Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
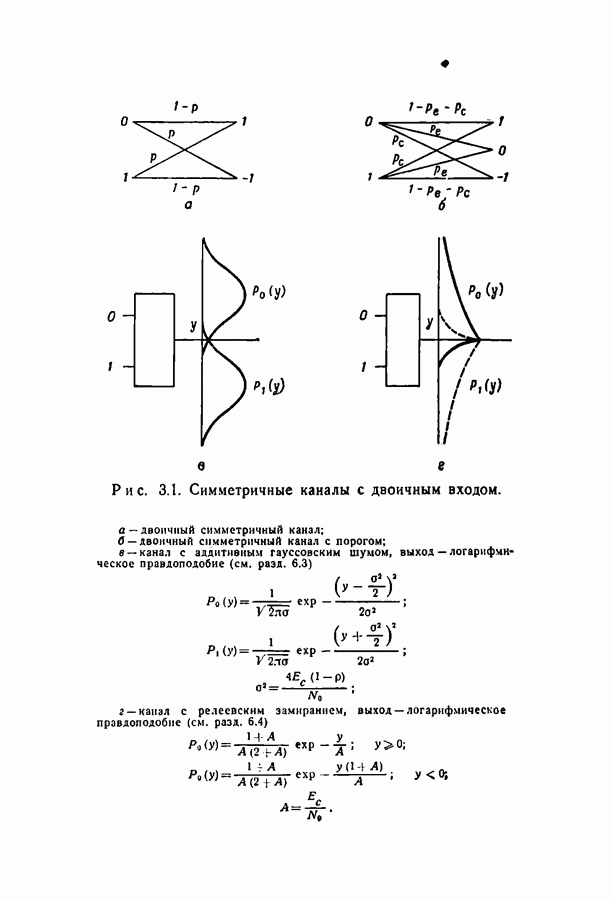
4.3. Вероятность ошибки при использовании метода вероятностного декодированияЗадача математического анализа вероятностного декодирования трудна, однако можно легко получить одну очень слабую оценку вероятности ошибки. Рассмотрим ДСК с вероятностью перехода Модифицируем метод декодирования следующим образом. Если не удовлетворены обе проверки, соответствующие ветвям, выходящим из символа первого яруса, инвертируем этот символ; проделаем то же во втором ярусе, используя измененные символы, и т. д. вплоть до символа Вероятность ошибки декодирования символа Найдем теперь вероятность того, что использование модифицированного метода приведет к неправильному решению относительно символа в первом ярусе. Если принятый символ искажен (вероятность такого события равна
Поскольку ошибка исправляется только в том случае, когда не удовлетворены оба проверочных соотношения, содержащие символ, получим следующее выражение для вероятности того, что символ принят с ошибкой, а затем исправлен:
Аналогичные рассуждения приводят к следующему выражению для вероятности того, что символ в первом ярусе был принят правильно, но затем был изменен из-за неудовлетворенных проверочных соотношений:
Объединяя выражения (4.8) и (4.9), получаем вероятность неправильного решения относительно символа в первом ярусе при таком методе декодирования:
Отсюда по индукции легко следует, что если
Покажем теперь, что при достаточно малых
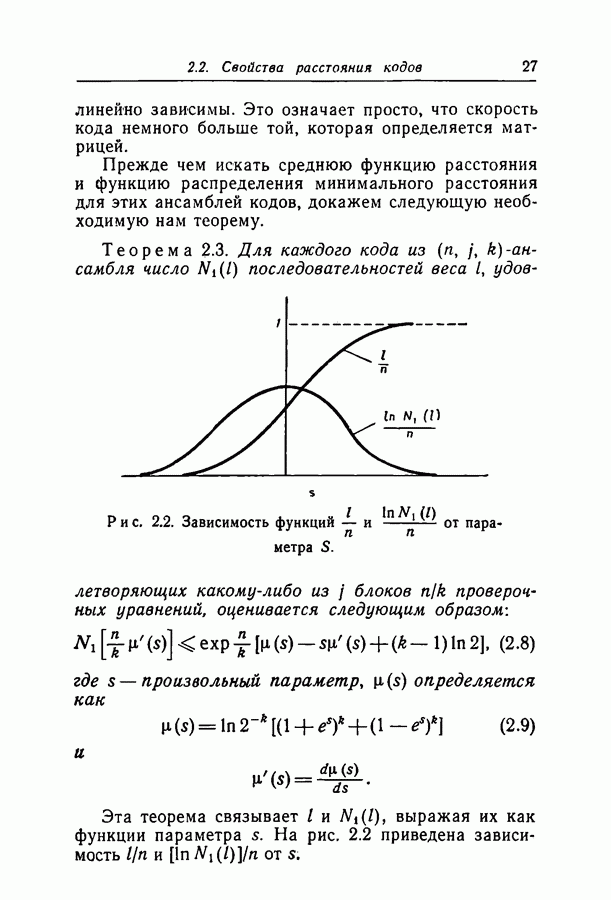
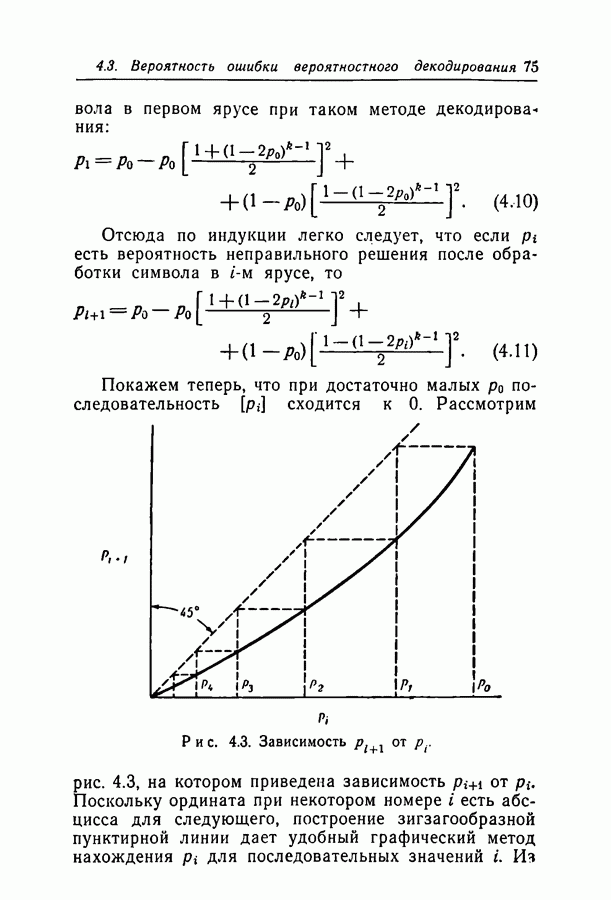
Рис. 4.3. Зависимость Рассмотрим рис. 4.3, на котором приведена зависимость рис. 4.3 можно видеть, что если
то последовательность
Рис. 4.4. Максимальные значения Скорость, с которой
А отсюда для достаточно больших
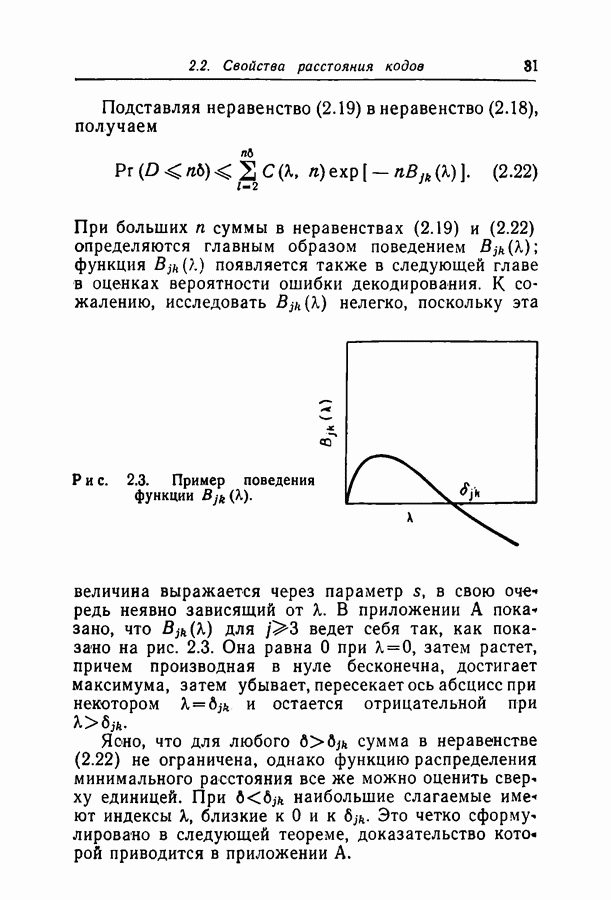
где С — константа, не зависящая от Подобные же рассуждения можно провести и в случае кодов, в которых число проверочных множеств на символ больше трех. Более сильный результат можно получить, если инвертировать символ всякий раз, когда не удовлетворено большее чем некоторое целое число
Теперь можно выбрать целое
Из этого неравенства видно, что Доказательство того, что вероятность ошибки декодирования стремится к нулю с увеличением числа итераций при достаточно малых значениях вероятности перехода, остается прежним. Однако асимптотическое поведение последовательности Используя эти значения
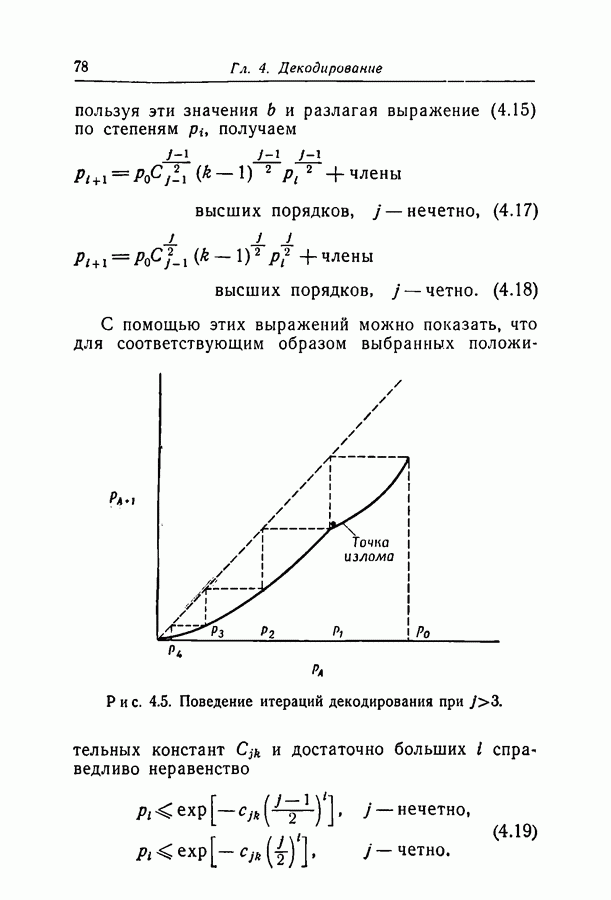
Рис. 4.5. Поведение итераций декодирования при С помощью этих выражений можно показать, что для соответствующим образом выбранных положительных констант
Интересно связать этот результат с длиной кодового блока. В m-м ярусе дерева всего
Объединяя неравенства (4.19) и (4.20), получаем оценку вероятности ошибки декодирования кода, удовлетворяющего условиям (4.20):
При
раз больше, вероятность ошибки декодирования убывала бы экспоненциально с Другой способ оценки вероятностного метода декодирования состоит в вычислении распределения вероятностей логарифмических отношений правдоподобий для ряда итераций. Такой подход позволяет выяснить, можно ли с помощью кода с фиксированными
|
 |
Оглавление
|
























































































































 и будем сначала исследовать
и будем сначала исследовать  -код с
-код с  в котором каждый символ содержится в трех проверочных множествах. Рассмотрим дерево проверочных множеств — такое, как приведенное на рис. 4.1 и содержащее
в котором каждый символ содержится в трех проверочных множествах. Рассмотрим дерево проверочных множеств — такое, как приведенное на рис. 4.1 и содержащее  независимых ярусов, но перенумеруем ярусы сверху вниз, так что самый верхний ярус станет нулевым, а декодируемый символ окажется
независимых ярусов, но перенумеруем ярусы сверху вниз, так что самый верхний ярус станет нулевым, а декодируемый символ окажется  ярусом.
ярусом.

 после проведения такого процесса служит оценкой сверху вероятности неправильного решения после
после проведения такого процесса служит оценкой сверху вероятности неправильного решения после  итераций в вероятностной схеме декодирования. В обоих методах решение принимается только по принятым символам в
итераций в вероятностной схеме декодирования. В обоих методах решение принимается только по принятым символам в  -ярусном дереве, однако метод вероятностного декодирования всегда дает наиболее достоверное решение на основе имеющейся информации.
-ярусном дереве, однако метод вероятностного декодирования всегда дает наиболее достоверное решение на основе имеющейся информации.
 проверочные соотношения, включающие этот символ, не будут удовлетворены тогда и только тогда, когда будет искажено четное число (включая и нуль) среди остальных
проверочные соотношения, включающие этот символ, не будут удовлетворены тогда и только тогда, когда будет искажено четное число (включая и нуль) среди остальных  символов проверочного множества. По лемме 4.1 вероятность четного числа ошибок в
символов проверочного множества. По лемме 4.1 вероятность четного числа ошибок в  символах равна
символах равна




 есть вероятность неправильного решения после обработки символа в
есть вероятность неправильного решения после обработки символа в  ярусе, то
ярусе, то

 последовательность
последовательность  сходится к 0.
сходится к 0.

 от
от 
 от
от  Поскольку ордината при некотором номере
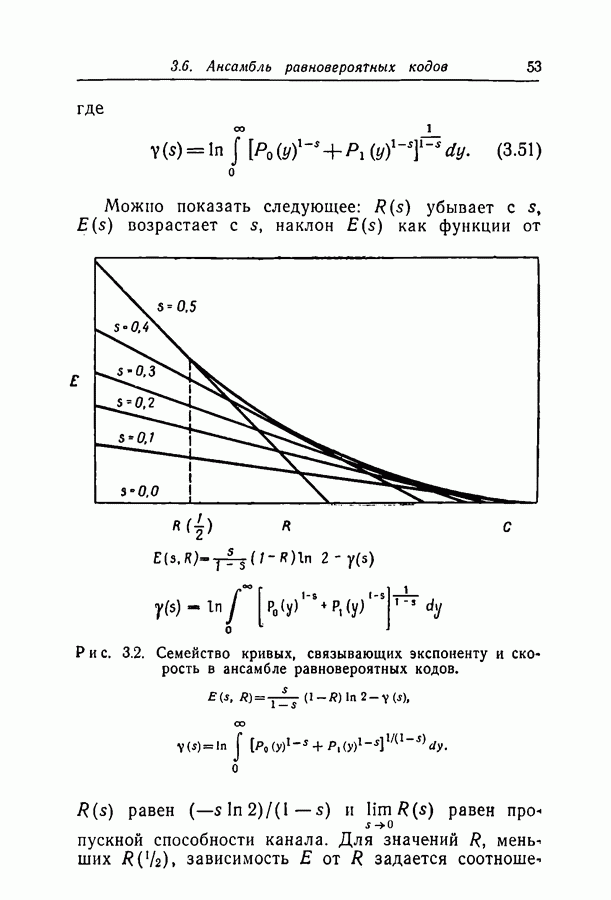
Поскольку ордината при некотором номере  есть абсцисса для следующего, построение зигзагообразной пунктирной линии дает удобный графический метод нахождения
есть абсцисса для следующего, построение зигзагообразной пунктирной линии дает удобный графический метод нахождения  для последовательных значений
для последовательных значений  Из
Из

 Из равенства (4.11) видно, что неравенство в (4.12) выполняется при достаточно малых
Из равенства (4.11) видно, что неравенство в (4.12) выполняется при достаточно малых  На рис. 4.4 приведены макси» мальные значения
На рис. 4.4 приведены макси» мальные значения  для нескольких значений
для нескольких значений 

 при которых слабая оценка сходится.
при которых слабая оценка сходится.
 стремится к нулю, можно определить, заметив, что из равенства (4.11) для малых
стремится к нулю, можно определить, заметив, что из равенства (4.11) для малых  следует, что
следует, что



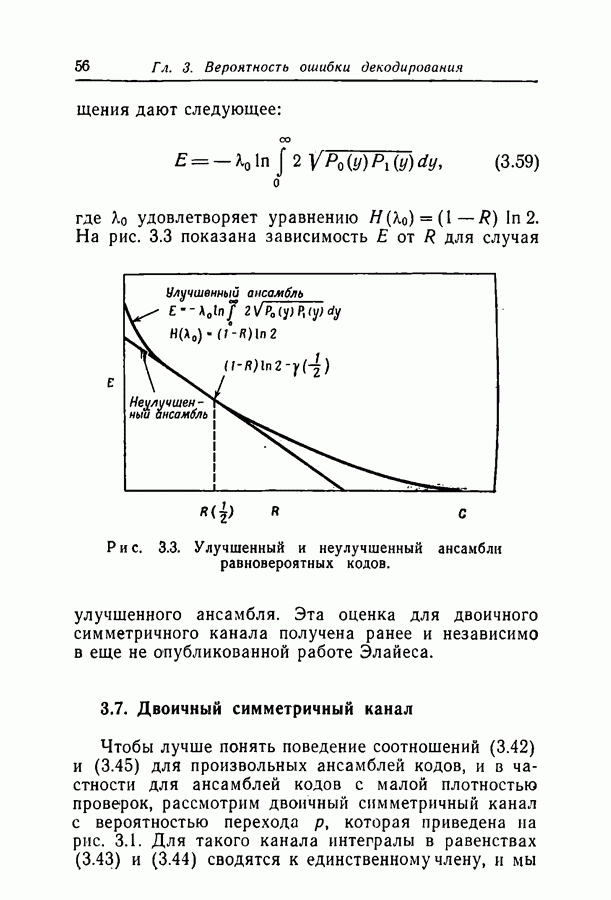
 Поскольку число независимых итераций в дереве растет логарифмически с длиной блока, эта оценка вероятности ошибки декодирования стремится к нулю как малая отрицательная степень длины блока. Столь медленная сходимость к нулю, по-видимому, вызвана модификацией метода декодирования и требованием полной независимости и не присуща вероятностному декодированию в целом.
Поскольку число независимых итераций в дереве растет логарифмически с длиной блока, эта оценка вероятности ошибки декодирования стремится к нулю как малая отрицательная степень длины блока. Столь медленная сходимость к нулю, по-видимому, вызвана модификацией метода декодирования и требованием полной независимости и не присуща вероятностному декодированию в целом.
 проверочных соотношений, содержащих этот символ; величину
проверочных соотношений, содержащих этот символ; величину  мы установим ниже. Пользуясь таким критерием и рассуждая так же, как и при выводе равенства (4.11), получим
мы установим ниже. Пользуясь таким критерием и рассуждая так же, как и при выводе равенства (4.11), получим

 так, чтобы минимизировать
так, чтобы минимизировать  Решением будет наименьшее целое
Решением будет наименьшее целое  для которого
для которого

 уменьшается с уменьшением
уменьшается с уменьшением  На рис. 4.5 приведена зависимость
На рис. 4.5 приведена зависимость  от
от  с учетом того, что
с учетом того, что  выбрано меняющимся в соответствии с условием (4.16). Точка излома отвечает изменению
выбрано меняющимся в соответствии с условием (4.16). Точка излома отвечает изменению 
 при стремлении к нулю меняется. Из неравенства (4.16) следует, что
при стремлении к нулю меняется. Из неравенства (4.16) следует, что  для достаточно малых
для достаточно малых  принимает значение
принимает значение  при четном
при четном  при нечетном
при нечетном  .
.
 и разлагая выражение (4.15) по степеням
и разлагая выражение (4.15) по степеням  получаем
получаем



 и достаточно больших
и достаточно больших  справедливо неравенство
справедливо неравенство

 символов;
символов;  должно быть не меньше этой величины, что и дает нам левую часть соотношения (4.20). С другой стороны, в приложении В приводится специальный метод построения кодов, для которых выполняется правое неравенство в соотношении (4.20)
должно быть не меньше этой величины, что и дает нам левую часть соотношения (4.20). С другой стороны, в приложении В приводится специальный метод построения кодов, для которых выполняется правое неравенство в соотношении (4.20)


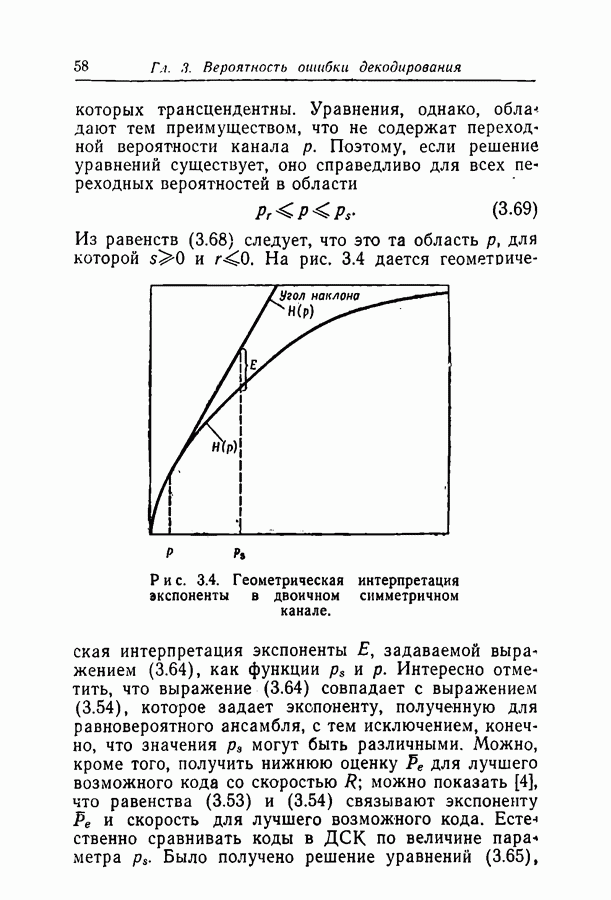
 эта оценка вероятности ошибки декодирования убывает экспоненциально с корнем из
эта оценка вероятности ошибки декодирования убывает экспоненциально с корнем из  Заметим, что если бы число итераций
Заметим, что если бы число итераций  выполняемых без возникновения зависимостей, было в
выполняемых без возникновения зависимостей, было в

 Существует гипотеза о том, что итерирование после проявления зависимостей в вероятностной схеме декодирования даст такую экспоненциальную оценку.
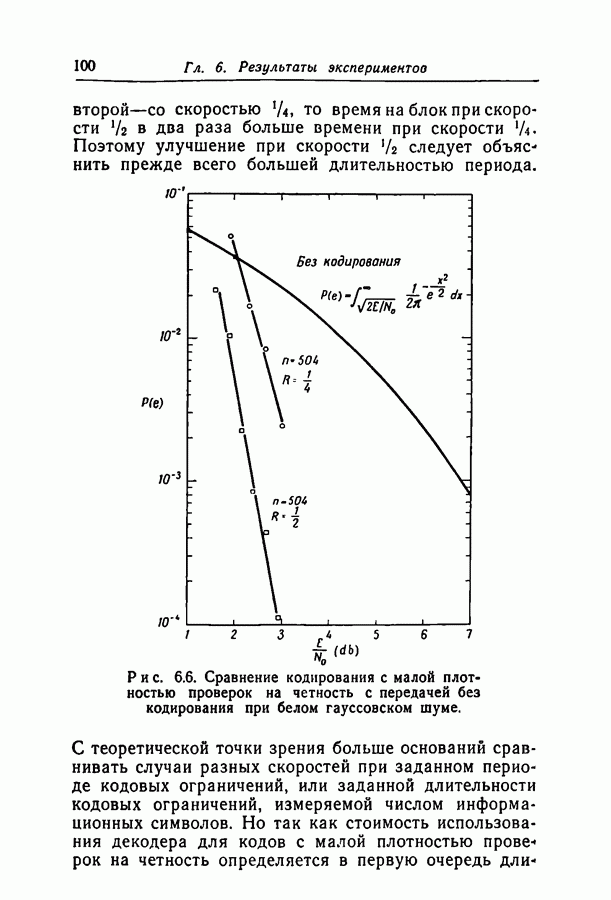
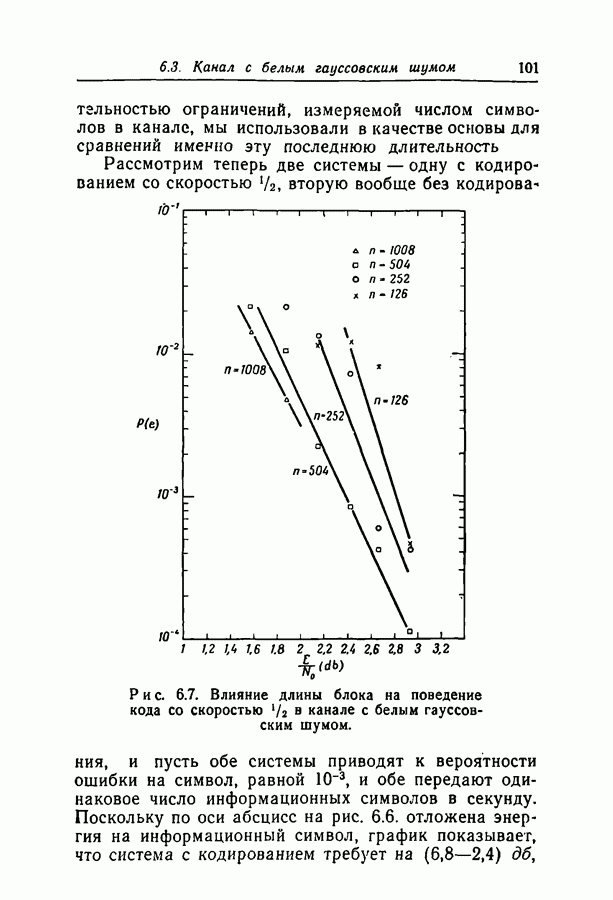
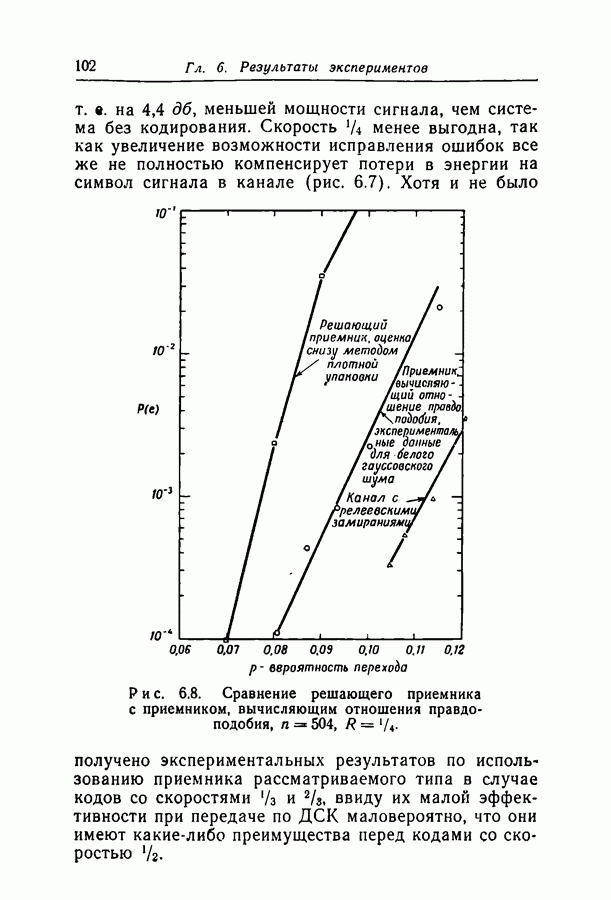
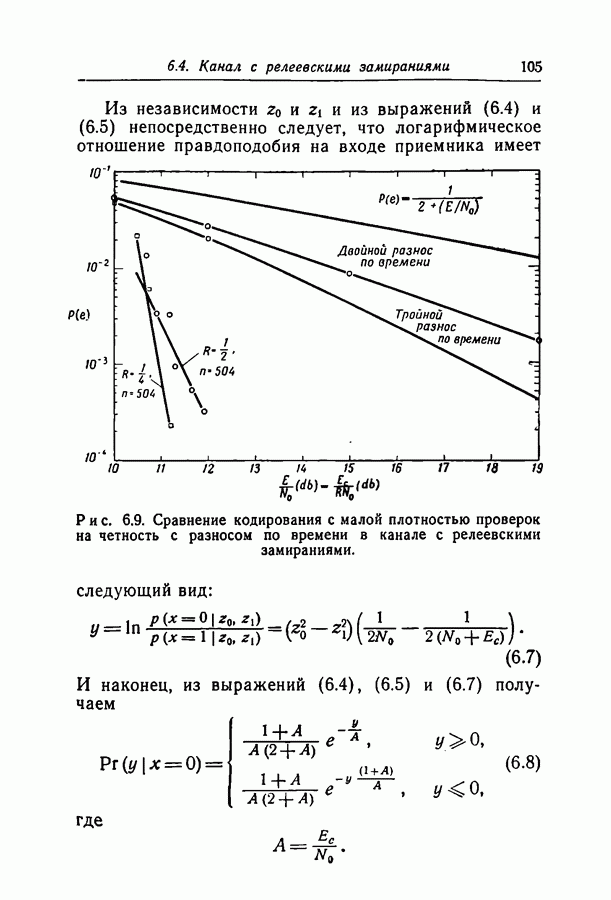
Существует гипотеза о том, что итерирование после проявления зависимостей в вероятностной схеме декодирования даст такую экспоненциальную оценку.
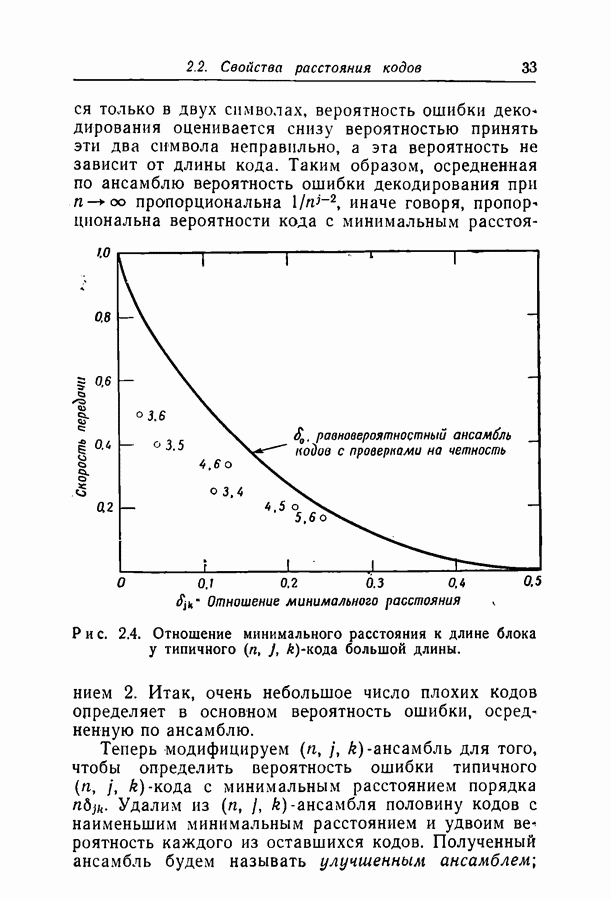
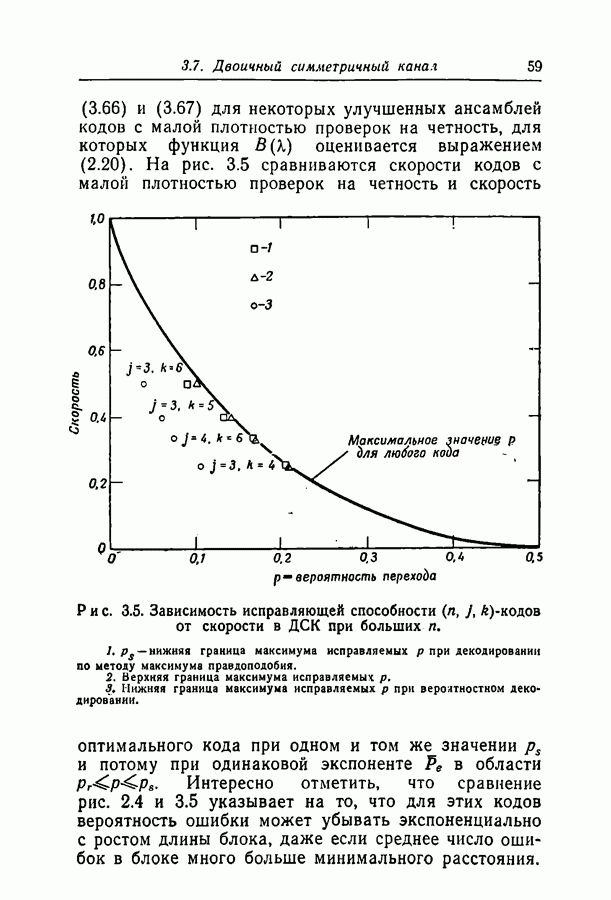
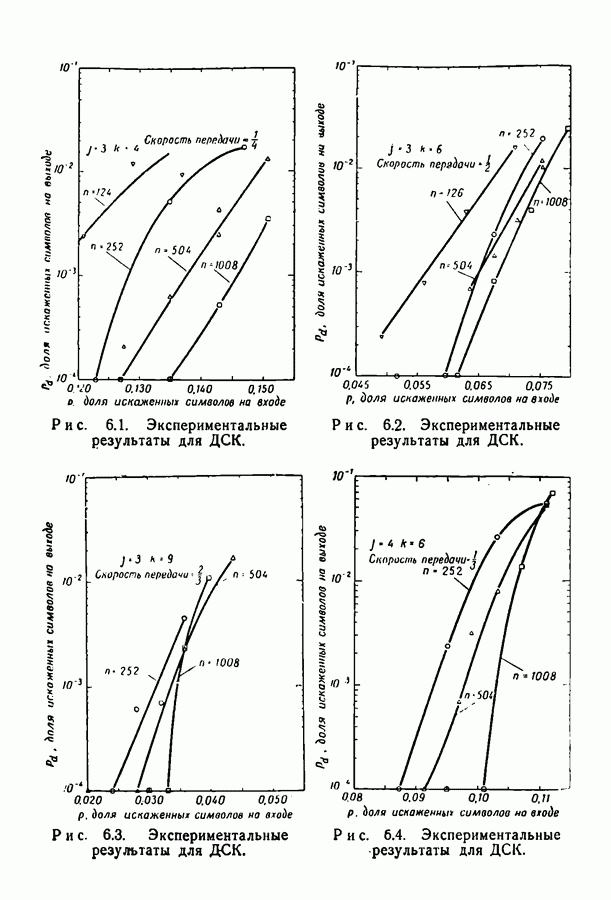
 добиться сколь угодно малой вероятности ошибки при передаче по заданному каналу. Расчеты на вычислительной машине ИБМ-709 показали, что код с
добиться сколь угодно малой вероятности ошибки при передаче по заданному каналу. Расчеты на вычислительной машине ИБМ-709 показали, что код с  пригоден для каналов с вероятностями перехода вплоть до 0,07, а код с
пригоден для каналов с вероятностями перехода вплоть до 0,07, а код с  пригоден для каналов с вероятностями вплоть до 0,144. Эти цифры особенно интересны, поскольку опровергают установившееся мнение о том, что пороговая скорость последовательного декодирования ограничивает интервал скоростей, при которых вообще возможны сколько-нибудь простые методы декодирования.
пригоден для каналов с вероятностями вплоть до 0,144. Эти цифры особенно интересны, поскольку опровергают установившееся мнение о том, что пороговая скорость последовательного декодирования ограничивает интервал скоростей, при которых вообще возможны сколько-нибудь простые методы декодирования.