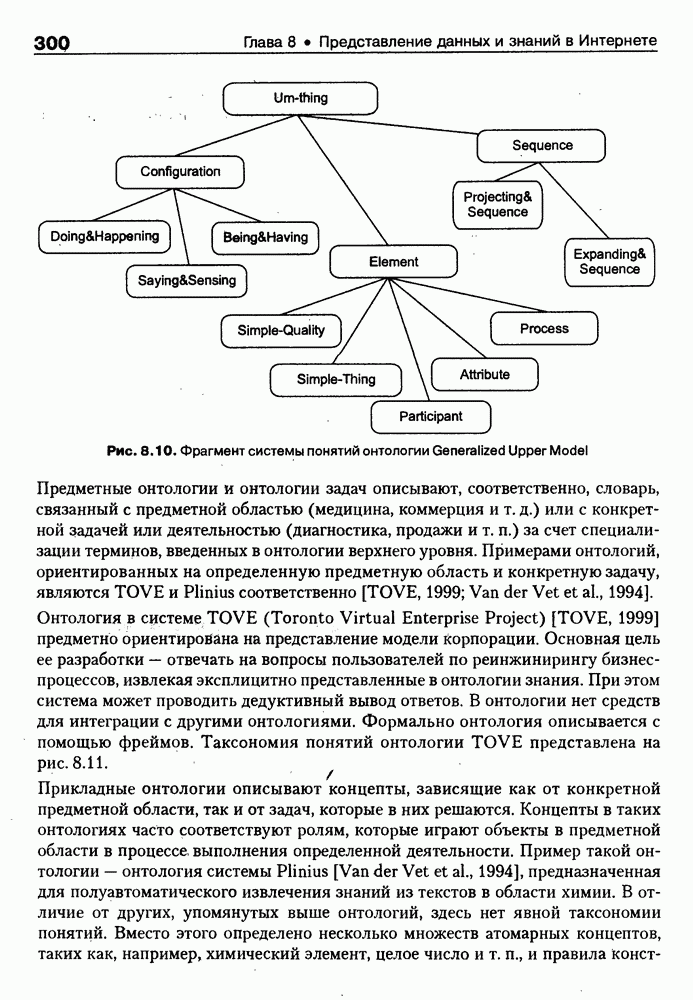
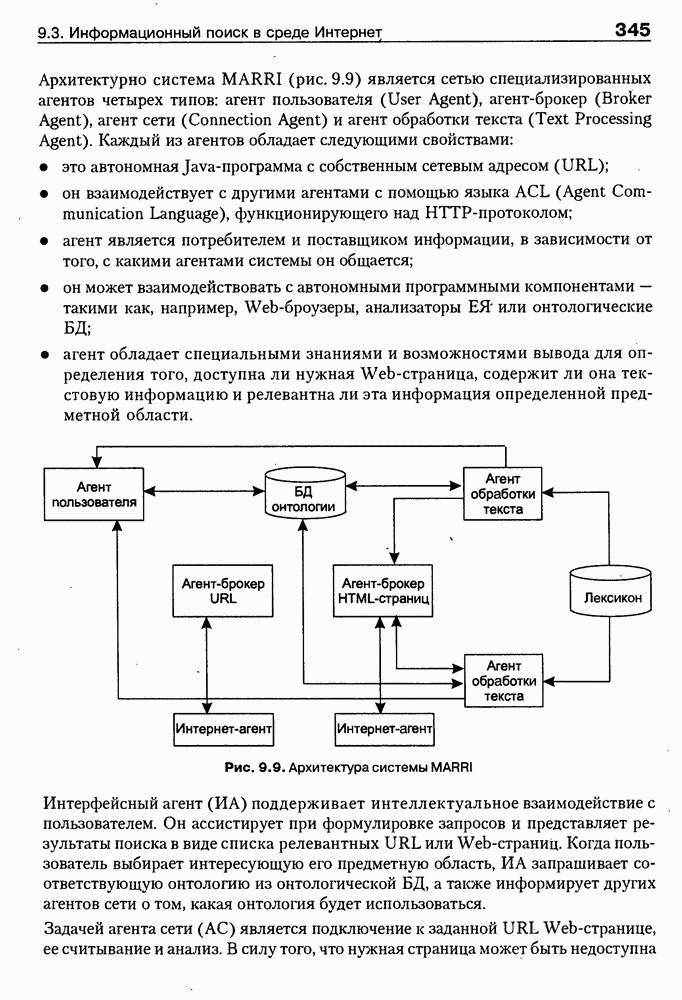
9.3.3. Системы интеллектуальных поисковых агентовСегодня в развитии систем поиска и обработки Интернет-ресурсов наметился явный сдвиг в сторону использования средств ИИ, в частности представления знаний и вывода на знаниях, интеллектуальных механизмов обучения, анализа естественно-языковых текстов и некоторых других. Как правило, системы интеллектуального поиска разрабатываются либо в серьезных фирмах, владеющих технологиями разработки и реализации интеллектуальных агентов, либо в исследовательских лабораториях университетов. Справедливости ради следует заметить, что коммерческие версии таких систем часто декларируют больше, чем реализовано в действительности, а исследовательские разработки обычно существуют в виде демонстрационных версий с ограниченными возможностями, хотя в теоретическом плане последние интереснее. Для конкретизации дальнейшего изложения остановимся сначала более подробно на нескольких, интересных на наш взгляд, коммерческих системах интеллектуального поиска и обработки информации в сети Интернет, а завершим обсуждение рассмотрением нескольких исследовательских проектов в этой области, использующих онтологии. Autonomy и Webcompass — системы интеллектуального поиска и обработки информацииОбсуждаемые ниже версии агентных поисковых систем Autonomy [Autonomy, 1998] и Webcompass [Webcompass 1999] созданы во второй половине 90-х годов. Цели их разработки практически одинаковые — обеспечить пользователя интегрированными средствами поиска релевантной его интересам информации в сети Интернет, организация найденных документов в рамках определенных тем, а также автоматизация процессов самого поиска. Вместе с тем проектные решения, принятые разработчиками, здесь существенно разные. Первое различие между этими системами в ориентации на разные категории пользователей. Система Autonomy представляет собой совокупность программных агентов для интеллектуального поиска и обработки информации, организованных в рамках специализированной оболочки, предназначенной скорее для конечных пользователей, чем предметных специалистов. Такая установка влечет за собой специальную организацию интерфейсов, интуитивно понятную и прозрачную для новичков. По сути, пользователю здесь предлагается парадигма «антропоморфного» общения со всеми компонентами системы и «игровой» подход к решению достаточно сложных задач (рис. 9.7). (см. скан) Рис. 9.7. Главная панель системы Autonomy Система Webcompass архитектурно тоже состоит из агентно-ориентированных компонентов, поддерживающих все основные процессы, которые должны быть реализованы в полномасштабном программном комплексе поиска и анализа информации. Но ориентирована эта система, прежде всего, на «продвинутых» пользователей, которые хотят и могут сформировать структурное описание области своих интересов. Коммуникационный центр Webcompass (рис. 9.8) предлагает пользователю парадигму многооконного интерфейса, характерную для современных офисных приложений, и систему структурных редакторов для спецификации предметной области, поисковых запросов и управляющей информации. Второе различие между системами Autonomy и Webcompass — в подходе к описанию предметной области поиска. В первых версиях системы Autonomy использовалась технология нейросетей и специальный метод представления, разработанный для фирмы AgentWare (так тогда называлась фирма, выпустившая релиз системы Autonomy) коллективом Neurodynamics из Кембриджа. В основе технологии лежат методы распознавания образов и обработки сигналов. При этом системой формируется представление о том, какими должны быть релевантные документы, используемые в дальнейшем на этапе поиска информации. В системе Webcompass описание предметной области основано на использовании таксономии понятий, связанных между собой отношениями типа is a, part of, has part, is a kind of и некоторых других. Ограничением такого представления является то, что между понятиями не может быть больше одного отношения. (см. скан) Рис. 9.8. Коммуникационный центр системы Webcompass Третье различие между обсуждаемыми системами состоит в используемых средствах спецификации запросов. В системе Autonomy запрос на поиск представляется на естественном языке. Система анализирует текст автоматически и извлекает из него смысловое содержание, которое помещается в специальный конфигурационный файл. При этом внутреннее представление запроса тоже представляется нейросетью, в узлах которой располагаются ключевые слова и выражения. Запрос к системе Webcompass базируется на «прямом» использовании сформированного пользователем описания предметной области. Поскольку здесь такое описание представлено таксономией понятий (ключевые слова и выражения), то для формирования запроса достаточно просто промаркировать интересующие пользователя темы. На основании этих пометок система сама формирует запрос на поиск релевантной информации. Собственно поиск релевантной информации в системе Autonomy ведется с использованием методов нечеткой логики. В основе поискового алгоритма лежит «Механизм динамических рассуждений» (МДР), разработанный уже упоминавшимся коллективом Neurodynamics. Базовые функции МДР — сравнение концептов (по входному тексту определяются ссылки на документы из заранее составленного списка с наиболее релевантной информацией для поиска); создание агента (формируются концепты из тренировочного текста и из других подходящих источников для использования их агентом); стандартный поиск слов в тексте. Поиск в системе Webcompass ведется на основе ключевых слов. При этом он осуществляется сразу на 35 машинах поиска, которые задаются списком. Этот список можно изменять, а кроме того, добавить адреса для поиска в интранет, Usenet, FTP и Gopher ресурсах. Система проверяет каждую найденную ссылку на доступность и, анализируя найденную информацию, составляет краткое резюме документов, а также определяет степень соответствия сайта запросу пользователя, ранжируя найденные документы от 1 до 100. Остальные функциональные возможности рассматриваемых систем скорее сходны, чем различны. Это формирование репозиториев результатов, наличие фонового режима поиска информации и некоторые другие. Из интересных особенностей системы Autonomy, отсутствующих в системе Webcompass в явном виде, можно отметить режим обучения поисковых агентов. Оценивая рассмотренные выше системы и класс агентных систем данного типа можно отметить их следующие достоинства: • возможность простой модификации используемых машин поиска; • использование словарей терминов для обработки запросов; • создание кратких аннотаций найденных документов; • поддержка настраиваемых баз данных по темам поиска и результатам; • классифицикация результатов поиска по темам, запоминание и автоматическое обновление ссылок на источники; • использование результатов поиска для улучшения его качества в той же области в будущем. Недостатком таких систем является, как правило, слабая обучаемость агентов. Поэтому такие системы являются полезными инструментами при поиске информации в Интернете, но не могут сделать этот поиск полностью автоматическим и эффективным с точки зрения пользователя. Справедливости ради отметим, что в последнее время фирмы, выпускавшие системы Autonomy и Webcompass, рассмотренные выше, а также многие другие фирмы, работающие на рынке информационных технологий, активно используют последние наработки в этой области, полученные в исследовательских лабораториях и проектах, связанных с проблематикой искусственного интеллекта. Учитывая вышесказанное, сейчас на авансцену развития агентных технологий вообще и использования их при поиске информации в частности выходят проблемы представления знаний, механизмы вывода новых знаний, описание модели мира, моделирование рассуждений в рамках агентного подхода. По существу, именно эти аспекты и являются ключевыми при создании интеллектуальных систем поиска информации в сети Интернет в разных исследовательских проектах, к обсуждению которых мы и переходим. Проект системы MARRIСистема MARRI [Villemin, 1999] разработана для поиска Web-страниц, релевантных запросам в определенной предметной области. Для решения поставленных задач система использует знания, представленные в виде онтологии, которая в данном случае понимается как множество концептов и связей между ними. Базисное предположение разработчиков состоит в том, что релевантные тексты состоят из значимых для предметной области предложений, содержащих фрагменты, «сопоставимые» с онтологией предметной области. Предполагается, что одни агенты — агенты сети — для предварительного отбора используют стандартные машины поиска, а другие — специализированные агенты — осуществляют поверхностный анализ полученных Web-страниц, затем проверяют их на соответствие так называемому онтологическому тесту и возвращают пользователю лишь те страницы, которые успешно прошли данный тест. Суть онтологического теста состоит в следующем. Сначала осуществляется морфологический и синтаксический анализ предложений полученного от агентов сети текста и строится его синтаксическое дерево; затем осуществляется определение типа предложения (утвердительное, отрицательное и т. п.) и тип речевого акта, который это предложение отражает. Для дальнейшего анализа выбираются только простые утвердительные предложения со структурой NP VP NP, где NP — именная группа, a VP — глагольная группа. При этом неявно предполагается, что структура знаний о предметной области отражена в структуре предложений, описывающих концепты. Поэтому, если анализируемое предложение действительно описывает некоторый концепт, значимые для предметной области слова уже присутствуют в онтологии. С учетом всего вышесказанного, онтологический тест выполняется следующим образом: • существительные (или, в общем случае, именные группы) отображаются на концепты онтологии, а глаголы (или, в общем случае, глагольные группы) — на роли; • в глагольной группе выделяется для дальнейшей обработки основной глагол (V). Если он отсутствует в онтологии, тест возвращает «неудачу», иначе: • в левой «верхней» именной группе выделяется базисное существительное • проверяется ограничение (семантическое отношение) S между N и V. При этом возможны следующие варианты: - N и V действительно связаны отношением S, которое представлено в онтологии; - в онтологии отношением - если же предыдущие два варианта не имеют места, тест возвращает «неудачу»; - аналогичная процедура выполняется и для правой «верхней» именной группы. Таким образом, онтологический тест в случае успеха поволяет «наложить» анализируемый текст на онтологию предметной области. Архитектурно система MARRI (рис. 9.9) является сетью специализированных агентов четырех типов: агент пользователя (User Agent), агент-брокер (Broker Agent), агент сети Connection Agent) и агент обработки текста (Text Processing Agent). Каждый из агентов обладает следующими свойствами: • это автономная Java-nporpaммa с собственным сетевым адресом (URL); • он взаимодействует с другими агентами с помощью языка CL (Agent Communication Language), функционирующего над HTTP-протоколом; • агент является потребителем и поставщиком информации, в зависимости от того, с какими агентами системы он общается; • он может взаимодействовать с автономными программными компонентами — такими как, например, Web-броузеры, анализаторы ЕЯ или онтологические БД; • агент обладает специальными знаниями и возможностями вывода для определения того, доступна ли нужная web-страница, содержит ли она текстовую информацию и релевантна ли эта информация определенной предметной области.
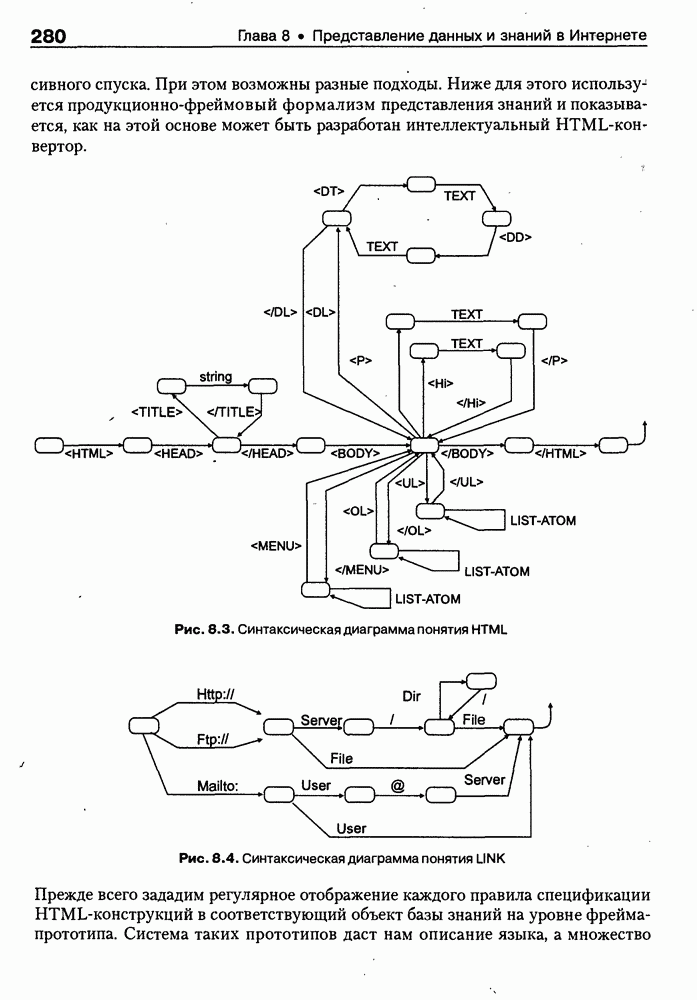
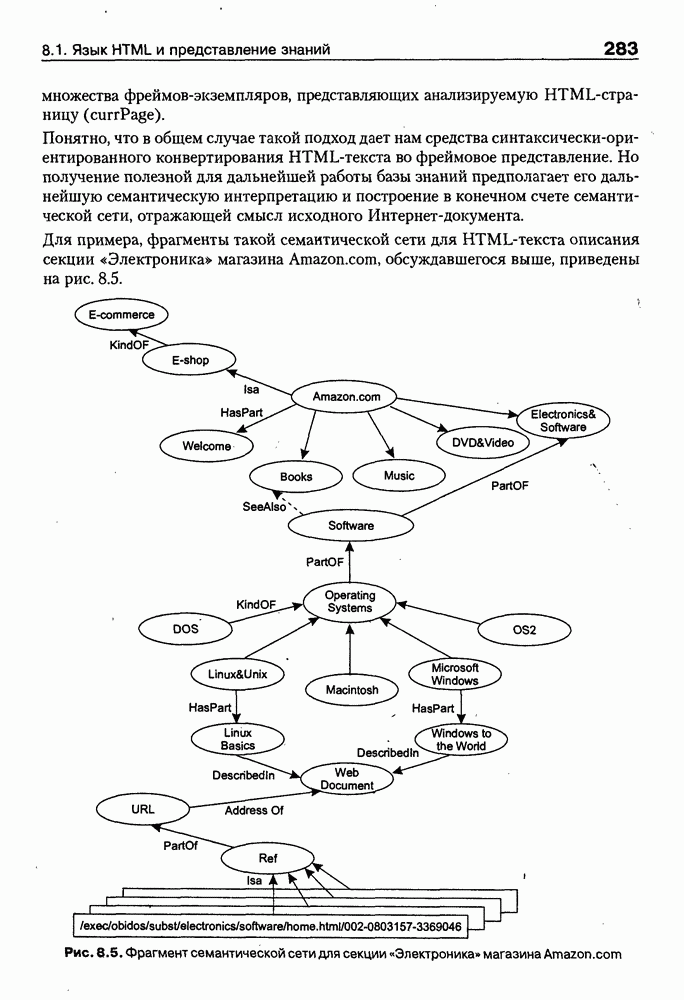
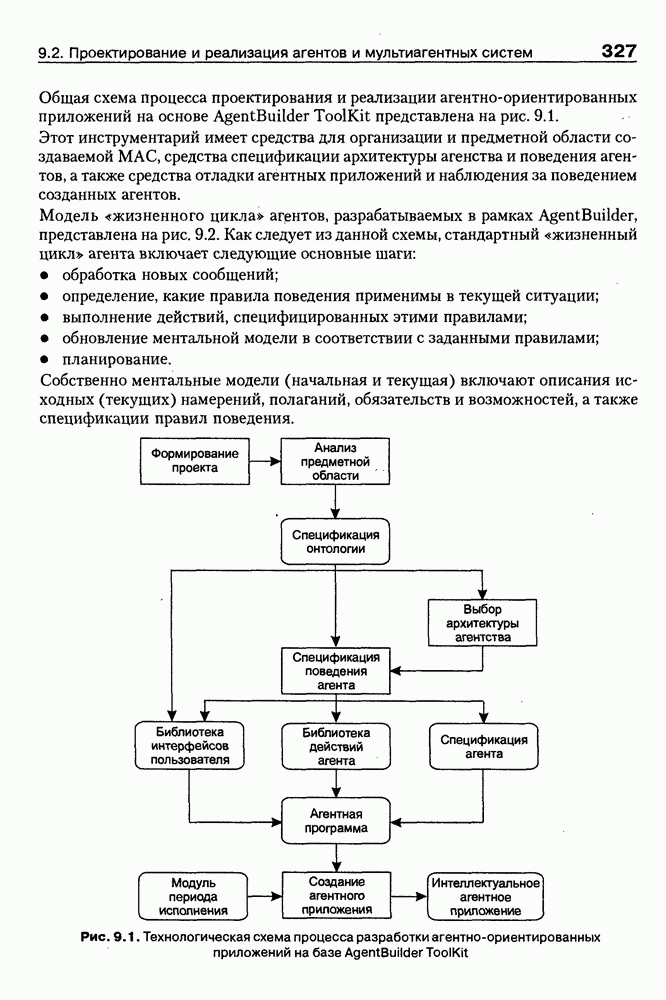
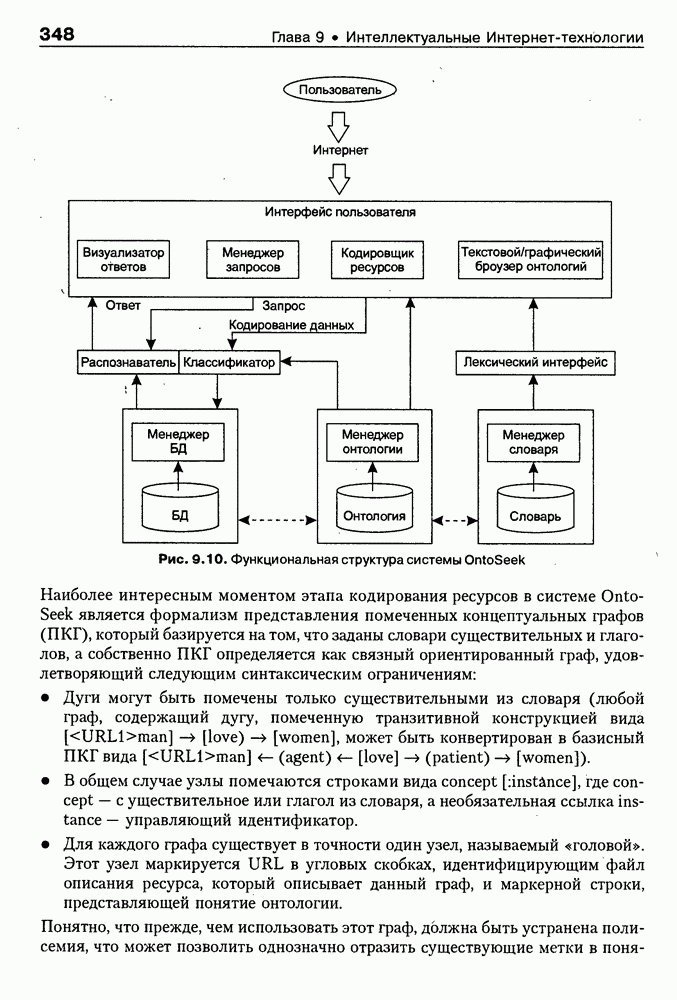
Рис. 9.9. Архитектура системы MARRI Интерфейсный агент (ИА) поддерживает интеллектуальное взаимодействие с пользователем. Он ассистирует при формулировке запросов и представляет результаты поиска в виде списка релевантных URL или Web-страниц. Когда пользователь выбирает интересующую его предметную область, ИА запрашивает соответствующую онтологию из онтологической БД, а также информирует других агентов сети о том, какая онтология будет использоваться. Задачей агента сети (АС) является подключение к заданной URL Web-странице, ее считывание и анализ. В силу того, что нужная страница может быть недоступна или неинтересна по содержанию, АС должен «уметь» обрабатывать исключительные ситуации, а также анализировать собственно текст, представленный на считанной странице. В системе MARRI задействованы два типа агентов-брокеров: брокер URL и брокер HTML. Первые предназначены для «сопровождения» списков Интернет-адресов, поставляемых броузером, а вторые — для запоминания полученных Web-страниц и распределения их между агентами обработки текста (АОТ) для дальнейшего анализа. Целью функционирования АОТ является семантический анализ Web-страниц для проверки их релевантности на базе соответствующей онтологии. Предварительно эти же агенты преобразуют HTML-текст к определенному структурному представлению, с которым работают морфологический и синтаксический анализаторы. Результат обработки текста представляется в виде синтаксического дерева, которое должно отождествиться с определенным фрагментом используемой онтологии. С архитектурной точки зрения система MARRI, по сегодняшним меркам, является почти традиционной. Ее отличительная черта — представление агентов автономными Java-программами с собственными сетевыми адресами, что неявно предполагает их мобильность и/или распределенность по сети. Такое решение было бы весьма интересным, если бы не политика контроля за безопасностью сервера, которая не допускает в настоящее время регистрацию и запуск Java-npoграмм, не сертифицированных на данном сервере. Прототип системы реализован на языке Java (версия 1.1.3). Для тестирования его разработаны две (очень грубых) онтологии — одна в области электронной коммерции (около 200 элементов), а вторая — в области Интернет-безопасности клиентских приложений (около 450 элементов). Предполагается развитие этих онтологий и интеграция их с соответствующими онтологиями, уже существующими на онтологических серверах. Прототип системы OntoSeekРазработка и реализация прототипа системы «содержательного» доступа к WWW-ресурсам OntoSeek — результат 2-летней работы, выполненной в кооперации Corinto (Consorzio di Ricerca Nazionale Tecnologia Oggetti - National Research Consortium for Object Technology) и Ladseb-CNR (National Research Council - Institute of Systems Science and Biomedical Engineering), как части проекта по поиску и повторному использованию программных компонентов [Gua-rino, et al., 1999]. Система OntoSeek разработана для содержательного извлечения информации из доступных в режиме on-line «желтых» страниц (yellow pages) и каталогов. В рамках системы совместно используются механизмы поиска по содержанию, управляемые соответствующей онтологией (ontology-driven content-matching mechanism), и достаточно мощный формализм представления. При создании OntoSeek были приняты следующие проектные решения: • использование ограниченного числа ЕЯ-терминов для точного описания ресурсов на фазе кодирования; • полная «терминологическая свобода» в запросах за счет управляемого онтологией семантического отображения их на описания ресурсов; • интерактивное ассистирование пользователю в процессе формулировки запроса, его обобщения и/или конкретизации, а также приняты во внимание: - текущее состояние исследований в области Интернет-архитектур; - необходимость достижения высокой точности и приемлемой эффективности на больших массивах данных; - важность хорошей масштабируемости и портабельности принимаемых решений. Система работает как с гомогенными, так и с гетерогенными каталогами продуктов. Понятно, что второй вариант сложнее. Поэтому в системе OntoSeek для представления запросов и описания ресурсов используется модификация простых концептуальных графов Дж. Совы [Sowa, 1984], которые обладают существенно более мощными выразительными возможностями и гибкостью по сравнению с обычно используемыми списками типа «атрибут-значение». Для концептуальных графов проблема контекстного отождествления редуцируется до управляемого онтологией поиска в графе. При этом узлы и дуги сопоставимы, если онтология «показывает», что между ними существует заданное отношение, вместе с тем, поскольку система базируется на использовании лингвистической онтологии, узлы концептуального графа должны быть привязаны к соответствующим лексическим единицам, причем для этого должны выполняться определенные семантические ограничения. На этапе планирования проекта вместо разработки собственной лингвистической онтологии были проанализированы доступные Интернет-ресурсы и выбрана онтология Sensus [Knight et al., 1994], которая обладает простой таксономической структурой, имеет объем около Функциональная структура системы OntoSeek представлена на рис. 9.10. На фазе кодирования описание ресурсов конвертируется в концептуальный граф. Для этого «поверхностные» узлы и дуги, отмеченные пользователем, с помощью лексического интерфейса трансформируются в смыслы, заданные в словаре. Таким образом, «граф слов» транслируется в «граф смыслов», причем каждому понятию последнего сопоставляется соответствующий узел онтологии. После семантической валидации концептуального графа на основе использования онтологии он запоминается в БД. Рис. 9.10. (см. скан) Функциональная структура системы OntoSeek Наиболее интересным моментом этапа кодирования ресурсов в системе OntoSeek является формализм представления помеченных концептуальных графов (ПКГ), который базируется на том, что заданы словари существительных и глаголов, а собственно ПКГ определяется как связный ориентированный граф, удовлетворяющий следующим синтаксическим ограничениям: • Дуги могут быть помечены только существительными из словаря (любой граф, содержащий дугу, помеченную транзитивной конструкцией вида • В общем случае узлы помечаются строками вида oncept [instance], где concept — с уществительное или глагол из словаря, а необязательная ссылка instance — управляющий идентификатор. • Для каждого графа существует в точности один узел, называемый «головой». Этот узел маркируется URL в угловых скобках, идентифицирующим файл описания ресурса, который описывает данный граф, и маркерной строки, представляющей понятие онтологии. Понятно, что прежде, чем использовать этот граф, должна быть устранена полисемия, что может позволить однозначно отразить существующие метки в понятия онтологии. После выполнения этой процедуры семантическая интерпретация ПКГ происходит следующим образом: • каждый узел, помеченный «словом» А, представляет класс экземпляров соответствующего концепта. При наличии в описании идентификатора экземпляра узел определяет синглетон, содержащий этот экземпляр. Если А — глагол, узел фиксирует его номинализацию (например, узел с пометкой «love» определяет класс событий «любить»); • каждая дуга с пометкой С из узла А в узел В определяет соответствующее непустое отношение; • в целом граф с «головой» А и Процесс поиска осуществляется следующим образом. Пользователь представляет свой запрос тоже в виде концептуального графа, который после устранения лексической неоднозначности и семантической валидации передается компоненте отождествления, работающей с БД. Здесь ищутся графы, удовлетворяющие запросу и ограничениям, заданным в онтологии, после чего ответ представляется пользователю в виде HTML-отчета. Семантика графа запроса и процедура его построения аналогичны рассмотренной выше процедуре кодирования ресурсов, но имеет следующие отличия: • на месте URL может быть задана переменная; • переменными может быть помечено произвольное число узлов. Так, например, запрос вида Таким образом, предполагается, что граф запроса • Q изоморфен подграфу графа R; • пометки графа • «голова» графа Реализация системы OntoSeek выполнена в парадигме «клиент-сервер». Архитектурным ядром ее является сервер онтологий, обеспечивающий для приложений интерфейсы доступа и/или манипулирования данными модели онтологии, а также поддержки БД концептуальных графов. Заметим, что последняя может строиться и пополняться не только в интерактивном режиме, но и за счет скомпилированных описаний ПКГ, представленных на языке XML. Компонента БД в системе OntoSeek выделена в отдельный блок, что позволяет легко заменить при необходимости используемую СУБД. Проект начался зимой 1996 г. - на заре эры языка Java. Поэтому прототип был реализован на языке C++. В настоящее время авторы предполагают провести реинжиниринг системы на основе использования новейших Интернет-технологий. Таким образом, использование онтологий для интеллектуальной работы с Интер-нет-ресурсами является в настоящее время «горячей» точкой исследований и практических применений. Специалистам в этой области хорошо известны Интернет-сайты организаций и проектов, связанных с созданием и использованием онтологий, но даже у них при выборе онтологии, «подходящей» для конкретного приложения, возникают определенные проблемы. Основные из них: отсутствие стандартного набора свойств, характеризующих онтологию с точки зрения ее пользователя; уникальность логической структуры представления релевантной информации на каждом «онтологическом» сайте; высокая трудоемкость поиска подходящей онтологии. Учитывая вышесказанное, в заключение данного параграфа рассмотрим пример интеллектуального агента, который демонстрирует онтологический подход к поиску на Web и выбору для использования собственно онтологий. (ONTO) — агент поиска и выбора онтологийЦелью разработки интеллектуального WWW-брокера выбора онтологий на Web [Vega et al., 1999] было решение проблемы ассистирования при выборе онтологий. Для этого потребовалось сформировать перечень свойств, которые позволяют охарактеризовать онтологию с точки зрения ее будущего пользователя и предложить единую логическую структуру соответствующих описаний; разработать специальную ссылочную онтологию (Reference Ontology), в рамках которой представлены описания существующих на Web онтологий; реализовать интеллектуального агента (ONTO), использующего ссылочную онтологию в качестве источника знаний для поиска онтологий, удовлетворяющих заданному множеству ограничений. Для решения первой из перечисленных задач авторы Как следует из приведенной таксономии, идентификация дает информацию об онтологии, как таковой, ее разработчиках и дистрибьюторах; описание — общую информацию, аннотацию онтологии, некоторые детали проектирования и реализации, требования к аппаратуре и программному обеспечению, ценовые характеристики и перечень применений; функциональность — представление о том, как использовать онтологию в приложениях. При решении задачи разработки ссылочной онтологии авторы В качестве источников знаний для построения ссылочной онтологии была использована уже обсуждавшаяся таксономия свойств, концептуальная модель • модульность (онтология должна была быть модульной, чтобы обеспечить гибкость и различные варианты использования); • специализация (концепты определялись таким образом, чтобы обеспечить их классификацию по общим свойствам и гарантировать наследование таких свойств); • разнообразие (знания представлялись в онтологии таким образом, чтобы использовать преимущества множественного наследования и облегчить добавление новых концептов); • минимизация семантических расстояний (аналогичные концепты группировались и представлялись как подклассы одного класса на базе одних и тех же примитивов); • максимизация связей между таксономиями; • стандартизация имен (везде, где это было возможно, для именования отношений использовалась конкатенация имен концептов, которые ими связывались). Анализ концептуальной модели • некоторые важные классы отсутствуют (например, классы Server и Languages, которые должны быть подклассами класса Computer-Support в онтологии Product); • некоторые важные отношения опущены (например, отношение istributed-by между понятиями продукта и организации); • некоторые важные свойства не представлены (например, Research-Topic-Webpages, Туре-of-Ontology и некоторые другие). Таблица 9.2. (см. скан) Таксономия свойств, используемых для описания онтологий Поэтому был проведен реинжиниринг Для реализации интеллектуальных WWW-брокеров поиска онтологий была предложена архитектура Onto Agent, представленная на рис. 9.11. Рис. 9.11. (см. скан) Архитектура OntoAgent В рамках Данной архитектуры выделяются брокер построения модели предметной области (Domain Model Builder Broker) и WWW-брокер поиска модели (WWW Domain Model Retrieval Broker). Первый из них ориентирован на формирование концептуальной структуры онтологий, которые будут в поле зрения будущей экспертизы. Этот модуль включает: • Коллекционера онтологической информации (Ontology Information Collector) - WWW-интерфейс, ориентированный на сбор информации от распределенных по сети агентов (программных агентов и собственно пользователей). • Концептуализатора экземпляров (An Instance Conceptualizer) — преобразователь данных от WWW-интерфейса в экземпляр онтологии, специфицированный на уровне формализма представления знаний. • Генератора/Транслятора онтологий (Ontology Generator/Translator) — компоненты отображения концептуального представления онтологий на целевые языки реализации, что обеспечивает доступ к ним из удаленных приложений. Целью второго модуля является обеспечение доступа к накопленной информации и представление ее наилучшим для пользователя образом. Этот модуль включает: • Формирователя запросов (A Query Builder) — компоненту построения запросов с использованием словаря брокера и при необходимости переформулирования и/или уточнения запросов пользователя. • Транслятор запросов (A Query Translator) — преобразователя запроса в представление, совместимое с языком реализации онтологии. • Машину вывода (An Inference Engine) — блок поиска ответа на запрос. • Формирователя ответов (An Answer Builder) — компоненту, которая служит для представления информации, найденной машиной вывода. По сути дела, рассмотренные выше компоненты составляют технологию построения WWW-брокеров для поиска информации на основе онтологий. А примером ее использования является интеллектуальный Оценивая представленный подход в целом, можно отметить, что он хорошо коррелирует по своим идеям и целям с уже обсуждавшейся системой Ontobroker. Однако в случае Все вышесказанное показывает, что использование агентов и особенно интеллектуальных агентов при сборе, поиске и анализе информации имеет ряд преимуществ, основные из которых сводятся к следующему [Pagina Н., 1996]: • они могут обеспечить пользователю доступ ко всем Интернет-сервисам и сетевым протоколам; • отдельный агент может быть занят одной или несколькими задачами параллельно; • преимущества агентов в том, что они могут осуществлять поиск по заданию пользователя после его отключения от сети; • мобильность (если она присутствует) позволяет агентам искать информацию сразу на сервере, что увеличивает скорость и точность поиска, уменьшая загрузку сети; • они могут создавать собственную базу информационных ресурсов, которая обновляется и расширяется с каждым поиском; • возможность агентов сотрудничать друг с другом позволяет использовать накопленный опыт; • агенты могут использовать модель пользователя для корректировки и уточнения запросов; • они могут адаптироваться под предпочтения и желания пользователя и, изучив их, искать полезную информацию заранее; • агенты способны искать информацию, учитывая контекст. Они могут вывести этот контекст из запроса, например построив модель мира пользователя; • агенты могут искать информацию интеллектуально, например используя словари, тезаурусы и онтологии, а также средства вывода релевантной информации, не представленной явно ни в запросе, ни в найденных документах. Именно поэтому с применением и развитием агентных технологий на основе методов и средств искусственного интеллекта связываются самые серьезные перспективы перехода от пространств данных к пространствам знаний в глобальных и локальных сетях.
|
 |
Оглавление
|


















































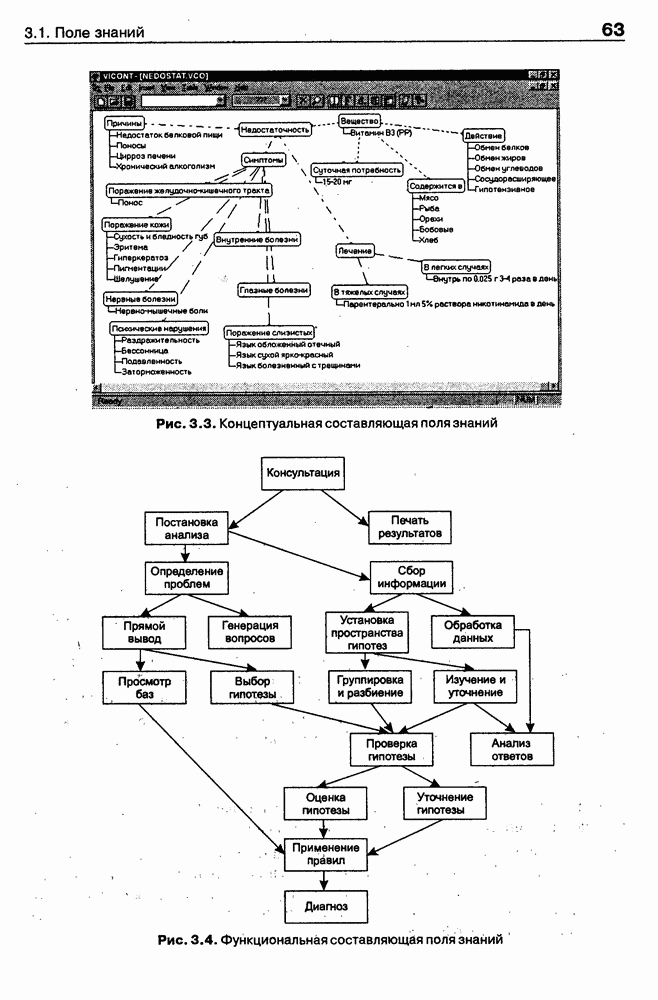
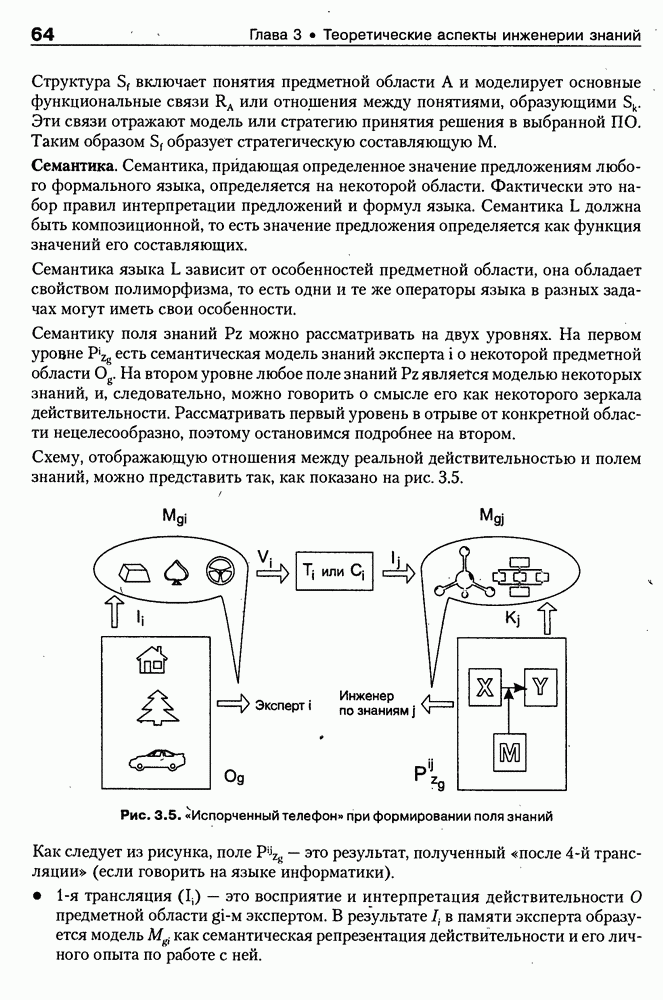





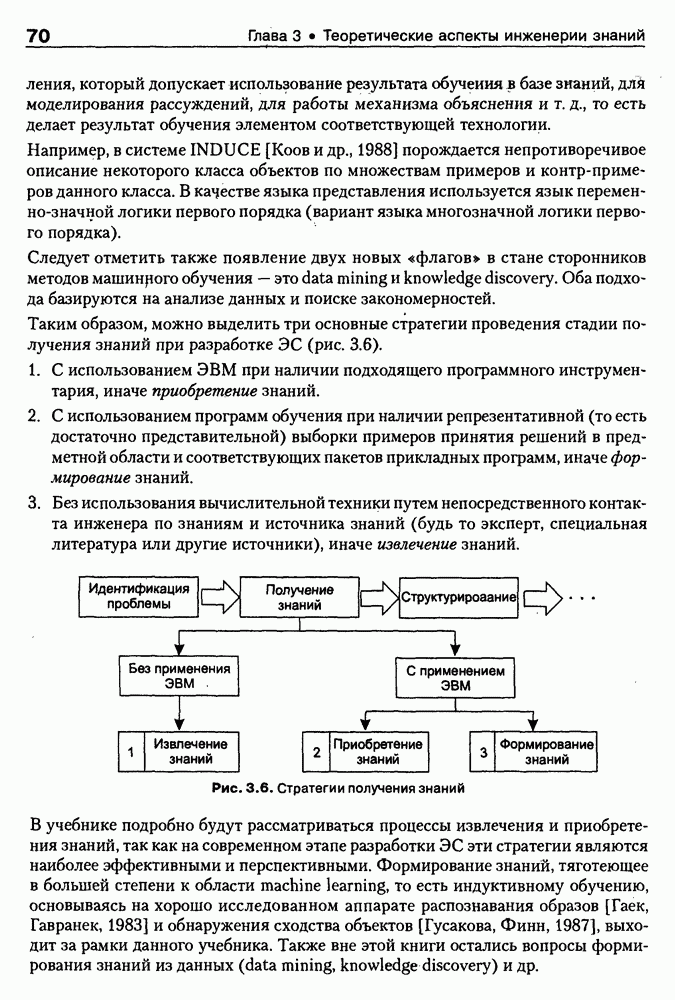










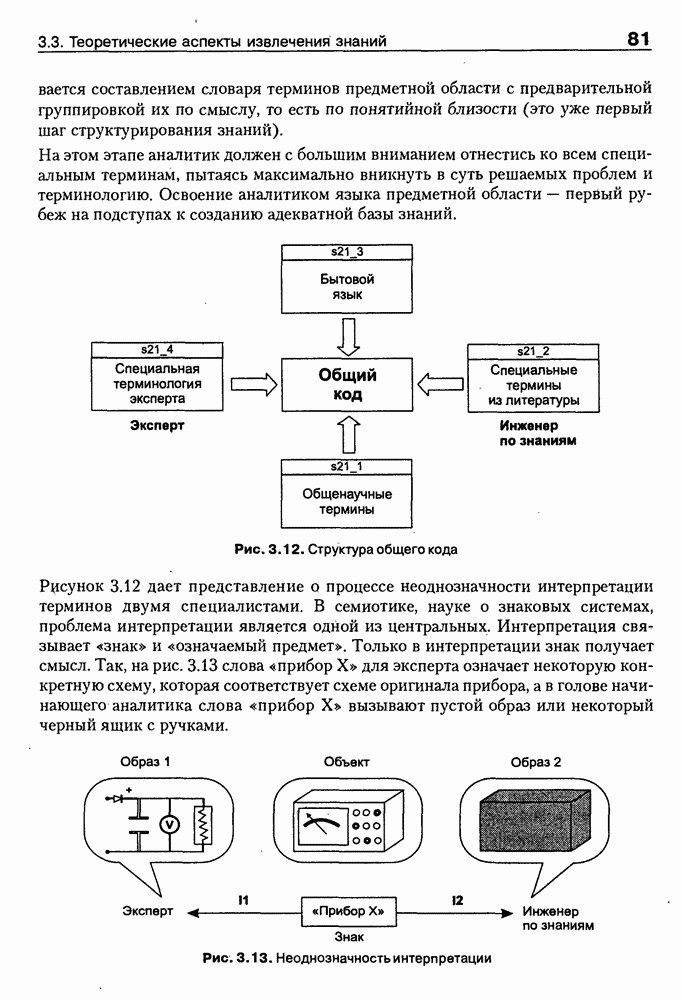








































































































































































































































































 Если оно отсутствует в онтологии, тест возвращает «неудачу», иначе:
Если оно отсутствует в онтологии, тест возвращает «неудачу», иначе:
 связаны существительное N и глагол V, причем
связаны существительное N и глагол V, причем  является подклассом
является подклассом  подклассом V;
подклассом V;

 узлов, в основном выделенных из тезауруса WordNet [Beckwith et al., 1990], а также доступна для исследовательских целей в свободном режиме.
узлов, в основном выделенных из тезауруса WordNet [Beckwith et al., 1990], а также доступна для исследовательских целей в свободном режиме.
 может быть конвертирован в базисный ПКГ вида
может быть конвертирован в базисный ПКГ вида 
 определяют класс экземпляров А, описываемых ресурсом, помеченным
определяют класс экземпляров А, описываемых ресурсом, помеченным 
 вернет множество URL на документы, описывающие автомобили с радиоприемниками в качестве части, а запрос вида
вернет множество URL на документы, описывающие автомобили с радиоприемниками в качестве части, а запрос вида  — множество URL на документы, описывающие радиоприемник как часть автомобиля. И более того, композиция этих запросов вида
— множество URL на документы, описывающие радиоприемник как часть автомобиля. И более того, композиция этих запросов вида  может быть использована для получения документов обоих тилов.
может быть использована для получения документов обоих тилов.
 отождествляется с графом описания ресурса
отождествляется с графом описания ресурса  если:
если:
 соответствуют пометкам графа Q;
соответствуют пометкам графа Q;
 соответствует узлу, помеченному переменной в графе
соответствует узлу, помеченному переменной в графе  Последнее условие необходимо, если мы хотим «сосредоточиться» на ресурсах, соответствующих запросу в точности.
Последнее условие необходимо, если мы хотим «сосредоточиться» на ресурсах, соответствующих запросу в точности.
 детально проанализировали онтологии, представленные на Web, и построили таксономию свойств, используемых для описания онтологий (табл. 9.2). Для удобства дальнейшего использования все свойства сгруппированы в категории идентификации, описания и функциональности.
детально проанализировали онтологии, представленные на Web, и построили таксономию свойств, используемых для описания онтологий (табл. 9.2). Для удобства дальнейшего использования все свойства сгруппированы в категории идентификации, описания и функциональности.
 использовали уже обсуждавшуюся выше технологию METHONTOLOGY и инструментарий ODE [Blazquez et al., 1998]. При этом, в соответствии с общими тенденциями по созданию разделяемых онтологий и, по-видимому, в силу того, что один из авторов обсуждаемой работы (Gomez-Perez) является провайдер-агентом международного проекта по построению разделяемых баз знаний [Benjamins et al., 1998], Reference Ontology была «имплантирована» в онтологию Product инициативы
использовали уже обсуждавшуюся выше технологию METHONTOLOGY и инструментарий ODE [Blazquez et al., 1998]. При этом, в соответствии с общими тенденциями по созданию разделяемых онтологий и, по-видимому, в силу того, что один из авторов обсуждаемой работы (Gomez-Perez) является провайдер-агентом международного проекта по построению разделяемых баз знаний [Benjamins et al., 1998], Reference Ontology была «имплантирована» в онтологию Product инициативы 
 и свойства, выделенные в рамках разработки онтологии исследовательских тем (Research-Topic) инициативы
и свойства, выделенные в рамках разработки онтологии исследовательских тем (Research-Topic) инициативы  Критерии, которые применялись при имплантации ссылочной онтологии в онтологию
Критерии, которые применялись при имплантации ссылочной онтологии в онтологию  — следующие:
— следующие:
 онтологии с точки зрения перечисленных выше критериев и ссылочной онтологии показал, что:
онтологии с точки зрения перечисленных выше критериев и ссылочной онтологии показал, что:
 онтологии, который позволил расширить ее новыми концептами, отношениями и свойствами, с одной стороны, и специализировать уже представленные знания таким образом, чтобы использовать их для сравнения различных онтологий.
онтологии, который позволил расширить ее новыми концептами, отношениями и свойствами, с одной стороны, и специализировать уже представленные знания таким образом, чтобы использовать их для сравнения различных онтологий.
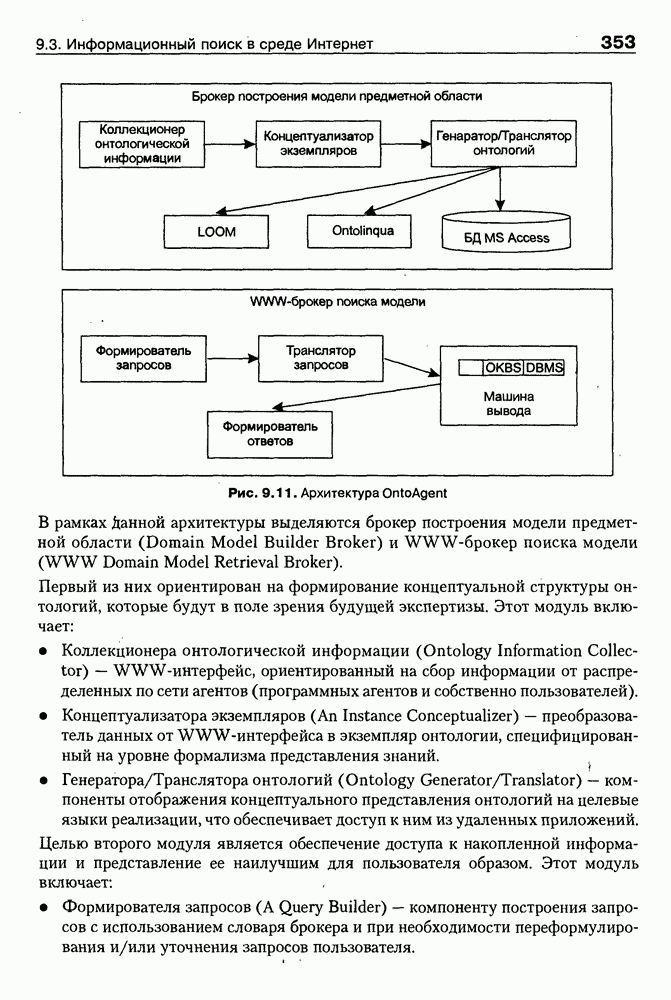
 агент. Его брокер построения модели предметной области работает со ссылочной онтологией, а входной запрос строится как соответствующая HTML-форма. Брокер поиска ответов реализован в настоящее время как Java-апплет и как автономное Java-приложение. Результаты поиска онтологий, удовлетворяющих запросу, возвращаются пользователю в виде HTML-формы.
агент. Его брокер построения модели предметной области работает со ссылочной онтологией, а входной запрос строится как соответствующая HTML-форма. Брокер поиска ответов реализован в настоящее время как Java-апплет и как автономное Java-приложение. Результаты поиска онтологий, удовлетворяющих запросу, возвращаются пользователю в виде HTML-формы.
 агента для хранения формализаций онтологий используется база данных, а для поиска — стандартные средства на основе SQL. Самостоятельную ценность данного проекта представляет ссылочная онтология, которая может использоваться не только для целей поиска, но и для стандартизации описаний онтологий вообще.
агента для хранения формализаций онтологий используется база данных, а для поиска — стандартные средства на основе SQL. Самостоятельную ценность данного проекта представляет ссылочная онтология, которая может использоваться не только для целей поиска, но и для стандартизации описаний онтологий вообще.