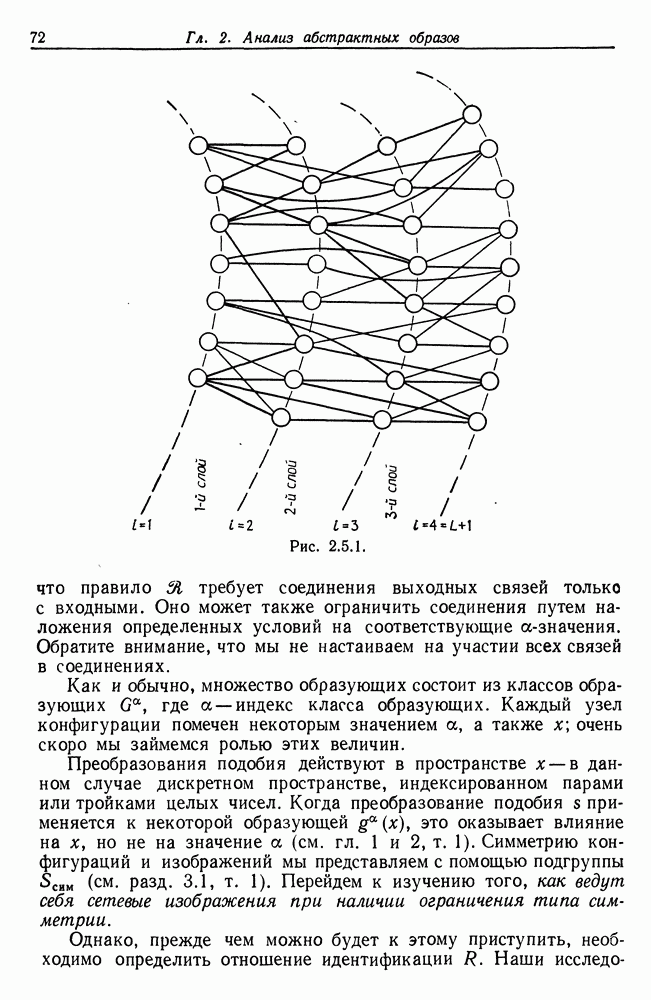
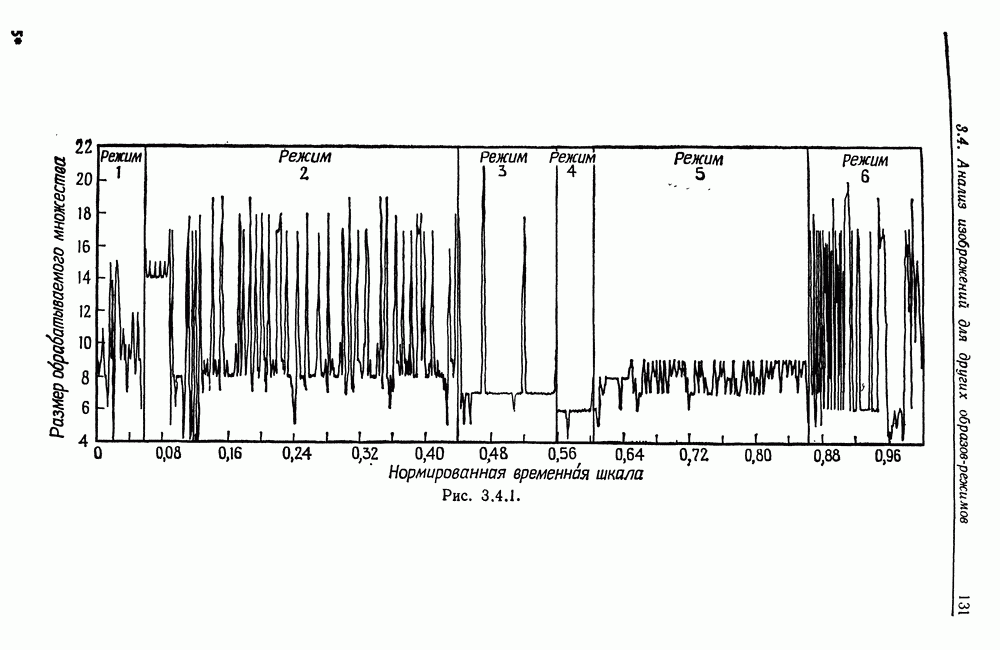
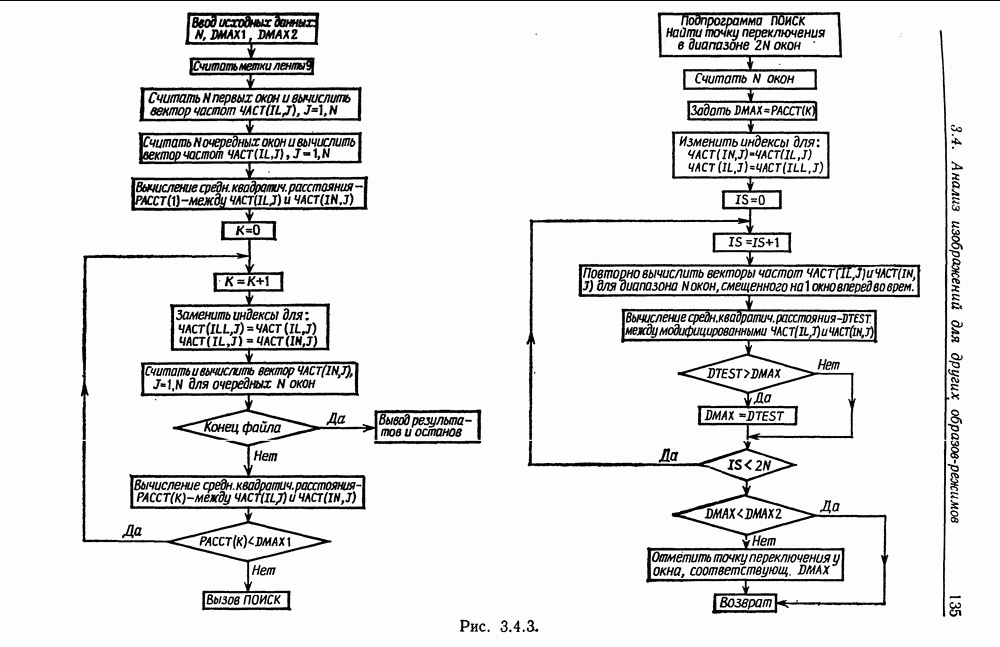
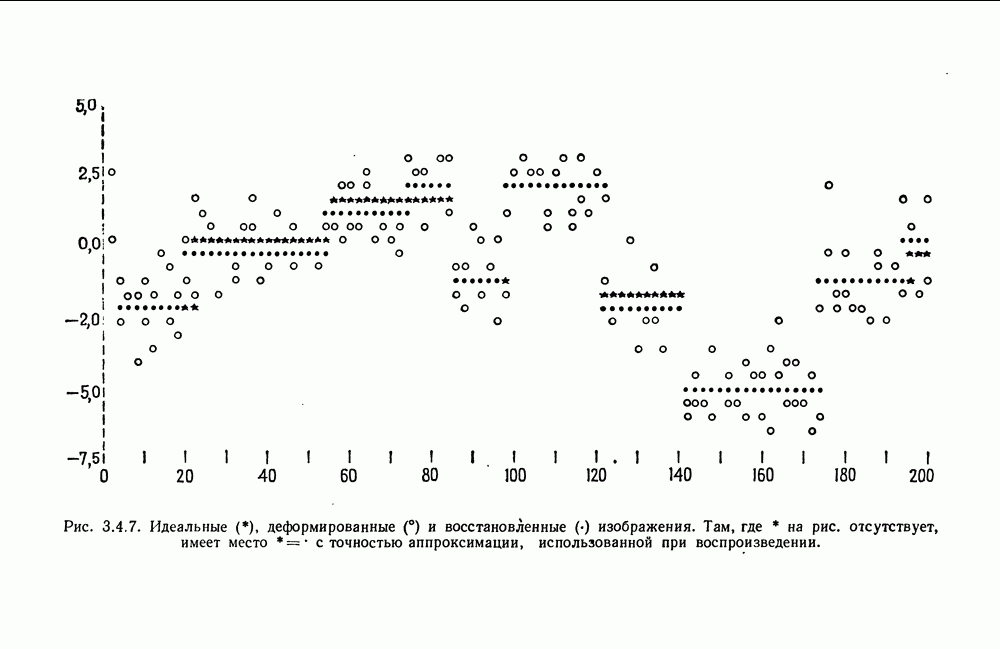
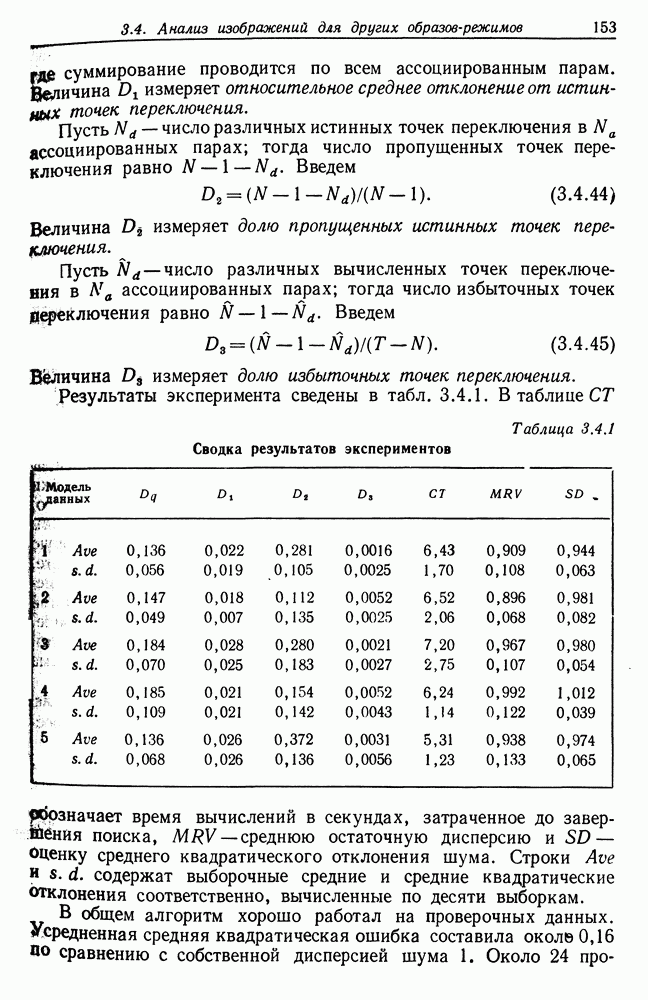
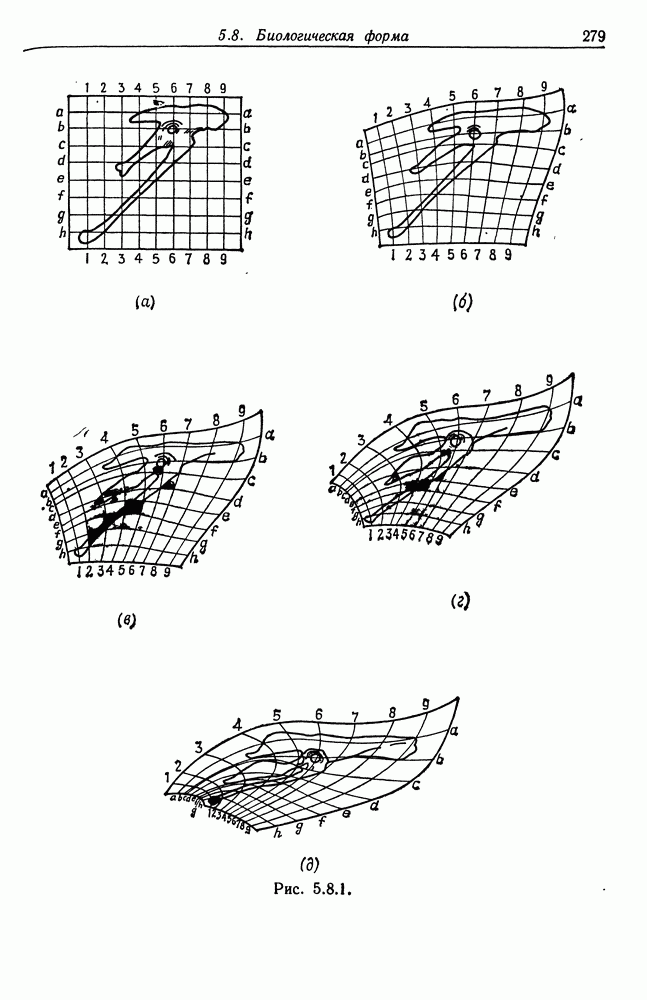
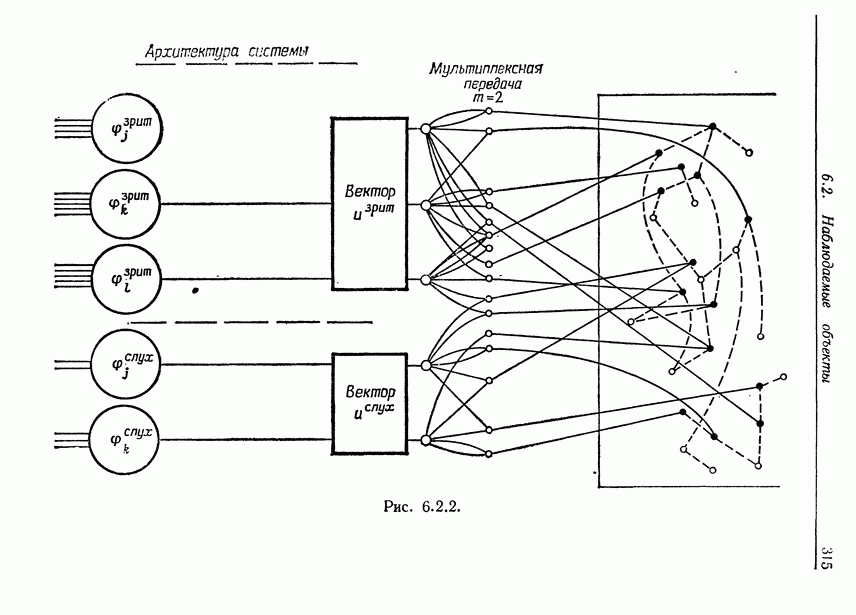
7.2. Абдукция некоторых языковых образов
Исходя из общих положений предыдущего раздела, мы попытаемся теперь сконструировать алгоритмы абдукции применительно к случаю, когда образы принадлежат некоторому формальному языку. Это будет конкретным примером того, как вывод, основанный на деформациях, может быть осуществлен в рамках случая 7.1.2.
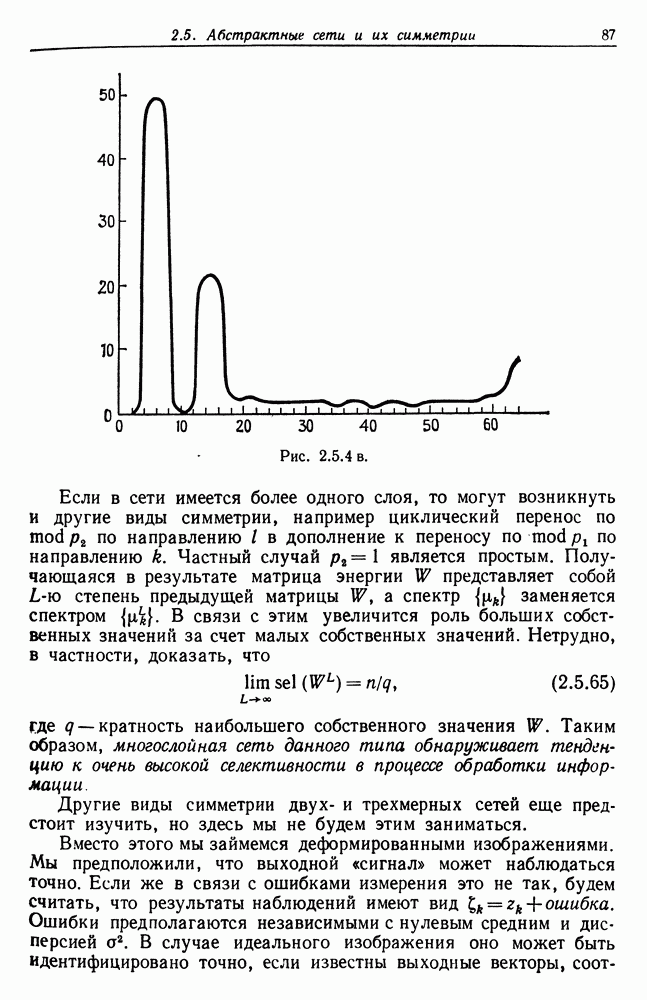
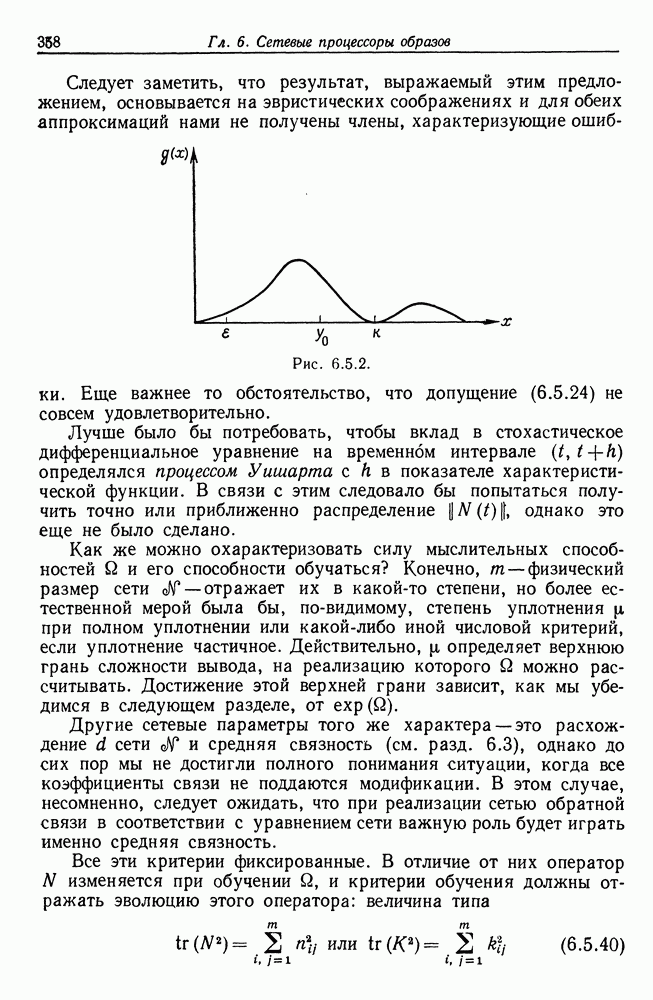
Прежде чем решить, какой тип формального языка мы будем использовать, остановимся кратко на информационном потоке, возникающем в процессе абдукции. Существо  (источник речи) живет в среде, которая характеризуется некоторой алгеброй изображения
(источник речи) живет в среде, которая характеризуется некоторой алгеброй изображения  (см. рис. 7.2.1). Заданное изображение
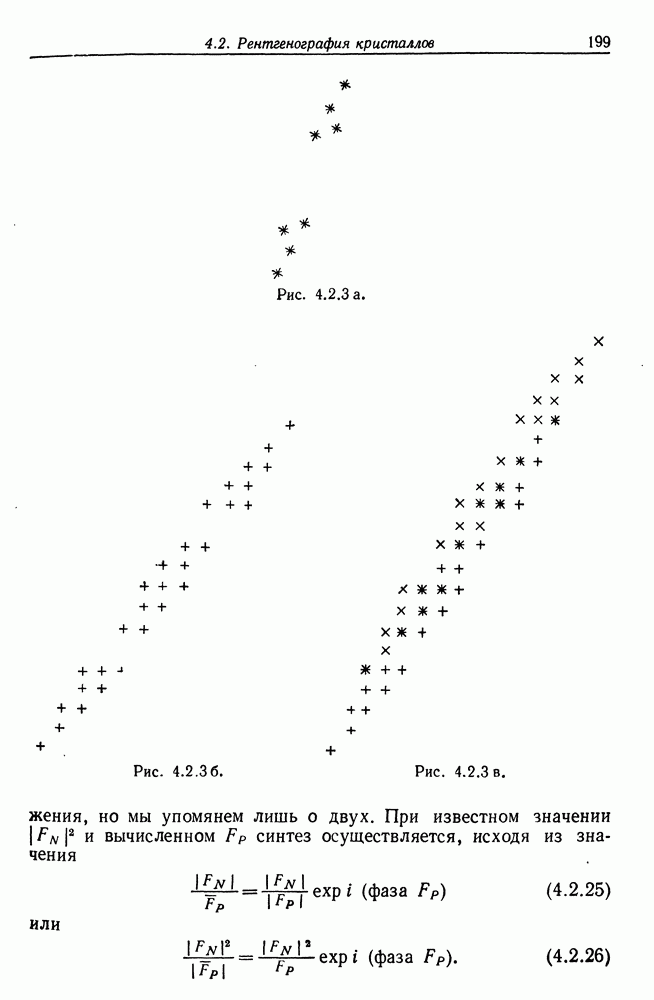
(см. рис. 7.2.1). Заданное изображение  может породить множество различных предложений, принадлежащих языку
может породить множество различных предложений, принадлежащих языку  который описывается некоторой грамматикой Это означает, что процессор изображений отображает алгебру изображений
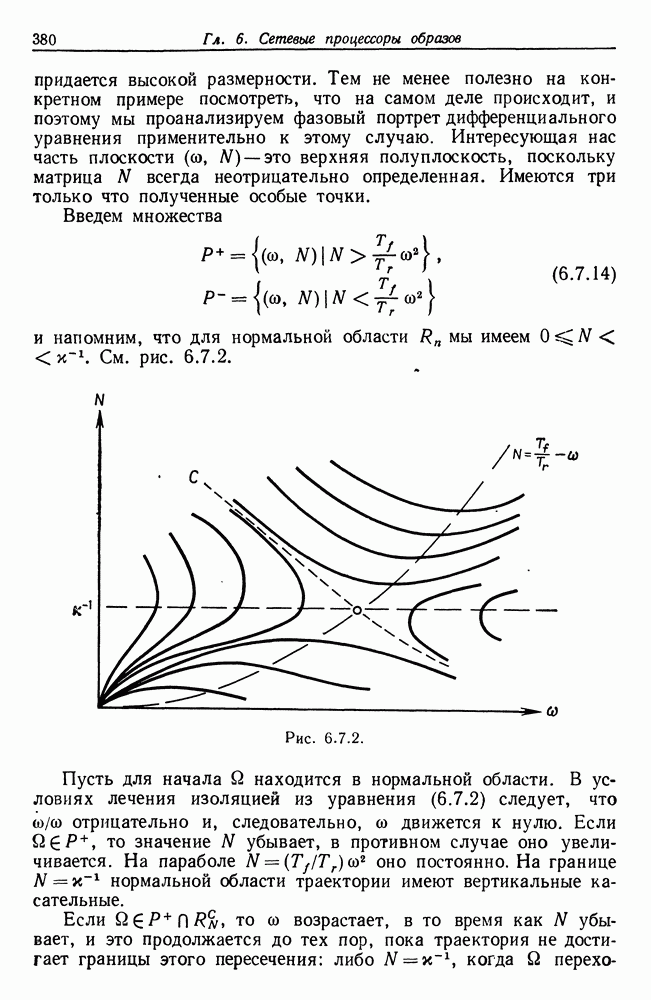
который описывается некоторой грамматикой Это означает, что процессор изображений отображает алгебру изображений  в некоторую другую алгебру изображений, так что оператор изображений, «преобразователь»,
в некоторую другую алгебру изображений, так что оператор изображений, «преобразователь»,
представленный на этом рисунке, переводит изображения микромира в языковые изображения.
Пример работы такого оператора изображения можно найти в разд. 2.4. Как уже указывалось, отображение многозначно, поскольку некоторое заданное изображение  принадлежащее
принадлежащее  может породить множество синтаксически правильных предложений, соответствующих грамматике
может породить множество синтаксически правильных предложений, соответствующих грамматике  и согласующихся с изображением I семантически.
и согласующихся с изображением I семантически.

Рис. 7.2.1.
Затем предложения языка  подвергаются воздействию механизма деформации на рисунке этому соответствует второй оператор изображения, изменяющий подизображение. Результат предъявляется учителю и запоминается в кратковременной памяти
подвергаются воздействию механизма деформации на рисунке этому соответствует второй оператор изображения, изменяющий подизображение. Результат предъявляется учителю и запоминается в кратковременной памяти  вместе с указанием, полученным от учителя, и недеформированным предложением. Допустим, что учитель отвечает только «да» или «нет» в соответствии с грамматической правильностью конкретного предложения. Мы будем обозначать функцию грамматической правильности через
вместе с указанием, полученным от учителя, и недеформированным предложением. Допустим, что учитель отвечает только «да» или «нет» в соответствии с грамматической правильностью конкретного предложения. Мы будем обозначать функцию грамматической правильности через  она, разумеется, неизвестна
она, разумеется, неизвестна  априори. Значениями этой функции служат «ДА» и «НЕТ». Алгоритм абдукции обрабатывает эти три входа и передает результат в форме, которую еще следует определить, в долговременную память, после чего кратковременная память очищается. По мере того как будет обрабатываться все большее число предложений, можно ожидать, что алгоритм сойдется к некоторой
априори. Значениями этой функции служат «ДА» и «НЕТ». Алгоритм абдукции обрабатывает эти три входа и передает результат в форме, которую еще следует определить, в долговременную память, после чего кратковременная память очищается. По мере того как будет обрабатываться все большее число предложений, можно ожидать, что алгоритм сойдется к некоторой
предельной грамматике, эквивалентной в слабом смысле грамматике причем параметры работы алгоритма будут характеризовать распределение вероятностей на 
В данной главе мы будем изучать абдукцию языка  при полном отсутствии семантических входных сигналов, и, следовательно, связь
при полном отсутствии семантических входных сигналов, и, следовательно, связь  с памятью, изображенная на рис. 7.2.1 пунктиром, отсутствует. Случай наличия семантического входа, поступающего из алгебры изображений
с памятью, изображенная на рис. 7.2.1 пунктиром, отсутствует. Случай наличия семантического входа, поступающего из алгебры изображений  представляет собой перспективную исследовательскую проблему, которая здесь, однако, изучаться не будет.
представляет собой перспективную исследовательскую проблему, которая здесь, однако, изучаться не будет.
На рисунке представлены два оператора изображения: преобразователь, на выходе которого воспроизводятся предложения языка и  механизм деформации, кратко рассмотренный в предыдущем разделе и воспроизводящий на выходе цепочки символов того же словаря терминалов, что используется и во входных сообщениях. Определение алгоритма абдукции должно подробно задавать последний, и теперь мы перейдем к этому вопросу.
механизм деформации, кратко рассмотренный в предыдущем разделе и воспроизводящий на выходе цепочки символов того же словаря терминалов, что используется и во входных сообщениях. Определение алгоритма абдукции должно подробно задавать последний, и теперь мы перейдем к этому вопросу.
Во-первых, следует решить, какой тип грамматики должен здесь использоваться. Простым, но не тривиальным типом  Ляется автоматная грамматика, и именно ее мы будем использовать в качестве дальнейшие подробности, а также некоторые исторические сведения можно найти в примечаниях.
Ляется автоматная грамматика, и именно ее мы будем использовать в качестве дальнейшие подробности, а также некоторые исторические сведения можно найти в примечаниях.
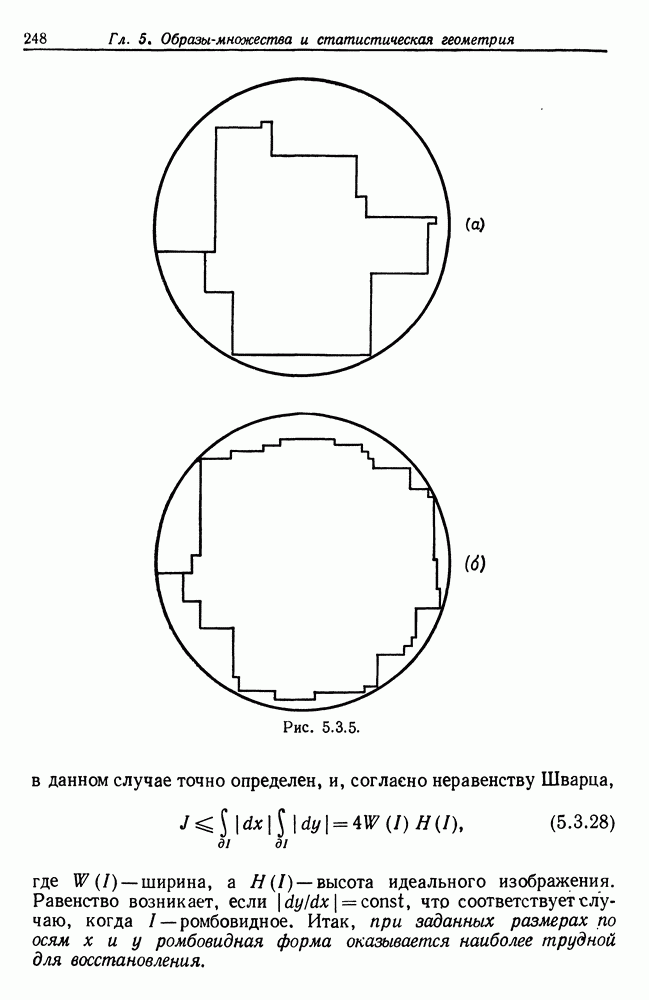
Здесь мы пользуемся теми же допущениями и обозначениями, что и в т. 1, разд. 2.4, 2.10 и 3.2. Словарь терминалов  содержит
содержит  слов, обозначаемых в общем случае буквами
слов, обозначаемых в общем случае буквами  или этими же буквами, снабженными при необходимости нижними индексами. Синтаксические переменные, или нетерминальные элементы, образуют некоторое множество
или этими же буквами, снабженными при необходимости нижними индексами. Синтаксические переменные, или нетерминальные элементы, образуют некоторое множество  включающее
включающее  элементов, которые обозначаются буквами
элементов, которые обозначаются буквами  или этими же буквами, снабженными при необходимости нижними индексами. Правила подстановки имеют вид
или этими же буквами, снабженными при необходимости нижними индексами. Правила подстановки имеют вид

последний тип правил приводит к окончанию вывода. Число правил подстановки обозначается через  Соответствующие вероятности, образующие некоторую матрицу
Соответствующие вероятности, образующие некоторую матрицу  и вектор
и вектор  обозначаются как
обозначаются как  соответственно. Кроме того,
соответственно. Кроме того,

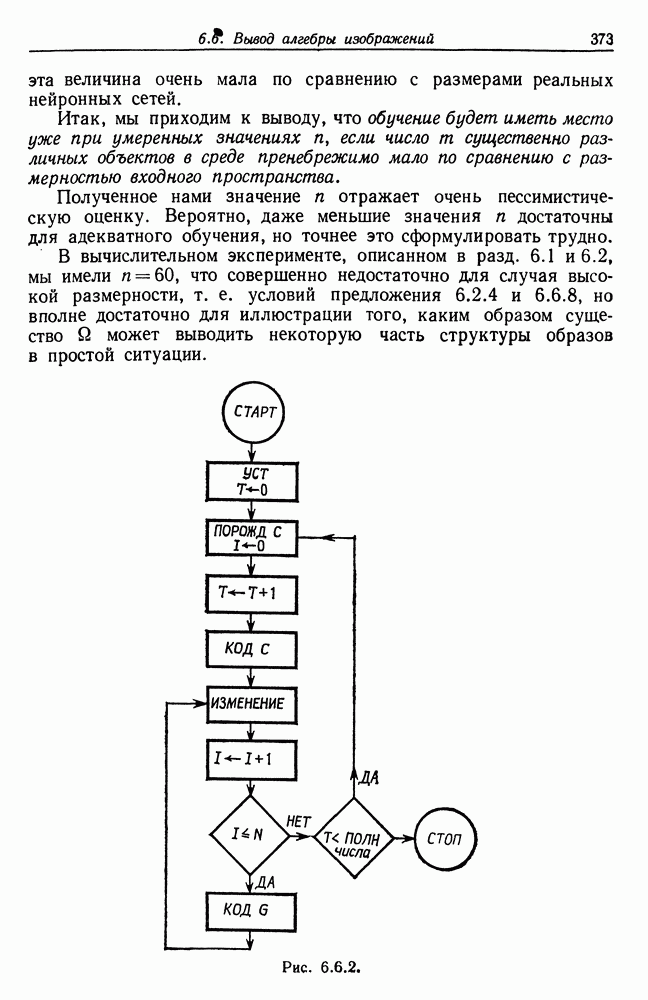
При наших стандартных допущениях проблема состоятельности модели с синтаксически управляемой вероятностью автоматически
решается положительно (см. теорема 2.10.7, гл. 2, т. 1, с. 76). Следовательно на  существует хорошо определенная вероятностная мера. Напомним, что в данном случае регулярные конфигурации характеризуются типом соединения ЛИНЕЙНЫЙ и показатели связей принимают значения из
существует хорошо определенная вероятностная мера. Напомним, что в данном случае регулярные конфигурации характеризуются типом соединения ЛИНЕЙНЫЙ и показатели связей принимают значения из  Естественно, внутренние связи должны удовлетворять отношению связи
Естественно, внутренние связи должны удовлетворять отношению связи  Соответствующие изображения представляют собой «предложения» с одной входной и одной выходной связями.
Соответствующие изображения представляют собой «предложения» с одной входной и одной выходной связями.
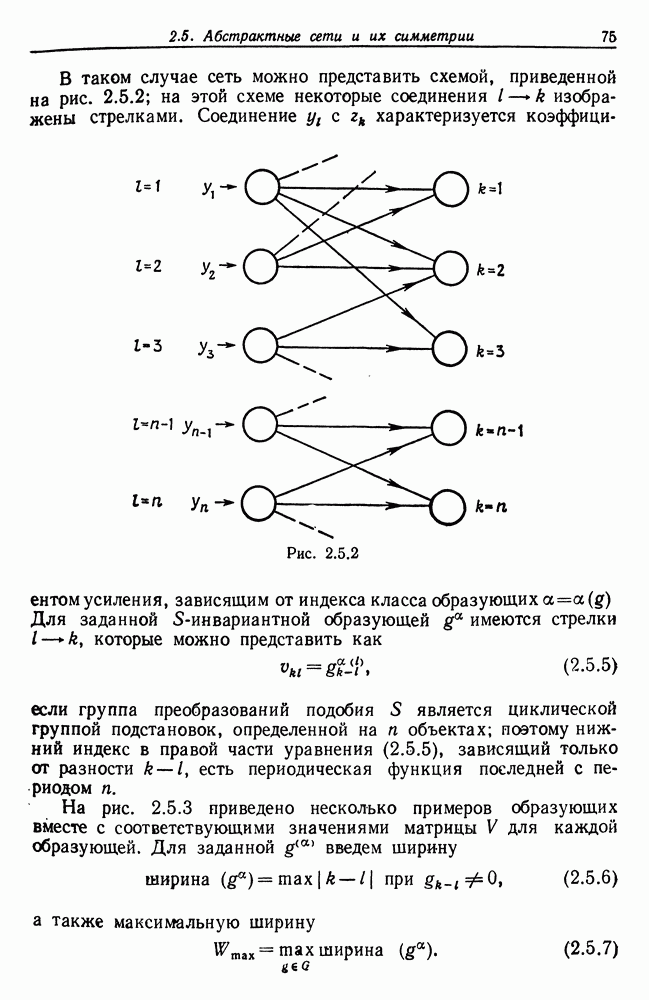
Образующая представляет, собой правило подстановки типа (7.2.1), так что ее можно рассматривать как некоторый элемент из  т. е. слово, вместе с входными и выходными связями
т. е. слово, вместе с входными и выходными связями  или
или  где
где  представляет заключительное состояние. Начальное состояние будет выбираться как
представляет заключительное состояние. Начальное состояние будет выбираться как 
Заманчиво рассматривать образующую просто как некоторое слово из  Это, однако, неправильно, поскольку вполне может оказаться, что одно и то же слово
Это, однако, неправильно, поскольку вполне может оказаться, что одно и то же слово  появляется в двух различных правилах
появляется в двух различных правилах  Следовательно, отображение
Следовательно, отображение  может быть многозначным, что, как мы убедимся ниже, имеет важные последствия.
может быть многозначным, что, как мы убедимся ниже, имеет важные последствия.
Пусть  фиксированы в
фиксированы в  выберем две произвольные цепочки
выберем две произвольные цепочки  Если всегда верно, что связанные конкатенацией цепочки
Если всегда верно, что связанные конкатенацией цепочки  одновременно являются или не являются выводимыми в данной грамматике, то мы говорим, что
одновременно являются или не являются выводимыми в данной грамматике, то мы говорим, что  т. е. они эквивалентны (или конгруэнтны). Другими словами,
т. е. они эквивалентны (или конгруэнтны). Другими словами,

Это позволяет разбить  на классы эквивалентности. Отметим, что эквивалентность (7.2.3) требует, чтобы правая часть была справедлива при любых и и
на классы эквивалентности. Отметим, что эквивалентность (7.2.3) требует, чтобы правая часть была справедлива при любых и и  Следовательно, потребуется выполнить бесконечное число проверок, поскольку
Следовательно, потребуется выполнить бесконечное число проверок, поскольку  бесконечен. Недостаточно провести проверку для одного
бесконечен. Недостаточно провести проверку для одного  или некоторого конечного числа случаев. Тем не менее возникает ощущение, что если это соотношение справедливо для многих комбинаций
или некоторого конечного числа случаев. Тем не менее возникает ощущение, что если это соотношение справедливо для многих комбинаций  , то, вероятно,
, то, вероятно,  эквивалентны в некотором смысле, который точно еще не определен.
эквивалентны в некотором смысле, который точно еще не определен.
Нам понадобится следующее простое утверждение.
Лемма 7.2.1. Для того чтобы выполнялось  необходимо и достаточно, чтобы для любой образующей вида
необходимо и достаточно, чтобы для любой образующей вида  существовала образующая вида
существовала образующая вида  и наоборот.
и наоборот.
Доказательство. Рассмотрим два слова  и цепочки
и цепочки  Если для всякой образующей
Если для всякой образующей  существует образующая
существует образующая  то очевидно, что
то очевидно, что  и поскольку это справедливо для любых
и поскольку это справедливо для любых  то отсюда следует, что
то отсюда следует, что 
Выберем, с другой стороны,  так, чтобы выполнялось
так, чтобы выполнялось  Если
Если  выводима в данной грамматике и и переводит
выводима в данной грамматике и и переводит
начальное состояние в  переводит
переводит  состояние в
состояние в  переводит
переводит  то для того, чтобы
то для того, чтобы  также была выводима в данной грамматике, необходимо соответствие внутренних связей. Следовательно, должно существовать некоторое правило вида
также была выводима в данной грамматике, необходимо соответствие внутренних связей. Следовательно, должно существовать некоторое правило вида  и, таким образом, доказательство закончено.
и, таким образом, доказательство закончено.
Чтобы выделить свойство эквивалентности, выбираем в качестве преобразований подобия множество всех тех подстановок образующих, которые не затрагивают эквивалентность, так что если  причем.
причем.  некоторый
некоторый  Это определяет классы образующих
Это определяет классы образующих  инвариантные относительно S.
инвариантные относительно S.

Рис. 7.2.2.
Естественно,  не известны изначально и должны быть установлены посредством обучения в процессе абдукции. Мы начнем с некоторого множества
не известны изначально и должны быть установлены посредством обучения в процессе абдукции. Мы начнем с некоторого множества  преобразований изображений, причем
преобразований изображений, причем 
Таблица 7.2.1 (продолжение)
необязательно должны образовывать группу. В качестве первой задачи, которой будут посвящены разд. 7.3 и 7.4, мы выберем определение (неизвестных) классов слов.
Чтобы наше изложение было как можно более конкретным, мы воспользуемся некоторой «тестовой грамматикой». Конечно, можно было бы выбрать грамматику со словарем, состоящим из абстрактных символов, поскольку здесь мы не имеем дела с обработкой естественного языка. Однако по дидактическим соображениям мы выбрали грамматику, порождающую цепочки «английского» типа, с тем, чтобы результат было легче читать. Поскольку семантическая основа отсутствует, оказалось необходимым «подкрутить» грамматику так, чтобы избежать совершенно бессмысленных предложений.
Для данной грамматики  , в том числе пунктуационный знак
, в том числе пунктуационный знак  перечень слов терминального словаря приведен в табл. 7.2.1. Эти 52 «слова» сгруппированы в 23 класса слов, обозначенных, например,
перечень слов терминального словаря приведен в табл. 7.2.1. Эти 52 «слова» сгруппированы в 23 класса слов, обозначенных, например,  для определяющих слов,
для определяющих слов,  для слов, обозначающих людей, и т. д.
для слов, обозначающих людей, и т. д.
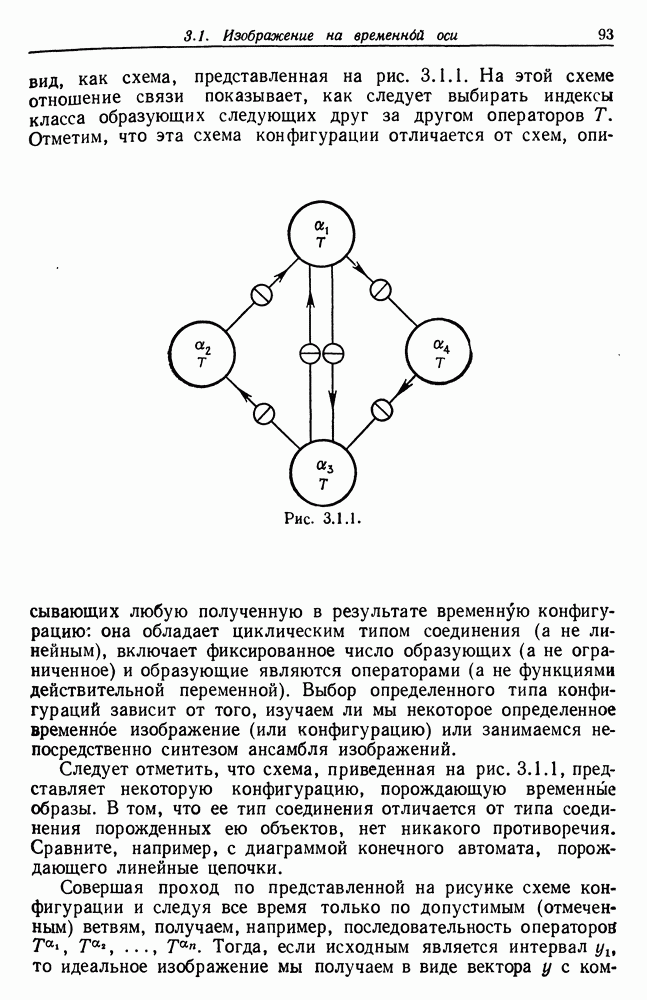
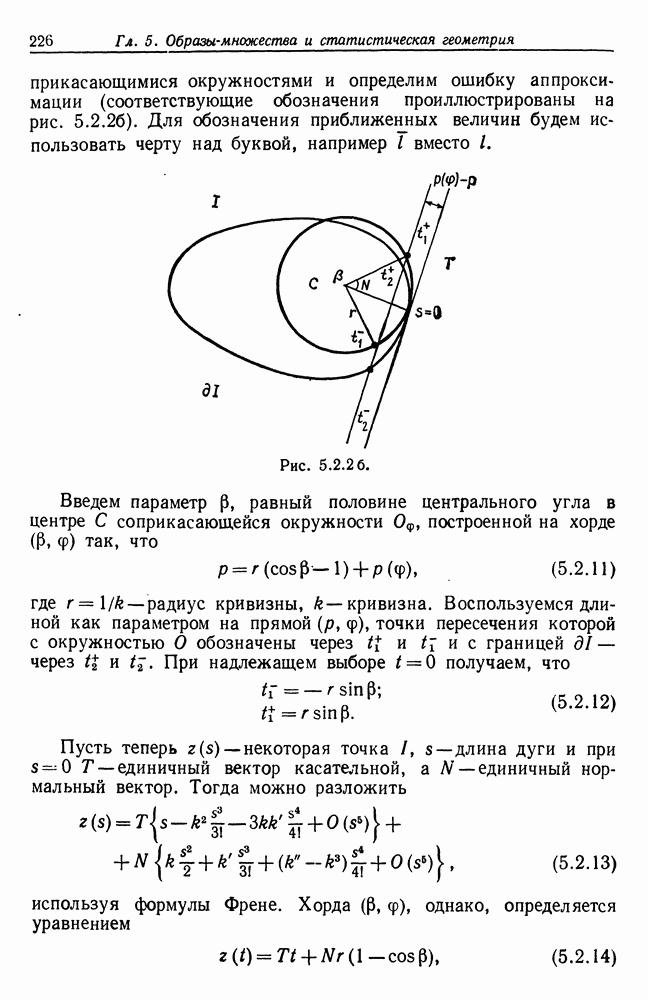
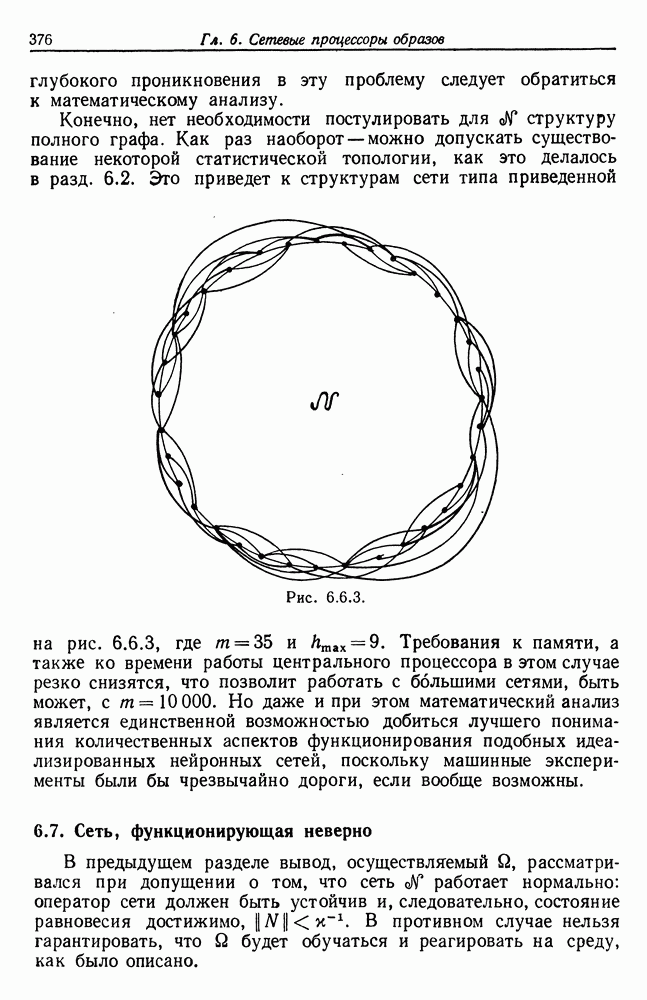
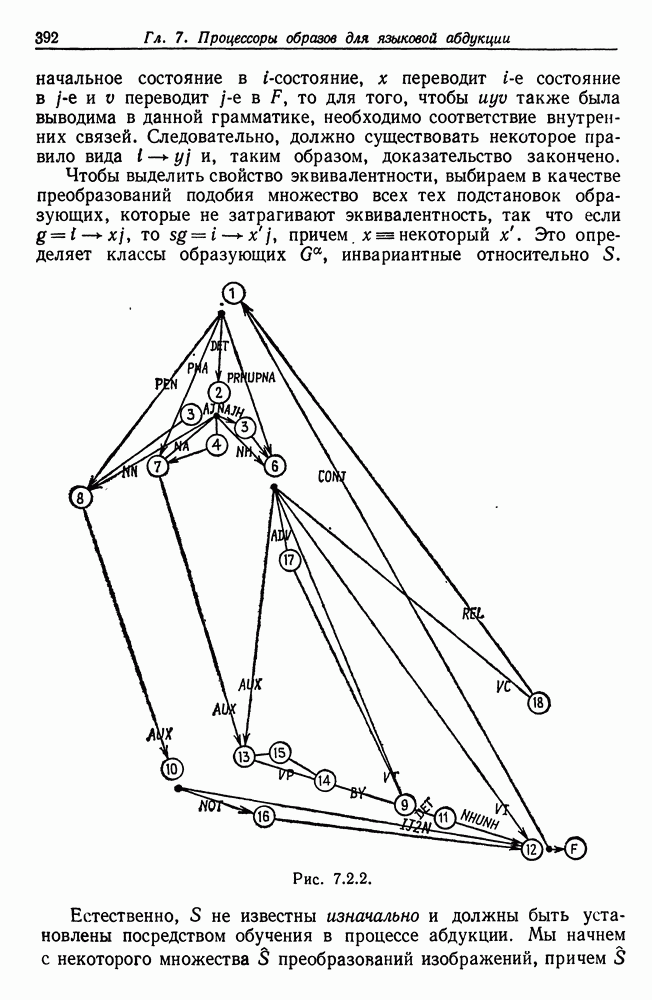
Тестовая грамматика  имеет 19 состояний, включая заключительное состояние
имеет 19 состояний, включая заключительное состояние  (см. рис. 7.2.2.) Это соответствует образующим, перечисленным в табл. 7.2.2, где, например,
(см. рис. 7.2.2.) Это соответствует образующим, перечисленным в табл. 7.2.2, где, например, 
Таблица 7.7.2 (см. скан)
7 на самом деле представляет два правила подстановки, так как класс слов  содержит два слова. В общем мы располагаем 87 правилами.
содержит два слова. В общем мы располагаем 87 правилами.
Программа порождает предложения языка  так, как эта описано в разд. 3.2 т. 1. Реализация, естественно, зависит от вероятностей, сопоставленных образующим. Многие предложения вполне разумны, например такие, как
так, как эта описано в разд. 3.2 т. 1. Реализация, естественно, зависит от вероятностей, сопоставленных образующим. Многие предложения вполне разумны, например такие, как  (Ему помогает мальчик),
(Ему помогает мальчик),  (Джон говорит),
(Джон говорит),  (Стол — не синий). Некоторые предложения имеют несколько сомнительный характер, скажем такие, как
(Стол — не синий). Некоторые предложения имеют несколько сомнительный характер, скажем такие, как  (Джон утверждает, что Джон поет) или
(Джон утверждает, что Джон поет) или  (Какой-нибудь ценный стол — не зеленый). Реже появляются совсем странные предложения, например
(Какой-нибудь ценный стол — не зеленый). Реже появляются совсем странные предложения, например  (Он утверждает, что мужчина утверждает, что женщине помогает собака) или
(Он утверждает, что мужчина утверждает, что женщине помогает собака) или  (Ей неистово нравится мальчик в та время, как он говорит). Можно также отметить, что некоторые превосходные на вид английские предложения, порожденные на основе заданного словаря терминалов, не допускаются
(Ей неистово нравится мальчик в та время, как он говорит). Можно также отметить, что некоторые превосходные на вид английские предложения, порожденные на основе заданного словаря терминалов, не допускаются  как,
как,
например,  (Роверу нравится девочка). В целом наша грамматика достаточно сложна.
(Роверу нравится девочка). В целом наша грамматика достаточно сложна.
Рассмотрим теперь четыре образующие вида  . Слова в классе
. Слова в классе  явно взаимно эквивалентны. Аналогичным образом четыре образующие типа
явно взаимно эквивалентны. Аналогичным образом четыре образующие типа  используют слова класса
используют слова класса  которые эквивалентны друг другу. Все эти восемь образующих переходят из состояния 11 в состояние 12, и может возникнуть искушение считать элементы класса
которые эквивалентны друг другу. Все эти восемь образующих переходят из состояния 11 в состояние 12, и может возникнуть искушение считать элементы класса  эквивалентными элементам класса
эквивалентными элементам класса  На самом деле это, однако, не так, поскольку лемма 7.2.1 указывает, что для этого необходимо наличие, например, для образующих
На самом деле это, однако, не так, поскольку лемма 7.2.1 указывает, что для этого необходимо наличие, например, для образующих  образующих вида
образующих вида  . Последние в
. Последние в  отсутствуют, и, следовательно, эквивалентность классов
отсутствуют, и, следовательно, эквивалентность классов  и
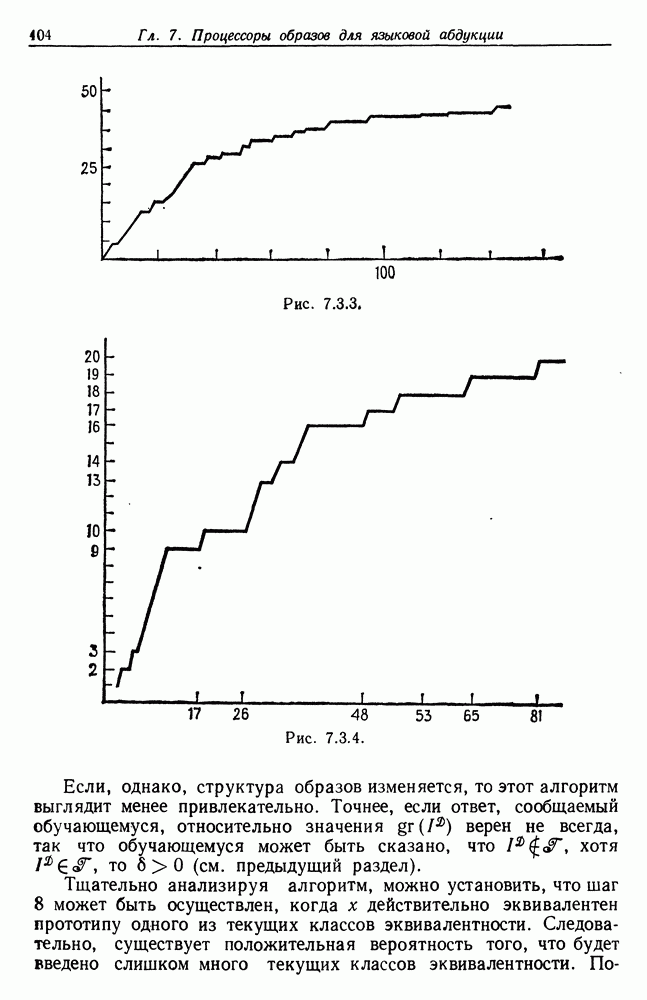
и  не имеет места; последнее приводит к существенным затруднениям, которые будут изучаться в следующем разделе.
не имеет места; последнее приводит к существенным затруднениям, которые будут изучаться в следующем разделе.