Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
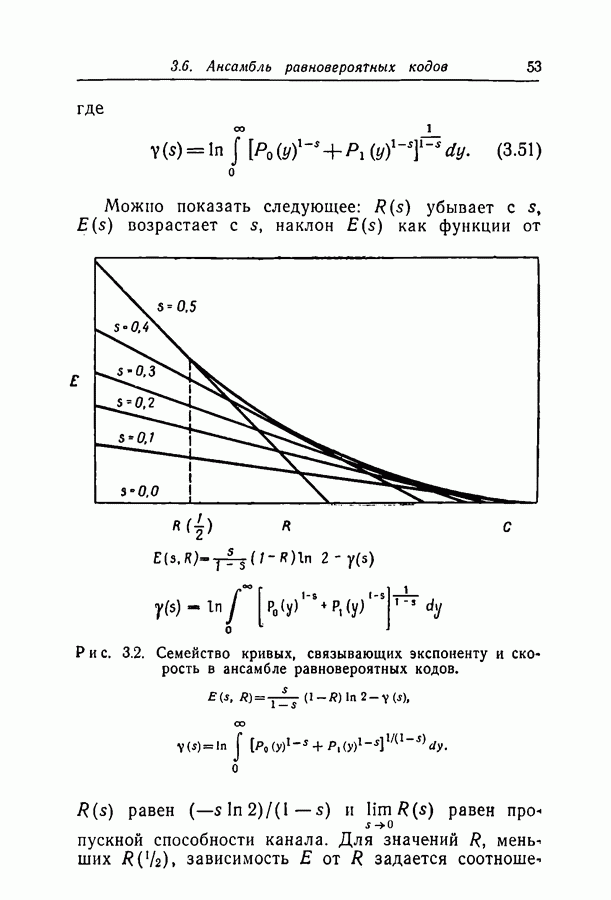
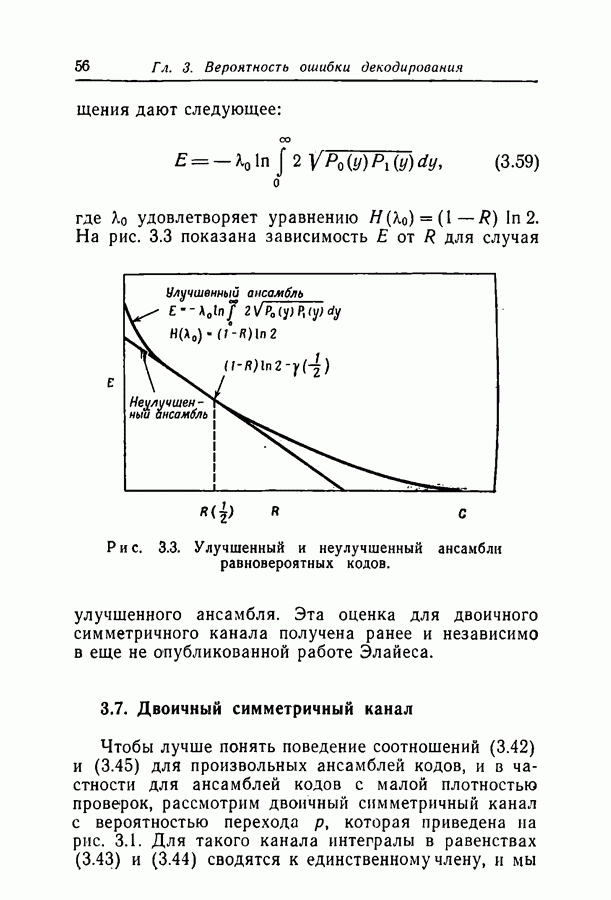
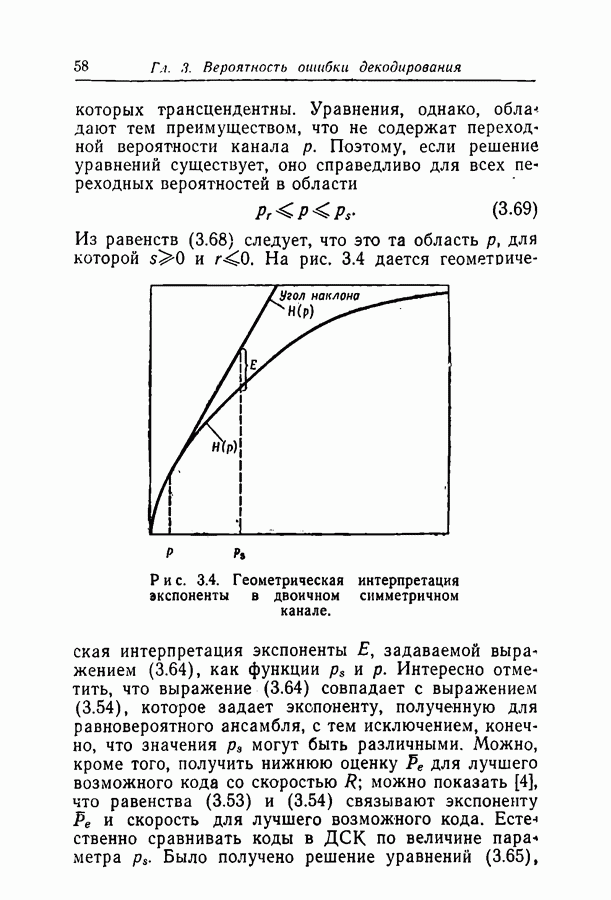
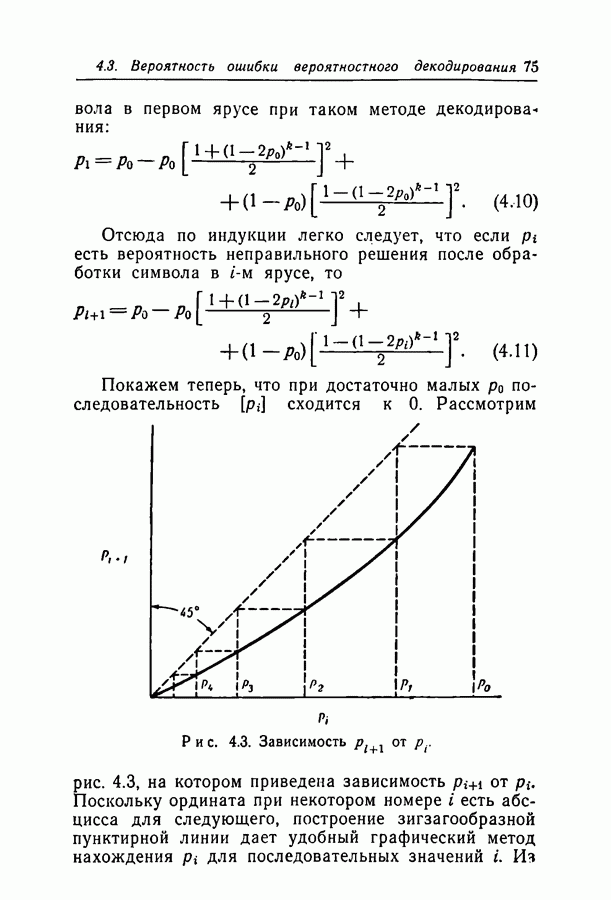
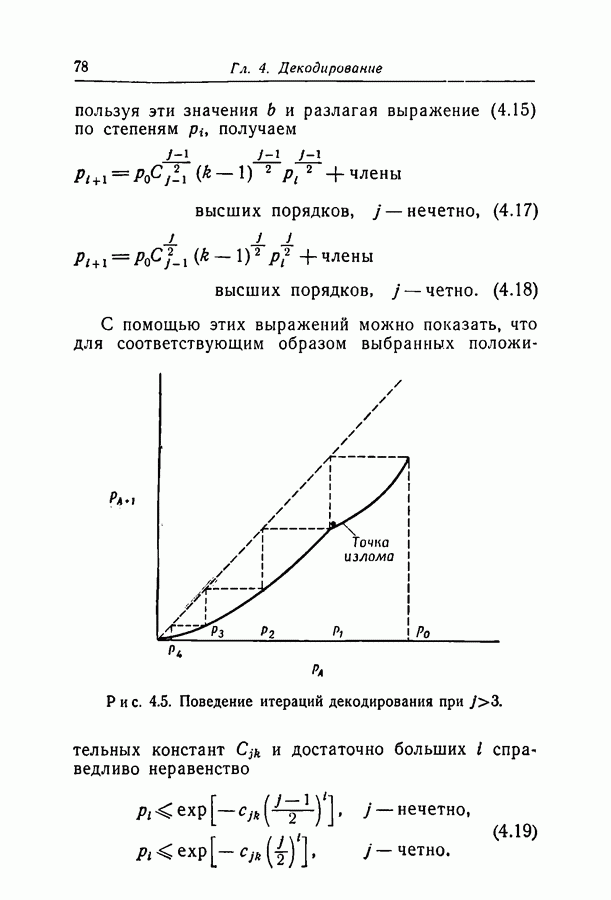
Глава 4. ДЕКОДИРОВАНИЕ4.1. ВведениеВ гл. 3 исследовалась вероятность ошибки декодирования Здесь мы опишем два метода декодирования, для которых достигается, по-видимому, разумный компромисс между сложностью метода и вероятностью ошибки декодирования. Первый метод особенно прост, но применим только в ДСК и при скоростях, много меньших пропускной способности. Второй метод, основанный на декодировании непосредственно по апостериорным вероятностям на выходе канала, обладает большими возможностями; однако его легче понять после знакомства с первым. По первому методу декодер вычисляет все проверки на четность и затем изменяет все символы, со держащиеся больше чем в некотором фиксированном числе неудовлетворившихся проверочных соотношений. Проверки на четность вычисляются снова с использованием новых значений символов, и весь процесс повторяется до тех пор, пока не будут удовлетворены все проверочные уравнения. Такой метод декодирования естествен, если проверочные множества невелики, поскольку их большинство либо содержит один символ, искаженный передачей, либо не содержит таких символов.
Рис. 4.1. Дерево Таким образом, если большинство проверочных соотношений, проверяющих некоторый символ, оказываются неудовлетворенными, то это почти определенно указывает на то, что этот символ ошибочен. Пусть, например, при передаче исказился первый символ кода, приведенного на рис. 2.1. Тогда 1, 6 и 11 проверочные соотношения окажутся нарушенными и все три соотношения, проверяющие первый символ, не будут удовлетворены. С другой стороны, окажется неудовлетворенным не больше чем одно из трех уравнений, проверяющих любой другой символ блока. Для того чтобы показать, как может быть исправлен некоторый символ корнем дерева, а каждая линия, выходящая из корня, представляет собой содержащее его проверочное множество. Все остальные символы, содержащиеся в этих проверочных множествах, представлены узлами первого яруса дерева. Линии, идущие от первого яруса ко второму, представляют собой другие проверочные множества, содержащие символы первого яруса, а узлы второго яруса представляют собой оставшиеся символы этих проверочных множеств. Заметим, что при построении следующих ярусов дерева один и тот же символ может появиться больше одного раза; такое положение мы рассмотрим в разд. 4.2. Допустим теперь, что при передаче были искажены символ Итак, при декодировании некоторого символа могут оказаться полезными символы и проверочные соотношения, на первый взгляд никак не связанные с ним. Описываемый ниже вероятностный метод декодирования использует эти дополнительные символы и проверочные соотношения более систематическим образом.
|
 |
Оглавление
|
































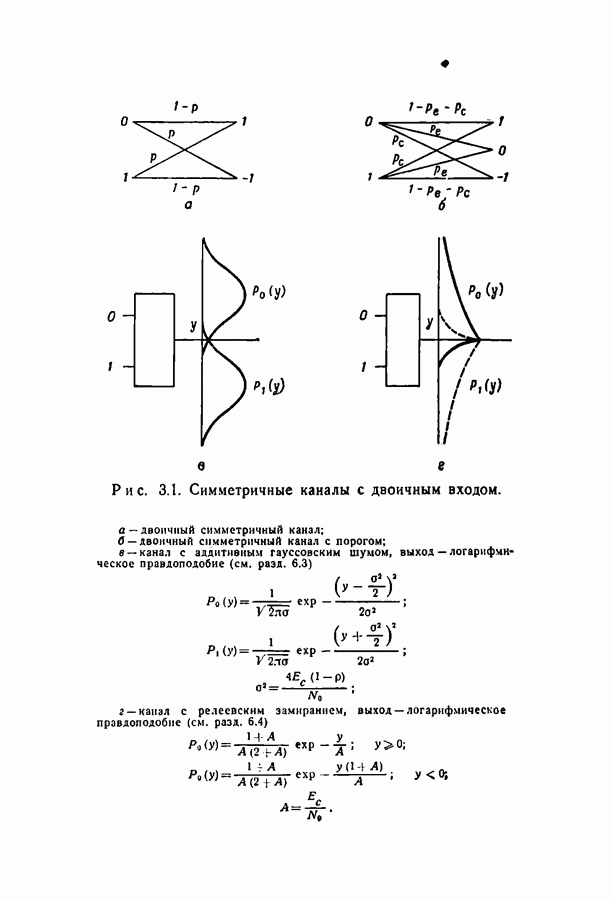
















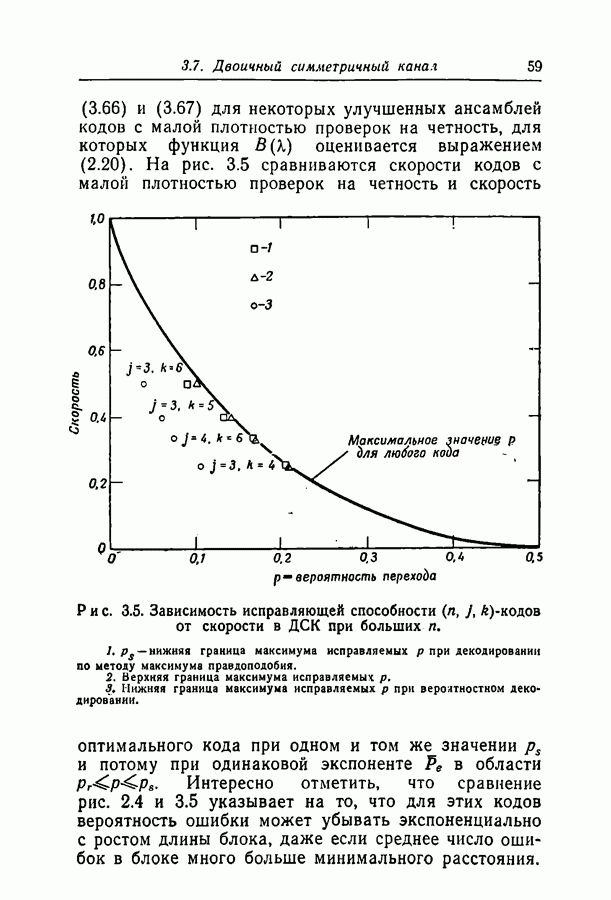


































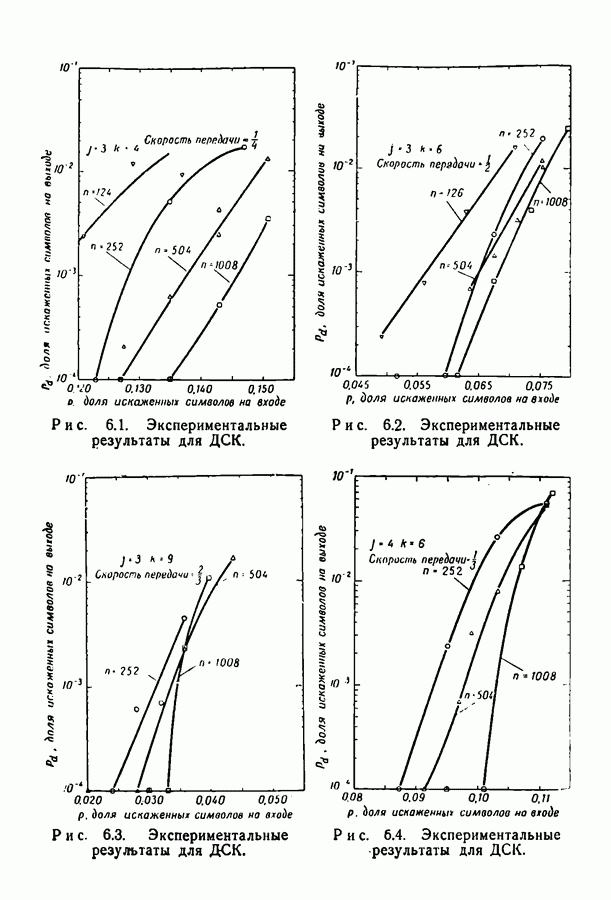
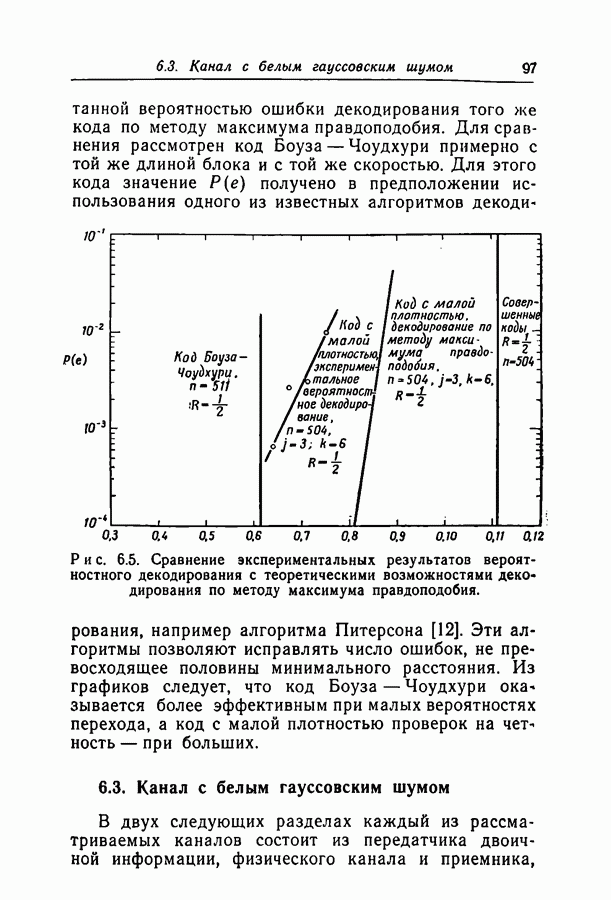






































 -кодов в различных каналах с двоичным входом при декодировании по максимуму правдоподобия. Этот метод декодирования удобен, так как он минимизирует вероятность ошибки и таким образом позволяет измерить эффективность кода вне зависимости от метода декодирования. Однако практическое применение декодера, работающего по максимуму правдоподобия и действительно сравнивающего принятую последовательность со всеми кодовыми словами, выглядит не очень заманчиво. Это особенно справедливо при большой длине блока, поскольку объем кодового словаря растет экспоненциально с ростом длины блока. Было бы лучше иметь сравнительно простой (в смысле конструкции, объема памяти и числа операций) декодер, даже если он несколько увеличивает вероятность ошибки. Если же требуется меньшая вероятность ошибки, можно просто увеличить длину кодового блока.
-кодов в различных каналах с двоичным входом при декодировании по максимуму правдоподобия. Этот метод декодирования удобен, так как он минимизирует вероятность ошибки и таким образом позволяет измерить эффективность кода вне зависимости от метода декодирования. Однако практическое применение декодера, работающего по максимуму правдоподобия и действительно сравнивающего принятую последовательность со всеми кодовыми словами, выглядит не очень заманчиво. Это особенно справедливо при большой длине блока, поскольку объем кодового словаря растет экспоненциально с ростом длины блока. Было бы лучше иметь сравнительно простой (в смысле конструкции, объема памяти и числа операций) декодер, даже если он несколько увеличивает вероятность ошибки. Если же требуется меньшая вероятность ошибки, можно просто увеличить длину кодового блока.

 проверочных множеств.
проверочных множеств.
 даже в том случае, когда его проверочное множество содержит больше одного искаженного символа, рассмотрим древовидную структуру, приведенную на рис. 4.1. Символ
даже в том случае, когда его проверочное множество содержит больше одного искаженного символа, рассмотрим древовидную структуру, приведенную на рис. 4.1. Символ  представлен
представлен
 и несколько символов первого яруса. Тогда на первом эташе декодирования неискаженные символы второго яруса и их проверочные соотношения позволяют иоправить ошибки в первом ярусе. А это в свою очередь позволяет исправить символ
и несколько символов первого яруса. Тогда на первом эташе декодирования неискаженные символы второго яруса и их проверочные соотношения позволяют иоправить ошибки в первом ярусе. А это в свою очередь позволяет исправить символ  на втором этапе декодирования.
на втором этапе декодирования.