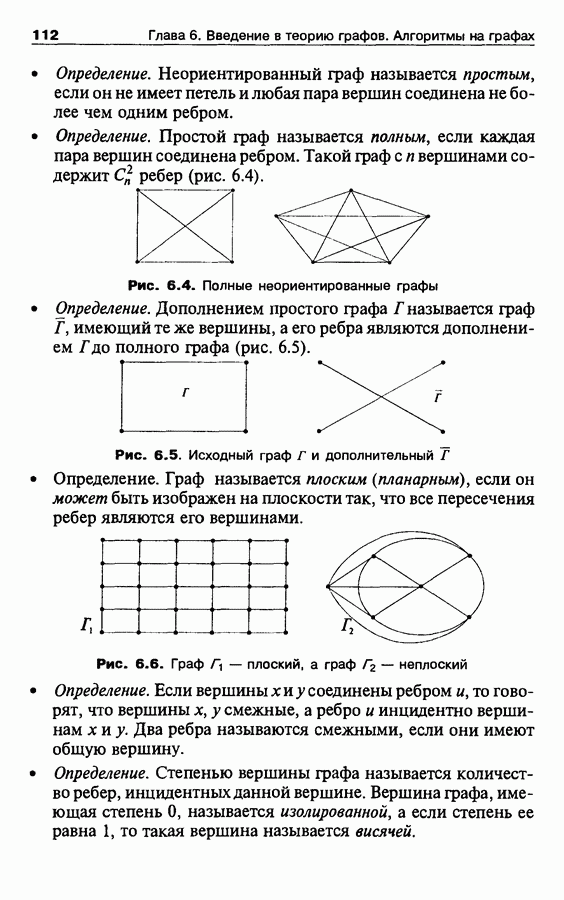
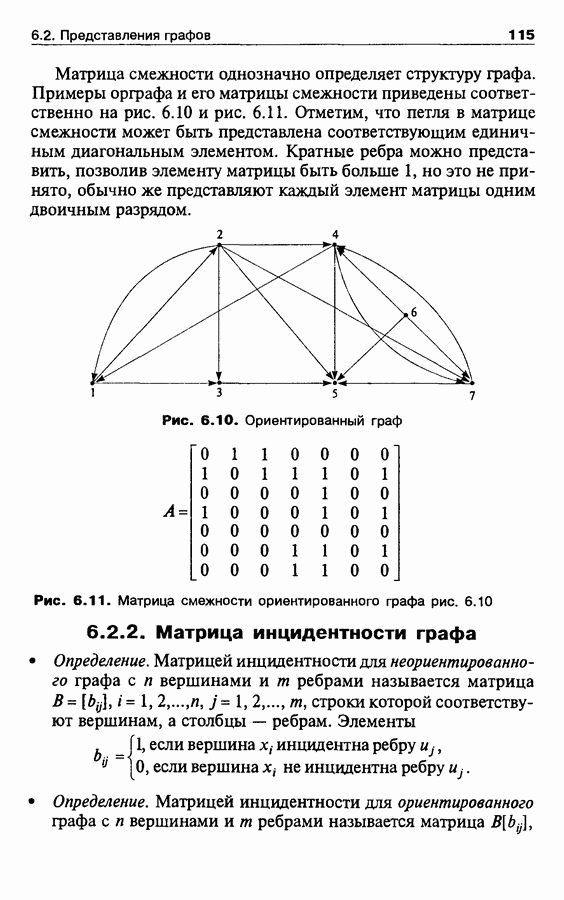
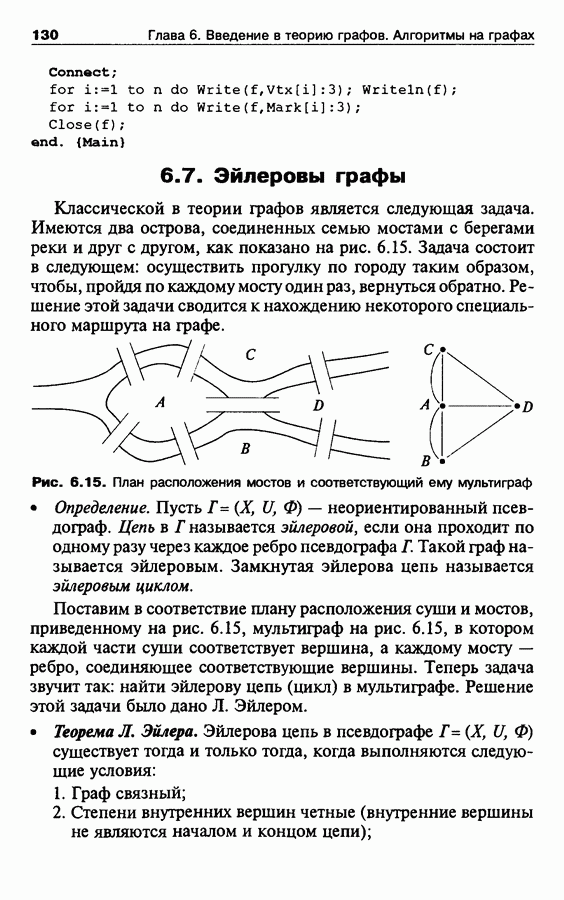
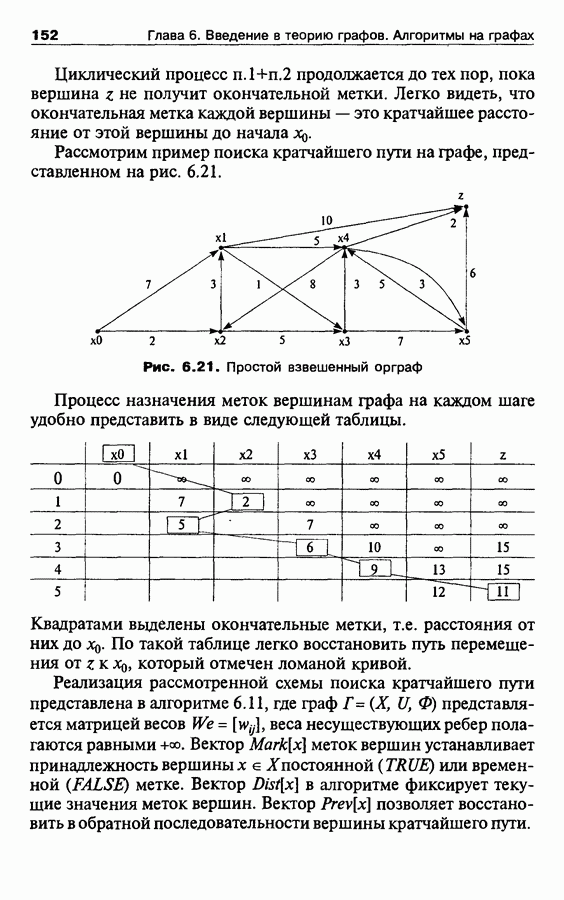
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
5.5. Последовательный поискЗадача поиска является фундаментальной в алгоритмах на дискретных структурах. Удивительно то, что, накладывая незначительные ограничения на структуру исходных данных, можно получить множество разнообразных стратегий поиска различной степени эффективности. При последовательном поиске подразумевается исследование элементов множества Алгоритм 5.7. Последовательный поиск (см. скан) Оценим среднюю сложность поиска элементов множества Рассмотрим распределение частот обращения к элементам в общем случае. Пусть Тогда Последний пример показывает, что даже простой последовательный поиск требует выбора разумной структуры данных множества, который бы повышал эффективность работы алгоритма. Более того, это общепринятая стратегия, время от времени переупорядочивать данные, для большинства последовательных файлов во внешней памяти, когда последовательная природа файла диктуется техническими характеристиками носителя информации. Алгоритм последовательного поиска данных одинаково эффективно выполняется при размещении множества
|
 |
Оглавление
|
















































































































































































































































































 в том порядке, в котором они встречаются. «Начни сначала и продвигайся, пока не найдешь нужный элемент; тогда остановись». Такая последовательная процедура является очевидным способом поиска. Алгоритм 5.7 выполняет последовательный поиск элемента z в множестве
в том порядке, в котором они встречаются. «Начни сначала и продвигайся, пока не найдешь нужный элемент; тогда остановись». Такая последовательная процедура является очевидным способом поиска. Алгоритм 5.7 выполняет последовательный поиск элемента z в множестве  Несмотря на свою простоту, последовательный поиск содержит ряд очень интересных идей.
Несмотря на свою простоту, последовательный поиск содержит ряд очень интересных идей.
 Для нахождения
Для нахождения  элемента
элемента  требуется
требуется  сравнений. Для вычисления же среднего времени поиска необходимо задать информацию о частоте обращения к каждому элементу множества. Будем предполагать, что частота обращения распределена равномерно, т.е. что ко всем элементам обращаются одинаково часто. Тогда средняя сложность поиска элемента множества является
сравнений. Для вычисления же среднего времени поиска необходимо задать информацию о частоте обращения к каждому элементу множества. Будем предполагать, что частота обращения распределена равномерно, т.е. что ко всем элементам обращаются одинаково часто. Тогда средняя сложность поиска элемента множества является  линеиной.
линеиной.
 обозначает частоту (распределение вероятностей) обращения к элементу
обозначает частоту (распределение вероятностей) обращения к элементу  где
где  В этом случае средняя сложность (математическое ожидание) поиска элемента будет равна
В этом случае средняя сложность (математическое ожидание) поиска элемента будет равна  Хорошим приближением распределения частот к действительности является закон Зипфа:
Хорошим приближением распределения частот к действительности является закон Зипфа:  для
для  Зипф заметил, что
Зипф заметил, что  наиболее употребительное в тексте на естественном языке слово встречается с частотой, приблизительно обратно пропорциональной
наиболее употребительное в тексте на естественном языке слово встречается с частотой, приблизительно обратно пропорциональной  Нормирующая константа выбирается так, что
Нормирующая константа выбирается так, что  Пусть элементы множества
Пусть элементы множества  упорядочены согласно указанным частотам.
упорядочены согласно указанным частотам.
 и среднее время успешного поиска составит
и среднее время успешного поиска составит  что много меньше
что много меньше 
 на смежной или связанной памяти.
на смежной или связанной памяти.