Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
6.5. Моделирование самоподобных случайных процессовИсследования реальных трафиков в цифровых сетях связи (Internet, Ethernet, Telnet и др.) показали, что они лучше всего описываются самоподобными случайными процессами. В данном параграфе рассмотрим некоторые из наиболее распространенных распределений, используемых при моделировании пульсирующих источников.
Одним из первых неэкспоненциальных распределений, которые были применены при моделировании сетевого трафика, является логнормальное распределение. Определение логнормального распределения основывается на нормальном распределении в виде функциональной зависимости
где
где
На основе известных значений
Генерировать логнормальные СВ
где Для моделирования размеров передаваемых файлов, типовых сообщений, Web-страниц часто используется распределение Парето, которое имеет следующий вид
где Известно, что ЭВМ позволяет генерировать равномерно
распределенные СВ
откуда
Таким образом, получаем следующее выражение для моделирования СВ с ПРВ Парето:
где
Параметр
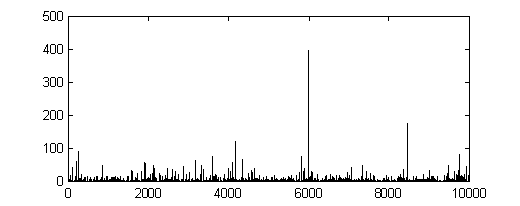
где Пример сгенерированной случайной последовательности с
параметрами
Рис. 6.5. Пример фрактальной случайной последовательности с ПРВ Парето Другим примером ПРВ для генерирования самоподобных трафиков является распределение Вейбулла, которое имеет следующий вид:
где
Существуют разные способы подбора
распределения Вейбулла: метод наименьших квадратов, метод моментов, оценка
максимального правдоподобия и др [6,7]. Однако наиболее простым и надежным
способом является метод максимального правдоподобия, при котором оценка
параметра
В свою очередь, оценка параметра
На основе вычисленных значений
трафика
Следует заметить, что если размер
буфера резко возрастает при уменьшении Зная средний объем использования буфера, по формуле Литтла можно определить среднее время нахождения единицы данных (байт, пакет, и т.д.) в буфере:
где
где
|
 |
Оглавление
|
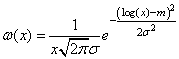 , при
, при 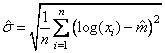 .
.
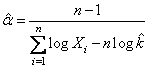 ,
,
 .
.
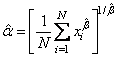 .
.
 ,
,