Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
3.3. Верхняя оценка вероятности ошибки декодированияПусть
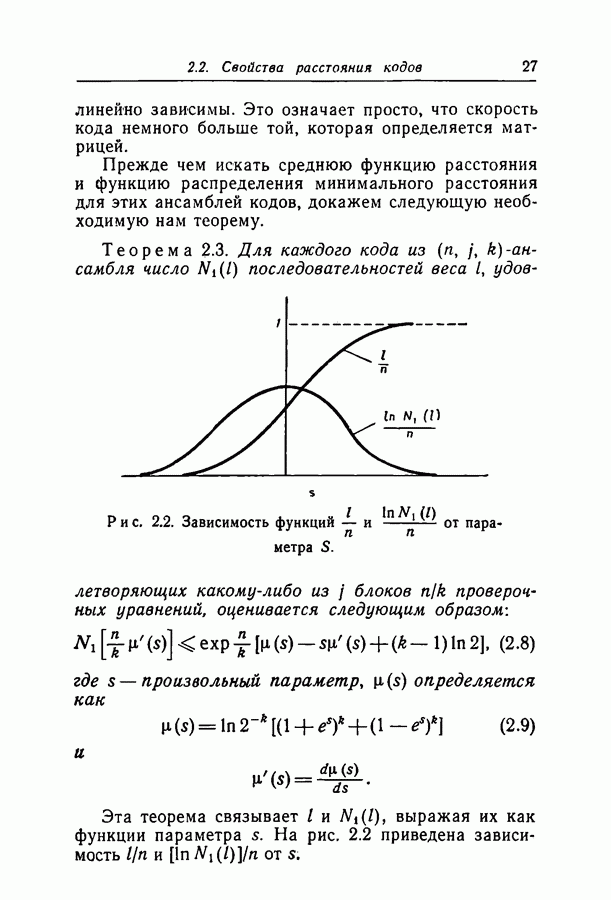
(кликните для просмотра скана) кодовые слова, где
для некоторого Вероятность ошибки декодирования можно, таким образом, оценить сверху вероятностью выполнения неравенства (3.2). С неравенством (3.2) легче иметь дело, если мы возьмем логарифмы от обеих его частей; при этом получается следующее неравенство для сумм случайных величин:
Кроме того, по причинам, обсуждаемым ниже, мы вычтем из обеих частей неравенства (3.2) некоторую произвольную функцию выхода
для некоторых
Определим теперь расстояние
Определим, кроме того, расстояние
Из соотношений (3.4), (3.6) и (3.7) нетрудно видеть, что ошибка декодирования происходит только тогда, когда
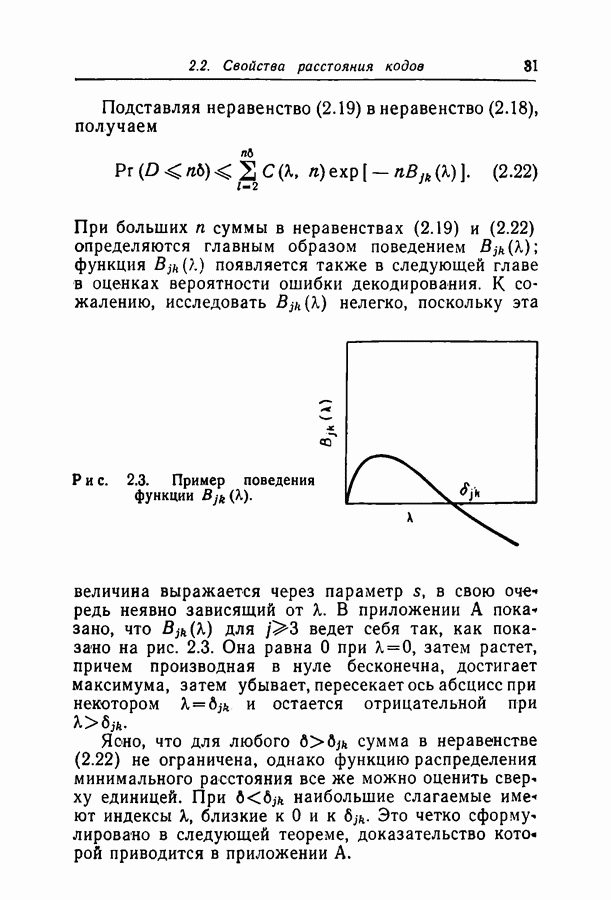
Наиболее очевидный метод упрощения неравенства (3.8) заключается в оценке сверху вероятности объединения событий суммой вероятностей событий. Это, однако, не дает хорошей оценки, поскольку в том случае, когда расстояние
где
Теперь мы можем отдельно оценить
Заметим, что неравенство (3.9) есть точное выражение для Заметим, наконец, что
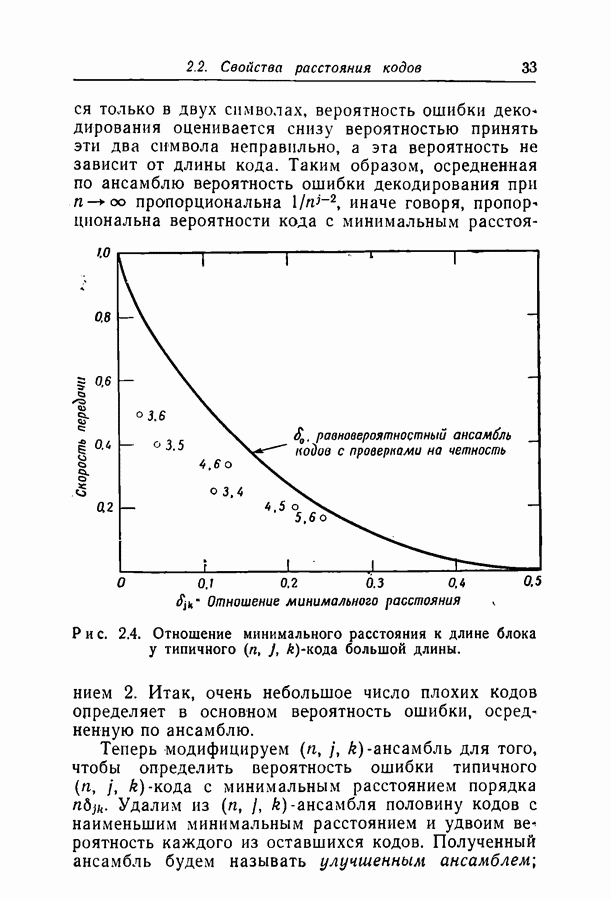
|
 |
Оглавление
|
































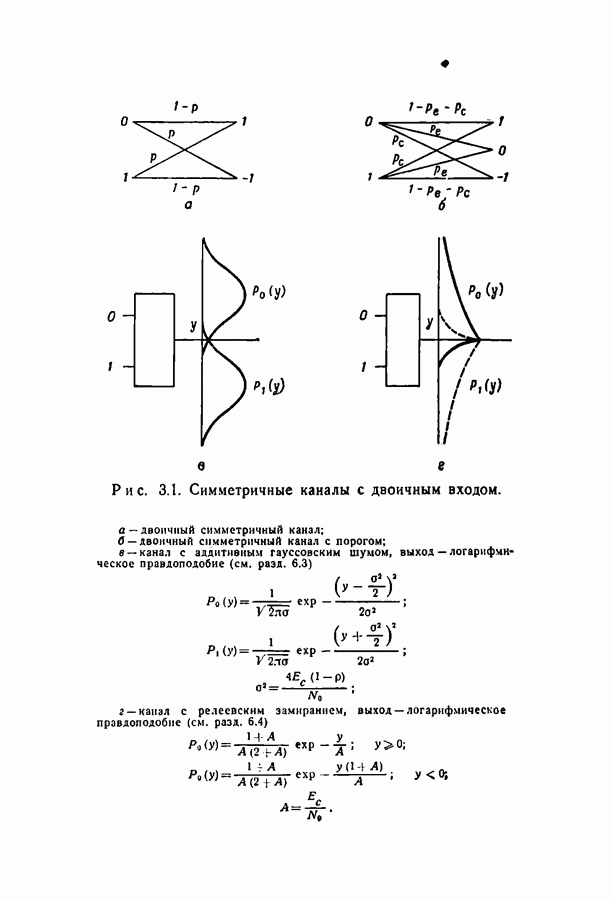













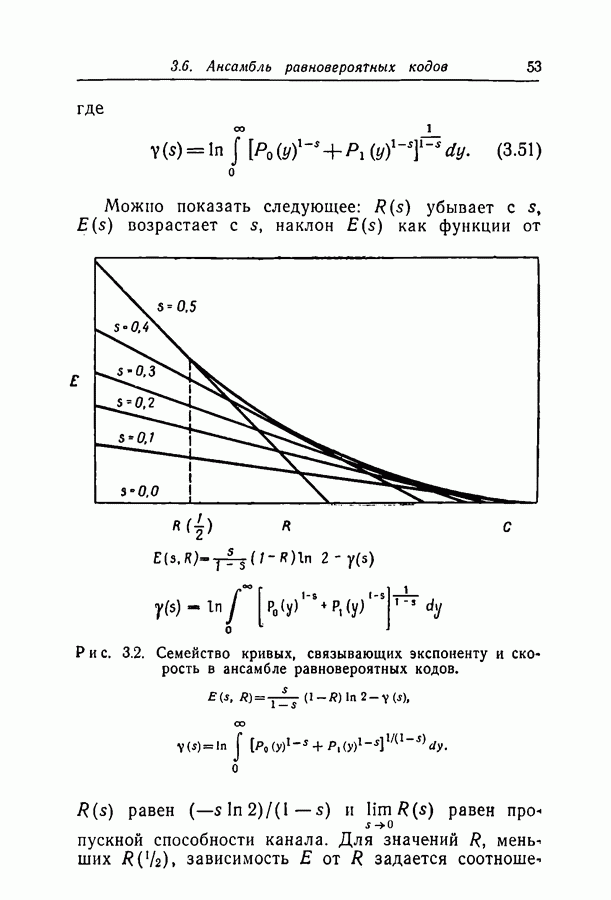


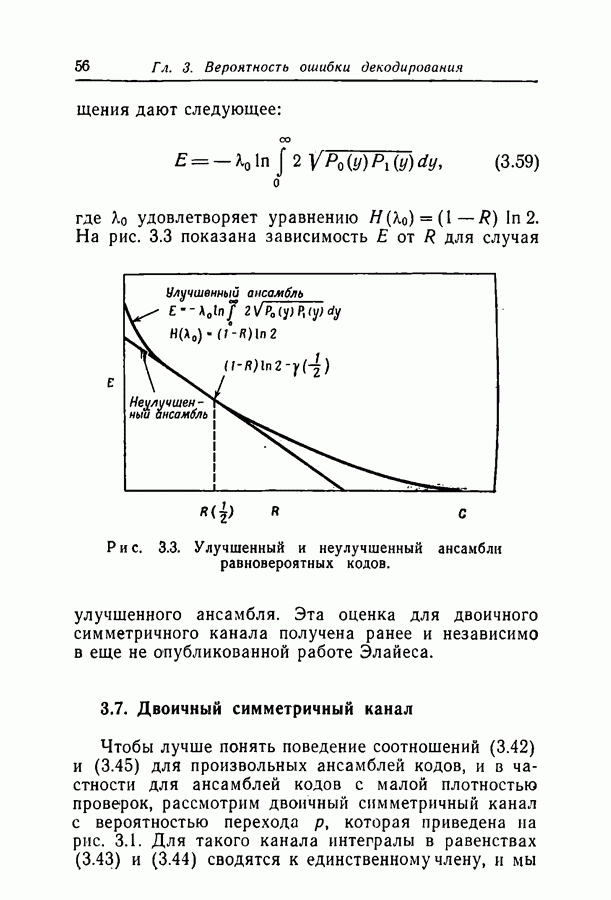

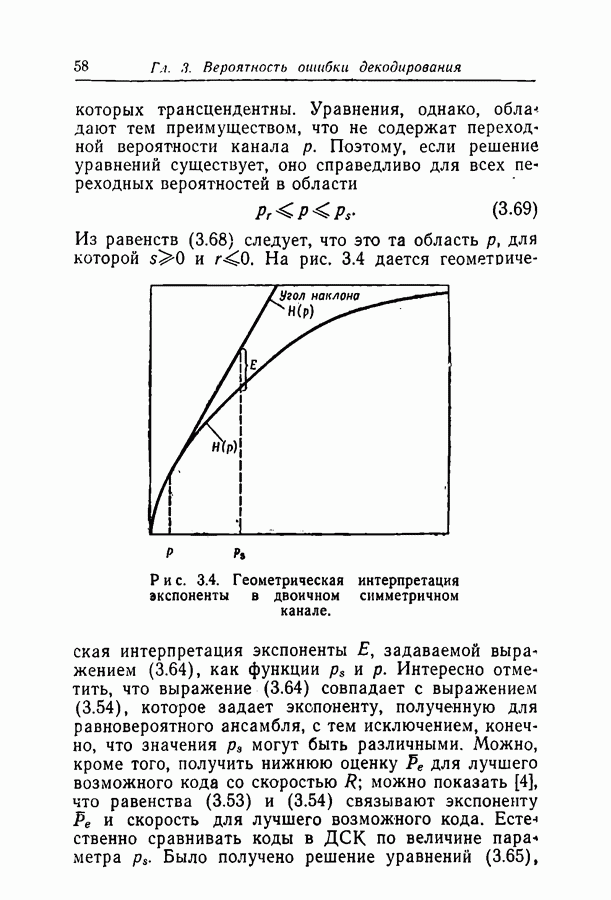
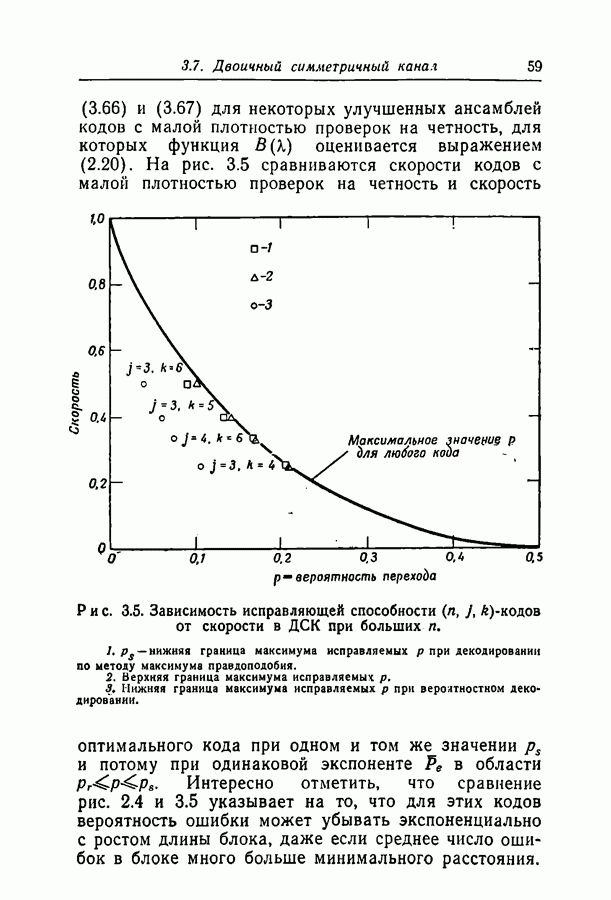




































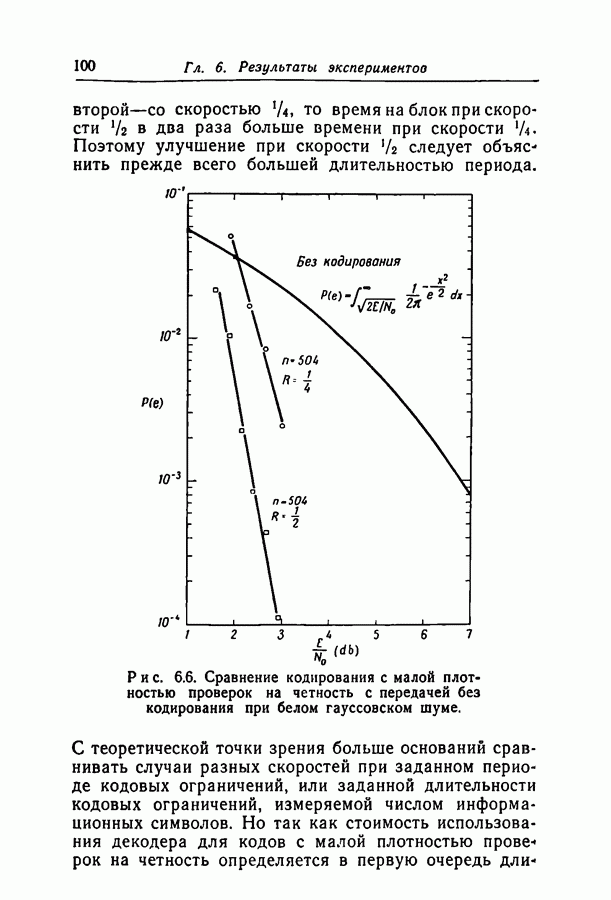
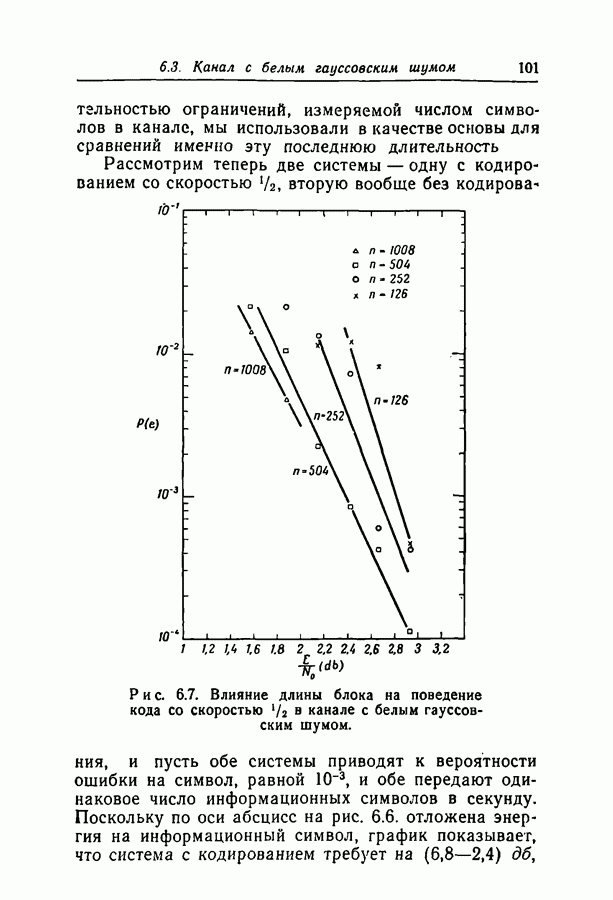
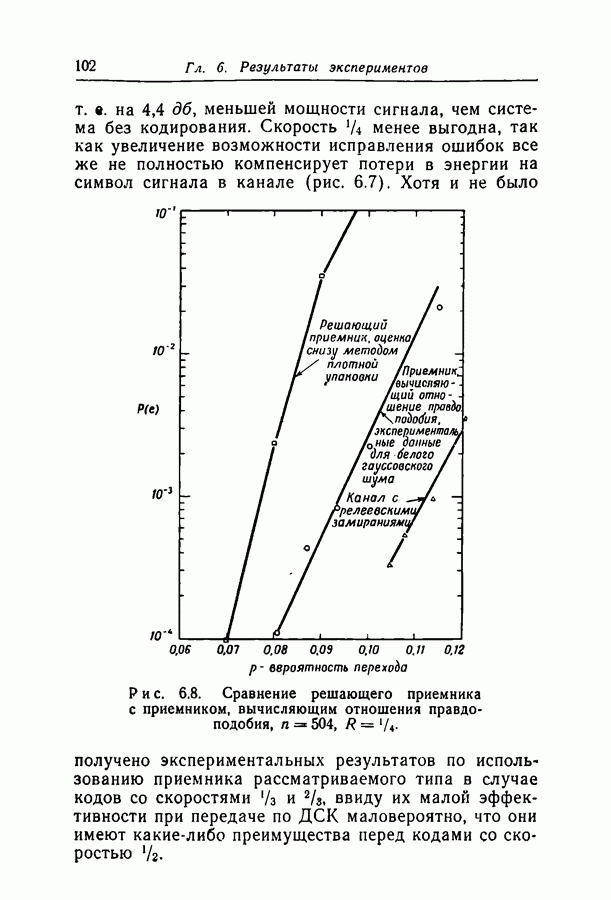


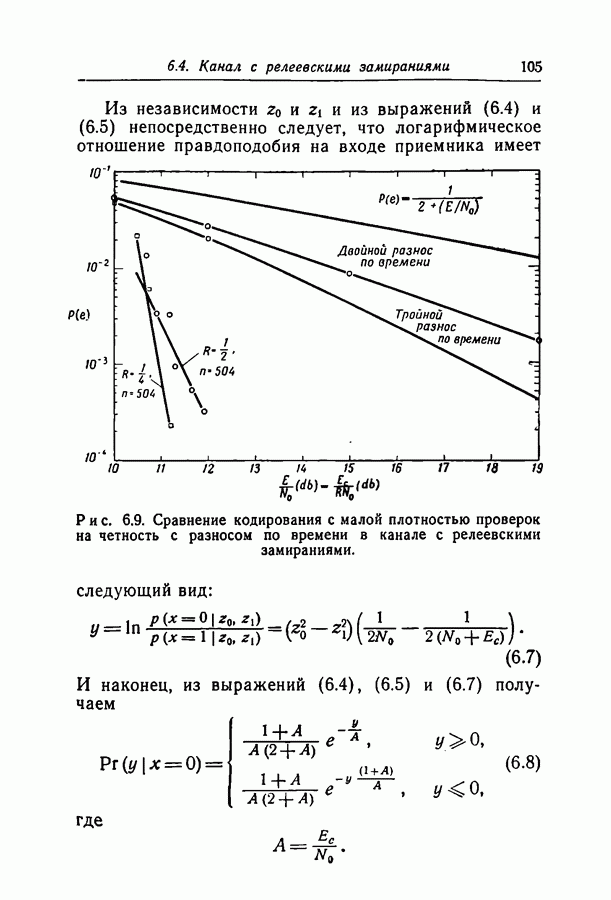


































 переданное кодовое слово,
переданное кодовое слово,  принятая последовательность. Пусть
принятая последовательность. Пусть  остальные
остальные

 Ошибка при декодировании по методу максимума правдоподобия происходит, если
Ошибка при декодировании по методу максимума правдоподобия происходит, если  для некоторого
для некоторого  Ошибка декодирования может также произойти при
Ошибка декодирования может также произойти при  Оценивая вероятность ошибки декодирования сверху, мы можем считать, что в таком случае всегда происходят ошибки. Основываясь на допущении о независимости
Оценивая вероятность ошибки декодирования сверху, мы можем считать, что в таком случае всегда происходят ошибки. Основываясь на допущении о независимости  использований канала, можно записать условие для того, чтобы имела место ошибка
использований канала, можно записать условие для того, чтобы имела место ошибка

 при
при  .
.

 и умножим обе части на —1, получая при этом следующее условие для того, чтобы имела место ошибка декодирования:
и умножим обе части на —1, получая при этом следующее условие для того, чтобы имела место ошибка декодирования:

 Наложим следующее ограничение на
Наложим следующее ограничение на  положительна, если положительна
положительна, если положительна  или
или  и
и

 между входом
между входом  и выходом
и выходом 

 между
между

 для некоторого
для некоторого  отличного от
отличного от  Точнее, вероятность ошибки декодирования
Точнее, вероятность ошибки декодирования  оценивается следующим образом:
оценивается следующим образом:
 событие, заключающееся в том, что
событие, заключающееся в том, что 
 очень велико, скажем больше некоторой соответствующим образом выбранной константы
очень велико, скажем больше некоторой соответствующим образом выбранной константы  весьма вероятно, что оно больше большинства величин
весьма вероятно, что оно больше большинства величин  поэтому ошибка декодирования учитывается в этой оценке много раз. Чтобы обойти эту трудность, мы будем отдельно оценивать события, для которых
поэтому ошибка декодирования учитывается в этой оценке много раз. Чтобы обойти эту трудность, мы будем отдельно оценивать события, для которых  Параметр
Параметр  произволен, и оптимизация по нему будет проведена позже. Разобьем неравенство (3.8) следующим образом:
произволен, и оптимизация по нему будет проведена позже. Разобьем неравенство (3.8) следующим образом:

 событие, заключающееся в том, что
событие, заключающееся в том, что 
 событие, заключающееся в том, что
событие, заключающееся в том, что 


 если не считать того, что мы приняли, что неопределенность (т. е. случай, когда
если не считать того, что мы приняли, что неопределенность (т. е. случай, когда  всегда вызывает ошибку. Таким образом, произвольность выбора
всегда вызывает ошибку. Таким образом, произвольность выбора  не оказывает влияния на неравенство (3.9), поскольку от этого выбора не зависит, какое слово декодируется, когда передано слово
не оказывает влияния на неравенство (3.9), поскольку от этого выбора не зависит, какое слово декодируется, когда передано слово  Однако выбор
Однако выбор  влияет на неравенства (3.10) и (3.11), поскольку эта функция определяет множество выходных последовательностей
влияет на неравенства (3.10) и (3.11), поскольку эта функция определяет множество выходных последовательностей  для которых
для которых 
 определены в равенстве (3.7) как суммы случайных величии, поэтому задача оценки
определены в равенстве (3.7) как суммы случайных величии, поэтому задача оценки  сведена с помощью неравенств (3.10) и (3.11) к задаче оценки хвостов распределений сумм случайных величин. Это лучше всего делается с помощью оценок по методу Чернова, краткое изложение которого можно найти в приложении В. Более подробно они даны в работе Фано
сведена с помощью неравенств (3.10) и (3.11) к задаче оценки хвостов распределений сумм случайных величин. Это лучше всего делается с помощью оценок по методу Чернова, краткое изложение которого можно найти в приложении В. Более подробно они даны в работе Фано 