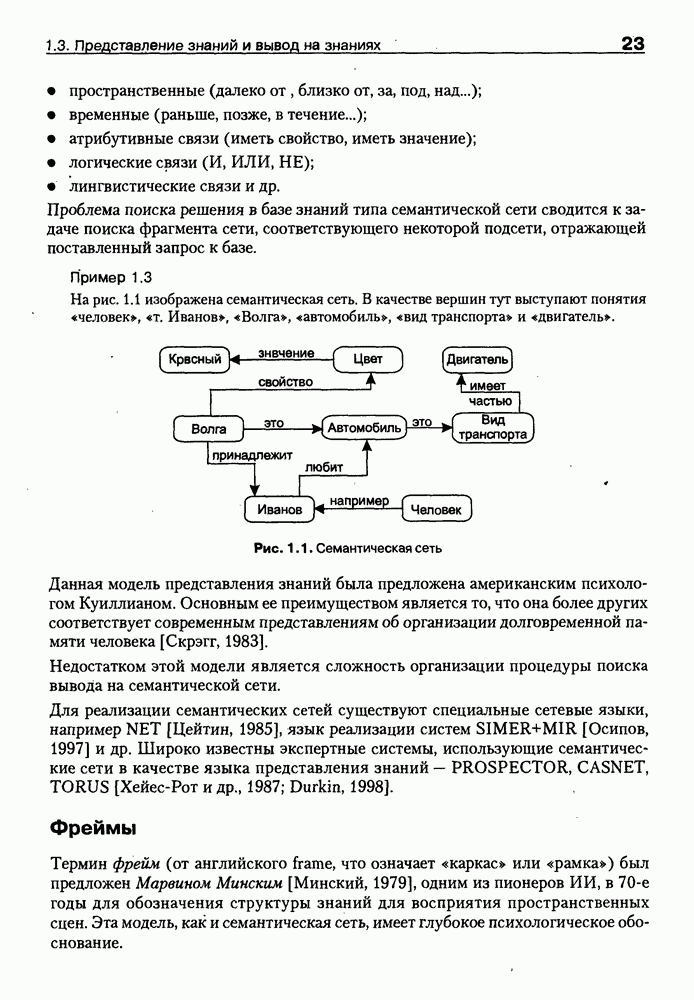
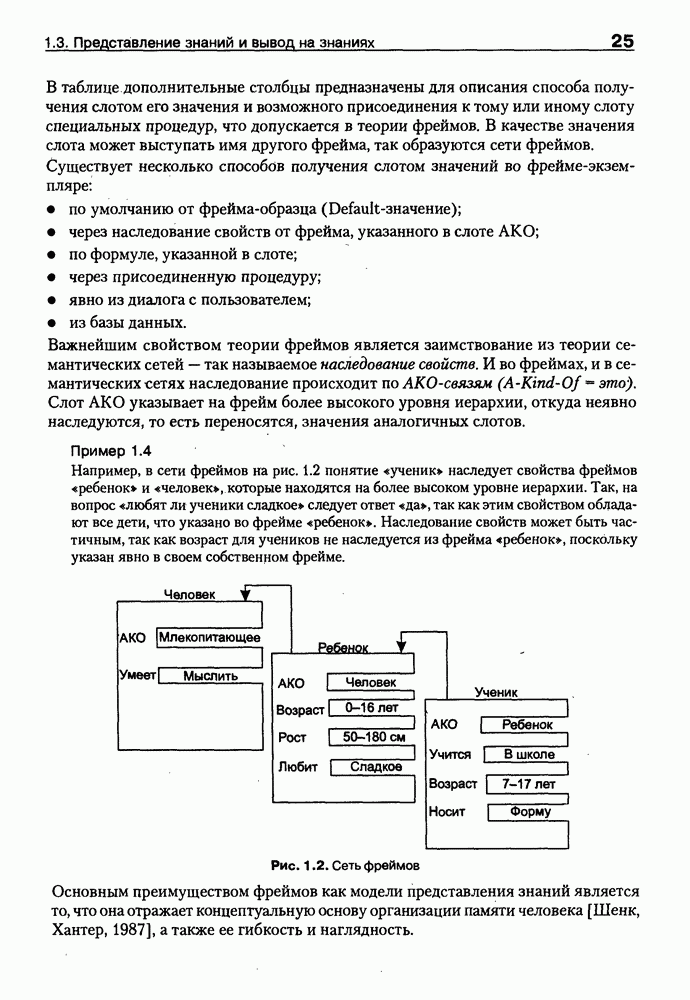
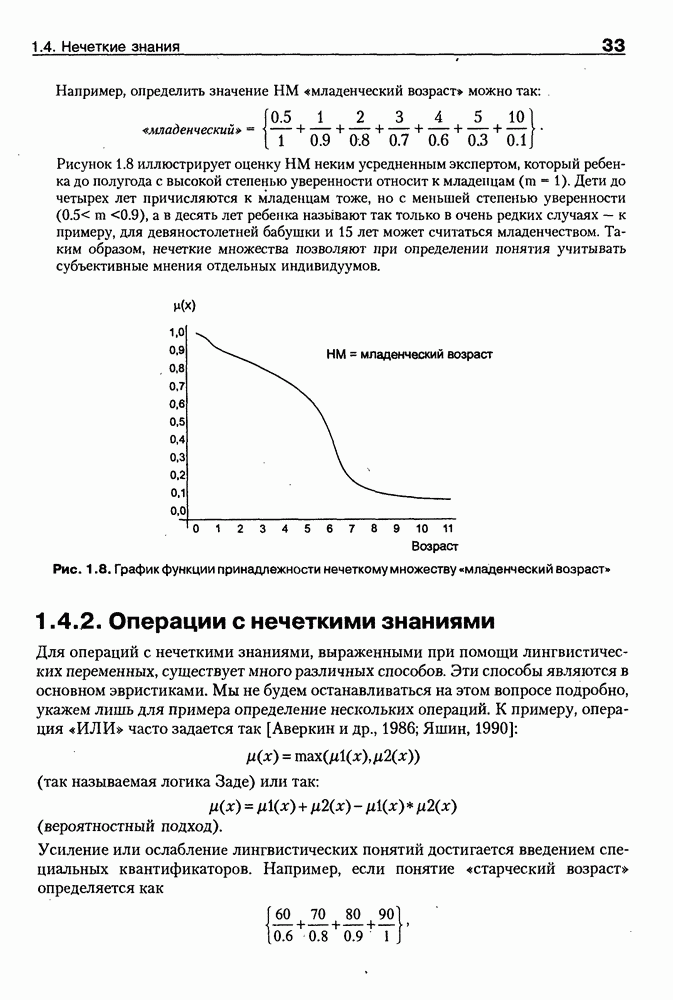
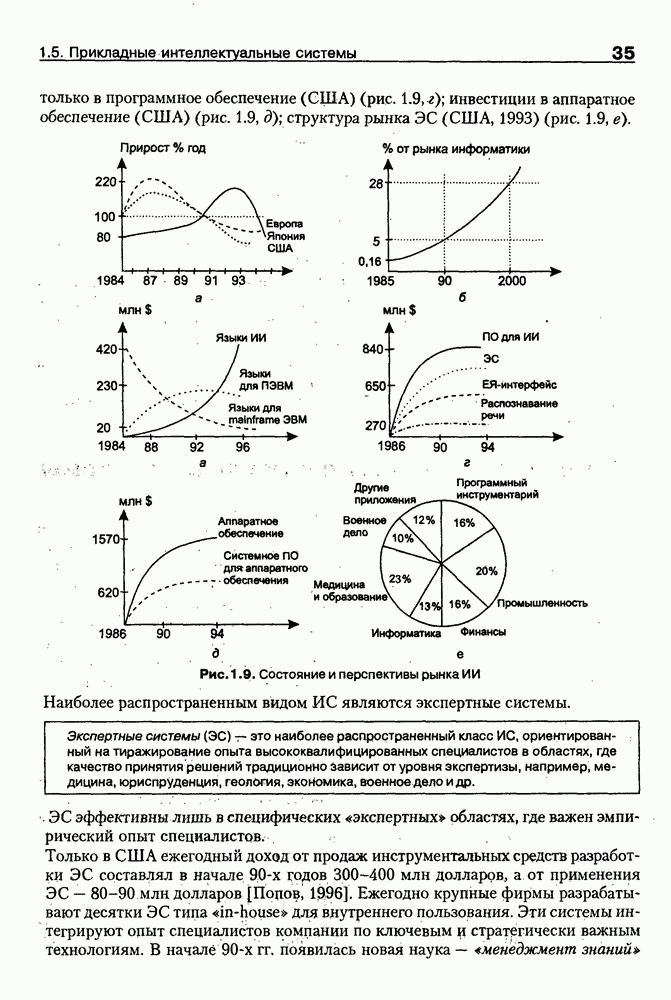
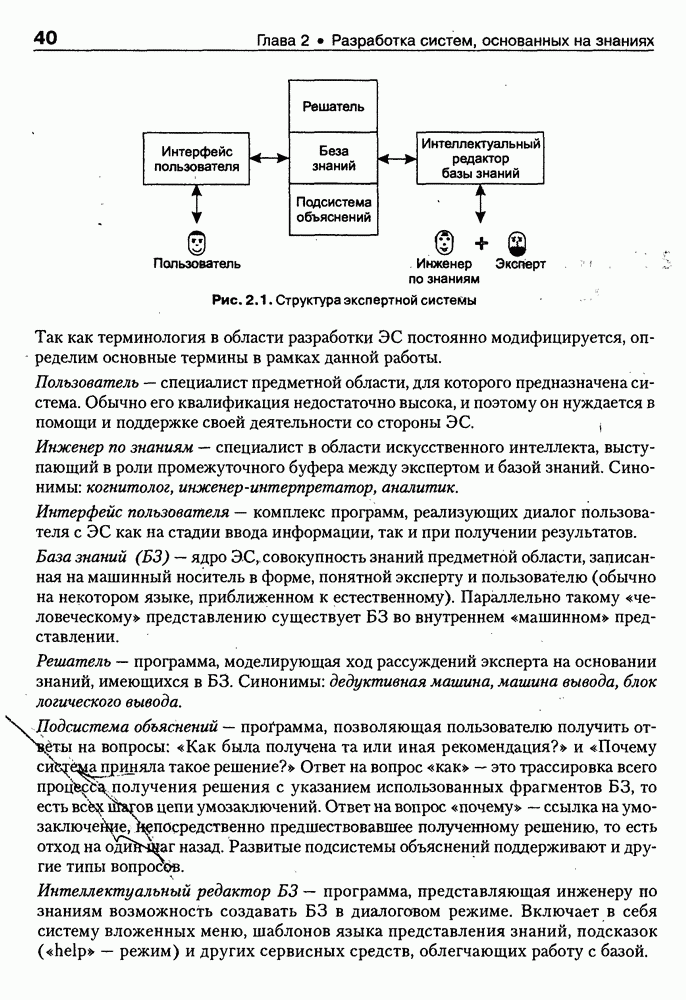
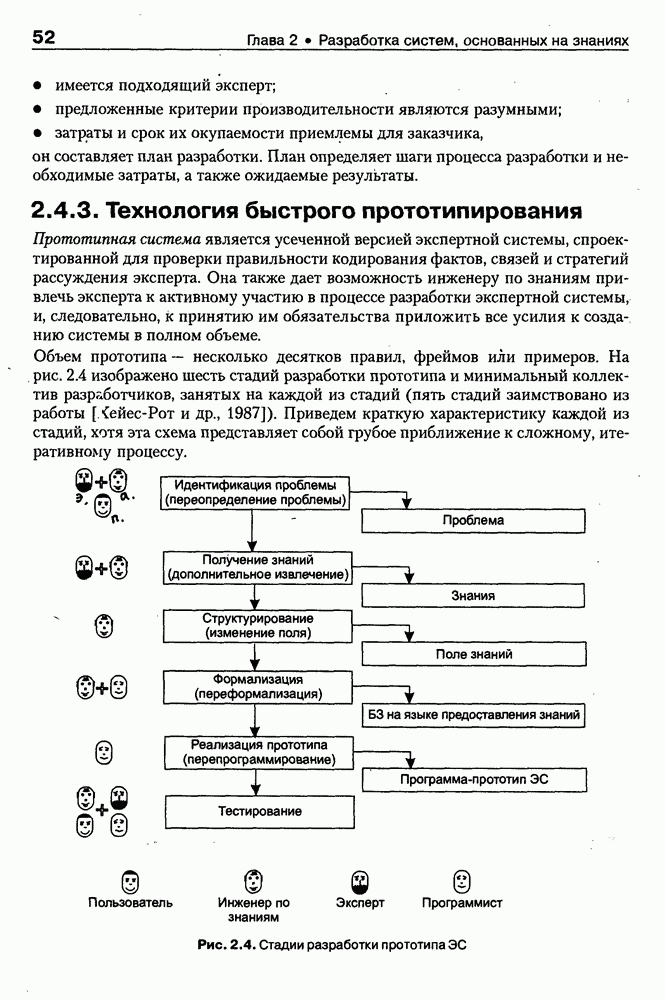
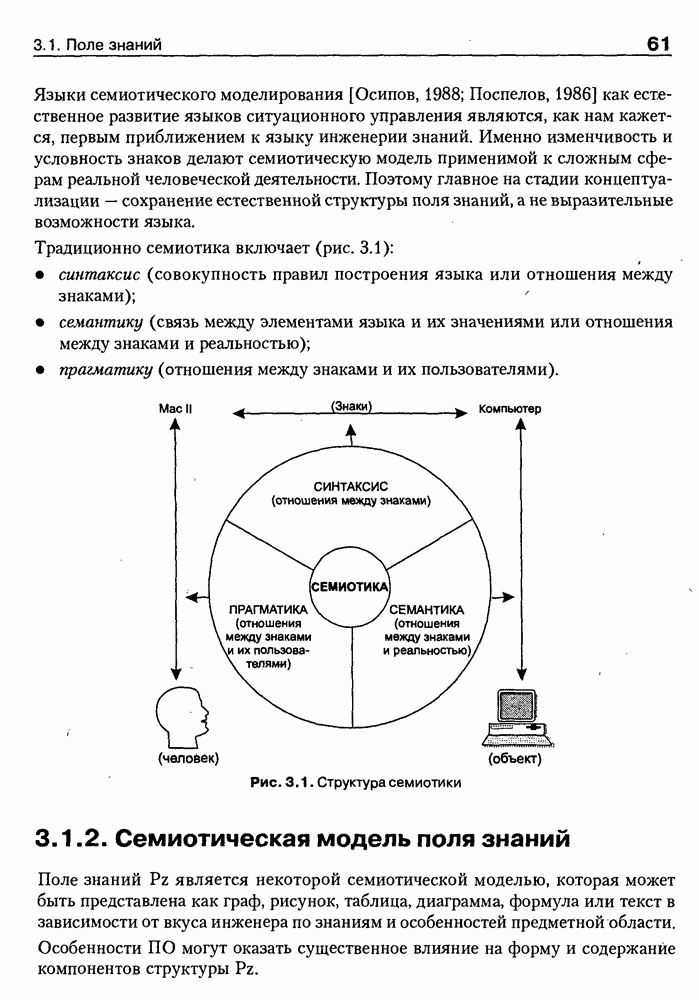
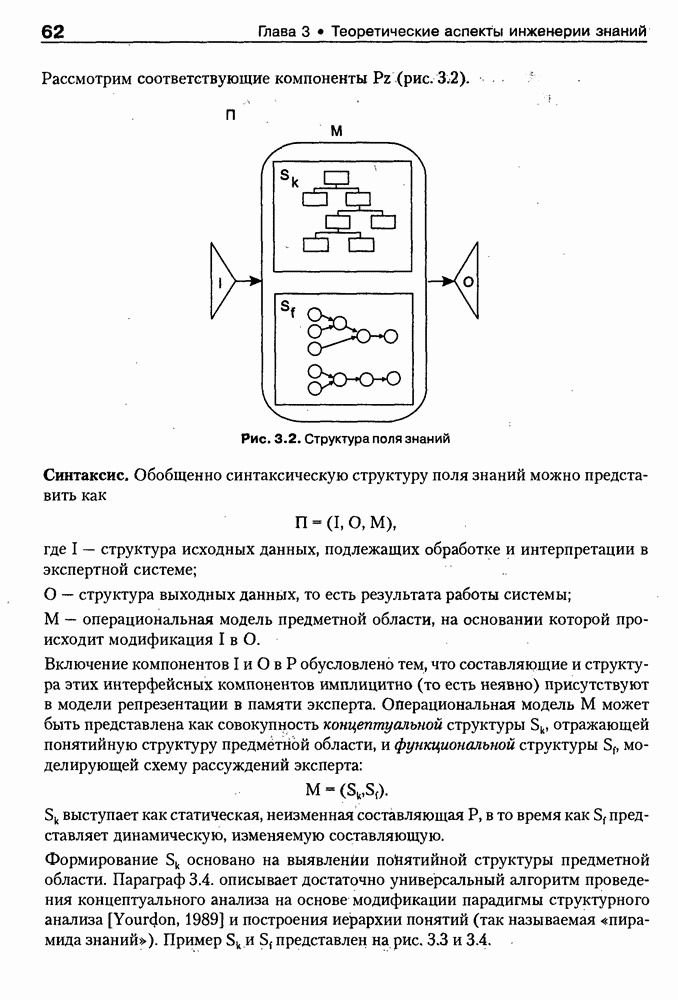
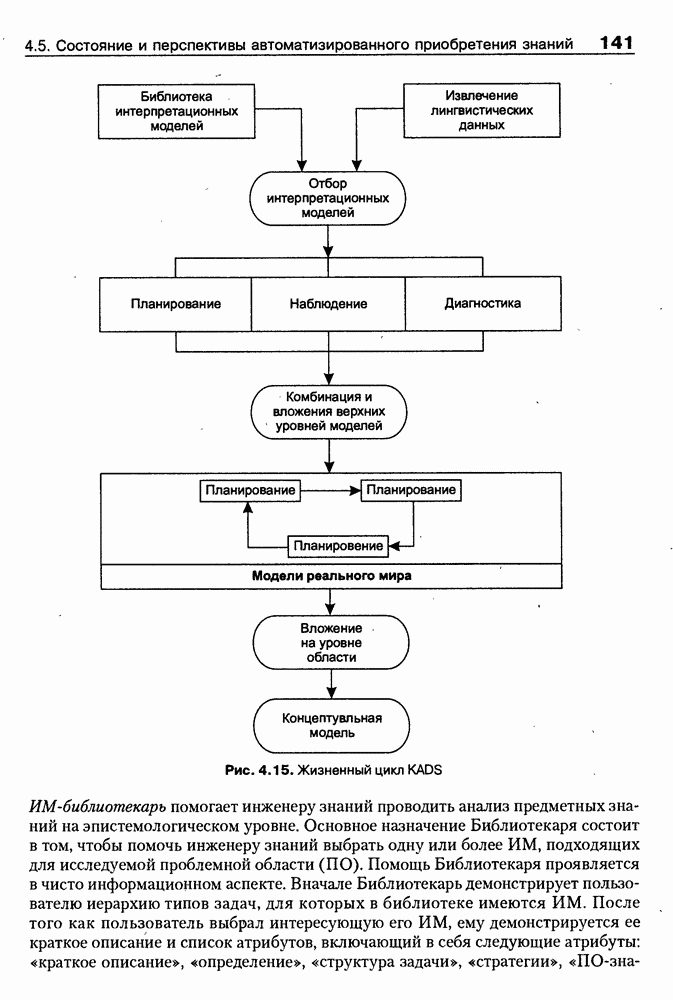
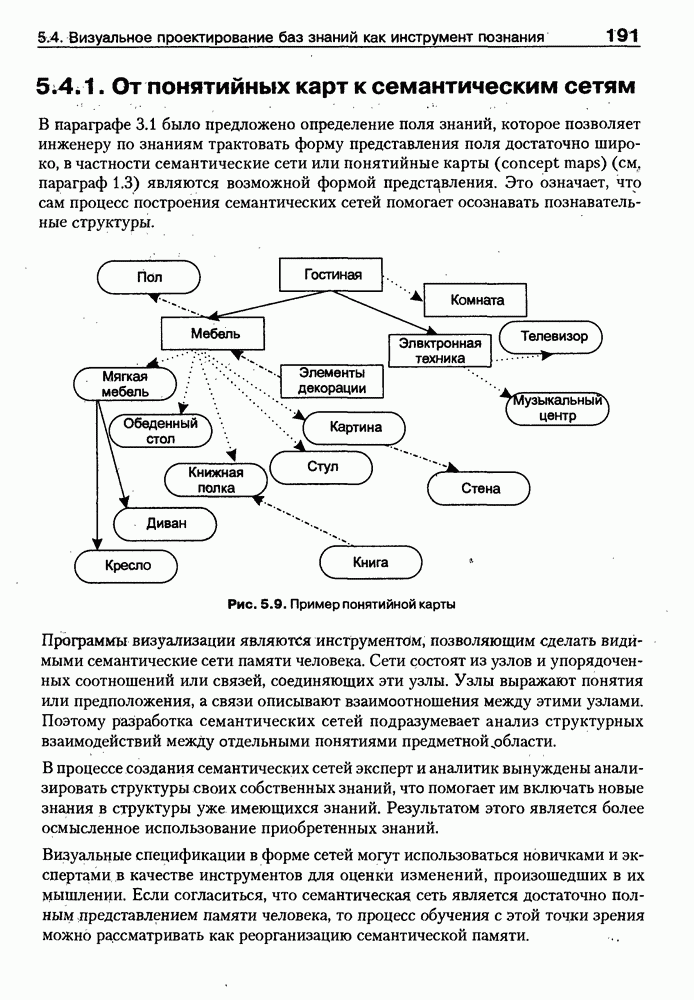
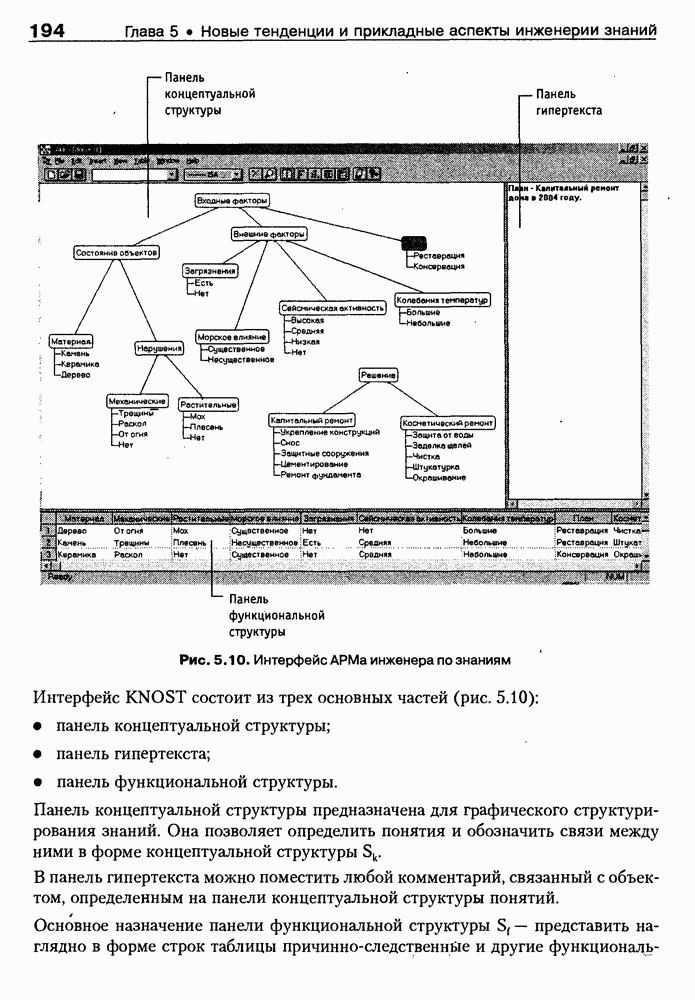
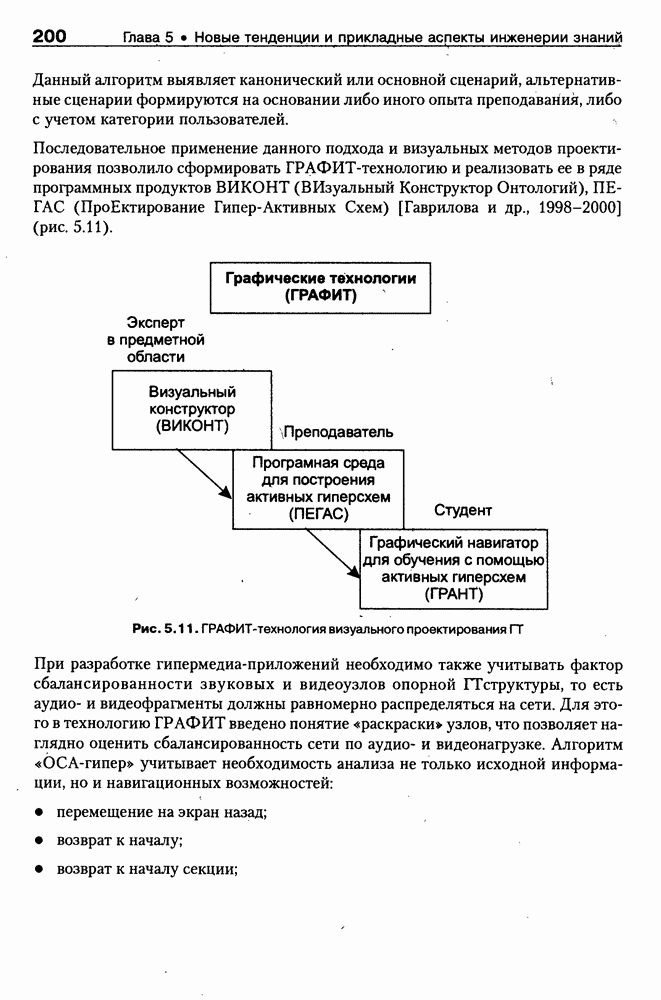
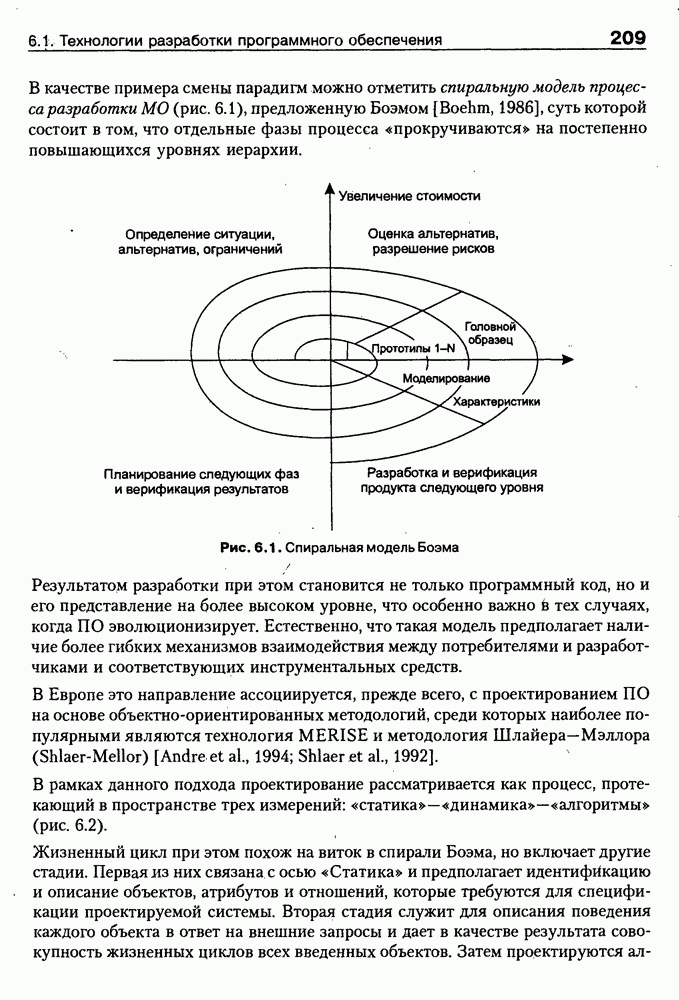
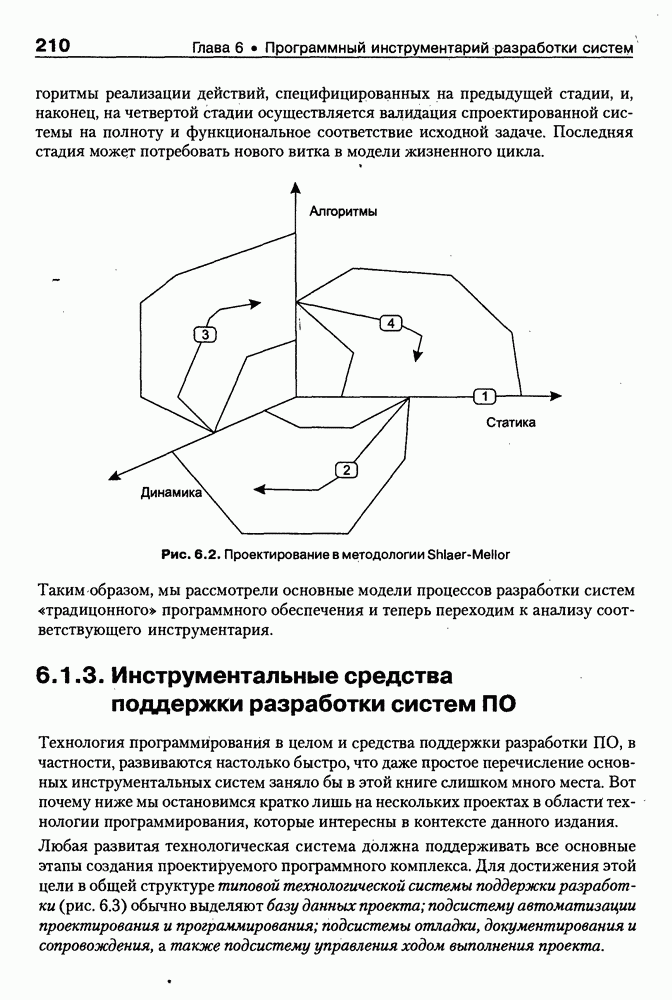
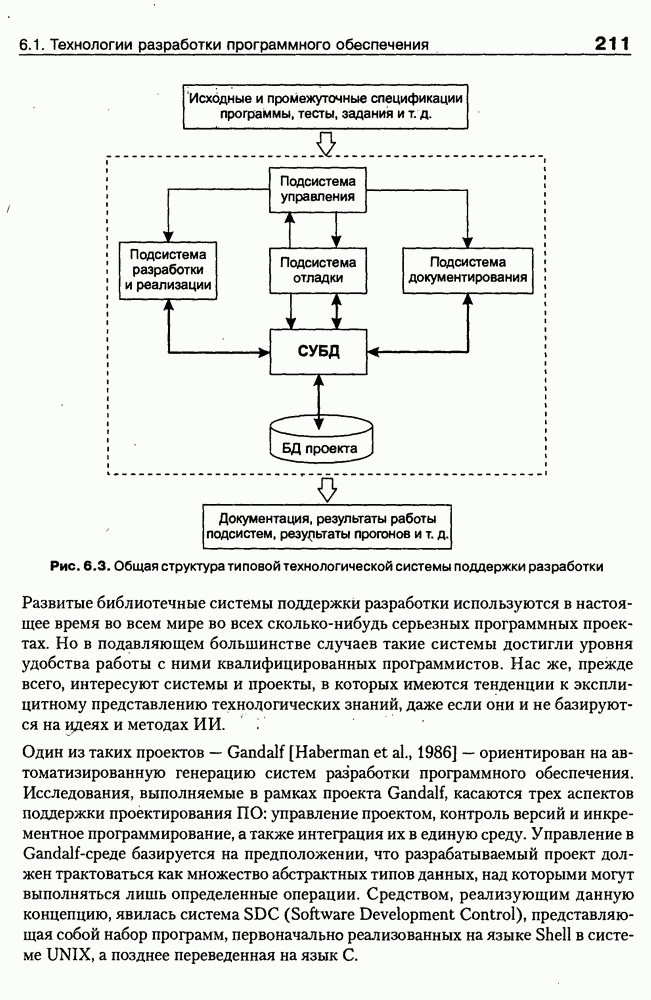
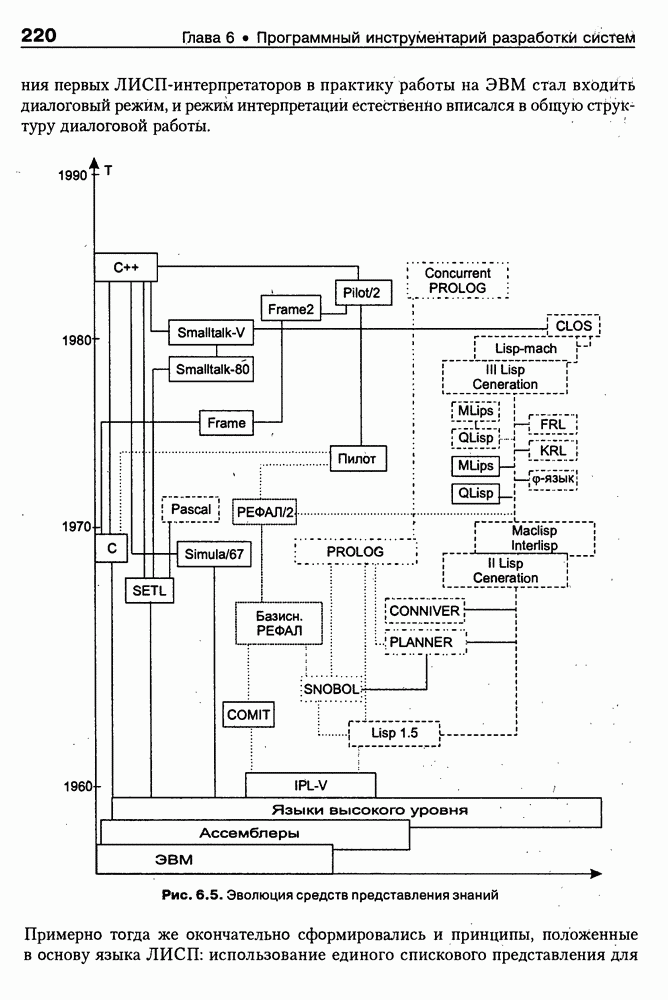
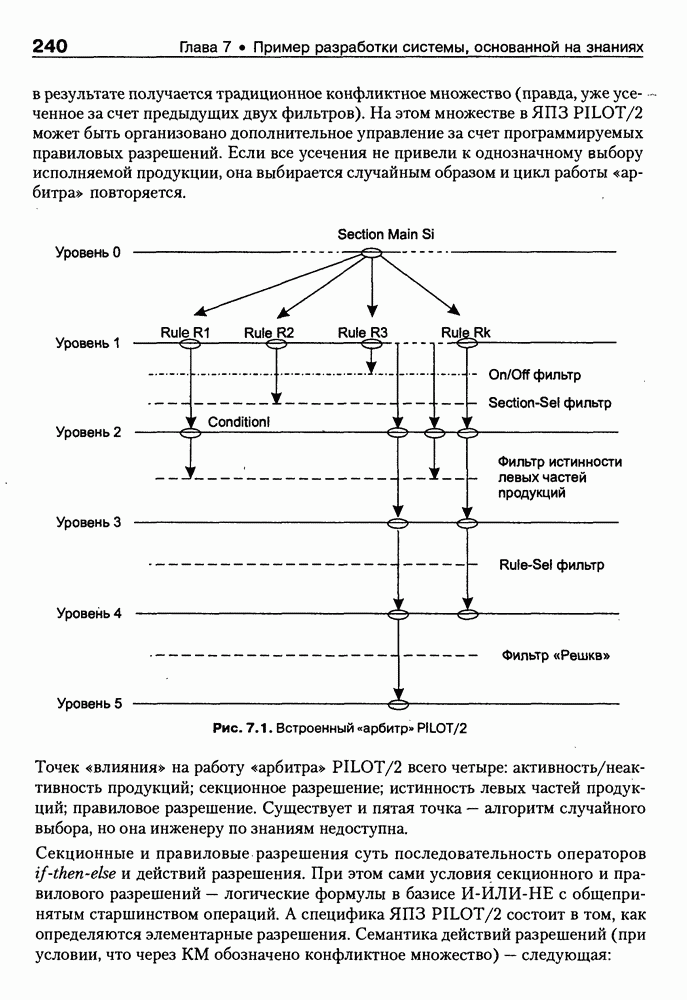
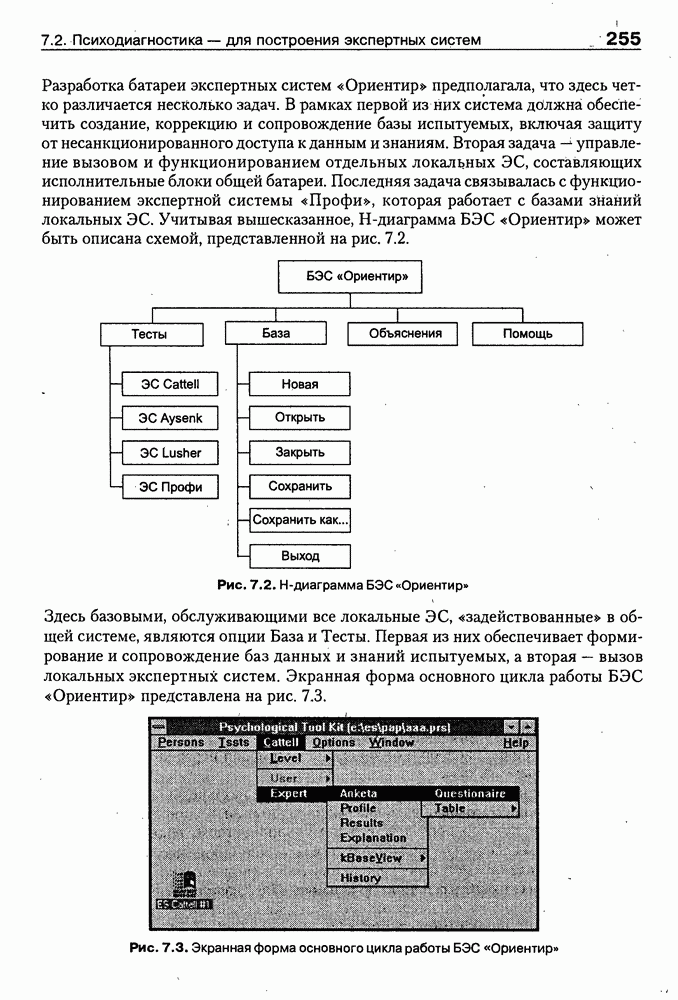
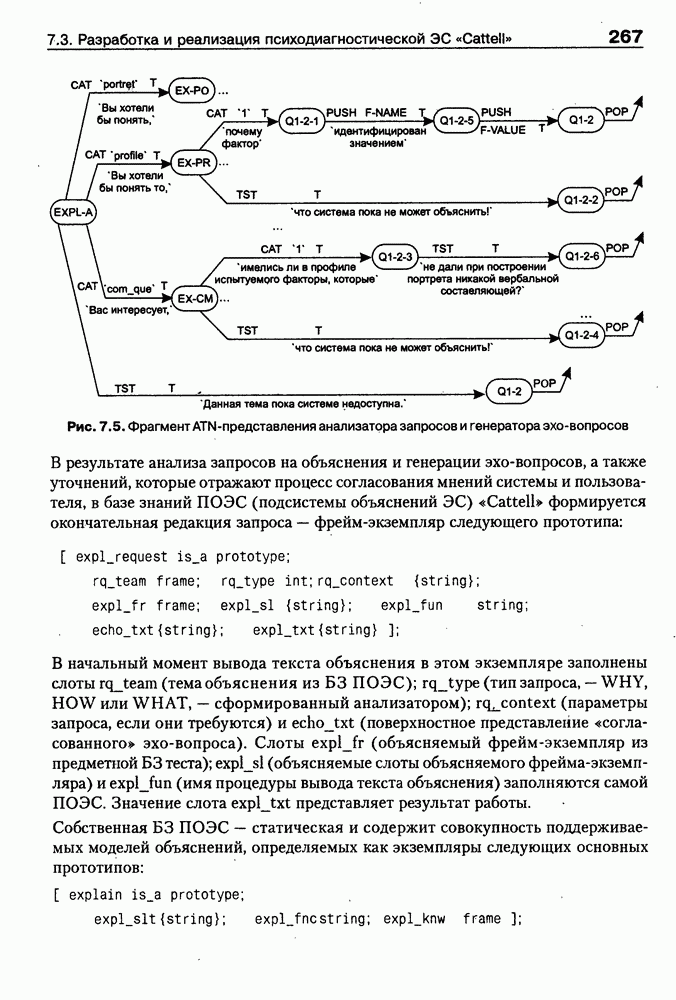
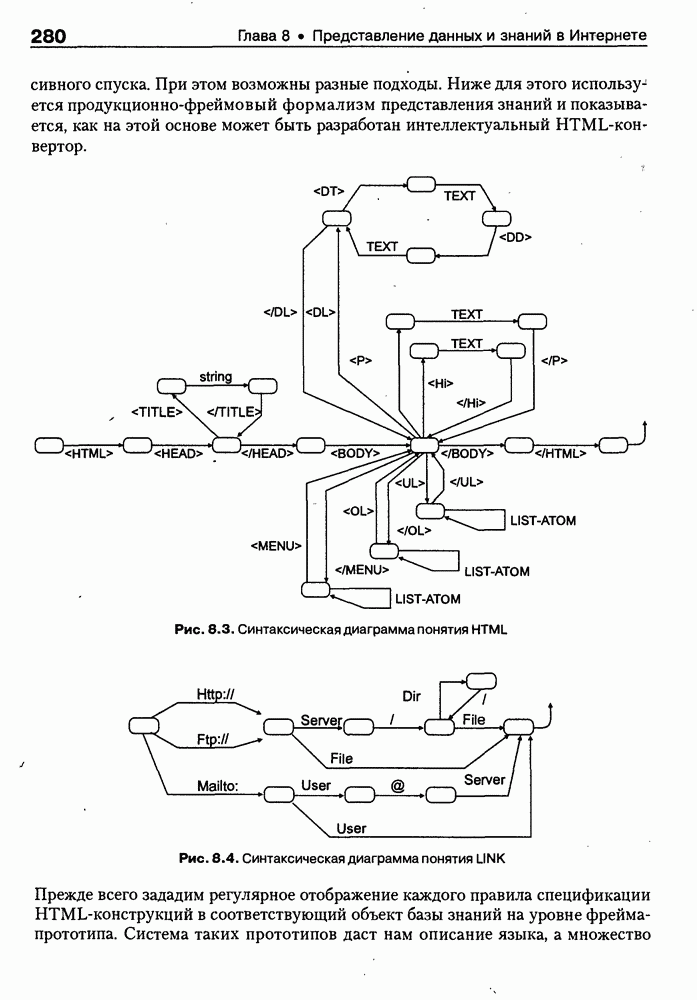
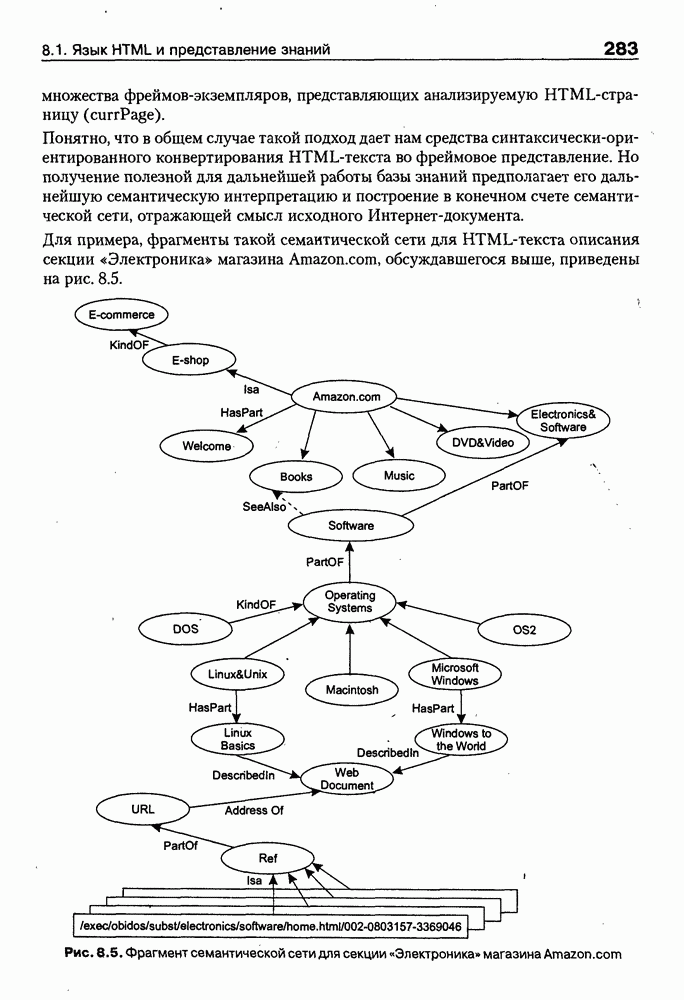
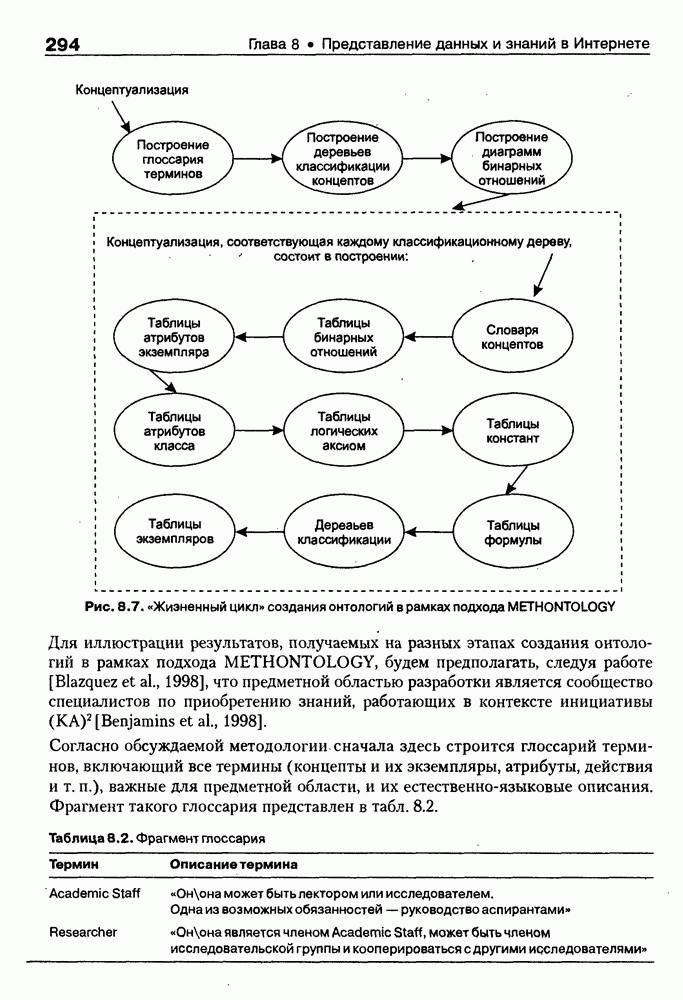
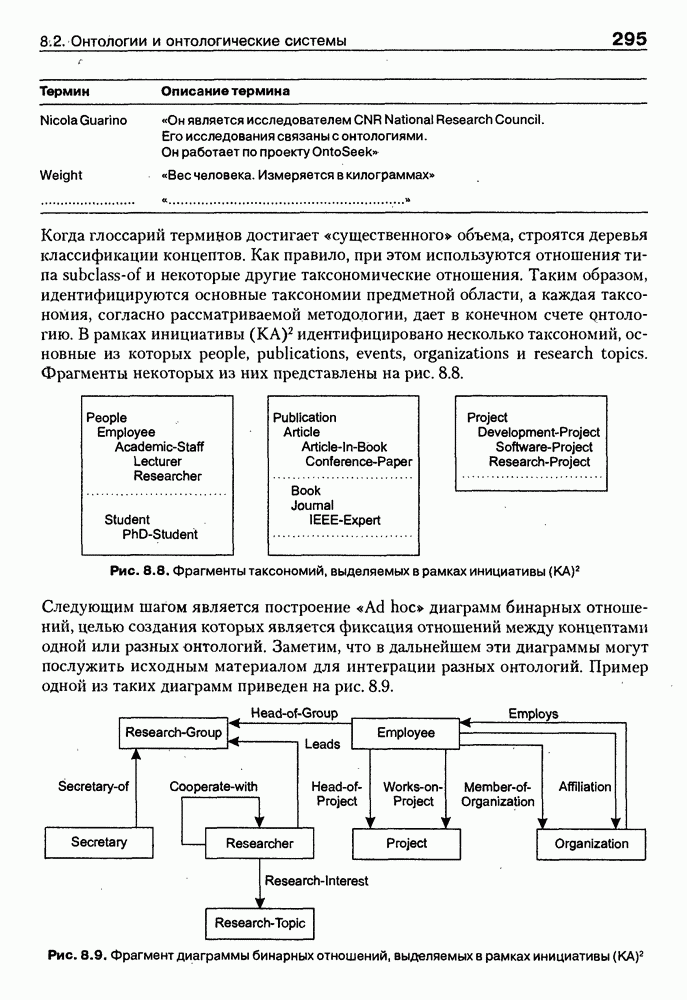
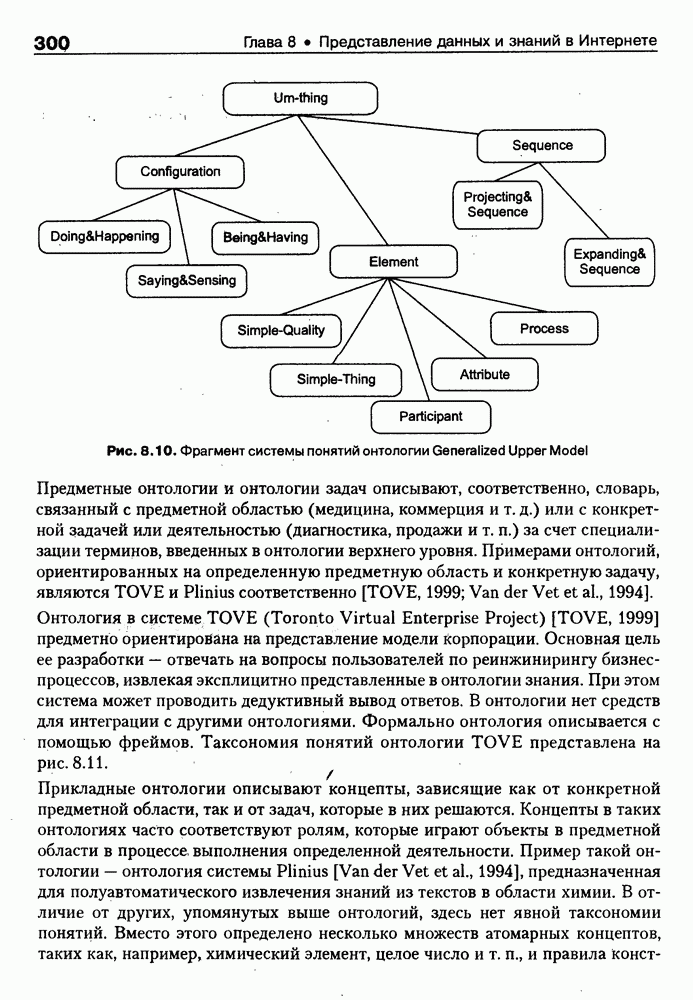
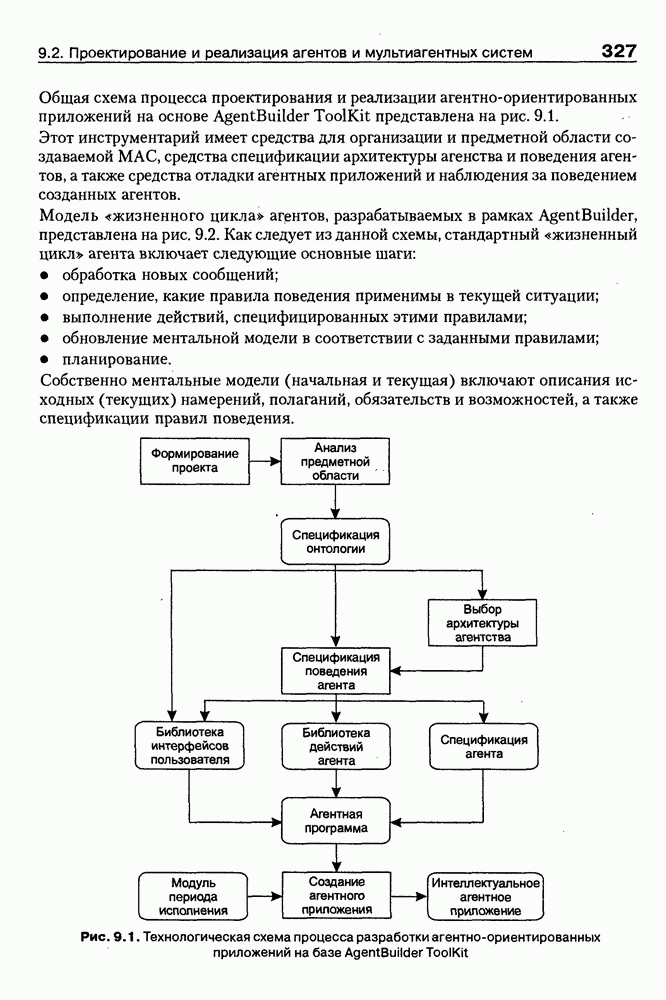
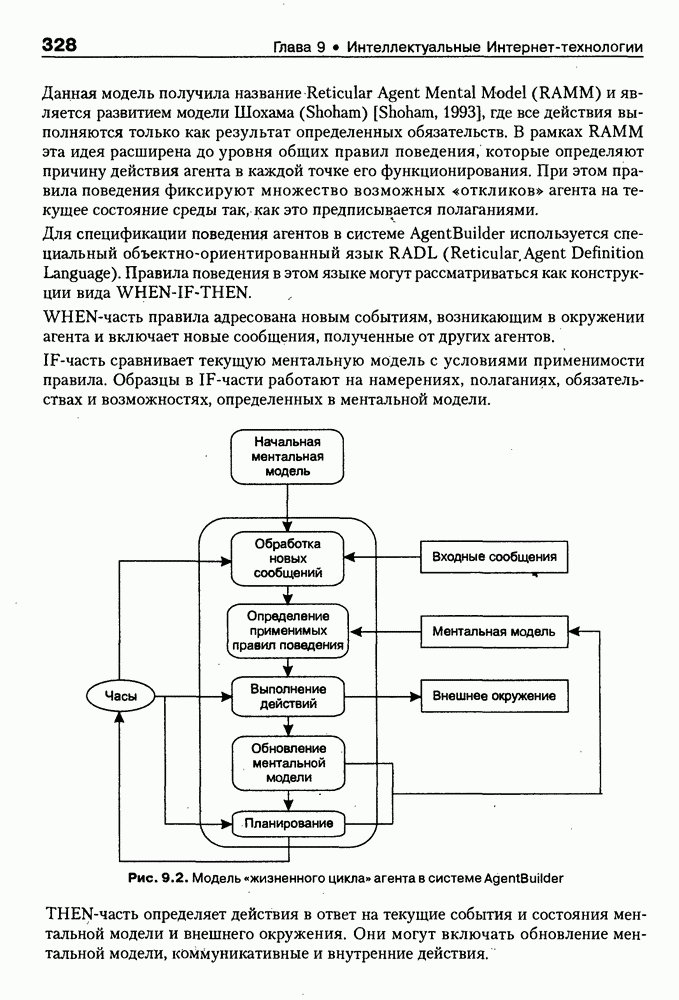
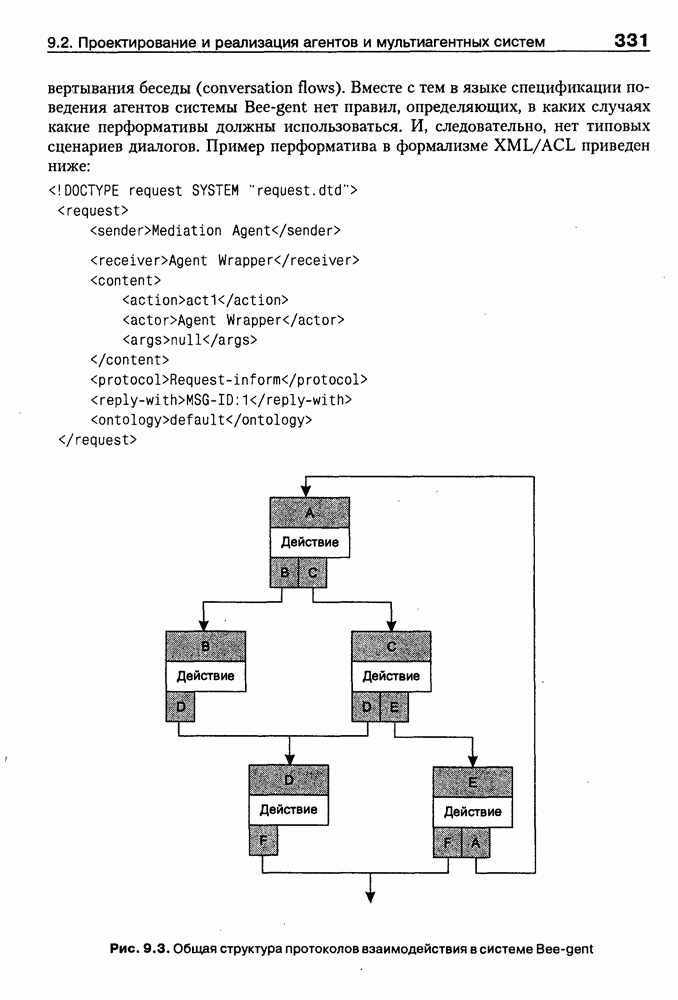
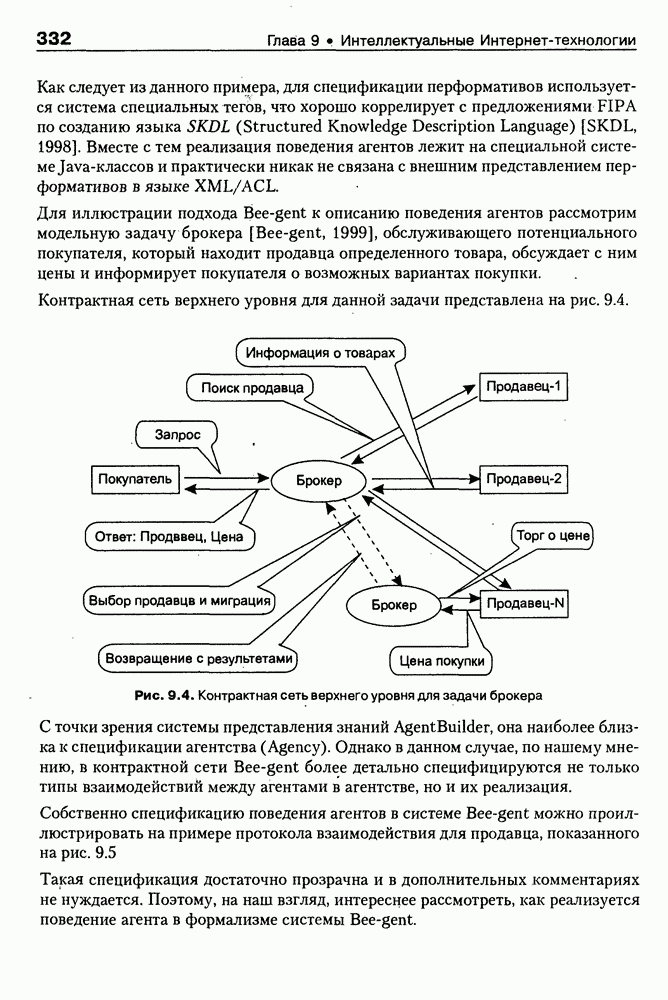
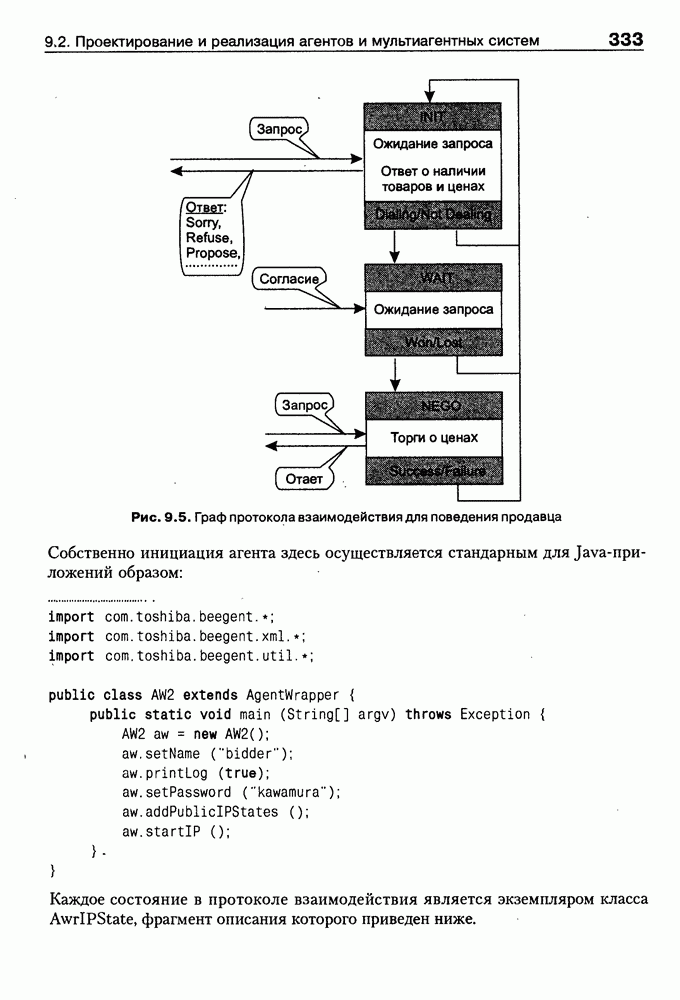
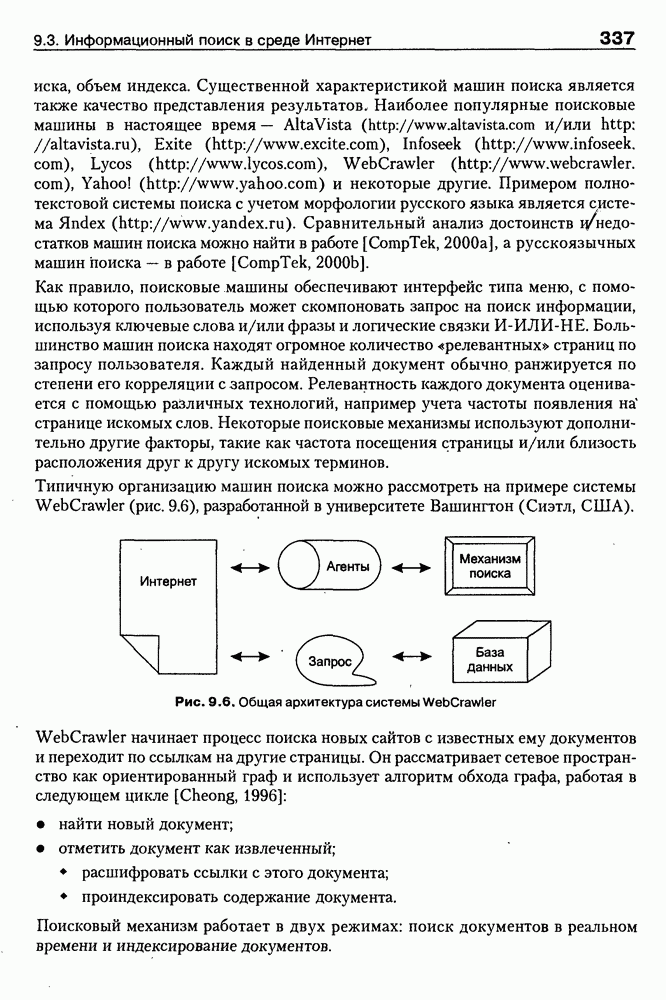
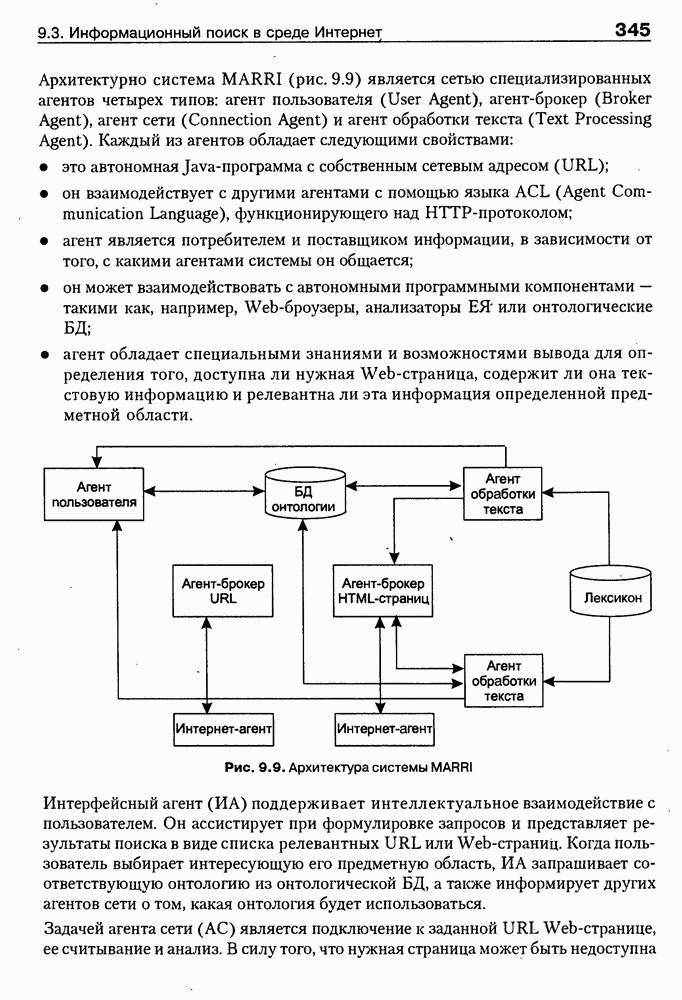
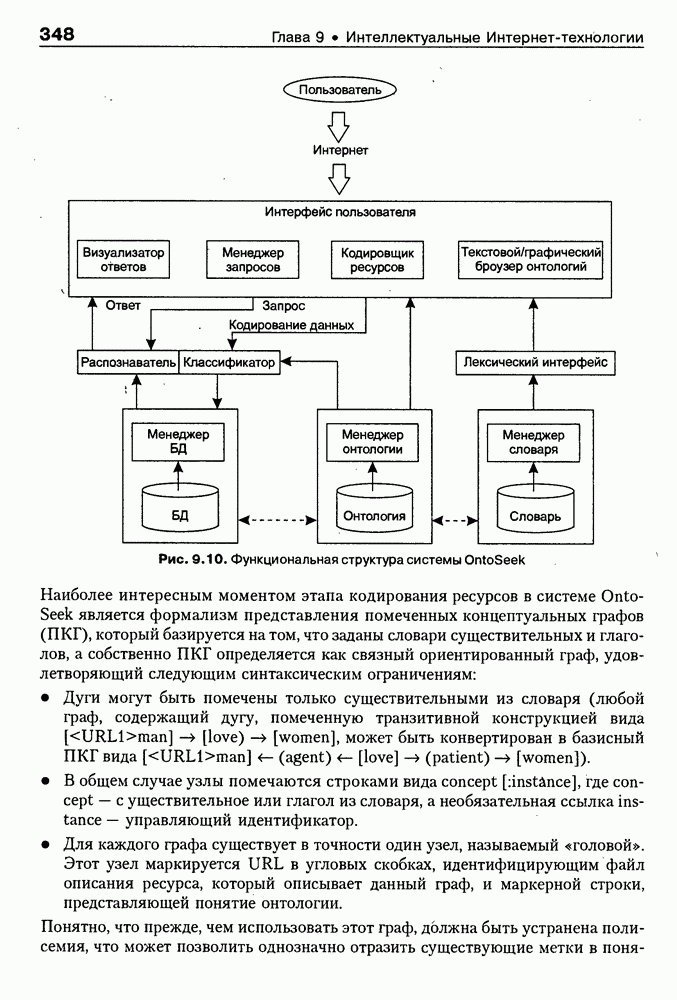
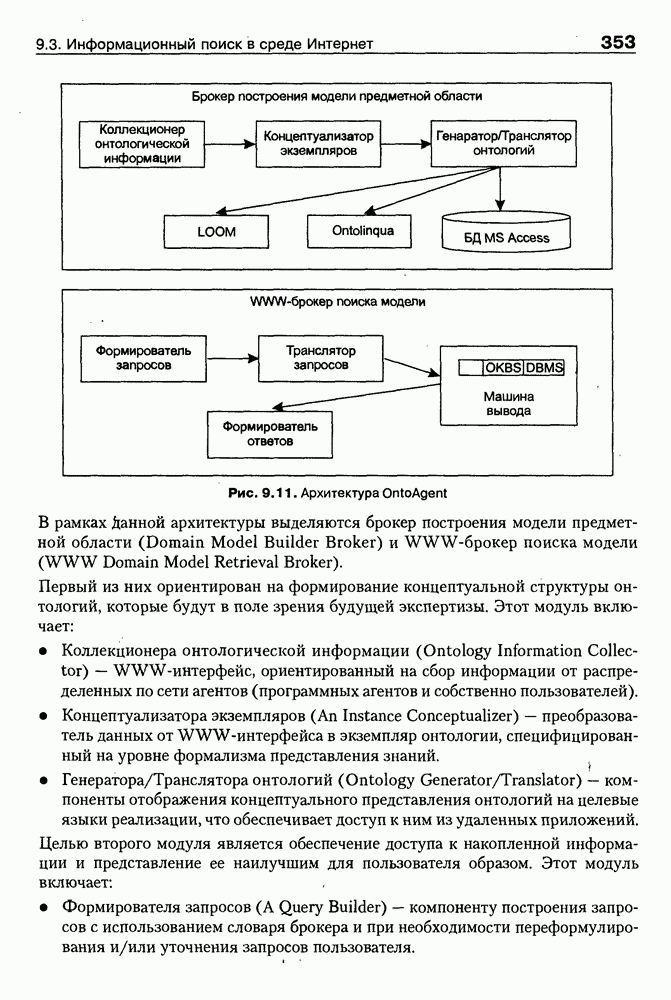
8.3. Системы и средства представления онтологических знаний
8.3.1. Основные подходы
В настоящее время во всем мире исследования по пространствам знаний в среде Интернет [Khoroshevsky, 1998] ведутся широким фронтом. И одним из ключевых аспектов в таких исследованиях являются алгоритмические и программные средства представления онтологических знаний и работы с онтологиями.
В качестве примеров исследовательских проектов по данной тематике можно указать Cooperative Information Gathering Project из лаборатории Распределенного ИИ университета Массачусет; проект экстрактирования знаний из гипертекстов на основе использования методов машинного обучения, выполняемого в университете Карнеги Мэллон; работы Knowledge Technology Group лаборатории Sun Microsystems по технологии обработки знаний (проект «Precision Content Retrieval»), целью которого является построение концептуальной
таксономии фраз, выделяемых из индексированных материалов, и многие другие [Lesser et al, 1998; Luke et al., 1996; Woods et al., 1999]. Общей целью практически всех таких проектов является разработка новых подходов к построению пространств знаний и средств работы с ними, где бы обеспечивались:
• использование семантики для управления процессом ответа на запросы;
• возможность построения ответов с хорошо определенной семантикой и простым синтаксисом, которые могли бы быть «поняты» и обработаны программными агентами или другими программными средствами;
• возможность гомогенного доступа к информации, которая физически распределена и гетерогенно представлена в Интернете;
• получение информации, которая явно не присутствует среди фактов, полученных из сети, но может быть выведена из других фактов и базовых знаний.
Впечатляющая коллекция ссылок на такие проекты представлена в Интернете по адресу  но наиболее интересными с точки зрения темы данного раздела, по-видимому, являются инициатива
но наиболее интересными с точки зрения темы данного раздела, по-видимому, являются инициатива  [Benjamins et al.,
[Benjamins et al.,
1998] и проект SHOE [Heflin et al., 1998], которые и обсуждаются ниже.